

Abstract
Data‐driven science is heralded as a new paradigm in materials science. In this field, data is the new resource, and knowledge is extracted from materials datasets that are too big or complex for traditional human reasoning—typically with the intent to discover new or improved materials or materials phenomena. Multiple factors, including the open science movement, national funding, and progress in information technology, have fueled its development. Such related tools as materials databases, machine learning, and high‐throughput methods are now established as parts of the materials research toolset. However, there are a variety of challenges that impede progress in data‐driven materials science: data veracity, integration of experimental and computational data, data longevity, standardization, and the gap between industrial interests and academic efforts. In this perspective article, the historical development and current state of data‐driven materials science, building from the early evolution of open science to the rapid expansion of materials data infrastructures are discussed. Key successes and challenges so far are also reviewed, providing a perspective on the future development of the field.
Keywords: artificial intelligence, databases, data science, machine learning, materials, materials science, open innovation, open science
The current state of data‐driven materials science is reviewed, with a focus on materials data infrastructures and stakeholders from academia, the public, government, and industry. From a historical perspective, the field has matured greatly, however, key challenges—relevance, completeness, standardization, acceptance, and longevity—that still need to be resolved to create the Materials Ultimate Search Engine (MUSE) are identified.
1. Introduction
In this perspective article, we review the current state of data‐driven materials science with a focus on materials data infrastructures. Data‐driven invokes associations with big data, data management, open data and artificial intelligence (e.g., machine learning). The public debate of these terms is currently dominated by internet giants like Google, Amazon, and Facebook who also lead the technological development of data infrastructures, algorithms, and analysis tools. Compared to these e‐commerce and social media developments, the field of data‐driven materials science is still under construction. By way of analogy, it is nonetheless still instructive to imagine a Materials “Google”—the Materials Ultimate Search Engine (MUSE). In this article, we address what it takes to develop such a search tool for materials.
Materials science, the study of the characteristics and applications of materials is a well established discipline that combines chemistry, physics, and engineering research. Materials scientists frequently dream of designing new materials from scratch for use in society.1 However, instead of finding new materials using the MUSE, they discover new materials through conventional experimental, theoretical, or computational research (see left panel of Figure 1 ). This pipeline through which new materials are discovered, designed, developed, manufactured, and deployed remains slow, costly, and highly inefficient: By the time a new material comes to market, the patent protection of the original invention is at the end of its tenure, and proprietary advantage is lost2 (see also ref. 3). By applying data science to materials research, we now have a way to accelerate the materials value chain from discovery to deployment.
Figure 1.
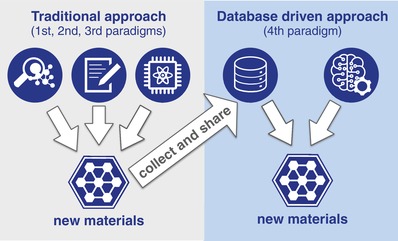
Materials discovery schematic. In the traditional approach, new materials are discovered by experimentation, theory, or computation (also referred to as 1st, 2nd, and 3rd paradigms and symbolized by the three icons at the top of the left panel). In the 4th paradigm of data‐driven materials science, available data is gathered in data infrastructures, and machine learning approaches discover new materials.
Data science has developed out of the growing demand for open science combined with the meteoric rise of AI and machine learning. As these innovative technologies allow ever‐larger datasets to be processed and hidden correlations to be unveiled, data‐driven science is emerging as the fourth scientific paradigm4, 5 (cf. Figure 1) following the first three eras of experimentally, theoretically, and computationally propelled scientific discoveries. Often connected to the fourth industrial revolution6 or the second machine age,7 such data‐driven approaches permeate science, business, politics, and even social life. Since materials innovation is a critical, well‐recognized driver of economic development and societal progress, it is important that new trends, such as data science, are embraced if they have the potential to advance the field.
Data‐driven materials science and materials informatics are umbrella terms for the scientific practice of systematically extracting knowledge from materials datasets. This practice differs from traditional scientific approaches in materials research by the volume of processed data and the more automated way information is extracted (cf. Figure 1), for example, through the use of machine learning (see refs. 5, 8, 9, 10, 11, 12, 13, 14, 15, 16, 17, 18, 19, 20, 21, 22, 23 for recent review articles on machine learning in materials science). In our MUSE analogy, this would be the search and find part. In addition to data processing and data analysis tools, data‐driven materials science also requires physical infrastructures that host and preserve that data. These would be the data storage part of our MUSE example, which, as physical infrastructures, require dedicated community efforts and sustained investment to become and remain operational.
Stakeholders in academia, industry, governments, and the public attach different meanings and expectations to data‐driven materials science. The actual material science is carried out in academia and research and development (R&D) departments in industry. Scientists at universities and companies not only produce materials data that could then be stored in data facilities, they are also the primary user group of materials data infrastructures. In the wake of digitalization, industry has a further interest in digitizing materials data and incorporating data‐driven materials science into their value chain. Policy makers and governmental or private funding agencies may have an interest in promoting open science data and can stir scientific developments through policy and funding decisions. The general public benefits from materials science by quality‐of‐life enhancement through new products and technologies. They have an indirect interest in data‐driven materials science as a means to accelerate innovations and follow developments in science and open data in the media. Together these stakeholders form an ecosystem of mutual benefit. The vitality of this ecosystem is crucial for the success and the longevity of data‐driven materials science.
In this article, we embed our perspective in the emerging field of data‐driven materials science in the context of the open science movement, which has shaped the philosophy and design of several materials science data infrastructures. We discuss how these infrastructures grew historically from simple databases into data centers that then progressed into materials discovery platforms, and we detail the current state of data infrastructure. A list of current challenges provides the gateway to the second part of this article, in which we delve deeper into data organization, acquisition, quality, and machine learning. We conclude with an industrial perspective that addresses the future and longevity of materials data infrastructures.
2. Open Science Movement
Many of the fundamental aspects of data‐driven materials science are built upon the key elements of the Open Science movement. The European Commission outlines24 Open Science as “…a new approach to the scientific process based on cooperative work and new ways of diffusing knowledge by using digital technologies and new collaborative tools.” Here we reflect on those aspects of Open Science that are particularly relevant to the birth and future of data‐driven materials science.
Openness in science was initially curtailed by the prestige wars between the patrons of early scientists and their associated, convoluted encryption schemes.25 Once more professional scientific practice developed, scientists embraced the idea of accessibility of research as a cornerstone of progress, and this has been generally mandated by public policy. As early as 1710 in the UK, the Copyright Act endowed the ownership of copyright to authors rather than publishers, encouraging authors to deposit manuscripts into national libraries to make them publicly accessible. In addition to accessibility, public accountability and scientific reproducibility have remained powerful driving forces in the way science has been conducted and disseminated, and significant deviations from these norms are of great concern to the community.26 More recently in the 1990s, the development of the internet transformed this debate as it became possible to make nearly all aspects of the scientific research process easily accessible, from preliminary data to final publications. While arguments over fair allocation of rewards for scientific achievement versus full and early research dissemination remain challenging,27 and intellectual property management regularly introduces conflicts,28 the era of Open Science29, 30 (or indeed Open Innovation31) is here to stay and contributes to scientific advancement overall.32 Open‐access journals and data, and open‐source software have significant impacts on the Open Science movement.
2.1. The Rise of Open Access Publishing
Building on the foundations of the very first online journals, websites like arXiv (established in 1991) took the first steps in providing Open Access to scientific publications. As more content became available online, and the need for physical copies of journals in libraries rapidly diminished, many expected a significant reduction in the cost of journal subscriptions. When this did not happen, it catalyzed the Open Access movement and other alternatives to conventional scientific publishing practices. At present, over 50% of newly published articles are Open Access, and conservative estimates place achievement of complete Open Access by 2040.33, 34 Current Open Access approaches tend to fall into two classes (or hybrids thereof34): gold, where the article is freely available at the point of publication; and green, where the authors can deposit the article in a public repository, for example, at their home institution. Some publishers require an embargo period before deposition in a public repository, but there is little evidence in terms of publisher income to support the existence of such embargoes.27 Many funding agencies have embraced Open Access publishing as a way to improve public transparency and accountability, and these agencies have made it a condition for support—this includes all European Union funding for 2020 and beyond.35 As such, Open Access is at the heart of the Open Science movement and certainly overlaps with one of the critical developments in data‐driven science, Open Data.
2.2. Open Access Data
The initiative to make data Open Access can be traced to efforts to establish scientific global data centers in the 1950s,36 largely as a way to store data long term and make it internationally accessible—all data was fully available for the cost of printing and delivery. Following this change, demands for scientific data sharing continued to rise, especially after the development of the internet and the tantalizing prospect of easy upload and download of data globally.
While many scientists were quick to embrace this, it took a decade for Open Data to appear as a clear objective and topic for scientific policy. In 2004, science ministers of most developed countries signed an agreement that all publicly funded archive data should be made available, with the guidelines for this following in 2007.37 As is often the case, the scientific communities themselves were ahead of policy changes, and many bespoke scientific databases had already proliferated, providing data repositories in almost every field across the globe. There are now thousands of them, and finding useful ways to search for a relevant repository, let alone data within it, requires serious effort.38
Motivation to make this effort is increasing rapidly, with many journals and funding agencies demanding the availability of data tied to publication or grants. Contributing to many aspects of the Open Science initiative, the Public Library of Science39 has pioneered this development, with a clear policy on data sharing for its publications and likely rejection if policies are not followed. Other major publishers have also been active, with at least the creation of specific Open Data journals,40 policies,41 and collaboration with Open Data initiatives.42 Many funding agencies now insist on a data management plan with all submissions, and this plan must give a detailed account of how data will be stored, secured, and shared—with particular attention to the Open Science rules of the agency in question.
In an attempt to provide unifying guidelines for the widely varying groups interested in Open Data and to aid in data management development, the FAIR Data Principles were established.43, 44 These principles have been adopted by several major players in global data management (see Table 1 ). The ideas behind making data searchable, accessible, flexible, and reusable at the core of FAIR are also the concepts that make the power of data‐driven science actually attainable.
Table 1.
List of current major materials data infrastructures. The entries are divided into non‐commercial (top) and commercial (bottom). Note that some platforms are named after the leading research project and may host multiple services under different names. As contact person we listed the director(s) of each infrastructure, in such cases, where they were clearly identifiable. Data volume numbers reflect the state in April 2019
| Name | Website | Contact | Overview | Ref. |
|---|---|---|---|---|
| AFLOW | aflowlib.org | Stefano Curtarolo, Duke University | Computational data consisting of 2 118 033 material compounds and 281 698 389 calculated properties with focus on inorganic crystal structures. Incorporates multiple computational modules for automating high‐throughput first principles calculations. | 83, 91 |
| Computational Materials Repository | cmr.fysik.dtu.dk | Kristian Thygesen and Karsten Jacobsen, DTU | Computational datasets from a diverse set of applications. Data creation and analysis with the Atomic Simulation Environment (ASE). | 92, 93, 94 |
| Crystallography Open Database | crystallography.net | Open‐access collection of crystal structures of organic, inorganic, metal–organic compounds and minerals, excluding biopolymers. | 95, 96 | |
| HTEM | htem.nrel.gov | Caleb Phillips and Andriy Zakutayev, NREL | Properties of thin films synthesized using combinatorial methods. Contains 57 597 thin film samples, across a wide range of materials (oxides, nitrides, sulfide, intermetallics). | 97, 98 |
| Khazana | khazana.gatech.edu | Rampi Ramprasad, Georgia Institute of Technology | Platform to store structure and property data created by atomistic simulations, and tools to design materials by learning from the data. Tools include Polymer Genome and AGNI. | 99, 100, 101 |
| MARVEL NCCR | nccr‐marvel.ch | Nicola Marzari, EPFL | Materials informatics platform for data‐driven high‐throughput quantum simulations. Data available at materialscloud.org, powered by the AiiDA‐infrastructure. | 85 |
| Materials Data Facility (MDF) | materialsdatafacility.org | Ben Blaiszik and Ian Foster, University of Chicago | Data publication network for computational and experimental datasets. Data exploration through the Forge python package. | 102, 103 |
| Materials Project | materialsproject.org | Kristin Persson, LBNL | Online platform for materials exploration containing data of 86 680 inorganic compounds, 21 954 molecules and 530 243 nanoporous materials. Develops various open‐source software libraries, including pymatgen, custodian, FireWorks, and atomate. | 84, 104 |
| MatNavi/NIMS | mits.nims.go.jp | Yibin Xu, NIMS | An integrated material database system comprising ten databases, four application systems and the NIMS Structural Datasheet Online. | 105 |
| NOMAD CoE | nomad‐coe.eu | Matthias Scheffler, FHI/Max Planck Society | Provides storage for full input and output files of all important computational materials science codes, with multiple big‐data services built on top. Contains over 50 236 539 total energy calculations. | 106, 107 |
| Organic Materials Database | omdb.mathub.io | Alexander Balatsky, Nordita | Open access electronic structure database for 3‐dimensional organic crystals. Contains approximately 24 000 materials. | 108, 109 |
| Open Quantum Materials Database | oqmd.org | Chris Wolverton, Northwestern University | Database of DFT‐calculated thermodynamic and structural properties with focus on inorganic crystal structures. Contains 563 247 entries with support for full download and advanced usage through the qmpy python package. | 90, 110 |
| Open Materials Database | openmaterialsdb.se | Rickard Armiento, Linköping University | Computational database primarily based on structures from the Crystallography Open Database. Data creation and analysis with High‐Throughput Toolkit (httk). | 111, 112 |
| SUNCAT | suncat.stanford.edu | Thomas Francisco Jaramillo, SLAC/Stanford University | Materials informatics center for atomic‐scale design of catalysts. Online tools and computational results for 112 157 surface reactions and barriers available at catalysis‐hub.org. | 89, 113 |
| Citrine Informatics | citrine.io | Bryce Meredig and Greg Mulholland | A materials informatics platform combining data infrastructure and AI. Open database and analytics platform for material and chemical information available at the Citrination platform: citrination.com. | 114, 115 |
| Exabyte.io | exabyte.io | Timur Bazhirov | Cloud‐based modelling platform for materials informatics. | 116, 117 |
| Granta Design | grantadesign.com | Mike Ashby and David Cebon | R&D organization offering data, tools and expertise for materials design. | 118 |
| Materials Design | materialsdesign.com | Clive M. Freeman, Erich Wimmer and Stephen J. Mumby | Software products and services for chemical, metallurgical, electronic, polymeric, and materials science research applications. | 119, 120, 121 |
| Materials Platform for Data Science | mpds.io | Evgeny Blokhin | Online edition of the PAULING FILE with focus on curated experimental data for inorganic materials. | 122, 123 |
| MaterialsZone | materials.zone | Assaf Anderson and Barak Sela | Provides a notebook‐based materials informatics environment together with experimental data. | 124 |
| SpringerMaterials | materials.springer.com | Michael Klinge | Curated data covering multiple material classes, property types, and applications. A set of advanced functionalities for visualizing and analyzing data provided through SpringerMaterials Interactive. | 125 |
2.3. Open‐Source Software for Science
The development of open‐source software entails the final element of the Open Science movement. Its development started in parallel with the earliest computing hardware efforts, with nearly all software freely available in the public domain as part of large academic and corporate collaborations. Since the relative cost of software compared to hardware has increased, this openness began to steadily decline until the early 1980s with the launch of the GNU project and the parallel explosion of Linux and the internet in the early 1990s. This provided a powerful platform and toolset for the collaborative development of software that could then be freely downloaded, culminating in the active open‐source movement in 1997.45 In particular, it suited the kind of focused, rapidly changing software that characterizes nearly all scientific applications.
In 2005, the creation (by Linus Torvalds) and rapid adoption of Git as a distributed revision control system, closely followed by hosting site GitHub, put the seal on the standard approach for open‐source scientific software development that remains to this day. It became possible to manage updates to codes from a large development team, while providing a platform for feedback, bug notification, and feature requests from users. It is now possible to find Open Source software for nearly every aspect of a scientific project,46 from electronic lab notebooks,47 experimental toolsets,48 and simulation packages,49 to machine learning libraries50 and online collaborative writing sites.51 With freely accessible data, Open Access publications explaining the science behind it, and a wealth of open‐source software to mine it, the way is clear for innovative data‐driven science.
