

Abstract
Perceptual recalibration allows listeners to adapt to talker-specific pronunciations, such as atypical realizations of specific sounds. Such recalibration can facilitate robust speech recognition. However, indiscriminate recalibration following any atypically pronounced words also risks interpreting pronunciations as characteristic of a talker that are in reality due to incidental, short-lived factors (such as a speech error). We investigate whether the mechanisms underlying perceptual recalibration involve inferences about the causes for unexpected pronunciations. In five experiments, we ask whether perceptual recalibration is blocked if the atypical pronunciations of an unfamiliar talker can also be attributed to other incidental causes. We investigated three potential incidental causes for atypical pronunciations: the talker is intoxicated, the talker speaks unusually fast, or the atypical pronunciations occur only in the context of tongue twisters. In all five experiments, we find robust evidence for perceptual recalibration, but little evidence that the presence of incidental causes block perceptual recalibration. We discuss these results in light of other recent findings that incidental causes can block perceptual recalibration.
Keywords: speech perception, perceptual recalibration, causal inference, adaptation, tongue twister, intoxicated speech
Talkers differ from each other in their meaning-to-sound mappings: the same word produced in the same context will differ acoustically and phonetically depending on the talker. How listeners overcome this problem has continued to be one of the pressing questions in research on speech perception. One important part of the answer seems to be adaptive mechanisms during speech perception. Adaptation is observed when listeners are exposed to unfamiliar talkers with non-native or otherwise atypical pronunciations (e.g., Bradlow & Bent, 2008; Sidaras, Alexander & Nygaard, 2009; Xie, Theodore & Myers, 2017). While listeners might initially experience processing difficulty, some of this difficulty can be overcome within minutes of exposure (Clarke & Garrett, 2004; Xie, Weatherholtz, Bainton, Rowe, Burchill, Liu & Jaeger, 2018). The adaptive nature of the speech perception system is also evident in a phenomenon called perceptual recalibration. When exposed to an unfamiliar talker with atypical pronunciations of a sound category, listeners adapt the categorization boundary between those sound categories (e.g., Eisner & McQueen, 2006; Kraljic & Samuel, 2005; Norris, McQueen & Cutler, 2003; Reinisch & Holt, 2014; Vroomen & Baart, 2009). For example, after exposure to a talker who produces /s/ in a way that makes it sound more like an /∫/,1 listeners change the boundary along the /s/-/∫/ continuum, so that more sounds along that continuum are now categorized as /s/.
Intuitively, recalibration facilitates robust speech perception, helping listeners to overcome inter-talker variability in the sound-meaning mapping. While the existence of perceptual recalibration is now firmly established, questions remain about the nature of its underlying mechanisms (for review, see Weatherholtz & Jaeger, 2016). Here we ask whether recalibration applies indiscriminately when an unfamiliar talker with atypical pronunciation is encountered, or whether perceptual recalibration can be cancelled if there is evidence that the input is not characteristic of the talker—for example, because the pronunciation might have resulted from an incidental cause (e.g., the talker is chewing gum).
In an influential study, Kraljic, Samuel & Brennan (2008) found that perceptual recalibration to atypical pronunciations of /∫/ was blocked when the atypical pronunciations could be attributed to an incidental cause. In their experiments, atypical pronunciations were either paired with a video showing the talker producing the shifted word with a pen in their mouth or with a pen in their hand. Kraljic and colleagues identified perceptual recalibration when the shifted pronunciations were paired with videos where the talker has a pen in the hand. When the talker had a pen in the mouth while producing the atypical sound, perceptual recalibration was blocked. One explanation for this blocking is that listeners attribute the atypical pronunciations to the pen (Liu & Jaeger 2018; for related discussion, see Arnold, Kam & Tanenhaus 2007; Kraljic et al. 2008). Inferences about the causes for unexpected pronunciations would allow listeners to determine whether they should expect the same talker to sound similar on future occasions, or whether the observed deviation from expected pronunciations was incidental (though alternative explanations have been proposed, Kraljic & Samuel 2011).
As of yet, this ‘pen-in-the-mouth’ effect remains the only manipulation of incidental causes for which blocking of perceptual recalibration has been investigated. It is thus an open question as to whether other incidental causes can block (or at least reduce) recalibration, as would be expected if causal inferences underlie the pen-in-the-mouth effect. More generally, relatively little is known about the extent to which listeners take into account alternative causes when interpreting linguistic input. Some studies have found similar effects on other aspects of language understanding—in particular, alternative causes presented in explicit instructions (e.g., Arnold et al. 2007; Dix, Gardner, Lawrence, Morgan, Sullivan & Kurumada 2018; Grodner & Sedivy 2011; Kurumada, Brown, Bibyk & Tanenhaus 2018, as summarized in Rohde & Kurumada 2018). For example, listeners tend to anticipate unfamiliar objects as referents following a speech disfluency (“Click on [pause] thee uh red...”), as evidenced in anticipatory eye-movements in a visual world paradigm (Arnold et al., 2007). This effect was blocked when listeners were told that the speaker suffered from a pathology that made naming objects difficult. Results like these suggest that listeners can in principle integrate the presence of alternative causes for the linguistic input they observe during the interpretation of that input. Whether similar inferences can affect perceptual recalibration or other adaptive processes during speech perception remains an open question.
Here we investigate listeners’ perceptual recalibration when atypical pronunciations of /s/ or /∫/ are presented in the context of incidental causes. Across five experiments, we investigate the effects of three incidental causes: alleged intoxication, faster than usual speech rate, and tongue twisters. Any of these factors can cause atypical pronunciation of the /s/-/∫/ contrast, though our focus lies on tongue twisters. Anyone who grew up in an English-speaking environment is likely familiar with well-known tongue twisters like “She sells seashells by the seashore.” or “Peter Piper picked a peck of pickled peppers.” Tongue twisters are notoriously difficult for talkers to produce and often result in speech errors when produced quickly. This is precisely the property that makes tongue twisters a suitable manipulation for the present purpose. While categorical speech errors—such as full phoneme exchanges—are rare in spontaneous speech (<0.1–2%, as estimated in Garnham, Shillcock, Brown, Mill & Cutler, 1981; Levelt, 1993; Wijnen, 1992), the rate of speech errors increases drastically when speakers have to produce sequences of similar sounding words in production experiments (up to 8–17%, according to Choe & Redford, 2012; Motley & Baars, 1976) and even more so in the context of tongue twisters. Because of perceptual biases, these numbers likely underestimate the true rate of speech errors (by some estimates by a factor of three or more, Alderete & Davies 2018; Ferber 1991). We draw on this increased incidence of production errors in tongue twister contexts compared to non-tongue twister contexts. Specifically, we ask whether participants are less likely to expect all pronunciations of a talker to sound atypical when all previously observed atypical pronunciations by that talker occurred in tongue twisters, compared to when previously observed atypical pronunciations occurred in non-tongue twister contexts.
All our experiments employ graded phonetic deviations from typical pronunciations, rather than categorical speech errors. Traditionally, the study of speech errors in productions has focused on categorical errors (phoneme substitution, deletion, transposition, omission, or addition, e.g., Fromkin, 1971). However, recent analyses suggest that speech errors are often graded noncategorical deviations from the intended pronunciation (Frisch & Wright, 2002; Goldrick & Blumstein, 2006; Goldstein, Pouplier, Chen, Saltzman & Byrd, 2007; McMillan & Corley, 2010; Mowrey & MacKay, 1990; Pouplier, 2007). For example, Frisch & Wright (2002) measured the percentage of voicing, duration of frication, and the amplitude of frication for the /s/ and /z/ contrasts, produced in a tongue twister context. Frisch and Wright found that errors often exhibited phonetic characteristics that placed them along the continuum between /s/ and /z/, rather than being categorical substitution of one sound for the other. Similarly, Navas (2001, as cited in Goldrick and Blumstein, 2006) found that some fricative errors exhibited spectral characteristics that were between typical /s/ and /∫/ pronunciations (for a concise summary of related works, see Alderete & Davies, 2018, p. 27–29).
This makes tongue twisters a suitable incidental cause for the present purpose: similar (experimenter-created) gradient pronunciations are used in perceptual recalibration experiments, including the experiments we present here. Imagine you hear a talker produce the tongue twister “She sells seashells by the seashore.” The talker might pronounce the beginning of this phrase as “She shells”, shifting the /s/ in “sells” towards (but not completely) the /∫/ in “shells”. If listeners can take into account incidental causes, they should infer that this pronunciation might not be typical for the talker, and therefore not predictive of future pronunciations of /s/ by the same talker. We would thus expect that perceptual recalibration is reduced if the talker’s shifted pronunciations only ever occur in the context of tongue twisters.
Overview of experiments
Experiment 1 verifies that we are able to detect perceptual recalibration using our paradigm. After we establish that we indeed can detect perceptual recalibration to shifted sounds, we test whether perceptual recalibration is blocked when shifted sounds during exposure only occur within a tongue twister context (e.g., “passion mansion passive passion”). Blocking of perceptual recalibration is expected if listeners’ fully attribute the atypical pronunciation to the tongue twister context, and thus infer that those atypical pronunciations are not informative about how the same talker’s speech outside of tongue twister contexts.
Anticipating our results, we find robust evidence of perceptual recalibration. However, we do not find significant evidence that the tongue twister condition blocks perceptual recalibration: the perceptual recalibration effect in Experiment 1 does not differ significantly across non-tongue twister and tongue twister contexts. This leads us to conduct Experiment 2, which establishes that we can in principle detect statistically significant differences between exposure that elicits perceptual recalibration (as in Experiment 1) and exposure that does not elicit perceptual recalibration (as in Experiment 2). Experiment 3 explores whether the presentation of explicit instructions about plausible incidental causes for shifted pronunciations—e.g., that the talker is intoxicated—can block perceptual recalibration. We again find robust perceptual recalibration effects across all conditions, and no significant evidence that incidental causes can block perceptual recalibration. This leads us to assess the plausibility of our tongue twister contexts, and compare them against attested tongue twisters like “Peter Piper Pepper Peter”. Experiment 4 identifies the most convincing tongue twister contexts and assesses whether perceptual recalibration can be blocked when only those most plausible tongue twisters are used. We again observe robust perceptual recalibration after exposure to non-tongue twister contexts. And, again, we find no significant blocking of perceptual recalibration after exposure to tongue twister contexts. Finally, Experiment 5 tests whether perceptual recalibration is reduced if the shifted pronunciation occurs together with clear signs of production difficulty.
Like the planned analyses for Experiments 1-4, Experiment 5 fails to find significant evidence that listeners integrate incidental causes to explain away atypical pronunciations. These findings contrast with the robust pen-in-the-mouth effect, which has been replicated across a number experiments (Kraljic et al., 2008; Kraljic & Samuel, 2011), including in paradigms similar to the one employed here (Liu & Jaeger, 2018). There is, however, some evidence in support of causal inference during perceptual recalibration: the non-significant effects we observe go in the predicted direction (reduced perceptual recalibration in the presence of an incidental cause) in five out of six between-subject comparisons. Prompted by reviewers, we thus conducted post-hoc analyses. These analyses reveal some (albeit weak) evidence consistent with the hypothesis that incidental causes can reduce the magnitude of perceptual recalibration.
In the general discussion, we review how our results narrow down possible explanations for the effect of visually presented causes like the pen in the mouth. Broadly speaking, one possibility is that the pen-in-the-mouth effect does not originate in causal inferences, contrary to our earlier interpretation (Liu & Jaeger, 2018). This would, however, raise the need for alternative explanations of previous findings that have been attributed to causal inferences (for discussion, see Kraljic & Samuel, 2011). Another possibility is that the pen-in-the-mouth effect does originate in causal inferences but that visual information, or specifically visual information about articulation, has a special status during speech processing—for example, because of special mechanisms dedicated to the integration of audio-visual percepts (cf. Rosenblum 2008; Tuomainen, Andersen, Tiippana & Sams 2005). Finally, our results are compatible with the hypothesis that perceptual recalibration is affected by causal inferences, provided that these inferences are exquisitely sensitive to the probability of the hypothesized incidental cause resulting in the observed auditory percepts. We discuss the properties of our experiments that afford this latter interpretation, and determine future steps to distinguish between the different accounts.
Analysis and reporting approach
Following standard procedure from our lab, we report all studies conducted for this project. Three auxiliary experiments that yielded identical results to experiments we report in detail are presented in supplementary information available via OSF https://osf.io/ungba/, and summarized in the main text. Unless explicitly mentioned otherwise, analyses were planned prior to inspection of the data.
The number of participants and test items included in the analysis was held constant across all experiments, and was chosen so as to achieve sufficient power based on the effect sizes reported in similar previous research (for details, see Methods). We confirmed that we have high power by parametrically generating 10,000 data sets with an effect size estimated from previous work—specifically, half the estimate observed in Liu & Jaeger (2018). These estimates were intended, and turn out, to be conservative (the effect sizes observed in the experiments reported below are larger than those assumed in the power analyses). These simulations estimate the power of our analyses to detect perceptual recalibration (Label effect in predicted direction)—detected in all experiments reported below—at > 95%, and the power to detect blocking of perceptual recalibration (interaction of Label and Context effects in predicted direction)—detected in none of our experiments—at > 81% (for explanation of the conditions, see below). All data and analyses are available at https://osf.io/ungba/.
Aggregate demographic information about participants
Since the demographic composition of our participants did not vary significantly across experiments, we report aggregate information here. All demographic categories were based verbatim on NIH reporting requirements. Across all experiments presented here, 48% of our participants reported as “female”, and 47% report as “male”, and 5% declined to report gender. The mean age of our participants was 36.3 years, with an interquartile range of 27–42 years (SD = 19; 4% declined to report). All participants reported to be at least 18 years of age. With regard to ethnicity, 9% of the participants reported as “Hispanic”, 85% as “Non-Hispanic”, and 6% declined to report. With regard to race, 74% report as “White”, 8% as “Black or African American”, 7% as “Asian”, 4% as “More than one race”, 1% as “American Indian/Alaska Native” or “Native Hawaiian or other Pacific Islander”, 1% as other and 5% declined to report. As we have no theoretical reasons to investigate demographic effects on the outcomes reported in the present study, we refrained from doing so.
Experiment 1
We begin by verifying that we can detect perceptual recalibration to atypical pronunciations of /s/ and /∫/ in a new variant of an exposure-test paradigm that accommodates our present goals. The general structure of our experiments is summarized in Figure 1 and elaborated on below. Following previous perceptual recalibration experiments, our experiment consisted of an exposure block intended to induce perceptual recalibration, followed by a test block to assess the degree of perceptual recalibration (Eisner & McQueen, 2005; Kraljic et al., 2008; Kraljic & Samuel, 2005, 2011; Liu & Jaeger, 2018; Norris et al., 2003).
Figure 1.

Structure of experiments. During the exposure block, participants heard 24 four-word phrases and were asked to transcribe them. Exposure was manipulated between participants. During the test block, all participants categorized sounds as either /asi/ or /a∫i/.
In order to study the effects of tongue twisters, listeners in the present study heard four word phrases during exposure, some of which contained the shifted /?s∫/ sound (either an /s/ shifted towards and /∫/ or vice versa; for details, see Methods). Specifically, we used a 2 × 2 between-participant design in the exposure block (Label x Context). Participants heard a shifted sound replace the /s/ sound (S-Label condition) or the /∫/ sound (∫-Label condition), and these atypical pronunciations either occurred in a Tongue Twister Context (e.g., “passive massive pa?s∫ion passive”) or a Non-Tongue Twister Context (e.g., “holler tamper pa?s∫ion holler”). The Tongue Twister Context contained sound sequences intended to make it more difficult to produce than the Non-Tongue Twister Context. This was intended to make it seem likely to participants that any atypical pronunciation in the Tongue Twister Context was due to an incidental speech error. We employ the /s/ and /∫/ contrast because these sounds are commonly exchanged for each other in speech errors (Shattuck-Hufnagel & Klatt, 1979). This makes it more likely that atypical pronunciations of /s/ and /∫/ in a tongue twister context will be seen as a plausible speech error.
The test block did not vary across participants, and followed previous perceptual recalibration experiments (Kraljic & Samuel, 2005; Liu & Jaeger, 2018; Norris et al., 2003). During test, we assess whether exposure affected categorization along an /s/-/∫/ continuum, as expected from previous studies on perceptual recalibration. We then examine whether this perceptual recalibration effect could be blocked or reduced depending on the context in which /s/ and /∫/ appeared.
