

Abstract
Background
Crossover designs are commonly utilised in randomised controlled trials investigating treatments for long-term chronic illnesses. One problem with this design is its inherent repeated measures necessitate the availability of an estimate of the within-person standard deviation (SD) to perform a sample size calculation, which may be rarely available at the design stage of a trial. Interim sample size re-estimation designs can be used to help alleviate this issue by adapting the sample size mid-way through the trial, using accrued information in a statistically robust way.
Methods
The AIM HY-INFORM study is part of the Informative Markers in Hypertension (AIM HY) Programme and comprises two crossover trials, each with a planned recruitment of 600 participants. The objective of the study is to test whether blood pressure response to first line antihypertensive treatment depends on ethnicity. An interim analysis is planned to reassess the assumptions of the planned sample size for the study. The aims of this paper are: (1) to provide a formula for sample size re-estimation in both crossover trials; and (2) to present a simulation study of the planned interim analysis to investigate alternative within-person SDs to that assumed.
Results
The AIM HY-INFORM protocol sample size calculation fixes the within-person SD to be 8 mmHg, giving > 90% power for a primary treatment effect of 4 mmHg. Using the method developed here and simulating the interim sample size reassessment, if we were to see a larger within-person SD of 9 mmHg at interim, 640 participants for 90% power 90% of the time in the three-period three-treatment design would be required. Similarly, in the four-period four-treatment crossover design, 602 participants would be required.
Conclusions
The formulas presented here provide a method for re-estimating the sample size in crossover trials. In the context of the AIM HY-INFORM study, simulating the interim analysis allows us to explore the results of a possible increase in the within-person SD from that assumed. Simulations show that without increasing the planned sample size of 600 participants, we can reasonably still expect to achieve 80% power with a small increase in the within-person SD from that assumed.
Trial registration
ClinicalTrials.gov, NCT02847338. Registered on 28 July 2016.
Keywords: Crossover trial, Sample size calculation, Simulation study, AIM HY-INFORM study, Hypertension
Background
Randomised crossover trials are a well-established design for long-term chronic illnesses such as hypertension [1]. The UK hypertension NICE guidance (CG127) stratifies hypertension treatment by age and self-defined ethnicity (SDE), with guidelines adopting a ‘black versus white’ approach [2]. The problems with this stratification include a lack of data from UK populations supporting the current SDE stratification and no reference to South Asians – the largest ethnic minority group in the UK [2]. Consequently, the primary objective of the AIM HY-INFORM study is to determine if the response to existing first-line antihypertensive drugs differs by ethnic group, white British, black African/African Caribbean or South Asian, for participants who are newly diagnosed or established hypertensives.
The AIM HY-INFORM study comprises two open-label, randomised crossover trials: one three-period three-treatment (monotherapy) trial for participants newly diagnosed with hypertension and one four-period four-treatment (dual therapy) trial for participants with existing hypertension. The primary outcome is systolic blood pressure (SBP) mmHg; linear mixed models are the preferred method of analysis for a crossover design with a continuous outcome variable [1]. Repeated measurements of SBP taken from the same participant are correlated and this correlation needs to be accounted for in sample size calculations. That is, sample size estimation for any repeated measures design requires an estimate of the within-person standard deviation (SD). Taking estimates of the within-person SD from other studies can be unreliable due to differences in the study population and participant attributes, instruments and measurement techniques, or other background conditions, which can result in trials that are either under or over-powered [3, 4]. With the absence of reliable prior estimates of the within-person SD available for the AIM-HY INFORM study, in particular for South Asian ethnicities, the calculation of the required sample size to ensure the desired power to detect a single treatment-by-ethnic interaction is challenging.
To address this issue in many repeated measures contexts, sample size re-estimation designs have been considered [3, 5–7]. However, there is little, directly applicable work on sample size re-estimation at interim for crossover designs. Zucker and Denne describe a strategy to deal with the unknown within-person SD in a two-stage, repeated measures design that examines the accrued data at an interim point, obtaining an estimate of the within-person SD. They then use this estimate to update the covariance parameter in the linear mixed model and modify the sample size required to ensure the trial has sufficient power [3]. Moreover, a collection of papers have addressed sample size re-estimation in bioequivalence trials using a two-period two-treatment crossover design [8–11]. While more recently, methodology for blinded and unblinded sample size re-estimation in multi-treatment crossover trials balanced for period was described [12]. None of these papers, however, directly allows for re-estimation in the context of the AIM HY-INFORM study, for reasons that will be described shortly.