3. Materials Data Infrastructures
Having established the context for Open Science, we next review the emergence of materials data infrastructures that collect, host, and provide materials data to stakeholders. We first reflect on early digital materials infrastructures before discussing the current state.
3.1. Development of Materials Infrastructures
The increasing capabilities of first‐principles methods—and the increasing capabilities of computational science in general—have accelerated materials researchers interest for new, computer‐based pathways to materials discovery and design—better, faster, and cheaper than ever before. Perhaps one of the first attempts to use materials information in a different and more efficient way was the development of the Calculation of Phase Diagrams (CALPHAD, 1970s) method and database, in which multiple calculations of phase diagrams were put in a centralized database to speed up the design and development of new alloys.52 In the 1990s, the increasing capability to collect, store and analyze “big data” led researchers to explore the potential of data‐science in scientific research (for more information, see ref. 4). With these innovative ideas up in the air, material scientists at the Massachusetts Institute of Technology (MIT) developed tools to predict the properties of materials from datasets.53 Around the same time, researchers at the Technical University of Denmark demonstrated the potential of evolutionary algorithms in finding materials with specific properties,54 or to use high‐throughput screening for candidate materials with key parameters to narrow down the number of required experiments.55, 56, 57 The researchers at MIT even envisioned how with such computational tools a “virtual materials laboratory” could be build, in which new materials are designed and tested based on computer calculations.53 These ideas eventually led to the launch of a curated database that is now called the Materials Project.58, 59 This Open Access (see Section 2.2) database would use high‐throughput computing to uncover the properties of all known inorganic materials and enable future researchers to find appropriate materials through interactive exploration and data mining.59, 60
As big data and data science became increasingly fashionable, the US government announced the launch of the Materials Genome Initiative (MGI) in 2011.61 This initiative emphasized the usefulness of data informatics for materials discovery and design. As similar efforts were launched around the world promoting the availability and accessibility of digital data in science, a trend was set and a new paradigm of materials science emerged:5 data‐driven materials science. Set to reduce time and investment needed to support the typical 10–20 year research‐development‐commercialization cycle for new materials, more and more Open Access materials data initiatives opened worldwide, as illustrated by Figures 2 and 3 .
Figure 2.
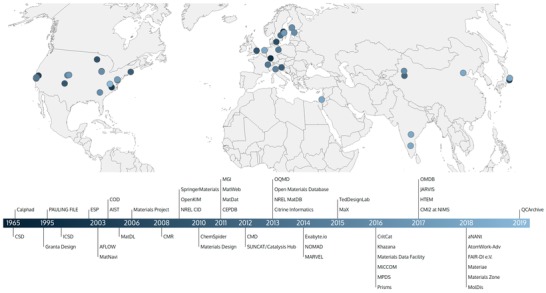
Timeline and geographic distribution of materials data infrastructures and companies. The colour of the dots represents the time of establishment. The map shows that historically more centers have emerged in the U.S. and Europe, with Asia catching up over time. In addition, the U.S. has a higher renewal rate than Europe, as can be seen in the larger number of ligher colored dots. CSD: Cambridge Structural Database, ICSD: Inorganic Crystal Structure Database, ESP: Electronic Structure Project, AFLOW: Automatic‐Flow for Materials Discovery, AIST: National Institute of Advanced Industrial Science and Technology Databases, COD: Crystallography Open Database, MatDL: Materials Digital Library, CMR: Computational Materials Repository, NREL CID: NREL Center for Inverse Design, CEPDB: The Clean Energy Project Database, MGI: Materials Genome Initiative, CMD: Computational Materials Network, OQMD: Open Quantum Materials Database, NOMAD: Novel Materials Discovery Laboratory, MaX: Materials Design at the Exascale, MICCOM: Midwest Integrated Center for Computational Materials, MPDS: Materials Platform for Data Science, CMI2: Center for Materials Research by Information Integration, HTEM: High Throughput Experimental Materials Database, JARVIS: Joint Automated Repository for Various Integrated Simulations, OMDB: Organic Materials Database, QCArchive: The Quantum Chemistry Archive.
Figure 3.
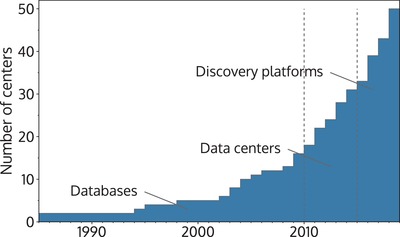
Number of materials informatics projects and infrastructures as function of time (see Figure 2 and Table 1 for details on individual projects and infrastructures). We divide the time axis into three periods that reflect the evolution of the data infrastructures (see text for details).
Most of the early materials data initiatives started as databases that hosted data and offered search functionality with the idea to encourage materials scientists to share their data with a larger community. The launch of the Materials Genome Initiative became a defining moment in data‐driven materials science (see Figure 3) as databases evolved into data centers that offered rudimentary materials and data analysis services. The emerging interest around data mining and AI made materials scientists increasingly eager to use such algorithms in their research. As a result, the focus of most centers transitioned to developing workflows that would enable scientists to search, mine, and query the databases. This marks another turning point in the history of data‐driven materials science, with infrastructures becoming materials discovery platforms (see Figure 3), whose self‐declared mission is to facilitate the discovery of novel materials.
The distinction between databases, data centers and materials discovery platforms introduced in the previous paragraph is based on the loose definitions given in the paragraph. The terminology reflects our impression of the evolution of materials data infrastructures and provides a simple classification scheme to distinguish different infrastructure types. For the remainder of the article, we will use materials data infrastructure as the most general and encompassing term to refer to either of the three types.
The spillover effect from data science to materials science is currently boosting the emerging field of data driven materials science or materials informatics.5 The computational possibilities of machines to analyze and detect patterns in data has created a new feedback loop in the relationship between hypothesis and experiment, which facilitates the next step to mix human trial‐and‐error experimental and computational research with “artificial intuition” (or to use data mining tools to approach human‐like intuition to suggest candidate materials that are further refined via computational and experimental research).
Big data and data science are also prevalent in other scientific fields. In chemistry, databases emerged earlier than in materials science,62, 63, 64 as exemplified by Chemical Abstracts Service (CAS), the principal chemical database provider65, 66 whose first database was created in 1965.66, 67 Carefully produced and curated datasets were essential for developments in quantum chemistry.68, 69, 70, 71 In particle physics, the CERN Open Data Portal72 offers more than 1 petabyte of open data for research conducted at their facilities. In biology, a variety of databases and metadatabases store biological information, for example, ConsensusPathDB73 for human protein–protein, genetic, metabolic, signaling, gene regulatory, and drug–target interactions; the protein data bank74 that houses 3D structural data of large biological molecules; and the International Nucleotide Sequence Database Collaboration75, 76 that collects and disseminates DNA and RNA sequences. In this perspective article, our focus is on materials science, but it is clear that the “4th scientific paradigm”4 is emerging in other fields as well.
3.2. Overview of Current Materials Infrastructures
Figure 3 depicts a clear rise of active materials infrastructures, many of which have developed into very mature and stable services used in everyday research processes.77, 78, 79, 80 Table 1 shows a summary of the most prominent materials discovery platforms in existence today. As these platforms have matured, the range of different services they provide has grown (for another perspective on the components of materials data infrastructures see ref. 21), and Table 2 shows their features. Data infrastructures that have emerged at the time of submission of this article, such as, e.g., QCArchive81 have not yet been included in Tabels 1 and 2.
Table 2.
Services provided by the selected materials data infrastructures. Open Access: provides partial or full free access to data. Computational data: contains data originating from software simulations. Experimental data: contains data originating from experiments. Data upload: allows upload of own data, with the possibility of issuing Digital Object Identifiers (DOIs). Workflow management tools: provide or collaborate in the development of open‐source software tools for workflow management. Web API: data can be accessed remotely with automated scripts. Data analysis tools: provide online or offline data analysis tools, including machine learning
| Open access | Comp. data | Exp. data | Data upload (DOIs) | Workflow management tools | Web API | Data analysis tools | |
|---|---|---|---|---|---|---|---|
| AFLOW | ✓ | ✓ | ✓ | ✓ | ✓ | ||
| Computational Materials Repository | ✓ | ✓ | ✓ | ✓ | |||
| Crystallography Open Database | ✓ | ✓ | ✓ | ✓ | |||
| HTEM | ✓ | ✓ | ✓ | ✓ | ✓ | ||
| Khazana | ✓ | ✓ | ✓ | ✓ | |||
| MARVEL NCCR | ✓ | ✓ | ✓ | ✓ | ✓ | ||
| Materials Data Facility (MDF) | ✓ | ✓ | ✓ | ✓ (DOI) a) | ✓ | ||
| Materials Project | ✓ | ✓ | ✓ | ✓ | ✓ | ||
| MatNavi/NIMS | ✓ | ✓ | ✓ | ✓ | |||
| NOMAD CoE | ✓ | ✓ | ✓ (DOI) | ✓ | ✓ | ||
| Organic Materials Database | ✓ | ✓ | ✓ | ||||
| Open Quantum Materials Database | ✓ | ✓ | ✓ | ||||
| Open Materials Database | ✓ | ✓ | ✓ | ✓ | ✓ | ✓ | |
| SUNCAT | ✓ | ✓ | ✓ | ✓ | |||
| Citrine Informatics | ✓ b) | ✓ | ✓ | ✓ | ✓ | ✓ | |
| Exabyte.io | ✓ | ✓ | |||||
| Granta Design | ✓ | ✓ | ✓ | ||||
| Materials Design | ✓ | ✓ | ✓ | ||||
| Materials Platform for Data Science | ✓ c) | ✓ | ✓ | ✓ | ✓ | ||
| Materials Zone | ✓ | ✓ | |||||
| Springer Materials | ✓ | ✓ |
Upload requires access to private/institutional storage space
Open access to a subset of data
Open access to limited set of materials properties.
Perhaps the most important service that a data platform has to offer is an efficient distribution channel for the data stored within. Often the data is accessible through a webpage that its clients can access online. This has the lowest adoption barrier since no additional software is needed and the data can be explored visually through a browser. Examples of such services include the Novel Materials Discovery Laboratory (NOMAD) Encyclopedia,82 AFLOWlib,83 the Materials Project,84 and the Materials Cloud.85 A browser‐based method is, however, rarely useful for materials informatics applications, which require automated access to large volumes of data. To facilitate access to large data volumes, it is typical to offer an application programming interface (API) to users to enable automatic data crawling. This is often done by defining a Representational State Transfer (REST) or GraphQL interface to the data.86, 87, 88, 89 These interfaces allow automated access through programmable queries. Another way, as adopted by OQMD,90 for example, is to offer an offline version of the database as a direct download to users. Offline access provides the most flexibility and performance but typically requires knowledge on how to interact with the underlying database with Structured Query Language (SQL) or object‐relational‐mapping (ORM). That said, a full download is not practical for large data volumes.
As the amounts of data produced by materials science increases, a practical concern over long‐term storage of this data is emerging. There is also increasing pressure from funding agencies and other institutions to ensure the correct and safe long‐term storage of data. To answer this demand, some data infrastructures now provide data storage services for materials data. Currently, Springer‐Nature lists two recommended data repositories for materials science:126 the NOMAD Repository107 and the Materials Cloud.127 Both of these free services are for computational materials data, accept uploads from any source, and guarantee data storage for at least 10 years after data deposition. Often the data volumes in experimental studies, especially in imaging, far outnumber computational efforts. For instance, electron microscopes can easily generate tens of gigabytes of data in a day of operation.128 Because of this higher volume, it is much more challenging to organize central and free data storage for experimental data. Instead the storage space is provided by the host university or laboratory, as in the case of the Materials Data Facility,102 which is a collaboration between US universities and research centers. In addition to the materials‐science‐specific storage solution, there are also free solutions to store generic scientific data, such as Zenodo,129 Dryad,130 Figshare,131 and Dataverse.132
The online analytics tools85, 117, 133 provided by data infrastructures are fairly modern additions that have emerged from the rise and popularity of interactive browser content and notebook‐based environments, such as the Jupyter notebook.134 These online tools range from simple tutorials to realistic materials property prediction and materials discovery through machine learning. They can be used without local hardware or software resources and have therefore become an important channel for dissemination and learning. Some platforms also participate in the development of Open Source software (see Section 2.3) libraries for performing offline data analysis on materials data.135, 136, 137, 138 Such libraries have high reuse value for scientists working with materials data and, through Open Source distribution and contribution mechanisms, can remain in active use beyond the lifetime of individual projects.
The value of materials data has also been recognized by materials informatics companies. We have included a selection of these companies in Tables 1 and 2. A major selling point of these companies is the access they provide to privately owned, highly curated materials property data that is inherently valuable in R&D. In sufficiently large quantities, this kind of materials data can help firms immensely in selecting optimal materials for products, without having to spend additional expenses on building their own research infrastructure. Another recently emerging business model revolves around selling access to software environments with a Software as a Service (SaaS) model. In this model, companies offer on‐demand access to preconfigured cloud‐based environments for materials informatics. Such services can be valuable for companies and research laboratories because they can be used according to current demand, do not require large one‐off investments in hardware, and do not require specialized skills in software configuration and system management.
3.3. Current Challenges
Having reviewed the current state of data infrastructures in materials science, we now return to the MUSE analogy. The previous two sections illustrated that despite enormous process in data‐driven materials science, several challenges need to be overcome before a powerful materials search engine and discovery tool takes shape. The challenges are depicted in Figure 4 and are raised here briefly before being discussed in detail in corresponding sections.
Figure 4.
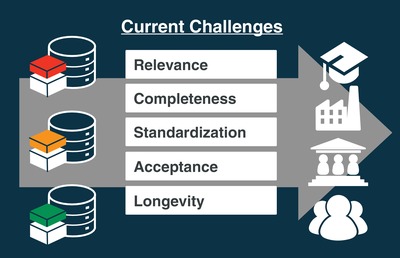
Challenges faced by materials data infrastructures (on the left) on the way to increase the adoption by stakeholders from academia, industry, governments and the public (depicted on the right).
3.3.1. Relevance and Adoption
Materials data infrastructures must provide relevant data and information to be adopted by stakeholders, be it scientific communities, industries, governments, or the public. Relevance is determined by data volume, data type, and data quality, and entails data completeness, and data homogeneity. Different communities will have different specifications of these terms, which makes it challenging to develop general and interdisciplinary infrastructures that can be adopted. Relevance and adoption are therefore closely related to the subsequent challenges of completeness, standardization, and acceptance.
Relevance also includes tools that operate on the data and help users to classify, analyze, and correlate data. Machine learning has gained the most prominence in this regard and is reviewed in Section 7. Since machine learning is always data hungry, it makes sense to integrate machine learning applications directly into materials data infrastructures. Challenges to such one‐stop‐shop solutions, which would increase the acceptance of materials infrastructures, include the wide variety of available machine learning approaches and data diversity. For data to be informative for machine learning algorithms, its features and properties need to be relevant and complete.
3.3.2. Completeness
Completeness is “the quality of being whole or perfect and having nothing missing.” While ideal completeness is hard to attain in practice, data infrastructures today suffer from a real, severe completeness problem: they contain mostly computational and almost no experimental data (cf. Table 2). This state of affairs is rooted in the historic development of data‐driven materials science presented in Section 3.1. Since computational data comes in a digital format, computational scientists were early adopters of database platforms. Moreover computational data is currently more homogeneous and easier to curate than experimental data.139 Facilitating a seamless comparison between computational and experimental data is, however, an important step toward validating theoretical predictions and in driving materials discovery and development efforts:139 materials that are identified as promising still require further evaluation, selection, and experimentation. Building synergies among computational and experimental databases thus remains an important challenge for the future of data‐driven materials science, which we address in Sections 4 and 5.
