

Abstract
The advancement of synthetic biology requires the ability to create new DNA sequences to produce unique behaviors in biological systems. Automation is increasingly employed to carry out well-established assembly methods of DNA fragments in a multiplexed, high-throughput fashion, allowing many different configurations to be tested simultaneously. However, metrics are required to determine when automation is warranted based on factors such as assembly methodology, protocol details, and number of samples. The goal of our synthetic biology automation work is to develop and test protocols, hardware, and software to investigate and optimize DNA assembly through quantifiable metrics. We performed a parameter analysis of DNA assembly to develop a standardized, highly efficient, and reproducible Modular Cloning protocol, suitable to be used both manually, and with liquid-handling robots. We created a key DNA assembly metric (Q-metric) to characterize a given automation method’s advantages over conventional manual manipulations with regards to researchers’ highest-priority parameters: output, cost, and time. A software tool called Puppeteer was developed to formally capture these metrics, help define the assembly design, and provide human and robotic liquid handling instructions. Altogether, we contribute to a growing foundation of standardizing practices, metrics, and protocols for automating DNA assembly.
Keywords: DNA assembly, Liquid-handling robots, Metrics, Synthetic Biology, Standards
Introduction
DNA assembly technology is central to synthetic biology research. While there have been many powerful advancements in DNA assembly,1–6 large scale experimental efforts would benefit from establishing more standard engineering practices and metrics. These practices and metrics would enable and evaluate, respectively, the automation capabilities of the processes involved. There are often comparisons made of DNA assembly to electronic circuit manufacturing.7–9 However, the types of metrics that apply to the latter do not necessarily translate to the former. The methodologies of assembling electronic parts have well defined metrics for commonly accepted practices. Such metrics have yet to become well-established for DNA assembly methods, which are often impacted by the vast sequence space possible for DNA-based designs. The many permutations of DNA sequence constructs make biological systems particularly well-suited for performing advanced biological functions and control that can be exploited in many applications.10–11 However, this feature along with varying construct-specific sensitivity to assembly method parameters can make standard practices elusive for the assembling of DNA-based devices.
As the field of synthetic biology grows, there is a need in industry and academia for best practices, metrics, and protocols for DNA assembly to enable automation, reproducibility, as well as meaningful sharing of reliable results.12 While many methodologies exist for DNA assembly, virtually none have risen as the standard for automation or been thoroughly evaluated using quantitative metrics. Academic labs require the ability for their results to be replicated by others, and variations between DNA assembly protocols can cause challenges for other groups trying to replicate tricky assemblies. Industry and academia would benefit from standardization and automation to develop high-fidelity and high-throughput DNA assemblies in a cost-effective manner. Adoption of these standards cannot be made compulsory, but the field would be well-served to take up a unified set of methods and measurements to facilitate communication between researchers and compare results across separate experiments and institutions.
Incorporating standard practices into DNA assembly workflows will also allow for the facilitation of experimentation including the choice of automated processes.13 The use of integrated automation to design, build, and test systems is well-established in traditional rapid prototyping and can be applied with equal benefit to DNA assembly. Hillson et al. developed the j5 DNA Assembly Design Software to enable design of multipart DNA assemblies in silico14; and Linshiz et al. developed automated methods for generating human and machine readable liquid-handling robot instructions for the construction of DNA.15 However, there is a need for the next step to develop metrics that facilitate comparisons across both hardware platforms and assembly methods. Rapid, multiplexed, and high-throughput automated methods can accelerate the pace of development of experimental and industrial production. But researchers should understand these processes’ tolerances and bounds, and assess whether the affordability, efficiency, and reproducibility of automation compares favorably with manual methods for a particular experiment.16 In many cases, an experiment’s scale is the primary reason for using automation instead of manual methods.
Along with the automation of any process comes the necessity of computer-aided handling of the process, as well as the tracking of material traversing the possible routes through the system.17 Automation of DNA assembly requires the conversion of protocols to a language that both a human and a machine can understand, which is non-trivial and often requires redundant systems to achieve both. In addition, the flexibility to track samples through multiple possible methods based on measurements throughout the process can require an adaptable system that relies on consistent performance and well-established metrics that indicate a clear course of action.
