

Abstract
The use of DNA as a nanoscale construction material has been a rapidly developing field since the 1980s, in particular since the introduction of scaffolded DNA origami in 2006. Although software is available for DNA origami design, the user is generally limited to architectures where finding the scaffold path through the object is trivial. Herein, we demonstrate the automated conversion of arbitrary two‐dimensional sheets in the form of digital meshes into scaffolded DNA nanostructures. We investigate the properties of DNA meshes based on three different internal frameworks in standard folding buffer and physiological salt buffers. We then employ the triangulated internal framework and produce four 2D structures with complex outlines and internal features. We demonstrate that this highly automated technique is capable of producing complex DNA nanostructures that fold with high yield to their programmed configurations, covering around 70 % more surface area than classic origami flat sheets.
Keywords: atomic force microscopy, DNA origami, DNA structures, molecular simulation
Since its introduction in the 1980s,1 DNA nanotechnology has been a rapidly growing and diversifying field. This growth has accelerated since the introduction of scaffolded DNA origami in 2006.2 In a DNA origami structure, a long strand, called the scaffold, traverses the entire structure pairing with hundreds of oligonucleotides, called staple strands, that hold the structure together. The structures are often based around a square or honeycomb lattice3 where finding the scaffold path and designing staples is relatively easy, especially when using software like caDNAno.4 DNA nanostructures based on small polyhedra have been demonstrated with both scaffolded5 and non‐scaffolded6 designs. Scaffolded DNA nanostructures based on meshwork designs have also been demonstrated with crossing four‐arm junctions,7 with others containing meshes with two DNA double helices per edge.8 However, no general strategy for producing arbitrary wireframe 2D structures has been demonstrated.
A major branch of research has been the addition of functional elements to DNA nanostructures to give them novel properties. Carbon nanotubes and metal nanoparticles have been added for electronic9 and plasmonic10 applications. Proteins have been added for templating enzymatic reactions11 or cell signaling studies.12 Fluorophores have been added to study energy transfer13 and to create nanoscale barcodes.14 DNA origami structures have also been used to control the shape of metal particles15 and graphene sheets.16 Demonstrations of drug loading17 and lipid encapsulation18 indicate that DNA nanostructures could serve as drug delivery tools. Many applications rely on single layer DNA objects as they offer the largest 2D canvas for functionalization and are rigid when immobilized on surfaces.
Building on Rothemund's method2 for scaffolded DNA nanostructures, we recently developed a method for automatically generating wireframe structures from polyhedral meshes.19 This method relies on an algorithm for finding an Eulerian scaffold path through the mesh and then automatically generating the staple strands needed for folding the structure. For the algorithmic process to work, the method was previously restricted to inflatable meshes (that can be smoothly transformed into a ball); herein we expand this method to allow the generation of scaffolded DNA nanostructures from arbitrary 2D meshes. We first generate rectangular meshes based on the three regular tessellations (the tiling of a plane with one or more repeating polygons) and investigate their properties with AFM. Then, we use the triangulated 3‐tesselation to generate four DNA designs from 2D meshes.
In the pipeline, the mesh is first reconditioned to remove odd degree vertices (those with an odd number of incident edges) by the introduction of double edges,20 meaning that in the final design, some edges may be converted into two parallel double helices. This is necessary since it is not possible to find an Eulerian circuit scaffold routing through a mesh with odd degree vertices.21 Next, a routing algorithm finds an A‐trail22 route through the mesh, visiting all edges once (except for the double edges) and transiting at the vertices by only exiting on an edge that is a cyclical neighbor to the entering edge (i.e. never crossing across the vertex). A‐trail routing ensures that the scaffold routing does not cross at the vertices and that the designed scaffold path is not knotted.19
After a scaffold route has been found through the mesh, a first approximation of the DNA design is created as a set of rigid cylinders representing the DNA helices connected by springs. This model is simulated in a physical simulation engine19 and the strain of all springs is calculated. Then, the lengths of the edges are iteratively modified to minimize the strain of the springs. When this has finished, the structure is imported to vHelix,28 our custom plug‐in for Autodesk Maya for staple design and export.