3.3.3. Standardization
Some form of standardization is essential in the widespread adoption of a new paradigm or technology.140, 141 Stakeholders can only participate in the development of a technology if they speak a common language. The language analog in data‐driven materials science is metadata. Metadata provides relations (the grammar) between data items (the words). Developing standardized metadata for materials science that is informative, exhaustive, and adaptable is an outstanding challenge. We address the first steps toward creating a materials ontology in Section 4. Such an ontology, or classification system, would be the foundation for materials science metadata and the evolution of different materials science dialects into a common language.
3.3.4. Acceptance and Ecosystems
Materials data infrastructures will only be useful if they are accepted as a useful tool by various stakeholders. Apart from being relevant and complete, data infrastructures have to be user friendly to be widely adopted. User friendliness includes easy upload and download of data. Easy data upload also facilitates completeness since it reduces hurdles to data sharing. Widespread acceptance furthermore requires trust in the stored data, and this can only be achieved through data curation. Data curation is the management and quality control of data throughout its lifecycle, from creation and initial storage to the time when it is archived for posterity or becomes obsolete and is deleted. We address the challenges pertaining to data creation and curation in Sections 5 and 6.
Infrastructure acceptance is different for different stakeholders. Current infrastructures are predominantly built and used by scientists in academia, as detailed in the previous section. Industry interest and participation has not been systematically studied, and it is dependent mostly on anecdotal evidence. Some materials companies leverage the value of reference databases (e.g., IBM142 and ASM International143), while others contract the services of intermediaries (cf. Table I and Table II). Apart from this, industry seems to still be exploring the opportunities and potential benefits of materials informatics144 without full engagement with academia.
The disconnect between academic and corporate R&D in many fields makes industry involvement more difficult in this specific case. A hurdle to widespread industry adoption is the materials gap—the fact that industry requires other data than what is currently stored in the available materials data platforms. Ecosystems that facilitate the interaction between academic, corporate, governmental, and public stakeholders are a potential solution that we discuss further in Section 9.
3.3.5. Longevity and Diffusion
With increasing awareness for open and data‐driven science, national, and international funding for the development of Open Science (see Section 2) is rising, and new materials data platforms are emerging in their wake. However, longevity and diffusion of innovations and new technologies are rarely considered by funding agencies, and long‐term financial support for sustained operation is not guaranteed. The initial wave of digital materials infrastructures were built predominantly by materials scientists whose main focus lies in basic science. The long‐term maintenance and usability of infrastructure is often only a secondary priority for most scientists. As a result, these digital infrastructures are in danger of becoming digital ruins of the expansion of Open Science. We discuss potential solutions in Section 9.
Next we explore central topics and applications around data‐driven materials science to provide insight into these challenges and into the successes of data‐driven materials science.
4. Materials Ontology
We begin our more detailed review sections with the relevance, completeness, and standardization challenges. One of the first decisions in the planning of a materials data infrastructure is which types of materials will be relevant to its intended user base. The most complete representation of these materials will then have to be stored in the database of the infrastructure. The storage requires standardization and the development of metadata formats. Storing only the raw materials data without any metadata would be futile because raw data is neither searchable nor suitable for machine learning.
The development of a metadata framework requires materials classification schemes from which metadata entries and relations can be derived. Crude classification schemes group materials by their functional properties (electronic, optical, mechanical), topological characteristics (bulk, surface, nanotube, polymer, see Figure 5 ), or by material type (ceramics, metals, glasses, polymers, or composites). More sophisticated classification schemes are clearly needed to facilitate data‐driven materials science. In addition, the origin of the raw data needs to be encoded in the metadata. For real samples, these would be the synthesis and processing conditions and the history of the sample since creation. For virtual samples, the generating computer code and the computational settings need to be known. This clearly demands the classification and organization of materials data in a materials ontology.
Figure 5.
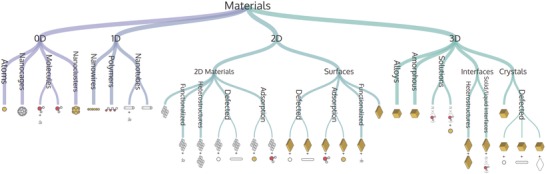
Example of an ontological hierarchy for the structural characterization of materials: a materials tree of life. Adapted under the terms of the Creative Commons Attribution 4.0 International License.145 Copyright 2018, the Authors, Published by Springer Nature.
Ontology is originally a field of philosophy defined as the study of properties, events, processes, and relations of existence.146 In computer science, the term ontology has been co‐opted to more specifically mean a formal collection of entities, relationships between those entities, and inference rules that are shared by a community. In materials science, a materials ontology would be a classification scheme for materials, their properties, units, and limits, and their interrelations. Defining an ontology is conceptually important for the purpose of establishing a standard that can be shared by different people working with the same data, and it is a practical necessity in database design. The ontology concept is also closely linked to the ability to search data: the ontology defines the available search terms and facilitates semantic reasoning, which then facilitates complex searches.
Creating the necessary machinery for ontologies in materials science is a tremendous task. An ontology structure has to be developed, suitable formats and standards for encoding meaning have to be defined, and wide‐spread adoption of the ontology has to be ensured. For example, a substantial part of information available on the internet today consists of human written text. To interpret the information contained within this text requires human reasoning or sophisticated natural language processing software. But there is a complementary standard by the World Wide Web Consortium called Semantic Web that defines an explicit, machine‐readable format (Resource Description Framework, RDF) to organize information on the web. It provides an ontology language (Web Ontology Language, OWL) to describe ontologies for sharing concepts across content creators.147 If this semantic web standard were embraced by the web community, it would significantly boost information sharing across the internet and unleash the power of automated semantic reasoning by artificial intelligence.148 As of now, this powerful idea remains largely unrealized.
Similarly in materials science, a standardized ontology that ensures a complete representation of materials has not yet emerged. Currently various ontologies and less‐than‐formal standards compete. NOMAD Meta‐info,86, 149 ESCDF,86 and OpenKIM150 are the first attempts to categorize computational results in atomistic materials science. PLINIUS151 is used in the field of ceramics, ONTORULE152 in the steel industry, SLACKS153 for laminated composites, and PIF,154 Ashino,155 EMMO,156 MatOnto,157 Premap,158 and MatOWL159 represent general materials science data. Although the development of these materials ontologies has accelerated, they are not nearly as mature as in other fields, for example, the biosciences.160 Especially for industrial purposes, these publicly available ontologies are typically insufficient, forcing companies to create their own internal, domain‐specific ontologies.156
The lack of standardization aggravates data sharing. Computational science, for example, still relies on file‐based data exchanges between different codes. Such file‐based data exchange requires interfacing software, significant human resources, and expertise on how the data is structured. Moreover, incompatible standards lead to conversion errors and data loss. These interoperability problems could be solved by a common ontology and a standardized representation of knowledge within this ontology. Fitting existing and novel data into such an ontological framework would still be a tedious and error‐prone task for humans. Existing tools and techniques could, however, be used to simplify and automate this process. Data curation services161 help in organizing and annotating data, natural language processing can be used to mine data from scientific literature,162, 163 and automated structural classification helps in categorizing the contents.145, 164, 165
The ontologies themselves could also be constructed semiautomatically by observing the nomenclature and the relation of concepts used in the literature.166, 167 If widely adopted in materials infrastructures, this standardization would enable the vision of a powerful search platform for materials science. Once defined and filled, AI solutions would benefit from it. One could envision virtual AI agents helping scientists to answer complex questions related to material performance and synthesis by analyzing materials databases and scientific literature. Such AI agents would not only aid basic research, they would also help businesses that could then more effectively leverage existing scientific knowledge in their R&D.
Recently there have been promising efforts in trying to unify the nomenclature and standards in materials science by the European Materials Modelling Council,156 the Research Data Alliance (RDA),168 and by a collaboration between NOMAD scientists and the Centre Européen de Calcul Atomique et Moléculaire (CECAM).86 A concrete example of such collaboration is the Open Databases Integration for Materials Design (OPTiMaDe) consortium.169 OPTiMaDe is building a common interface for accessing data from multiple materials platforms. The diversity of subfields and stakeholders in materials science might make it impossible to define one universal materials ontology. We, however, recommend that unifying ontologies whenever possible and disseminating these efforts to the materials science community are key steps in making the most out of the rich body of materials data created with the modern experimental and computational methods discussed next.
In summary, standardization facilitates data sharing. A materials ontology is a classification scheme for materials that enables standardization. Ontologies also ensure completeness of materials data since everything that falls outside of an ontology by definition indicates a lack of completeness in the ontology. Attempts at constructing materials ontologies are underway. However, more needs to be done to ensure that relevant materials and relevant materials properties are incorporated into existing materials infrastructures. Otherwise our MUSE will return irrelevant information when queried.
5. Data Creation
We now stay with the challenges of relevance and completeness and address how enough relevant data can be generated to feed a materials infrastructure. Once again, we encounter standardization but this time in the context of standards for generating data. We briefly review techniques and recent improvements in data creation methodology—so‐called high‐throughput methods—that are enabling experimental and computational scientists to efficiently create data for data‐hungry repositories and applications.
For experimental materials data, the introduction and refinement of deposition and analysis methods has had perhaps the greatest impact on data creation efficiency. In 1965, the first composition gradients could be achieved in thin‐film material codeposition,170 offering a more efficient replacement for the one‐by‐one creation and study of materials. Since then, multiple improved materials synthesis and characterization techniques have been introduced.171, 172, 173, 174, 175 They have enabled the rapid generation of composition–structure–property relationships.176, 177, 178, 179, 180 State‐of‐the‐art deposition techniques, such as combinatorial laser‐molecular beam epitaxy (CLMBE)173 introduced around the year 2000, can be used to create temperature and composition gradients across the sample and provide control of the deposition in three dimensions.
These new methods facilitate a finer and more complete sampling of structural phases and chemical compositions in a single experiment. They efficiently create materials libraries—experimental samples with one or more composition or phase gradients. Each library represents part of a well‐defined materials space. Measurements from such materials libraries are now made accessible through Open Access online services, such as the High Throughput Experimental Materials (HTEM) database.97
In contrast, and perhaps surprisingly, the high‐throughput creation of computational materials data has only become common practice in the 21st century.90, 181, 182 Thanks to Moore's law and massively parallel computing architectures, available computational power has increased steadily, and computational data creation has quickly taken advantage of this power, even surpassing experimental efforts. For example, the Open Quantum Materials Database (OQMD) performs virtual high‐throughput materials synthesis by decorating known crystal structure prototypes with new elements. It has now grown from the initial set of roughly 30,000 experimentally known crystal structures from Inorganic Crystal Structure Database (ICSD) to more than 560,000 computationally predicted materials.90, 110 High‐throughput workflows have now matured and are increasingly applied to screen also complex properties such as coupling and reorganization energies in organic crystals.183, 184
In the creation of such massive datasets, it is increasingly important to adhere to computational standards. This standardization has been pioneered by the Materials Project and the Automatic‐Flow for Materials Discovery (AFLOW)‐consortium (see Table 1), with comprehensive specifications for the methodological details, such as k‐point grid densities, cutoff energies, pseudopotentials, and convergence criteria, related to density functional theory (DFT) calculations.185, 186, 187 This standardization ensures that data can be made cross‐compatible within a database or even across databases.
Relatively recent additions to computational materials science are workflow management tools like FireWorks,188 atomate,189 AiiDa,190 and AFLOWπ.191 These tools enable researchers to build automated and robust workflows for creating consistent datasets. Workflows connect different computational steps and checks into a single computational graph. The computational steps generate data, and checks aid with automated recovery from errors that might occur in a computational step, for instance due to incorrect computational settings or hardware failures. An example of a workflow graph from FireWorks is given in Figure 6 .
Figure 6.
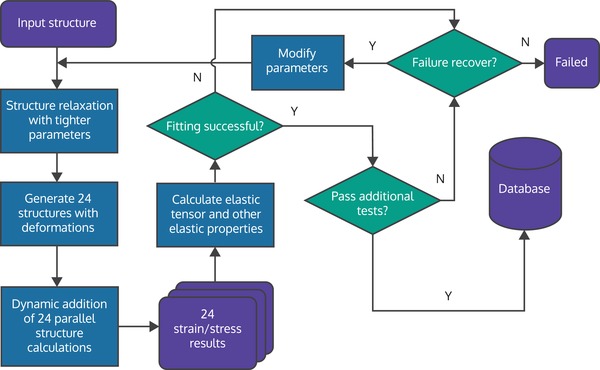
A computational workflow used in creating a dataset of elastic tensors with the FireWorks workflow manager. The indigo boxes correspond to inputs or results, lighter blue boxes correspond to actions, and green diamonds correspond to decisions. Adapted with permission.188 Copyright 2019, Wiley.
In summary, materials data needs to be created in sufficient volumes for materials infrastructures to be relevant and complete enough. To fulfill this need, high‐throughput experimental and computational methods have emerged. The level of automation and efficiency provided by these methods ensures that the bandwidth at which materials data can be created should not be an issue for the MUSE of the future.
6. Data Quality
From data generation, we move on to data quality. As already alluded to in the previous section, the quality of data is related to standardization in the generation of data and considerably affects the acceptance of data infrastructures.
Big data is often characterized in terms of four Vs: volume, velocity, variety, and veracity. Each V poses a challenge, although the volume challenge could, in principle, be solved by more storage space, and the velocity challenge of faster data generation could be addressed by faster computer processing and accelerated measurement and fabrication techniques. Increased variety is more a challenge for standardization and ontology integration, yet it is also a benefit for machine learning and materials discovery algorithms. Veracity, however, is the most problematic because it is a softer measure of how to quantify the degree of trust in data and how to improve its trustworthiness.
Data veracity has two aspects: bias and variance. In an experiment or a calculation, the bias of the result is quantified as the offset of the average result from the ground truth, whereas variance is quantified by its probabilistic definition as the spread of the results over identical runs. Note that the variance and bias discussed here originate from approximations in theoretical models or experimental uncertainties, not from stochastic processes in the experiment or calculations, for example in molecular dynamics simulations. We also disambiguate the use of bias and variance here from the same terminology commonly used in machine learning.
For users of data infrastructures, it is important to know the quality of available datasets. However both data bias and its veracity may be hard to quantify.
In the computational realm, variance can be caused by different computational environments or differences in implementation but it is typically negligible even between different software implementations.192 Computational variance is also often one or several orders of magnitude lower than the corresponding experimental variance.193 The veracity of computational data is thus dominated by bias—offset from the experimental ground truth. The estimation of this bias depends on access to experimental data or comparison to results from a higher‐level theory.194 The bias also depends on the types of chemical elements in the materials. Some computational approaches or approximations may break down for specific groups of elements, such as dispersion‐governed compounds, magnetic materials, strongly correlated materials, and relativistic effects in heavy elements, leading to much larger errors for these groups of materials.193
While computational scientists have full control over their simulations, experimental scientists often face errors that are beyond the control of their experimental setup. Bias in measurements can be due to incomplete knowledge of a sample's content and history, as well as interactions between the sample and the environment. Variance can be caused by material imperfections and contaminants, and experimental uncertainties introduced by the equipment. As such, it is typically difficult to discriminate between bias and variance in experimental errors. If there are no comparable experimental facilities, this can also make it hard to assess the data quality. In some cases, quality‐controlled commercial equipment and widely accepted standard procedures are available when performing measurements. However, there is often a need to use custom‐built equipment or to measure materials for which the standard procedures are not applicable, making it harder to reproduce and validate results. This difficulty of controlling more elaborate experimental setups means that reliable experimental data exists for simple systems, such as small molecules195 or elemental crystals,193 but for more complex systems and measurements, the data quality may be harder to determine.