Developing metrics to quantitatively evaluate the benefits of DNA assembly automation has proven challenging as there are a wide variety of DNA assembly methods and hardware available.18 However, since the evaluation of all of these protocols is similar, we developed a new type of metric, “Q-metrics,” to quantitate the benefit of automation. Q-metrics originated from chemistry to describe the energy released or required for a chemical reaction, and were later used to evaluate the ratio of energy output to energy input of nuclear fusion reactors enabling a comparative metric to determine if a specific reactor will breakeven (Q = 1).19 Q-values, or Q-metrics, have been used extensively in determining the economic viability of fusion to provide a quantitative measurement for when a nuclear fusion reactor is economically viable.20 Instead of comparing energy output, our Q-metrics compare factors representing researchers’ resources: cost and time (Eq. 1 and 2):
| (Eq. 1) |
| (Eq. 2) |
Q-metrics are automation method-dependent and a set of Q-metrics are made for each available liquid-handling robot. An example calculation can be seen in Supplemental Table 1.
Here we apply all of these factors, proposed standard practices and metrics, automation, and computer-aided processing, to achieve efficient and high-throughput DNA assembly. We explore the effects on efficiency of automation, including the incorporation of a computer aided workflow we call Puppeteer.
Materials and Methods
Evaluating DNA Assembly Efficiency
Using the Modular Cloning (MoClo) DNA assembly methodology6, we tested changes in DNA assembly outcomes (i.e. blue/white colony screening results) across a variety of parameters including the total number of DNA parts in a reaction (2 parts, 5 parts, and 8 parts), the final concentration of the individual DNA parts (1 nM, 2 nM, and 4 nM), as well as the plating volume of recovered transformation reactions (5% or 50% of recovery volume). A summary of the DNA parts used in this experiment is in Supplemental Table 2, and DNA part sequences can be found in our SynBioHub repository.21 20 μL MoClo reactions were prepared as follows: 2 μL of each DNA part (concentrations varying from 10 nM to 40 nM), 2 μL 10x T4 DNA Ligase Buffer (Promega C126B), 1 μL BsaI restriction enzyme (New England BioLabs R0535), 0.5 μL T4 HC DNA Ligase (Promega M179A), and 6.5 μL autoclaved distilled, deionized water. All DNA samples were quantified by absorbance at 280 nm, employing a NanoDrop 2000 spectrophotometer (Thermo Fisher Scientific). A detailed protocol for each reaction can be found in Supplemental Protocols 1, 2, and 3. Reactions were incubated using the following parameters: 37°C for 2 hours, 50°C for 5 minutes, 80°C for 10 minutes, then stored at −20°C until transformation. MoClo reactions were then transformed using the following protocol: 2 μL of each reaction was added to 20 μL of Bioline Alpha-Select Gold competent cells (BIO-85027) and incubated on ice for 30 minutes. Cells were then heat-shocked at 42°C for 30 seconds using a water bath, then placed on ice for 2 minutes. Next, 180 μL of Super Optimal Broth with catabolite repression (SOC) media was added to each reaction, and cells were recovered while shaking at 37°C, 300 rpm, for 1 hour. We plated the transformation reactions on Lennox Lysogeny Broth (LB) + agar plates containing 30 μg/μl of kanamycin with 0.5 mM Isopropyl β-D-1-thiogalactopyranoside (IPTG) and 40 µg/mL X-Gal (Zymo Research X1001–25). We plated each transformation reaction twice consisting of 5% and 50% of the resulting culture volume and incubated overnight at 37°C. Additional protocol details for each reaction are in Supplemental Protocols 1, 2 and 3.
Head-to-Head: Automated vs. Manual
We next sought to directly compare DNA assembly metrics of 5-part MoClo reactions prepared either manually (at the bench, by the researcher) or using a Tecan Freedom EVO 150 automated liquid-handling platform, with an emphasis on capturing data that would later be fed into our Q-metrics calculations. We performed two different experiments, the first using only a single combination of promoter, RBS, gene, terminator, and backbone, and the second that explored 42 different combinations of similar 5-part DNA assemblies. A detailed list of the DNA parts used in these experiments can be found in Supplemental Table 2. We prepared reactions using the same protocol detailed previously, keeping the final concentration of all DNA parts constant at 2 nM. Transformations were performed by adding 2 μL of each reaction to 20 μL of NEB 5-alpha competent cells (C2987P), following vendor’s instructions. 10% of each resulting culture (20 μL) was mixed with 30 μL of LB media and then plated onto LB + agar plates containing 30 μg/μL kanamycin, 0.5 mM IPTG, and 40 µg/mL X-Gal. We randomly chose 10 white colonies to sequence throughout the assembled regions spanning promoter, RBS, gene, and terminator. Sanger sequencing confirmed that all clones screened were correct and complete assemblies. Additional protocol details for each reaction can be found in Supplemental Protocols 2 and 3.
