

Abstract
Penalized regression methods that perform simultaneous model selection and estimation are ubiquitous in statistical modeling. The use of such methods is often unavoidable as manual inspection of all possible models quickly becomes intractable when there are more than a handful of predictors. However, automated methods usually fail to incorporate domain-knowledge, exploratory analyses, or other factors that might guide a more interactive model-building approach. A hybrid approach is to use penalized regression to identify a set of candidate models and then to use interactive model-building to examine this candidate set more closely. To identify a set of candidate models, we derive point and interval estimators of the probability that each model along a solution path will minimize a given model selection criterion, for example, Akaike information criterion, Bayesian information criterion (AIC, BIC), etc., conditional on the observed solution path. Then models with a high probability of selection are considered for further examination. Thus, the proposed methodology attempts to strike a balance between algorithmic modeling approaches that are computationally efficient but fail to incorporate expert knowledge, and interactive modeling approaches that are labor intensive but informed by experience, intuition, and domain knowledge. Supplementary materials for this article are available online.
Keywords: Conditional distribution, Lasso, Prediction sets
1. Introduction
Penalized estimation is a popular means of regression model fitting that is quickly becoming a standard tool among quantitative researchers working across nearly all areas of science. Examples include the Lasso (Tibshirani 1996), SCAD (Fan and Li 2001), Elastic Net (Zou and Hastie 2005), and the adaptive Lasso (Zou 2006). One appealing feature of these methods is that they perform simultaneous model selection and estimation, thereby automating model-building at least partially. This is especially beneficial in settings where the number of predictors is large, precluding manual inspection of all possible models. However, a consequence is that the analyst becomes increasingly dependent on an estimation algorithm that has neither the subject-matter knowledge nor the intuition that might guide a less automated and more interactive model-building process (Henderson and Velleman 1981; Cox 2001). A hybrid approach is to use penalized estimation to construct a small subset of models, for example, the sequence of models occurring on a solution path, and then to apply interactive model-building techniques to choose a model from among these. We develop and advocate such a hybrid approach wherein a set of candidate models are identified using a solution path, and then models along this path are prioritized using their conditional probability of selection according to one or more tuning parameter selection methods. We envision this approach as being useful in at least two ways: (i) it facilitates interactive, expert-knowledge-driven exploration of high-quality candidate models even when the initial pool of models is large; and (ii) it provides valid conditional prediction sets for a data-driven tuning parameter given the observed design matrix and solution path, which is applicable for a large class of tuning parameter selection methods.
There is a vast literature on tuning parameter selection methods. Classical methods include Mallow’s Cp (Mallows 1973), Akaike information criterion (AIC; Akaike 1974), Bayesian information criterion (BIC; Schwarz 1978), cross-validation, and generalized cross-validation (Golub, Heath, and Wahba 1979). More recent work on tuning parameter selection, driven by interest in high-dimensional data, includes new information-theoretic selection methods (Chen and Chen 2008; Wang, Li, and Leng 2009; Zhang, Li, and Tsai 2010; Wang and Zhu 2011; Kim, Kwon, and Choi 2012; Fan and Tang 2013; Hui, Warton, and Foster 2015) as well as resampling-based approaches (Hall, Lee, and Park 2009; Meinshausen and Bühlmann 2010; Feng and Yu 2013; Sun, Wang, and Fang 2013; Shah and Samworth 2013). The foregoing methods select a single tuning parameter and hence a single fitted model. Our goal is to quantify the stability of these methods by constructing conditional prediction sets for data-driven tuning parameters and to use these prediction sets to prioritize models for further, expert-guided exploration. Given one or more tuning parameter selection methods, we identify all models with sufficiently large conditional probability of being selected given the design matrix and observed solution path.
In Section 2, we review penalized linear regression. In Section 3, we derive exact and asymptotic estimators of the sampling distribution of a data-driven tuning parameter. We examine the performance of the proposed methods through simulation studies in Section 4. In Section 5, we illustrate the proposed methods using two data examples. A concluding discussion is given in Section 6. Technical details are relegated to the supplement materials.
2. Penalized Linear Regression
We assume that the data are generated according to the linear model , for i = 1, … , n, where ϵ1, … , ϵn are independent, identically distributed errors with expectation zero, β0 = (β01, … , β0p)⊺, and X1, … ,Xn are predictors that can be regarded as either fixed or random. Let Y = (Y1, Y2, … , Yn)⊺ be the vector of responses and X = (X1, X2, … , Xn)⊺ the design matrix with the first column equal to 1n×1. Let denote the empirical distribution. We consider penalized least-square estimators
where fj(·), j = 2, … , p are penalty functions. For example, corresponds to the Lasso, and corresponds to the adaptive Lasso, where is the ordinary least-square estimator and γ > 0 is a constant.
For any Λ ⊆ [0, ∞) define the solution path along Λ as ; we write to denote . While the solution path along Λ may contain a continuum of coefficient vectors, it is commonly viewed as containing a finite set of unique models corresponding to each unique combination of nonzero elements of coefficients in , that is, the set of models . The number of models in is typically much smaller, for example, Op{min(n, p)}, than the set of all of 2p possible models. Thus, the set of models along the solution path are a natural and computationally manageable subset ofmodels for further investigation. Standard practice is to choose a single value of the tuning parameter, say , that optimizes some prespecified criterion and subsequently a single model ]. However, the selected tuning parameter is a random variable and there may be multiple models along the solution path where the support of the selected tuning parameter is large, for example, where is a τ upper-level set of the conditional distribution of given and X. If these models can be identified from the observed data, then they can be reported as potential candidate models or a single model can be chosen from among them using expert judgment and other factors not captured in the estimation algorithm. Also, unlikely models can be ruled out. To formalize this procedure, we consider selection methods within the framework of generalized information criterion.
Define the generalized information criterion as
| (1) |
where , , and wn is a sequence of positive constants, with wn = log(n)/n and wn = 2/n yielding BIC and AIC, respectively. We consider data-driven tuning parameters of the form We focus primarily on the setting where n > p as the GIC is not well-defined if p ≥ n However, we provide an illustrative example in Section 5 where p > n wherein our method is applied after an initial screening step; this two-stage procedure is in line with our vision for using automated methods to identify a small set of candidate models for further consideration. We also present extensions of key distributional approximations to the setting where p diverges with n in the Appendix.
3. Estimating the Conditional Distribution of
In this section, we characterize and derive estimators of the conditional distribution of given and X. We first show that conditioning on and X is equivalent to conditioning on X⊺Y and X. We then show that is a nondecreasing function of the sum of squares error of the full model . Therefore, the conditional distribution of is completely determined by the conditional distribution of .