The combination of high bias in computational results and the difficulty of controlling errors in experiments makes the overall estimation of data veracity in materials science particularly hard. One example is given by the formation energies of crystals for which computational and experimental values notably differ. This discrepancy is caused by both systematic errors in the computational methodology and experimental uncertainties.196 Due to the species‐specific nature of the computational error and the vastness of compositional and structural space, it is impossible to make an exhaustive brute‐force comparison between experiment and computation. However intelligent error extrapolation schemes are being developed. In one such scheme, the computational error of nonconverged energies for crystals with two different chemical species—compared to fully converged energies—can be estimated by using a linear combination of errors from solids with only one chemical species.197 Such schemes could also be extended to estimate the error between experimental and computational data. This will require systematic data collection from both experiment and computation but it may prove to be fertile for practical error estimation.
In summary, data quality is important to ensure standardization of data and to increase acceptance of data infrastructures, but it is challenging to quantify. Two indicators of quality are bias and variance. Systematic data collection and new extrapolation schemes would facilitate bias and variance assessments in the future.
7. Data Analytics
To increase the adoption of data infrastructures, developers are adding tools and apps to their data platforms that operate directly on the data in the infrastructure's database. These tools add value to the data and enhance its relevance. Many tools now include machine learning. Here we briefly review the main types of machine learning and illustrate how they could add value to material infrastructures.
7.1. Introduction to Machine Learning
Machine learning is the scientific study of how to construct computer programs that automatically improve with experience.198 More specifically, machine learning algorithms use statistical models and optimization algorithms to reveal patterns in training data to make predictions or decisions without being explicitly programmed to perform a certain task. The advantage over human learning is that computers can often handle much larger and higher dimensional data, and suitable approximations can be automatically found by monitoring how well the models generalize to unseen data.
Many of the statistical methods in machine learning have been around for decades. For example, Marvin Minsky built the first hardware implementation of a neural network199 in 1951. Our current AI boom has been facilitated by the rapid hardware development for information storage and processing, the conscious effort of data gathering and curation, as well as increased developments of machine learning methods and libraries by private companies, the public sector and academia, driven by the potential that machine learning can unlock from previously untapped data resources. Today machine learning is a key ingredient of materials informatics, as showcased by various reviews on the topic.5, 8, 9, 10, 13, 14, 17, 18, 22, 23
Machine learning can be divided into different subfields that are characterized by the available data. Supervised learning is the most mature and powerful of these subfields and is used in the majority of machine learning studies in the physical sciences.17 Supervised learning applies in situations where a machine learning model is trained on input–output pairs from a real process to produce optimal outputs for unseen inputs. Typical applications are predictions of physical properties (like formation energies200, 201, 202 or molecular properties203, 204, 205, 206, 207) given the input features of a material or process (e.g., geometry, physical properties, external conditions).
In unsupervised learning, only input data is given to a model but no output. The machine is then tasked with a learning objective, for example to find rankings or patterns for this input. Unsupervised learning is often used to preprocess input data, such as dimensionality reduction by principal component analysis (PCA),208, 209 or aiding the analysis of complex output data like visualization of high‐dimensional data with T‐distributed stochastic neighbor embedding (T‐SNE)97, 210 or sketchmap.211
Finally reinforcement learning is a rapidly emerging field with promising applications in tasks that require machine creativity. In reinforcement learning, a model is given a task of choosing a set of actions to optimize a long‐term goal. As such, it differs from supervised learning because no correct input–output pairs are presented for individual actions, but the training is a mixture of exploration and exploitation guided by a long‐term reward.212 This mode of learning can be useful in the exploration of compound and material spaces like exploration of grain‐boundary structures with evolutionary algorithms213 and the search for new molecules with objective‐reinforced generative adversarial networks.214
The knowledge contained in a machine learning model is encoded in the parameters of the model, and it is, in principle, tractable. However the number of parameters can reach into the millions, which makes these models quite opaque to human interpretation. This is different from the scientific approach thus far, which has relied on deriving and discovering physical laws that are encoded in humanly readable equations. For commercial applications, the transparency of the models is not as important as their performance, but for advancing scientific understanding and wider acceptance, better human interpretability would be beneficial. Recent examples of approaches that analyze machine learning models to reveal their mechanisms include the analysis of input feature importance,200 explicit formulation of the input in algebraic form,215, 216 and analysis of convolutional neural network filters.217
7.2. Specifics of Machine Learning in Materials Science
Currently the applications of machine learning in materials science are rich and diverse, ranging from catalyst design,19, 80 exploring the mechanisms of high‐temperature superconductivity,218, 219 to predicting excitation spectra.206 Building such applications can generally be broken down to four key steps: data acquisition, feature engineering, model building, and analysis. These steps are illustrated in Figure 7 . They are, however, interdependent and often multiple iterations of each step are required to create a successful machine learning system. Specialized software frameworks220, 221, 222 have been developed to aid the set‐up and build and management of machine learning models.
Figure 7.
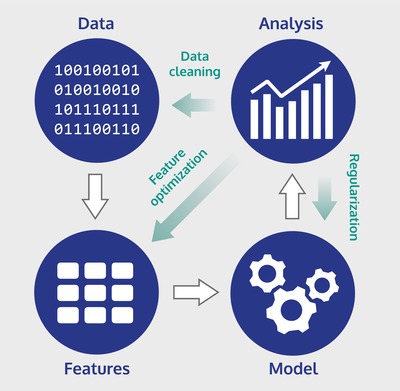
Key steps in building a machine learning model. The white arrows indicate the flow of data, green arrows indicate actions that can be identified and performed after analysis to improve the performance of the model.
While machine learning generally requires data, the amount of data depends on the specific problem. Figure 8 illustrates the trade‐off between the available data volume and the complexity of the underlying process for different machine learning approaches. Problems in the top‐left corner are not suitable for machine learning due to the low amount of available data. The further to the right a problem sits, the more suitable it becomes for machine learning. In practice, it is often difficult to place machine learning methods and new problems in this diagram. Thus rapid prototyping of the problem is frequently a key to successful machine learning. Since we have control over only one of these parameters—the amount of data—the importance of open data access, materials databases, efficient data creation, and data veracity is paramount for the success of machine learning.
Figure 8.
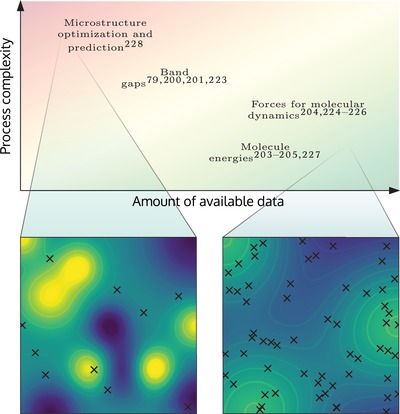
The machine learning domain in terms of data volume and the complexity of the physical process, with selected examples placed in this domain. The complexity of a physical process here means the complex, nonlinear structures present in the data. Two opposing learning scenarios, a hard and an easy one, are illustrated in the lower panel. In these two cases, the underlying physical process is represented by a colored contour map, and the sampling of this process is represented by black crosses.223, 224, 225, 226, 227, 228
Machine learning models expect input data in alpha‐numerical form, typically as an array of letters or more often as numbers. Raw data, however, is usually unsuitable for machine learning. The first task in building a machine learning model is therefore to extract informative features from the raw data (cf. Figure 7). Feature engineering refers to the act of introducing domain expertise to the learning model by affecting which features are used. It can be beneficial to apply problem‐specific feature transformations, called feature extraction,212 which exploit known symmetries in the input for example, making it easier for the model to learn a unique mapping. This can be especially important for input features that encode atomic geometries. Physical properties exhibit symmetries with respect to translation, rotation, and index permutation in the Cartesian coordinates representing a geometry. Using a transformation that makes the input invariant with respect to these symmetries will help the learning process by creating a unique mapping from an atomic geometry to its properties. Such structural descriptors have been successfully applied in the prediction of molecular and crystalline properties,203, 205, 229 and there their development has exploded in recent years.202, 203, 205, 229, 230, 231, 232, 233, 234, 235, 236, 237, 238 To facilitate easier navigation through descriptor choices, application‐neutral software libraries for descriptors are being developed.239, 240 In contrast to human‐driven feature engineering, the optimal features can also be discovered more systematically by learning them directly from the data with feature learning. In the simplest form this can be achieved by methods like principal component analysis (PCA),208 which is based on the variance of the input features. In the other extreme, the features may be formed by an encoder as a nonlinear latent space within an autoencoder neural network.241 Analyzing the features used by the machine learning model in making a decision forms the basis of understanding and verifying the correctness of the model. Integrating such analysis into the workflow of building machine learning models is still lacking in many cases, hindering their acceptance and interpretability.
After feature selection (cf. Figure 7), the machine learning algorithm must be chosen (see different machine learning types discussed at the beginning of this section). Each algorithm has its own application domain, and there is currently no algorithm that is optimal for all problems.10 This conundrum is also known as the “no free lunch theorem.”242 Some common choices include feed‐forward neural networks,243 decision trees,244 kernel ridge regression,245 support vector regression,245 and Gaussian processes.246 These approaches are common in computer science and are available in generic software packages that help select the best model for a task.50, 247, 248, 249, 250, 251, 252, 253, 254 Apart from such generic approaches and packages, machine learning models are often customized to materials science. One example is the creation of custom neural network architectures201, 204, 206, 255, 256 that have been designed specifically for atomistic geometries, reducing the need for feature engineering.
One practical concern in model selection is the amount of data that is available for training the model. Methods like kernel ridge regression require an inversion of a matrix whose size is proportional to the number of training samples. This restricts their usability for large datasets because the time taken by a brute force inversion scales as with the dataset size n. Other models like neural networks can handle larger datasets since they can be trained by using small batches of the training data, and their performance can be monitored during training. At the other end of the spectrum we find powerful tools for small datasets such as, regression with Gaussian processes and Bayesian optimization,18, 257 the extraction of effective materials descriptors with subgroup discovery258 or compressed sensing as done in, e.g., the least absolute shrinkage and selection operator (LASSO) or the sure independence screening and sparsifying operator (SISSO).215, 216 Also some forms of input are better suited for certain models. For example, images exhibit a high degree of correlation between adjacent input points. Models that exploit such correlations, like convolutional neural networks,259 may then be the best choice. In other cases, the input features have no apparent correlations or have completely different numerical ranges, and decision trees may exhibit the best performance.244
The final step in the machine learning workflow is the performance assessment (cf. Figure 7). This analysis guides all other aspects of learning ‐ from excluding corrupt learning samples to optimizing the features and the model itself. The analysis step is general for all application areas of machine learning. For a more in‐depth introduction, we refer the reader to existing literature.198, 212 The goal of this step is to ensure that the model generalizes well to unseen data. Two common problems are over‐ and underfitting. In over‐fitting, the model becomes too specific. It reproduces the training data very well but performs poorly on new data. In underfitting, the model learns rules that are too general and averages through training and through new data. The balancing act between over‐ and underfitting is called the bias‐variance trade‐off, and it is typically controlled with cross‐validation and careful dataset design. The whole dataset is usually split into a training set, from which a further validation set for hyperparameter optimization can be split off, and a test set. Model performance is then evaluated on the test set. The dataset contents and the exact way the data is split into training and test sets can affect the reported performance and in some cases lead to unrealistic results. Often the sampling of training examples is not very even in the input space, as the samples can exhibit high levels of clustering—for example, the dataset may comprise of multiple clustered material types that have very similar properties. In such cases the model is able to interpolate very well even if it has only been trained on one representative of each cluster, but its performance will start to deteriorate for unseen material types, which are hard to leave out of the training set with purely random selection. Due to this effect randomly split training and test sets can offer unrealistic performance metrics and alternative cross‐validation strategies like leave‐one‐cluster‐out cross‐validation (LOCO CV)260 offer more realistic performance metrics.
All the key elements for successfully applying machine learning in materials science are in place, as illustrated also by the applications showcased in the next section. However, several challenges prevail. For example, selecting the optimal combination of data, features, machine learning models and analysis tools can be a formidable task, especially because the field is advancing so rapidly and practices become outdated quickly. Careful curation and standardization of both data and machine learning models can to some degree mitigate the problem, but not enough benchmark sets have been established in the community. Also, available data volumes are often still too small to apply machine learning tools that have been successful in other domains, e.g., commerce or social media.
Another challenge is the exchange of pre‐trained models. Projects such as OpenML261 and DLHub262 are first examples for model‐and‐data sharing platforms that enable transfer learning, but more could be done. Metric assessment is a further challenge. The reported performance for machine learning models is an important selection criterion for adopting certain models or features. However, performance metrics are not yet standardized. Standardized datasets help, but more attention should be devoted to the selection of test and training sets to obtain more realistic error bars.
We have already discussed the challenge of interpretability. As the exact way input data informs the machine learning model is often blindly guided by the model optimization and hidden behind internal parameters, better methods for interpreting the decisions made by machine learning models are required. Although the natural sciences rarely have to worry about ethical consequences—unlike the social sciences that are now adopting AI into their decision making263 —a critical evaluation of the decision mechanisms is important for understanding the shortcomings of machine learning models and to advance scientific understanding.
In summary, machine learning is a powerful concept for data analysis and materials informatics. Machine learning is a field undergoing very active development, and a plethora of suitable machine learning methods has been applied to materials science. Increasingly such machine learning tools are incorporated directly into data infrastructures. In our MUSE analogy, they will provide meaningful answers to our “searches.”
8. Applications
Staying with relevance and adoption, we now briefly present areas in which data‐driven materials science has been applied successfully. Success stories are important for the development of any field as they inspire trust and commitment in stakeholders. We have identified three major research objectives for which we think data‐driven approaches have the largest impact on materials science: materials discovery, understanding materials phenomena, and advancing materials modelling. We review these three areas briefly and present relevant studies.
Materials discovery is a complex problem in which a list of target specifications are given and the optimal material is sought. Such discovery is often performed by using a forward solution—simply calculating the key properties for a pool of candidate materials to identify the best ones for further in‐depth analysis, characterization, and verification. By using existing or dynamically generated materials data, scientists can build heuristic models (often through machine learning) to dramatically speed up the identification of best candidate materials for experimental synthesis. Although experimental synthesizability is often a bottleneck, there are multiple studies that have verified that this approach has the power to accelerate the discovery of novel or improved materials. The examples that have already resulted in experimentally synthesized novel compounds include new molecules for efficient organic light emitting diodes (OLEDs),264 polymer dielectrics for electrostatic energy storage,265 novel gallide Heusler structures,266 NiTi‐based shape memory alloys with small thermal dissipation,267 lead‐free piezoelectrics268 and metallic glasses,269 and high‐entropy alloys270 for structural applications requiring hardness and corrosion resistance. Furthermore, multiple novel materials identified by this virtual screening are awaiting experimental validation, including photovoltaics,271, 272 photoelectrochemical water splitting materials,273, 274 topological insulators,275, 276 and novel binary or ternary crystal structures.277, 278
If the desired candidate material is not in the pool of materials that are being screened with the forward solution, then it cannot be found in this way. In such cases, the problem has to be inverted, that is, a mapping from the target property space to materials space has to be found. For solid clusters, simple inverse relations have recently been established between X‐ray absorption (XAS) spectroscopy279, 280, 281 and coordination shells of atoms. For molecules, neural‐network‐based auto encoders and decoders282 were combined with a grammar‐based variational autoencoder283 to map from the discrete molecular space into a continuous latent space (in which optimizations can be performed) and back again. Even with such sophisticated models, it is not easy to generate valid, synthesizable molecules and materials with the wanted properties, and inverse predictions remain difficult in practice.
