

Supplemental Digital Content is available in the text.
Keywords: Record linkage, Data linkage methods, Epidemiologic methods, Bias, Data accuracy, Linkage error, Prescription drug monitoring programs
Background:
The use of Prescription Drug Monitoring Program (PDMP) data has greatly increased in recent years as these data have accumulated as part of the response to the opioid epidemic in the United States. We evaluated the accuracy of record linkage approaches using the Controlled Substance Monitoring Database (Tennessee’s [TN] PDMP, 2012–2016) and mortality data on all drug overdose decedents in Tennessee (2013–2016).
Methods:
We compared total, missed, and false positive (FP) matches (with manual verification of all FPs) across approaches that included a variety of data cleaning and matching methods (probabilistic/fuzzy vs. deterministic) for patient and death linkages, and prescription history. We evaluated the influence of linkage approaches on key prescription measures used in public health analyses. We evaluated characteristics (e.g., age, education, sex) of missed matches and incorrect matches to consider potential bias.
Results:
The most accurate probabilistic/fuzzy matching approach identified 4,714 overdose deaths (vs. the deterministic approach, n = 4,572), with a low FP linkage error (<1%) and high correct match proportion (95% vs. 92% and ~90% for probabilistic approaches not using comprehensive data cleaning). Estimation of all prescription measures improved (vs. deterministic approach). For example, frequency (%) of decedents filling an oxycodone prescription in the last 60 days (n = 1,371 [32%] vs. n = 1,443 [33%]). Missed overdose decedents were more likely to be younger, male, nonwhite, and of higher education.
Conclusion:
Implications of study findings include underreporting, prescribing and outcome misclassification, and reduced generalizability to population risk groups, information of importance to epidemiologists and researchers using PDMP data.
In the late 1990s and 2000s, use of prescription opioids for acute and chronic pain, and associated morbidity and mortality, increased substantially in the United States, resulting in the need for regulation and policy to reduce opioid misuse and abuse.1,2 Prescription Drug Monitoring Programs (PDMPs), now operational in all 50 states and one United States territory,3 support the monitoring of prescribing practices and potential misuse of controlled substances. PDMPs provide information to health care professionals about a patient’s prescription history to help identify potential misuse, abuse, and inappropriate prescribing.3 Ideally, this information can be used to guide appropriate care and implement risk mitigation strategies for substance use disorder and overdose.4–7
Use of PDMP data for public health surveillance and epidemiologic studies has increased in recent years with the implementation of PDMPs through the United States, including cohort studies of linked PDMP and health outcome data.8–14 Methods for data/record linkage (including de-duplication [matching individuals within the same data source] and linkage of individuals between data sources) [see Dusetzina et al.15 and Sayers et al.16 for a review of terms and concepts in linkage methodology]) can influence complete patient identification and medical history.17–20 Accuracy of data/record linkage (hereafter referred to as record linkage) is particularly important for cohort studies and can influence estimation of incidence and mortality rates, and effect estimates due to misclassification of covariates, exposures, and outcomes, as well as generalizability of results if certain groups are excluded (e.g., individuals of lower socioeconomic status).21–25
The accurate identification of patient entities, and thereby patient prescription history, is a key challenge with PDMP data, which include millions of patient records with non-standardized data entry for identifying fields, such as name and address. We developed comprehensive strategies for record linkage using Tennessee’s (TN) PDMP data (the Controlled Substance Monitoring Database [CSMD]) and vital statistics mortality data for all drug overdose decedents from TN’s death statistical files. These methodologies and lessons learned can be helpful to public health epidemiologists and researchers using PDMP data. Our first objective was to evaluate the accuracy of several record linkage approaches using varying methods in data cleaning, standardization, and linkage (e.g., deterministic vs. probabilistic/fuzzy) and determine the most accurate approach for use in epidemiologic studies using linked PDMP data. Our second objective was to quantify the influence of the linkage approaches on the estimation of frequently reported opioid and benzodiazepine prescribing measures. Our third objective was to describe characteristics of matched, unmatched, and incorrectly matched records to evaluate the potential for measurement error and selection bias in analyses using PDMP and mortality data.
METHODS
Study Design and Data Sources
Figure 1 provides an overview of study design, population, and data sources.
FIGURE 1.