3.1. Conditioning on the Solution Path
We assume that fj(βj, ℙn), j = 2, … , p depends on the observed data only through X⊺Y and X⊺X; this assumption is natural as X⊺X and X⊺Y are sufficient statistics for the conditional mean of Y given X under the assumed linear model. Under this assumption, , from which it can be seen that the solution path is completely determined by X⊺X and X⊺Y. On the other hand, given and X, we can recover X⊺Y using . Therefore, conditioning on solution path and design matrix is equivalent to conditioning on X⊺Y and X (see Lemma C.1 in the Appendix).
In the case of adaptive Lasso, we assume that X is full column rank so that fj(βj; ℙn), which depends on , is well-defined. It can be seen that if X is full column rank, then the entire solution path is determined by X⊺X and Conditioning on the solution path is also practically relevant because it is consistent with the common practice wherein an analyst is presented with a full solution path and then proceeds to identify a model as a point along this path.
3.2. Exact Distribution of
We assume that the models along the solution path are determined by the sequence of tuning parameters , so that is the total number of tuning parameters to be considered. The following lemma characterizes the conditional distribution of .
Lemma 1.
The selected tuning parameter, , is completely determined by . Furthermore, assume is a nondecreasing function of λ, write , then for each fixed = s and X = x, the map σ2 ↦ λ(s, x, σ2) is nondecreasing.
The assumption that is nondecreasing function of λ holds under mild conditions, for example, if is a decreasing function of λ and the original penalized problem can be recast as constrained minimization problem of the form minimize ||Y − X β||2 subject to the constraint . It is well known that Lasso satisfies this property. If the error is normally distributed, then is independent of (, X) and follows a chi-square distribution with n − p degrees of freedom. Therefore, the preceding lemma shows that, under normal errors, the conditional distribution of given is a nondecreasing function of a chi-square random variable. The remaining results stated in this section do not require the assumption that is nondecreasing in λ; rather, the results are stated in terms of a finite but arbitrary sequence of tuning parameter values.
Define . For k = 1, … , , define , , , and
where wn is from Equation (1). The quantities in the foregoing definitions are all measurable with respect to X and and thus, for probability statements conditional on X and , they are regarded as constants.
The following proposition gives the exact conditional distribution of given and X.
Proposition 1.
Define with the convention that if is empty, and . Then,
Provided that the conditional distribution of given ( is known or can be consistently estimated, the preceding proposition can be used to construct conditional prediction sets for . A (1 − α) × 100% conditional prediction set is , where . Alternatively, as discussed previously, one can construct the τ upper-level set , for any τ ∈ (0, 1).
Define and . If the errors are normally distributed then
| (2) |
Plugging into this expression yields an estimator for pk.
Define . Then a (1 − α) × 100% projection confidence interval (Berger and Boos 1994) for pk (Equation (2)) is
| (3) |
Where is a (1−α) × 100% confidence interval for . Thus, an estimator of is
| (4) |
Remark 1. The assumption that X is full rank is not necessary for Proposition 1. Note that the conclusions depend only on the quantities , , and , which are computable even when X is not full rank.
3.3. Limiting Conditional Distribution of
As discussed above, if the errors are assumed tobe normally distributed then exact distribution theory for is possible using a transformed chi-square random variable. Here, we consider asymptotic approximations that apply more generally.
Denote the third and fourth moment of ϵ as μ3,ϵ and μ4,ϵ respectively. Define
where . And write Φp+1 (t) to denote the cumulative distribution function of a standard (p + 1 )-dimensional multivariate normal distribution evaluated at t. For u, v ∈ ℝp+1 write u ≤ v to mean component-wise inequality. The following are standard results from ordinary linear regression under common regularity conditions summarized in Section C in the Appendix (see the proof of Proposition 2).
Proposition 2.
The asymptotic joint distribution of and is multivariate normal with mean zero and covariance Σ, that is,
Because we assume that X is full column rank, conditioning on (, X) is equivalent to conditioning on (, X) (in the sense that they generate the same σ-algebra). Therefore to approximate the conditional distribution of given (, X), we construct an estimator of Σ, say , and then use the above proposition to form a plug-in estimator of the distribution of given . Define
| (5) |
and subsequently , , , , and . The estimated conditional distribution of is
| (6) |
This approximation, coupled with Proposition 1, can be used to approximate the conditional distribution of when a chi-squared approximation is not feasible.
Henceforth, we assume that the errors are symmetric about zero, in which case the third moment of ϵi, μ3ϵ, is zero, which implies is asymptotically independent of . Therefore,
| (7) |
where μ4,ϵ is the fourth moment of ϵi. Define
Suppose that is a (1 − α) x 100% asymptotic confidence region for μ4,ϵ − and , then
| (8) |
is an approximate (1 − α) × 100% projection confidence interval for pk (see Proposition C.1 in Section C of the Appendix.).
We construct the confidence set using Wald confidence region:
where is the estimated covariance matrix of . Then the optimization problem in Equation (9) is solved using an augmented Lagrangian method (Bertsekas 2014). An estimator of is
| (9) |
Proposition 2 is stated in terms of fixed p and diverging n. We show in the Appendix that the approximation in Equation (7) remains valid in the setting as well as the setting where provided that an appropriate screening step is applied as a first step. We illustrate this screening approach with a high-dimensional example in our simulation experiments.
3.4. Bootstrap Approximation to the Distribution of
In small samples, it may be preferable to estimate the conditional distribution of using the bootstrap. Let γ(b) = (γ1(b), … , γn(b))⊺ be a sample drawn with replacement from . Define , where Px = X(X⊺X)−X⊺. This bootstrap method differs from the usual residual bootstrap in ordinary linear regression because our goal is to estimate the conditional distribution of . We accomplish this by multiplying the error vector by (I − Px), which ensures that so that Y(b) produces the same solution path as the original sample Y. The conditional distribution of the tuning parameter is estimated by generating b = 1,…, B bootstrap samples and calculating the corresponding tuning parameter for each bootstrap sample. See Proposition C.2 in Section C of the Appendix for a statement of the asymptotic equivalence between the proposed bootstrap method and the normal approximation given in Equation (6).
4. Simulation Studies
In this section, we investigate the finite-sample performance of the proposed methods using a series of simulation experiments. We focus on the Lasso tuned using BIC. Simulated datasets are generated from the model , where ϵi, i = 1, … , n are generated independently from a standard normal distribution and Xi, i = 1, … , n are generated independently from a multivariate normal distribution with mean zero and autoregressive covariance structure, Cj,k = ρ|j−k|, with ρ = 0 or 0.5 and 1 ≤ j, k ≤ 20, or 200. For the regression coefficients β0, we consider the following four settings:
Model 1: β0 = c1×(1, 1, 1, 1, 0, 0, 0, 0, … , 0)⊺;
Model 2: β0 = c2×(1, 1, 1, 1, 0, 0, 0, 0, 1, 1, 1, 1, … , 0)⊺;
Model 3: β0 = c3×(3, 2, 1, 0, 0, 0, 0, … , 0)⊺;
Model 4: β0 = c4×(3, 2, 1, 0, 0, 0, 0, 0, 3, 2, 1, 0, … , 0)⊺;
where c1, … , c4 are constants chosen so that the population R2 of each model is 0.5 under the definition R2 = 1 − var(Y|X)/var(Y). For each combination of parameter settings, 10,000 datasets were generated; the bootstrap estimator was constructed using 5000 bootstrap replications.
