

Abstract
As machine learning models continue to increase in complexity, collecting large hand-labeled training sets has become one of the biggest roadblocks in practice. Instead, weaker forms of supervision that provide noisier but cheaper labels are often used. However, these weak supervision sources have diverse and unknown accuracies, may output correlated labels, and may label different tasks or apply at different levels of granularity. We propose a framework for integrating and modeling such weak supervision sources by viewing them as labeling different related sub-tasks of a problem, which we refer to as the multi-task weak supervision setting. We show that by solving a matrix completion-style problem, we can recover the accuracies of these multi-task sources given their dependency structure, but without any labeled data, leading to higher-quality supervision for training an end model. Theoretically, we show that the generalization error of models trained with this approach improves with the number of unlabeled data points, and characterize the scaling with respect to the task and dependency structures. On three fine-grained classification problems, we show that our approach leads to average gains of 20.2 points in accuracy over a traditional supervised approach, 6.8 points over a majority vote baseline, and 4.1 points over a previously proposed weak supervision method that models tasks separately.
1. Introduction
One of the greatest roadblocks to using modern machine learning models is collecting hand-labeled training data at the massive scale they require. In real-world settings where domain expertise is needed and modeling goals change frequently, hand-labeling training sets is prohibitively slow, expensive, and static. For these reasons, practitioners are increasingly turning to weak supervision techniques wherein noisier, often programmatically-generated labels are used instead. Common weak supervision sources include external knowledge bases [24; 37; 8; 31], heuristic patterns [14; 27], feature annotations [23; 36], and noisy crowd labels [17; 11]. The use of these sources has led to state-of-the-art results in a range of domains [37; 35]. A theme of weak supervision is that using the full diversity of available sources is critical to training high-quality models [27; 37].
The key technical difficulty of weak supervision is determining how to combine the labels of multiple sources that have different, unknown accuracies, may be correlated, and may label at different levels of granularity. In our experience with users in academia and industry, the complexity of real world weak supervision sources makes this integration phase the key time sink and stumbling block. For example, if we are training a model to classify entities in text, we may have one available source of high-quality but coarse-grained labels (e.g. “Person” vs. “Organization”) and one source that provides lower-quality but finer-grained labels (e.g. “Doctor” vs. “Lawyer”); moreover, these sources might be correlated due to some shared component or data source [2; 33]. Handling such diversity requires addressing a core technical challenge: estimating the unknown accuracies of multi-granular and potentially correlated supervision sources without any labeled data.
To overcome this challenge, we propose MeTaL, a framework for modeling and integrating weak supervision sources with different unknown accuracies, correlations, and granularities. In MeTaL, we view each source as labeling one of several related sub-tasks of a problem—we refer to this as the multi-task weak supervision setting. We then show that given the dependency structure of the sources, we can use their observed agreement and disagreement rates to recover their unknown accuracies. Moreover, we exploit the relationship structure between tasks to observe additional cross-task agreements and disagreements, effectively providing extra signal from which to learn. In contrast to previous approaches based on sampling from the posterior of a graphical model directly [28; 2], we develop a simple and scalable matrix completion-style algorithm, which we are able to analyze by applying strong matrix concentration bounds [32]. We use this algorithm to learn and model the accuracies of diverse weak supervision sources, and then combine their labels to produce training data that can be used to supervise arbitrary models, including increasingly popular multi-task learning models [5; 29].
Compared to previous methods which only handled the single-task setting [28; 27], and generally considered conditionally-independent sources [1; 11], we demonstrate that our multi-task aware approach leads to average gains of 4.1 points in accuracy in our experiments, and has at least three additional benefits. First, many dependency structures between weak supervision sources may lead to non-identifiable models of their accuracies, where a unique solution cannot be recovered. We provide a compiler-like check to establish identifiability—i.e. the existence of a unique set of source accuracies—for arbitrary dependency structures, without resorting to the standard assumption of non-adversarial sources [11], alerting users to this potential stumbling block that we have observed in practice. Next, we provide sample complexity bounds that characterize the benefit of adding additional unlabeled data and the scaling with respect to the user-specified task and dependency structure. While previous approaches required thousands of sources to give non-vacuous bounds, we capture regimes with small numbers of sources, better reflecting the real-world uses of weak supervision we have observed. Finally, we are able to solve our proposed problem directly with SGD, leading to over 100× faster runtimes compared to prior Gibbs-sampling based approaches [28; 26], and enabling simple implementation using libraries like PyTorch.
We validate our framework on three fine-grained classification tasks in named entity recognition, relation extraction, and medical document classification, for which we have diverse weak supervision sources at multiple levels of granularity. We show that by modeling them as labeling hierarchically-related sub-tasks and utilizing unlabeled data, we can get an average improvement of 20.2 points in accuracy over a traditional supervised approach, 6.8 points over a basic majority voting weak supervision baseline, and 4.1 points over data programming [28], an existing weak supervision approach in the literature that is not multi-task-aware. We also extend our framework to handle unipolar sources that only label one class, a critical aspect of weak supervision in practice that leads to an average 2.8 point contribution to our gains over majority vote. From a practical standpoint, we argue that our framework represents an efficient way for practitioners to supervise modern machine learning models, including new multi-task variants, for complex tasks by opportunistically using the diverse weak supervision sources available to them. To further validate this, we have released an open-source implementation of our framework.1
2. Related Work
Our work builds on and extends various settings studied in machine learning.
Weak Supervision:
We draw motivation from recent work which models and integrates weak supervision using generative models [28; 27; 2] and other methods [13; 18]. These approaches, however, do not handle multi-granularity or multi-task weak supervision, require expensive sampling-based techniques that may lead to non-identifiable solutions, and leave room for sharper theoretical characterization of weak supervision scaling properties. More generally, our work is motivated by a wide range of specific weak supervision techniques, which include traditional distant supervision approaches [24; 8; 37; 15; 31], co-training methods [4], pattern-based supervision [14; 37], and feature-annotation techniques [23; 36; 21].
Crowdsourcing:
Our approach also has connections to the crowdsourcing literature [17; 11], and in particular to spectral and method of moments-based approaches [38; 9; 12; 1]. In contrast, the goal of our work is to support and explore settings not covered by crowdsourcing work, such as sources with correlated outputs, the proposed multi-task supervision setting, and regimes wherein a small number of labelers (weak supervision sources) each label a large number of items (data points). Moreover, we theoretically characterize the generalization performance of an end model trained with the weakly labeled data.
Multi-Task Learning:
Our proposed approach is motivated by recent progress on multi-task learning models [5; 29; 30], in particular their need for multiple large hand-labeled training datasets. We note that the focus of our paper is on generating supervision for these models, not on the particular multi-task learning model being trained, which we seek to control for by fixing a simple architecture in our experiments.
Our work is also related to recent techniques for estimating classifier accuracies without labeled data in the presence of structural constraints [26]. We use matrix structure estimation [22] and concentration bounds [32] for our core results.
3. Programming Machine Learning with Weak Supervision
As modern machine learning models become both more complex and more performant on a range of tasks, developers increasingly interact with them by programmatically generating noisier or weak supervision. These approaches of effectively programming machine learning models have recently been formalized by the following pipeline [28; 27]: First, users provide one or more weak supervision sources, which are applied to unlabeled data to generate a set of noisy labels. These labels may overlap and conflict; we model and combine them via a label model in order to produce a final set of training labels. These labels are then used to train some discriminative model, which we refer to as the end model. This programmatic weak supervision approach can utilize sources ranging from heuristic rules to other models, and in this way can also be viewed as a pragmatic and flexible form of multi-source transfer learning.
In our experiences with users from science and industry, we have found it critical to utilize all available sources of weak supervision for complex modeling problems, including ones which label at multiple levels of granularity. However, this diverse, multi-granular weak supervision does not easily fit into existing paradigms. We propose a formulation where each weak supervision source labels some sub-task of a problem, which we refer to as the multi-task weak supervision setting. We consider an example:
Example 1
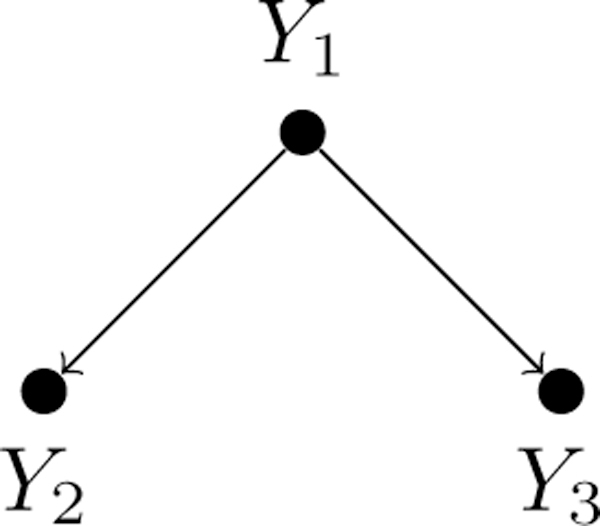
A developer wants to train a fine-grained Named Entity Recognition (NER) model to classify mentions of entities in the news (Figure 2). She has a multitude of available weak supervision sources which she believes have relevant signal for her problem—for example, pattern matchers, dictionaries, and pre-trained generic NER taggers. However, it is unclear how to properly use and combine them: some of them label phrases coarsely as PERSON versus ORGANIZATION, while others classify specific fine-grained types of people or organizations, with a range of unknown accuracies. In our framework, she can represent them as labeling tasks of different granularities—e.g. Y1 = {Person, Org}, Y2 = {Doctor, Lawyer, N/A}, Y3 = {Hospital, Office, N/A}, where the label N/A applies, for example, when the type-of-person task is applied to an organization.
Figure 2:

An example fine-grained entity classification problem, where weak supervision sources label three sub-tasks of different granularities: (i) Person vs. Organization, (ii) Doctor vs. Lawyer (or N/A), (iii) Hospital vs. Office (or N/A). The example weak supervision sources use a pattern heuristic and dictionary lookup respectively.
In our proposed multi-task supervision setting, the user specifies a set of structurally-related tasks, and then provides a set of weak supervision sources which are user-defined functions that either label each data point or abstain for each task, and may have some user-specified dependency structure. These sources can be arbitrary black-box functions, and can thus subsume a range of weak supervision approaches relevant to both text and other data modalities, including use of pattern-based heuristics, distant supervision [24], crowd labels, other weak or biased classifiers, declarative rules over unsupervised feature extractors [33], and more. Our goal is to estimate the unknown accuracies of these sources, combine their outputs, and use the resulting labels to train an end model.