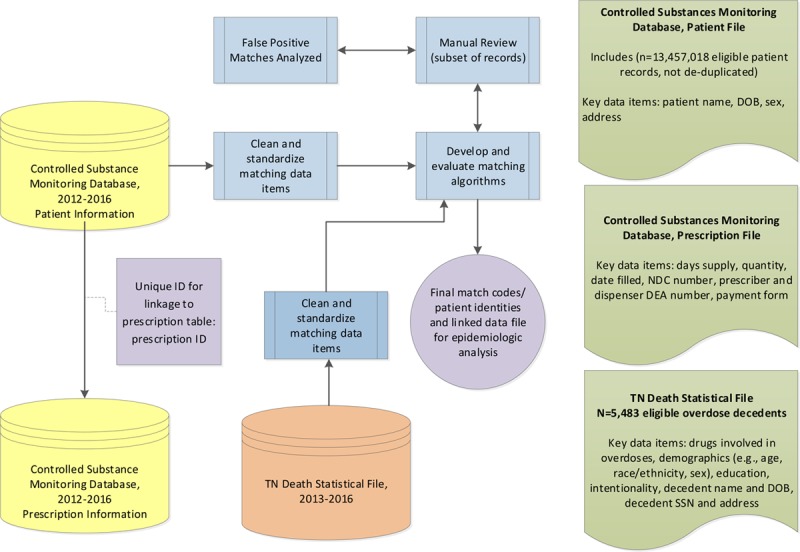
Study Data Sources, Study Population, and Entity Resolution/Record Linkage Methods
Controlled Substance Monitoring Database (2012–2016)
In accordance with the Controlled Substance Monitoring Act of 2002, the Tennessee Department of Health established the CSMD to monitor the dispensing of Schedule II–V controlled substances on December 1, 2006, with over 18 million prescriptions reported each year since 2011.26 Data (eTable 1; http://links.lww.com/EDE/B594, provides the raw primary fields used for the present study) are collected using the American Society for Automation in Pharmacy specifications (https://www.asapnet.org). Prescriptions are reported by dispensers, which are largely pharmacies (although some veterinarians are dispensers). In the CSMD, there is no unique patient identifier required to be collected consistently such as social security number (SSN). Potentially identifying fields collected consistently for use in record linkage in the patient file of >13 million records included first name, middle name, last name, date of birth (DOB), and address.
Death Statistical Files (2013–2016)
TN’s death certificates provide causes, place, and manner of death.27 Each death certificate is classified with an underlying cause of death using the International Classification of Diseases, 10th Revision (ICD-10) codes and up to 20 additional multiple cause of death ICD-10 codes by the National Center for Health Statistics. Additional data collected include name, address, DOB, date of death, and sociodemographic information (e.g., sex, race, ethnicity, education, and marital status). Eligible decedents included TN residents aged ≥18 years with an underlying cause of death due to all drug overdose during 2013–2016 (n = 5,483). ICD-10 codes for all drug overdoses included X40–X44 (unintentional drug poisoning codes); X60–X64 (intentional drug poisoning codes); X85 (homicide/assault drug poisoning codes); and Y10–Y14 (undetermined intent drug poisoning codes).
Record Linkage Methodology
Overview
The first approach used comprehensive name cleaning with both standard15 and data-specific programming techniques using Statistical Analysis Software (SAS) and a multi-step deterministic matching approach using Structured Query Language (SQL), used in our previous case-only study of overdose decedents.28 The second through fifth approaches utilized probabilistic/fuzzy matching algorithms with varying sensitivity codes using SAS Data Management Studio Software.29 We also tested our in-house data cleaning techniques developed in SAS vs. the SAS Data Management Studio standardization approach using raw data.
Cleaning and Standardizing Matching Data Items
Name-cleaning strategies for the CSMD were described in detail previously30 (with additional methodology and code available in the eAppendix 2; http://links.lww.com/EDE/B594). Briefly, extra spaces and non-alphanumeric characters, and non-name text were removed, and prefixes/suffixes were placed in separate fields. Similar approaches were used for cleaning and parsing name fields in the death files; however, name cleaning was more extensive in the CSMD largely due to lack of standardization at data entry and the large size of the data (>13 million patient records). Address was not used as a primary patient identification variable in the CSMD (due to potential changes in address across prescription records), but was used to identify potential false positive (FP) matches and to confirm match status via manual review, described below. Address fields were geocoded using ArcGIS, version 10.6 (ESRI, Redlands, CA), with a minimum match score of 85 and a spelling sensitivity of 80. Geocoding was successful for 94% of records in the death file and 91% of records in the CSMD patient file. For addresses that could not be geocoded, manual review was used to determine if the address was a match between records when assessing potential FP matches.
Deterministic Data Matching (Approach 1)
The first approach used the comprehensive name cleaning protocol implemented in SAS and deterministic matching in SQL on exact DOB, any last name, and any first name. The matched set (regardless of approach) could have one death record matched to one patient record or multiple patient records, depending on the number of matched patient records and associated prescription histories in the CSMD for the decedent.
Fuzzy/Probabilistic Data Matching (Approaches 2–5)
Approach 2 used the same comprehensive name cleaning protocol, with probabilistic/fuzzy matching sensitivity codes of 85 for names and 95 for DOB in the SAS Data Management Studio software. It is worth noting that the SAS Data Management Studio-derived sensitivity codes are not the sensitivity (and corresponding specificity) metrics commonly used in epidemiology.15 Sensitivity codes from SAS Data Management Studio are based on a combination of standardization/fuzzy matching techniques (e.g., regular expression processing, phonetics, transformations) using natural language processing to create a threshold value that ranges from 50 to 95 (in five-level increments).29 Approach 3 followed the same methods as approach 2, but varied on SAS Data Management Studio-derived sensitivity values (used 85 for both names and DOB). We conducted Approaches 4 and 5 using SAS Data Management Studio software for standardization and matching, with unclean names and DOB entered directly. Standardization in SAS Data Management Studio uses the SAS Data Quality Knowledge Base, a repository of rules, and reference data.29 The difference between approach 4 and approach 5 was in the sensitivity values. Specifically, approach 4 used sensitivity values of 85 for names and 95 for DOB; while approach 5 used the lower sensitivity value of 85 for both names and DOB.
