

Abstract
Some individuals are better at learning about rewarding situations, whereas others are inclined to avoid punishments (i.e., enhanced approach or avoidance learning, respectively). In reinforcement learning, action values are increased when outcomes are better than predicted (positive prediction errors [PEs]) and decreased for worse than predicted outcomes (negative PEs). Because actions with high and low values are approached and avoided, respectively, individual differences in the neural encoding of PEs may influence the balance between approach–avoidance learning. Recent correlational approaches also indicate that biases in approach–avoidance learning involve hemispheric asymmetries in dopamine function. However, the computational and neural mechanisms underpinning such learning biases remain unknown. Here we assessed hemispheric reward asymmetry in striatal activity in 34 human participants who performed a task involving rewards and punishments. We show that the relative difference in reward response between hemispheres relates to individual biases in approach–avoidance learning. Moreover, using a computational modeling approach, we demonstrate that better encoding of positive (vs negative) PEs in dopaminergic midbrain regions is associated with better approach (vs avoidance) learning, specifically in participants with larger reward responses in the left (vs right) ventral striatum. Thus, individual dispositions or traits may be determined by neural processes acting to constrain learning about specific aspects of the world.
SIGNIFICANCE STATEMENT Individuals differ in how they behave toward rewards or punishments. Here, we demonstrate that functional hemispheric asymmetries measured in dopaminergic reward regions dictate whether someone will learn to choose rewarding options or instead avoid punishing outcomes. We also show that hemispheric reward asymmetries involve a differential neural encoding of signals controlling approach and avoidance learning. We thus provide experimental evidence for a mechanism that accounts for individual differences in approach and avoidance learning. Disabling mental illnesses have previously been associated with hemispheric asymmetries in dopamine function and extreme biases in approach–avoidance behavior. By showing that these observations implicate biased learning processes, the present study may offer important insights into the development and maintenance of some psychiatric disorders.
Keywords: approach, asymmetry, avoidance, dopamine, reinforcement, reward
Introduction
Much of human behavior is directed toward gaining rewards, such as food, money, or praise (approach behaviors), and toward avoiding punishments, such as loss, pain, or humiliation (avoidance behaviors). People are differently motivated to initiate approach and avoidance behaviors (Elliot, 2008), and also display differences in their ability to learn cues associated with positive and negative outcomes (approach–avoidance learning) (Frank et al., 2005; Smillie et al., 2007).
The influential reinforcement sensitivity theory proposed that two separate motivational systems underlie approach and avoidance behaviors (Gray, 1981). The Behavioral Activation System (BAS) would prioritize positive and rewarding stimuli and activate reward-seeking behaviors, whereas the Behavioral Inhibition System (BIS) responds to negative and punishing stimuli and activates behavioral inhibition and avoidance. Individual biases in approach–avoidance motivation may thus implicate an imbalance in the reactivity of these distinct systems. At the brain level, self-reported biases in approach–avoidance motivation correlate with the relative difference in resting state EEG alpha power between left and right frontal brain areas (Sutton and Davidson, 1997; Pizzagalli et al., 2005), suggesting that the relative strength between the BAS and the BIS could be reflected in hemispheric differences in spontaneous brain activation. More recently, it has been reported that hemispheric asymmetries in dopamine (DA) function are associated with biases in approach–avoidance motivation. For example, Parkinson's disease (PD) patients with larger loss of DA neurons in the left and right hemisphere displayed relatively decreased approach and avoidance motivation, respectively (Porat et al., 2014), as well as decreased approach and avoidance learning, respectively (Maril et al., 2013). Similar findings were found in healthy controls where participants with increased DA tone in the left and right hemisphere, respectively, displayed increased approach and avoidance motivation and learning (Tomer et al., 2014). The latter studies suggest that motivational biases are related to hemispheric asymmetries in DA function, adding to the already established role of DA in motivation processes (Bromberg-Martin et al., 2010). However, it is unclear exactly how hemispheric asymmetries in DA function may influence learning strategies and decision making processes.
Reinforcement learning theory is an effective way of describing this learning process, where an action's value is updated based on the mismatch between its predicted outcome and an actual outcome, the so-called prediction error (PE) (Sutton and Barto, 1998). An action's value is incremented whenever its outcome is better than expected (i.e., positive PE; outcome − prediction > 0), whereas its value is decremented following an outcome that is worse than expected (i.e., negative PE; outcome − prediction < 0). The neural correlates of PEs have been reported in midbrain DA neurons, including the ventral tegmental area (VTA) and the substantia nigra (SN) (Schultz et al., 1997; Schultz, 1998). For example, unexpected rewards (positive PEs) increase the firing rates of midbrain DA neurons, whereas unexpected omissions of rewards (negative PEs) decrease the firing rates (Schultz et al., 1997; Tobler et al., 2003). Encoding of PEs is casually linked to learning (Steinberg et al., 2013), and altered neural encoding of PEs has been associated with deficits in value-based learning (Tobler et al., 2006; Schönberg et al., 2007).
In the present study, we directly tested whether an asymmetry in neural activity across dopaminergic regions in favor of the left hemisphere (i.e., relatively increased reward response in the left than right hemisphere) implicates better approach than avoidance learning, as well as better neural encoding of positive (vs negative) PEs. We estimated approach–avoidance biases in learning using a reward task in which participants learned to associate different symbols with different reward probabilities (Frank et al., 2004). Hemispheric differences in DA function were estimated during the reward task as the differential neural response of the left and right nucleus accumbens (NAcc) to positive and negative feedback. Finally, neural responses to positive and negative PEs in the midbrain were estimated by combining a computational reinforcement learning model with fMRI.
Materials and Methods
Participants
Forty-two healthy participants with no previous history of neurological or psychological disorders participated in the study. All participants provided written consent according to the ethical regulations of the Geneva University Hospital, and the study was performed in accordance with the Declaration of Helsinki. Data from 8 participants had to be excluded for the following reasons: falling asleep in the MRI scanner (n = 2), failure to follow task instructions (n = 2), and failure to reach the performance criteria in the probabilistic selection task (n = 4, see below). Finally, data from 34 right-handed and native French-speaking participants (14 females; average ± SEM age, 23.41 ± 0.78 years) were included in the analyses.
Probabilistic selection task (PST)
In the PST, participants learned the values of different symbols by associating each symbol with different reward probabilities (Frank et al., 2004). The first (main) training phase took place outside the MRI scanner. Each trial started with a central fixation cross presented for 0.5–2.0 s (randomly jittered with an average presentation time of 1.25 s) followed by one of three possible pairs of symbols presented for 1.0 s. The symbols were shown to the right and to the left of the central fixation, and participants were instructed to select one symbol by pressing the corresponding button using their right hand (Fig. 1A). Feedback, a positive or negative smiley face, was presented 1 s following symbol presentation and was presented for 0.6 s. Feedback depended on the reward probability associated with each symbol (Fig. 1B). In AB pairs, the probability of a positive outcome was 80% for the A symbol and 20% for the B symbol. For CD and EF pairs, the probabilities were 70/30 and 60/40, respectively. The words “Too slow!” appeared on the screen instead of a smiley face if no response had been given within 1 s following the symbol presentation. Each pair of symbols was presented 20 times in a block in a pseudorandom order (each pair was presented once before any other pair was repeated). In addition, each symbol was presented an equal number of times on the left and the right side of the central fixation. Between participants, the symbols were randomly assigned to the different pairs and the reward probabilities were randomly assigned to different symbols.
Figure 1.

A, One training trial in the probabilistic selection task. After fixation, two symbols were presented and participants selected one symbol within 1 s. After 1 s, positive or negative feedback was presented based on the reward probability associated with the selected symbol. RT, Response time. B, Reward probabilities associated with each pair and symbol. The symbols associated with each reward probability were randomized between participants.
