

Abstract
Background
The growing interest in observational trials using patient data from electronic medical records poses challenges to both efficiency and quality of clinical data collection and management. Even with the help of electronic data capture systems and electronic case report forms (eCRFs), the manual data entry process followed by chart review is still time consuming.
Objective
To facilitate the data entry process, we developed a natural language processing–driven medical information extraction system (NLP-MIES) based on the i2b2 reference standard. We aimed to evaluate whether the NLP-MIES–based eCRF application could improve the accuracy and efficiency of the data entry process.
Methods
We conducted a randomized and controlled field experiment, and 24 eligible participants were recruited (12 for the manual group and 12 for NLP-MIES–supported group). We simulated the real-world eCRF completion process using our system and compared the performance of data entry on two research topics, pediatric congenital heart disease and pneumonia.
Results
For the congenital heart disease condition, the NLP-MIES–supported group increased accuracy by 15% (95% CI 4%-120%, P=.03) and reduced elapsed time by 33% (95% CI 22%-42%, P<.001) compared with the manual group. For the pneumonia condition, the NLP-MIES–supported group increased accuracy by 18% (95% CI 6%-32%, P=.008) and reduced elapsed time by 31% (95% CI 19%-41%, P<.001).
Conclusions
Our system could improve both the accuracy and efficiency of the data entry process.
Keywords: electronic data capture, electric medical records, case report form, natural language processing, field research
Introduction
According to ClinicalTrials.gov [1], the number of clinical trials worldwide has increased exponentially in recent years. Clinicians and researchers use evidence from interventional and observational trials to determine the effectiveness of treatments or interventions. Interventional trials, such as randomized controlled trials, compare the efficacy of interventions under relatively ideal cohorts to get unbiased estimates of effects. However, reality is far more complicated, and these ideal cohorts limit generalizability of results obtained to broader patient populations and settings. Moreover, due to high expenses and the short research cycle, interventional trials could hardly provide evaluations of effectiveness and safety for large populations and long-term follow-ups. As supplements, many observational trials, such as retrospective cohort studies, cross-sectional studies, and real-world evidence studies, use patient historical data collected at the point of care to compare effectiveness and safety of treatments in clinical practice settings in nonexperimental ways. Such observational trials usually have larger cohort sizes and longer follow-up periods. Growing interest in using these approaches poses new challenges to effective and efficient collection of patient electronic medical records (EMRs).
Manual data entry based on paper-and-pen case report forms (CRFs) followed by chart review is the conventional way of clinical trial data collection. With the development of health care information technology, electronic data capture (EDC) systems, which accelerate the data collection process and assure data quality with real-time data entry, review, analysis, and verification [2], emerge as a timely solution that is in high demand. Driven by the prevalent use of EDC systems, CRFs gradually transitioned from paper to electronic forms [3]. Many studies have suggested that data entry using electronic CRF (eCRF) applications of EDC systems could achieve higher efficiency and accuracy at a lower cost than the conventional paper-and-pen approach [2,4-8]. However, neither EDC nor eCRF fundamentally changed the essential ways of how the data are collected. Especially for observational trials using patient data, researchers still need to manually transcribe the data one by one from EMRs. The data entry process takes time and becomes a significant efficiency bottleneck.
The 2018 guidance from the US Food and Drug Administration [9] emphasized the importance of interoperability between electronic health records (EHRs) and EDCs. It also promoted the idea of secondary use of source data at the time of care to prepopulate eCRFs without specific user efforts. The guidance focused more on the use of structured data, such as demographics, vital signs, and laboratory data, but little on the use of unstructured clinical narratives, which account for about 80% of the patient care information [10]. To achieve data interoperability for these unstructured narratives, many EDC systems created predesigned patient information templates including standardized documentation or forms for coded data entry in lieu of free text documentation to structuralize the medical records [11,12]. Clinicians record patient information under the guidance of these templates, and at the same time the system stored the coded data from templates for future analysis. Patient information templates can help data collection for research and patient care, integrate EDC and EMRs, and automatically prepopulate the eCRF. However, limitations of the templates were obvious. For clinicians, the one-size-fits-all templates restricted freedom of expression. For researchers, the predesigned data elements limited usability of the data in different research topics.
The development of natural language processing (NLP) technologies provides new potential for better secondary use of free unstructured EMR data. Informatics for integrating biology and the bedside (i2b2) has posed NLP challenges to extract information, including clinical finding, test, treatment, medication, clinical event, and time information, from clinical notes and discharge summaries [13-16] and promoted a series of commercial medical applications focusing on post hoc structuralization of medical records [17-19]. Nonetheless, as one of the main topics on secondary use of patient EMR, unstructured data collection based on NLP technology has not been well studied.
In order to fill in this gap, we developed an NLP-driven medical information extraction system (NLP-MIES) based on i2b2 reference standards for concept extraction, assertion, and relation classification. After manually constructing eCRFs and binding data elements using concepts from the Systematized Nomenclature of Medicine–Clinical Terms (SNOMED-CT) or the radiology-specific ontology (RadLex) developed by the Radiological Society of North America, our system can scan clinical notes and image diagnostic reports, find related medical concepts, and automatically prepopulate data elements with associated values. To further compare the accuracy and efficiency between manual data entry and NLP technology–supported data entry, we conducted a randomized and controlled field experiment. We created a mock-up eCRF application that enables users to review medical records and enter, modify, and verify the data prepopulated by NLP-MIES. We recruited clinicians and researchers to use the application to finish a certain amount of simply designed eCRFs in the limited time. Based on these designs, we simulated a real-world eCRF filling process and aimed to quantitatively evaluate how NLP technologies could improve efficacy of data collection of clinical research and identify potential problems that are not neglectable in future NLP-driven EDC design.