Evaluation of the Accuracy of Matching Algorithms
Accuracy measures included number of matches, FPs (i.e., incorrect matches) and false negatives (i.e., missed matches) for both overdose deaths and prescriptions.15,31 These were evaluated for patient to death matches, unique overdose decedents, and prescriptions to eligible decedents. Many duplicate patient records exist, due to name and address variations entered by pharmacy staff, and each of these is linked to one or more prescriptions filled.32 eFigure 3(http://links.lww.com/EDE/B594) provides example patient records from the CSMD within a de-duplicated matched set to illustrate how data issues in available patient information may affect identification of patient entities and complete prescription history.
FP Method for Identification of Matches for Manual Review (Death and CSMD)
Determining if a match was a true FP was not straightforward, due to lack of a unique identifier in the CSMD and data quality issues with names (e.g., nicknames, misspellings) and address (e.g., missing data, wrong street number, change in address). Therefore, we developed an approach to identify potential FPs, which were then reviewed manually to classify as follows:(1) not an FP (able to confirm a correct match), (2)possible FP (i.e., unable to confirm true match status based on available information), and (3) true FP (confident an incorrect match). One author manually reviewed all potential FP matches for each approach, and a second author confirmed all potential and true FP matches for approaches 2–5.
We used differences in either full name or DOB to identify potential FPs for patient and death record matches. To reduce burden of manual review for FPs, we used a systematic stepwise approach considering name, DOB, original and geocoded address, and SSN (when available in both death and the CSMD [SSN is missing for close to 70% of records as it is not a required variable]), to reduce the pool of potential FPs for manual review. For the first matching approach (deterministic only), we also evaluated the usefulness of middle names in identifying FPs and confirming match status. For approaches 2–4, which incorporated probabilistic/fuzzy matching, we evaluated the primary data issues resulting in potential FP identification and summarized the frequency of these by approach.
Statistical Analysis
We calculated descriptive statistics for continuous variables (e.g., median, and interquartile ranges [IQR]) for total, opioid, and benzodiazepine prescriptions, and opioid and benzodiazepine days’ supply. Total morphine milligram equivalents for opioid analgesics were calculated for the last 60 and 180 days before overdose. Chi-square analyses were conducted for categorical variables, including number of prescribers or dispensers in the year before overdose (1,2,3,4, ≥5), any prescription use (any, opioid analgesic, buprenorphine for medication-assisted treatment, oxycodone, hydrocodone, and benzodiazepine use) in the last 60 days before overdose, active opioid or benzodiazepine prescription at overdose (where prescription end date overlapped date of death by at least one day), and cash payment for an opioid analgesic. Drug classifications used the Centers for Disease Control Drug Classification table for controlled substances.33 We calculated the frequency of matches, missed matches, FPs, and the FP linkage error rate by linkage approach. We conducted data management and/or statistical analyses using SAS version 9.4 (Cary, NC), Microsoft SQL Server Management Studio Version 17 (Redmond, WA), and SAS Data Management Studio version 2.7 (Cary, NC). The primary site Institutional Review Board for human subjects research approved this study.
RESULTS
Figure 1 provides an overview of study design and population. Table 1 displays number of deaths and prescriptions, and potential FP matches identified for manual review for each linkage approach. Approach 3 (comprehensive name cleaning/standardization and probabilistic/fuzzy matching) resulted in the highest number of matched overdose deaths (n = 4,714) (versus the deterministic approach (n = 4,572)) and prescriptions (n = 250,082), with 154 more overdose deaths and 17,632 more prescriptions included than the deterministic approach 1. Approach 5 had the highest number of potential FP matches identified that required manual review.
TABLE 1.
Results from Deterministic and Probabilistic Record Linkage Approaches for All Drug Overdose Decedents in the TN Death Statistical Files (2013–2016) and CSMD (2012–2016)

We conducted a comprehensive evaluation and analysis to identify possible and true FP patient (CSMD) and death (TN death statistical file) matches. For approach 1 (deterministic record linkage), we identified the initial potential FPs matches as those with discrepancies in full names between the patient and death record (largely due to situations where an individual had 2 last names or differences in middle name fields) (n = 14,906). After removing records confirmed as true matches based on comparison of address and/or SSN, a total of 8,671 potential FPs matches remained (Table 1). We evaluated the use of middle name to help identify FPs and confirm true match status. However, this matching variable was found to provide limited additional utility to determine match status, and was not used subsequently. After manual review, we identified 344 matched records that we considered possible FPs (could not completely confirm match status without additional identifying information) and 0 true FP matches, representing 161 unique overdose decedents and 3,134 prescriptions.
