

Abstract
As the evidence of predictive processes playing a role in a wide variety of cognitive domains increases, the brain as a predictive machine becomes a central idea in neuroscience. In auditory processing, a considerable amount of progress has been made using variations of the Oddball design, but most of the existing work seems restricted to predictions based on physical features or conditional rules linking successive stimuli. To characterize the predictive capacity of the brain to abstract rules, we present here two experiments that use speech-like stimuli to overcome limitations and avoid common confounds. Pseudowords were presented in isolation, intermixed with infrequent deviants that contained unexpected phoneme sequences. As hypothesized, the occurrence of unexpected sequences of phonemes reliably elicited an early prediction error signal. These prediction error signals do not seemed to be modulated by attentional manipulations due to different task instructions, suggesting that the predictions are deployed even when the task at hand does not volitionally involve error detection. In contrast, the amount of syllables congruent with a standard pseudoword presented before the point of deviance exerted a strong modulation. Prediction error’s amplitude doubled when two congruent syllables were presented instead of one, despite keeping local transitional probabilities constant. This suggests that auditory predictions can be built integrating information beyond the immediate past. In sum, the results presented here further contribute to the understanding of the predictive capabilities of the human auditory system when facing complex stimuli and abstract rules.
Keywords: auditory processing, EEG, predictive coding
Significance Statement
The generation of predictions seem to be a prevalent brain computation. In the case of auditory processing this information is intrinsically temporal. The study of auditory predictions has been largely circumscribed to unexpected physical stimuli features or rules connecting consecutive stimuli. In contrast, our everyday experience suggest that the human auditory system is capable of more sophisticated predictions. This becomes evident in the case of speech processing, where abstract rules with long range dependencies are universal. In this article, we present two EEG experiments that use speech-like stimuli to explore the predictive capabilities of the human auditory system. The results presented here increase the understanding of the ability of our auditory system to implement predictions using information beyond the immediate past.
Introduction
In recent years, the study of predictive processes has drawn increasing attention in neuroscience. In this context, Predictive Coding has emerged as a popular theory, which states that the brain constructs a hierarchy of predictions of incoming stimuli at multiple levels of processing (Friston, 2005, 2009, 2010; Bubic et al., 2010; Hobson and Friston, 2012). This proposal has received mounting empirical evidence (Wacongne et al., 2011; Den Ouden et al., 2012; Phillips et al., 2015, 2016).
A wealth of experiments in the study of predictive coding are variations of the Oddball design (Squires et al., 1975; Heilbron and Chait, 2018), where frequent acoustic stimuli establish predictable sequences, which are at times violated. Besides designs using tones, the use of speech-like stimuli offers a number of advantages. Within speech, abstract rules are ubiquitous, allowing to test abstract predictions that go beyond physical stimuli features and local transitional probabilities. These properties make speech processing an excellent testbed for the study of the brain’s signals to abstract rules establishment and its violations.
Speech perception requires the fast extraction of meaning from a complex auditory signal (Boudewyn et al., 2015; Kleinschmidt and Jaeger, 2015) and the generation of predictions might be an efficient solution to achieve fast and accurate comprehension (Kleinschmidt and Jaeger, 2015; Hauk, 2016). Although the proposal that predictive processes play a role in speech processing has been criticized (Norris et al., 2000; Van Petten and Luka, 2012; Huettig and Mani, 2016), evidence suggests that predictions are deployed at several speech processing levels (Lewis and Bastiaansen, 2015). At the syntactic level, listeners’ knowledge influence sentence parsing (Farmer et al., 2006; Wilson and Garnsey, 2009; Traxler, 2014; Baart and Samuel, 2015). Lexico-semantic processing can be facilitated by contextual predictability (Van Petten et al., 1999; Schuster et al., 2016).
EEG studies have identified an ERP known as N400, whose amplitude is inversely correlated with the semantic predictability of words in context (Kutas and Hillyard, 1980; Van Petten et al., 1999; Kutas and Federmeier, 2000, 2011; Brink et al., 2001; DeLong et al., 2005; Freunberger and Roehm, 2016). EEG evidence has also shown that forthcoming phonemes can be predicted using syntactic (DeLong et al., 2005), semantic (Kashino, 2006; Groppe et al., 2010; Bendixen et al., 2014), phonological (Cornell et al., 2011; Hestvik and Durvasula, 2016; Scharinger et al., 2016; Schluter et al., 2016), and phonotactic information (Dehaene-Lambertz et al., 2000; Sun et al., 2015; Ylinen et al., 2016).
As the generation of predictions seem to be a prevalent brain computation (Friston, 2010, 2009), we propose that phonological predictions are generated during speech perception in the absence of semantic and syntactic information. To test this hypothesis, we performed two EEG experiments with an Oddball design. The use of speech stimuli allowed us to test for predictions based on an abstract rule that go beyond local transitional probabilities.
Pseudowords were presented in a context that did not contain syntactic or semantic information. We expected that the presentation of deviants, constructed using the same phonemes as standard pseudowords but in an unexpected sequence, would elicit an early prediction error signal like the mismatch negativity (MMN; Friston, 2005; Näätänen et al., 2007; Garrido et al., 2009; Wacongne et al., 2011; Chennu et al., 2013; Winkler and Schröger, 2015). The presence of this prediction error signal would imply that listeners’ brains generate predictions about incoming phonemes within pseudoword.
We propose that abstract predictions are deployed regardless of the task at hand. To test this, experiments 1 and 2 differed with respect to the instructions given to the participants. While in experiment 1 participants were instructed to count the occurrence of deviants, in experiment 2, they were required to learn all pseudowords. We expected that an early prediction error signal would be present in both experiments, implying that predictions are deployed even if the task at hand does not require error detection and independent of the strategy of rule-learning.
Finally, to test whether these predictions are constructed using information beyond local transitional probabilities, we tested whether the amplitude of prediction error would be modulated by the amount of phonemes presented before the point of deviance. We expected to find higher prediction error (higher amplitudes) when longer sequences of phonemes that are congruent with a standard pseudoword are presented. This modulation would not occur if predictions were made based solely on local transitional probabilities between phonemes.
Taken together, these experiments allowed us to study the predictive capabilities of the brain networks underlying the extraction of abstract rules.
Materials and Methods
Stimuli set, unprocessed data and processing scripts can be found at https://osf.io/tuvy6/.
Participants
Participants were self-reported right handed, Italian native speakers recruited from the city of Trieste with no auditory or language-related problems. Participants signed informed consent and received a monetary compensation of 15€. Thirty participants (10 male, 20 female, mean aged 22.86 ± 3.42 years) took part in experiment 1, and 29 participants (9 male and 20 female, mean aged 23.24 ± 3.52 years) took part in experiment 2. After data preprocessing, participants contributing with <30 clean EEG trials per condition were excluded from analysis (one participant excluded from each experiment). The remaining participants had sufficient trials to be included in a single subject statistical analysis and all contribute similarly to the group variance. Additionally, one participant was excluded from experiment 1 due to poor behavioral performance. Therefore, 28 participants (10 male, 18 female, mean age 23.25 ± 3.23 years) from experiment 1 and 28 participants (8 male and 20 female, mean age 23.10 ± 3.51 years) from experiment 2 were included in the final analyses.
Stimuli
Six pseudowords divided in three sets of two pseudowords each were used as stimuli. We applied a series of constrains in the construction of our stimuli to ensure that the resulting pseudowords would resemble real Italian words. First we consulted the phonItalia lexical database (Goslin et al., 2014) to identify syllable candidates composed by 1 consonant followed by 1 vowel (i.e., two phonemes each). To exclude monosyllabic words and onomatopoeias, we removed syllables with a token frequency above the 70th percentile. Next, to keep syllables that could take any position within a word, we removed syllables with initial, middle or final position token frequencies either bellow the 20th percentile or above the 90th percentile. This selection procedure allowed us to identify 24 syllable candidates that are not monosyllabic words (in Italian) and have an even frequency distribution across positions within a word.
Using these syllable candidates, we constructed two trisyllabic pseudowords that contained no vowel or consonant repetitions. Additionally, no syllables were repeated between these two pseudowords. Hereafter, these pseudowords will be referred to as STD (i.e., standard) pseudowords. Taking these STD pseudowords as a base, we constructed two different types of deviant pseudowords. The first deviant type, to which we will refer as XYY, consisted of the 1st syllable of a STD pseudoword and the 2nd and 3rd of the other STD pseudoword. The second type of deviant, to which we will refer as XXY, consisted of the 1st and 2nd syllable of a STD pseudoword, and the 3rd of the other STD pseudoword. Finally, two additional pseudowords with a XYX structure were constructed, only to be used as NEW pseudowords in a forced choice test at the end of experiment 2. None of these deviant pseudowords contained either consonant or vowel repetitions.
Audio file of these two STD pseudowords were generated using the MBROLA speech synthesizer (Dutoit et al., 1996) and the Italian female diphone database it4. Consonant and vowel durations were set to 150 and 175 ms, respectively, hence, pseudowords duration was 975 ms. Once the two STD pseudowords were produced, deviants were constructed by cross-splicing (i.e., cutting and replacing sound segments) the audio of the STD.
In natural speech, phonemes are co-articulated (i.e., the sound of each phoneme is influenced by the preceding and the forthcoming phoneme). Hence, using cross-splicing to generate the deviant pseudowords could result in sharp transitions that would sound unnatural. Because of this, we took measures to obtain a natural render for our stimuli (Steinberg et al., 2012). For the first and last syllable position, the vowels of both STD pseudowords had similar first and second formants. As one STD pseudoword had the vowel “o” in the first syllable, the other STD pseudoword had the vowel “u” at the same position. In the case of the third syllable, while one STD pseudoword used the vowel “i,” the other one used the vowel “e.” In the case of the second syllable, both STD pseudowords had “a” as the vowel (Fig. 1A). For each syllable position, the consonants of both STD pseudowords had the same mode of articulation. Finally, the point of cutting was set close to zero amplitude. These measures had the effect of reducing the difference between both STD pseudowords at the points of syllable transitions so that when cross-spliced to construct the deviant pseudowords, these would not contain sharp transitions.
Figure 1.

A, Scatter plot of 1st and 2nd formant of each vowel. B, Stimulus set in IPA notation. Deviant pseudowords were produced by cross-splicing the two STD pseudowords either at the end of the first syllable (XYY) or at the end of the second syllable (XXY). Two additional NEW pseudowords with a XYX structure were used only in a forced choice test at the end of experiment 2. C, In both experiments, stimuli were presented in 13 blocks separated by 20 s. Within each block, pseudowords were presented with an inter stimulus interval between 900 and 1300 ms. The first blocks consisted solely of STD pseudowords. Subsequent blocks were composed of 84% STD pseudowords 8% XYY deviant pseudowords and 8% XXY deviant pseudowords. Pseudoword order was pseudo-random. A minimum of two and a maximum of four STD pseudowords were presented between deviants and no deviants were presented more than two times consecutively.