4. Modeling Multi-Task Weak Supervision
The core technical challenge of the multi-task weak supervision setting is recovering the unknown accuracies of weak supervision sources given their dependency structure and a schema of the tasks they label, but without any ground-truth labeled data. We define a new algorithm for recovering the accuracies in this setting using a matrix completion-style optimization objective. We establish conditions under which the resulting estimator returns a unique solution. We then analyze the sample complexity of our estimator, characterizing its scaling with respect to the amount of unlabeled data, as well as the task schema and dependency structure, and show how the estimation error affects the generalization performance of the end model we aim to train. Finally, we highlight how our approach handles abstentions and unipolar sources, two critical scenarios in the weak supervision setting.
4.1. A Multi-Task Weak Supervision Estimator
Problem Setup
Let X ∈ be a data point and Y = [Y1, Y2,...,Yt]T be a vector of categorical task labels, Yi ∈ {1,...,ki}, corresponding to t tasks, where (X, Y) is drawn i.i.d. from a distribution (for a glossary of all variables used, see Appendix A.1).
The user provides a specification of how these tasks relate to each other; we denote this schema as the task structure Gtask. The task structure expresses logical relationships between tasks, defining a feasible set of label vectors , such that Y ∈ . For example, Figure 2 illustrates a hierarchical task structure over three tasks of different granularities pertaining to a fine-grained entity classification problem. Here, the tasks are related by logical subsumption relationships: for example, if Y2 = DOCTOR, this implies that Y1 = PERSON, and that Y3 = N/A, since the task label Y3 concerns types of organizations, which is inapplicable to persons. Thus, in this task structure, Y = [PERSON, DOCTOR, N/A]T is in while Y = [PERSON, N/A, HOSPITAL]T is not. While task structures are often simple to define, as in the previous example, or are explicitly defined by existing resources—such as ontologies or graphs—we note that if no task structure is provided, our approach becomes equivalent to modeling the t tasks separately, a baseline we consider in the experiments.
In our setting, rather than observing the true label Y, we have access to m multi-task weak supervision sources si ∈ S which emit label vectors λi that contain labels for some subset of the t tasks. Let 0 denote a null or abstaining label, and let the coverage set τi ⊆ {1,...,t} be the fixed set of tasks for which the ith source emits non-zero labels, such that ∈ τi. For convenience, we let τ0 = {1,...,t} so that τ0 = . For example, a source from our previous example might have a coverage set τi = {1, 3}, emitting coarse-grained labels such as = [PERSON, 0, N/A]T. Note that sources often label multiple tasks implicitly due to the constraints of the task structure; for example, a source that labels types of people (Y2) also implicitly labels people vs. organizations (Y1 = PERSON), and types of organizations (as Y3 = N/A). Thus sources tailored to different tasks still have agreements and disagreements; we use this additional cross-task signal in our approach.
The user also provides the conditional dependency structure of the sources as a graph Gsource = (V, E), where V = {Y, , ,...,} (Figure 3). Specifically, if (, ) is not an edge in Gsource, this means that is independent of conditioned on Y and the other source labels. Note that if Gsource is unknown, it can be estimated using statistical techniques such as [2]. Importantly, we do not know anything about the strengths of the correlations in Gsource, or the sources’ accuracies.
Figure 3:

An example of a weak supervision source dependency graph Gsource (left) and its junction tree representation (right), where Y is a vector-valued random variable with a feasible set of values, Y ∈ . Here, the output of sources 1 and 2 are modeled as dependent conditioned on Y. This results in a junction tree with singleton separator sets, Y. Here, the observable cliques are O = {, , , , {, }} ⊂ .
Our overall goal is to apply the set of weak supervision sources S = {s1,...,sm} to an unlabeled dataset U consisting of n data points, then use the resulting weakly-labeled training set to supervise an end model (Figure 1). This weakly-labeled training set will contain overlapping and conflicting labels, from sources with unknown accuracies and correlations. To handle this, we will learn a label model Pμ(Y|λ), parameterized by a vector of source correlations and accuracies μ, which for each data point X takes as input the noisy labels λ = {,...,} and outputs a single probabilistic label vector Succinctly, given a user-provided tuple (U, S, Gsource, Gtask), our key technical challenge is recovering the parameters μ without access to ground truth labels Y.
Figure 1:
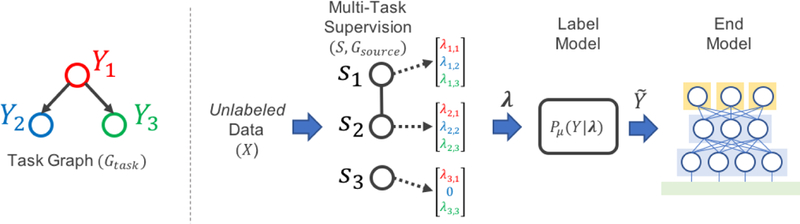
A schematic of the MeTaL pipeline. To generate training data for an end model, such as a multi-task model as in our experiments, the user inputs a task graph Gtask defining the relationships between task labels Y1,…Yt; a set of unlabeled data points X; a set of multi-task weak supervision sources si which each output a vector of task labels for X; and the dependency structure between these sources, Gsource. We train a label model to learn the accuracies of the sources, outputting a vector of probabilistic training labels for training the end model.
Modeling Multi-Task Sources
To learn a label model over multi-task sources, we introduce sufficient statistics over the random variables in Gsource-Let be the set of cliques in Gsource, and define an indicator random variable for the event of a clique C ∈ taking on a set of values yC:
where (yC)i ∈ τi. We define as the vector of indicator random variables for all combinations of all but one of the labels emitted by each variable in clique C—thereby defining a minimal set of statistics—and define ψ(C) accordingly for any set of cliques C ⊆ . Then is the vector of sufficient statistics for the label model we want to learn.
We work with two simplifying conditions in this section. First, we consider the setting where Gsource is triangulated and has a junction tree representation with singleton separator sets. If this is not the case, edges can always be added to Gsource to make this setting hold; otherwise, we describe how our approach can directly handle non-singleton separator sets in Appendix A.3.3.
Second, we use a simplified class-conditional model of the noisy labeling process, where we learn one accuracy parameter for each label value that each source si emits. This is equivalent to assuming that a source may have a different accuracy on each different class, but that if it emits a certain label incorrectly, it does so uniformly over the different true labels Y. This is a more expressive model than the commonly considered one, where each source is modeled by a single accuracy parameter, e.g. in [11; 28], and in particular allows us to capture the unipolar setting considered later on. For further details, see Appendix A.3.4.
Our Approach
The chief technical difficulty in our problem is that we do not observe Y. We overcome this by analyzing the covariance matrix of an observable subset of the cliques in Gsource, leading to a matrix completion-style approach for recovering μ. We leverage two pieces of information: (i) the observability of part of Cov [ψ()], and (ii) a result from [22] which states that the inverse covariance matrix Cov [ψ()]−1 is structured according to Gsource, i.e., if there is no edge between and in Gsource, then the corresponding entries are 0.
We start by considering two disjoint subsets of : the set of observable cliques, O ⊆ —i.e., those cliques not containing Y—and the separator set cliques of the junction tree, ⊆ . In the setting we consider in this section, = {Y} (see Figure 3). We can then write the covariance matrix of the indicator variables for O ∪ , Cov [ψ(O ∪ )], in block form, similar to [6], as:
| (1) |
and similarly define its inverse:
| (2) |
Here, is the observable block of Σ, where is the unobserved block which is a function of μ, the label model parameters that we wish to recover. Finally, is a function of the class balance P(Y).
We make two observations about Σ. First, while the full form of Σ is the covariance of the || − 1 indicator variables for each individual value of Y but one, given our simplified class-conditional label model, we in fact only need a single indicator variable for Y (see Appendix A.3.4); thus, Σs is a scalar. Second, Σ is a function of the class balance P(Y), which we assume is either known, or has been estimated according to the unsupervised approach we detail in Appendix A.3.5. Thus, given ΣO and Σ, our goal is to recover the vector ΣO from which we can recover μ.
Algorithm 1.
Source Accuracy Estimation for Multi-Task Weak Supervision
| Input: Observed labeling rates and covariance class balance and variance Σ; correlation sparsity structure Ω |
| return ExpandTied |
Applying the block matrix inversion lemma, we have:
| (3) |
where we can then express (3) as:
| (4) |
The right hand side of (4) consists of an empirically observable term, and a rank-one term, zzT, which we can solve for to directly recover μ. For the left hand side, we apply an extension of Corollary 1 from [22] (see Appendix A.3.2) to conclude that KO has graph-structured sparsity, i.e., it has zeros determined by the structure of dependencies between the sources in Gsource. This suggests an algorithmic approach of estimating z as a matrix completion problem in order to recover an estimate of μ (Algorithm 1). In more detail: let Ω be the set of indices (i, j) where (KO)i,j = 0, determined by Gsource, yielding a system of equations,
| (5) |
which is now a matrix completion problem. Define ||A||Ω as the Frobenius norm of A with entries not in Ω set to zero; then we can rewrite (5) as We solve this equation to estimate z, and thereby recover ΣO, from which we can directly recover the label model parameters μ algebraically.
Checking for Identifiability
A first question is: which dependency structures Gsource lead to unique solutions for μ? This question presents a stumbling block for users, who might attempt to use non-identifiable sets of correlated weak supervision sources.
We provide a simple, testable condition for identifiability. Let Ginv be the inverse graph of Gsource; note that Ω is the edge set of Ginv expanded to include all indicator random variables ψ(). Then, let MΩ be a matrix with dimensions |Ω| × dO such that each row in MΩ corresponds to a pair (i, j) ∈ Ω with 1’s in positions i and j and 0’s elsewhere.
Taking the log of the squared entries of (5), we get a system of linear equations MΩl = qΩ, where li = log and Assuming we can solve this system (which we can always ensure by adding sources; see Appendix), we can uniquely recover the meaning our model is identifiable up to sign.