Methods
Natural Language Processing–Driven Medical Information Extraction System
We leveraged the methods developed for the 2010 i2b2/Veterans Affairs (VA) challenge as the primary reference for Chinese medical NLP machine learning practices in NLP-MIES, which includes Chinese word segmentation, named entity recognition, assertion classification, and relation extraction [14,20-22]. On the basis of the predefined entities (medical problems, tests, treatments) and relation types (medical problems and treatments, medical problems and tests, medical problems and other medical problems) from the 2010 i2b2/VA challenge, in order to extract more information from medical records, we added four new entities (body structure, observable, qualifier, value) and four new types of relations (body structures and observables, medical problems and observables, observables and qualifiers, observables and values). After preprocessing by an associated value dimension algorithm [23], entities from medical texts can be rearranged according to their relations. We then adopted an improved longest common subsequence algorithm to map these aligned entities and relations into Chinese SNOMED-CT and RadLex concepts and synonyms [24]. Figure 1 shows the overall workflow of NLP-MIES.
Figure 1.
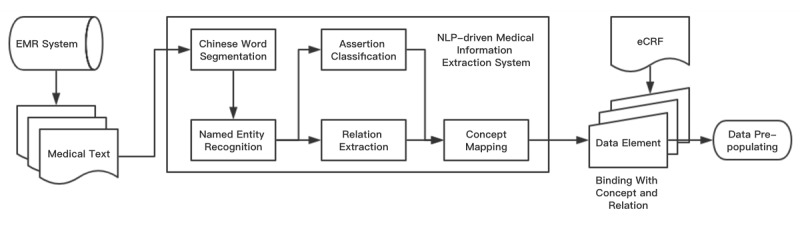
Workflow of the natural language processing–driven medical information extraction system. EMR: electronic medical record; NLP: natural language processing; eCRF: electronic case report form.
Electronic Clinical Research Form
We constructed simple eCRFs for two disease conditions (pediatric congenital heart disease and pneumonia) to evaluate the efficacy of NLP-MIES. To make the eCRFs closer to the real ones, we invited clinical researchers from the departments of pediatric cardiothoracic surgery and pediatric respiratory medicine to help design the eCRFs. The types of CRF data elements include true-false (participant judges whether a certain condition or medical problem exists, doesn’t exist, or is not mentioned in a certain case and chooses the button accordingly—for example, patient had a disturbance of consciousness: true, false, or not mentioned); multiple choice (participant should click the button corresponding to one or more conditions or medical problems associated with a certain patient—for example, which of the following are the chief complaints of the patient: cardiac murmur, cyanosis, or dyspnea); and fill-in-the-blank (participant should enter the value for each data element—for example, the lesion size of ventricular septal defect is ___ cm). Figures 2 and 3 show examples of eCRF design.
Figure 2.
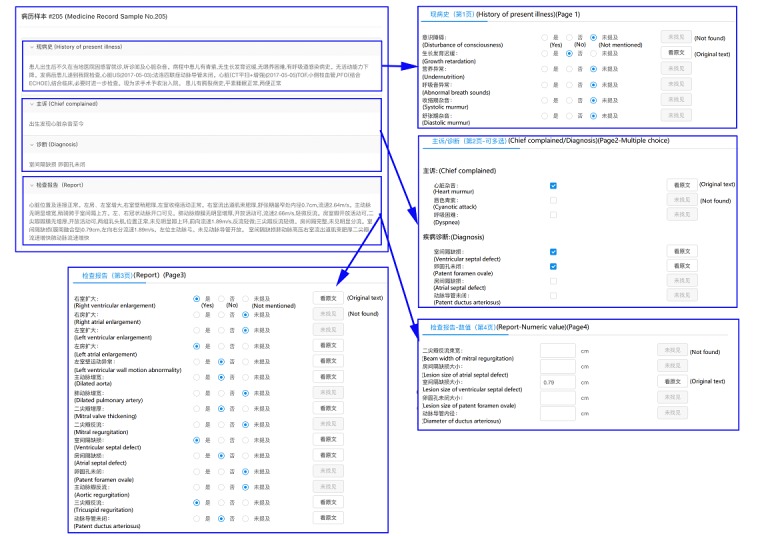
Electronic case report form design for congenital heart disease.
Figure 3.
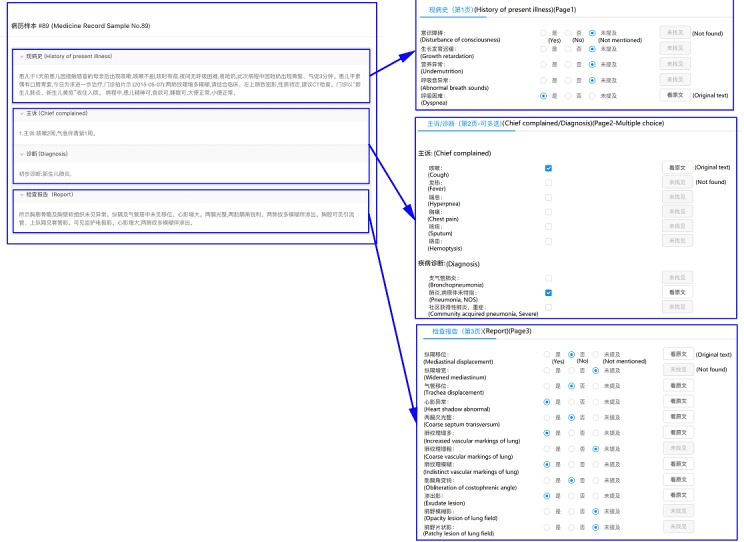
Electronic case report form design for pneumonia.
