

Abstract
Background
As the most commonly occurring form of mental illness worldwide, depression poses significant health and economic burdens to both the individual and community. Different types of depression pose different levels of risk. Individuals who suffer from mild forms of depression may recover without any assistance or be effectively managed by primary care or family practitioners. However, other forms of depression are far more severe and require advanced care by certified mental health providers. However, identifying cases of depression that require advanced care may be challenging to primary care providers and health care team members whose skill sets run broad rather than deep.
Objective
This study aimed to leverage a comprehensive range of patient-level diagnostic, behavioral, and demographic data, as well as past visit history data from a statewide health information exchange to build decision models capable of predicting the need of advanced care for depression across patients presenting at Eskenazi Health, the public safety net health system for Marion County, Indianapolis, Indiana.
Methods
Patient-level diagnostic, behavioral, demographic, and past visit history data extracted from structured datasets were merged with outcome variables extracted from unstructured free-text datasets and were used to train random forest decision models that predicted the need of advanced care for depression across (1) the overall patient population and (2) various subsets of patients at higher risk for depression-related adverse events; patients with a past diagnosis of depression; patients with a Charlson comorbidity index of ≥1; patients with a Charlson comorbidity index of ≥2; and all unique patients identified across the 3 above-mentioned high-risk groups.
Results
The overall patient population consisted of 84,317 adult (aged ≥18 years) patients. A total of 6992 (8.29%) of these patients were in need of advanced care for depression. Decision models for high-risk patient groups yielded area under the curve (AUC) scores between 86.31% and 94.43%. The decision model for the overall patient population yielded a comparatively lower AUC score of 78.87%. The variance of optimal sensitivity and specificity for all decision models, as identified using Youden J Index, is as follows: sensitivity=68.79% to 83.91% and specificity=76.03% to 92.18%.
Conclusions
This study demonstrates the ability to automate screening for patients in need of advanced care for depression across (1) an overall patient population or (2) various high-risk patient groups using structured datasets covering acute and chronic conditions, patient demographics, behaviors, and past visit history. Furthermore, these results show considerable potential to enable preventative care and can be easily integrated into existing clinical workflows to improve access to wraparound health care services.
Keywords: depression, supervised machine learning, delivery of health care
Introduction
Background
Depression is the most commonly occurring mental illness worldwide [1]. It negatively affects how up to 350 million persons worldwide think, feel, and interact [2]. Depression poses significant health and economic burdens to both the individual and community [3]. Previous studies have presented a strong comorbidity between mental health and medical conditions [4]. Depression is highly prevalent among patients suffering from various chronic conditions [5,6]. Such patients may suffer up to a 10-to-25-year reduction in life expectancy [7,8]. Depression is also a leading cause of disability for Americans aged between 15 and 44 years [9]. The incremental economic burden of depression covering medical, pharmaceutical, workplace, and suicide-related costs in the United States was evaluated at US $210.5 billion in 2010, a 21.5% increase from 2005 [10].
Different types of depression pose different levels of risk. Individuals who suffer from mild forms of depression may recover without any assistance. Other less severe cases can be effectively managed by primary care or family practitioners [11-13]. However, other forms of depression are far more severe and require advanced care above and beyond that provided by primary care or family practitioners [14,15]. Identifying cases of depression that require advanced care may be challenging to primary care providers and health care team members whose skill sets run broad rather than deep. Training health care teams to successfully identify patients with severe depression would resolve the problem but is unfeasible given cost, effort, and time considerations [16,17]. Social stigma and ignorance of health issues also encourage depression sufferers to downplay their condition, further increasing difficulty in detection and assessment [18].
Many health care systems leverage screening tools such as the Beck Depression Scale [19], the Patient Health Questionnaire-9 (PHQ-9) [20], PHQ-15 [21], the Cornell Scale for Depression in Dementia [22], and the Hamilton Rating Scale for Depression [23] to evaluate depression severity. However, such tools are not optimal as they (1) tie up significant resources [24], (2) rely heavily on potentially inaccurate patient-reported outcomes for decision making [25], and (3) utilize only a small subset of clinical and behavioral data for decision making. In addition, traditional depression screening approaches may increase risk of overdiagnosis and overtreatment of depression across community and primary care settings [26-28] without contributing to better mental health [29]. Recent studies have questioned the benefits of routine screening [30,31] as well as the US Preventive Services Task Force recommendations to screen adults for depression in primary care settings where staff-assisted depression management programs are available [29].
Given such limitations, it is more appropriate to develop machine learning–based screening approaches capable of leveraging more comprehensive patient datasets representing a patient’s overall health status to identify individuals who cannot be treated at primary care alone and would suffer from worsening health conditions unless they are provided with specialized, high-intensity treatment for depression [14,15]. Machine learning enables us to learn from multiple primary and secondary care datasets that might be missed by a clinician because of cognitive burden, and therefore, are a suitable solution to this challenge.
Objectives
For purposes of this research, we have defined individuals whose quality of life and health status will degrade if they do not receive specialized treatment above and beyond primary care as patients in need of advanced care for depression. Operationally, such patients would be identified by evaluating clinical data to detect patients who had received referrals to a certified mental health provider for specialized treatment for depression, indicating that their illnesses cannot be treated at primary care alone. In this study, we leveraged data obtained from varied structured and unstructured datasets to build decision models capable of identifying patients in need of advanced care for depression.
Methods
Patient Population
We identified a population of 84,317 adult patients (≥18 years of age) with at least 1 primary care visit between the years 2011 and 2016 at Eskenazi Health, a leading health care provider in Indianapolis, Indiana.