Figure 2 and Table 2 display results regarding the evaluation, analysis, and final classification of FP matches (i.e., patient [CSMD] and death [TN death statistical file] matches) after manual review for the linkage approaches that utilized fuzzy/probabilistic matching. The total number of FPs between a death and patient record based on name and/or DOB ranged from 1,500 for approach 2 to 3,935 for approach 5. Approach 2 resulted in the fewest and approach 5 the most potential FP matches for manual review (i.e., match status could not be confirmed using available address or SSN [Figure 2]).
FIGURE 2.
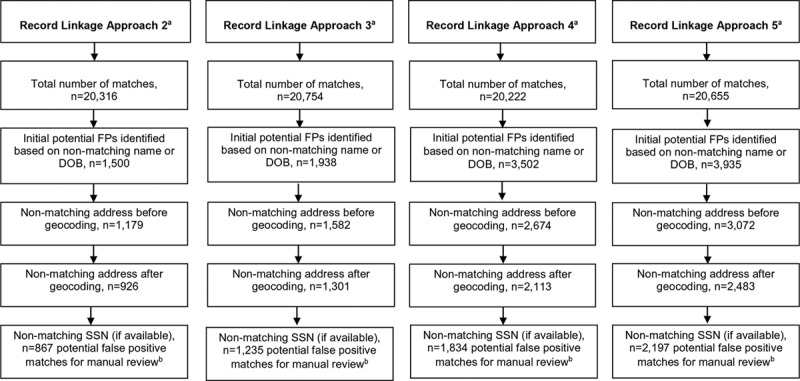
Identification of FP Matches for Manual Review for Four Fuzzy/Probabilistic Record Linkage Approaches aSee Table 1 for approach descriptions. bResults from manual review are summarized in Table 2.
TABLE 2.
Manual Review of Potential FP Matches from Fuzzy/Probabilistic Matching Algorithms and Final Classification
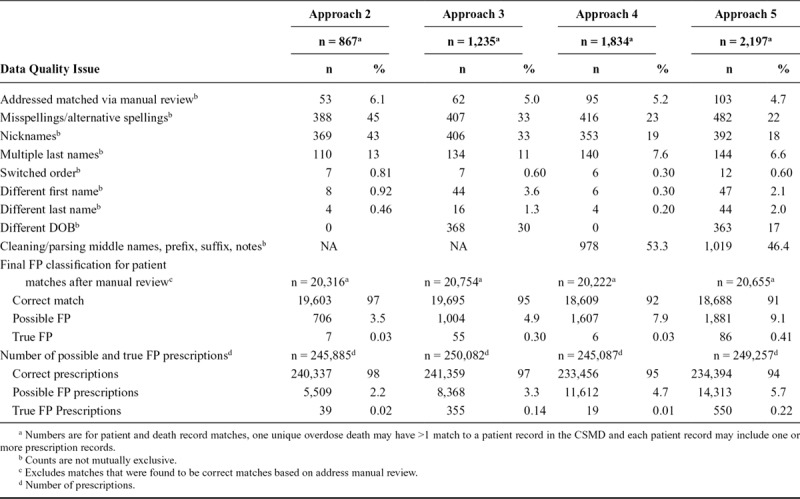
As shown in Table 2, the most common data quality issues resulting in a potential FP match included missing and alternative spellings, nicknames, multiple last names (and where applicable, different DOB). For approaches 3 and 5, which used raw data without cleaning, the primary data quality issue was unclean text data issues (addressed in our other approaches that implemented comprehensive name cleaning). The true FP error rate among all CSMD patient and death record matches was <1.0%, regardless of approach. The correct match proportion ranged from 91% in approach 5 to 97% in approach 2.
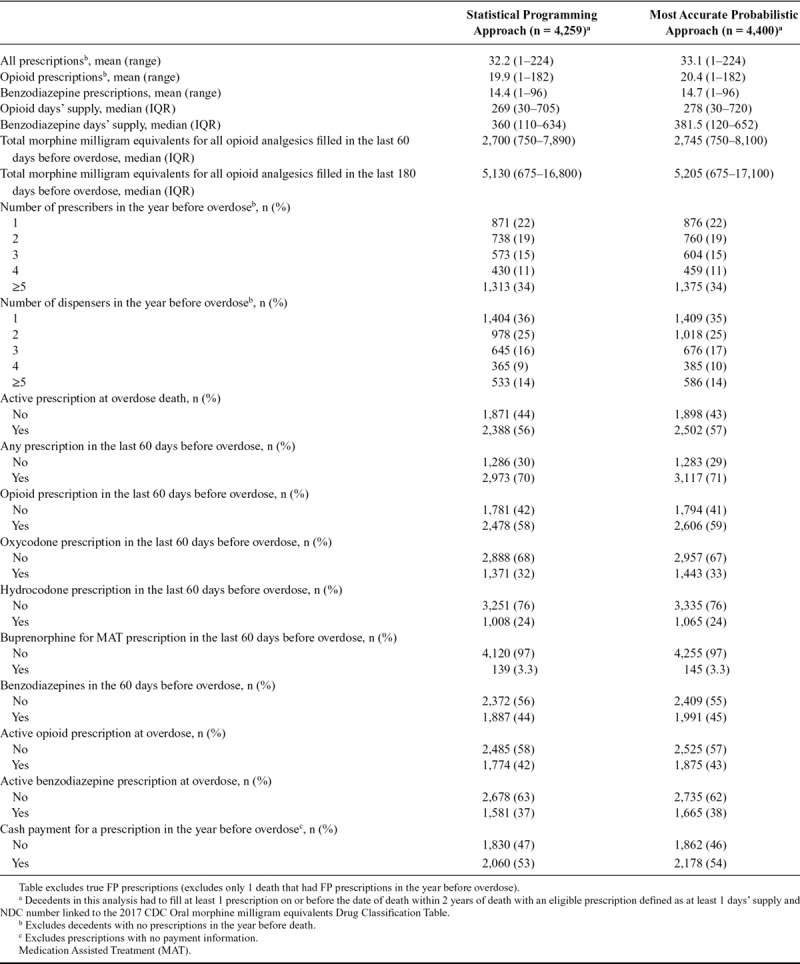