The final set consisted of two STD, two XYY deviants, two XXY deviants, and two NEW pseudowords (Fig. 1B). All pseudowords were checked by a native Italian speaker linguist to ensure that they sounded as plausible but not real Italian words.
While previous work in the literature has shown that the generation of predictions can serve word processing, phonemes in these experiments were either omitted (Bendixen et al., 2014), or replaced either by other phonemes (Cornell et al., 2013; Politzer-Ahles et al., 2016; Schluter et al., 2017) or by a non-linguistic sound (Kashino, 2006; Groppe et al., 2010). Because of this, changes in low level auditory features might have contributed to the recorded signals. In the case of our stimuli set, any difference in the EEG recording found between the STD condition and the deviant conditions could not be attributed to differences in instantaneous low-level features. Instead, they could in principle only be attributed to the violation of the abstract rule learnt during the experiment (Paavilainen, 2013), according to which given a syllable Xn, the next syllable of the word should be Xn + 1.
Note that in the case of the stimuli used here, the only feature that defined a pseudoword as deviant was that following the syllable Xn, instead of the usual syllable Xn + 1, the syllable Yn + 1 (which belongs to a different STD pseudoword) was presented. Additionally, as the overall frequency of presentation of all syllables used to construct the stimuli was the same, this design avoids a common confound between expectation and frequency of presentation (Heilbron and Chait, 2018).
Experimental design
Participants were requested to minimize movement throughout the experiment, except during breaks between blocks. No particular instructions were given with respect to when to blink, as eye blink artefacts can be removed using independent component analysis (ICA; Delorme and Makeig, 2004; Chaumon et al., 2015).
Experiments followed an Oddball design, divided in 13 blocks with an average duration of 3.3 min each. During each block, a total of 98 pseudowords were presented, with an inter stimulus interval that varied between 900 and 1300 ms. During the first of such blocks, only STD pseudowords were presented. Subsequently, participants completed 12 blocks composed of 84% Standard pseudowords 8% XYY deviant pseudowords and 8% XXY deviant pseudowords. Within each block, pseudoword order was pseudo-random. A minimum of two and a maximum of four STD pseudowords were presented between deviants and no deviants were presented more than two times consecutively (Fig. 1C).
In experiment 1, participants were instructed to learn all made up “words” (i.e., pseudowords) in block one, and from block 2 onwards count the occurrence of “mistaken words” (i.e., deviant pseudowords) and write down the number of mistaken words during the pauses between blocks.
In experiment 2, participants were not informed about the presence of deviants and were simply instructed to learn all made up words (i.e., pseudowords). To ensure that the participant would pay attention during the experiment, they were informed that they would be subject to a test after the word learning task. After listening to the blocks of pseudowords, behavioral performance was assessed, by means of a forced choice test. On each trial, participants heard two pseudowords in sequence and were requested to choose the one that most likely was presented during the experiment. Participants completed four trials for each of six contrasts between conditions, for a total of 24 trials, presented in pseudorandom order (only 1 repetition of contrast type was allowed). The contrasts between conditions were “STD versus XYY,” “STD versus XXY,” “XYY versus XXY,” “STD versus NEW,” “XYY versus NEW,” and “XXY versus NEW.” Participants reported their answers verbally and the experimenter entered them through keyboard. Order of presentation of pseudowords within trial was counterbalanced.
Data acquisition setup
EEG data were collected using a 128 passive electrode system (Geodesic EEG System 300, Electrical Geodesics, Inc.) referenced to the vertex. EEG signal was bandpass filtered by hardware between 0.1 and 100 Hz, and digitalized at 250 Hz. Electrode impedance was kept below 100 kΩ (equivalent to 10-kΩ standard amplifiers; Johnson et al., 2001). Participants were tested in a soundproof faraday cage while sitting on a chair in front of a LCD 19-inch monitor. Sound was delivered via a loudspeaker located behind the monitor, at a comfortable sound intensity of ∼60 dB. Experiments were programmed in MATLAB (MathWorks, Inc., RRID: SCR_001622) using the Psychophysics Toolbox extensions (Brainard, 1997; Pelli, 1997; RRID: SCR_002881). Pseudoword onset was marked on the EEG data by sending both a digital input signal (DIN) and a TCP/IP mark.
EEG data preprocessing
EEG data preprocessing was performed in MATLAB using custom code and the EEGLAB toolbox (Delorme and Makeig, 2004; RRID: SCR_007292). After being imported to EEGLAB, the data of each subject was bandpass filtered (0.1–30 Hz). As the anti-aliasing filter of the EGI 300 Amp introduces a delay of 36 ms, latencies of all events were corrected. The entire learning block, and the first six trials of each block, where excluded from analysis. Data were segmented into 1848-ms-long epochs starting 300 ms before pseudoword onset. Bad channels were rejected using the 3 available methods of EEGLAB’s pop_rejchan function. Kurtosis threshold was set to 4σ, Joint probability threshold was set to 4σ, and Abnormal spectra was checked between 1 and 30 Hz, with a threshold of 3σ (Delorme and Makeig, 2004). Following this automatic cleaning, additional channels were rejected by visual inspection of continuous data and spectra. ICA was use to remove eye blinks (Delorme and Makeig, 2004; Chaumon et al., 2015). Following, data were re-referenced to the average of all electrodes and baseline corrected using the 300 ms before pseudoword onset. Next, we performed trial rejection by eliminating trials containing extreme values (±200 mV) and improbable trials (EEGLAB pop_jointprob 4σ for both Single Channel and All Channels). Finally, missing channels were interpolated (EEGLAB pop_interp, “spherical”).
Only after this cleaning procedure the data were divided into conditions. Given that STD pseudowords were presented far more frequently than deviant pseudowords, the datasets of each condition were pruned by randomly discarding trials to obtain exactly the same number of trials per condition. For example, if after trial rejection a participant had 763 STD trials, 76 XYY trials, and 68 XXY trials, then 68 randomly picked trials per condition were kept and the rest were discarded. Participants contributing with <30 clean EEG trials per condition were excluded from analysis (one participant was excluded from each experiment applying this criterion). After this, the mean amount of trials per participant and condition were 70.18 ± 16.57 (minimum = 35) for experiment 1 and 82.50 ± 13.76 (minimum = 41) for experiment 2. For each condition, the mean of all trials of each subject was calculated and saved into a final dataset. The result of preprocessing was 1 dataset per condition, containing the mean of each subject.
Deviant conditions differed between each other with respect to the amount of syllables presented before the point of deviance. to render possible the comparison of the deviant conditions, we re-segmented the trials of both deviant conditions so that the points of deviance would be aligned. The resulting epochs had a length of 1224 ms, starting 325 ms before the point of deviance. Additionally, as the processing of a pseudoword has an intrinsic temporal dynamic, we eliminated these confounding factors by subtracting the activation elicited by the STD condition from each deviant condition.
EEG regions of interest (ROIs)
Statistical analysis of EEG data were restricted to two predefined spatiotemporal ROIs. The first one consisted on a fronto-central ROI comprised of 13 electrodes and spanned over a 325-ms time window starting at the point of deviance of each deviant condition. With respect to word onset, this window spanned from 325 to 650 ms for the XYY condition, and from 650 to 975 ms for the XXY condition. This ROI coincided with the region were an early prediction error response like the MMN could be expected (Duncan et al., 2009; Bendixen et al., 2012; Wacongne et al., 2012; Lecaignard et al., 2015). The second ROI consisted on a Parietal ROI composed of 21 electrodes and temporally extended from 200 ms after the point of deviance of each deviant condition, to the end of the epoch. With respect to word onset, this window started at 525 ms for the XYY condition, and at 850 ms for the XXY condition. This ROI corresponded to the region were a P3b response would be expected (Comerchero and Polich, 1999; Polich, 2007; Duncan et al., 2009). As this component is strongly modulated by top-down attention (Sergent et al., 2005; Bekinschtein et al., 2009; Pegado et al., 2010; Dehaene and Changeux, 2011), it was used to test whether the attentional manipulation between experiments 1 and 2 was successful.
Statistical analysis
EEG group level contrast between conditions was performed using a nonparametric clustering methods, introduced first by Bullmore et al. (1999) and implemented in the FieldTrip toolbox for EEG/MEG analysis (Oostenveld et al., 2011; RRID: SCR_004849). This method offers a straightforward and intuitive solution to the Multiple Comparisons problem. It relies on the fact that EEG data has a spatiotemporal structure. A true effect should not be isolated but should instead spread over different electrodes and over time. Instead of assessing for differences between conditions in a point by point fashion, which would lead to a very big number of comparisons, this method groups together adjacent spatiotemporal points.
The procedure is as follows. For every point in time and space, the EEG signal of two conditions is statistically compared. In our case, we used a nonparametric permutation t test for this step. The t values of adjacent spatiotemporal points with ps < 0.05 are clustered together and a cluster-level statistic is calculated by summing the t values within a cluster. Once these candidate clusters have been defined, their probability of occurrence under the null hypothesis of no difference between conditions is assessed using a nonparametric permutation test. In this test, conditions are shuffled and cluster-level t values are calculated as before. This step is repeated 5000 times, and on each iteration, the most extreme cluster-level t value is retained. This allows to construct a histogram of expected cluster-level t values under the null hypothesis of no difference between the conditions. Cluster level p values are calculated as the proportion of expected t values under the null hypothesis that are more extreme than the observed t value. For further details, see Maris and Oostenveld (2007).
Additionally, to corroborate results found at the group level were robust and not driven by outliers, we performed a test at the participant level. For each individual participant, the mean amplitude over the time of the detected group level cluster was calculated, and the conditions of interest were submitted to a paired t test to obtain a t value. Next, the t values from all participants were converted to 1 if they show a difference between conditions in the same direction as the group lever cluster or 0 if otherwise. A one-tailed binomial test was performed on these transformed t values, with equal or lower likelihood as null hypothesis. The logic of this analysis is that if an effect is true at the group level, then the majority of participants should show a difference between conditions in the same direction. Note that the test used is one-tailed because the hypothesis to test is directional.
All effect sizes reported are Hedges’ g (Hedges, 1981; Lakens, 2013), which is less biased than Cohen’s d, as it applies a correction for small sample sizes. Effect sizes were calculated using the measures of effect size toolbox (Hentschke and Stüttgen, 2011). Additional statistical analysis were performed using JASP version 0.8.6 (Bayesian analyses; JASPteam, 2017) and RStudio version 1.1.456 (linear mixed effects models; RStudioTeam, 2016; RRID: SCR_000432).
