

Abstract
We present a variational principle for the extraction of a time-dependent orthonormal basis from random realizations of transient systems. The optimality condition of the variational principle leads to a closed-form evolution equation for the orthonormal basis and its coefficients. The extracted modes are associated with the most transient subspace of the system, and they provide a reduced description of the transient dynamics that may be used for reduced-order modelling, filtering and prediction. The presented method is matrix free; it relies only on the observables of the system and ignores any information about the underlying system. In that sense, the presented reduction is purely observation driven and may be applied to systems whose models are not known. The presented method has linear computational complexity and memory storage requirement with respect to the number of observables and the number of random realizations. Therefore, it may be used for a large number of observations and samples. The effectiveness of the proposed method is tested on four examples: (i) stochastic advection equation, (ii) stochastic Burgers equation, (iii) a reduced description of transient instability of Kuramoto–Sivashinsky, and (iv) a transient vertical jet governed by the incompressible Navier–Stokes equation. In these examples, we contrast the performance of the time-dependent basis versus static basis such as proper orthogonal decomposition, dynamic mode decomposition and polynomial chaos expansion.
Keywords: observation driven, matrix free, transient dynamics, finite-time instabilities, time-dependent modes, dimension reduction
1. Introduction
The ability to discover intrinsic structure from data has been called the fourth paradigm of scientific discovery [1]. Dimension reduction enables such discoveries and clearly belongs to the fourth paradigm. The goal of dimension reduction is to map high-dimensional data into a meaningful representation of reduced dimensionality. As a result, dimension reduction has been widely used in classification, visualization and compression of high-dimensional data [2]. In the scientific and engineering applications dimension reduction has been used to build reduced-order models to propagate uncertainty, control and optimization [3,4].
This paper focuses on dimension reduction of vector-valued observables generated by a time-dependent stochastic system where ω denotes a random observation. A linear reduction model seeks to approximate the target x with
| 1.1 |
where is a deterministic matrix whose columns can be regarded as modes and are the reduced stochastic variable, where r is the reduction size and ϵ is the reduction error. Both U and z are in general time dependent. In view of equation (1.1), polynomial chaos expansion (PCE) can be seen as a special case where z is represented by PCE—a static (i.e. time independent) basis—while U = U(t) is time dependent. PCE has reached widespread popularity especially for steady-state and parabolic stochastic partial differential equations (SPDEs) [5]. However, for time-dependent dynamical systems with transient instabilities the number of PCE terms required for a given level of accuracy must rapidly increase [6]. Similarly, it was shown in [7] that the reduction size of PCE must increase in time to maintain a given accuracy. On the other hand, data-driven methods such as proper orthogonal decomposition (POD) and dynamic mode decomposition (DMD) belong to a class of methods where the modes U are static and they are computed from numerical/experimental observations of the dynamical system and z(t;ω) is often obtained by projection of the data to these modes [8]. For highly transient systems, DMD and POD require a large number of modes to capture transient time behaviour [9,10]. This is partly because both DMD and POD decompositions seek to obtain an optimal reduction of the data in a time-average sense. In the case of DMD a best-fit linear dynamical system matrix A is sought so that ∥xk+1 − Axk∥2 is minimized across all snapshots, where k shows the time snapshots. Similarly, the POD is an optimal basis for all snapshots. However, transient instabilities, for example, by definition have a short lifetime. The effect of these transient instabilities may be lost in a reduction based on time average.
More recently dynamically orthogonal (DO) [11] and bi-orthogonal (BO) [12] expansions have proven promising in tackling time-dependent SPDEs. In these reduction techniques both U(t) and z(t;ω) are dynamic and they evolve with time. In a DO/BO framework, exact evolution equations for the evolution of U(t) and z(t;ω) are derived. In the case of SPDEs, the evolution equation for U(t) is a system of deterministic PDEs that are solved fully coupled with a system of stochastic ordinary differential equations (SODEs) and an evolution equation for the mean equation. Although DO and BO algorithms lead to different evolution equations for the stochastic coefficient and the spatial basis, it is shown in [13,14] that both of these methods are equivalent, i.e. the BO and DO reductions span the same subspaces. In deterministic applications, time-dependent bases have been used for dimension reduction of deterministic Schrödinger equations by the multi-configuration time-dependent Hartree (MCTDH) method [15,16], and later by Koch & Lubich [17]. Recently, optimally time-dependent (OTD) reduction was introduced [18], in which an evolution equation for a set of orthonormal modes is found that captures the most instantaneously transient subspace of a dynamical system [19].
The motivation for this paper is to obtain a reduced description of transient dynamics that relies only on random observations—i.e. an equation-free reduction. This is in contrast to model-dependent reduction techniques, for example DO and BO methodologies, which require high-dimensional ODEs/PDEs to be solved to determine the time-dependent modes. When stochastic governing equations are complex, the derivation of evolution equations for the DO/BO coefficients can become very difficult, if not impossible. The reliance on the model in these techniques impedes their application in complex multi-physics/multi-component systems. For example, it is still unknown how to determine the boundary conditions for DO/BO modes in a case of a single-physics/single-domain PDE subject to random boundary conditions [20]. Moreover, the evolution equation for the DO/BO modes is tied to the equation that governs the dynamical system at hand, which would require a case-by-case implementation. On the other hand, in the era of extreme-scale computing, concurrent high-fidelity numerical simulations are expected to be routinely possible [21]. These simulations generate an unprecedented amount of streaming data, whose low-rank structure can be exploited using a data-driven approach. The low-rank structure can then be used for diagnostic purposes or to build reduced-order models.
The objective of this paper is to find a reduced description of the transient dynamics that is observation driven and discards any information about the underlying model. To this end, we present a variational principle for the determination of a set of time-dependent orthonormal modes that capture the low-dimensional structure from observations of the stochastic system. We note that the presented method is used to perform dimension reduction and not reduced-order modelling. The structure of the paper is as follows. In §2, we present the variational principle for the extraction of the time-dependent modes and their coefficients. In §3, we present four demonstration cases: (i) the stochastic advection equation, (ii) the stochastic Burgers equation, (iii) the Kuramoto–Sivashinsky equation, and (iv) a transient vertical jet in quiescent background flow governed by incompressible Navier–Stokes equations. In §4, we present the conclusions of our work.
