

Abstract
Identifying the minimal number of parameters needed to describe a dataset is a challenging problem known in the literature as intrinsic dimension estimation. All the existing intrinsic dimension estimators are not reliable whenever the dataset is locally undersampled, and this is at the core of the so called curse of dimensionality. Here we introduce a new intrinsic dimension estimator that leverages on simple properties of the tangent space of a manifold and extends the usual correlation integral estimator to alleviate the extreme undersampling problem. Based on this insight, we explore a multiscale generalization of the algorithm that is capable of (i) identifying multiple dimensionalities in a dataset, and (ii) providing accurate estimates of the intrinsic dimension of extremely curved manifolds. We test the method on manifolds generated from global transformations of high-contrast images, relevant for invariant object recognition and considered a challenge for state-of-the-art intrinsic dimension estimators.
Subject terms: Applied mathematics, Computational science
Introduction
Processing, analyzing and extracting information from high dimensional data is at the core of the modern research in machine learning and pattern recognition. One of the main challenges in this field is to decompose and compress, without losing information, the redundant representations of complex data that are produced across diverse scientific disciplines, including computer vision, signal processing and bioinformatics. Manifold learning and dimensional reduction1–3 are the main techniques employed to perform this task. Several of these approaches work under the reasonable assumption that the points (or samples) of a dataset, represented as vectors of real numbers lying in a space of large embedding dimension D, actually belong to a manifold , whose intrinsic dimension (ID) d is much lower than D. The problem of providing accurate estimates for this number has been recognized multiple times and in different contexts: in psychometry by Shepard4,5, in computer science by Trunk6, Fukunaga and Olsen7, in physics by Grassberger, Procaccia8,9, and Takens10. More recently, Intrinsic Dimension Estimation (IDE) has been reconsidered with the advent of big data analysis, artificial intelligence and demanding molecular dynamics simulations, and several estimators to measure the intrinsic dimension have been proposed11–22.
IDE is a remarkably challenging problem, On one side, it is globally affected by manifold curvature. When a manifold is curved, the smallest Euclidean space in which it can be embedded isometrically has a bigger dimension than the true ID of the manifold, biasing global estimators towards overestimation. On the other side, it is locally affected by the so called curse of dimensionality23. When a manifold has large ID (), it is exponentially hard (in the ID) to sample its local structure, leading to a systematic underestimation error in local estimators.
Standard Algorithms For IDE and Extreme Locally Undersampled Regime
Algorithms for intrinsic dimension estimation can be roughly classified in two groups12. Projective methods compute the eigenvalues of the D × D covariance matrix CX of the data X, defined as , where xiμ is the i-th component of the μ-th sample vector of the dataset xμ (μ = 1, …, N). The ID is then estimated by looking for jumps in the magnitude of the sorted eigenvalues of CX (see top left panel in Fig. 1). Principal component analysis (PCA) is the main representative of this class of algorithms. Both a global (gPCA) and a multiscale version (mPCA) of the algorithm are used15,24. In the former one evaluates the covariance matrix on the whole dataset X, whereas in the latter one performs the spectral analysis on local subsets X(x0,rc) of X, obtained by selecting one particular point x0 and including in the local covariance matrix only those points that lie inside a cutoff radius rc, which is then varied.
Figure 1.