We further divided the data element true-false into two parts based on where the elements should be retrieved from: admission records (true-false I) or imaging reports (true-false II). All data elements were bound with SNOMED-CT or RadLex concepts and relations, such as disturbance of consciousness (concept, medical problem, SNOMED-CT ID: 3006004), cardiac murmur (concept, medical problem, SNOMED-CT ID: 42842009), lesion size (concept, observable, SNOMED-CT ID: 246116008) of (relation, medical problems and observables) ventricular septal defect (concept, medical problem, RadLex ID: RID3277).
Medical Text From the Electronic Medical Record System
For the congenital heart disease condition, we included admission records and ultrasonic cardiogram reports from pediatric patients aged 2 hours to 14 years with congenital heart disease (including atrial septal defect, ventricular septal defect, patent ductus arteriosus, patent foramen ovale, etc) attending the department of cardiothoracic surgery of Shanghai Children’s Medical Center from July 1, 2016, to July 1, 2017.
For the pneumonia condition, we included admission records and chest x-ray reports from pediatric patients aged 6 months to 14 years with pneumonia (including bronchopneumonia, viral pneumonia, bacterial pneumonia, mycoplasma pneumonia, lobar pneumonia, lobular pneumonia, etc) attending the department of respiratory medicine of Shanghai Children’s Medical Center from July 1, 2016, to July 1, 2017.
All medical texts were from the EMR system of Shanghai Children’s Medical Center and were de-identified. We randomly selected 60 patient cases for each condition. A total of 120 cases and 240 medical texts were included.
System Functions and Human-Computer Interaction
We developed a graphical user interface for easy browsing of imported patient medical texts as shown in Figure 4. User can see imported admission records, imaging reports, and eCRFs on the screen. When NLP-MIES was enabled, our system automatically scanned the texts, found medical concepts mentioned in raw texts, identified assertion or value information, and prepopulated the data elements accordingly. Our system recorded the raw text location where each medical concept was extracted. When necessary, user could directly click the “back to” button to highlight the location for further data verification. Each eCRF was divided into three or four parts according to the types of data elements (Figures 2 and 3). During the experiment, the elapsed time for finishing each part was automatically recorded by system.
Figure 4.
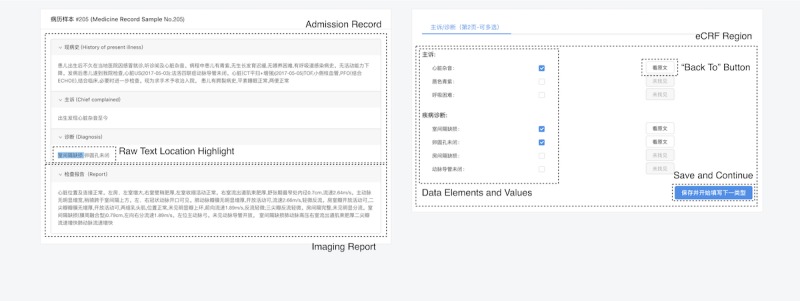
Graphic user interface for electronic case report form (eCRF) data entry.
Gold Standard
The ground truth results of eCRFs for all 120 cases were provided by three clinical researchers involved in the eCRF design. We used a two-step strategy to create our gold standard. First, two invited researchers independently extracted data from medical texts and populated eCRFs using an eCRF application but without the support of NLP-MIES. Our system automatically recorded the populated values and elapsed time for each data entry. Second, for pairs in which the two researchers did not have complete agreement, a third researcher resolved inconsistent data extraction between the two researchers.
Study Design
We conducted a randomized and controlled field experiment at Shanghai Children’s Medical Center to evaluate whether the NLP-MIES group was more effective and efficient than the manual group in the data entry process of eCRF. Participants holding medical degrees, having clinical research experience, or working as clinicians were eligible for inclusion and recruited in this study. The study was approved by the Human Research Ethics Committees of Shanghai Children’s Medical Center. Written informed consent was obtained from all participants prior to randomization.
We randomly allocated the volunteers to two groups by using a completely randomized digital table:
Manual group: participants should check the data elements in the eCRF, find related information in the medical text, and click or enter values accordingly.
NLP-MIES–supported group: NLP-MIES prepopulated the data elements in the eCRF. Participants should check the data elements, find related information in the medical text, and verify or correct values accordingly.
Before the experiment, all participants were authorized and trained to use the system and eCRF-based data entry. We chose a relatively quiet place for the experiment to reduce the potential effect of other environmental factors. Each participant was provided with a laptop and asked to complete all cases from 2:00 pm to 5:00 pm. Participants failing to complete the eCRFs in that time frame were excluded from the data analysis. The order of the 120 cases was randomly shuffled for each participant.
Outcomes and Statistical Analysis
We calculated average accuracy and elapsed time for each participant to finish all assigned eCRFs and compared the differences between the manual and NLP-MIES–supported group. To further analyze data entry errors made by participants under the support of NLP-MIES, we performed a post hoc error analysis for the results provided by NLP-MIES–supported group. We calculated the percentages of two types of data entry errors: error with modification and error without modification. We defined an error with modification as a data entry error made when a participant incorrectly modified a prepopulated result and an error without modification as a data entry error made when a participant kept an incorrect prepopulated result.
Educational and psychological studies have indicated that the distributions of the measurements of how many points participants could get in a certain test and how much time it would take a participant to respond to a certain stimulus (reaction time) were right-skewed [25-27]. Thus, we expected the data for each participant’s average accuracy and elapsed time for finishing eCRFs would not be normally distributed and described them using their median and interquartile range. To evaluate the differences between groups, we made a logarithmic transformation of the data and performed independent group t tests with SAS 9.2 (SAS Institute) software. P value, logarithmic mean difference (MD), ratio of change in geometric mean (exponential of logarithmic mean difference), and corresponding 95% confidence interval were calculated [28]. We considered two-sided P values <.05 as statistically significant.
