

Multidrug combination therapy is an important strategy for treating tuberculosis, the world’s deadliest bacterial infection. Long treatment durations and growing rates of drug resistance have created an urgent need for new approaches to prioritize effective drug regimens. Hence, we developed a computational model called INDIGO-MTB that identifies synergistic drug regimens from an immense set of possible drug combinations using the pathogen response transcriptome elicited by individual drugs. Although the underlying input data for INDIGO-MTB was generated under in vitro broth culture conditions, the predictions from INDIGO-MTB correlated significantly with in vivo drug regimen efficacy from clinical trials. INDIGO-MTB also identified the transcription factor Rv1353c as a regulator of multiple drug interaction outcomes, which could be targeted for rationally enhancing drug synergy.
Keywords: tuberculosis, drug combinations, transcription factors, drug synergy, transcriptomics, Mycobacterium tuberculosis, computer modeling, drug interactions, gene expression
ABSTRACT
The rapid spread of multidrug-resistant strains has created a pressing need for new drug regimens to treat tuberculosis (TB), which kills 1.8 million people each year. Identifying new regimens has been challenging due to the slow growth of the pathogen Mycobacterium tuberculosis (MTB), coupled with the large number of possible drug combinations. Here we present a computational model (INDIGO-MTB) that identified synergistic regimens featuring existing and emerging anti-TB drugs after screening in silico more than 1 million potential drug combinations using MTB drug transcriptomic profiles. INDIGO-MTB further predicted the gene Rv1353c as a key transcriptional regulator of multiple drug interactions, and we confirmed experimentally that Rv1353c upregulation reduces the antagonism of the bedaquiline-streptomycin combination. A retrospective analysis of 57 clinical trials of TB regimens using INDIGO-MTB revealed that synergistic combinations were significantly more efficacious than antagonistic combinations (P value = 1 × 10−4) based on the percentage of patients with negative sputum cultures after 8 weeks of treatment. Our study establishes a framework for rapid assessment of TB drug combinations and is also applicable to other bacterial pathogens.
INTRODUCTION
Tuberculosis (TB) is a global health threat of staggering proportions, taking a human life every 30 seconds (1). To ensure adequate treatment and combat onset of resistance, TB patients receive multidrug therapy. However, the frontline regimen of four drugs and 6 months of treatment has not changed in 50 years, and resistance is spreading. In response, experts have called for entirely new regimens to combat the TB pandemic (2). While some new anti-TB agents are beginning to emerge (3), optimizing individual agents into effective regimens remains a significant challenge.
At present, combinations are designed and tested empirically, driven in part by clinical intuition. A standard approach to evaluate drug interactions experimentally utilizes checkerboard assays, which involves exposing the pathogen to different dose combinations of constituent drugs in a regimen. New approaches have been developed to increase throughput of checkerboard assays, either by reducing the number of doses required or by using computational optimization to find optimal doses (4–6).
Even with these developments, the enormous and expanding number of potential drug combinations renders regimen optimization by comprehensive experimental testing infeasible. The 28 drugs used to treat TB (7–10) could be assembled into nearly 24,000 different three- or four-drug combinations. Adding just two new agents to that list increases the number of different combinations to almost 32,000. Thus, there is a need for high-throughput approaches that can prioritize new drug combinations based on data generated from individual drugs. For example, a feedback-based approach was recently used to determine the optimal dosing of multidrug regimens (4, 5). However, this approach still requires hundreds of dose-specific measurements for training the algorithm, all of which must be redone whenever a new agent is under consideration. Computational tools such as metabolic modeling, kinetic modeling, and statistical modeling (11–13) have limited power in this context because direct targets are not known for many compounds. Existing approaches are also limited in the scale at which potential combinations could be evaluated computationally—currently around hundreds. Furthermore, empirical approaches based on drug similarity (or dissimilarity) are less effective in predicting interaction outcomes for new drug classes, and they also lack a model for antagonism (14). Drugs with similar targets can have both synergistic and antagonistic outcomes (14).
To address this challenge, here we extend an in silico tool that we recently created—inferring drug interactions using chemogenomics and orthology (INDIGO) (14)—to predict synergy/antagonism in combinations of two or more drugs. The original INDIGO model used chemogenomic profiling data under exposure to individual drugs (15, 16) as input data to identify drug response genes (14). The scientific premise underlying INDIGO is that drug synergy and antagonism arise because of coordinated, system-level molecular changes involving multiple cellular processes. Importantly, INDIGO can learn patterns from known drug interactions, which can then be used to forecast outcomes for new drugs and conditions. INDIGO can thus provide insights on the underlying mechanism of drug interactions in an unbiased fashion. INDIGO can assess millions of combination regimens without requiring information about the drug target or mode of action. Once an optimal drug regimen can be determined using INDIGO, the dose regimens could be further optimized using feedback-based dose optimization techniques (4, 5).
The goal of this study is to identify antibiotic combinations that are most promising for TB drug development. We have adapted INDIGO to make use of transcriptomic data to identify drug response genes, which are more widely available than chemogenomic data for most nonmodel organisms, including Mycobacterium tuberculosis (MTB) (Fig. 1). We then harness a large compendium of publicly available and in-house-generated transcriptomic data to show that INDIGO can successfully estimate drug interactions in MTB. We further integrate INDIGO with known MTB gene regulatory networks to identify transcription factors (TFs) that influence the extent of synergy between drugs. False-positive results and outliers from our model represent existing knowledge gaps and can inform future drug interaction experiments. The significant correlation of INDIGO-MTB predictions with both in vitro validations of novel predictions and in vivo efficacy metrics from clinical trials indicate that the INDIGO-MTB model has great promise for selecting novel TB drug regimens. INDIGO-MTB further provides unbiased insights on underlying cellular processes that influence drug interactions.
FIG 1.

Schematic of INDIGO-MTB. INDIGO uses drug-gene associations inferred from transcriptomic data and experimentally measured drug-drug interactions as inputs to train a computational model that can infer interactions between new combinations of drugs. It does this by learning patterns in the drug-gene associations that are correlated with synergy and antagonism. In the example above, MTB upregulation of both gene 1 and gene 3 in response to the drugs measured in monotherapy is predictive of antagonism when the drugs are combined. By perturbing individual genes and known targets of transcription factors (TFs) in the model, we can infer the impact of individual gene and TF activity, respectively, on drug interactions and subsequently engineer interaction outcomes.
RESULTS
Construction of the INDIGO-MTB model from drug response transcriptomes.
The INDIGO approach requires a list of drug-gene associations and known drug-drug interaction data as input for building a chemical-genetic model of drug interactions. A gene is assumed to have a chemical-genetic association with a drug if a change in its expression leads to a statistically significant alteration in sensitivity to the drug of interest. A drug-gene association network is created by integrating chemogenomic profiling data from hundreds of drugs. This static network is then converted into a predictive model by leveraging the powerful statistical learning tool, Random Forest (17). This algorithm builds decision trees using genes in the drug-gene association network and identifies those that are predictive of drug interaction outcomes using a training data set. The training data comprises known drug interactions. This trained network model can be used to forecast interactions for novel drug combinations (Fig. 1; see also Fig. S1 in the supplemental material).
Schematic of INDIGO-MTB modeling workflow (A to C) and the experimental assays to measure drug interaction (D to F). (A) The input data sets for training the INDIGO algorithm are (i) the transcriptomic profiles of drugs and (ii) the corresponding FIC scores of known drug-drug interactions. From each transcriptome profile of MTB response to an individual drug, we defined a corresponding drug-gene interaction matrix by assigning a value of 1 to genes that changed in expression by more than twofold (up or down) after exposure to drug, and setting all other genes to a value of 0. Only genes that are upregulated are shown in the remaining panels for simplicity. (B) For each drug combination, INDIGO calculates a “joint” drug-gene interaction matrix using a linear combination of the drug-gene interaction matrices of each constituent individual drug. The joint profile captures both the similarity and uniqueness in the transcriptome response profiles of the individual drugs in each combination. The INDIGO algorithm then uses a machine learning approach called random forest to create a mathematical model that associates the FIC score of each drug combination to its corresponding joint drug-gene interaction matrix. Random forest builds a series of decision trees to identify specific patterns in the drug-gene interaction matrices that significantly associate with the value of the corresponding drug-drug interaction FIC scores. (C) Once built, the INDIGO-MTB model requires only the transcriptomic response profile elicited by a new compound of interest as input to predict FIC scores of combinations featuring the compound of interest. (D) Representative checkerboard assay experiments of a synergistic and antagonistic drug pair. Cultures were exposed to serial dilutions of drugs (designated in the rows and columns) for 7 days, and bacterial viability was quantified by measuring ATP levels with the BacTiter Glo reagent. The thick black boxes denote the individual drug MIC wells, and the boxes with numbers denote concentrations that yielded iso-equivalent inhibition (each of the numbers represent the FIC score calculated based on the drug concentrations associated with corresponding well). (E and F) Representative DiaMOND assay experiments of a synergistic and antagonistic drug pair (E) or triplet (F). Cultures were exposed to drugs in 384-well plates, and growth was measured by OD600. The FIC for a drug combination was calculated as the ratio between the observed and expected IC50 dose of the drug combination. For two-drug combinations the expected IC50 dose is defined as the intersection of the line (additivity line) drawn between the IC50 doses for each individual drug. For three-drug combinations, the expected IC50 dose is defined as the intersection of the drug combination dose response and the plane (additivity plane) created by connecting the IC50 doses for each individual drug. Download FIG S1, JPG file, 0.5 MB (519.8KB, jpg) .
{kind=link}
Copyright © 2019 Ma et al.
This content is distributed under the terms of the Creative Commons Attribution 4.0 International license.
While in the prior study, drug-gene associations were obtained from chemogenomic profiles of Escherichia coli, these comprehensive gene deletion/drug response data are difficult to generate experimentally for most pathogens. We hence hypothesized that transcriptomic data, which quantifies the responses of every gene to a given perturbation, could provide a readily available alternate resource for analysis. This solution could circumvent the limitation that chemogenomic data are not available for most pathogens, including MTB. Generating gene expression data for response to monotherapy drug exposure is straightforward, and there are already publicly available transcriptomic profiles for many anti-TB agents.
We compiled transcriptome data profiling MTB responses to different compounds and metabolic perturbations from the literature. We augmented this compendium by generating MTB transcriptomic response profiles for emerging TB agents (Materials and Methods; see Table S1A in the supplemental material). In addition to these transcriptomic data, we also used chemogenomic data from E. coli (16), with E. coli genes matched to corresponding orthologous genes in the MTB genome. Our prior study showed that INDIGO can infer interactions in MTB with significant accuracy using orthologous gene mapping (correlation R = 0.54; P value = 0.006). This was based on the observation that genes predictive of drug-drug interactions were surprisingly conserved between E. coli and MTB. In cases where multiple data sets profiled the same compound, we prioritized data from MTB profiled with the latest transcriptomic technology whenever possible. We normalized this drug response compendium using the ComBat algorithm (18) to account for interstudy and technology-specific (i.e., microarray, transcriptome sequencing [RNA-seq]) variation in transcriptomic data (Materials and Methods). Overall, this compendium contains data for 164 compounds and 65 metabolic perturbations (see Table S1A for the full list) (12, 19, 20).
(A) Compendium of transcriptomic/chemogenomic data for INDIGO-MTB. (B) Training combinations with associated FIC interaction indices. (C) List of all possible pairwise interaction scores (164 compounds and 65 perturbations). (D) INDIGO-MTB predictions along with corresponding experimental (in vitro) and clinical validation data. Highlighted combinations are novel, i.e., not used in training set. (E) Pathway enrichment analysis using the top 500 predictive genes. (F) DiaMOND distribution transformation. (G) Impact of various thresholds for finding differentially expressed genes after drug treatment. Changing the log fold change threshold from 4- to 32-fold showed similar correlation with the experimental test set interactions as the default threshold (2-fold). The use of a fold change threshold to binarize the data was performed to reduce the noise in the data sets. Overall, this analysis shows that the INDIGO model is robust for the thresholds used. At the highest threshold (32-fold), a slightly higher correlation was observed, although it was not significantly better than the default settings based on partial correlation analysis (P value > 0.05). (H) Impact of using various machine learning algorithms for predicting drug interactions. Download Table S1, XLSX file, 1.1 MB (1.1MB, xlsx) .
Copyright © 2019 Ma et al.
This content is distributed under the terms of the Creative Commons Attribution 4.0 International license.
To train INDIGO-MTB, we compiled drug interaction values in MTB for 202 drug combination regimens from the literature, featuring compounds with available chemogenomic or transcriptomic profiles (Table S1B). The drugs in the training set consist of well-established anti-TB drugs, including rifampin (RIF), isoniazid (INH), streptomycin (STM), several fluoroquinolones, as well as new drugs such as bedaquiline (BDQ). The extent of interaction between drugs was quantified in these studies by the standard fractional inhibitory concentration (FIC) index (21), or the DiaMOND interaction score (6). For both of these metrics, synergy implies that the same amount of growth inhibition is achieved with a lower dose when both drugs are combined. We used statistical data normalization to combine these data sets, similar to our approach for combining transcriptomic data from various studies and platforms (Materials and Methods). This allowed us to account for the new technology-specific variation in drug interaction score distribution. If separate studies in literature provided conflicting interaction scores for a drug combination, we included both values to incorporate this experimental uncertainty into the model.