Results and Discussion
Evaluating DNA Assembly Metrics
DNA assembly can be evaluated by many methods. Our analysis focused on the common white-blue colony-forming unit (CFU) screening assay where assembly reactions were transformed into highly-competent bacterial cells and plated on media supplemented with X-Gal and IPTG. In this screen, colonies formed from cells containing empty destination vectors yield blue CFUs, while those containing properly assembled DNA produce white CFUs. While identifying a desired clone typically requires only a few white CFU, much can be learned from the total number of white CFU, as well as the percent of white CFU present. As our proof-of-concept using MoClo, we wanted to understand how different factors (number of DNA parts, total assembly size, and concentration of DNA parts) affect the overall success of the process. Our goal of this parameter sweep was to understand critical variables when performing MoClo DNA assembly. We used the original modular cloning protocol suggested by Weber et al.22 as a starting point. The full protocol for our experiment can be read in Supplemental Protocol 1.
We first wanted to assess the effect the number of DNA parts would have on assemblies of a comparable final size. Briefly, we assembled three similarly-sized assemblies (2828, 3152, and 3285 bp), composed of 2, 5, or 8 parts respectively, using identical protocols. Regardless of part concentration, as the number of parts in a given assembly increased, white CFU decreased (Figure 1A). While the lowest number of undesired blue CFU resulted from the 5-part assembly (Figure 1B), the highest percentage of white CFU was observed in reactions having the fewest parts, which decreased as the number of parts increased (Figure 1C), though more total blue CFU were present with the 2 and 8 part assemblies. Figure 1 illustrates that while the 2-part assembly had more blue CFU (Figure 1B) than the 5-part assembly, its percentage of white CFU was higher than the 5-part assembly, likely due to the lower number of parts needing to assemble in the reaction (Figure 1C). The opposite is true for the 8-part assembly, where a likely hypothesis would be a lower probability that all 8 parts will fully assemble as intended in solution.23–24
Figure 1.
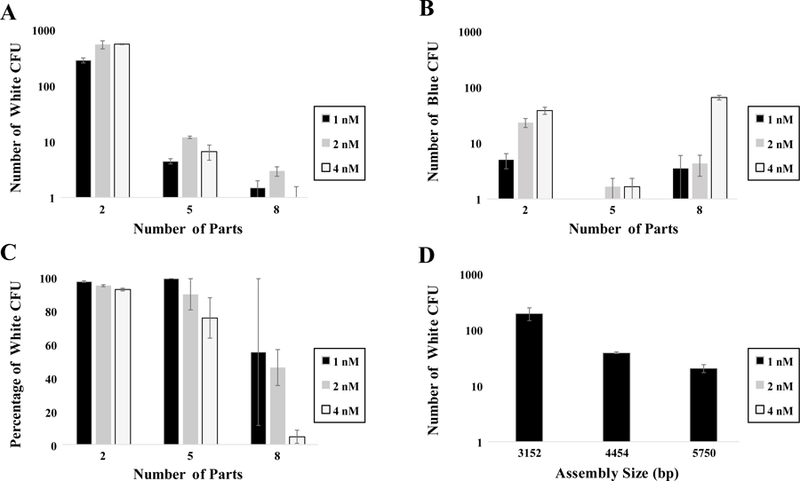
Parameter sweep performed to analyze, optimize, and standardize Modular Cloning DNA assembly protocol for differing number of parts (A, B), part concentration (C), and total assembly size (D).
Next, we investigated the process of building three differently-sized 5-part assemblies using identical assembly protocols. As expected, we saw the most white CFU from the smallest size assembly (3152 bp) and fewest from the largest assembly (5750 bp) (Figure 1D). This data suggests there may be a limit to the size of DNA construct that can be assembled or transformed with this method, potentially necessitating alternative methods for larger constructs. This finding agrees with previous studies showing that larger circuits are more difficult to transform,25 and more parts in an assembly reaction decrease the probability of a complete assembly coming together.26 Junction fidelity of MoClo overhangs has also been shown in literature to impact CFU.27 To mitigate the effects of different junction fidelities, all of our test parts used the same four MoClo overhangs for all assemblies.
We then tested our 2, 5, and 8 part assemblies with different final DNA part concentrations (1 nM, 2 nM, and 4 nM) with a particular focus on identifying concentrations that would yield a reasonable number of white CFUs for reactions with varying numbers of DNA parts. In general, as DNA part concentration increased, white CFU percentage decreased (Figure 1C). As the number of parts increased, the negative impact of higher part concentration was exacerbated. We hypothesize that more total DNA going into a reaction, either with more parts or higher part concentration, may overwhelm the processing power of the available enzymes, limiting the overall reaction efficiency. These deficiencies might be addressed through increasing enzyme concentration, altering the balance of ligase versus endonuclease, or adjusting reaction temperatures or times. We also note that due to lower total CFU counts for 5 and 8 part assemblies, error bars are larger.
