

Abstract
Health sciences research often involves both right- and interval-censored events because the occurrence of a symptomatic disease can only be observed up to the end of follow-up, while the occurrence of an asymptomatic disease can only be detected through periodic examinations. We formulate the effects of potentially time-dependent covariates on the joint distribution of multiple right- and interval-censored events through semiparametric proportional hazards models with random effects that capture the dependence both within and between the two types of events. We consider nonparametric maximum likelihood estimation and develop a simple and stable EM algorithm for computation. We show that the resulting estimators are consistent and the parametric components are asymptotically normal and efficient with a covariance matrix that can be consistently estimated by profile likelihood or nonparametric bootstrap. In addition, we leverage the joint modelling to provide dynamic prediction of disease incidence based on the evolving event history. Furthermore, we assess the performance of the proposed methods through extensive simulation studies. Finally, we provide an application to a major epidemiological cohort study. Supplementary materials for this article are available online.
Keywords: Dynamic prediction, Joint models, Nonparametric likelihood, Proportional hazards, Random effects, Semiparametric efficiency
1. Introduction
Many clinical and epidemiological studies are concerned with multiple types of diseases, which may be symptomatic or asymptomatic. Time to the development of a symptomatic disease is right-censored if the disease does not occur during the follow-up, whereas time to the development of an asymptomatic disease is typically interval-censored because the disease occurrence can only be monitored periodically using biomarkers. In the Atherosclerosis Risk in Communities (ARIC) study (The ARIC Investigators 1989), for instance, subjects were followed for up to 27 years for symptomatic cardiovascular diseases, such as myocardial infarction (MI) and stroke, through reviews of hospital records; they were also examined over five clinic visits, with the first four at approximately 3-year intervals, for occurrences of asymptomatic diseases, such as diabetes and hypertension.
There is a large body of literature on the joint analysis of correlated right-censored events (Kalbfleisch and Prentice 2002, chap. 10; Hougaard 2012), as well as a growing body of literature on correlated interval-censored events (Goggins and Finkelstein 2000; Kim and Xue 2002; Wen and Chen 2013; Chen et al. 2014; Zeng, Gao, and Lin 2017). In addition, there is a considerable amount of literature on competing risks and semi-competing risks (Fine and Gray 1999; Fine, Jiang, and Chappell 2001; Kalbfleisch and Prentice 2002, chap. 8). However, the existing literature has treated right-censored and interval-censored events separately. Joint modeling of the two kinds of data would allow investigators to evaluate the effects of covariates on both kinds of events and to predict the occurrence of a symptomatic disease given the history of asymptomatic diseases.
In this article, we relate potentially time-dependent covariates to the joint distribution of multiple types of right- and interval-censored event times through semiparametric proportional hazards models with random effects. Specifically, we assume a shared random effect for the interval-censored events, which affects the right-censored events with unknown coefficients. We assume an additional shared random effect for the right-censored events to capture their own dependence. The proposed models allow semi-competing risks and are reminiscent of selection models for joint modeling of survival and longitudinal data (Hogan and Laird 1997).
We estimate the model parameters through nonparametric maximum likelihood estimation, under which the baseline hazard functions are completely nonparametric. We develop a simple EM algorithm that converges stably for arbitrary sample sizes, even with time-dependent covariates. We show that the resulting estimators are consistent and the parametric components are asymptotically normal and asymptotically efficient. We also show that the covariance matrix of the parametric components can be estimated consistently with profile likelihood or nonparametric bootstrap. We pay special attention to the estimation of the conditional distribution function given the event history, which can be used to predict disease occurrence dynamically. Finally, we assess the performance of the proposed numerical and inferential procedures through extensive simulation studies and provide a substantive application to the ARIC data on diabetes, hypertension, stroke, MI, and death.
2. Methods
2.1. Data, Models, and Likelihood
Suppose that there are K1 types of asymptomatic events occurring at times T1, …, TK1 and K2 types of symptomatic events occurring at times , where K = K1 + K2. Let Xk (·) be a p-vector of possibly time-dependent external covariates for the event time Tk. For k = 1,…, K1, the hazard function of Tk conditional on covariate Xk and random effect b1 is given by
| (1) |
where β is a set of unknown regression parameters, λk (·) is an arbitrary baseline hazard function, and b1 is a latent normal random variable with mean zero and variance . For k = K1 + 1, …, K, the hazard function of Tk conditional on covariates Xk and random effects b1 and b2 is given by
| (2) |
where λk (·) is an arbitrary baseline hazard function, is a set of unknown coefficients, and b2 is a latent normal random variable with mean zero and variance . Write . By letting Xk depend on k, models (1) and (2) allow the regression parameters to be different among the K events by appropriate definitions of dummy variables; see Lin (1994).
Figure 2.