Results
Given that deviant conditions differed in the time point at which a pseudoword could be identified as a deviant (325 and 650 ms from pseudoword onset for XYY and XXY conditions, respectively), instead of defining time 0 as onset of stimulus presentation, we will use the time point of deviance of each condition as such. In other words, all times reported are with respect to the point of deviance. Furthermore, comparisons across deviants and experiment were performed on the difference wave between STD and deviant, and with all trials re-segmented to align the point of deviance, as described in Materials and Methods.
Behavioral results
In experiment 1, participants were requested to count the occurrence of mistaken words (i.e., deviant pseudowords) on each block. On average, participants reported 15.22 (out of 16 presented) deviant pseudowords per block (σ = 2.56). For each participant, we checked the number of blocks with a deviant count further than 2 s from the mean. While most of the participants reported a deviant count within these limits for all the blocks, three participants had one block with a lower count, and one participant had all 12 blocks outside this limit. This participant reported a mean of only 3.58 deviants per block, therefore, was excluded from the analysis. After excluding this participant and 1 other participant that contributed with <30 clean EEG trials per condition, the mean number of deviants reported per block increases to 15.62 (σ = 1.41). This performance is close to ceiling (16).
Note that the method of asking participants to mentally count the occurrence of deviants does not allow us to determine with certainty neither the occurrence of false alarms, nor the detection rate for each deviant condition. Despite this, given that the mean count of deviant was close to the actual number of deviants presented, we can conclude that in experiment 1, participants were able to perform the task with high accuracy for both deviant conditions.
Contrary to experiment 1, during experiment 2, participants were not aware of the presence of deviant pseudowords. Despite this, at the end of the experiment, they were requested to perform a forced choice test in which each stimuli condition was contrasted against the others and against new pseudowords not presented during the blocks. The mean preference in each contrast was calculated for each participant and a one sample t test was performed at the group level to test against the null hypothesis of no difference from chance (i.e., 50%). Results were corrected for multiple comparisons using the Bonferroni–Holm method.
Participants preferred STD pseudowords over both deviant pseudoword types. They choose STD pseudowords over XYY deviants on 67.24% of the trials (t(28) = 3.57, p = 0.0051, g = 0.66 [0.25, 1.06]) and over XXY deviants on 69.82% of the trials (t(28) = 4.07, p = 0.0017, g = 0.75 [0.33, 1.16]). When both deviant types were contrasted, participants preferred XYY over XXY deviants on 62.06% of the trials, but this preference was not reliable (t(28) = –2.31, p = 0.056, g = 0.43 [0.04, 0.80]).
Next, we contrasted the pseudowords used in the experiment against NEW pseudowords that were not previously presented. Participants preferred STD pseudowords over NEW pseudowords on 85.34% of the trials (t(28) = 10.39, p = 2.461e-10, g = 1.92 [1.30, 2.54]) and XXY deviants over new pseudowords on 64.65% of the trials (t(28) = 2.99, p = 0.0169, g = 0.55 [0.16, 0.94]). XYY deviants on the contrary, could not be distinguished from NEW pseudowords as they were preferred on only 55.17% of the trials (t(28) = 1.03, p = 0.3117, g = 0.19 [–0.17, 0.55]).
These behavioral results allowed us to corroborate that participants paid attention during the blocks of pseudowords. They also indicate that in experiment 2, despite the fact that the instructions provided did not explicitly distinguish between standard and deviant pseudowords, participants displayed a preference for STD pseudowords over both deviant pseudoword types. Although both deviant types had the same probability of occurrence, while XXY deviants could be distinguished from NEW pseudowords, XYY could not. Taken together, these behavioral results suggest that participants were sensitive to the frequency of occurrence of the different pseudowords.
EEG evidence of abstract rule extraction via phonological predictions
To test whether phonological predictions are deployed during speech perception in the absence of semantic and syntactic information, we used clustering (see Materials and Methods) to compared each deviant condition against the STD condition, focusing the analysis on the fronto-central ROI, where the presentation of a deviant pseudoword was expected to elicit an early prediction error signal.
In experiment 1, XYY deviants elicited such response, peaking in amplitude at 155 ms (t(27) = –89.77, p = 0.0004, g = –0.90 [–1.35, –0.44]), followed by a positive deflection with peak amplitude at 227 ms (t(27) = 36.81, p = 0.0208, g = 0.57 [0.09, 1.05]; Fig. 2A). XXY deviant also elicited a prediction error response with peak amplitude at 170 ms (t(27) = –125.20, p = 0.0002, g = –0.91 [–1.35, –0.47]), followed by a positive deflection with peak amplitude at 246 ms (t(27) = 57.88, p = 0.0126, g = 0.60 [0.21, 1.00]; Fig. 2B).
Figure 2.

Early prediction error elicited by both deviant types in experiments 1 (A, B) and 2 (C, D). On each panel: right, grand average over fronto-central ROI. Vertical dashed lines indicate syllable boundaries. Time 0 indicates the point at which deviance occur. Shaded areas denote 95% CI. Horizontal light gray line delimits time window of analysis. Middle gray horizontal line indicates p < 0.05 (cluster corrected). Black horizontal line indicates p < 0.01 (cluster corrected). Left top, Topography of the difference wave, mean over the time of the negative cluster. Left bottom, Individual participants’ t values calculated over mean cluster time.
The results of experiment 1 show that the presentation of a deviants pseudoword, composed by an unexpected sequence of syllables, elicited prediction error signals. Since in experiment 1 participants were instructed to count mistaken (i.e., deviant) pseudowords, we sought to replicate these results under conditions more akin to natural speech perception. Experiment 2, while using the same stimuli and Oddball design of experiment 1, differed with respect to the instructions given to the participants. In experiment 2, participants were asked to learn all pseudowords, without informing them of the presence of deviants.
Once more our analysis of the fronto-central ROI revealed that both deviant types evoked a prediction error signal. XYY deviants elicited a response peaking in amplitude at 151 ms (t(27) = –100.79, p = 0.0004, g = –0.54 [–0.85, –0.23]; Fig. 2C). In the case of XXY deviants, peak amplitude was reached at 158 ms (t(27) = –138.13, p = 0.0006, g = –0.78 [–1.14, –0.41]; Fig. 2D). Results at the group level were corroborated by performing a test participant by participant, as described in the Methods section. This analysis showed that in both experiments and for both deviant conditions, the majority of the participants displayed a difference between conditions in the direction congruent with the tested hypothesis (experiment 1: XYY deviant, 24/28 85.71% p = 9e-5; XXY deviant, 26/28 92.86% p = 1.52e-6. Experiment 2: XYY deviant, 22/28 78.57% p = 0.00186; XXY deviant, 24/28 85.71% p = 9e-5).
Taken together, the results of experiments 1 and 2 show that the presentation of deviants composed by an unexpected sequence of syllables trigger an early prediction error signal. The presence of this error signal indicates that a prediction about the forthcoming syllables had been made, even when the context did not contain any syntactic or semantic information.
Neural signals to violations of abstract rules under different instructions
To test whether predictions are deployed regardless of the task at hand, experiments 1 and 2 used the same stimuli and design, but differed in the instructions given to the participants. While in experiment 1 participants were requested to count the occurrence of deviants, in experiment 2, they were not informed about the presence of deviants and were instead requested to learn all pseudowords. Despite this difference, as we reported at the beginning of this section, the presentation of deviant pseudowords elicited an early prediction error signal in both experiments.
To confirm that the change in instructions successfully induced a different attention allocation between experiments, we analyzed the signal recorded at the parietal ROI. If the attentional manipulation was successful, the presentation of a deviant pseudoword should elicit a P3b response only in experiment 1, where deviant detection was relevant for the task at hand (Bekinschtein et al., 2009).
In experiment 1, our analysis of the parietal ROI revealed that both deviant types elicited the expected P3b response. In the case of the XYY deviant, P3b response started at 251 ms and reached 50% of its area under the curve at 743 ms (t(27) = 1625.05, p = 0.0002, g = 1.77 [1.03, 2.51]; Fig. 3A). In turn, the P3b response elicited by the XXY deviant started at 262 ms and reached 50% of its area under the curve at 578 ms (t(27) = 1149.20, p = 0.0002, g = 1.97 [1.17, 2.76]; Fig. 3B). Furthermore, the amplitude of the P3b component was modulated by deviant type. XXY deviants elicited a higher amplitude P3b response than XYY deviants (t(27) = 225.97, p = 0.0018, g = 0.47 [0.13, 0.80]; Fig. 4C). This comparison was performed on the difference wave between STD and each deviant condition, with the point of deviance temporally aligned.
Figure 3.

A P3b response was elicited by both deviant types in experiments 1 (A, B), but not detected in experiment 2 (C, D). On each panel: right, grand average over parietal ROI. Vertical dashed lines indicate syllable boundaries. Time 0 indicates the point at which deviance occur. Shaded areas denote 95% CI. Horizontal light gray line delimits time window of analysis. Middle gray horizontal line indicates p < 0.05 (cluster corrected). Black horizontal line indicates p < 0.01 (cluster corrected). Left top, Topography of the difference wave, mean over the time of the positive cluster. Left bottom, Individual participants’ t values calculated over mean cluster time.
Figure 4.
