

Abstract
Purpose
Numerous image reconstruction methodologies for positron emission tomography (PET) have been developed that incorporate magnetic resonance (MR) imaging structural information, producing reconstructed images with improved suppression of noise and reduced partial volume effects. However, the influence of MR structural information also increases the possibility of suppression or bias of structures present only in the PET data (PET‐unique regions). To address this, further developments for MR‐informed methods have been proposed, for example, through inclusion of the current reconstructed PET image, alongside the MR image, in the iterative reconstruction process. In this present work, a number of kernel and maximum a posteriori (MAP) methodologies are compared, with the aim of identifying methods that enable a favorable trade‐off between the suppression of noise and the retention of unique features present in the PET data.
Methods
The reconstruction methods investigated were: the MR‐informed conventional and spatially compact kernel methods, referred to as KEM and KEM largest value sparsification (LVS) respectively; the MR‐informed Bowsher and Gaussian MR‐guided MAP methods; and the PET‐MR‐informed hybrid kernel and anato‐functional MAP methods. The trade‐off between improving the reconstruction of the whole brain region and the PET‐unique regions was investigated for all methods in comparison with postsmoothed maximum likelihood expectation maximization (MLEM), evaluated in terms of structural similarity index (SSIM), normalized root mean square error (NRMSE), bias, and standard deviation. Both simulated BrainWeb (10 noise realizations) and real [18F] fluorodeoxyglucose (FDG) three‐dimensional datasets were used. The real [18F]FDG dataset was augmented with simulated tumors to allow comparison of the reconstruction methodologies for the case of known regions of PET‐MR discrepancy and evaluated at full counts (100%) and at a reduced (10%) count level.
Results
For the high‐count simulated and real data studies, the anato‐functional MAP method performed better than the other methods under investigation (MR‐informed, PET‐MR‐informed and postsmoothed MLEM), in terms of achieving the best trade‐off for the reconstruction of the whole brain and PET‐unique regions, assessed in terms of the SSIM, NRMSE, and bias vs standard deviation. The inclusion of PET information in the anato‐functional MAP method enables the reconstruction of PET‐unique regions to attain similarly low levels of bias as unsmoothed MLEM, while moderately improving the whole brain image quality for low levels of regularization. However, for low count simulated datasets the anato‐functional MAP method performs poorly, due to the inclusion of noisy PET information in the regularization term. For the low counts simulated dataset, KEM LVS and to a lesser extent, HKEM performed better than the other methods under investigation in terms of achieving the best trade‐off for the reconstruction of the whole brain and PET‐unique regions, assessed in terms of the SSIM, NRMSE, and bias vs standard deviation.
Conclusion
For the reconstruction of noisy data, multiple MR‐informed methods produce favorable whole brain vs PET‐unique region trade‐off in terms of the image quality metrics of SSIM and NRMSE, comfortably outperforming the whole image denoising of postsmoothed MLEM.
Keywords: kernel, MAPEM, MR-informed, PET, reconstruction
1. Introduction
Positron emission tomography (PET) is a versatile and clinically impactful medical imaging modality, in the diagnosis or management of neurological disorders, cancers, and cardiovascular diseases. Despite PET's clinical utility, the associated image quality is generally inferior to other anatomically driven imaging modalities, such as magnetic resonance imaging (MRI). There are two dominant factors that degrade the reconstructed PET image quality: (a) high Poisson noise in the PET data, a consequence of the limited injected dose and limited sensitivity of current clinical PET scanners; (b) poor spatial resolution (~4 mm), due to the finite detector size, photon acollinearity and positron range (among other factors). The limited PET system resolution leads to partial volume effects (PVEs), such as the spillover of small high‐intensity regions to neighboring voxels, introducing bias in regional quantification. To address these issues, anatomical images (such as MR) have been exploited, through utilizing shared PET‐MR structural information within the reconstruction process. Anatomical MR images, such as T1 or T2 weighted, provide structural information that the PET radiotracer distribution is likely to correlate with, at least in part. This functional anatomical correspondence is particularly evident for neurological [18F]fluorodeoxyglucose (FDG) PET scans, where the radiotracer distribution is well delineated between the white and gray matter boundaries. Numerous such MR‐informed reconstruction methodologies have now been proposed in the literature.1, 2, 3, 4, 5, 6, 7, 8
One recent example of MR‐informed PET reconstruction in the current literature is the MR‐informed kernel method (KEM).9, 10 The kernel method extracts structural information from the corresponding MR image, forming a set of spatial basis functions. These structural basis functions reparameterize the reconstruction process, restricting the reconstructed image to be comprised from a linear combination of these spatial basis functions. MR‐informed KEM has subsequently been extended to produce more spatially compact basis functions, referred to as KEM largest value sparsification (LVS),11 to aid the recovery of PET‐unique features. PET‐unique features are considered to be structures that are present in the PET image, but which are not present or have a different structure in the MR image. In contrast to conventional KEM, KEM LVS uses a composite feature vector comprised of both MR intensity and spatial information, the relative weighting between these two features is used to select the contributing voxels for each basis function. Therefore, in relatively uniform MR regions where the MR intensity values are similar, spatially close voxels will be selected over more disparate voxels, thereby helping recovery of PET‐unique features. More generally, KEM has been applied to a range of reconstruction problems,12, 13, 14, 15, 16, 17, 18, 19, 20, 21 and is an example of a broader cohort of algorithms that reparameterize the emission image into an alternative set of basis functions.22, 23, 24