Here, we present the framework for sample size re-estimation in both our 3 × 3 (monotherapy) and 4 × 4 (dual therapy) settings. Precisely, the study design and models used are described, along with the methods developed for re-estimation of the required sample size. The planned interim analysis in the AIM HY-INFORM study states in the protocol that after 50 individuals have completed their treatment sequence, the sample size calculation for both the mono and dual-therapy treatment rotations will be recalculated using a mid-trial estimate of the within-person SD. Therefore, following our initial descriptions, results from a simulation study carried out ahead of trial recruitment, with the aim of simulating the interim analysis to explore the effect of a larger within-person SD from that assumed in the protocol are presented.
Methods
Study design
AIM HY-INFORM is a multicentre, prospective study comprising two randomised, open-label crossover trials (three-period three-treatment monotherapy and four-period four-treatment dual therapy) in a multi-ethnic cohort of hypertensive participants, where each study requires separate randomisation to treatment sequences [2].
Participants on both trials self-identify into one of the following three ethnic groups (SDE):
White (white British, white Irish or any other white background);
Black or black British (black Caribbean, black African or any other black background);
Asian or Asian British (Asian Indian, Asian Pakistani, Asian Bangladeshi or any other South Asian background).
The monotherapy study is a 24-week three-period three-treatment crossover trial of newly diagnosed hypertensives with Ambulatory Blood Pressure Monitoring (ABPM) ≥ 135/85 mmHg. After initial screening and baseline measurement collection, participants are randomised with equal allocation to one of six sequences of treatments from two three-period three-treatment Latin square designs: ABC; ACB; BAC; BCA; CAB; and CBA [13]. Here, treatment A is 1–2 weeks of Amlodipine 5 mg followed by 6 –7 weeks of Amlodipine 10 mg, treatment B is 1–2 weeks of Lisinopril 10 mg followed by 6–7 weeks of Lisinopril 20 mg and treatment C is approximately eight weeks of 25 mg Chlortalidone (Fig. 1).
Fig. 1.
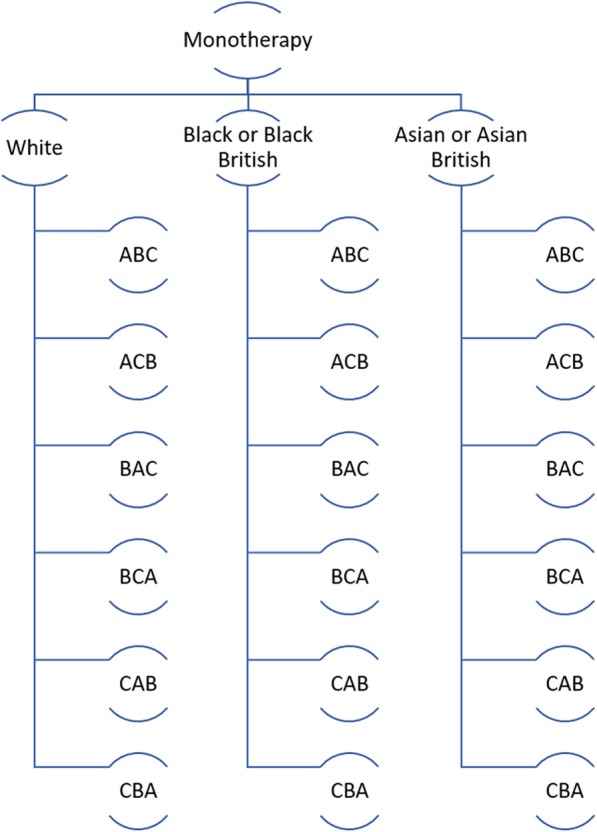
Participants receive each treatment A, B and C; they are randomised to a treatment sequence according to two three-period three-treatment Latin square designs: ABC, ACB, BAC, BCA, CAB and CBA, balanced by ethnic group
The dual-therapy study is a 32-week four-period four-treatment crossover trial of established hypertensives with ABPM > 135/85 and < 200/110. After initial screening and baseline measurement collection, participants are randomised with equal allocation to one of four sequences of treatments from a four-treatment four-period Williams square design: ABDC; BCAD; CDBA; and DACB. There are 24 possible Latin squares for a four-treatment crossover design; the design used here is one of six special cases of the Latin square design which are balanced for first-order carry-over and are known as Williams Squares [13, 14].