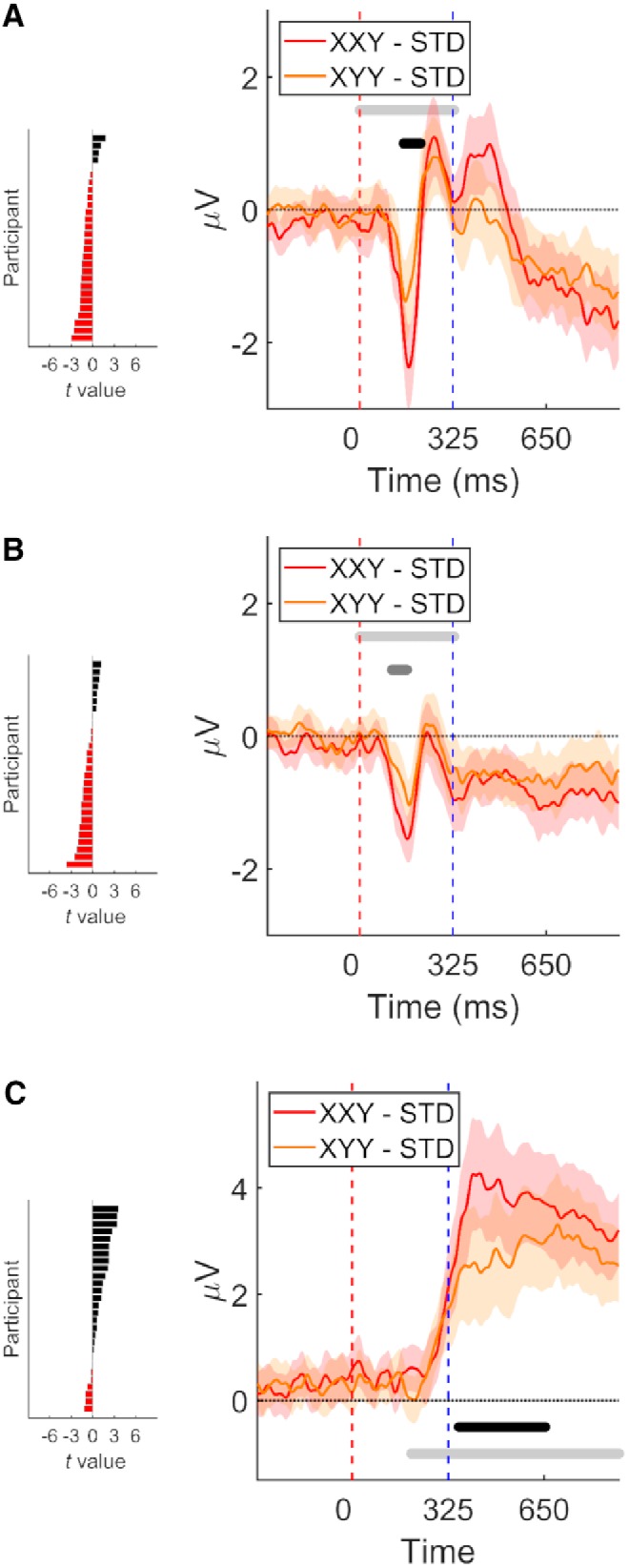
Comparison of signals elicited by each deviant type (difference waves, deviant minus STD). On each panel: right, grand average over fronto-central ROI (A, B) or parietal ROI (C). Trials were re-segmented and locked to the point of deviance, indicated by time 0. Shaded areas denote 95% CI. Horizontal light gray line delimits time window of interest. Middle gray horizontal line indicates p < 0.05 (cluster corrected). Black horizontal line demarks p < 0.01. Early prediction error signals detected in experiments 1 (A) and 2 (B). P3b detected in experiment 1 (C). Left, Individual participants’ t values calculated over mean cluster time.
While in experiment 1 both deviant conditions elicited a clear P3b response, in experiment 2, only positivities of lower amplitude were detected. For the XYY deviant, clustering analysis detected a series of 3 consecutive positive clusters, the first of which started at 543 ms (t(27) = 99.39, p = 0.0092, g = 0.70 [0.15, 1.26]; t(27) = 94.46, p = 0.0098, g = 0.60 [0.11, 1.09]; t(27) = 44.64, p = 0.0362, g = 0.65 [0.11, 1.20]). In the case of the XXY deviant condition, a single positive cluster was found, starting at 402 ms and reaching 50% of its area under the curve at 394 ms (t(27) = 385.57, p = 0.0014, g = 0.82 [0.21, 1.43]).
Next, to further confirm that the attentional manipulation between experiments was successful, we contrasted the recorded signals across experiments using clustering analysis. We expected to find higher amplitudes in experiment 1, due to the presence of the P3b elicited by the deviants. We were able to confirm this for both deviants (XYY: t(54) = 875.00, p = 0.0002, g = 1.41 [0.80, 1.99]; XXY: t(54) = 734.07, p = 0.0002, g = 1.26 [0.66, 1.82]). Analyses were performed on the difference between STD and deviant conditions. These results confirm that the top-down attention paid to deviants was indeed different between experiments.
Having confirmed that the attentional manipulation between experiments was successful, and considering that regardless of this, an early prediction error signal was registered in both experiments, we decided to test whether the prediction error signals recorded across experiments where indeed equivalent. As our hypothesis stated that there would be no difference in prediction error amplitude across experiments (i.e., a null hypothesis), a Bayesian independent samples t test (Bayes factor; Rouder et al., 2009) was used for these comparisons. This test measures the relative evidence between the null and alternative hypothesis, allowing to assess evidence in favor of the null (Leppink et al., 2017). Tests were performed using a Cauchy prior with scale value of r = 1.
We compared the amplitude of the early prediction error signals registered over the fronto-central ROI, elicited by each deviant condition across experiments, by taking the mean amplitude in a 44-ms time window (equal to the duration of the shortest cluster) centered at the peak of the detected negativity. For both deviant types, Bayes factor showed only anecdotal evidence in favor of no difference between experiments (XYY deviants: BF01 = 2.48, g = 0.32 [–0.20, 0.85]; XXY deviants: BF01 = 1.14, g = 0.48 [–0.06, 1.01]). Analyses were performed on the difference between STD and deviant conditions.
Taken together, these results suggest that even if the task at hand does not explicitly imply deviance detection, phonological predictions are proactively deployed. However, it should be noted that the results with respect to the modulation of early prediction error by top down attention are inconclusive.
Predictions beyond local transitional probabilities
The prediction error signals described above could reflect violations of predictions based on local transitional probabilities, or alternatively these predictions could be constructed by considering information in a longer cognitive time window. To shed light on this issue, we contrasted conditions where deviance occurred at different time points within a pseudoword. The logic behind this comparison is that if predictions are built not solely on the basis of local transitional probabilities, an increase in the number of syllables presented before the point of deviance would elicit higher amplitude prediction error signals. In XXY, the second syllable lends further evidence that the pseudoword is about to be completed, but then this prediction is violated in the last syllable, while in XYY, the prediction is broken earlier.
In both experiments, the early prediction error signal elicited by XXY deviants had a bigger amplitude than the signal elicited by XYY deviants (experiment 1: t(27) = –53.95, p = 0.0094, g = –0.64 [–1.06, - 0.23]. Experiment 2: t(27) = –38.02, p = 0.0204, g = –0.62 [–1.12, –0.12]; Fig. 4A,B). This suggests that prediction strength can be modulated by the amount of preceding syllables that are congruent with a STD pseudoword. Once more, we corroborated these results by performing a test participant by participant, as described in the Methods section. This analysis showed that in both experiments, the majority of the participants displayed higher amplitude prediction error signals for the XXY deviant (experiment 1: 24/28 85.71% p = 9e-5; experiment 2: 21/28 75.00% p = 0.00627).
It remained possible that small discrepancies in the number of STD trials presented before the deviants of each condition might be in part driving these effects. To rule out this possible confound, we fitted linear mixed effects models (using the lme4 package in RStudio, Bates et al., 2015; RStudioTeam, 2016) to predict single trial prediction error amplitude using deviant type and amount of preceding STD trials (STD count) as fixed factors, and including participant as random factor [PE ∼ Dev + STD_count + (1 + Dev | participant); R2 experiment 1 = 0.0124, R2 experiment 2 = 0.0116]. An effect of deviant type was found in both experiments (experiment 1: B = –0.94, t(3929) = –3.705, p = 0.00021; experiment 2: B = –0.67, t(4619) = –3.530, p = 0.00042). In contrast, no effects of STD count were found (experiment 1: B = –0.007, t(3929) = –0.092, p = 0.92; experiment 2: B = 0.059, t(4619) = 1.172, p = 0.24). These results rule out the possibility that a substantial part of the difference in prediction error amplitude between deviant conditions would be driven by a difference in mean STD count preceding the deviants.
Discussion
As we argued in the Introduction, the experimental designs typically used to study prediction in auditory processing share a number of limitations. The majority of the experimental designs used are variations of the Oddball paradigm (Heilbron and Chait, 2018). In most of these experimental designs, what defines a particular stimulus as deviant is the disruption of an established physical feature such as pitch, duration, intensity, side of stimulation or the presence of a gap (Näätänen et al., 2007). This limitation applies to the classical Oddball paradigm, optimum-1 (Näätänen et al., 2004), omission (Yabe et al., 1997), and roving-standard (Garrido et al., 2008) designs.
While these designs define standard and deviant stimuli on the basis of their physical features, other designs explore the sensitivity of the predictive system to higher order regularities or abstract rules that define the relationship between successive stimuli. For example, Paavilainen et al. (2007) presented to their participants sequences of sinusoidal tone pips for which the duration varied randomly between short (50 ms) and long (150 ms). Importantly, the duration of each tone predicted the pitch of the next one, which could be either low (1000 Hz) or high (1500 Hz). The authors found that the violation of this arbitrary abstract rule, linking duration of a tone with pitch of the next, elicited an early error signal (MMN response). Other examples of paradigms that test for prediction of higher order regularities are the unexpected repetition (Wacongne et al., 2012) and repetition versus expectation (Todorovic and de Lange, 2012) designs (for review of abstract rule designs, see Paavilainen, 2013).
Abstract rule designs have given support to predictive coding by showing that putative early prediction error signals, like the MMN response, cannot be fully explained by simple adaptation to standard stimuli (and lack of adaptation to deviant stimuli). But in all the designs mentioned above, the rules used established relationships only between consecutive stimuli. Therefore, these experimental designs only allow to study the sensitivity of the predictive system to local transitional probabilities.
To the best of our knowledge, there are only two paradigms that allow to test violations of an abstract rule beyond local transitional probabilities. In the local/global paradigm (Bekinschtein et al., 2009), tones are presented in groups of five. This allows to establish regularities both locally (transitional probabilities between tones within groups) and globally (between groups change, only tractable over a time range of seconds). In the RAND-REG designs (Barascud et al., 2016), tones are presented in succession at multiple possible pitches, switching between randomness and regular patterns. In these experiments, the detection of a regular pattern requires to consider several consecutive tones (one full cycle plus four tones according to an ideal observer model). While the local/global and RAND-REG designs allow to study predictions that integrate information beyond adjacent stimuli, these designs use tone stimuli that are far less complex than naturally occurring sounds.
As evidence suggests that the generation of predictions might be one of the strategies that the speech processing system uses to parse the speech signal (Hickok, 2012; Boudewyn et al., 2015; Kleinschmidt and Jaeger, 2015; Norris et al., 2015; Hauk, 2016), and given that abstract rules and long range dependencies are ubiquitous in language, one way to overcome the limitations of the experimental designs described above is to use speech-like stimuli.
In the context of speech processing, it has been shown that listeners tend to hallucinate the presence of phonemes replaced by tones. The strength of this illusion depend on how much the preceding context is informative about the missing phoneme (Kashino, 2006; Groppe et al., 2010). Similarly, when a phoneme is omitted from a word (Bendixen et al., 2014), this can elicit a MMN (Näätänen et al., 2007), which is a marker of violation of expectations (Friston, 2005; Winkler and Schröger, 2015), but only if the context in which the phoneme omission occurs contains semantic information that makes the omitted phoneme predictable. Phoneme replacements can also elicit a MMN response when the replacement violates a phonotactic rule of the language of the listener (Dehaene-Lambertz et al., 2000; Sun et al., 2015; Ylinen et al., 2016). Furthermore, and particularly framed in the context of predictive coding, it has been shown that the amplitude of the MMN response elicited by phoneme replacement is modulated by the availability of phonological evidence (i.e., degree of feature specification) of the preceding standard words before the presentation of a deviant (Scharinger et al., 2012a,b, 2016).