Patient Subset Selection
We sought to predict the need for advanced care for depression across (1) the overall patient population and (2) different groups of high-risk patient populations. We selected 3 high-risk patient groups: group A: patients with a past diagnosis of depression, group B: patients with a Charlson Comorbidity Index [32] of ≥1, and group C: patients with a Charlson Comorbidity Index of ≥2. Patients with a past diagnosis of depression were flagged as a high-risk group as their illness may re-emerge or worsen based on other health conditions. Patients with Charlson indexes ≥1 and ≥2 were selected because of the high prevalence of depression among patients suffering from one or many chronic illnesses [33] and its ability to worsen health outcomes of patients. Thresholds of ≥1 and ≥2 were selected because they captured patient populations that were adequately large for machine learning processes, as well as the cost/effort of potential implementation. We also identified a fourth group (Group D) that comprised all unique patients identified in groups A to C.
We trained models for different populations to capture as many of the overall number of patients in need of advanced care for depression and to identify which patient groups were most suitable for use in screening for need of advanced care. Furthermore, focusing on a smaller population of high-risk patients may be easier to operationalize and cost-efficient to implement across chronic care clinics. Groups A to D were identified by analyzing diagnostic data on each of the 84,317 unique patients (master patient list) for past diagnosis of depression and to calculate Charlson Comorbidity Index for each patient.
Data Preparation
In a previous effort, we developed a depression taxonomy [34] using knowledge-based terminology extraction of the Unified Medical Language System (UMLS) Metathesaurus [35]. The taxonomy was developed by performing a literature search on Ovid Medline to identify publications that discuss depression and its treatment and then using Metamap [36], a Natural Language Processing–based tool to map these abstracts against the UMLS Metathesaurus, a large, multipurpose, multilingual thesaurus that contains millions of biomedical and health-related concepts, synonymous names, and their relationships across 199 medical dictionaries [37]. The most frequently occurring UMLS concepts were compiled into a terminology using the Web Ontology Language, a semantic Web language that is widely used to represent ontologies. These features presented a wide variety of diagnostic, demographic, and behavioral features that impacted the onset and severity of depression [34].
We obtained longitudinal health records on each patient from the Indiana Network for Patient Care (INPC), a statewide health information exchange [38,39]. Thus, our dataset included records on each patient, including data that may have been captured at any hospital system that participated in the INPC. The dataset included a wide array of patient data, including patient demographic, diagnostic, behavioral, and visit data reported in both structured and unstructured form. All diagnostic data were obtained in the form of structured International Classification of Diseases, ninth revision (ICD-9) and ICD-10 codes. We assessed extracted data against the depression terminology and used relationships presented within the UMLS Metathesaurus to identify ICD codes for inclusion as features. We tabulated vectors of features for each patient group under study. We predict current risk levels based on past patient data. We did not assess the impact of temporality because of our dataset representing a (1) relatively short time period and (2) an older population with high chronic conditions that do not change significantly over time. In the event that the patient under study had received a referral for depression treatment, the data vector only comprised medical data recorded up to 24 hours before the aforesaid referral order. If no past referrals for depression treatment were present, then the vector comprised all available data on the patient. A master data vector encompassing all 84,317 patients was also created using the same approach.
Preparation of Gold Standard
We applied regular expressions to physician referrals to certified mental health providers to identify referrals where the physician was recommending specialized treatment for depression. We determined that our use of regex patterns was 100% accurate via manual review.
Decision Model Building
We split each of the 5 data vectors (4 patient subgroups and 1 master data vector) into random groups of 90% training data and 10% test data. Each training dataset was used to train a decision model using the random forest classification algorithm [40]. The random forest algorithm was selected because of its track record of successful use in decision modeling for health care challenges [41,42] and its ability to develop interpretable machine learning predictions [43]. We used Python programming language (version 2.7.6) for all data preprocessing tasks and the Python scikit-learn package for decision model development and testing [44].
Analysis
Each decision model was evaluated using the 10% holdout test set. Results produced by each decision model were evaluated using area under the curve (AUC) values, which measure classifier accuracy. Youden J Index [45] was used to identify optimal sensitivity and specificity for each decision model.
A flowchart representing our workflow from patient group selection to decision model evaluation can be seen in Figure 1.
Figure 1.
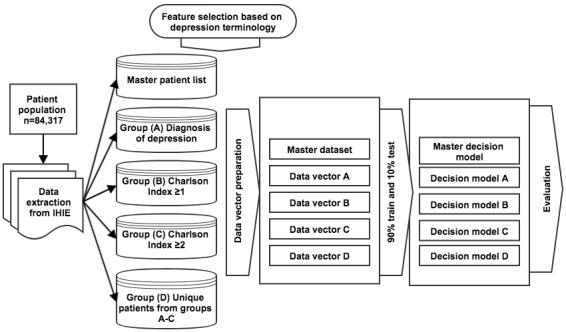
A flowchart representing our workflow from patient group selection to decision model evaluation. IHIE: Indiana Health Information Exchange.
Results
Evaluation of Patient Groups
We identified a total of 12,432 patients with a diagnosis of depression (group A), 32,249 patients with a Charlson Index of 1 or greater (group B), and 7415 patients with a Charlson Index of 2 or more (group C). Overall, these 3 groups identified a total of 37,560 unique patients (group D).
The master patient list as well as each of the 4 high-risk patient groups represented an adult, urban population: predominantly female and with high disease burdens (Table 1). The populations identified by their Charlson Indexes were older (mean age >50 years) than the population identified with depression (46.31 mean age). In addition, populations identified based on Charlson Indexes were predominantly African American. In contrast, the population with a past diagnosis of depression was predominantly composed of non-Hispanic whites. As anticipated, the prevalence of depression across a patient population with a Charlson Index of 1 or greater (30.18%) and a patient population with a Charlson Index of 2 or greater (37.25%) was greater than across the master patient list (19%).
Table 1.
