

Abstract
PURPOSE
Cancer stage is a key determinant of outcomes; however, stage is not available in claims-based data sources used for real-world evaluations. We compare multiple methods for classifying lung cancer stage from claims data.
METHODS
Our study used the linked SEER-Medicare data. The patient samples included fee-for-service Medicare beneficiaries diagnosed with lung cancer from 2010 to 2011 (development cohort) and 2012 to 2013 (validation cohort) who received chemotherapy. Classification algorithms considered Medicare Part A and B claims for care in the 3 months before and after chemotherapy initiation. We developed a clinical algorithm to predict stage IV (v I to III) cancer on the basis of treatment patterns (surgery, radiotherapy, chemotherapy). We also considered an ensemble of claims-based machine learning algorithms. Classification methods were trained in the development cohort, and performance was measured in both cohorts. The SEER data were the gold standard for cancer stage.
RESULTS
Development and validation cohorts included 14,760 and 14,620 patients with lung cancer, respectively. Validation analyses assessed clinical, random forest, and simple logistic regression algorithms. The best performing classifier within the development cohort was the random forests, but this performance was not replicated in validation analysis. Logistic regression had stable performance across cohorts. Compared with the clinical algorithm, the 14-variable logistic regression algorithm demonstrated higher accuracy in both the development (77% v 71%) and validation cohorts (77% v 73%), with improved specificity for stage IV disease.
CONCLUSION
Machine learning algorithms have potential to improve lung cancer stage classification but may be prone to overfitting. Use of ensembles, cross-validation, and external validation can aid generalizability. Degradation of accuracy between development and validation cohorts suggests the need for caution in implementing machine learning in research or care delivery.
INTRODUCTION
Cancer stage is a critical determinant of health outcomes and spending for patients with cancer, as well as a key criterion for determining appropriate cancer treatments. As health care providers and policy makers increasingly seek to use existing health care data to gain insights into health care quality and costs, the unavailability of cancer staging information in administrative data is a substantial obstacle. Without cancer stage information, claims-based analyses of cancer outcomes lack a critical variable that mediates both cancer treatments and health outcomes.
CONTEXT
Key Objective
To examine multiple analytic approaches for classifying lung cancer stage group (stage IV v I to III) using health care claims among patients receiving chemotherapy for lung cancer.
Knowledge Generated
We compared the accuracy of an algorithm on the basis of clinical logic with multiple machine learning algorithms for classifying lung cancer stage group from Medicare claims records. The selected classifiers (random forest and logistic regression) demonstrated improved accuracy compared with the clinical algorithm, and logistic regression exhibited the greatest stability (77% accuracy in both development and validation analyses).
Relevance
The stage classification approach described here can be used in stratified or risk-adjusted analyses of real-world health care delivery and health outcomes among patients receiving chemotherapy for lung cancer. Our results are most relevant to analyses of Medicare claims records; additional study is needed to test generalizability in other populations (eg, commercially insured populations).
To improve the utility of administrative data sources, prior studies have proposed various approaches to infer cancer stage from information readily available in claims data, including diagnosis and procedure codes.1-4 These approaches rely heavily on secondary site diagnosis codes, which indicate the presence of a distant metastatic site (eg, International Classification of Diseases, Ninth Revision, Clinical Modification [ICD-9-CM] code 197.7: malignant neoplasm of liver, secondary). Because use of these secondary site codes is not required for payment (and is therefore variable), these approaches have shown good specificity (generally ≥ 80%) but poor sensitivity (≤ 60%) for identifying patients with advanced cancer. Correspondingly poor accuracy has hampered the uptake of stage inference algorithms. Accordingly, analyses of cancer care quality, outcomes, and costs have relied heavily on linkages of administrative data with clinical data from cancer registries, such as the linked SEER-Medicare data.5 The SEER-Medicare data are limited by their focus on older, fee-for-service Medicare beneficiaries living in SEER regions and by the lag time required to produce the data linkage. Nevertheless, these data have been tremendously fruitful for understanding real-world cancer care delivery and outcomes.
In this report, we describe several approaches for classifying cancer stage group from health care claims data among fee-for-service Medicare beneficiaries. We focus on patients receiving chemotherapy within 6 months of cancer diagnosis, because this population has particular policy relevance in the context of episode-based payment models that are structured around chemotherapy receipt.6,7 The first approach involves specification of a clinical algorithm that assigns cancer stage on the basis of procedure and associated diagnosis codes for chemotherapy, radiotherapy, and lung cancer resection surgeries. In the latter approaches, we apply machine learning techniques for stage classification, using a curated and clinically informed data set of demographic, diagnostic, and treatment-related variables derived from Medicare claims.