Results
Participant Characteristics
We recruited a total of 24 eligible participants, 12 for the manual group and 12 for the NLP-MIES–supported group. All the participants successfully completed the eCRFs within the required time. The mean age of participants was 24.66 (SD 2.30) years (manual group 24.70 [SD 2.47] years, NLP-MIES group 24.48 [SD 2.36] years; P=.73); 33% (8/24) of participants were men and 67% (16/24) were women. There were no significant differences between the characteristics of the participants in the two groups.
The overall interoperator consistency rate was 96.85% (1627/1680) for the congenital heart disease condition and 94.82% (1081/1440) for the pneumonia condition (Multimedia Appendix 1).
Accuracy
The overall average accuracy for the congenital heart disease and pneumonia eCRFs was significantly higher in the NLP-MIES–supported group than the manual group (congenital heart disease, P=.03; pneumonia, P=.008; Table 1). For the congenital heart disease eCRFs, the logarithmic MD of average accuracy between groups was 0.14 (95% CI 0.03-0.25), corresponding to an increase of 15% (95% CI 4%-120%) in geometric mean. Similarly, for the pneumonia eCRFs, the logarithmic MD was 0.17 (95% CI 0.06-0.28), corresponding to an increase of 18% (95% CI 6%-32%) in geometric mean. Comparing by types of data elements, the average accuracy was significantly higher in the NLP-MIES–supported group for all types except true-false II and fill-in-the-blank on the congenital heart disease eCRFs. The average accuracy of NLP-MIES prepopulation was slightly higher than median average accuracy of the manual group but lower than that of the NLP-MIES–supported group for most data element types.
Table 1.
Average accuracy for electronic case report form data entry.
| Type of disease and data element | NLPa only | Manual group (median, IQRb) | NLP-MIESc group (median, IQR) | Logarithmic mean difference (95% CI) | Ratio of change in geometric mean (95% CI) | P value | |
| Congenital heart disease |
|
|
|
|
|
||
|
|
True-false Id | 97.50 | 79.17 (66.74, 84.17) | 96.81 (95.69, 97.29) | 0.41 (0.04 to 0.79) | 1.51 (1.03 to 2.20) | .04 |
|
|
True-false IIe | 92.00 | 95.39 (92.67, 95.89) | 97.78 (97.19, 98.44) | 0.21 (–0.01 to 0.10) | 1.10 (0.99 to 1.24) | .10 |
|
|
Multiple choice | 89.33 | 82.80 (73.13, 85.83) | 95.00 (94.58, 97.42) | 0.29 (0.10 to 0.49) | 1.34 (1.10 to 1.63) | .009 |
|
|
Fill-in-the-blank | 94.17 | 96.33 (95.25, 97.00) | 97.00 (95.83, 97.42) | 0.01 (–0.01 to 0.02) | 1.01 (0.99 to 1.02) | .22 |
|
|
Overall | 92.77 | 90.42 (87.75, 92.68) | 97.17 (96.83, 97.44) | 0.14 (0.03 to 0.25) | 1.15 (1.04 to 2.20) | .03 |
| Pneumonia |
|
|
|
|
|
|
|
|
|
True-false I | 88.00 | 70.83 (65.25, 77.75) | 88.17 (87.25, 89.00) | 0.30 (0.11 to 0.50) | 1.35 (1.11 to 1.65) | .009f |
|
|
True-false II | 94.44 | 91.25 (88.26, 93.78) | 95.83 (95.21, 96.81) | 0.11 (0.01 to 0.21) | 1.12 (1.01 to 1.23) | .04 |
|
|
Multiple choice | 80.83 | 67.50 (50.21, 72.50) | 81.25 (77.92, 85.00) | 0.33 (0.14 to 0.52) | 1.39 (1.15 to 1.68) | .003f |
|
|
Overall | 84.15 | 84.21 (80.53, 86.23) | 92.19 (91.49, 93.20) | 0.17 (0.06 to 0.28) | 1.18 (1.06 to 1.32) | .008 |
aNLP: natural language processing.
bIQR: interquartile range.
cNLP-MIES: NLP-driven medical information extraction system.
dTrue-false I: data elements retrieved from admissions records.
eTrue-false II: data elements retrieved from imaging reports (ultrasonic cardiogram or chest x-ray).
fIndependent group t test.
Elapsed Time
The overall average time elapsed for congenital heart disease and pneumonia eCRFs was significantly lower in the NLP-MIES–supported group than the manual group (congenital heart disease, P<.001; pneumonia, P<.001; Table 2). For the congenital heart disease eCRFs, the logarithmic MD of average time elapsed was –0.40 (95% CI –0.55 to –0.25), corresponding to a reduction of 33% (95% CI 22% to 42%) in geometric mean. For the pneumonia eCRFs, the logarithmic MD was –0.37 (95% CI –0.53 to –0.21), corresponding to a reduction of 31% (95% CI 19% to 41%) in geometric mean. Comparing by types of data elements, the average elapsed time was significantly lower in the NLP-MIES–supported group for all types.
Table 2.