Characteristics of the master patient list/groups of high-risk patients used for decision model building.
| Characteristic of interest | Master patient set: all patients (N=84,317) |
Group A: patients with a past diagnosis of depression |
Group B: patients with a Charlson Index of ≥1 |
Group C: patients with a Charlson Index of ≥2 |
Group D: all unique patients in groups A-C |
||
| Patient group size, n (%) | —a | 12,432 (14.74) | 32,249 (38.25) | 7415 (8.8) | 37,560 (44.5) | ||
| Need of advanced care for depression, n (%) | 6992 (8.29) | 3683 (30.04) | 4016 (12.94) | 1026 (21.6) | 5612 (80.26) | ||
| Demographics | |||||||
| Age (years), mean (SD) | 43.88 (15.60) | 46.31 (14.74) | 51.94 (14.55) | 59.50 (12.33) | 50.31 (14.93) | ||
| Male gender (%) | 35.09 | 30.22 | 39.8 | 43.98 | 42.03 | ||
| Race/ethnicity (%) | |||||||
| White (non-Hispanic) | 25.21 | 44.62 | 33.38 | 37.02 | 35.31 | ||
| African American (non-Hispanic) | 37.23 | 32.01 | 42.78 | 47.26 | 40.12 | ||
| Hispanic or Latino | 19.47 | 11.12 | 10.60 | 4.94 | 7.38 | ||
| Diagnoses | |||||||
| Depression (%) | 19.07 | 100 | 30.18 | 37.25 | 37.51 | ||
| Charlson Index score, mean (SD) | 0.77 (1.21) | 0.22 (0.75) | 1.89 (1.27) | 3.85 (1.14) | 1.62 (1.35) | ||
| Hospitalizations, mean (SD) | |||||||
| EDb visits during current month | 0.21 (1.03) | 0.33 (1.48) | 0.26 (1.15) | 0.31 (1.14) | 0.27 (1.17) | ||
| ED visits before previous months | 3.73 (14.40) | 4.69 (18.73) | 8.63 (24.2) | 10.71 (31.36) | 8.03 (23.67) | ||
aNot applicable.
bED: emergency department.
Figure 2 presents a Venn diagram presenting overlap across the high-risk patient groups identified for the study.
Figure 2.
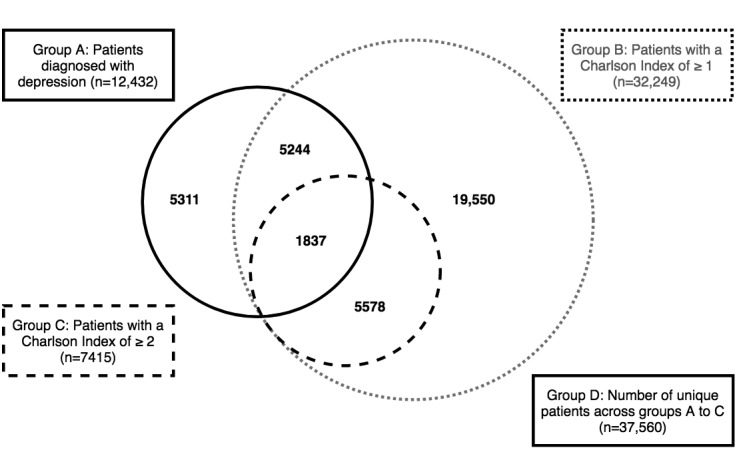
Overlap between the patient groups identified for the study.
A total of 6992 (8.29%) of the 84,317 patients in the master patient list were in need of advanced care for depression. Group A captured 3683 (52.68%) of these patients, group B captured 4016 (57.43%), and group C captured 1026 (14.67%). Overall, all 3 patient groups were able to identify 5612 (80.26%) of all patients in need of advanced care for depression.
Feature Selection Using the Depression Terminology
Comparison of patient data against the depression terminology resulted in the identification of 1150 unique concepts for inclusion in each decision model. A description of features included in each of the decision models is presented in Multimedia Appendix 1.
Decision Model Performance
The decision model predicting need of advanced care across the master population reported a moderate AUC score of 78.87% (optimal sensitivity=68.79%, optimal specificity=76.30%). However, decision models to predict need of advanced care across patients’ groups A to D performed significantly better. Group A (patients with a past diagnosis of depression) reported an AUC score of 87.29% (optimal sensitivity=77.84%, optimal specificity=82.66%). Group B (patients with a Charlson Index of ≥1) reported an AUC score of 91.78% (optimal sensitivity=81.05%, optimal specificity=89.21%). Group C (patients with a Charlson Index of ≥ 2) reported an AUC score of 94.43% (optimal sensitivity=83.91%, optimal specificity=92.18%), whereas Group D (list of unique patients from groups A-C) reported an AUC score of 86.31% (Figure 3; optimal sensitivity=75.31%, optimal specificity=76.03%). Precision-recall curves for each decision model are presented in Multimedia Appendix 2.
Figure 3.
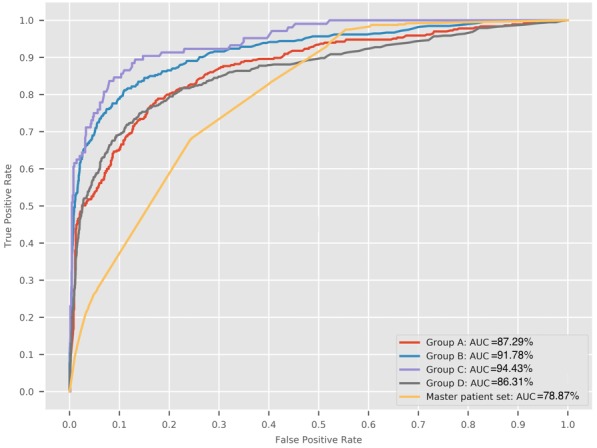
Receiver operating characteristic curves produced by decision models predicting need of advanced care across each patient group under study. AUC: area under the curve.