METHODS
Data Source
We used SEER-Medicare linked data for all analyses. The SEER program of the National Cancer Institute collects uniformly reported data from population-based cancer registries, including cancer site, stage, month of diagnosis, and other clinical variables from areas covering 28% of the United States.5 Since 1991, the National Cancer Institute has linked SEER data with Medicare administrative data for more than 94% of SEER registry patients diagnosed with cancer at age 65 years or older.8 Medicare data used in this analysis included fee-for-service inpatient, outpatient, provider carrier (Physician/Supplier Part B), and durable medical equipment claims.
Study Sample
We identified all fee-for-service Medicare beneficiaries in the SEER-Medicare linked data with a new diagnosis of lung cancer from 2010 to 2013 (the most recent 4-year period for which data were available at the time this study was conducted). We then restricted our study sample to patients who had an index chemotherapy claim within 6 months of cancer diagnosis that was associated with an ICD-9-CM diagnosis code for lung cancer. We identified qualifying chemotherapy agents on the basis of the chemotherapy trigger list developed for the Oncology Care Model (OCM), a Centers for Medicare and Medicaid Services (CMS) payment model designed around 6-month chemotherapy treatment episodes.9 Patients were excluded from the analytic sample if they had incomplete cancer stage information or if they were not enrolled in fee-for-service Medicare for the entire treatment ascertainment period (3 months before through 3 months after the date of first chemotherapy within 6 months of diagnosis). Cohort selection is described further in Appendix Figure A1.
SEER-derived staging variables on the basis of American Joint Committee on Cancer (version 6) were used as the gold standard for assigning lung cancer stage group.10 We used SEER collaborative stage fields (local, regional, metastatic) to assign stage for 1.4% of patient cases with missing data for the American Joint Committee on Cancer staging variables.
The study sample was split into two cohorts for algorithm development (2010 to 2011 diagnoses) and validation (2012 to 2013 diagnoses). Using successive time periods for algorithm development and validation approximates how these or similar classification algorithms would be implemented for common real-world uses.
Algorithm Development
Clinical algorithm.
The clinical algorithm classified patients with lung cancer into cancer stage groups on the basis of treatments received in the 3 months before and after the chemotherapy trigger date (classification period). Specifically, we examined receipt and timing of treatment with chemotherapy (including specific agents), radiation therapy (including number of fractions and use of cranial irradiation), and surgery (pneumonectomy, lobectomy, or wedge resection). Receipt of medical treatment was determined from Medicare claims files, using ICD-9-CM procedure codes, Healthcare Common Procedure Coding System procedure codes, and drug codes (Healthcare Common Procedure Coding System J codes for medications administered in outpatient and office-based settings). The clinical algorithm was iteratively revised within a 50% subset of the development cohort until the research team determined that further optimization was impractical, as measured by joint sensitivity and specificity. These analyses were performed in SAS software (version 9.4; SAS Institute, Cary, NC).
The final clinical algorithm classified patients into six terminal branches, with each branch representing a treatment approach for either stage I to III or stage IV lung cancer (Fig 1). For example, patients undergoing lung cancer resection surgery in the 3 months before or after starting chemotherapy were classified as having stage I to III lung cancer, as were patients receiving 20 or more fractions of concurrent chemoradiotherapy. Patients who were treated with chemotherapy only, without surgery or extended-fraction radiotherapy, were classified as having stage 4 disease. Specifications for the clinical algorithm are listed in Appendix Table A1.
FIG 1.

Schematic of clinical algorithm. NSCLC, non–small-cell lung cancer.
Machine learning algorithms.
We deployed multiple machine learning algorithms to identify a high-performing classifier for lung cancer stage group.11,12 The ensemble of algorithms considered logistic regressions, random forests, generalized additive regressions, classification trees, and pruned classification trees, using 10-fold cross-validation. Because of our interest in practical use and simplicity, our ensemble aimed to select the single best individual algorithm rather than a complex weighted average of algorithms. The development cohort input data set for the machine learning ensemble contained 102 variables derived from or linkable with the Medicare claims data, using the same measurement period as the clinical algorithm (3 months before and after the initial chemotherapy date). Variables included each of the classification nodes of the clinical algorithm, as well as additional variables for demographic characteristics (age, sex, race/ethnicity, geographic region, and census tract–level variables characterizing median household income, proportion of residents without a high school education, and proportion of residents living in poverty), lung cancer–related diagnosis codes (eg, number of 162.x diagnosis codes), secondary malignancy codes (196.x to 198.x, 199.0), evaluation and management codes, and indicators for receipt of specific chemotherapy agents, radiation therapy, and lung cancer–related surgeries. We used the CMS chronic conditions warehouse to flag comorbid conditions before the first chemotherapy date. Variables in the machine learning data set are listed in Appendix Tables A2 and A3.