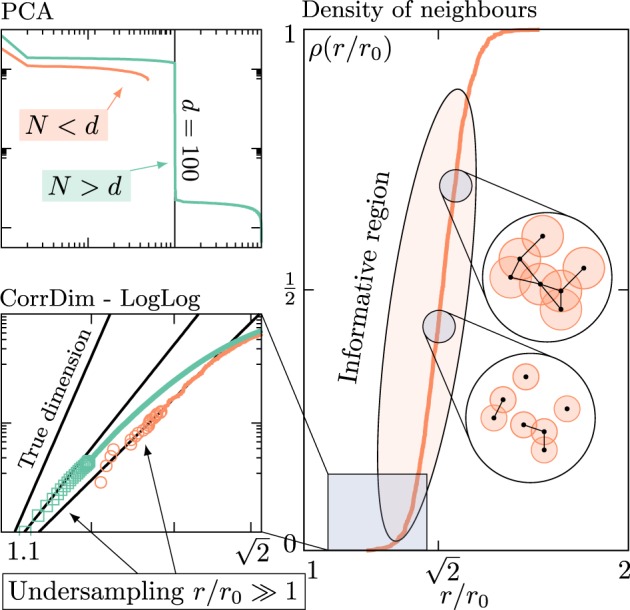
Standard projective [Principal Component Analysis (PCA)] and geometric [Correlation Dimension (CorrDim) and its generalizations] methods for intrinsic dimension estimation fail due to undersampling. (Top left) PCA estimates the intrinsic dimension d of linearly embedded datasets by detecting abrupt jumps in the magnitude of the sorted eigenvalues of the corresponding correlation matrix. This method works whenever the number of samples N in the dataset is sufficiently large (), and the jump occurs between the d-th and (d + 1)-th eigenvalues (green line in the plot corresponding to a dataset of N = 1000 samples drawn uniformly from a hypercube in dimension d = 100). In the opposite undersampled regime N < d, PCA is inconclusive (orange line in the plot, same dataset with N = 50 samples). (Bottom left) Geometric methods, such as the CorrDim or the more general k-nearest-neighbours estimators, are based on the scaling of the density of neighbours ρ(r/r0) at a small cutoff distance r with respect to the average diameter r0 of the dataset. In particular, for r/r0 → 0 independently on the details of the datasets, so that a log-log linear fit estimates the ID as the slope of the fitting line. However, the small r regime is exponentially (in the ID, [23]) difficult to sample. This effect is at the origin of the so-called curse of dimensionality, and it induces a systematic underestimation of the ID. As N increases, though one is able to sample smaller r regions as shown in the plot (orange line N = 50, green line N = 1000 as above), convergence to the true dimension (d = 100 in the plot) is not possible. (Right) The density of neighbours ρ is more generally defined at any cutoff distance r. The regime is the one used to compute CorrDim. In the remaining region , the density ρ increases and eventually approaches one, indicating that the underlying proximity graph (see insets) gets more and more connected. We observe that this region is easily sampled at any fixed N (plot at N = 50), but the functional form of ρ in this informative regime is in principle dependent on the details of the dataset.
The main limitation of the global PCA is that it can only detect the correct ID of linearly embedded manifolds (i.e. linear manifolds embedded trivially via rotations and translations), systematically overestimating the ID of curved/non-linearly embedded datasets. The mPCA could in principle fix this issue. However, PCA only works if the number of samples , otherwise being inconclusive (see top left panel of Fig. 1). This is a major drawback in the multiscale case, since to measure the correct ID the cutoff radius rc needs to be small enough, implying that the sampling of the manifold must be dense enough to guarantee that a sufficient number of samples lies inside the subsets X(x0, rc). Another technical issue that makes mPCA difficult to employ for IDE is the fact that the amplitude of the “jump” in the magnitude of the sorted eigenvalues depends on the data, and the choice of a threshold size is somewhat arbitrary.
The other group of estimators belongs to the so-called geometric (or fractal) methods. Their common ancestor is the correlation dimension (CorrDim) introduced by Grassberger and Procaccia9 to measure the fractal dimension of strange attractors in the context of dynamical systems. This estimator is based on the observation that the density of neighbours (also known as correlation integral in the literature) with a given cutoff distance r
| 1 |
scales as for r → 0 and therefore one can extract the ID by measuring the slope of the linear part of ρ as a function of r in log-log scale, since the relation holds (see bottom left panel of Fig. 1).
CorrDim is very effective for the estimation of low IDs (), whereas it systematically underestimates in the case of manifolds with larger IDs. This drawback is well known in the literature18 and is only partially mitigated by more recent and advanced generalizations of CorrDim based on k-nearest-neighbors distances12. The reason why all these algorithms systematically fail for is due to a fundamental limitation of most geometric methods: indeed it is possible to prove23 that the accurate estimation of the ID requires a number of samples N which grows exponentially in the intrinsic dimension d. As a consequence, one observes a systematic undersampling of the small radius region of the density of neighbors ρX(r), as shown for the CorrDim estimator in the bottom left panel of Fig. 1.
Both mPCA and CorrDim, as well as their more recent generalizations such as DANCo18, are based on the fundamental fact that, locally, samples in a dataset are effectively drawn uniformly from a d-dimensional disk linearly embedded in . This is the informal way to state rigorous results based on the tangent space approximation to smooth manifolds and embeddings18,25. On one side, local neighbourhoods of large ID datasets () need a number of points N exponential in the ID to be sufficiently sampled; on the other hand, the tangent space approximation needs dense sampling of small patches of the manifold to be used in practice. This incompatibility of requirements is the so called curse of dimensionality, and defines a theoretical limit for all multiscale projective and geometric ID estimators.