All experiments reported below use a web-based crowdsourcing paradigm. This allows us to collect data more quickly, and from a more heterogeneous participant group than lab-based paradigms. This was particularly helpful for the present studies, which include a total of 960 participants. We have employed similar web-based paradigms in previous work on speech perception (e.g., Bicknell, Bushong, Tanenhaus & Jaeger, 2019; Burchill, Liu & Jaeger, 2018; Bushong & Jaeger, 2017; Kleinschmidt, Raizada & Jaeger, 2015; Xie et al., 2018), including lexically-guided perceptual recalibration to /s/ and /∫/ (Liu & Jaeger, 2018).
Method
Participants.
173 total participants were recruited to achieve a target of 40 participants for each of the four between-participant conditions (S/∫-Label crossed with the Tongue Twister/Non-Tongue Twister Context). The same holds for all perceptual recalibration experiments presented below, in order to avoid unnecessary researchers’ degrees of freedom. The targeted number of participants is comparable to previous experiments on perceptual recalibration (e.g., ~ 48 in Kraljic and Samuel, 2005; ~ 25 participants Norris et al., 2003).
The experiment took about 10 minutes, and participants were paid $1.00 ($6/hour). Participants were instructed to participate only if they were native speakers of English, and if they would complete the experiment while wearing headphones in a quiet room.
Exclusion criteria were determined prior to conducting the experiment, closely following previous work (specifically, all applicable criteria from Liu and Jaeger, 2018). Based on these criteria, 8 participants were excluded based on their incorrect response to a catch question asking them to identify whether the exposure talker was male or female (the talker was clearly a female speaker), and 2 participants were excluded for reporting that they did not wear headphones during the experiment (7.5% total exclusion rate). Both the catch question and the headphone question were part of a post-experiment exit survey described below. 3 participants were excluded for likely confusing their response keys during the test block, as evidenced by inverted categorization boundaries (more /s/ responses at the /∫/ end of the continuum), which would not be expected under any theory of speech perception.
Materials. Exposure Block: Transcription Task.
Participants heard and transcribed 24 four-word phrases (all phrases given in Tables 1 and 2). The condition (Label x Context) that the participant was in dictated the specific set of phrases they would hear. 8 of these phrases contained a shifted pronunciation of either /s/ or /∫/, depending on the Label condition. We chose to have 8 shifted pronunciations because we had previously found perceptual recalibration to /s/ and /∫/ in similar paradigms with 6 and 10 shifted pronunciations, and little to no benefit for more than 10 shifted pronunciations (Liu & Jaeger 2018; see also Kleinschmidt & Jaeger 2011). Our power simulations were based on half the effect size found in previous work for 10 shifted pronunciations (see appendix for details).
Table 1.
Stimuli for S-Label condition (Experiment 1). The 8 shaded rows in each condition represent the critical stimuli containing a shifted sound (?s∫). The non-shaded rows in each condition are the 16 filler phrases. 8 of the filler phrases were identical across all conditions, and contained no fricative sounds. The other filler phrases were balanced between the critical phrases so that participants in the Tongue Twister Context and the Non-Tongue Twister Context of each Label condition would hear the exact same recordings. Items marked with an asterisk (*) represent the subset of items used in Experiment 4 and 5. We note that our design implies that there are 3-times as many unshifted sounds as atypical shifted critical sounds. This differs from previous work and is addressed in Experiment 2.
| Tongue Twister Context (S-Label) |
Non-Tongue Twister Context (S-Label) |
|---|---|
| passion mansion pa ?s∫ive passion * | holler tamper pa ?s∫ive holler * |
| pushing cushion ki?s∫ing pushing | kelly bigot ki ?s∫ing kelly |
| crucial glacial cla?s∫ic crucial | gecko ruby cla?s∫ic gecko |
| pension mission po ?s∫sum pension | tamer hater po?s∫sum tamer |
| cashew kosher ca ?s∫tle cashew * | layman hating ca?s∫tle hating * |
| blushing pressure blo ?s∫om blushing * | header leaning blo ?s∫om leaning * |
| ration washing ran ?s∫om ration * | yapping nodded ran ?s∫om nodded * |
| bishop gusher go ?s∫ip bishop | wacky talent go ?s∫ip talent |
| holler tamper hamper holler * | passion mansion hamper passion * |
| kelly bigot belly kelly | pushing cushion belly pushing |
| gecko ruby raking gecko | crucial glacial raking crucial |
| tamer hater hammer tamer | pension mission hammer pension |
| layman hating human hating * | cashew kosher human cashew * |
| header leaning leader leaning * | blushing pressure leader blushing * |
| yapping nodded napping nodded * | ration washing napping ration * |
| wacky talent tacky talent | bishop gusher tacky bishop |
| weary deepen dairy deepen * | weary deepen dairy deepen * |
| polly gaping goalie gaping * | polly gaping goalie gaping * |
| carry making marry making | carry making marry making |
| debit rookie rabbit rookie * | debit rookie rabbit rookie * |
| hidden berry button berry | hidden berry button berry |
| bullet happy hamlet happy * | bullet happy hamlet happy * |
| wacko tamer taco tamer | wacko tamer taco tamer |
| weary deepen dairy deepen | weary deepen dairy deepen |
Table 2.
Stimuli for ∫-Label condition (Experiment 1). For details, see caption of Table 1.
| Tongue Twister Context (∫-Label) |
Non-Tongue Twister Context (∫-Label) |
|---|---|
| passive massive pa ?s∫ion passive * | holler tamper pa ?s∫ion holler * |
| kissing missing cu?s∫ion kissing | kelly bigot cu ?s∫ion kelly |
| classic glassy cru?s∫ial classic | gecko ruby cru?s∫ial gecko |
| tossing possum pen ?s∫ion tossing | tamer hater pen ?s∫ion tamer |
| castle missile ca ?s∫ew castle * | layman hating ca ?s∫ew hating * |
| blossom pressing blu ?s∫ing blossom * | header leaning blu ?s∫ing leaning * |
| ransom wussy ra ?s∫ion ransom * | yapping nodded ra?s∫ion nodded * |
| gossip bicep bi?s∫op gossip | wacky talent bi ?s∫op talent |
| holler tamper hamper holler * | passive massive hamper passive * |
| kelly bigot belly kelly | kissing missing belly kissing |
| gecko ruby raking gecko | classic glassy raking classic |
| tamer hater hammer tamer | tossing possum hammer tossing |
| layman hating human hating * | castle missile human castle * |
| header leaning leader leaning * | blossom pressing leader blossom * |
| yapping nodded napping nodded * | ransom wussy napping ransom * |
| wacky talent tacky talent | gossip bicep tacky gossip |
| weary deepen dairy deepen * | weary deepen dairy deepen * |
| polly gaping goalie gaping * | polly gaping goalie gaping * |
| carry making marry making | carry making marry making |
| debit rookie rabbit rookie * | debit rookie rabbit rookie * |
| hidden berry button berry | hidden berry button berry |
| bullet happy hamlet happy * | bullet happy hamlet happy * |
| wacko tamer taco tamer | wacko tamer taco tamer |
| weary deepen dairy deepen | weary deepen dairy deepen |
| passion mansion pa?s∫ive passion * | holler tamper pa ?s∫ive holler * |
We refer to the phrases that contained a shifted pronunciation as critical phrases. The eight critical phrases occurred in either a Tongue Twister or Non-Tongue Twister Context, described below. The other 16 phrases were filler phrases. Critical words were always bi-syllabic, and the /s/ and /∫/ sound always occurred at the beginning of the second syllable. This was to ensure that the “critical phonemes ... [were] well-articulated and ... preceded by relatively strong lexical information” (Kraljic and Samuel, 2005, p.147). In Kraljic and Samuel’s study, critical sounds occurred at syllable onsets late in words, with most words having 3, sometimes 4, syllables. Our decision to use bi-syllabic words might have reduced the strength of the lexical information preceding the critical sounds (as our results show, this was not an issue), but allowed us to closely match the phonotactic context in critical words for /s/ and /∫/ sounds (e.g., passive—passion). For the same reason, /s/ and /∫/ sounds were always surrounded by either a vowel or nasal sound.
Following previous work, none of the other words contained any other fricative sounds (incl. /s/ and /∫/). Lists for stimuli presentation were created by Latin square design over Label and Context. One pseudo-randomized stimulus order (and its reverse) was created in which no more than two critical phrases occurred in a row. This resulted in eight lists (2 Label x 2 Context * 2 Orders = 8 Lists).
We first describe the creation of the shifted pronunciations. We then describe the structure of the critical phrases in the Tongue Twister Context, followed by the structure of the filler phrases in the Tongue Twister Context. Finally, we describe the structure of the critical and filler phrases in the Non-Tongue Twister Context. Phrases were recorded at a natural speech rate, with durations of about 2–2.5 seconds.
Creation of shifted pronunciations.
The third word in the phrase was the critical word: the /s/ or /∫/ in this word was shifted toward its fricative counterpart (i.e. /∫/ or /s/, respectively). To create these atypical productions, the talker (a 25 year old female, native talker of American English) recorded two versions of each phrase, one containing the normal pronunciation of the third word (e.g., passive) and one containing the atypical pronunciation of the third word with the fricative counterpart (e.g., pashive). The pronunciation containing the fricative counterpart never resulted in a real word, which allowed the participant to use lexical knowledge to disambiguate the identity of the shifted fricative. The /s/ and /∫/ of the two recordings were blended using FricativeMakerPro (McMurray, Rhone & Galle, 2012) to create a continuum with 31 steps for that word (e.g., ranging from passive to pashive). Following Kraljic and Samuel (2005), three native English speakers then independently listened to these words to identify the word that sounded maximally ambiguous. The average of their responses was selected as the shifted /?s∫/ word that was presented to participants. Each shifted pronunciation was then inserted back into the phrases corresponding to the Tongue Twister and Non-Tongue Twister Context, which we describe next.
Critical phrases in Tongue Twister Context.
We created 8 four-word phrases in each Label condition that contained an atypical pronunciation of either /s/ or /∫/ in the third word position (e.g., passion mansion pa?s∫ive passion). Specifically, the phrases were of the structure S1 S2 ?s∫ S1 (or ∫1 ∫2 ?s∫ ∫1), where S1 and S2 were words which contained the /s/ sound, and ?s∫was a word that contained the shifted /?s∫/ sound. These tongue twister phrases had a number of structural properties that were intended to make it plausible that they would elicit mispronunciations of /s/ as /∫/ (or more /∫/-sounding /s/ sounds) in the S-label condition (and vice versa in the ∫-label condition). For example, the /s/ and /∫/ sounds in our experiment all appeared word medially, as speech errors are more likely to affect sounds that share a word position than when they do not (Shattuck-Hufnagel, 1983; Wilshire, 1999).
Additionally, we positioned the atypical /s/ and /∫/ sounds in the third word position, preceding a word with a typical pronunciation of the counterpart fricative, because speech errors are likely to anticipate upcoming sounds (Wilshire, 1999). In other words, the third word in our tongue twister phrases were shifted towards the fricative in the first, second, and fourth word of our phrases.
Finally, as much as possible, the first and second word in the phrase shared a common vowel in the second syllable, and either the first or second word in the phrase shared a common onset with the third word. For example, consider the phrase “passive massive pa?s∫ion passive”. The first and second words (passive and massive) share the vowel in the second syllable (in fact, they share the entire syllable), and the first and third word share a common onset (passive and passion). This stimulus structure was chosen to approximate the type of tongue twisters used in speech error eliciting experiments (e.g., Sevald & Dell, 1994; Shattuck-Hufnagel & Klatt, 1979; Wilshire, 1999). For example, Wilshire (1999) employed tongue twisters consisting of four monosyllabic words, where the word-initial phoneme varied in the structure ABBA, and the word-final phoneme varied in the structure ABAB (e.g., palm neck name pack).
Filler phrases in the Tongue Twister Context.
We created 16 four-word filler phrases. In 4 of these phrases, the first word was repeated in the fourth position (e.g., holler tamper hamper holler), and in 12 of these phrases, the second word was repeated in the fourth position (e.g., weary deepen dairy deepen). When combined with the 8 critical phrases described above this resulted in each participant hearing 12 examples where the first word was repeated in the fourth position, and 12 examples where the second word was repeated in the fourth position. This was done so that participants would not be able to consistently anticipate the fourth word.
Additionally, for each four-word filler phrase, we aimed to select pairs of phonemes to use for the onsets of the first and second syllables of each word that had no (or a very low) incidence of speech errors with each other, based on the MIT confusion matrix of 1,620 single phoneme errors (Shattuck-Hufnagel & Klatt, 1979). For example, for the filler phrase “holler tamper hamper holler”, both the pairs h/t and l/p are exchanged for each other the fewest number of times in that matrix (0 occurrences).
Critical and filler phrases in the Non-Tongue Twister Context.
For each Label condition, participants in the Non-Tongue Twister Context heard exactly the same recordings of words as those in the Tongue Twister Context. To achieve this, for each of the critical phrases in the Tongue Twister Context, we spliced the third word (containing the shifted /?s∫/) into one of the filler phrases. For example, in the S-Label / Tongue Twister condition, one of the critical phrases is “passion mansion pa?s∫ive passion” and one of the filler phrases is “holler tamper hamper holler”. In the S-Label / Non-Tongue Twister condition, the critical phrase becomes “holler tamper pa?s∫ive holler” and the filler phrase becomes “passion mansion hamper passion” (see Tables 1 and 2 for full list of stimuli). Thus, in the Tongue Twister Context, the word containing a shifted /?s∫/ occurs in a phrase that was created to make speech errors seem plausible, while in the Non-Tongue Twister Context, it does not.
Test Block: Categorization Task.
Following previous work, the same talker who recorded the exposure stimuli was recorded saying the nonce words /asi/ and /a∫i/. These nonce words were blended together using FricativeMakerPro (McMurray et al., 2012) to create a continuum of 31 steps ranging from /asi/ to /a∫i/. We selected 7 of these steps to serve as test steps based on initial informal piloting: five steps were centered close to the point of maximal ambiguity, and two steps represented category endpoints. This procedure closely follows previous work, though the specific numbers of test tokens and their placement along the continuum varies somewhat across works (e.g., Kraljic & Samuel, 2006; Liu & Jaeger, 2018; Norris et al., 2003; Vroomen, van Linden, De Gelder & Bertelson, 2007). The results reported in Figure 3 below confirm that the seven test steps span the /s/-/∫/ continuum, as intended.
Figure 3.

Proportion of /∫/ responses as a function of Continuum Step (Experiment 1). Participants in the ∫-Label condition (blue triangle) shift towards /s/ and participants in the S-Label condition (red circle) shift towards /∫/ for both Context conditions. Error bars show 95% confidence intervals obtained via non-parametric bootstrap over the by-participant means. Note that our analysis follows previous work and collapses across continuum steps.
Procedure.
The experiment began with instructions, one practice trial, the exposure block, the test block, and the post-experimental survey. This general structure was identical to that employed in many previous perceptual recalibration experiments. Previous work has often employed lexical decision tasks during exposure (e.g., Kraljic & Samuel, 2005; Liu & Jaeger, 2018; Norris et al., 2003; Zhang & Samuel, 2014), though perceptual recalibration has also been found for a broad variety of different tasks during exposure (e.g., passive listening with catch trials, e.g., Bertelson, Vroomen & De Gelder 2003; Vroomen et al. 2007; ABX discrimination, Clarke-Davidson, Luce & Sawusch 2008; categorization, Clayards, Tanenhaus, Aslin & Jacobs 2008; Kleinschmidt et al. 2015; for further review and comparison of various paradigms, see Drouin & Theodore 2018). Here we employ a transcription task during exposure, a paradigm often employed in related work on accent adaptation (e.g., Bradlow & Bent, 2008; Baese-Berk, Bradlow & Wright, 2013; Tzeng, Alexander, Sidaras & Nygaard, 2016; Xie, Liu & Jaeger, 2019).
During the practice trial, participants heard a male, native American-English accented talker saying the words “grumpy kitten table pretty”. This talker was clearly different from the exposure and test talker, who was female. After the phrase, participants were asked to transcribe the words that they heard, separated by spaces. The trial was repeated until participants correctly transcribed the words. The purpose of the practice trial was to familiarize participants with the task and to allow them to adjust the volume to a comfortable listening level.