Given estimates of the we can see from (5) that the sign of a single zi determines the sign of all other zj reachable from zi in Ginv. Thus to ensure a unique solution, we only need to pick a sign for each connected component in Ginv. In the case where the sources are assumed to be independent, e.g., [10; 38; 11], it suffices to make the assumption that the sources are on average non-adversarial; i.e., select the sign of the zi that leads to higher average accuracies of the sources. Even a single source that is conditionally independent from all the other sources will cause Ginv to be fully connected, meaning we can use this symmetry breaking assumption in the majority of cases even with correlated sources. Otherwise, a sufficient condition is the standard one of assuming non-adversarial sources, i.e. that all sources have greater than random accuracy. For further details, see Appendix B.1.
Source Accuracy Estimation Algorithm
Now that we know when a set of sources with correlation structure Gsource is identifiable, yielding a unique z, we can estimate the accuracies μ using Algorithm 1. We also use the function ExpandTied, which is a simple algebraic expansion of tied parameters according to the simplified class-conditional model used in this section; see Appendix A.3.4 for details. In Figure 4, we plot the performance of our algorithm on synthetic data, showing its scaling with the number of unlabeled data points n, the density of pairwise dependencies in Gsource, and the runtime performance as compared to a prior Gibbs sampling-based approach. Next, we theoretically analyze the scaling of the error
Figure 4:
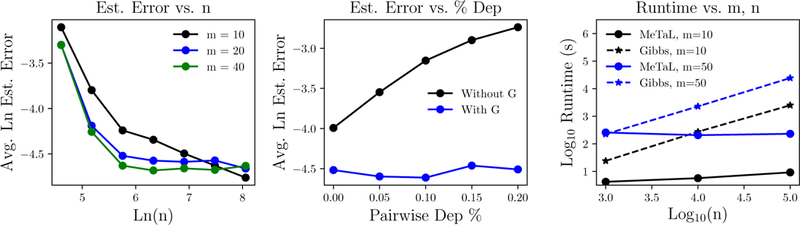
(Left) Estimation error decreases with increasing n. (Middle) Given Gsource, our model successfully recovers the source accuracies even with many pairwise dependencies among sources, where a naive conditionally-independent model fails. (Right) The runtime of MeTaL is independent of n after an initial matrix multiply, and can thus be multiple orders of magnitude faster than Gibbs sampling-based approaches [28].
4.2. Theoretical Analysis: Scaling with Diverse Multi-Task Supervision
Our ultimate goal is to train an end model using the source labels, denoised and combined by the label model we have estimated. We connect the generalization error of this end model to the estimation error of Algorithm 1, ultimately showing that the generalization error scales as where n is the number of unlabeled data points. This key result establishes the same asymptotic scaling as traditionally supervised learning methods, but with respect to unlabeled data points.
Let be the probabilistic label (i.e. distribution) predicted by our label model, given the source labels λ as input, which we compute using the estimated We then train an end multi-task discriminative model parameterized by w, by minimizing the expected loss with respect to the label model over n unlabeled data points. Let be a bounded multi-task loss function such that without loss of generality l(w, X, Y) ≤ 1; then we minimize the empirical noise aware loss:
| (6) |
and let be the w that minimizes the true noise-aware loss. This minimization can be performed by standard methods and is not the focus of our paper; let the solution satisfy We make several assumptions, following [28]: (1) that for some label model parameters μ*, sampling is the same as sampling from the true distribution, (λ, Y) ~ ; and (2) that the task labels Ys are independent of the features of the end model given λ sampled from that is, the output of the optimal label model provides sufficient information to discern the true label. Then we have the following result:
Theorem 1
Let minimize the expected noise aware loss, using weak supervision source parameters estimated with Algorithm 1. Let minimize the empirical noise aware loss with and let the assumptions above hold. Then the generalization error is bounded by:
Thus, to control the generalization error, we must control which we do in Theorem 2:
Theorem 2
Let be an estimate of μ* produced by Algorithm 1 run over n unlabeled data points. Let Then, we have:
Interpreting the Bound
We briefly explain the key terms controlling the bound in Theorem 2; more detail is found in Appendix B. Our primary result is that the estimation error scales as Next, the largest singular value of the pseudoinverse has a deep connection to the density of the graph Ginv. The smaller this quantity, the more information we have about Ginv, and the easier it is to estimate the accuracies. Next, λmin(ΣO), the smallest eigenvalue of the observed covariance matrix, reflects the conditioning of ΣO; better conditioning yields easier estimation, and is roughly determined by how far away from random guessing the worst weak supervision source is, as well as how conditionally independent the sources are. λmax(KO), the largest eigenvalue of the upper-left block of the inverse covariance matrix, similarly reflects the overall conditioning of Σ. Finally, the smallest entry of the inverse observed matrix, reflects the smallest non-zero correlation between source accuracies; distinguishing between small correlations and independent sources requires more samples.
4.3. Extensions: Abstentions & Unipolar Sources
We briefly highlight two extensions handled by our approach which we have found empirically critical: handling abstentions, and modeling unipolar sources.
Handling Abstentions.
One fundamental aspect of the weak supervision setting is that sources may abstain from labeling a data point entirely—that is, they may have incomplete and differing coverage [27; 10]. We can easily deal with this case by extending the coverage ranges τi of the sources to include the vector of all zeros, and we do so in the experiments.
Handling Unipolar Sources.
Finally, we highlight the fact that our approach models class conditional source accuracies, in particular motivated by the case we have frequently observed in practice of unipolar weak supervision sources, i.e., sources that each only label a single class or abstain. In practice, we find that users most commonly use such unipolar sources; for example, a common template for a heuristic-based weak supervision source over text is one that looks for a specific pattern, and if the pattern is present emits a specific label, else abstains. As compared to prior approaches that did not model class-conditional accuracies, e.g. [28], we show in our experiments that we can use our class-conditional modeling approach to yield an improvement of 2.8 points in accuracy.
5. Experiments
We validate our approach on three fine-grained classification problems—entity classification, relation classification, and document classification—where weak supervision sources are available at both coarser and finer-grained levels (e.g. as in Figure 2). We evaluate the predictive accuracy of end models supervised with training data produced by several approaches, finding that our approach outperforms traditional hand-labeled supervision by 20.2 points, a baseline majority vote weak supervision approach by 6.8 points, and a prior weak supervision denoising approach [28] that is not multi-task-aware by 4.1 points.
Datasets
Each dataset consists of a large (3k-63k) amount of unlabeled training data and a small (200–350) amount of labeled data which we refer to as the development set, which we use for (a) a traditional supervision baseline, and (b) for hyperparameter tuning of the end model (see Appendix C). The average number of weak supervision sources per task was 13, with sources expressed as Python functions, averaging 4 lines of code and comprising a mix of pattern matching heuristics, external knowledge base or dictionary lookups, and pre-trained models. In all three cases, we choose the decomposition into sub-tasks so as to align with weak supervision sources that are either available or natural to express.
Named Entity Recognition (NER):
We represent a fine-grained named entity recognition problem—tagging entity mentions in text documents—as a hierarchy of three sub-tasks over the OntoNotes dataset [34]: Y1 ∈ {Person, Organization}, Y2 ∈ {Businessperson, Other Person, N/A}, Y3 ∈ {Company, Other Org, N/A}, where again we use N/A to represent “not applicable”.
Relation Extraction (RE):
We represent a relation extraction problem—classifying entity-entity relation mentions in text documents—as a hierarchy of six sub-tasks which either concern labeling the subject, object, or subject-object pair of a possible or candidate relation in the TACRED dataset [39]. For example, we might label a relation as having a Person subject, Location object, and Place-of-Residence relation type.
Medical Document Classification (Doc):
We represent a radiology report triaging (i.e. document classification) problem from the OpenI dataset [25] as a hierarchy of three sub-tasks: Y1 ∈ {Acute, Non-Acute}, Y2 ∈ {Urgent, Emergent, N/A}, Y3 ∈ {Normal, Non-Urgent, N/A}.
End Model Protocol
Our goal was to test the performance of a basic multi-task end model using training labels produced by various different approaches. We use an architecture consisting of a shared bidirectional LSTM input layer with pre-trained embeddings, shared linear intermediate layers, and a separate final linear layer (“task head”) for each task. Hyperparameters were selected with an initial search for each application (see Appendix), then fixed.
Core Validation
We compare the accuracy of the end multi-task model trained with labels from our approach versus those from three baseline approaches (Table 1):
Traditional Supervision [Gold (Dev)]: We train the end model using the small hand-labeled development set.
Hierarchical Majority Vote [MV]: We use a hierarchical majority vote of the weak supervision source labels: i.e. for each data point, for each task we take the majority vote and proceed down the task tree accordingly. This procedure can be thought of as a hard decision tree, or a cascade of if-then statements as in a rule-based approach.
Data Programming [DP]: We model each task separately using the data programming approach for denoising weak supervision [27].
Table 1: Performance Comparison of Different Supervision Approaches.
We compare the micro accuracy (avg. over 10 trials) with 95% confidence intervals of an end multi-task model trained using the training labels from the hand-labeled development set (Gold Dev), hierarchical majority vote (MV), data programming (DP), and our approach (MeTaL).
| NER | RE | Doc | Average | |
|---|---|---|---|---|
| Gold (Dev) | 63.7 ± 2.1 | 28.4 ± 2.3 | 62.7 ± 4.5 | 51.6 |
| MV | 76.9 ± 2.6 | 43.9 ± 2.6 | 74.2 ± 1.2 | 65.0 |
| DP [28] | 78.4 ± 1.2 | 49.0 ± 2.7 | 75.8 ± 0.9 | 67.7 |
| MeTaL | 82.2 ± 0.8 | 56.7 ± 2.1 | 76.6 ± 0.4 | 71.8 |
In all settings, we used the same end model architecture as described above. Note that while we choose to model these problems as consisting of multiple sub-tasks, we evaluate with respect to the broad primary task of fine-grained classification (for subtask-specific scores, see Appendix). We observe in Table 1 that our approach of leveraging multi-granularity weak supervision leads to large gains—20.2 points over traditional supervision with the development set, 6.8 points over hierarchical majority vote, and 4.1 points over data programming.
Ablations
We examine individual factors:
Unipolar Correction:
Modeling unipolar sources (Sec 4.3), which we find to be especially common when fine-grained tasks are involved, leads to an average gain of 2.8 points of accuracy in MeTaL performance.
Joint Task Modeling:
Next, we use our algorithm to estimate the accuracies of sources for each task separately, to observe the empirical impact of modeling the multi-task setting jointly as proposed. We see average gains of 1.3 points in accuracy (see Appendix).