For participants on dual therapy, treatment A is eight weeks of Amlodipine 5 mg and Lisinopril 20 mg, treatment B is eight weeks of Amlodipine 5 mg and Chlortalidone 25 mg, treatment C is eight weeks of Lisinopril 20 mg and Chlortalidone 25 mg and treatment D is eight weeks of Amiloride 10 mg and Chlortalidone 25 mg (Fig. 2).
Fig. 2.
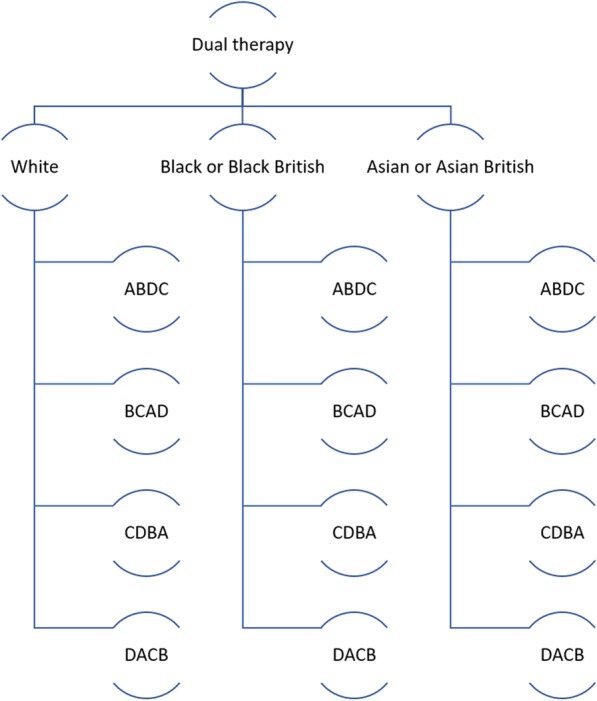
Participants receive each treatment A, B, C and D; they are randomised to a treatment sequence according to a four-period four-treatment Williams square design: ABDC, BCAD, CDBA and DACB, balanced by ethnic group
The two randomised crossover trials (monotherapy and dual therapy) are open-label and require separate randomisation to treatment sequence. To control for balance permuted blocks within strata are implemented with an allocation ratio: 1:1:1:1:1:1 for the monotherapy trial and 1:1:1:1 for the dual-therapy trial.
The monotherapy and dual-therapy trials are distinct and analysed using separate linear mixed models. The primary outcome of both trials is seated automated office SBP mmHg as measured eight weeks (± 4 days) after receiving each treatment. The primary objective of the trials is to test for a significant treatment-by-ethnic group interaction.
With the absence of an available estimate of the within-participant SD for the trial participants, the protocol estimates a sample size of 600 participants assuming a fixed within-person SD of 8 mmHg, based on previous clinical trial data in people representative of the general population with either high normal blood pressure or mild hypertension [2]. More precisely, for a within-person SD of 8 mmHg and a single treatment-by-ethnic interaction of 3 mmHg, with all other interactions being 0 mmHg, the protocol outlines that a sample size of 600 participants produces 81.3% power to detect treatment-by-ethnic interactions using a global test of interaction at a 5% significance level. For the same fixed within-person SD of 8 mmHg and a larger single treatment-by-ethnic interaction of 4 mmHg, a sample size of 600 participants would give 98% power to detect a single treatment-by-ethnic interaction. A 10% over-recruitment allows for loss to follow-up, resulting in 220 planned enrolments from each ethnic group, for each trial [3].
In order to check the assumptions that the within-person SD is 8 mmHg, there is a planned interim analysis after approximately 50 participants have completed their treatment sequence. The aim of the interim analysis is twofold: (1) to obtain an estimate of the within participant SD from trial participants; and (2) to use this estimate to calculate the sample size required for either 80 or 90% power to detect a treatment-by-ethnic interaction using a global test of interaction at a 5% significance level. The aim here is to describe the method for the sample size re-estimation and present results from a simulation study carried out ahead of the interim analysis.
Sample size calculations for the protocol along with simulations, sample size and power calculations for the interim analysis were carried out using Stata Statistical Software: Release 14 (StataCorp LP, College Station, TX, USA).
Models and sample size calculations
Sample size re-estimation in the three-period three-treatment monotherapy crossover
The linear mixed effects model for the three-period three-treatment crossover study has fixed effects for treatment, period, ethnic group and treatment-by-ethnic group interactions. Additionally, subject is included as a random effect. This is our unrestricted model. We compare this unrestricted model with a nested restricted model that does not contain the treatment-by-ethnic group interaction terms.