During training, participants were instructed to increase the number of outcomes with happy smiley faces while decreasing the number of outcomes with sad smiley faces. The training continued until the selection rate of the A and C symbols exceeded 60% and 55%, respectively, within one block, or until 45 min had passed without reaching both criteria (Frank and O'Reilly, 2006). Data from participants failing to reach the criteria were excluded from further analyses (n = 4). This procedure ensured that all participants reached an above chance level of performance for the two most asymmetrical pairs in the task before entering the MRI scanner. On average, participants required 3.735 (SEM = ±0.555) training blocks to reach the criteria. Subsequent phases occurred in the MRI scanner. Two additional training blocks were thus performed in the scanner, which allowed investigating the neural correlates of reward and reinforcement learning processes. This training was identical to the training outside the scanner, with the exception that the central fixation cross was presented for 2.0–5.0 s (randomly jittered with an average presentation time of 3.5 s) so as to be suitable for an event-related fMRI design. Next, participants underwent a test phase, in which they were presented with 12 novel pairs (AC, AD, AE, AF, BC, BD, BE, BF, CE, CF, DE, and DF), created by mixing the symbols from the original trained pairs (AB, CD, and EF). This test phase was similar to the training blocks performed inside the scanner, with the exception that no feedback was presented to prevent further learning of the new pairs. Participants were instructed to perform the task as well as possible and to trust their instinct, or guess, when uncertain. Each pair was presented eight times in a pseudorandom order (again, each pair was presented once before any other pair was repeated), and each symbol was presented an equal number of times on each side of the central fixation. Both sessions (i.e., the two training blocks and the test phase) lasted ∼10.5 min each, for a total scanning time of 21 min.
As in previous studies (Frank et al., 2004), the bias in approach versus avoidance learning was defined as the proportion of trials in which the A symbol was selected (i.e., reflecting approach learning) minus the proportion of trials in the test phase in which the B symbol was rejected (i.e., reflecting avoidance learning).
Reinforcement learning model
Computational learning models provide a mechanistic approach to studying learning-related trial-by-trial variations in behavior (Watkins and Dayan, 1992) and in neural activity (Gläscher and O'Doherty, 2010). Here, we used a slightly modified version of the classical Q-learning model to account for differences in learning from positive and negative outcomes (Frank et al., 2007). In this modified “approach–avoidance” model, each symbol i is assigned a value Qi, which depends on its feedback history. That is, the value Qi is updated each time the corresponding symbol has been selected as follows:
where Qi(t) is the value for the selected symbol i in trial t, αP and αN are the learning rates for positive and negative outcomes (denoted by the + and − subscripts, respectively), and r is the reward outcome (set to 1 for positive outcomes and 0 for negative outcomes). The probability of selecting a specific symbol is modeled by a softmax rule as follows:
 |
In this example, pA is the probability of selecting symbol A in an AB pair. The βtraining controls “exploit versus explore” behavior during the training. When this parameter is small, symbols with the highest Q value are most likely selected (exploitation), whereas a large value leads to selections less dependent on the symbol's value (exploration). The three parameters αP, αN, and βtraining were fitted to each participant's training data by minimizing the negative log-likelihood estimate (LLE) as follows:
 |
where pi(t) is the probability of selecting symbol i in trial t. To avoid local minima, the search was repeated from 100 different starting points.
During the test phase, the final Q values from the training stage were used as inputs to the soft-max rule to estimate choice probabilities in each trial. Using the same procedure as previously described one parameter βtest (estimating “exploit vs explore” behavior during the testing) was fitted to each individual's data by minimizing the log-likelihood estimate.
For tests of the model fit, the model was compared with a parameter-free “random choice model” that assumes all choices are random and equiprobable, as well as to a canonical model with only one learning rate. Model fits were compared using the Bayesian Information Criterion (BIC) (Schwarz, 1978), which allows comparing the fits of models using different numbers of free parameters as follows:
 |
where K is the number of free parameters and n is the number of choice trials. The random choice model was also used to compute a standardized metric of model fit, a pseudo-R2 statistic (Gershman et al., 2009) defined as 1 − LLEfitted/LLErandom, where LLErandom is the log data likelihood under the chance model and LLEfitted is that under the fit model.
Statistical methods
Significance levels were obtained by comparing observed results with null distributions, as obtained by Monte Carlo methods (Howell, 2013). The null hypothesis states that there is no difference between the means of the conditions and/or groups. Thus, for example, when performing the equivalence of a paired t test using Monte Carlo methods, the null distribution is constructed by the following: (1) randomly shuffling observations between the two conditions for each participant; (2) recording the mean difference between the two conditions; and (3) repeating this procedure a large number of times (n = 10,000 for the present study). An estimate of significance (i.e., p values) for a two-tailed test is obtained by calculating the proportion of trials in which the observed mean is larger or smaller than the means making up the null distribution. Similar procedures were used for ANOVAs and correlation coefficients. The advantage of using Monte Carlo methods is that normal distributions are no longer required, unlike when performing traditional t tests and ANOVAs. Spearman's rank correlation coefficient was used to estimate the relationship between two variables.
MRI data
Image acquisition.
MRI images were acquired using a 3T whole-body MRI scanner (Trio TIM, Siemens) with a 12-channel head coil. Standard structural images were acquired with a T1-weighted 3D sequence (MPRAGE, TR/TI/TE = 1900/900/2.27 ms, flip angle = 9 degrees, voxel dimensions = 1 mm isotropic, 256 × 256 × 192 voxels). Proton density structural images were acquired with a turbo spin echo sequence (TR/TE = 6000/8.4 ms, flip angle = 149 degrees, voxel dimensions = 0.8 × 0.8 × 3 mm, 205 × 205 × 60 voxels). The proton density scan was used to localize the SN/VTA in the midbrain. The acquisition volume was oriented to scan the brain from the lower part of the pons to the top of the thalamus. Functional images were acquired with a susceptibility-weighted EPI sequence (TR/TE = 2100/30 ms, flip angle = 80 degrees, voxel dimensions = 3.2 mm isotropic, 64 × 64 × 36 voxels, 36 slices acquired in descending order with a slice gap of 20%).
MRI data analysis.
All fMRI data were preprocessed and then analyzed using the GLM for event-related designs in SPM8 (Welcome Department of Imaging Neuroscience, London; http://www.fil.ion.ucl.ac.uk/spm). During preprocessing, all functional volumes were realigned to the mean image, coregistered to the structural T1 image, corrected for slice timing, normalized to the MNI EPI template, and smoothed using an 8 mm FWHM Gaussian kernel. Statistical analyses were performed on a voxelwise basis across the whole brain. At the first-level analysis, individual events were modeled by a standard synthetic hemodynamic response function, and six rigid-body realignment parameters were included as nuisance covariates when estimating statistical maps. Contrasts between conditions (see below) were then calculated and the contrast images entered into second-level tests implemented in SPM.
Reward processing and reinforcement learning
Hemispheric asymmetries in reward processing and the neural correlates of PEs were investigated during the training blocks performed inside the MRI scanner. The corresponding event-related design included four event types time-locked to the feedback onset and depending on the side of the selected symbol (i.e., left, right) and the feedback type (i.e., positive, negative). Model-derived PEs were added as parametric modulators for each event type. Additionally, to ensure that the neural activity related to the PEs was not confounded by motor aspects, response times were added as an additional parametric modulator. Crucially, to remove motor-related neural activity from the neural activity related to the PEs, the vectors containing the PEs were orthogonalized with respect to the response times. Hemispheric reward asymmetry was estimated as the difference in beta coefficients of the feedback onset predictors for positive and negative feedback for the left versus the right NAcc.
 |
The beta coefficients were extracted from 3 mm spheres centered on the coordinates of the peak activation within the NAcc ROI (see below).
Brain activity related to PE encoding in the midbrain was localized using a VTA ROI (see below) and the linear combination of the beta coefficients related to positive and negative PEs. This mean signal of PE encoding was then assessed further by looking at the contribution of positive and negative PEs separately.