2. Methodology
(a). Set-up
We consider a stochastic dynamical system in the form of
| 2.1 |
where x is the state space and the above dynamical system is finite dimensional, i.e. , or infinite dimensional, expressed, for example, by SPDEs, and is a d-dimensional random space with the joint probability given by ρ(ξ). The dynamical system may not be known and the proposed reduction relies only on vector-valued observations of the above system. We base our formulation on continuous-time observations, represented by matrix , whose columns contain vector-valued observations of the stochastic system at time t,
Each column of this matrix is obtained by first drawing a random sample of ξ with joint probability distribution of ρ(ξ) and solving the forward model given by equation (2.1). Before we proceed we introduce the sample mean operator,
where represents the sample weights. For example, for standard Monte Carlo samples, wξ = 1/s, where is a column vector with all elements equal to 1. For cases where controlled observations of system (2.1) is possible, the probabilistic collocation strategy may be used for sampling. In that case wξ represents the associated probabilistic collocation weights. Similarly, represents the associated weights in the state space. For applications governed by SPDEs, wx may be chosen as space integration weights (e.g. quadrature weights), such that wTxu approximates , where Ω is the spatial domain and u contains vector-valued observations of spatial function u. We assume that T(t) has zero mean, i.e. . This is accomplished by subtracting the ensemble mean from all the realizations. Let us define the inner product in both state and random spaces,
and
where Wx = diag(wx) and Wξ = diag(wξ) are matrices of size n × n and s × s, respectively. Therefore, 〈ui, uj〉 is an inner product of ui and uj in the state space, and is an inner product of yi and yj in the random space. Our goal is to build a low-rank approximation that can capture transient behaviour in the stochastic data T(t). To this end, we seek a reduction in the form of
| 2.2 |
with
and
where and and is a set of orthonormal modes, i.e. 〈ui(t), uj(t)〉 = δij and is the reduction error. In the proposed form U(t) represents a time-dependent low-rank subspace, which we will refer to as the dynamic basis (DB), and Y(t) are the stochastic coefficients of the DB; we will refer to Y(t) as the stochastic coefficients. In the following we present a variational principle that results in closed-form evolution equations for the DB U(t) and the stochastic coefficients Y(t).
(b). Variational principle
In this section we present a variational principle from which the evolution equations of the low-rank approximation are derived. Our goal is to build a low-rank approximation that can capture transient data. To this end, we first introduce a weighted Frobenius norm,
| 2.3 |
where Ti,j is the entry of matrix T at the ith row and the jth column. Now we consider the variational principle in the form of
| 2.4 |
subject to the orthonormality condition of the modes, i.e. 〈ui(t), uj(t)〉 = δij. The variational principle (2.4) seeks to minimize the difference between the rate of change of all observations and the DB reduction, and the control parameters are and . To incorporate the orthonormality condition, we observe that
| 2.5 |
and we denote . It is clear from the above equation that ϕij(t) is a skew-symmetric matrix, i.e. ϕij(t) = − ϕji(t). We incorporate the orthonormality constraint into the variational principle via Lagrange multipliers. This follows:
| 2.6 |
where λij(t), i, j = 1, …, r are the Lagrange multipliers. In appendix A, we show that the first-order optimality condition of the above functional leads to the closed-form evolution equation of U(t) and Y(t) as given by
| 2.7 |
and
| 2.8 |
where is the reduced covariance matrix () and is the orthogonal projection matrix to the space spanned by the complement of U(t), i.e. .
Solving equations (2.7) and (2.8) requires determination of ϕ(t). We show in appendix B that for any skew-symmetric matrix ϕ(t) the above reduction remains equivalent for all times. Equivalent reductions can be defined as follows: the two reduced subspaces {Y(t), U(t)} and , where and , are equivalent if there exists a transformation matrix such that and , where R(t) is an orthogonal rotation matrix, i.e. R(t)TR(t) = I. Therefore, changing ϕ(t) does not affect any of the subspaces that U(t) and Y(t) span, and it will only lead to an in-subpsace rotation. In the rest of this paper, we take the simplest case of ϕ(t)≡0. In that case the evolution of the DB reduces to
| 2.9 |
and
| 2.10 |
To compute the right-hand side of equation (2.9), U(t)U(t)T may not be computed or stored explicitly. This can be done by observing that
where and . Therefore, the evolution equations for the DB and the reduced manifold are given by
| 2.11 |
and
| 2.12 |
Besides the simplicity of the above evolution equations, the choice of ϕ(t) = 0 also leads to an insightful interpretation of the DB reduction, namely the update of the DB is always orthogonal to the space spanned by U(t), i.e. , and this update is driven by the projection of onto the orthogonal complement of U(t) (see equation (2.11)). This means that if is in the span of U(t), then
However, when is not in the span of U(t), it results in . This built-in adaptivity of the DB allows U(t) to ‘follow’ the data instantaneously. The Y(t) coefficients are updated by projection of onto the space spanned by U(t) (see equation (2.12)). Therefore, the evolution equation of Y(t) captures the evolution of T(t) within the subspace U(t).
The model-driven counterpart of equations (2.9) and (2.10) is the DO decomposition [11]. In the DO decomposition of SPDEs, a system of deterministic PDEs are derived for the evolution of the time-dependent orthonormal modes and a system of SODEs are derived for the evolution of the stochastic coefficients. These two systems coupled with the mean evolution equation must be solved simultaneously. The DO decomposition does not require observations of the system, since in the DO formulation evolution equations for U(t) and Y(t) are derived from the model instead of the observation. DO is intrusive and obtaining the time-dependent basis requires solving coupled ODE/PDE systems, which must be derived and solved for the application at hand. On the other hand, equations (2.9) and (2.10) are not PDEs and they only involve simple matrix vector operations irrespective of the data generator, i.e. the dynamical system. In other words, the DB reduction is agnostic with regard to the underlying model that generates the observation and observations may come from a system whose model is not known. As we demonstrate in §3c, even if the DB observations are chosen to be the solution of the entire computational domain, DO and DB are, in general, not equivalent, i.e. DO and DB bases do not span the same subspace. This is mainly because the DB samples, i.e. the columns of T(t), are the solution of the state equation and therefore they represent the true solution, while in the DO decomposition the samples are generated in the reduced subspace and therefore they are affected by the reduced-order modelling error. Finally, the DB reduction can be applied to nonlinear observables of the dynamical system or partial observations. See §3d for the demonstration of the latter feature of DB.
(c). Workflow and computational complexity
The DB reduction is governed by time-continuous evolution equations (2.11) and (2.12). For time-discrete data these equations must be discretized in time. Here we summarize all the steps required for solving equations (2.11) and (2.12).
Step 1. Given the time-discrete realizations in the form of , k = 0, 1, 2, …, K we compute zero-mean by subtracting the instantaneous sample mean from the data: , where 11×s is a row vector of size s whose all elements are equal to 1.
Step 2. We compute the initial condition for Y0 and U0 by performing Karhunen–Loève (KL) decomposition of the T0 at t = 0. This follows:
where vectors are an orthonormal basis, are the stochastic coefficients, λi are their corresponding eigenvalues and E0 is the reduction error. The initial conditions for U(t) and the stochastic coefficients Y(t) are then given by: ui0 = vi and for i = 1, 2, …, r.
Step 3. The time derivative of the observations can be estimated via finite difference schemes. For example, the fourth-order central finite difference approximation takes the form of
For the first two time steps one-sided finite-difference schemes may be used.
Step 4. Evolve the DB and the stochastic coefficients to the next time step k using a time-integration scheme. We use the fourth-order Runge–Kutta scheme. A comparison with a lower-order time integration scheme is given in the last demonstration case.
