

Abstract
Economic theory distinguishes two concepts of utility: decision utility, objectively quantifiable by choices, and experienced utility, referring to the satisfaction by an obtainment. To date, experienced utility is typically measured with subjective ratings. This study intended to quantify experienced utility by global levels of neuronal activity. Neuronal activity was measured by means of electroencephalographic (EEG) responses to gain and omission of graded monetary rewards at the level of the EEG topography in human subjects. A novel analysis approach allowed approximating psychophysiological value functions for the experienced utility of monetary rewards. In addition, we identified the time windows of the event-related potentials (ERP) and the respective intracortical sources, in which variations in neuronal activity were significantly related to the value or valence of outcomes. Results indicate that value functions of experienced utility and regret disproportionally increase with monetary value, and thus contradict the compressing value functions of decision utility. The temporal pattern of outcome evaluation suggests an initial (∼250 ms) coarse evaluation regarding the valence, concurrent with a finer-grained evaluation of the value of gained rewards, whereas the evaluation of the value of omitted rewards emerges later. We hypothesize that this temporal double dissociation is explained by reward prediction errors. Finally, a late, yet unreported, reward-sensitive ERP topography (∼500 ms) was identified. The sources of these topographical covariations are estimated in the ventromedial prefrontal cortex, the medial frontal gyrus, the anterior and posterior cingulate cortex and the hippocampus/amygdala. The results provide important new evidence regarding “how,” “when,” and “where” the brain evaluates outcomes with different hedonic impact.
Introduction
To optimize behavior, an organism needs to assess the experienced utility of actions or objects compared with its expected utility. The expected utility of a prospect is behaviorally inferred from revealed choices (Becker et al., 1964). Conversely, the experienced utility, referring to the hedonic impact of an obtainment (Bentham, 1798), is more difficult to objectively quantify because it represents a transient subjective state of emotion.
Recent research using functional magnetic resonance imaging has identified neuronal structures that are involved in the evaluation of rewarding and punishing outcomes and therefore implicitly provide physiologically based correlates of experienced utility and experienced regret (Knutson et al., 2003; O'Doherty et al., 2003; Coricelli et al., 2007; D'Ardenne et al., 2008). Electroencephalography (EEG) studies revealed insights to the temporal course of outcome evaluation. Besides others, most prominently two event-related potentials (ERP) have been identified: the feedback error-related negativity (fERN) (Holroyd et al., 2003; Hajcak et al., 2005) and its pendant, the feedback correct-related positivity (fCRP) (Holroyd et al., 2008). The fERN amplitude increases when outcomes are worse than expected, whereas the fCRP is more pronounced, when outcomes are better than expected. Consequently, the difference between the expectation and outcome is thought to define the experienced utility of the outcome (Yeung et al., 2005; Potts et al., 2006).
Until this present study, it has not been investigated how different magnitudes of outcomes are related to the magnitude of global brain activity. From a logical point of view, neuronal activity elicited by stimuli solely differing in reward magnitude must reflect their hedonic impacts. Consequently, the quantification of the magnitude of brain responses of a reasonable sample of different rewards would enable to construct value functions for experienced utility in the case of gain and experienced regret in the case of omission. Value functions for experienced utility and regret may be of profound interest because they could help clarify why people sometimes fail to choose what maximizes their happiness (Hsee and Hastie, 2006).
To derive such value functions, high-density EEG was recorded while subjects played a wheel-of-fortune game, during which they could win graded monetary rewards. In addition, we aimed to extend knowledge on electrophysiological responses to rewards by circumventing common methodological issues: a majority of previous studies investigated only difference waveforms between two conditions, such as two magnitudes of outcomes. Hence, it is impossible to deduce the source of the variance (Luck, 2005). Another potential drawback of the “classical” ERP approach is that waveforms are observed at a small number of previously selected electrodes. These electrodes are not representative for the underlying spatiotemporal distribution of brain activity (Murray et al., 2008). Extending the classical ERP approach, we investigated outcome-related responses at the ERP topography using the whole set of electrodes. With topographic EEG measures, the full spatial and temporal information of EEG is available and thus can be used to estimate the intracerebral sources of EEG activity. Using this information, we delineated latency and localization of brain activity covarying (and not only differing) with reward value.
Materials and Methods
Subjects.
Sixteen healthy subjects (10 female, 6 male; mean ± SD age, 26.4 ± 5.0 years) were recruited at the University of Zurich. Subjects reported having no psychiatric conditions. The local ethics review committee approved the study. Subjects signed informed consent documents before the start of the experiment.
Procedure.
Subjects were seated at 1 m distance from a computer screen (resolution, 1024 × 768 pixels; screen size, 17 inches) in a sound, light, and electrically shielded EEG recording room and played a wheel-of-fortune game (Fig. 1).
Figure 1.

Course of the experimental paradigm. A, Reward at stake is presented (e.g., 50 Swiss centimes). B, Subject chooses color via button press. C, The inner rectangle starts alternating and stops after 3500–3800 ms. D, If the chosen color (outer rectangle) and the inner rectangle match, the subject wins. If the two rectangles are of different color, the potential reward is omitted. E, After the presentation of a blank screen for 1 s, the next trial starts with a different reward value at stake. iti, Intertrial interval.
On each trial of the experiment, three coins were presented to the subjects. The sum of the three coins indicated the monetary reward value at stake. The reward value was pseudorandomly assigned, ranging from 10 Swiss centimes to 1 Swiss franc (≈0.75€). To ensure visual similarity between the different monetary reward values, three coins were always presented with one or two visually scrambled coins, depending on the monetary value (for an example, see Fig. 1).
