

Abstract
The macaque ventral premotor area F5 hosts two types of visuomotor grasping neurons: “canonical” neurons, which respond to visually presented objects and underlie visuomotor transformation for grasping, and “mirror” neurons, which respond during the observation of others' action, likely playing a role in action understanding. Some previous evidence suggested that canonical and mirror neurons could be anatomically segregated in different sectors of area F5. Here we investigated the functional properties of single neurons in the hand field of area F5 using various tasks similar to those originally designed to investigate visual responses to objects and actions. By using linear multielectrode probes, we were able to simultaneously record different types of neurons and to precisely localize their cortical depth. We recorded 464 neurons, of which 243 showed visuomotor properties. Canonical and mirror neurons were often present in the same cortical sites; and, most interestingly, a set of neurons showed both canonical and mirror properties, discharging to object presentation as well as during the observation of experimenter's goal-directed acts (canonical-mirror neurons). Typically, visual responses to objects were constrained to the monkey peripersonal space, whereas action observation responses were less space-selective. Control experiments showed that space-constrained coding of objects mostly relies on an operational (action possibility) rather than metric (absolute distance) reference frame. Interestingly, canonical-mirror neurons appear to code object as target for both one's own and other's action, suggesting that they could play a role in predictive representation of others' impending actions.
Keywords: area F5, canonical neurons, macaque, mirror neurons, visuomotor neurons
Introduction
The monkey ventral premotor area F5 hosts two types of hand-related neurons: purely motor neurons (Rizzolatti et al., 1988; Raos et al., 2006; Maranesi et al., 2012), discharging only during the execution of specific motor acts, and visuomotor neurons (Gallese et al., 1996; Murata et al., 1997), which in addition to their motor discharge also activate during visual stimulation. Based on the visual stimulus that activates them, visuomotor neurons have been further subdivided into “canonical” neurons and “mirror” neurons (Rizzolatti and Kalaska, 2012).
Canonical neurons discharge both when the monkey observes graspable objects and when it actively grasps them, often showing a similar visual and motor selectivity for a specific object (or set of objects) (Murata et al., 1997; Raos et al., 2006). Because of this property, canonical neurons are deemed to be crucial for the transformations of object physical properties into the most appropriate motor act (Jeannerod et al., 1995). Indeed, the reversible inactivation of the F5 sector in which canonical neurons are located impairs visually guided grasping (Fogassi et al., 2001).
Mirror neurons become active both when the monkey grasps an object and when it observes another agent doing it; but according to earlier studies, “the sight of the object alone is ineffective” (Gallese et al., 1996; Rizzolatti et al., 1996). Thus, the crucial feature of mirror neurons consists of matching the sensory description of an observed act with its corresponding motor representation in the observer's brain, suggesting that they can underlie a specific form of understanding of others' behavior (Umiltà et al., 2001; Kohler et al., 2002; Rizzolatti and Sinigaglia, 2010).
The existence of these two classes of visuomotor neurons suggests that motor representations can be activated, in the premotor cortex, either by the sight of potential target objects or by the observation of other's actions. Some evidence has suggested that canonical and mirror neurons could be anatomically segregated in different sectors of area F5 (Fogassi et al., 2001; Raos et al., 2006): the former mostly buried in the posterior bank of the arcuate sulcus (area F5p) and the latter hosted in the adjacent convexity of area F5 (area F5c) (Belmalih et al., 2009; Maranesi et al., 2012). However, previous studies mainly focused on the neuronal coding of either objects or observed actions. Thus, whether and to which extent motor representations of objects and actions are processed by segregated neuronal populations are still unclear.
Here we used linear multielectrode probes to simultaneously record single-neuron activity from multiple sites located at different cortical depths in area F5. By using a large set of tasks typically designed to characterize neuronal responses to motor execution, object presentation, and action observation, we showed, for the first time, that canonical and mirror neurons can be found in the same cortical site. Furthermore, single neurons do exist which respond to both visually presented objects and actions. Interestingly, the space sector from which this information comes has a crucial influence on neuronal response.
Materials and Methods
Experiments were performed on one Macaca nemestrina (M1, male, 9 kg) and one Macaca mulatta (M2, male, 7 kg). Before recordings, monkeys were habituated to sit in a primate chair and to interact with the experimenters. Then, they were trained to perform the visuomotor tasks described below using the hand (left) contralateral to the hemisphere to be recorded (right). When the training was completed, a head fixation system and a plastic recording chamber were implanted under general anesthesia (ketamine hydrocloride, 5 mg/kg i.m. and medetomidine hydrocloride, 0.1 mg/kg i.m.), followed by postsurgical pain medications. Surgical procedures were the same as previously described (Rozzi et al., 2006; Bonini et al., 2010). All the experimental protocols were approved by the Veterinarian Animal Care and Use Committee of the University of Parma and complied with the European law on the humane care and use of laboratory animals.
Apparatus and behavioral paradigm.
Both monkeys were trained to perform a visuomotor task (VMT) and an observation task (OT) by means of the apparatus showed in Figure 1A–C.
Figure 1.

Apparatus, tasks phases, and conditions of the VMT and OT. A, Box and apparatus settled for performing the VMT. B, C, Box and apparatus settled for performing the OT in the monkey's extrapersonal (OTe) and peripersonal (OTp) space. Dashed circles represent the physical extension of the 5° tolerance window for monkey's eye position during each task. D, Task phases of object fixation, grasping in the light, and grasping in the dark conditions of the VMT. The temporal structure and task phases of the observation tasks are identical to those of the corresponding conditions of the VMT.
The VMT was a modified version of the paradigm originally devised by Sakata and coworkers (Murata et al., 1996, 1997, 2000; Raos et al., 2006). The monkey was seated on a primate chair in front of a box. Figure 1A shows the box from the monkey's point of view. The box was divided horizontally into two sectors by a half-mirror: the upper sector contained a small black tube with a white light-emitting diode (LED) that could project a spot of light on the half-mirror surface; the lower sector contained a sliding plane hosting three different objects. When the LED was turned on (in complete darkness), the half-mirror reflected the spot of light so that it appeared to the monkey as located in the lower sector (fixation point), in the exact position of the center of mass of the not-yet-visible target object. The objects (a ring, a small cone, and a big cone) were chosen because they afforded three of the most represented grip types commonly used by macaques in their natural environment (Macfarlane and Graziano, 2009), namely, the following: hook grip (in which the index finger enters the ring), side grip (performed by opposing the thumb and the lateral surface of the index finger), and whole-hand prehension (obtained by opposing all the fingers to the palm). Objects were presented, one at a time, during different experimental trials, through a 7 cm opening located on the monkey sagittal plane at a reaching distance from its hand starting position. A stripe of white LEDs located on the lower sector of the box allowed us to illuminate it during specific phases of the task. Because of the half-mirror, the fixation point remained visible in the middle of the object, even when the lower sector of the box was illuminated.
The same apparatus was also used to perform the OT in the monkey's extrapersonal space (OTe; Fig. 1B). The box remained always in complete darkness, but a window in the left upper part of its back, constituted by another half-mirror, could be back illuminated to show the external space in which a plane (contiguous to the internal horizontal half-mirror) was located. The plane was used to present the object to be grasped by the experimenters or to be fixated by the monkey, as shown in Figure 1B. The monkey was required to keep its hand still on the initial fixed position and to maintain fixation on a spot (a small white LED) located on the external plane between the experimenter's hand starting position and the target. The fixation point was seen by the monkey through the mirror at a distance of 60 cm from its head. This apparatus enabled to present the fixation point in complete darkness, without enlightening the object. Three objects identical to those grasped by the monkey during the VMT were randomly presented one at a time by means of a rotating turntable. Objects were changed during the intertrial period and in complete darkness. The experimenter's act was seen by the monkey from a 90° visual perspective (side view), with the experimenter's hand located inside the monkey's visual field from the beginning of each trial.