The exposure block trials followed the exact same format as the practice trial, except that participants did not receive feedback on the accuracy of their transcriptions and each trial was only played once. Participants heard 24 trials, separated by an inter-trial interval of 1000ms. With a total of 96 words (24 four-word trials), the amount of exposure was similar to our previous web-based studies in which we found perceptual recalibration for /s/-/∫/ (e.g., 60–160 trials across the three experiments reported in Liu and Jaeger, 2018).
One difference of the current study to the more common lexical decision paradigm is the relative proportion of unshifted and atypical pronunciations. In the present study, due to the necessary repetition of sounds in the Tongue Twister Context, participants heard three times as many non-shifted pronunciations (of /s/ or /∫/) as shifted pronunciations, whereas previous studies have exposed participants to equal number of unshifted and atypical pronunciations. Most accounts of perceptual recalibration would predict that the degree of boundary shift primarily depends on the number of atypical pronunciations (Experiment 2 assesses and confirms this assumption). The number of atypical pronunciation and their relative proportion out of all trials in the present study (8 critical atypical items out of 96, i.e., 8.3%) was similar compared to previous web-based studies in which we found perceptual recalibration for /s/-/∫/ (e.g., 6–16 atypical items at a rate of 10% of all items, in Liu and Jaeger, 2018).
During the test block participants, categorized seven steps on the /asi/-/a∫i/ continuum as either /asi/ or /a∫i/, five times each. The steps were played in five cycles (trial bins), each containing a random ordering of the seven steps. Participants indicated their responses using the ‘X’ and ‘M’ keys on their keyboard. Key bindings were counterbalanced across participants. This test procedure is identical to that of our previous web-based studies in which we found perceptual recalibration for /s/-/∫/, except that we halved the number of trials bins from 10 to 5. We did so because our previous work found that the perceptual recalibration effect is largest at the beginning of the test block and then steadily decreases (Liu and Jaeger, 2018; confirmed below).
Finally, participants answered a questionnaire that asked about their audio equipment, language background, technical difficulties, and attention during the experiment.
Scoring transcription accuracy during exposure.
An undergraduate research assistant compiled a list of common misspellings for each word (e.g., spelling polly as pollie or poly). Transcription accuracy was automatically scored for matches to the expected transcriptions; any word that was also on the list of common misspellings was labeled as correct. We counted a word’s transcription as correct regardless of whether the four words had been transcribed in the correct order. The same scoring approach was used for all other experiments reported below. If word order mistakes were counted, transcription accuracies would decrease by about 7.8% across all experiments (range = 5.8–12.1%). None of the results reported in this paper change if order mistakes are counted (for full information, see supplementary data information).
Results
We first summarize our analyses of transcription accuracy during the exposure block. We then turn to the critical results from the test block, comparing the Label and Context conditions. We employ mixed logistic regression (Breslow & Clayton, 1993; Jaeger, 2008) to analyze responses during both the exposure and the test phase, as both involve binary dependent variables.
Exposure Block: Transcription accuracy.
Following previous work, we analyzed two aspects of transcription accuracy during exposure. We first examined the overall accuracy in order to assess whether participants were listening to the stimuli. Then, we assessed whether participants transcribed the critical shifted words correctly. A failure to do so might suggest that participants did not recognize the words, which in turn might reduce the magnitude of perceptual recalibration. Figure 2 summarizes the overall transcription accuracy for all experiments.
Figure 2.

Transcription accuracy during exposure for all experiments and between-participant conditions. Transparent points show by-participant averages. Solid point ranges show the mean and bootstrapped 95% confidence interval over those by-participant averages.
For Experiment 1, the overall transcription accuracy averaged over by-participant means was 88.4% (SD = 7.0%). Table 3 shows accuracies by between-participant conditions. Given the challenging task of transcribing 24 sequences of four semantically unrelated words spoken at a rate of about two words/second, we take this to be adequate performance, indicating that participants were paying attention during the exposure block. To assess whether transcription accuracy differed between conditions, we conducted a mixed logit regression predicting trial-level accuracy (1 = correct, 0 = incorrect) from Label (always sum-coded:∫-Label = 1 vs. S-Label = −1), Context (sum-coded: Non-Tongue Twister = 1 vs. Tongue Twister = −1), and their interaction. The analysis included by-participant intercepts and by-item random intercepts and slopes for Context, Label, and their interaction. An item was defined as the nth row of Tables 1 and 2. For example, the first rows of Tables 1 and 2 together constitute one item.
Table 3.
Transcription accuracy by Label and Context condition with standard deviations in parentheses (Experiment 1)
| Percent of Words Correctly Transcribed | ||
|---|---|---|
| ∫-Label | S-Label | |
| Non-tongue twister | 90.7% (3.6%) | 85.9% (10.7%) |
| Tongue twister | 89.1% (6%) | 87.8% (5.9%) |
Participants in the ∫-Label condition transcribed significantly more words correctly than those in the S-Label condition = 0.27, z = 3.11, p < 0.002). This effect was small (see Table 3), and does not hold across all experiments (see Figure 2). To foreshadow the results of Experiments 2-5, Experiment 3b exhibited the same effect as Experiment 1 ( = 0.18, z = 2.21, p < 0.03), but Experiment 3a exhibited a similarly small effect in the opposite direction—lower accuracy in the ∫-Label condition = −0.20, z = −2.61, p < 0.01). No main effects of Label condition were observed in Experiments 2, 4b, and 5. More importantly given our interest in tongue twister contexts, neither the effects of Context (p > 0.92), nor its interaction between with Label was significant (p > 0.48). It is thus unlikely that any effect of Context (or lack thereof) on the categorization boundary during the test phase could be confounded by overall task engagement.
Next, we analyzed the proportion of correctly transcribed critical shifted words with the exact same analysis approach. The mean transcription accuracy of shifted words in Experiment 1 was 84.8% (SD = 16.3). Table 4 shows accuracies by between-participant conditions. The mixed logit regression found that participants in the ∫-Label condition transcribed significantly more shifted words correctly than those in the S-Label condition = 0.56, z = 4.28, p < 0.0001). This effect was larger than for overall accuracy, possibly driving the effects on overall accuracy. More importantly, neither the effects of Context (p > 0.85), nor its interaction between with Label was significant (p > 0.84). The same holds for all experiments reported below: none of our Context manipulations had a significant main effect on the overall accuracy, or the accuracy with which shifted tokens were transcribed; similarly, Context never interacted significantly with the Label condition (though there were marginally significant interactions in Experiments 3b and 5).
Table 4.
Transcription accuracy for only the eight critical shifted words (Experiment 1)
| Percent of Words Correctly Transcribed | ||
|---|---|---|
| ∫-Label | S-Label | |
| Non-tongue twister | 90.6% (10.9%) | 83.1% (22.6%) |
| Tongue twister | 83.4% (13.7%) | 82.2% (14.9%) |
In short, there is no reason to expect that differences in task engagement during exposure, or differences in participants’ ability to recognize and process the shifted words would confound the analyses of the test data reported below. Still, in order to address our own concerns and those of reviewers’, additional control analyses are reported in the supplementary information, available at https://osf.io/ungba/. Specifically, we repeated all analyses of category boundary shifts during the test block (for all experiments) while also including the participant’s transcription accuracy during exposure as a predictor, as well as all interactions of that predictor with all other variables in the analysis. All of these analyses confirmed the results we report below: while higher accuracy during exposure predicted larger perceptual recalibration effects during test in some of the experiments, this effect never changed the significance of Label or its interaction with Context. This was the case regardless of the specific accuracy measure employed.
Test Block: Changes in the categorization boundary.
We present two planned analyses. Both analyses are trial-level analyses over all data from the test block. The first analysis follows standard practice, and analyzes the average proportion of /∫/ responses ignoring continuum steps and trial order. This resembles the analyses of variance presented in the majority of studies on perceptual recalibration. The second analysis assesses the perceptual recalibration effect at the beginning of the test block. The reason for this second (planned) analysis is found in our previous work: in Liu and Jaeger (2018) we found that perceptual recalibration effect continuously reduced during the test block, perhaps due to the uniform distribution of stimuli across the /asi/-/a∫i/ continuum. This means that the standard analysis—assessing average perceptual recalibration across the entire test block—can substantially underestimate the true perceptual recalibration (as we confirm this below). Such undoing of perceptual recalibration effects during testing is expected if perceptual recalibration reflects distributional learning (as argued in, e.g., Kleinschmidt & Jaeger, 2015; Lancia & Winter, 2013).
Our second analysis directly addresses this possibility by capturing changes in perceptual recalibration during test, and providing a measure of perceptual recalibration at the beginning of the test block. As we show below, this increases our ability to detect effects on perceptual recalibration (such as the hypothesized blocking of perceptual recalibration). Following our previous work, all subsequent analyses are based on this alternative approach.
For the Non-Tongue Twister Context we predict the same type of perceptual recalibration as in previous studies with different exposure tasks (Kraljic et al., 2008; Kraljic and Samuel, 2005, 2011; Liu and Jaeger, 2018; Norris et al., 2003): participants in the J-Label should shift their category boundary towards /s/ and thus categorize more sounds as /∫/, and participants in the S-Label shift their category boundary towards /∫/ and thus should categorize more sounds as /s/.
In the Tongue Twister Context, participants heard the same shifted pronunciations as in the Non-Tongue Twister Context, but embedded in a tongue twister. If the tongue twister context provided participants with a plausible causal explanation for the atypical pronunciations, then participants may attribute these atypical pronunciations to an incidental cause, leading them to adapt less or not at all (as observed for visually provided cause in Kraljic et al., 2008; Kraljic & Samuel, 2011; Liu & Jaeger, 2018).
Average perceptual recalibration across the test block.
Figure 3 shows the categorization curve for all four conditions of Experiment 1 (averaged across all trial bins). We conducted mixed logit regression, where we predicted /∫/ responses (1 = /∫/ response, 0 = /s/ response) by Label (sum-coded: ∫-Label = 1 vs. S-Label = −1) and Context (sum-coded: Non-Tongue Twister = 1 vs. Tongue Twister = −1), and their interaction. The analysis included by-participant random intercepts, which constitutes the maximal random effect structure for our design.
This revealed that overall more /∫/ responses were observed in the ∫-Label condition than in the S-Label condition ( = 0.30, z = 5.0, p < 0.001; Figure 3). This is consistent with perceptual recalibration, and a shift in the categorization boundary based on Label. The output from the model is shown in Table 5. Critically, there was no significant difference of Context (p = 0.41) nor was there a significant interaction between Label and Context (p = 0.69). This suggests that participants who heard the atypical pronunciations in the Tongue Twister Context adapted just as strongly as those who had heard these pronunciations in the Non-Tongue Twister Context, contrary to what we had originally predicted.
Table 5.
Mixed logit regression predicting proportion of /∫/ responses from Label, Condition, and their interaction (Experiment 1). Coding: Label (sum coded: ∫-Label = 1 vs. S-Label = −1) and Condition (Non-Tongue Twister Context = 1 vs. Tongue Twister Context = −1). Rows that are critical to our analysis are highlighted in grey.
| Predictors | Parameter Estimates |
Significance Test |
||
|---|---|---|---|---|
| Coef () | Std Err | z | p | |
| (Intercept) | −0.10 | 0.06 | −1.62 | 0.10 |
| Label (J vs. S) | 0.30 | 0.06 | 5.0 | <0.001 |
| Context (NonTT vs. TT) | −0.05 | 0.06 | −0.8 | 0.41 |
| Label:Context | 0.02 | 0.06 | 0.40 | 0.69 |
Measuring perceptual recalibration at the beginning of test block.
Replicating Liu and Jaeger (2018), we find that participant responses move towards a 50/50 (empirical logit of 0) asi/-/a∫i/ baseline over the course of the test block (Figure 4). Following Liu and Jaeger (2018), we thus conducted an additional analysis to assess the perceptual recalibration effect at the very beginning of the test block. We employed mixed logit regression to predict /∫/ responses from Label (sum-coded: ∫-Label = 1 vs. S-Label = −1), Context (sum-coded: Non-Tongue Twister = 1 vs. Tongue Twister = −1), Trial Bin (coded continuously with the first trial bin as 0), and their interactions (Table 6). The estimated effect of Label thus represents the estimate of the recalibration effect across both Context conditions during the first trial bin of the test block. This and all subsequent analyses of this type included by-participant random intercepts (models with by-participant random slopes for Trial Bin did not converge or led to singular fits, except for Experiment 3a).
Figure 4.

Proportion of /∫/ responses as a function of exposure condition and Trial Bin (Experiment 1). Proportions of /∫/ responses were empirical logit transformed for ease of comparison with the model’s prediction. Points show empirical means for each trial bin. Solid lines show predictions of the model we use to obtain corrected estimates of the category boundary shift at the beginning of the test block. Error bars show 95% confidence intervals obtained via non-parametric bootstrap over the by-participant means. Over the course of testing, categorization responses in all exposure conditions move towards 0 empirical logits (i.e., 50/50 /s/ and /∫/ responses, dashed line).
Table 6.
Mixed logit regression predicting proportion of /∫/ responses from Label, Condition, and their interaction (Experiment 1). Coding: Label (sum coded: ∫-Label = 1 vs. S-Label = −1), Condition (Non-Tongue Twister Context = 1 vs. Tongue Twister Context = −1), Trial Bin (First bin = 0). Rows that are critical to our analysis are highlighted in grey.
| Predictors | Parameter Estimates |
Significance Test |
||
|---|---|---|---|---|
| Coef () | Std Err | z | p | |
| (Intercept) | −0.25 | 0.07 | −3.37 | <0.001 |
| Label (J vs. S) | 0.56 | 0.07 | 7.59 | <0.001 |
| Context (NonTT vs. TT) | −0.07 | 0.07 | −1.00 | 0.32 |
| Trial Bin (First bin = 0) | 0.07 | 0.02 | 3.63 | <0.001 |
| Label:Context | 0.01 | 0.07 | 0.19 | 0.85 |
| Label:TrialBin | −0.13 | 0.02 | −6.27 | <0.001 |
| Context:TrialBin | 0.01 | 0.02 | 0.56 | 0.57 |
| Label:Context:TrialBin | 0.01 | 0.02 | 0.27 | 0.79 |
We again found that participants in the J-Label condition provided more /∫/ responses than those in the S-Label condition ( = 0.56, z = 7.59, p < 0.001). That is, the true perceptual recalibration effect at the beginning of the test block (1.12 log-odds = * 2 since we used −1 vs. 1 sum-coding) is almost twice as large as the estimate one obtains from averaging across the entire test block (0.6 log-odds). This validates the need for the advanced analysis, which we continue to use throughout the remainder of the paper.
The total number of /∫/ responses tended to increase over trial bins ( = 0.07, z = 3.65, p < 0.001), and that this differed between Label conditions, in a way consistent with convergence towards 50/50: participants in the ∫-Label condition tended to provide fewer /∫/ responses in later trial bins, compared to those in the S-Label condition ( = −0.13, z = −6.27, p < 0.001). This behavior is clearly visible in Figure 4.2
Critically, the interaction between Label and Context was again non-significant (p = 0.85), suggesting that even in the first trial bin there was no evidence that the effect of perceptual recalibration differed depending on whether the shifted pronunciations were embedded in a tongue twister context or not (see Figure 4).
Discussion
In Experiment 1, we find that exposure to atypical pronunciations of /s/ or /∫/ from one talker leads participants to change how they categorize sounds on the /s/-/∫/ continuum. Specifically, participants who are exposed to words containing atypical sounds labeled as /∫/ then categorize more sounds as /∫/, leading to a shift in their categorization curve towards /s/. This replicates the results of previous perceptual recalibration studies, but in a novel multi-word phrase transcription paradigm. The size of the perceptual recalibration effect at the beginning of the test block was comparable to previous work. Specifically, Liu and Jaeger (2018) found a perceptual recalibration effect (the difference between the two Label conditions) of 1.65 log-odds for 10 critical tokens (Experiment 1) and a perceptual recalibration effect of a little under 1.0 log-odds for 6 critical tokens (Experiment 2).3 The present result of 1.12 log-odds for 8 critical tokens thus falls within the expected range. This provides initial validation of the present paradigm, as most theories of perceptual recalibration would predict the effect to increase with the number of critical tokens.
Our paradigm differs from the standard perceptual recalibration paradigm in that participants heard three times as many typical pronunciations as they heard shifted pro-nunciations (e.g. participants in the ∫-Label condition heard 24 typical /s/, and 8 shifted /∫/). This contrasts with previous experiments, where participants typically heard equal numbers of typical and shifted pronunciations.