By pressing one of two buttons, subjects chose a color (green or red) to bet on. Depending on the chosen color, a rectangle surrounding the picture with the coins adapted its color accordingly. At 500 ms after the button press, a second rectangle, framed by the outer rectangle, started to alternate in coloring from red to green and back. The speed of alternation asymptotically decreased until the inner rectangle stopped after 3500–3800 ms. A trial was won if the inner and outer rectangle matched color, increasing the actual balance of a subject for the amount of money played for. Whenever the color of the inner and outer rectangle was different, the money at stake was omitted. The time point of definite outcome was indicated through a white border of the inner rectangle. The picture indicating the outcome was presented for 1500 ms. The next trial started after the presentation (1000 ms) of a blank screen with a fixation cross.
In each of 300 trials, a real monetary reward was at stake. Each reward value was played for 30 times, with a probability of 50% for gain and omission, resulting in a total monetary gain of 82.50 Swiss francs. Subjects were informed about the probability to win. Because the analysis (outlined below) is sensitive to unbalanced numbers of observations, we chose to pseudorandomly predefine the sequences of outcomes of trials using randomized arrays (obtained at www.random.org). Consequently, the 20 experimental conditions [reward value (10) × outcome (2)] were randomly distributed in time. There were six blocks of 50 trials for each subject presented in different random order. The subjects were truthfully told that they could keep the money they won. Because the total gain was equal for all subjects, they were asked before the experiment whether they knew about any other participants and their gain. If a subject indicated they knew another's gain, a different randomization procedure was available, resulting in a similar gain (85 Swiss francs). None of the subjects indicated knowing about the monetary gains of others.
EEG data acquisition and preprocessing.
Scalp EEG was recorded at 250 Hz with a Geodesics system (Electrical Geodesics) from 129 scalp electrodes referenced to the vertex. Impedances were maintained at 30 kΩ or less. Twenty electrodes located on the outermost circumference (chin and neck) were omitted, because the head model implemented in standardized low-resolution electromagnetic tomography (sLORETA) (Pascual-Marqui, 2002), which was used to localize intracerebral sources, does not cover these electrodes. The remaining 109 electrodes were submitted to additional analysis. The EEG was filtered offline from 1.5 to 30 Hz. Eye movement artifacts were removed from the data using independent component analysis. Trials containing additional artifacts after visual inspection were excluded from the ERP analysis. EEG data was recomputed against the average reference. Artifact-free EEG epochs of 1200 ms were extracted with onsets 200 ms before the presentation of the outcome stimuli (Fig. 1D). The average ± SD number of artifact-free data epochs from each subject was as follows: 134.4 ± 15.2 (of 150) for the rewarded outcomes and 132.0 ± 16.2 (of 150) for the omitted outcomes. ERP maps of each reward condition were averaged for each subject, and grand-average ERPs across subjects were computed for each reward condition and across reward conditions.
Definition of the time window of analysis: consistent ERP topography across subjects.
To restrain the temporal window of analysis, we followed a recently suggested approach (Koenig and Melie-Garcia, 2009, 2010) that detects the time periods in the ERP in which similar intracortical generators are active across subjects. Because similar generators imply similar topographies, topographies across subjects are tested for consistency. For this test, the global field power (GFP) of the grand mean ERPs is taken as the measure of effect size. The null hypothesis states that for each time point, the GFP of the grand mean ERP (i.e., the mean ERP across subjects of the mean ERPs within subjects) may be observed by chance. To test this hypothesis, the GFP of the grand mean ERP was compared with 5000 GFPs of the grand mean ERPs that were constructed by randomly shuffling the measurements across electrodes of the grand mean ERP within each subject. To obtain the probability of the null hypothesis, the percentage of cases was computed in which the GFP obtained after randomization was larger than the GFP obtained in the observed data. This procedure was applied for grand means of won outcomes, lost outcomes, and all outcomes.
Topographic analysis of covariance.
Topographic analyses of covariance (TANCOVA) was used to identify the time points in which the global scalp field potentials significantly covaried with the external variables. This method of analysis introduced by Koenig et al. (2008) relies on the fact that ERP fields are additive. Therefore, the existence of a source that is active proportionally to an external variable results in a single topography that is added to the ERP proportionally to the external variable. To retrieve the topography that is proportional to the external variable at a given point in time, the covariance of the external variable with the potentials at each electrode at that point in time is computed. The obtained covariance map β represents the map corresponding to the generators that activate proportionally to the external variable at the given point in time. Using the GFP of this covariance map as an effect size allows testing time frame for time frame for significant covariation by applying randomization statistics as described by Koenig et al. (2008).
For the time windows indicating significant (p < 0.01) consistent scalp topographies across subjects, TANCOVAs were computed for the variables: reward value of gains (levels: 10), reward value of omitted outcomes (levels: 10), and valence (gains vs omitted rewards) (levels: 2). Because it was not known whether reward value contributes linearly to the scalp field map, we tested different, monotonic functions to relate reward with the electrophysiological data with the goal of maximizing the correspondence of the actual reward value and the electrophysiological index of reward representation. Reward values xi were therefore transformed using a power function with parameter α (α < 1, concave function; α = 1, linear function; α > 1, convex function):
where i is the reward level, x is the reward (ranging from 0 to 1), and xi′ is the covariate used for the computation of the covariance maps. α was varied in the range of 0.01 to 10 with increments of 0.1. For each subject and value of α, covariance maps β between the transformed reward values and the potentials at each electrode and each included point in time were computed as follows:
where v is the scalp potential at electrode e, time point t, and reward level i. These covariance maps were then used to compute, for each reward level, an electrophysiological index s̄i of reward using the following equation (Koenig et al. 2008):
and where s̄i is the mean of st,i across time.