Experimental validation of the INDIGO-MTB model.
The INDIGO-MTB model trained on these drug interaction data was used to infer interaction outcomes for new drugs and regimens. Given that our compendium has 164 compounds and 65 perturbations, INDIGO-MTB estimated all 26,106 potential pairwise interactions and all 1,975,354 potential three-way interactions. Table S1C shows the entire list of pairwise combinations and interaction scores.
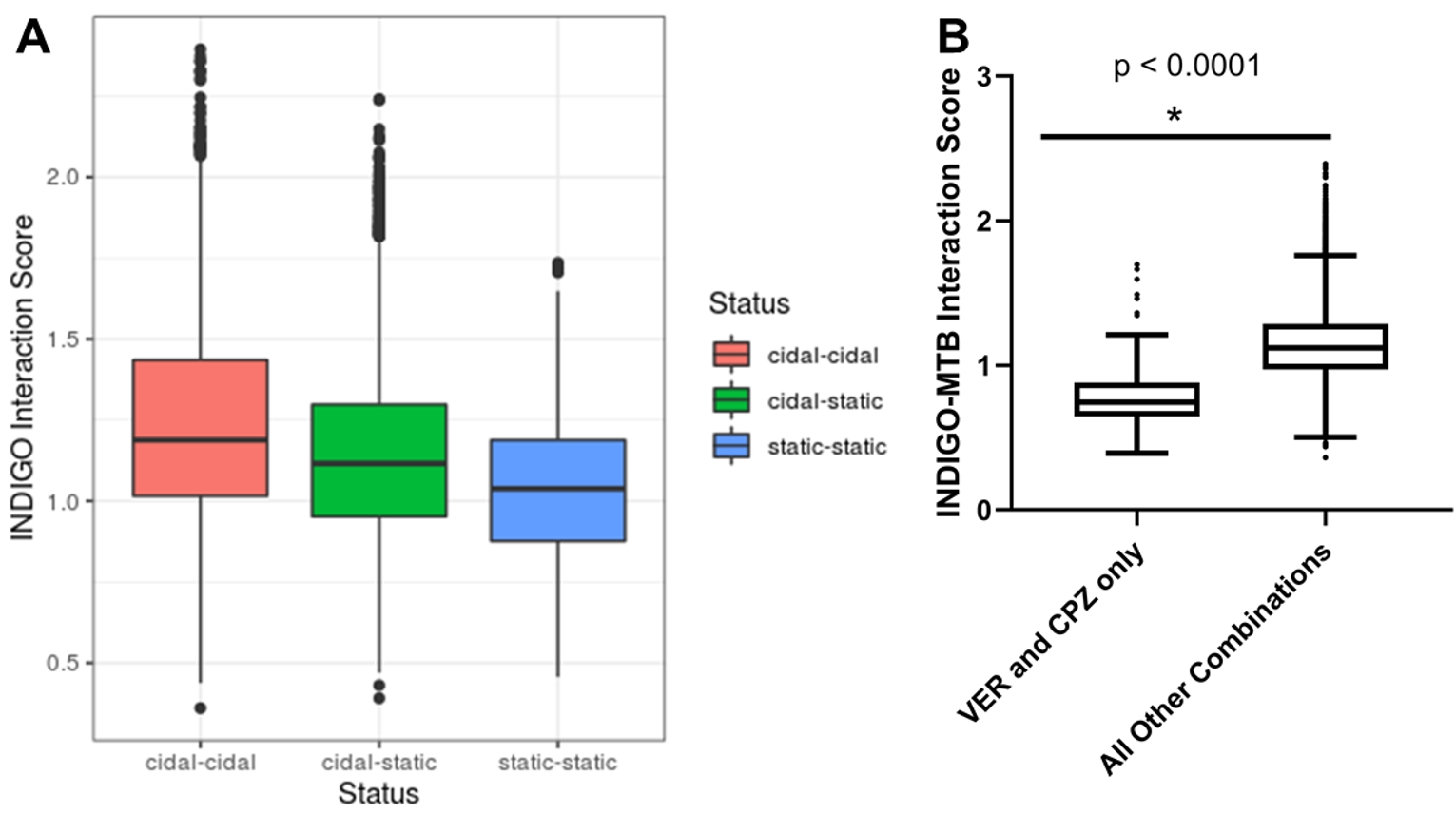
We observed striking associations between specific compounds and interactions that were highly synergistic or antagonistic. In particular, combinations containing the drugs chlorpromazine and verapamil were highly enriched for synergistic interactions; 77% of chlorpromazine-containing combinations and 80% of verapamil-containing combinations were found to interact synergistically (FIC < 0.9) (Fig. S2). Verapamil is an efflux pump inhibitor that influences membrane potential (22) and has been previously been shown to potentiate the activity of several anti-TB drugs (23–25). In contrast, all pairwise combinations featuring sutezolid were found to be antagonistic.
Distributions of INDIGO-MTB interaction scores for combinations featuring different drugs. (A) Box plots of interaction scores of combinations featuring only bacteriostatic drugs (blue) is shifted toward synergy (interaction score = 1.03 ± 0.2), relative to combinations featuring bactericidal drugs (red) (interaction score = 1.25 ± 0.3). Combinations featuring bactericidal drugs appear to have the most antagonistic INDIGO-MTB interaction scores. (B) Distribution of INDIGO-MTB interaction scores for combinations involving verapamil (VER) or chlorpromazine (CPZ). The distribution of interaction scores for these drugs is significantly lower than the interaction score distribution for combinations featuring other drugs (P value < 1 × 10−16, nonparametric Kolmogorov-Smirnov test), suggesting that combinations featuring these drugs are enriched for synergy. The box plots display the first quartile (1Q), median, and the third quartile (3Q) of the distribution of INDIGO-MTB scores for pairs of drugs, at least one of which are VER or CPZ compared against all possible combinations excluding these two antibiotics. Download FIG S2, JPG file, 0.2 MB (161.3KB, jpg) .
{kind=link}
Copyright © 2019 Ma et al.
This content is distributed under the terms of the Creative Commons Attribution 4.0 International license.
Previous work had found that combinations of bacteriostatic drugs paired with bactericidal drugs were likely to be antagonistic against E. coli (26). INDIGO-MTB uncovered a similar trend in the MTB drug interactions; combinations featuring a bacteriostatic drug and a bactericidal drug had significantly more antagonistic interaction scores than combinations featuring only bacteriostatic drugs (P < 10−12). Interestingly, combinations featuring only bactericidal drugs also had significantly more antagonistic interaction scores than combinations featuring only bacteriostatic drugs (P < 10−12) (Fig. S2).
To evaluate the accuracy of INDIGO-MTB, we experimentally measured interactions between a set of two-drug and three-drug combinations, and we compared these measurements against the interaction scores from INDIGO-MTB. The compounds featured in the tested combinations are all FDA-approved agents that have diverse mechanisms of action and are either part of current first- and second-line TB therapy or have been previously studied for their anti-tubercular activity. The interaction outcomes for the test set combinations spanned the entire range of INDIGO-MTB predicted interaction scores, enabling a rigorous assessment of INDIGO-MTB (Fig. 2A and Fig. S3). We quantified the interaction outcome either by traditional checkerboard assays or the high-throughput DiaMOND method for three-way combinations (Materials and Methods). Given the diverse methodologies used in literature for measuring drug interactions, we included combinations frequently measured in prior literature involving INH, RIF, and STM as reference combinations in our test set. In addition, among the test set combinations, 10 combinations involved pairwise subsets of three-way combinations that were measured using DiaMOND methodology to infer three-way interactions. Overall, among the 36 combinations in the experimental validation set, 24 combinations were completely “novel,” i.e., never seen by INDIGO. The sample size (N = 24 combinations) for the test set chosen for experimental validation is sufficiently powered to significantly assess the accuracy of INDIGO’s correlation with the experimental data (Materials and Methods).
FIG 2.

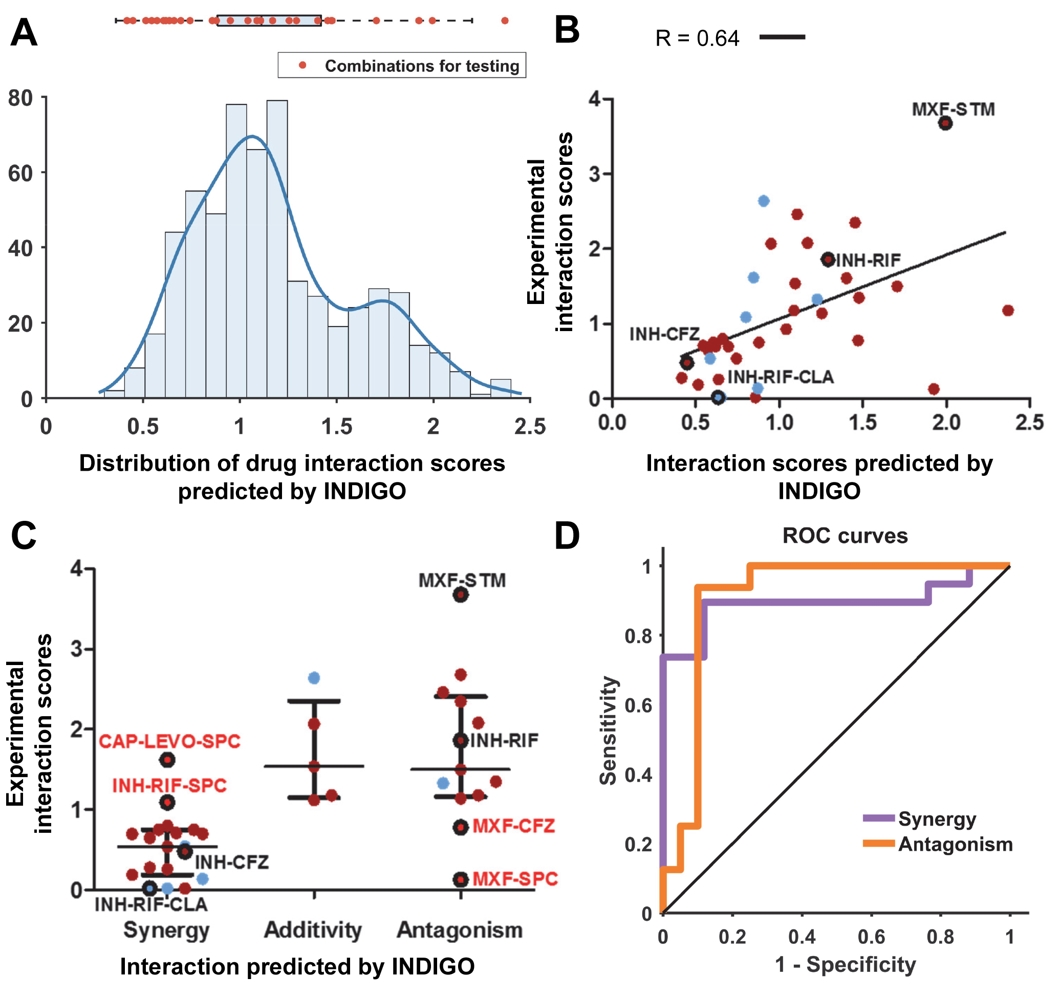
INDIGO-MTB accurately predicts novel drug interactions. (A) Drug combinations chosen for experimental testing span the entire range of drug interaction predictions by INDIGO. The histogram and box plot above it show the distribution of pairwise drug interaction scores for the 35 high-interest TB agents (the edges of the box plot demarcate the 25th and 75th percentile, and the dashed line extends between the 1st and 99th percentile). The interaction scores of the combinations chosen for testing are shown as red dots. The 35 high-interest agents contain drugs either currently used to treat TB or have been used in the past to treat TB (58). (B) Comparison of INDIGO-MTB interaction scores with experimental in vitro interaction scores. Each symbol indicates a specific drug combination. Dark red dots mark two-drug regimens (R = 0.62, P = 9.3 × 10−3), and blue dots mark three-drug regimens (R = 0.64, P = 8.81 × 10−2). The specific combinations mentioned in the text are highlighted in the plot. For both experimental and INDIGO-MTB scores, values less than 0.9 indicate synergy, values between 0.9 and 1.1 denote additivity, and values greater than 1.1 indicate antagonism. (C) Dot plot of experimentally measured drug interaction scores versus the INDIGO-MTB predicted drug interaction type. The dots labeled in red font denote outlier combinations that were misclassified by INDIGO-MTB. The interaction scores were significantly different between predicted synergistic and antagonistic combinations (P = 0.0009, Komolgorov-Smirnov test). The horizontal lines in the box plot represent the median and the first and third quartiles. (D) Receiver operating curves (ROC) plotting sensitivity versus specificity for INDIGO-MTB predictions of synergy and antagonism for both two-drug and three-drug combinations in the validation set. Sensitivity measures the true positive rate, which is the fraction of true positive interactions correctly identified; specificity measures the true negative rate. The area under the ROC (AUC) values provides an estimate of the sensitivity and specificity of model predictions over a range of thresholds. The AUC values are 0.89 and 0.91 for synergy and antagonism, respectively. (sensitivity = 90.9% and specificity = 84.6% for synergy; sensitivity = 66.6% and specificity = 91.7% for predicting antagonism).