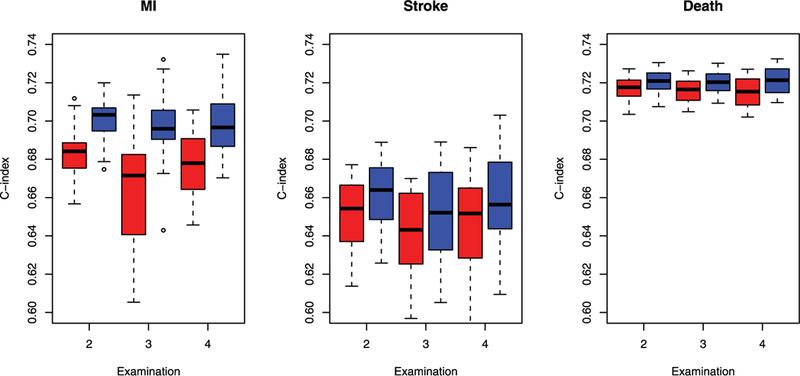
Boxplots of the estimates of the C-index at each examination in the ARIC study. The red boxes pertain to the univariate model of Fine and Gray (1999) for MI and stroke and the standard proportional hazards model for death. The blue boxes pertain to the proposed joint model.
We implicitly assume that K1 and K2 are greater than one; otherwise, some of the parameters need to be fixed to ensure identifiability. For example, if K1 = K2 = 1, we require and γ1 = 1; if K1 > 1 and K2 = 1, we require ; and if K1 = 1 and K2 > 1, we require one of the γk’s to be 1. In the last scenario, we may set different γk to 1 and choose the model that yields the largest value of the likelihood function.
Remark 1.
The random effects b1 and b2 characterize the underlying health conditions for the asymptomatic and symptomatic events, respectively. The random effect for the asymptomatic events affects the kth symptomatic event through the unknown coefficient γk. For example, in the ARIC study, b1 represents the common pathways for diabetes and hypertension, such as obesity, inflammation, oxidative stress, and insulin resistance, which also serve as potential risk factors for MI, stroke, and death. The random effect b2 represents the underlying propensity for major cardiovascular diseases and death.
Suppose that the asymptomatic event time Tk (k = 1, …, K1 ) is monitored at a sequence of positive time points and is known to lie in the interval (Lk, Rk], where Lk = max{Ukl : Ukl < Tk, l = 0, …, Mk}, and Rk = min{Ukl : Ukl ≥ Tk, l = 1, …, Mk + 1}, with Uk0 = 0 and . Let Ck denote the censoring time on the symptomatic event time Tk (k = K1 + 1, …, K) such that we observe Yk = min(Tk, Ck) and Δk = I(Tk ≤ Ck), where I(·) is the indicator function. For a random sample of n subjects, the data consist of {Oi : i = 1, …, n}, where
We assume that {Uikl : k = 1, …, K1; l = 1, …, Mik} and {Cik : k = K1 + 1, …, K} are independent of {Tik : k = 1, …, K} and bi ≡ (bi1, bi2) conditional on {Xik (·) : k = 1, …, K}. Then, the likelihood concerning the parameters θ ≡ (β, γ, Ʃ) and A ≡ (Λ1, …, ΛK) is
where , , and
In some studies, one of the symptomatic events is terminal (e.g., death), such that we have a semi-competing risks set-up (Fine, Jiang, and Chappell 2001), where the occurrence of the terminal event precludes the development of the other events but not vice versa. Without loss of generality, suppose that the Kth event is terminal. Then the monitoring times for Tk (k ≤ K1) consist of the Ukl’s that are smaller than TK , and the censoring time for Tk (k = K1 + 1, …, K − 1) is min(Ck, TK). Conditional on (b1, b2), the event times T1, …, TK−1 are mutually independent and are independent of the monitoring times and censoring times. Thus, for any set Sk that may depend on the monitoring times and censoring times, the joint probability of T1 ∈ S1, …, TK −1 ∈ SK−1 conditional on (b1, b2 ) is equal to with Sk as a deterministic set. Therefore, the likelihood remains the same as before.
2.2. Estimation Procedure
We adopt the nonparametric maximum likelihood estimation approach. For k = 1, …, K1, let be the ordered sequence of all Lik and Rik with Rik < ∞. For k = K1 + 1, …, K, let be the ordered sequence of all Yik with Δik = 1. The estimator for Λk (k = 1, …, K) is a step function that jumps only at with respective jump sizes . We maximize the objective function
over θ and λ1, …., λK, where
Xikl = Xik (tkl) for k = 1, …, K and l 1, …, mk, and Λk{Yik} is the jump size of Λk at Yik.
Direct maximization of the objective function is difficult due to the lack of analytical expressions for λ1, …, λK . We introduce latent Poisson random variables to form a likelihood equivalent to the objective function such that the maximum likelihood estimators can be easily obtained via a simple EM algorithm. For k = 1, …, K1, we denote and introduce independent Poisson random variables with means λkl exp(βTXikl + bi1). Conditional on bi1, the likelihood function of is
Let and . The observed-data likehood for Aik = 0 and Bik > 0 given bi1 is equal to
which is the same as . Therefore, the objective function Ln(θ,A) can be viewed as the observed-data likelihood for {Aik = 0, Bik > 0 : i = 1, …, n; k = 1, …, K1} ∪ {Yik,Δik : i = 1, …, n; k = K1 + 1, …, K} with as latent variables. In view of the foregoing results, we propose an EM algorithm treating Wikl and bi as missing data.