To generate relatively parsimonious algorithms with greater potential for practical use, we implemented a variable reduction approach using the least absolute shrinkage and selection operator (LASSO) to select variable sets within each cross-validation fold.13,14 We investigated six different thresholds for the maximum number of variables selected by the LASSO, including at most 10, 15, 20, 30, 40, or 50 variables. These reduced subsets of variables were then provided to each of the included algorithms, some of which might perform additional variable selection on the subset. Thus, each of the candidate machine learning algorithms was included six times in the ensemble, once with each variable threshold. A previous ensemble approach for lung cancer stage classification did not consider parsimony and produced a complex weighted average of five algorithms, relying on more than 100 variables.15 These analyses were performed in the R statistical programming language (version 3.1.0; R Foundation, Vienna, Austria).
Analysis
Candidate algorithms from the machine learning ensemble were evaluated based on cross-validated area under the curve (AUC), sensitivity, specificity, and accuracy for classifying stage IV versus stage I to III disease. Results from the development cohort for sensitivity, specificity, and accuracy were calculated for all data for our classification approaches, rather than their respective internal holdout data, as well as for the validation cohort. This yielded the most effective comparison with the clinical literature, because these evaluation metrics are typically reported for an entire study cohort. We present two classifiers from among the machine learning approaches for comparison with the clinical algorithm, balancing parsimony and performance of the fixed algorithms in the two cohorts.
RESULTS
Population
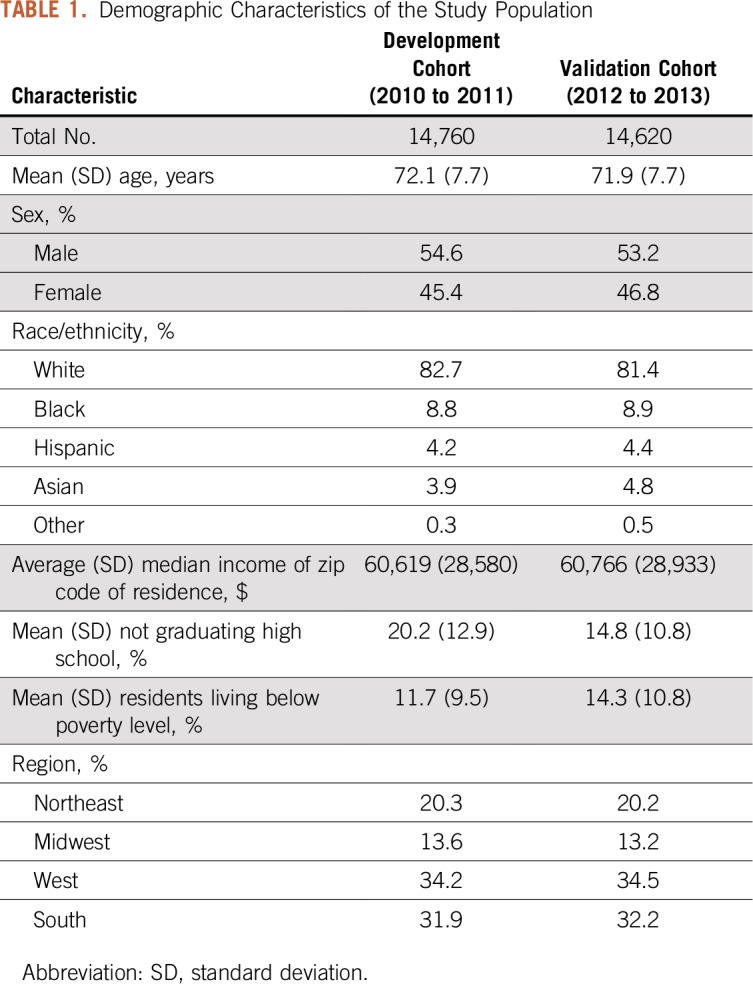
There were 14,760 patients with a new lung cancer diagnosis from 2010 to 2011 (development cohort) and 14,620 patients from 2012 to 2013 (validation cohort). The mean ages in the development and validation cohorts were 72.1 and 71.9 years, respectively. Additional demographic information is listed in Table 1 and Appendix Tables A2 and A3. The proportion of patients with stage 4 lung cancer (based on SEER registry data) was 50.8% in the development cohort and 52.0% in the validation cohort.