Step 5. Perform a Gram–Schmidt orthonormalization on the DB U(t). Although the DB remains orthonormal by construction, the numerical orthonormality of U(t) may not be preserved owing to the nonlinearity of the evolution equations (2.11) and (2.12). An enforcement of orthonormality of U(t) resolves this issue. Now steps 3–5 can be repeated in a time-loop until completion of all time steps.
A quick inspection of the evolution equations (2.11) and (2.12) reveals two favourable properties with regard to the computational cost and memory storage requirement of the DB reduction. (i) The computational complexity of solving the evolution equations (2.11) and (2.12) is , i.e. linear computational complexity with respect to the reduction size r, the size of the observations in state space n and the sample size s. We note that given that r is often a small number, i.e. r≪n and r≪s, the cost of inverting the covariance matrix C(t) is often negligible. (ii) The memory storage requirement is also linear with respect to n, r and s. This is because at each time instant only computation of is required, which can be computed from a few snapshots of T(t). This allows for loading matrix T(t) in small time batches. The linear computational and memory complexity of the DB reduction may be exploited for applications with very large datasets.
(d). Mode ranking within the subspace
In this section we present a ranking criterion within the dynamic subspace U(t). This can be accomplished by using the reduced covariance matrix C(t), which, in general, is a full matrix and this implies that the Y(t) coefficients are in general correlated. The uncorrelated Y(t) coefficients may be computed via the eigen-decomposition of the covariance matrix C(t). To this end, let
| 2.13 |
be the eigenvalue decomposition of matrix C(t), where is a matrix of eigenvectors of C(t) and Λ(t) = diag(λ1(t), λ2(t), …, λr(t)) is a diagonal matrix of the eigenvalues of matrix C(t). The uncorrelated Y(t) coefficients and the DB associated with these uncorrelated coefficients, denoted by and , are obtained by an in-subspace rotation,
It is easy to verify that coefficients are uncorrelated, i.e. . We adopt a variance-based ranking for . Since matrix C(t) is positive semidefinite, without loss of generality, let λ1(t)≥λ2(t)≥ · s≥λr(t)≥0, where λi(t) is the variance of .
Since are obtained by an in-subspace rotation of {Y(t), U(t)}, they are equivalent representations of the low-rank dynamics, i.e. , where we have used ψ(t)ψ(t)T = I, since eigenvectors of a symmetric matrix (C(t)) are orthonormal. In all the demonstration cases in this paper, we use the ranked uncorrelated representation of the DB for the analysis of the results. For the sake of simplicity in the notation, we use {Y(t), U(t)} to refer to the ranked uncorrelated representation instead of , noting that both of these representations are equivalent.
3. Demonstration cases
(a). Stochastic advection equation
As the first example, we apply DB reduction to a one-dimensional stochastic advection equation. As we will show in this section, the stochastic advection equation chosen here is exactly two dimensional, when expressed versus the DB. It also has an exact analytical solution for the DB U and the stochastic coefficients Y, which enables an appropriate verification of the DB algorithm. The stochastic advection equation is given by
| 3.1 |
subject to periodic boundary conditions at the ends of the spatial domain x ± 1 and the initial condition of u0(x;ξ). In the above equation Tf is the final time. The solution to the above equation is a stochastic random field in the form of u(x, t;ξ). The stochastic advection speed V (ξ) and the deterministic initial condition are chosen to be
where ξ is a one-dimensional uniform random variable defined on [ − 1, 1], σ is a constant and is the mean of the transport velocity. The exact solution of equation (3.1) is
and its mean and variance are
and
The expectation operator is given by , where ρ(ξ) = 1/2 is the probability density function. The total variance is equal to
The mean-subtracted stochastic field can be expressed with the following two dimensional expansion:
| 3.2 |
where
It is easy to verify that the two-dimensional expansion of the above random field satisfies the DB orthonormality condition in the continuous form, i.e.
The expansion of the stochastic field as expressed above in equation (3.2) is in BO form since .
The details of solving the evolution equations of the DB U(t) and the stochastic coefficients Y(t) are as follows. The matrix-valued random observations T(t) are generated by solving the stochastic advection equation (3.1) at s = 65 collocation points. These sampling points are chosen to be the roots of the Legendre polynomial of order 65, defined on the interval of ξ∈[ − 1, 1]. The 65 realizations of equation (3.1) are generated using a deterministic solver that uses Fourier modes of order n = 128 for space discretization and fourth-order Runge–Kutta with Δt = 0.001 for time advancement. The final time is set to Tf = 10 for all realizations.
We first performed dimension reduction of size r = 2. In figure 1a, the total variance Σ(t) obtained from the reduction is compared against the exact variance. The total variance of the low-rank approximation is obtained by , where λi(t) are the eigenvalues of the covariance matrix C. We also solved the stochastic advection equation (3.1) using the probabilistic collocation method (PCM), in which the stochastic solution is approximated as
where ϕi(ξ) are the Legendre chaos polynomials of order i, vi(x, t) are space–time coefficients and e(x, t;ξ) is the expansion error. In figure 1a, the total variance obtained from different reduction sizes r of the PCM are also shown, where it can be seen that as the size of the PCM expansion increases the PCM variance follows the exact solution for a longer time, but eventually the PCM error increases and even a 20-dimensional PCM reduction under-performs the DB reduction with r = 2. For the long-term error analysis for this problem using the PCE, the reader may refer to [7]. We note that in the PCM reduction the stochastic basis is fixed a priori, i.e. the polynomial chaos ϕi(ξ), while in the DB reduction the stochastic coefficients yi(ξ, t) are time dependent and intuitively this enables the stochastic coefficient to adapt instantaneously to the data according to the variational principle (2.6).
Figure 1.

Stochastic advection equation. (a) Comparison of the total variance of the dynamic basis (DB) reduction and polynomial chaos method (PCM) with the exact solution. (b) Comparison of the eigenvalues of the covariance matrix obtained from the DB reduction with those of the exact solution. The exact solution is exactly two dimensional when expressed in terms of the DB, and the variance picked up by the third mode is zero (order of round-off error). (Online version in colour.)
In figure 1b the covariance eigenvalues of the DB reduction with r = 3 are compared against the exact solution. Since the solution is two dimensional when expressed versus the DB, the third mode must remain inactive. As shown in figure 1b, this is confirmed numerically as the third eigenvalue does not pick up energy, while the first two eigenvalues are in excellent agreement with the exact solution. In general small eigenvalues of the covariance matrix may cause numerical instability owing to the computation of C−1 in equation (2.11). The issue of singularity of matrix C can be resolved by computing the pseudo-inverse of the covariance matrix. See [14] for similar treatment of the singularity of the covariance matrix. In figure 2, the DB and the stochastic coefficients are compared against the analytical values for two different times. In both cases excellent agreement is observed.
Figure 2.