ROIs
A priori ROIs used for small volume corrections (SVCs) were created based on previous literature. For the NAcc ROI, center coordinates were obtained from a recent study (Neto et al., 2008) (left NAcc: MNI x = −9, y = 9, z = −8; right NAcc: MNI x = 9, y = 8, z = −8). The NAcc ROI was created by combining two spheres (radius = 5 mm) centered on these coordinates into one NAcc mask. For the VTA/SN ROI, center coordinates were obtained from a recent study (Adcock et al., 2006) (left SN/VTA: x = −4, y = 15, z = −9; right SN/VTA: x = 5, y = −14, z = −8). The SN/VTA ROI was created by combining two spheres (radius = 5 mm) into one SN/VTA mask, in accordance with a recently described procedure (Shohamy and Wagner, 2008).
Statistical analyses
The obtained results are reported using a threshold of p < 0.001 and a minimum cluster size of five contiguous voxels. SVCs using a threshold of p < 0.05 Family-Wise Error Rate for multiple comparisons were obtained using the a priori ROIs reported above. Conditions were compared using traditional t tests implemented in SPM.
Results
Behavior
Training phase
Figure 2A displays performance as a function of training for the different pairs. Because participants displayed individual differences in the number of trials required to reach the performance criteria, performance was averaged across 10 bins of trials for each participant and pair (i.e., the bin size for a participant requiring 120 trials is 4 trials, whereas the bin size is 6 trials for a participant requiring 180 trials).
Figure 2.
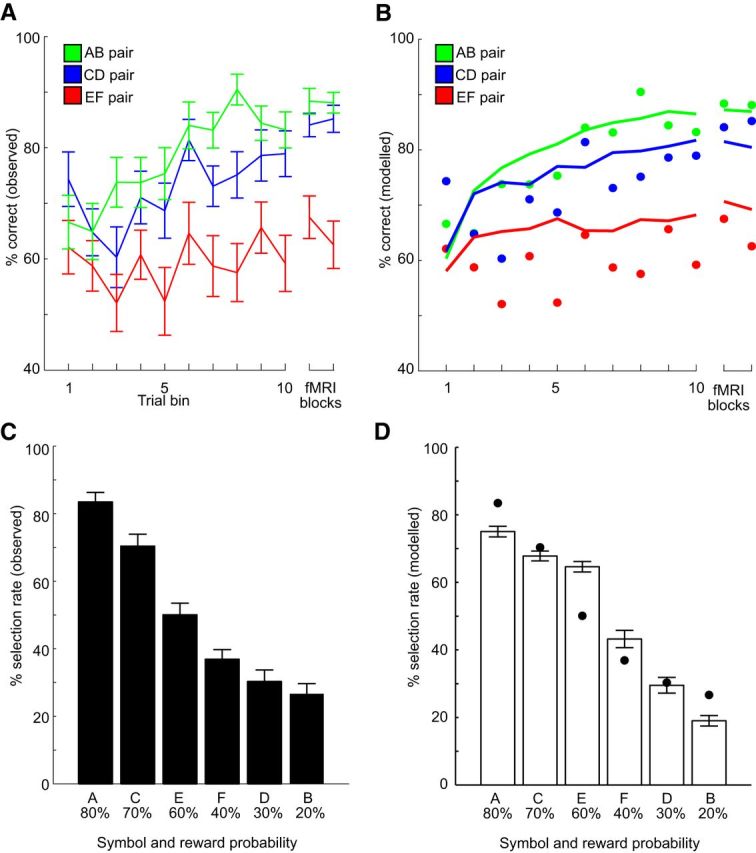
A, Performance as a function of training (mean ± SEM). Participants improved performance as training progressed, as indicated by increased performance at the end of training. Performance increased most rapidly for AB pairs where the difference in reward probability between the symbols was largest. B, Performance, as derived from the reinforcement learning model, as a function of training. Overall, the predicted performance (solid lines) provides a good fit to the observed performance (dots). C, Selection rate during the test phase with novel pairs (mean ± SEM). Symbols with higher and lower reward probabilities during the training were more likely to be selected and avoided in the novel pairs. D, Selection rate, as derived from the reinforcement learning model, during the test phase with novel pairs (mean ± SEM). Overall, the predicted performance (white bars) provides a good fit to the observed performance (black dots).
Next, performance was linearly regressed across trial bins for each pair and participant, and the resulting learning slopes were submitted to a one-factor ANOVA with factor Pair (AB, CD, EF). There was a significant effect of Pair (F(2,66) = 3.73, p = 0.029) because the learning slopes were significantly steeper for AB pairs (mean slope = 0.021, SEM = ±0.004) compared with EF pairs (mean slope = 0.006, SEM = ±0.004, p = 0.015), whereas CD pairs (mean slope = 0.017, SEM = ±0.004) displayed a marginal trend compared with EF pairs (p = 0.090), but no difference compared with AB pairs (p = 0.362). These results suggest that learning was easier in pairs where the difference in reward probability between the symbols was large. Of note, there was no evidence of lateralization effects as the selection rate of a symbol did not depend on which side it was presented (Table 1; all p > 0.17), nor did participants respond faster when selecting a symbol in different visual fields (Table 1; all p > 0.23).
Table 1.
Selection rates and response timesa
| Symbol (reward probability) | Selection rateb |
Reaction timec |
||
|---|---|---|---|---|
| LVF | RVF | LVF | RVF | |
| A (80%) | 0.801 (0.026) | 0.768 (0.033) | 642.618 (15.527) | 630.368 (13.773) |
| C (70%) | 0.753 (0.030) | 0.734 (0.030) | 673.927 (16.759) | 659.485 (14.996) |
| E (60%) | 0.620 (0.033) | 0.590 (0.033) | 712.677 (16.037) | 699.647 (17.512) |
| F (40%) | 0.410 (0.033) | 0.380 (0.033) | 693.985 (19.050) | 704.294 (21.377) |
| D (30%) | 0.266 (0.030) | 0.247 (0.030) | 689.179 (21.942) | 694.536 (25.254) |
| B (20%) | 0.232 (0.033) | 0.199 (0.026) | 681.889 (24.866) | 703.741 (29.640) |
aData are mean (SEM). LVF, Left visual field; RVF, right visual field.
bNo symbol was selected more often in one visual field (all p > 0.17).
cResponse times did not differ for symbols selected in different visual fields (all p > 0.23).
Figure 2B displays the “approach–avoidance” model fit to the behavioral data. The fitted parameters and estimates of model fits are displayed in Table 2.
Table 2.
Model fitsa
| Model | −LL | BIC | Pseudo-R2 | α | αP | αN | βtraining |
|---|---|---|---|---|---|---|---|
| Training | |||||||
| Canonical | 181.857 (31.188) | 187.606 (32.174) | 0.292 (0.050) | 0.149 (0.026) | — | — | 0.232 (0.040) |
| Approach–avoidance | 172.272 (29.544) | 180.895 (31.023) | 0.327 (0.056) | — | 0.279 (0.048) | 0.065 (0.011) | 0.214 (0.037) |
| Random choice | 240.767 (22.860) | 240.767 (22.860) | — | — | — | — | — |
| Testing | βtest | ||||||
| Canonical | 74.0520 (3.9488) | 76.4234 (3.9500) | 0.0723 (0.0474) | — | — | — | 0.911 (0.029) |
| Approach–avoidance | 69.8957 (3.7446) | 72.2671 (3.7443) | 0.1194 (0.0479) | — | — | — | 0.878 (0.032) |
| Random choice | 240.767 (22.860) | 240.767 (22.860) | — | — | — | — | — |
aData are mean (SEM). LL, Log-likelihood; BIC, Bayes Information Criterion; α, learning rate for the Canonical model; αP and αN, learning rates for positive and negative outcomes, respectively, for the approach–avoidance model; βtraining and βtest, exploration–exploitation parameters for the training and test sessions, respectively.