The correspondence between s̄i and xi was defined by the squared Pearson's correlation coefficient r2 between the two vectors, which is equivalent to the percentage of common variance. The individual optimal α was defined at which this correspondence was maximal. In a next step, we assessed whether the r2 and α values of best-fitting functions significantly differ from the corresponding r2 values and a linear function (α = 1), using Wilcoxon's signed-rank tests and paired t tests, when appropriate. The median of the α values of the best-fitting functions entered the randomization test, described in the following section. To visually confirm the goodness of fit of the value functions, the values of st,i were plotted.
According to Koenig et al. (2008), a randomization procedure (5000 iterations) was used to identify at which time points of the ERP the global scalp field potentials significantly covaried with the previously determined best-fitting value function. Because this test calculates whether the ERP topography covaries above chance level for each time frame independently, the problem of multiple testing needs to be addressed. Following the same rationale of randomization statistics as for determining significance levels for each time frame, we calculated whether the duration of a time window of continuous significant covariation might be observed by chance. Thus, the probability of falsely detecting certain duration of a significant effect was computed. Details on this particular test are explicated by Koenig and Melie-Garcia (2009, 2010). Results are reported with a threshold for significance of p < 0.01. For significant time windows, the false-positive probability of the duration (FPP-D) is indicated. The whole analytical procedure was conducted for the won outcome conditions and the reward omission outcome conditions separately. Because the variable reward valence has only two levels and can be considered as a special case of a covariational analysis (with parameters of 1 for won and −1 for omission) (Koenig et al., 2008), the analysis steps of fitting the best function were unnecessary.
Source localization.
Because the generated TANCOVA maps represent a linear transformation of the topographical data, they can directly be submitted to source localization procedures (Koenig et al., 2008). The inverse solution of the ERP data was calculated using sLORETA (http://www.uzh.ch/keyinst/loreta.htm) (Pascual-Marqui, 2002). This method computes the current density magnitude (amperes per square millimeter) of each voxel, localizing the neural generators of the electrical activity by assuming similar activation among neighboring neuronal clusters. The solution space was computed on a spherical head model with anatomical constraints (Spinelli et al., 2000) and comprised 3005 solution points equidistantly distributed within the gray matter of the cerebral cortex and limbic structures of the Montreal Neurological Institute (MNI) 152 average brain. Anatomical labels are reported using an appropriate correction from Talairach–Tournoux to MNI space (Brett et al., 2002). The obtained tomography represents the intracerebral generators of the scalp field data accounting for the effects observed in the external variable with the full spatial resolution of the measured data. The graphical rendering of intracerebral sources and the ERP topographies was performed using the Cartool software (brainmapping.unige.ch/cartool) (Brunet et al., 2011).
Results
Behavioral results
The behavioral task consisted of pseudorandomly assigned gained and omitted rewards, and the subjects were informed that the chance to win was 50% throughout the experiment. Nevertheless, we were interested how frequently subjects changed their choice of color to bet on, depending on the outcome and type of the previous trial. Results indicated no significant difference in the frequency of changing the choice for a color, depending on neither the value at stake (F(9,135) = 0.942; p < 0.491), nor the outcomes (gain/loss) (F(1,15) = 0.262; p < 0.616), nor on the interaction of both (F(9,135) = 0.492; p < 0.878).
Consistent topography across subjects
The test for consistent ERP topographies of the grand means across subjects revealed significant (p < 0.01) consistency for a time window from −100 to 564 ms (with the outcome as temporal reference), with an inconsistent time window at 132–140 ms. It is noteworthy that such a short period of inconsistency within a larger time window of consistent ERP topography typically occurs when ERP topographies change polarity, indicating that ERP sources are in transition to new stable states. The topography of the grand mean of gain trials was consistent across subjects from −72 to 544 ms. Similarly, the grand mean ERP topography of all omission trials was consistent from −112 to 568 ms, with inconsistent time frames at 132–140, 396–408, and 464- 24 ms. The information of the obtained consistent time frames was submitted to the proceeding analysis steps of reward value function estimation and the TANCOVA (see Fig. 3A).
Figure 3.

Overview of ERP: results. A, Results of the topographic consistency test for all outcomes (first row), gains only (second row), and omissions (third row). Black areas indicate the significance level (inversely log-transformed) of the test. Areas exceeding the p < 0.01 mark restrict the time window of the TANCOVA. The gray areas depicted within indicate the GFP. B, Moment-by-moment significance level of the TANCOVA. The height of the area indicates the significance level (inversely log-transformed) of covariation between ERP topographies and valence (first row), value of gains (second row), and value of omissions (third row). C, Plot of the electrophysiological index of reward st,i as function of time and reward level (see Eq. 3). D, Covariance maps of the ERP data of the respective time frames of strong covariance. E, Source estimation of the covariance maps. The loci of maximal CSD (e.g., representing the maximal contribution to the covariance in the ERP topography) are framed in red. It is worth emphasizing that, in all conditions, similar sources differently contribute to the covariance at the level of the ERP topography.
Estimation of value functions
The value functions for gains and omissions were estimated subject-wise according to the criterion of the maximal sum of explained variance in the ERP data during the time of consistent topography. For both gains and omissions, convex functions fitted the ERP data best [αgains: median (Mdn), 2.41; median absolute deviation (MAD), 4.28; αomission: Mdn, 3.56; MAD, 3.21] (Fig. 2). Wilcoxon's signed-rank tests indicated that αomission differed significantly (Z = 2.694, p < 0.007) from α = 1 (linear function) and that there is a trend for a significant difference between αgains (Z = 1.890, p < 0.059) and α = 1. Furthermore, paired t tests revealed that the functions with optimized α values explain significantly more variance in the ERPs than linear functions (gains, T(15) = 3.991, p < 0.001; omission, T(15) = 4.238, p < 0.001).