TABLE 1.
Demographic Characteristics of the Study Population
Clinical Algorithm
In the development cohort, the clinical algorithm exhibited an overall accuracy of 71% and a specificity of 53% for classification of stage 4 cancer (Table 2). The performance of the clinical algorithm was similar in the validation cohort (accuracy, 73%; specificity, 55%).
TABLE 2.
Comparative Performance Clinical and Machine-Learning Classification Algorithms

Machine Learning Algorithms
On the basis of our variable reduction strategy, the LASSO variable selection tool identified six candidate variable sets of eight, 12, 14, 23, 33, and 44 variables. The random forests were the best performing classifiers for stage group at all covariate thresholds in the development cohort. All six random forests had similar performance with respect to cross-validated AUC (77% to 78%), as did other algorithms (eg, logistic regression cross-validated AUC was 76% to 77%). Only the algorithms with 33 and 44 variables achieved an accuracy of 90% or greater in the development cohort. The 14-variable random forest algorithm exhibited an overall accuracy of 81%, with specificity of 84% in the development cohort. However, the performance of this algorithm deteriorated in the validation cohort, with an accuracy of 78% (Table 2). In contrast, the logistic regressions had stable performance across all covariate thresholds and across the development and validation cohorts, while also improving on the clinical algorithm with respect to specificity (78% v 55%) and accuracy (77% v 73%).
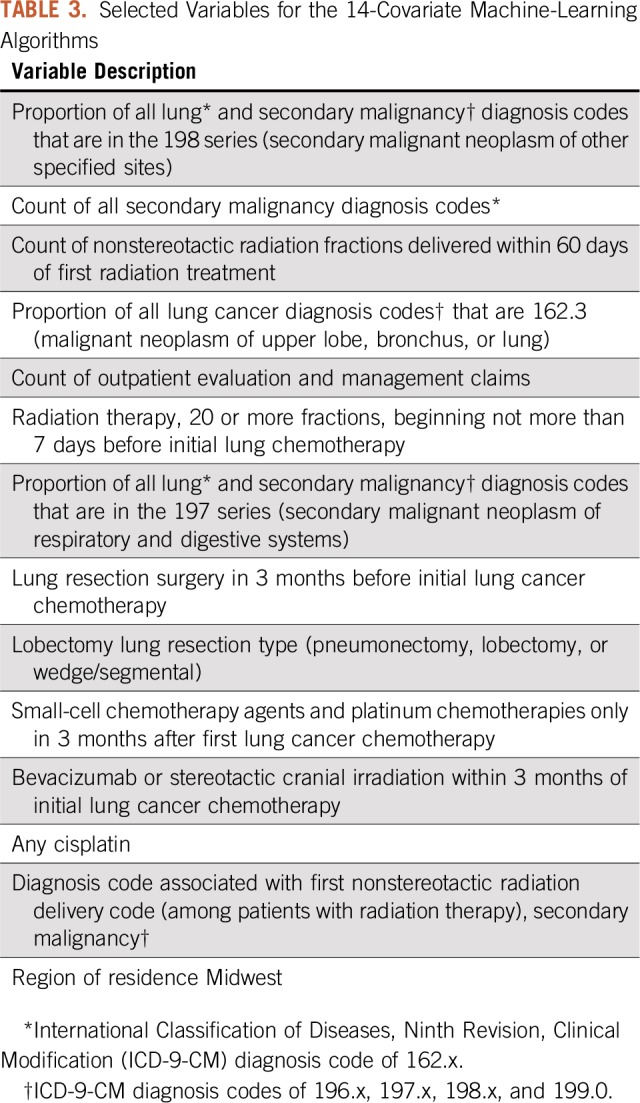
The covariates from the 14-variable algorithms are listed in Table 3 and include the count of all secondary malignancy codes, ratio measures of lung cancer and secondary malignancy diagnosis codes, indicators of specific patterns of radiotherapy, surgery, and chemotherapy receipt, and an indicator for residence in the US Midwest. In sensitivity analyses, we investigated whether other algorithms with more or fewer variables fit in the development cohort yielded improved performance in the validation cohort. No other variable thresholds or algorithms improved meaningfully on the findings for the 14-variable logistic regression (results not shown).
TABLE 3.