The approach–avoidance model provided a significantly better fit to behavioral data (mean BIC = 178.272, SEM = ±30.573) compared with both the random choice model (mean BIC = 240.767, SEM = ±22.860, p < 0.0001) and the canonical model (mean BIC = 187.606, SEM = ± 32.174, p = 0.020). To estimate how much variance in the choice behavior was accounted for by the approach–avoidance model, the pseudo-R2 value was calculated, which showed that the approach–avoidance model accounted for a large proportion of the variance in choice behavior (mean pseudo-R2 = 32.67%, SEM ±5.60), which was also significantly larger compared with the canonical model (mean pseudo-R2 = 29.20%, SEM ±5.00, p = 0.0003).
Test phase
During the test phase, the symbols were mixed to create novel pairs and participants were instructed to select the best symbol in each novel pair. Figure 2C displays the selection rate for each symbol during the test phase. A one-factor ANOVA with factor Symbol revealed a main effect (F(5,165) = 52.31, p < 0.0001), indicating that symbols associated with higher reward probabilities were more likely to be selected, whereas symbols associated with lower reward probabilities were less likely to be selected (i.e., more likely to be avoided). This result suggests that participants were able to use the learned reward probabilities during the test phase. The model-derived selection rate is displayed in Figure 2D, and fitted parameters and model fits are displayed in Table 2. The approach–avoidance model provided a significantly better fit to behavioral data (mean BIC = 71.558, SEM = ±3.698) compared with the random model (mean BIC = 79.467, SEM = ±13.629, p = 0.003), but although the fit was on average better compared with the canonical model, the difference was not significant (mean BIC = 74.052, SEM = ±3.949, p = 0.350). The pseudo-R2 value indicated that the approach–avoidance model accounted for a large proportion of the variance in choice behavior (mean pseudo-R2 = 17.60% SEM = ±0.05), but again this difference was not significantly different from the canonical model (mean pseudo-R2 = 13.20% SEM = ±0.04, p = 0.425). The variance explained is smaller compared with the training phase, plausibly reflecting difficulties in generalizing reward probabilities from the training phase to the novel pairs.
Of note, the model overestimates the hit rate for EF pairs during training (Fig. 2B), an effect that transfers also the testing phase (Fig. 2D). We addressed this issue by fitting a new model with two learning rates (i.e., related to positive and negative outcomes, respectively) and one “exploration–exploitation” parameter β for each trained pair (i.e., nine parameters in total). This analysis revealed significantly more randomness in the choices for EF pairs, as indicated by larger β values (mean βEF = 1.628, SEM = ±0.423) compared with both AB pairs (mean βAB = 0.349, SEM = ±0.092, p < 0.003) and CD pairs (mean βCD = 0.150, SEM = ±0.030, p < 0.0001). This result could be expected as EF pairs are the most difficult (Fig. 2A). Moreover, the fitted β parameter across all pairs in the approach–avoidance model was closer to β parameter values of AB and CD pairs (mean βAB, CD, EF = 0.214, SEM = ±0.037), a logical result as there are twice as many trials with less random choice (i.e., AB and CD) pairs. However, this result means that the randomness of choices in EF pairs is severely underestimated by the “approach–avoidance” model, something that explains why the model overestimates performance for the EF pairs. Importantly, we found no significant differences in the neural correlates of PE encoding between the “approach–avoidance” and the nine-parameter model, suggesting that the overestimation of performance for EF pairs did not significantly impact the subsequent results.
fMRI
Hemispheric asymmetry in reward processing
We first identified brain regions showing increased response to positive versus negative feedback (Fig. 3A). Activity in the bilateral NAcc was higher for positive versus negative feedback (left NAcc: peak voxel MNI, x = −6, y = 11, z = −11, t(33) = 4.051, pSVC = 0.004; right NAcc peak voxel MNI, x = 9, y = 11, z = −11, t(33) = 6.376, pSVC < 0.000001). These results are in accordance with a recent coordinate-based meta-analysis reporting that both left and right anterior striatum are more involved in the processing of positive (vs negative) events (Bartra, 2013).
Figure 3.
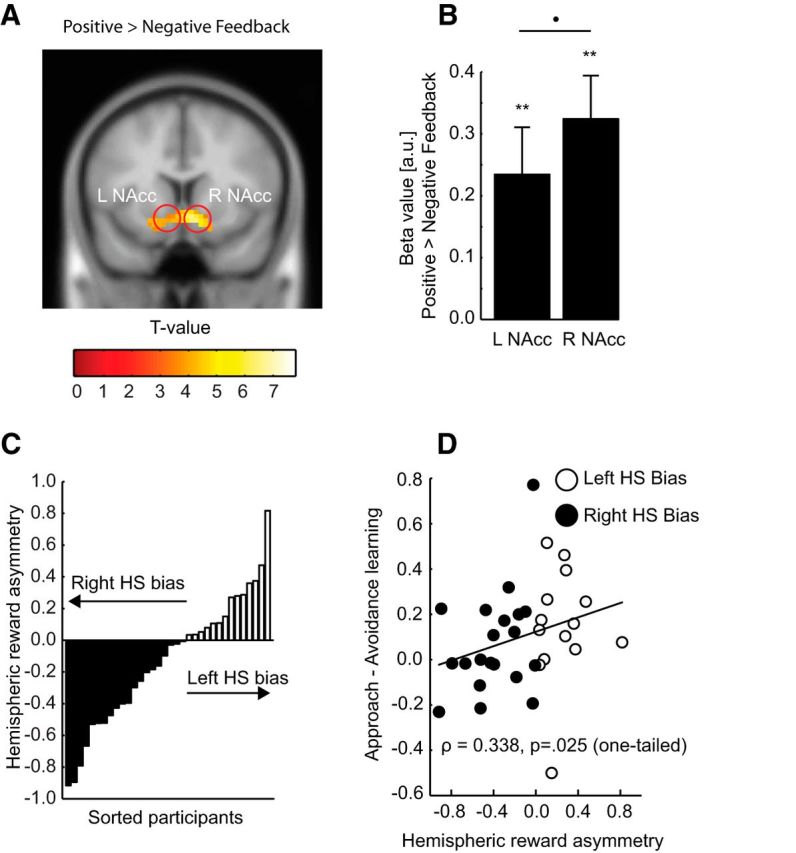
A, Neural response to positive compared with negative feedback was significantly larger in both the left and right NAcc. Red circles represent the left and right NAcc ROIs. B, Average beta value (mean ± SEM) for positive relative negative feedback extracted from 3-mm-radius spheres centered on the coordinates of the peak voxel within the left and right NAcc ROIs. **p < 0.001. •p < 0.1. C, Distribution of individual differences in hemispheric reward asymmetry. Fourteen participants displayed larger reward responsiveness in the left NAcc, whereas 20 participants displayed larger reward responsiveness in the right NAcc. D, Learning bias (approach vs avoidance learning) as a function of hemispheric reward asymmetry. Participants with a relatively larger relative reward response in the left (resp. right) NAcc displayed relatively more approach (resp. avoidance) learning. HS, Hemisphere.
Next, to assess hemispheric differences in reward responsiveness between individuals, an asymmetry index was estimated for each individual by calculating the difference in neural response to positive and negative feedback between the right and left NAcc. For each participant, the neural response to positive and negative feedback was extracted from two 3-mm-radius spheres centered on the peak voxels of the contrast positive > negative feedback in the left and the right NAcc (Fig. 3B). Individual differences in hemispheric reward asymmetry are displayed in Figure 3C with 14 participants displaying relatively larger reward responses in the left compared with the right NAcc, whereas 20 participants displayed the reverse pattern. To investigate the separate contributions of positive and negative feedback to the hemispheric reward asymmetry, beta coefficients for positive and negative feedback in the left and right NAcc were extracted using the same procedure. Next, the difference in neural responses across hemispheres for positive and negative feedback was correlated with the hemispheric reward asymmetry separately. Although not reaching standard levels of significance, there was evidence of both hemispheric asymmetries in positive and negative feedback contributing to the hemispheric reward asymmetry (positive feedback: ρ = 0.338, p = 0.051; negative feedback: ρ = −0.273, p = 0.119).