End Model Generalization:
Though not possible in many settings, in our experiments we can directly apply the label model to make predictions. In Table 6, we show that the end model improves performance by an average 3.4 points in accuracy, validating that the models trained do indeed learn to generalize beyond the provided weak supervision. Moreover, the largest generalization gain of 7 points in accuracy came from the dataset with the most available unlabeled data (n=63k), demonstrating scaling consistent with the predictions of our theory (Fig. 5). This ability to leverage additional unlabeled data and more sophisticated end models are key advantages of the weak supervision approach in practice.
Figure 5:
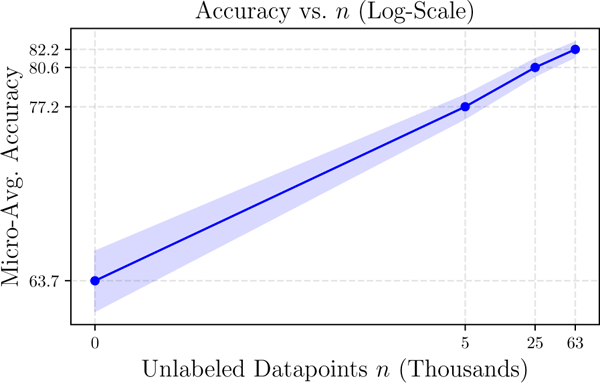
In the OntoNotes dataset, end model accuracy scales with the amount of available unlabeled data.
6. Conclusion
We presented MeTaL, a framework for training models with weak supervision from diverse, multi-task sources having different granularities, accuracies, and correlations. We tackle the core challenge of recovering the unknown source accuracies via a scalable matrix completion-style algorithm, introduce theoretical bounds characterizing the key scaling with respect to unlabeled data, and demonstrate empirical gains on real-world datasets. In future work, we hope to learn the task relationship structure and cover a broader range of settings where labeled training data is a bottleneck.
Figure 6:
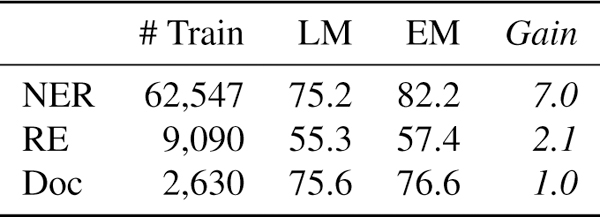
Using the label model (LM) predictions directly versus using an end model trained on them (EM).
Acknowledgements
We gratefully acknowledge the support of DARPA under Nos. FA87501720095 (D3M) and FA86501827865 (SDH), NIH under No. N000141712266 (Mobilize), NSF under Nos. CCF1763315 (Beyond Sparsity), CCF1563078 (Volume to Velocity), and DGE-114747 (NSF GRF), ONR under No. N000141712266 (Unifying Weak Supervision), the Moore Foundation, NXP, Xilinx, LETI-CEA, Intel, Google, NEC, Toshiba, TSMC, ARM, Hitachi, BASF, Accenture, Ericsson, Qualcomm, Analog Devices, the Okawa Foundation, and American Family Insurance, the Stanford Interdisciplinary Graduate and Bio-X fellowships, the Intelligence Community Postdoctoral Fellowship, and members of the Stanford DAWN project: Intel, Microsoft, Teradata, Facebook, Google, Ant Financial, NEC, SAP, and VMWare. The U.S. Government is authorized to reproduce and distribute reprints for Governmental purposes notwithstanding any copyright notation thereon. Any opinions, findings, and conclusions or recommendations expressed in this material are those of the authors and do not necessarily reflect the views, policies, or endorsements, either expressed or implied, of DARPA, NIH, ONR, or the U.S. Government.
A. Problem Setup & Modeling Approach
In Section A, we review our problem setup and modeling approach in more detail, and for more general settings than in the body. In Section B, we provide an overview, additional interpretation, and the proofs of our main theoretical results. Finally, in Section C, we go over additional details of our experimental setup.
We begin in Section A.1 with a glossary of the symbols and notation used throughout this paper. Then, in Section A.2 we present the setup of our multi-task weak supervision problem, and in Section A.3 we present our approach for modeling multi-task weak supervision, and the matrix completion-style algorithm used to estimate the model parameters. Finally, in Section A.4, we present in more detail the subcase of hierarchical tasks considered in the main body of the paper.
A.1. Glossary of Symbols
Table 2:
Glossary of variables and symbols used in this paper.
| Symbol | Used for |
|---|---|
| X | Data point, X ∈ |
| n | Number of data points |
| Ys | Label for one of the t classification tasks, Ys ∈ {1,...,ks} |
| t | Number of tasks |
| Y | Vector of task labels Y = [Y1, Y2,...,Yt]T |
| r | Cardinality of the output space, r = || |
| G task | Task structure graph |
| Output space of allowable task labels defined by Gtask, Y ∈ | |
| Distribution from which we assume (X, Y) data points are sampled i.i.d. | |
| si | Weak supervision source, a function mapping X to a label vector |
| Label vector ∈ output by the ith source for X | |
| m | Number of sources |
| λ | m × t matrix of labels output by the m sources for X |
| 0 | Source output space, which is augmented to include elements set to zero |
| τi | Coverage set of - the tasks si gives non-zero labels to; for convenience, τ0 = {1,…,t} |
| τi | The output space for given coverage set τi |
| The output space with all but the first value, for defining a minimal set of statistics | |
| G source | Source dependency graph, Gsource = (V, E), V = {Y, ,...,} |
| Cliqueset (maximal and non-maximal) of Gsource | |
| The maximal cliques (nodes) and separator sets of the junction tree over Gsource | |
| Ψ(C, yC) | The indicator variable for the variables in clique C ∈ taking on values yC, (yC)i ∈ τi |
| μ | The parameters of our label model we aim to estimate; |
| O | The set of observable cliques, i.e. those corresponding to cliques without Y |
| Σ | Generalized covariance matrix of O ⊆ , Σ ≡ Cov [Ψ(O ⊆ )] |
| K | The inverse generalized covariance matrix K = Σ−1 |
| dO, d | The dimensions of O and respectively |
| G aug | The augmented source dependencies graph Gaug = (Ψ, Eaug) |
| Ω | The edge set of the inverse graph of Gaug |
| P | Diagonal matrix of class prior probabilities, P(Y) |
| Pμ (Y, λ) | The label model parameterized by μ |
| The probabilistic training label, i.e. Pμ(Y|λ) | |
| fw (X) | The end model trained using (X, ) |
A.2. Problem Setup
Let X ∈ be a data point and Y = [Y1, Y2,...,Yt]T be a vector of task labels corresponding to t tasks. We consider categorical task labels, Yi ∈ {1,..., ki} for i ∈ {1,...,t}. We assume (X, Y) pairs are sampled i.i.d. from distribution ; to keep the notation manageable, we do not place subscripts on the sample tuples.
Task Structure
The tasks are related by a task graph Gtask. Here, we consider schemas expressing logical relationships between tasks, which thus define feasible sets of label vectors , such that Y ∈ . We let r = || be the number of feasible task vectors. In section A.4, we consider the particular subcase of a hierarchical task structure as used in the experiments section of the paper.
Multi-Task Sources
We now consider multi-task weak supervision sources si ∈ S, which represent noisy and potentially incomplete sources of labels, which have unknown accuracies and correlations. Each source si outputs label vectors , which contain non-zero labels for some of the tasks, such that is in the feasible set but potentially with some elements set to zero, denoting a null vote or abstention for that task. Let 0 denote this extended set which includes certain task labels set to zero.
We also assume that each source has a fixed task coverage set τi, such that ()s ≠ 0 for s ∈ τi, and ()s = 0 for s ∉ τi; let τi ⊆ 0 be the range of given coverage set τi. For convenience, we let τ0 = {1,...,t} so that τ0 = . The intuitive idea of the task coverage set is that some labelers may choose not to label certain tasks; Example 2 illustrates this notion. Note that sources can also abstain for a data point, meaning they emit no label (which we denote with a symbol ); we include this in τi. Thus we have si : ↦ τi, where, again, denotes the output of the function si.
Problem Statement
Our overall goal is to use the noisy or weak, multi-task supervision from the set of m sources, S = {s1,...,sm}, applied to an unlabeled dataset U consisting of n data points, to supervise an end model . Since the sources have unknown accuracies, and will generally output noisy and incomplete labels that will overlap and conflict, our intermediate goal is to learn a label model which takes as input the source labels and outputs a set of probabilistic label vectors, for each X, which can then be used to train the end model. Succinctly, given a user-provided tuple (U, S, Gsource, Gtask), our goal is to recover the parameters μ.
The key technical challenge in this approach then consists of learning the parameters of this label model—corresponding to the conditional accuracies of the sources (and, for technical reasons we shall shortly explain, cliques of correlated sources)—given that we do not have access to the ground truth labels Y. We discuss our approach to overcoming this core technical challenge in the subsequent section.
A.3. Our Approach: Modeling Multi-Task Sources
Our goal is to estimate the parameters μ of a label model that produces probabilistic training labels given the observed source outputs, without access to the ground truth labels Y. We do this in three steps:
We start by defining a graphical model over the weak supervision source outputs and the true (latent) variable Y, (,...,, Y), using the conditional independence structure Gsource between the sources.
- Next, we analyze the generalized covariance matrix Σ (following Loh & Wainwright [22]), which is defined over binary indicator variables for each value of each clique (or specific subsets of cliques) in Gsource. We consider two specific subsets of the cliques in Gsource, the observable cliques O and the separator sets , such that:
where ΣO is the block of Σ that we can observe, and ΣO is a function of μ, the parameters (corresponding to source and clique accuracies) we wish to recover. We then apply a result by Loh and Wainwright [22] to establish the sparsity pattern of K = Σ−1. This allows us to apply the block-matrix inversion lemma to reformulate our problem as solving a matrix completion-style objective. Finally, we describe how to recover the class balance P(Y); with this and the estimate of μ, we then describe how to compute the probabilistic training labels
We start by focusing on the setting where Gsource has a junction tree with singleton separator sets; we note that a version of Gsource where this holds can always be formed by adding edges to the graph. We then discuss how to handle graphs with non-singleton separator sets, and finally describe different settings where our problem reduces to rank-one matrix completion. In Section B, we introduce theoretical results for the resulting model and provide our model estimation strategy.
Figure 7:

A simple example of a weak supervision source dependency graph Gsource (left) and its junction tree representation (right). Here Y is as a vector-valued variable with a feasible set of values, Y ∈ ||, and the output of sources 1 and 2 are modeled as dependent conditioned on Y. This results in a junction tree with singleton separator sets Y. Here, the observable cliques are O = {, , , , {, }} ⊂ .