Historically new materials were often discovered by first understanding fundamental materials phenomena and then applying them to look for other materials that might fit the same physical laws. Machine learning based predictions conceal these physical laws and do not provide the same understanding of materials‐property relations. By changing the objective to understanding the underlying materials phenomena (asking why instead of what), we can hope to use reductionistic approaches to transcribe data into laws and equations that are more typically associated with scientific progress. In vast and high‐dimensional materials data landscapes, for which human‐intuition is ill‐suited, this discovery of materials phenomena can be aided by a data‐driven approach. The fundamental mathematical formulation of physical laws, such as conservation laws and differential equations, can be automatically deduced from data.284, 285, 286 Methods based on compressed sensing215, 216 provide a systematic way of identifying the algebraic form of the descriptors that capture the underlying mechanisms behind material properties, providing a more natural basis for human interpretation. These methods have been successful in identifying physically meaningful descriptors that control the stability of perovskites287 and monolayer metal oxides coatings.288 Another idea is to map high‐dimensional data into more easily human analyzable two‐ or 2D maps with unsupervised learning. This idea of “materials cartography” has been used to identify common features for high‐temperature superconductor materials,218 to group molecules into intuitive maps that can reveal key structure–property relations,211 find phase transitions in complex systems,289 or establish the key descriptors in the catalytic properties of metal surfaces.290
The final application area is related to advancing materials modelling with automated construction of surrogate models directly from data. These surrogate models can replace the laborious fitting of semiempirical models, and if trained with highly accurate data are able to reproduce complex chemical phenomena with very low computational cost by sacrificing some of the accuracy. Such AI‐based modelling tools are able to assist even in very challenging tasks, as demonstrated by IBM RXN291—a free online tool that uses a machine translation inspired architecture to predict the product of chemical reaction from the structural formulas of the reactants. Another example is the creation of classical force fields from DFT training data.204, 224, 225, 226, 292
The promise of these methods is to achieve near DFT‐level accuracy in the physical and chemical description of a system but at the much lower computational cost that is closer to classical force fields. These machine learned force fields enable studies of systems and mechanisms that have so far been out of the realm of computational studies, such as identifying the growth mechanism of amorphous carbon coatings293 under deposition and the composition and activity of nanoclusters in aqueous solutions.294 The implementations have now also made their way into established molecular dynamics software, where they can in some cases be used as a plug‐and‐play replacement for traditional force fields.295, 296, 297, 298
Going one step up in the theoretical ladder, energies of very accurate, yet computationally very expensive coupled cluster theory calculations have been learned.22, 299, 300, 301 Another example is the training of exchange‐correlation functionals or direct potential‐to‐density mappings from density or wave‐function based methods.302, 303 Such efforts are an exciting step in expanding existing theoretical knowledge to new time and size regimes in materials modelling.
In summary, machine learning and data‐driven approaches are being applied in materials science. The wider the range of successful applications, the higher the acceptance of materials data infrastructures will be. New applications will, in turn, challenge established machine learning methods, which will have to be further developed to address these challenges. This creates a feedback loop with developments in computer and data science and ensures that our MUSE continues to learn.
9. Stakeholder Relations
In previous sections, we have addressed the acceptance of materials data infrastructures from a technological viewpoint. We now reflect on how materials data infrastructures are currently received by different stakeholders. Strong support from stakeholders is needed to guarantee the diffusion of innovations to a wider pool of stakeholders and to ensure the longevity of data infrastructures.
Materials scientists in academia are actively pushing the frontiers of materials informatics to advance and accelerate materials design and discovery. However emerging fields require the interaction of various actors and stakeholders from different communities (academia, government, industry, and the public, cf. Figure 9 a) to generate understanding of the field and negotiate community boundaries.304 A recent socioeconomic study investigated the emerging field of data‐driven materials science. It identified that the field is scattered and largely lacking a supportive ecosystem with nonacademic stakeholders.305, 306
Figure 9.
a) Schematic of an ecosystem in data‐driven materials science with materials data platforms at the center. In this ecosystem, different stakeholders from universities, the public, industry, and government facilitate the development of a technology. b–d) Possible relationships between data platforms and industry, discussed in the text.
The socioeconomic study identified visionary scientists at academic institutions who have pursued their idiosyncratic research objectives using trending topics in public discussions and governmental funding, including Open Science, Big Data, and AI. At the same time, government and funding agencies have provided strategic research openings focused on propelling the field of data‐driven science in general. However, the focus on materials science applications or on finding and developing industry applications has been limited by the lack of targeted funding opportunities. With the exception of the US, which released substantial government funding to advance the field of data‐driven materials science via the Materials Genome Initiative,61 most government‐sponsored funding schemes have been more general. In the European Union, two successful projects have been funded (MaX307 and NOMAD CoE106). However both centers were facilitated by the European Union's Horizon 2020 high‐performance computing grants rather than funding schemes focused on data‐driven materials science. Until now, no call tailored to the exploration and exploitation of data‐driven materials science has been issued by the EU, although this may change in the new framework program. Nevertheless national differences exist. For example in Switzerland, the importance of data‐driven materials science has been acknowledged by the support for the MARVEL National Center of Competence in Research (NCCR).85 In 2018 in Finland, a Future Makers funding call was opened specifically focused on the initiation of “high‐level, ambitious strategic research openings that combine internationally top‐level science and industrial impact … to build long‐term sustainable renewal and competitiveness of the Finnish technology industry based on … data‐based materials science”.308 Despite the call, none of the applications from materials science were funded.
The socioeconomic study further concludes that industry has remained seemingly reluctant to invest in data‐driven scientific applications in materials research and development. This reluctance could be driven by government hesitation to fund data‐driven materials science, but it could also be the result of the material industries' desire to work with proprietary databases, the generally long timeframe for the development of new materials (10–20 years), and/or the limited number of manufacturing employees with informatics backgrounds.144 Industries do, however, capitalize on the creation and appropriation of (new) knowledge,309 and new materials could advance such fields as health, energy, aerospace, automotive, semiconductor, and consumer goods:144 materials informatics provides unprecedented opportunities for an industry to better use the existing vast “storehouses of information” 310 that firms possess to propel materials innovation at greater rates and lower costs. Despite the potential gains, uptake by industrial partners is challenging. Although materials companies generate enormous quantities of R&D data, this data is often undocumented and intangible. Before proprietary databases could be created, the archival data of companies needs to be structured, connected, and updated. Ignoring the identified challenges—acceptance (easy data upload and download, data curation, materials gap), standardization, and longevity—slows down industry adoption of data‐driven materials science even further. In addition, firms face significant challenges to become or transform into data‐driven organizations as they require different skills, knowledge, and resources.311
To capitalize on their data, three business models can be applied or are considered for application.305, 306 First, firms can consult and collaborate directly with established data platforms (see Figure 9b), for example those discussed in Figures 2 and 3. Traditionally such collaborations take the form of strategic interfirm alliances that influence companies' potential for knowledge creation.312 Propelled by the drive for Open Science from policy players, Open Innovation is another potential form of collaboration in which firms open their internal innovation processes by purposefully allowing knowledge to freely circulate among all actors to accelerate internal innovation.31 As a result, such data platforms offer data and services that can be used by academia and industries alike.
In the second model, if a firm does not wish to collaborate, it can consider building a proprietary digital infrastructure by dedicating a large, one‐off investment in hardware and by acquiring software and specialized skills in software configuration and system management313 (Figure 9c). This integration requires attracting computer scientists or materials scientists with extensive coding capabilities.
A final business model is developed around new intermediaries that position themselves between data platforms and industry (Figure 9d). Examples of such new intermediaries are materials informatics companies—often spin‐off companies from academic efforts—that sell access to privately owned, highly curated materials property data that can be linked to data repositories within the firm and used in R&D processes. Collaboration with start‐ups and companies (e.g., Citrine Informatics, Exabyte.io, Materials Design, and Granta Design115, 116, 118, 121) can help firms develop new skills, capabilities, and knowledge.312, 314
Each of these data platform–industry relationships have implications for the larger ecosystem of data‐driven materials science. That is, industry and academia often hold contradicting interests. From the academic perspective, commercial business opportunities stimulate private data ownership and proprietary databases (e.g., Figure 9c), which can be detrimental for scientific progress since valuable data stays locked in the private domain. Furthermore, industries outside materials science are quickly recruiting academic employees with new coding and machine learning expertise in the field; this raises concerns over a possible “brain drain” from universities. Nevertheless the establishment and institutionalization of data science and machine learning for materials science within educational institutions could result in an increase in research funding, students, and industry interest or collaboration.305
At the same time, industries' need for these newly‐skilled employees raises fear of “job loss” among established scientists within R&D departments in those firms. However, materials that are identified as promising through the materials informatics paradigm still require further evaluation, selection, experimentation, certification, and manufacturing. Building synergies among computational and experimental researchers therefore remains a key enabler toward reaping the benefits of data‐driven materials science in firms.305
In summary, the field of data‐driven materials science is still in its infancy, with an emerging ecosystem, ongoing community boundary negotiations, limited governmental funding, and an as yet disinterested industry. To establish data‐driven materials science as a new paradigm in materials research, joint ecosystem efforts between research, industry, and public and governmental organizations are necessary.
10. Take‐Home Messages
In this review article, we provide an overview of the current state of data‐driven materials science. From a historical perspective, the field has matured greatly, but we identify key challenges—relevance, completeness, standardization, acceptance, and longevity—that still need to be resolved to create the MUSE. Better standardization of materials data through a materials ontology would immensely help sharing, integrating, and employing AI‐powered analysis of materials data. Creating feedback mechanisms between experimental and computational data for error estimation provides a way toward solving the veracity problem in materials data. The use of machine learning is transformational for research, but it requires conscious efforts in the curation and standardization of both data and machine learning models, and techniques to make the models more interpretable. The synergy between academic developments and industrial interest remains a major challenge, but it is key to creating a sustainable ecosystem for materials data and expertise. Despite these challenges, there has been a dramatic rise in data‐driven materials science using the full spectrum of this new paradigm. And doubtless we have only seen a glimpse of this data‐driven revolution.
Conflict of Interest
The authors declare no conflict of interest.
Acknowledgements
The authors thank Nina Granqvist, Kunal Ghosh, Ben Alldritt, Antti M. Rousi, Milica Todorović, Sven Bossuyt, Miguel Caro, David Gao, Matthias Scheffler, Bryce Meredig, and Heidi Henrickson for insightful discussions and a careful reading of our manuscript. Computing resources from the Aalto Science‐IT project and CSC IT Center for Science, Finland, are gratefully acknowledged. This project had received funding from the European Union's Horizon 2020 research and innovation programme under grant agreement number 676580 with The Novel Materials Discovery (NOMAD) Laboratory, a European Center of Excellence, and from the Jenny and Antti Wihuri Foundation. This work was furthermore supported by the Academy of Finland through its Centres of Excellence Programme 2015–2017 under project number 284621, as well as projects 305632, 311012, and 314862. A.S.F. was supported by the World Premier International Research Center Initiative (WPI), MEXT, Japan. This article is part of the Advanced Science 5th anniversary interdisciplinary article series, in which the journal's executive advisory board members highlight top research in their fields.
Himanen L., Geurts A., Foster A. S., Rinke P., Data‐Driven Materials Science: Status, Challenges, and Perspectives. Adv. Sci. 2019, 6, 1900808 10.1002/advs.201900808
References
- 1. Ceder G., Science 1998, 280, 1099. [Google Scholar]
- 2. Eagar T. W., Technol. Rev. 1995, 98, 42. [Google Scholar]
- 3. Boren M., Chan V., Musso C., In McKinsey on Chemicals, Vol. 4 McKinsey & Company Industry Publications, 2012. [Google Scholar]
- 4. Hey T., Tansley S., Tolle K., The Fourth Paradigm: Data‐Intensive Scientific Discovery, Microsoft Research, Redmond, WA, USA: 2009. [Google Scholar]
- 5. Agrawal A., Choudhary A., APL Mater. 2016, 4, 053208. [Google Scholar]
- 6. Schwab K., The Fourth Industrial Revolution, https://www.foreignaffairs.com/articles/2015-12-12/fourth-industrial-revolution (accessed: August 2019).
- 7. Brynjolfsson E., McAfee A., Second Machine Age. Work, Progress, and Prosperity in a Time of Brilliant Technologies, W. W. Norton & Company, New York City, NY, USA: 2014. [Google Scholar]
- 8. Rajan K., Mater. Today 2005, 8, 38. [Google Scholar]
- 9. Rajan K., Annu. Rev. Mater. Res. 2015, 45, 153. [Google Scholar]
- 10. Liu Y., Zhao T., Ju W., Shi S., J. Materiomics 2017, 3, 159. [Google Scholar]
- 11. Zdeborová L., Nat. Phys. 2017, 13, 420. [Google Scholar]
- 12. Rupp M., Int. J. Quantum Chem. 2015, 115, 1058. [Google Scholar]
- 13. Ramprasad R., Batra R., Pilania G., Mannodi‐Kanakkithodi A., Kim C., npj Comput. Mater. 2017, 3, 54. [Google Scholar]
- 14. Ward L., Wolverton C., Curr. Opin. Solid State Mater. Sci. 2017, 21, 167. [Google Scholar]
- 15. Mueller T., Kusne A. G., Ramprasad R., Machine Learning in Materials Science. John Wiley & Sons, Hoboken, NJ, USA: 2016, Ch. 4, pp. 186–273. [Google Scholar]
- 16. Zunger A., Nat. Rev. Chem. 2018, 2, 0121. [Google Scholar]
- 17. Butler K. T., Davies D. W., Cartwright H., Isayev O., Walsh A., Nature 2018, 559, 547. [DOI] [PubMed] [Google Scholar]
- 18. Gubernatis J. E., Lookman T., Phys. Rev. Mater. 2018, 2, 120301. [Google Scholar]
- 19. Goldsmith B. R., Esterhuizen J., Liu J. X., Bartel C. J., Sutton C., AIChE J. 2018, 64, 2311. [Google Scholar]
- 20. Takahashi K., Tanaka Y., Dalton Trans. 2016, 45, 10497. [DOI] [PubMed] [Google Scholar]
- 21.The Minerals Metals & Materials Society (TMS), Building a Materials Data Infrastructure: Opening New Pathways to Discovery and Innovation in Science and Engineering. TMS, Pittsburgh, PA: 2017. [Google Scholar]
- 22. Bartók A. P., De S., Poelking C., Bernstein N., Kermode J. R., Csányi G., Ceriotti M., Sci. Adv. 2017, 3, 12. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 23. Gu G. H., J. Noh, I. Kim, Y. Jung, J. Mater. Chem. A 2019, 7, 17096. [Google Scholar]
- 24. Walsh K., editor, Open Innovation, Open Science, Open to the World—A Vision for Europe, European Commission, Luxembourg City, Luxembourg: 2016. [Google Scholar]
- 25. Regazzi J. J., Scholarly Communications: A History from Content as King to Content as Kingmaker, Rowman & Littlefield, Lanham: 2015. [Google Scholar]
- 26. Fanelli D., Proc. Natl. Acad. Sci. USA 2018, 115, 2628. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 27. Tennant J. P., Waldner F., Jacques D. C., Masuzzo P., Collister L. B., Hartgerink C. H. J., F1000Research 2016, 5, 632. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 28. Esanu J. M., Uhlir P. F., in The Role of Scientific and Technical Data and Information in The Public Domain: Proc. of A Symp. The National Academies Press, Washington, D.C. 2003. [PubMed] [Google Scholar]
- 29. Open Science , https://openscience.com (accessed: August 2019).
- 30. FOSTER , https://www.fosteropenscience.eu (accessed: August 2019).
- 31. Chesborough H. W., Open Innovation: The New Imperative for Creating and Profiting from Technology. Harvard Business Press, Brighton, MA, USA: 2006. [Google Scholar]
- 32. McKiernan E. C., Bourne P. E., Brown C. T., Buck S., Kenall A., Lin J., McDougall D., Nosek B. A., Ram K., Soderberg C. K., Spies J. R., Thaney K., Updegrove A., Woo K. H., Yarkoni T., eLife 2016, 5, 372. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 33. When will everything be Open Access?, https://blog.impactstory.org/oa-by-when/ (accessed: August 2019).
- 34. Piwowar H., Priem J., Larivière V., Alperin J. P., Matthias L., Norlander B., Farley A., West J., Haustein S., PeerJ 2018, 6, e4375. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 35. Schiltz M., PLOS Biol. 2018, 16, 1. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 36. ICSU World Data System , https://www.icsu-wds.org (accessed: August 2019).