We then directly tested the hypothesis that hemispheric asymmetries in DA function relate to biased approach–avoidance learning. Individual asymmetry in NAcc response to reward correlated significantly with the learning bias (Figure 3D; ρ = 0.338, p = 0.025, one-tailed) because participants with larger neural response to positive versus negative feedback in the left (relative to the right) NAcc displayed increased approach learning (relative to avoidance learning). Performing the same analysis on hemispheric asymmetries in positive and negative feedback separately revealed no significant correlations (positive feedback: ρ = 0.054, p = 0.763; negative feedback: ρ = −0.114, p = 0.518).
Extending previous studies, which showed that relatively increased DA receptor binding or reduced loss of DA neuron in the left hemisphere is associated with relatively increased approach behaviors (Maril et al., 2013; Porat et al., 2014; Tomer et al., 2014), the present fMRI result suggests a critical role for phasic reward responses in determining individual differences in motivational learning.
PEs
Contrasts used to identify ROIs need to be unbiased with respect to the subsequent correlation analyses (Kriegeskorte et al., 2009; Vul et al., 2009). For this reason, we first identified brain regions indicative of mean PE signaling by localizing the maxima from the net PE contrast (the net PE is the linear combination of the contrasts for positive and negative PEs). Next, this mean signal was assessed further by looking at the neural correlates of positive and negative PE signaling separately.
The neural response to net PEs is displayed in Figure 4A. Overall, brain activity in the VTA/SN ROI correlated significantly with net PEs (SN/VTA ROI peak voxel; MNI, x = 6, y = −16, z = −5, t(33) = 4.216, pSVC = 0.003). To better visualize the midbrain dopaminergic regions, the same activity is overlaid on the average proton density structural scan in Figure 4A. The VTA is medial to the SN, which can be identified as a white strip (D'Ardenne et al., 2008).
Figure 4.
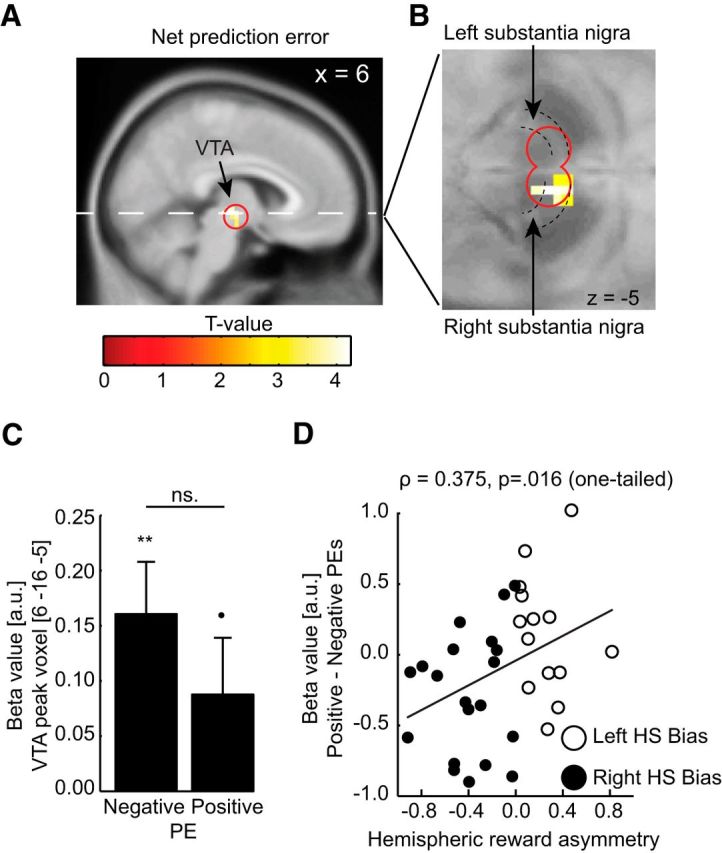
A, Neural activity within the SN/VTA ROI tracked net PEs. Red circle represents the SN/VTA ROI. B, The neural correlate of net PEs overlaid on an average proton density structural image. The substantia nigra can be identified as a white strip surrounding the ventral tegmental area. C, Neural activity in the dopaminergic midbrain (MNI: x = 6, y = 16, z = −5) correlating with negative and positive PEs (mean ± SEM). **p < 0.01. •p < 0.1. ns., Not significant. D, Relative encoding of positive versus negative PEs as a function of hemispheric reward asymmetry. Participants with a relatively larger reward response in the left (vs the right) NAcc displayed relatively better encoding of positive (vs negative) PEs. HS, Hemisphere.
Next, activity from the peak voxel (MNI, x = 6, y = −16, z = −5) was extracted for positive and negative PEs separately (Fig. 4B). Activity correlated significantly for negative PEs (mean activity = 0.161, SEM = 0.047, p = 0.002) and marginally so for positive PEs (mean activity = 0.090, SEM = 0.051, p = 0.094), with no difference between positive and negative PEs (p = 0.373). Of note, the extracted activity represents the strength of the correlation between neural activity and the PEs. Thus, the positive correlation found for both negative and positive PEs indicates that neural activity is stronger for large positive PEs (i.e., for unexpected rewards compared with expected rewards) and weaker for large negative PEs (i.e., for unexpected omissions of rewards compared with expected omissions). Provided that the dopaminergic midbrain tracks both positive and negative PEs, this result is in accordance with previous studies showing that unexpected rewards and omissions increases and decreases phasic activity of DA neurons, respectively (Schultz et al., 1997; Schultz and Dickinson, 2000; Tobler et al., 2003; D'Ardenne et al., 2008).
Critically, we predicted that participants with increased neural response to positive versus negative feedback in the left NAcc (associated with relatively better approach learning) should also display better encoding of positive relative negative PEs. As predicted, the hemispheric reward asymmetry negatively correlated with the relative neural response to positive versus negative PEs (Figure 4C; ρ = 0.375, p = 0.016, one-tailed). This result is consistent with previous studies indicating relatively greater involvement of the DA system in the left hemisphere in behavioral approach, but more importantly, also shows that the expression of post-learning behavioral biases can be directly related to biases during the learning.
Discussion
The present study addressed whether hemispheric asymmetries in reward processing implicate individual differences in approach–avoidance learning and the neural encoding of positive–negative PEs.
Hemispheric reward asymmetry relates to approach–avoidance learning
A main finding of the present study is that participants with increased reward response in the left NAcc displayed better approach learning and conversely for participants displaying stronger reward response in the right NAcc who had better avoidance learning. While this result is in line with previous studies reporting that approach and avoidance learning might relate to asymmetric loss of DA neurons in PD patients (Maril et al., 2013; Porat et al., 2014) or asymmetric D2 receptor binding in the striatum (Tomer et al., 2014), our study provides direct evidence that biased approach–avoidance motivation and learning are linked to asymmetries in the transient response of dopaminergic brain regions to rewards. Below, we suggest that asymmetries in DA function reported in previous studies may plausibly indicate asymmetries in the phasic response to rewards in the NAcc. First, the loss of midbrain DA neurons dampens phasic responses to rewards in both the midbrain and striatal projection sites, including the NAcc (van der Vegt et al., 2013). Second, manipulating striatal DA function by pharmacological agents strongly affects phasic responses to rewards in the NAcc (Knutson and Gibbs, 2007). Our results thus offer a new view on existing data by linking approach–avoidance learning to hemispheric asymmetries in the phasic response to rewards.