A.3.1. Defining a Multi-Task Source Model
We consider a model Gsource = (V, E), where V = {Y, ,...,}, and E consists of pairwise interactions (i.e. we consider an Ising model, or equivalently, a graph rather than a hypergraph of correlations). We assume that Gsource is provided by the user. However, if Gsource is unknown, there are various techniques for estimating it statistically [2] or even from static analysis if the sources are heuristic functions [33]. We provide an example Gsource with singleton separator sets in Figure 7.
Augmented Sufficient Statistics
Finally, we extend the random variables in V by defining a matrix of indicator statistics over all cliques in Gsource, in order to estimate all the parameters needed for our label model Pμ. We assume that the provided Gsource is chordal, meaning it has no chordless cycles of length greater than three; if not, the graph can easily be triangulated to satisfy this property, in which case we work with this augmented version.
Let be the set of maximal and non-maximal cliques in the chordal graph Gsource. We start by defining a binary indicator random variable for the event of a clique C ∈ in the graph Gsource = (V, E) taking on a set of values yC:
where contains all but one values of τi, thereby leading to a minimal set of statistics. Note that in our notation, V0 = Y, τ0 = , and Vi>0 = . Accordingly, we define as the vector of indicator random variables for all combinations of all but one of the labels emitted by each variable in clique C, and define Ψ(C) accordingly for any set of cliques C ⊆ , Then is the vector of sufficient statistics for the label model we want to learn. Our model estimation goal is now stated simply: we wish to estimate μ, without access to the ground truth labels Y.
A.3.2. Model Estimation without Ground Truth Using Inverse Covariance Structure
Our goal is to estimate this, along with the class balance P(Y) (which we assume we know, or else estimate using the approach in Section A.3.5), is sufficient information to compute Pμ(Y|λ). If we had access to a large enough set of ground truth labels Y, we could simply take the empirical expectation however in our setting we cannot directly observe this. Instead, we proceed by analyzing a sub-block of the covariance matrix of Ψ(), which corresponds to the generalized covariance matrix of our graphical model as in [22], and leverage two key pieces of information:
A sub-block of this generalized covariance matrix is observable, and
By a simple extension of Corollary 1 in [22], we know the sparsity structure of the inverse generalized covariance matrix Σ−1, i.e. we know that it will have elements equal to zero according to the structure of Gsource.
Since Gsource is triangulated, it admits a junction tree representation [19], which has maximal cliques (nodes) and separator sets . Note that we follow the convention that includes the full powerset of separator set cliques, i.e. all subset cliques of separator set cliques are also included in . We proceed by considering two specific subsets of the cliques of our graphical model Gsource: those that are observable (i.e. not containing Y), O = {C | Y ∉ C, C ∈ C}, and the set of separator set cliques (which will always contain Y, and thus be unobservable).
For simplicity of exposition, we start by considering graphs Gsource which have singleton separator sets; given our graph structure, this means that = {{Y}}. Note that in general we will write single-element sets without braces when their type is obvious from context, so we have = {Y}. Intuitively, this corresponds to models where weak supervision sources are correlated in fully-connected clusters, corresponding to real-world settings in which sources are correlated due to shared data sources, code, or heuristics. However, we can always either (i) add edges to Gsource such that this is the case, or (ii) extend our approach to many settings where Gsource does not have singleton separator sets (see Section A.3.3).
In this singleton separator set setting of = {Y}, we now have:
where Ψ(O) and Ψ(Y) are the corresponding vectors of minimal indicator variables. We define corresponding dimensions dO and d:
We now decompose the generalized covariance matrix and its inverse as:
| (7) |
This is similar to the form used in [6], but with several important differences: we consider discrete (rather than Gaussian) random variables and have additional knowledge of the graph structure. Here, ΣO is the observable block of the generalized covariance matrix Σ, and ΣO is the unobserved block which is a function of μ, the parameters (corresponding to source and source clique accuracies) we wish to recover. Note that with the singleton separator sets we are considering, Σ is a function of the class balance P(Y), which we assume is either known, or has been estimated according to the unsupervised approach we detail in Section A.3.5. Therefore, we assume that Σ is also known. Concretely then, our goal is to recover ΣO given ΣO, Σ.
We start by applying the block matrix inversion lemma to get the equation:
| (8) |
Next, let We justify this decomposition by showing that this term is positive semidefinite. We start by applying the Woodbury matrix inversion lemma:
| (9) |
Now, note that ΣO and Σ are both covariance matrices themselves and are therefore PSD. Furthermore, from [22] we know that Σ−1 must exist, which implies that ΣO and Σ are invertible (and thus in fact positive definite). Therefore we also have that and therefore (9) is positive definite, and can therefore always be expressed as JJT for some J. Therefore, we can write (8) as:
Finally, define we then have:
| (10) |
Note that where dH = r − 1, and therefore ZZT is a rank-(r − 1) matrix. Therefore, we now have a form (10) that appears close to being a matrix completion-style problem. We complete the connection by leveraging the known sparsity structure of KO.
Define Gaug = (Ψ, Eaug) to be the augmented version of our graph Gsource. In other words, let i = (C1, yC1) and j = (C2, yC2) according to the indexing scheme of our augmented indicator variables; then, (i, j) ∈ Eaug if C1, C2 are subsets of the same maximal clique in Gsource. Then, let Ginv-aug = (Ψ, Ω) be the inverse graph of Gaug, such that and vice-versa.
We start with a result that extends Corollary 1 in Loh & Wainwright [22] to our specific setting where we consider a set of the variables that contains all observable cliques, O, and all separator sets (note that this result holds for all , not just = {Y}):
Corollary 1
Let U = O ∪ . Let ΣU be the generalized covariance matrix for U. Then whenever i, j correspond to cliques C1, C2 respectively such that C1, C2 are not subsets of the same maximal clique.
Proof: We partition the cliques into two sets, U and W = \ U. Let Σ be the full generalized covariance matrix (i.e. including all maximal and non-maximal cliques) and Γ = Σ−1. Thus we have:
By the block matrix inversion lemma we have:
We now follow the proof structure of Corollary 1 of [22]. We know KU is graph structured by Theorem 1 of [22]. Next, using the same argument as in the proof of Corollary 1 of [22], we know that Kw, and therefore is block-diagonal. Intuitively, because the set U contains all of the separator set cliques, and due to the running intersection property of a junction tree, each clique in W belongs to precisely one maximal clique-leading to block diagonal structure of KW. We thus need only to show that the following quantity is zero for two cliques Ci, Cj that are not subsets of the same maximal clique, with corresponding indices i, j:
where B are the indices corresponding to the blocks in which correspond to maximal cliques. Our argument follows again as in Corollary 1 of [22]: since U contains the separator sets, if the two cliques C1, C2 are not subsets of the same maximal clique, then for each B, either (KUW)i,B or must be zero, completing the proof.
Now, by Corollary 1, we know that Ki,j = 0 if (i, j) ∈ Ω. Let AΩ denote a matrix A with all entries (i, j) ∉ Ω masked to zero. Then, we have:
| (11) |
Thus, given the dependency graph Gsource, we can solve for Z as a rank-(r − 1) matrix completion problem, with mask Ω. Defining the semi-norm we can solve:
| (12) |
Now, we have an estimate of Z. Note that at this point, we can only recover Z up to orthogonal transformations. We proceed by considering a reduced rank-one model, detailed in Section A.3.4, and in Section B.1 establish concrete conditions under which this model is uniquely identifiable.
We denote this rank-one setting by switching to writing Z as in which case we now have:
| (13) |
Once we have recovered z uniquely (see Section B.1), we next need to recover We use the fact that which we can confirm explicitly below, starting from the definition of c:
Thus, we can directly recover an estimate of ΣO from the observed ΣO, known Σ, and estimated z. Finally, we have:
| (14) |
Here, we can clearly observe , and given that we know the class balance P(Y), we also have therefore we can compute . Our goal now is to recover the columns , which together make up μ; we can do this based on the constraints of our rank-one model (Section A.3.4), thus recovering an estimate of μ, which given the uniqueness of (Section B.1) is also unique. The overall procedure is described in the main body, in Algorithm 1.
A.3.3. Handling Non-Singleton Separator Sets
Now, we consider the setting where Gsource has arbitrary separator sets. Let We see that we could solve this using our standard approach—this time, involving a rank-dS matrix completion problem—except for the fact that we do not know Σ, as it now involves terms besides the class balance.
Note first of all that we can always add edges between sources to Gsource such that it has singleton separator sets (intuitively, this consists of “completing the clusters”), and as long as our problem is still identifiable (see Section B.1), we can simply solve this instance as above.
Instead, we can also take a multi-step approach, wherein we first consider one or more subgraphs of Gsource that contain only singleton separator sets, and contain the cliques in . We can then solve this problem as before, which then gives us the needed information to identify the elements of Σ in our full problem, which we can then solve. In particular, we see that this multi-step approach is possible whenever the graph Gsource has at least three components that are disconnected except for through Y.
A.3.4. Rank-One Settings
We now consider settings where we can estimate the parameters of our label model, μ, involving only a rank-one matrix completion problem.
First, in the simplest setting of a single-task problem with binary class variable, Y ∈ {0,1} and Gsource with singleton separator sets, dH = r − 1 = 1 and our problem is directly a rank-one instance.
Next, we consider the setting of general Y, with || = r and Gsource with singleton separator sets. By default, our problem now involves a rank-(r − 1) matrix completion problem. However, we can reduce this to involving only a rank-one matrix completion problem by adding one simplifying assuption to our model: namely, that sources emit different incorrect labels with uniform conditional probability. Concretely, we add the assumption that:
| (15) |
Note that this is the same assumption as in the main body, but expressed more explicitly with respect to a clique C. For example, under this assumption, is the same for all y′ such that y′ ≠ y. As another example, is the same for all y′ such that y′ ≠ y. Intuitively, under this commonly-used model, we are not modeling the different class-wise errors a source makes, but rather just whether it is correct or not given the correctness of other sources it is correlated with. The idea then is that with assumption (15) even though |H| = r − 1 (and thus ΣO has r − 1 columns), we only actually need to solve for a single parameter per element of O.