Table 3 displays prescription characteristics for approach 1 compared with approach 3 (identified as the most accurate approach based on number of matches and false negative and FP linkage errors). Approach 1 underestimated all prescription measures, including number of prescriptions, days’ supply for prescriptions, total morphine milligram equivalents, and frequency of prescriptions across different types (opioids, benzodiazepines) and timing (active at overdose and 60 days before overdose). The overall differences in distributions, when compared with frequencies, were small. For example, 1,371 (32%) and 1,443 (33%) of decedents with a prescription filled for oxycodone in the 60 days before overdose for approach 1 and approach 3, respectively. While the proportions are similar, 72 additional patients were identified in approach 3 (when compared with approach 1). We also provide the difference in proportions and 95% confidence intervals in eTable 4; http://links.lww.com/EDE/B594.
TABLE 3.
Influence of Entity Resolution/Record Linkage Approaches on PDMP Prescription Measures for All Drug Overdose Decedents in Tennessee
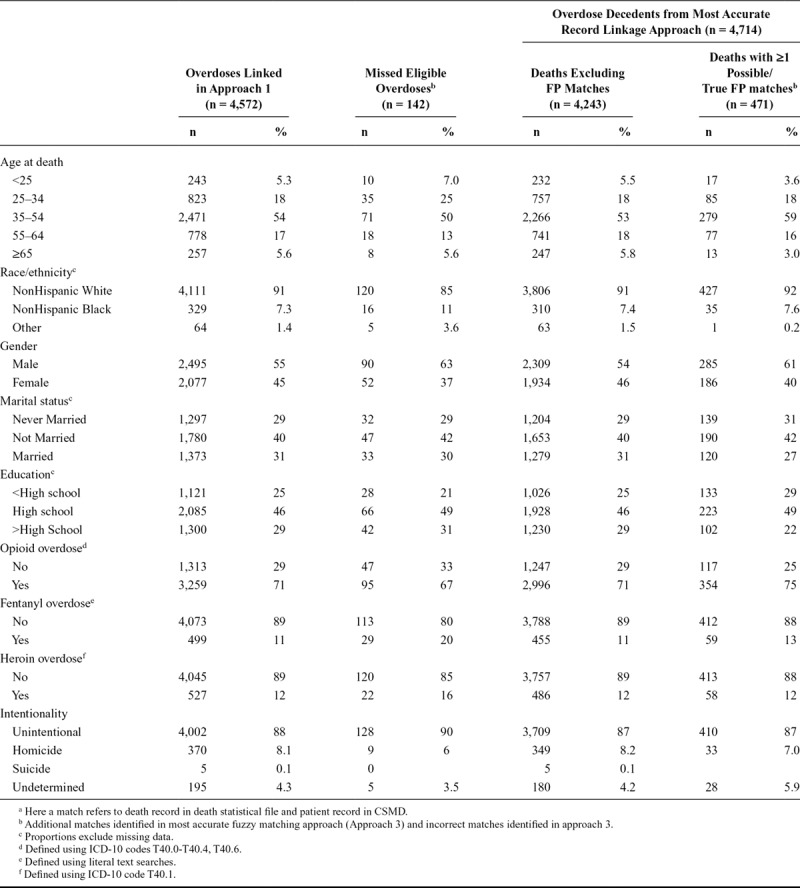
We compared decedents missed in approach 1, but included in the most accurate approach (i.e., approach 3), to understand the characteristics of decedents excluded from the population when using the deterministic approach (Table 4). Missed overdose decedents were more likely to be younger, male, nonwhite, and of higher education. A higher proportion of eligible fentanyl and heroin decedents (i.e., with a prescription history in the CSMD who should have been linked), and unintentional overdoses, were found among missed matches. We also compared characteristics of overdose deaths with 1 or more possible/true FP matches to decedents with no incorrect matches (Table 4). Decedents with FP matches were more likely to be middle-aged, male, unmarried at time of overdose, and of lower education.
TABLE 4.