For estimating the τ upper-level set, , we consider:
(AsympNor) the plug-in estimator based on the normal approximation to the distribution of pk;
(Bootstrap) the estimator based on the bootstrap approximation to the sampling distribution of pk as described in Section 3.4;
(UP1) the estimator based on a 90% projection confidence set as in Equation (4);
(UP2) the estimator based on a 90% projection confidence set as in Equation (10);
(Akaike) the estimator based on Akaike weights: , with wn = 2/n (Burnham and Anderson 2003);
(ApproxPost) the estimator based on approximate posterior distribution: , with Wn = log(n)/n (Burnham and Anderson 2003).
We define the performance of these estimators in terms of their true and false discovery rates. Provided that is nonempty, define the true discovery rate of an estimator as
where # denotes the number of elements in a set. Provided is nonempty with probability one, define the false discovery rate of an estimator as
Here, we present results for τ = 0.05; results for τ = 0.1 and τ = 0.2 are presented in the supplemental materials. The results for p = 20, n = 50 and p = 100, n = 200 are presented in Tables 1 and 2, respectively. AsympNor and the Bootstrap perform similarly with a TDR above 0.9 and an FDR below 0.10. As expected, methods based on the upper bound of the confidence interval achieve higher TDR but at the price of higher FDR. Methods based on Akaike weights and approximate posterior have the worst performances in terms of discovery rate of . The poor performance is not surprising as these methods were not designed for conditional inference.
Table 1.
Discovery rate for p = 20, n = 50.
| AsympNor |
Bootstrap |
UP1 |
UP2 |
Akaike |
ApproxPost |
||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| Model | ρ | TDR | FDR | TDR | FDR | TDR | FDR | TDR | FDR | TDR | FDR | TDR | FDR |
| 0 | 0.90 | 0.10 | 0.90 | 0.10 | 1.00 | 0.32 | 0.99 | 0.36 | 0.54 | 0.83 | 0.90 | 0.58 | |
| 1 | 0.5 | 0.92 | 0.09 | 0.92 | 0.09 | 1.00 | 0.29 | 0.99 | 0.34 | 0.61 | 0.83 | 0.95 | 0.58 |
| 0 | 0.88 | 0.11 | 0.88 | 0.10 | 0.99 | 0.30 | 0.99 | 0.34 | 0.46 | 0.83 | 0.82 | 0.59 | |
| 2 | 0.5 | 0.89 | 0.10 | 0.90 | 0.10 | 1.00 | 0.35 | 0.99 | 0.36 | 0.55 | 0.82 | 0.89 | 0.59 |
| 0 | 0.92 | 0.09 | 0.92 | 0.09 | 1.00 | 0.29 | 0.99 | 0.34 | 0.57 | 0.84 | 0.94 | 0.58 | |
| 3 | 0.5 | 0.93 | 0.08 | 0.93 | 0.08 | 1.00 | 0.27 | 0.99 | 0.32 | 0.64 | 0.83 | 0.96 | 0.57 |
| 0 | 0.89 | 0.11 | 0.90 | 0.10 | 0.99 | 0.32 | 0.99 | 0.36 | 0.50 | 0.84 | 0.88 | 0.59 | |
| 4 | 0.5 | 0.91 | 0.10 | 0.91 | 0.09 | 0.99 | 0.33 | 0.99 | 0.35 | 0.58 | 0.83 | 0.92 | 0.58 |
Table 2.
Discovery rate for p = 100, n = 200.
| AsympNor |
Bootstrap |
UP1 |
UP2 |
Akaike |
ApproxPost |
||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| Model | ρ | TDR | FDR | TDR | FDR | TDR | FDR | TDR | FDR | TDR | FDR | TDR | FDR |
| 0 | 0.97 | 0.03 | 0.97 | 0.03 | 1.00 | 0.12 | 1.00 | 0.13 | 0.11 | 0.98 | 1.00 | 0.58 | |
| 1 | 0.5 | 0.98 | 0.03 | 0.98 | 0.02 | 1.00 | 0.09 | 1.00 | 0.10 | 0.24 | 0.95 | 1.00 | 0.56 |
| 0 | 0.95 | 0.04 | 0.95 | 0.04 | 1.00 | 0.17 | 1.00 | 0.18 | 0.05 | 0.99 | 0.98 | 0.59 | |
| 2 | 0.5 | 0.96 | 0.03 | 0.96 | 0.03 | 1.00 | 0.14 | 1.00 | 0.15 | 0.12 | 0.97 | 0.99 | 0.58 |
| 0 | 0.97 | 0.03 | 0.97 | 0.03 | 1.00 | 0.12 | 1.00 | 0.13 | 0.16 | 0.97 | 1.00 | 0.57 | |
| 3 | 0.5 | 0.98 | 0.02 | 0.98 | 0.02 | 1.00 | 0.09 | 1.00 | 0.10 | 0.28 | 0.94 | 1.00 | 0.56 |
| 0 | 0.96 | 0.04 | 0.96 | 0.04 | 1.00 | 0.14 | 1.00 | 0.16 | 0.07 | 0.98 | 0.99 | 0.59 | |
| 4 | 0.5 | 0.97 | 0.03 | 0.97 | 0.03 | 1.00 | 0.12 | 1.00 | 0.13 | 0.16 | 0.97 | 1.00 | 0.57 |
We also evaluated the coverage of the proposed confidence intervals based on assumption of normality assumption as well as the asymptotic approximation. In calculating the coverage probabilities, we restricted calculations to the set (λ : 0.9999 > > 0.0001}. Nominal coverage is set at 0.90. The results are presented in Table 3. The confidence intervals based on normality (Equation (3)) achieve nominal coverage in all cases. The confidence intervals based on an asymptotic approximation undercover slightly, though coverage approaches nominal levels as n increases.
Table 3.
Coverage probability. Results are based on 10,000 replicated datasets.
| ρ | Approximate |
Normality |
|||
|---|---|---|---|---|---|
| 0 | 0.5 | 0 | 0.5 | ||
| Model 1 | 0.86 | 0.85 | 0.92 | 0.91 | |
| n = 50 | Model 2 | 0.86 | 0.85 | 0.91 | 0.91 |
| p = 20 | Model 3 | 0.85 | 0.85 | 0.91 | 0.91 |
| Model 4 | 0.86 | 0.85 | 0.92 | 0.91 | |
| Model 1 | 0.88 | 0.88 | 0.91 | 0.90 | |
| n = 200 | Model 2 | 0.87 | 0.88 | 0.91 | 0.91 |
| p = 100 | Model 3 | 0.87 | 0.87 | 0.91 | 0.90 |
| Model 4 | 0.87 | 0.88 | 0.91 | 0.90 | |
5. Illustrative Data Examples
In this section, we apply the proposed methods to two datasets. The first dataset informs the relationship of pollution and other factors related to urban-living, and to age-adjusted mortality (McDonald and Schwing 1973; Luo, Stefanski, and Boos 2006); and the second regards the relationship between gene mutations and drug resistance level (Rhee et al. 2006). We demonstrate that reporting a single model may not be appropriate in these two examples and that the proposed methods have the potential to identify interesting models warranting further examination. As in the simulation experiments, we consider the Lasso estimator tuned using BIC.