Selected Variables for the 14-Covariate Machine-Learning Algorithms
Comparison of Clinical and Machine Learning Approaches
Given our goals of accuracy and parsimony, we selected the logistic regression with 14 variables as the best algorithm for overall performance (inclusive of accuracy, sensitivity, and specificity). However, the logistic regression had lower specificity than the clinical algorithm in both cohorts. The three-way agreement of the clinical algorithm, logistic regression, and SEER-recorded stage in the validation cohort is summarized in Table 4.
TABLE 4.
Three-Way Agreement of the Clinical Algorithm, Logistic Regression, and SEER-Recorded Stage

DISCUSSION
We demonstrated that claims-based algorithms can classify lung cancer stage group (stage IV v I to III) with good sensitivity, specificity, and accuracy among patients receiving initial chemotherapy. The machine learning algorithms modestly outperformed the clinical classification algorithm in both development and validation cohorts. Performance of the random forests algorithm declined nontrivially in the validation cohort (compared with performance in the development cohort), whereas a simple logistic regression showed stability across development and validation cohorts. Secondary site diagnosis codes figured prominently in both the random forests and logistic regression algorithms, despite moderate to poor sensitivity for detection of advanced-stage disease in prior studies.3,4
Both our clinical algorithm and machine learning approaches were designed to incorporate oncology knowledge. Notably, we imposed considerable structure onto the machine learning development in the preanalytic phase, categorizing codes for related clinical concepts, creating variables for counts of procedure and diagnosis codes, and defining ratio measures (eg, percentage of lung cancer diagnosis codes that were malignant neoplasm of upper lobe, bronchus, or lung). As such, our machine learning approaches represent a fusion of applied clinical information with data-adaptive statistical learning. This strategy for building computational tools is likely more efficient than an unstructured approach that ignores clinical input and may be more robust to changes in billing, coding, and practice patterns.
Our findings help inform the use of machine learning classification algorithms to enhance claims-based analyses of cancer outcomes. By extension, our approach can support the concept of a “learning health care information system for cancer,”16(p235) with the ultimate goal of facilitating knowledge generation from observational data. Additional potential roles for a high-fidelity claims-based stage classification algorithm lie in the domains of quality measurement and risk adjustment; both are likely to be critical components of value-based payment approaches for cancer care.
This work was motivated in substantial part by the OCM, an episode-based payment model run by CMS.6,9 The OCM is a payment model built on the scaffolding of fee-for-service medicine, with the potential for performance-based payments to oncology practices that meet quality standards and reduce total Medicare spending below the target price for a 6-month episode. To evaluate whether the incentive structures of the model affect quality and outcomes of care, it will be necessary to conduct stage-adjusted analyses of treatment patterns and patient outcomes. It is our intent that machine learning approaches for classifying cancer stage can be used in the evaluation of the OCM and other value-based payment programs, helping to evaluate the quality and outcomes of care delivered within these models. In this context, it is relevant to ask if our classification algorithm is good enough to be deployed. The logistic regression successfully classified stage group in 77% of patients in the validation cohort, with sensitivity and specificity both exceeding 75%, comparing favorably with previously reported stage classification approaches.1-4 Even so, 23% of patients were misclassified according to the gold standard of SEER staging. We contend that our stage classification tool, although imperfect, nevertheless provides useful, valuable context for understanding and contextualizing the outcomes of patients with lung cancer. We strongly support additional study to confirm (and improve) the robustness, generalizability, and adaptability of our classification tool.
A strength of this analysis is its use of the SEER-Medicare linked data as the gold standard for cancer stage. At present, SEER-Medicare is essentially the only large-scale US data source (and one of few large data sources internationally) where cancer stage information is reliably linked to clinical claims and survival data. The unique features of the SEER-Medicare data have enabled sophisticated analyses of cancer outcomes in well-defined, real-world populations. Because the SEER-Medicare data include large numbers of patients with incident cancers, they permit analyses of rare patient subgroups and outcomes. By using SEER-Medicare data to develop algorithms for stage classification, we further extend the potential value of SEER-Medicare data to help classify cancer stage in other claims-based data sources, such as the larger, unlinked Medicare data and claims-based data sets derived from commercial insurers.
Our analysis has several limitations. Medicare administrative claims are generated for billing purposes and may contain incomplete, unverified, or incorrect diagnostic information. The machine learning algorithms rely on a broad array of diagnosis and procedure codes, including the secondary malignancy codes (malignant neoplasm of secondary site). When used alone, these secondary malignancy codes have shown poor sensitivity for identification of advanced-stage disease.1-4 However, secondary malignancy codes represent only one of multiple input sets for our machine learning algorithms. Moreover, our machine learning approach differs substantially from previously described algorithms.