By means of the same apparatus, the OT was also performed within the monkey's peripersonal space (OTp; Fig. 1C). In this case, only the big cone was used as a target. The experimenter's motor act was seen by the monkey from a 90° point of view.
The VMT included three basic conditions, as illustrated in Figure 1D: object fixation, grasping in the light, and grasping in the dark. Each of them started when the monkey held its hand on a fixed starting position, after a variable intertrial period ranging from 1 to 1.5 s.
Object fixation. The fixation point was presented and the monkey was required to start fixating it within 1.2 s. Fixation onset determined the presentation of a cue sound (a pure low tone constituted by a 300 Hz sine wave), which was associated with object fixation trials. After 0.8 s, the lower sector of the box was illuminated and one of the objects became visible. Then, after a variable time lag (0.8–1.2 s), the sound ceased and the monkey had to maintain fixation for 1.2 s to receive a drop of juice as a reward (Pressure reward delivery system, Crist Instruments).
Grasping in the light. The temporal sequence of events in this condition was identical to that of object fixation condition, but a different cue sound (a pure high tone constituted by a 1200 Hz sine wave) instructed the monkey to grasp the subsequently presented object. Therefore, when the sound ceased (go signal), the monkey had to reach, grasp, and pull the object within 1.2 s. Then it had to hold the object steadily for at least 0.8 s. If the task was performed correctly without breaking fixation, the reward was automatically delivered.
Grasping in the dark. The entire temporal sequence of events in this condition was identical to that of grasping in the light. However, when the cue sound (the same high tone as in grasping in the light) ceased (go signal), the light inside the box was automatically turned off and the monkey performed the subsequent motor acts in complete darkness. Because the fixation point was visible for the entire duration of each trial, it provided a spatial guidance for reaching the object in the absence of visual feedback. In this paradigm, grasping in the light and grasping in the dark trials were identical and unpredictable until the cue sound ceased (go signal): thus, action planning was the same in both conditions, and the only difference between them was the presence/absence of visual feedback from the acting hand and the target object.
The OTe was based on the same sequence of events and temporal constraints as in the monkey VMT. In particular, the experimenter performed the first two conditions (object fixation and grasping in the light) while the monkey had to simply maintain fixation to get the reward. In the OTp, only grasping in the light condition was performed, using as a target the big cone. In both observation tasks, the monkey could only see the experimenter's hand, not the whole agent's body.
In both VMT and OT, the task phases were automatically controlled and monitored by a LabView-based software, enabling to interrupt the trial if the monkey broke fixation, made an incorrect movement, or did not respect the task temporal constrains described above. In all these cases, no reward was delivered. After correct accomplishment of a trial, the monkey was automatically rewarded with the same amount of juice in all conditions.
The activity of each neuron was recorded in 15 trials for each basic condition, for a total of 135 trials in the VMT, 90 trials in the OTe, and 15 trials in the OTp (using the big cone as target). In all sessions, we also recorded 15 additional control trials in which the monkey was presented, in complete darkness and with its hand still on the starting position, with the fixation point alone: after a variable time lag (<1 s) from fixation onset, the reward was delivered. These trials have been used to verify the possible presence of neuronal responses resulting from mouth movements, which could otherwise be confounded with hand-related activity, particularly during the holding epoch that precedes the reward delivery. Neurons showing predominantly mouth responses were thus excluded from the dataset.
Recording techniques.
Neuronal recordings were performed by means of multielectrode linear arrays (see Fig. 3A). We used 16 channel U-probes (Plexon) and 16 channel silicon probes (Atlas Neuroengineering) (Herwik et al., 2009; Ruther et al., 2010). The U-probes had a diameter of 185 μm. The recording sites had a diameter of 15 μm and were spaced 250 μm from each other. The impedance of the recording sites was in the range of 0.3–1 mΩ measured at 1 kHz. Atlas probes had a rectangular section (140 μm × 100 μm); each recording site had a diameter of 35 and 250 μm intersites spacing. The impedance of the recording sites was in the range of 0.5–1.5 mΩ. Both types of probes were inserted through the intact dura by means of a manually driven stereotaxic micromanipulator mounted on the recording chamber. All penetrations were performed perpendicularly to the cortical surface, with a penetration angle of ∼40° relative to the sagittal plane. Further details on the devices and techniques used to handle Atlas probes have been provided previously (Bonini et al., 2013). Concerning the U-probes, it was inserted through a guide tube. First, we lowered the guide tube, pressing on the dura to make it dimpling as much as possible (on average 3–4 mm). Based on previous measures, and taking into account the amount of dimpling, the probe could then be rapidly and safely lowered into the brain so that approximately half of the recording sites were inside the cortex. After that, the guide tube was retracted to simply lean on the dura: this enabled to eliminate mechanical pulsations without exerting excessive pressure, providing optimal mechanical stability for the recording. This operation took only a few minutes. Finally, based on the inspection of the recorded signal and preliminary acquisition of multiunit activity, the probe was precisely positioned so that all 15 recording sites were inside the cortex.
Figure 3.

A, Schematic drawing of a linear multielectrode probe and example of the multiunit activity simultaneously recorded during a typical penetration. The multiunit activity, which is the aggregate spiking activity of a number of neurons in the vicinity of an electrode (Supèr and Roelfsema, 2005), is plotted in spikes based on color code and aligned (white line) on the moment when the monkey started pulling the target object (45 trials for each panel, with the three objects pooled together). The location of this penetration, performed in M1, is shown by the asterisk in the functional map of Figure 2. B, Example of a purely motor neuron (Unit A), a canonical neuron (Unit B), and a mirror neuron (Unit C), simultaneously recorded and off-line sorted from the multiunit activity of channel 13 of the penetration shown in A. For each neuron, the gap in the histogram and rastergram is used to indicate that the activity on its left side has been aligned on object presentation (first vertical dashed line in the left panel), whereas that on its right side is aligned on the pulling onset (second vertical dashed line in the right panel) of the same trial. The gray shaded areas represent the time windows used for statistical analysis of neuronal response. Markers: dark green, cue sound onset; light green, cue sound offset (go signal); orange, detachment of the hand from the starting position (reaching onset); red, reward delivery at the end of the trial. The same markers have been used to identify the behavioral event of interest of both the visuomotor and observation tasks.
Recordings were grounded to the guide tube or to the head-holding system (in case of Atlas probes, where no guide tube was used) and referenced to the first (proximal) recording site of the probe, which was left subdural but just outside the cortical surface, thus enabling the removal of most of artifacts and providing an optimal signal-to-noise ratio. With both types of probes, we waited approximately half an hour before starting acquisition of neuronal activity to ensure an optimal mechanical stability.
The signal was amplified and sampled at 40 kHz with a 16 channel Omniplex recording system (Plexon). Online spike sorting was performed on all channels using dedicated software (Plexon), but all final quantitative analyses were performed offline, as described in the subsequent sections.
Recording of behavioral events and definition of epochs of interest.