One potential concern is that the increased number of typical pronunciations that participants heard might have affected how participants categorized sounds, and that this overrides any potential effect of causal attribution—and thus the hypothesized effect of tongue twisters on the adaptation to atypical pronunciations. For example, work on selective adaptation has found that repeated presentations of typical instances of one phoneme leads listeners to categorize fewer sounds as that same phoneme. This effect has variously been attributed to the fatigue of “linguistic feature detectors” or other phonetic assignment processes (Eimas & Corbit, 1973; Samuel, 1986), or a shrinking of the variance for the listener’s underlying distribution for that phonetic category or a change in the prior probability for a category (Kleinschmidt & Jaeger, 2016).
Two considerations ameliorate this concern. First, there are striking differences between the present paradigm and selective adaptation studies. For example, selective adaptation paradigms tend to repeat the typical stimulus many dozens of times (e.g., Samuel 1989; Vroomen et al. 2007). Second, we observe effect sizes that match what is expected under previous perceptual recalibration experiments. This would be rather unexpected, if the differences in paradigms had a large effect on our results.
Still, it is theoretically possible that the shift in categorization boundary in Experiment 1 is driven by the repeated typical sounds, rather than the shifted sounds. In that case, no effect of Context is expected (both context conditions contained equally many unshifted typical sounds, and Tongue Twister contexts are not expected to block the effect of exposure to typical pronunciations). We thus decided to conduct Experiment 2 to directly address the possibility that the shift in the categorization boundary in Experiment 1 was driven entirely by the repetition of unshifted phonemes. As we detail below, Experiment 2 also serves as a baseline to both Experiment 1 and the subsequent experiments.
Experiment 2
Experiment 2 tests whether the shift in the categorization boundary for the /s/ and /∫/ phonemes that we observed in Experiment 1 could be driven solely by the higher number of typical unshifted, compared to atypical shifted, tokens. To this end, we presented participants with only typical, unshifted instances of /s/ and /∫/ (interspersed with the same filler trials as in Experiment 1). These typical sounds were presented in the same Non-Tongue Twister Contexts used in Experiment 1, so that the only difference to Experiment 1 was that the atypical pronunciations were replaced with unshifted productions. In Experiment 2, participants in the ∫-Label group heard three times as many unshifted /s/ as unshifted /∫/, and participants in the S-Label group heard three times as many unshifted /∫/ as unshifted /s/.
If Experiment 2 finds the same shift in the categorization boundary as Experiment 1, this would constitute strong evidence that the effect observed in Experiment 1 is, in fact, not due to perceptual recalibration (since Experiment 2 does not contain any atypical pronunciations of /s/ or /∫/). However, if we fail to find a difference between the two Label conditions in Experiment 2 or if the difference is weaker than it is in Experiment 1, this would suggest that the effect from Experiment 1 is at least in part due to perceptual recalibration. This in turn would raise the question why the perceptual recalibration effect in Experiment 1 is not blocked by the presence of an incidental cause.
Method
Participants.
We recruited 86 participants on Amazon Mechanical Turk for a target of 40 participants in each of the two Label conditions after exclusions. 2 participants were excluded for not correctly identifying the speaker as female, 1 participant for not wearing headphones, and 3 for inverted categorization functions. As in Experiment 1, participants were paid $1 for this experiment, which took roughly 10 minutes ($6/hr).
Materials.
The stimuli used during the exposure block were identical to the stimuli from the Non-Tongue Twister Context of Experiment 1, except that we substituted the critical atypical pronunciation with the typical pronunciation of the same word. These typical pronunciations were the endpoints of the continuum used to create the atypical pronunciations that contained shifted /?s∫/. For example, in the Non-Tongue Twister Context condition of Experiment 1, participants would hear “holler tamper pa?s∫ive holler”, but in the current condition, participants would hear “holler tamper passive holler”. All other stimuli were identical. We thus refer to the current conditions as “Unshifted” conditions, and the Non-Tongue Twister Context conditions from Experiment 1 as “Shifted” conditions.
Procedure.
The procedure was identical to Experiment 1.
Results
We first analyze the results from the test block to assess whether participants in the S-Label condition differed in how they categorized sounds compared to participants in the ∫-Label condition. We next compare the difference between Label conditions in the current experiment (Unshifted condition) with the difference in Label conditions (perceptual recalibration effect) identified in the Non-Tongue Twister Context of Experiment 1 (Shifted condition). Taken together our results suggest that the effect in Experiment 1 is unlikely to be due solely to the higher number of typical pronunciations, and thus is likely to reflect perceptual recalibration.
The transcription accuracies for Experiment 2 and all subsequent experiments are summarized in Figure 2. With an overall accuracy of 89.8% (SD = 6.5%), transcriptions in Experiment 2 were similar to Experiment 1 (88.4%). For details, see supplementary information.
Test Block: Changes in the categorization boundary.
First, we assessed whether there was a difference in categorization between the two Label conditions. To do this, we conducted mixed logit regression, where we predicted categorization by Label condition (sum-coded: ∫-Label = 1 vs. S-Label = −1), Trial Bin (First bin = 0), and their interaction. This analysis is presented in Table 7.
Table 7.
Mixed logit regression predicting proportion of /∫/ responses from Label, Condition, and their interaction (Experiment 2). Coding: Label (sum coded: ∫-Label = 1 vs. S-Label = −1), Trial Bin (First bin = 0). Rows that are critical to our analysis are highlighted in grey.
| Predictors | Parameter Estimates |
Significance Test |
||
|---|---|---|---|---|
| Coef () | Std Err | z | p | |
| (Intercept) | 0.01 | 0.11 | 0.11 | 0.91 |
| Label (∫ vs. S) | 0.17 | 0.11 | 1.49 | 0.14 |
| TrialBin (First bin = 0) | 0.02 | 0.03 | 0.55 | 0.59 |
| Label:TrialBin | −0.05 | 0.03 | −1.7 | =0.09 |
We did not identify a significant effect of Label at the first Trial Bin ( = 0.17, z = 1.49, p = 0.14). Numerically, the effect trended in the same direction as the significant effect in Experiment 1, though it was much smaller (0.34 log-odds in Experiment 2, compared to 1.12 in log-odds Experiment 1). To more directly test whether the effect in Experiment 1 could have been caused simply by the higher proportion of typical pronunciations, we compared the Unshifted condition (Experiment 2) to the Shifted condition (Non-Tongue Twister condition of Experiment 1). These two conditions are identical with the exception that the critical words contained unshifted /s/ or /∫/ instead of the shifted /?s∫/. We conducted a mixed logit regression predicting categorization by Label condition (sum-coded: J-Label = 1 vs. S-Label = −1), Shift (sum-coded: Shifted = 1 vs. Unshifted = −1), Trial Bin (First bin = 0), and their interactions. The results are presented in Table 8 and visualized in Figure 5.
Table 8.
Mixed logit regression predicting proportion of /∫/ responses from Label, Condition, and their interaction (Experiments 1 and 2). Coding: Label (sum coded: ∫-Label = 1 vs. S-Label = −1), Shift condition (sum-coded: Shifted critical pronunciation (Experiment 1) = 1 vs. Unshifted pronunciations (Experiment 2) = −1), Trial Bin (First bin = 0). Rows that are critical to our analysis are highlighted in grey.
| Predictors | Parameter Estimates |
Significance Test |
||
|---|---|---|---|---|
| Coef () | Std Err | z | p | |
| (Intercept) | −0.16 | 0.08 | −1.98 | = 0.05 |
| Label (∫ vs. S) | 0.37 | 0.08 | 4.66 | <0.001 |
| Shift (Shifted vs. Unshifted) | −0.17 | 0.08 | −2.13 | <0.05 |
| TrialBin (First bin = 0) | 0.05 | 0.02 | 2.5 | <0.01 |
| Label:Shift | 0.21 | 0.08 | 2.59 | <0.01 |
| Label:TrialBin | −0.09 | 0.02 | −4.21 | <0.001 |
| Shift:TrialBin | 0.04 | 0.02 | 1.73 | =0.08 |
| Label:Shift:TrialBin | −0.04 | 0.02 | −1.84 | =0.07 |
Figure 5.

Empirical logits of /∫/ responses as a function of Trial Bin (Experiments 1 and 2). For further information, see caption of Figure 4. To facilitate comparison across experiments, the range of the y-axes is held constant here and in all other result plots.
Participants in the ∫-Label condition tended to categorize more sounds as /∫/ ( = 0.37, z = 4.67, p < 0.001). Critically, there was a significant interaction between Label and Shift = 0.21, z = 2.6, p < 0.01), and participants who heard shifted critical words categorized significantly fewer sounds as /∫/ than those who heard unshifted critical words ( = −0.17, z = −2.13, p < 0.05). Simple effect analysis confirmed that the Label condition had an effect in Experiment 1 ( = 0.58, z = 5.10, p < 0.0001) but not Experiment 2 ( = 0.17, z = 1.48, p > 0.14).
Discussion
The results of Experiment 2 suggest that it is unlikely that the effects of the Label condition in Experiment 1 originate solely in the larger proportion of unshifted, compared to shifted, pronunciations. This result is not unexpected given differences between the current experiment and paradigms used to study selective adaptation. Experiments on selective adaptation tend to repeat the typical pronunciation many dozens of times (e.g., Bowers, Kazanina & Andermane, 2016; Samuel, 1989, 1997; Vroomen et al., 2007). By contrast, in the current experiment, the repeated typical sounds totaled only 24 tokens. It would thus have been surprising to see large selective adaptation effects as driving the effects in Experiment 1. Experiment 2 confirmed this.
Experiment 2 also serves as a baseline for Experiment 1 and all subsequent experiments we report: in Experiment 2, participants were exposed to only typical sounds and never heard shifted sounds. A comparison of the left panel in Figure 5 (Experiment 2) to the right panel (the Non-Tongue Twister condition in Experiment 1) suggest that the perceptual recalibration effect is driven by only the S-Label condition. This was confirmed by a simple effect analysis comparing the two conditions: participants who were exposed to shifted S-Label words in Experiment 1 identified significantly fewer sounds as /∫/ than those who had been exposed to unshifted S-Label words in Experiment 2 ( = −0.38, z = −3.23, p < 0.01); in contrast, there was no difference between Experiments 1 and 2 for participants in the ∫-Label condition (p = 0.82). The same asymmetry was found when comparing Experiment 1 to an alternative baseline experiment (reported as Experiment 2b in the supplementary information). In the alternative baseline experiment participants were exposed only to filler phrases—i.e., the complete absence of any /s/ or /∫/ during exposure—and then measured category shifts during the same test phase as in Experiments 1-2. The categorization boundary observed in that experiment was identical to that observed in Experiment 2.
This asymmetry differs from previous experiments in which we identified perceptual recalibration away from the baseline for both /s/ and /∫/ (Liu and Jaeger, 2018). Similar asymmetries have, however, been observed in other work (e.g., Drouin, Theodore & Myers 2016; Zhang & Samuel 2014). Indeed, which of two sound categories elicits perceptual recalibration can differ between experiments (for review, see Samuel, 2016, p. 111), possibly due to stimulus-specific properties and, in particular, the placement of the test continuum relative to the acoustic properties of exposure tokens (for evidence and discussion, see Drouin et al., 2016).
Finally, Experiment 2 further ameliorates concerns that Experiment 1 may suffer from lack of power to detect effects of tongue twister contexts. Our power simulations (see Appendix) found more than 95% power to detect the effect of Label and more than 80% power to detect blocking of those effects. Experiment 2 shows that we can indeed detect the absence or blocking of a perceptual recalibration effect, compared to Experiment 1.
Experiments 3a and 3b
One possibility for why the tongue twister context did not block adaptation in Experiment 1 is that the tongue twister context we provided was not a sufficiently plausible cause of the atypical pronunciations for participants. If participants did not view the tongue twister context to cause production difficulties, in the way a real tongue twister would, then it is not surprising that we do not find blocking of adaptation when shifted pronunciations are presented in this context.
In the current experiment, we address this possibility in two ways. In Experiment 3a, we increase the plausibility that our tongue twisters would be viewed as tongue twisters, as intended. Production experiments have found an increased incidence of errors when speech rate is increased (MacKay, 1982). To increase the plausibility that our tongue twisters would be viewed as likely to have caused the atypical pronunciations, we increase the speech rate of our stimuli. Additionally, we provide participants in the Tongue Twister Context with explicit information stating that they will hear tongue twisters that may have been difficult for the talker to produce. Explicit instructions of this type have sometimes been found to facilitate attribution to alternative causes, such as intended here (e.g., Arnold et al., 2007, discussed below). In Experiment 3b, we provide participants with an alternative (non-tongue twister) cause for the atypical pronunciations. We inform participants that the talker is intoxicated. These experiments taken together allow us to assess whether inferences about causes during speech perception may be influenced by explicit instructions.
Experiment 3a
Method
Participants.
We recruited 177 participants on Amazon Mechanical Turk to achieve a target of 40 participants in each of four conditions (S-Label/∫-Label x Tongue Twister/Non-Tongue Twister). 7 participants were excluded for not correctly identifying the speaker as female and 10 participants for not wearing headphones (9.6% exclusion rate). Participants were paid $1 for this experiment, which took roughly 10 minutes ($6/hr).
Materials and Procedure.
For this experiment, we used the exact stimuli from Experiment 1. We increased the tempo of the stimuli by 23%, the maximum speed-up at which the stimuli still sounded natural. We used the free software Audacity (https://www.audacityteam.org/), so that the speed of the stimuli changed, but the pitch and formants remained unchanged. Since static spectral cues are highly predictive of the /s/ vs. /∫/ contrast (e.g., McMurray et al., 2012, Table 3), this procedure is unlikely to change the perceived shift of our exposure tokens. Since these cues are duration invariant, we also do not expect that the increase in speech rate during exposure affects the perception of the test stimuli (which had the same speech rate as in Experiments 1 and 2).
The procedure of Experiment 3a was identical to that of Experiment 1, except that we added an additional prompt for participants in the Tongue Twister Context condition. This prompt emphasized the tongue twister as a plausible cause for the atypical pronunciations. We did so because Experiment 1 had not found an effect of the Tongue Twister Context on blocking the perceptual recalibration effect. Participants in the Tongue Twister Context were shown the following prompt:
“A number of the phrases that the speaker was asked to say are difficult tongue twisters. You might notice that the speaker occasionally mispronounces certain words slightly because of this. Do not worry about the mispronunciations. Just transcribe the words as best as you can.”
Participants in the Non-Tongue Twister Context were not shown the prompt. The rest of the procedure was identical to that of Experiment 1. Transcription accuracy (84.8%, SD = 10.1%) was somewhat lower than in Experiment 1, likely because of the increased speech rate in Experiment 3a.
Results
Test Block: Changes in the categorization boundary.
As in Experiments 1 and 2, we used mixed logit regression to predict /∫/ responses from Label (sum-coded: ∫-Label = 1 vs. S-Label = −1), Context (sum-coded: Non-Tongue Twister = 1 vs. Tongue Twister = −1), Trial Bin (coded continuously with the first trial bin as 0), and their interactions (Table 9). For Experiment 3a, the analysis converged with by-participant intercepts and slopes for Trial Bin.
Table 9.
Mixed logit regression predicting proportion of /∫/ responses from Label, Condition, and their interaction (Experiment 3a). Coding: Label (sum coded: ∫-Label = 1 vs. S-Label = −1), Context (NonTT = 1 vs. TT = −1), Trial Bin (First bin = 0). Rows that are critical to our analysis are highlighted in grey.
| Predictors | Parameter Estimates |
Significance Test |
||
|---|---|---|---|---|
| Coef () | Std Err | z | p | |
| (Intercept) | −0.47 | 0.13 | −3.69 | <0.001 |
| Label (∫ vs. S) | 0.63 | 0.13 | 4.92 | <0.001 |
| Context (NonTT vs. TT) | 0.08 | 0.13 | 0.61 | 0.54 |
| TrialBin (First bin = 0) | 0.08 | 0.03 | 3.1 | <0.002 |
| Label:Context | 0.08 | 0.13 | 0.67 | 0.50 |
| Label:TrialBin | −0.15 | 0.03 | −5.79 | <0.001 |
| Context:TrialBin | −0.04 | 0.03 | −1.52 | =0.13 |
| Label:Context:TrialBin | −0.01 | 0.03 | −0.40 | 0.69 |
At the beginning of the test block, participants in the J-Label condition provided more /∫/ responses than those in the S-Label condition ( = 0.63, z = 4.92, p < 0.001). Furthermore, the total number of /∫/ responses tended to increase over trial bins ( = 0.08, z = 3.1, p < 0.002), and that this differed between Label conditions, in a way consistent with convergence towards 50/50: participants in the ∫-Label condition tended to provide fewer /∫/ responses in later trials bins, compared to those in the S-Label condition ( = −0.15, z = −5.79, p < 0.001). Critically, however, we did not identify a significant effect of Context (p = 0.54) or interaction between Context and Label (p = 0.50). This suggests that the categorization of stimuli during the test block was not strongly affected by whether the shifted stimuli were presented in a Tongue Twister Context or Non-Tongue Twister Context. It is worth pointing out though that the interaction is numerically in the predicted direction. This is also visible in Figure 6.