Reduction of the solution of the stochastic advection equation using the dynamic basis (DB): (a) DB and (b) stochastic coefficient (phase portrait). (Online version in colour.)
(b). Nonlinear dynamics: stochastic Burgers
The purpose of this example is to study the effect of nonlinearity in the context of comparing the DB reduction with the DO decomposition [11]. In both of these reductions an evolution equation for a time-dependent basis U(t) is derived and a low-rank approximation is obtained by projecting the full-dimensional model (for DO) or data (for DB). A comparison with BO is not presented as DO and BO are equivalent [13]. To this end, we consider the Burgers equation:
| 3.3 |
with ν = 0.005 and subject to periodic boundary conditions and random initial conditions,
| 3.4 |
where
and
where ξ1 and ξ2 are two independent uniform random variables with unit variance in the interval [ − 1, 1] and σ1 and σ2 are the respective standard deviations in each random dimension. To generate data T(t) for the DB, equation (3.3) is sampled at 64 collocation points in the ξ1 − ξ2 space. These points were generated by the tensor product of the roots of the seventh-order Legendre chaos polynomials in each random direction. For the sake of comparison, the same collocation points are used to solve the evolution dY/dt in the DO formulation. For the DO formulation of the Burgers equation, see [14]. Third-order Runge–Kutta is used to integrate both DO and DB equations in time with the same Δt = 0.001 and the Fourier spectral method with n = 1024 points is used for the space discretization. The same number of Fourier modes is used to solve the DO equation and to generate samples for T(t).
We also compared the DB/DO reduction with the KL decomposition, which is the optimal L2 reduction in the sense of the reconstruction error,
| 3.5 |
The KL decomposition requires an eigenvalue problem to be solved for each time instant, which for s≪n has and computational complexity to compute and invert the full covariance matrix , respectively, and similarly for n≪s has and computational complexity. This operation can be cost prohibitive for large datasets, e.g. extreme-scale computing applications [21]. On the other hand, in the DB formulation, the variational principle is formed with respect to the rate of change in the data (see equation (2.4)), whose optimality condition yields computationally scalable evolution equations for U(t) and Y(t).
In figure 3 the results for DB, DO and KL reductions are shown. We chose a reduction size of r = 5 in all cases. Two cases are considered, as follows. Case I: σ1 = σ2 = 0.05 and case II: σ1 = σ2 = 0.5. In the first row of figure 3 the reconstruction error (figure 3a) and the eigenvalues Λ(t) of the covariance matrix C(t) (figure 3b) are shown. For the KL reduction, r largest eigenvalues of the full covariance matrix are shown. Similarly, the second row shows the results for the reconstruction error and the eigenvalues of the covariance matrix for case II. In figure 3b,d the energy of the mean is also shown, where is the sample mean, i.e. . It is clear that for case I the energy of the mean is roughly two orders of magnitude larger than the variance, i.e. the sum of all eigenvalues. In that sense, the random initial condition amounts to a small perturbation around the mean state and, therefore, the evolution of the random initial condition can be approximated by linearized dynamics around the mean state . It is clear that for this case the DB, DO and KL reductions are nearly identical. However, for case II, the nonlinear effects are much stronger, as evidenced by observing that the energy of the mean is comparable to the eigenvalues of the covariance matrix; see figure 3d. In this case a significant discrepancy between DO and DB reductions is observed, while DB is closer to KL with smaller reconstruction error; see figure 3c.
Figure 3.

The effect of nonlinearity and comparison of dynamic basis (DB) reduction with dynamically orthogonal (DO) decomposition and Karhunen–Loève (KL) decomposition. (a,c) Reconstruction error and (b,d) eigenvalues of the covariance matrix and the energy of the mean of the samples: , where . (a,b) σ1 = σ2 = 0.05 and (c,d) σ1 = σ2 = 0.5. (Online version in colour.)
One source of discrepancy between DO and DB is that, in the DO formulation, the samples are generated on the fly by the reduced-order model. Therefore, the samples generated by DO deviate from the truth. This is not, however, the case in DB, where the samples, represented by T(t), are the truth. On the other hand, in the case of linear dynamics, the discrepancy between the samples generated by DO and the truth approaches zero. For the proof, see appendix A of [14] and theorem 2.4 in [18]. This explains why the DO and DB are nearly identical for linear regimes, i.e. case I, and are different for nonlinear regimes, i.e. case II.
(c). Transient instability: Kuramoto–Sivashinsky
One of the main utilities of a low-rank approximation of high-dimensional dynamical systems is to provide an interpretable explanation of complex spatio-temporal dynamics. In this section, we demonstrate the application of the DB reduction to the one-dimensional stochastic Kuramoto–Sivashinsky equation. This equation has been widely studied for chaotic spatio-temporal dynamics in wide-ranging applications, including reaction–diffusion systems [22], fluctuations in fluid films on inclines [23] and instabilities in laminar flame fronts [24]. The Kuramoto–Sivashinsky equation exhibits intrinsic instabilities and as a result the stochastic perturbations may undergo a significant growth. The spontaneity of the instability makes it a challenging problem for any reduction technique as the reduced subspace during the transition could be very different from that of the equilibrium states. We apply the DB reduction to realizations of the Kuramoto–Sivashinsky system to demonstrate how the U(t) ‘follows’ the dynamics as the observations undergo a transient instability. This transient instability is visualized in figure 4a, where a sudden transition occurs near t = 0.75. The solution shown in figure 4a is one realization of the Kuramoto–Sivashinsky equation with the following set-up. We consider Kuramoto–Sivashinsky equation
| 3.6 |
with ϵ = 0.01 and subject to random initial condition
| 3.7 |
Figure 4.

Kuramato–Sivashinsky: (a) solution u(x, t) shows a sudden transition; covariance kernel of the random perturbation with correlation length (b) lc = 2.5 and (c) lc = 0.05. (Online version in colour.)
In the above equation ub(x) is chosen to be the terminal solution of equation (3.6) after long-time integration. The random perturbation of the initial condition, denoted by u′(x;ξ), is set to have periodic covariance given by
where σ is the standard deviation and lc is the correlation length. We perform KL decomposition
where λi and ϕi(x) are the ith eigenvalue and eigenfunction of the covariance kernel. The random perturbation is then approximated as
where ξi∈[0, 1] are independent uniform random numbers with unit variance. The dimension d is chosen such that 99% of the energy is captured by the KL decomposition. Decreasing lc increases the number of dimensions required to capture the energy threshold. We consider two cases of low-dimensional and high-dimensional random perturbations with lc = 2.5 and lc = 0.05, respectively. The covariance kernels for these two correlation lengths are shown in figure 4.