The top 20 features for each decision model can be seen in Multimedia Appendix 3. Multimedia Appendix 4 presents the co-occurrence of these top 20 features across each decision model under study. In assessing the top ranked features selected for each decision model, we found significant overlap among the top features for each of the high-risk patient populations. Furthermore, essential (primary) hypertension, depression, gender, and number of outpatient visits appears in the top 20 feature lists for every patient population under test.
To demonstrate that the models did not suffer from overtraining, we added an additional evaluation step where we compared model performance across smaller feature subset sizes. We ranked all features for each decision model using information gain aka. Kullback-Leibler divergence [46]. For each patient subgroup, we used the ranked feature lists to build multiple decision models starting with a decision model trained using only the 5 top ranking features, iteratively adding on the next most important feature, retraining the model and evaluating performance using F1 core. We continued this process until we had trained n-5 models using all n features in the feature set. As an example, for patient group A, we began by building a decision model consisting of 5 patient-centric features and assessing its performance using F1 score. Afterwards, we added in the 6th most important feature and retrained a decision model consisting of these 6 features. We continued building models and evaluating F1 scores until we had included all features from each dataset. The results of this exercise (Multimedia Appendix 5) demonstrated that model performance plateaued after the top 10 to 20 features and that inclusion of further features did not improve model performance. This demonstrates that the models were not overfit and that they reached optimal performance after a relatively small number of features.
Discussion
Principal Findings
The decision model to predict need of advanced care for depression across the overall patient population achieved an AUC score of 78.87%. In comparison, decision models that predicted need of advanced care across 4 high-risk patient groups performed better, with AUC scores ranging from 86.31 to 94.43%. In addition, optimal sensitivity and specificity for each decision model was significantly high and demonstrated the models’ potential for practical implementation.
We attribute the comparatively lower performance of the decision model developed using the overall population to the unbalanced nature of the gold standard [47] caused by the relatively low prevalence (8.29%) of patients in need of advanced care and the sparsity of data available for some of the patients in the overall patient population. The high performance of the decision models built using high-risk patient groups could be attributed to the higher prevalence of patients in need of advanced care. Although various publications have presented approaches to address data imbalance [48,49], we did not pursue such as approach as we wished to focus on demonstrating methods that could be replicated across other datasets that may or may not be imbalanced.
In assessing prediction performance, group C (patients with a Charlson Index ≥2) yielded the highest AUC score (97.43%). Groups A (patients with a diagnosis of depression) and B (patients with a Charlson Index ≥1) reported lesser AUC scores. Group C captured the least number of patients in need of advanced care in comparison with groups A and B. However, it is noteworthy that none of the decision models developed using high-risk populations could capture all patients in need of advanced care. Overall, all 3 models could capture only 80.26% of all patients in need of advanced care. The remainder (19.74%) of the patients in need of advanced care did not qualify for any of the three high-risk patient populations. We hypothesize that a share of the missing 19.74% patients would have fallen into 1 of the 3 high-risk patient groups had more comprehensive data been available, and thus, been eligible for detection.
We present a novel application of machine learning to address a question of significant clinical relevance. We demonstrated the ability to predict the need of advanced care for depression across various patient populations with considerable predictive performance. These efforts can easily be integrated into existing hospital workflows [42]. As wraparound services are not delivered by primary care providers [50], the ability to identify and refer patients in need of such services is extremely important [51]. Our efforts yield a highly accurate, automated approach for identifying patients in need of wraparound services for mental health, which is of growing importance to health care organizations and incentivized by changing reimbursement policies. By predicting the need for advanced care across various high-risk populations, we offer potential implementers the option of selecting the best screening approach that meets their needs. Our approach is also well suited to leverage increasing health information technology adoption and interoperability of health care datasets for community-wide health transformations [52,53]. In the field of population health informatics, it enables organizations to leverage widespread acceptance and use of machine learning for cross organizational collaboration and management of various datasets [53] while giving implementers the freedom to select methods best suited for each hospital system. Furthermore, such applications of predictive modeling could support organization-level population health initiatives as risk stratification is fundamental to identifying those patients who are most in need of services to improve health and well-being. In addition, implementing such solutions at primary care ensure that facilitating the entry of all patients into the health care system is more efficient than stand-alone implementations at each chronic care clinic. Thus, our approach presents the ability to effectively identify need of advanced care for depression without risk of overdiagnosis and overtreatment and without the use of manual screening mechanisms.
There is limited knowledge on the best approach to integrate machine learning approaches into existing clinical workflows. As highlighted above, primary care facilities are the point of entry by which a majority of patients suffering from depression seek care [54,55]. However, application of machine learning solutions to screen every primary care visit may be cost-intensive and inefficient for certain clinical practices. Thus, alternate models to evaluate a subset of high-risk patients in need of advanced care for depression would be useful. The 2 potential high-risk patient populations are (1) patients already diagnosed with depression and (2) patients with chronic conditions, who are thus, are at higher risk of suffering from depression [56]. Models built using these subsets may be more practical and result in better machine learning performance than models built using all primary care patients because of variability of underlying data and higher prevalence of outcome of interest, which enables better model training.
We identified several limitations in our study approach. We adopted a binary (present/absent) flag for each feature used to train decision models. We hypothesize that switching to tabulated counts for each feature will increase the granularity of the feature vector, thereby increasing model performance. The patient group used in our study was obtained from the Eskenazi Health system, a safety-net population with significant health burdens. Thus, our models may not generalize to other commercially insured or broader populations. Our diagnostic data were limited to ICD codes. Integrating medications, laboratory, and clinical procedure data may further improve decision model performance. Furthermore, studies present that social determinants of health such as low-educational attainment, poverty, unemployment, and social isolation may have a significant impact on depression and the need for treatment [57,58]. We propose to expand our models using social determinants of health to assess their impact on decision model performance.