Restricted model, assuming n participants are recruited in total:
Unrestricted model:
Here
i = 1, …, n/18 indicates a particular individual, j = 1, 2, 3 indicates the time period, k = 1, …, 6 indicates the sequence a particular individual was allocated and l = 1, 2, 3 indicates which of the three ethnicities a particular individual self-defined as. That is, i, k and l together completely prescribe a particular individual in the trial (there are n unique combinations of these three indices);
μ is an intercept term (the mean of the values yi1k1);
τd(j, k) is the direct effect of the treatment administered to a participant on sequence k in period j. That is, d(j, k) ∈ {A, B, C}. For identifiability purposes, we set τA = 0;
πj is a fixed effect for period, with π1 = 0 for identifiability;
el is a fixed effect for ethnic group, with e1 = 0 for identifiability;
θd(j, k)l is a fixed interaction effect for treatment d(j, k) by ethnic group l. For identifiability, we set θA1 = θA2 = θA3 = θB1 = θC1 = 0.
is a random participant effect;
is the residual error.
We perform a global Wald test to see if the unrestricted model gives a significantly better fit than the restricted, in order to test the primary hypothesis of whether there is an interaction between treatment and ethnic group. To perform sample size re-estimation, we require the sampling distribution of a suitable test statistic under the null and alternative hypotheses.
Precisely, setting θ = (θB2, θB3, θC2, θC3)⊤, we test the following null hypothesis of no treatment-by-ethnic interactions
against the following alternative
Denoting by our estimates of the interaction terms computed using conventional maximum likelihood estimation, we can test H0 using the following test statistic
Moreover, we power our trial for an alternative in which there is a single non-zero treatment-by-ethnic interaction (θB2 = δ, i.e. θ = δ = (δ, 0, 0, 0)⊤).
The complexity of performing a hypothesis test in this setting, either in a fixed design or following sample size re-estimation, arises from the fact that the sampling distribution of T, the random unknown value of t, is in general complex to compute. Explicitly, while the numerator degrees of freedom in a suitable F-test would be 4, the denominator degrees of freedom is difficult to assign. Kenward and Roger [15] provided a comprehensive solution to this problem for fixed sample designs by computing the exact denominator degrees of freedom, but unfortunately their approach does not lend itself naturally to sample size re-estimation, as the degrees of freedom specification procedure is data-dependent.
Accordingly, Grayling et al. [12] specified the denominator degrees of freedom as that of a corresponding multi-level single-stage ANOVA design. For our unrestricted model this would designate the denominator degrees of freedom, ν, for sample size n, as
Here, the 3n term arises as the total number of measurements accrued, while 1 degree of freedom is subtracted for each participant, and for each fixed effect in the model. Thus, at the interim we suppose that we would reject H0 at the end of the trial when t > F−1(1 − α, 0, 4, 2n − 10), where F−1(q, 0, m, n) is the 100q th quantile of an F(0, a, b)-distribution (a central F-distribution on a and b degrees of freedom). Combining this with a suitable non-central F-distribution under the chosen alternative at which the trial is to be powered, interim re-estimation can then be performed.
Such an approach, however, was found by Grayling et al. [12] to, in many circumstances, lead to a notable inflation of the type-I error rate, and frequently provide power slightly below the desired level under the specified alternative. Therefore, they discussed the utility of a potential α-adjustment procedure, of using the above methodology for interim re-estimation but performing the final hypothesis test using the method of Kenward and Roger [15], and they explored the advantages of a sample size inflation factor. A problem with these adjustments as individual amendments to the basic re-estimation procedure described above, however, is that predicting their impact on both the type-I error rate and the power can be difficult.
Consequently, here, desiring to accurately control the type-I error rate while maintaining a high level of power, we make a heuristic conservative adjustment to the above degrees of freedom based on Hotelling’s T2 distribution [16].
Precisely, for x1, …, xn~Np(ϕ, Ω), the test statistic , Hotelling’s T2 distribution on p and n − 1 degrees of freedom. We can work with this distribution using standard statistical software via the following relationship
In our case, we therefore suppose H0 will be rejected when
Moreover, to attain power 1 − β we can search for the minimal integer n such that
for
Such a search is easy to perform using interval bisection over the discrete n. The final problem therefore is to specify . In the Appendix, we justify the use of
where is the interim estimated within person SD, computed using REML (for the reasons outlined below).
With this, our methodology for re-estimating the required sample size in the 3 × 3 trial is complete. However, we must still specify how the final analysis will be performed.