INDIGO accurately forecasts interactions among the 36 test set drug combinations against MTB. This figure shows the comparison between INDIGO-MTB interaction scores and experiments for all 36 combinations in the validation set. This figure complements Fig. 2, which compares INDIGO predictions with the 24 novel combinations (subset of 36 test combinations). (A) Drug combinations chosen for experimental testing span the entire range of drug interaction predictions by INDIGO. The histogram and box plot above it show the distribution of pairwise drug interaction scores for the 35 high-interest TB agents (the boundaries of the box plot denote the 25th and 75th percentiles of the distribution, and the dashed lines extend between 1st and 99th percentiles). The red dots denote the combinations selected for experimental validation. (B) Comparison of INDIGO-MTB interaction scores with in vitro interaction scores. For both experimental and model-predicted scores, values less than 0.9 indicate synergy, values between 0.9 and 1.1 denote additivity, and values greater than 1.1 indicate antagonism. Each dot indicates a specific drug combination. Dark red dots mark two-drug regimens (R = 0.63, P ∼ 10−4), and blue dots mark three-drug regimens (R = 0.68, P ∼ 10−2). The specific combinations mentioned in the text are highlighted in the plot. (C) Dot plot of experimentally measured drug interaction scores versus the INDIGO-MTB predicted drug interaction type. The dots labeled in red font denote outlier combinations that were misclassified by INDIGO-MTB. The interaction scores were significantly different between predicted synergistic and antagonistic combinations (P = 6 × 10−5). The horizontal lines in the box plot represent the median and the first and third quartiles. (D) Sensitivity versus specificity curves for INDIGO-MTB predictions of synergy and antagonism for both two-drug and three-drug combinations in the validation set. The AUC values are 0.89 (P = 4 × 10−5) and 0.91 (P = 4.1 × 10−5) for synergy and antagonism, respectively. (sensitivity = 88.4% and specificity = 86.5% for synergy; sensitivity = 79.4% and specificity = 90% for predicting antagonism). Download FIG S3, JPG file, 0.3 MB (291.1KB, jpg) .
{kind=link}
Copyright © 2019 Ma et al.
This content is distributed under the terms of the Creative Commons Attribution 4.0 International license.
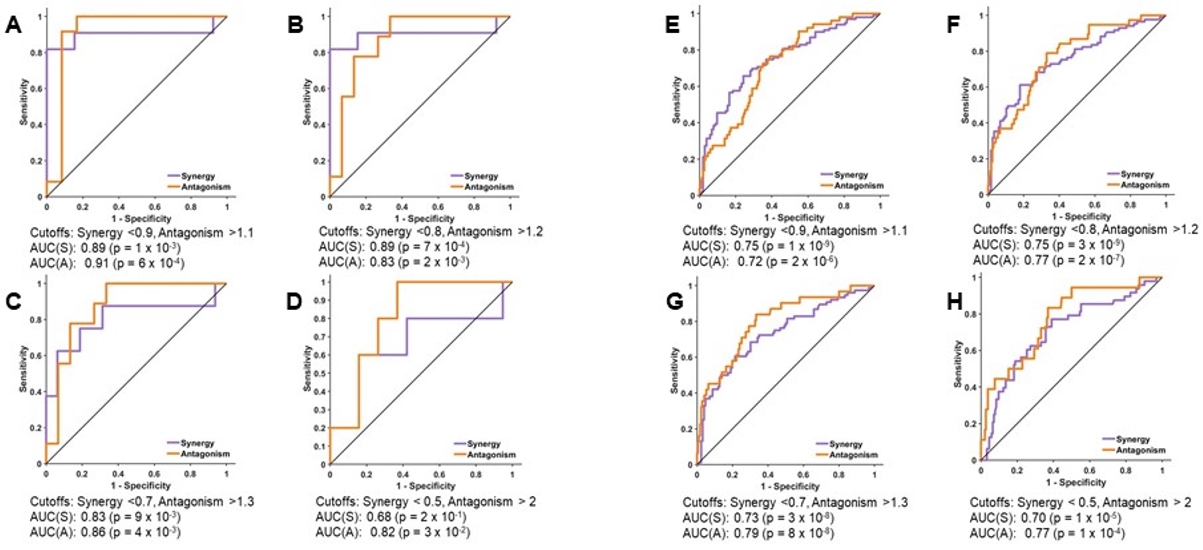
We first classified experimentally measured combinations as synergistic, additive, or antagonistic. INDIGO-MTB-predicted interaction scores were significantly different between these three classes (P value = 0.0064, Kruskal-Wallis rank sum test [Fig. 2C]). In addition, there was a significant difference between INDIGO-MTB predictions for synergistic and antagonistic combinations (P value = 0.0009, nonparametric Komolgorov-Smirnov test). Receiver operating curve (ROC) analysis of INDIGO-MTB predictive performance yielded an area under the curve (AUC) of 0.89 (P = 1.2 × 10−3) and 0.91 (P = 6.7 × 10−4) for detecting synergy and antagonism in the validation set, respectively (Fig. 2D). These results are robust for the choice of thresholds used for classifying interactions as synergistic or antagonistic (Fig. S4). We next performed a quantitative comparison between INDIGO-MTB interaction scores and the corresponding in vitro experimentally measured FIC indices using the scale invariant metric, Spearman’s rank correlation (R) (Fig. 2B). We observed a high degree of correlation between model prediction and experimental measurements for all combinations (R = 0.63, P = 9.5 × 10−4), and also after separating pairwise (R = 0.62 ± 0.03, P = 9 × 10−3) and three-way interactions (R = 0.64 ± 0.1, P = 8 × 10−2). The correlation with INDIGO-MTB predictions is identical for both the novel set (rank correlation R = 0.63) and for the total validation set (R = 0.64 for all 36 combinations). Thus, not only can INDIGO qualitatively differentiate synergy and antagonism, but it can also quantitatively separate regimens based on their extent of synergy.
Receiver operating curves (ROC) for INDIGO-MTB predictions of synergy and antagonism for various thresholds of synergy and antagonism. (A to D) ROC curves generated from the independent test data. Sensitivity measures the true positive rate, which is the fraction of true positive interactions correctly identified; specificity measures the true negative rate. The area under the ROC curve (AUC) values provides an estimate of the sensitivity and specificity of model predictions over a range of thresholds. At the highest threshold for synergy (i.e., FIC < 0.5), the accuracy of the model is reduced likely due to majority of the interactions in the test set being classified as neutral. (E to H) ROC curves INDIGO-MTB tested using 10-fold cross-validation analysis. In cross-validation analysis, 10% of the training data set is withheld, and predictions are made using an INDIGO-MTB model trained using the remaining 90% of the training data. Performance metrics are then calculated based on prediction on the withheld data. This analysis is repeated 10 times to cover the entire training data set. The plots show the sensitivity versus specificity curves for INDIGO-MTB predictions of synergy and antagonism for various thresholds of synergy and antagonism. The cross-validation accuracy is surprisingly lower than the test set accuracy, as the training set comprises data from 15 different studies that were done in diverse labs and batches with different drugs and methodologies. In our prior study (14), the training and test data were obtained from a single source, and consequently, the cross-validation accuracy matched the test set accuracy. Download FIG S4, JPG file, 0.3 MB (256.4KB, jpg) .
{kind=link}
Copyright © 2019 Ma et al.
This content is distributed under the terms of the Creative Commons Attribution 4.0 International license.
Of note, we validated the INDIGO-MTB prediction that the combination of moxifloxacin (MXF) and spectinomycin (SPC) are pairwise antagonistic (DiaMOND FIC = 1.50) but could be made more synergistic with the addition of clofazimine (CFZ) (DiaMOND FIC = 0.14). The synergy identified between capreomycin (CAP) and CFZ (DiaMOND FIC = 0.70) and strong antagonism between STM and MXF (FIC = 3.68) were also experimentally confirmed. These results, along with 10-fold cross-validation analysis of the training data (Fig. S4), show that INDIGO-MTB can successfully infer novel interactions among drugs with known transcriptome profiles.
While most predictions were confirmed experimentally, there were systematic inconsistencies between the model and experiments for some individual drugs. For example, half of the inconsistencies arose in combinations featuring spectinomycin (SPC). Although SPC has been found to synergize with several anti-TB drugs with multiple modes of action (27, 28), the model tends to overpredict synergy for combinations that include SPC. This may be in part because SPC predictions were based on chemogenomic data from E. coli rather than MTB response transcriptomes.
Given the high accuracy of our model for both pairwise and multidrug combinations, we inferred interactions for 35 promising TB drugs using INDIGO-MTB. The resulting compendium of 6,545 three-way, 52,360 four-way, and the top 100 synergistic and antagonistic combinations from 324,632 five-way combinations is provided as a supplement to serve as a resource for guiding future drug combination screens (Table S2 and Table S3).
Two-way and three-way INDIGO-MTB scores for 35 high-interest TB drugs. Download Table S2, XLSX file, 1.2 MB (1.2MB, xlsx) .
Copyright © 2019 Ma et al.
This content is distributed under the terms of the Creative Commons Attribution 4.0 International license.
Four-way and five-way INDIGO-MTB scores for 35 high-interest TB drugs. Download Table S3, XLSX file, 2.2 MB (2.2MB, xlsx) .
Copyright © 2019 Ma et al.
This content is distributed under the terms of the Creative Commons Attribution 4.0 International license.
In vitro drug synergy is correlated with a surrogate marker of clinical efficacy.
We next tested whether in vitro drug interaction outcomes would be predictive of clinical efficacy. A systematic evaluation of the clinical relevance of in vitro drug interactions on treatment efficacy is lacking (29). We therefore compared INDIGO-MTB in vitro drug interaction predictions with a meta-analysis of data assembled from 57 phase 2 clinical trials (30). These trials reported regimen efficacy outcomes by sputum culture conversion rates of TB patients at 2 months. If separate clinical studies reported conflicting efficacy scores for a drug regimen, we used both values for comparison with INDIGO-MTB to incorporate this uncertainty.
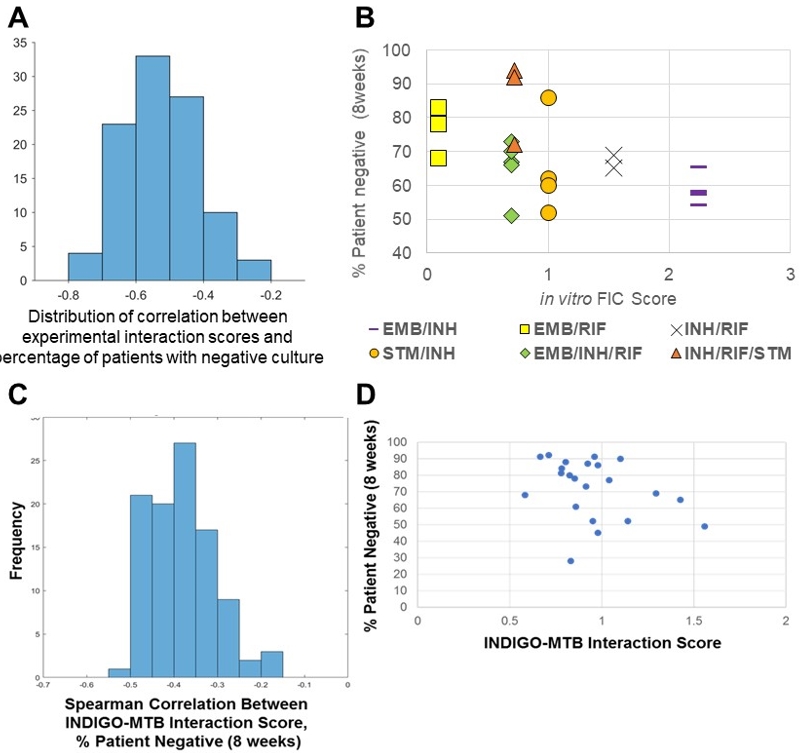
We found a highly significant degree of correlation between the INDIGO-MTB interaction scores and the sputum culture conversion rates for the corresponding combinations (R = −0.55 ± 0.04, P ∼ 10−5; see Fig. 3A and Table S1D). The results show that regimens predicted to have greater synergy performed better in the clinical trials. For example, the INH-RIF-STM regimen (green) was predicted to be synergistic in vitro, and this combination conferred high patient culture negativity (∼94%) at 2 months (Fig. 3A). In contrast, the pairwise combinations of INH-STM (yellow) and INH-RIF (pink) were identified as antagonistic, and both drug pairs resulted in low sputum conversion rates. There was a highly significant difference in sputum conversion between synergistic and antagonistic combinations (P ∼ 10−4) (Fig. 3B), the difference in clinical outcome for synergistic-additive (P = 0.038) and additive-antagonistic (P = 0.016) interactions were significant as well.
FIG 3.

INDIGO-MTB drug interaction scores correlate with sputum culture negativity at 2 months. (A) Comparison of model predictions with sputum conversion rates in human patients after 8 weeks of treatment in clinical trials (R = −0.55, P ∼ 10−5). Higher patient negative percentages indicate more-effective regimens. Each dot indicates a specific drug combination reported from a specific clinical trial. Dots highlighted in the legend are drug combinations of interest mentioned in the text. (B) Dot plot of sputum conversion rates against the INDIGO-MTB-predicted drug interaction type. The dots labeled in red font denote outlier combinations that were misclassified by INDIGO-MTB. The horizontal lines represent the first quartile, third quartile, and median (the widest horizontal line). The colored dots correspond to combinations highlighted in the legend.