Our analysis was limited to Medicare beneficiaries living in SEER areas receiving initial chemotherapy for lung cancer, and additional research is needed to assess the performance of these algorithms among commercially insured patients, contemporaneous patient populations, patients receiving treatment for recurrent (rather than incident) disease, and patients who do not receive chemotherapy. The emergence of new monoclonal antibody immunotherapies, including nivolumab, pembrolizumab, atezolizumab, and durvalumab, is of particular salience in lung cancer.17-20 First approved in 2014, immunotherapy drugs are transforming lung cancer treatment, particularly for stage IV disease. It is uncertain how our classification approach will perform in the context of these treatments. Nevertheless, the machine learning algorithms we report here rely substantially on diagnosis codes and less on chemotherapy treatment codes.
The algorithms may also be sensitive to changes in billing patterns (as reflected in claims data). One recent change is the transition from the ICD-9-CM diagnosis coding system (extant during our evaluation period) to the current standard of ICD-10-CM. Fortunately, the cancer diagnosis codes used in this analysis can be cross-walked to the newer ICD-10 system without substantial ambiguity. Finally, we focused on classifying patients as having stage IV versus stage I to III lung cancer, but treatment patterns and outcomes also differ substantially for patients with stage 1 to 2 versus stage 3 cancers, as well as by lung cancer histology (eg, adenocarcinoma, squamous cell, or small cell). These differences in treatment patterns, such as the use of combined-modality chemoradiotherapy with or without durvalumab as a principal treatment for stage 3 non–small-cell lung cancer, offer the possibility that further, more granular claims-based subclassification may be feasible. However, additional research is needed to assess the ability of machine learning algorithms to further classify patients with lung cancer into more detailed, clinically relevant subgroups.
In conclusion, validated algorithms hold promise to classify cancer stage using claims data without linked registry data. As such, algorithms similar to those reported here could serve a facilitating role in building a learning health care information system, providing necessary structure for clinically relevant, real-world analyses of cancer care delivery processes, quality measures, and clinical outcomes. Ongoing evaluation and updating will be necessary for tools such as these to assess and refit the classification estimators in the context of changing treatment patterns and care delivery settings.
ACKNOWLEDGMENT
We acknowledge the efforts of the National Cancer Institute; the Office of Research, Development and Information of the Centers for Medicare and Medicaid Services; Information Management Services; and the SEER program tumor registries in the creation of the SEER-Medicare database. We are grateful to Michael Liu, MD, PhD, Robert Wolf, MS, and Joyce Lii, MS, for expert statistical programming assistance; Lauren Riedel for administrative assistance; and Barbara J. McNeil, MD, PhD, and Andrea Hassol, MPH, for helpful comments on an earlier draft of the manuscript.
Appendix
FIG A1.

Selection of patient cohorts. ESRD, end-stage renal disease; HMO, health maintenance organization. (*) Diagnosis date set as 15th day of diagnosis month. (†) Excluding 29 patients because of missing zip code of residence.
TABLE A1.
Diagnosis, Chemotherapy, and Procedure Codes for Lung Cancer
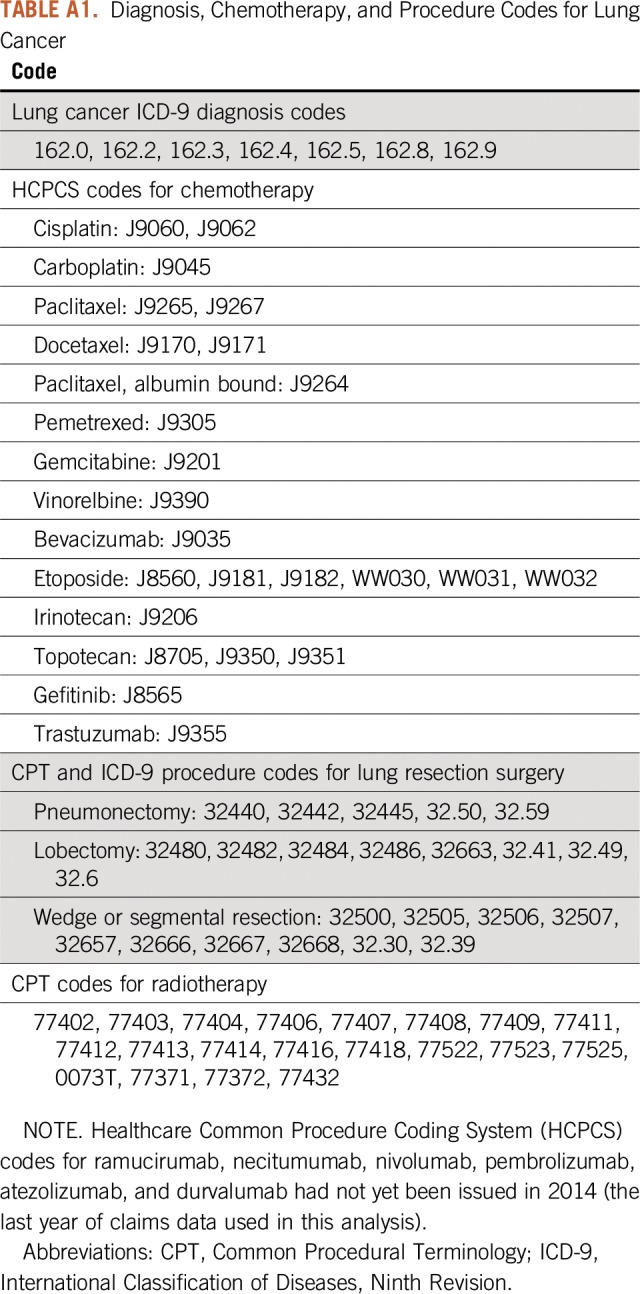
TABLE A2.