In order to try and break the curse of dimensionality, additional information about the probability distribution of the data must be assumed. The main ingredient of our spell is the assumption that data are locally isotropic. This suggests to consider the average correlation integral for hyperspheres . We will leverage on this observation to develop a novel geometric ID estimator for linearly embedded manifolds, which departs from the small radius limit of the density of neighbors ρX(r) and considers this quantity at finite radius r. We show in the following that this method overcomes the extreme undersampling issue caused by the curse of dimensionality and displays a remarkable robustness to non-uniform sampling and noise. Based on the intriguing features reported above, we propose a multiscale generalization of the estimator, capable of providing the correct ID for datasets extracted from highly curved or multidimensional manifolds.
Full Correlation Integral (FCI) Estimator
The tangent space approximation suggests that a special role in the IDE problem is played by uniformly sampled d-dimensional disks linearly embedded. The average correlation integral for the boundary of this manifold, which is the (d − 1)-dimensional sphere of radius rs, can be analytically evaluated as (see Materials and methods)
| 2 |
where 2F1 is the (2,1)-hypergeometric function, Ωd is the d-dimensional solid angle and is the adimensional cutoff radius. We take (Eq. 2) as the definition of the full correlation integral, to stress that we work away from the small radius limit employed for CorrDim.
It is worth noticing that the FCI has a sigmoidal shape which is steeper as the ID grows (see for instance the black lines in the top left panel of Fig. 2). This observation translates into a simple exact algorithm to determine the ID d of linearly embedded spherical datasets, by performing a non-linear regression of the empirical density of neighbours using the FCI in (Eq. 2). More in general, this protocol is exact for linearly embedded Euclidean spaces sampled with a rotational invariant probability distribution, by projecting onto the unit sphere and adding one to the ID estimated on this new dataset. We summarize our FCI estimator in two steps:
compute the center of mass b of the empirical data as and translate each datapoint by this quantity, so that the resulting dataset is centered at the origin. Then normalize each sample;
measure the empirical correlation integral of the dataset as a function of the radius r and perform a non-linear regression of this empirical density of neighbours using the FCI in (Eq. 2) as the non-linear model and d and rs as the free parameters; as the normalization step artificially removes one degree of freedom, increase the estimated ID by one.
Figure 2.

Intrinsic Dimension (ID) estimation is possible in the extreme undersampled regime for arbitrarly large ID with the Full Correlation Integral (FCI) estimator, in the case of linearly embedded and slightly curved manifolds, possibily non uniformly sampled and with noise. (Top left) We show the density of neighbours ρ of preprocessed (centered and normalized) data (number of samples N = 500) extracted from {0, 1}d linearly embedded in D = 60 dimensions (), for d = (5, 15, 30). We are able to efficiently extract the correct ID even though this is a highly non-uniformly sampled dataset, whose ρ displays manifold-dependent features (in this case, step-like patterns). Moreover, we observe that, as we increase d, the density of neighbours of this dataset quickly converges to our functional form. It is worth noticing that the whole functional form (Eq. 2) is needed for the fit; in fact, a local fit of the slope of ρ at half-height would result in an incorrect ID estimation. (Bottom left) We show the density of neighbours ρ of preprocessed data (N = 500) extracted uniformly from {0, 1}d, [0, 1]d and from with multivariate gaussian distribution, for d = 15 and linearly embedded in D = 60 dimensions. All plot lines are compatible with the same functional form (Eq. 2), pointing to an intriguing manifestation of “universality” for high-dimensional data. (Center) To highlight the predictive power of the FCI method for a broad spectrum of dimensionalities (ranging from d = 4 to d = 200), we exhibit the estimated ID versus the number of sample points N for the linearly embedded hypercube . Error bars are computed by averaging over 10 samples for each pair (N,d). (Top right) We asses quantitatively the predictive power of the FCI method by computing the average relative error |(dest − d)/d| (over 20 random instances) of the estimated ID in the range 5 ≤ d ≤ 1000, 5 ≤ N ≤ 1000. We observe that at we have an error of the order of 1% almost independently on the ID, and that ID estimation is possible also in the extreme undersampled N < d regime. (Bottom right) The FCI method estimates the correct ID even when the data are corrupted by noise. Here we consider a linearly embedded hypercube dataset and add on the top of that a 60-dimensional gaussian noise of standard deviation σ. We observe a sharp transition in the estimated ID between the regime in which the noise is a perturbation ( and dest = 40) and the regime in which the noise covers the signal ( and dest = 60).