5.1. Pollution and Mortality
As our first illustrative example we consider data on mortality rates recorded in 60 metropolitan areas. Prior analyses of these data focused on the regression of age-adjusted mortality on 15 predictors that are grouped into three broad categories: weather, socioeconomic factors, and pollution. A copy of the dataset and a detailed description of each predictor are provided in the supplemental materials.
Ignoring uncertainty in the tuning parameter selection, the LASSO estimator tuned using BIC leads to a model with six variables, Percent Non-White, Education, SO2 Pollution Potential, Precipitation, Mean January Temperature, and Population Per Mile. However, the estimated conditional sampling distribution of the tuning parameter indicates that a larger model with eight predictors is approximately equally probable. Figure 1 displays the solution path with the estimated selection probabilities using both the asymptotic normal and bootstrap approximations. The estimated conditional distribution of the tuning parameter is displayed in Table 4; 90% confidence intervals based on Equations (3) and (9) are presented. The LASSO coefficient estimates are presented in Table B.1 of the Appendix.
Figure 1.
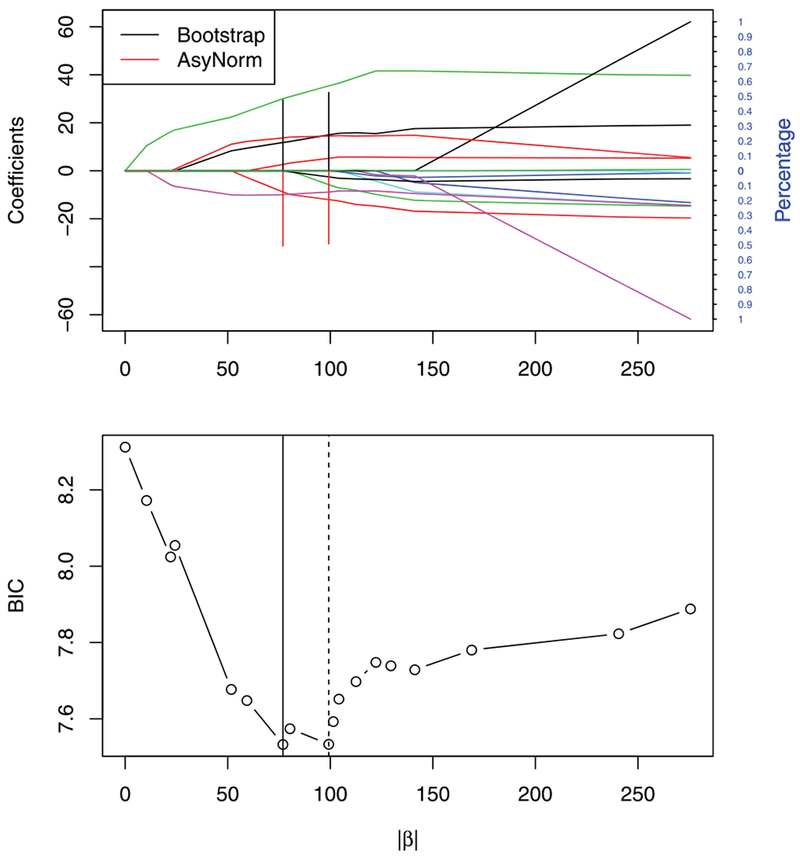
The top figure shows LASSO solution path of mortality rates data; The vertical lines above and belowx-axis correspond to the distribution estimated by bootstrap and asymptotic normal approximation, respectively. The bottom figure shows BIC values for candidate models along solution path. The solid vertical line corresponds to the model with six variables and smallest BIC value. The dashed vertical line corresponds to a model with eight variables.
Table 4.
Estimated conditional distribution of the tuning parameter for the mortality rates data. Both the asymptotic normal approximation and the bootstrap had only two support points, {124.21,288.20}.
| λ | 288.20 | 124.21 |
|---|---|---|
| Model size | 6 | 8 |
| Probability mass normal | 0.51 | 0.49 |
| Probability mass bootstrap | 0.48 | 0.52 |
| 90% CI based on normality | (0.052,0.950) | (0.048, 0.948) |
| 90% Approximate CI | (0.009,0.848) | (0.154, 1.000) |
We further investigate the model with eight predictors. The eighth predictor added to the model is Mean July Temperature. Fitting a simple linear regression of mortality on Mean July Temperature yields a p-value of 0.03 compared with a p-value of 0.81 in the regression of mortality on Mean January Temperature. This is in line with Katsouyanni et al. (1993) who concluded that high temperatures are related to the mortality rate. It can be seen that in this case, reporting a single model may not be appropriate. Rather, it may be more informative to report the two models that contain essentially all of the mass of the conditional distribution of the tuning parameter.
For comparison, results from forward stepwise regression are presented in Figure 2. The smallest BIC value corresponds to Step 5 of the procedure which corresponds to a model with the five predictors: Percent Non-White, Education, Mean January Temperature, SO2 Pollution Potential, and Precipitation. This model is smaller than the model selected by LASSO tuned using BIC. This may be because forward stepwise regression is greedy in that at each step it seeks a variable that captures maximum variation in the residuals. Thus, if a candidate variable is correlated with those selected in previous steps, it may be difficult to see the improvement in the fitted model. In such cases, it might be preferable to use the solution path to generate a candidate set of models.
Figure 2.