Three-dimensional random perturbation. We consider a correlation length of lc = 2.5 and σ = 0.1. The three-dimensional (d = 3) expansion of the KL decomposition captures more than 99% of the energy of the covariance kernel. We sample the Kuramoto–Sivashinsky equation at probabilistic Q = 5 collocation points in each ξi direction; therefore, the total number of samples is s = 53. Correspondingly, the sample weights wξ are the probabilistic collocation weights. We use chebfun [25] as a blackbox solver to solve the Kuramoto–Sivashinsky equation (3.6) for s = 53 realizations of the random initial condition. The solution is post-processed with fixed Chebyshev polynomial order n = 256. Matrix T is sampled at discrete times with a constant time interval of dt = 0.001 from t = 0 to Tf = 1.2. This time interval encompasses the transition period that occurs, 0.6 < t < 1.0.
We perform DB reduction with size r = 4. In figure 5a, the eigenvalues of the reduced covariance matrix versus time are shown. The eigenvalues of the covariance matrix represent variance or the energy associated with the DB. The first three DBs associated with the three largest eigenvalues of the covariance matrix are shown in figure 5b–d.
Figure 5.

Dynamic basis (DB) reduction for the Kuramoto–Sivashinsky equation with reduction size r = 4. (a) Eigenvalues of reduced covariance matrix. The first three modes at different time instants: (b) u1, (c) u2 and (d) u3. (Online version in colour.)
We first observe that the energy of the first mode remains roughly constant for 0 < t < 0.5. However, the second and third modes undergo four orders of magnitude growth during the same period. Correspondingly, the first DB remains nearly static for 0 < t < 0.5 (see figure 5b). However, u2 and u3 are evolving during the same time interval (figure 5c,d). The second and third modes have near-eigenvalue crossings periodically in this interval, which causes very rapid changes in the modes when their eigenvalues become close. The significant growth of the energy of the second and third modes reveals the transient unstable directions of the dynamical system. However, these two modes are ‘buried’ underneath the most energetic mode, e.g. the first mode. We note that detecting the unstable directions is crucial for control of these systems [26]. Detecting these directions can be used in building precursors of sudden transitions or rare events in transient systems.
We also computed DMD modes to compare against the DB reduction. DMD has been very successful as a diagnostic tool to characterize complex dynamical systems. However, it is difficult for DMD to handle transient phenomena. To this end, we computed the DMD modes for a deterministic realization of the Kuramoto–Sivashinsky equation. The realization is generated by solving the Kuramoto–Sivashinsky equation for the collocation point ξ0 = ( − 0.91, − 0.54, 0.91). This collocation point is chosen arbitrarily and any other collocation point would result in the same qualitative observations that we make in this section. To compute the DMD modes we first performed singular value decomposition (SVD) of the mean-subtracted snapshots of the Kuramoto–Sivashinsky equation in the span of t∈[0, Tf] for ξ0 = ( − 0.91, − 0.54, 0.91). The SVD truncation threshold was set to 99%, where σi are the singular values and N is the total number of snapshots. The 99% threshold resulted in n = 11 low-rank approximations. We then computed the DMD modes Φ according to the procedure explained in [8]. The DMD-reconstructed data were then computed using: , where bk is the initial amplitude of each mode, Φk's are the DMD eigenvectors and ωk's are the eigenvalues associated with DMD modes. In figure 6, we compare the reconstruction of the DMD with n = 11 and DB with r = 4. The DB reconstruction obtained by: , where yi(t, ξ0) are the stochastic coefficients associated with ξ0 = ( − 0.91, − 0.54, 0.91), i.e. a fixed row (s) of matrix Y. It is clear that DMD fails to capture the transient instability, while DB reconstruction looks qualitatively accurate.
Figure 6.

Reconstruction of a Kuramoto–Sivashinsky sample with: (a) true solution; (b) reconstruction with dynamic mode decomposition and (c) reconstruction with dynamic basis. (Online version in colour.)
We perform a quantitative comparison between DMD and DB. We rank the n = 11 DMD modes based on their growth rates from increasing to decreasing, and we perform DMD reconstruction for r = 2, 4, 6 and 8. We also perform DB for the same reduction sizes. We then compute the reconstruction error: , where K is the total number of snapshots and u(tk) is the reconstructed solution based on DMD or DB. In table 1, the reconstruction errors ϵ for DB and DMD are shown. DMD is incapable of converging to the true solution as the size of DMD modes increases; however, DB converges to the true solution as the reduction size increases. The limitation of DMD for capturing transient dynamics has been recognized before; see for example [9], chapter 1, section 1.5.2.
Table 1.
Reconstruction error of the Kuramoto–Sivashinsky equation: comparison between dynamic mode decomposition (DMD) and dynamic basis (DB).
| r | 2 | 4 | 6 | 8 |
|---|---|---|---|---|
| error (DMD) | 9.01 × 10−2 | 9.027 × 10−2 | 9.18 × 10−2 | 9.24 × 10−2 |
| error (DB) | 2.10 × 10−1 | 6.92 × 10−3 | 1.88 × 10−3 | 8.92 × 10−4 |
One-hundred-dimensional random perturbation. In this section we present the results of DB reduction of a 100-dimensional random initial condition with a correlation length of lc = 0.05 (figure 5c). To capture the small scales of the random initial condition the state space is represented with a Chebyshev polynomial of order n = 1024. We draw Monte Carlo samples of the initial condition with sample sizes of s = 1000 and s = 5000. We note that these sample sizes are quite small given the high dimensionality of the random space. However, as we demonstrate here the DB reduction extracts the low-dimensional structure of the observables despite the severely low number of samples. We choose a reduction size of r = 6. In figure 7 the eigenvalues of the covariance matrix for the sample sizes are shown. As is clear, the DB reductions with sample sizes of 1000 and 5000 are very close before and during the transition. This implies that, despite the high dimensionality of the random space, the transient response has a low-dimensional structure—albeit a highly time-dependent one—that is effectively captured with the proposed reduction with severely sparse samples.
Figure 7.
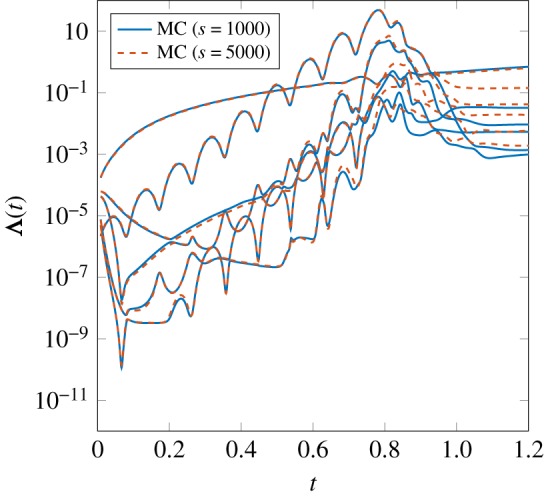
Dynamic basis reduction of the Kuramoto–Sivashinsky equation subject to 100 random initial conditions. Two Monte Carlo (MC) sample sizes of s = 1000 and s = 5000 are shown. The reduction size is r = 6. (Online version in colour.)