Figure 6.
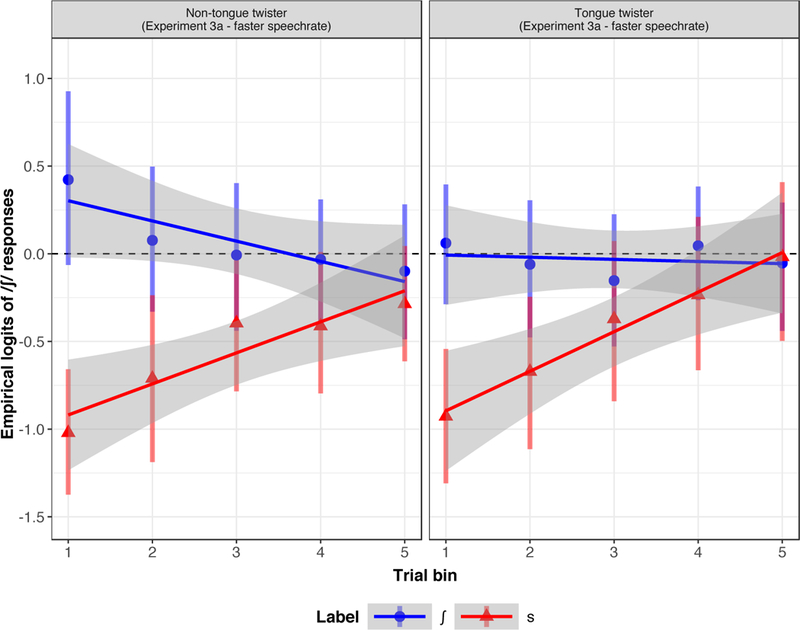
Empirical logits of /∫/ responses as a function of Trial Bin (Experiment 3a). For further information, see caption of Figure 4.
Additional planned analyses reported in the supplementary information found that i) the magnitude of perceptual recalibration in Experiment 3a was identical to that of Experiment 1 and ii) Experiment 3a again only finds perceptual recalibration in the S-Label condition (compared to the unshifted baseline from Experiment 2). These results also suggest that the increased speech rate did not affect perceptual recalibration.
Experiment 3b
In Experiment 3b, we further explore whether explicitly provided information about the talker can affect adaptation. We attempt to block perceptual recalibration by providing participants with an alternate reason why the talker might sound atypical. Specifically, we test whether instructions that talker in the experiment was intoxicated during the exposure block, but not during the test block, reduce or block the perceptual recalibration effect. We chose to use this alternate cause for two reasons. First, when intoxicated, speech errors become more common (Chin & Pisoni, 1997; Cutler & Henton, 2004). Second, the specific significant shift that we used to observe perceptual recalibration (/s/ shifting towards /∫/) has been documented as one effect of intoxication on speech production (Chin & Pisoni, 1997; Heigl, 2018). Both of these factors combined make it plausible that intoxication may provide listeners with a plausible cause for the atypical pronunciation that they hear.
Method
Participants.
We recruited 180 participants on Amazon Mechanical Turk, for a target of 40 participants in each of four conditions (S-Label/∫-Label x Intoxicated/Sober). Three participants were excluded for not correctly identifying the speaker as female, 7 participants for not wearing headphones, and 1 for inverted categorization functions. We included one additional catch question in our post-experiment questionnaire to verify that participants were reading directions and were aware of when the talker was intoxicated or not (explained in Materials below). Nine additional participants were excluded for providing the incorrect response to this catch question (overall exclusion rate: 11.1%). Participants were paid $1 for this experiment, which took roughly 10 minutes ($6/hr).
Materials and Procedure.
The stimuli used during the exposure block were identical to the stimuli used in the Non-Tongue Twister condition of Experiment 1. As in Experiment 1, for half of participants, the atypical, shifted pronunciations occurred in words containing /s/ (S-Label condition), and for the other half of participants, the atypical, shifted pronunciations occurred in words containing /∫/ (∫-Label condition).
In both the Intoxicated and Sober conditions, participants were told that the purpose of the experiment was to understand how “people understand speech from speakers who are either intoxicated or not”. These groups only differed by the instructions that they saw preceding the exposure block. In the Sober condition, participants were told that they would hear words produced by “a speaker who is NOT intoxicated”. In the Intoxicated condition, participants were told that they would hear words produced by “an intoxicated speaker who had just drunk several cans of beer.”
Crucially, in both conditions, preceding the test block, participants were told that the same talker recorded additional words one week later. They were told that during this recording session, the speaker “reported that she had NOT drunk any beer, wine, or other alcoholic beverage in the past three days” and that we “confirmed this by testing her blood alcohol content (BAC = 0.00)”. The rationale was that participants who were told that the talker was intoxicated would attribute the atypical pronunciations to her temporary, intoxicated state, and that their responses during the test block would therefore not show an effect of perceptual recalibration.
In the post-experiment questionnaire, we added an extra question in order to verify that participants read the critical prompt regarding the state of intoxication of the talker. Specifically, we asked the following:
The instructions that you read told you when the speaker you heard was intoxicated or not intoxicated. Please select the statement that best describes what the instructions told you. Reminder: the first section was where the speaker produced four word phrases, and the second section was where they produced asi/ashi words.
The possible responses were:
First section: Intoxicated. Second section: Not intoxicated.
First section: Not intoxicated. Second section: Intoxicated.
Both sections: Intoxicated.
Both sections: Not intoxicated.
The correct response for participants in the Intoxicated condition was (1) and the correct response for participants in the Sober condition was (4). As reported above, we excluded participants when they answered this critical question incorrectly. Transcription accuracy (89.6%, SD = 6.8%) was similar to Experiment 1, which is expected given that the stimuli in Experiment 3b are identical to those of the Non-Tongue Twister condition in Experiment 1.
Results
Test Block: Changes in the categorization boundary.
We used mixed logit regression to predict /∫/ responses from Label (sum-coded: ∫-Label = 1 vs. S-Label = −1), Context (sum-coded: Sober = 1 vs. Intoxicated = −1), Trial Bin (coded continuously with the first trial bin as 0), and their interactions (Table 10).
Table 10.
Mixed logit regression predicting proportion of /∫/ responses from Label, Condition, and their interaction (Experiment 3b). Coding: Label (sum coded: ∫-Label = 1 vs. S-Label = −1), Context (Sober = 1 vs. Intoxicated = −1), Trial Bin (First bin = 0). Rows that are critical to our analysis are highlighted in grey.
| Predictors | Parameter Estimates |
Significance Test |
||
|---|---|---|---|---|
| Coef () | Std Err | z | p | |
| (Intercept) | −0.35 | 0.11 | −3.09 | <0.001 |
| Label (∫ vs. S) | 0.58 | 0.11 | 5.13 | <0.001 |
| Context (Sober vs. Intoxicated) | 0.03 | 0.11 | 0.25 | 0.8 |
| TrialBin (First bin = 0) | 0.02 | 0.02 | 0.93 | 0.35 |
| Label:Context | 0.09 | 0.11 | 0.77 | 0.44 |
| Label:TrialBin | −0.08 | 0.02 | −3.81 | <0.001 |
| Context:TrialBin | 0.01 | 0.02 | 0.32 | 0.75 |
| Label:Context:TrialBin | −0.02 | 0.02 | −0.88 | 0.38 |
At the beginning of the test block, participants in the ∫-Label condition provided more /∫/ responses than those in the S-Label condition ( = 0.58, z = 5.13, p < 0.001). Critically, however, we did not identify a significant effect of Context (Sober vs. Intoxicated: p = 0.8) or interaction between Context and Label (p = 0.44). It is worth pointing out though that the interaction is again numerically in the predicted direction, as it was in Experiment 3a. This is also visible in Figure 7. Further simple effect comparison against Experiment 2 confirmed that, again, the perceptual recalibration we found in Experiment 3b was driven by only the S-Label condition (analysis not reported here).
Figure 7.

Empirical logits of /∫/ responses as a function of Trial Bin (Experiment 3b). For further information, see caption of Figure 4.
Additional planned analyses reported in the supplementary information found that i) the magnitude of perceptual recalibration in Experiment 3b was identical to that of Experiment 1 and ii) Experiment 3a again only finds perceptual recalibration in the S-Label condition (compared to the unshifted baseline from Experiment 2). This, too, suggests that the manipulation in Experiment 3b did not affect perceptual recalibration.
Discussion
The results of Experiments 3a and 3b are interesting in light of some experiments that have found causal attribution effects of information provided via explicit instructions on aspects of language processing, other than speech perception (e.g., Arnold et al., 2007; Grodner & Sedivy, 2011; Niedzielski, 1999). For example, Arnold et al. (2007) reported that explicitly telling participants that a talker had object agnosia lead to differences in participant expectations during reference comprehension. Other experiments, however, have found little (Pogue, Kurumada & Tanenhaus, 2016) or no role of explicit instructions (Dix et al., 2018). We discuss these and other studies in the context of the current experiments in more detail in the General Discussion.
In Experiments 3a and 3b, we again observe robust perceptual recalibration effects for exposure to shifted pronunciations of /s/. And we again fail to observe significant blocking of perceptual recalibration in the presence of an incidental cause for the shifted pronunciations. That is, unlike visual evidence of a pen in the mouth during exposure, none of the incidental causes explored in Experiments 1, 3a, and 3b seems to prevent perceptual recalibration. The findings of Experiments 1-3 are thus problematic for theories that attribute the effect of the pen in the mouth to inferences about causes during speech adaptation (Liu & Jaeger, 2018), although both experiments exhibit trends in the predicted direction. One possibility that explains why we may have failed to find blocking of adaptation is that participants do not perceive the tongue twisters, even with the explicit instructions, as plausible tongue twisters. We explore this possibility in Experiments 4a and 4b.
Experiments 4a and 4b
Experiment 4 assesses the possibility that participants in Experiments 1 and 3a considered it implausible that the shifted pronunciations in the Tongue Twister Context were due to incidental speech errors, rather than being characteristic of the talker. Two considerations guide the design of Experiment 4.
First, speech errors are very rare in everyday speech production. Hearing multiple speech errors—all of them on the same type of sound—make it less likely that the mispronunciation is not characteristic of the talker, even when those mispronunciations occur in a tongue twister. Specifically, Experiments 1 and 3a exposed participants to 8 different speech errors, all involving the same sound (either /s/ or /∫/). Given that speech errors only occur in tongue twister contexts about 8–17% of the time (Choe & Redford, 2012; Motley & Baars, 1976), this high incidence of errors could have led participants to infer that the atypical pronunciations are characteristic of how the talker typically sounds. Second, it is possible that some of our tongue twister contexts are perceived to be more likely to cause speech errors than others. The less plausible a tongue twister context is perceived to be, the more likely listeners should be to attribute the shifted pronunciation to the talker rather than the context. Either of these two possibilities could explain the failure to observe blocking of perceptual recalibration in Experiments 1 and 3a.
In Experiment 4, we attempt to remedy both of these concerns. We identify the top four plausible tongue twisters in Experiment 4a, cutting down the number of tongue twisters we use from eight to four. In Experiment 4b, we first validate the that exposure to only these four items in a Non-Tongue Twister Context results in perceptual recalibration (it does), and then test whether exposure to the same four items in a Tongue Twister Context blocks perceptual recalibration.
Experiment 4a
Method
Participants.
90 participants participated in our experiment to achieve a target of 20 participants for each of the four between-participant conditions (S/∫-Label crossed with the Tongue Twister/Non-Tongue Twister Context). They were paid $0.50 for this Experiment, which took about five minutes ($6/hour). 4 participants were excluded for not answering the catch question correctly. 6 were excluded for reporting that they did not wear headphones.
Materials and Procedure.
In this experiment, participants listened to stimuli one at a time and rated them on a Likert scale from 1 (“Not at all like a tongue twister”) to 7 (“Definitely a tongue twister”). Participants were presented with the 30% sped-up stimuli from Experiment 3a (using the same lists), with the addition of three control tongue twisters. The three control tongue twisters were taken from well-known tongue twisters, and were adjusted to roughly match the structure of the other phrases (disyllable words, repeated words):
Betty Botter Butter Betty
Peter Piper Pepper Peter
Soldier Shoulder Soldier Shoulder
Each participant thus provided 27 total judgments. Following the experiment, participants completed the same post-experiment questionnaire as in Experiments 1-3.
Results
First, we wished to assess whether our tongue twisters were perceived as more tongue-twister-like than the filler stimuli. We compared the ratings of our tongue twister stimuli to both the filler stimuli and attested tongue twisters. Figure 8 shows the mean ratings for attested tongue twisters, our tongue twisters, non-tongue twister stimuli, and fillers without any /s/ or /∫/. To remove individual variability in how participants used the rating scale, we first standardized ratings by participant for plotting. Linear mixed-effects analyses of the un-standardized ratings are reported in the supplementary materials, and confirmed what is visible in Figure 8. Tongue twisters were rated as more tongue-twister-like than the filler stimuli (as intended), but less tongue-twister-like than attested tongue twisters. We postpone discussion of possible reasons for this until after Experiment 4b. We found no differences in ratings between the S- and J-Label condition for any of the different stimuli types, including the Tongue Twisters we created for our experiments (p > .3; S-Label: mean rating = 4.7 (SD = 1.0); ∫-Label: mean rating = 4.5 (SD = 0.7)). This suggests that the Tongue Twister Context was not viewed as more plausible for one Label condition compared to the other.
Figure 8.

Mean ratings for each stimulus type (Experiment 4a). For plotting, responses were standardized within participants prior to taking by-participant means (high values indicate “more tongue twister-like”). Error bars show 95% confidence intervals obtained via non-parametric bootstrap over the by-participant means.
Second, we wished to assess whether certain tongue twisters within our stimuli were perceived as more tongue-twister-like than others. For each Label condition, we computed the average ratings for each of the eight tongue twister phrases. These averaged between 3.5 and 5.4. We then selected the four tongue twisters out of these eight with the highest tongue twister ratings in both the S-Label and ∫-Label conditions. We use these tongue twisters for a shortened version of Experiment 1 in Experiment 4b.
Experiment 4b
Method
Participants.
179 participants participated in this experiment, for achieve the targeted 40 participants in each of four conditions (S-Label/∫-Label x Tongue Twister/Non-Tongue Twister Context). 14 participants were excluded for providing an incorrect answer to the catch question, 3 participants were excluded for an inverted category boundary, and 2 participants were excluded for not wearing headphones (10.6% overall exclusion rate). Participants were paid $0.70 for this experiment, which took about 7 minutes ($6/hour).
Materials and Procedure.
The materials that we used for this experiment were a subset of the materials used in Experiment 3a (i.e., the stimuli for which speech rate was increased by 30% compared to Experiment 1). For each Label condition, these consisted of half of the critical phrases (four instead of eight), as well as half of the filler phrases (eight instead of sixteen). These are the items marked with an asterisk (*) in Tables 1 and 2.
Transcription accuracy (82.8%, SD = 11.4%) was about 6% lower than in Experiment 1 and about 2% lower than in Experiment 3a.
Results
Test Block: Changes in the categorization boundary.
As in all previous experiments, we performed mixed logit regression to predict /∫/ responses from Label (sum-coded: ∫-Label = 1 vs. S-Label = −1), Context (sum-coded: Non-Tongue Twister = 1 vs. Tongue Twister = −1), Trial Bin (coded continuously with the first trial bin as 0), and their interactions. This is shown in Table 11 and visualized in Figure 9.
Table 11.