Average elapsed time for electronic case report form data entry.
| Type of disease and data element | Manual group seconds (median, IQRa) | NLP-MIESb group seconds (median, IQR) | Logarithmic mean difference (95% CI) | Ratio of change in geometric mean (95% CI) | P value | |
| Congenital heart disease |
|
|
|
|
|
|
|
|
True-false Ic | 26.43 (21.43, 30.24) | 13.84 (11.83, 16.06) | –0.71 (–1.02 to –0.39) | 0.49 (0.36 to 0.68) | <.001 |
|
|
True-false IId | 49.48 (43.08, 51.44) | 35.47 (31.34, 38.63) | –0.29 (–0.46 to –0.11) | 0.75 (0.63 to 0.89) | .003 |
|
|
Multiple choice | 9.70 (10.61, 12.29) | 7.34 (7.47, 8.55) | –0.36 (–0.53 to –0.19) | 0.70 (0.59 to 0.82) | <.001 |
|
|
Fill-in-the-blank | 18.41 (17.35, 19.60) | 12.38 (11.38, 14.70) | –0.34 (–0.50 to –0.17) | 0.71 (0.60 to 0.84) | <.001 |
|
|
Overall | 103.79 (94.59, 109.39) | 69.73 (60.91, 79.66) | –0.40 (–0.55 to –0.25) | 0.67 (0.58 to 0.78) | <.001 |
| Pneumonia |
|
|
|
|
|
|
|
|
True-false I | 28.71 (25.61, 32.61) | 15.82 (14.36, 16.88) | –0.64 (–0.97 to –0.30) | 0.53 (0.38 to 0.74) | .001 |
|
|
True-false II | 31.59 (28.29, 32.49) | 25.22 (22.07, 28.80) | –0.19 (–0.35 to –0.03) | 0.83 (0.71 to 0.97) | .02 |
|
|
Multiple choice | 11.02 (10.65, 12.05) | 8.61 (8.05, 9.25) | –0.33 (–0.51 to –0.15) | 0.72 (0.60 to 0.86) | .001 |
|
|
Overall | 73.28 (65.80, 74.47) | 49.42 (44.33, 53.88) | –0.37 (–0.53 to –0.21) | 0.69 (0.59 to 0.81) | <.001 |
aIQR: interquartile range.
bNLP-MIES: NLP-driven medical information extraction system.
cTrue-false I: data elements retrieved from admissions records.
dTrue-false II: data elements retrieved from imaging reports (ultrasonic cardiogram or chest x-ray).
Error Analysis
Post hoc error analysis showed that errors without modification held the majority of error cases in all types of data elements (Table 3), and the overall percentage of errors without modification was almost 2.5 time higher than the percentage of errors with modification.
Table 3.
Error analysis for natural language processing–driven medical information extraction system–supported data entry.
| Types | Errors, n (%) | |||
|
|
True-false (n=1167) | Multiple choice (n=439) | Fill-in-the-blank (n=121) | Total (N=1727) |
| Errors with modification | 325 (27.85) | 158 (36.00) | 16 (13.22) | 499 (28.89) |
| Errors without modification | 842 (72.15) | 281 (64.01) | 105 (86.78) | 1228 (71.11) |
Discussion
Principal Findings
In this field experiment, we created a mock-up eCRF application with NLP-supported data entry and simulated a real-world eCRF completion process. Results showed a consistent trend across all eCRF topics and data element types indicating NLP-MIES could significantly improve the accuracy and efficiency of data entry. In quantitative evaluation, data entry under the support of NLP-MIES could increase accuracy by approximately (relative change in geometric mean is similar to the change in arithmetic mean) [29] 15% to 18% and reduce elapsed time by one-third.
Many potential factors could contribute to the increased accuracy and efficiency of NLP-MIES–aided data entry. First, we considered NLP-MIES–aided data entry as in essence a process of double-checking—an NLP-MIES check followed by a manual check. In clinical practice, double-checking is a widely used and trusted approach that could significantly reduce medical errors [30,31]. Second, we tried several ways to establish participant trust in NLP-MIES: ensuring NLP-MIES entry accuracy (not worse or even better than manual entry), providing better interpretability (one-click back to raw text), and simplifying system interaction [28]. Third, the overall time elapsed for the manual group was about 50% more than the NLP-MIES–supported group. In our study, higher accuracy was achieved for pneumonia cases than congenital heart disease cases; it may be that extracted information on congenital heart disease cases was more complicated than that of pneumonia cases.
In our post hoc error analysis, we considered errors with modification as cognitive errors. Participants made cognitive errors because they failed to find correct answers (due to limitation of knowledge or lack of training) even though they noticed prepopulated answers were wrong. We considered most errors without modification as commission errors. Participants made commission errors because they followed the prepopulated answers that were incorrect. The result of error analysis indicated that commission errors dominated the data entry quality under the support of NLP-MIES. Overreliance could be a key factor for commission errors and as a side effect of participant trust in NLP-MIES [29]. One possible solution to this problem could be to use NLP-MIES as an independent investigator. In real-world clinical research data management, at least two investigators independently enter data for each case to reduce commission errors and then submit the entries to the clinical research associates (CRAs). The CRAs review and verify the entries to ensure data completeness and quality [30]. In our scenario, the NLP system could act as an independent investigator and provide data entry directly to CRAs rather than prepopulate data for other investigators, and CRAs could make final decisions based on both NLP-MIES–supported and manual entries.
Strengths and Limitations
As far as we know, this is the first study, especially in Chinese language settings, that quantitatively evaluated how NLP technologies could improve the efficiency and efficacy of data collection of clinical research. We believe NLP technologies would be a vital link in the great chain of data exchange between EHRs and EDC. It can potentially extract and transform data from medical text in real time and pose fewer restrictions on clinician freedom of expressions and workflows. In addition, our mock-up NLP-driven eCRF application provided graphical user interface for easy browsing and validation of source text data and data entries to ensure data quality. We believe that the results of our study can provide guidance of future research and development of NLP-driven EDC systems as well as the integration of EDC and EMR systems.