We can operationalize this by forming a new graph with a binarized version of Y, YB ∈ {0,1}, such that the r classes are mapped to either 0 or 1. We see that this new variable still results in the same structure of dependencies Gsource, and still allows us to recover the parameters αy (and thus μ). We now have:
We now solve in the same rank-one way as in the binary Y case. Now, for singleton cliques, {, Y}, given that we know P(Y), we can directly recover P( = y |Y = y′) for all y′, given our simplified model.
For non-singleton cliques {λC, Y}, note that we can directly recover in the exact same way. From these, computed for all cliques, we can then recover any probability in our model. For example, for y′ ≠ y:
In this way, we can recover all of the parameters μ while only involving a rank-one matrix completion problem. Note that this also suggests a way to solve for the more general model, i.e. without (15), using a hierarchical classification approach.
A.3.5. Recovering the Class Balance P & Computing P (Y|λ)
We now turn to the task of recovering the class balance P(Y), for Y ∈ . In many practical settings, P(Y) can be estimated from a small labeled sample, or may be known in advance. However here, we consider using a subset of conditionally independent sources, s1,...,sk to estimate P(Y). We note first of all that simply taking the majority vote of these sources is a biased estimator.
Instead, we consider a simplified version of the matrix completion-based approach taken so far. Here, we consider a subset of the sources s1,...,sk such that they are conditionally independent given Gsource, i.e. and consider only the unary indicator statistics. Denote the vector of these unary indicator statistics over the conditionally independent subset of sources as ϕ, and let the observed overlaps matrix between sources i and j be Note that due to the conditional independence of and , for any k, l we have:
Letting Bi be the matrix of conditional probabilities, and P be the diagonal matrix such that we can re-express the above as:
Since P is composed of strictly positive elements, and is diagonal (and thus PSD), we re-express this as:
| (16) |
where We could now try to recover P by decomposing the observed Ai,j to recover the and from there recover P via the relation:
| (17) |
since summing the column of corresponding to label Y is equal to by the law of total probability. However, note that for any orthogonal matrix U also satisfies (16), and could thus lead to a potentially infinite number of incorrect estimates of P.
Class Balance Identifiability with Three-Way View Constraint
A different approach involves considering the three-way overlaps observed as Ai,j,k. This is equivalent to performing a tensor decomposition. Note that above, the problem is that matrix decomposition is typically invariant to rotations and reflections; tensor decompositions have easier-to-meet uniqueness conditions (and are thus more rigid).
Specifically, we apply Kruskal’s classical identifiability condition for unique 3-tensor decomposition. Consider some tensor
where Xr, Yr, Zr are column vectors that make up the matrices X, Y, Z. The Kruskal rank kX of X is the largest k such that any k columns of X are linearly independent. Then, the decomposition above is unique if kX + kY + kZ ≥ 2R + 2 [20; 3]. In our case, our triple views have R = |Y|, and we have
| (18) |
Thus, if we have identifiability. Thus, it is sufficient to have the columns of each of the be linearly independent. Note that each of the have columns with the same sum, so these columns are only linearly dependent if they are equal, which would only be the case if the sources were random voters.
Thus, we can use (18) to recover the in a stable fashion, and then use (17) to recover the P(Y).
Figure 8:
Example task hierarchy Gtask for a three-task classification problem. Task Y1 classifies a data point X as a PERSON or BUILDING. If Y1 classifies X as a PERSON, Y2 is used to distinguish between DOCTOR and NON-DOCTOR. Similarly, if Y2 classifies X as a BUILDING, Y3 is used to distinguish between HOSPITAL and NON-HOSPITAL. Tasks Y2, Y3 are more specific, or finer-grained tasks, constrained by their parent task Y1.
A.3.6. Predicting Labels with the Label Model
Once we have an estimate of μ, we can make predictions with the label model—i.e. generate our probabilistic training labels Pμ(Y| λ)—using the junction tree we have already defined over Gsource. Specifically, let be the set of maximal cliques (nodes) in the junction tree, and let be the set of separator sets. Then we have:
where again, Thus, we can directly compute the predicted labels Pμ(Y| λ) based on the estimated parameters μ.
A.4. Example: Hierarchical Multi-Task Supervision
We now consider the specific case of hierarchical multi-task supervision, which can be thought of as consisting of coarser- and finer-grained labels, or alternatively higher- and lower-level labels, and provides a way to supervise e.g. fine-grained classification tasks at multiple levels of granularity. Specifically, consider a task label vector Y= [Y1,...,Yt]T as before, this time with Ys ∈ {N/A, 1,...,ks}, where we will explain the meaning of the special value N/A shortly. We then assume that the tasks Ys are related by a task hierarchy which is a hierarchy Gtask = (V, E) with vertex set V = {Y1, Y2,..., Yt} and directed edge set E. The task structure reflects constraints imposed by higher level (more general) tasks on lower level (more specific) tasks. The following example illustrates a simple tree task structure:
Example 2
Let Y1 classify a data point X as either a PERSON (Y1 = 1) or BUILDING (Y1 = 2). If Y1 = 1, indicating that X represents a PERSON, then Y2 can further label X as a DOCTOR or NON-DOCTOR. Y3 is used to distinguish between HOSPITAL and NON-HOSPITAL in the case that Y1 = 2. The corresponding graph Gtask is shown in Figure 8. If Y1 = 2, then task Y2 is not applicable, since Y2 is only suitable for persons; in this case, Y2 takes the value N/A. In this way the task hierarchy defines a feasible set of task vector values: Y = [1, 1, N/A]T, [1, 2, N/A]T, [2, N/A, 1]T, [2, N/A, 2]T are valid, while e.g. Y = [1,1,2]T is not.
As in the example, for certain configurations of Y’s, the parent tasks logically constrain the one or more of the children tasks to be irrelevant, or rather, to have inapplicable label values. In this case, the task takes on the value N/A. In Example 2, we have that if Y1 = 1, representing a building, then Y2 is inactive (since X corresponds to a building). We define the symbol N/A (for incompatible) for this scenario. More concretely, let (Yi) = {Yj : (Yj, Yj) ∈ E} be the in-neighborhood of Yi. Then, the values of the members of (Yi) determine whether Yi = N/A, i.e., {Yi = N/A} is deterministic conditioned on (Yi).
Hierarchical Multi-Task Sources
Observe that in the mutually-exclusive task hierarchy just described, the value of a descendant task label Yd determines the values of all other task labels in the hierarchy besides its descendants. For example, in Example 2, a label Y2 = 1 ⇒ (Y1 = 1, Y3 = N/A); in other words, knowing that X is a DOCTOR also implies that X is a PERSON and not a BUILDING.
For a source with coverage set ti, the label it gives to the lowest task in the task hierarchy which is non-zero and non-N/A determines the entire label vector output by . E.g. if the lowest task that labels in the hierarchy is Y1 = 1, then this implies that it outputs vector [1,0, N/A]T. Thus, in this sense, we can think of each sources as labeling one specific task in the hierarchy, and thus can talk about coarser- and finer-grained sources.
Reduced-Rank Form: Modeling Local Accuracies
In some cases, we can make slightly different modeling assumptions that reflect the nature of the task structure, and additionally can result in reduced-rank forms of our model. In particular, for the hierarchical setting introduced here, we can divide the statistics μ into local and global subsets, and for example focus on modeling only the local ones to once again reduce to rank-one form.
To motivate with our running example: a finer-grained source that labels DOCTOR versus NON-DOCTOR probably is not accurate on the building type subtask; we can model this source using one accuracy parameter for the former label set (the local accuracy) and a different (or no parameter) for the global accuracy on irrelevant tasks. More specifically, for cliques involving , we can model P(, Y) for all Y with only non-N/A values in the coverage set of using a single parameter, and call this the local accuracy; and we can either model μ for the other Y using one or more other parameters, or simply set it to a fixed value and not model it, to reduce to rank one form, as we do in the experiments. In particular, this allows us to capture our observation in practice that if a developer is writing a source to distinguish between labels at one sub-tree, they are probably not designing or testing it to be accurate on any of the other subtrees.
B. Theoretical Results
In this section, we focus on theoretical results for the basic rank-one model considered in the main body of the paper. In Section B.1, we start by going through the conditions for identifiability in more detail for the rank-one case. In Section B.2, we provide additional interpretation for the expression of our primary theoretical result bounding the estimation error of the label model. In Section B.3, we then provide the proof of Theorem 1, connecting this estimation error to the generalization error of the end model; and in Section B.4, we provide the full proof of the main bound.
B.1. Conditions for Identifiability
We consider the rank-one setting as in the main body, where we have
| (19) |
where Ω is the inverse augmented edge set, i.e. a pair of indices (i, j), corresponding to elements of Ψ(), and therefore to cliques A, B ∈ , is in Ω if A, B are not part of the same maximal clique in Gsource (and therefore (KO)i,j = 0). This defines a set of |Ω| equations, which we can encode using a matrix MΩ, where if (i, j) is the (r − 1)th entry in Ω, then
| (20) |
Let then by squaring and taking the log of both sides of 19, we get a system of linear equations:
| (21) |
Thus, we can identify z (and therefore μ) up to sign if the system of linear equations (21) has a solution.
Notes on Invertibility of MΩ
Note that if the inverse augmented edge graph consists of a connected triangle (or any odd-numbered cycle), e.g. Ω = {(i, j), (j, k), (i, k)}, then we can solve for the zi up to sign, and therefore MΩ must be invertible:
and so on for zj, zk. Note additionally that if other zi are connected to this triangle, then we can also solve for them up to sign as well. Therefore, if Ω contains at least one triangle (or odd-numbered cycle) per connected component, then MΩ is invertible.
Also note that this is all in reference to the inverse source dependency graph, which will generally be dense (assuming the correlation structure between sources is generally sparse). For example, note that if we have one source that is conditionally independent of all the other sources, then Ω is fully connected, and therefore if there is a triangle in Ω, then MΩ is invertible.
Identifying the Signs of the zi
Finally, note that if we know the sign of one zi, then this determines the signs of every other zj in the same connected component. Therefore, for z to be uniquely identifiable, we need only know the sign of one of the zi in each connected component. As noted already, if even one source is conditionally independent of all the other sources, then Ω is fully connected; in this case, we can simply assume that the average source is better than random, and therefore identify the signs of z without any additional information.
B.2. Interpreting the Main Bound
We re-state Theorem 2, which bounds the average error on the estimate of the label model parameters, providing more detail on and interpreting the terms of the bound.