Here, we use REML estimation as it takes into account the uncertainty in the fixed parameters in the model into account when estimating the random parameters, in theory leading to better estimates of the variance components with reduced bias when the number of groups is small [17]. Additionally, we use the Kenward–Roger approximation [15] to compute the denominator degrees of freedom in the final F-test. These choices are again made in order to limit the possibility of observing inflation to the type-I error rate. As AIM HY-INFORM is a confirmatory trial of treatment differences between different ethnic groups, inflation of the type-I errors should be avoided.
Sample size re-estimation in the four-period four-treatment dual-therapy crossover
The dual-therapy trial is a four-period four-treatment crossover. It will compare the same restricted and unrestricted models as for the three-period three-treatment monotherapy trial. However, we now have
i = 1, …, n/12, j = 1, …, 4, k = 1, …, 4, and l = 1, 2, 3;
d(j, k) ∈ {A, B, C, D};
For identifiability, we set θA1 = θA2 = θA3 = θB1 = θC1 = θD1 = 0.
Here, setting θ = (θB2, θB3, θC2, θC3, θD2, θD3)⊤, we again test the following hypotheses
For our test is once more based upon
Applying the Hotelling’s T2 based adjustment described above, in this case at interim we suppose H0 will be rejected when
and choose the required sample size by determining the minimal n such that
for
with δ = (δ, 0, 0, 0, 0, 0)⊤, and where in the Appendix we now justify the use of
Finally, as for the 3 × 3 trial, the final analysis is performed using REML estimation and the Kenward–Roger correction.
At the interim, 50 participants have completed either three treatment periods if they are on the monotherapy trial, or four treatment periods if they are on the dual-therapy trial. Inherently, we have more data from the four-treatment crossover and may anticipate better performance in this setting. It is important to note that at this stage we are not concerned with estimating treatment effects, we simply want the estimate, , of the within-person variance required for the sample size calculations outlined above.
Simulation design
To consider the variation in the estimate of the within-person SD, a simulation study was carried out to investigate the effect on the requisite final sample size for different treatment effects and within-person SD scenarios, based on the sample size re-estimation calculations described above. In the protocol, the sample size calculation fixes the SD to be 8 mmHg giving power equal to 98% for a single 4 mmHg interaction effect with 600 participants, and 81.3% power with 600 participants and a single 3 mmHg interaction effect.
Two separate simulation studies have been carried out assuming participants are on either the monotherapy or dual-therapy treatment regimes, in all cases assuming that each participant has received three (monotherapy) or four (dual-therapy) treatments and that there are no missing values. Participants are randomly generated with approximately equal numbers of participants on each of the six treatment sequences—ABC, ACB, BAC, BCA, CAB and CBA—for monotherapy and four treatment sequences—ABDC, BCAD, CDBA and DACB—for dual therapy. We consider scenarios in which 80% and 90% power to detect treatment-by-ethnic interactions are desired, using our outlined global test of interaction at a 5% significance level are assumed.
What is important to realise is that in sample size calculations the within-person SD is typically fixed. In our simulation study, we set the desired power, the strength of a single treatment-by-ethnic interaction and a within-person SD, and solve for sample size across numerous replicates. Accordingly, of principle interest is the distribution of the interim estimated values of the within-participant SD and the distribution of the final required sample sizes.
The factors varied and held constant in these simulations are outlined in Table 1, resulting in 2 × 2 = 4 scenarios to assess for each of the two trials, with 1000 simulations carried out for each scenario-trial combination. We assume that there is no carryover effect and no treatment-by-period interaction. The between-person SD is held constant at 10 mmHg, we do not need to consider varying this as the procedures should be invariant to σb with a sample size of 50.
Table 1.
Fixed and constant parameter values for the interim analysis simulations
| Description | Constant factors | Factors varied |
|---|---|---|
| Interim sample size | n = 50 | |
| Minimum required sample size | n = 600 | |
| Number of simulations | 1000 | |
| Between-person SD | σb = 10 mmHg | |
| Within person SD | σe = 9, 10 mmHg | |
| Overall mean SBP (mmHg) | μ = 140 mmHg | |
| Single treatment-by-ethnic interaction (mmHg) | δ = 3, 4 mmHg | |
| Period effect (mmHg) | πj = 0 mmHg, ∀j | |
| Power to detect a single ethnic by treatment interaction at 5% significance level (%) | 1 − β = 0.1,0.2 |
Our methodology for re-estimating the sample size requires a minimum acceptable sample size. In the protocol, a sample size of 600 is estimated for each monotherapy and dual-therapy trial, based on a within-person SD of 8 mmHg. As there is no plan to reduce the sample size at interim, we therefore set a minimum sample size of 600 for all simulations and scenarios investigated. Matlab and Stata code for sample size calculations can be found in Additional files 1, 2, 3 and 4.