The A‐trail routing algorithm requires as input the local order of rotation of edges around the vertices, and for polyhedral graphs, this order can be obtained uniquely using a planar embedding algorithm.23 However, multiple planar embeddings may exist for the graph of a flat sheet (see Figure S1 in the Supporting Information). These embeddings will not share the cyclic ordering of edges in all vertices, and an A‐trail route found in one embedding may not be an A‐trail route for another embedding (see Figure S2). On the other hand, we can fetch the correct local rotation from the face descriptions in the mesh description file (PLY, see below) when the following two conditions are met: 1) all the faces must be described with a consistent orientation, either clockwise or counter‐clockwise, as viewed from one side; 2) the design should not contain any vertex with two incident holes (for example, if two holes of the three‐hole disc in Figure 1 shared a common vertex). We have now implemented a new algorithmic pipeline, described in detail in the Supporting Information, incorporating these changes to also allow flat sheets to be used as an input.
Figure 1.

Example pipeline for the production of a 2D DNA structure from a mesh. A) First, an arbitrarily sized mesh (gray) is created in a 3D graphics software program. From this canvas, the desired mesh (red) is produced by deleting the extra edges and vertices. B) The edges and vertices of the mesh can then be remodeled to create the desired shape. C) An uninterrupted scaffold path through the mesh is then found algorithmically. D) A physical simulation where the DNA helices are represented by rigid cylinders connected by springs is used to generate a DNA model with minimized internal tension. E) This DNA model is imported to vHelix where the final DNA staple design and sequences are generated.
As demonstrated in Figure 1, meshes can be easily created in 3D graphics software. If a mesh with a complex outline and/or complex internal features is required, a large regular mesh can first be created as a canvas. The user can then sculpt the desired mesh by deleting faces from the larger canvas mesh. Standard modeling functions such as extrusions can be used to add extra features to the mesh. In combination with this, the user can move vertices and rescale faces or edges to fine tune the mesh that will template the DNA design. Next, the user exports the mesh to the PLY format and our software28 automatically finds a scaffold route through the mesh and creates a DNA model with minimal tension. The size of the final DNA model is determined by a user specified scaling value.28
First, we investigated the effect of varying the vertex geometries by producing rectangular structures with different internal tessellations. A tessellation where the geometry of every vertex is identical is called a regular tessellation. Only three regular tessellations exist: the 6‐tesselation, consisting of a honeycomb tiling of hexagons, the 4‐tessellation, consisting of a tiling of squares, and the 3‐tesselation, consisting of a tiling of triangles. In these tessellations, the number of edges entering every vertex, or the vertex degree, is identical for all vertices: three for the 6‐tessellation, four for the 4‐tessellation, and six for the 3‐tesselation. This means that the different tessellation will have different vertex degrees and different vertex geometries. Because it is not possible to find a scaffold routing in a mesh containing odd degree vertices, this means that the 6‐tessellation will have its vertices converted into four‐degree vertices by the introduction of double edges. Despite this, the three different tessellations give rectangular sheets with clear differences of internal structure as is visible in Figure 2.
Figure 2.

DNA 2D sheets based on regular tessellations. A) Internal frameworks of DNA 2D structures based on the 6‐tesselation (left), 4‐tesselation (center), and 3‐tesselation (right). Insets: full design structures (drawn to scale). B) 2×2 μm field‐of‐view AFM images of the structures folded with 10 mm MgCl2. C, D) 250×250 nm AFM images of the structures folded with 10 mm MgCl2 buffer (C) or PBS (D). E) 100×40 nm expanded portions of areas marked by boxes in (D). F) Histograms, with data measured from AFM images, where the x‐axis is area per base pair measured in nm2 and the y‐axis shows the number of structures (n). Additional data provided in Figure S5 and Table S1. All scale bars=100 nm.
First, we folded the structures in a standard DNA origami folding buffer containing 10 mm MgCl2 (see the Supporting Information for all buffer components) and assayed the folding quality using agarose gel electrophoreses (Figure S4). This assay revealed monodisperse folding with no visible aggregation. Next, we undertook atomic force microscopy (AFM) of the structures in folding buffer. This further revealed that the flat sheet structures had successfully folded into monodisperse structures with a high degree of similarity to the designs. AFM also revealed internal features of the structures, further indicating that the structures had truly folded as predicted (Figure 2).