Distinct contact-sensitive devices (Crist Instruments) were used to detect when the monkey or the experimenter (grounded) touched with the hand the metal surface of the starting position or one of the target objects. A further device was connected to the switch located behind each object, to signal the onset and tonic phase of object pulling. Each of these devices provided a TTL signal, which was used by LabView-based software to monitor the monkey's performance and to control the generation and presentation of auditory and visual cue signals of the behavioral paradigm.
Eye position was monitored in parallel with neuronal activity with an eye tracking system composed by a 50 Hz CCD video camera (Ganz, F11CH4) provided with an infrared filter and two spots of infrared light. Analog signal related to horizontal and vertical eye position was fed to a computer equipped with dedicated software (Pupil), enabling calibration and basic processing of eye position signals. The monkey was required to maintain its gaze on the fixation point (tolerance radius 5°; Fig. 1A–C, dashed circles around the fixation spots) during all the tasks to avoid possible differences in neural activity due to gaze behavior (Maranesi et al., 2013). Eye position signal was monitored by the same LabView-based software dedicated to the control of the behavioral paradigm.
The same LabView-based software also generated different digital output signals associated with auditory and visual stimuli, the target object presented in each trial, the reward delivery, and possible errors made by the monkey during the task (i.e., when the monkey broke fixation). These signals, together with the TTL signals related to the main behavioral events described above, were fed to the Omniplex system to be recorded together with the neuronal activity. These signals were subsequently used to align neurons activity in different trials and conditions, to construct the response histograms and the data files for statistical analysis.
Based on digital signals related to the main behavioral events, we defined different epochs of interest: (1) baseline, 500 ms before object presentation; (2) object presentation, from 50 to 450 ms after switching on the light; (3) grasping, 500 ms before pulling onset; and (4) holding, from pulling onset to 500 ms after this event. The same epochs were used to analyze neuronal responses during both the VMT and the OT performed in different spaces. During baseline, the monkey had its hand still on the starting position; it was staring at the fixation point and was already aware of whether the ongoing trial was a go or a no-go trial.
Data analyses.
The raw signals related to all trials of a recording session (N = 255) were merged together and high-pass filtered offline (300 Hz). Single units were then isolated using principal component and template matching techniques provided by dedicate offline sorting software (Plexon). For each isolated unit, we verified that the projection of its spikes in the 3D space formed by the first two principal components and the acquisition time remained stable for the entire duration of the session (Bonini et al., 2013), and that the percentage of interspike intervals <1 ms was <0.5%. With the type of probes used in this study, the recording stability was extremely good: in case of relevant changes in the neuronal activity during acquisition, the entire penetration was discarded and the data not included in the dataset.
After identification of single units that remained stable over the duration of the experiment, we first classified neurons significantly activated during grasping and/or holding epoch/s of the VMT compared with baseline, both during grasping in the light and grasping in the dark. To this purpose, we used a 2 × 3 × 3 repeated-measures ANOVA (factors: light/dark, object, and epoch). We classified as grasping neurons all neurons discharging differently during grasping and/or holding of at least one among the three target objects compared with baseline, both during grasping in the light and in the dark (p < 0.01). Possible responses to object presentation relative to baseline were assessed, considering both conditions (grasping and fixation), by means of a 2 × 3 × 2 repeated-measures ANOVA (factors: condition, object, and epoch), with a significance criterion of p < 0.01. The same analyses were applied to test action observation and object presentation responses in the OTe. Possible responses to action observation in the OTp were tested by means of a one-way repeated-measures ANOVA (factor: epoch), whereas object presentation responses relative to baseline, in the same task, were assessed with a paired sample t test (all p levels <0.01). In addition to p levels, each neuron was considered to be modulated in a specific task (VMT, OTe, or OTp) if it fired at least 5 spikes/s in the preferred condition of that task.
Population analyses were performed taking into account single-neuron responses expressed in terms of net-normalized mean activity (Bonini et al., 2010). For each neuron, the mean activity was calculated every 20 ms bins in all the recorded trials of all the experimental conditions to be compared. Then, the absolute highest activity value was taken to divide the value of each single bin in all conditions (normalized mean activity, ranging from 0 to 1). The average response of the neuron during the baseline period was finally subtracted from that of each bin, providing the net-normalized vector. Because neurons with inhibitory responses constitute a small percentage in our dataset (in total <7% of all the recorded neurons), we included these cells in the population analyses after inverting their response.
To compare the selectivity of some neuronal populations for different visual stimuli (object and action) presented in the peripersonal and extrapersonal space, we calculated, for each cell, an object-action contrast index for the peripersonal space (CIp), and another one for the extrapersonal space (CIe), as follows:
where Op and Oe are the discharge during object presentation in the peripersonal and extrapersonal space, respectively; Ap and Ae are the discharge during action observation in the peripersonal and extrapersonal space, respectively; Pmax is the highest value between Op and Ap; Emax is the highest value between Oe and Ae; and Nmax is the highest value among all those used for calculating the two indexes. The weighting factor (Pmax/Nmax or Emax/Nmax) added at the end of each formula enables to downsize the CI when the neuron is weakly activated in one of the two spaces compared with the other, so that the index values better reflect the relevance of object-action contrast provided by the neuron discharge in the different spaces.
Results
Twenty-three penetrations were performed in the hand sector of area F5 of the two monkeys (M1, N = 10; M2, N = 13). A total of 345 cortical sites were studied. A preliminary electrophysiological mapping of part of the exposed cortical region performed before the experimental sessions allowed us to identify area F5 based on the observed functional properties, and to distinguish it from adjacent areas F4, F2, and the frontal eye field (for a detailed description of the anatomo-functional organization of area F5 and neighboring areas, see Fogassi et al., 2001; Maranesi et al., 2012). Figure 2 shows the general functional map of the investigated region in the two monkeys. The blue shaded areas correspond to the cortical sectors from which neurons described in the present study were recorded.
Figure 2.

Functional map of body parts movement derived from preliminary recordings in each monkey. The light blue shaded area identifies, in each monkey, the hand sector of area F5 where the penetrations included in the present study (data not shown) have been performed. Penetrations were performed at an approximate angle of 40° relative to the sagittal plane. Each penetration in the recording region was located within a maximum of 3 mm from penetrations performed in FEF. The asterisk in the map of M1 identifies the location of the exemplary penetration shown in Figure 3. As, Arcuate sulcus; FEF, frontal eye fields; R, rostral; C, caudal; M, medial; L, lateral. The junction of the spur with the arcuate sulcus is located (in anteroposterior and mediolateral stereotaxic coordinates) at 21.5–20 in M1 and 22–18 in M2.
Figure 3A illustrates a probe and an example of multiunit activity simultaneously recorded from 15 channels. For each channel, the activity is aligned to hand grasping (onset of object pulling phase) during the VMT. This penetration constitutes a typical example of the pattern of activity recorded from the investigated sector of area F5. It is clear that the strongest modulations of multiunit activity occurred in the deepest sites, whereas in the most superficial ones the activity was weaker. This pattern most likely derives from recordings performed in the crown and the upper part of the posterior bank of inferior arcuate sulcus (Belmalih et al., 2009). The exact location of this penetration in the recorded region is indicated with the asterisk in Figure 2 (M1).