The studies described in the previous paragraph have provided compelling evidence of the role that predictions play in speech processing, but besides using speech as complex auditory stimuli, they incorporate in their designs other linguistic factors such as syntax, semantic information, and phonotactics. We proposed that phonological prediction might be generated within words, even in the absence of these additional sources of information. To test this, we performed two EEG Oddball experiments in which only phonological information was available to generate phonological predictions. Importantly, the deviant pseudowords used in these experiments were constructed by cross-splicing standard pseudowords. Therefore, each phoneme in a deviant pseudoword was acoustically identical to a phoneme in a standard pseudoword. The only feature that defined a pseudoword as deviant, was that following the syllable Xn, instead of the usual syllable Xn + 1, the syllable Yn + 1, which belongs to a different pseudoword, was presented. In this way, the ERP responses registered in these experiments could not be elicited by low frequency of occurrence of a given sound, or a change in instantaneous low level auditory features, but by the violation of an abstract rule (Paavilainen, 2013). As the stimuli did not contain consecutive phoneme repetitions, the registered responses cannot be explained by stimulus specific adaptation. Additionally, this stimuli design avoids a common confound between repetition and expectation (Todorovic and de Lange, 2012; Heilbron and Chait, 2018).
In both of the experiments presented here, the occurrence of an unexpected sequence of phonemes, reliably elicited an early prediction error signal, compatible with a MMN response (Näätänen, 2000; Näätänen et al., 2007). This ERP is a well-established prediction error signal that can be interpreted as the result of comparing a prediction with the actual bottom-up input (Friston, 2005; Garrido et al., 2009; Wacongne et al., 2011; Winkler and Czigler, 2012; Chennu et al., 2013; Paavilainen, 2013). The presence of this early prediction error signal, elicited by the presentation of an unexpected sequence of phonemes, can be considered as evidence that a prediction about the forthcoming phonemes had been made.
Experiments 1 and 2 differed in the instructions given to the participants. While in experiment 1 participants were instructed to count the occurrence of mistaken words (i.e., deviants), in experiment 2, they were not informed about the occurrence of deviants and were simply instructed to learn all the pseudowords. This aimed to induce in experiment 2, an attentional state that resembles more closely the one held during natural speech processing.
To confirm the effects of this attentional manipulation, we tested for the presence of a P3b component in both experiments. While clustering analysis detected clear P3b components in experiment 1, only smaller positivities were detected in experiment 2. This suggest that participants noted the difference in frequency of occurrence between STD and deviant pseudowords, even when they were not instructed to detect deviants. In line with this, the behavioral results from experiment 2 show that participants preferred STD pseudowords over both deviant pseudoword types.
Despite this, when contrasting the signals recorded between experiments, we could verify that the amplitude in the P3b time window was roughly four times higher in experiment 1. As the P3b component is an index of to top-down attention (Sergent et al., 2005; Bekinschtein et al., 2009; Dehaene and Changeux, 2011; Faugeras et al., 2011; Chennu and Bekinschtein, 2012; Strauss et al., 2015), this difference indicates that the degree to which top-down attention was deployed was different between experiments.
Despite the difference in instructions and in concomitant top-down attention between experiments, unexpected sequence of phonemes reliably elicited an early prediction error signal. This suggests that phonological predictions can be deployed, even if the task at hand does not require detecting abnormalities in the speech stream. Given that the results of our Bayesian analysis comparing amplitude of prediction error across experiments were inconclusive, the modulatory role that top-down attention might exert on these predictions remains an open question. As the attention allocation held by the participants during experiment 2 resembles closely the one use for natural speech processing, these results imply that the language comprehension system proactively anticipates incoming phonemes within individual words.
One way in which these phonological predictions could be implemented is by extracting the local transitional probabilities between adjacent syllables (Endress and Mehler, 2009; Koelsch, 2016). Our data indicates that this is unlikely, as we found that the amplitude of prediction error signals was modulated by the amount of syllables presented before the point of deviance. When two congruent syllables were presented before the point of deviance (XXY), the amplitudes were higher than when only one congruent syllable was presented (XYY). As the local transitional probabilities between X1 and X2 were the same as between X2 and X3 (0.92), this increase in amplitude indicates that the information used to generate predictions was not restricted to consecutive syllables. Instead prediction strength was modulated by integrating information from several past phonemes.
It has been shown that the number of phonological features differing between standard and deviants can modulate the amplitude of the MMN response (Cornell et al., 2013; Scharinger et al., 2016; Schluter et al., 2017). Taking this into account, the difference in prediction error amplitude between deviant conditions may be captured by this feature. Taking the position of Mioni (1993) and Kramer (2009), who propose that in the case of Italian, affricates do not constitute a separate class of manner of articulation, the phonological features that change from STD to deviant in our stimuli set are the following. Syllables in the 2nd position (XYY deviant) differ in their consonant voicing, place of articulation and manner of articulation. Syllables in the 3rd position (XXY deviant) differ in their consonant voicing and place of articulation, and in their vowel height (Mioni, 1993; Kramer, 2009; Paoli, 2016). While it should be noted that whether all these phonological features have a neural representation is on itself an open debate (Hestvik and Durvasula, 2016; Politzer-Ahles et al., 2016; Schluter et al., 2016, 2017), in the case of our stimuli set, the number of phonological features that change for each deviant condition is the same.
Finally, when the point of deviance is reached, more time has elapsed from pseudoword onset in the case of XXY deviants, compared to XYY deviants. This difference in time from pseudoword onset could contribute to the difference in MMN amplitude, but we find this improbable. Behavioral gating experiments (Tyler, 1984) and MEG experiments (Brodbeck et al., 2018) have shown that between 50 and 100 ms from word onset are enough to generate a prediction regarding the initial phoneme of a word. In the case of XYY deviants, the point of deviance is reached 325 ms after pseudoword onset, which is more than three times the suggested minimum time for prediction generation. Therefore, the difference in elapsed time before deviance between conditions is unlikely to contribute to the observed difference in prediction error amplitude.
One tentative interpretation for the difference in prediction error amplitude between deviant conditions is that, as language processing is characterized by extensive communication across representational levels (Davis and Johnsrude, 2007; Kuperberg and Jaeger, 2016), a lexical level of processing could be involved. Specifically, when a phoneme of a word is perceived, this could be used to pre-activate that word’s lexical representation, with consecutive phonemes reinforcing the prediction of congruent words.
Taken together, our results suggest that even when no higher-level linguistic information such as syntax and semantics is present, the human auditory system can use phonological information from several past phonemes to generate predictions about forthcoming phonemes. In the experiments presented here, participants were exposed to new pseudowords that were learned in a period of minutes. This implies a formidable capacity of the auditory system to learn sequences of phonemes composing new words and generate predictions within those words. This capacity might play a fundamental role in the difficult task of mapping a complex, variable and noisy signal as speech into meaning. Moreover, the experiments presented here use stimuli and abstract rules more complex and ecologically valid that the ones routinely used in the study of auditory prediction, allowing to show that the auditory system can proactively generate predictions.
Synthesis
Reviewing Editor: Bradley Postle, University of Wisconsin
Decisions are customarily a result of the Reviewing Editor and the peer reviewers coming together and discussing their recommendations until a consensus is reached. When revisions are invited, a fact-based synthesis statement explaining their decision and outlining what is needed to prepare a revision will be listed below. The following reviewer(s) agreed to reveal their identity: Sounak Mohanta, Mathias Scharinger.
Here is the full text of the two reviews:
Statistics
R1
The submitted manuscript has shown neural evidence of phonological regularities sufficient to generate prediction in speech like stimuli and deviance from the predictions giving rise to early error signals. The authors have also shown that irrespective of the relevance of the deviant stimuli in performing the task correctly, these predictions are generated. Their finding about error signal's amplitude being modulated by the number of congruent syllables presented is compelling as it demonstrates the an important working principle in speech perception (as the authors argue in lines 479-483). Overall, the manuscript presents sufficient evidence regarding how predictions are generated in speech when there is no lexical and semantic content. This sheds light on the bare bone mechanisms of speech perception which studies with natural speech stimuli, i.e. having lexical and semantic information, will be unable to comment on.
1) RE: Predictions beyond transitional probabilities (line 365-374):
While accessing statistical significance of difference of error signal between XXY and XYY, it is unclear whether the authors have controlled for the number of STD words presented before that.
For example, let's consider the following train of sounds for XXY and XYY respectively - STD STD STD STD XXY and STD STD XYY. To correctly point that the significant difference in error signal between XXY and XYY is due to the repletion of the X syllable in the deviant word and not due to more number STDs in the train, the statistical model needs to have number of STDs presented as a covariate. Having this in the results will rule out possibilities of explaining the error signal as an effect of number of STDs presented. This is an important control that should be included to make a comment about transitional probabilities.
Major comment:
1) As I have already elaborated in the comments regarding statistics, it is important to control for the number of STD(s) presented before the deviant word. This will strongly support the claim made in that section
Minor comment:
1) In the last paragraph of “Phonological predictions under different instructions,” (line 359-364) authors demonstrate if the error signal is different between experiment 1 and experiment 2. My interpretation is -the statistical analysis is done on the Fronto-Central ROI centre of detected negativity. Having the ROI name clearly stated at the beginning of the last paragraph will help the reader understand the logic, as rest of the section has results from the parietal ROI. The sudden shift might throw the reader off.
2) Line 260: Should be “excluded” instead of “exclude”.
R2
Summary:
In the paper entitled “Predictive Coding beyond simple tone-based oddball designs”, the authors attempted to test the hypothesis that predictive coding is also reflected in oddball designs where recurrence to transitional probabilities is less likely and where complex stimuli set up abstract rules. For this purpose, they use three-syllable pseudowords in standard position and two types of deviants differing in either the second or the third syllable. The oddball paradigm was employed in two experiments that differed in the subject's task (deviant counting in Experiment 1, learning of all stimuli in Experiment 2).
The authors observed an error signal elicited by the mismatching syllable in both Experiments, with the later deviance resulting in a larger response than the earlier response. Additionally, they observed a P3b response in Experiment 1 (with attention on the deviants), but not in Experiment 2.
The conclusion is that Predictive Coding operates on a phonological level, independently of semantics and syntax, and involving the immediate past: The “more” context, the stronger the prediction, and consequently, the larger the prediction error signal.
Overall evaluation:
The study presented is embedded in a currently much-studied brain principle hypothesis - predictive coding - and adds important evidence that predictions play a role on the level of phonology / speech sounds. The study is well conducted, features a sound setup and a sound analysis, and interprets the results in an adequate way. Therefore, in principle, the paper should be published; however, in its current form, there are some major shortcomings that should be amended in a revision. I will first elucidate the two main problems before tackling some minor issues and clarification questions.