We acknowledge that incompleteness of EMR data [59] may impact model performance. Use of claims data may have enabled us to identify a greater number of patients in need of specified treatment into each of our patient subgroups [60]. Furthermore, our outcome of interest are patients in need of advanced care, as identified by primary care providers. Thus, we were unable to account for patients who received advanced care for depression without a past referral. Such patients could have been identified from claims data and used to augment our gold standard.
We selected the random forest classification algorithm for decision-model building based on the need to develop high performance models that were easily interpretable to our clinical audience [42,43]. Other, more advanced decision-modeling approaches such as neural networks [61] have shown potential to improve machine learning performance across various health care challenges. However, neural networks are more complex, cost-intensive, and difficult to interpret [62], making it harder to gain provider acceptance of such models. In addition, it is unclear if they can contribute to our study given the significant performance measures already achieved using random forest models. We recommend that neural networks be considered in a scenario where the sequence or temporality of clinical events is being evaluated, or where the performance of random forest models is unsatisfactory.
In conclusion, these results present considerable potential to enable preventative care and can be potentially integrated into existing clinical workflows to improve access to wraparound health care services.
Conclusions
Our efforts demonstrate the ability to identify patients in need of advanced care for depression across (1) an overall patient population and (2) various groups of high-risk patients using a wide range of acute and chronic conditions, patient demographics, behaviors, and past visit history. Although all models yielded significant performance accuracy, models focused on high-risk patient populations yielded comparatively better results. Furthermore, our methods present a replicable approach for implementers to adopt based on their own needs and priorities. However, decision model performance may differ based on the availability of patient data at each health care system. These results show considerable potential to enable preventative care and can be easily integrated into existing clinical workflows to improve access to wraparound health care services.
Acknowledgments
This research received no specific grant from any funding agency in the public, commercial, or not-for-profit sectors.
Abbreviations
- AUC
area under the curve
- ICD
International Classification of Diseases
- INPC
Indiana Network for Patient Care
- PHQ
Patient Health Questionnaire
- UMLS
Unified Medical Language System
Types of patient data used in decision-model building.
Precision-recall curve for each decision model under study.
List of 20 top features (ranked in order of best to worst) for each decision model, together with their least absolute shrinkage and selection operator scores.
Co-occurrence of top 20 features across each of the patient populations under test (1=most important, 20=least important).
F1 scores for each decision model trained using iteratively increasing feature subset sizes. For clarity, our plot includes only models trained using the top 50 features for each patient subgroup.
{kind=link}
Footnotes
Authors' Contributions: The primary author proposed and completed the study as part of his doctoral dissertation. The coauthors, who are all members of his dissertation committee, contributed significantly to the acquisition, analysis, and interpretation of data, rigor of the methodology and analysis, as well as contributing to write the manuscript.
Conflicts of Interest: None declared.
References
- 1.World Health Organization. 2012. Depression: A Global Crisis. World Mental Health Day, October 10 2012 https://www.who.int/mental_health/management/depression/wfmh_paper_depression_wmhd_2012.pdf.
- 2.American Psychiatric Association. 2016. [2018-01-01]. What is Depression? https://www.psychiatry.org/patients-families/depression/what-is-depression.
- 3.Lépine JP, Briley M. The increasing burden of depression. Neuropsychiatr Dis Treat. 2011;7(Suppl 1):3–7. doi: 10.2147/NDT.S19617. doi: 10.2147/NDT.S19617. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 4.Goodell S, Druss BG, Walker ER. Mental disorders and medical comorbidity. Synth Proj Res Synth Rep. 2011 Feb;(21):1–26. https://www.rwjf.org/en/library/research/2011/02/mental-disorders-and-medical-comorbidity.html. [PubMed] [Google Scholar]
- 5.Yohannes A, Willgoss T, Baldwin R, Connolly M. Depression and anxiety in chronic heart failure and chronic obstructive pulmonary disease: prevalence, relevance, clinical implications and management principles. Int J Geriatr Psychiatry. 2010 Dec;25(12):1209–21. doi: 10.1002/gps.2463. [DOI] [PubMed] [Google Scholar]
- 6.Nouwen A, Winkley K, Twisk J, Lloyd C, Peyrot M, Ismail K, Pouwer F, European Depression in Diabetes (EDID) Research Consortium Type 2 diabetes mellitus as a risk factor for the onset of depression: a systematic review and meta-analysis. Diabetologia. 2010 Dec;53(12):2480–6. doi: 10.1007/s00125-010-1874-x. http://europepmc.org/abstract/MED/20711716. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 7.World Health Organization. 2016. [2018-03-01]. Premature Death Among People With Severe Mental Disorders http://www.who.int/mental_health/management/info_sheet.pdf. [PubMed]