Theorem 2
Let be an estimate of μ* produced by Algorithm 1 run over n unlabeled data points. Let Then, we have:
Influence of the largest singular value of the pseudoinverse Note that As we shall see below, measures a quantity related to the structure of the graph Ginv. The smaller this quantity, the more information we have about Ginv, and the easier it is to estimate the accuracies. The smallest value of (corresponding to the largest value of the eigenvalue) is ~ the square of this quantity in the bound reduces the m2 cost of estimating the covariance matrix to m.
It is not hard to see that
Here, deg(Ginv) are the degrees of the nodes in Ginv and Adj(Ginv) is its adjacency matrix. This form closely resembles the graph Laplacian, which differs in the sign of the adjacency matrix term: (G) = diag(deg(G)) − Adj(G). We bound
where dmin is the lowest-degree node in Ginv (that is, the source s with fewest appearances in Ω). In general, computing λmin(Adj(Ginv))) can be challenging. A closely related task can be done via Cheeger inequalities, which state that
where λmin((G)) is the smallest non-zero eigenvalue of (G) and
is the Cheeger constant of the graph [7]. The utility of the Cheeger constant is that it measures the presence of a bottleneck in the graph; the presence of such a bottleneck limits the graph density and is thus beneficial when estimating the structure in our case. Our Cheeger-constant like term acts the same way.
Now, in the easiest and most common case is that of conditionally independent sources [9; 38; 9; 17]., Adj(Ginv) has 1’s everywhere but the diagonal, and we can compute explicitly that
In the general setting, we must compute the minimal eigenvalue of the adjacency matrix, which is tractable, for example, for tree structures.
Influence of λmin(ΣO) the smallest eigenvalue of the observed matrix. This quantity reflects the conditioning of the observed (correlation) matrix; the better conditioned the matrix, the easier it is to estimate ΣO.
Influence of ()min the smallest entry of the inverse observed matrix. This quantity contributes to Σ−1, the geenralized precision matrix that we centrally use; it is a measure of the smallest non-zero correlation between source accuracies (that is, the smallest correlation between non-independent source accuracies). Note that the tail bound of Theorem 2 scales as exp(−(()min)2 This is natural, as distinguishing between small correlations and independencies requires more samples.
B.3. Proof of Theorem 1
Let be the true data generating distribution, such that (X, Y) ~ . Let Pμ(Y|λ) be the label model parameterized by μ and conditioned on the observed source labels λ. Furthermore, assume that:
For some optimal label model parameters (λ, Y) = P(λ, Y);
The label Y is independent of the features of our end model given the source labels λ
That is, we assume that (i) the optimal label model, parameterized by μ*, correctly matches the true distribution of source labels λ drawn from the true distribution, (s(X), Y) ~ ; and (ii) that these labels λ provide sufficient information to discern the label Y. We note that these assumptions are the ones used in prior work [28], and are intended primarily to illustrate the connection between the estimation accuracy of which we bound in Theorem 2, and the end model performance.
Now, suppose that we have an end model parameterized by w, and that to learn these parameters we minimize a normalized bounded loss function l(w, X, Y), such that without loss of generality, l(w, X, Y) ≤ 1. Normally our goal would be to find parameters that minimize the expected loss, which we denote w*:
| (22) |
However, since we do not have access to the true labels Y, we instead minimize the expected noise-aware loss, producing an estimate
| (23) |
In practice, we actually minimize the empirical version of the noise aware loss over an unlabeled dataset U = {X(1),...,X(n)}, producing an estimate
| (24) |
Let w* be the expected loss L, let be the minimizer of the noice-aware loss for estimated label model parameters μ, Lμ, and let be the minimize of the empirical noice aware loss Our goal is to bound the generalization risk- the difference between the expected loss of our empirically estimated parameters and of the optimal parameters,
| (25) |
Additionally, since analyzing the empirical risk minimization error is standard and not specific to our setting, we simply assume that error where γ(n) is a decreasing function of the number of unlabeled data points n.
To start, using the law of total expectation first, followed by our assumption (2) about condtional independence, and finally using our assumption (1) about our optimal label model we have that:
Now, we have:
where in the first step we use our result that L = Lμ* as well as add and subtract terms; and in the second step we use the fact that We now have our generalization risk controlled primarily by which is the difference between the expected noise aware losses given the estimated label model parameters μ and the true label model parameters μ*. Next, we see that, for any w′:
where we have now bounded by the size of the structured output space ||, and a term having to do with the difference between the probability distributions of μ and μ*.
Now, we use the result from [16] (Lemma 19) which establishes that the log probabilities of discrete factor graphs with indicator features (such as our model Pμ(λ, Y)) are (l∞, 2)-Lipschitz with respect to their parameters, and the fact that for to get:
where we use the fact that the statement of Lemma 19 also holds for every marginal distribution as well. Therefore, we finally have:
B.4. Proof of Theorem 2
Proof: First we briefly provide a roadmap of the proof of Theorem 2. We consider estimating with our procedure in the rank-one setting, and we seek a tail bound on The challenge here is that the observed matrix we see is itself constructed from a series of observed i.i.d. samples We bound (through a matrix concentration inequality) the error and view ΔO as a perturbation of ΣO. Afterwards, we use a series of perturbation analyses to ultimately bound and then use this directly to bound each of the perturbation results is in terms of ΔO.
We begin with some notation. We write the following perturbations (note that all the terms written with Δ are additive, while the S term is relative)
Now we start our perturbation analysis:
Subtracting , we get
| (26) |
The rest of the analysis requires us to bound the norms for each of these terms.
Left-most term.
We have that
Here, we bounded Then, note that so therefore In the last inequality, we use this to imply that Next we work on bounding We have
Thus,
| (27) |
Bounding c.
We will need a bound on c to bound z. We have that
Applying the Woodbury matrix inversion lemma, we have:
Now, by the blockwise inversion lemma, we know that
So we then have:
Bounding z.
We’ll use our bound on c, since
In the last inequality, we used the fact that Now we want to control
Perturbation bound.
We have the perturbation bound
| (28) |
We need to work on the term To avoid overly heavy notation, we write and Then we have:
Here, the second inequality uses and the fourth inequality sums over squared values. Next, we use the perturbation bound so that we have
Then, plugging this into (28), we get that
| (29) |
Bounding δz.
Note also that We have that
where in the fourth step, we used the bound for small a. Then, we have
| (30) |
Putting it together.
Using (26), we have that
Where in the first inequality, we use the triangle inequality and the fact that and in the third inequality, we relied on the fact that we can control so that we can make it small enough and thus take Now we can plug in our bounds on from before:
For convenience, we set Recall that
and
Then, we have
Again we can take t small so that t2 ≤ t. Simplifying further, we have
Finally, since the is smaller than the left-hand term inside the parentheses, we can write
| (31) |
Concentration bound.
We need to bound t = ||ΔO ||, the error when estimating ΣO from observations over n unlabeled data points.
To start, recall that O is the set of observable cliques, is the corresponding vector of minimal statistics, and For notational convenience, let Then we have:
We start by applying the matrix Hoeffding inequality [32] to bound the first term, and thus clearly We seek a sequence of symmetric matrices First, note that, for some vectors x, v,
using Cauchy-Schwarz; therefore so that
Next, note that Now, we use this to see that:
Therefore, let and note that We then have
And thus,
| (32) |
Next, we bound Δr. We see that:
where is the perturbation for a single element of ψ(O). We can then apply the standard Hoeffding’s bound to get:
Combining the bounds for ||ΔR|| and ||Δr||, we get:
| (33) |
Final steps
Now, we use the bound on t in (31) and the concentration bound above to write
where
Given we recover We assume is known, and we can bound the error introduced by as above, which we see can be folded into the looser bound for the error in
Finally, we expand the rank-one form algebraically, according to our weight tying in the rank one model we use. Suppose in the rank one reduction (see Section A.3.4), we let Then each element of μ1 that we track corresponds to either the probability of being correct, or the probability of being incorrect, for each source clique C and label output combination yC, and this value is simply copied r − 1 times (for the other, weight-tied incorrect values), except for potentially one entry where it is multiplied by (r − 1) and then subtracted from 1 (to transform from incorrect to correct). Therefore, Thus, we have:
where V is defined as above. We only have one more step:
Here, we used the fact that □
C. Experimental Details
C.1. Data Balancing and Label Model Training Procedure
For each application, rebalancing was applied via direct subsampling to the training set in the manner that was found to most improve development set micro-averaged accuracy. Specifically, we rebalance with respect to the median class for OpenI (i.e., removing examples from majority class such that none had more than the original median class), the minimum class for TACRED, and perform no rebalancing for OntoNotes. For generative model training, we use stochastic gradient descent with a step size, step number, and penalty listed in Table 3 below. These parameters were found via 10-trial coarse random search, with all values determined via maximum micro-averaged accuracy evaluated on the development set.
C.2. End Model Training Procedure
Before training over multiple iterations to attain averaged results for reporting, a 10-trial random search over learning rate and regularization with the Adam optimizer was performed for each application based on micro-averaged development set accuracy. Learning rate was decayed by an order of magnitude if no increases in training loss improvement or development set accuracy were observed for 10 epochs, and the learning rate was frozen during the first 5 epochs. Models are reported using early stopping, wherein the best performing model on the development set is eventually used for evaluation on the held-out test set, and maximum epoch number is set for each application at a point beyond which minimal additional decrease in training loss was observed.
C.3. Dataset Statistics
We give additional detail in here (see Table 4) on the different datasets used for the experimental portion of this work. All data in the development and test sets is labeled with ground truth, while data in the training set is treated as unlabeled. Each dataset has a particular advantage in our study. The OntoNotes set, for instance, contains a particularly large number of relevant data points (over 63k), which enables us to investigate empirical performance scaling with the number of unlabeled data points. Further, the richness of the TACRED dataset allowed for the creation of an 8-class, 7-sub-task hierarchical classification problem, which demonstrates the utility of being able to supervise at each of the three levels of task granularity. Finally, the OpenI dataset represents a real-world, non-benchmark problem drawn from the domain of medical triage, and domain expert input was directly leveraged to create the relevant supervision sources. The fact that these domain expert weak supervision sources naturally occurred at multiple levels of granularity, and that the could be easily integrated to train an effective end model, demonstrates the utility of the MeTaL framework in practical settings.