In the M-step, we maximize the conditional expectation of the complete-data log-likelihood given the observed data so as to update the parameters. In particular, the conditional expectation of the complete-data log-likelihood is
| (3) |
where denotes the conditional expectation given the observed data , with . To update the parameters, we first differentiate (3) with respect to λkl (k = 1, …, K; l = 1, … ,mk) to obtain the updating formulas for λk:
| (4) |
for k = 1,…, K and l = 1 , …, mk and
| (5) |
for k = K1+1; l = K and l = 1, …, mk). We then update β by solving the equation.
and update γk by solving the equation
The two equations are obtained by differentiating (3) with respect to βk or γk and replacing λkl by the right hand side of (4) or (5). Finally, we update by for j = 1, 2.
In the E-step, we evaluate the conditional expectation of and the other terms of bi given the observed data for i = 1, …, n. Specifically, the conditional expectation of given and bi is
Note that the density of bi given is proportional to . We evaluate the conditional expectation of Wikl and the other terms through numerical integration over bi with Gauss–Hermite quadratures.
We iterate between the E-step and M-step until convergence. In the M-step, the high-dimensional nuisance parameters λkl (k = 1, …, K; l = 1, …, mk) are calculated explicitly, such that inversion of high-dimensional matrices is avoided. We denote the final estimators for θ and A as and .
2.3. Asymptotic Theory
We establish the asymptotic properties of under the following regularity conditions.
Condition 1.
The true value of θ, denoted by θ0 ≡ (β0, γ0, Ʃ0), belongs to the interior of a known compact set , where , and S ⊂ (0, ∞) × (0, ∞).
Condition 2.
For k = 1, …, K, the true value Λk0 (·) of Λk (·) is strictly increasing and continuously differentiable in [0, τk] with Λk0 (0) = 0.
Condition 3.
For k = 1, …, K1, the monitoring times have finite support Uk with the least upper bound τk. The number of potential monitoring times Mk is positive with E(Mk) < ∞. There exists a positive constant η such that . In addition, there exists a probability measure μk in Uk such that the bivariate distribution function of (Ukm, Uk,m+1) conditional on (Mk, Xk) is dominated by μk × μk and its Radon–Nikodym derivative, denoted by , can be expanded to a positive and twice-continuously differentiable function in the .
Condition 4.
For k = K1 + 1, …, K, let τk denote the study duration time and Uk = [0, τk]. There exists a positive constant δ such that almost surely.
Condition 5.
With probability 1, Xk (·) has bounded total variation in Uk. If there exists a constant vector a1 and a deterministic function a2k (t) such that for any t ∈ Uk and any k ∈ {1, …, K} with probability 1, then a1 = 0 and a2k (t) = 0 for any t ∈ Uk and any k ∈ {1, …, K}.
Remark 2.
Conditions 1, 2, and 5 are standard conditions for failure time regression with time-dependent covariates. Condition 3 pertains to the joint distribution of monitoring times of the asymptomatic events. It requires that two adjacent monitoring times are separated by at least η; otherwise, the data may contain exact observations, which require a different theoretical treatment. The dominating measure μk is chosen as the Lebesgue measure if the monitoring times are continuous random variables and as the counting measure if monitorings occur only at a finite number of time points. The number of potential monitoring times Mk can be fixed or random, is possibly different among study subjects and event types, and is allowed to depend on covariates. Condition 4 implies that there is a positive probability for the kth symptomatic event to be observed in the time interval [0, τk].
We state the strong consistency of and the weak convergence of in two theorems.
Theorem 1.
Under Conditions 1−5, , and , where denotes the supremum norm on Uk for k = 1,…,K.
Theorem 2.
Under Conditions 1−5, converges weakly to a ( p + K2 + 2)-dimensional zero-mean normal random vector with a covariance matrix that attains the semiparametric efficiency bound.
The proofs of all theorems are provided in the Section S.1 of the supplementary materials.
We propose two approaches to estimate the covariance matrix of . The first approach makes use of the profile likelihood (Murphy and Van der Vaart 2000). Specifically, we define the profile log-likelihood function
where Ck is the set of step functions with nonnegative jumps at tkl (k = 1, …, K; l = 1, …, mk). We estimate the covariance matrix of by the inverse of
where pli is the ith subject’s contribution to pln, ej is the jth canonical vector in , a⊗2 = aaT, and hn is a constant of order n−1/2. To evaluate the profile likelihood, we use the EM algorithm of Section 2.2 but only update Λ1, …, ΛK in the M-step.
Alternatively, we approximate the asymptotic distribution of by bootstrapping the observations. In particular, we draw a simple random sample of size n with replacement from the observed data {Oi : i = 1, …, n}. Let be the estimator of θ bootstrap sample. The empirical distribution in the bootstrap sample. The empirical distribution of can be used to approximate the distribution of Confidence intervals for θ0 can be constructed by the Wald method (with the variance of ) or from the empirical percentiles of . The following theorem states the asymptotic properties of thereby validating the bootstrap procedure.
Theorem 3.
Under Conditions 1−5, the conditional distribution of given the data converges weakly to the asymptotic distribution of .