Characteristics of Missed Matches and FP Matches for Overdose Decedentsa
DISCUSSION
In our study using PDMP and mortality data, we evaluated the accuracy of record linkage approaches using varying methods for cleaning, standardization, and matching, and developed a systematic process to identify and exclude FPs prior to analyses. The number of matches (for overdose decedents to their patient record[s] in the CSMD) was improved when we implemented a comprehensive name-cleaning protocol using database-specific techniques via statistical programming and incorporating probabilistic/fuzzy matching (when compared with deterministic). The most accurate approach identified an additional 142 overdose deaths, and the trade-off with increased FP matches (i.e., patient and death record matches) was small (FP linkage error of <1%). Further, the correct match proportion after manual review was ~95% (compared with 92% and ~91% for the probabilistic approaches not including comprehensive data cleaning).
Assessment of the accuracy of linkage approaches, including missed and FP matches, and consideration of potential misclassification of study variables and selection bias is needed to improve validity and results interpretation in public health analyses and epidemiologic studies.15,17,19,25,34 Deterministic linkage generally has high specificity, with a trade-off in sensitivity,15 potentially resulting in underestimation of health statistics.24 However, this depends on the completeness and accuracy of identifiers and deterministic linkage approaches (e.g., exact matching or multi-stage). Probabilistic linkage is generally more sensitive (fewer missed matches), with a potential increase in FPs.15,16,31 In our study, the most accurate approach resulted in improved estimation of descriptive prescription measures of common interest in public health and epidemiologic analyses (compared with the deterministic approach). Other studies have shown that probabilistic matching can improve sensitivity and linkage rates, including record linkage studies utilizing health claims, vital statistics, and hospital administrative data.19,20,25,35 The reduction in missed matches can reduce bias in study estimates and improve study generalizability by including eligible records/study participants that may have been missed,20,24,25,35 which we demonstrate in our study. Specifically, we found that decedents who would have been excluded using only a deterministic approach but included using a probabilistic approach tended to be younger, nonwhite, male, and of higher education. We also found that the distributions for characteristics of decedents with one or more true or possible FP matches were potentially different from the population identified for analysis using the most accurate approach, with a higher proportion in the age group 35–54 years (59% vs. 53%), of male gender (61% vs. 54%), and of lower education (<high school 29% vs. 25%). Our findings, which should be interpreted with the caveat that they are descriptive, highlight the importance of considering both false negatives and FPs on study variable measurement and potential selection bias.
We show that approaches used to identify prescription history in PDMP data, and for linking patients to health outcomes, have important implications for accuracy and bias, including underreporting, prescribing and outcome misclassification, and reduced generalizability to all populations at risk. We believe the methods can be used by public health epidemiologists and researchers to improve validity and interpretation for public health analyses and epidemiologic studies using PDMP data, regardless of setting. Our study is unique in that we evaluated multiple record linkage approaches, considering both cleaning and standardization of fields before use (often overlooked but critical components of best practices in record linkage methodology16), as well as comparison of matching methods (deterministic and probabilistic/fuzzy matching). We demonstrated that our own in-house database-specific cleaning methodology improved accuracy (see eAppendix 2; http://links.lww.com/EDE/B594), including increased number of outcome linkages, and reduced FP linkage errors. We also developed an approach to identify and exclude FPs, which can improve quality of findings enabling exclusion of incorrect matches prior to analysis. We found that using additional available potential identifiers, even if only available for a subset of records, can reduce burden in manual review of potential FP records for match status validation. Further, we provide an analysis of the primary reasons for FP matches, which could be used to select high priority records for manual review when time and/or resources are limited.
A limitation of our study is that we did not have a true “gold standard” identifier that would enable us to confirm all death and patient records matches (such as SSN or health medical record number). This is generally required for calculation of sensitivity and specificity,35,36 as it is a way to confirm true match status without manual review. However, we did manually review all potential FP matches for each linkage approach, with systematic evaluation and analysis to identify true FPs. Therefore, our estimates of correct matches (excluding any overdose deaths with one or more true FP match), should be quite accurate, although the possibility of some human error remains. Another limitation of our work is that we focused on mortality data only. It is important to note that this record linkage framework can be applied beyond mortality to other health data, such as infectious disease (e.g., blood-borne infections associated with injection drug use such as Hepatitis C) and administrative data, to enable evaluations of new risk factors and identification of susceptible populations and high risk groups.37–39 Finally, we did not evaluate the influence of matching approaches on effect estimates for health outcomes associations as this was beyond the scope of the present study. Future studies using PDMP data, such as those of prescribing patterns and fatal and nonfatal overdose or use of prescription opioids during pregnancy and infant outcomes can provide opportunities for future research that apply the methodologies of the current work in multiple settings and populations.
Public Health Implications
The use of PDMP data for epidemiologic studies and public health surveillance has greatly increased in recent years as these data have accumulated as part of the response to the opioid epidemic. We comprehensively evaluated multiple record linkage approaches using PDMP data, including an analysis of FPs and assessment of potential for bias by comparing prescribing measures, characteristics of missed and incorrect matches, and excluding potentially incorrect matches identified by manual review. We show that approaches used to identify prescription history in PDMP data, and for linking patients to mortality outcomes, a common outcome of interest, have important implications for accuracy and bias. These implications, which apply to public health analyses used to inform prevention and intervention efforts as well as epidemiologic studies, include underreporting, prescribing and outcome misclassification, and potential for reduced generalizability to all population risk groups.