Results
Simulation of the interim analysis and re-estimation of the sample size: monotherapy
In the trial protocol, the sample size calculation fixed the SD to be 8 mmHg, giving > 80% power with 600 participants. With simulations, sampling variation means that we have a range of possible estimates of within-person SD which means that in this case 90% of the time 640 participants would usually be fine to give us 90% power to detect the primary effect for a within person SD of 9 mmHg and a single treatment-by-ethnic interaction of 4 mmHg (Fig. 3). A larger within-person SD of 10 mmHg would mean that in 75% of the time 705 participants would usually be fine to give us 90% power to detect the same planned treatment effect (Fig. 3).
Fig. 3.

Cumulative density function for re-estimated sample size assuming 80% or 90% power to detect treatment-by-ethnic interactions using a global test of interaction at the 5% significance level for participants on the monotherapy treatment regime
Assuming a smaller single treatment-by-ethnic interaction of 3 mmHg, and a 1 mmHg increase in the assumed within-person SD, 75% of the time with a sample size of 797 participants would give us 80% power to detect the primary hypothesis. A 2 mmHg increase in within-person SD from that assumed in the protocol means that 75% of the time with a sample size of 979 participants would give us 80% power detect a treatment effect of 3 mmHg (Fig. 3). As would be expected, smaller values of δ, and larger values of σe, imply larger required sample sizes. Figure 3 shows for the scenario with σe = 9 mmHg and δ = 4 mmHg more than the planned 600 particpiants are required because of the nature of sample size re-estimation and the methodology used here. The conservative approach adopted here to try and control the type-I error rate means we have to push the sample size up a little to keep the type-II error rate down. That is, the use of Kenward–Roger and the Hotelling adjustments pushes the power down compared to the methodology used for the initial 600 estimate, so it is inevitable that the simulations here produce > 600 for the sample size re-estimation designs.
Simulation of the interim analysis and re-estimation of the sample size: dual therapy
For the dual-therapy trial, sample sizes required for the different simulation scenarios are similar to those estimated for the monotherapy trial. For 90% power to detect a treatment effect of 4 mmHg, 90% of the time 602 participants would usually be fine when the within-person SD is 9 mmHg. A larger within-person SD of 10 mmHg would mean that 75% of the time 692 participants would usually be fine to give us 90% power to detect the same treatment effect (Fig. 4). In both scenarios, the dual-therapy trial requires slightly fewer participants.
Fig. 4.

Cumulative density function for re-estimated sample size assuming 80% or 90% power to detect treatment-by-ethnic interactions using a global test of interaction at the 5% significance level for participants of the dual-therapy treatment regime
Assuming a smaller single treatment-by-ethnic interaction of 3 mmHg, a 1 mmHg increase in the assumed within-person SD 75% of the time a sample size of 782 participants would give us 80% power to detect the primary hypothesis. A 2 mmHg increase in within-person SD from that assumed in the protocol means that 75% of trials with a sample size of 966 participants would give us 80% power detect a planned treatment effect of 3 mmHg; again, in both scenarios, fewer participants are required than in the monotherapy trial, as a result of having more measurements overall in the dual-therapy trial.
In summary, for the same simulated treatment-by-ethnic interaction an increase in within-person SD requires a large sample size. For the same simulated within-person SD, a smaller planned treatment effect also requires a larger sample size, which is what would be expected from sample size calculation theory. The fact that the dual-therapy trial when compared with the monotherapy trial requires slightly fewer participants when comparing like-for-like is a result of the increased number of denominator degrees of freedom in the sample size calculation for the four-period four-treatment compared with the three-period three-treatment crossover: 3n – 14 = 136 compared with 2n – 10 = 90 when n = 50. The increased number in the denominator degrees of freedom in the four-period four-treatment compared with the three-period three-treatment crossover is in turn due to the increased number of observations per participant in the four-by-four crossover trial.
Discussion
A novel method for sample size re-estimation has been described for three-period three-treatment and four-period four-treatment crossover trials. Here we have dealt with a more complicated covariance matrix in a 3 × 3 and 4 × 4 randomised crossover setting that incorporates both a global test and allows for interaction terms in the linear mixed model.