(d). Transient vertical jet
In this section we perform dynamic reduction for a two-dimensional transient vertical jet flushed into quiescent background flow. The jet is driven by random boundary conditions as described in this section. We note that, in the DO/BO formulation, it is still not known how to determine the boundary condition for the DO/BO modes in the case of random boundary conditions [20]. However, in the DB formulation the boundary conditions for the DB modes are optimally determined via the variational principle. The schematic of the problem is shown in figure 8a. To generate the samples, we performed direct numerical simulation (DNS) of the two-dimensional incompressible Navier–Stokes equations,
and
where u(x, t;ξ) is the random velocity field with two components of u = (u, v) and the spatial coordinates of x = (x, y), and p(x, t;ξ) is the random pressure field and Re = 500 is the Reynolds number. We consider a stochastic jet velocity given by
| 3.8 |
Figure 8.

Transient vertical jet in quiescent flow. (a) Schematic of the problem. (b) The three most energetic proper orthogonal decomposition (POD) modes. (Online version in colour.)
The mean of the prescribed jet boundary condition is similar to that found in previous studies [27,28]. The random component of the boundary condition is represented by a uniform random field with the covariance kernel specified by
where lc = 0.5 and σ = 0.01. The dimension d = 2 is chosen such that 99% of the energy is captured by the KL decomposition. We performed DNS using the spectral/hp element method with Ne = 1604 and a spectral polynomial order of p = 5. With these settings, the size of the discrete phase space is roughly n = 115 000 when accounting for the two components of the velocity vector field. The time integration was performed using the third-order stiffly stable scheme [29] with time intervals of Δt = 5 × 10−3. We sample the DNS at PCM points with Q = 6 quadrature points in each random dimension. Therefore, the total number of samples is s = Q2 = 36.
As a reference reduction, we first computed the POD modes. Since POD modes are often used in deterministic flows, we explain how these modes are computed in a stochastic setting. To do so, we first formed the matrix T that contains all mean-subtracted snapshots of all 36 samples, i.e. the entire DNS data. We then performed SVD of this matrix. The POD modes are then computed as the left singular eigenvectors of matrix T. Therefore, the computed POD modes are an optimal basis for the entire DNS data in the second norm sense. In figure 8b, the first three POD modes associated with the largest singular values are shown.
We solved the evolution equations (2.11) and (2.12) with r = 3 with a fourth-order Runge–Kutta integration scheme. The time snapshots of matrix T were obtained by skipping every three time steps of the DNS, i.e. the time interval of DB evolution is Δt = 2 × 10−2 .
In figure 9, we show the results of the state of the DB for three time snapshots at t1 = 2, t2 = 6 and t3 = 10 time units, with each row showing the results at a fixed time. For the purpose of visualizing the mean, we solved a passive scalar transport equation along with the Navier–Stokes equation with Schmidt number Sc = 1. See [18] for more details of a similar approach for visualization. In the leftmost column, the mean data are visualized by the scalar transport intensity. The mean shows the puff growing in size as the jet entrains the quiescent background flow while advecting upward. In the middle three columns, the first three most dominant dynamic bases are visualized by their vorticity: ωzi = ∂ui/∂y − ∂vi/∂x. The evolution of the DB along with the data is clearly seen. The DB reveals the spatio-temporal coherent structures in the flow. Similar to the POD modes (figure 8b), the higher modes of the DB show finer spatial structures. However, the POD modes are static and they are optimal in a time-average sense, as opposed to the DB that evolves according to . We will compare the POD reduction error with that of the DB. In the rightmost column, the low-dimensional attractor is visualized by plotting the iso-surface of the joint probability density function πy1y2y3 of the three most dominant stochastic coefficients: y1, y2 and y3. Since the DNS are sampled at PCM points, the PCE is used to generate more samples for visualizing πy1y2y3 in the post-processing stage. The attractor clearly shows a low-dimensional manifold as it evolves in time.
Figure 9.

Dynamic basis reduction of a transient vertical jet in quiescent flow. Left: Flow mean visualized by a passive scalar. Middle: The three most dominant dynamics modes are visualized by vorticity ωz. Right: The iso-surface of the joint probability density function πy1y2y3 of the first three dynamic modes. Each row shows the state of the reduction at a fixed time with first row: t1 = 2; second row: t2 = 6; and third row: t3 = 10. (Online version in colour.)
We now leverage the data-driven feature of the DB reduction and we apply it to partial observations. To this end, we applied the DB with a reduction size of r = 3 to a subset of the observations, as shown by the circle in figure 10. Therefore, the data matrix T only includes points that are inside the circle in figure 10 and points outside of the circle are not included in the DB calculation. The extracted DBs associated with the three modes are also shown in the three middle columns of figure 10 for t = 2, 6 and 10. In this case the dynamics represent a locally orthonormal basis. At t = 2, the vortex has not reached the region of interest (ROI); however, owing to the incompressibility of the flow, the random boundary conditions affect the entire domain and the DB modes capture this effect with more strength in the lower part of the ROI. The attractor at the corresponding times is shown in the right column of figure 10. The low-dimensional attractor exhibits a different structure from that of the full domain shown in figure 9. Applying the DB reduction to a subset of observations enables the extraction of local low-dimensional structures by ‘zooming in’ to a ROI. Moreover, this enables the employment of the DB reduction in a domain decomposition scheme [30], where each domain has a set of locally orthonormal DBs. This is in contrast to the DO/BO decompositions, where neither of the decompositions can be applied to a subset of the full domain. This is because both DO and BO are model driven and as such they would require the specification of the boundary conditions for the mean and the spatial modes at the boundaries of the ROI. Clearly, these time-dependent values at the arbitrary boundaries are not known.
Figure 10.

Dynamic basis reduction of a transient vertical jet in quiescent flow with a clipped domain. Only data points that lie inside the circle are used in the dynamic basis reduction. Left: Flow mean visualized by a passive scalar. Middle: the three most dominant dynamics modes are visualized by vorticity ωz. Right: The iso-surface of the joint probability density function πy1y2y3 of the first three dynamic modes. Each row shows the state of the reduction at a fixed time with first row: t1 = 2; second row: t1 = 6; and third row: t3 = 10. (Online version in colour.)
In figure 11a, we make a comparison between POD and DB reconstruction errors, given by equation (3.5), in which the POD mode U represents the first r dominant POD modes and Y is obtained via the orthogonal projection of the data onto U, i.e. Y(t) = 〈U, T(t)〉. As shown in figure 11, the reduction of the DB with r = 2 is comparable to that of POD with r = 20 for long time, and in the early evolution (i.e. t < 4) the error of DB (r = 2) is smaller than that of POD with r = 50. A similar behaviour is observed for DB r = 3, 4 and 5, where a 10-fold increase in POD reduction size is required to have a comparable reduction error with DB. We also observe that the DB error increases with time. This is the result of two effects: (i) as the jet advects upward, the uncertainty grows and more modes are required to better estimate the observations; and (ii) the effect of unresolved modes in the DB reduction. In the case of drastic reduction, for example r = 2, discarding the unresolved modes will lead to an increase in error over time. The effect of unresolved modes can be properly studied in the Mori–Zwanzig formalism [31]. As can be seen in figure 11a increasing the number of DBs significantly decreases the error and the growth rate of the error.