Figure 2.
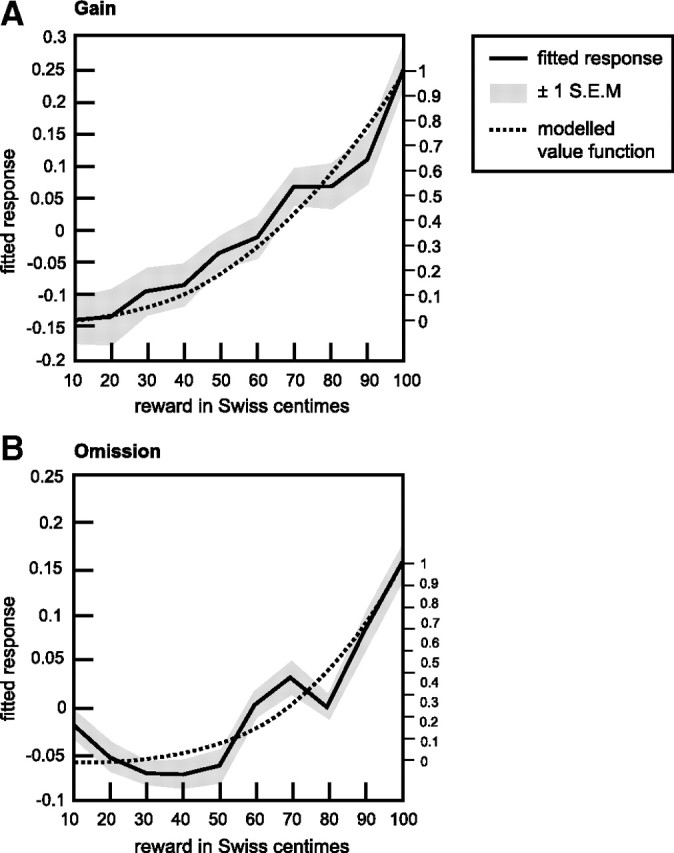
Electroencephalographically derived value functions. Mean electrophysiological indices of reward (s̄i; for details, see Eq. 3) as function of actual reward for the gain and omission conditions. Solid lines show the average across consistent time frames and subjects and indicate a convex, nonlinear relation between monetary rewards and ERP responses. Gray areas represent ±1 SEM. The dotted lines illustrate the estimated value functions, which corresponded most closely to the exhibited ERP responses and thus explained most variance in the data.
The model functions with optimized α values explained on average 49.66% of variance in the omission ERPs during the time of consistent topography. For gains, the functions with optimized α values explained on average 49.86% of variance in the gain ERPs during the time of consistent topography.
Topographic analysis of covariance
The TANCOVA on the variable valence revealed significantly (p < 0.01) covarying EEG topographies in the time windows 268–304 ms (FPP-D ≤ 0.036) and 464–508 ms (FPP-D ≤ 0.028) after outcome onset. Unexpectedly early (16 ms after onset of outcomes to 40 ms), there was a trend (p < 0.05) for significantly differing ERP topographies with respect to valence. The p value plot indicates that the p value starts to decrease before the outcome of the game is presented; thus, this effect cannot be the result of a physiological reaction to the valence of outcomes. The analysis further indicated significant (p < 0.01) covariance for the variable reward value of won outcomes during the time periods of 280–296 ms (FPP-D ≤ 0.056) and 484–504 ms (FPP-D ≤ 0.038) after outcome onset. For reward values of omitted outcomes, ERP topographies indicated a trend (p < 0.05) for significant covariations with reward value during a time window of 360–380 ms after outcome onset (Fig. 3B). Plots of the electrophysiological index of reward st,i as function of time and reward level (Fig. 3C) should provide an insight on how the different reward levels contribute to the overall representation of reward across time.
Source localization
sLORETA was used to localize the intracranial generators of the ERP covariance maps for each time point in the ERPs. The reported intracranial generators represent the averaged time windows of significant covariance derived in the TANCOVA. Therefore, this approach revealed the relative contribution of intracranial sources covarying with the external variables. Overall, source localization revealed a neuronal network that sensitively responds to information about rewarding (or disappointing in the case of omissions) outcomes that includes the ventromedial prefrontal cortex (VMPFC), anterior and posterior cingulate cortex (ACC/PCC), the hippocampus and amygdala (Hipp/Amy), and the medial frontal gyrus (MFG).
The point of maximal current source density (CSD) for valence during the time window of 248–312 ms was found in VMPFC (MNI: x = −9, y = 42, z = −16). The time window from 456 to 520 ms indicated maximal CSD in the right Hipp/Amy (MNI: x = 29, y = −12, z = −26). The covariance maps of value coding after gains at the time windows of 268–304 ms revealed maximal CSD at the left MFG (MNI: x = −32, y = 8, z = 60). For the time window of 480–512 ms highest CSD was found at the VMPFC (MNI: x = −3, y = 35, z = −21). The covariance maps of value coding after omitted rewards at the time window of 360–380 ms revealed maximal CSD at the right Hipp/Amy (MNI: x = 29, y = −12, z = −26) (Fig. 3E).