Major concerns:
1) The authors seem to put much emphasis on the claim that oddball paradigms are confined to tone studies or studies where deviances are realized as replacements (e.g. coughs) or silences (gaps). Thus, one is led to believe that there are no studies on words or pseudowords that attempt to provide evidence for predictive coding in speech processing.
This is however not the case. A growing body of literature tries to test the hypothesis that deviance responses in oddball paradigms depend on the phonological makeup of words and single speech sounds (to name but a few:
*Cornell, S. A., Lahiri, A., & Eulitz, C. (2011). “What you encode is not necessarily what you store”: Evidence for sparse feature representations from mismatch negativity. Brain Research, 1394, 79-89.
*Cornell, S. A., Lahiri, A., & Eulitz, C. (2013). Inequality across consonantal contrasts in speech perception: Evidence from mismatch negativity. Journal of experimental psychology. Human perception and performance, 39(3), 757-772.
*Hestvik, A., & Durvasula, K. (2015). Neurobiological evidence for voicing underspecification in English. Brain and Language, 152, 28-43.
*Politzer-Ahles, S., Schluter, K., Wu, K., & Almeida, D. (2016). Asymmetries in the perception of Mandarin tones: Evidence from mismatch negativity. Journal of Experimental Psychology. Human Perception and Performance.
*Schluter, K., Politzer-Ahles, S., & Almeida, D. (2016). No place for /h/: an ERP investigation of English fricative place features. Language, Cognition and Neuroscience, 31(6), 728-740.
*Schluter, K. T., Politzer-Ahles, S., Al Kaabi, M., & Almeida, D. (2017). Laryngeal features are phonetically abstract: mismatch negativity evidence from arabic, english, and russian. Frontiers in Psychology, 8, 746.)
While these studies do not directly speak to the principle of predictive coding, they demonstrate that the error signal may be asymmetrically modulated depending on which sound (word) comes first. This in turn depends on the phonological specification of the respective sounds.
A line of studies that explicitly try to link the above-mentioned rationales to predictive coding has recently appeared (e.g.
*Scharinger, M., Bendixen, A., Trujillo-Barreto, N. J., & Obleser, J. (2012). A sparse neural code for some speech sounds but not for others. PLoS ONE, 7(7), e40953. doi:40910.41371/journal.pone.0040953.
*Scharinger, M., Monahan, P., & Idsardi, W. J. (2012). Asymmetries in the processing of vowel height. Journal of Speech, Language, and Hearing Research, 55, 903-918.
*Scharinger, M., Monahan, P. J., & Idsardi, W. J. (2016). Linguistic category structure influences early auditory processing: Converging evidence from mismatch responses and cortical oscillations. Neuroimage, 128, 293-301).
In short, these studies claim that the “strength” of prediction is based on the available phonological “evidence” or, as they put it, “phonological features” that make up sounds.
A more specific sound generates a stronger prediction than a less specific sound (in phonological terms). These claims were supported by the results elicited in oddball paradigms: Violation of “stronger” predictions resulted in larger error signals.
This line of research appears to be relevant to the work presented here and should ideally be acknowledged in a revised version. However, more problematic is a prediction that can be made on the basis of these studies and that presents a major confound for the current study. I will explain in (2).
2) The authors convincingly show that deviances at later positions (third syllable) in the pseudowords elicited stronger error signals than deviances at earlier positions (second syllable).
The temporal difference, however, aligns with a phonological difference.
If I interpret Figure 1 correctly, the deviance in the second syllable is of the type fa / dza. I interpret the “dz” as affricate, i.e. as one complex sound. This means that the difference (in phonological terms) is restricted to the consonant, and can be referred to as difference in “manner of articulation”. The deviance in the third syllable, by contrast, is of the type dze / tsi; phonologically, it involves a voicing contrast on the consonant and a height contrast on the vowel! That is, the later contrast is also phonologically “stronger”!
The above-referenced studies converge in showing that the more phonological features differ between standard and deviant, the stronger the error signal will be. That is, given this alternative interpretation, the authors cannot tease apart a time-based interpretation from a phonological interpretation.
I do not think, however, that this presents a major challenge to the overall claim of the authors (viz. “abstract rules”) - it would only mean that the temporal explanation / interpretation should be toned down.
Minor issues:
- Why did the authors choose an active oddball design, rather than a passive one? I understand the rationale of the task differences, but most previous studies seem to be based on passive paradigms. It would have been possible to compare active vs. passive.
- What electrode system (active, passive) did the authors use? I was wondering about the relatively high impedances reported. Commonly, they are kept below 5 kO.
- p. 10 l.177: Capitalize “experiment”
- Rationale of behavioral task in Experiment 2: The result of this task suggests that the frequency with which participants encountered the pseudowords predicts the preference in the forced-choice task.
What's more, even the similarity to the most frequently encountered pseudowords is reflected in the task, with XXY preferred over XYY. The results of this task are not further discussed. Could you be more specific of why the task is necessary and what it might show?
- Why did you use average reference? There is a (certainly disputable) recommendation for online nose-reference and offline linked-mastoid reference for oddball paradigms with EEG, especially if the responses are to be expected on mid-line channels.
- What was the result of your pruning operation? Did it result in the same number of standards and deviants, and similarly for all conditions? What was the minimum number of stimuli after pruning?
- The authors use a two-step statistical approach. However, their method starts from group level and returns to the subject level. Why? Why not take subject-level first and compare resulting t-values against 0 on the group level? This is the procedure that appears to be intended in fieldtrip, and has been used previously (e.g. Henry, M. J., & Obleser, J. (2012). Frequency modulation entrains slow neural oscillations and optimizes human listening behavior. Proceedings of the National Academy of Sciences of the United States of America, 109(49), 20095-20100. doi:10.1073/pnas.1213390109). Furthermore, what were group level clusters obtained in the current study? Why did the authors use this particular method that is tailored towards determining relevant clusters in time and space, but then focus on a priori on ROIs and TOIs (temporal regions of interest)?
- Regarding the t-test on p. 15, result section: it is not clear on what these tests are based? Deviant-standard differences? Furthermore, the t-values are extremely high, why? The corresponding p-values, by contrast, are not as small as expected.
- For the comparison between experiments: Did you use a standardization (e.g. z-score) of the dependent variable?
References
- Baart M, Samuel AG (2015) Early processing of auditory lexical predictions revealed by ERPs. Neurosci Lett 585:98–102. 10.1016/j.neulet.2014.11.044 [DOI] [PubMed] [Google Scholar]
- Barascud N, Pearce MT, Griffiths TD, Friston KJ, Chait M (2016) Brain responses in humans reveal ideal observer-like sensitivity to complex acoustic patterns. Proc Natl Acad Sci USA 113:E616–E625. 10.1073/pnas.1508523113 [DOI] [PMC free article] [PubMed] [Google Scholar]
- Bates D, Mächler M, Bolker B, Walker S (2015) Fitting linear mixed-effects models using lme4. J Stat Softw 67:1–48. 10.18637/jss.v067.i01 [DOI] [Google Scholar]
- Bekinschtein TA, Dehaene S, Rohaut B, Tadel F, Cohen L, Naccache L (2009) Neural signature of the conscious processing of auditory regularities. Proc Natl Acad Sci USA 106:1672–1677. 10.1073/pnas.0809667106 [DOI] [PMC free article] [PubMed] [Google Scholar]
- Bendixen A, SanMiguel I, Schröger E (2012) Early electrophysiological indicators for predictive processing in audition: a review. Int J Psychophysiol 83:120–131. 10.1016/j.ijpsycho.2011.08.003 [DOI] [PubMed] [Google Scholar]
- Bendixen A, Scharinger M, Strauß A, Obleser J (2014) Prediction in the service of comprehension: modulated early brain responses to omitted speech segments. Cortex 53:9–26. 10.1016/j.cortex.2014.01.001 [DOI] [PubMed] [Google Scholar]
- Boudewyn MA, Corlett PR, Friston K, Brown M, Kuperberg GR (2015) A hierarchical generative framework of language processing: linking language perception, interpretation, and production abnormalities in schizophrenia. Front Hum Neurosci 9: 643. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Brainard D (1997) The psychophysics toolbox. Spat Vis 10:433–436. [PubMed] [Google Scholar]
- Brink VD, Brown CM, Hagoort P (2001) Electrophysiological evidence for early contextual influences during spoken-word recognition: N200 versus N400 effects. J Cogn Neurosci 13:967–985. 10.1162/089892901753165872 [DOI] [PubMed] [Google Scholar]
- Brodbeck C, Hong LE, Simon JZ (2018) Rapid transformation from auditory to linguistic representations of continuous speech. Curr Biol 28:3976–3983.e5. 10.1016/j.cub.2018.10.042 [DOI] [PMC free article] [PubMed] [Google Scholar]
- Bubic A, von Cramon DY, Schubotz RI (2010) Prediction, cognition and the brain. Front Hum Neurosci 4:25. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Bullmore ET, Suckling J, Overmeyer S, Rabe-Hesketh S, Taylor E, Brammer MJ (1999) Global, voxel, and cluster tests, by theory and permutation, for a difference between two groups of structural MR images of the brain. IEEE Trans Med Imaging 18:32–42. 10.1109/42.750253 [DOI] [PubMed] [Google Scholar]