We isolated 479 single neurons (Table 1). Virtually all of them (N = 464) discharged significantly during grasping execution. The remaining 15 neurons, which displayed purely visual responses, have not been considered in the present dataset. Among all the recorded neurons, 221 were purely motor (“pm” in Table 1; 47.6%), whereas the remaining (N = 243) were visuomotor. Some visuomotor neurons responded only to action observation (mirror neurons, “m” in Table 1; N = 137, 56.4%), others to object presentation (canonical neurons, “c” in Table 1; N = 46, 18.9%), whereas the remaining constituted a new class of cells showing responses to both action observation and object presentation (canonical-mirror neurons, “cm” in Table 1; N = 60, 24.7%). Figure 3B shows examples of purely motor (Unit A), canonical (Unit B), and mirror (Unit C) neurons, simultaneously recorded from the same channel (channel 13).
Table 1.
Number of the recorded neurons showing mirror, canonical, or canonical-mirror properties, in relation to the space in which the stimulus (object and/or action) was locateda
| Visual response in the extrapersonal space | Visual response in the peripersonal space |
Total | |||
|---|---|---|---|---|---|
| Action | Objectb | Object-actionb | No visual | ||
| Action | 36m | 9cm | 13cm | 35m | 93 |
| Object | 0cm | 2c | 0cm | 0c | 2 |
| Object-action | 4cm | 4cm | 4cm | 7cm | 19 |
| No visual | 66m | 44c | 19cm | 221pm | 350 |
| Total | 106 | 59 | 36 | 263 | 464 |
aLetters in superscript identify mirror (m), canonical (c), canonical-mirror (cm) and purely-motor (pm) neurons.
bVisual responses to object presentation in the peripersonal space were based on the VMT.
Figure 4 shows different examples of canonical-mirror neurons. Unit A responded to object presentation during the VMT but not during the OTe, although it discharged during action observation during OTp. Nineteen of the 60 canonical-mirror neurons (31.7%) displayed a similar behavior (Table 1). Unit B exemplifies another frequently observed response pattern (N = 13, 21.6%; Table 1). This neuron fired during visual presentation of the ring in the VMT, whereas it was inhibited during the visual presentation of the small and big cones. In contrast, it did not show any significant object presentation response during the OTe, although it discharged during action observation in both OTp and OTe. Unit C showed a further response pattern being activated during object presentation in the VMT and during action observation in the OTe. Nine neurons (15.0%; Table 1) showed this type of behavior. All canonical-mirror neurons so far considered (68.3%) did not respond to object presentation in OTe, whereas all of the remaining (31.7%), which did respond to object presentation in the OTe, also showed a response to action observation in the same task. An example is Unit D shown in Figure 4.
Figure 4.

Examples of canonical-mirror neurons. Differences in the baseline firing rates shown by some of the neurons between VMT and OT depend on the different behavioral setting that characterizes the two task contexts because, in the period used as baseline, the monkey was already fixating and was instructed on the ongoing task context and experimental condition. However, these differences do not affect the results of data analyses (see Materials and Methods) and their interpretation. Conventions as in Figure 3B.
Figure 5 shows the depth distribution of all the recorded neurons classified as mirror (orange), canonical (blue), canonical-mirror (red), and purely motor (gray) neurons. Because this region has been defined as “poorly laminated” (Belmalih et al., 2009, their Fig. 2A), we could only analyze the distribution along the probe shaft (in depth) of the recorded neurons, with no relationship to cortical laminae. It is clear that there is a general drop in the overall number of isolated cells between 2 and 2.25 mm of depth (Fig. 3A): most (N = 125, 56.6%) purely motor neurons are located in deepest sites (2.25–3.75 mm), whereas the majority of mirror neurons (N = 77, 56.3%) are hosted in the superficial ones (0.25–1.75 mm). Nevertheless, each type of neuron is represented in all the investigated depths, and no significant depth segregation emerges for the different neuronal classes.
Figure 5.
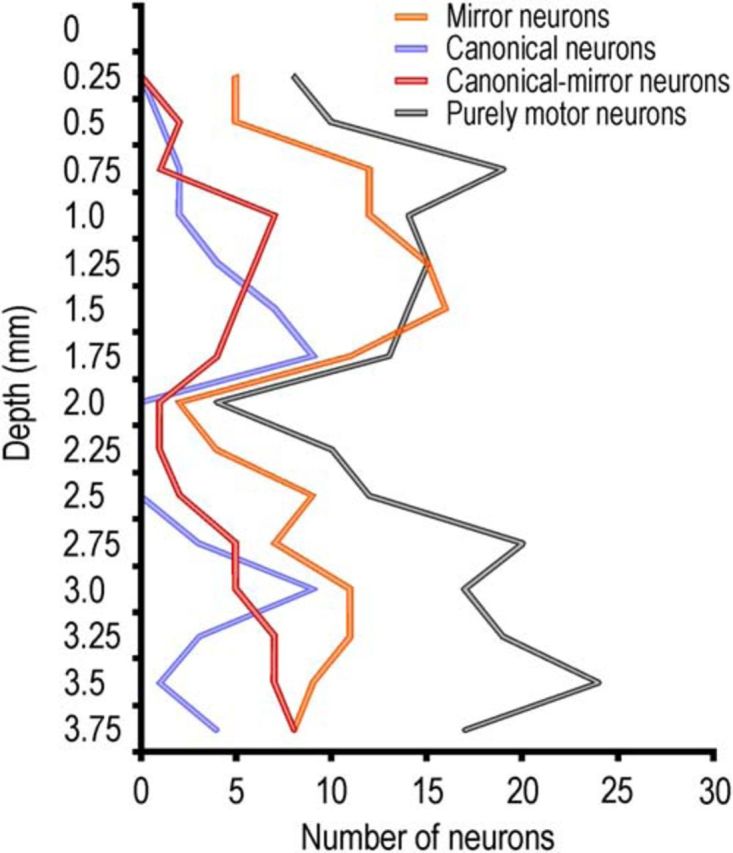
Depth distribution of all the recorded neurons. A similar profile of property distribution characterized the recordings performed at different rostrocaudal levels.
A striking difference between visuomotor neuron categories concerns the space selectivity of their visual responses. Figure 6 shows that visual responses to observed actions of mirror neurons can either be selective for the peripersonal (N = 66, 48.2%) or the extrapersonal space (N = 35, 25.6%), or they can be present in both space sectors (N = 36, 26.2%). In contrast, responses to visually presented objects by canonical neurons are virtually all constrained to the peripersonal space (N = 44, 95.7%). Interestingly, the space selectivity of canonical-mirror neurons response to observed action was uniformly distributed between the peripersonal and extrapersonal space, whereas object presentation responses of most of them (N = 41, 68.3%) were constrained to the peripersonal space (χ2 = 16.13, p < 0.001).
Figure 6.

Histograms showing the relative proportion of mirror, canonical-mirror, and canonical neurons selectively responding to visual stimuli presented either in the peripersonal (black) or extrapersonal (white) space, or activated for stimuli presented in both space sectors (gray). Histograms for canonical-mirror neurons have been represented twice to show the space selectivity of both their response to mirror (on the left) and canonical (on the right).