Among the combinations assessed clinically, only four two-way and two three-way drug combinations had experimental in vitro drug interaction data. We next compared the correlation of in vitro experimentally measured drug interaction with the corresponding sputum conversion rates. We found that in vitro experimental drug interaction scores also correlated significantly (R = −0.52 ± 0.1, P = 0.01) with clinical sputum conversion by sampling analysis (Fig. S5). This correlation is comparable to the value observed with INDIGO-MTB across all 57 clinical trials.
Impact of variation between clinical trials and experimental drug interaction studies on correlation between drug synergy and clinical efficacy. Since multiple clinical trials and experimental studies had measured the clinical efficacy outcome (sputum conversion rates) and in vitro FIC scores for drug combinations, we assessed the robustness of correlations between clinical efficacy data and both experimentally measured (A and B) and model-predicted (C and D) interaction scores by performing sampling analysis. (A) Distribution of the correlation between in vitro experimentally measured drug interaction scores with corresponding sputum conversion rates. Since multiple experimental studies had measured the in vitro interaction outcome for these combinations, we performed sampling analysis by randomly choosing one representative study for each combination to determine the average correlation. We found that the in vitro experimental drug interaction scores correlated significantly (mean R = −0.52, P ∼ 0.01, average of 100 trials) with clinical sputum conversion by this sampling analysis. Panel B shows one representative trial with R = −0.52. For comparison, INDIGO-MTB achieved a similar correlation across all 57 clinical trials (R = −0.55, P ∼ 10−5). (B) Comparison of experimental FIC scores with sputum conversion rates in human patients after 8 weeks of treatment in clinical trials, with each regimen represented by FIC data from a single experimental study (R = −0.52, P = 0.01). Data shown for four two-way and two three-way drug combinations that had both experimental in vitro drug interaction data and sputum conversion rates. Each dot indicates a specific drug combination reported from a specific clinical trial. The combinations corresponding to each dot are provided in the legend. (C) Histogram visualizing the distribution of the correlations between INDIGO-MTB predictions and clinical efficacy based on sampling analysis. We performed sampling analysis by randomly choosing one representative clinical trial for each combination to determine the average correlation with INDIGO-MTB-predicted interaction scores. We observed a significant correlation between interaction scores and the sputum culture conversion rates (mean R = −0.38 average of 100 random sampling trials, P value = 0.001). Panel D shows data from one representative trial with R = −0.37. Download FIG S5, JPG file, 0.2 MB (174.1KB, jpg) .
{kind=link}
Copyright © 2019 Ma et al.
This content is distributed under the terms of the Creative Commons Attribution 4.0 International license.
Despite the strong overall concordance between in vitro synergy and in vivo sputum culture conversion rates, we found some outlier combinations that were inferred to be synergistic but had poor clinical outcomes. All the outlier regimens contained pyrazinamide (PZA), whose interaction scores were estimated based on transcriptomes that were generated under acidic conditions, which were unlike the conditions of the other drug profiles. Furthermore, the RIF-MXF combination was identified to be antagonistic by both our model and experiments, but it has good in vivo efficacy. It is hypothesized to be effective because of its ability to suppress resistance despite being antagonistic (31). Hence, synergy alone does not always imply clinical efficacy. Numerous other factors can impact treatment outcome. Combinations can perform well despite being antagonistic. Overall, our results suggest that drug synergy is significantly correlated with treatment efficacy at 8 weeks, and identifying synergistic drug interactions is a promising strategy to prioritize combination regimens.
Inferring molecular mediators of drug synergy.
To interrogate what molecular processes underlie INDIGO-MTB’s predictive ability, we identified genes in the INDIGO-MTB model that most strongly influenced drug interaction scores. Genes were in silico “deleted” from the INDIGO-MTB model (i.e., excluded from the model prediction) and assigned an importance score by INDIGO-MTB proportional to their relative contribution in calculating drug interaction scores. The top 500 genes sorted based on their importance score accounted for 97% of INDIGO-MTB’s predictive ability. We performed pathway enrichment analysis using literature-curated pathways from the KEGG database (32, 33) to determine overrepresented pathways among the top 500 informative genes (Table S1E). Metabolic pathways were highly enriched overall, and the most overrepresented pathway was oxidative phosphorylation, which is targeted by BDQ. The model thus suggests that targeting this pathway might have an impact on drug interaction outcomes.
We hypothesized that we could gain further insights into the genetic regulation of drug interaction outcomes. To do this, we analyzed the INDIGO-MTB model in the context of the MTB transcriptional regulatory network (TRN). The TRN was reconstructed by transcriptome profiling of a comprehensive library of transcription factor induction (TFI) strains (34, 35). The regulon (i.e., set of functional targets) for each transcription factor (TF) was defined as those genes that significantly changed expression upon chemical induction of the TF expression.
To assess the system-level impact of each TF on drug interactions, we performed in silico deletions of entire regulon-defined gene sets and assessed the effect on the INDIGO-MTB interaction scores. We identified regulon deletions that disrupt a specific drug interaction and those that influence multiple drug interaction outcomes. For this analysis, we considered all 36 pairwise combinations comprising the drugs INH, RIF, STM, MXF, CFZ, BDQ, capreomycin (CAP), ethionamide, and pretomanid (PA824). The drugs tested are all current first- and second-line TB agents that can be prescribed together as part of therapy and have differing mechanisms of action. From this analysis, INDIGO-MTB identified the transcription factor Rv1353c as having the highest impact on drug interactions among all the TFs (Fig. S6A). INDIGO-MTB estimated that Rv1353c would shift the interaction scores for almost every pairwise interaction toward synergy upon induction (Δscore = −0.6 ± 0.1). The exception was the combination CFZ-STM, for which INDIGO-MTB predicted a minimal interaction shift associated with TF induction (Δscore = −0.2) (Fig. S6B).
Impact of transcription factor (TF) deletion on drug interaction scores. (A) The average predicted impact of deleting each of the 206 TFs on all 36 pairwise combinations comprising INH, RIF, STM, MXF, CFZ, BDQ, CAP, ETA, and PA824 is shown. Rv1353c had the biggest average impact on all the combinations and was chosen for experimental validation. (B) Predicted impact of Rv1353c deletion on drug interaction scores. The plot shows the relative absolute difference in FIC scores on all 36 pairwise combinations comprising INH, RIF, STM, MXF, CFZ, BDQ, CAP, ETA, and PA824. Interestingly, combinations with STM showed both the highest and lowest change in interaction score. The interactions in bold type were chosen for experimental testing. All the chosen combinations were also antagonistic or additive, thus changing the activity of Rv1353c could be used to make these combinations more synergistic. (C) In vitro experimentally measured drug interaction scores for Rv1353c genetic perturbation strains exposed to drug combinations. The error bars represent the standard deviations between replicates. Download FIG S6, JPG file, 0.1 MB (131.2KB, jpg) .
{kind=link}
Copyright © 2019 Ma et al.
This content is distributed under the terms of the Creative Commons Attribution 4.0 International license.
We tested these model predictions by comparing the interactions of three representative drug combinations with the following three genetic perturbations: (i) TF induction, measured in the TFI strain with the presence of chemical induction; (ii) TF disruption, measured in a knockout strain (see Materials and Methods); and (iii) baseline TF levels, measured in the genetic wild-type strain, H37Rv and the TFI strain in the absence of chemical induction. We selected two drug combinations for which strong interaction shifts were inferred upon TF induction (BDQ-STM Δscore = −0.7; CAP-STM Δscore = −0.7), as well as the CFZ-STM combination for which the model estimated minimal interaction shift. The baseline interactions between the drug combinations differ substantially (BDQ-STM is additive, whereas CAP-STM and CFZ-STM are both antagonistic [Fig. S6C]). Figure 4 shows the difference in experimentally measured interaction scores of each drug combination for the genetic perturbation conditions relative to the wild type (Materials and Methods). The results show that when Rv1353c is induced, interactions for both BDQ-STM and CAP-STM shift toward synergy (ΔFIC = −0.2 ± 0.1, P = 0.03 for BDQ-STM; ΔFIC = −0.5 ± 0.2, P = 0.01 for CAP-STM), and when Rv1353c is disrupted, interactions for both BDQ-STM and CAP-STM shift toward antagonism (ΔFIC = 0.3 ± 0.2, P = 0.001 for BDQ-STM; ΔFIC= 0.2 ± 0.2, P = 0.04 for CAP-STM). In contrast, there appears to be no significant shifts in interaction for CFZ-STM with either induction or disruption of Rv1353c (ΔFIC = −0.0004 ± 0.3, P = 0.5 for disruption; ΔFIC= −0.03 ± 0.1, P = 0.03 for induction). Collectively, these results confirm the INDIGO-MTB predictions.
FIG 4.

Rv1353c influences interactions between drug combinations. The in vitro experimentally measured drug interaction scores are quantified for the three selected drug interactions, plotted as the difference in FIC score of the gene perturbation relative to the wild-type strain (H37Rv). The red bars denote values for the knockout (KO) strain, and the blue bars show values for the strain with Rv1353c induced. Negative values indicate shifts toward synergy, and positive values indicate shifts toward antagonism. The asterisk and dagger indicate that differences are significantly greater or less than zero, respectively (P < 0.05, one-tailed one-sample t test). The error bars represent the standard deviations between replicates.
DISCUSSION
Here, we constructed an INDIGO-MTB model to predict in vitro synergy and antagonism of antituberculosis drug combinations using transcriptomic data. Our model complements existing experimental strategies by increasing throughput and by identifying potential drug interaction mechanisms. Our analysis using INDIGO-MTB revealed novel synergy between clinically promising drug combinations, uncovered the role of the TF Rv1353c in influencing drug interaction outcomes, and found a significant association between in vitro drug interaction outcomes and clinical efficacy. These results suggest that using INDIGO-MTB to identify synergistic regimens is a promising strategy for prioritizing combination therapies. While significant challenges exist, constructing a high-quality model of drug interactions in vitro is the first step toward inferring in vivo efficacy. No theoretical method currently exists that can comprehensively screen thousands of combinations even in vitro. The significant correlation between INDIGO interaction scores with both in vitro data and clinical efficacy data supports the utility of our approach.
INDIGO-MTB outperforms existing strategies in terms of throughput. The largest studies of MTB have so far analyzed up to 200 unique drug combinations (36). Here, we have estimated outcomes for 13,366 pairwise and 721,764 three-way combinations of 164 drugs with significant accuracy based on our prospective validation. While many of the drugs might have poor anti-TB activity on their own, they may greatly enhance synergy when added to existing regimens. For example, we found that chlorpromazine, originally used for treating psychiatric disorders, synergizes with BDQ, resulting in fourfold reductions in inhibitory concentrations (see Fig. S7A in the supplemental material). Thus, INDIGO can facilitate repurposing of drugs to treat TB.
(A) In vitro experimentally measured interaction score measured between bedaquiline (BDQ) and chlorpromazine (CPZ). The heatmap shows a representative checkerboard assay experiment, in which MTB H37Rv cultures were exposed to different pairwise concentrations of BDQ and CPZ in 96-well plate format, designated in the columns and rows, respectively. Cultures were exposed to drugs for 7 days, and bacterial viability was quantified by measuring ATP levels with the BacTiter Glo reagent. The thick black boxes denote the individual drug MIC wells, and the boxes with numbers denote concentrations that yielded iso-equivalent inhibition (each of the numbers represents the FIC score calculated based on the drug concentrations associated with corresponding well). (B) Correlation analysis of FIC average values calculated from checkerboard assays measured by AlamarBlue or BacTiter Glo. Each point represents the average of the FIC indices of equivalently inhibited concentrations on an individual checkerboard plate. Pearson’s R for this is 0.78 (P < 0.0001). Download FIG S7, JPG file, 0.1 MB (145.7KB, jpg) .
{kind=link}
Copyright © 2019 Ma et al.
This content is distributed under the terms of the Creative Commons Attribution 4.0 International license.
INDIGO complements other preclinical methods such as mouse models in prioritizing regimens for clinical evaluation. A systematic comparison across multiple mouse studies is challenging due to the lack of quantitative raw data and variation in metrics reported in the literature. Nevertheless, combinations identified by INDIGO to be highly synergistic (top 0.01% [see Tables S2 and S3 in the supplemental material]) were also found to be highly efficacious in recent mouse studies. Combinations involving BDQ and CFZ alone or in a three-drug combination with PZA, ethambutol (EMB), RIF, or INH were all found to be synergistic by INDIGO and showed high bactericidal activity in mouse models (5, 37–39). Four-way drug combinations involving BDQ, CFZ, and PZA with EMB or SQ109 were also synergistic in mouse studies (5, 37–39). In addition to these combinations studied in mouse models, INDIGO-MTB also uncovered highly synergistic novel four-drug and five-drug combinations that are promising candidates for preclinical evaluation, such as the combination with BDQ, CFZ, RIF, CLA, and the antimalarial antifolate compound P218, and a four-drug combination involving BDQ, RIF, PA824, and the antipsychotic drug thioridazine (Table S3).