2.4. Dynamic Prediction
Given the fitted joint model, we can predict future events by updating the event history. For a subject with covariates X, let O(t ) denote the event history at time t > 0, which includes the interval-censored observations of the asymptomatic events {Lk(t ), Rk(t) : k = 1, …, K1}, and the right-censored observations of the symptomatic events {Yk(t ),Δk(t) : k = K1 + 1, …, K}.
If no event history is available, the density of the random effect b can be estimated by . We estimate the survival function of Tk, denoted by P(Tk ≥ t|X), by
where
and the integral is evaluated by numerical integration with Gauss–Hermite quadratures. Here, the function sk(t; X, b) can be interpreted as the conditional survival probability of Tk at time t given b and X.
In the semi-competing risks set-up, where one of the symptomatic events is terminal, it is more meaningful to use the cumulative incidence function to predict the event time of interest. Without loss of generality, we assume the Kth event is terminal. The cumulative incidence function of the kth event
(k = 1, …, K − 1) is given by
which can be estimated by
Here, the function sk(t; X, b) can be interpreted as the conditional survival probability of Tk at time t given TK ≥ t, b, and X.
At time t0 > 0, we update the posterior density of b given the event history O(t0) so as to perform dynamic prediction. Note that the posterior density of b is proportional to
If the subject has not developed the kth event or the terminal event by time t0, that is, Yk(t0) = YK (t0) = t0 and Δk(t0) =ΔK (t0) = 0, we estimate the conditional cumulative incidence function of the kth event, P(Tk ≤ t, Tk ≤ TK|O(t0 ), X), by
In practice, it is desirable to identify subjects who are at increased risk as the event history is accumulating. In the same vein as the risk score under the standard proportional hazards model, we use the risk score to dynamically predict the kth event (k = K1 + 1, …, K), where is a suitable estimator of b given the event history O(t0). The estimator can be the posterior mean or mode of b or an imputed value from the posterior distribution. For example, the risk score using the posterior mean is given by
The risk score quantifies the subject-specific risk and can be very useful to both individual patients and clinicians when making decisions about lifestyle modifications and preventive medical treatments.
3. Simulation Studies
We conducted simulation studies to assess the performance of the proposed methods. We considered one time-independent covariate X1 ∼ Unif(0, 1) and one time-dependent covariate X2(t) = I(t ≤ V)B1 + I(t > V)B2, where B1 and B2 are independent Bernoulli(0.5), V ∼ Unif(0, τ), and τ = 4. We considered two asymptomatic events and two symptomatic events. We set Xk = ek ⊗ (X1, X2)T, where ek is the kth canonical vector in , and ⊗ denotes the Kronecker product. We set β = (0.5, 0.4, 0.5,−0.2,−0.5, 0.5,−0.5, 0.5)T, Λ1(t) = 0.5t, Λk(t) = log{1 + t/(k − 1)} for k = 2, 3, 4, γ3 = γ4 = 0.25, and σ21 = σ22 = 1. Both symptomatic events were censored by C ∼ Unif(2τ/3, τ), such that the censoring rates are 33% and 39%, respectively. The series of monitoring times were generated sequentially, with Um = Um−1 + 0.1 + Unif (0, 0.5) for m ≥ 1 and U0 = 0. The last monitoring time is the largest Um that is smaller than C. We set n = 100 or 200 and simulated 2000 replicates. For each dataset, we applied the proposed EM algorithm by setting the initial value of β to 0, the initial values of γk and σk2 to 1 and the initial value of λkl to 1/mk. We used 20 quadrature points for integration with respect to each random effect and set the convergence threshold to 10−3. For variance estimation, we set hn = 5n−1/2 for profile likelihood and used 100 bootstrap samples.
Table 1 summarizes the simulation results. The biases for all parameter estimators are small, especially for n = 200. Both the profile-likelihood and bootstrap variance estimators for are accurate, especially for n = 200. Both variance estimators for tend to overestimate the true variabilities, but the coverage probabilities of the confidence intervals get closer to the nominal level as sample size increases. The profile-likelihood variance estimators for and overestimate the true variabilities, while the bootstrap variance estimators for and accurately reflect the true variabilities. Figure S.1(a) of the Supplemental Materials shows the estimation of the baseline survival functions with sample size n = 200. The estimators are virtually unbiased.
Table 1.
Summary statistics for the simulation studies without a terminal event.