Canonical-mirror neurons differently encode object and action in space
To better investigate the relationship between object and action coding in space, for each canonical-mirror neuron we computed an object-action contrast index (CI; see Materials and Methods) for both the peripersonal and extrapersonal space, separately. Positive values of CI indicate a stronger visual response for object relative to action, whereas negative values indicate stronger response for action relative to object. Figure 7A shows the distribution of CI values of canonical-mirror neurons relative to peripersonal (horizontal axis) and extrapersonal (vertical axis) space. Most neurons (32 of 60) fall in the third quadrant, which means that they responded more strongly during action observation compared with object presentation in both spaces. Furthermore, it is also clear that the CI distribution differs between the peripersonal and extrapersonal space in that extrapersonal space is associated with more negative CIs than the peripersonal space (mean ± SD for peripersonal space −0.025 ± 0.26, extrapersonal space −0.109 ± 0.16, paired-samples t test, t = 2.04, p = 0.045). Thus, most of area F5 canonical-mirror neurons responded similarly to objects and actions in the peripersonal space, although they showed relatively stronger visual responses to action observation than to object presentation when visual stimuli were presented in the extrapersonal space.
Figure 7.

A, Distribution of object-action contrast indexes computed for all canonical-mirror neurons in the peripersonal and extrapersonal space. There is a relative advantage for action (light gray bars represent negative values) compared with object (dark gray bars represent positive values) coding in the extrapersonal, but not in the peripersonal, space. B, Time course and intensity of the net normalized response of canonical-mirror neuronal population relative to the preferred (red) and not preferred (blue) target object. The activity is aligned on the light onset during fixation (left) and grasping (center) condition, as well as on the object pulling onset (right). Gray shaded regions identify the time windows used for statistical analysis of neural activity: Pulling onset divides the grasping period into two epochs: an “early grasping” (gray shading on the left of the alignment point) and “pulling” (gray shading on the right of the alignment point). Obj pres, object presentation epoch.
A population analysis performed on all canonical-mirror neurons confirmed these findings. Figure 7B shows the time course and intensity of the activity of the whole neuronal population (N = 60) during different epochs of the VMT and of the OTe and OTp. For each neuron, the object that evoked the strongest response (in terms of absolute firing rate) during grasping execution was selected as the preferred one, whereas the one evoking the weakest response was selected as the nonpreferred. Then, based on this criterion, response vectors of the different single neurons were pooled together to form the population vectors in all tasks and conditions (see Materials and Methods). A 2 × 3 repeated-measures ANOVA (factors: object and epoch) clearly showed that canonical-mirror neurons exhibited a strong discharge during both grasping epochs (early grasping and pulling phases) compared with baseline (main effect epoch: F(2,118) = 65.99, p < 0.001), and the response was stronger during early grasping than during the pulling phase (p < 0.001).
Object presentation response was investigated by means of a 2 × 2 repeated-measures ANOVA (factors: object and epoch) applied to the fixation and grasping conditions of the VMT, separately. These analyses revealed significant main effects of the factor epoch in both fixation (F(1,59) = 62.38, p < 0.001) and grasping (F(1,59) = 64.99, p < 0.001) conditions. In this latter case, the visual presentation response was also clearly selective for the motorically preferred object relative to the nonpreferred one (interaction of object and epoch: F(1,59) = 12.70, p < 0.001). The same analyses were performed on canonical-mirror neurons studied with the OTe. They evidenced a clear response during both epochs of grasping observation relative to baseline (F(2,118) = 31.74, p < 0.001), with a stronger discharge during early grasping than the pulling phase (p < 0.05). Furthermore, they also revealed the presence of a significant response to object presentation during both fixation (main effect epoch: F(1,59) = 10.70, p < 0.005) and grasping (main effect epoch: F(1,59) = 15.14, p < 0.001) condition. However, these object presentation responses were dramatically reduced compared with their corresponding conditions (fixation and grasping) of the VMT (paired samples t tests with p < 0.001 for both comparisons).
In addition to the different space in which object presentation occurred (extrapersonal vs peripersonal), the extremely weak object presentation response observed during the OTe compared with the VMT might also be accounted for by other factors: (1) the different task demand (action observation vs execution) in which object presentation occurred; and (2) the different visual perspective from which the object was seen in the two tasks (90° rotation in the OT relative to the VMT). However, during the OTp, both task demand and visual perspective from which the object was seen were the same as in the OTe. Thus, the space in which the action was performed remained the only difference between the two tasks.
Population analyses of canonical-mirror neurons responses during the OTp (Fig. 7B) clearly showed a robust response to object presentation relative to baseline (paired sample t test, t = 3.75, p < 0.001), in addition to a strong response to action observation (one-way repeated-measures ANOVA, F(2,118) = 28.19, p < 0.001). Interestingly, this response was not significantly different from the object presentation responses observed during the fixation condition of the VMT (paired sample t tests, p > 0.35 for both comparisons), although it was stronger than the one evoked by the visual presentation of objects in the same condition of the OTe (t = 2.09, p < 0.05). This finding clearly demonstrates that, although canonical-mirror neuronal population can code observed actions when they are presented both in the peripersonal and extrapersonal space, object coding appears to be more markedly constrained to the peripersonal space, regardless of task demand and object orientation.
Is this space-constrained coding of objects a hallmark of canonical-mirror neurons or does it apply to canonical neurons as well? To verify this issue, we compared the visual responses of canonical-mirror (N = 60) and canonical (N = 46) neurons to object presentation in different conditions. The proportion of neurons showing visual selectivity for one or two of the presented objects was similar between canonical (13 of 46) and canonical-mirror neurons (23 of 60, χ2 = 1.17, p = 0.28). However, these two subpopulations differed from one another in many respects. First, although most of canonical neurons (N = 32, 69.6%) responded to object presentation during both grasping execution and object fixation trials of the VMT, an even higher fraction of canonical-mirror neurons showed the same behavior (N = 55, 91.8%, χ2 = 5.94, p = 0.015). Second, although almost all (44 of 46) canonical neurons did not respond to object presented in the OTe, a significant proportion of canonical-mirror neurons discharged to object presentation in this condition (19/60, χ2 = 12.23, p < 0.001). Interestingly, all the 19 canonical-mirror neurons responding to object presentation in the OTe also responded to the subsequently performed experimenter's action.
A third striking difference between canonical and canonical-mirror neurons emerged when comparing their visual presentation responses in the VMT with those during the OTp, in which the object was seen by the monkey rotated by 90° with respect to the VMT. Figure 8A shows that a lower proportion of canonical (N = 9, 19.6%) than canonical-mirror (N = 36, 60%) neurons responded to the object rotated by 90° (χ2 = 17.43, p < 0.001). Furthermore, although the responses of canonical-mirror neurons to the presentation of an object in the peripersonal space rotated by 90° (during the OTp) or presented at 0° (fixation condition of the VMT) were positively correlated (r = 0.69, p < 0.001), this did not occur for canonical neurons (r = 0.26, p = 0.08) (Fig. 8B). This effect was found to be still significant, even when outliers (values exceeding the mean ± 2 SDs of each distribution) are removed (8 of 60 among canonical-mirror neurons and 5 of 46 among canonical neurons). The correlations coefficients (obviously) decreased (from 0.69 to 0.33 for canonical-mirror neurons and from 0.26 to −0.08 for canonical neurons), but still that of canonical-mirror neuron remained significant (p = 0.015), whereas that of canonical neuron remained not significant.
Figure 8.

A, Pie-chart showing the proportion of canonical-mirror (left) and canonical (right) neurons with visual presentation responses selective or unselective for a specific orientation of the presented object. B, Correlation between the visual responses triggered by object presented with 0° and 90° orientation in canonical-mirror and canonical neurons. C, Comparison among object presentation responses during the fixation (OTe-fix) and grasping (OTe-grasp) conditions of the OTe, the OTp, and the fixation (VMT-fix) and grasping (VMT-grasp) conditions of the VMT. *p < 0.001. ns, not significant.