Discussion
This study aimed to extend knowledge on reward processing by investigating ERP responses at the level of the EEG topography. This approach offers several attractions: it combines the full spatial representation of EEG data with a high time resolution and direct access to neuronal signaling. In addition, it is possible to collect a large number of trials within a short time. These factors made it possible to provide novel contributions to the understanding of “how,” “where,” and “when” reward is processed.
“How” is monetary reward translated into brain activity?
We determined the form of relation between ERP topographies and associated monetary reward values. This functional form describes how the global response of brain activity is related to stimuli indicating gain and omission of different monetary rewards. Because we ensured that these stimuli solely differed with respect to the magnitude of the outcome, it is conceivable that the response of brain activity (measured at the ERP topography) corresponds to the experienced utility or regret of a more or less favorable outcome. Contrary to our expectations, the results revealed convex value functions for gains and omissions. Therefore, the sensitivity of the electrophysiological response nonlinearly increased for larger values. This finding is in contrast to concave utility functions derived from revealed choices (decision utility) and stimulus–intensity coding functions, following the psychophysics of diminishing sensitivity (Kahneman and Tversky, 1979). It is possible that the discrepancy between the value functions is attributable to the low monetary values at stake in our experiment. However, as reported for value functions of decision utility, it is assumable that value functions for experienced utility might not change with rising stakes (Fehr-Duda et al., 2010). In addition, it has been shown that reward value is neuronally coded in relation to possible outcomes and not at an absolute scale (Nieuwenhuis et al., 2005; Tobler et al., 2005; Elliott et al., 2008; De Martino et al., 2009; Fujiwara et al., 2009). New experiments are called for to examine the robustness of this unforeseen result, thus allowing to propose conscientious psychological interpretations of value functions for experienced utility and experienced regret.
“Where” is value and valence processed?
Source solutions revealed a network of brain areas, which sensitively responded to information about rewarding (or disappointing) outcomes that includes the VMPFC, ACC/PCC, hippocampus/amygdala, and MFG. Interestingly, the characteristic topographies of covariance of the specific time windows and conditions seems not to result from structurally dissociable neuronal processes as suggested previously (Yeung and Sanfey, 2004; Yacubian et al., 2006). Instead, it seems that a common network is involved in the processing of distinct aspects of reward information; the components are differentially engaged depending on the specific step in processing.
For example, the VMPFC responds sensitively to the valence of the outcome and the value of gains but to a lesser extent to the value of omissions. This is in line with previous studies showing that activity in the VMPFC increases after rewarding outcomes compared with omissions (Knutson et al., 2003) and is correlated with experienced value (Smith et al., 2010) and pleasantness ratings (Lebreton et al., 2009). In addition, the MFG predominantly responded to information about value but scarcely to valence. This conforms to linear increasing activity with the reward value of gains (Elliott et al., 2003). The source solution indicated most prominent (but not exclusive) omission-sensitive activity in the hippocampus in vicinity to the amygdala. The potential involvement of the amygdala replicates previous results showing that the amygdala encodes negative prediction errors (e.g., worse than expected outcomes) (Yacubian et al., 2006) but also responds to rewards (Breiter et al., 2001) and is generally believed to encode the emotional significance of stimuli, be it appetitive or aversive (Shabel and Janak, 2009). Similarly, besides the processing of mnemonic functions, the observation of reward-dependent variation of activity in the hippocampus is compatible with the key role played by this structure in reward and emotion (Blood and Zatorre, 2001).
We are aware that the precision of the EEG source localization is limited, and it likely cannot distinguish activity, for example, in the amygdala from hippocampal activity. Nevertheless, at a more general level, it has been shown that mediotemporal activity or activity in the VMPFC (or orbitofrontal cortex) can be reliably retrieved from scalp EEG using similar source reconstruction techniques as in our study (Lantz et al., 1997, 2001; Pizzagalli et al., 2003; Zumsteg et al., 2005).
“When” is reward information processed?
The results indicate that, at a first stage (∼250–300 ms after outcome), two factors of outcomes are processed: a coarse evaluation along a good–bad dimension (valence) and a concurrent, finer-grained evaluation of positive outcomes (value). The value of omitted rewards covaried with the ERP topography at a greater latency (∼360 ms after outcome). Importantly, during this time window, ERP topographies did not differ with respect to the valence of outcomes. The results therefore revealed a concurrent processing of valence and value of gained rewards and a later processing of omitted reward values.
We conjecture that this scheme of brain responses may be driven through cortical input of midbrain reward prediction error (RPE) signals. Seminal experiments of Schultz et al. (1997) have shown that, for rewards at chance, a positive RPE is generated, which is represented by a phasic increase in spiking activity. This increase is scaled to the value of gained rewards (Fiorillo et al., 2003; Bayer and Glimcher, 2005). It was suggested that these phasic fluctuations of dopaminergic midbrain activity modulate activity in the ACC (Holroyd and Coles, 2002; Holroyd et al., 2003). Furthermore, in line with our results, several studies revealed that the dopaminergic midbrain is effectively connected (besides others) with the VMPFC, MFG, and hippocampus/amygdala (for review, see Camara et al., 2009). In the case of the omission of a reward, a depression in spiking activity typically follows (Schultz et al., 1997). Therefore, the difference between the depression and any scaled increase of spikes makes it possible that valence and value of gains are concurrently encoded.
For scaled negative RPEs (e.g., modulated through omitted rewards of different magnitude), the quantification of spike depression appears to be limited (Fiorillo et al., 2003) because the range of the spiking rate of dopaminergic midbrain neurons from the baseline rate (3–8 spikes/s) (Niv and Schoenbaum, 2008) to zero spiking is marginal. This might explain why the value of omitted rewards is not processed at the same time as value of gains in the present study.