|
n =
100 |
n =
200 |
|||||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|
| Profile |
Bootstrap |
Profile |
Bootstrap |
|||||||||
| Bias | SE | SEE | CP | SEE | CP | Bias | SE | SEE | CP | SEE | CP | |
| β11 | 0.006 | 0.585 | 0.597 | 0.961 | 0.627 | 0.967 | 0.027 | 0.405 | 0.399 | 0.947 | 0.412 | 0.953 |
| β12 | 0.029 | 0.327 | 0.321 | 0.941 | 0.348 | 0.960 | 0.019 | 0.222 | 0.216 | 0.949 | 0.228 | 0.953 |
| β21 | 0.015 | 0.623 | 0.609 | 0.946 | 0.648 | 0.963 | 0.014 | 0.410 | 0.409 | 0.951 | 0.424 | 0.958 |
| β22 | −0.005 | 0.341 | 0.329 | 0.940 | 0.355 | 0.962 | −0.002 | 0.225 | 0.222 | 0.9(51 | 0.233 | 0.961 |
| β31 | −0.022 | 0.617 | 0.635 | 0.957 | 0.610 | 0.949 | −0.004 | 0.416 | 0.428 | 0.960 | 0.420 | 0.948 |
| β32 | −0.002 | 0.319 | 0.338 | 0.965 | 0.322 | 0.949 | 0.009 | 0.221 | 0.229 | 0.958 | 0.222 | 0.947 |
| β41 | −0.012 | 0.623 | 0.651 | 0.969 | 0.629 | 0.955 | 0.006 | 0.449 | 0.440 | 0.947 | 0.431 | 0.942 |
| β42 | 0.004 | 0.330 | 0.348 | 0.967 | 0.332 | 0.950 | −0.001 | 0.231 | 0.235 | 0.955 | 0.229 | 0.945 |
| γ3 | −0.012 | 0.227 | 0.252 | 0.979 | 0.260 | 0.971 | −0.012 | 0.159 | 0.171 | 0.962 | 0.170 | 0.960 |
| γ3 | −0.013 | 0.237 | 0.260 | 0.976 | 0.266 | 0.972 | −0.016 | 0.162 | 0.173 | 0.966 | 0.177 | 0.963 |
| 0.062 | 0.445 | 0.751 | 0.978 | 0.493 | 0.956 | 0.031 | 0.317 | 0.482 | 0.982 | 0.318 | 0.946 | |
| −0.102 | 0.413 | 0.510 | 0.993 | 0.482 | 0.971 | −0.062 | 0.297 | 0.335 | 0.987 | 0.312 | 0.974 | |
NOTE: SE and SEE denote, respectively, the empirical standard error and mean standard error estimator. CP stands for the empirical coverage probability of the % confidence interval based on the Wald method for the profile-likelihood approach and the % symmetric confidence interval for the bootstrap approach. For γ3, γ4, , and , bias and SEE are based on the median instead of the mean, and SE is based on the mean absolute deviation. For and , the confidence intervals are based on the log transformation.
We considered a second setup with an additional terminal event. We set Xk = ek ⊗ (X1, X2)T, where ek is the kth canonical vector in . In addition, we set β = (0.5, 0.4, 0.5, −0.2, −0.5, 0.5, −0.5, 0.5, 0.3, −0.2)T, Λ5 (t) = log(1 + t/4), and γ5 = 0.25. The terminal event was also censored by C. The censoring rates for the right-censored events are 51%, 58%, and 43%, respectively. The results are shown in Table S.1 and Figure S.1(b) of the supplemental materials. The conclusions are similar to the case of no terminal event.
We assessed the performance of dynamic prediction based on the conditional cumulative incidence function in the setting with a terminal event. Suppose that at the first monitoring time t0 = 1, event 2 has occurred but events 1, 3, and 4 have not. Figure 1 shows the estimation of the baseline cumulative incidence functions (pertaining to X = 0) for events 3 and 4 given the event history at time t0 = 1. The estimators slightly underestimate the true values at the right tail, but the biases get smaller as n increases.
Figure 1.
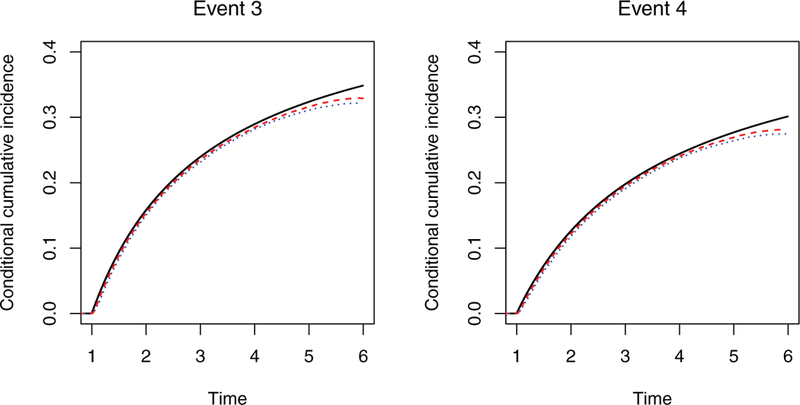
Estimation of the baseline cumulative incidence function conditional on the event history. The solid black curve, dotted blue curve, and dashed red curve pertain, respectively, to the true value and the mean estimates from the proposed method with n = 100 and n = 200.
To investigate the performance of the proposed dynamic prediction methods under misspecified models, we conducted another set of simulation studies where the event times were generated from the proportional odds, instead of the proportional hazards, models with random effects. As shown in Section S.2 of the supplemental materials, the dynamic prediction is still quite accurate.
4. ARIC Study
ARIC is a perspective epidemiological cohort study conducted in four U.S. communities: Forsyth County, NC; Jackson, MS; Minneapolis, MN; and Washington County, MD. A total of 15792 participants received a baseline examination between 1987 and 1989 and four subsequent examinations in 1990–1992, 1993–1995, 1996–1998, and 2011–2013. At each examination, medical data were collected, such that interval-censored observations for diabetes and hypertension were obtained. The participants were also followed for cardiovascular diseases through reviews of hospital records, such that potentially right-censored observations on MI, stroke, and death were collected.