Figure 11.

(a) Comparison of the reduction error between the dynamic basis (DB) and proper orthogonal decomposition (POD). (b) Effect of the discretization scheme for computing and evolution of the DB. First-order Euler explicit (EE1), fourth-order central finite difference (FD4) and Runge–Kutta (RK4). Identifiers are shown in the form of X–Y: X shows the discretization scheme used for estimating and Y shows the time-advancement scheme for solving the evolution equation for the DB. (Online version in colour.)
In figure 11b, we show the results of different time discretization schemes for: (i) computing with two different schemes of first-order Euler explicit (EE1) and fourth-order central finite difference (FD4) and (ii) the time advancement of U(t) and Y(t) via equations (2.11) and (2.12) with EE1 and fourth-order Runge–Kutta (RK4). All four combinations of the above schemes are considered with the identifiers in the form of X-Y, where the first part of the identifier (X) shows the discretization scheme used for estimating and the second part of the identifier (Y) shows the time-advancement scheme for solving equations (2.11) and (2.12). In particular we considered these schemes: EE1-EE1, EE1-RK4, FD4-EE1 and FD4-RK4. We used DB with a size of r = 5 for all these schemes. The errors of schemes EE1-EE1 and FD4-EE1 are very close—suggesting that the time-advancement error of solving equations (2.11) and (2.12) is the primary source of error and increasing the accuracy of estimating does not improve the overall accuracy. Comparing the errors of EE1-EE1 with those of EE1-RK4 confirms that the error can be reduced by increasing the accuracy of the time integrator of the evolution equations for U and Y. However, comparing the errors of EE1-RK4 with those of FD4-RK4 demonstrates that the primary contributor to the error for the scheme EE1-RK4 is the estimation of . The totality of these observations shows that both the accuracy of estimating and solving the evolution equations of the DB affect the reduction error potentially significantly. Obviously, if Δt is decreased, the contribution of the time-discretization error will become less significant than that of the reduction error.
4. Conclusion
The objective of this paper is to develop a reduced description of the transient dynamics that relies on the observables of the dynamics. To this end, we present a variational principle whose optimality conditions lead to a closed-form evolution equation for a set of time-dependent orthonormal modes and their associated coefficients, referred to as the dynamic basis. The DB is driven by the time derivative of the random observations, and it does not require the underlying dynamical system that generates the observables. In that sense, the proposed reduction is purely observation driven and may apply to systems whose models are not known.
The application of the DB was demonstrated for a variety of examples. (i) The advection equation with random wave speed for which the exact solution for the DB was derived and was used for validation purposes. (ii) Stochastic Burgers equation, for which DB reduction was compared with KL and DO decompositions. (iii) Kuramoto–Sivashisky equation subject to random initial conditions where it was shown that the DB captures the transient intrinsic instability—even in the presence of a high-dimensional random initial condition. The performance of the DB reduction was compared against the DMD. (iv) Navier–Stokes equations subject to random boundary conditions for which we compared the effectiveness of the DB versus POD, as an example of static-basis reductions.
The DB evolution equation has a linear computational complexity with respect to the number of observables and the number of random realizations. This is a favourable feature if applications of large dimension are of interest, for example weather forecast, ocean models and turbulent flows.
Supplementary Material
Acknowledgements
The author would like to thank Prof. Karniadakis for useful comments. This research was also supported in part by the University of Pittsburgh Center for Research Computing through the resources provided. The author gratefully acknowledges the allocated computer time on the Stampede supercomputers, awarded by the XSEDE program, allocation no. ECS140006.
Appendix A. Optimality condition of the variational principle
In the following we show that the first-order optimality condition of the variational principle (2.6) leads to closed-form evolution equations for U and Y. For the sake of brevity we drop the explicit dependence on (t) in the following derivation. We first observe that
The first-order optimality condition requires and for k = 1, 2, …, r. We first observe that the gradient of with respect to can be expressed as
| A 1 |
To eliminate λkj, we take the inner product of the above equation by ul
where we have made use of the definition of . Rearranging the above equation results in
After multiplying equation (A 1) from the left by W−1x/2 and substituting λjk from the above equation we obtain
In the vectorized form the above equation can be written as
where Cij = yTiWξyj is the covariance matrix. Similarly,
| A 2 |
In the above expression we have made use of since both and are scalars. By multiplying the above equation (A 2) by W−1ξ/2 from the left and replacing uTkWxuj = δkj and , we obtain
In the vectorized form the above equation can be expressed as
Appendix B. Proof of equivalence of reductions
Theorem B.1. —
Suppose that {Y, U} and satisfy the evolution equations (2.7) and (2.8) with different choices of ϕ functions denoted by and , respectively. We also assume that the two reductions are initially equivalent, i.e. and , where is an orthogonal rotation matrix. Then {Y, U} and are equivalent for t > 0, with a rotation matrix governed by the matrix differential equation .
Proof. —
We replace and into the evolution equations (2.7) and (2.8). The evolution of the DB can be written as
Therefore,
where and, therefore, , where C are are similar matrices and have the same eigenvalues. In the last equation we have used and made use of the identity R−1 = RT. The evolution of the stochastic coefficients can be written as
Therefore,
▪
Data accessibility
The code and data used in this paper can be obtained from: https://github.com/hbabaee/Dynamic-Basis. The package Chebfun must be installed to run the codes.
Competing interests
I declare I have no competing interests.
Funding
The research has been supported by the NASA Transformational Tools and Technologies (TTT) Project, grant no. 80NSSC18M0150, and an award by the American Chemical Society, Petroleum Research Fund, grant no. 59081-DN19.
References
- 1.Hey T, Tansley S, Tolle K. 2009. The fourth paradigm: data-intensive scientific discovery. Redmond, WA: Microsoft Research.
- 2.van der Maaten LJP, Postma EO, van den Herik HJ. 2009. Dimensionality reduction: a comparative review. See https://lvdmaaten.github.io/publications/papers/TR_Dimensionality_Reduction_Review_2009.pdf.