Since numerous factors could impact in vivo efficacy that are not considered during in vitro studies, it is not a priori clear if there should be a significant correlation between in vitro synergy and in vivo efficacy. Thus, we performed a systematic comparison of in vitro drug interaction scores with clinical efficacy of drug combination regimens. Notably, here we observed a statistically significant correlation between in vitro drug interaction scores and the percentage of TB patients showing negative sputum culture after 2 months of treatment in clinical trials, with synergistic drug combinations showing greater clinical efficacy. A negative sputum culture result at 8 weeks is a useful early measure of TB treatment efficacy that correlates well with relapse rates (40, 41). The correlation that we observed between in vitro INDIGO-MTB predictions and sputum conversion rates is notable, given the huge variability between clinical studies.
While existing high-throughput approaches are strictly nonmechanistic, INDIGO can reveal the relative contribution of underlying cellular pathways on drug interaction outcomes. Our analysis suggests that drug transporters and central metabolic pathways may play a role in influencing drug interaction outcomes. This is consistent with recent studies on the role of bacterial metabolic state in impacting drug interaction outcomes (42, 43). Contextualizing INDIGO-MTB with the MTB transcriptional regulatory network revealed genetic regulators of drug interaction response. This analysis uncovered the role of the transcription factor Rv1353c as a broad regulator of drug interaction outcomes. Rv1353c is an uncharacterized nonessential helix-turn-helix type transcriptional regulator (44–48) that has previously been found to be deleted in several clinical isolates (49). When induced under log-phase growth, Rv1353c activates 44 genes enriched for fatty acid biosynthesis and represses 50 genes, including 2 of the top 5 most informative INDIGO-MTB predictor genes (Rv1857 and Rv1856c) (34). Interestingly, INDIGO-MTB simulations suggest minimal shifts in drug interaction scores upon perturbing either Rv1857 or Rv1856 individually, suggesting that the underlying molecular mechanisms mediating drug interactions may be partially epistatic in nature. Collectively, this suggests that knowledge of the underlying mechanism of drug interaction can be used to engineer synergy between combination regimens. Our approach provides a rational strategy to identify genetic targets that enhance synergy between existing regimens and introduces a potentially new way to engineer effective regimens by modifying the interactions between the constituent drugs.
While the INDIGO approach has demonstrated significant utility in predicting synergy and antagonism of drug combinations, it nevertheless has several key limitations. First, INDIGO-MTB requires as input transcriptome data profiling of MTB response to each drug for which drug interaction predictions are necessary. Transcriptomes are significantly faster and less expensive to generate than the chemogenomic profiles used to power the original INDIGO models. This has enabled us to use species-specific data to build INDIGO-MTB. Among the 35 TB drugs of interest, the input data for only 10 drugs (28%) are derived from E. coli chemogenomic data. The correlation observed in the current study, wherein the model was constructed using MTB response transcriptomes elicited by drug exposure, is higher than the correlation observed in our prior study, which used chemogenomic data to infer interactions (R = 0.62 for pairwise and 0.64 for three-way interactions for the current study versus R = 0.52 for pairwise and 0.56 for three-way interactions in the E. coli chemogenomic study [14, 50]). Notably, while predictions using E. coli data were statistically significant, many of the incorrect predictions from our model, such as drug combinations involving spectinomycin, might be attributed to challenges of extrapolating predictions from E. coli using gene orthology information alone. Our results suggest that gene expression changes encapsulate molecular response information that is as informative of drug interaction phenotypes as gene deletion studies. The updated INDIGO approach can hence be applied to other pathogens that lack chemogenomic data. With reduced sequencing costs, transcriptomic data are unlikely to be a substantial limitation in the future. Further, while the number of possible combinations increases exponentially with the number of drugs, the number of transcriptomes required increases only linearly. Hence, INDIGO-MTB and other methods that use responses elicited by individual drugs will be more cost-effective and time effective.
A second limitation stems from the fact that INDIGO-MTB predictions are currently based on data gathered from log-phase in vitro broth culture conditions, which are markedly different from the in vivo microenvironments. Outliers from our experimental validation involving PZA (which is relatively more active under low pH conditions) substantiate the notion that the underlying environmental context can influence the model accuracy. The INDIGO algorithm is currently blind to MTB molecular responses to drugs in the host context. Training our model using MTB transcriptome profiling data generated using an appropriate environmental condition (e.g., MTB in a macrophage or mouse infection model) might address this limitation in the future. A recent study has expanded the INDIGO model to enable in silico prediction of the impact of different microenvironments in E. coli (50). Hence, building an accurate INDIGO model for MTB can provide a foundation for addressing this in vivo complexity.
Finally, while synergy is associated with a better treatment outcome on average, other factors such as resistance evolution, toxicity, and drug pharmacokinetics will also influence treatment success. In addition, there is considerable heterogeneity in clinical trial efficacy based on patient population, dose, and location. The curation of numerous clinical studies and ability to predict interactions in high throughput provided us with sufficient statistical power to test the association between synergy and in vivo efficacy despite this heterogeneity. In the future, incorporating additional factors associated with drug behavior in the host may further improve the correlation between model predictions and clinical outcomes.
MATERIALS AND METHODS
Culture conditions.
MTB strains were cultured in Middlebrook 7H9 with the oleic acid, bovine albumin, dextrose, and catalase (OADC) supplement (Difco) and with 0.05% Tween 80 at 37°C under aerobic conditions with constant agitation to mid-log phase, as described previously (34, 51). Strains containing the anhydrotetracycline (ATc)-inducible expression vector were grown with the addition of 50 μg/ml hygromycin B to maintain the plasmid. To induce expression of the transcription factor Rv1353c, 20 ng/μl of ATc was added to the culture medium. Growth was monitored by the optical density at 600 nm (OD600).
The Rv1353c overexpression strain was generated previously (34, 35). Briefly, the Rv1353c gene was cloned into a tagged, inducible vector that placed the gene under the control of a tetracycline-inducible promoter (52) and added a C-terminal FLAG epitope tag. This construct was transformed into MTB H37Rv using standard methods. The strain is available from the BEI Resources Strain Repository at ATCC (www.beiresources.org) (NR-46512).
Phage knockout strain generation.
The H37Rv ΔRv1353c strain was constructed by a specialized transduction method (53) using a gene-specific specialized transducing phage phasmid DNA provided by the Jacobs lab and the previously described protocol (53). Briefly, high-titer phage stocks were generated by transfecting the phasmid DNA into Mycobacterium smegmatis mc2155 at 30°C, and growing the resulting phage plaques on an agar pad with a lawn of mc2155. Transduction-competent H37Rv was incubated with high-titer phage stock for 24 h at 37°C, and the transduced bacteria were plated on 7H10 supplemented with 50 μg/ml hygromycin B to select for deletion-substitution mutants.
Drug susceptibility and checkerboard drug-drug interaction experiments.
Strains were grown to log phase (OD600 ≈ 0.3), diluted to a final OD600 ≈ 0.005 (equivalent to 106 [CFU]/ml), and dispensed into 96-well flat-bottom plates (Corning, Acton, MA) at a final volume of 200 μl, containing 1% dimethyl sulfoxide (DMSO) and various concentrations of drugs in the different wells. On each plate, control wells for each of the strains studied were included, containing (i) no drug and 1% DMSO vehicle and (ii) 1% culture and no drug with 1% DMSO vehicle to measure viability in the absence of drug exposure.
For drug susceptibility assays to measure the MIC, serial twofold dilutions of an individual drug were arrayed in the different columns. For checkerboard drug interaction assays, twofold dilutions of the first drug were arrayed in the columns and twofold dilutions of a second drug were arrayed in the rows.
Plates were incubated at 37°C for 7 days. Cellular viability was assayed on day 7 by the BacTiter-Glo (Promega, Madison, WI) and alamarBlue cell proliferation (Bio-Rad, Hercules, CA) assay kits according to the manufacturer’s recommendations. Briefly, we added 20 μl of culture from each well to 20 μl of BacTiter-Glo microbial cell viability assay reagent, incubated at room temperature protected from direct light for 20 min, and read luminescence intensity using a FluoStar Omega plate reader (BMG Lab Tech, Cary, NC). For alamarBlue, we added 20 μl of alamarBlue reagent to 180 μl of culture, incubated for 12 h protected from direct light, and read fluorescence intensity at emission wavelength of 590 nm after excitation at 544 nm. Figure S7B in the supplemental material shows the strong concordance between the two methods—BacTiter-Glo and alamarBlue.
For drug susceptibility assays, the MIC was determined as the lowest drug concentration that resulted in MTB viability comparable to the 1% culture control. For checkerboard assays, the drug interaction was quantified by the fractional inhibitory concentration (FIC) index, equal to where CA is the concentration of drug A when combined with drug B yielding an iso-effective inhibition comparable to the MIC and CB is the concentration of drug B when combined with drug A yielding an iso-effective inhibition. The value for FIC can be extended to any arbitrary number of drug combinations as follows:
Each MIC and checkerboard experiment was performed 2 times, with 2 biological replicates per experiment. The mean FIC index across all iso-effective concentrations was calculated for each biological replicate to determine reproducibility, and data across biological replicates were summarized by averaging (Fig. S1).
DiaMOND drug-drug interaction experiments.
DiaMOND drug interaction experiments were performed in biological triplicate as previously described (6). Rather than sampling the entire set of dose combinations used in a traditional checkerboard assay, DiaMOND samples a subset of dose responses and approximates the shape of the contour of the chosen phenotype (e.g., where 50% growth inhibition [IC50] is observed). For example, a two-drug combination requires three dose responses (each individual drug dose response and an equipotent drug combination dose response) rather than the entire set of possible dose combinations.
Individual drug dose-response ranges were chosen for each drug such that the IC50 dose was close to the center and doses were linearly spaced to provide high-resolution IC50 determination. Drug combination dose response ranges contained equipotent mixtures of two or three drugs (e.g., a two-drug combination would contain one half of the IC50 dose for each drug and a three-drug combination would contain one third of the IC50 of each drug).
Briefly, MTB strain H37Rv cultures were grown to mid-log phase (OD600 ≈ 0.6), diluted to OD600 ≈ 0.05, and added to drug-containing plates. Drugs were dispensed into 384-well plates using a digital drug dispenser (D300e digital dispenser; HP) and 50-μl diluted MTB cultures were overlaid. Drug treatment plates were incubated in humidified containers for 5 days at 37°C without agitation. Growth was measured by OD600 using a plate reader (Synergy Neo2; Biotek). Two technical replicates were performed, and the average of each technical replicate was used to calculate FIC scores.
The FIC for a drug combination was calculated as the ratio between the observed and expected IC50 dose of the drug combination as previously described (6). FICs from each of three biological replicates were calculated to determine reproducibility, and data across biological replicates were summarized by averaging. Briefly, the growth measurements were normalized (background subtracted, normalized to untreated), and the observed IC50 doses were calculated for each individual and combination drug dose response. The expected IC50 dose for the drug combination was then calculated using the IC50s of the individual drugs, based on the null hypothesis that the interaction is additive. For two-drug combinations, the expected IC50 dose is defined as the intersection of the line (additivity line) drawn between the IC50 doses for each individual drug. For three-drug combinations, the expected IC50 dose is defined as the intersection of the drug combination dose response and the plane (additivity plane) created by connecting the IC50 doses for each individual drug (Fig. S1).
RNA-seq transcriptome profile data generation.
To profile the MTB transcriptome response to exposure of individual drugs, cultures were diluted to an OD600 ∼ 0.2 (equivalent to 108 CFU/ml) and exposed to a MIC-equivalent dose of drug for approximately 16 h.
RNA was isolated from these cultures as described previously (34, 51). Briefly, cell pellets in TRIzol were transferred to a tube containing Lysing Matrix B (QBiogene) and vigorously shaken at maximum speed for 30 s in a FastPrep 120 homogenizer (QBiogene) three times, with cooling on ice between shakes. This mixture was centrifuged at maximum speed for 1 min, and the supernatant was transferred to a tube containing 300 μl chloroform and Heavy Phase Lock Gel (Eppendorf), inverted for 2 min, and centrifuged at maximum speed for 5 min. RNA in the aqueous phase was then precipitated with 300 μl isopropanol and 300 μl high-salt solution (0.8 M Na citrate, 1.2 M NaCl). RNA was purified using a RNeasy kit following the manufacturer’s recommendations (Qiagen) with one on-column DNase treatment (Qiagen). Total RNA yield was quantified using a Nanodrop (Thermo Scientific).
To enrich the mRNA, rRNA was depleted from samples using the RiboZero rRNA removal (bacteria) magnetic kit (Illumina Inc., San Diego, CA). The products of this reaction were prepared for Illumina sequencing using the NEBNext Ultra RNA Library Prep kit for Illumina (New England Biolabs, Ipswich, MA) according to the manufacturer’s instructions, and using the AMPure XP reagent (Agencourt Bioscience Corporation, Beverly, MA) for size selection and cleanup of adaptor-ligated DNA. We used the NEBNext Multiplex Oligos for Illumina (Dual Index Primers Set 1) to barcode the DNA libraries associated with each replicate and enable multiplexing of 96 libraries per sequencing run. The prepared libraries were quantified using the Kapa quantitative PCR (qPCR) quantification kit, and were sequenced at the University of Washington Northwest Genomics Center with the Illumina NextSeq 500 High Output v2 kit (Illumina Inc., San Diego, CA). The sequencing generated an average of 75 million base-pair paired-end raw read counts per library.