However, it has been suggested that scaled negative RPEs are coded by means of the duration of the pauses in spiking (Bayer et al., 2007). Consequently, it only makes sense to pass the information about the value of negative RPEs from midbrain structures to higher cognitive processing after the full expiration of the pause. In line with this, omitted reward values in this study significantly covaried with the ERP topography ∼110 ms after the first significant effect of valence coding.
Although we were exploring measures at the level of the ERP topography, by and large our results are supported through findings of research focusing on ERP responses of individual electrodes (Hajcak et al., 2005; Potts et al., 2006; Hewig et al., 2008; Holroyd et al., 2008; San Martin et al., 2010). For example, underpinning the hypothesis of dopaminergically driven ERP topographies, Cohen et al. (2007) showed that, during a time window in the range of the first processing of valence and value of gains, power and phase coherence values of ERPs after wins but not losses were modulated by reward probability, which, like reward value, modulates the magnitude of RPEs. Regarding the omission-sensitive ERP topography, previous studies reported that the amplitude of the (highly similar in terms of topography and latency) P300 reflects a pure coding of value regardless of valence in the P300 component (Yeung and Sanfey, 2004; Sato et al., 2005), whereas others indicated that the P300 is sensitive to valence and value (Hajcak et al., 2005; Holroyd and Krigolson, 2007; Wu and Zhou, 2009).
Besides the above-discussed results, which are within the temporal range of previously reported feedback-related ERPs, the ERP topography in a later time window (∼470 ms after feedback) significantly varied as a result of valence and value differences of the gains. Again, the ERP topography did not reflect an influence of the value of omitted rewards. The processing of valence and value of gains similarly involved the VMPFC and hippocampus/amygdala. Activity in the VMPFC more strongly covaried with the value of gains, whereas activity in the Hipp/Amy exhibited the strongest source of valence-dependent variation. The finding of a later, yet not reported, reward-sensitive ERP topography demonstrates one of the key advantages of our analysis approach, namely the a priori unrestrained analysis of all electrodes and time points of the post-outcome epoch.
To conclude, the present results demonstrate a measure of experienced utility by means of brain activity. In addition, ERP responses to different aspects of reward information recruit similar but differently weighted neuronal structures in a specific temporal sequence. The time course of processing argues in favor of dopaminergically driven activity.
Footnotes
This work was funded by the GfK-Nuremberg e.V., the nonprofit association of the GfK Group. We thank Roberto Pascual-Marqui, Lorena Gianotti, Daria Knoch, and Christoph Michel for many useful discussions and ideas.
References
- Bayer HM, Glimcher PW. Midbrain dopamine neurons encode a quantitative reward prediction error signal. Neuron. 2005;47:129–141. doi: 10.1016/j.neuron.2005.05.020. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Bayer HM, Lau B, Glimcher PW. Statistics of midbrain dopamine neuron spike trains in the awake primate. J Neurophysiol. 2007;98:1428–1439. doi: 10.1152/jn.01140.2006. [DOI] [PubMed] [Google Scholar]
- Becker GM, DeGroot MH, Marschak J. Measuring utility by a single-response sequential method. Behav Sci. 1964;9:226–232. doi: 10.1002/bs.3830090304. [DOI] [PubMed] [Google Scholar]
- Bentham J. Reprint. Oxford: Blackwell; 1798. An introduction to the principle of morals and legislations. 1948. [Google Scholar]
- Blood AJ, Zatorre RJ. Intensely pleasurable responses to music correlate with activity in brain regions implicated in reward and emotion. Proc Natl Acad Sci U S A. 2001;98:11818–11823. doi: 10.1073/pnas.191355898. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Breiter HC, Aharon I, Kahneman D, Dale A, Shizgal P. Functional imaging of neural responses to expectancy and experience of monetary gains and losses. Neuron. 2001;30:619–639. doi: 10.1016/s0896-6273(01)00303-8. [DOI] [PubMed] [Google Scholar]
- Brett M, Johnsrude IS, Owen AM. The problem of functional localization in the human brain. Nat Rev Neurosci. 2002;3:243–249. doi: 10.1038/nrn756. [DOI] [PubMed] [Google Scholar]
- Brunet D, Murray MM, Michel CM. Spatiotemporal analysis of multichannel EEG: CARTOOL. Comput Intell Neurosci. 2011;2011:813870. doi: 10.1155/2011/813870. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Camara E, Rodriguez-Fornells A, Ye Z, Münte TF. Reward networks in the brain as captured by connectivity measures. Front Neurosci. 2009;3:350–362. doi: 10.3389/neuro.01.034.2009. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Cohen MX, Elger CE, Ranganath C. Reward expectation modulates feedback-related negativity and EEG spectra. Neuroimage. 2007;35:968–978. doi: 10.1016/j.neuroimage.2006.11.056. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Coricelli G, Dolan RJ, Sirigu A. Brain, emotion and decision making: the paradigmatic example of regret. Trends Cogn Sci. 2007;11:258–265. doi: 10.1016/j.tics.2007.04.003. [DOI] [PubMed] [Google Scholar]