- 8.Hawton K, Casañas IC, Haw C, Saunders K. Risk factors for suicide in individuals with depression: a systematic review. J Affect Disord. 2013 May;147(1-3):17–28. doi: 10.1016/j.jad.2013.01.004. [DOI] [PubMed] [Google Scholar]
- 9.Mathers C, Fat DM, Boerma JT. World Health Organization. 2008. The Global Burden of Disease: 2004 Update https://www.who.int/healthinfo/global_burden_disease/2004_report_update/en/
- 10.Greenberg PE, Fournier AA, Sisitsky T, Pike CT, Kessler RC. The economic burden of adults with major depressive disorder in the United States (2005 and 2010) J Clin Psychiatry. 2015 Feb;76(2):155–62. doi: 10.4088/JCP.14m09298. http://www.psychiatrist.com/jcp/article/pages/2015/v76n02/v76n0204.aspx. [DOI] [PubMed] [Google Scholar]
- 11.Wagner HR, Burns B, Broadhead W, Yarnall K, Sigmon A, Gaynes B. Minor depression in family practice: functional morbidity, co-morbidity, service utilization and outcomes. Psychol Med. 2000 Nov;30(6):1377–90. doi: 10.1017/S0033291799002998. [DOI] [PubMed] [Google Scholar]
- 12.Wells KB, Sherbourne C, Schoenbaum M, Duan N, Meredith L, Unützer J, Miranda J, Carney MF, Rubenstein LV. Impact of disseminating quality improvement programs for depression in managed primary care: a randomized controlled trial. J Am Med Assoc. 2000 Jan 12;283(2):212–20. doi: 10.1001/jama.283.2.212. [DOI] [PubMed] [Google Scholar]
- 13.Williams Jr JW, Barrett J, Oxman T, Frank E, Katon W, Sullivan M, Cornell J, Sengupta A. Treatment of dysthymia and minor depression in primary care: a randomized controlled trial in older adults. J Am Med Assoc. 2000 Sep 27;284(12):1519–26. doi: 10.1001/jama.284.12.1519. [DOI] [PubMed] [Google Scholar]
- 14.Saloheimo HP, Markowitz J, Saloheimo TH, Laitinen JJ, Sundell J, Huttunen MO, Aro AT, Mikkonen T, Katila OH. Psychotherapy effectiveness for major depression: a randomized trial in a Finnish community. BMC Psychiatry. 2016 May 6;16:131. doi: 10.1186/s12888-016-0838-1. https://bmcpsychiatry.biomedcentral.com/articles/10.1186/s12888-016-0838-1. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 15.Cuijpers P, van Straten A, Andersson G, van Oppen P. Psychotherapy for depression in adults: a meta-analysis of comparative outcome studies. J Consult Clin Psychol. 2008 Dec;76(6):909–22. doi: 10.1037/a0013075. [DOI] [PubMed] [Google Scholar]
- 16.Sharp LK, Lipsky MS. Screening for depression across the lifespan: a review of measures for use in primary care settings. Am Fam Physician. 2002 Sep 15;66(6):1001–8. http://www.aafp.org/link_out?pmid=12358212. [PubMed] [Google Scholar]
- 17.US Preventive Services Task Force Screening for depression in adults: US preventive services task force recommendation statement. Ann Intern Med. 2009 Dec 1;151(11):784–92. doi: 10.7326/0003-4819-151-11-200912010-00006. [DOI] [PubMed] [Google Scholar]
- 18.Corrigan P. How stigma interferes with mental health care. Am Psychol. 2004 Oct;59(7):614–25. doi: 10.1037/0003-066X.59.7.614. [DOI] [PubMed] [Google Scholar]
- 19.Beck AT, Steer RA, Brown GK. BDI-II, Beck Depression Inventory: Manual. Second Edition. San Antonio, Texas: Psychological Corporation; 1996. [Google Scholar]
- 20.Gilbody S, Richards D, Brealey S, Hewitt C. Screening for depression in medical settings with the patient health questionnaire (PHQ): a diagnostic meta-analysis. J Gen Intern Med. 2007 Nov;22(11):1596–602. doi: 10.1007/s11606-007-0333-y. http://europepmc.org/abstract/MED/17874169. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 21.Kroenke K, Spitzer RL, Williams JB. The PHQ-15: validity of a new measure for evaluating the severity of somatic symptoms. Psychosom Med. 2002;64(2):258–66. doi: 10.1097/00006842-200203000-00008. [DOI] [PubMed] [Google Scholar]
- 22.Alexopoulos GS, Abrams RC, Young RC, Shamoian CA. Cornell scale for depression in dementia. Biol Psychiatry. 1988 Feb 1;23(3):271–84. doi: 10.1016/0006-3223(88)90038-8. [DOI] [PubMed] [Google Scholar]
- 23.Williams JB. Standardizing the Hamilton depression rating scale: past, present, and future. Eur Arch Psychiatry Clin Neurosci. 2001;251(Suppl 2):II6–12. doi: 10.1007/BF03035120. [DOI] [PubMed] [Google Scholar]
- 24.Valenstein M, Vijan S, Zeber JE, Boehm K, Buttar A. The cost-utility of screening for depression in primary care. Ann Intern Med. 2001 Mar 6;134(5):345–60. doi: 10.7326/0003-4819-134-5-200103060-00007. [DOI] [PubMed] [Google Scholar]
- 25.Kerr LK, Kerr Jr LD. Screening tools for depression in primary care: the effects of culture, gender, and somatic symptoms on the detection of depression. West J Med. 2001 Nov;175(5):349–52. doi: 10.1136/ewjm.175.5.349. http://europepmc.org/abstract/MED/11694495. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 26.Mojtabai R, Olfson M. Proportion of antidepressants prescribed without a psychiatric diagnosis is growing. Health Aff (Millwood) 2011 Aug;30(8):1434–42. doi: 10.1377/hlthaff.2010.1024. [DOI] [PubMed] [Google Scholar]
- 27.Mojtabai R. Clinician-identified depression in community settings: concordance with structured-interview diagnoses. Psychother Psychosom. 2013;82(3):161–9. doi: 10.1159/000345968. [DOI] [PubMed] [Google Scholar]