Encoding positive–negative PEs controls approach–avoidance learning
A second main finding of the present study is that larger neural responses to rewards in the left (resp. right) NAcc are not only associated with better approach (resp. avoidance) learning, but also with better encoding of positive (resp. negative) PEs. PEs are defined as the mismatch between actual and predicted outcomes. Positive and negative PEs signal outcomes that are better or worse than expected, leading to increments and decrements of action values, respectively. Action values determine which actions should be approached or avoided, suggesting that positive and negative PEs underpin approach and avoidance learning. As a stronger correlation between PEs and brain activity indicates a better neural representation of the learning signals needed for adaptive behaviors, better approach–avoidance learning should be reflected in better neural encoding of positive–negative PEs. This notion was corroborated by our results as participants with larger responses to rewards in the left (vs the right) NAcc displayed a stronger correlation between neural activity in the midbrain and positive PEs (vs negative PEs), as well as increased approach (vs avoidance learning). Of note, splitting participants into two groups based on whether they are better approach or avoidance learners (Frank et al., 2005; Baker et al., 2013) revealed that approach and avoidance learners also differed in the relative ability to encode positive and negative PEs in the midbrain (data not shown). This result confirms our finding that positive and negative PEs underpin approach and avoidance learning, respectively.
Some previous studies reported factors associated with biases in approach versus avoidance learning, such as the expression of DA genes (Frank et al., 2007), pharmacological manipulations of DA function (Frank and O'Reilly, 2006), loss of midbrain DA neurons (Frank et al., 2004; Bódi et al., 2009), or individual differences in the neural response to punishment (Frank et al., 2005). Here, by using a computational account combined with individual measures of learning and brain activity, we offer unprecedented evidence that midbrain PE encoding underlies individual differences in approach–avoidance learning, as we describe in more detail below.
The influence of PEs on action selection and biases in approach–avoidance learning
How can differential encoding of positive and negative PEs lead to behavioral biases? On the one hand, Frank et al. (2005) proposed that actions are stored in pre/motor cortex and executed through thalamocortical projections relaying information from the basal ganglia to the cortex. Activation of striatal DA receptors would facilitate action execution, whereas reduced activation of DA receptors suppresses action execution (through disinhibition or inhibition of the thalamus, respectively). These effects are themselves controlled by phasic bursts or dips in the activity of midbrain DA neurons elicited by action outcomes, so that action execution is facilitated for frequently rewarded actions (approach learning), whereas action suppression is facilitated for frequently punished actions (avoidance learning). On the other hand, phasic activity of midbrain DA neurons is closely associated with the encoding of PEs (Schultz et al., 1997; Schultz and Dickinson, 2000; Tobler et al., 2003) and learning (Tobler et al., 2006; Steinberg et al., 2013). Thus, learning depends on the accurate representation of PEs in the phasic activity of midbrain DA neurons. In particular, better neural encoding of positive and negative PEs indicates that phasic bursts and dips better represent the learning signals needed for adaptive changes in approach and avoidance behaviors. Thus, a relative difference in the neural encoding of positive and negative PEs in midbrain DA neurons should be associated with a relative difference in approach and avoidance learning, as our results demonstrate.
Previous observations suggest that overall DA activity (rather than hemispheric asymmetries) may affect approach–avoidance learning. In particular, unmedicated PD patients with altered DA function are better avoidance learners, whereas the same patients on DA medication were better approach learners (Frank et al., 2004; Bódi et al., 2009). These results have also been replicated using pharmacological manipulations of striatal DA function in healthy controls (Frank and O'Reilly, 2006). Frank (2005) proposed a computational model to account for these biases in approach–avoidance learning as a function of overall differences in striatal DA function, where increased and decreased overall DA function leads to more disinhibition (approach learning) and inhibition (avoidance learning) of the thalamus.
Here, we rather suggest that it is the relative encoding of positive and negative PEs that determines behavioral biases. This proposal differs but is compatible with the Frank (2005) model. Supporting both views, pharmacological manipulations of DA function influence the neural encoding of PEs (Jocham et al., 2011; Chowdhury et al., 2013). Thus, as it has not been shown experimentally how pharmacological manipulations of DA function influence the neural mechanisms underlying approach–avoidance learning, further work is needed to fully understand the interaction between approach–avoidance learning, the neural encoding of PEs, and pharmacological manipulations of the DA system.
Hemispheric asymmetries in DA function, cognition, and mental illness
There are similarities between behavioral biases associated with hemispheric asymmetries in DA function and behavioral biases expressed in some psychiatric disorders. For example, some evidence suggests that schizophrenia may be associated with abnormal hemispheric asymmetries in DA function (Reynolds, 1983; Hietala et al., 1999), and cognitive abilities potentially related to hemispheric DA asymmetry and function, such as associative processing and creativity (K.C.A., K.C.D., S.S., unpublished data), are also modified in schizophrenia (Spitzer, 1997; Kaufman and Paul, 2014) and by schizotypical traits (Mohr et al., 2001; Folley and Park, 2005). Moreover, extreme biases in approach and avoidance behaviors have been associated with depression, anxiety, gambling, and drug addiction (Zuckerman and Neeb, 1979; Stein and Stein, 2008; Stephens et al., 2010; Paulus and Yu, 2012), and the development and maintenance of such disorders may depend on biases in approach–avoidance learning (Mineka and Oehlberg, 2008). However, although there is evidence for the involvement of hemispheric asymmetries in psychopathologies (Flor-Henry, 1978; Sutton and Davidson, 1997; Yöney, 2001), very few studies have investigated the relationship between hemispheric asymmetries in DA function and mental disorders. Thus, studying the relationship between hemispheric brain asymmetries in DA function and behavior may help understanding the mechanisms underpinning mental disorders.
Limitations
One limitation of the present study is the correlational nature of the relationship between hemispheric asymmetries in reward processing and the neural encoding of positive–negative PEs; thus, it is unclear how the relative activation of the left and right NAcc influences the encoding of positive and negative PEs in the midbrain. One speculation is that individual differences in approach–avoidance behaviors modulate the connectivity of the left and right NAcc to other brain regions involved in affective and executive functions (Cservenka et al., 2014; Coveleskie et al., 2015), something that may in turn modulate mesolimbic reward processing (Krawczyk, 2002; Ballard et al., 2011). However, more work is needed to fully understand the link between hemispheric asymmetries in DA function and the neural mechanisms mediating behavioral biases.
In conclusion, to our knowledge, this is the first study to show hemispheric asymmetries in DA function using fMRI. Moreover, we demonstrate that specific computational and neuronal biases in learning processes underlie biases in approach and avoidance behaviors. Thus, these results significantly extend previous studies that investigated the role of DA and hemispheric asymmetries in DA function on cognition. Additionally, because of several shared behavioral characteristics between hemispheric asymmetries in DA function and some psychopathologies, further study of DA asymmetries may provide novel insights into the pathophysiology of mental disorders.
Footnotes
This work was supported by Swiss National Science Foundation Grant 320030_135653 and by the Swiss Center for Affective Sciences.
The authors declare no competing financial interests.