Mixed logit regression predicting proportion of /∫/ responses from Label, Condition, and their interaction (Experiment 4b). Coding: Label (sum coded: ∫-Label = 1 vs. S-Label = −1), Context (NotTT = 1 vs. TT = −1), Trial Bin (First bin = 0). Rows that are critical to our analysis are highlighted in grey.
| Predictors | Parameter Estimates |
Significance Test |
||
|---|---|---|---|---|
| Coef () | Std Err | z | p | |
| (Intercept) | −0.02 | 0.08 | −0.27 | 0.79 |
| Label (∫ vs. S) | 0.36 | 0.08 | 4.48 | <0.001 |
| Context (NonTT vs. TT) | −0.01 | 0.08 | −0.07 | 0.95 |
| TrialBin (First bin = 0) | 0.02 | 0.02 | 1.08 | 0.28 |
| Label:Context | 0.11 | 0.08 | 1.32 | 0.19 |
| Label:TrialBin | −0.09 | 0.02 | −4.33 | <0.001 |
| Context:TrialBin | −0.02 | 0.02 | −0.82 | 0.41 |
| Label:Context:TrialBin | −0.05 | 0.02 | −2.36 | <0.05 |
Figure 9.

Empirical logits of /∫/ responses as a function of Trial Bin (Experiment 4b). For further information, see caption of Figure 4.
The results are visualized in Figure 9. At the beginning of the test block, participants in the ∫-Label condition provided more /∫/ responses than those in the S-Label condition ( = 0.36, z = 4.48, p < 0.001). This shows that the four shifted exposure items were sufficient to elicit perceptual recalibration. There was no main effect of Context (p = 0.95) and, critically, we did not identify a significant interaction between Context and Label (p = 0.19), though the interaction again trends in the predicted direction (as also evident in Figure 9).4
Additional planned analyses reported in the supplementary information found that the magnitude of perceptual recalibration in Experiment 4b (4 shifted sounds, 0.72 log-odds perceptual recalibration) was numerically, but not significantly, smaller than in Experiment 3a (8 shifted sounds, 1.18 log-odds). This is expected given that the two experiments differed in the number of shifted sounds.
Discussion
Experiment 4 reduced the number of critical items with atypical, shifted pronunciations in order to reduce the probability that listeners would infer that the shifted sound is characteristic of the talker. We halved the number of critical tongue twister items and fillers, and used only the four most plausible tongue twister contexts. We again identified evidence for perceptual recalibration in both the Tongue Twister and Non-Tongue Twister Contexts. We observed numerically, but not significantly, weaker perceptual recalibration (the simple effect of Label condition) in the Tongue Twister Context than in the Non-Tongue Twister Context, in line with the hypothesis that participants might attribute the talker’s shifted pronunciation to the context.
It is possible that we were unable to detect this effect because the tongue twisters we created were not perceived to be sufficiently plausible to elicit shifted pronunciations. While our Tongue Twister contexts were rated as more tongue twister-like than our Non-Tongue Twister context, they received lower ratings compared to attested tongue twisters. This might make it less likely that participants attribute the atypical pronunciations to the tongue twister, instead attributing it to the talker. This in turn would explain the lack of a significant interaction of the Label and Context conditions. We return to this possibility in the general discussion. First, we present one final experiment aimed at increasing the probability that listeners interpret the shifted pronunciations in Tongue Twister contexts as incidental errors, rather than characteristic of the talker.
Experiment 5
In Experiment 5, we provide additional bottom-up evidence for the Tongue Twister Context, in order to increase the plausibility of our tongue twister phrases. We conducted an informal review of speech errors in tongue twisters on Youtube.com, and observed that naturally occurring tongue twisters often contain additional evidence that a talker experienced a production difficulty. Indeed, self-corrections have been observed in more than 50% of all speech errors (Nooteboom, 1980), and self-monitoring mechanisms appear in the majority of models of speech production (see Postma, 2000 for a review). We incorporate these properties of speech errors into the stimuli for our Experiment 5.
We exposed participants to the same stimuli as in Experiment 4b, except that we edited the stimuli to add auditory evidence of a repair or audible frustration due to production difficulty. Specifically, we created two new Tongue Twister Context conditions. In the first new condition, the talker makes a stutter during the atypical pronunciation following the first syllable, and then attempts to repair their error by repeating the word (Difficulty During Context). In our stimuli, this repair always resulted in a second atypical pronunciation of the same word. This design decision was made so as to avoid presenting both typical and atypical pronunciations of the same sound, which would be a deviation from perceptual recalibration paradigms. We note, however, that this context condition may unintentionally reinforce the possibility that the atypical pronunciation reflects how the talker typically sounds, as the talker’s repair still contains an atypical pronunciation.
The prediction for the Difficulty During Context thus depends on how participants (on average) interpret this condition. If participants interpret this context as an unsuccessful repair, and thus as evidence that the talker considered the atypical pronunciation to deviate from the intended pronunciation, perceptual recalibration should be reduced or blocked. If, on the other hand, participants take the repeated atypical pronunciation as further evidence that the atypical pronunciation is characteristic of the talker, we should see as much or more perceptual recalibration in this context condition, as in the Non-Tongue Twister condition.
The second new context condition of Experiment 5 avoids this problem, leading to clearer predictions. In this condition, the talker emits a sound of frustration following the production of the atypical pronunciation (Difficulty After Context). This provides the listener with evidence that the talker is aware of the production error that they made, and that they found it to be deviating from their own internal criterion of how that word should sound. We note that the Difficulty After Context also corresponds most closely to what we observed in the majority of speech errors in tongue twisters on Youtube.com. The predictions for the Difficulty After Context are clear: if causal inferences attribute the atypical pronunciation to a speech error, perceptual recalibration should be reduced or blocked in this condition, compared to the Non-Tongue Twister Context.
Method
Participants.
167 participants participated in this Experiment 5, for a target of 40 participants in each Label and Context condition (S-Label/∫-Label x During/After). 3 participants were excluded for providing an incorrect answer to the catch question and 4 participants were excluded for an inverted category boundary (4.2% overall exclusion rate). Participants were paid $0.70 for this 7 minute long experiment ($6/hour).
Materials and Procedure.
The materials for this experiment were identical to the ones used in the Tongue Twister Context condition in Experiment 4b, with slight modifications to the critical stimuli. Namely, in the During Context, for the eight critical phrases containing an atypical pronunciation, we inserted a sign of production difficulty before the second syllable of the atypical pronunciation, followed by a repair. For example, for the phrase “passion mansion pa?shive passion” was produced as “passion massion pa [stutter] pa?s∫ive passion”. In the After Context, after the atypical pronunciation, we inserted a sigh to signal frustration. For example, for the phrase “passion mansion pa?s∫ive passion” was produced as “passion massion pa?s∫ive [ugh] passion”. A separate norming experiment (reported as Experiment 5b in the supplementary information) verified that participants indeed perceived that the talker had more difficulty with the phrases containing overt signs of production difficulties (Experiment 5), compared to those without (Experiments 1-4).
With 80.4% (SD = 10.2%), transcription accuracy in Experiment 5 was the lowest of all experiments, possibly due to the additional difficulty of transcribing phrases with overt signs of production difficulty. For example, participants might have been unsure whether or not to transcribe the word containing the production difficulty/repair.
Results
Test Block: Changes in the categorization boundary.
We performed an analysis of the data from the current experiment, combined with the data from the Non-Tongue Twister condition of Experiment 4b. We wished to assess whether either the insertion of a sign of production difficulty coupled with a repair (During Context) or a sign of production difficulty following an atypical pronunciation (After Context) in the Tongue Twister Context may result in a reduction or blocking of the perceptual recalibration effect identified in the Non-Tongue Twister Context.
We performed mixed logit regression to predict /∫/ responses from Label (sum-coded: ∫-Label = 1 vs. S-Label = −1), Context (treatment coded, with the Non-Tongue Twister Context as the comparison level), Trial Bin (coded continuously with the first trial bin as 0), and their interactions. This is shown in Table 12 and visualized in Figure 10.
Table 12.
Mixed logit regression predicting proportion of /∫/ responses from Label, Condition, and their interaction (Experiment 5). Coding: Label (sum coded: ∫-Label = 1 vs. S-Label = −1), Context (treatment coded, with the Non-Tongue Twister Context as the comparison level), Trial Bin (First bin = 0). Rows that are critical to our analysis are highlighted in grey.
| Predictors | Parameter Estimates |
Significance Test |
||
|---|---|---|---|---|
| Coef () | Std Err | z | p | |
| (Intercept) | −0.03 | 0.13 | −0.23 | 0.82 |
| Label (∫ vs. S) | 0.48 | 0.13 | 3.69 | <0.001 |
| Contextl (During vs. NonTT) | −0.37 | 0.19 | −1.98 | <0.05 |
| Context2 (After vs. NonTT) | −0.27 | 0.19 | −1.46 | 0.15 |
| TrialBin (First bin = 0) | 0.01 | 0.03 | 0.19 | 0.85 |
| Label:Context1 | 0.15 | 0.19 | 0.78 | 0.43 |
| Label:Context2 | −0.15 | 0.19 | −0.82 | 0.41 |
| Label:TrialBin | −0.14 | 0.03 | −4.76 | <0.001 |
| Context1:TrialBin | 0.06 | 0.04 | 1.38 | 0.17 |
| Context2:TrialBin | 0.01 | 0.04 | 0.18 | 0.86 |
| Label:Context1:TrialBin | −0.02 | 0.04 | −0.48 | 0.63 |
| Label:Context2:TrialBin | 0.07 | 0.04 | 1.81 | =0.07 |
Figure 10.
Empirical logits of /∫/ responses as a function of Trial Bin (Experiment 5). For further information, see caption of Figure 4.
A significant interaction between Context and Label for either of the comparisons of the Tongue Twister Contexts against the Non-Tongue Twister Context (During Context vs. Non-Tongue Twister Context, or After Context vs. Non-Tongue Twister Context) would suggest that the Tongue Twister Context, when combined with a sign of production difficulty, resulted in a difference in participants’ categorization boundaries during the test block, compared to the Non-Tongue Twister Context.
Though we found that participants in the During Context provided overall significantly fewer /∫/ responses than those in the Non-Tongue Twister Context ( = −0.37, z = −2.0, p < 0.05), we failed to identify any significant interaction between Label and either Context comparison (ps > 0.41). Simple effects analysis revealed that the effect of Label was significant for all three contexts (ps < 0.05), though numerically smaller in the After Context (difference between the ∫-Label and S-Label condition = 0.66 in log-odds) compared to the Non-Tongue Twister Context (0.96 in log-odds) and the During Context (1.26 in log-odds). This is visualized in Figure 10 (see differences in Trial Bin 1).
In summary, we again find a robust effect of perceptual recalibration, and no significant effects that would indicate that listeners take into account incidental causes. We note, however, that the relative size of the perceptual recalibration effects is in line with a possibility we raised above: participants might have interpreted only the Difficulty After Context as good evidence that the talker recognized the atypical pronunciation as unintended (and thus not characteristic of her speech); unintentionally, the design of our Difficulty During Context—which involved repetition of the atypical pronunciation in the repair—might have reinforced, rather than weakened, participants’ belief that the atypical pronunciation is characteristic of the talker. This would explain the numerical pattern we observed in Experiment 5. We return to this possibility below.
General discussion
In five experiments, we explore the role of inferences about alternative causes during speech perception. We identify robust perceptual recalibration following exposure to as few as four and eight shifted pronunciations embedded within four-word phrases. Recalibration was observed despite the fact that critical target words with atypical pronunciations only account for less than 10% of all words heard during exposure (see also Kraljic & Samuel, 2005; Kraljic et al., 2008). This reliably replicates perceptual recalibration in a web-based paradigm, despite variability in the audio equipment across participants (see also Liu & Jaeger, 2018; Kleinschmidt & Jaeger, 2012). Additionally, we replicate the effect that learning from exposure is unlearned during test, due to exposure to a uniform distribution of sounds during test (Liu & Jaeger, 2018). This confirms that the common practice of reporting recalibration averaged across the entire test phase systematically under-estimates the adaptivity of the perceptual system: at the beginning of the test phase, perceptual recalibration is often twice as large as when averaged across all block. The analysis we employed throughout the present study takes this into account.
The goal of the present study was to identify whether perceptual recalibration is affected by the presence of an alternative cause for the atypical pronunciations. Previous studies found that exposure to an atypical pronunciation paired with a video of the talker with a pen in her mouth resulted in a complete blocking of the adaptation effect for at least one of the exposure (Label) conditions (Kraljic et al., 2008; Kraljic & Samuel, 2011; Liu & Jaeger, 2018). One explanation for this is that listeners attribute the atypical pronunciation to the pen. This would block perceptual learning, either because listeners do not store the atypical pronunciations as part of their talker-specific experience (since they do not attribute the atypicality of the pronunciation to the talker), or because listeners store the atypical pronunciations but do so together with the contextual information that a pen was in the speaker’s mouth. According to the latter explanation (proposed in Kraljic & Samuel, 2011), perceptual recalibration is blocked because no pen is present during the test trials (unlike exposure trials, test trials in were auditory only) so that listeners might not consider the input they experienced during exposure as relevant to the categorization of the test stimuli. Either of these two explanations attributes pen-in-the-mouth effect to causal inferences—either during the storage of previously experienced input (in order to determine what constitutes relevant context) or during its retrieval (e.g., in order to determine what previous experience is relevant to the processing of the current input; see discussion in Liu & Jaeger, 2018).
In contrast to the pen-in-the-mouth effect, we do not find significant reduction of perceptual recalibration for any of the incidental causes we explored. It is, however, note-worthy that the interaction of Context and Label condition went in the expected direction in five out of six between-participant comparisons (in Experiments 3a, 3b, 4b, and in the Difficulty After condition in Experiment 5). This consistency in the non-significant trends is quite unexpected by chance alone (Wilcoxon signed rank test with continuity correction: V = 17.5, p = 0.13). Prompted by reviews, we conducted two sets of post-hoc tests. Before we discuss our results further, we briefly summarize these tests (for details, see the supplementary information at https://osf.io/ungba/).
Summary of post-hoc tests prompted by reviews
The first post-hoc test pooled all experiments together to assess the effect of Context (sum-coded: Non-Tongue Twister or Sober = 1 vs. Tongue Twister or Intoxicated = −1). This mixed logit regression was otherwise identical to the analyses of all individual experiments, including all other predictors, their coding, and the random effects. The critical interaction between Label condition and Context went in the expected direction, but was not significant ( = 0.06, z = 1.3, p = 0.19). We also repeated this analysis with a Bayesian framework in order to obtain a well-formed, and more intuitive, measure of evidentiary support (Wagenmakers, 2007). This analysis compared the relative probability of the hypothesis that incidental causes reduce the magnitude of perceptual recalibration against the hypothesis that they increase the magnitude of perceptual recalibration. In line with the numerical trend we observe, the analysis estimated the posterior probability of the former hypothesis to be 89% (BF = 8.0; for details, see supplementary information).
This first post-hoc test ignored that we expect stronger effects in the latter experiments (for all the same reasons that motivated these experiments, on which we further elaborate below). The second set of post-hoc tests re-analyzed the data from all experiments separately. These additional tests also addressed another potential shortcoming of the analyses presented above: As one reviewer pointed out, our procedure of estimating effects of the Label condition in the first trial bin sometimes over-estimates perceptual recalibration in the Tongue Twister condition and under-estimates the perceptual recalibration in the Non-Tongue Twister Condition. This is visible, for example, in Figure 4 for Experiment 4b.
We thus repeated the same analysis reported above for all experiments, but over only the responses in the first trial bin (i.e., excluding all other data and excluding Trial Bin as a predictor). These analyses have less power as they are based on less data, but do not make the linearity assumption made in the main analyses reported above. This second set of post-hoc analyses replicated the significant main effect of Label for all experiments for all experiments (ps < 0.004). The critical interaction between Label and Context was significant for Experiment 4b ( = 0.21, z = 2.31, p < 0.02), surviving Bonferroni correction (αcorrected = .025). Simple effects analysis revealed significant effects of the Label condition for the Non-Tongue Twister condition ( = 0.61, z = 4.77, p < 0.0001), but not the Tongue Twister condition ( = 0.19, z = 1.56, p < 0.12). In all other experiments, the interaction between Context and Label was not significant (ps > 0.14). In short, while the present studies return some evidence compatible with causal inference accounts, this support is weak—in contrast to previous studies with visually presented causes. All posthoc analyses are reported in full in the supplementary information, along with the data from all experiments.