While the focus of this study was on total CFU number and white-blue percentage, we also examined common molecular biology metrics such as transformation efficiency. Molecular and synthetic biology literature has reported transformation efficiency variously as CFU/µL reaction28, CFU/fmol DNA and CFU/pg DNA29, depending on the context. From a biochemical standpoint, we should favor CFU/fmol DNA as a more useful metric than CFU/pg DNA, since the size of the DNA construct is factored in. The unit CFU/µL reaction may be more meaningful to industry as it gives the user information about how much assembly reaction mix is required to obtain the target number of CFU while minimizing reagent cost. However, we calculated these values (Supplemental Figure 1) for every assembly reaction performed, and saw the expected close correlation between all three measurements, meaning one value can be estimated or even simply mathematically converted (fmol to pg) from either other metric. From a culmination of all data gathered, we selected the small size (3152 bp), 5-part assembly at a part concentration of 2 nM (maximizing the number of white colonies with minimal blue colonies) to follow through in our head-to-head study comparing manual versus automated DNA assembly.
DNA Assembly Using Liquid-Handling Robots
Once the assembly protocol standardization was finalized, we uploaded our 5-part assembly GenBank files into our Puppeteer software. The software generates both human-readable manual, and Tecan robotic liquid-handling instructions. A demo of the Puppeteer software is available via GitHub, and instructions can be found in Supplemental Protocol 4. Puppeteer pulled DNA part sequence information from our SynBio Hub in silico library to define a total of 42 unique assemblies which were all composed of 5 parts, had properly matching MoClo DNA overhangs, and followed the defined assembly organization of Promoter : Ribosome Binding Site (RBS) : Gene : Terminator : Destination Vector. Using these instructions, we performed a head-to-head study to compare hands-on time, cost, and assembly efficiency between assemblies performed either on a Tecan robot, or manually by a graduate student at Boston University and by an assistant staff member at MIT-Lincoln Laboratory. We manually performed transfers to a thermocycler, as well as subsequent transformation steps, for all methods. We also executed DNA dilutions manually, and DNA source plate layout was summarized in a human-readable experimental summary file generated by Puppeteer.
One challenge of using our Tecan robot was the minimum allowable volume for reproducible fluid transfer, which was 2 µL for our hardware setup. We standardized all reactions to have this as a minimum transfer volume, giving us a total reaction volume of 20 µL for both manual and automated assembly. Another challenge was dead volume in the source DNA plate. Depending on the liquid handling hardware used, varying amounts of additional liquid are required in each well that is accessed. The current version of Puppeteer does not account for this, however future versions of the software will adjust reagent volume needs based on the platform used and its respective dead volume requirements. An additional risk is that of evaporation of reagents over the course of pipetting tasks being executed for an assembly job. Use of an alternative liquid-handling system such as an acoustic dispenser with reproducible fluid transfers in the nL regime would drastically improve both timing (using acoustics as opposed to a robotic arm and disposable tips to move fluid) and cost (lower reagent volume required)15, and would address many of these issues. An advantage of using the Tecan liquid-handling robot paired with the Puppeteer assembly software was that after the sample was transferred to the source plate, the Tecan instructions generated by Puppeteer allowed the researcher to simply run the machine and perform other tasks instead of entering pipette steps manually into the robot control software (EvoWare), which is very time-consuming for combinatorial assembly. The benefit here is that automating tedious pipetting tasks would free up valuable researcher time.
Our head-to-head study between manual vs. automated assembly showed no notable difference in number of CFU or percent white CFU (data not shown). Sanger sequencing of plasmid insert regions of 3 white colonies from 10 randomly chosen plates confirmed the assemblies were correct for all DNA parts and overhangs as well. Our Q-metrics (Figure 2) confirmed the straightforward expectation that single assemblies are preferably done manually, whereas performing a set of 42 assemblies is better suited to automated methods.
Figure 2.
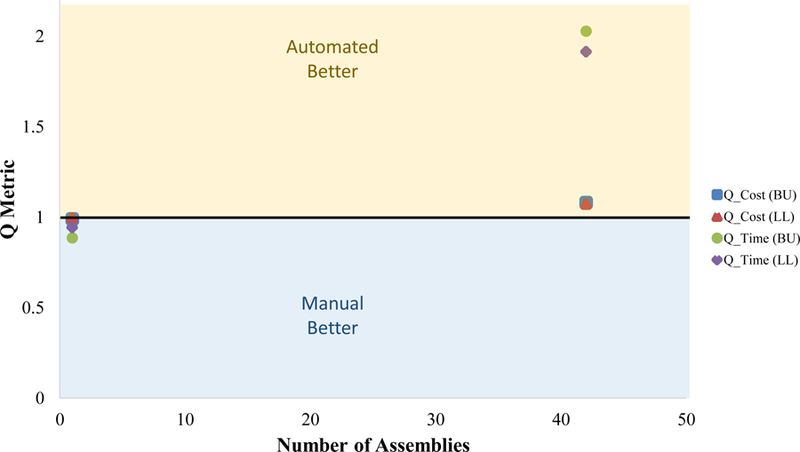
Graph showing results of head-to-head study comparing manual and automated DNA assembly methods using a liquid-handling robot. Q-metrics are defined in Eq. (1) and Eq. (2). A Q-metric higher than 1 infers cost savings using robotics; whereas the opposite is true for Q-metrics less than 1. The labels BU and LL refer to where the manual assembly took place (Boston University or Lincoln Laboratory), and both are compared to the automated Tecan liquid-handling robot located at BU.