We discuss the technical details regarding the fitting protocol in the Methods.
Robustness of the Fci Estimator
We now provide strong numerical evidence that the FCI estimator goes well beyond the exact results summarized above by testing it on multiple synthetic non-spherical datasets.
First, we notice that manifold-dependent features tend to disappear from the empirical correlation integral as the ID grows, quickly converging to the FCI prediction for angularly uniform data. In the top left panel of Fig. 2, we highlight this effect by showing the empirical correlation integral for three single instances (d = 5, 15, 30) of the dataset uniformly drawn from {0, 1}d, linearly embedded in D = 60 dimensions (). Among the many datasets breaking rotational invariance that we have investigated, this is one of those where manifold-dependent features are more pronounced: we observe a ladder-type pattern that quickly disappears as the ID grows from 5 to 30. Nonetheless, even in the low-dimensional case, where the steps may affect the ID estimation, the FCI method works. We stress that in many relevant cases, including linearly embedded and uniformly sampled hypercubes (), deviations from (Eq. 2) are negligible even in low dimension. In the bottom left panel of Fig. 2, we substantiate this point by comparing the empirical FCI the three datasets , , and a rotationally invariant dataset sampled with radial Gaussian distribution .
The FCI estimator shares some similarities with the one recently introduced in19 by Granata and Carnevale; here the authors use a derivative of our empirical correlation integral as the non-linear model to fit the mid-height section of the curve. Compared to the method of Granata and Carnevale, the FCI estimator has two additional major strengths. First, the normalization procedure sets a common typical scale for all datasets, making the comparison with (Eq. 2) straightforward. Second, and perhaps more importantly, our non-linear fit is performed by taking into account the whole functional form in (Eq. 2), and not only the mid-height local portion of the empirical FCI; as the top left panel of Fig. 2 shows, manifold-dependent features are hardly avoided if the fit is performed locally.
Our estimator is robust to extreme undersampling and to noise, as highlighted in the center and right panels of Fig. 2 for the dataset. In a broad ID range (up to d = 103), we provide accurate estimates even in the regime N < d with a relative average error that decays quickly with the number of samples N (almost independently from the ID); as a matter of fact, for N = 100 the error is already below one percent. The method is also particularly robust to Gaussian noise, showing a sharp crossover between the regime where the ID is correctly retrieved to a phase where the noise covers the signal.
So far, we have applied and verified the performance of our algorithm only on linearly embedded manifolds. More in general, we have verified that the FCI estimator correctly identifies the ID even in the case of simple non-linear polynomial embeddings or of slightly curved manifolds. However, the method presented above is global, thus it is expected to fail on manifolds with high intrinsic curvature. As in the case of the global PCA15,24, we can overcome this issue by providing a suitable multiscale generalization of the FCI estimator.
Multiscale FCI Estimator
We perform a multiscale analysis of the FCI estimator by selecting a random sample x0 in the dataset and a cutoff radius rc. We then apply the FCI estimation method to the set of points whose distance from x0 is less then rc. In this way, we obtain a local ID estimate dx0(rc) that depends on the cutoff radius. Varying rc and x0, we obtain a family of curves that describes the local ID of the dataset at different scales (see also left panel in Fig. 3). Another possibility to perform the multiscale analysis is to control the number of neighbors used for the local ID estimation; this parameter is clearly in one-to-one correspondence with the cutoff radius.
Figure 3.