- Chaumon M, Bishop DV, Busch NA (2015) A practical guide to the selection of independent components of the electroencephalogram for artifact correction. J Neurosci Methods 250:47–63. 10.1016/j.jneumeth.2015.02.025 [DOI] [PubMed] [Google Scholar]
- Chennu S, Bekinschtein TA (2012) Arousal modulates auditory attention and awareness: insights from sleep, sedation, and disorders of consciousness. Front Psychol 3:65 10.3389/fpsyg.2012.00065 [DOI] [PMC free article] [PubMed] [Google Scholar]
- Chennu S, Noreika V, Gueorguiev D, Blenkmann A, Kochen S, Ibáñez A, Owen AM, Bekinschtein TA (2013) Expectation and attention in hierarchical auditory prediction. J Neurosci 33:11194–11205. 10.1523/JNEUROSCI.0114-13.2013 [DOI] [PMC free article] [PubMed] [Google Scholar]
- Comerchero MD, Polich J (1999) P3a and P3b from typical auditory and visual stimuli. Clin Neurophysiol 110:24–30. 10.1016/S0168-5597(98)00033-1 [DOI] [PubMed] [Google Scholar]
- Cornell SA, Lahiri A, Eulitz C (2011) “What you encode is not necessarily what you store”: evidence for sparse feature representations from mismatch negativity. Brain Res 1394:79–89. 10.1016/j.brainres.2011.04.001 [DOI] [PubMed] [Google Scholar]
- Cornell SA, Lahiri A, Eulitz C (2013) Inequality across consonantal contrasts in speech perception: evidence from mismatch negativity. J Exp Psychol Hum Percept Perform 39:757–772. 10.1037/a0030862 [DOI] [PubMed] [Google Scholar]
- Davis MH, Johnsrude IS (2007) Hearing speech sounds: top-down influences on the interface between audition and speech perception. Hear Res 229:132–147. 10.1016/j.heares.2007.01.014 [DOI] [PubMed] [Google Scholar]
- Dehaene S, Changeux JP (2011) Experimental and theoretical approaches to conscious processing. Neuron 70:200–227. 10.1016/j.neuron.2011.03.018 [DOI] [PubMed] [Google Scholar]
- Dehaene-Lambertz G, Dupoux E, Gout A (2000) Electrophysiological correlates of phonological processing: a cross-linguistic study. J Cogn Neurosci 12:635–647. 10.1162/089892900562390 [DOI] [PubMed] [Google Scholar]
- DeLong K. a, Urbach TP, Kutas M (2005) Probabilistic word pre-activation during language comprehension inferred from electrical brain activity. Nat Neurosci 8:1117–1121. 10.1038/nn1504 [DOI] [PubMed] [Google Scholar]
- Delorme A, Makeig S (2004) EEGLAB: an open source toolbox for analysis of single-trial EEG dynamics including independent component analysis. J Neurosci Methods 134:9–21. 10.1016/j.jneumeth.2003.10.009 [DOI] [PubMed] [Google Scholar]
- Den Ouden HEM, Kok P, de Lange FP (2012) How prediction errors shape perception, attention, and motivation. Front Psychol 3:548 10.3389/fpsyg.2012.00548 [DOI] [PMC free article] [PubMed] [Google Scholar]
- Duncan CC, Barry RJ, Connolly JF, Fischer C, Michie PT, Näätänen R, Polich J, Reinvang I, Van Petten C (2009) Event-related potentials in clinical research: guidelines for eliciting, recording, and quantifying mismatch negativity, P300, and N400. Clin Neurophysiol 120:1883–1908. 10.1016/j.clinph.2009.07.045 [DOI] [PubMed] [Google Scholar]
- Dutoit T, Pagel V, Pierret N, Bataille F, Vrecken OVD (1996) The MBROLA project: towards a set of high quality speechnnsynthesizers free of use for non commercial purposes. Proceeding of Fourth International Conference on Spoken Language Processing. ICSLP 1996, 3:2–5. [Google Scholar]
- Endress AD, Mehler J (2009) The surprising power of statistical learning: when fragment knowledge leads to false memories of unheard words. J Mem Lang 60:351–367. 10.1016/j.jml.2008.10.003 [DOI] [Google Scholar]
- Farmer T. a, Christiansen MH, Monaghan P (2006) Phonological typicality influences on-line sentence comprehension. Proc Natl Acad Sci USA 103:12203–12208. 10.1073/pnas.0602173103 [DOI] [PMC free article] [PubMed] [Google Scholar]
- Faugeras F, Rohaut B, Weiss N, Bekinschtein T. a, Galanaud D, Puybasset L, Bolgert F, Sergent C, Cohen L, Dehaene S, Naccache L (2011) Probing consciousness with event-related potentials in the vegetative state. Neurology 77:264–268. 10.1212/WNL.0b013e3182217ee8 [DOI] [PMC free article] [PubMed] [Google Scholar]
- Freunberger D, Roehm D (2016) Semantic prediction in language comprehension: evidence from brain potentials. Lang Cogn Neurosci 31:1193–1205. 10.1080/23273798.2016.1205202 [DOI] [PMC free article] [PubMed] [Google Scholar]
- Friston K (2005) A theory of cortical responses. Philos Trans R Soc Lond B Biol Scie 360:815–836. 10.1098/rstb.2005.1622 [DOI] [PMC free article] [PubMed] [Google Scholar]
- Friston K (2009) The free-energy principle: a rough guide to the brain? Trends Cogn Sci 13:293–301. 10.1016/j.tics.2009.04.005 [DOI] [PubMed] [Google Scholar]
- Friston K (2010) The free-energy principle: a unified brain theory? Nat Rev Neurosci 11:127–138. 10.1038/nrn2787 [DOI] [PubMed] [Google Scholar]
- Garrido MI, Friston KJ, Kiebel SJ, Stephan KE, Baldeweg T, Kilner JM (2008) The functional anatomy of the MMN: a DCM study of the roving paradigm. Neuroimage 42:936–944. 10.1016/j.neuroimage.2008.05.018 [DOI] [PMC free article] [PubMed] [Google Scholar]
- Garrido MI, Kilner JM, Stephan KE, Friston KJ (2009) The mismatch negativity: a review of underlying mechanisms. Clin Neurophysiol 120:453–463. 10.1016/j.clinph.2008.11.029 [DOI] [PMC free article] [PubMed] [Google Scholar]
- Goslin J, Galluzzi C, Romani C (2014) PhonItalia: a phonological lexicon for Italian. Behav Res Methods 46:872–886. 10.3758/s13428-013-0400-8 [DOI] [PubMed] [Google Scholar]
- Groppe DM, Choi M, Huang T, Schilz J, Topkins B, Urbach TP, Kutas M (2010) The phonemic restoration effect reveals pre-N400 effect of supportive sentence context in speech perception. Brain Res 1361:54–66. 10.1016/j.brainres.2010.09.003 [DOI] [PMC free article] [PubMed] [Google Scholar]
- Hauk O (2016) Preface to special issue “prediction in language comprehension and production.” Lang Cogn Neurosci 31:1–3. 10.1080/23273798.2015.1102300 [DOI] [PMC free article] [PubMed] [Google Scholar]
- Hedges LV (1981) Distribution theory for Glass’s estimator of effect size and related estimators. J Educ Behav Stat 6:107–128. 10.3102/10769986006002107 [DOI] [Google Scholar]
- Heilbron M, Chait M (2018) Great expectations: is there evidence for predictive coding in auditory cortex? Neuroscience 389:54–73. 10.1016/j.neuroscience.2017.07.061 [DOI] [PubMed] [Google Scholar]
- Hentschke H, Stüttgen MC (2011) Computation of measures of effect size for neuroscience data sets. Eur J Neurosci 34:1887–1894. 10.1111/j.1460-9568.2011.07902.x [DOI] [PubMed] [Google Scholar]
- Hestvik A, Durvasula K (2016) Neurobiological evidence for voicing underspecification in English. Brain Lang 152:28–43. 10.1016/j.bandl.2015.10.007 [DOI] [PubMed] [Google Scholar]
- Hickok G (2012) The cortical organization of speech processing: feedback control and predictive coding the context of a dual-stream model. J Commun Disord 45:393–402. 10.1016/j.jcomdis.2012.06.004 [DOI] [PMC free article] [PubMed] [Google Scholar]
- Hobson JA, Friston KJ (2012) Waking and dreaming consciousness: neurobiological and functional considerations. Prog Neurobiol 98:82–98. 10.1016/j.pneurobio.2012.05.003 [DOI] [PMC free article] [PubMed] [Google Scholar]
- Huettig F, Mani N (2016) Is prediction necessary to understand language? Probably not. Lang Cogn Neurosci 31:19–31. [Google Scholar]
- JASPteam (2017) JASP (version 0.8) [Computer software]. Available at https://jasp-stats.org/.
- Johnson MH, Haan MD, Oliver A, Smith W (2001) Recording and analyzing high-density event-related potentials with infants using the geodesic sensor net. Dev Neuropsychol 19:295–323. 10.1207/S15326942DN1903_4 [DOI] [PubMed] [Google Scholar]
- Kashino M (2006) Phonemic restoration: the brain creates missing speech sounds. Acoust Sci Technol 27:318–321. 10.1250/ast.27.318 [DOI] [Google Scholar]
- Kleinschmidt D, Jaeger TF (2015) Robust speech perception: recognize the familiar, generalize to the similar, and adapt to the novel. Psychol Rev 122:148–203. 10.1037/a0038695 [DOI] [PMC free article] [PubMed] [Google Scholar]
- Koelsch S (2016) Under the hood of statistical learning: a statistical MMN reflects the magnitude of transitional probabilities in auditory sequences. Sci Rep 6:19741 10.1038/srep19741 [DOI] [PMC free article] [PubMed] [Google Scholar]
- Kramer M (2009) The phonology of Italian. Oxford: Oxford University Press. [Google Scholar]
- Kuperberg GR, Jaeger TF (2016) What do we mean by prediction in language comprehension? Lang Cogn Neurosci 31:32–59. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Kutas M, Hillyard S (1980) Reading senseless sentences: brain potentials reflect semantic incongruity. Science 207:203–205. 10.1126/science.7350657 [DOI] [PubMed] [Google Scholar]
- Kutas M, Federmeier KKD (2000) Electrophysiology reveals semantic memory use in language comprehension. Trends Cogn Sci 4:463–470. 10.1016/S1364-6613(00)01560-6 [DOI] [PubMed] [Google Scholar]
- Kutas M, Federmeier KD (2011) Thirty years and counting: finding meaning in the N400 component of the event-related brain potential (ERP). Annu Rev Psychol 62:621–647. 10.1146/annurev.psych.093008.131123 [DOI] [PMC free article] [PubMed] [Google Scholar]
- Lakens D (2013) Calculating and reporting effect sizes to facilitate cumulative science: a practical primer for t-tests and ANOVAs. Front Psychol 4:863 10.3389/fpsyg.2013.00863 [DOI] [PMC free article] [PubMed] [Google Scholar]
- Lecaignard F, Bertrand O, Gimenez G, Mattout J, Caclin A (2015) Implicit learning of predictable sound sequences modulates human brain responses at different levels of the auditory hierarchy. Front Hum Neurosci 9:505 10.3389/fnhum.2015.00505 [DOI] [PMC free article] [PubMed] [Google Scholar]