AFM also revealed that the overall shapes of the sheets based on the 6‐ and 4‐tessellation did not fully spread out (Figure 2 C). The 6‐tesselation spread well along its long axis but did not fully stretch out along its short axis. The 4‐tesselation did not fully stretch to a regular square but instead appeared to form a rhombus shape. In the DNA designs both of these structures consist of vertices connecting four DNA double helices that is, Holliday junctions. The structure of Holliday junctions is well studied and it is known to exist in stacked or unstacked conformations.24 In the unstacked conformation (represented in Figure 2 A, center), the four DNA helices form a planar cross with right angles. This conformation is however mostly present in the absence of divalent cations. When divalent cations, like Mg2+, are present, the Holliday junction will tend to transition into its stacked conformation where the arms of the junctions form a 60° angle. As the structures were folded and imaged in the presence of 10 mm MgCl2 it is not surprising that the junctions conform into this angled form, leading to a deformation of the overall shape.
Wireframe origami has been shown to fold and remain stable in buffers containing only monovalent salts;19, 25 this may be of great importance for applications where a high concentration of divalent cations is detrimental. Close‐packed origami can be folded with monovalent salts only26 but the concentrations required there are significantly higher than what can be found in physiological buffers.
We tested folding the structures in phosphate‐buffered saline (PBS), a buffer with around 150 mm Na+ that is commonly used in cell‐culture studies. Unfortunately, it is very challenging to perform AFM imaging on DNA origami structures in liquid without divalent salts as they form a charge bridge with the negatively charged mica leading to immobilization. We were able to image structures that were first folded in PBS and then subsequently imaged in a buffer containing 10 mm NaCl and 1–3 mm NiSO4. This demonstrated that the structures could indeed fold in buffers containing only monovalent cations. The AFM data also seem to indicate that the 6‐tesselation, and in particular the 4‐tesselation, stretched out more, consistent with previous findings of unstacking of junctions in the absence of divalent cations.
One of the main motivations for using flat sheet nanostructures for applications is the relatively large 2D canvas offered for functionalization. However, the scaffold raster fill used in classic DNA origami flat sheets may not offer the largest possible surface coverage for a given scaffold strand. Herein, we use the AFM data to measure the areas of the new flat sheets (Figure 2; Figure S5) and compare them with a twist corrected version of the rectangle flat sheet originally published by Rothemund.2 This sheet has an average surface area of 6600 nm2. The new mesh‐based flat sheets have significantly larger surface areas of 13 800, 15 100, and 12 800 nm2 (absolute areas of the sheets) for the 6‐, 4‐, and 3‐tessellations, respectively. These new sheets, however, use 10–17 % more bases in their scaffold. Still, taking this into account, the mesh‐based sheets offer 70–95 % more surface area per scaffold base (Table S1). Here, the 3‐tesselation with a 70 % larger relative surface coverage may be the most relevant comparison as it folds to its programmed shape.
As the design based on the triangulated 3‐tesselation folded into its predicted shape in both buffer conditions, we used this tessellation to create four more structures with both external and internal features. First, a simple ring made from triangulated double faces and an internal diameter of circa 80 nm was designed (Figure 3 A). Inspired by the original work on DNA origami, we designed a triangulated three‐hole disc with a diameter of circa 120 nm. We also made a hand‐shaped sheet with thin finger features made from single triangulated faces, as well as a nanostructured shape representation of the map of Scandinavia, showing Norway, Sweden, and Finland, where internal helices also outline the borders between the countries.
Figure 3.
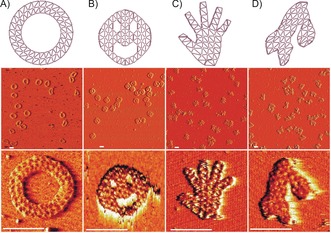
2D sheets based on a triangulated mesh. A) A ring with an inner diameter of 80 nm. B) A three‐hole disc with a diameter of 120 nm. C) A hand‐shaped mesh. D) A mesh shape with an outline representing Norway, Sweden, and Finland. Middle row: 2×2 μm field‐of‐view AFM images of the structures. Bottom row: 200×200 nm AFM images of the structures. All scale bars=100 nm.
These structures folded well into their shapes as indicated by agarose gel electrophoresis (Figure S4), which demonstrated a clean monomeric folding except for the three‐hole disc where some dimerization is seen. AFM was again employed to investigate the folding (Figure 3). As these structures contained finer features, like the fingers on the hand, than the regular sheets, some deformation can be seen in some of the meshes in AFM. However, many structures appeared well‐formed (Table S2).