- 37. OECD , OECD Principles and Guidelines for Access to Research Data from Public Funding, OECD Publishing, Paris, France: 2007. [Google Scholar]
- 38. re3data.org , https://www.re3data.org (accessed: August 2019).
- 39. PLOS , https://www.plos.org (accessed: August 2019).
- 40. Scientific Data , https://www.nature.com/sdata/ (accessed: August 2019).
- 41. Sharing Research Data for Journal Authors , https://www.elsevier.com/authors/author-services/research-data (accessed: August 2019).
- 42. CODATA , The Committee on Data for Science and Technology, https://www.codata.org (accessed: August 2019).
- 43. Wilkinson M. D., Dumontier M., Aalbersberg I. J., Appleton G., Axton M., Baak A., Blomberg N., Boiten J.‐W., da Silva Santos L. B., Bourne P. E., Bouwman J., Brookes A. J., Clark T., Crosas M., Dillo I., Dumon O., Edmunds S., Evelo C. T., Finkers R., Gonzalez‐Beltran A., Gray A. J. G., Groth P., Goble C., Grethe J. S., Heringa J., t Hoen P. A. C., Hooft R., Kuhn T., Kok R., Kok J., et al., Sci. Data 2016, 3, 160018. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 44. Draxl C., Scheffler M., MRS Bull. 2018, 43, 9. [Google Scholar]
- 45. Kelty C. M., Two Bits: The Cultural Significance of Free Software, Duke University Press Books, Durham, NC, USA: 2008. [Google Scholar]
- 46. The OpenScience Project , https://openscience.org (accessed: August 2019).
- 47. Kwok R., Nature 2018, 560, 269. [DOI] [PubMed] [Google Scholar]
- 48. Horcas I., Fernández R., Gómez‐Rodríguez J. M., Colchero J., Gómez‐Herrero J., Baro A. M., Rev. Sci. Instrum. 2007, 78, 013705. [DOI] [PubMed] [Google Scholar]
- 49. Plimpton S., J. Comput. Phys. 1995, 117, 1. [Google Scholar]
- 50. Pedregosa F., Varoquaux G., Gramfort A., Michel V., Thirion B., Grisel O., Blondel M., Prettenhofer P., Weiss R., Dubourg V., Vanderplas J., Passos A., Cournapeau D., Brucher M., Perrot M., Duchesnay E., J. Mach. Learn. Res. 2011, 12, 2825. [Google Scholar]
- 51. Overleaf , https://www.overleaf.com (accessed: August 2019).
- 52. Kaufman L., Agren J., Scr. Mater. 2014, 70, 3. [Google Scholar]
- 53. Ceder G., Aydinol M. K., Kohan A. F., Comput. Mater. Sci. 1997, 8, 161. [Google Scholar]
- 54. Jóhannesson G. H., Bligaard T., Ruban A. V., Skriver H. L., Jacobsen K. W., Nørskov J., Phys. Rev. Lett. 2002, 88, 255506. [DOI] [PubMed] [Google Scholar]
- 55. Greeley J., Nørskov J. K., Surf. Sci. 2007, 601, 1590. [Google Scholar]
- 56. Hummelshøj J., Abild‐Pedersen F., Studt F., Bligaard T., Nørskov J. K., Angew. Chem. 2012, 124, 278; Angew. Chem., Int. Ed 2012, 51, 272. [DOI] [PubMed] [Google Scholar]
- 57. Greeley J., Jaramillo T. F., Bonde J., Chorkendorff I., Nørskov J. K., Nat. Mater. 2006, 5, 909. [DOI] [PubMed] [Google Scholar]
- 58. Ceder G., Morgan D., Fischer C., Tibbetts K., Curtarolo S., MRS Bull. 2006, 31, 981. [Google Scholar]
- 59. Jain A., Ong S. P., Hautier G., Chen W., Richards W. D., Dacek S., Cholia S., Gunter D., Skinner D., Ceder G., Persson K. a., APL Mater. 2013, 1, 011002. [Google Scholar]
- 60. Jain A., Hautier G., Moore C. J., Ong S. P., Fischer C. C., Mueller T., Persson K. A., Ceder G., Comput. Mater. Sci. 2011, 50, 2295. [Google Scholar]
- 61. Materials Genome Initiative , https://www.mgi.gov/ (accessed: August 2019).
- 62. Hann M., Green R., Curr. Opin. Chem. Biol. 1999, 3, 379. [DOI] [PubMed] [Google Scholar]
- 63. Noordik J., Cheminformatics Developments: History, Reviews and Current Research, IOS Press, Clifton, VA, USA: 2004. [Google Scholar]
- 64. Willett P., Wiley Interdiscip. Rev. Comput. Mol. Sci. 2011, 1, 46. [Google Scholar]
- 65. Baker D. B., Horiszny J. W., Metanomski W. V., J. Chem. Inf. Model. 1980, 20, 193. [Google Scholar]
- 66. Weisgerber D. W., J. Assoc. Inf. Sci. Technol. 1997, 48, 349. [Google Scholar]
- 67. Leiter D. P., Morgan H. L., Stobaugh R. E., J. Chem. Doc. 1965, 5, 238. [Google Scholar]
- 68. Curtiss L. A., Raghavachari K., Trucks G. W., Pople J. A., J. Chem. Phys. 1991, 94, 7221. [Google Scholar]
- 69. Curtiss L. A., Raghavachari K., Redfern P. C., Pople J. A., J. Chem. Phys. 1997, 106, 1063. [Google Scholar]
- 70. Goerigk L., Grimme S., J. Chem. Theory Comput. 2011, 7, 291. [DOI] [PubMed] [Google Scholar]
- 71. Mata R. A., Suhm M. A., Angew. Chem. 2017, 129, 11155; Angew. Chem., Int. Ed 2017, 56, 11011. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 72. CERN Open Data Portal , https://opendata.cern.ch (accessed: August 2019).
- 73. Wierling C., Lehrach H., Herwig R., Kamburov A., Nucleic Acids Res. 2008, 37, D623. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 74. Berman H., Henrick K., Nakamura H., Nat. Struct. Biol. 2003, 10, 980. [DOI] [PubMed] [Google Scholar]
- 75. Karsch‐Mizrachi I., Takagi T., Cochrane G., Nucleic Acids Res. 2011, 40, D33. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 76. Brunak S., Danchin A., Hattori M., Nakamura H., Shinozaki K., Matise T., Preuss D., Science 2002, 298, 1333. [DOI] [PubMed] [Google Scholar]
- 77. Sarker P., Harrington T., Toher C., Oses C., Samiee M., Maria J.‐P., Brenner D. W., Vecchio K. S., Curtarolo S., Nat. Commun. 2018, 9, 4980. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 78. Xie T., Grossman J. C., Phys. Rev. Lett. 2018, 120, 145301. [DOI] [PubMed] [Google Scholar]
- 79. Pilania G., Mannodi‐Kanakkithodi A., Uberuaga B. P., Ramprasad R., Gubernatis J. E., Lookman T., Sci. Rep. 2016, 6, 19375. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 80. Jäger M. O. J., Morooka E. V., Canova F. F., Himanen L., Foster A. S., npj Comput. Mater. 2018, 4, 37. [Google Scholar]
- 81. QCArchive , https://qcarchive.molssi.org (accessed: August 2019).
- 82. NOMAD Encyclopedia , https://encyclopedia.nomad-coe.eu (accessed: August 2019).
- 83. AFlow—Automatic FLOW for Materials Discovery , https://aflowlib.org (accessed: August 2019).
- 84. Materials Project , https://materialsproject.org (accessed: August 2019).
- 85. Materials Cloud , https://www.materialscloud.org (accessed: August 2019).
- 86. Ghiringhelli L. M., Carbogno C., Levchenko S., Mohamed F., Huhs G., Lüders M., Oliveira M., Scheffler M., npj Comput. Mater. 2017, 3, 46. [Google Scholar]
- 87. Taylor R. H., Rose F., Toher C., Levy O., Yang K., Nardelli M. B., Curtarolo S., Comput. Mater. Sci. 2014, 93, 178. [Google Scholar]
- 88. Ong S. P., Richards W. D., Jain A., Hautier G., Kocher M., Cholia S., Gunter D., Chevrier V. L., Persson K. A., Ceder G., Comput. Mater. Sci. 2013, 68, 314. [Google Scholar]
- 89. Catalysis Hub , https://www.catalysis-hub.org/ (accessed: August 2019).
- 90. Saal J. E., Kirklin S., Aykol M., Meredig B., Wolverton C., JOM 2013, 65, 1501. [Google Scholar]
- 91. Curtarolo S., Setyawan W., Wang S., Xue J., Yang K., Taylor R., Nelson L. J., Hart G., Sanvito S., Nardelli M. Buongiorno, Mingo N., Levy O., Comput. Mater. Sci. 2012, 58, 227. [Google Scholar]
- 92. Castelli I. E., Landis D. D., Thygesen K. S., Dahl S., Chorkendorff I., Jaramillo T. F., Jacobsen K. W., Energy Environ. Sci. 2012, 5, 9034. [Google Scholar]
- 93. Computational Materials Repository , https://cmr.fysik.dtu.dk (accessed: August 2019).
- 94. Landis D. D., Hummelshøj J. S., Nestorov S., Greeley J., Dułak M., Bligaard T., Nørskov J. K., Jacobsen K. W., Comput. Sci. Eng. 2012, 14, 51. [Google Scholar]
- 95. Gražulis S., Daškevič A., Merkys A., Chateigner D., Lutterotti L., Quirós M., Serebryanaya N. R., Moeck P., Downs R. T., Le Bail A., Nucleic Acids Res. 2011, 40, 420. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 96. Crystallography Open Database , https://crystallography.net (accessed: August 2019).
- 97. Zakutayev A., Wunder N., Schwarting M., Perkins J. D., White R., Munch K., Tumas W., Phillips C., Sci. Data 2018, 5, 1. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 98. HTEM , https://htem.nrel.gov (accessed: August 2019).
- 99. Khazana: A Computational Materials Knowledgebase , https://khazana.gatech.edu/ (accessed: August 2019).
- 100. Kim C., Chandrasekaran A., Huan T. D., Das D., Ramprasad R., J. Phys. Chem. C 2018, 122, 17575. [Google Scholar]
- 101. Botu V., Batra R., Chapman J., Ramprasad R., J. Phys. Chem. C 2017, 121, 511. [Google Scholar]
- 102. Blaiszik B., Chard K., Pruyne J., Ananthakrishnan R., Tuecke S., Foster I., JOM 2016, 68, 2045. [Google Scholar]
- 103. The Materials Data Facility (MDF) , https://materialsdatafacility.org (accessed: August 2019).
- 104. Jain A., Ong S. P., Hautier G., Chen W., Richards W. D., Dacek S., Cholia S., Gunter D., Skinner D., Ceder G., Persson K. A., APL Mater. 2013, 1, 011002. [Google Scholar]
- 105. NIMS Materials Database (MatNavi) , https://mits.nims.go.jp/index_en.html (accessed: August 2019).
- 106. The Novel Materials Discovery (NOMAD) Laboratory , https://nomad-coe.eu/ (accessed: August 2019).
- 107. NOMAD Repository , https://repository.nomad-coe.eu (accessed: August 2019).
- 108. Borysov S. S., Geilhufe R. M., Balatsky A. V., PLOS ONE 2017, 12, 1. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 109. Organic Materials Database , https://omdb.mathub.io (accessed: August 2019).
- 110. OQMD , https://oqmd.org (accessed: August 2019).
- 111. Open materials database , https://openmaterialsdb.se/ (accessed: August 2019).
- 112. The high‐throughput toolkit (httk) , https://httk.openmaterialsdb.se (accessed: August 2019).
- 113. SUNCAT , https://suncat.stanford.edu/ (accessed: August 2019).
- 114. O'Mara J., Meredig B., Michel K., JOM 2016, 68, 2031. [Google Scholar]
- 115. Citrine Informatics , https://citrine.io/ (accessed: August 2019).
- 116. Exabyte.io , https://exabyte.io/ (accessed: August 2019).
- 117. Bazhirov T., Mohammadi M., Ding K., Barabash S., presented at APS March Meeting Abstracts, 2017, C1.007.
- 118. Granta Design , https://www.grantadesign.com/ (accessed: August 2019).
- 119. Rozanska X., Stewart J. J. P., Ungerer P., Leblanc B., Freeman C., Saxe P., Wimmer E., J. Chem. Eng. Data 2014, 59, 3136. [Google Scholar]
- 120. Rozanska X., Ungerer P., Leblanc B., Saxe P., Wimmer E., Oil Gas Sci. Technol. 2015, 70, 405. [Google Scholar]
- 121. Materials Design Inc , https://www.materialsdesign.com/ (accessed: August 2019).
- 122. Blokhin E., Villars P., in Handbook of Materials Modeling: Methods: Theory and Modeling (Eds: Andreoni W., Yip S.), Springer International Publishing, Dordrecht, Netherlands: 2018, pp. 1–26. [Google Scholar]
- 123. Materials Platform for Data Science , https://mpds.io (accessed: August 2019).
- 124. MaterialsZone , https://www.materials.zone (accessed: August 2019).
- 125. SpringerMaterials , https://materials.springer.com (accessed: August 2019).
- 126. Springer Nature Recommended Repositories , https://www.springernature.com/de/authors/research-data-policy/repositories/12327124 (accessed: August 2019).
- 127. Materials Cloud , https://www.materialscloud.org (accessed: August 2019).
- 128. Kalidindi S. R., De Graef M., Annu. Rev. Mater. Res. 2015, 45, 171. [Google Scholar]
- 129. Zenodo , https://zenodo.org/ (accessed: August 2019).
- 130. Dryad , https://datadryad.org (accessed: August 2019).
- 131. Figshare , https://figshare.com (accessed: August 2019).
- 132. The Dataverse Project , https://dataverse.org (accessed: August 2019).
- 133. NOMAD Big‐Data Analytics , https://analytics-toolkit.nomad-coe.eu/home/ (accessed: August 2019).
- 134. Kluyver T., Ragan‐Kelley B., Pérez F., Granger B., Bussonnier M., Frederic J., Kelley K., Hamrick J., Grout J., Corlay S., Ivanov P., Avila D., Abdalla S., Willing C. (Eds: Loizides F., Schmidt B.), Positioning and Power in Academic Publishing: Players, Agents and Agendas. IOS Press, Clifton, VA, USA: 2016, 87–90. [Google Scholar]
- 135. Larsen A. H., Mortensen J. J., Blomqvist J., Castelli I. E., Christensen R., Dułak M., Friis J., Groves M. N., Hammer B., Hargus C., Hermes E. D., Jennings P. C., Jensen P. B., Kermode J., Kitchin J. R., Kolsbjerg E. L., Kubal J., Kaasbjerg K., Lysgaard S., Maronsson J. B., Maxson T., Olsen T., Pastewka L., Peterson A., Rostgaard C., Schiøtz J., Schütt O., Strange M., Thygesen K. S., Vegge T., et al., J. Phys. Condens. Matter 2017, 29, 273002. [DOI] [PubMed] [Google Scholar]
- 136. Ong S. P., Richards W. D., Jain A., Hautier G., Kocher M., Cholia S., Gunter D., Chevrier V. L., Persson K. A., Ceder G., Comput. Mater. Sci. 2013, 68, 314. [Google Scholar]
- 137. qmpy , https://oqmd.org/static/docs/index.html (accessed: August 2019).
- 138. NOMAD CoE , nomad‐lab, https://gitlab.mpcdf.mpg.de/nomad-lab (accessed: August 2019).