Descriptive Statistics of Candidate Variables for Machine-Learning Algorithms: Development Cohort (n = 14,760)

TABLE A3.
Descriptive Statistics of Candidate Variables for Machine-Learning Algorithms: Validation Cohort (n = 14,620)

Footnotes
Supported in part by Contract No. HHSM-500-2014-00026I from the Centers for Medicare and Medicaid Services, US Department of Health and Human Services, under which analyses on which this report is based were performed; by Grant No. K24CA181510 from the National Cancer Institute (N.L.K.); and by a Career Development Award from the Cancer Conquer Foundation (G.A.B.). Collection of cancer incidence data used in this study was supported by the California Department of Public Health as part of the statewide cancer reporting program mandated by California Health and Safety Code Section 103885; the National Cancer Institute SEER program under Contract No. HHSN261201000140C awarded to the Cancer Prevention Institute of California, Contract No. HHSN261201000035C awarded to the University of Southern California, and Contract No. HHSN261201000034C awarded to the Public Health Institute; and the Centers for Disease Control and Prevention National Program of Cancer Registries under Agreement No. U58DP003862-01 awarded to the California Department of Public Health.
Presented in part in abstract form at the 2018 Annual Meeting of the American Society of Clinical Oncology, Chicago, IL, June 1-5, 2018.
This study used the linked SEER-Medicare database. The interpretation and reporting of these data are the sole responsibility of the authors. The ideas and opinions expressed herein are those of the authors, and endorsement by the State of California Department of Public Health, the National Cancer Institute, and the Centers for Disease Control and Prevention or their contractors and subcontractors is not intended, nor should it be inferred.
AUTHOR CONTRIBUTIONS
Conception and design: Gabriel A. Brooks, Mary Beth Landrum, Sherri Rose, Nancy L. Keating
Financial support: Nancy L. Keating
Administrative support: Nancy L. Keating
Collection and assembly of data: Nancy L. Keating
Data analysis and interpretation: All authors
Manuscript writing: All authors
Final approval of manuscript: All authors
Accountable for all aspects of the work: All authors
AUTHORS' DISCLOSURES OF POTENTIAL CONFLICTS OF INTEREST
The following represents disclosure information provided by authors of this manuscript. All relationships are considered compensated. Relationships are self-held unless noted. I = Immediate Family Member, Inst = My Institution. Relationships may not relate to the subject matter of this manuscript. For more information about ASCO's conflict of interest policy, please refer to www.asco.org/rwc or ascopubs.org/jco/site/ifc.
Gabriel A. Brooks
Consulting or Advisory Role: Abt Associates, CareCentrix
Sherri Rose
Consulting or Advisory Role: Kantar Health
No other potential conflicts of interest were reported.