- 28.Dowrick C, Frances A. Medicalising unhappiness: new classification of depression risks more patients being put on drug treatment from which they will not benefit. Br Med J. 2013 Dec 9;347:f7140. doi: 10.1136/bmj.f7140. [DOI] [PubMed] [Google Scholar]
- 29.Thombs BD, Ziegelstein RC, Roseman M, Kloda LA, Ioannidis JP. There are no randomized controlled trials that support the United States Preventive Services Task Force Guideline on screening for depression in primary care: a systematic review. BMC Med. 2014 Jan 28;12:13. doi: 10.1186/1741-7015-12-13. https://bmcmedicine.biomedcentral.com/articles/10.1186/1741-7015-12-13. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 30.Thombs BD, Coyne JC, Cuijpers P, de Jonge P, Gilbody S, Ioannidis JP, Johnson BT, Patten SB, Turner EH, Ziegelstein RC. Rethinking recommendations for screening for depression in primary care. CMAJ. 2012 Mar 6;184(4):413–8. doi: 10.1503/cmaj.111035. http://www.cmaj.ca/cgi/pmidlookup?view=long&pmid=21930744. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 31.Gilbody S, Sheldon T, Wessely S. Should we screen for depression? Br Med J. 2006 Apr 29;332(7548):1027–30. doi: 10.1136/bmj.332.7548.1027. http://europepmc.org/abstract/MED/16644833. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 32.Charlson ME, Charlson RE, Peterson JC, Marinopoulos SS, Briggs WM, Hollenberg JP. The Charlson comorbidity index is adapted to predict costs of chronic disease in primary care patients. J Clin Epidemiol. 2008 Dec;61(12):1234–40. doi: 10.1016/j.jclinepi.2008.01.006. [DOI] [PubMed] [Google Scholar]
- 33.DeJean D, Giacomini M, Vanstone M, Brundisini F. Patient experiences of depression and anxiety with chronic disease: a systematic review and qualitative meta-synthesis. Ont Health Technol Assess Ser. 2013;13(16):1–33. http://europepmc.org/abstract/MED/24228079. [PMC free article] [PubMed] [Google Scholar]
- 34.Kasthurirathne SN. IUPUI Scholar Works Repository. 2018. The Use of Clinical, Behavioral, and Social Determinants of Health to Improve Identification of Patients in Need of Advanced Care for Depression https://scholarworks.iupui.edu/bitstream/handle/1805/17765/Kasthurirathne_iupui_0104D_10328.pdf?sequence=1&isAllowed=y.
- 35.National Library of Medicine - National Institutes of Health. 2016. [2018-02-01]. Unified Medical Language System® (UMLS®): Metathesaurus https://www.nlm.nih.gov/research/umls/knowledge_sources/metathesaurus/
- 36.Aronson AR, Lang FM. An overview of MetaMap: historical perspective and recent advances. J Am Med Inform Assoc. 2010;17(3):229–36. doi: 10.1136/jamia.2009.002733. http://europepmc.org/abstract/MED/20442139. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 37.National Library of Medicine - National Institutes of Health. 2015. [2018-01-01]. Fact Sheet: Unified Medical Language System https://www.nlm.nih.gov/pubs/factsheets/umls.html.
- 38.McDonald CJ, Overhage JM, Barnes M, Schadow G, Blevins L, Dexter PR, Mamlin B, INPC Management Committee The Indiana network for patient care: a working local health information infrastructure. An example of a working infrastructure collaboration that links data from five health systems and hundreds of millions of entries. Health Aff (Millwood) 2005;24(5):1214–20. doi: 10.1377/hlthaff.24.5.1214. [DOI] [PubMed] [Google Scholar]
- 39.Overhage JM. The Indiana health information exchange. In: Dixon BE, editor. Health Information Exchange: Navigating and Managing a Network of Health Information Systems. Waltham, MA: Academic Press; 2016. pp. 267–79. [Google Scholar]
- 40.Breiman L. Random forests. Mach Learn. 2001;45(1):5–32. doi: 10.1023/A:1010933404324. [DOI] [Google Scholar]
- 41.Kasthurirathne SN, Dixon BE, Gichoya J, Xu H, Xia Y, Mamlin B, Grannis S. Toward better public health reporting using existing off the shelf approaches: a comparison of alternative cancer detection approaches using plaintext medical data and non-dictionary based feature selection. J Biomed Inform. 2016 Apr;60:145–52. doi: 10.1016/j.jbi.2016.01.008. https://linkinghub.elsevier.com/retrieve/pii/S1532-0464(16)00009-5. [DOI] [PubMed] [Google Scholar]
- 42.Kasthurirathne SN, Vest JR, Menachemi N, Halverson PK, Grannis SJ. Assessing the capacity of social determinants of health data to augment predictive models identifying patients in need of wraparound social services. J Am Med Inform Assoc. 2018 Dec 1;25(1):47–53. doi: 10.1093/jamia/ocx130. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 43.Qi Y. Random forest for bioinformatics. In: Zhang C, Ma Y, editors. Ensemble Machine Learning: Methods and Applications. New York: Springer; 2012. pp. 307–23. [Google Scholar]
- 44.Pedregosa F, Varoquaux G, Gramfort A, Michel V, Thirion B, Grisel O, Blondel M, Prettenhofer P, Weiss R, Dubourg V, Vanderplas J, Passos A, Cournapeau D, Brucher M, Perrot M, Duchesnay E. Scikit-Learn: Machine Learning in Python. J Mach Learn Res. 2011;12:2825–30. http://www.jmlr.org/papers/volume12/pedregosa11a/pedregosa11a.pdf. [Google Scholar]
- 45.Youden WJ. Index for rating diagnostic tests. Cancer. 1950 Jan;3(1):32–5. doi: 10.1002/1097-0142(1950)3:1<32::aid-cncr2820030106>3.0.co;2-3. [DOI] [PubMed] [Google Scholar]
- 46.Polani D. Kullback-leibler divergence. In: Dubitzky W, Wolkenhauer O, Cho KH, Yokota H, editors. Encyclopedia of Systems Biology. New York: Springer; 2013. pp. 1087–8. [Google Scholar]