- 139. Alberi K., Nardelli M. B., Zakutayev A., Mitas L., Curtarolo S., Jain A., Fornari M., Marzari N., Takeuchi I., Green M. L., Kanatzidis M., Toney M. F., Butenko S., Meredig B., Lany S., Kattner U., Davydov A., Toberer E. S., Stevanovic V., Walsh A., Park N.‐G., Aspuru‐Guzik A., Tabor D. P., Nelson J., Murphy J., Setlur A., Gregoire J., Li H., Xiao R., Ludwig A., et al., J. Phys. D 2018, 52, 013001. [Google Scholar]
- 140. Garud R., Jain S., Kumaraswamy A., Acad. Manag. J. 2002, 45, 196. [Google Scholar]
- 141. Brunsson N., Rasche A., Seidl D., Organ. Stud. 2012, 33, 613. [Google Scholar]
- 142. Johnson R. C., IBM Launches Accelerated Discovery Lab, https://www.eetimes.com/document.asp?doc_id=1319758 (accessed: August 2019).
- 143. ASM International online databases , https://www.asminternational.org/materials-resources/online-databases (accessed: August 2019).
- 144. Meredig B., Curr. Opin. Solid State Mater. Sci. 2016, 21, 159. [Google Scholar]
- 145. Himanen L., Rinke P., Foster A. S., npj Comput. Mater. 2018, 4, 52. [Google Scholar]
- 146. Smith B., Blackwell Guide to the Philosophy of Computing and Information (Ed: Floridi L.). Blackwell Publishers, Cambridge, MA, USA: 2003, pp. 155–166. [Google Scholar]
- 147. Feigenbaum L., Herman I., Hongsermeier T., Neumann E., Stephens S., Sci. Am. 2007, 297, 90. [PubMed] [Google Scholar]
- 148. Berners‐Lee T., Hendler J., Lassila O., Sci. Am. 2001, 284, 34.11396337 [Google Scholar]
- 149. NOMAD Meta Info , https://metainfo.nomad-coe.eu/nomadmetainfo_public/archive.html (accessed: August 2019).
- 150. Tadmor E. B., Elliott R. S., Sethna J. P., Miller R. E., Becker C. A., JOM 2011, 63, 17. [Google Scholar]
- 151. Vet P. E., Speel P.‐h., Mars N., in Proc. of 11th European Conference on Artificial Intelligence (ECAI'94) (Ed: A. G. Cohn), John Wiley & Sons, New York, NY, USA: 1994, pp. 187–205. [Google Scholar]
- 152. de Sainte Marie C., Iglesias Escudero M., Rosina P., In Rudolph S., Gutierrez C., editors, Web Reasoning and Rule Systems. Springer Berlin Heidelberg, Berlin, Heidelberg, 2011, pp. 24–29. [Google Scholar]
- 153. Premkumar V., Krishnamurty S., Wileden J. C., Grosse I. R., Adv. Eng. Inform. 2014, 28, 91. [Google Scholar]
- 154. Michel K., Meredig B., MRS Bull. 2016, 41, 8, 617. [Google Scholar]
- 155. Ashiron T., Data Sci. J. 2010, 9, 54. [Google Scholar]
- 156. European Materials Modelling Council , Report on Workshop on Interoperability in Materials Modelling, 2017.
- 157. Cheung K., Drennan J., Hunter J., in AAAI Spring Symposium: Semantic Scientific Knowledge Integration (Eds: McGuinness D. L., Fox P., Boyan B.), The AAAI Press, Menlo Park, CA, USA: 2008, pp. 9–14. [Google Scholar]
- 158. Bhat M., Shah S., Das P., Kumar P., Kulkarni N., Ghaisas S. S., Reddy S. S., in ICoRD'13 (Eds: Chakrabarti A., Prakash R. V.), Springer India, India: 2013, pp. 1315–1329. [Google Scholar]
- 159. Zhang X., Hu C., Li H., Data Sci. J. 2009, 8, 1. [Google Scholar]
- 160. Zhang X., Zhao C., Wang X., Comput. Ind. 2015, 73, 8. [Google Scholar]
- 161. Qresp: Curation and Exploration of Reproducible Scientific Papers , https://qresp.org (accessed: August 2019).
- 162. Swain M. C., Cole J. M., J. Chem. Inf. Model 2016, 56, 1894. [DOI] [PubMed] [Google Scholar]
- 163. Kim E., Huang K., Saunders A., McCallum A., Ceder G., Olivetti E., Chem. Mater. 2017, 29, 9436. [Google Scholar]
- 164. Hinuma Y., Togo A., Hayashi H., Tanaka I., e‐prints, arXiv:1506.01455, 2015.
- 165. Hicks D., Oses C., Gossett E., Gomez G., Taylor R., Toher C., Mehl M. J., Levy O., Curtarolo S., Acta Crystallogr. A 2018, 74. [DOI] [PubMed] [Google Scholar]
- 166. Maedche A., Staab S., IEEE Intell. Syst. 2001, 16, 72. [Google Scholar]
- 167. Copestake A., Corbett P., Murray‐Rust P., Rupp C., Siddharthan A., Teufel S., Waldron B., in Proc. of the UK e‐Science Programme All Hands Meeting 2006 (AHM2006) (Ed: S. J. Cox), National e‐Science Centre, Edinburgh, Scotland: 2006. [Google Scholar]
- 168. International Materials Resource Registries WG , https://www.rd-alliance.org/groups/working-group-international-materials-resource-registries.html (accessed: August 2019).
- 169. OPTiMaDe , https://www.optimade.org (accessed: August 2019).
- 170. Kennedy K., Stefansky T., Davy G., Zackay V. F., Parker E. R., J. Appl. Phys. 1965, 36, 3808. [Google Scholar]
- 171. Hanak J. J., J. Mater. Sci. 1970, 5, 964. [Google Scholar]
- 172. Xiang X. D., Sun X., Briceno G., Lou Y., Wang K.‐A., Chang H., Wallace‐Freedman W. G., Chen S.‐W., Schultz P. G., Science 1995, 268, 1738. [DOI] [PubMed] [Google Scholar]
- 173. Koinuma H., Kawasaki M., Itoh T., Ohtomo A., Murakami M., Jin Z., Matsumoto Y., Physica C 2000, 335, 245. [Google Scholar]
- 174. Fukumura T., Ohtani M., Kawasaki M., Okimoto Y., Kageyama T., Koida T., Hasegawa T., Tokura Y., Koinuma H., Appl. Phys. Lett. 2000, 77, 3426. [Google Scholar]
- 175. Kneiß M., Storm P., Benndorf G., Grundmann M., von Wenckstern H., ACS Comb. Sci. 2018, 20, 643. [DOI] [PubMed] [Google Scholar]
- 176. Koinuma H., Takeuchi I., Nat. Mater. 2004, 3, 429. [DOI] [PubMed] [Google Scholar]
- 177. Rajan K., Annu. Rev. Mater. Res. 2008, 38, 299. [Google Scholar]
- 178. Potyrailo R., Rajan K., Stoewe K., Takeuchi I., Chisholm B., Lam H., ACS Comb. Sci. 2011, 13, 579. [DOI] [PubMed] [Google Scholar]
- 179. Chikyo T., Sci. Technol. Adv. Mater. 2011, 12, 050301. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 180. von Wenckstern H., Splith D., Werner A., Müller S., Lorenz M., Grundmann M., ACS Comb. Sci. 2015, 17, 710. [DOI] [PubMed] [Google Scholar]
- 181. Curtarolo S., Setyawan W., Hart G. L., Jahnatek M., Chepulskii R. V., Taylor R. H., Wang S., Xue J., Yang K., Levy O., Mehl M. J., Stokes H. T., Demchenko D. O., Morgan D., Comput. Mater. Sci. 2012, 58, 218. [Google Scholar]
- 182. Curtarolo S., Hart G. L. W., Nardelli M. B., Mingo N., Sanvito S., Levy O., Nat. Mater. 2013, 12, 191. [DOI] [PubMed] [Google Scholar]
- 183. Schober C., Reuter K., Oberhofer H., J. Phys. Chem. Lett. 2016, 7, 3973. [DOI] [PubMed] [Google Scholar]
- 184. Kunkel C., Schober C., Margraf J. T., Reuter K., Oberhofer H., Chem. Mater. 2019, 31, 969. [Google Scholar]
- 185. Jain A., Hautier G., Moore C. J., Ong S. P., Fischer C. C., Mueller T., Persson K. A., Ceder G., Comput. Mater. Sci. 2011, 50, 2295. [Google Scholar]
- 186. Calderon C. E., Plata J. J., Toher C., Oses C., Levy O., Fornari M., Natan A., Mehl M. J., Hart G., Nardelli M. B., Curtarolo S., Comput. Mater. Sci. 2015, 108, 233. [Google Scholar]
- 187. Setyawan W., Curtarolo S., Comput. Mater. Sci. 2010, 49, 299. [Google Scholar]
- 188. Jain A., Ong S. P., Chen W., Medasani B., Qu X., Kocher M., Brafman M., Petretto G., Rignanese G.‐M., Hautier G., Gunter D., Persson K. A., Concur. Comp. Pract. E 2015, 27, 5037. [Google Scholar]
- 189. Mathew K., Montoya J. H., Faghaninia A., Dwarakanath S., Aykol M., Tang H., Chu I. heng, Smidt T., Bocklund B., Horton M., Dagdelen J., Wood B., Liu Z.‐K., Neaton J., Ong S. P., Persson K., Jain A., Comput. Mater. Sci. 2017, 139, 140. [Google Scholar]
- 190. Pizzi G., Cepellotti A., Sabatini R., Marzari N., Kozinsky B., Comput. Mater. Sci. 2016, 111, 218. [Google Scholar]
- 191. Supka A. R., Lyons T. E., Liyanage L., D'Amico P., Orabi R. A. R. A., Mahatara S., Gopal P., Toher C., Ceresoli D., Calzolari A., Curtarolo S., Nardelli M. B., Fornari M., Comput. Mater. Sci. 2017, 136, 76. [Google Scholar]
- 192. Lejaeghere K., Bihlmayer G., Björkman T., Blaha P., Blügel S., Blum V., Caliste D., Castelli I. E., Clark S. J., Dal Corso A., de Gironcoli S., Deutsch T., Dewhurst J. K., Di Marco I., Draxl C., Dułak M., Eriksson O., Flores‐Livas J. A., Garrity K. F., Genovese L., Giannozzi P., Giantomassi M., Goedecker S., Gonze X., Grånäs O., Gross E. K. U., Gulans A., Gygi F., Hamann D. R., Hasnip P. J., et al., Science 2016, 351, 6280. [DOI] [PubMed] [Google Scholar]
- 193. Lejaeghere K., Van Speybroeck V., Van Oost G., Cottenier S., Crit. Rev. Solid State 2014, 39, 1. [Google Scholar]
- 194. Zhang I. Y., Logsdail A. J., Ren X., Levchenko S. V., Ghiringhelli L., Scheffler M., New J. Phys. 2019, 21, 013025. [Google Scholar]
- 195. Curtiss L. A., Raghavachari K., Redfern P. C., Pople J. A., J. Chem. Phys. 2000, 112, 7374. [Google Scholar]
- 196. Kirklin S., Saal J. E., Meredig B., Thompson A., Doak J. W., Aykol M., Rühl S., Wolverton C., npj Comput. Mater. 2015, 1, 15010. [Google Scholar]
- 197. Error estimates from high‐accuracy electronic structure reference calculations, online notebook, https://analytics-toolkit.nomad-coe.eu/notebook-edit/data/shared/tutorialsNew/errorbars/errorbars_html.bkr (accessed: August 2019).
- 198. Mitchell T., Machine Learning, McGraw‐Hill, New York: 1997. [Google Scholar]
- 199. Russell S., Artificial Intelligence: A Modern Approach, Prentice Hall, Upper Saddle River, NJ: 2010. [Google Scholar]
- 200. Isayev O., Oses C., Toher C., Gossett E., Curtarolo S., Tropsha A., Nat. Commun. 2017, 8, 15679. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 201. Xie T., Grossman J. C., Phys. Rev. Lett. 2018, 120, 145301. [DOI] [PubMed] [Google Scholar]
- 202. Ward L., Liu R., Krishna A., Hegde V. I., Agrawal A., Choudhary A., Wolverton C., Phys. Rev. B 2017, 96, 1. [Google Scholar]
- 203. Rupp M., Tkatchenko A., Müller K.‐R., von Lilienfeld O. A., Phys. Rev. Lett. 2012, 108, 058301. [DOI] [PubMed] [Google Scholar]
- 204. Schütt K. T., Sauceda H. E., Kindermans P. J., Tkatchenko A., Müller K. R., J. Chem. Phys. 2018, 148, 24. [DOI] [PubMed] [Google Scholar]
- 205. Faber F. A., Christensen A. S., Huang B., Von Lilienfeld O. A., J. Chem. Phys. 2018, 148, 24. [DOI] [PubMed] [Google Scholar]
- 206. Ghosh K., Stuke A., Todorović M., Jørgensen P. B., Schmidt M. N., Vehtari A., Rinke P., Adv. Sci. 2019, 6, 1801367. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 207. Stuke A., Todorović M., Rupp M., Kunkel C., Ghosh K., Himanen L., Rinke P., J. Chem. Phys. 2019, 150, 204121. [DOI] [PubMed] [Google Scholar]
- 208. Jolliffe I. T., Principal Component Analysis, Springer, New York, NY: 2002. [Google Scholar]
- 209. Rajan K., Suh C., Mendez P. F., Stat. Anal. Data Min. 2009, 1, 361. [Google Scholar]
- 210. van der Maaten L., J. Mach. Learn. Res. 2008, 9, 2579. [Google Scholar]
- 211. Ceriotti M., Tribello G. A., Parrinello M., Proc. Natl. Acad. Sci. USA 2011, 108, 13023. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 212. Bishop C., Pattern Recognition and Machine Learning, Springer, New York: 2006. [Google Scholar]
- 213. Samanta A., Li B., Rudd R. E., Frolov T., Nat. Commun. 2018, 9. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 214. Lima Guimaraes G., Sanchez‐Lengeling B., Outeiral C., Cunha Farias P. L., Aspuru‐Guzik A., e‐prints, arXiv:1705.10843, 2017.
- 215. Ghiringhelli L. M., Vybiral J., Levchenko S. V., Draxl C., Scheffler M., Phys. Rev. Lett. 2015, 114, 105503. [DOI] [PubMed] [Google Scholar]
- 216. Ouyang R., Curtarolo S., Ahmetcik E., Scheffler M., Ghiringhelli L. M., Phys. Rev. Mater. 2018, 2, 083802. [Google Scholar]
- 217. Ziletti A., Kumar D., Scheffler M., Ghiringhelli L. M., Nat. Commun. 2018, 9, 1. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 218. Isayev O., Fourches D., Muratov E. N., Oses C., Rasch K., Tropsha A., Curtarolo S., Chem. Mater. 2015, 27, 735. [Google Scholar]
- 219. Stanev V., Oses C., Takeuchi I., npj Comput. Mater. 2018, 4, 29. [Google Scholar]
- 220. Ward L., Dunn A., Faghaninia A., Zimmermann N., Bajaj S., Wang Q., Montoya J., Chen J., Bystrom K., Dylla M., Chard K., Asta M., Persson K., Snyder G., Foster I., Jain A., Comput. Mater. Sci. 2018, 152, 60. [Google Scholar]
- 221. Haghighatlari M., Hachmann J., ChemML—A Machine Learning and Informatics Program Suite for Chemical and Materials Data Mining, https://hachmannlab.github.io/chemml.
- 222. DeepChem , https://deepchem.io (accessed: August 2019).