Supplementary Material
Footnotes
Supported by the Centers for Disease Control & Prevention [Prescription Drug Overdose Prevention for States Program (5 NU17CE002731-02-00) to the Tennessee Department of Health. Its contents are solely the responsibility of the authors and do not necessarily represent the official views of the Centers for Disease Control and Prevention or the Department of Health and Human Services.
The authors report no conflicts of interest.
Supplemental digital content is available through direct URL citations in the HTML and PDF versions of this article (www.epidem.com).
The data are not publicly available as the Controlled Substance Monitoring Database is not available for external data use at this time based on the current laws governing use of this database. Code used for this study (as feasible) and supplemental methodology information are available in the Supplemental Digital Content.
REFERENCES
- 1.Meldrum ML. The ongoing opioid prescription epidemic: historical context. Am J Public Health. 2016;106:1365–1366. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 2.Dasgupta N, Beletsky L, Ciccarone D. Opioid crisis: no easy fix to its social and economic determinants. Am J Public Health. 2018;108:182–186. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 3.Prescription Drug Monitoring Program Training and Technical Assistance Center. http://www.pdmpassist.org/pdf/PDMP_Program_Status_20170824.pdf. Accessed 20 January 2018.
- 4.Lin DH, Lucas E, Murimi IB, et al. Physician attitudes and experiences with Maryland’s prescription drug monitoring program (PDMP). Addiction. 2017;112:311–319. [DOI] [PubMed] [Google Scholar]
- 5.McCauley JL, Leite RS, Gordan VV, et al. ; National Dental Practice-Based Research Network Collaborative Group. Opioid prescribing and risk mitigation implementation in the management of acute pain: results from the national dental practice-based research network. J Am Dent Assoc. 2018;149:353–362. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 6.Christianson H, Driscoll E, Hull A. Alaska nurse practitioners’ barriers to use of prescription drug monitoring programs. J Am Assoc Nurse Pract. 2018;30:35–42. [DOI] [PubMed] [Google Scholar]
- 7.Suffoletto B, Lynch M, Pacella CB, Yealy DM, Callaway CW. The effect of a statewide mandatory prescription drug monitoring program on opioid prescribing by emergency medicine providers across 15 hospitals in a single health system. J Pain. 2018;19:430–438. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 8.Dasgupta N, Funk MJ, Proescholdbell S, Hirsch A, Ribisl KM, Marshall S. Cohort study of the impact of high-dose opioid analgesics on overdose mortality. Pain Med. 2016;17:85–98. [DOI] [PubMed] [Google Scholar]
- 9.Deyo RA, Hallvik SE, Hildebran C, et al. Association between initial opioid prescribing patterns and subsequent long-term use among opioid-naïve patients: a Statewide Retrospective Cohort Study. J Gen Intern Med. 2017;32:21–27. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 10.O’Kane N, Hallvik SE, Marino M, et al. Preparing a prescription drug monitoring program data set for research purposes. Pharmacoepidemiol Drug Saf. 2016;25:993–997. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 11.Fink PB, Deyo RA, Hallvik SE, Hildebran C. Opioid prescribing patterns and patient outcomes by prescriber type in the oregon prescription drug monitoring program. Pain Med. 2018;19:2481–2486. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 12.Hallvik SE, Geissert P, Wakeland W, et al. Opioid-prescribing continuity and risky opioid prescriptions. Ann Fam Med. 2018;16:440–442. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 13.Geissert P, Hallvik S, Van Otterloo J, et al. High-risk prescribing and opioid overdose: prospects for prescription drug monitoring program-based proactive alerts. Pain. 2018;159:150–156. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 14.Deyo RA, Hallvik SE, Hildebran C, et al. Association of prescription drug monitoring program use with opioid prescribing and health outcomes: a comparison of program users and nonusers. J Pain. 2018;19:166–177. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 15.Dusetzina S, Tyree S, Meyer A, Meyer A, Green L, Carpenter W. Linking data for health services research: a framework and instructional guide (Prepared by the University of North Carolina at Chapel Hill under Contract No. 290-2010-000141.) AHRQ Publication No. 14-EHC033-EF. September 2014. Rockville, MD: Agency for Healthcare Research and Quality; www.effectivehealthcare.ahrq.gov/reports/final.cfm. [PubMed] [Google Scholar]
- 16.Sayers A, Ben-Shlomo Y, Blom AW, Steele F. Probabilistic record linkage. Int J Epidemiol. 2016;45:954–964. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 17.Joffe E, Byrne MJ, Reeder P, et al. A benchmark comparison of deterministic and probabilistic methods for defining manual review datasets in duplicate records reconciliation. J Am Med Inform Assoc. 2014;21:97–104. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 18.McCoy AB, Wright A, Kahn MG, Shapiro JS, Bernstam EV, Sittig DF. Matching identifiers in electronic health records: implications for duplicate records and patient safety. BMJ Qual Saf. 2013;22:219–224. [DOI] [PubMed] [Google Scholar]