- Leppink J, O’Sullivan P, Winston K (2017) Evidence against vs. in favour of a null hypothesis. Perspect Med Educ 6:115–118. 10.1007/s40037-017-0332-6 [DOI] [PMC free article] [PubMed] [Google Scholar]
- Lewis AG, Bastiaansen M (2015) A predictive coding framework for rapid neural dynamics during sentence-level language comprehension. Cortex 68:155–168. 10.1016/j.cortex.2015.02.014 [DOI] [PubMed] [Google Scholar]
- Maris E, Oostenveld R (2007) Nonparametric statistical testing of EEG- and MEG-data. J Neurosci Methods 164:177–190. 10.1016/j.jneumeth.2007.03.024 [DOI] [PubMed] [Google Scholar]
- Mioni A (1993) Fonetica e fonologia In: Introduzione all’italiano contemporaneo, Le strutture (Sobrero A, ed), pp 101–139. Rome: Laterza. [Google Scholar]
- Näätänen R (2000) Mismatch negativity (MMN): perspectives for application. Int J Psychophysiol 37:3–10. 10.1016/S0167-8760(00)00091-X [DOI] [PubMed] [Google Scholar]
- Näätänen R, Pakarinen S, Rinne T, Takegata R (2004) The mismatch negativity (MMN): towards the optimal paradigm. Clin Neurophysiol 115:140–144. 10.1016/j.clinph.2003.04.001 [DOI] [PubMed] [Google Scholar]
- Näätänen R, Paavilainen P, Rinne T, Alho K (2007) The mismatch negativity (MMN) in basic research of central auditory processing: a review. Clin Neurophysiol 118:2544–2590. 10.1016/j.clinph.2007.04.026 [DOI] [PubMed] [Google Scholar]
- Norris D, McQueen JM, Cutler A (2000) Merging information in speech recognition: feedback is never necessary. Behav Brain Sci 23:299–325. 10.1017/S0140525X00003241 [DOI] [PubMed] [Google Scholar]
- Norris D, McQueen JM, Cutler A (2015) Prediction, Bayesian inference and feedback in speech recognition. Lang Cogn Neurosci 31:4–18. 10.1080/23273798.2015.1081703 [DOI] [PMC free article] [PubMed] [Google Scholar]
- Oostenveld R, Fries P, Maris E, Schoffelen JM (2011) FieldTrip: open source software for advanced analysis of MEG, EEG, and invasive electrophysiological data. Comput Intell Neurosci 2011:156869 10.1155/2011/156869 [DOI] [PMC free article] [PubMed] [Google Scholar]
- Paavilainen P (2013) The mismatch-negativity (MMN) component of the auditory event-related potential to violations of abstract regularities: a review. Int J Psychophysiol 88:109–123. 10.1016/j.ijpsycho.2013.03.015 [DOI] [PubMed] [Google Scholar]
- Paavilainen P, Arajärvi P, Takegata R (2007) Preattentive detection of nonsalient contingencies between auditory features. Neuroreport 18:159–163. 10.1097/WNR.0b013e328010e2ac [DOI] [PubMed] [Google Scholar]
- Paoli S (2016) A short guide to Italian phonetics and phonology for students of Italian Paper V. Oxford: Oxford University Press. [Google Scholar]
- Pegado F, Bekinschtein T, Chausson N, Dehaene S, Cohen L, Naccache L (2010) Probing the lifetimes of auditory novelty detection processes. Neuropsychologia 48:3145–3154. 10.1016/j.neuropsychologia.2010.06.030 [DOI] [PubMed] [Google Scholar]
- Pelli D (1997) The VideoToolbox software for visual psychophysics: transforming numbers into movies. Spat Vis 10:437–442. 10.1163/156856897X00366 [DOI] [PubMed] [Google Scholar]
- Phillips HN, Blenkmann A, Hughes LE, Bekinschtein TA, Rowe JB (2015) Hierarchical organization of frontotemporal networks for the prediction of stimuli across multiple dimensions. J Neurosci 35:9255–9264. 10.1523/JNEUROSCI.5095-14.2015 [DOI] [PMC free article] [PubMed] [Google Scholar]
- Phillips HN, Blenkmann A, Hughes LE, Kochen S, Bekinschtein TA, Cam CA, Rowe JB (2016) Convergent evidence for hierarchical prediction networks from human electrocorticography and magnetoencephalography. Cortex 82:192–205. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Polich J (2007) Updating P300: an integrative theory of P3a and P3b. Clin Neurophysiol 118:2128–2148. 10.1016/j.clinph.2007.04.019 [DOI] [PMC free article] [PubMed] [Google Scholar]
- Politzer-Ahles S, Schluter K, Wu K, Almeida D (2016) Asymmetries in the perception of Mandarin tones: evidence from mismatch negativity. J Exp Psychol Hum Percept Perform 42:1547–1570. 10.1037/xhp0000242 [DOI] [PubMed] [Google Scholar]
- Rouder JN, Speckman PL, Sun D, Morey RD, Iverson G (2009) Bayesian t tests for accepting and rejecting the null hypothesis. Psychon Bull Rev 16:225–237. 10.3758/PBR.16.2.225 [DOI] [PubMed] [Google Scholar]
- RStudioTeam (2016) RStudio: integrated development environment for R. Available at http://www.rstudio.com/.
- Scharinger M, Bendixen A, Trujillo-Barreto NJ, Obleser J (2012a) A sparse neural code for some speech sounds but not for others. PLoS One 7 10.1371/journal.pone.0040953 [DOI] [PMC free article] [PubMed] [Google Scholar]
- Scharinger M, Monahan PJ, Idsardi WJ (2012b) Asymmetries in the processing of vowel height. J Speech Lang Hear Res 55:903–918. 10.1044/1092-4388(2011/11-0065) [DOI] [PubMed] [Google Scholar]
- Scharinger M, Monahan PJ, Idsardi WJ (2016) Linguistic category structure influences early auditory processing: converging evidence from mismatch responses and cortical oscillations. Neuroimage 128:293–301. 10.1016/j.neuroimage.2016.01.003 [DOI] [PMC free article] [PubMed] [Google Scholar]
- Schluter K, Politzer-Ahles S, Almeida D (2016) No place for/h/: an ERP investigation of English fricative place features. Lang Cogn Neurosci 31:728–740. 10.1080/23273798.2016.1151058 [DOI] [PMC free article] [PubMed] [Google Scholar]
- Schluter KT, Politzer-Ahles S, Al Kaabi M, Almeida D (2017) Laryngeal features are phonetically abstract: mismatch negativity evidence from Arabic, English, and Russian. Front Psychol 8:746 10.3389/fpsyg.2017.00746 [DOI] [PMC free article] [PubMed] [Google Scholar]
- Schuster S, Hawelka S, Hutzler F, Kronbichler M, Richlan F (2016) Words in context: the effects of length, frequency, and predictability on brain responses during natural reading. Cereb Cortex 26:3889–3904. 10.1093/cercor/bhw184 [DOI] [PMC free article] [PubMed] [Google Scholar]
- Sergent C, Baillet S, Dehaene S (2005) Timing of the brain events underlying access to consciousness during the attentional blink. Nat Neurosci 8:1391–400. 10.1038/nn1549 [DOI] [PubMed] [Google Scholar]
- Squires NK, Squires KC, Hillyard SA (1975) Two varieties of long-latency positive waves evoked by unpredictable auditory stimuli in man. Electroencephalogr Clin Neurophysiol 38:387–401. 10.1016/0013-4694(75)90263-1 [DOI] [PubMed] [Google Scholar]
- Steinberg J, Truckenbrodt H, Jacobsen T (2012) The role of stimulus cross-splicing in an event-related potentials study. Misleading formant transitions hinder automatic phonological processing. J Acoust Soc Am 131:3120–3140. 10.1121/1.3688515 [DOI] [PubMed] [Google Scholar]
- Strauss M, Sitt JD, King J-R, Elbaz M, Azizi L, Buiatti M, Naccache L, van Wassenhove V, Dehaene S (2015) Disruption of hierarchical predictive coding during sleep. Proc Natl Acad Sci USA 112:E1353–E1362. 10.1073/pnas.1501026112 [DOI] [PMC free article] [PubMed] [Google Scholar]
- Sun Y, Giavazzi M, Adda-Decker M, Barbosa LS, Kouider S, Bachoud-Lévi A-C, Jacquemot C, Peperkamp S (2015) Complex linguistic rules modulate early auditory brain responses. Brain Lang 149:55–65. 10.1016/j.bandl.2015.06.009 [DOI] [PubMed] [Google Scholar]
- Todorovic A, de Lange FP (2012) Repetition suppression and expectation suppression are dissociable in time in early auditory evoked fields. J Neurosci 32:13389–13395. 10.1523/JNEUROSCI.2227-12.2012 [DOI] [PMC free article] [PubMed] [Google Scholar]
- Traxler MJ (2014) Trends in syntactic parsing: anticipation, Bayesian estimation, and good-enough parsing. Trends Cogn Sci 18:605–611. 10.1016/j.tics.2014.08.001 [DOI] [PMC free article] [PubMed] [Google Scholar]
- Tyler LK (1984) The structure of the initial cohort: evidence from gating. Percept Psychophys 36:417–427. 10.3758/BF03207496 [DOI] [PubMed] [Google Scholar]
- Van Petten C, Luka BJ (2012) Prediction during language comprehension: benefits, costs, and ERP components. Int J Psychophysiol 83:176–190. 10.1016/j.ijpsycho.2011.09.015 [DOI] [PubMed] [Google Scholar]
- Van Petten C, Coulson S, Rubin S, Plante E, Parks M (1999) Time course of word identification and semantic integration in spoken language. J Exp Psychol Learn Mem Cogn 25:394–417. 10.1037//0278-7393.25.2.394 [DOI] [PubMed] [Google Scholar]
- Wacongne C, Labyt E, van Wassenhove V, Bekinschtein T, Naccache L, Dehaene S (2011) Evidence for a hierarchy of predictions and prediction errors in human cortex. Proc Natl Acad Sci USA 108:20754–20759. 10.1073/pnas.1117807108 [DOI] [PMC free article] [PubMed] [Google Scholar]
- Wacongne C, Changeux JP, Dehaene S (2012) A neuronal model of predictive coding accounting for the mismatch negativity. J Neurosci 32:3665–3678. 10.1523/JNEUROSCI.5003-11.2012 [DOI] [PMC free article] [PubMed] [Google Scholar]
- Wilson MP, Garnsey SM (2009) Making simple sentences hard: verb bias effects in simple direct object sentences. J Mem Lang 60:368–392. 10.1016/j.jml.2008.09.005 [DOI] [PMC free article] [PubMed] [Google Scholar]
- Winkler I, Czigler I (2012) Evidence from auditory and visual event-related potential (ERP) studies of deviance detection (MMN and vMMN) linking predictive coding theories and perceptual object representations. Int J Psychophysiol 83:132–143. 10.1016/j.ijpsycho.2011.10.001 [DOI] [PubMed] [Google Scholar]
- Winkler I, Schröger E (2015) Auditory perceptual objects as generative models: setting the stage for communication by sound. Brain Lang 148:1–22. 10.1016/j.bandl.2015.05.003 [DOI] [PubMed] [Google Scholar]
- Yabe H, Tervaniemi M, Reinikainen K, Näätänen R (1997) Temporal window of integration revealed by MMN to sound omission. Neuroreport 8:1971–1974. 10.1097/00001756-199705260-00035 [DOI] [PubMed] [Google Scholar]
- Ylinen S, Huuskonen M, Mikkola K, Saure E, Sinkkonen T, Paavilainen P (2016) Predictive coding of phonological rules in auditory cortex: a mismatch negativity study. Brain Lang 162:72–80. 10.1016/j.bandl.2016.08.007 [DOI] [PubMed] [Google Scholar]