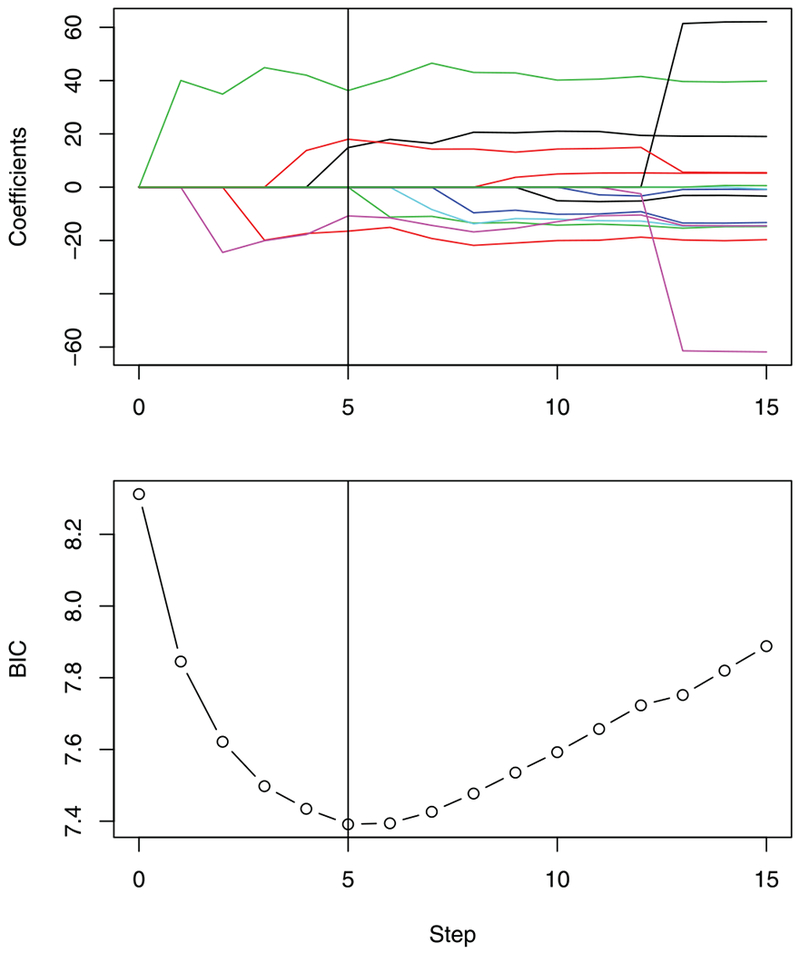
The top figure shows forward stepwise regression solution path of mortality rates data; The vertical line corresponds to the model which minimizes BIC. The bottom figures show BIC values for candidate models along solution path. The solid vertical line corresponds to the smallest BIC value.
5.2. ATV Drug Resistance
Our second example considers mutations that affect resistance to Atazanavir (ATV), a protease inhibitor for HIV (Rhee et al. 2006; Barber et al. 2015). After preprocessing, the dataset contains 328 observations and 361 predictors of gene mutations. The response is a measure of drug resistance for ATV. Because p > n in this example, we use 100 observations for screening 50 important predictors, ranked by Pearson correlation with response. We then fit a linear model using the Lasso applied to the remaining 228 observations with the 50 important predictors selected at screening.
The estimated conditional distribution of the tuning parameter and 90% confidence intervals are presented in Table 5; the estimated distribution is overlaid on the solution path in Figure 3. It can be seen that the estimated distribution of the tuning parameter mainly favors two models.
Table 5.
Estimated conditional distribution of the tuning parameter for ATV drug resistance data.
| λ | 1347.92 | 1101.71 | 805.53 |
|---|---|---|---|
| Model size | 10 | 12 | 15 |
| Probability mass normal | 0.443 | 0.045 | 0.472 |
| Probability mass bootstrap | 0.494 | 0.047 | 0.454 |
| 90% CI based on normality | (0.019, 0.896) | (0.026,0.127) | (0.059, 0.959) |
| 90% Approximate CI | (0.000, 0.751) | (0.020, 0.064) | (0.020, 1) |
Figure 3.

The top figure shows LASSO solution path of ATV drug resistance data; The vertical lines above and below x-axis correspond to the distribution estimated by bootstrap and asymptotic normal approximation, respectively. The bottom figure shows BIC values for candidate models along solution path. The solid vertical line corresponds to the model with 15 variables and smallest BIC value. The dashed vertical lines correspond to model with 12 and 10 variables.
Similar to Barber et al. (2015), we evaluate candidate models based on treatment selected mutations (TSM) panels, which provide a surrogate for the true important mutations. The model minimizing BIC contains 15 variables, while two of them correspond to the same mutation. This leads to 14 unique mutation locations, and four locations are potential false discoveries (as assessed by TSM); see Table 5. Therefore, the surrogate-based estimated false discovery rate is 4/14 ≈ 0.29. For tuning parameter λ = 1101.71, 11 unique positions are identified, and two locations are potential false discoveries. Tuning parameter λ = 1347.92 leads to nine unique locations with one potential false discovery. The corresponding surrogate-based estimated false discovery rate is 1/9 ≈ 0.11, a decrease of 20% compared with the model minimizing BIC. Thus, in this case it might not be appropriate to report the single model selected by BIC.
6. Conclusion
We proposed two simple procedures for estimating the conditional distribution of a data-driven tuning parameter in penalized regression given the observed solution path and design matrix. Our objective was to quantify the stability of selected models and thereby identify a set of potential models for consideration by domain experts. A plot of the solution path with the estimated selection probabilities or upper confidence bounds overlaid, for example, Figures 1 and 3, is one means of easily conveying uncertainty in the tuning parameter and identifying models that warrant additional investigation. It is noteworthy that in both examples the identified sets of likely models are not contiguous in size. Thus, our methods provide a theoretically motivated, confidence-set-based alternative to the practice of considering models near in size to the BIC-chosen LASSO model.
Supplementary Material
Acknowledgments
Funding
The authors gratefully acknowledge funding from the National Science Foundation (DMS-1555141, DMS-1557733, DMS-1513579) and the National Institutes of Health (P01 CA142538).
Appendix A: Simulation Results
Table A.1.
Discovery rate for p = 20, n = 50; τ = 0.1.
| Model | ρ | AsympNor |
Bootstrap |
UP1 |
UP2 |
Akaike |
ApproxPost |
||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| TDR | FDR | TDR | FDR | TDR | FDR | TDR | FDR | TDR | FDR | TDR | FDR | ||
| 0 | 0.90 | 0.10 | 0.90 | 0.10 | 1.00 | 0.33 | 0.99 | 0.37 | 0.42 | 0.80 | 0.89 | 0.48 | |
| 1 | 05 | 0.92 | 0.08 | 0.92 | 0.08 | 1.00 | 0.30 | 0.99 | 0.33 | 0.48 | 0.78 | 0.93 | 0.48 |
| 0 | 0.87 | 0.11 | 0.88 | 0.11 | 0.99 | 0.33 | 0.99 | 0.36 | 0.35 | 0.81 | 0.81 | 0.48 | |
| 2 | 05 | 0.89 | 0.10 | 0.89 | 0.11 | 1.00 | 0.35 | 0.99 | 0.36 | 0.45 | 0.78 | 0.87 | 0.47 |
| 0 | 0.91 | 0.09 | 0.92 | 0.09 | 1.00 | 0.29 | 0.99 | 0.34 | 0.44 | 0.80 | 0.93 | 0.48 | |
| 3 | 05 | 0.92 | 0.07 | 0.93 | 0.08 | 1.00 | 026 | 0.99 | 0.30 | 0.50 | 0.78 | 0.96 | 0.49 |
| 0 | 0.89 | 0.10 | 0.90 | 0.10 | 1.00 | 0.34 | 0.99 | 0.37 | 0.39 | 0.80 | 0.87 | 0.48 | |
| 4 | 05 | 0.90 | 0.10 | 0.91 | 0.10 | 1.00 | 0.34 | 0.99 | 0.35 | 0.46 | 0.79 | 0.91 | 0.48 |
Table A.2.