Table 3:
Model architecture and training parameter details.
| OntoNotes | TACRED | OpenI | |
|---|---|---|---|
| Label Model Training | |||
|
| |||
| Step Size | 5e-3 | 1e-2 | 5e-4 |
| Regularization | 1e-4 | 4e-4 | 1e-3 |
| Step Number | 50 | 25 | 50 |
|
| |||
| End Model Architecture | |||
|
| |||
| Embedding Initialization | PubMed | FastText EN | Random |
| Embedding Size | 100 | 300 | 200 |
| LSTM Hidden Size | 150 | 250 | 150 |
| LSTM Layers | 1 | 2 | 1 |
| Intermediate Layer Dimensions | 200, 50 | 200, 50, 25 | 200, 50 |
|
| |||
| End Model Training | |||
|
| |||
| Learning Rate | 1e-2 | 1e-3 | 1e-3 |
| Regularization | 1e-4 | 1e-4 | 1e-3 |
| Epochs | 20 | 30 | 50 |
| Dropout | 0.25 | 0.25 | 0.1 |
Table 4:
Dataset split sizes and sub-task structure for the three fine-grained classification tasks on which we evaluate MeTaL.
| # Train | #Dev | # Test | Tree Depth | # Tasks | # Sources/Task | |
|---|---|---|---|---|---|---|
| OntoNotes (NER) | 62,547 | 350 | 345 | 2 | 3 | 11 |
| TACRED (RE) | 9,090 | 350 | 2174 | 3 | 7 | 9 |
| OpenI (Doc) | 2,630 | 200 | 378 | 2 | 3 | 19 |
C.4. Task Accuracies
For clarity, we present in Table 5 the individual task accuracies of both the learned MeTaL model and MV for each experiment. These accuracies are computed from the output of evaluating each model on the test set with ties broken randomly.
C.5. Ablation Study: Unipolar Correction and Joint Modeling
We perform an additional ablation to demonstrate the relative gains of modeling unipolar supervision sources and jointly modeling accuracies across multiple tasks with respect to the data programming (DP) baseline [27]. Results of this investigation are presented in Table 6. We observe an average improvement of 2.8 points using the unipolar correction (DP-UI), and an additional 1.3 points from joint modeling within MeTaL, resulting in an aggregate gain of 4.1 accuracy points over the data programming baseline.
Table 5:
Label model task accuracies for each task for for both our approach and majority vote (MeTaL/MV)
| OntoNotes | TACRED | OpenI | |
|---|---|---|---|
| Task 1 | |||
| MV | 93.3 | 74.2 | 83.9 |
| MeTaL | 91.9 | 80.5 | 84.1 |
|
| |||
| Task 2 | |||
| MV | 73.3 | 46.2 | 77.8 |
| MeTaL | 7S.6 | 6S.9 | 83.7 |
|
| |||
| Task 3 | |||
| MV | 71.4 | 74.9 | 61.7 |
| MeTaL | 74.1 | 74.8 | 61.7 |
|
| |||
| Task 4 | |||
| MV | - | 34.4 | - |
| MeTaL | - | 60.2 | - |
|
| |||
| Task 5 | |||
| MV | - | 36.2 | - |
| MeTaL | - | 40.2 | - |
|
| |||
| Task 6 | |||
| MV | - | 56.3 | - |
| MeTaL | - | 49.9 | - |
|
| |||
| Task 6 | |||
| MV | - | 36.8 | - |
| MeTaL | - | 56.3 | - |
Table 6: Effect of Unipolar Correction.
We compare the micro accuracy (avg. over 10 trials) with 95% confidence intervals of a model trained using data programming (DP), data program with a unipolar correction (DP-UI), and our approach (MeTaL).
| OntoNotes (NER) | TACRED (RE) | OpenI (Doc) | Average | |
|---|---|---|---|---|
| DP [28] | 78.4 ± 1.2 | 49.0 ± 2.7 | 75.8 ± 0.9 | 67.7 |
| DP-UI | 81.0 ± 1.2 | 54.2 ± 2.6 | 76.4 ± 0.5 | 70.5 |
| MeTaL | 82.2 ± 0.8 | 56.7 ± 2.1 | 76.6 ± 0.4 | 71.8 |
Footnotes
References
- [1].Anandkumar A, Ge R, Hsu D, Kakade SM, and Telgarsky M Tensor decompositions for learning latent variable models. The Journal of Machine Learning Research, 15(1):2773–2832, 2014. [Google Scholar]
- [2].Bach SH, He B, Ratner AJ, and Ré C Learning the structure of generative models without labeled data, 2017. [PMC free article] [PubMed] [Google Scholar]
- [3].Bhaskara A, Charikar M, and Vijayaraghavan A Uniqueness of tensor decompositions with applications to polynomial identifiability, 2014. [Google Scholar]
- [4].Blum A and Mitchell T Combining labeled and unlabeled data with co-training, 1998. [Google Scholar]
- [5].Caruana R Multitask learning: A knowledge-based source of inductive bias, 1993. [Google Scholar]
- [6].Chandrasekaran V, Parrilo PA, and Willsky AS Latent variable graphical model selection via convex optimization. In Communication, Control, and Computing (Allerton), 2010 48th Annual Allerton Conference on, pages 1610–1613. IEEE, 2010. [Google Scholar]
- [7].Chung FRK Laplacians of graphs and cheeger inequalities. 1996. [Google Scholar]
- [8].Craven M and Kumlien J Constructing biological knowledge bases by extracting information from text sources, 1999. [PubMed] [Google Scholar]
- [9].Dalvi N, Dasgupta A, Kumar R, and Rastogi V Aggregating crowdsourced binary ratings, 2013. [Google Scholar]
- [10].Dalvi N, Dasgupta A, Kumar R, and Rastogi V Aggregating crowdsourced binary ratings, 2013. [Google Scholar]
- [11].Dawid APand Skene AM Maximum likelihood estimation of observer error-rates using the em algorithm. Applied statistics, pages 20–28, 1979. [Google Scholar]
- [12].Ghosh A, Kale S, and McAfee P Who moderates the moderators?: Crowdsourcing abuse detection in user-generated content, 2011. [Google Scholar]
- [13].Guan MY, Gulshan V, Dai AM, and Hinton GE Who said what: Modeling individual labelers improves classification. arXiv preprint arXiv:1703.08774, 2017. [Google Scholar]
- [14].Gupta S and Manning CD Improved pattern learning for bootstrapped entity extraction., 2014. [Google Scholar]
- [15].Hoffmann R, Zhang C, Ling X, Zettlemoyer L, and Weld DS Knowledge-based weak supervision for information extraction of overlapping relations, 2011. [Google Scholar]
- [16].Honorio J Lipschitz parametrization of probabilistic graphical models. arXiv preprint arXiv:1202.3733, 2012. [Google Scholar]
- [17].Karger DR, Oh S, and Shah D Iterative learning for reliable crowdsourcing systems, 2011. [Google Scholar]
- [18].Khetan A, Lipton ZC, and Anandkumar A Learning from noisy singly-labeled data. arXiv preprint arXiv:1712.04577, 2017. [Google Scholar]
- [19].Koller D, Friedman N, and Bach F Probabilistic graphical models: principles and techniques. MIT press, 2009. [Google Scholar]
- [20].Kruskal JB Three-way arrays: rank and uniqueness of trilinear decompositions, with application to arithmetic complexity and statistics. Linear algebra and its applications, 18(2):95–138, 1977. [Google Scholar]
- [21].Liang P, Jordan MI, and Klein D Learning from measurements in exponential families, 2009. [Google Scholar]
- [22].Loh P-L and Wainwright MJ Structure estimation for discrete graphical models: Generalized covariance matrices and their inverses, 2012. [Google Scholar]
- [23].Mann GS and McCallum A Generalized expectation criteria for semi-supervised learning with weakly labeled data. JMLR, 11(Feb):955–984, 2010. [Google Scholar]
- [24].Mintz M, Bills S, Snow R, and Jurafsky D Distant supervision for relation extraction without labeled data, 2009. [Google Scholar]
- [25].National Institutes of Health. Open-i. 2017.
- [26].Platanios E, Poon H, Mitchell TM, and Horvitz EJ Estimating accuracy from unlabeled data: A probabilistic logic approach, 2017. [Google Scholar]
- [27].Ratner A, Bach S, Ehrenberg H, Fries J, Wu S, and Ré C Snorkel: Rapid training data creation with weak supervision, 2018. [DOI] [PMC free article] [PubMed] [Google Scholar]
- [28].Ratner AJ, De Sa CM, Wu S, Selsam D, and é C Data programming: Creating large training sets, quickly, 2016. [PMC free article] [PubMed] [Google Scholar]
- [29].Ruder S An overview of multi-task learning in deep neural networks. CoRR, abs/1706.05098, 2017. [Google Scholar]
- [30].Søgaard A and Goldberg Y Deep multi-task learning with low level tasks supervised at lower layers, 2016. [Google Scholar]
- [31].Takamatsu S, Sato I, and Nakagawa H Reducing wrong labels in distant supervision for relation extraction, 2012. [Google Scholar]
- [32].Tropp JA An introduction to matrix concentration inequalities. Foundations and Trends® in Machine Learning, 8(1–2):1–230, 2015. [Google Scholar]
- [33].Varma P, He BD, Bajaj P, Khandwala N, Banerjee I, Rubin D, and Ré C Inferring generative model structure with static analysis, 2017. [PMC free article] [PubMed] [Google Scholar]
- [34].Weischedel R, Hovy E, Marcus M, Palmer M, Belvin R, Pradhan S, Ramshaw L, and Xue N Ontonotes: A large training corpus for enhanced processing. Handbook of Natural Language Processing and Machine Translation. Springer, 2011. [Google Scholar]
- [35].Xiao T, Xia T, Yang Y, Huang C, and Wang X Learning from massive noisy labeled data for image classification, 2015. [Google Scholar]
- [36].Zaidan OF and Eisner J Modeling annotators: A generative approach to learning from annotator rationales, 2008. [Google Scholar]
- [37].Zhang C, Ré C, Cafarella M, De Sa C, Ratner A, Shin J, Wang F, and Wu S DeepDive: Declarative knowledgebase construction. Commun. ACM, 60(5):93–102, 2017. [Google Scholar]
- [38].Zhang Y, Chen X, Zhou D, and Jordan MI Spectral methods meet em: A provably optimal algorithm for crowdsourcing, 2014. [Google Scholar]
- [39].Zhang Y, Zhong V, Chen D, Angeli G, and Manning CD Position-aware attention and supervised data improve slot filling, 2017. [Google Scholar]