REFERENCES
- 1.Cooper GS, Yuan Z, Stange KC, et al. The utility of Medicare claims data for measuring cancer stage. Med Care. 1999;37:706–711. doi: 10.1097/00005650-199907000-00010. [DOI] [PubMed] [Google Scholar]
- 2.Nordstrom BL, Whyte JL, Stolar M, et al. Identification of metastatic cancer in claims data. Pharmacoepidemiol Drug Saf. 2012;21(suppl 2):21–28. doi: 10.1002/pds.3247. [DOI] [PubMed] [Google Scholar]
- 3. Chawla N, Yabroff KR, Mariotto A, et al: Limited validity of diagnosis codes in Medicare claims for identifying cancer metastases and inferring stage. Ann Epidemiol 24:666-672, 672.e1-2, 2014. [DOI] [PMC free article] [PubMed]
- 4.Whyte JL, Engel-Nitz NM, Teitelbaum A, et al. An evaluation of algorithms for identifying metastatic breast, lung, or colorectal cancer in administrative claims data. Med Care. 2015;53:e49–e57. doi: 10.1097/MLR.0b013e318289c3fb. [DOI] [PubMed] [Google Scholar]
- 5.Warren JL, Klabunde CN, Schrag D, et al. Overview of the SEER-Medicare data: Content, research applications, and generalizability to the United States elderly population. Med Care. 2002;40(s) uppl:IV-3–IV-18. doi: 10.1097/01.MLR.0000020942.47004.03. [DOI] [PubMed] [Google Scholar]
- 6.Kline RM, Bazell C, Smith E, et al. Centers for Medicare and Medicaid Services: Using an episode-based payment model to improve oncology care. J Oncol Pract. 2015;11:114–116. doi: 10.1200/JOP.2014.002337. [DOI] [PubMed] [Google Scholar]
- 7.Newcomer LN, Gould B, Page RD, et al. Changing physician incentives for affordable, quality cancer care: Results of an episode payment model. J Oncol Pract. 2014;10:322–326. doi: 10.1200/JOP.2014.001488. [DOI] [PubMed] [Google Scholar]
- 8.Potosky AL, Riley GF, Lubitz JD, et al. Potential for cancer related health services research using a linked Medicare-tumor registry database. Med Care. 1993;31:732–748. [PubMed] [Google Scholar]
- 9.Centers for Medicare and Medicaid Services Oncology Care Model. https://innovation.cms.gov/initiatives/oncology-care/
- 10. Greene FL, Page DL, Fleming ID, et al: AJCC Cancer Staging Manual (ed 6). New York, NY, Springer, 2002. [Google Scholar]
- 11.van der Laan MJ, Polley EC, Hubbard AE. Super learner. Stat Appl Genet Mol Biol. 2007;6:e25. doi: 10.2202/1544-6115.1309. [DOI] [PubMed] [Google Scholar]
- 12. van der Laan MJ, Rose S: Targeted Learning: Causal Inference for Observational and Experimental Data. New York, NY, Springer Science & Business Media, 2011. [Google Scholar]
- 13.Tibshirani R. Regression shrinkage and selection via the Lasso. J Roy Stat Soc B Met. 1996;58:267–288. [Google Scholar]
- 14.Rose S, Bergquist SL, Layton TJ. Computational health economics for identification of unprofitable health care enrollees. Biostatistics. 2017;18:682–694. doi: 10.1093/biostatistics/kxx012. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 15.Bergquist SL, Brooks GA, Keating NL, et al. Classifying lung cancer severity with ensemble machine learning in health care claims data. Proc Mach Learn Res. 2017;68:25–38. [PMC free article] [PubMed] [Google Scholar]
- 16. Levit L, Balogh E, Nass S, et al: Delivering High-Quality Cancer Care: Charting a New Course for a System in Crisis. Washington, DC, Institute of Medicine, 2013. [PubMed] [Google Scholar]
- 17.Borghaei H, Paz-Ares L, Horn L, et al. Nivolumab versus docetaxel in advanced nonsquamous non–small-cell lung cancer. N Engl J Med. 2015;373:1627–1639. doi: 10.1056/NEJMoa1507643. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 18.Garon EB, Rizvi NA, Hui R, et al. Pembrolizumab for the treatment of non-small-cell lung cancer. N Engl J Med. 2015;372:2018–2028. doi: 10.1056/NEJMoa1501824. [DOI] [PubMed] [Google Scholar]
- 19.Antonia SJ, Villegas A, Daniel D, et al. Durvalumab after chemoradiotherapy in stage III non-small-cell lung cancer. N Engl J Med. 2017;377:1919–1929. doi: 10.1056/NEJMoa1709937. [DOI] [PubMed] [Google Scholar]
- 20.Fehrenbacher L, Spira A, Ballinger M, et al. Atezolizumab versus docetaxel for patients with previously treated non-small-cell lung cancer (POPLAR): A multicentre, open-label, phase 2 randomised controlled trial. Lancet. 2016;387:1837–1846. doi: 10.1016/S0140-6736(16)00587-0. [DOI] [PubMed] [Google Scholar]