Discovery rate for p = 100, n = 200; τ = 0.1.
| Model | ρ | AsympNor |
Bootstrap |
UP1 |
UP2 |
Akaike |
ApproxPost |
||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| TDR | FDR | TDR | FDR | TDR | FDR | TDR | FDR | TDR | FDR | TDR | FDR | ||
| 0 | 0.97 | 0.03 | 0.97 | 0.03 | 1.00 | 0.13 | 1.00 | 0.14 | 0.07 | 0.97 | 0.99 | 0.42 | |
| 1 | 0.5 | 0.97 | 0.02 | 0.97 | 0.02 | 1.00 | 0.10 | 1.00 | 0.10 | 0.15 | 0.93 | 1.00 | 0.40 |
| 0 | 0.95 | 0.04 | 0.95 | 0.04 | 1.00 | 0.17 | 1.00 | 0.18 | 0.03 | 0.99 | 0.98 | 0.42 | |
| 2 | 0.5 | 0.96 | 0.04 | 0.96 | 0.04 | 1.00 | 0.14 | 1.00 | 0.15 | 0.07 | 0.97 | 0.99 | 0.42 |
| 0 | 0.97 | 0.03 | 0.97 | 0.03 | 1.00 | 0.12 | 1.00 | 0.13 | 0.09 | 0.96 | 0.99 | 0.42 | |
| 3 | 0.5 | 0.98 | 0.02 | 0.98 | 0.02 | 1.00 | 0.09 | 1.00 | 0.10 | 0.17 | 0.93 | 1.00 | 0.40 |
| 0 | 0.96 | 0.04 | 0.96 | 0.04 | 1.00 | 0.14 | 1.00 | 0.15 | 0.04 | 0.98 | 0.99 | 0.42 | |
| 4 | 0.5 | 0.97 | 0.03 | 0.97 | 0.03 | 1.00 | 0.12 | 1.00 | 0.13 | 0.09 | 0.96 | 0.99 | 0.42 |
Table A3.
Discovery rate for p = 20, n = 50; τ = 0.2.
| Model | ρ | AsympNor |
Bootstrap |
UP1 |
UP2 |
Akaike |
ApproxPost |
||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| TDR | FDR | TDR | FDR | TDR | FDR | TDR | FDR | TDR | FDR | TDR | FDR | ||
| 0 | 0.89 | 0.11 | 0.89 | 0.11 | 0.99 | 0.34 | 0.99 | 0.39 | 0.25 | 0.69 | 0.84 | 0.22 | |
| 1 | 0.5 | 0.91 | 0.08 | 0.91 | 0.08 | 1.00 | 0.29 | 0.99 | 0.34 | 0.29 | 0.65 | 0.90 | 0.22 |
| 0 | 0.86 | 0.13 | 0.86 | 0.13 | 0.99 | 0.36 | 0.99 | 0.41 | 0.22 | 0.73 | 0.77 | 0.23 | |
| 2 | 0.5 | 0.88 | 0.11 | 0.88 | 0.12 | 0.99 | 0.37 | 0.99 | 0.40 | 0.28 | 0.65 | 0.83 | 0.23 |
| 0 | 0.91 | 0.09 | 0.91 | 0.09 | 1.00 | 0.30 | 0.99 | 0.35 | 0.26 | 0.68 | 0.89 | 0.23 | |
| 3 | 0.5 | 0.92 | 0.07 | 0.92 | 0.08 | 1.00 | 0.26 | 0.99 | 0.31 | 0.31 | 0.64 | 0.92 | 0.23 |
| 0 | 0.88 | 0.11 | 0.88 | 0.11 | 0.99 | 0.35 | 0.99 | 0.40 | 0.23 | 0.71 | 0.83 | 0.22 | |
| 4 | 0.5 | 0.89 | 0.10 | 0.90 | 0.10 | 0.99 | 0.34 | 0.99 | 0.38 | 0.28 | 0.66 | 0.86 | 0.23 |
Table A.4.
Discovery rate for p = 100, n = 200; τ = 0.2.
| Model | ρ | AsympNor |
Bootstrap |
UP1 |
UP2 |
Akaike |
ApproxPost |
||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| TDR | FDR | TDR | FDR | TDR | FDR | TDR | FDR | TDR | FDR | TDR | FDR | ||
| 0 | 0.97 | 0.03 | 0.97 | 0.03 | 1.00 | 0.13 | 1.00 | 0.13 | 0.03 | 0.94 | 0.98 | 0.22 | |
| 1 | 0.5 | 0.97 | 0.03 | 0.97 | 0.03 | 1.00 | 0.10 | 1.00 | 0.11 | 0.07 | 0.88 | 0.99 | 0.21 |
| 0 | 0.95 | 0.05 | 0.95 | 0.05 | 1.00 | 0.17 | 1.00 | 0.18 | 0.01 | 0.98 | 0.96 | 0.21 | |
| 2 | 0.5 | 0.96 | 0.04 | 0.96 | 0.04 | 1.00 | 0.14 | 1.00 | 0.15 | 0.03 | 0.93 | 0.98 | 0.21 |
| 0 | 0.97 | 0.03 | 0.97 | 0.03 | 1.00 | 0.12 | 1.00 | 0.12 | 0.04 | 0.91 | 0.99 | 0.21 | |
| 3 | 0.5 | 0.98 | 0.03 | 0.98 | 0.03 | 1.00 | 0.09 | 1.00 | 0.10 | 0.09 | 0.86 | 0.99 | 0.20 |
| 0 | 0.96 | 0.04 | 0.96 | 0.04 | 1.00 | 0.15 | 1.00 | 0.16 | 0.02 | 0.96 | 0.97 | 0.21 | |
| 4 | 0.5 | 0.97 | 0.03 | 0.97 | 0.03 | 1.00 | 0.12 | 1.00 | 0.13 | 0.04 | 0.92 | 0.99 | 0.21 |
Appendix B: Additional Results for Real-Data
Table B.1.
Coefficient estimates for pollution and mortality data; columns BIC-8 and BIC-6 correspond to lasso estimateswith eight and six predictors, respectively; columns Refit-8 and Refit-6 correspond to refitting coefficient with eight and six predictors; column FS-5 corresponds to model selected by forward stepwise regression.
| Variable | Lasso |
FS-5 | |||
|---|---|---|---|---|---|
| BIC-8 | Refit-8 | BIC-6 | Refit-6 | ||
| Mean annual precipitation | 14.95 | 17.76 | 11.78 | 14.85 | 14.86 |
| Mean January temperature | −12.04 | −14.26 | −8.80 | −16.61 | −16.50 |
| Mean July temperature | −5.80 | −11.71 | 0 | 0 | 0 |
| Median school years | −8.89 | −8.05 | −9.99 | −9.75 | −10.80 |
| Pct of housing units with facilities | −2.55 | −4.69 | 0 | 0 | 0 |
| Population per square mile | 5.15 | 7.11 | 2.62 | 6.039 | 0 |
| Pct of non-White | 35.38 | 39.98 | 30.04 | 36.98 | 36.27 |
| Pollution potential of sulfur dioxide | 14.47 | 14.92 | 13.66 | 15.51 | 18.00 |
Appendix C: Proof and Technical Details
Lemma C.1.