Although the results of our field experiment demonstrated beneficial outcomes for NLP-MIES–supported data entry, there were limitations. First, we did not evaluate the efficacy of NLP-MIES under different prepopulation. Early research has indicated that improving accuracy of the automation system itself may not necessarily improve the performance of human-computer collaboration [31]. Moreover, some studies suggest that automation systems with low accuracy can affect human-computer collaboration and trust [32]. Second, there might be significant differences between our eCRFs and real-world CRFs in contents and types of data elements. Thus, it is inappropriate to extrapolate our quantitative results to real-world settings. Third, since NLP-MIES was designed for Chinese medical records and tested in Chinese eCRFs only, the efficiency of this methodology based on the i2b2 reference standard needs further evaluation in other languages.
Conclusions
In this study, we developed an NLP-driven medical information extraction system based on i2b2 reference standards to facilitate the data entry process of eCRFs for clinical research. We conducted a randomized and controlled field experiment to simulate a real-world data entry process and evaluated the efficacy of our system. The results of our study showed NLP-MIES could significantly improve the accuracy and efficiency of data entry.
Acknowledgments
We would like to thank Gen Gu (software development engineer—natural language processing, Synyi Research, Shanghai, China), Junjie Cai (software development engineer—machine learning, Synyi Research), and Xiaopeng Jia (software development engineer—backend, Synyi Research) for their help and advice during the development of NLP-MIES and the eCRF application. This work was supported by the Shanghai Collaborative Innovation Center for Translational Medicine (TM201720), National Science Foundation of China (81872637, 81728017, 81602868), Shanghai Municipal Commission of Health and Family Planning (201840324, 20164Y0095), National Science and Technology Commission for the Association of Diabetes and Nutrition in Adolescents (2016YFC1305203), Shanghai Children’s Health Service Capacity Construction (GDEK201708), National Human Genetic Resources Sharing Service Platform (2005DKA21300), Science and Technology Development Program of Pudong Shanghai New District (PKJ2017-Y01), Medical and Engineering Cooperation Project of Shanghai Jiao Tong University (YG2017ZD15), Shanghai Professional and Technical Services Platform (18DZ2294100), and the 2019 Science and Technology Innovation–Biomedical Supporting Program of the Shanghai Science and Technology Committee (19441904400).
Abbreviations
- CRA
clinical research associate
- CRF
case report form
- eCRF
electronic case report form
- EDC
electronic data capture
- EHR
electronic health record
- EMR
electronic medical record
- i2b2
informatics for integrating biology and the bedside
- IQR
interquartile range
- MD
mean difference
- NLP
natural language processing
- NLP-MIES
natural language processing–driven medical information extraction system
- SNOMED-CT
Systematized Nomenclature of Medicine–Clinical Terms
- VA
Veterans Affairs
Interoperator agreement and elapsed time for each electronic case report form topic.
Footnotes
Authors' Contributions: JH and KC drafted the manuscript and contributed equally to this work. SL, KC, and SZ designed the study. JH and LF collected the data. SL and LZ obtained the funding. LF and KC were involved in data cleaning and verification, and KC analyzed the data. SL, KC, LZ, and FW contributed to the interpretation of the results and critical revision of the manuscript for important intellectual content. SL had the primary responsibility for the final content. All authors have read and approved the final manuscript.
Conflicts of Interest: None declared.
References
- 1.ClinicalTrials.gov. [2019-06-12]. Trends, charts, and maps https://clinicaltrials.gov/ct2/resources/trends .
- 2.Walther B, Hossin S, Townend J, Abernethy N, Parker D, Jeffries D. Comparison of electronic data capture (EDC) with the standard data capture method for clinical trial data. PLoS One. 2011;6(9):e25348. doi: 10.1371/journal.pone.0025348. http://dx.plos.org/10.1371/journal.pone.0025348 .PONE-D-11-05243 [DOI] [PMC free article] [PubMed] [Google Scholar]
- 3.Bellary S, Krishnankutty B, Latha MS. Basics of case report form designing in clinical research. Perspect Clin Res. 2014 Oct;5(4):159–166. doi: 10.4103/2229-3485.140555. http://www.picronline.org/article.asp?issn=2229-3485;year=2014;volume=5;issue=4;spage=159;epage=166;aulast=Bellary .PCR-5-159 [DOI] [PMC free article] [PubMed] [Google Scholar]
- 4.Fleischmann R, Decker A, Kraft A, Mai K, Schmidt S. Mobile electronic versus paper case report forms in clinical trials: a randomized controlled trial. BMC Med Res Methodol. 2017 Dec 01;17(1):153. doi: 10.1186/s12874-017-0429-y. https://bmcmedresmethodol.biomedcentral.com/articles/10.1186/s12874-017-0429-y .10.1186/s12874-017-0429-y [DOI] [PMC free article] [PubMed] [Google Scholar]
- 5.Dillon DG, Pirie F, Rice S, Pomilla C, Sandhu MS, Motala AA, Young EH, African Partnership for Chronic Disease Research (APCDR) Open-source electronic data capture system offered increased accuracy and cost-effectiveness compared with paper methods in Africa. J Clin Epidemiol. 2014 Dec;67(12):1358–1363. doi: 10.1016/j.jclinepi.2014.06.012. https://linkinghub.elsevier.com/retrieve/pii/S0895-4356(14)00238-8 .S0895-4356(14)00238-8 [DOI] [PMC free article] [PubMed] [Google Scholar]
- 6.Ene-Iordache B, Carminati S, Antiga L, Rubis N, Ruggenenti P, Remuzzi G, Remuzzi A. Developing regulatory-compliant electronic case report forms for clinical trials: experience with the demand trial. J Am Med Inform Assoc. 2009;16(3):404–408. doi: 10.1197/jamia.M2787. http://europepmc.org/abstract/MED/19261946 .M2787 [DOI] [PMC free article] [PubMed] [Google Scholar]
- 7.Le Jeannic A, Quelen C, Alberti C, Durand-Zaleski I, CompaRec Investigators Comparison of two data collection processes in clinical studies: electronic and paper case report forms. BMC Med Res Methodol. 2014 Jan 17;14:7. doi: 10.1186/1471-2288-14-7. https://bmcmedresmethodol.biomedcentral.com/articles/10.1186/1471-2288-14-7 .1471-2288-14-7 [DOI] [PMC free article] [PubMed] [Google Scholar]
- 8.Thriemer K, Ley B, Ame SM, Puri MK, Hashim R, Chang NY, Salim LA, Ochiai RL, Wierzba TF, Clemens JD, Deen JL, Ali SM, Ali M. Replacing paper data collection forms with electronic data entry in the field: findings from a study of community-acquired bloodstream infections in Pemba, Zanzibar. BMC Res Notes. 2012;5:113. doi: 10.1186/1756-0500-5-113. http://www.biomedcentral.com/1756-0500/5/113 .1756-0500-5-113 [DOI] [PMC free article] [PubMed] [Google Scholar]
- 9.Food and Drug Administration. [2019-06-12]. Use of electronic health record data in clinical investigations: guidance for industry https://www.fda.gov/downloads/Drugs/GuidanceComplianceRegulatoryInformation/Guidances/UCM501068.pdf .