In contrast to reparameterizing the reconstruction process, MR information can alternatively be included into the reconstruction process through the addition of a regularizing term in either a Bayesian maximum a posteriori (MAP) or penalized maximum likelihood (PL) framework.25, 26 In this work, the regularized methods investigated are restricted to an image‐weighted quadratic potential function in the prior. Multiple alternatives to the quadratic prior have been proposed in the literature (e.g., relative difference, total variation, Lange, Kaipio),27, 28, 29 which predominantly seek to reduce smoothing across genuine boundaries in comparison with the quadratic prior. However, due to the inclusion of anatomical boundary information through the image‐weighting factors, shared PET‐MR boundaries are expected to be well recovered irrespective of the potential function used in the prior. For such reasons, the consequence of varying penalty functions (for instance using the relative difference instead of the quadratic penalty function) while including image‐weighting factors in the prior has been shown to be minimal.30
The selection of MR(only)‐informed weighting factors under comparison in this work is the Gaussian similarity kernel31, 32 and the asymmetric Bowsher prior,5 due to their enduring popularity, and ability to match the performance of more involved MR‐informed methods.30, 33, 34 In addition, these methods use spatial similarity matrices to extract MR structures, in a comparable way to the kernel methods. Thus, all methods investigated in this study can be considered to be part of the same group of algorithms which include MR information through similarity matrices. These MR‐derived similarity matrices are incorporated into the reconstruction process via the kernel method (KEM & KEM LVS) or MAP (Gaussian MR‐Guided and Bowsher).
The kernel and MAP MR‐informed reconstruction methodologies have all demonstrated reduced noise35 and reduced PVE properties, in comparison with the routinely used maximum likelihood expectation maximization (MLEM)36 or ordered subsets expectation maximization (OSEM) algorithms.37 Due to the reduction of PVE through incorporating MR information, major improvements in regional quantification can be realized.38, 39 This is of particular importance for the assessment and diagnosis of neurological diseases including Alzheimer's, epilepsy, and Parkinson's disease, where quantification of MR visible anatomical regions is essential.6, 40, 41, 42, 43, 44 Despite these beneficial properties achieved through the inclusion of MR information, adverse consequences also arise, such as increased susceptibility to suppressing PET‐unique high‐intensity regions.10, 30 This is a major pitfall for the visual diagnostic interpretation of PET images, in particular for oncological cases, where PET imaging has been shown to improve the diagnosis and subsequent treatment of cancers.45 Specifically, for brain and neck cancers [18F]FDG PET has played an increasing role in the diagnosis and planning.46, 47 One potential avenue currently under investigation for reducing the suppression of these high‐intensity PET‐unique regions is to extend the MR guidance to include the reconstructed PET image at each iteration. This concept was implemented firstly via MAP (regularization)3, 48, 49 and has recently been extended to a kernel (reparameterization)50, 51 implementation. Such methods shall be referred to as PET‐MR‐informed, from which this work shall compare the anato‐functional (a MAP method),52 and the hybrid kernel method (HKEM).50, 51 Alternative PET‐MR‐informed methods are present in the literature, which incorporate both PET and MR information in the regularization term, including joint Shannon entropy4, 53 and parallel level sets priors.54, 55 While such methods remain active within the PET reconstruction field, they do not lie within the same group of algorithms under comparison that determine PET‐MR similarity via a local neighborhood similarity matrix.
In this work, a comparison between MR‐informed and PET‐MR‐informed kernel and MAP methods is undertaken, in order to clarify whether the inclusion of MR information into the PET reconstruction process in the above forms can universally improve the reconstructed images, for shared and discrepant PET‐MR regions alike. In particular, we focus on the trade‐off between whole brain image quality, evaluated in terms of structural similarity (SSIM) and normalized root mean square error (NRMSE), and the faithful recovery of structures unique to the PET data, evaluated in terms of bias and mean values, and whether the inclusion of PET data into the guidance process reduces the suppression of the PET‐unique regions.
2. Materials and Methods
2.1. Theory
The reconstructed PET image represents the spatial distribution of an injected radiotracer. The injected radiotracer undergoes radioactive decay within the patient, expelling positrons that rapidly annihilate, with each annihilation event producing a pair of photons with opposite trajectories that are detected by the PET scanner along a particular line of response. The measured counts (m) for each and every line of response correspond to a set of Poisson random variables, the values of which can be related to the expected counts through the Poisson likelihood. Through maximizing the Poisson likelihood with respect to the emission image (θ), the most likely expected counts distribution is calculated. The EM algorithm is a popular iterative method to maximize the Poisson likelihood objective function56:
| (1) |
| (2) |
| (3) |
where A is the system matrix, b is the scatters and randoms (background counts), and q is the model of the expectation of the measured projection data. In addition to the measured PET data which are susceptible to noise, alternative sources of information can be incorporated into the reconstruction process to reduce the noise and PVEs in the reconstructed image. As alluded to above, the inclusion of prior information (in particular anatomical boundaries) can be achieved through either kernel (reparameterization) or MAP (regularisation) reconstruction methods. The particular methods investigated are summarized in Tables 1 and 2.
Table 1.
Summary of the six magnetic resonance (MR)‐informed methods expressed in terms of the generalized Gaussian [Eq. (19)], indicating how each weight matrix or basis function is derived.
| Method |
|
MR‐derived weights | PET derived weights | k‐nearest neighbors | Weights and basis functions | |||
|---|---|---|---|---|---|---|---|---|
| Regularization | ||||||||
| Gaussian MR‐guided |
|
|
1 | Uses whole neighborhood |