If the penalty function fj(βj; ℙn) depends on the data only through X⊺Y and X, then the distribution of conditional on and X is equal to the distribution of conditional on X⊺Y and X.
Proof. , from which it can be seen that the solution path is completely determined by X⊺X and X⊺Y. On the other hand, given and X, we can recover X⊺Y using = X⊺X{(X⊺X)−1X⊺Y} = XTY. □
Lemma C.2.
Suppose that b(·) and c(·) are nonnegative valued functions defined on [0, ∞] such that b(λ) is a nondecreasing for λ ≥ 0 with b(0) = 0. For x ≥ 0, define
and
Then λ(x) is nondecreasing in x ≥ 0.
Proof of Lemma C.2. Supposed x1 ≤ x2, we need to show that λ(x1) ≤ λ(x2). First, consider the difference of H(x2, λ) and H(x1, λ)
which is nonnegative for every λ and nonincreasing in λ. Therefore if λ(x1) = argminλ H(x1, λ), it follows that
The last inequality follows from that log{1 + (x2 − x1 )/(x1 + b(λ))} is nonnegative and nonincreasing with respect to λ. □
Proof of Lemma 1. Recall that the information criterion can also be expressed as
where .
Because Dλ is a deterministic function of λ conditional on the solution path and design matrix, the only variability in is due to . Therefore, is a function of .
Then monotonicity comes immediately by observing that Dλ is a non-decreasing function for λ ≥ 0 with D(0) = 0 and invokng Lemma C.2. □
Lemma C.3.
Let and X be fixed. If , then iff and if , then iff .
Proof of Lemma C.3. Consider the case ,
The case follows by a similar argument. □
Proof of Proposition 1. The proof follows from the fact that
□
To prove Proposition 2, we assume:
(A1F): under a fixed design , , where C ∈ ℝp×p is nonnegative definite and μxx ∈ ℝp;
(A1R): under a random design, with probability one, , and , where C ∈ ℝp×p is nonnegative definite and μx ∈ ℝp;
(A2): .
Under assumptions (A1F) and (A2), we have the following well-known results, which facilitate the proof of Proposition 2.
Lemma C.4.
Proof of Proposition 2. First consider the fixed design model. Let
Then is a solution to the equation
A Taylor series expansion around the true value (β0, ) results in
where ψ′ is the derivative of ψ and
Rearranging it leads to
Because −, it follows that
by consistency of .
Then by the multivariate Lindberg–Feller CLT,
Finally, is op(1) as of
Therefore by Slutsky’s theorem,
| (C.1) |
Then, for the random design, because and almost surely, assumption A1F holds for almost every sequence x1, x2, …. Therefore Equation (C.1) holds for almost every sequence x1, x2,…. □
Lemma C.5.
Suppose ϵ1, ϵ2, … , ϵn are normally distributed with mean zero and variance , then plugging estimator need not be a consistent estimator for pk, where and are defined in Section 3.2.
Proof. We show that there exist sequences for which is not consistent for pk. Considering the case X⊺X = n × I2 with X1 = 1n×1 and = 1, then
where and corresponds least-square estimate for X2. And
For the sequence of , where c is any constant, it follows that . And then
which is not op(1). Therefore, is not a consistent estimator for p1. □
Proposition C.1.
Assume the distribution of ϵi, i = 1, … , n is symmetric about zero, then for any ϵ > 0,
| (C.2) |
where is an asymptotically (1 − α) × 100% confidence region for μ4,ϵ − and .
Proof. Denote the event that as A,
□
Lemma C.6.
For any s ≥ 1, assume , then
where ms = E|ϵ1|s.
Proof of Lemma C.6.
But and , so that . Then by Strong Law of Large Numbers, . And thus . □
Lemma C.7.
Assume (A1F) and (A2), then
conditionally almost surely.
Proof of Lemma C.7. Denote , then we have
Then by noting conditionally almost surely (Theorem 2.2 of Freedman 1981), is op(1) conditionally almost surely. □
Proposition C.2.
Under the assumptions (A1F) and (A2), and further assuming that E|ϵi|4+δ < ∞ and for any δ > 0, then conditionally almost surely. □
Proof of Proposition C.2. Recall
Because almost surely by Lemma C.7, has the same asymptotic distribution as n−1γ(b)⊺γ(b). Then because the γ1(b), γ2(b), … , γn(b) are sampled from different distribution for every n, the Lindberg central limit theorem is used to obtain the asymptotic distribution. The conditional mean of is
The conditional variance is
Use Lemma C.6, and . So the conditional variance converges to almost surely.
Then to verify the Lyapunov condition,
which is o(1) almost surely by invoking Lemma C.6. And thus conditionally almost surely. □
C1. Theoretical Results for High Dimensions
Proposition C.3.
If p = o(n1/2), then
Proof of Proposition C.3. We know , where converges to in distribution. It remains to prove .
By expectation of quadratic form, we have . Therefore, . This completes the proof. □
Now we study the distribution of variance estimator after screening. First, we restate Theorem 1 from Fan and Lv (2008) with slight modification. Denote A0 to be the true index of nonzero regression coefficients, and S to be the screened subset. Assume Conditions 1–4 in Fan and Lv (2008) hold for some 2κ + τ < 1/2, then we have the following result.
Theorem C.1 (Accuracy of SIS). Under Conditions 1–4 in Fan and Lv (2008), if 2κ + τ < 1/2, there exists θ > 1/2, we have
where C is a positive constant, and the size of S is O(n1−θ).
From above result, we have a screening approach to reduce number of predictors from huge scale, O(exp(nc)), to a smaller scale, . Denote Denote X = (X(1)⊺, X(2)⊺)⊺, X(1), X(2) are corresponding to the first and second half of design matrix, respectively. Similarly, define Y(1), Y(2). Then the variance estimator is defined as
where m = n/2, and is the projection matrix constructed from screened subset S and second half of design matrix, X(2).
Proposition C.4.
Under Conditions 1–4 in Fan and Lv (2008), if 2κ + τ < 1/2, then
Proof of Proposition C.4.
For the first term, we know converges to . It remains to prove the remaining term are op(1). For the second term, we know
Therefore it is op(1). For the third term,
where the last inequality follows Condition 3 in Fan and Lv (2008), var(Y ) = O(1). And thus it is op(1). For the last term,
which is o(1). This completes the proof. □
Footnotes
Color versions of one or more of the figures in this article are available online at www.tandfonline.com/r/TECH.