- 10.Meystre SM, Savova GK, Kipper-Schuler KC, Hurdle JF. Extracting information from textual documents in the electronic health record: a review of recent research. Yearb Med Inform. 2008:128–144.me08010128 [PubMed] [Google Scholar]
- 11.Matsumura Y, Hattori A, Manabe S, Takahashi D, Yamamoto Y, Murata T, Nakagawa A, Mihara N, Takeda T. Case report form reporter: a key component for the integration of electronic medical records and the electronic data capture system. Stud Health Technol Inform. 2017;245:516–520. [PubMed] [Google Scholar]
- 12.El Fadly A, Rance B, Lucas N, Mead C, Chatellier G, Lastic P, Jaulent M, Daniel C. Integrating clinical research with the Healthcare Enterprise: from the RE-USE project to the EHR4CR platform. J Biomed Inform. 2011 Dec;44 Suppl 1:S94–S102. doi: 10.1016/j.jbi.2011.07.007. https://linkinghub.elsevier.com/retrieve/pii/S1532-0464(11)00125-0 .S1532-0464(11)00125-0 [DOI] [PubMed] [Google Scholar]
- 13.Patrick J, Li M. High accuracy information extraction of medication information from clinical notes: 2009 i2b2 medication extraction challenge. J Am Med Inform Assoc. 2010 Oct;17(5):524–527. doi: 10.1136/jamia.2010.003939. http://jamia.oxfordjournals.org/cgi/pmidlookup?view=long&pmid=20819856 .17/5/524 [DOI] [PMC free article] [PubMed] [Google Scholar]
- 14.Uzuner O, South BR, Shen S, DuVall SL. 2010 i2b2/VA challenge on concepts, assertions, and relations in clinical text. J Am Med Inform Assoc. 2011;18(5):552–556. doi: 10.1136/amiajnl-2011-000203. http://europepmc.org/abstract/MED/21685143 .amiajnl-2011-000203 [DOI] [PMC free article] [PubMed] [Google Scholar]
- 15.Xu Y, Liu J, Wu J, Wang Y, Tu Z, Sun J, Tsujii J, Chang EI. A classification approach to coreference in discharge summaries: 2011 i2b2 challenge. J Am Med Inform Assoc. 2012;19(5):897–905. doi: 10.1136/amiajnl-2011-000734. http://europepmc.org/abstract/MED/22505762 .amiajnl-2011-000734 [DOI] [PMC free article] [PubMed] [Google Scholar]
- 16.Sun W, Rumshisky A, Uzuner O. Evaluating temporal relations in clinical text: 2012 i2b2 Challenge. J Am Med Inform Assoc. 2013;20(5):806–813. doi: 10.1136/amiajnl-2013-001628. http://europepmc.org/abstract/MED/23564629 .amiajnl-2013-001628 [DOI] [PMC free article] [PubMed] [Google Scholar]
- 17.Jagannathan V, Mullett CJ, Arbogast JG, Halbritter KA, Yellapragada D, Regulapati S, Bandaru P. Assessment of commercial NLP engines for medication information extraction from dictated clinical notes. Int J Med Inform. 2009 Apr;78(4):284–291. doi: 10.1016/j.ijmedinf.2008.08.006.S1386-5056(08)00153-6 [DOI] [PubMed] [Google Scholar]
- 18.Xu H, Stenner SP, Doan S, Johnson KB, Waitman LR, Denny JC. MedEx: a medication information extraction system for clinical narratives. J Am Med Inform Assoc. 2010;17(1):19–24. doi: 10.1197/jamia.M3378. http://jamia.oxfordjournals.org/cgi/pmidlookup?view=long&pmid=20064797 .17/1/19 [DOI] [PMC free article] [PubMed] [Google Scholar]
- 19.Zeng QT, Goryachev S, Weiss S, Sordo M, Murphy SN, Lazarus R. Extracting principal diagnosis, co-morbidity and smoking status for asthma research: evaluation of a natural language processing system. BMC Med Inform Decis Mak. 2006;6:30. doi: 10.1186/1472-6947-6-30. http://bmcmedinformdecismak.biomedcentral.com/articles/10.1186/1472-6947-6-30 .1472-6947-6-30 [DOI] [PMC free article] [PubMed] [Google Scholar]
- 20.Lei J, Tang B, Lu X, Gao K, Jiang M, Xu H. A comprehensive study of named entity recognition in Chinese clinical text. J Am Med Inform Assoc. 2014;21(5):808–814. doi: 10.1136/amiajnl-2013-002381. http://europepmc.org/abstract/MED/24347408 .amiajnl-2013-002381 [DOI] [PMC free article] [PubMed] [Google Scholar]
- 21.Jiang M, Chen Y, Liu M, Rosenbloom ST, Mani S, Denny JC, Xu H. A study of machine-learning-based approaches to extract clinical entities and their assertions from discharge summaries. J Am Med Inform Assoc. 2011;18(5):601–606. doi: 10.1136/amiajnl-2011-000163. http://europepmc.org/abstract/MED/21508414 .amiajnl-2011-000163 [DOI] [PMC free article] [PubMed] [Google Scholar]