- D'Ardenne K, McClure SM, Nystrom LE, Cohen JD. BOLD responses reflecting dopaminergic signals in the human ventral tegmental area. Science. 2008;319:1264–1267. doi: 10.1126/science.1150605. [DOI] [PubMed] [Google Scholar]
- De Martino B, Kumaran D, Holt B, Dolan RJ. The neurobiology of reference-dependent value computation. J Neurosci. 2009;29:3833–3842. doi: 10.1523/JNEUROSCI.4832-08.2009. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Elliott R, Newman JL, Longe OA, Deakin JF. Differential response patterns in the striatum and orbitofrontal cortex to financial reward in humans: a parametric functional magnetic resonance imaging study. J Neurosci. 2003;23:303–307. doi: 10.1523/JNEUROSCI.23-01-00303.2003. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Elliott R, Agnew Z, Deakin JF. Medial orbitofrontal cortex codes relative rather than absolute value of financial rewards in humans. Eur J Neurosci. 2008;27:2213–2218. doi: 10.1111/j.1460-9568.2008.06202.x. [DOI] [PubMed] [Google Scholar]
- Fehr-Duda H, Bruhin A, Epper T, Schubert R. Rationality on the rise: why relative risk aversion increases with stake size. J Risk Uncertainty. 2010;40:147–180. [Google Scholar]
- Fiorillo CD, Tobler PN, Schultz W. Discrete coding of reward probability and uncertainty by dopamine neurons. Science. 2003;299:1898–1902. doi: 10.1126/science.1077349. [DOI] [PubMed] [Google Scholar]
- Fujiwara J, Tobler PN, Taira M, Iijima T, Tsutsui K. A parametric relief signal in human ventrolateral prefrontal cortex. Neuroimage. 2009;44:1163–1170. doi: 10.1016/j.neuroimage.2008.09.050. [DOI] [PubMed] [Google Scholar]
- Hajcak G, Holroyd CB, Moser JS, Simons RF. Brain potentials associated with expected and unexpected good and bad outcomes. Psychophysiology. 2005;42:161–170. doi: 10.1111/j.1469-8986.2005.00278.x. [DOI] [PubMed] [Google Scholar]
- Hewig J, Trippe RH, Hecht H, Coles MG, Holroyd CB, Miltner WH. An electrophysiological analysis of coaching in Blackjack. Cortex. 2008;44:1197–1205. doi: 10.1016/j.cortex.2007.07.006. [DOI] [PubMed] [Google Scholar]
- Holroyd CB, Coles MG. The neural basis of human error processing: reinforcement learning, dopamine, and the error-related negativity. Psychol Rev. 2002;109:679–709. doi: 10.1037/0033-295X.109.4.679. [DOI] [PubMed] [Google Scholar]
- Holroyd CB, Krigolson OE. Reward prediction error signals associated with a modified time estimation task. Psychophysiology. 2007;44:913–917. doi: 10.1111/j.1469-8986.2007.00561.x. [DOI] [PubMed] [Google Scholar]
- Holroyd CB, Nieuwenhuis S, Yeung N, Cohen JD. Errors in reward prediction are reflected in the event-related brain potential. Neuroreport. 2003;14:2481–2484. doi: 10.1097/00001756-200312190-00037. [DOI] [PubMed] [Google Scholar]
- Holroyd CB, Pakzad-Vaezi KL, Krigolson OE. The feedback correct-related positivity: sensitivity of the event-related brain potential to unexpected positive feedback. Psychophysiology. 2008;45:688–697. doi: 10.1111/j.1469-8986.2008.00668.x. [DOI] [PubMed] [Google Scholar]
- Hsee CK, Hastie R. Decision and experience: why don't we choose what makes us happy? Trends Cogn Sci. 2006;10:31–37. doi: 10.1016/j.tics.2005.11.007. [DOI] [PubMed] [Google Scholar]
- Kahneman D, Tversky A. Prospect theory: an analysis of decision under risk. Econometrica. 1979;47:263–291. [Google Scholar]
- Knutson B, Fong GW, Bennett SM, Adams CM, Hommer D. A region of mesial prefrontal cortex tracks monetarily rewarding outcomes: characterization with rapid event-related fMRI. Neuroimage. 2003;18:263–272. doi: 10.1016/s1053-8119(02)00057-5. [DOI] [PubMed] [Google Scholar]
- Koenig T, Melie-Garcia L. Statistical Analysis of multichannel scalp field data. In: Michel C, editor. Electrical neuroimaging. New York: Cambridge UP; 2009. pp. 169–189. [Google Scholar]
- Koenig T, Melie-García L. A method to determine the presence of averaged event-related fields using randomization tests. Brain Topogr. 2010;23:233–242. doi: 10.1007/s10548-010-0142-1. [DOI] [PubMed] [Google Scholar]
- Koenig T, Melie-García L, Stein M, Strik W, Lehmann C. Establishing correlations of scalp field maps with other experimental variables using covariance analysis and resampling methods. Clin Neurophysiol. 2008;119:1262–1270. doi: 10.1016/j.clinph.2007.12.023. [DOI] [PubMed] [Google Scholar]
- Lantz G, Michel CM, Pascual-Marqui RD, Spinelli L, Seeck M, Seri S, Landis T, Rosen I. Extracranial localization of intracranial interictal epileptiform activity using LORETA (low resolution electromagnetic tomography) Electroencephalogr Clin Neurophysiol. 1997;102:414–422. doi: 10.1016/s0921-884x(96)96551-0. [DOI] [PubMed] [Google Scholar]