We related the disease incidence to race, sex, and five baseline risk factors: age, body mass index (BMI), glucose level, systolic blood pressure, and smoking status. Since the Jackson cohort is composed of black subjects only, and neither Minneapolis nor Washington County cohorts contain black subjects, we included the cohort×race indicators as predictors. We excluded subjects with prevalent cases at baseline or missing covariate values to obtain a total of 8728 subjects. During the study, 17.3%, 46.8%, 8.3%, and 5.1% of the subjects developed diabetes, hypertension, MI, and stroke, respectively, while 28.7% died.
We jointly modeled the asymptomatic and symptomatic events in the ARIC study with equations (1) and (2). For variance estimation, we used the profile likelihood approach with hn = 5n−1/2. Tables 2 and 3 show the estimation results for the regression parameters. Several characteristics and baseline risk factors are found to be predictive of the events. Older subjects have higher risks of hypertension, MI, stroke, and death than younger subjects. Males have lower risk of hypertension but higher risks of MI, stroke, and death than females. Smokers have significantly higher risks for all events than non-smokers. In addition, higher baseline BMI increases the risks of diabetes, hypertension, and MI; higher baseline glucose level increases the risks of diabetes, stroke, and death; and higher baseline value of systolic blood pressure increases the risks of all considered events.
Table 2.
Estimation results for the regression parameters of the asymptomatic events in the ARIC study.
| Diabetes |
Hypertension |
|||||
|---|---|---|---|---|---|---|
| Covariate | Estimate | Std error | p-value | Estimate | Std error | p-value |
| Forsyth County, white | −0.5332 | 0.1817 | 0.0033 | −0.5032 | 0.0615 | <0.0001 |
| Jackson, black | −0.1356 | 0.1806 | 0.4530 | −0.1075 | 0.0673 | 0.1104 |
| Minneapolis, white | −0.9415 | 0.1802 | <0.0001 | −0.5747 | 0.0579 | <0.0001 |
| Washington County, white | −0.3778 | 0.1778 | 0.0336 | −0.3798 | 0.0592 | <0.0001 |
| Age | −0.0093 | 0.0057 | 0.1025 | 0.0166 | 0.0036 | <0.0001 |
| Male | −0.0655 | 0.0593 | 0.2694 | −0.2329 | 0.0396 | <0.0001 |
| BMI | 0.0911 | 0.0059 | <0.0001 | 0.0254 | 0.0044 | <0.0001 |
| Glucose | 0.1075 | 0.0033 | <0.0001 | 0.0004 | 0.0023 | 0.8744 |
| Systolic blood pressure | 0.0096 | 0.0026 | 0.0003 | 0.0780 | 0.0022 | <0.0001 |
| Smoker | 0.4576 | 0.0674 | <0.0001 | 0.3134 | 0.0468 | <0.0001 |
NOTE: The blacks in Forsyth County form the reference group for the cohort×race variables.
Table 3.
Estimation results for the regression parameters of the symptomatic events in the ARIC study.
| Ml |
Stroke |
Death |
|||||||
|---|---|---|---|---|---|---|---|---|---|
| Covariate | Estimate | Std error | p-value | Estimate | Std error | p-value | Estimate | Std error | p-value |
| Forsyth County, white | 0.0467 | 0.2477 | 0.8504 | 0.1308 | 0.3688 | 0.7228 | −0.2475 | 0.1049 | 0.0183 |
| Jackson, black | −0.3121 | 0.2681 | 0.2444 | 0.6622 | 0.3755 | 0.0778 | 0.1871 | 0.1118 | 0.0941 |
| Minneapolis, white | −0.1052 | 0.2476 | 0.6710 | 0.0507 | 0.3688 | 0.8907 | −0.3262 | 0.1040 | 0.0017 |
| Washington County, white | 0.1953 | 0.2457 | 0.4266 | 0.5013 | 0.3653 | 0.1700 | −0.1194 | 0.1032 | 0.2471 |
| Age | 0.0805 | 0.0078 | <0.0001 | 0.1121 | 0.0099 | <0.0001 | 0.1465 | 0.0054 | <0.0001 |
| Male | 0.9279 | 0.0901 | <0.0001 | 0.4050 | 0.1071 | 0.0002 | 0.6108 | 0.0545 | <0.0001 |
| BMI | 0.0273 | 0.0101 | 0.0068 | −0.0010 | 0.0123 | 0.9356 | 0.0080 | 0.0060 | 0.1847 |
| Glucose | 0.0059 | 0.0046 | 0.2007 | 0.0215 | 0.0057 | 0.0002 | 0.0104 | 0.0030 | 0.0006 |
| Systolic blood pressure | 0.0135 | 0.0036 | 0.0002 | 0.0192 | 0.0047 | <0.0001 | 0.0089 | 0.0022 | 0.0001 |
| Smoker | 1.2378 | 0.0888 | <0.0001 | 1.0023 | 0.1127 | <0.0001 | 1.3045 | 0.0599 | <0.0001 |
NOTE: See the Note to Table 2
The estimation results for the remaining parametric components are shown in Table S.2 of the supplemental materials. The variance components σ12 and σ22 are significantly larger than zero, indicating strong correlation among the asymptomatic events and among the symptomatic events. The parameters γMI, γ Stroke, and γDeath are also significantly larger than zero, reflecting the strong positive dependence of the symptomatic events on the asymptomatic events. The Akaike information criterion (AIC) for the proposed model is 108852.8. For comparisons, we also fit a model with one random effect shared by all events. The corresponding AIC is 109000.6, and the p-value for the likelihood ratio test is less than 0.0001, indicating that the proposed model provides a much better fit to the data than the model with one shared random effect.