We close by discussing explanations our results and the contrast to previous findings. We begin with potential limitations of causal inferences in speech perception. Then, we discuss the importance of using plausible causes, and provide ideas for future directions of research in this area.
Incidental causes during spoken language understanding
One explanation for the difference between the present findings and those of earlier work is that visual information—perhaps, in particular, visual information about articulation that occurs concurrently with the auditory input—has a privileged role during speech perception. Such visual information can influence phoneme perception and appears to be strongly integrated with auditory input (e.g., Tuomainen et al., 2005). This is demonstrated by the McGurk effect, in which an auditory /ba/ dubbed onto a video of a talker producing /ga/ results in a percept of /da/ (McGurk & MacDonald, 1976). The incidental causes employed in the present study either were not presented visually (tongue twisters) or were presented visually, but did not constitute audio-visual speech percept (explicit instruction preceding exposure, e.g., when participants were told that the talker was intoxicated).
We know of no previous work that has directly addressed whether causal inference during perception are affected by incidental causes that are not presented visually and concurrently with the speech signal.5 There are, however, two lines of research that are of relevance to this question.
First, there is the observation that listeners are generally capable of integrating evidence about a talker from a diverse array of sources—both visual and non-visual during language comprehension—and regardless of whether the evidence is presented concurrently with the language input (e.g., Arnold et al., 2007; Dix et al., 2018; Grodner & Sedivy, 2011; Hay, Nolan & Drager, 2006; Hay, Warren & Drager, 2006; McGowan, 2015; Pogue et al., 2016). This includes hypothetical incidental causes that are indicated through explicit instructions. For example, Grodner & Sedivy (2011) provided listeners with instructions that a talker “had an impairment that caused language and social problems”. They found that listeners used these instructions to modulate their pragmatic processing of sentences from that (unreliable) talker (see also Dix et al., 2018). A similar effect has been observed for the processing of disfluencies (Arnold et al., 2007). Eye-tracking visual world experiments demonstrate that listeners are sensitive to the presence of disfluencies: following a disfluency (“Click on [pause] thee uh red ...”), listeners anticipated references to unfamiliar objects with difficult names, as opposed to familiar object with simpler names (see also Arnold, Tanenhaus, Altmann & Fagnano, 2004). In the absence of a disfluency, listeners’ eye-movements exhibited the opposite preference. This suggests that listeners take into account that disfluencies tend to precede referential expressions that are associated with production difficulty. Crucially, when another group of listeners was told that the talker had a language impairment—a difficulty recognizing and naming objects—listeners’ eye-movements no longer exhibited sensitivity to disfluencies. Arnold and colleagues interpreted this blocking of the typical interpretation of disfluencies to inferences about alternative causes for disfluencies (in this case, the talker’s language impairment). These findings suggest that explicitly indicated incidental causes can affect some aspects of language processing. It is worth noting though that these studies have investigated higher-level aspects of language processing, rather than speech perception.
A second line of experiments demonstrates that explicit instructions can guide listeners’ expectations about how a talker will sound. For example, informing a listener that a talker is from a particular region can affect vowel perception (Niedzielski, 1999; Hay et al., 2006). Niedzielski found that listeners interpreted the same vowel sound differently when they were told that the talker was from Canada, as opposed to from Detroit. The dialects of two regions differ in how they tend to pronounce the same vowels, and listeners’ interpretation of the acoustic input reflected these differences. Expectations about talker identity and accent do not necessarily need to be initiated through explicit instructions. Similar effects on vowel perception have been identified when listeners are provided with answer-sheets labeled as “Australian” or “New Zealander” (Australian and New Zealand English differ in their vowel system, Hay et al., 2006), when a stuffed animal strongly associated with either Australia or New Zealand was displayed in the experiment room (Hay & Drager, 2010), and when listeners were provided with images of talkers of different ages/social classes that were associated with particular vowel variants (Hay et al., 2006). Beyond vowel perception, similar effects have been identified for talker intelligibility (e.g., McGowan, 2015).
Results like these show that explicit instruction, and more indirect implicit contextual effects, can generally affect speech perception. They leave open, however, specifically whether causal inference during perception can be affected by incidental causes that are not presented visually and concurrently with the speech signal. Previous work thus does not rule out that perceptual recalibration is insensitive to the incidental causes we employed in our experiments. We note, however, that such insensitivity would leave open why all but one of the non-significant context effects numerically trend in the direction expected under the causal inference account. In the remainder of the discussion, we entertain alternative explanations of our results.
Directions for future work: Increasing the probability that atypical pronunciations are inferred to reflect incidental speech errors
Listeners can be highly attuned to the plausibility of different causes for observations they make in the speech input. For example, in the aforementioned study by Arnold et al. (2007), though the authors found an effect of explaining away on reference comprehension when listeners were informed a talker had object agnosia, they found no such effect when listeners were provided with evidence that the talker was distracted by construction noise or beeps. It is possible that listeners found the construction noise or beeps implausible causes for the talker’s disfluency.6 A couple of other studies have found similar sensitivity to subtle changes in the presentation of incidental causes (compare Grodner & Sedivy, 2011; Dix et al., 2018).
The present experiments were designed to make our tongue twister contexts plausible causes for speech errors. We used tongue twister contexts that were modeled after attested tongue twisters. We used critical sounds that are known to frequently be the target of speech errors. We created shifted sounds that were meant to resemble graded, noncategorical speech errors has been observed in naturally occurring tongue twisters. We then selected those tongue twisters that were rated to be most plausible by another set of participants (Experiments 4 and 5).
However, it is possible that despite our precautions, participants did not perceive our manipulations as likely to explain the atypical pronunciations. We close by discussing three properties of our experiments that might have contributed to this, all three of which are related to the ‘plausibility’ of our stimuli under the hypothesis that the atypical pronunciations resulted from incidental speech errors.
First, it is possible that our tongue twister context were perceived as not sufficiently likely to induce any type of speech error. Naturally occurring tongue twister errors typically involve repeated reiteration of a phrase (e.g., passion mansion passive passion passion mansion passive passion ..., Wilshire 1999). For reasons we discuss next, we did not incorporate this property of natural tongue twisters into the design of our study. The present experiments are the first to investigate perceptual recalibration in the context of tongue twisters. We thus kept the design of the experiments as comparable as possible to previous work on perceptual recalibration. Any deviation from typical perceptual recalibration paradigms would have to be carefully piloted (as we did in Experiments 1 and 2). In particular, repetition of tongue twister contexts would require design decisions as to whether the critical sound (e.g., /∫/) is always shifted or only sometimes.
Neither design decision is without potential problems. If the critical sound is always shifted, this results in a large number of shifted sounds, which makes it more likely that the atypical pronunciations is characteristic of the talker. This potential confound would counter the intended effect of the manipulation. If, on the other hand, only some of the instances of the critical sound are shifted, this would provide listeners with evidence that the talker does not always produce the shifted pronunciation. As exposure to some shifted and some normal pronunciation is likely to result in less perceptual recalibration, it would be important to also compare this hypothetical tongue twister condition to another condition with the same number of shifted and unshifted sounds outside of tongue twister contexts.7 We take this to be an interesting direction for future work, but note that such a design would likely require even larger numbers of participants in order to be able to detect significant differences among already reduced effects.
A second possibility is that the manipulations in our experiments, for whatever reasons, were not viewed as plausible causes for the type of atypical, shifted pronunciation we employed. Specifically, the type of atypical pronunciation that participants heard in our experiments might not plausibly stem from speech errors due to, e.g., faster speech rates, intoxication, or tongue twisters. Comparison to the acoustic properties of naturally occurring graded speech errors (as collected in, e.g., Alderete & Davies, 2018) would be required to address this possibility. In the supplementary materials we report Experiment 5b, in which participants rated whether the stimuli from Experiments 1-5 involved production difficulty. Experiment 5b finds that tongue twisters were perceived as (somewhat) more likely to involve production difficulty only for phrases with shifted /∫/, but not for phrases with shifted /s/. It is thus possible that we failed to find blocking of perceptual recalibration of /s/—the only shifted sound for which we found clear perceptual recalibration to begin with in the present experiments—because tongue twisters were not perceived as causing increased production difficulty for /s/.
A third possibility is that the pattern of atypical pronunciations we exposed participants to is perceived as unlikely to stem solely from incidental speech errors. In the present experiments, atypical pronunciations always occurred with the same sound (either always /s/ or always with /∫/). This pattern might be objectively unlikely to occur if the atypical pronunciations are uncharacteristic of the talker, and just reflect incidental speech errors. For example, if the tongue twister contexts—which alternated between words with /s/- and words with /∫/-onsets—are indeed the cause for the atypical pronunciations, why would speech errors always occur on just one of the two types of onsets (as is the case in our experiments)? Additionally, all of the atypical pronunciations in our experiments were about half-way shifted between the two phonemes /s/ and /∫/. While phonetic blends do occur as the result of speech errors (e.g. Frisch & Wright, 2002; Goldstein et al., 2007; McMillan & Corley, 2010; Pouplier, 2007), it is unclear how likely it would be for 4 (Experiments 4 and 5) or even 8 (Experiments 1 and 3) of such gradient speech errors to occur, in the absence of more categorical speech errors.
For example, in a large-scale study of natural speech, Alderete & Davies (2018) find that about 19% of speech errors are graded. This begins to estimate how likely it would be to observe four such errors in a row, though we note this number has to be understood as a lower bound, as gradient speech errors are particularly difficult to distinguish from the distribution of phonetic realizations that is expected even in the absence of any error. Simplifying somewhat, inference-based theories of perceptual recalibration (like the ideal adapter framework, Kleinschmidt & Jaeger, 2015) predict that the degree of change in the category boundary after an observation is a function of the observation’s improbability. An observation can be perceived as probable either because it is probable under the distribution of phonetic realization resulting from an error or because it is probable under the distribution expected in the absence of an error. Future work on databases like those developed by Alderete & Davies (2018) should allow estimates of both of these components.
Summary
The present results rule out naive causal inference accounts for blocking in perceptual recalibration. Either 1) perceptual recalibration is unaffected by causal inferences and the result from earlier studies with visually presented incidental cues (pen in the mouth) are due to other mechanisms; 2) perceptual recalibration can be affected by causal inferences, but only for visually presented causes; or 3) perceptual recalibration is affected by causal inference regardless of the modality of the evidence, but the speech perception system is acutely attuned to what constitutes a plausible incidental cause for an observed deviation from expected pronunciations (and the present experiments failed to present sufficient plausible incidental causes). Variants of the paradigm we have developed here can be used in future work to distinguish between these three explanations.
Supplementary Material
Public significance statement:
This study investigates the mechanisms operating during human speech perception. The results suggests limits in the types of information that can be integrated during real-time processing of spoken language.
Acknowledgements
The authors are grateful for particularly helpful feedback from John Alderete, Athanassios Protopapas, Arty Samuel, Rachel Theodore, Xin Xie, and an anonymous reviewer. Earlier presentations of this work benefitted from feedback from Ehsan Hogue, Crystal Lee, Michael K. Tanenhaus, Davy Temperley, Xin Xie, as well as members of the Human Language Processing lab at the University of Rochester. The research presented here was funded by NIH R01 grant HD075797 to T. Florian Jaeger. The views expressed here do not necessarily reflect those of the funding agency.
Appendix
Power analyses
This section is best understood after reading Experiment 1. We outline our approach to the power analysis for Experiment 1. Since the effect sizes for the Label and Context effects we observe across experiments are rather constant, and since the number of subjects per condition (40 successful subjects) and the number and type of of test items are held entirely constant across all experiments, the power estimates provided in the main text are representative for all experiments. The script for the power analysis is shared at https://osf.io/ungba/.
We conducted parametric generative power analysis (for examples of this approach, see Jaeger, Graff, Croft & Pontillo, 2011; Montero-Melis, Eisenbeiss, Narasimhan, Ibarretxe-Antunano, Kita, Kopecka, Lüpke, Nikitina, Tragel, Jaeger & others, 2017). We used the same type of mixed logistics regression model employed below to analyze the /s/ vs. /∫/ responses during the test block to generate 10,000 simulated data sets with hypothesized effects for Label, Context, and their interaction. Each of the 10,000 generated data sets was then analyzed in the same way as reported below. The goal of this was to determine whether we can detect 1) significant effects of perceptual recalibration (main effect of Label condition) and 2) significant blocking of perceptual recalibration (interaction of Label and Context conditions). Power for each of these effects was calculated as the percentage of times out of the 10,000 simulated data sets the underlying effect (present in the data generation process) was successfully detected.
As a conservative estimate of the effect of Label, we halved the Label effect observed in the first test block of Liu and Jaeger (2018; β = .56 log-odds). As a conservative effect of the interaction between Label and Context condition, we used half the size of the Label effect β = .28)—i.e., our power analyses assess whether we would be able to detect a halving of the perceptual recalibration effect in the Tongue Twister condition, compared to the Non-Tongue Twister condition. As an additional conservative step, our power analyses pretend that we have only the data from the first block (i.e., 7 instead of 35 test trials). Finally, we used a conservative (large) estimate for by-subject variance of the intercept, the only random effect in our analyses. Specifically, we set this variance to twice that observed in Experiment 1 (σ2 = .9).
These steps were taken to avoid over-optimism due to possibly inflated effect size estimates reported in previous work. We initially assumed both the intercept and the main effect of Context to have an effect of 0 log-odds. Here, we instead report power for a simulation based on estimates for the intercept β = −.25 log-odds) and Context β = −.07) from Experiment 1, as this estimates the constraints of the present experiments more closely.
Figure 11 shows the distribution of z-values for the Label effect (perceptual recalibration) and its interaction with Context (the blocking of recalibration) across the 10,000 simulated data sets. As reported in the main text, power was very high for both effects (> 95% for the Label effect and > 81% for the interaction with Context).
Figure 11.

Distribution of z-values for the effect of Label and its interaction with Context across the 10,000 simulated data sets. Points outside of the shaded area indicate significant effect. Effects in the predicted direction have positive z-values.
Footnotes
Throughout this paper, slashes indicate phonological transcriptions based on the international phonetic alphabet. The symbol /∫/ refers to the sound spelled “sh” in English.
We note an important—at first blush potentially counter-intuitive—methodological consequence that also applies to the study of other adaptation and learning phenomena: longer test blocks, intended to collect more test data in order to increase statistical power, can actually result in less power to detect learning effects if the test block is structured in a way that leads to undoing of the learning effect, and analyses do not take into account that learning might continue throughout the test block (for discussion, see Jaeger 2010, p. 53; Jaeger, Burchill & Bushong 2019).
The analyses in Liu and Jaeger (2018) employed (.5 vs. −.5) sum-coding, whereas the present analyses use (1 vs. −1) sum-coding. Whenever we compare effect sizes below, we adjust for this difference (which does not affect significance testing).
We note that our approach to estimate effects in the first trial bin seems to over-estimate perceptual recalibration in the Tongue-Twister condition, compared to the Non-Tongue Twister condition. We return to this in the discussion.
Some studies have investigated whether the type of task listeners are instructed to do during exposure affects perceptual recalibration (for an excellent review and references, see Drouin & Theodore, 2018). These studies do not manipulate incidental causes, but rather aim to manipulate the degree of attention to specific aspects of language processing.
Independent of this possibility, the finding is compatible with a causal inference account, provided talkers still tend to be more likely to produce disfluencies before unfamiliar, complex references when they are distracted, even if distraction increases the overall frequency of disfluencies (see also Arnold et al., 2007, p. 928).
It would further be important to mix shifted and unshifted sounds, since perceptual recalibration is known not to occur if all initial instances of a sound category produced by an unfamiliar talker are unshifted (Kraljic et al., 2008). Though perceptual recalibration experiments do not typically expose participants to mixtures of shifted and unshifted sounds, other paradigms have employed mixtures of shifts and found boundary shifts closely resembling perceptual recalibration (e.g., Clayards et al., 2008; Munson, 2011; Kleinschmidt et al., 2015).
Contributor Information
Linda Liu, Amazon Alexa.