In conclusion, we have demonstrated that producing 2D DNA nanostructures from meshes is a simple yet powerful method, yielding novel structures with interesting properties. We find that the rigidity of the structures is highly dependent on the meshwork design. Multiple meshworks can be combined in one mesh; this could be utilized to create structures with both rigid and flexible segments. The recent advances in the simulation27 of DNA nanostructures indicate that it may soon be possible to predict the properties of such structures. We find that triangulated meshes fold successfully to their programmed shape and at the same time give 70 % more surface coverage for a given scaffold strand compared to classic DNA origami flat sheets, and in addition can be folded and remain stable under physiological salt conditions.
Supporting information
As a service to our authors and readers, this journal provides supporting information supplied by the authors. Such materials are peer reviewed and may be re‐organized for online delivery, but are not copy‐edited or typeset. Technical support issues arising from supporting information (other than missing files) should be addressed to the authors.
Supplementary
Acknowledgements
This work was funded through grants from the Swedish Research Council (2013‐5883 to B.H.), the Swedish Foundation for Strategic Research (grant FFL12‐0219 to B.H.), the Knut and Alice Wallenberg Foundation (grant KAW2014.0241 to B.H.), and the European Research Council (Grant agreement no. 617791 to A.T.). E.B. was also funded by a Wallenberg Scholars grant to Olle Inganäs. The work of A.M. was funded by the Helsinki Doctoral Education Network on Information and Communications Technology (HICT) and facilitated by the computational resources provided by the Aalto Science‐IT project. We thank Anne‐Louise Bank Kodal and Kurt Gothelf (Aarhus University) for help with early experimental testing.
E. Benson, A. Mohammed, A. Bosco, A. I. Teixeira, P. Orponen, B. Högberg, Angew. Chem. Int. Ed. 2016, 55, 8869.
References
- 1. Seeman N. C., J. Theor. Biol. 1982, 99, 237. [DOI] [PubMed] [Google Scholar]
- 2. Rothemund P. W. K., Nature 2006, 440, 297. [DOI] [PubMed] [Google Scholar]
- 3. Douglas S. M., Dietz H., Liedl T., Högberg B., Graf F., Shih W. M., Nature 2009, 459, 414. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 4. Douglas S. M., Marblestone A. H., Teerapittayanon S., Vazquez A., Church G. M., Shih W. M., Nucleic Acids Res. 2009, 37, 5001. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 5.
- 5a. Shih W. M., Quispe J. D., Joyce G. F., Nature 2004, 427, 618; [DOI] [PubMed] [Google Scholar]
- 5b. Iinuma R., Ke Y., Jungmann R., Schlichthaerle T., Woehrstein J. B., Yin P., Science 2014, 344, 65. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 6.
- 6a. Chen J. H., Seeman N. C., Nature 1991, 350, 631; [DOI] [PubMed] [Google Scholar]
- 6b. Bhatia D., Mehtab S., Krishnan R., Indi S. S., Basu A., Krishnan Y., Angew. Chem. Int. Ed. 2009, 48, 4134; [DOI] [PubMed] [Google Scholar]; Angew. Chem. 2009, 121, 4198; [Google Scholar]
- 6c. Walsh A. S., Yin H., Erben C. M., Wood M. J. A., Turberfield A. J., ACS Nano 2011, 5, 5427; [DOI] [PubMed] [Google Scholar]
- 6d. He Y., Ye T., Su M., Zhang C., Ribbe A. E., Jiang W., Mao C., Nature 2008, 452, 198; [DOI] [PubMed] [Google Scholar]
- 6e. Sadowski J. P., Calvert C. R., Zhang D. Y., Pierce N. A., Yin P., ACS Nano 2014, 8, 3251. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 7. Han D., Pal S., Yang Y., Jiang S., Nangreave J., Liu Y., Yan H., Science 2013, 339, 1412. [DOI] [PubMed] [Google Scholar]
- 8. Zhang F., Jiang S., Wu S., Li Y., Mao C., Liu Y., Yan H., Nat. Nanotechnol. 2015, 10, 779. [DOI] [PubMed] [Google Scholar]
- 9. Maune H. T., Han S.-P., Barish R. D., Bockrath M., Iii W. A. G., Rothemund P. W. K., Winfree E., Nat. Nanotechnol. 2010, 5, 61. [DOI] [PubMed] [Google Scholar]
- 10. Kuzyk A., Schreiber R., Fan Z., Pardatscher G., Roller E.-M., Högele A., Simmel F. C., Govorov A. O., Liedl T., Nature 2012, 483, 311. [DOI] [PubMed] [Google Scholar]
- 11. Voigt N. V., Tørring T., Rotaru A., Jacobsen M. F., Ravnsbaek J. B., Subramani R., Mamdouh W., Kjems J., Mokhir A., Besenbacher F., et al., Nat. Nanotechnol. 2010, 5, 200. [DOI] [PubMed] [Google Scholar]
- 12. Shaw A., Lundin V., Petrova E., Fördős F., Benson E., Al-Amin A., Herland A., Blokzijl A., Högberg B., Teixeira A. I., Nat. Methods 2014, 11, 841. [DOI] [PubMed] [Google Scholar]
- 13. Acuna G. P., Bucher M., Stein I. H., Steinhauer C., Kuzyk A., Holzmeister P., Schreiber R., Moroz A., Stefani F. D., Liedl T., et al., ACS Nano 2012, 6, 3189. [DOI] [PubMed] [Google Scholar]
- 14. Lin C., Jungmann R., Leifer A. M., Li C., Levner D., Church G. M., Shih W. M., Yin P., Nat. Chem. 2012, 4, 832. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 15.