The simulation study allowed us to explore the outcome for a possible increase in the within-person SD from that assumed and used for the sample size calculations in the protocol ahead of trial recruitment and the interim analysis. As would be expected, an increase in the within-person SD or a smaller primary treatment effect would require a larger sample size. The fact that the dual-therapy trial requires slightly fewer participants than the monotherapy trial when all variables are like for like is a consequence of the increased degrees of freedom in the denominator of the F-test which is used in the sample size calculation. The simulation of the interim sample size indicates that we can only realistically aim for 80% in these scenarios without increasing the sample size above 600 participants.
Conclusions
The formulas presented here provide a means for re-estimating the sample size in both three-period three-treatment and four-period four-treatment crossover trials. In the context of the AIM HY-INFORM study, simulating the planned interim analysis allows us to explore the outcome for a possible increase in the within-person SD from that assumed in the protocol. Simulations show that without increasing the planned sample size of 600 participants, on each crossover trial, we can reasonably still expect to achieve 80% power with a small increased in the within person SD from that assumed.
Supplementary information
Additional file 3. Three-period three-treatment sample size calculation code (Stata ado file).
Additional file 4. Four-period four-treatment sample size calculation code (Stata ado file).
Acknowledgements
We would like to acknowledge funding from the Medical Research Council, the British Heart Foundation and sponsorship from Cambridge University Hospitals NHS Foundation Trust for the Ancestry and biological Informative Markers for stratification of Hypertension: the (AIM HY) Study, and Chief Investigators Prof. Ian B. Wilkinson and Prof. Phil J. Chowienczyk. JW would like to thank Professor Ian White and Dr. Tim Morris for simulation study methods advice. JW is supported by the Medical Research Council grant reference MR/M016560/1, M.J.G. and A.P.M are supported by Medical Research Council grant reference MC_UU_00002/3. We are grateful to Caroline Fairhurst and Helen Mossop for taking the time to review our work and for their constructive comments that have improved this manuscript.
Abbreviations
- ABPM
Ambulatory blood pressure monitoring (mmHg)
- AIM HY-INFORM
ComparIsoN oF Optimal HypeRtension RegiMens (Part of the Informative Markers in Hypertension (AIM HY) Programme – AIM HY-INFORM)
- SBP
Systolic blood pressure (mmHg)
Appendix
Here, we justify our specified values for , used in the sample size re-estimation procedures. To begin, consider the 3 × 3 trial and cast our unrestricted linear mixed model in the form
where β = (μ, π2, π3, τB, τC, e2, e3, θB2, θB3, θC2, θC3)⊤. Then, the maximum likelihood estimator of the fixed effects β at the end of trial is
with Σ = ZCov(u)ZT + Cov(ϵ). We then have
See, for example, Fitzmaurice et al. [18] for further details.
In our case, and This implies that Σ is block diagonal, with n blocks of the 3 × 3 matrix Σ3, say, where
It can then be shown by verifying that
Now
where Xkl is the design matrix for a single individual on treatment k, of ethnicity l.
Thus can be found by evaluating the above expression, which can be readily achieved computationally using a symbolic algebra package. Performing these calculations in Matlab, and extracting the sub-component corresponding to , we identified that
It is for this reason that we utilise
in our re-estimation procedure.
Equivalent calculations for the 4 × 4 trial also demonstrate that
Authors’ contributions
MJG developed the method for sample size re-assessment. JW produced all simulation results and analysis of the data. JW drafted the manuscript. MJG and APM critically revised the manuscript for important intellectual content. All authors approved the final version.
Funding
The AIM HY program is co-funded by the Medical Research Council and British Heart Foundation (Medical Research Council Reference: MR/M016560/1; EUDRACT number 2016–000165-23).
Availability of data and materials
The datasets generated and analysed during the current study are available from the corresponding author on reasonable request.
Ethics approval and consent to participate
Not applicable.
Consent for publication
Consent for publication was not required as no individual person data are reported.
Competing interests
The authors declare that they have no competing interests.
Footnotes
Publisher’s Note
Springer Nature remains neutral with regard to jurisdictional claims in published maps and institutional affiliations.
Contributor Information
Julie Wych, Email: julie.wych@mrc-bsu.cam.ac.uk.
Michael J. Grayling, Email: michael.grayling@ncl.ac.uk
Adrian P. Mander, Email: mandera@cardiff.ac.uk
Supplementary information
Supplementary information accompanies this paper at 10.1186/s13063-019-3724-6.