The multiscale generalization of the FCI estimator provides a state-of-the-art tool to tackle the ID estimation for complex datasets with multidimensional features and high intrinsic curvature. The multiscale FCI method selects single points in the dataset and their neighbours at a fixed maximum distance rcutoff, which is then varied. The FCI estimator is then used on each neighbourhood, giving an estimation for a local ID dest(rcutoff). Crucially, the robustness to extreme local undersampling of the FCI estimator allows to shrink the radius of the neighbourhoods rcutoff, giving a reliable estimate of local IDs, that appear as pronounced plateaux in the dest vs rcutoff plot. Alternatively, one can look at dest(n), where n is the number of nearest neighbours used in the estimation, keeping more control on the number of points used in the local estimation. (Left) We present an illustrative application of the multiscale FCI method in the case of the Swiss Roll dataset (N = 2000) for two particular samples. Both samples hint to the correct ID estimation dest = 2. We observe that the sample extracted from the highly curved inner region of the Swiss Roll provides an overestimated ID whereas the sample from the outer and flatter region exhibits a plateau at the correct ID. This suggests to use the minimum dest reached as an estimator for the true ID, but a more careful analysis is needed. (Top center) We apply the multiscale FCI method to a highly curved manifold (N = 10000) introduced in13, challenging to all ID estimators (see also Materials and methods for its parametric defintion). The local dest spans the range between the true ID to the embedding dimension . (Bottom center) We show the multiscale FCI analysis on a multidimensional manifold which is built as the union of two intersecting hypercubes datasets and , each one consisting of N = 1000 samples. At small number of neighbours, we observe spurious effects due to vary sparse sampling of the neighbourhoods; quick convergence to the true IDs is then observed. (Right) As a last validation test, we generate an artifical dataset of bitmap images with multiple “blobs” with five degrees of freedom each (see Materials and methods), that we use as a proxy for curved manifolds of transformations of high contrast images. The multiscale analysis works nicely in either the one (d = 5) and three (d = 15) blob cases, although for multiple blobs we observe that the high curvature reflects in band that spans more than ten dimensions.
First, we look at a paradigmatic curved manifold studied in the literature, the Swiss roll (left panel in Fig. 3). In general, we observe three regimes: for very small cutoff radius, the local estimation by the FCI is not reliable due to the extreme scarcity of neighbouring points (). For very large cutoff radius, the local ID converges to the global FCI estimation, as more and more samples lie inside the cutoff radius. In between, if the manifold is sampled densely enough, we observe a plateau. In the central bottom panel of Fig. 3, we show two representative samples of the dataset (N = 2000), chosen from regions with very different curvatures. When the curvature is large, the height of the plateau identifies an overestimated ID, which drifts towards the embedding dimension as expected. On the other hand, when the curvature is small, the correct ID is identified. This observation suggests that the best estimator for the multiscale analysis could be the minimum ID identified in the plateau region. We use this heuristic in the tests below, but we leave a more detailed investigation of the multiscale method for future work.
Now we move to multidimensional datasets and non-trivially curved manifolds, which are considered challenges for state-of-the-art ID estimators. In the bottom center panel of Fig. 3, we show the multiscale analysis for an instance of the dataset (N = 1000 + 1000), representing two intersecting hypercubes with different IDs. Two plateaux at d = 20 and d = 30 are clearly visible and allow to infer the multidimensionality of the dataset (in this case the measured local dimension is displayed as a function of the number of neighbors used for the estimation). In the top center panel of Fig. 3, we display the same analysis for an instance of the dataset (N = 2500), first introduced in13 and considered a challenging dataset for ID estimation for its high intrinsic curvature. Although a thorough comparison of the performance of our algorithm with state-of-art ID estimators is out of the scope of our investigation (see18 or26 for nice recent meta-analysis), we observe that our prediction is pretty accurate (state-of-the-art estimators such as DANCo find on the dataset sampled in the same conditions).
This excellent accuracy on highly curved manifolds, combined –at the same time– with the removal of the well known underestimation issue common to all geometric methods, provides two major advantages of our algorithm over other traditional schemes used for ID estimation and suggests to test and validate it on the manifolds of global transfomations (e.g. translations, rotations, dilations) generated by high contrast images, relevant in the context of invariant object recognition. These manifolds often feature high local curvature, since even infinitesimal transformations produce almost orthogonal tangent spaces27,28.
As a more demanding test for our multiscale FCI estimator, we report a preliminary investigation of a manifold (artificially generated) that belongs to this class, where we can keep under control the intrinsic dimensionality (see right panels of Fig. 3). We consider bitmap images with multiple blobs (possibly overlapping) with five degrees of freedom each (two for translations, one for rotation, two for asphericity and dilation, see also Materials and methods). Even here the multiscale analysis provides a reliable indicator, as we can convince by looking at the one and three blob cases (d = 5 and d = 15 respectively). It is worth noticing that whereas single points are affected by the high curvature of the manifold (resulting in higher ID estimations), the minimum of the plateaux works again nicely as the estimator of the correct ID.
Comparison with Existing Methods
As a preliminary quantitative comparison with the existing ID estimators, we analysed all datasets presented in Fig. 3 with a selection of geometric and projective estimators available in the literature.
On the side of geometric estimators, we studied the Takens estimator10, the correlation dimension8 and the estimator introduced in13, using the code available at https://www.ml.uni-saarland.de/code/IntDim/IntDim.htm. The results of the analysis are presented in Fig. 4: geometric methods are reliable in low dimension, independently from the curvature of the manifold under exam, whereas for ID > 10 they start to experience the familiar underestimation issue.