- 223. Zhuo Y., Tehrani A. M., Brgoch J., J. Phys. Chem. Lett. 2018, 9, 1668. [DOI] [PubMed] [Google Scholar]
- 224. Smith J. S., Isayev O., Roitberg A. E., Chem. Sci. 2017, 8, 3192. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 225. Bartók A. P., Payne M. C., Kondor R., Csányi G., Phys. Rev. Lett. 2010, 104, 1. [DOI] [PubMed] [Google Scholar]
- 226. Li Z., Kermode J. R., De Vita A., Phys. Rev. Lett. 2015, 114, 096405. [DOI] [PubMed] [Google Scholar]
- 227. De S., Bartók A. P., Csányi G., Ceriotti M., Phys. Chem. Chem. Phys. 2016, 18, 13754. [DOI] [PubMed] [Google Scholar]
- 228. Liu R., Kumar A., Chen Z., Agrawal A., Sundararaghavan V., Choudhary A., Sci. Rep. 2015, 5, 1. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 229. Isayev O., Oses C., Toher C., Gossett E., Curtarolo S., Tropsha A., Nat. Commun. 2017, 8, 15679. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 230. Montavon G., Hansen K., Fazli S., Rupp M., Biegler F., Ziehe A., Tkatchenko A., Lilienfeld A. V., Müller K.‐R., in Advances in Neural Information Processing Systems, Vol. 25 (Eds: Pereira F., Burges C. J. C., Bottou L., Weinberger K. Q.), Curran Associates, Red Hook, NY, USA: 2012, pp. 440–448. [Google Scholar]
- 231. Hansen K., Biegler F., Ramakrishnan R., Pronobis W., Von Lilienfeld O. A., Müller K. R., Tkatchenko A., J. Phys. Chem. Lett. 2015, 6, 2326. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 232. Faber F., Lindmaa A., v. Lilienfeld O. A., Armiento R., Int. J. Quantum Chem. 2015, 115, 1094. [Google Scholar]
- 233. Bartók A. P., Kondor R., Csányi G., Phys. Rev. B 2013, 87, 184115. [Google Scholar]
- 234. Huo H., Rupp M., e‐prints, , arXiv:1704.06439, 2017.
- 235. Behler J., J. Chem. Phys. 2011, 134, 074106. [DOI] [PubMed] [Google Scholar]
- 236. Gastegger M., Schwiedrzik L., Bittermann M., Berzsenyi F., Marquetand P., J. Chem. Phys. 2018, 148, 24. [DOI] [PubMed] [Google Scholar]
- 237. Faber F. A., Lindmaa A., Von Lilienfeld O. A., Armiento R., Phys. Rev. Lett. 2016, 117, 2. [DOI] [PubMed] [Google Scholar]
- 238. Pronobis W., Tkatchenko A., Müller K. R., J. Chem. Theory Comput. 2018. [DOI] [PubMed] [Google Scholar]
- 239. Himanen L., Jäger M. O. J., Morooka E. V., Federici Canova F., Ranawat Y. S., Gao D. Z., Rinke P., Foster A. S., e‐prints, arXiv:1904.08875, 2019.
- 240. Christensen A. S., Faber F. A., Huang B., Bratholm L. A., Tkatchenko A., Muller K.‐R., von Lilienfeld O. A., QML: A Python Toolkit for Quantum Machine Learning, https://github.com/qmlcode/qml (accessed: August 2019).
- 241. Goodfellow I., Bengio Y., Courville A., Deep Learning, MIT Press, Cambridge, MA, USA: 2016. [Google Scholar]
- 242. Wolpert D. H., Macready W. G., IEEE Trans. Evol. Comput. 1997, 1, 67. [Google Scholar]
- 243. Schmidhuber J., Neural Netw. 2015, 61, 85. [DOI] [PubMed] [Google Scholar]
- 244. Rokach L., Maimon O., Data Mining With Decision Trees: Theory and Applications, World Scientific Publishing Co., Inc., River Edge, NJ, USA, 2nd edition: 2014. [Google Scholar]
- 245. Shawe‐Taylor J., Cristianini N., Kernel Methods for Pattern Analysis, Cambridge University Press, New York, NY, USA: 2004. [Google Scholar]
- 246. Rasmussen C., Gaussian Processes for Machine Learning, MIT Press, Cambridge, MA: 2006. [Google Scholar]
- 247. Chollet , François and others, Keras, https://keras.io (accessed: August 2019).
- 248. Abadi M., Agarwal A., Barham P., Brevdo E., Chen Z., Citro C., Corrado G. S., Davis A., Dean J., Devin M., Ghemawat S., Goodfellow I., Harp A., Irving G., Isard M., Jia Y., Jozefowicz R., Kaiser L., Kudlur M., Levenberg J., Mané D., Monga R., Moore S., Murray D., Olah C., Schuster M., Shlens J., Steiner B., Sutskever I., Talwar K., Tucker P., Vanhoucke V., Vasudevan V., Viégas F., Vinyals O., Warden P., Wattenberg M., Wicke M., Yu Y., Zheng X. TensorFlow: Large‐Scale Machine Learning on Heterogeneous Systems, https://www.tensorflow.org.
- 249. Chen T., Guestrin C., in, Proc. of the 22nd ACM SIGKDD International Conference on Knowledge Discovery and Data Mining, KDD'16. ACM, New York, NY, USA, 2016, pp. 785–794. [Google Scholar]
- 250. Jia Y., Shelhamer E., Donahue J., Karayev S., Long J., Girshick R., Guadarrama S., Darrell T., in Proc. of the 22Nd ACM Int. Conf. on Multimedia (Eds: Hua K. A., Rui Y., Steinmetz R., Hanjalic A., Natsev A., Zhu W.), MM '14. ACM, New York, NY, USA: 2014. [Google Scholar]
- 251. Theano Development Team , e‐prints, abs/1605.02688, 2016.
- 252. PyTorch , https://pytorch.org (accessed: August 2019).
- 253. GPy: A Gaussian process framework in python, https://github.com/SheffieldML/GPy (accessed: August 2019).
- 254. Eclipse Deeplearning4j Development Team , Deeplearning4j: Open‐source distributed deep learning for the jvm, apache software foundation license 2.0, https://deeplearning4j.org.
- 255. Arbabzadah F., Chmiela S., Müller K. R., Tkatchenko A., Nat. Commun. 2017, 8, 6. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 256. Gilmer J., Schoenholz S. S., Riley P. F., Vinyals O., Dahl G. E., in Proc. of the 34th Int. Conf. on Machine Learning (Eds: Precup D., Teh Y. W.), PMLR, Sydney, Australia: 2017, p. 1263. [Google Scholar]
- 257. Todorović M., Gutmann M. U., Corander J., Rinke P., npj Comput. Mater. 2019, 5, 35. [Google Scholar]
- 258. Goldsmith B. R., Boley M., Vreeken J., Scheffler M., Ghiringhelli L. M., New J. Phys. 2017, 19, 013031. [Google Scholar]
- 259. LeCun Y., Bengio Y., In Arbib M. A., editor, Convolutional Networks for Images, Speech, and Time Series . MIT Press, Cambridge, MA, USA, 1998, pp. 255–258. [Google Scholar]
- 260. Meredig B., Antono E., Church C., Hutchinson M., Ling J., Paradiso S., Blaiszik B., Foster I., Gibbons B., Hattrick‐Simpers J., Mehta A., Ward L., Mol. Syst. Des. Eng. 2018, 3, 819. [Google Scholar]
- 261. Vanschoren J., van Rijn J. N., Bischl B., Torgo L., SIGKDD Explor. 2013, 15, 49. [Google Scholar]
- 262. Chard R., Li Z., Chard K., Ward L., Babuji Y., Woodard A., Tuecke S., Blaiszik B., Franklin M. J., Foster I., e‐prints, arXiv:1811.11213, 2018.
- 263. Irving G., Askell A., Ai safety needs social scientists 2019, 10.23915/distill.00014 (accessed: August 2019). [DOI]
- 264. Gómez‐Bombarelli R., Aguilera‐Iparraguirre J., Hirzel T. D., Duvenaud D., Maclaurin D., Blood‐Forsythe M. A., Chae H. S., Einzinger M., Ha D. G., Wu T., Markopoulos G., Jeon S., Kang H., Miyazaki H., Numata M., Kim S., Huang W., Hong S. I., Baldo M., Adams R. P., Aspuru‐Guzik A., Nat. Mater. 2016, 15, 1120. [DOI] [PubMed] [Google Scholar]
- 265. Mannodi‐Kanakkithodi A., Treich G. M., Huan T. D., Ma R., Tefferi M., Cao Y., Sotzing G. A., Ramprasad R., Adv. Mater. 2016, 28, 6277. [DOI] [PubMed] [Google Scholar]
- 266. Oliynyk A. O., Antono E., Sparks T. D., Ghadbeigi L., Gaultois M. W., Meredig B., Mar A., Chem. Mater. 2016, 28, 7324. [Google Scholar]
- 267. Xue D., Balachandran P. V., Hogden J., Theiler J., Xue D., Lookman T., Nat. Commun. 2016, 7, 1. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 268. Xue D., Balachandran P. V., Yuan R., Hu T., Qian X., Dougherty E. R., Lookman T., Proc. Natl. Acad. Sci. USA 2016, 113, 47, 13301. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 269. Ren F., Ward L., Williams T., Laws K. J., Wolverton C., Hattrick‐Simpers J., Mehta A., Sci. Adv. 2018, 4, 4. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 270. Wen C., Zhang Y., Wang C., Xue D., Bai Y., Antonov S., Dai L., Lookman T., Su Y., Acta Mater. 2019, 170, 109. [Google Scholar]
- 271. Yu L., Zunger A., Phys. Rev. Lett. 2012, 108, 068701. [DOI] [PubMed] [Google Scholar]
- 272. Baquião D. J., Dalpian G. M., Comput. Mater. Sci. 2019, 158, 382. [Google Scholar]
- 273. Castelli I. E., Hüser F., Pandey M., Li H., Thygesen K. S., Seger B., Jain A., Persson K. A., Ceder G., Jacobsen K. W., Adv. Energy Mater. 2015, 5, 1400915. [Google Scholar]
- 274. Castelli I. E., Olsen T., Datta S., Landis D. D., Dahl S., Thygesen K. S., Jacobsen K. W., Energy Environ. Sci. 2012, 5, 5814. [Google Scholar]
- 275. Yang K., Setyawan W., Wang S., Buongiorno Nardelli M., Curtarolo S., Nat. Mater. 2012, 11, 614. [DOI] [PubMed] [Google Scholar]
- 276. Cao G., Liu H., Chen X.‐Q., Sun Y., Liang J., Yu R., Zhang Z., Sci. Bull. 2017, 62, 1649. [DOI] [PubMed] [Google Scholar]
- 277. Hautier G., Fischer C. C., Jain A., Mueller T., Ceder G., Chem. Mater. 2010, 22, 3762. [Google Scholar]
- 278. Meredig B., Agrawal A., Kirklin S., Saal J. E., Doak J. W., Thompson A., Zhang K., Choudhary A., Wolverton C., Phys. Rev. B 2014, 094104, 1. [Google Scholar]
- 279. Timoshenko J., Lu D., Lin Y., Frenkel A. I., J. Phys. Chem. Lett. 2017, 8, 5091. [DOI] [PubMed] [Google Scholar]
- 280. Timoshenko J., Anspoks A., Cintins A., Kuzmin A., Purans J., Frenkel A. I., Phys. Rev. Lett. 2018, 120, 225502. [DOI] [PubMed] [Google Scholar]
- 281. Zheng C., Mathew K., Chen C., Chen Y., Tang H., Dozier A., Kas J. J., Vila F. D., Rehr J. J., Piper L. F. J., Persson K. A., Ong S. P., npj Comput. Mater. 2018, 4, 12. [Google Scholar]
- 282. Gómez‐Bombarelli R., Wei J. N., Duvenaud D., Hernández‐Lobato J. M., Sánchez‐Lengeling B., Sheberla D., Aguilera‐Iparraguirre J., Hirzel T. D., Adams R. P., Aspuru‐Guzik A., ACS Cent. Sci. 2018, 4, 268. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 283. Kusner M. J., Paige B., Hernández‐Lobato J. M., in Proc. of the 34th Int. Conf. on Machine Learning (Eds: Precup D., Teh Y. W.), PMLR, Sydney, Australia, 2017, pp. 1945–1954. [Google Scholar]
- 284. Schmidt M., Lipson H., Science 2009, 324, 81. [DOI] [PubMed] [Google Scholar]
- 285. Rudy S. H., Brunton S. L., Proctor J. L., Kutz J. N., Sci. Adv. 2017, 3, 4. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 286. Raissi M., Perdikaris P., Karniadakis G., J. Comput. Phys. 2019, 378, 686. [Google Scholar]
- 287. Bartel C. J., Sutton C., Goldsmith B. R., Ouyang R., Musgrave C. B., Ghiringhelli L. M., Scheffler M., Sci. Adv. 2019, 5, 2. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 288. Jonayat A. S. M., van Duin A. C. T., Janik M. J., ACS Appl. Energy Mater. 2018, 1, 6217. [Google Scholar]
- 289. Wang L., Phys. Rev. B 2016, 94, 195105. [Google Scholar]
- 290. Chowdhury A. J., Yang W., Walker E., Mamun O., Heyden A., Terejanu G. A., J. Phys. Chem. C 2018, 122, 28142. [Google Scholar]
- 291. Schwaller P., Laino T., Gaudin T., Bolgar P., Bekas C., Lee A. A., e‐prints, arXiv:1811.02633, 2018.
- 292. Huan T. D., Batra R., Chapman J., Krishnan S., Chen L., Ramprasad R., npj Comput. Mater. 2017, 3, 37. [Google Scholar]
- 293. Caro M. A., Deringer V. L., Koskinen J., Laurila T., Csányi G., Phys. Rev. Lett. 2018, 120, 166101. [DOI] [PubMed] [Google Scholar]
- 294. Artrith N., Kolpak A. M., Nano Lett. 2014, 14, 2670. [DOI] [PubMed] [Google Scholar]
- 295. Botu V., Batra R., Chapman J., Ramprasad R., J. Phys. Chem. C 2017, 121, 511. [Google Scholar]
- 296. Singraber A., Behler J., Dellago C., J. Chem. Theory Comput. 2019, 15, 1827. [DOI] [PubMed] [Google Scholar]
- 297. Wang H., Zhang L., Han J., E W., Comput. Phys. Commun 2018, 228, 178. [Google Scholar]
- 298. Bartók A. P., Kermode J., Bernstein N., Csányi G., Phys. Rev. X 2018, 8, 041048. [Google Scholar]
- 299. Margraf J. T., Reuter K., J. Phys. Chem. A 2018, 122, 6343. [DOI] [PubMed] [Google Scholar]
- 300. Smith J. S., Nebgen B. T., Zubatyuk R., Lubbers N., Devereux C., Barros K., Tretiak S., Isayev O., Roitberg A., ChemRxiv, Preprint, 2018.
- 301. Wilkins D. M., Grisafi A., Yang Y., Lao K. U., DiStasio R. A., Ceriotti M., Proc. Natl. Acad. Sci. USA 2019, 116, 3401. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 302. Snyder J. C., Rupp M., Hansen K., Müller K. R., Burke K., Phys. Rev. Lett. 2012, 108, 1. [DOI] [PubMed] [Google Scholar]
- 303. Brockherde F., Vogt L., Li L., Tuckerman M. E., Burke K., Müller K. R., Nat. Commun. 2017, 8, 1. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 304. Granqvist N., Laurila J., Organ. Stud. 2011, 32, 253. [Google Scholar]
- 305. Geurts A., Ethnographic field notes from Database‐Driven Materials Science & Technology study.
- 306. Geurts A., Granqvist N., Rinke P., manuscript in preparation.
- 307. MaX ‐ Materials design at the Exascale , https://www.max-centre.eu/ (accessed: August 2019).
- 308. Future makers funding program 2018, https://techfinland100.fi/future-makers-funding-program-2018/ (accessed: August 2019).
- 309. Katila R., Ahuja G., Acad. Manage. J. 2002, 45, 1183. [Google Scholar]
- 310. Garud R., Nayyar P., Strategic Manage. J. 1994, 15, 365. [Google Scholar]
- 311. Geurts A., Technol. Forecast. Soc. Change 2018, 128, 311. [Google Scholar]
- 312. Schilling M. A., Organ. Sci. 2015, 26, 668. [Google Scholar]
- 313. Teece D., Res. Policy 1986, 15, 285. [Google Scholar]
- 314. Gawer A., Cusumano M. A., Platform Leadership How Intel, Microsoft, and Cisco Drive Industry Innovation, Harvard Business Press, Brighton, MA, USA: 2002. [Google Scholar]