The primary reason for our Q-metrics favoring automation at high numbers of assemblies is the savings in staff time. Both Q-cost and Q-time use staff time for salary and manual assembly calculations, respectively (Supplemental Table 1). With multiplexing, Q-time shows a more significant increase than Q-cost, as the dominant factor in the 42-plex assembly was the reagent cost (~84% of the total cost). Q-cost could be dramatically improved by reducing the volume of the reaction, which is possible with other fluidic handlers such as piezoelectric and acoustic liquid transferring robots, which can transfer small fluidic volumes (nL) more reliably than manual pipetting, and can do so much faster, mitigating potential evaporation of source plate reagents over the course of a larger assembly job. Finally, it is of note that our study infers a linear relationship between Q-metric and the number of assemblies based on our calculations carried out in Supplemental Table 1. Further development of Q-metrics to include additional cost factors (i.e., capital equipment, robot maintenance, and facility costs) and time factors (i.e., additional automation of transformation and plating) could change the behavior of these metrics as the number of assemblies increases. Our Q-metrics calculations are meant to serve as an example of how users could calculate their own automation Q-metrics. Supplementary Table 1 is meant to serve as a flexible, customizable tool for any user’s approach. Additional costs and time can be added to provide greater accuracy of these metrics as sometimes factors such as wash solvents, tips, and plates can drastically drive up costs in certain approaches. One can calculate Q-metrics for their own automation platforms by inputting their specific factors such as technician salary, reagent costs, and setup time into our Q-metric template in Supplemental Table 1.
In this study, the transition phase from “prefer manual” to “prefer automated” does not require high numbers of assemblies to benefit from automation. For other laboratories and conditions, different reagent costs and staff salaries will yield different results, potentially shifting the transition point in either direction. In our case, Q-time considered only hands-on time done by an experienced user; however, new users would have to be treated differently. And Q-cost only considered costs from the assembly itself and did not include upfront capital equipment costs nor maintenance costs for the liquid-handling robot. We intend to incorporate these additional cost elements into our Q-metrics to enable quick cost/benefit analyses to groups interesting in acquiring new hardware. Also, while our setup times were similar for a single assembly and 42 assemblies, moving beyond a single well-plate will impact time and cost. Finally, other robotic liquid-handling systems will require a similar study to be performed to benchmark speed and optimize the protocol for a new robot. The use of Q-metrics to evaluate the specific needs of a given context is easily adaptable to include additional factors such as amortization of equipment costs or employee training times.
Puppeteer Gene Assembly Wizard
Developing a pipeline for automated DNA assembly requires both hardware and software. The Puppeteer software platform manages the automation planning and scheduling aspects of the pipeline, taking a user-defined assembly composed of available DNA parts (e.g. promoters, ribosome binding sequences, coding sequences, terminators, and vectors) in GenBank format from an in silico library as the input. Puppeteer uses this information to create an assembly plan that takes into account possible successful combinatorial permutations of parts that meet the user’s specification. This plan is then transformed into a series of protocols given the target assembly format and the capabilities of the lab. Currently, Puppeteer is available as a proof-of-concept that can provide up to 96 possible design combinations of promoters, RBSs, genes, terminators, and vector backbones. While the position of each DNA component is fixed in the demo, the full version of Puppeteer we are developing now will allow the user to define the part ‘category’ and assembly order. Future Puppeteer will generate full factorial designs for all compatible series of parts within the user-defined order, but can be down-selected afterward by the user if not all combinations are desired. The current output of Puppeteer is threefold: 1) final assembled composite DNA sequence files (GenBank format) which feed back into the user’s SynBioHub in silico library; 2) liquid handling instructions for performing the DNA assembly with the user-selected liquid-handling format (robots, or manually by hand) and; 3) assembly evaluation Q-metrics that determine the relative cost and time savings of each liquid-handling option (Figure 3). SynBioHub is an open-source design repository for synthetic biology, built in Synthetic Biology Open Language (SBOL), and serves as a standard for genetic designs enabling sharing design parts. The adoption and use of SynBioHub, a community-driven effort, has the potential to overcome the reproducibility challenge across laboratories by helping to address the current lack of information about published designs.30 Puppeteer imports part libraries from SynBioHub and exports selected assemblies made using the software.