Read alignment was carried out using a custom processing pipeline that harnesses the Bowtie 2 utilities (54, 55), which is available at https://github.com/sturkarslan/DuffyNGS, and https://github.com/sturkarslan/DuffyTools. The transcriptome sequencing (RNA-seq) data profiling response to drug exposure generated for this study are publicly available at the Gene Expression Omnibus (GEO) under accession no. GSE119585.
Gene expression data analysis.
The RNA-seq transcriptome profiling data that we generated were supplemented with microarray and RNA-seq transcriptome profiling data sets from literature that were downloaded from GEO, along with associated gene accession identifiers. The log2-transformed fold change values of average gene expression in each treatment group were determined for all studies, relative to the experiment’s negative control. All genes that significantly changed by more than twofold (up or down) after each drug treatment were used as input features for INDIGO-MTB. The results are robust for the thresholds chosen for finding differentially expressed genes (Table S1G).
ComBat (18) normalization was used to minimize batch effects in the data, which uses empirical Bayes approach to estimate each batch’s corrected mean and variance. The effectiveness of normalization was checked using principal-component analysis. This version of the transcriptomic/chemogenomic matrix represented the drug-gene network that was required to build the INDIGO-MTB model.
The drug-gene interaction profiles for each drug are then used by INDIGO to create a “joint” interaction profile for a drug combination (Fig. S1). INDIGO assumes that the cellular response to drug combinations is a linear function of the cellular response to individual drugs. This assumption is based on prior experimental studies that found that a linear model best explained transcriptional response of cells treated with drug combinations (56, 57). Further, in our prior study with E. coli, we found that other models of profile integration, such as correlation or profile overlap performed poorly in predicting drug interactions compared to the linear integration model (14).
Quantifying drug-drug interaction scores for model training.
To train INDIGO-MTB, checkerboard FIC indices of drug combinations were collected after conducting literature search (n = 140). We also included FIC50 indices that were calculated using the DiaMOND approach (n = 62) (6). Since the DiaMOND study had a distinct distribution from other checkerboard studies from the literature (mean = 1.05 and 0.99, standard deviation = 0.32 and 0.81 for DiaMOND and checkerboard, respectively), we statistically transformed the DiaMOND scores so that the overall distribution of the DiaMOND-measured scores had the same mean and standard deviation as the remaining checkerboard data sets. The normalized scores were used for training INDIGO-MTB (Table S1F). Similarly, the DiaMOND data generated in this study for validation was normalized using the same approach prior to comparison with INDIGO-MTB predictions. The average interaction score in the final training set was 1.01, suggesting that the training data set is not significantly biased toward synergy or antagonism.
Statistical analyses.
Our experimental test set is sufficiently powered statistically to significantly assess the accuracy of INDIGO’s correlation with the experimental data. For example, the probability of getting a correlation of 0.62 achieved by INDIGO by random chance is less than 1 in 103. We statistically estimated that we need only 14 samples to detect a correlation of 0.6 (R ≥ 0.6) with a P value of 0.01. Our test set sample size is significantly larger than this number.
Spearman rank correlations were computed using the statistical software R. Differences between the means of each group in box plots were compared using two-sample one-tailed Komolgorov-Smirnov tests in R. To further assess the robustness of our results to variation in clinical trials, we performed sampling analysis by choosing one representative clinical trial randomly for each regimen. We observed a significant correlation between predicted interaction scores and the sputum culture conversion rates (mean rank correlation R = −0.38 average of 100 random sampling trials) (Fig. S7B).
The significance of the AUC values from the ROC analysis was calculated by randomly permuting the class labels (synergy or antagonism) of the test data set 1,000 times. The difference in accuracy of the actual model with the random permuted models was compared using a t test.
We used the random forest algorithm that is part of the machine learning toolbox in MATLAB. The regression random forest algorithm was used with default parameters for the number of predictors sampled (default value – N/3, where N is the number of variables). Hyperparameter tuning of parameters in the training set instead of using default parameters also resulted in a similar accuracy in the test set (Table S1H). Random forests are perfectly suited for our analysis as they can achieve high accuracy even with small sample sizes and can be easily interpreted. The training set used here is relatively small for deep neural networks which require thousands of samples. On the other hand, support vector machine (SVM) and decision trees can be built with small sample sizes but do not achieve high accuracy as random forests. The accuracy using these approaches with default parameters is lower than random forests with default parameters (Table S1H).
Data availability.
The INDIGO-MTB model and associated data sets are available from the Synapse bioinformatics repository (Synapse identifier or accession no. syn18824984) (https://www.synapse.org/INDIGO_MTB) (doi:10.7303/syn18824984). The data reported in the paper are available in the supplemental material. The RNA-seq data generated for this study are available in the Gene Expression Omnibus database under accession no. GSE119585.
ACKNOWLEDGMENTS
We gratefully acknowledge the laboratory of William R. Jacobs, Jr., for providing the phage that enabled us to make the Rv1353c knockout strain. We gratefully acknowledge Andréanne Lupien, Anthony Vocat, and Stewart T. Cole for providing us a sample of PBTZ169 for our study. We also gratefully acknowledge the laboratory of Timothy Sterling for providing us with ofloxacin-resistant clinical strains. We also thank Jessica Winkler, Laura Green, and Reiling Liao for their technical assistance and Awanti Sambarey for her feedback on the manuscript.
This work was supported by the National Institutes of Health (grant numbers U 19 AI106761 [D.R.S., S.C.], U19 AI111276 [D.R.S.], U19 AI135976 [D.R.S.], 5T32AI007509 [S.M.], P50 GM107618-01A1 [B.B.A.], and UL1TR002240 [S.C.]; NIH Director’s New Innovator Award 1DP2LM011952-01 [B.B.A.]) and the University of Michigan Precision Health and MCUBED (S.C.).
S.M. conceived of the study, led the design, generated experimental checkerboard and RNA-seq data, analyzed the experimental data, and drafted the manuscript. S.J. codeveloped the INDIGO-MTB model and generated the model predictions. J.L.-F. generated DIAMOND experimental drug interaction data and drafted the manuscript. J.L. generated experimental checkerboard drug interaction data and RNA-seq data. B.B.A. organized the DIAMOND experimental drug interaction data generation and drafted the manuscript. D.R.S. and S.C. conceived of the study, led the design, organized the data analysis, and drafted the manuscript, and S.C. also codeveloped the INDIGO-MTB model.
Footnotes
This article is a direct contribution from David R. Sherman, a Fellow of the American Academy of Microbiology, who arranged for and secured reviews by Tim van Opijnen, Boston College, and Christopher Sassetti, University of Massachusetts Medical School.
Citation Ma S, Jaipalli S, Larkins-Ford J, Lohmiller J, Aldridge BB, Sherman DR, Chandrasekaran S. 2019. Transcriptomic signatures predict regulators of drug synergy and clinical regimen efficacy against tuberculosis. mBio 10:e02627-19. https://doi.org/10.1128/mBio.02627-19.
REFERENCES
- 1.World Health Organization. 2016. Global tuberculosis report 2016. World Health Organization, Geneva, Switzerland. [Google Scholar]
- 2.Mdluli K, Kaneko T, Upton A. 2015. The tuberculosis drug discovery and development pipeline and emerging drug targets. Cold Spring Harb Perspect Med 5:a021154. doi: 10.1101/cshperspect.a021154. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 3.Zumla A, Chakaya J, Centis R, D’Ambrosio L, Mwaba P, Bates M, Kapata N, Nyirenda T, Chanda D, Mfinanga S, Hoelscher M, Maeurer M, Migliori GB. 2015. Tuberculosis treatment and management–an update on treatment regimens, trials, new drugs, and adjunct therapies. Lancet Respir Med 3:220–234. doi: 10.1016/S2213-2600(15)00063-6. [DOI] [PubMed] [Google Scholar]
- 4.Silva A, Lee BY, Clemens DL, Kee T, Ding X, Ho CM, Horwitz MA. 2016. Output-driven feedback system control platform optimizes combinatorial therapy of tuberculosis using a macrophage cell culture model. Proc Natl Acad Sci U S A 113:E2172–E2179. doi: 10.1073/pnas.1600812113. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 5.Lee BY, Clemens DL, Silva A, Dillon BJ, Maslesa-Galic S, Nava S, Ding X, Ho CM, Horwitz MA. 2017. Drug regimens identified and optimized by output-driven platform markedly reduce tuberculosis treatment time. Nat Commun 8:14183. doi: 10.1038/ncomms14183. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 6.Cokol M, Kuru N, Bicak E, Larkins-Ford J, Aldridge BB. 2017. Efficient measurement and factorization of high-order drug interactions in Mycobacterium tuberculosis. Sci Adv 3:e1701881. doi: 10.1126/sciadv.1701881. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 7.World Health Organization. 2010. Treatment of tuberculosis: guidelines. World Health Organization, Geneva, Switzerland. [Google Scholar]
- 8.World Health Organization. 2016. WHO treatment guidelines for drug-resistant tuberculosis, 2016 update. World Health Organization, Geneva, Switzerland. [Google Scholar]
- 9.Dheda K, Gumbo T, Gandhi NR, Murray M, Theron G, Udwadia Z, Migliori GB, Warren R. 2014. Global control of tuberculosis: from extensively drug-resistant to untreatable tuberculosis. Lancet Respir Med 2:321–338. doi: 10.1016/S2213-2600(14)70031-1. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 10.Falzon D, Schunemann HJ, Harausz E, Gonzalez-Angulo L, Lienhardt C, Jaramillo E, Weyer K. 2017. World Health Organization treatment guidelines for drug-resistant tuberculosis, 2016 update. Eur Respir J 49:1602308. doi: 10.1183/13993003.02308-2016. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 11.Ekins S, Pottorf R, Reynolds RC, Williams AJ, Clark AM, Freundlich JS. 2014. Looking back to the future: predicting in vivo efficacy of small molecules versus Mycobacterium tuberculosis. J Chem Inf Model 54:1070–1082. doi: 10.1021/ci500077v. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 12.Ma S, Minch KJ, Rustad TR, Hobbs S, Zhou SL, Sherman DR, Price ND. 2015. Integrated modeling of gene regulatory and metabolic networks in Mycobacterium tuberculosis. PLoS Comput Biol 11:e1004543. doi: 10.1371/journal.pcbi.1004543. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 13.Peterson EJR, Ma S, Sherman DR, Baliga NS. 2016. Network analysis identifies Rv0324 and Rv0880 as regulators of bedaquiline tolerance in Mycobacterium tuberculosis. Nat Microbiol 1:16078. [CrossRef] doi: 10.1038/nmicrobiol.2016.78. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 14.Chandrasekaran S, Cokol-Cakmak M, Sahin N, Yilancioglu K, Kazan H, Collins JJ, Cokol M. 2016. Chemogenomics and orthology-based design of antibiotic combination therapies. Mol Syst Biol 12:872. doi: 10.15252/msb.20156777. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 15.Bredel M, Jacoby E. 2004. Chemogenomics: an emerging strategy for rapid target and drug discovery. Nat Rev Genet 5:262–275. doi: 10.1038/nrg1317. [DOI] [PubMed] [Google Scholar]
- 16.Nichols RJ, Sen S, Choo YJ, Beltrao P, Zietek M, Chaba R, Lee S, Kazmierczak KM, Lee KJ, Wong A, Shales M, Lovett S, Winkler ME, Krogan NJ, Typas A, Gross CA. 2011. Phenotypic landscape of a bacterial cell. Cell 144:143–156. doi: 10.1016/j.cell.2010.11.052. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 17.Breiman L. 2001. Random forests. Machine Learning 45:5–32. doi: 10.1023/A:1010933404324. [DOI] [Google Scholar]