Figure 4.

Comparison between ID estimators on curved and multidimensional datasets. Geometrical methods fail on high-ID datasets, even if the embedding is linear. Global PCA behaves complementarily, retrieving correctly the ID in this case, but losing predictivity on curved datasets. This issue is not fixed by perfoming multiscale PCA, since we often lack a clear signature for estimating the ID, e.g. a gap in the magnitude of the sorted eigenvalues. Even if we use the less stringent criterion (often used in the literature, see for instance24) of identifying the ID as the minimum number of eigenvalues such that their mass is larger than 0.95, we lack a signature of persistence as in the case of our estimator (the plateau as a function of the cutoff radius). In the right panel we plot the twelve averaged eigenvalues of the correlation matrix of the manifold as a function of the cutoff scale (the average is performed over all the different balls of the same radius centered around each point) to highlight this issue. No evidence of the correct ID can be found using the common criteria reported above. Where not available (N.A.) is reported, the code of13 returned either 0 or infinity. We expect however that the results would be very similar to those obtained with CorrDim.
Principal component analysis, on the contrary, identifies correctly the ID even in high dimension, as long as the manifold is linearly embedded. In particular, in the case of the multidimensional dataset examined here, we are able to identify two different gaps in the magnitude of the sorted eigenvalues at the correct IDs. On curved manifolds instead, global PCA overestimates dramatically as expected. This problem should be in principle fixed by performing a multiscale analsyis (mPCA) as proposed in24. However, for the curved manifolds considered here, this does not lead to a significant improvement in the ID estimation. The irrelevant (D − ID) eigenvalues of the correlation matrix should go much faster to zero than the remaining relevant ones when the cutoff radius is reduced. In practice, we are not able to identify a clear signature of this phenomenon and we can only establish loose bounds on the ID (see also the Fig. 4).
Discussion
In this manuscript we introduced the FCI estimator for the ID of spherically sampled, linearly embedded datasets, showing that it is robust to noise and non-idealities and more importantly that it works effectively in the extreme undersampled regime (N < d).
We performed a multiscale analysis of the FCI estimator on challenging datasets, featuring high curvature and multidimensionality, showing that we can extract the correct ID as the minimum local dest. Further work will be needed to fully explore this observation and to construct a proper multiscale estimator.
We performed a preliminary comparative analysis of our estimation framework against some representative geometric and projective ID estimators, and found that the multiscale FCI can provide reliable predictions in a variety of different regimes, while the other estimators tipically excel only under specific conditions (small dimension for geometric estimators, small curvature for projective estimators).
We leave open to future investigations the analysis of high dimensional manifolds of high contrast images taken from the Machine Learning literature, as well as the possibility of combining our estimator with state-of-the-art techniques for dimensional reduction and manifold learning, or, even more ambitiously, to elaborate on it in order to propose a novel more effective toolbox for these tasks.
Beyond these applications, ID estimation has been very recently used29,30 by the Machine Learning community as a tool to understand how deep neural networks transform and compress information in their hidden layers. Here the authors observe that the range of IDs of many training sets (such as Fashion-MNIST and CIFAR-10) processed through the hidden layers of a DNN is between 10 and 100. This is the typical regime where our ID estimator overcomes standard methods, so that it would be interesting to use it to reproduce these analysis.
Materials and Methods
Average correlation integral for uniformly sampled hyperspheres
Here we derive the average correlation integral Eq. (2) for a dataset uniformly sampled from the hypersphere or radius rs, i.e.
| 3 |
where α and β are spherical coordinates (i.e. αi ∈ (0, π)∀i = 2…d and α1 ∈ (0, 2π) and the same for βi), is the d-dimensional spherical volume element and x(⋅) is the function that converts spherical coordinates into (d + 1)-dimensional Euclidean coordinates on the sphere of radius rs. is the d-dimensional solid angle. The integral can be evaluated by choosing the spherical coordinates β such that their azimuth axis is in the direction of α, so that
| 4 |
The integrals in α and in β1…βd−1 are trivial, giving
| 5 |
where .
Empirical full correlation integral and fitting procedure
The empirical full correlation integral is easily computed in Mathematica 12 using the following one-liner:
Module[{dists = Sort@(Norm[#[1] – #[2]] & /@ Subsets[sample, {2}])}, Transpose[{dists, N@(Range[Length[dists]] – 1)/Length[dists]\}]]
The non-linear fit for the FCI estimator was performed using the default function FindFit, with d and rs as free parameters. The empirical full correlation integral was preprocessed before the application of FindFit by extracting a RandomSample of of its points to speed-up the fitting procedure.