Figure 3.
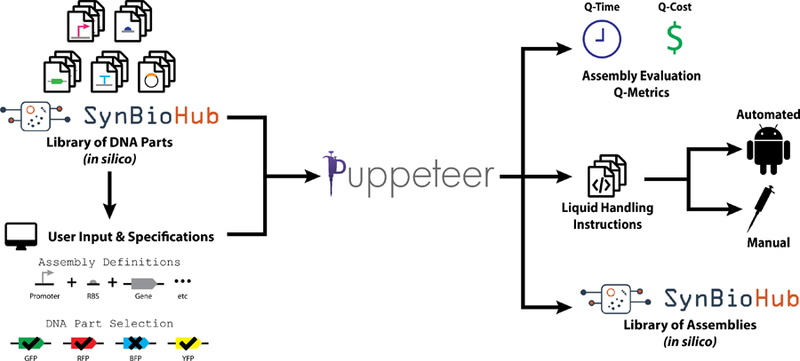
Schematic for DNA assembly pipeline automated by Puppeteer Gene Assembly Wizard software. The left portion of the figure illustrates that Puppeteer can connect to remote repositories of DNA parts (e.g. SynBioHub) as well as take input regarding required final DNA assemblies. The output of the process (right) is a protocol description for humans or liquid handling robotics that meets the Q-metrics reported.
The Q-metrics output by PuppeteerLite are currently hard-coded to output the values corresponding to a 42-part assembly, but the full Puppeteer software in development now will be generate Q-values at run-time based on the assembly job submitted, and the liquid handling hardware chosen, in a future release. The liquid handling instructions are particularly helpful as programming the Tecan in EvoWare took 2 hours, rather than the minutes it took to generate the same pipetting commands using Puppeteer. Generating the pipetting commands for DNA assembly tasks where the source and destination wells are a function of the job submitted is particularly problematic and time consuming if done manually, since reagent plate layouts will likely change between jobs, requiring new commands to be generated for each job submitted. Manual generation also increases the possibility of human-based errors, necessitating a software tool that can procedurally generate pipetting commands based on unique job submissions. Overall, Puppeteer guides the user from DNA parts to final assemblies (both in vitro and in silico), and provides quantitative metrics to assess when automated platforms will save both cost and time. The instructions to run our Puppeteer demo can be found on Supplemental Protocol 4.
Conclusions
Automation and standardization of synthetic biology processes require new tools and metrics that can support rapid, reproducible, systematic DNA assembly and screening. Our work demonstrates a useful methodology (Q-metrics) to analyze pipelines for DNA assembly, enabling better sharing, automation, and evaluation of these protocols to quantify their worth.
To guarantee the generation and collection of robust, repeatable DNA assembly data, we tested a Modular Cloning methodology-based protocol in two different laboratories (Boston University and MIT Lincoln Laboratory). Protocols were standardized between the two laboratories and assembly parameters were optimized through a parameter sweep, studying the impact of the number of DNA parts, the DNA part concentration, and the total size of DNA assembly products. We used our optimized protocol to then execute the assembly of 42 DNA circuits manually and automated via an off-the-shelf liquid-handling robot. While the non-labor costs and cloning efficiencies remained similar, there was a significant decrease in researcher hands-on time when using a liquid handling robot.
We augmented DNA assembly automation using our design-and-build software tool, Puppeteer, to plan both physical and in silico assembly of DNA parts. Using only GenBank files as inputs, Puppeteer provides a platform that integrates the steps of genetic circuit design, planning, and building, while providing useful metrics (Q-metrics) to evaluate the automated assembly process. Our Q-metrics provide a quantitative approach to tackle the question of when to automate, and their flexibility in calculation can allow users to explore and identify which factors contribute to their costs and time in automation. While our work described here focuses on a relatively simple subset of the processes necessary to automate DNA assembly, namely the preparation of DNA assembly reactions, we are working to incorporate downstream bacterial transformation and plating, as well as colony picking and plasmid DNA isolation into the automated workflow. These additional processes will be used to update our Q-metrics to present a more holistic and informative picture of the entire DNA assembly process. Altogether, our work provides a proof-of-concept design of an automated DNA assembly pipeline suitable for testing and evaluation to enable scale-up of assembly construction.
Supplementary Material
Supplemental Figure 1. Different types of transformation efficiency metrics plotted against each other.