- 18.Johnson WE, Li C, Rabinovic A. 2007. Adjusting batch effects in microarray expression data using empirical Bayes methods. Biostatistics 8:118–127. doi: 10.1093/biostatistics/kxj037. [DOI] [PubMed] [Google Scholar]
- 19.Boshoff HI, Myers TG, Copp BR, McNeil MR, Wilson MA, Barry CE III. 2004. The transcriptional responses of Mycobacterium tuberculosis to inhibitors of metabolism: novel insights into drug mechanisms of action. J Biol Chem 279:40174–40184. doi: 10.1074/jbc.M406796200. [DOI] [PubMed] [Google Scholar]
- 20.Ioerger TR, O’Malley T, Liao R, Guinn KM, Hickey MJ, Mohaideen N, Murphy KC, Boshoff HIM, Mizrahi V, Rubin EJ, Sassetti CM, Barry CE, Sherman DR, Parish T, Sacchettini JC. 2013. Identification of new drug targets and resistance mechanisms in Mycobacterium tuberculosis. PLoS One 8:e75245. doi: 10.1371/journal.pone.0075245. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 21.Berenbaum MC. 1989. What is synergy? Pharmacol Rev 41:93–141. [PubMed] [Google Scholar]
- 22.Chen C, Gardete S, Jansen RS, Shetty A, Dick T, Rhee KY, Dartois V. 2018. Verapamil targets membrane energetics in Mycobacterium tuberculosis. Antimicrob Agents Chemother 62:e02107-17. doi: 10.1128/AAC.02107-17. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 23.Gupta S, Tyagi S, Almeida DV, Maiga MC, Ammerman NC, Bishai WR. 2013. Acceleration of tuberculosis treatment by adjunctive therapy with verapamil as an efflux inhibitor. Am J Respir Crit Care Med 188:600–607. doi: 10.1164/rccm.201304-0650OC. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 24.Gupta S, Cohen KA, Winglee K, Maiga M, Diarra B, Bishai WR. 2014. Efflux inhibition with verapamil potentiates bedaquiline in Mycobacterium tuberculosis. Antimicrob Agents Chemother 58:574–576. doi: 10.1128/AAC.01462-13. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 25.Demitto FDO, do Amaral RCR, Maltempe FG, Siqueira VLD, Scodro RBDL, Lopes MA, Caleffi-Ferracioli KR, Canezin PH, Cardoso RF. 2015. In vitro activity of rifampicin and verapamil combination in multidrug-resistant Mycobacterium tuberculosis. PLoS One 10:e0116545. doi: 10.1371/journal.pone.0116545. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 26.Ocampo PS, Lázár V, Papp B, Arnoldini M, Abel zur Wiesch P, Busa-Fekete R, Fekete G, Pál C, Ackermann M, Bonhoeffer S. 2014. Antagonism between bacteriostatic and bactericidal antibiotics is prevalent. Antimicrob Agents Chemother 58:4573–4582. doi: 10.1128/AAC.02463-14. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 27.Robertson GT, Scherman MS, Bruhn DF, Liu J, Hastings C, McNeil MR, Butler MM, Bowlin TL, Lee RB, Lee RE, Lenaerts AJ. 2017. Spectinamides are effective partner agents for the treatment of tuberculosis in multiple mouse infection models. J Antimicrob Chemother 72:770–777. doi: 10.1093/jac/dkw467. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 28.Lee RE, Hurdle JG, Liu J, Bruhn DF, Matt T, Scherman MS, Vaddady PK, Zheng Z, Qi J, Akbergenov R, Das S, Madhura DB, Rathi C, Trivedi A, Villellas C, Lee RB, Rakesh, Waidyarachchi SL, Sun D, McNeil MR, Ainsa JA, Boshoff HI, Gonzalez-Juarrero M, Meibohm B, Bottger EC, Lenaerts AJ. 2014. Spectinamides: a new class of semisynthetic antituberculosis agents that overcome native drug efflux. Nat Med 20:152–158. doi: 10.1038/nm.3458. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 29.Franzblau SG, DeGroote MA, Cho SH, Andries K, Nuermberger E, Orme IM, Mdluli K, Angulo-Barturen I, Dick T, Dartois V, Lenaerts AJ. 2012. Comprehensive analysis of methods used for the evaluation of compounds against Mycobacterium tuberculosis. Tuberculosis (Edinb) 92:453–488. doi: 10.1016/j.tube.2012.07.003. [DOI] [PubMed] [Google Scholar]
- 30.Bonnett LJ, Ken-Dror G, Koh G, Davies GR. 2017. Comparing the efficacy of drug regimens for pulmonary tuberculosis: meta-analysis of endpoints in early-phase clinical trials. Clin Infect Dis 65:46–54. doi: 10.1093/cid/cix247. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 31.Drusano GL, Sgambati N, Eichas A, Brown DL, Kulawy R, Louie A. 2010. The combination of rifampin plus moxifloxacin is synergistic for suppression of resistance but antagonistic for cell kill of Mycobacterium tuberculosis as determined in a hollow-fiber infection model. mBio 1:e00139-10. doi: 10.1128/mBio.00139-10. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 32.Kanehisa M, Goto S. 2000. KEGG: Kyoto Encyclopedia of Genes and Genomes. Nucleic Acids Res 28:27–30. doi: 10.1093/nar/28.1.27. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 33.Kanehisa M, Sato Y, Kawashima M, Furumichi M, Tanabe M. 2016. KEGG as a reference resource for gene and protein annotation. Nucleic Acids Res 44:D457–D462. doi: 10.1093/nar/gkv1070. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 34.Rustad TR, Minch KJ, Ma S, Winkler JK, Hobbs S, Hickey M, Brabant W, Turkarslan S, Price ND, Baliga NS, Sherman DR. 2014. Mapping and manipulating the Mycobacterium tuberculosis transcriptome using a transcription factor overexpression-derived regulatory network. Genome Biol 15:502. doi: 10.1186/PREACCEPT-1701638048134699. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 35.Galagan JE, Minch K, Peterson M, Lyubetskaya A, Azizi E, Sweet L, Gomes A, Rustad T, Dolganov G, Glotova I, Abeel T, Mahwinney C, Kennedy AD, Allard R, Brabant W, Krueger A, Jaini S, Honda B, Yu WH, Hickey MJ, Zucker J, Garay C, Weiner B, Sisk P, Stolte C, Winkler JK, Van de Peer Y, Iazzetti P, Camacho D, Dreyfuss J, Liu Y, Dorhoi A, Mollenkopf HJ, Drogaris P, Lamontagne J, Zhou Y, Piquenot J, Park ST, Raman S, Kaufmann SH, Mohney RP, Chelsky D, Moody DB, Sherman DR, Schoolnik GK. 2013. The Mycobacterium tuberculosis regulatory network and hypoxia. Nature 499:178–183. doi: 10.1038/nature12337. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 36.Singh R, Ramachandran V, Shandil R, Sharma S, Khandelwal S, Karmarkar M, Kumar N, Solapure S, Saralaya R, Nanduri R, Panduga V, Reddy J, Prabhakar KR, Rajagopalan S, Rao N, Narayanan S, Anandkumar A, Balasubramanian V, Datta S. 2015. In silico-based high-throughput screen for discovery of novel combinations for tuberculosis treatment. Antimicrob Agents Chemother 59:5664–5674. doi: 10.1128/AAC.05148-14. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 37.Lee BY, Clemens DL, Silva A, Dillon BJ, Maslesa-Galic S, Nava S, Ho CM, Horwitz MA. 2018. Ultra-rapid near universal TB drug regimen identified via parabolic response surface platform cures mice of both conventional and high susceptibility. PLoS One 13:e0207469. doi: 10.1371/journal.pone.0207469. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 38.Almeida D, Ioerger T, Tyagi S, Li SY, Mdluli K, Andries K, Grosset J, Sacchettini J, Nuermberger E. 2016. Mutations in pepQ confer low-level resistance to bedaquiline and clofazimine in Mycobacterium tuberculosis. Antimicrob Agents Chemother 60:4590–4599. doi: 10.1128/AAC.00753-16. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 39.Tasneen R, Li SY, Peloquin CA, Taylor D, Williams KN, Andries K, Mdluli KE, Nuermberger EL. 2011. Sterilizing activity of novel TMC207- and PA-824-containing regimens in a murine model of tuberculosis. Antimicrob Agents Chemother 55:5485–5492. doi: 10.1128/AAC.05293-11. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 40.Mitchison DA. 1996. Modern methods for assessing the drugs used in the chemotherapy of mycobacterial disease. Soc Appl Bacteriol Symp Ser 25:72S–80S. [PubMed] [Google Scholar]
- 41.Mitchison DA. 1993. Assessment of new sterilizing drugs for treating pulmonary tuberculosis by culture at 2 months. Am Rev Respir Dis 147:1062–1063. doi: 10.1164/ajrccm/147.4.1062. [DOI] [PubMed] [Google Scholar]
- 42.Chevereau G, Bollenbach T. 2015. Systematic discovery of drug interaction mechanisms. Mol Syst Biol 11:807. doi: 10.15252/msb.20156098. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 43.Lobritz MA, Belenky P, Porter CB, Gutierrez A, Yang JH, Schwarz EG, Dwyer DJ, Khalil AS, Collins JJ. 2015. Antibiotic efficacy is linked to bacterial cellular respiration. Proc Natl Acad Sci U S A 112:8173–8180. doi: 10.1073/pnas.1509743112. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 44.Kapopoulou A, Lew JM, Cole ST. 2011. The MycoBrowser portal: a comprehensive and manually annotated resource for mycobacterial genomes. Tuberculosis (Edinb) 91:8–13. doi: 10.1016/j.tube.2010.09.006. [DOI] [PubMed] [Google Scholar]
- 45.UniProt Consortium. 2018. UniProt: the universal protein knowledgebase. Nucleic Acids Res 46:2699. doi: 10.1093/nar/gky092. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 46.DeJesus MA, Gerrick ER, Xu W, Park SW, Long JE, Boutte CC, Rubin EJ, Schnappinger D, Ehrt S, Fortune SM, Sassetti CM, Ioerger TR. 2017. Comprehensive essentiality analysis of the Mycobacterium tuberculosis genome via saturating transposon mutagenesis. mBio 8:e02133-16. doi: 10.1128/mBio.02133-16. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 47.Sassetti CM, Boyd DH, Rubin EJ. 2003. Genes required for mycobacterial growth defined by high density mutagenesis. Mol Microbiol 48:77–84. doi: 10.1046/j.1365-2958.2003.03425.x. [DOI] [PubMed] [Google Scholar]
- 48.Griffin JE, Gawronski JD, Dejesus MA, Ioerger TR, Akerley BJ, Sassetti CM. 2011. High-resolution phenotypic profiling defines genes essential for mycobacterial growth and cholesterol catabolism. PLoS Pathog 7:e1002251. doi: 10.1371/journal.ppat.1002251. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 49.Tsolaki AG, Hirsh AE, DeRiemer K, Enciso JA, Wong MZ, Hannan M, Goguet de la Salmoniere YO, Aman K, Kato-Maeda M, Small PM. 2004. Functional and evolutionary genomics of Mycobacterium tuberculosis: insights from genomic deletions in 100 strains. Proc Natl Acad Sci U S A 101:4865–4870. doi: 10.1073/pnas.0305634101. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 50.Cokol M, Li C, Chandrasekaran S. 2018. Chemogenomic model identifies synergistic drug combinations robust to the pathogen microenvironment. PLoS Comput Biol 14:e1006677. doi: 10.1371/journal.pcbi.1006677. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 51.Rustad TR, Harrell MI, Liao R, Sherman DR. 2008. The enduring hypoxic response of Mycobacterium tuberculosis. PLoS One 3:e1502. doi: 10.1371/journal.pone.0001502. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 52.Ehrt S, Guo XV, Hickey CM, Ryou M, Monteleone M, Riley LW, Schnappinger D. 2005. Controlling gene expression in mycobacteria with anhydrotetracycline and Tet repressor. Nucleic Acids Res 33:e21. doi: 10.1093/nar/gni013. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 53.Jain P, Hsu T, Arai M, Biermann K, Thaler DS, Nguyen A, Gonzalez PA, Tufariello JM, Kriakov J, Chen B, Larsen MH, Jacobs WR Jr. 2014. Specialized transduction designed for precise high-throughput unmarked deletions in Mycobacterium tuberculosis. mBio 5:e01245-14. doi: 10.1128/mBio.01245-14. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 54.Langmead B, Salzberg SL. 2012. Fast gapped-read alignment with Bowtie 2. Nat Methods 9:357–359. doi: 10.1038/nmeth.1923. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 55.Li H, Handsaker B, Wysoker A, Fennell T, Ruan J, Homer N, Marth G, Abecasis G, Durbin R, 1000 Genome Project Data Processing Subgroup. 2009. The Sequence Alignment/Map format and SAMtools. Bioinformatics 25:2078–2079. doi: 10.1093/bioinformatics/btp352. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 56.Geva-Zatorsky N, Dekel E, Cohen AA, Danon T, Cohen L, Alon U. 2010. Protein dynamics in drug combinations: a linear superposition of individual-drug responses. Cell 140:643–651. doi: 10.1016/j.cell.2010.02.011. [DOI] [PubMed] [Google Scholar]
- 57.Pritchard JR, Bruno PM, Gilbert LA, Capron KL, Lauffenburger DA, Hemann MT. 2013. Defining principles of combination drug mechanisms of action. Proc Natl Acad Sci U S A 110:E170–E179. doi: 10.1073/pnas.1210419110. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 58.Libardo MDJ, Boshoff HIM, Barry CE III. 2018. The present state of the tuberculosis drug development pipeline. Curr Opin Pharmacol 42:81–94. doi: 10.1016/j.coph.2018.08.001. [DOI] [PMC free article] [PubMed] [Google Scholar]
Associated Data
This section collects any data citations, data availability statements, or supplementary materials included in this article.