|
|||
| Bowsher | 0 | 1 | 1 | w.r.t. xj |

|
|||
| Anato‐functional |
|
|
|
Uses whole neighborhood |

|
|||
| Reparameterization | ||||||||
| KEM |
|
|
1 | w.r.t. xj |

|
|||
| KEM LVS |
|
|
1 | w.r.t. |

|
|||
| HKEM |
|
|
|
w.r.t. |

|
|||
HKEM, hybrid kernel method; LVS, largest value sparsification; PET, positron emission tomography.
Table 2.
Summary of each magnetic resonance (MR)‐informed method’s parameters. Each method underwent a restructured grid search, using a 108 and 107 count three‐dimensional‐simulated dataset, to determine the chosen parameters, which gave the best whole brain to positron emission tomography (PET)‐unique region structural similarity index (SSIM) trade‐off. The range of values over which the grid search was evaluated, and the chosen parameters are stated.
| Method | Parameters for high‐count data | Parameters for low‐count data | ||||||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| Fixed | Varied | Chosen | Fixed | Varied | Chosen | |||||||||
| Regularization | ||||||||||||||
| Gaussian MR‐guided | N/A |
|
|
N/A |
|
|
||||||||
| Bowsher | N/A |
|
|
N/A |
|
|
||||||||
| Anato‐functional |
|
|
|
0.5 |
|
|
||||||||
| Reparameterization | ||||||||||||||
| KEM | N/A |
|
|
N/A |
|
|
||||||||
| KEM LVS | = 40 |
|
|
= 40 |
|
|
||||||||
| HKEM |
|
|
|
, |
|
|
||||||||
2.1.1. Kernel method
MR‐informed KEM reparameterizes the emission image into a set of MR‐derived spatial basis functions (K).
| (4) |
The coefficients of these spatial basis functions (K) are estimated through maximizing the reparameterized Poisson log likelihood objective function, with respect to the basis function coefficients. Through the reparameterization of the emission image, and the nonnegativity constraint of the EM algorithm, the possible solution space is restricted. Provided the basis functions are of sufficient size, the emission image will be inhibited from forming noisy images, while retaining shared PET‐MR structures.
Kernel basis functions are spatial similarity matrices between each voxel and their neighboring voxels. Each kernel basis function is described through comparing a central voxel with its neighboring voxels. Only comparing voxels that lie within a predefined spatial neighborhood prevents the inclusion of long‐range correlations and reduces the computational burden. In a similar vein to the Bowsher prior, only the k‐nearest neighbors (kNN) in feature space are selected to contribute to a given voxel’s basis function. The Euclidean distance was used to determine the k‐nearest neighbors. The values of the kernel basis functions (within the spatial neighborhood) are generally calculated from the radial Gaussian kernel [see Eq. (5) below], acting on the feature vector representation of each voxel. Figure 1 illustrates this basis function calculation for a generalized patch feature vector. For all methods compared, the spatial neighborhood has a side length of five and the feature vector is implemented as a scalar, simply by using only the individual voxel intensity. For MR‐informed KEM this gives
| (5) |
where x refers to the MR voxel intensity values and is the standard deviation applied for the MR voxel‐based Gaussian. The resultant kernel basis functions together form the kernel matrix K, with which the emission image is reparameterized. The kernel matrix for all kernel implementations is row normalized in accordance with.9 Through reparameterizing the EM update equation, the spatial basis function coefficients are found, which maximize the likelihood with respect to the measured projection data:
| (6) |
Figure 1.
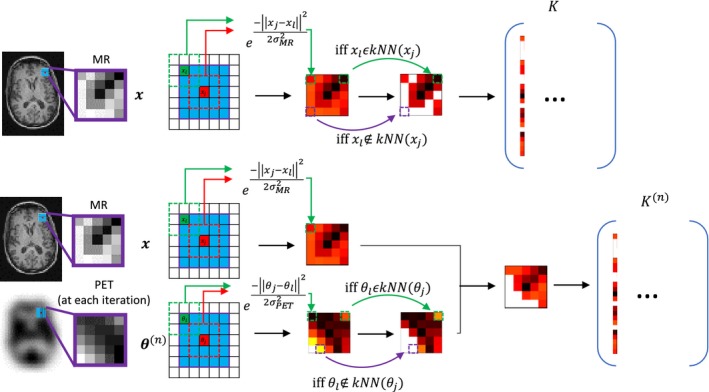