Supplemental Protocol 1. Parameter Sweep
Supplemental Protocol 2. Head-to-Head 1 Assembly
Supplemental Protocol 3. Head-to-Head 42 Assemblies
Supplemental Protocol 4. Instructions for running the available Puppeteer Demo online.
Supplemental Table 1. A sample calculation of Q-cost and Q-time metrics for the 42 assembly head-to-head study.
Supplemental Table 2. Table of DNA parts used in this experiment.
Acknowledgements
Funding
The authors wish to acknowledge the following sources of financial support. Research reported in this publication was supported by the National Cancer Institute of the National Institutes of Health under award number R01CA173712, the National Institute of General Medical Sciences of the National Institutes of Health grant P50 GM098792 and the National Science Foundation’s Expeditions in Computing Program under grants 1522074, 1521925, and 1521759. Distribution statement: approved for public release; distribution unlimited. This material is based upon work supported by MIT under Air Force Contract No. FA8721-05-C-0002 and/or FA8702-15-D-0001. Any opinions, findings, conclusions or recommendations expressed in this material are those of the author(s) and do not necessarily reflect the views of MIT.
We also acknowledge the software engineering effort and insights of the Software & Application Innovation Lab (SAIL) within the Hariri Institute for Computing at Boston University as well as the efforts of Dr. Swapnil Bhatia now with Catalog DNA.
Footnotes
Declaration of Conflicting Interests
Douglas Densmore declares his involvement with the companies Lattice Automation (Boston, MA) and Asimov (Cambridge, MA); however, all authors declare no conflicts of interest with respect to the research, authorship, and/or publication of this article.
References
- 1.Casini A; MacDonald JT; De Jonghe J; Christodoulou G; Freemont PS; Baldwin GS; Ellis T, One-pot DNA construction for synthetic biology: the Modular Overlap-Directed Assembly with Linkers (MODAL) strategy. Nucleic Acids Res 2014, 42 (1), e7. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 2.Ellis T; Adie T; Baldwin GS, DNA assembly for synthetic biology: from parts to pathways and beyond. Integrative Biology 2011, 3 (2), 109–118. [DOI] [PubMed] [Google Scholar]
- 3.Chao R; Yuan Y; Zhao H, Recent advances in DNA assembly technologies. FEMS yeast research 2015, 15 (1), 1–9. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 4.De Paoli HC; Tuskan GA; Yang X, An innovative platform for quick and flexible joining of assorted DNA fragments. Scientific reports 2016, 6, 19278. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 5.Torella JP; Lienert F; Boehm CR; Chen J-H; Way JC; Silver PA, Unique nucleotide sequence–guided assembly of repetitive DNA parts for synthetic biology applications. Nature protocols 2014, 9 (9), 2075. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 6.Iverson SV; Haddock TL; Beal J; Densmore DM, CIDAR MoClo: Improved MoClo Assembly Standard and New E. coli Part Library Enable Rapid Combinatorial Design for Synthetic and Traditional Biology. ACS Synth Biol 2016, 5 (1), 99–103. [DOI] [PubMed] [Google Scholar]
- 7.McAdams HH; Arkin A, Gene regulation: Towards a circuit engineering discipline. Curr Biol 2000, 10 (8), R318–R320. [DOI] [PubMed] [Google Scholar]
- 8.Tschirhart T; Kim E; McKay R; Ueda H; Wu HC; Pottash AE; Zargar A; Negrete A; Shiloach J; Payne GF; Bentley WE, Electronic control of gene expression and cell behaviour in Escherichia coli through redox signalling. Nat Commun 2017, 8, 14030. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 9.Nielsen AA; Der BS; Shin J; Vaidyanathan P; Paralanov V; Strychalski EA; Ross D; Densmore D; Voigt CA, Genetic circuit design automation. Science 2016, 352 (6281), aac7341. [DOI] [PubMed] [Google Scholar]
- 10.Khalil AS; Collins JJ, Synthetic biology: applications come of age. Nat Rev Genet 2010, 11 (5), 367–79. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 11.Sekine R; Yamamura M, Design and Control of Synthetic Biological Systems In Natural Computing and Beyond, Springer: 2013; pp 104–114. [Google Scholar]
- 12.Hayden EC, The automated lab. Nature News 2014, 516 (7529), 131. [DOI] [PubMed] [Google Scholar]
- 13.Appleton E; Madsen C; Roehner N; Densmore D, Design Automation in Synthetic Biology. Cold Spring Harb Perspect Biol 2017, 9 (4). [DOI] [PMC free article] [PubMed] [Google Scholar]
- 14.Hillson NJ; Rosengarten RD; Keasling JD, j5 DNA assembly design automation software. ACS Synth Biol 2012, 1 (1), 14–21. [DOI] [PubMed] [Google Scholar]
- 15.Linshiz G; Stawski N; Goyal G; Bi C; Poust S; Sharma M; Mutalik V; Keasling JD; Hillson NJ, PR-PR: cross-platform laboratory automation system. ACS Synth Biol 2014, 3 (8), 515–24. [DOI] [PubMed] [Google Scholar]
- 16.Ortiz L; Pavan M; McCarthy L; Timmons J; Densmore DM, Automated Robotic Liquid Handling Assembly of Modular DNA Devices. J Vis Exp 2017, (130). [DOI] [PMC free article] [PubMed] [Google Scholar]
- 17.Appleton E; Densmore D; Madsen C; Roehner N, Needs and opportunities in bio-design automation: four areas for focus. Curr Opin Chem Biol 2017, 40, 111–118. [DOI] [PubMed] [Google Scholar]
- 18.NEB Synthetic Biology/DNA Assembly Selection Chart. https://www.neb.com/tools-and-resources/selection-charts/synthetic-biology-dna-assembly-selection-chart.