Figure 8C shows the average net activity of canonical-mirror and canonical neurons during visual presentation in different task conditions (one-way repeated-measures ANOVA). It is clear that, among canonical-mirror neurons (F(4,236) = 55.55, p < 0.001), the discharge to object presentation was similar among grasping conditions of the VMT and of the OTp. Both of them, in turn, showed stronger visual presentation responses relative to those recorded during the OTe (Bonferroni post hoc tests, p < 0.05 for both comparisons). Thus, these cells seemed to be tuned to the space in which the object was presented, regardless even of object orientation. In contrast, canonical neurons (F(4,180) = 102.03, p < 0.001) discharged more strongly to object presentation during the VMT, regardless of the condition (grasping or fixation), than during the OT, even when it was performed in the peripersonal space (p < 0.01 for all comparisons). Together, these data indicate that, although in both neuronal populations the visual presentation of an object evokes stronger responses when the stimulus is located within the monkey peripersonal space, the potential grasping act afforded by the object in the optimal orientation for grasping is crucial for canonical, but not for canonical-mirror, neurons.
Dissociation of pragmatic and metric representations of peripersonal space in F5 neurons
To better understand the relevance of space-constrained coding of objects in F5 grasping neurons, in a subset of penetrations (3 in M1 and 6 in M2), we tested neurons in a paradigm previously used to study metric or pragmatic space coding in area F5 mirror neurons (Caggiano et al., 2009). In particular, 22 canonical neurons and 16 canonical-mirror neurons (all showing significant responses to object presentation during the VMT) were also studied during the visual presentation of the three different objects (in a randomized fashion) in a modified condition of the VMT. This condition was identical to the grasping condition of the VMT, except that a transparent plastic barrier was interposed between the object and the monkey, thus preventing it from reaching the target, even when the cue sound was the high tone. Interestingly, from the first trial of this control experiment, none of the animals even attempted to reach for the target, clearly indicating that they perceived the presence of the obstacle and their consequent inability to interact with the target despite the instruction sound.
Among the tested neurons, a similar fraction (χ2 = 0.43, p = 0.51) of canonical-mirror (9 of 16) and canonical neurons (10 of 22) did not show any significant response to object presentation when the barrier was present (3 × 2 repeated-measures ANOVA, factors: object and epoch, p < 0.01), whereas the remaining ones showed a significant response to object presentation also when the barrier was present (3 canonical-mirror and 6 canonical neurons discharged more weakly when the barrier was present, whereas 4 canonical-mirror and 6 canonical neurons discharged similarly both with and without the barrier). Figure 9A shows an example of a canonical neuron with significant response to object presentation both during fixation and grasping condition of the VMT, with a clear selectivity for the small cone. However, the neuron did not respond to objects presented behind the barrier. Object presentation response cannot be accounted for by the actual execution of a grasping act on the presented target because when the barrier was present the activity was weaker, even when compared with the object presentation response during fixation trials (no grasping performed).
Figure 9.

A, Example of a canonical neuron recorded during a control experiment with the object presented behind a transparent plastic barrier. Object presentation responses are shown for the different objects in the different tasks and conditions. The green markers indicate the onset of the cue sound at the beginning of each trial. Other conventions as in Figure 3B. B, Time course and intensity of the net normalized response of canonical-mirror and canonical neuronal populations relative to the preferred (red) and not preferred (blue) target object. The activity is aligned on the light onset during different tasks and conditions. Other conventions as in Figure 7B.
To better understand the general impact of the barrier on object coding by canonical and canonical-mirror neurons, we performed population analyses of all the recorded cells in the different conditions. The time course and intensity of the activity of the two neuronal populations are shown in Figure 9B. A 2 × 2 repeated-measures ANOVA (factor: object and epoch) performed on each condition revealed that canonical-mirror and canonical neuronal populations responded to object presentation both during fixation and grasping conditions of the VMT (p < 0.001 for both comparisons and subpopulation). Furthermore, during grasping condition, both neuronal populations showed significant interaction effects of the factors object and epoch (object-action: F(1,21) = 9.65, p < 0.01; object: F(1,15) = 4.62, p < 0.05), indicating that the visual presentation of the preferred object evoked a stronger response than the not preferred one. Both subpopulations also responded when the object was presented behind the barrier (canonical-mirror: F(1,15) = 11.61, p < 0.005; canonical: F(1,21) = 8.08, p < 0.01), but in both cases the response (with the preferred object) was significantly weaker compared with both grasping (paired-samples t tests, canonical-mirror: t = 2.88, p < 0.05; canonical: t = 3.73, p < 0.005) and fixation (canonical-mirror: t = 2.31, p < 0.05; canonical: t = 2.39, p < 0.05) conditions of the VMT. Finally, visual presentation response in the OTe was not significantly different relative to baseline in both subpopulations. Together, these findings indicate that the pure visual presentation of an object (with no experimenter present) induces the discharge of both canonical and canonical-mirror neurons in area F5, but with a clear-cut selectivity for the peripersonal space. More importantly, peripersonal space appears to be mainly encoded in an operational, rather than metric, frame of reference.
Discussion
In the present study, we investigated the functional properties of single neurons in the hand field of area F5. Each isolated neuron was tested for its motor and visual responses by using tasks specifically designed to investigate the visuomotor properties of both canonical (Murata et al., 1997; Raos et al., 2006) and mirror (Gallese et al., 1996; Rizzolatti et al., 1996; Caggiano et al., 2009) neurons. The use of linear multielectrode probes to simultaneously record neurons at different cortical depths allowed us to investigate the depth distribution of different F5 neuron types.
The main findings of our study are the following. First, neurons with canonical and mirror properties are often present in the same cortical sites. Second, we found a new set of neurons showing both canonical and mirror properties (canonical-mirror neurons). Third, the location of object and action in the peripersonal or extrapersonal space is a factor that crucially affects the visual response of most visuomotor neurons. In particular, object presentation responses of canonical and canonical-mirror neurons typically require a stimulus in the peripersonal space, whereas action observation responses of mirror and canonical-mirror neurons are present when the stimuli are located both in the peripersonal and extrapersonal space. Interestingly, space-constrained responses to objects mostly rely on an operational (action possibility) rather than metric (absolute distance) reference frame.
Depth distribution of neurons encoding objects and actions
No previous study systematically investigated the depth distribution of mirror and canonical neurons in area F5. However, on the basis of the reports describing F5 neurons properties, it has been proposed that canonical neurons are located in the bank of the inferior arcuate sulcus (area F5p), whereas mirror neurons are hosted in the adjacent convexity (area F5c) (Rizzolatti and Kalaska, 2012). In the present study, we showed that this dichotomy is only approximate. Indeed, although mirror neurons appear to be slightly more concentrated in the first 2 mm of cortex, they are also present in the deepest investigated sites (up to 4 mm) (Kraskov et al., 2009), intermingled with canonical neurons.
The convergence of object and action information in the same sector of area F5 is in accord with several recent neurophysiological and anatomical data. First, electrophysiological studies on monkey area F5p and F5a showed that several visuomotor neurons in both these areas code visual stimuli (Theys et al., 2012) and contextual cues instructing specific grip types (Fluet et al., 2010). Second, monkey fMRI studies showed that the same sectors of area F5 (F5p and F5a, as well as F5c) become active during action observation (Nelissen et al., 2005, 2011). Third, anatomical evidence indicates that all the three sectors of area F5 are strongly reciprocally linked and share connections with parietal areas, which can convey information on both object and motor acts done by others (Borra et al., 2008; Gerbella et al., 2011).