To evaluate the performance of the proposed prediction methods, we randomly divided the study cohort into training and testing sets with equal numbers of subjects. We analyzed the training set to obtain parameter estimates, based on which we calculated the risk scores for subjects in the testing set, where the posterior means of the random effects were used. Specifically, at examinations 2, 3, and 4, we calculated the risk scores of MI or stroke for subjects who have not developed the disease. We evaluated the performance of the prediction using C-index (Uno et al. 2011) and compared it with that of the risk scores based on the standard models. In particular, for MI and stroke, we considered the univariate model of Fine and Gray (1999) with death as a competing risk; for death, we considered the standard proportional hazards model. The values of the C-index based on twenty randomly divided training/test tests are shown in Figure 2. The proposed risk score performs better than the risk score of the standard model at all examinations for all symptomatic events.
Figure 3 shows the estimated conditional cumulative incidence functions of MI and stroke for two smokers and two non-smokers who have different event histories at year 3 but with the same values of other risk factors. The risks of MI and stroke are considerably higher for the smokers than the non-smokers with the same event history. The estimated conditional probabilities for the subjects who have developed both diabetes and hypertension are higher than those who have not developed diabetes or hypertension.
Figure 3.
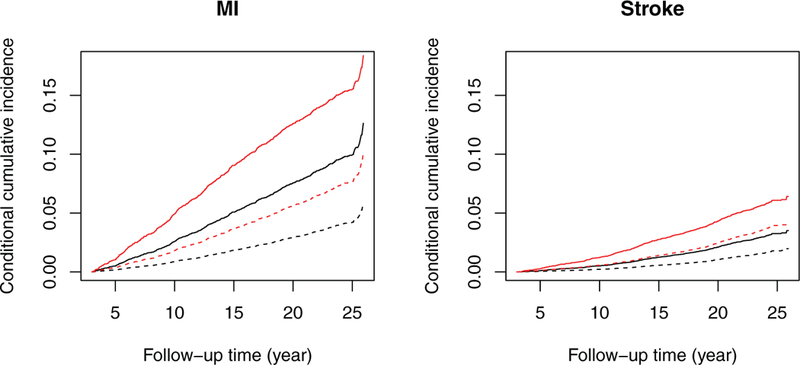
Estimation of the conditional cumulative incidence functions of MI and stroke for a 50-year-old white female residing in Forsyth County, NC, with BMI 40 kg/m2, glucose 98 mg/dL, and systolic blood pressure mmHg. The solid curves pertain to smokers, while the dashed curves pertain to non-smokers. The black curves pertain to subjects who have not developed diabetes or hypertension by year 3. The red curves pertain to subjects who have developed both diabetes and hypertension by year 3.
Figures S.2(a) and S.2(b) in the supplementary materials illustrate the estimation of the conditional cumulative incidence functions of stroke given different event histories. We estimated the cumulative incidence functions at time zero when only baseline covariates are available and then updated them at two examinations at year 3 and year 6 using the event histories. The development of diabetes, hypertension, and MI substantially increases the incidence of stroke, whereas the history of no diabetes, hypertension, or MI over the first six years entails lower incidence of stroke. For comparison, we show in Figures S.2(c) in the supplementary materials the estimated cumulative incidence function of stroke under the univariate model of Fine and Gray (1999), which does not condition on the event history and thus reflects the population average. This estimate lies between the two previous conditional estimates, as expected.
5. Discussion
In this article, we formulated the joint distribution of multiple right- and interval-censored events with proportional hazards models with random effects. We characterized the correlation structure of the asymptomatic and symptomatic events through two independent random effects and used unknown coefficients to capture the effects of the asymptomatic events on the symptomatic events. To our knowledge, no such modeling approach has been previously adopted.
We studied efficient nonparametric maximum likelihood estimation of the proposed joint model and established the asymptotic properties of the estimators through innovative use of modern empirical process theory. We showed the Glivenko–Cantelli and Donsker properties for the classes of functions of interest by carefully evaluating their bracketing numbers. The estimators of the cumulative baseline hazard functions for the symptomatic and asymptomatic events converge at different (n1/2 and n1/3) rates, such that separate treatments were required in the proofs.
The proposed EM algorithm performed well in both the simulation studies and the real example. There was no occurrence of nonconvergence in any of the simulated or real dataset. It took 2.5 or 12 minutes to analyze a simulated dataset with K = 5 events and sample sizes n = 100 or 200, respectively. It took ten days to analyze the ARIC data, which involves 8728 subjects with 10 covariates and 2232, 2291, 701, 431, and 2130 distinct jump times for diabetes, hypertension, MI, stroke, and death, respectively. We can alleviate the computational burden for such large studies by grouping or subsampling the examination times so as to reduce the number of distinct time points. In particular, the computing time was shortened to two days when the distinct values were reduced to 154, 162, 276, 229, and 311 by rounding the examination times to the nearest months in the ARIC data.