- 19.Krane KS; Halliday D, Introductory nuclear physics. Wiley New York: 1988; Vol. 465. [Google Scholar]
- 20.Zuvela K; Adlington I; Aljunied SS; Edwards J, Determining the best approach to commercial fusion power. PAM Review: Energy Science & Technology 2014, 1, 3–19. [Google Scholar]
- 21.Lab, C. LCP SynBioHub Repository. https://synbiohub.programmingbiology.org/public/LCP/bubdc_ice_folder_11/1.
- 22.Weber W; Fussenegger M, Synthetic gene networks methods and protocols In Methods in molecular biology, [Online] Humana Press,: New York, 2012; pp. 1 online resource (xi, 393 p. 10.1007/978-1-61779-412-4. [DOI] [Google Scholar]
- 23.Liang J; Liu Z; Low XZ; Ang EL; Zhao H, Twin-primer non-enzymatic DNA assembly: an efficient and accurate multi-part DNA assembly method. Nucleic acids research 2017, 45 (11), e94-e94. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 24.Storch M; Casini A; Mackrow B; Fleming T; Trewhitt H; Ellis T; Baldwin GS, BASIC: A New Biopart Assembly Standard for Idempotent Cloning Provides Accurate, Single-Tier DNA Assembly for Synthetic Biology. ACS Synth Biol 2015, 4 (7), 781–7. [DOI] [PubMed] [Google Scholar]
- 25.Hanahan D, Studies on transformation of Escherichia coli with plasmids. Journal of molecular biology 1983, 166 (4), 557–580. [DOI] [PubMed] [Google Scholar]
- 26.Casini A Advanced DNA assembly strategies and standards for synthetic biology. Imperial College London, 2015.
- 27.Vladimir P; Ong JL; Kucera RB; Langhorst BW; Bilotti K; Pryor JM; Cantor EJ; Canton B; Knight TF; Evans TC, Optimization of Golden Gate assembly through application of ligation sequence-dependent fidelity and bias profiling. bioRxiv 2018, 322297.
- 28.Patrick WG; Nielsen AA; Keating SJ; Levy TJ; Wang C-W; Rivera JJ; Mondragón-Palomino O; Carr PA; Voigt CA; Oxman N, DNA assembly in 3D printed fluidics. PloS One 2015, 10 (12), e0143636. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 29.Tee KL; Wong TS, Polishing the craft of genetic diversity creation in directed evolution. Biotechnol Adv 2013, 31 (8), 1707–21. [DOI] [PubMed] [Google Scholar]
- 30.McLaughlin JA; Myers CJ; Zundel Z; Mısırlı G. k.; Zhang M; Ofiteru ID; Goni-Moreno A; Wipat A, SynBioHub: A Standards-Enabled Design Repository for Synthetic Biology. ACS synthetic biology 2018, 7 (2), 682–688. [DOI] [PubMed] [Google Scholar]
Associated Data
This section collects any data citations, data availability statements, or supplementary materials included in this article.
Supplementary Materials
Supplemental Figure 1. Different types of transformation efficiency metrics plotted against each other.
Supplemental Protocol 1. Parameter Sweep
Supplemental Protocol 2. Head-to-Head 1 Assembly
Supplemental Protocol 3. Head-to-Head 42 Assemblies
Supplemental Protocol 4. Instructions for running the available Puppeteer Demo online.
Supplemental Table 1. A sample calculation of Q-cost and Q-time metrics for the 42 assembly head-to-head study.
Supplemental Table 2. Table of DNA parts used in this experiment.