These data, together with the present findings, strongly support the notion that object and action information converge in all sectors of area F5. Nevertheless, considering the results of reversible inactivation of different sectors of this area (Fogassi et al., 2001), it is plausible that the processing of the same information can underlie different functions in the various F5 sectors, depending upon their specific output.
Representation of objects as potential target of one's own and other's action in space
One of the most interesting findings of the present study is that the space from which visual information comes seems to act as a “functional gate” affecting object and action processing. In particular, object presentation responses are markedly constrained to the monkey's peripersonal space, whereas action observation responses, although often showing a spatial preference, are not confined to a specific space sector. This last finding is in agreement with previous work by Caggiano et al. (2009), showing the existence of F5 mirror neurons differentially modulated by the location of the observed motor act either in the peripersonal or the extrapersonal space.
Interestingly, the visual responses of most canonical neurons are also strictly dependent on a frontal presentation of the object (i.e., the way most suitable for grasping it). The activation of canonical neurons appears, therefore, to be conditional upon two factors: the presentation of the object within the monkey peripersonal space and its most suitable orientation to afford grasping. As classically proposed (Jeannerod et al., 1995), canonical neurons would provide a representation of the potential motor act afforded by the observed object, likely participating in the visuomotor transformation of object properties into the appropriate motor program for grasping it (Fogassi et al., 2001).
In contrast, the object presentation response of canonical-mirror neurons was less sensitive to the object orientation, and their discharges to object presentation at 0° and 90° were significantly correlated. One-third of these neurons responded to object presentation during the observation task performed in the extrapersonal space (see, e.g., Fig. 6D), whereas virtually no canonical neuron showed this behavior. The visual response of canonical-mirror neurons to the presentation of the rotated object during the observation tasks was also significant at the population level, particularly when the task was performed in the monkey's peripersonal space (Fig. 7B). Interestingly, in this latter case, the object presentation response was not significantly different from that obtained during the visuomotor task, in striking contrast with that observed in canonical neurons (Fig. 8C). Together, these findings suggest that the response of canonical-mirror neurons to object presentation is not related to the processing of object affordance for the monkey, and it does not play a relevant role in visuomotor transformations for grasping. Instead, the rotated object during an action observation task constitutes a potential target for the experimenter's action, suggesting that the object-triggered activation of canonical-mirror neurons may constitute a predictive representation of the impending action of the observed agent.
A series of recent human studies supports the idea that seeing the potential target for one's own or other's action can activate predictive motor representations in the observer's brain. First, a TMS study in humans has evidenced muscle-specific activation of the motor cortex not only when directly observing a specific hand action done by others, but also when a symbolic cue prompting that action was visually presented (Janssen et al., 2013), enabling a predictive “mirroring” of other's behavior. Second, another TMS study demonstrated that the recruitment of the motor system following visual presentation of objects is conditional upon the object location in the observer's peripersonal space (Cardellicchio et al., 2011). Third, behavioral studies support the idea that object affordances are processed not only when the object is presented within the observer's peripersonal space (Costantini et al., 2010), but also when it is located within the peripersonal space of an observed agent (Costantini et al., 2011). Interestingly, the studies by Costantini et al. (2010, 2011) also showed that object-affordance effects depend upon a pragmatic rather than metric coding of the peripersonal space.
The data of the present study are consistent with this latter observation. Indeed, most (∼75%) of the recorded canonical and canonical-mirror neurons discharged weakly to object presentation when it occurred behind a transparent plastic barrier, with approximately half of them showing no significant activation in this condition (Fig. 9). This finding clearly demonstrates that neuronal responses to object rely on the actual possibility for the monkey to interact with the observed stimulus, thus providing a pragmatic coding of objects in space. The space-constrained coding of objects as potential targets for self and others suggests that motor prediction might be useful both for planning actions and preparing behavioral reactions in the physical and social world.
Footnotes
The work was supported by the Italian Institute of Technology and the European Commission Grant Cogsystem FP7-250013. We thank Marco Bimbi for technical assistance, Monica Pongolini for help in data acquisition, and Luana Caselli for her contribution during initial phases of the experiments.
The authors declare no competing financial interests.
References
- Belmalih A, Borra E, Contini M, Gerbella M, Rozzi S, Luppino G. Multimodal architectonic subdivision of the rostral part (area F5) of the macaque ventral premotor cortex. J Comp Neurol. 2009;512:183–217. doi: 10.1002/cne.21892. [DOI] [PubMed] [Google Scholar]
- Bonini L, Rozzi S, Serventi FU, Simone L, Ferrari PF, Fogassi L. Ventral premotor and inferior parietal cortices make distinct contribution to action organization and intention understanding. Cereb Cortex. 2010;20:1372–1385. doi: 10.1093/cercor/bhp200. [DOI] [PubMed] [Google Scholar]
- Bonini L, Maranesi M, Livi A, Bruni S, Fogassi L, Holzhammer T, Paul O, Ruther P. Application of floating silicon-based linear multielectrode arrays for acute recording of single neuron activity in awake behaving monkeys. Biomed Tech (Berl) 2013 doi: 10.1515/bmt-2012-0099. doi: 10.1515/bmt-2012-0099. Advance online publication. Retrieved Oct. 26, 2013. [DOI] [PubMed] [Google Scholar]
- Borra E, Belmalih A, Calzavara R, Gerbella M, Murata A, Rozzi S, Luppino G. Cortical connections of the macaque anterior intraparietal (AIP) area. Cereb Cortex. 2008;18:1094–1111. doi: 10.1093/cercor/bhm146. [DOI] [PubMed] [Google Scholar]
- Caggiano V, Fogassi L, Rizzolatti G, Thier P, Casile A. Mirror neurons differentially encode the peripersonal and extrapersonal space of monkeys. Science. 2009;324:403–406. doi: 10.1126/science.1166818. [DOI] [PubMed] [Google Scholar]
- Cardellicchio P, Sinigaglia C, Costantini M. The space of affordances: a TMS study. Neuropsychologia. 2011;49:1369–1372. doi: 10.1016/j.neuropsychologia.2011.01.021. [DOI] [PubMed] [Google Scholar]