We proposed nonparametric bootstrap for variance estimation as an alternative to the conventional profile-likelihood approach. We established the validity of the bootstrap procedure and showed through simulation studies that bootstrap yields more accurate estimators of the variabilities for the variance components. To our knowledge, bootstrap with interval-censored data has not been rigorously studied. In large studies, bootstrap may be overly time-consuming. It would be worthwhile to develop other versions of bootstrap, such as subsampling bootstrap, to reduce computational burden.
In models (1) and (2), we distinguish asymptomatic from symptomatic events when modeling the correlation structures because it is of particular interest to study the effects of asymptomatic diseases, which are typically interval-censored, on symptomatic diseases, which are typically right-censored, and to use the former to predict the latter. We show in Section S.3 of the Supplementary Materials that our framework can be modified to allow any of the K event times to be interval- or right-censored.
ARIC is one of many epidemiological cohort studies with multiple symptomatic and asymptomatic events. Such events are also available in electronic health records. Indeed, other types of outcomes, such as longitudinal repeated measures and recurrent events, may also be available. The proposed joint model can be extended to accommodate additional multivariate outcomes and improve dynamic prediction.
Supplementary Material
Acknowledgments
The authors thank the staff and participants of the ARIC study for their important contributions.
Funding
This work was suported by the National Institutes of Health awards R01GM047845, R01AI029168, R01CA082659, and P01CA142538. The Atherosclerosis Risk in Communities Study is carried out as a collaborative study supported by National Heart, Lung, and Blood Institute contracts (HHSN268201100005C, HHSN268201100006C, HHSN268201100007C, HHSN268201100008C, HHSN268201100009C, HHSN268201100010C, HHSN268201100011C, and HHSN268201100012C).
References
- Chen MH, Chen LC, Lin KH, and Tong X (2014), “Analysis of Multivariate Interval Censoring by Diabetic Retinopathy Study,” Communications in Statistics: Simulation and Computation, 43, 1825–1835. [1] [Google Scholar]
- Fine JP, and Gray RJ (1999), “A Proportional Hazards Model for the Subdistribution of a Competing Risk,” Journal of the American Statistical Association, 94, 496–509. [1,8] [Google Scholar]
- Fine JP, Jiang H, and Chappell R (2001), “On Semi-Competing Risks Data,” Biometrika, 88, 907–919. [1,2] [Google Scholar]
- Goggins WB, and Finkelstein DM (2000), “A Proportional Hazards Model for Multivariate Interval-Censored Failure Time Data,” Biometrics, 56, 940–943. [1] [DOI] [PubMed] [Google Scholar]
- Hogan JW, and Laird NM (1997), “Model-Based Approaches to Analysing Incomplete Longitudinal and Failure Time Data,” Statistics in Medicine, 16, 259–272. [1] [DOI] [PubMed] [Google Scholar]
- Hougaard P (2012), Analysis of Multivariate Survival Data, New York: Springer; [1] [Google Scholar]
- Kalbfleisch JD, and Prentice RL (2002), The Statistical Analysis of Failure Time Data, Hoboken, NJ: Wiley; [1] [Google Scholar]
- Kim MY, and Xue X (2002), “The Analysis of Multivariate Interval-Censored Survival Data,” Statistics in Medicine, 21, 3715–3726. [1] [DOI] [PubMed] [Google Scholar]
- Lin DY (1994), “Cox Regression Analysis of Multivariate Failure Time Data: the Marginal Approach,” Statistics in Medicine, 13, 2233–2247. [2] [DOI] [PubMed] [Google Scholar]
- Murphy SA, and Van der Vaart AW (2000), “On Profile Likelihood,” Journal of the American Statistical Association, 95, 449–465. [4] [Google Scholar]
- The ARIC Investigators., (1989), “The Atherosclerosis Risk in Communities (ARIC) Study: Design and Objectives,” American Journal of Epidemiology, 129, 687–702. [1] [PubMed] [Google Scholar]
- Uno H, Cai T, Pencina MJ, D’Agostino RB, and Wei L (2011), “On the C-statistics for Evaluating Overall Adequacy of Risk Prediction Procedures With Censored Survival Data,” Statistics in Medicine, 30, 1105–1117. [8] [DOI] [PMC free article] [PubMed] [Google Scholar]
- Wen CC, and Chen YH (2013), “A Frailty Model Approach for Regression Analysis of Bivariate Interval-Censored Survival Data,” Statistica Sinica, 23, 383–408. [1] [Google Scholar]
- Zeng D, Gao F, and Lin D (2017), “Maximum Likelihood Estimation for Semiparametric Regression Models With Multivariate Interval-Censored Data,” Biometrika, 104, 505–525. [1] [DOI] [PMC free article] [PubMed] [Google Scholar]
Associated Data
This section collects any data citations, data availability statements, or supplementary materials included in this article.