- 47.Khalilia M, Chakraborty S, Popescu M. Predicting disease risks from highly imbalanced data using random forest. BMC Med Inform Decis Mak. 2011 Jul 29;11:51. doi: 10.1186/1472-6947-11-51. https://bmcmedinformdecismak.biomedcentral.com/articles/10.1186/1472-6947-11-51. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 48.Zong W, Huang GB, Chen YJ. Weighted extreme learning machine for imbalance learning. Neurocomputing. 2013 Feb;101:229–42. doi: 10.1016/j.neucom.2012.08.010. [DOI] [Google Scholar]
- 49.Lemaître G, Nogueira F, Aridas CK. Imbalanced-learn: a python toolbox to tackle the curse of imbalanced datasets in machine learning. J Mach Learn Res. 2017;18(1):559–63. https://dl.acm.org/citation.cfm?id=3122026. [Google Scholar]
- 50.Loeb DF, Binswanger IA, Candrian C, Bayliss EA. Primary care physician insights into a typology of the complex patient in primary care. Ann Fam Med. 2015 Sep;13(5):451–5. doi: 10.1370/afm.1840. http://www.annfammed.org/cgi/pmidlookup?view=long&pmid=26371266. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 51.Jackson GL, Powers BJ, Chatterjee R, Bettger JP, Kemper AR, Hasselblad V, Dolor RJ, Irvine RJ, Heidenfelder BL, Kendrick AS, Gray R, Williams JW. The patient centered medical home. A systematic review. Ann Intern Med. 2013 Dec 5;158(3):169–78. doi: 10.7326/0003-4819-158-3-201302050-00579. [DOI] [PubMed] [Google Scholar]
- 52.Kharrazi H, Weiner JP. IT-enabled community health interventions: challenges, opportunities, and future directions. EGEMS (Wash DC) 2014;2(3):1117. doi: 10.13063/2327-9214.1117. http://europepmc.org/abstract/MED/25848627. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 53.Kharrazi H, Lasser EC, Yasnoff WA, Loonsk J, Advani A, Lehmann HP, Chin D, Weiner J. A proposed national research and development agenda for population health informatics: summary recommendations from a national expert workshop. J Am Med Inform Assoc. 2017 Dec;24(1):2–12. doi: 10.1093/jamia/ocv210. http://europepmc.org/abstract/MED/27018264. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 54.Cape J, Whittington C, Buszewicz M, Wallace P, Underwood L. Brief psychological therapies for anxiety and depression in primary care: meta-analysis and meta-regression. BMC Med. 2010 Jun 25;8:38. doi: 10.1186/1741-7015-8-38. https://bmcmedicine.biomedcentral.com/articles/10.1186/1741-7015-8-38. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 55.Gilbody S, Littlewood E, Hewitt C, Brierley G, Tharmanathan P, Araya R, Barkham M, Bower P, Cooper C, Gask L, Kessler D, Lester H, Lovell K, Parry G, Richards DA, Andersen P, Brabyn S, Knowles S, Shepherd C, Tallon D, White D. Computerised cognitive behaviour therapy (cCBT) as treatment for depression in primary care (REEACT trial): large scale pragmatic randomised controlled trial. Br Med J. 2015;351:h5627. doi: 10.1136/bmj.h5627. http://europepmc.org/abstract/MED/26759375. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 56.Katon WJ. Epidemiology and treatment of depression in patients with chronic medical illness. Dialogues Clin Neurosci. 2011;13(1):7–23. doi: 10.31887/DCNS.2011.13.1/wkaton. http://europepmc.org/abstract/MED/21485743. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 57.World Health Organization. 2014. Social Determinants of Mental Health https://www.who.int/mental_health/publications/gulbenkian_paper_social_determinants_of_mental_health/en/
- 58.Fryers T, Melzer D, Jenkins R, Brugha T. The distribution of the common mental disorders: social inequalities in Europe. Clin Pract Epidemiol Ment Health. 2005 Sep 5;1:14. doi: 10.1186/1745-0179-1-14. https://cpementalhealth.biomedcentral.com/articles/10.1186/1745-0179-1-14. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 59.Kharrazi H, Chi W, Chang HY, Richards TM, Gallagher JM, Knudson SM, Weiner J. Comparing population-based risk-stratification model performance using demographic, diagnosis and medication data extracted from outpatient electronic health records versus administrative claims. Med Care. 2017 Dec;55(8):789–96. doi: 10.1097/MLR.0000000000000754. [DOI] [PubMed] [Google Scholar]
- 60.Kharrazi H, Anzaldi LJ, Hernandez L, Davison A, Boyd CM, Leff B, Kimura J, Weiner J. The value of unstructured electronic health record data in geriatric syndrome case identification. J Am Geriatr Soc. 2018 Aug;66(8):1499–507. doi: 10.1111/jgs.15411. [DOI] [PubMed] [Google Scholar]
- 61.Haykin S. Neural Networks: A Comprehensive Foundation. New York: Pearson; 2004. [Google Scholar]
- 62.Bengio Y, Courville A, Vincent P. Representation learning: a review and new perspectives. IEEE Trans Pattern Anal Mach Intell. 2013 Aug;35(8):1798–828. doi: 10.1109/TPAMI.2013.50. [DOI] [PubMed] [Google Scholar]
Associated Data
This section collects any data citations, data availability statements, or supplementary materials included in this article.
Supplementary Materials
Types of patient data used in decision-model building.
Precision-recall curve for each decision model under study.
List of 20 top features (ranked in order of best to worst) for each decision model, together with their least absolute shrinkage and selection operator scores.
Co-occurrence of top 20 features across each of the patient populations under test (1=most important, 20=least important).
F1 scores for each decision model trained using iteratively increasing feature subset sizes. For clarity, our plot includes only models trained using the top 50 features for each patient subgroup.