- 22.Rink B, Harabagiu S, Roberts K. Automatic extraction of relations between medical concepts in clinical texts. J Am Med Inform Assoc. 2011;18(5):594–600. doi: 10.1136/amiajnl-2011-000153. http://europepmc.org/abstract/MED/21846787 .amiajnl-2011-000153 [DOI] [PMC free article] [PubMed] [Google Scholar]
- 23.Ashish N, Dahm L, Boicey C. University of California, Irvine-Pathology Extraction Pipeline: the pathology extraction pipeline for information extraction from pathology reports. Health Informatics J. 2014 Dec;20(4):288–305. doi: 10.1177/1460458213494032.1460458213494032 [DOI] [PubMed] [Google Scholar]
- 24.Chen Y, Lu H, Li L. Automatic ICD-10 coding algorithm using an improved longest common subsequence based on semantic similarity. PLoS One. 2017;12(3):e0173410. doi: 10.1371/journal.pone.0173410. http://dx.plos.org/10.1371/journal.pone.0173410 .PONE-D-16-40232 [DOI] [PMC free article] [PubMed] [Google Scholar]
- 25.Bedard K, Ferrall C. Wage and test score dispersion: some international evidence. Economics of Education Review. 2003 Feb;22(1):31–43. doi: 10.1016/s0272-7757(01)00060-7. [DOI] [Google Scholar]
- 26.Ratcliff R. Methods for dealing with reaction time outliers. Psychol Bull. 1993 Nov;114(3):510–532. doi: 10.1037/0033-2909.114.3.510. [DOI] [PubMed] [Google Scholar]
- 27.Lo S, Andrews S. To transform or not to transform: using generalized linear mixed models to analyse reaction time data. Front Psychol. 2015;6:1171. doi: 10.3389/fpsyg.2015.01171. doi: 10.3389/fpsyg.2015.01171. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 28.Keene ON. The log transformation is special. Stat Med. 1995 Apr 30;14(8):811–819. doi: 10.1002/sim.4780140810. [DOI] [PubMed] [Google Scholar]
- 29.Friedrich JO, Adhikari NKJ, Beyene J. Ratio of geometric means to analyze continuous outcomes in meta-analysis: comparison to mean differences and ratio of arithmetic means using empiric data and simulation. Stat Med. 2012 Jul 30;31(17):1857–1886. doi: 10.1002/sim.4501. [DOI] [PubMed] [Google Scholar]
- 30.Schwappach DLB, Taxis K, Pfeiffer Y. Oncology nurses' beliefs and attitudes towards the double-check of chemotherapy medications: a cross-sectional survey study. BMC Health Serv Res. 2018 Dec 17;18(1):123. doi: 10.1186/s12913-018-2937-9. https://bmchealthservres.biomedcentral.com/articles/10.1186/s12913-018-2937-9 .10.1186/s12913-018-2937-9 [DOI] [PMC free article] [PubMed] [Google Scholar]
- 31.Ross LM, Wallace J, Paton JY. Medication errors in a paediatric teaching hospital in the UK: five years operational experience. Arch Dis Child. 2000 Dec;83(6):492–497. doi: 10.1136/adc.83.6.492. http://adc.bmj.com/cgi/pmidlookup?view=long&pmid=11087283 . [DOI] [PMC free article] [PubMed] [Google Scholar]
- 32.Montague EN, Kleiner BM, Winchester WW. Empirically understanding trust in medical technology. Int J Industr Ergonomics. 2009 Jul;39(4):628–634. doi: 10.1016/j.ergon.2009.01.004. [DOI] [Google Scholar]
- 33.Parasuraman R, Riley V. Humans and automation: use, misuse, disuse, abuse. Hum Factors. 2016 Nov 23;39(2):230–253. doi: 10.1518/001872097778543886. [DOI] [Google Scholar]
- 34.Krishnankutty B, Bellary S, Kumar NBR, Moodahadu LS. Data management in clinical research: an overview. Indian J Pharmacol. 2012 Mar;44(2):168–172. doi: 10.4103/0253-7613.93842. http://www.ijp-online.com/article.asp?issn=0253-7613;year=2012;volume=44;issue=2;spage=168;epage=172;aulast=Krishnankutty .IJPharm-44-168 [DOI] [PMC free article] [PubMed] [Google Scholar]
- 35.Sorkin RD, Woods DD. Systems with human monitors: a signal detection analysis. Hum–Comput Interact. 2009 Nov 11;1(1):49–75. doi: 10.1207/s15327051hci0101_2. [DOI] [Google Scholar]
- 36.Dzindolet MT, Peterson SA, Pomranky RA, Pierce LG, Beck HP. The role of trust in automation reliance. Int J Hum-Comput Stud. 2003 Jun;58(6):697–718. doi: 10.1016/S1071-5819(03)00038-7. [DOI] [Google Scholar]
Associated Data
This section collects any data citations, data availability statements, or supplementary materials included in this article.
Supplementary Materials
Interoperator agreement and elapsed time for each electronic case report form topic.