Supplementary Materials
Schematic of INDIGO-MTB modeling workflow (A to C) and the experimental assays to measure drug interaction (D to F). (A) The input data sets for training the INDIGO algorithm are (i) the transcriptomic profiles of drugs and (ii) the corresponding FIC scores of known drug-drug interactions. From each transcriptome profile of MTB response to an individual drug, we defined a corresponding drug-gene interaction matrix by assigning a value of 1 to genes that changed in expression by more than twofold (up or down) after exposure to drug, and setting all other genes to a value of 0. Only genes that are upregulated are shown in the remaining panels for simplicity. (B) For each drug combination, INDIGO calculates a “joint” drug-gene interaction matrix using a linear combination of the drug-gene interaction matrices of each constituent individual drug. The joint profile captures both the similarity and uniqueness in the transcriptome response profiles of the individual drugs in each combination. The INDIGO algorithm then uses a machine learning approach called random forest to create a mathematical model that associates the FIC score of each drug combination to its corresponding joint drug-gene interaction matrix. Random forest builds a series of decision trees to identify specific patterns in the drug-gene interaction matrices that significantly associate with the value of the corresponding drug-drug interaction FIC scores. (C) Once built, the INDIGO-MTB model requires only the transcriptomic response profile elicited by a new compound of interest as input to predict FIC scores of combinations featuring the compound of interest. (D) Representative checkerboard assay experiments of a synergistic and antagonistic drug pair. Cultures were exposed to serial dilutions of drugs (designated in the rows and columns) for 7 days, and bacterial viability was quantified by measuring ATP levels with the BacTiter Glo reagent. The thick black boxes denote the individual drug MIC wells, and the boxes with numbers denote concentrations that yielded iso-equivalent inhibition (each of the numbers represent the FIC score calculated based on the drug concentrations associated with corresponding well). (E and F) Representative DiaMOND assay experiments of a synergistic and antagonistic drug pair (E) or triplet (F). Cultures were exposed to drugs in 384-well plates, and growth was measured by OD600. The FIC for a drug combination was calculated as the ratio between the observed and expected IC50 dose of the drug combination. For two-drug combinations the expected IC50 dose is defined as the intersection of the line (additivity line) drawn between the IC50 doses for each individual drug. For three-drug combinations, the expected IC50 dose is defined as the intersection of the drug combination dose response and the plane (additivity plane) created by connecting the IC50 doses for each individual drug. Download FIG S1, JPG file, 0.5 MB (519.8KB, jpg) .
Copyright © 2019 Ma et al.
This content is distributed under the terms of the Creative Commons Attribution 4.0 International license.
(A) Compendium of transcriptomic/chemogenomic data for INDIGO-MTB. (B) Training combinations with associated FIC interaction indices. (C) List of all possible pairwise interaction scores (164 compounds and 65 perturbations). (D) INDIGO-MTB predictions along with corresponding experimental (in vitro) and clinical validation data. Highlighted combinations are novel, i.e., not used in training set. (E) Pathway enrichment analysis using the top 500 predictive genes. (F) DiaMOND distribution transformation. (G) Impact of various thresholds for finding differentially expressed genes after drug treatment. Changing the log fold change threshold from 4- to 32-fold showed similar correlation with the experimental test set interactions as the default threshold (2-fold). The use of a fold change threshold to binarize the data was performed to reduce the noise in the data sets. Overall, this analysis shows that the INDIGO model is robust for the thresholds used. At the highest threshold (32-fold), a slightly higher correlation was observed, although it was not significantly better than the default settings based on partial correlation analysis (P value > 0.05). (H) Impact of using various machine learning algorithms for predicting drug interactions. Download Table S1, XLSX file, 1.1 MB (1.1MB, xlsx) .
Copyright © 2019 Ma et al.
This content is distributed under the terms of the Creative Commons Attribution 4.0 International license.
Distributions of INDIGO-MTB interaction scores for combinations featuring different drugs. (A) Box plots of interaction scores of combinations featuring only bacteriostatic drugs (blue) is shifted toward synergy (interaction score = 1.03 ± 0.2), relative to combinations featuring bactericidal drugs (red) (interaction score = 1.25 ± 0.3). Combinations featuring bactericidal drugs appear to have the most antagonistic INDIGO-MTB interaction scores. (B) Distribution of INDIGO-MTB interaction scores for combinations involving verapamil (VER) or chlorpromazine (CPZ). The distribution of interaction scores for these drugs is significantly lower than the interaction score distribution for combinations featuring other drugs (P value < 1 × 10−16, nonparametric Kolmogorov-Smirnov test), suggesting that combinations featuring these drugs are enriched for synergy. The box plots display the first quartile (1Q), median, and the third quartile (3Q) of the distribution of INDIGO-MTB scores for pairs of drugs, at least one of which are VER or CPZ compared against all possible combinations excluding these two antibiotics. Download FIG S2, JPG file, 0.2 MB (161.3KB, jpg) .
Copyright © 2019 Ma et al.
This content is distributed under the terms of the Creative Commons Attribution 4.0 International license.
INDIGO accurately forecasts interactions among the 36 test set drug combinations against MTB. This figure shows the comparison between INDIGO-MTB interaction scores and experiments for all 36 combinations in the validation set. This figure complements Fig. 2, which compares INDIGO predictions with the 24 novel combinations (subset of 36 test combinations). (A) Drug combinations chosen for experimental testing span the entire range of drug interaction predictions by INDIGO. The histogram and box plot above it show the distribution of pairwise drug interaction scores for the 35 high-interest TB agents (the boundaries of the box plot denote the 25th and 75th percentiles of the distribution, and the dashed lines extend between 1st and 99th percentiles). The red dots denote the combinations selected for experimental validation. (B) Comparison of INDIGO-MTB interaction scores with in vitro interaction scores. For both experimental and model-predicted scores, values less than 0.9 indicate synergy, values between 0.9 and 1.1 denote additivity, and values greater than 1.1 indicate antagonism. Each dot indicates a specific drug combination. Dark red dots mark two-drug regimens (R = 0.63, P ∼ 10−4), and blue dots mark three-drug regimens (R = 0.68, P ∼ 10−2). The specific combinations mentioned in the text are highlighted in the plot. (C) Dot plot of experimentally measured drug interaction scores versus the INDIGO-MTB predicted drug interaction type. The dots labeled in red font denote outlier combinations that were misclassified by INDIGO-MTB. The interaction scores were significantly different between predicted synergistic and antagonistic combinations (P = 6 × 10−5). The horizontal lines in the box plot represent the median and the first and third quartiles. (D) Sensitivity versus specificity curves for INDIGO-MTB predictions of synergy and antagonism for both two-drug and three-drug combinations in the validation set. The AUC values are 0.89 (P = 4 × 10−5) and 0.91 (P = 4.1 × 10−5) for synergy and antagonism, respectively. (sensitivity = 88.4% and specificity = 86.5% for synergy; sensitivity = 79.4% and specificity = 90% for predicting antagonism). Download FIG S3, JPG file, 0.3 MB (291.1KB, jpg) .
Copyright © 2019 Ma et al.
This content is distributed under the terms of the Creative Commons Attribution 4.0 International license.
Receiver operating curves (ROC) for INDIGO-MTB predictions of synergy and antagonism for various thresholds of synergy and antagonism. (A to D) ROC curves generated from the independent test data. Sensitivity measures the true positive rate, which is the fraction of true positive interactions correctly identified; specificity measures the true negative rate. The area under the ROC curve (AUC) values provides an estimate of the sensitivity and specificity of model predictions over a range of thresholds. At the highest threshold for synergy (i.e., FIC < 0.5), the accuracy of the model is reduced likely due to majority of the interactions in the test set being classified as neutral. (E to H) ROC curves INDIGO-MTB tested using 10-fold cross-validation analysis. In cross-validation analysis, 10% of the training data set is withheld, and predictions are made using an INDIGO-MTB model trained using the remaining 90% of the training data. Performance metrics are then calculated based on prediction on the withheld data. This analysis is repeated 10 times to cover the entire training data set. The plots show the sensitivity versus specificity curves for INDIGO-MTB predictions of synergy and antagonism for various thresholds of synergy and antagonism. The cross-validation accuracy is surprisingly lower than the test set accuracy, as the training set comprises data from 15 different studies that were done in diverse labs and batches with different drugs and methodologies. In our prior study (14), the training and test data were obtained from a single source, and consequently, the cross-validation accuracy matched the test set accuracy. Download FIG S4, JPG file, 0.3 MB (256.4KB, jpg) .
Copyright © 2019 Ma et al.
This content is distributed under the terms of the Creative Commons Attribution 4.0 International license.
Two-way and three-way INDIGO-MTB scores for 35 high-interest TB drugs. Download Table S2, XLSX file, 1.2 MB (1.2MB, xlsx) .
Copyright © 2019 Ma et al.
This content is distributed under the terms of the Creative Commons Attribution 4.0 International license.
Four-way and five-way INDIGO-MTB scores for 35 high-interest TB drugs. Download Table S3, XLSX file, 2.2 MB (2.2MB, xlsx) .
Copyright © 2019 Ma et al.
This content is distributed under the terms of the Creative Commons Attribution 4.0 International license.
Impact of variation between clinical trials and experimental drug interaction studies on correlation between drug synergy and clinical efficacy. Since multiple clinical trials and experimental studies had measured the clinical efficacy outcome (sputum conversion rates) and in vitro FIC scores for drug combinations, we assessed the robustness of correlations between clinical efficacy data and both experimentally measured (A and B) and model-predicted (C and D) interaction scores by performing sampling analysis. (A) Distribution of the correlation between in vitro experimentally measured drug interaction scores with corresponding sputum conversion rates. Since multiple experimental studies had measured the in vitro interaction outcome for these combinations, we performed sampling analysis by randomly choosing one representative study for each combination to determine the average correlation. We found that the in vitro experimental drug interaction scores correlated significantly (mean R = −0.52, P ∼ 0.01, average of 100 trials) with clinical sputum conversion by this sampling analysis. Panel B shows one representative trial with R = −0.52. For comparison, INDIGO-MTB achieved a similar correlation across all 57 clinical trials (R = −0.55, P ∼ 10−5). (B) Comparison of experimental FIC scores with sputum conversion rates in human patients after 8 weeks of treatment in clinical trials, with each regimen represented by FIC data from a single experimental study (R = −0.52, P = 0.01). Data shown for four two-way and two three-way drug combinations that had both experimental in vitro drug interaction data and sputum conversion rates. Each dot indicates a specific drug combination reported from a specific clinical trial. The combinations corresponding to each dot are provided in the legend. (C) Histogram visualizing the distribution of the correlations between INDIGO-MTB predictions and clinical efficacy based on sampling analysis. We performed sampling analysis by randomly choosing one representative clinical trial for each combination to determine the average correlation with INDIGO-MTB-predicted interaction scores. We observed a significant correlation between interaction scores and the sputum culture conversion rates (mean R = −0.38 average of 100 random sampling trials, P value = 0.001). Panel D shows data from one representative trial with R = −0.37. Download FIG S5, JPG file, 0.2 MB (174.1KB, jpg) .
Copyright © 2019 Ma et al.
This content is distributed under the terms of the Creative Commons Attribution 4.0 International license.
Impact of transcription factor (TF) deletion on drug interaction scores. (A) The average predicted impact of deleting each of the 206 TFs on all 36 pairwise combinations comprising INH, RIF, STM, MXF, CFZ, BDQ, CAP, ETA, and PA824 is shown. Rv1353c had the biggest average impact on all the combinations and was chosen for experimental validation. (B) Predicted impact of Rv1353c deletion on drug interaction scores. The plot shows the relative absolute difference in FIC scores on all 36 pairwise combinations comprising INH, RIF, STM, MXF, CFZ, BDQ, CAP, ETA, and PA824. Interestingly, combinations with STM showed both the highest and lowest change in interaction score. The interactions in bold type were chosen for experimental testing. All the chosen combinations were also antagonistic or additive, thus changing the activity of Rv1353c could be used to make these combinations more synergistic. (C) In vitro experimentally measured drug interaction scores for Rv1353c genetic perturbation strains exposed to drug combinations. The error bars represent the standard deviations between replicates. Download FIG S6, JPG file, 0.1 MB (131.2KB, jpg) .
Copyright © 2019 Ma et al.
This content is distributed under the terms of the Creative Commons Attribution 4.0 International license.
(A) In vitro experimentally measured interaction score measured between bedaquiline (BDQ) and chlorpromazine (CPZ). The heatmap shows a representative checkerboard assay experiment, in which MTB H37Rv cultures were exposed to different pairwise concentrations of BDQ and CPZ in 96-well plate format, designated in the columns and rows, respectively. Cultures were exposed to drugs for 7 days, and bacterial viability was quantified by measuring ATP levels with the BacTiter Glo reagent. The thick black boxes denote the individual drug MIC wells, and the boxes with numbers denote concentrations that yielded iso-equivalent inhibition (each of the numbers represents the FIC score calculated based on the drug concentrations associated with corresponding well). (B) Correlation analysis of FIC average values calculated from checkerboard assays measured by AlamarBlue or BacTiter Glo. Each point represents the average of the FIC indices of equivalently inhibited concentrations on an individual checkerboard plate. Pearson’s R for this is 0.78 (P < 0.0001). Download FIG S7, JPG file, 0.1 MB (145.7KB, jpg) .
Copyright © 2019 Ma et al.
This content is distributed under the terms of the Creative Commons Attribution 4.0 International license.
Data Availability Statement
The INDIGO-MTB model and associated data sets are available from the Synapse bioinformatics repository (Synapse identifier or accession no. syn18824984) (https://www.synapse.org/INDIGO_MTB) (doi:10.7303/syn18824984). The data reported in the paper are available in the supplemental material. The RNA-seq data generated for this study are available in the Gene Expression Omnibus database under accession no. GSE119585.