- 19.Aldridge RW, Shaji K, Hayward AC, Abubakar I. Accuracy of probabilistic linkage using the enhanced matching system for public health and epidemiological studies. PLoS One. 2015;10:e0136179. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 20.Hagger-Johnson G, Harron K, Goldstein H, Aldridge R, Gilbert R. Probabilistic linkage to enhance deterministic algorithms and reduce data linkage errors in hospital administrative data. J Innov Health Inform. 2017;24:891. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 21.Brenner H, Schmidtmann I, Stegmaier C. Effects of record linkage errors on registry-based follow-up studies. Stat Med. 1997;16:2633–2643. [DOI] [PubMed] [Google Scholar]
- 22.Schmidlin K, Clough-Gorr KM, Spoerri A, Egger M, Zwahlen M; Swiss National Cohort. Impact of unlinked deaths and coding changes on mortality trends in the Swiss National Cohort. BMC Med Inform Decis Mak. 2013;13:1. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 23.Miller EA, McCarty FA, Parker JD. Racial and ethnic differences in a linkage with the national death index. Ethn Dis. 2017;27:77–84. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 24.Moore CL, Gidding HF, Law MG, Amin J. Poor record linkage sensitivity biased outcomes in a linked cohort analysis. J Clin Epidemiol. 2016;75:70–77. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 25.Harron KL, Doidge JC, Knight HE, et al. A guide to evaluating linkage quality for the analysis of linked data. Int J Epidemiol. 2017;46:1699–1710. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 26.Tennessee Department of Health. Tennessee Chronic Pain Guildelines (2017). https://www.tn.gov/content/dam/tn/health/healthprofboards/ChronicPainGuidelines.pdf. Accessed 1 May 2018.
- 27.Tennesseee Department of Health. Bureau of Policy, Planning and Assessment. Division of Health Statistics. Death Statistical File User Manual. January 2014. [Google Scholar]
- 28.Nechuta SJ, Tyndall BD, Mukhopadhyay S, McPheeters ML. Sociodemographic factors, prescription history and opioid overdose deaths: a statewide analysis using linked PDMP and mortality data. Drug Alcohol Depend. 2018;190:62–71. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 29.SAS Insitute Inc. SAS 9.4 Data Management: Overview. 2016Cary, NC: SAS Institute Inc. [Google Scholar]
- 30.Golladay M, Nechuta S. Lessons Learned: Deep Cleaning Procedure Design for Name Variables in the Tennessee CSMD. Available at: https://www.tn.gov/content/dam/tn/health/documents/opioid_response/CSMDNameCleaningReport.pdf. Accessed 29 April 2019.
- 31.Blakely T, Salmond C. Probabilistic record linkage and a method to calculate the positive predictive value. Int J Epidemiol. 2002;31:1246–1252. [DOI] [PubMed] [Google Scholar]
- 32.Prescription Drug Monitoring Program Training and Technical Assistance Center. Technical Assistance Guide. PDMP Suggested Practices to Ensure Pharmacy Compliance and Improve Data Integrity. April 13, 2015. Available here: http://www.pdmpassist.org/pdf/Resources/Pharmacy_compliance_data_quality_TAG__FINAL_20150615_A.pdf. Accessed 29 April 2019.
- 33.National Center for Injury Prevention and Control. CDC compilation of benzodiazepines, muscle relaxants, stimulants, zolpidem, and opioid analgesics with oral morphine milligram equivalent conversion factors, 2018 version. 2018. Atlanta, GA: Centers for Disease Control and Prevention; Available at https://www.cdc.gov/drugoverdose/resources/data.html. Accessed 29 April 2019. [Google Scholar]
- 34.Campbell KM. Impact of record-linkage methodology on performance indicators and multivariate relationships. J Subst Abuse Treat. 2009;36:110–117. [DOI] [PubMed] [Google Scholar]
- 35.Baldwin E, Johnson K, Berthoud H, Dublin S. Linking mothers and infants within electronic health records: a comparison of deterministic and probabilistic algorithms. Pharmacoepidemiol Drug Saf. 2015;24:45–51. [DOI] [PubMed] [Google Scholar]
- 36.Silveira DP, Artmann E. Accuracy of probabilistic record linkage applied to health databases: systematic review. Rev Saude Publica. 2009;43:875–882. [DOI] [PubMed] [Google Scholar]
- 37.Degenhardt L, Peacock A, Colledge S, et al. Global prevalence of injecting drug use and sociodemographic characteristics and prevalence of HIV, HBV, and HCV in people who inject drugs: a multistage systematic review. Lancet Glob Health. 2017;5:e1192–e1207. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 38.Lo-Ciganic WH, Huang JL, Zhang HH, et al. Evaluation of machine-learning algorithms for predicting opioid overdose risk among medicare beneficiaries with opioid prescriptions. JAMA Netw Open. 2019;2:e190968. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 39.Moyo P, Zhao X, Thorpe CT, et al. Dual receipt of prescription opioids from the fepartment of veterans affairs and medicare part D and prescription opioid overdose death among veterans: a Nested Case-Control Study. Ann Intern Med. 2019;170:433–442. [DOI] [PMC free article] [PubMed] [Google Scholar]