- Lantz G, Grave de Peralta Menendez R, Gonzalez Andino S, Michel CM. Noninvasive localization of electromagnetic epileptic activity. II. Demonstration of sublobar accuracy in patients with simultaneous surface and depth recordings. Brain Topogr. 2001;14:139–147. doi: 10.1023/a:1012996930489. [DOI] [PubMed] [Google Scholar]
- Lebreton M, Jorge S, Michel V, Thirion B, Pessiglione M. An automatic valuation system in the human brain: evidence from functional neuroimaging. Neuron. 2009;64:431–439. doi: 10.1016/j.neuron.2009.09.040. [DOI] [PubMed] [Google Scholar]
- Luck S. The event-related potential technique. Cambridge, MA: Massachusetts Institute of Technology; 2005. [Google Scholar]
- Murray MM, Brunet D, Michel CM. Topographic ERP analyses: a step-by-step tutorial review. Brain Topogr. 2008;20:249–264. doi: 10.1007/s10548-008-0054-5. [DOI] [PubMed] [Google Scholar]
- Nieuwenhuis S, Heslenfeld DJ, von Geusau NJ, Mars RB, Holroyd CB, Yeung N. Activity in human reward-sensitive brain areas is strongly context dependent. Neuroimage. 2005;25:1302–1309. doi: 10.1016/j.neuroimage.2004.12.043. [DOI] [PubMed] [Google Scholar]
- Niv Y, Schoenbaum G. Dialogues on prediction errors. Trends Cogn Sci. 2008;12:265–272. doi: 10.1016/j.tics.2008.03.006. [DOI] [PubMed] [Google Scholar]
- O'Doherty JP, Dayan P, Friston K, Critchley H, Dolan RJ. Temporal difference models and reward-related learning in the human brain. Neuron. 2003;38:329–337. doi: 10.1016/s0896-6273(03)00169-7. [DOI] [PubMed] [Google Scholar]
- Pascual-Marqui RD. Standardized low-resolution brain electromagnetic tomography (sLORETA): technical details. Methods Find Exp Clin Pharmacol. 2002;24D:5–12. 2002. [PubMed] [Google Scholar]
- Pizzagalli DA, Oakes TR, Davidson RJ. Coupling of theta activity and glucose metabolism in the human rostral anterior cingulate cortex: an EEG/PET study of normal and depressed subjects. Psychophysiology. 2003;40:939–949. doi: 10.1111/1469-8986.00112. [DOI] [PubMed] [Google Scholar]
- Potts GF, Martin LE, Burton P, Montague PR. When things are better or worse than expected: the medial frontal cortex and the allocation of processing resources. J Cogn Neurosci. 2006;18:1112–1119. doi: 10.1162/jocn.2006.18.7.1112. [DOI] [PubMed] [Google Scholar]
- San Martín R, Manes F, Hurtado E, Isla P, Ibañez A. Size and probability of rewards modulate the feedback error-related negativity associated with wins but not losses in a monetarily rewarded gambling task. Neuroimage. 2010;51:1194–1204. doi: 10.1016/j.neuroimage.2010.03.031. [DOI] [PubMed] [Google Scholar]
- Sato A, Yasuda A, Ohira H, Miyawaki K, Nishikawa M, Kumano H, Kuboki T. Effects of value and reward magnitude on feedback negativity and P300. Neuroreport. 2005;16:407–411. doi: 10.1097/00001756-200503150-00020. [DOI] [PubMed] [Google Scholar]
- Schultz W, Dayan P, Montague PR. A neural substrate of prediction and reward. Science. 1997;275:1593–1599. doi: 10.1126/science.275.5306.1593. [DOI] [PubMed] [Google Scholar]
- Shabel SJ, Janak PH. Substantial similarity in amygdala neuronal activity during conditioned appetitive and aversive emotional arousal. Proc Natl Acad Sci U S A. 2009;106:15031–15036. doi: 10.1073/pnas.0905580106. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Smith DV, Hayden BY, Truong TK, Song AW, Platt ML, Huettel SA. Distinct value signals in anterior and posterior ventromedial prefrontal cortex. J Neurosci. 2010;30:2490–2495. doi: 10.1523/JNEUROSCI.3319-09.2010. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Spinelli L, Andino SG, Lantz G, Seeck M, Michel CM. Electromagnetic inverse solutions in anatomically constrained spherical head models. Brain Topogr. 2000;13:115–125. doi: 10.1023/a:1026607118642. 2000. [DOI] [PubMed] [Google Scholar]
- Tobler PN, Fiorillo CD, Schultz W. Adaptive coding of reward value by dopamine neurons. Science. 2005;307:1642–1645. doi: 10.1126/science.1105370. [DOI] [PubMed] [Google Scholar]
- Wu Y, Zhou X. The P300 and reward valence, magnitude, and expectancy in outcome evaluation. Brain Res. 2009;1286:114–122. doi: 10.1016/j.brainres.2009.06.032. [DOI] [PubMed] [Google Scholar]
- Yacubian J, Gläscher J, Schroeder K, Sommer T, Braus DF, Büchel C. Dissociable systems for gain- and loss-related value predictions and errors of prediction in the human brain. J Neurosci. 2006;26:9530–9537. doi: 10.1523/JNEUROSCI.2915-06.2006. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Yeung N, Sanfey AG. Independent coding of reward magnitude and valence in the human brain. J Neurosci. 2004;24:6258–6264. doi: 10.1523/JNEUROSCI.4537-03.2004. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Yeung N, Holroyd CB, Cohen JD. ERP correlates of feedback and reward processing in the presence and absence of response choice. Cereb Cortex. 2005;15:535–544. doi: 10.1093/cercor/bhh153. [DOI] [PubMed] [Google Scholar]
- Zumsteg D, Friedman A, Wennberg RA, Wieser HG. Source localization of mesial temporal interictal epileptiform discharges: correlation with intracranial foramen ovale electrode recordings. Clin Neurophysiol. 2005;116:2810–2818. doi: 10.1016/j.clinph.2005.08.009. [DOI] [PubMed] [Google Scholar]