References
- 1.Jones B, Kenward MG. Design and analysis of crossover trials. 3. Boca Raton: Chapman and Hall/ CRC Press; 2014. [Google Scholar]
- 2.Mukhtar O, Cheriyan J, Cockcroft JR, Collier D, Coulson JM, Dasgupta I, et al. A randomized controlled crossover trial evaluating differential responses to antihypertensive drugs (used as mono- or dual therapy) on the basis of ethnicity: The comparIsoN oF Optimal Hypertension RegiMens; part of the Ancestry Informative Markers in HYpertension program—AIM-HY INFORM trial. Am Heart J. 2018;204:102–108. doi: 10.1016/j.ahj.2018.05.006. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 3.Zucker DM, Denne J. Sample-size redetermination for repeated measures studies. Biometrics. 2002;58:548–559. doi: 10.1111/j.0006-341X.2002.00548.x. [DOI] [PubMed] [Google Scholar]
- 4.Lenth RV. Some practical guidelines for effective sample size determination. Am Stat. 2001;55(3):187–193. doi: 10.1198/000313001317098149. [DOI] [Google Scholar]
- 5.Guo Y, Logan HL, Glueck DH, Muller KE. Selecting a sample size for studies with repeated measures. BMC Med Res Methodol. 2013;13:100. doi: 10.1186/1471-2288-13-100. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 6.Lui GF. Sample size calculations for studies with correlated observations. Biometrics. 1997;53(30):937–947. [PubMed] [Google Scholar]
- 7.Shih WJ, Gould AL. Re-evaluation design specifications of longitudinal clinical trials without unblinding when the key response is rate of change. Stat Med. 1995;14:2239–2248. doi: 10.1002/sim.4780142007. [DOI] [PubMed] [Google Scholar]
- 8.Potvin D, DiLiberti CE, Hauck WW, Parr AF, Schuirmann DJ, Smith RA. Sequential design approaches for bioequivalence studies with crossover designs. Pharm Stat. 2008;7:245–262. doi: 10.1002/pst.294. [DOI] [PubMed] [Google Scholar]
- 9.Montague TH, Potvin D, Diliberti CE, Hauck WW, Parr AF, Schuirmann DJ. Additional results for ‘Sequential design approaches for bioequivalence studies with crossover designs’. Pharm Stat. 2012;11:8–13. doi: 10.1002/pst.483. [DOI] [PubMed] [Google Scholar]
- 10.Golkowski D, Friede T, Kieser M. Blinded sample size re-estimation in crossover bioequivalence trials. Pharm Stat. 2014;13:157–162. doi: 10.1002/pst.1617. [DOI] [PubMed] [Google Scholar]
- 11.Xu J, Audet C, DiLiberti CE, Hauck WW, Montague TH, Parr AF, et al. Optimal adaptive sequential designs for crossover bioequivalence studies. Pharm Stat. 2016;15:15–27. doi: 10.1002/pst.1721. [DOI] [PubMed] [Google Scholar]
- 12.Grayling MJ, Mander AP, Wason JMS. Blinded and unblinded sample size reestimation in crossover trials balanced for period. Biom J. 2018;60:917–933. doi: 10.1002/bimj.201700092. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 13.Senn S. Crossover trials in clinical research. 2. Chichester: Wiley; 2002. [Google Scholar]
- 14.Williams EJ. Experimental designs balanced for the estimation of residual effects. Aust J Sci Res. 1949;2:149–168. [Google Scholar]
- 15.Kenward MG, Roger JH. Small sample inference for fixed effects from restricted maximum likelihood. Biometrics. 1997;53:983–997. doi: 10.2307/2533558. [DOI] [PubMed] [Google Scholar]
- 16.Hotelling H. The generalization of Student’s ratio. Ann Math Statist. 1931;2(3):360–378. doi: 10.1214/aoms/1177732979. [DOI] [Google Scholar]
- 17.Maas CJM, Hox JJ. Sufficient sample sizes for multilevel modelling. Methodology. 2005;1(3):86–92. doi: 10.1027/1614-2241.1.3.86. [DOI] [Google Scholar]
- 18.Fitzmaurice Garrett M., Laird Nan M., Ware James H. Applied Longitudinal Analysis. Hoboken, NJ, USA: John Wiley & Sons, Inc.; 2011. [Google Scholar]
Associated Data
This section collects any data citations, data availability statements, or supplementary materials included in this article.
Supplementary Materials
Additional file 3. Three-period three-treatment sample size calculation code (Stata ado file).
Additional file 4. Four-period four-treatment sample size calculation code (Stata ado file).
Data Availability Statement
The datasets generated and analysed during the current study are available from the corresponding author on reasonable request.