- 15a. Sun W., Boulais E., Hakobyan Y., Wang W. L., Guan A., Bathe M., Yin P., Science 2014, 346, 717; [DOI] [PMC free article] [PubMed] [Google Scholar]
- 15b. Pilo-Pais M., Goldberg S., Samano E., Labean T. H., Finkelstein G., Nano Lett. 2011, 11, 3489. [DOI] [PubMed] [Google Scholar]
- 16. Jin Z., Sun W., Ke Y., Shih C.-J., Paulus G. L. C., Wang Q. H., Mu B., Yin P., Strano M. S., Nat. Commun. 2013, 4, 1663. [DOI] [PubMed] [Google Scholar]
- 17.
- 17a. Zhao Y., Shaw A., Zeng X., Benson E., Nyström A. M., Högberg B., ACS Nano 2012, 6, 8684; [DOI] [PubMed] [Google Scholar]
- 17b. Jiang Q., Song C., Nangreave J., Liu X., Lin L., Qiu D., Wang Z.-G., Zou G., Liang X., Yan H., et al., J. Am. Chem. Soc. 2012, 134, 13396. [DOI] [PubMed] [Google Scholar]
- 18. Perrault S. D., Shih W. M., ACS Nano 2014, 8, 5132. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 19. Benson E., Mohammed A., Gardell J., Masich S., Czeizler E., Orponen P., Högberg B., Nature 2015, 523, 441. [DOI] [PubMed] [Google Scholar]
- 20. Edmonds J., Johnson E. L., Math. Program. 1973, 5, 88. [Google Scholar]
- 21. Euler L., Comment. Acad. Sci. Petropolitanae 1741, 8, 128. [Google Scholar]
- 22.H. Fleischner, Eulerian Graphs and Related Topics, North-Holland, 1990.
- 23. Whitney H., Am. J. Math. 1932, 54, 150. [Google Scholar]
- 24.
- 24a. Murchie A. I., Clegg R. M., von Kitzing E., Duckett D. R., Diekmann S., Lilley D. M., Nature 1989, 341, 763; [DOI] [PubMed] [Google Scholar]
- 24b. Mao C., Sun W., Seeman N. C., J. Am. Chem. Soc. 1999, 121, 5437. [Google Scholar]
- 25. Matthies M., Agarwal N. P., Schmidt T. L., Nano Lett. 2016, 16, 2108. [DOI] [PubMed] [Google Scholar]
- 26. Martin T. G., Dietz H., Nat. Commun. 2012, 3, 1103. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 27.
- 27a. Snodin B. E. K., Romano F., Rovigatti L., Ouldridge T. E., Louis A. A., Doye J. P. K., ACS Nano 2016, 10, 1724; [DOI] [PubMed] [Google Scholar]
- 27b. Pan K., Kim D.-N., Zhang F., Adendorff M. R., Yan H., Bathe M., Nat. Commun. 2014, 5, 5578. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 28.All tools, extensive documentation, and tutorials for implementing the pipeline in practice is available at http://www.vhelix.net.
Associated Data
This section collects any data citations, data availability statements, or supplementary materials included in this article.
Supplementary Materials
As a service to our authors and readers, this journal provides supporting information supplied by the authors. Such materials are peer reviewed and may be re‐organized for online delivery, but are not copy‐edited or typeset. Technical support issues arising from supporting information (other than missing files) should be addressed to the authors.
Supplementary