- Costantini M, Ambrosini E, Tieri G, Sinigaglia C, Committeri G. Where does an object trigger an action? An investigation about affordances in space. Exp Brain Res. 2010;207(1–2):95–103. doi: 10.1007/s00221-010-2435-8. [DOI] [PubMed] [Google Scholar]
- Costantini M, Committeri G, Sinigaglia C. Ready both to your and to my hands: mapping the action space of others. PLoS One. 2011;6:e17923. doi: 10.1371/journal.pone.0017923. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Fluet MC, Baumann MA, Scherberger H. Context-specific grasp movement representation in macaque ventral premotor cortex. J Neurosci. 2010;30:15175–15184. doi: 10.1523/JNEUROSCI.3343-10.2010. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Fogassi L, Gallese V, Buccino G, Craighero L, Fadiga L, Rizzolatti G. Cortical mechanism for the visual guidance of hand grasping movements in the monkey: a reversible inactivation study. Brain. 2001;124:571–586. doi: 10.1093/brain/124.3.571. [DOI] [PubMed] [Google Scholar]
- Gallese V, Fadiga L, Fogassi L, Rizzolatti G. Action recognition in the premotor cortex. Brain. 1996;119:593–609. doi: 10.1093/brain/119.2.593. [DOI] [PubMed] [Google Scholar]
- Gerbella M, Belmalih A, Borra E, Rozzi S, Luppino G. Cortical connections of the anterior (F5a) subdivision of the macaque ventral premotor area F5. Brain Struct Funct. 2011;216:43–65. doi: 10.1007/s00429-010-0293-6. [DOI] [PubMed] [Google Scholar]
- Herwik S, Kisban S, Aarts AAA, Seidl K, Girardeau G, Benchenane K, Zugaro MB, Wiener SI, Paul O, Neves HP, Ruther P. Fabrication technology for silicon-based microprobe arrays used in acute and sub-chronic neural recording. J Micromech Microeng. 2009;19 doi: 10.1088/0960-1317/19/7/074008. 074008. [DOI] [Google Scholar]
- Janssen L, Steenbergen B, Carson RG. Anticipatory planning reveals segmentation of cortical motor output during action observation. Cereb Cortex. 2013 doi: 10.1093/cercor/bht220. doi: 10.1093/cercor/bht220. Advance online publication. Retrieved Aug. 19, 2013. [DOI] [PubMed] [Google Scholar]
- Jeannerod M, Arbib MA, Rizzolatti G, Sakata H. Grasping objects: the cortical mechanisms of visuomotor transformation. Trends Neurosci. 1995;18:314–320. doi: 10.1016/0166-2236(95)93921-J. [DOI] [PubMed] [Google Scholar]
- Kohler E, Keysers C, Umiltà MA, Fogassi L, Gallese V, Rizzolatti G. Hearing sounds, understanding actions: action representation in mirror neurons. Science. 2002;297:846–848. doi: 10.1126/science.1070311. [DOI] [PubMed] [Google Scholar]
- Kraskov A, Dancause N, Quallo MM, Shepherd S, Lemon RN. Corticospinal neurons in macaque ventral premotor cortex with mirror properties: a potential mechanism for action suppression? Neuron. 2009;64:922–930. doi: 10.1016/j.neuron.2009.12.010. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Macfarlane NB, Graziano MS. Diversity of grip in Macaca mulatta. Exp Brain Res. 2009;197:255–268. doi: 10.1007/s00221-009-1909-z. [DOI] [PubMed] [Google Scholar]
- Maranesi M, Rodà F, Bonini L, Rozzi S, Ferrari PF, Fogassi L, Coudé G. Anatomo-functional organization of the ventral primary motor and premotor cortex in the macaque monkey. Eur J Neurosci. 2012;36:3376–3387. doi: 10.1111/j.1460-9568.2012.08252.x. [DOI] [PubMed] [Google Scholar]
- Maranesi M, Ugolotti Serventi F, Bruni S, Bimbi M, Fogassi L, Bonini L. Monkey gaze behavior during action observation and its relationship to mirror neuron activity. Eur J Neurosci. 2013;38:3721–3730. doi: 10.1111/ejn.12376. [DOI] [PubMed] [Google Scholar]
- Murata A, Gallese V, Kaseda M, Sakata H. Parietal neurons related to memory-guided hand manipulation. J Neurophysiol. 1996;75:2180–2186. doi: 10.1152/jn.1996.75.5.2180. [DOI] [PubMed] [Google Scholar]
- Murata A, Fadiga L, Fogassi L, Gallese V, Raos V, Rizzolatti G. Object representation in the ventral premotor cortex (area F5) of the monkey. J Neurophysiol. 1997;78:2226–2230. doi: 10.1152/jn.1997.78.4.2226. [DOI] [PubMed] [Google Scholar]
- Murata A, Gallese V, Luppino G, Kaseda M, Sakata H. Selectivity for the shape, size, and orientation of objects for grasping in neurons of monkey parietal area AIP. J Neurophysiol. 2000;83:2580–2601. doi: 10.1152/jn.2000.83.5.2580. [DOI] [PubMed] [Google Scholar]
- Nelissen K, Luppino G, Vanduffel W, Rizzolatti G, Orban GA. Observing others: multiple action representation in the frontal lobe. Science. 2005;310:332–336. doi: 10.1126/science.1115593. [DOI] [PubMed] [Google Scholar]
- Nelissen K, Borra E, Gerbella M, Rozzi S, Luppino G, Vanduffel W, Rizzolatti G, Orban GA. Action observation circuits in the macaque monkey cortex. J Neurosci. 2011;31:3743–3756. doi: 10.1523/JNEUROSCI.4803-10.2011. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Raos V, Umiltà MA, Murata A, Fogassi L, Gallese V. Functional properties of grasping-related neurons in the ventral premotor area F5 of the macaque monkey. J Neurophysiol. 2006;95:709–729. doi: 10.1152/jn.00463.2005. [DOI] [PubMed] [Google Scholar]
- Rizzolatti G, Kalaska J. Voluntary movement: the parietal and premotor cortex. In: Kandel E, Schwartz J, Jessell T, Siegelbaum S, Hudspeth AJ, editors. Principles of neural science. Ed 5. New York: McGraw-Hill; 2012. [Google Scholar]
- Rizzolatti G, Sinigaglia C. The functional role of the parieto-frontal mirror circuit: interpretations and misinterpretations. Nat Rev Neurosci. 2010;11:264–274. doi: 10.1038/nrn2805. [DOI] [PubMed] [Google Scholar]
- Rizzolatti G, Camarda R, Fogassi L, Gentilucci M, Luppino G, Matelli M. Functional organization of inferior area 6 in the macaque monkey: II. Area F5 and the control of distal movements. Exp Brain Res. 1988;71:491–507. doi: 10.1007/BF00248742. [DOI] [PubMed] [Google Scholar]
- Rizzolatti G, Fadiga L, Gallese V, Fogassi L. Premotor cortex and the recognition of motor actions. Brain Res Cogn Brain Res. 1996;3:131–141. doi: 10.1016/0926-6410(95)00038-0. [DOI] [PubMed] [Google Scholar]
- Rozzi S, Calzavara R, Belmalih A, Borra E, Gregoriou GG, Matelli M, Luppino G. Cortical connections of the inferior parietal cortical convexity of the macaque monkey. Cereb Cortex. 2006;16:1389–1417. doi: 10.1093/cercor/bhj076. [DOI] [PubMed] [Google Scholar]
- Ruther P, Herwik S, Kisban S, Seidl K, Paul O. Recent progress in neural probes using silicon MEMS technology. IEEJ Trans Elec Electron Eng. 2010;5:505–515. doi: 10.1002/tee.20566. [DOI] [Google Scholar]
- Supèr H, Roelfsema PR. Chronic multiunit recordings in behaving animals: advantages and limitations. Prog Brain Res. 2005;147:263–282. doi: 10.1016/S0079-6123(04)47020-4. [DOI] [PubMed] [Google Scholar]
- Theys T, Pani P, van Loon J, Goffin J, Janssen P. Selectivity for three-dimensional shape and grasping-related activity in the macaque ventral premotor cortex. J Neurosci. 2012;32:12038–12050. doi: 10.1523/JNEUROSCI.1790-12.2012. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Umiltà MA, Kohler E, Gallese V, Fogassi L, Fadiga L, Keysers C, Rizzolatti G. I know what you are doing: a neurophysiological study. Neuron. 2001;31:155–165. doi: 10.1016/S0896-6273(01)00337-3. [DOI] [PubMed] [Google Scholar]