Supplementary materials for this article are available online. Please go to http://www.tandfonline.com/r/TECH
Supplementary Materials
Simulation results: Simulation results for τ = 0.1 and 0.2 are presented in the online supplement to this article.
Proofs and technical details: Detailed proofs are provided in the online supplement to this article.
R package: R package for proposed methods.
References
- Akaike H (1974), “A New Look at the Statistical Model Identification,” IEEE Transactions on Automatic Control, 19, 716–723. [1] [Google Scholar]
- Barber RF, and Candès EJ, (2015), “Controlling the False Discovery Rate Via Knockoffs,” The Annals of Statistics, 43, 2055–2085. [6] [Google Scholar]
- Berger RL, and Boos DD (1994), “P Values Maximized Over a Confidence Set for the Nuisance Parameter,” Journal of the American Statistical Association, 89, 1012–1016. [3] [Google Scholar]
- Bertsekas DP (2014), Constrained Optimization and Lagrange Multiplier Methods, Boston,MA: Academic Press; [4] [Google Scholar]
- Burnham KP, and Anderson D (2003), Model Selection and Multi-Model Inference: A Practical Information-theoretic Approach, NewYork: Springer; [4] [Google Scholar]
- Chen J, and Chen Z (2008), “Extended Bayesian Information Criteria for Model Selection with Large Model Spaces,” Biometrika, 95, 759–771. [1] [Google Scholar]
- Cox DR (2001), “StatisticalModeling: The Two Cultures: Comment,” Statistical Science, 16, 216–218. [1] [Google Scholar]
- Fan J, and Li R (2001), “Variable Selection Via Nonconcave Penalized Likelihood and its Oracle Properties,” Journal of the American Statistical Association, 96, 1348–1360. [1] [Google Scholar]
- Fan J, and Lv J (2008), “Sure Independence Screening for Ultrahigh Dimensional Feature Space,” Journal of the Royal Statistical Society, Series B, 70, 849–911. [10,11] [DOI] [PMC free article] [PubMed] [Google Scholar]
- Fan Y, and Tang CY (2013), “Tuning Parameter Selection in High Dimensional Penalized Likelihood,” Journal of theRoyal Statistical Society, Series B, 75, 531–552. [1] [Google Scholar]
- Feng Y, and Yu Y (2013), “Consistent Cross-validation for Tuning Parameter Selection in High-dimensional Variable Selection.” arXiv preprint arXiv:1308.5390. [1] [Google Scholar]
- Freedman DA (1981), “Bootstrapping RegressionModels,” The Annals of Statistics, 9, 1218–1228. [10] [Google Scholar]
- Golub GH, Heath M, and Wahba G (1979), “Generalized Crossvalidation as a Method for Choosing a Good Ridge Parameter,” Technometrics, 21, 215–223. [1] [Google Scholar]
- Hall P, Lee ER, and Park BU (2009), “Bootstrap-based Penalty Choice for the Lasso, Achieving Oracle Performance,” Statistica Sinica, 19, 449–471. [1] [Google Scholar]
- Henderson HV, andVelleman PF (1981), “BuildingMultiple Regression Models Interactively,” Biometrics, 37, 391–411. [1] [Google Scholar]
- Hui FK, Warton DI, and Foster SD (2015), “Tuning Parameter Selection for the Adaptive Lasso Using Eric,” Journal of the American Statistical Association, 110, 262–269. [1] [Google Scholar]
- Katsouyanni K, Pantazopoulou A, Touloumi G, Tselepidaki I, Moustris K, Asimakopoulos D, Poulopoulou G, and Trichopoulos D (1993), “Evidence for Interaction BetweenAir Pollution andHighTemperature in the Causation of ExcessMortality,” Archives of Environmental Health: An International Journal, 48, 235–242. [6] [DOI] [PubMed] [Google Scholar]
- Kim Y, Kwon S, and Choi H (2012), “Consistent Model Selection Criteria on High Dimensions,” Journal of Machine Learning Research, 13, 1037–1057. [1] [Google Scholar]
- Luo X, Stefanski LA, and Boos DD (2006), “Tuning Variable Selection Procedures by Adding Noise,” Technometrics, 48, 165–175. [5] [Google Scholar]
- Mallows CL (1973), “Some Comments on Cp,” Technometrics, 15, 661–675. [1] [Google Scholar]
- McDonald GC, and Schwing RC (1973), “Instabilities of Regression Estimates Relating Air Pollution to Mortality,” Technometrics, 15, 463–481. [5] [Google Scholar]
- Meinshausen N, and Bühlmann P (2010), “Stability Selection,” Journal of the Royal Statistical Society, Series B, 72, 417–473. [1] [Google Scholar]
- Rhee S-Y, Taylor J,Wadhera G, Ben-Hur A, Brutlag DL, and Shafer RW (2006), “Genotypic Predictors of Human Immunodeficiency Virus Type 1 Drug Resistance,” Proceedings of the National Academy of Sciences, 103, 17355–17360. [5,6] [DOI] [PMC free article] [PubMed] [Google Scholar]
- Schwarz G (1978), “Estimating the Dimension of a Model,” The Annals of Statistics, 6, 461–464. [1] [Google Scholar]
- Shah RD, andSamworth RJ (2013), “Variable Selectionwith ErrorControl: Another Look at Stability Selection,” Journal of the Royal Statistical Society, Series B, 75, 55–80. [1] [Google Scholar]
- Sun W, Wang J, and Fang Y (2013), “Consistent Selection of Tuning Parameters Via Variable Selection Stability,” The Journal of Machine Learning Research, 14, 3419–3440. [1] [Google Scholar]
- Tibshirani R (1996), “Regression Shrinkage and Selection Via the Lasso,” Journal of the Royal Statistical Society, Series B, 58, 267–288. [1] [Google Scholar]
- Wang H, Li B, and Leng C (2009), “Shrinkage Tuning Parameter Selection with a Diverging Number of Parameters,” Journal of the Royal Statistical Society, Series B, 71, 671–683. [1] [Google Scholar]
- Wang T, and Zhu L (2011), “Consistent Tuning Parameter Selection in High Dimensional Sparse Linear Regression,” Journal of Multivariate Analysis, 102, 1141–1151. [1] [Google Scholar]
- Zhang Y, Li R, and Tsai C-L (2010), “Regularization Parameter Selections Via Generalized Information Criterion,” Journal of the American Statistical Association, 105, 312–323. [1] [DOI] [PMC free article] [PubMed] [Google Scholar]
- Zou H (2006), “The Adaptive Lasso and its Oracle Properties,” Journal of the American Statistical Association, 101, 1418–1429. [1] [Google Scholar]
- Zou H, and Hastie T (2005), “Regularization and Variable Selection Via the Elastic Net,” Journal of the Royal Statistical Society, Series B, 67, 301–320. [1] [Google Scholar]
Associated Data
This section collects any data citations, data availability statements, or supplementary materials included in this article.