Description of the datasets
In this section we briefly describe the datasets used in the presented numerical simulations. In the following, a linear embedding is the map that appends D − d zeros to its argument, and then rotates it in by a randomly chosen rotation matrix.
uniform sampling of {0, 1}d, linearly embedded.
sampling of with the multivariate Gaussian distribution of covariance matrix and null mean, linearly embedded.
uniform sampling of [0, 1]d, linearly embedded.
uniform sampling of [0, 2π]d, embedded with the map
uniform sampling of [0, 1]d, embedded with the map
dataset of high-contrast bitmap images (81 × 81 pixel) of n blobs. n = 1 images generation is described in the following section. n > 1 images are generated by summing n different n = 1 images.
High-contrast images datasets
The high-contrast images shown in Fig. 3 (right panel) were generated by assigning to each pixel of a l × l bitmap the following value vi,j:
| 6 |
with parameters
| l | side of the bitmap | fixed at 81 |
| Δx | horizontal translation | uniform in (−20, 20) |
| Δy | vertical translation | uniform in (−20, 20) |
| s | size | uniform in (1, 3) |
| e | eccentricity | uniform in (5, 10) |
| θ | angle of the major axis | uniform in (−π/2, π/2) |
Morover, any pixel of value less then 0.01 was manually set to 0 to increase the contrast of the image.
Acknowledgements
P.R. acknowledges funding by the European Union through the H2020 - MCIF Grant No. 766442.
Author contributions
V. Erba, M. Gherardi and P. Rotondo wrote the main manuscript text, prepared all figures and reviewed the manuscript with equal contribution.
Competing interests
The authors declare no competing interests.
Footnotes
Publisher’s note Springer Nature remains neutral with regard to jurisdictional claims in published maps and institutional affiliations.
References
- 1.Roweis S. T. Nonlinear Dimensionality Reduction by Locally Linear Embedding. Science. 2000;290(5500):2323–2326. doi: 10.1126/science.290.5500.2323. [DOI] [PubMed] [Google Scholar]
- 2.Tenenbaum J. B. A Global Geometric Framework for Nonlinear Dimensionality Reduction. Science. 2000;290(5500):2319–2323. doi: 10.1126/science.290.5500.2319. [DOI] [PubMed] [Google Scholar]
- 3.Lee, J. A. & Verleysen, M. editors. Nonlinear Dimensionality Reduction. Springer New York (2007).
- 4.Shepard Roger N. The analysis of proximities: Multidimensional scaling with an unknown distance function. I. Psychometrika. 1962;27(2):125–140. doi: 10.1007/BF02289630. [DOI] [Google Scholar]
- 5.Shepard Roger N. The analysis of proximities: Multidimensional scaling with an unknown distance function. II. Psychometrika. 1962;27(3):219–246. doi: 10.1007/BF02289621. [DOI] [Google Scholar]
- 6.Trunk G.V. Statistical estimation of the intrinsic dimensionality of data collections. Information and Control. 1968;12(5):508–525. doi: 10.1016/S0019-9958(68)90591-3. [DOI] [Google Scholar]
- 7.Fukunaga, K. & Olsen, D. R. An algorithm for finding intrinsic dimensionality of data. IEEE Transactions on Computers, C-20(2), 176–183, feb (1971).
- 8.Grassberger, P. & Procaccia I. Characterization of strange attractors. Physical Review Letters, 50(5), 346–349, jan (1983).
- 9.Grassberger, P. & Procaccia I. Measuring the strangeness of strange attractors. Physica D: Nonlinear Phenomena, 9(1–2), 189–208, oct (1983).
- 10.Takens F. Lecture Notes in Mathematics. Berlin, Heidelberg: Springer Berlin Heidelberg; 1985. On the numerical determination of the dimension of an attractor; pp. 99–106. [Google Scholar]
- 11.Kégl, B. Intrinsic dimension estimation using packing numbers. In Proceedings of the 15th International Conference on Neural Information Processing Systems, NIPS’02, pages 697–704, Cambridge, MA, USA, MIT Press (2002).
- 12.Levina, E. & Bickel, P. J. Maximum likelihood estimation of intrinsic dimension. In Proceedings of the 17th International Conference on Neural Information Processing Systems, NIPS’04, pages 777–784, Cambridge, MA, USA MIT Press (2004).