References
- Adcock et al., 2006.Adcock RA, Thangavel A, Whitfield-Gabrieli S, Knutson B, Gabrieli JD. Reward-motivated learning: mesolimbic activation precedes memory formation. Neuron. 2006;50:507–517. doi: 10.1016/j.neuron.2006.03.036. [DOI] [PubMed] [Google Scholar]
- Baker et al., 2013.Baker TE, Stockwell T, Holroyd CB. Constraints on decision making: implications from genetics, personality, and addiction. Cogn Affect Behav Neurosci. 2013;13:417–436. doi: 10.3758/s13415-013-0164-8. [DOI] [PubMed] [Google Scholar]
- Ballard et al., 2011.Ballard IC, Murty VP, Carter RM, MacInnes JJ, Huettel SA, Adcock RA. Dorsolateral prefrontal cortex drives mesolimbic dopaminergic regions to initiate motivated behavior. J Neurosci. 2011;31:10340–10346. doi: 10.1523/JNEUROSCI.0895-11.2011. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Bartra et al., 2013.Bartra O, McGuire JT, Kable JW. The valuation system: a coordinate-based meta-analysis of BOLD fMRI experiments examining neural correlates of subjective value. Neuroimage. 2013;76:412–427. doi: 10.1016/j.neuroimage.2013.02.063. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Bódi et al., 2009.Bódi N, Kéri S, Nagy H, Moustafa A, Myers CE, Daw N, Dibó G, Takáts A, Bereczki D, Gluck MA. Reward-learning and the novelty-seeking personality: a between- and within-subjects study of the effects of dopamine agonists on young Parkinson's patients. Brain. 2009;132:2385–2395. doi: 10.1093/brain/awp094. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Bromberg-Martin et al., 2010.Bromberg-Martin ES, Matsumoto M, Hikosaka O. Dopamine in motivational control: rewarding, aversive, and alerting. Neuron. 2010;68:815–834. doi: 10.1016/j.neuron.2010.11.022. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Chowdhury et al., 2013.Chowdhury R, Guitart-Masip M, Lambert C, Dayan P, Huys Q, Düzel E, Dolan RJ. Dopamine restores reward prediction errors in old age. Nat Neurosci. 2013;16:648–653. doi: 10.1038/nn.3364. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Coveleskie et al., 2015.Coveleskie K, Gupta A, Kilpatrick LA, Mayer ED, Ashe-McNalley C, Stains J, Labus JS, Mayer EA. Altered functional connectivity within the central reward network in overweight and obese women. Nutr Diabetes. 2015;5:e148. doi: 10.1038/nutd.2014.45. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Cservenka et al., 2014.Cservenka A, Casimo K, Fair DA, Nagel BJ. Resting state functional connectivity of the nucleus accumbens in youth with a family history of alcoholism. Psychiatr Res. 2014;221:210–219. doi: 10.1016/j.pscychresns.2013.12.004. [DOI] [PMC free article] [PubMed] [Google Scholar]
- D'Ardenne et al., 2008.D'Ardenne K, McClure SM, Nystrom LE, Cohen JD. BOLD responses reflecting dopaminergic signals in the human ventral tegmental area. Science. 2008;319:1264–1267. doi: 10.1126/science.1150605. [DOI] [PubMed] [Google Scholar]
- Elliot, 2008.Elliot A. Handbook of avoidance and approach motivation. New York: Psychology; 2008. [Google Scholar]
- Flor-Henry, 1978.Flor-Henry P. Gender, hemispheric specialization and psychopathology. Soc Sci Med. 1978;12:155–162. doi: 10.1016/0160-7987(78)90026-1. [DOI] [PubMed] [Google Scholar]
- Folley and Park, 2005.Folley BS, Park S. Verbal creativity and schizotypal personality in relation to prefrontal hemispheric laterality: a behavioral and near-infrared optical imaging study. Schizophr Res. 2005;80:271–282. doi: 10.1016/j.schres.2005.06.016. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Frank, 2005.Frank MJ. Dynamic dopamine modulation in the basal ganglia: a neurocomputational account of cognitive deficits in medicated and nonmedicated parkinsonism. J Cogn Neurosci. 2005;17:51–72. doi: 10.1162/0898929052880093. [DOI] [PubMed] [Google Scholar]
- Frank and O'Reilly, 2006.Frank MJ, O'Reilly RC. A mechanistic account of striatal dopamine function in human cognition: psychopharmacological studies with cabergoline and haloperidol. Behav Neurosci. 2006;120:497–517. doi: 10.1037/0735-7044.120.3.497. [DOI] [PubMed] [Google Scholar]
- Frank et al., 2004.Frank MJ, Seeberger LC, O'Reilly RC. By carrot or by stick: cognitive reinforcement learning in parkinsonism. Science. 2004;306:1940–1943. doi: 10.1126/science.1102941. [DOI] [PubMed] [Google Scholar]
- Frank et al., 2005.Frank MJ, Woroch BS, Curran T. Error-related negativity predicts reinforcement learning and conflict biases. Neuron. 2005;47:495–501. doi: 10.1016/j.neuron.2005.06.020. [DOI] [PubMed] [Google Scholar]
- Frank et al., 2007.Frank M, Moustafa A, Haughey H, Curran T, Hutchison K. Genetic triple dissociation reveals multiple roles for dopamine in reinforcement learning. Proc Natl Acad Sci U S. 2007;A:16311–16316. doi: 10.1073/pnas.0706111104. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Gershman et al., 2009.Gershman SJ, Pesaran B, Daw ND. Human reinforcement learning subdivides structured action spaces by learning effector-specific values. J Neurosci. 2009;29:13524–13531. doi: 10.1523/JNEUROSCI.2469-09.2009. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Gläscher and O'Doherty, 2010.Gläscher JP, O'Doherty JP. Model-based approaches to neuroimaging: combining reinforcement learning theory with fMRI data. Wiley Interdiscip Rev Cogn Sci. 2010;1:501–510. doi: 10.1002/wcs.57. [DOI] [PubMed] [Google Scholar]
- Gray, 1981.Gray J. A critique of Eysenck's theory of personality. In: Eysenck H, editor. A model for personality. Berlin: Springer; 1981. pp. 246–276. [Google Scholar]
- Hietala et al., 1999.Hietala J, Syvälahti E, Vilkman H, Vuorio K, **Räkköläinen V, Bergman J, Haaparanta M, Solin O, Kuoppamäki M, Eronen E, Ruotsalainen U, Salokangas RK. Depressive symptoms and presynaptic dopamine function in neuroleptic-naive schizophrenia. Schizophr Res. 1999;35:41–50. doi: 10.1016/S0920-9964(98)00113-3. [DOI] [PubMed] [Google Scholar]
- Howell, 2013.Howell D. Statistical methods for psychology. Ed 8. Belmont, CA: Wadsworth; 2013. [Google Scholar]
- Jocham et al., 2011.Jocham G, Klein T, Ullsperger M. Dopamine-mediated reinforcement learning signals in the striatum and ventromedial prefrontal cortex underlie value-based choices. J Neurosci. 2011;29:1606–1613. doi: 10.1523/JNEUROSCI.3904-10.2011. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Kaufman and Paul, 2014.Kaufman SB, Paul ES. Creativity and schizophrenia spectrum disorders across the arts and sciences. Front Psychol. 2014;5:1145. doi: 10.3389/fpsyg.2014.01145. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Knutson and Gibbs, 2007.Knutson B, Gibbs SE. Linking nucleus accumbens dopamine and blood oxygenation. Psychopharmacology. 2007;191:813–822. doi: 10.1007/s00213-006-0686-7. [DOI] [PubMed] [Google Scholar]
- Krawczyk, 2002.Krawczyk DC. Contributions of the prefrontal cortex to the neural basis of human decision making. Neurosci Biobehav Rev. 2002;26:631–664. doi: 10.1016/S0149-7634(02)00021-0. [DOI] [PubMed] [Google Scholar]