T. Florian Jaeger, University of Rochester Department of Brain and Cognitive Sciences Department of Computer Science.
References
- Alderete J & Davies M (2018). Investigating perceptual biases, data reliability, and data discovery in a methodology for collecting speech errors from audio recordings. Language and speech, 0023830918765012. [DOI] [PubMed] [Google Scholar]
- Arnold JE, Kam CLH, & Tanenhaus MK (2007). If you say thee uh you are describing something hard: The on-line attribution of disfluency during reference comprehension. Journal of Experimental Psychology: Learning, Memory, and Cognition, 33(5), 914. [DOI] [PubMed] [Google Scholar]
- Arnold JE, Tanenhaus MK, Altmann RJ, & Fagnano M (2004). The old and thee, uh, new: Disfluency and reference resolution. Psychological Science, 15(9), 578–582. [DOI] [PubMed] [Google Scholar]
- Baese-Berk MM, Bradlow AR, & Wright BA (2013). Accent-independent adaptation to foreign accented speech. The Journal of the Acoustical Society of America, 133(3), EL174–EL180. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Bertelson P, Vroomen J, & De Gelder B (2003). Visual recalibration of auditory speech identification: a mcgurk aftereffect. Psychological Science, 14(6), 592–597. [DOI] [PubMed] [Google Scholar]
- Bicknell K, Bushong W, Tanenhaus MK, & Jaeger T (2019). Listeners can maintain and rationally update uncertainty about prior words. Manuscript submitted for publication. [Google Scholar]
- Bowers JS, Kazanina N, & Andermane N (2016). Spoken word identification involves accessing position invariant phoneme representations. Journal of Memory and Language, 87, 71–83. [Google Scholar]
- Bradlow AR & Bent T (2008). Perceptual adaptation to non-native speech. Cognition, 106(2), 707–729. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Breslow NE & Clayton DG (1993). Approximate inference in generalized linear mixed models. Journal of the American statistical Association, 88(421), 9–25. [Google Scholar]
- Burchill Z, Liu L, & Jaeger TF (2018). Maintaining perceptual information during accent adaptation. PLOS ONE. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Bushong W & Jaeger T (2017). Maintenance of perceptual information in speech perception. In Proceedings of the 39th Annual Conference of the Cognitive Science Society (CogSci17), (pp. 1129–1134). Cognitive Science Society. [Google Scholar]
- Chin SB & Pisoni DB (1997). Alcohol and speech. Academic Press. [Google Scholar]
- Choe WK & Redford MA (2012). The distribution of speech errors in multi-word prosodic units. Laboratory phonology, 3(1), 5–26. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Clarke CM & Garrett MF (2004). Rapid adaptation to foreign-accented english. The Journal of the Acoustical Society of America, 116(6), 3647–3658. [DOI] [PubMed] [Google Scholar]
- Clarke-Davidson CM, Luce PA, & Sawusch JR (2008). Does perceptual learning in speech reflect changes in phonetic category representation or decision bias? Perception & psychophysics, 70 (4), 604–618. [DOI] [PubMed] [Google Scholar]
- Clayards M, Tanenhaus MK, Aslin RN, & Jacobs RA (2008). Perception of speech reflects optimal use of probabilistic speech cues. Cognition, 108(3), 804–809. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Cutler A & Henton CG (2004). There’s many a slip’twixt the cup and the lip In Quene V. v., Heuven H (Ed.), On Speech and Language: Studies for Sieb G. Nooteboom (pp. 37–45). Utrecht: Netherlands Graduate School of Linguistics (LOT). [Google Scholar]
- Dix S, Gardner B, Lawrence R, Morgan C, Sullivan A, & Kurumada C (2018). Integration of top-down and bottom-up information in online interpretations of scalar adjectives. Manuscript submitted for publication. [Google Scholar]
- Drouin JR & Theodore RM (2018). Lexically guided perceptual learning is robust to task-based changes in listening strategy. The Journal of the Acoustical Society of America, 144 (2), 1089–1099. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Drouin JR, Theodore RM, & Myers EB (2016). Lexically guided perceptual tuning of internal phonetic category structure. The Journal of the Acoustical Society of America, 140(4), EL307–EL313. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Eimas PD & Corbit JD (1973). Selective adaptation of linguistic feature detectors. Cognitive Psychology, 4 (1), 99–109. [Google Scholar]
- Eisner F & McQueen JM (2005). The specificity of perceptual learning in speech processing. Perception & psychophysics, 67(2), 224–238. [DOI] [PubMed] [Google Scholar]
- Eisner F & McQueen JM (2006). Perceptual learning in speech: Stability over time. The Journal of the Acoustical Society of America, 119(4), 1950–1953. [DOI] [PubMed] [Google Scholar]
- Ferber R (1991). Slip of the tongue or slip of the ear? on the perception and transcription of naturalistic slips of the tongue. Journal of Psycholinguistic Research, 20 (2), 105–122. [PubMed] [Google Scholar]
- Frisch SA & Wright R (2002). The phonetics of phonological speech errors: An acoustic analysis of slips of the tongue. Journal of Phonetics, 30 (2), 139–162. [Google Scholar]
- Fromkin VA (1971). The non-anomalous nature of anomalous utterances. Language, 27–52. [Google Scholar]
- Garnham A, Shillcock RC, Brown GD, Mill AI, & Cutler A (1981). Slips of the tongue in the london-lund corpus of spontaneous conversation. Linguistics, 19(7–8), 805–818. [Google Scholar]
- Goldrick M & Blumstein SE (2006). Cascading activation from phonological planning to articulatory processes: Evidence from tongue twisters. Language and Cognitive Processes, 21(6), 649–683. [Google Scholar]
- Goldstein L, Pouplier M, Chen L, Saltzman E, & Byrd D (2007). Dynamic action units slip in speech production errors. Cognition, 103(3), 386–412. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Grodner D & Sedivy JC (2011). The effect of speaker-specific information on pragmatic inferences. The processing and acquisition of reference, 239. [Google Scholar]
- Hay J & Drager K (2010). Stuffed toys and speech perception. An Interdisciplinary Journal of the Language Sciences. [Google Scholar]
- Hay J, Nolan A, & Drager K (2006). From fush to feesh: Exemplar priming in speech perception. The linguistic review, 23(3), 351–379. [Google Scholar]
- Hay J, Warren P, & Drager K (2006). Factors influencing speech perception in the context of a merger-in-progress. Journal of Phonetics, 34 (4), 458–484. [Google Scholar]
- Heigl B (2018). [s] under the influence of alcohol. http://www.gmu.edu/org/lingclub/WP/texts/8_Heigl2.pdf. Accessed: 2018–05-16.
- Jaeger TF (2008). Categorical data analysis: Away from anovas (transformation or not) and towards logit mixed models. Journal of memory and language, 59 (4), 434–446. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Jaeger TF (2010). Redundancy and reduction: speakers manage syntactic information density. Cognitive Psychology, 61 (1), 23–62. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Jaeger TF, Burchill Z, & Bushong W (2019). Strong evidence for expectation adaptation during language understanding, not a replication failure. a reply to harrington stack, james, and watson (2018). [Google Scholar]
- Jaeger TF, Graff P, Croft W, & Pontillo D (2011). Mixed effect models for genetic and areal dependencies in linguistic typology. Linguistic Typology, 15(2), 281–319. [Google Scholar]
- Kleinschmidt D & Jaeger TF (2011). A bayesian belief updating model of phonetic recalibration and selective adaptation. In Proceedings of the 2nd Workshop on Cognitive Modeling and Computational Linguistics, (pp. 10–19). Association for Computational Linguistics. [Google Scholar]
- Kleinschmidt DF & Jaeger TF (2012). A continuum of phonetic adaptation: Evaluating an incremental belief-updating model of recalibration and selective adaptation. In Proceedings of the 34th Annual Meeting of the Cognitive Science Society (CogSci12). [Google Scholar]
- Kleinschmidt DF & Jaeger TF (2015). Robust speech perception: recognize the familiar, generalize to the similar, and adapt to the novel. Psychological review, 122 (2), 148. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Kleinschmidt DF & Jaeger TF (2016). Re-examining selective adaptation: Fatiguing feature detectors, or distributional learning? Psychonomic bulletin & review, 23(3), 678–691. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Kleinschmidt DF, Raizada RD, & Jaeger T (2015). Supervised and unsupervised learning in phonetic adaptation. In Noelle D, Dale R, Warlaumont A, Yoshimi J, Matlock T, Jennings C, & PP M (Eds.), Proceedings of the 37th Annual Meeting of the Cognitive Science Society (CogSci15), (pp. 1129–1134). Cognitive Science Society. [Google Scholar]
- Kraljic T & Samuel AG (2005). Perceptual learning for speech: Is there a return to normal? Cognitive psychology, 51 (2), 141–178. [DOI] [PubMed] [Google Scholar]
- Kraljic T & Samuel AG (2006). Generalization in perceptual learning for speech. Psychonomic bulletin & review], 13(2), 262–268. [DOI] [PubMed] [Google Scholar]
- Kraljic T & Samuel AG (2011). Perceptual learning evidence for contextually-specific representations. Cognition, 121 (3), 459–465. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Kraljic T, Samuel AG, & Brennan SE (2008). First impressions and last resorts: How listeners adjust to speaker variability. Psychological science, 19(4), 332–338. [DOI] [PubMed] [Google Scholar]
- Kurumada C, Brown M, Bibyk S, & Tanenhaus MK (2018). Probabilistic inferences and adaptation in pragmatic interpretation of contrastive prosody. University of Rochester. [Google Scholar]
- Lancia L & Winter B (2013). The interaction between competition, learning, and habituation dynamics in speech perception. Laboratory Phonology, 4(1), 221–257. [Google Scholar]
- Levelt WJ (1993). Speaking: From intention to articulation, volume 1 MIT press. [Google Scholar]
- Liu L & Jaeger TF (2018). Inferring causes during speech perception. Cognition, 174, 55–70. [DOI] [PMC free article] [PubMed] [Google Scholar]
- MacKay DG (1982). The problems of flexibility, fluency, and speed-accuracy trade-off in skilled behavior. Psychological Review, 89(5), 483. [Google Scholar]
- McGowan KB (2015). Social expectation improves speech perception in noise. Language and Speech, 1–20. [DOI] [PubMed] [Google Scholar]
- McGurk H & MacDonald J (1976). Hearing lips and seeing voices. Nature, 264(5588), 746. [DOI] [PubMed] [Google Scholar]
- McMillan CT & Corley M (2010). Cascading influences on the production of speech: Evidence from articulation. Cognition, 117(3), 243–260. [DOI] [PMC free article] [PubMed] [Google Scholar]
- McMurray B, Rhone A, & Galle M (2012). Fricativemakerpro. [Google Scholar]
- Montero-Melis G, Eisenbeiss S, Narasimhan B, Ibarretxe-Antuñano I, Kita S, Kopecka A, Lüpke F, Nikitina T, Tragel I, Jaeger TF, et al. (2017). Satellite-vs. verb-framing underpredicts nonverbal motion categorization: Insights from a large language sample and simulations. Cognitive Semantics, 3(1), 36–61. [Google Scholar]
- Motley MT & Baars BJ (1976). Laboratory induction of verbal slips: A new method for psycholinguistic research. Communication Quarterly, 24 (2), 28–34. [Google Scholar]
- Mowrey RA & MacKay IR (1990). Phonological primitives: Electromyographic speech error evidence. The Journal of the Acoustical Society of America, 88(3), 1299–1312. [DOI] [PubMed] [Google Scholar]
- Munson CM (2011). Perceptual learning in speech reveals pathways of processing. PhD thesis, University of Iowa. [Google Scholar]
- Niedzielski N (1999). The effect of social information on the perception of sociolinguistic variables. Journal of language and social psychology, 18(1), 62–85. [Google Scholar]
- Norris D, McQueen JM, & Cutler A (2003). Perceptual learning in speech. Cognitive psychology, 47(2), 204–238. [DOI] [PubMed] [Google Scholar]
- Pogue A, Kurumada C, & Tanenhaus MK (2016). Talker-specific generalization of pragmatic inferences based on under-and over-informative prenominal adjective use. Frontiers in Psychology, 6, 2035. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Pouplier M (2007). Tongue kinematics during utterances elicited with the slip technique. Language and Speech, 50 (3), 311–341. [DOI] [PubMed] [Google Scholar]
- Reinisch E & Holt LL (2014). Lexically guided phonetic retuning of foreign-accented speech and its generalization. Journal of Experimental Psychology: Human Perception and Performance, 40(2), 539–555. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Rohde H & Kurumada C (2018). Alternatives and inferences in the communication of meaning. Current Topics in Language, 68, 215. [Google Scholar]
- Rosenblum LD (2008). Speech perception as a multimodal phenomenon. Current Directions in Psychological Science, 17(6), 405–409. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Samuel AG (1986). Red herring detectors and speech perception: In defense of selective adaptation. Cognitive psychology, 18 (4), 452–499. [DOI] [PubMed] [Google Scholar]
- Samuel AG (1989). Insights from a failure of selective adaptation: Syllable-initial and syllable-final consonants are different. Perception & Psychophysics, 45(6), 485–493. [DOI] [PubMed] [Google Scholar]
- Samuel AG (1997). Lexical activation produces potent phonemic percepts. Cognitive Psychology, 32 (2), 97–127. [DOI] [PubMed] [Google Scholar]
- Samuel AG (2016). Lexical representations are malleable for about one second: Evidence for the non-automaticity of perceptual recalibration. Cognitive psychology, 88, 88–114. [DOI] [PubMed] [Google Scholar]
- Sevald CA & Dell GS (1994). The sequential cuing effect in speech production. Cognition, 53(2), 91–127. [DOI] [PubMed] [Google Scholar]
- Shattuck-Hufnagel S (1983). Sublexical units and suprasegmental structure in speech production planning In The production of speech (pp. 109–136). Springer. [Google Scholar]
- Shattuck-Hufnagel S & Klatt DH (1979). The limited use of distinctive features and markedness in speech production: Evidence from speech error data. Journal of Verbal Learning and Verbal Behavior, 18(1), 41–55. [Google Scholar]
- Sidaras SK, Alexander JE, & Nygaard LC (2009). Perceptual learning of systematic variation in spanish-accented speech. The Journal of the Acoustical Society of America, 125(5), 3306–3316. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Tuomainen J, Andersen TS, Tiippana K, & Sams M (2005). Audio–visual speech perception is special. Cognition, 96(1), B13–B22. [DOI] [PubMed] [Google Scholar]
- Tzeng CY, Alexander JE, Sidaras SK, & Nygaard LC (2016). The role of training structure in perceptual learning of accented speech. Journal of Experimental Psychology: Human Perception and Performance, 42(11), 1793. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Vroomen J & Baart M (2009). Recalibration of phonetic categories by lipread speech: Measuring aftereffects after a 24-hour delay. Language and speech, 52(2–3), 341–350. [DOI] [PubMed] [Google Scholar]
- Vroomen J, van Linden S, De Gelder B, & Bertelson P (2007). Visual recalibration and selective adaptation in auditory-visual speech perception: Contrasting build-up courses. Neuropsychologia, 45(3), 572–577. [DOI] [PubMed] [Google Scholar]
- Wagenmakers EJ (2007). A practical solution to the pervasive problems of p values. Psychonomic Bulletin & Review, 14(5), 779–804. [DOI] [PubMed] [Google Scholar]
- Weatherholtz K & Jaeger TF (2016). Speech perception and generalization across talkers and accents. Oxf. Res. Encycl. Linguist. [Google Scholar]
- Wijnen F (1992). Incidental word and sound errors in young speakers. Journal of Memory and Language, 31 (6), 734–755. [Google Scholar]
- Wilshire CE (1999). The “tongue twister” paradigm as a technique for studying phonological encoding. Language and Speech, 42(1), 57–82. [Google Scholar]
- Xie X, Liu L, & Jaeger TF (2019). Cross-talker generalization in foreign-accented speech perception. [Google Scholar]
- Xie X, Theodore RM, & Myers EB (2017). More than a boundary shift: Perceptual adaptation to foreign-accented speech reshapes the internal structure of phonetic categories. Journal of Experimental Psychology: Human Perception and Performance, 43(1), 206. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Xie X, Weatherholtz K, Bainton L, Rowe E, Burchill Z, Liu L, & Jaeger TF (2018). Rapid adaptation to foreign-accented speech and its transfer to an unfamiliar talker. The Journal of the Acoustical Society of America, 143(4), 2013–2031. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Zhang X & Samuel AG (2014). Perceptual learning of speech under optimal and adverse conditions. Journal of Experimental Psychology: Human Perception and Performance, 40(1), 200. [DOI] [PMC free article] [PubMed] [Google Scholar]
Associated Data
This section collects any data citations, data availability statements, or supplementary materials included in this article.