- 13.Hein, M. & Audibert, J.-Y. Intrinsic dimensionality estimation of submanifolds in rd. In Proceedings of the 22nd international conference on Machine learning -ICML 05. ACM Press (2005).
- 14.Carter, K. M., Hero, A. O. & Raich, R. De-biasing for intrinsic dimension estimation. In 2007 IEEE/SP 14th Workshop on Statistical Signal Processing. IEEE, aug (2007).
- 15.Little, A. V., Lee, J., Jung, Y.-M. & Maggioni, M. Estimation of intrinsic dimensionality of samples from noisy low-dimensional manifolds in high dimensions with multiscale SVD. In 2009 IEEE/SP 15th Workshop on Statistical Signal Processing. IEEE, aug (2009).
- 16.Carter, K. M., Raich, R. & Hero, A. O. On local intrinsic dimension estimation and its applications. IEEE Transactions on Signal Processing, 58(2), 650–663, feb (2010).
- 17.Lombardi, G., Rozza, A., Ceruti, C., Casiraghi, E. & Campadelli, P. Minimum neighbor distance estimators of intrinsic dimension. In Machine Learning and Knowledge Discovery in Databases, pages 374–389. Springer Berlin Heidelberg (2011).
- 18.Ceruti Claudio, Bassis Simone, Rozza Alessandro, Lombardi Gabriele, Casiraghi Elena, Campadelli Paola. DANCo: An intrinsic dimensionality estimator exploiting angle and norm concentration. Pattern Recognition. 2014;47(8):2569–2581. doi: 10.1016/j.patcog.2014.02.013. [DOI] [Google Scholar]
- 19.Granata, D. & Carnevale, V. Accurate Estimation of the Intrinsic Dimension Using Graph Distances: Unraveling the Geometric Complexity of Datasets. Scientific Reports, 6(1), 31377, November (2016). [DOI] [PMC free article] [PubMed]
- 20.Facco, E., d’Errico, M., Rodriguez, A. & Laio, A. Estimating the intrinsic dimension of datasets by a minimal neighborhood information. Scientific Reports, 7(1), sep (2017). [DOI] [PMC free article] [PubMed]
- 21.Camastra, F. & Vinciarelli, A. Intrinsic dimension estimation of data: An approach based on grassberger–procaccia’s algorithm. Neural Processing Letters, 14(1), 27–34, Aug (2001).
- 22.Camastra, F. & Vinciarelli, A. Estimating the intrinsic dimension of data with a fractal-based method. IEEE Transactions on Pattern Analysis and Machine Intelligence, 24(10), 1404–1407, Oct (2002).
- 23.Eckmann, J.-P. & Ruelle, D. Fundamental limitations for estimating dimensions and Lyapunov exponents in dynamical systems. Physica D: Nonlinear Phenomena, 56(2–3), 185–187, May (1992).
- 24.Little, A. V., Maggioni, M. & Rosasco, L. Multiscale geometric methods for data sets I: Multiscale SVD, noise and curvature. Applied and Computational Harmonic Analysis, 43(3), 504–567, November (2017).
- 25.Daz, M., Quiroz, A. J. & Velasco, M. Local angles and dimension estimation from data on manifolds. Journal of Multivariate Analysis, 173, 229–247, sep (2019).
- 26.Amsaleg, L. et al. Estimating local intrinsic dimensionality. In Proceedings of the 21th ACM SIGKDD International Conference on Knowledge Discovery and Data Mining - KDD 15. ACM Press, (2015).
- 27.Bengio, Y. & Monperrus, M. Non-local manifold tangent learning. In Proceedings of the 17th International Conference on Neural Information Processing Systems, NIPS’04, pages 129–136, Cambridge, MA, USA, MIT Press (2004).
- 28.Bengio Y, Monperrus M, Larochelle H. Nonlocal estimation of manifold structure. Neural Computation. 2006;18(10):2509–2528. doi: 10.1162/neco.2006.18.10.2509. [DOI] [PubMed] [Google Scholar]
- 29.Ansuini, A., Laio, A., Macke, J. H. & Zoccolan, D. Intrinsic dimension of data representations in deep neural networks. arXiv e-prints, page arXiv:1905.12784, May (2019).
- 30.Recanatesi, S. et al. Dimensionality compression and expansion in Deep Neural Networks. arXiv e-prints, page arXiv:1906.00443, Jun (2019).