- Kriegeskorte et al., 2009.Kriegeskorte N, Simmons WK, Bellgowan PS, Baker CI. Circular analysis in systems neuroscience: the dangers of double dipping. Nat Neurosci. 2009;12:535–540. doi: 10.1038/nn.2303. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Maril et al., 2013.Maril S, Hassin-Baer S, Cohen O, Tomer R. Effects of asymmetric dopamine depletion on sensitivity to rewarding and aversive stimuli in Parkinson's disease. Neuropsychologica. 2013;51:818–824. doi: 10.1016/j.neuropsychologia.2013.02.003. [DOI] [PubMed] [Google Scholar]
- Mineka and Oehlberg, 2008.Mineka S, Oehlberg K. The relevance of recent developments in classical conditioning to understanding the etiology and maintenance of anxiety disorders. Acta Psychol. 2008;127:567–580. doi: 10.1016/j.actpsy.2007.11.007. [DOI] [PubMed] [Google Scholar]
- Mohr et al., 2001.Mohr C, Graves RE, Gianotti LR, Pizzagalli D, Brugger P. Loose but normal: a semantic association study. J Psycholinguist Res. 2001;30:475–483. doi: 10.1023/A:1010461429079. [DOI] [PubMed] [Google Scholar]
- Neto et al., 2008.Neto LL, Oliveira E, Correia F, Ferreira AG. The human nucleus accumbens: Where is it? A stereotactic, anatomical and magnetic resonance imaging study. Neuromodulation. 2008;11:13–22. doi: 10.1111/j.1525-1403.2007.00138.x. [DOI] [PubMed] [Google Scholar]
- Paulus and Yu, 2012.Paulus MP, Yu AJ. Emotion and decision-making: affect-driven belief systems in anxiety and depression. Trends Cogn Sci. 2012;16:476–483. doi: 10.1016/j.tics.2012.07.009. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Pizzagalli et al., 2005.Pizzagalli DA, Sherwood RJ, Henriques JB, Davidson RJ. Frontal brain asymmetry and reward responsiveness: a source-localization study. Psychol Sci. 2005;16:805–813. doi: 10.1111/j.1467-9280.2005.01618.x. [DOI] [PubMed] [Google Scholar]
- Porat et al., 2014.Porat O, Hassin-Baer S, Cohen OS, Markus A, Tomer R. Asymmetric dopamine loss differentially affects effort to maximize gain or minimize loss. Cortex. 2014;51:82–91. doi: 10.1016/j.cortex.2013.10.004. [DOI] [PubMed] [Google Scholar]
- Reynolds, 1983.Reynolds GP. Increased concentrations and lateral asymmetry of amygdala dopamine in schizophrenia. Nature. 1983;305:527–529. doi: 10.1038/305527a0. [DOI] [PubMed] [Google Scholar]
- Schönberg et al., 2007.Schönberg T, Daw ND, Joel D, O'Doherty JP. Reinforcement learning signals in the human striatum distinguish learners from nonlearners during reward-based decision making. J Neurosci. 2007;27:12860–12867. doi: 10.1523/JNEUROSCI.2496-07.2007. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Schultz, 1998.Schultz W. Predictive reward signal of dopamine neurons. J Neurophysiol. 1998;80:1–27. doi: 10.1152/jn.1998.80.1.1. [DOI] [PubMed] [Google Scholar]
- Schultz and Dickinson, 2000.Schultz W, Dickinson A. Neural coding of prediction errors. Annu Rev Neurosci. 2000;23:473–500. doi: 10.1146/annurev.neuro.23.1.473. [DOI] [PubMed] [Google Scholar]
- Schultz et al., 1997.Schultz W, Dayan P, Montague PR. A neural substrate of prediction and reward. Science. 1997;275:1593–1599. doi: 10.1126/science.275.5306.1593. [DOI] [PubMed] [Google Scholar]
- Schwarz, 1978.Schwarz G. Estimating the dimension of a model. Ann Stat. 1978;6:461–464. doi: 10.1214/aos/1176344136. [DOI] [Google Scholar]
- Shohamy and Wagner, 2008.Shohamy D, Wagner AD. Integrating memories in the human brain: hippocampal-midbrain encoding of overlapping events. Neuron. 2008;60:378–389. doi: 10.1016/j.neuron.2008.09.023. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Smillie et al., 2007.Smillie LD, Dalgleish LI, Jackson CJ. Distinguishing between learning and motivation in behavioral tests of the reinforcement sensitivity theory of personality. Pers Soc Psychol Bull. 2007;33:476–489. doi: 10.1177/0146167206296951. [DOI] [PubMed] [Google Scholar]
- Spitzer, 1997.Spitzer M. A cognitive neuroscience view of schizophrenic thought disorder. Schizophr Bull. 1997;23:29–50. doi: 10.1093/schbul/23.1.29. [DOI] [PubMed] [Google Scholar]
- Stein and Stein, 2008.Stein MB, Stein DJ. Social anxiety disorder. Lancet. 2008;371:1115–1125. doi: 10.1016/S0140-6736(08)60488-2. [DOI] [PubMed] [Google Scholar]
- Steinberg et al., 2013.Steinberg EE, Keiflin R, Boivin JR, Witten IB, Deisseroth K, Janak PH. A causal link between prediction errors, dopamine neurons and learning. Nat Neurosci. 2013;16:966–973. doi: 10.1038/nn.3413. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Stephens et al., 2010.Stephens DN, Duka T, Crombag HS, Cunningham CL, Heilig M, Crabbe JC. Reward sensitivity: issues of measurement, and achieving consilience between human and animal phenotypes. Addict Biol. 2010;15:145–168. doi: 10.1111/j.1369-1600.2009.00193.x. [DOI] [PubMed] [Google Scholar]
- Sutton and Barto, 1998.Sutton RS, Barto AG. Reinforcement learning: an introduction. Cambridge, MA: MIT; 1998. [Google Scholar]
- Sutton and Davidson, 1997.Sutton S, Davidson R. Prefrontal brain asymmetry: a biological substrate of the behavioral approach and inhibition systems. Psychol Sci. 1997;8:204–210. doi: 10.1111/j.1467-9280.1997.tb00413.x. [DOI] [Google Scholar]
- Tobler et al., 2003.Tobler PN, Dickinson A, Schultz W. Coding of predicted reward omission by dopamine neurons in a conditioned inhibition paradigm. J Neurosci. 2003;23:10402–10410. doi: 10.1523/JNEUROSCI.23-32-10402.2003. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Tobler et al., 2006.Tobler PN, O'Doherty JP, Dolan RJ, Schultz W. Human neural learning depends on reward prediction errors in the blocking paradigm. J Neurophysiol. 2006;95:301–310. doi: 10.1152/jn.00762.2005. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Tomer et al., 2014.Tomer R, Slagter HA, Christian BT, Fox AS, King CR, Murali D, Gluck MA, Davidson RJ. Love to win or hate to lose? Asymmetry of dopamine D2 receptor binding predicts sensitivity to reward vs punishment. J Cogn Neurosci. 2014;26:1039–1048. doi: 10.1162/jocn_a_00544. [DOI] [PMC free article] [PubMed] [Google Scholar]
- van der Vegt et al., 2013.van der Vegt JP, Hulme OJ, Zittel S, Madsen KH, Weiss MM, Buhmann C, Bloem BR, Münchau A, Siebner HR. Attenuated neural response to gamble outcomes in drug-naive patients with Parkinson's disease. Brain. 2013;136:1192–1203. doi: 10.1093/brain/awt027. [DOI] [PubMed] [Google Scholar]
- Vul et al., 2009.Vul E, Harris C, Winkielman P, Pashler H. Puzzlingly high correlations in fMRI studies of emotion, personality, and social cognition. Perspect Psychol Sci. 2009;4:274–290. doi: 10.1111/j.1745-6924.2009.01125.x. [DOI] [PubMed] [Google Scholar]
- Watkins and Dayan, 1992.Watkins CJ, Dayan P. Q-learning. Machine Learn. 1992;8:279–292. [Google Scholar]
- Yöney, 2001.Yöney T. Hemispheric specialization and psychopathology. Bull Clin Psychopharmacol. 2001;11:53–59. [Google Scholar]
- Zuckerman and Neeb, 1979.Zuckerman M, Neeb M. Sensation seeking and psychopathology. Psychiatr Res. 1979;1:255–264. doi: 10.1016/0165-1781(79)90007-6. [DOI] [PubMed] [Google Scholar]