- 3.Noack BR. 2016. From snapshots to modal expansions—bridging low residuals and pure frequencies. J. Fluid Mech. 802, 1–4. ( 10.1017/jfm.2016.416) [DOI] [Google Scholar]
- 4.Marzouk Y, Xiu D. 2009. A stochastic collocation approach to Bayesian inference in inverse problems. Commun. Comput. Phys. 6, 826–847. ( 10.4208/cicp.2009.v6.p826) [DOI] [Google Scholar]
- 5.Xiu D, Karniadakis GE. 2002. The Wiener–Askey polynomial chaos for stochastic differential equations. SIAM J. Sci. Comput. 24, 619–644. ( 10.1137/S1064827501387826) [DOI] [Google Scholar]
- 6.Branicki M, Majda AJ. 2012. Fundamental limitations of polynomial chaos for uncertainty quantification in systems with intermittent instabilities. Commun. Math. Sci. 11, 55–103. ( 10.4310/CMS.2013.v11.n1.a3) [DOI] [Google Scholar]
- 7.Wan X, Karniadakis GE. 2006. Long-term behavior of polynomial chaos in stochastic flow simulations. Comput. Methods Appl. Mech. Eng. 195, 5582–5596. ( 10.1016/j.cma.2005.10.016) [DOI] [Google Scholar]
- 8.Schmid PJ. 2010. Dynamic mode decomposition of numerical and experimental data. J. Fluid Mech. 656, 5–28. ( 10.1017/S0022112010001217) [DOI] [Google Scholar]
- 9.Kutz J, Brunton S, Brunton B, Proctor J. Dynamic mode decomposition: data-driven modeling of complex systems. Philadelphia, PA: Society for Industrial and Applied Mathematics.
- 10.Crommelin DT, Majda AJ. 2004. Strategies for model reduction: comparing different optimal bases. J. Atmos. Sci. 61, 2206–2217. () [DOI] [Google Scholar]
- 11.Sapsis TP, Lermusiaux PFJ. 2009. Dynamically orthogonal field equations for continuous stochastic dynamical systems. Physica D 238, 2347–2360. ( 10.1016/j.physd.2009.09.017) [DOI] [Google Scholar]
- 12.Cheng M, Hou TY, Zhang Z. 2013. A dynamically bi-orthogonal method for time-dependent stochastic partial differential equations I: derivation and algorithms. J. Comput. Phys. 242, 843–868. ( 10.1016/j.jcp.2013.02.033) [DOI] [Google Scholar]
- 13.Choi M, Sapsis TP, Karniadakis GE. 2014. On the equivalence of dynamically orthogonal and bi-orthogonal methods: theory and numerical simulations. J. Comput. Phys. 270, 1–20. ( 10.1016/j.jcp.2014.03.050) [DOI] [Google Scholar]
- 14.Babaee H, Choi M, Sapsis TP, Karniadakis GE. 2017. A robust bi-orthogonal/dynamically-orthogonal method using the covariance pseudo-inverse with application to stochastic flow problems. J. Comput. Phys. 344, 303–319. ( 10.1016/j.jcp.2017.04.057) [DOI] [Google Scholar]
- 15.Beck MH, Jäckle A, Worth GA, Meyer HD. 2000. The multiconfiguration time-dependent Hartree (MCTDH) method: a highly efficient algorithm for propagating wavepackets. Phys. Rep. 324, 1–105. ( 10.1016/S0370-1573(99)00047-2) [DOI] [Google Scholar]
- 16.Bardos C, Golse F, Gottlieb AD, Mauser NJ. 2003. Mean field dynamics of fermions and the time-dependent Hartree–Fock equation. J. Math. Pures Appl. 82, 665–683. ( 10.1016/S0021-7824(03)00023-0) [DOI] [Google Scholar]
- 17.Koch O, Lubich C. 2007. Dynamical low-rank approximation. SIAM J. Matrix Anal. Appl. 29, 434–454. ( 10.1137/050639703) [DOI] [Google Scholar]
- 18.Babaee H, Sapsis TP. 2016. A minimization principle for the description of modes associated with finite-time instabilities. Proc. R. Soc. A 472, 20150779 ( 10.1098/rspa.2015.0779) [DOI] [PMC free article] [PubMed] [Google Scholar]
- 19.Babaee H, Farazmand M, Haller G, Sapsis TP. 2017. Reduced-order description of transient instabilities and computation of finite-time Lyapunov exponents. Chaos 27, 063103 ( 10.1063/1.4984627) [DOI] [PubMed] [Google Scholar]
- 20.Musharbash E, Nobile F. 2018. Dual dynamically orthogonal approximation of incompressible Navier Stokes equations with random boundary conditions. J. Comput. Phys. 354, 135–162. ( 10.1016/j.jcp.2017.09.061) [DOI] [Google Scholar]
- 21.Exascale Mathematics Working Group. 2014. Applied mathematics research for exascale computing. Oakridge, TN: US Department of Energy. See https://collab.cels.anl.gov/display/examath/Exascale+Mathematics+Home.
- 22.Kuramoto Y, Tsuzuki T. 1976. Persistent propagation of concentration waves in dissipative media far from thermal equilibrium. Prog. Theor. Phys. 55, 356–369. ( 10.1143/PTP.55.356) [DOI] [Google Scholar]
- 23.Sivashinsky GI, Michelson DM. 1980. On irregular wavy flow of a liquid film down a vertical plane. Prog. Theor. Phys. 63, 2112–2114. ( 10.1143/PTP.63.2112) [DOI] [Google Scholar]
- 24.Sivashinsky GI. 1977. Nonlinear analysis of hydrodynamic instability in laminar flames—I. Derivation of basic equations. Acta Astronaut. 4, 1177–1206. ( 10.1016/0094-5765(77)90096-0) [DOI] [Google Scholar]
- 25.Driscoll TA, Hale N, Trefethen LN. 2014. Chebfun guide. Oxford, UK: Pafnuty Publications.
- 26.Blanchard A, Mowlavi S, Sapsis T. 2018. Control of linear instabilities by dynamically consistent order reduction on optimally time-dependent modes. Nonlinear Dyn. 95, 2745–2764. ( 10.1007/s11071-018-4720-1) [DOI] [Google Scholar]
- 27.Babaee H. 2013. Uncertainty quantification of film cooling effectiveness in gas turbines. Master's thesis, Louisiana State University, Baton Rouge, LA, USA.
- 28.Bagheri S, Schlatter P, Schmid PJ, Henningson DS. 2009. Global stability of a jet in crossflow. J. Fluid Mech. 624, 33–44. ( 10.1017/S0022112009006053) [DOI] [Google Scholar]
- 29.Karniadakis GE, Sherwin SJ. 2005. Spectral/hp element methods for computational fluid dynamics. Oxford, UK: Oxford University Press. [Google Scholar]
- 30.Zhang D, Babaee H, Karniadakis G. 2018. Stochastic domain decomposition via moment minimization. SIAM J. Sci. Comput. 40, A2152–A2173. ( 10.1137/17M1160756) [DOI] [Google Scholar]
- 31.Chorin AJ, Hald OH, Kupferman R. 2002. Optimal prediction with memory. Physica D 166, 239–257. ( 10.1016/S0167-2789(02)00446-3) [DOI] [Google Scholar]
Associated Data
This section collects any data citations, data availability statements, or supplementary materials included in this article.
Supplementary Materials
Data Availability Statement
The code and data used in this paper can be obtained from: https://github.com/hbabaee/Dynamic-Basis. The package Chebfun must be installed to run the codes.