The formation of the kernel basis functions for the MR‐informed kernel (top) and the hybrid kernel (bottom). The neighborhood comparison is shown for the generalized patch case. The resulting basis functions are equivalent to the weighting factors used in the magnetic resonance (MR)‐guided Gaussian and anato‐functional maximum a posteriori methods, provided the number of k‐nearest neighbors is equal to the spatial neighborhood. [Color figure can be viewed at http://wileyonlinelibrary.com]
An alternative means of sparsifying the kernel method has been proposed in Ref. 11, which uses a composite feature vector based on a weighted combination of the MR voxel values and their spatial location:
| (7) |
| (8) |
where r j refers to the spatial location of voxel j and refers to the spatial standard deviation. This method will be referred to as KEM LVS and has been shown to lead to more localized basis functions (Fig. S1), and thus better recovery of PET‐unique regions. A further extension of the kernel method is HKEM. HKEM includes the reconstructed PET image at each iteration into the kernel basis function value calculations, extending the Gaussian term to be comprised of a Gaussian applied to the current intensities of the reconstructed PET image, in product with a Gaussian applied to the intensities of the MR image. refers to the standard deviation applied for the PET voxel‐based Gaussian:
| (9) |
The HKEM implementation by Ref. 50, 51, uses all voxels within a spatial neighborhood to contribute to a basis function. An alternative implementation of HKEM would be to implement the k‐nearest neighbors search based on both PET and MR voxel values weighted by their standard deviation, in a similar manner to KEM LVS.
2.1.2. Maximum a posteriori (MAP)
Regularization of the objective function, in accordance with MAP or PL is achieved through the inclusion of a prior term R to the objective function, as follows:
| (10) |
Markov random fields are a common choice of prior that identify interactions between short‐range neighboring voxels (called cliques). For this case, is equivalent to the Gibbs energy function and is purely influenced by relationships between voxels within the same clique. The quadratic function can be chosen as the inter‐voxel penalty function, which will suppress the differences between neighboring voxels, encouraging a smooth radiotracer reconstruction. A general expression for the quadratic prior function is given by
| (11) |
with the weighting factors wjl quantifying how similar we expect the neighboring voxel to be to the central voxel within a given spatial neighborhood . A separable form of the MAP objective function for this weighted quadratic prior term [Eq (11)] is found through implementing De Pierro's decoupling rule,57 which employs a surrogate penalty term (using the principle of optimization transfer). The separable iterative update formula is explicitly presented in Ref. 32, 58 and repeated here for clarity:
| (12) |
| (13) |
| (14) |
| (15) |
In the case of no anatomical information, the weighting factors are indiscriminately set to 1/Nj, resulting in smoothing across uniform and boundary regions alike. Alternatively, the weighting factors can be obtained from a co‐registered MR image that shares boundary information with the PET data, to prevent over‐smoothing across shared PET‐MR boundaries. These weighting factors calculate the similarity between a chosen voxel and the voxels that lie within its spatial neighborhood. Two popular MR‐derived weights use the Gaussian and asymmetric Bowsher‐based formulations. Each method compares the central voxel's feature vector with the feature vector of each of its neighboring voxels, in turn. The Gaussian MR‐guided prior uses the radial Gaussian in feature space to determine the similarity of neighboring voxels, to a chosen voxel (again, as previously indicated, only single voxel scalar values are used as feature vectors in this work):
| (16) |
The weighting factors for all MAP methods are normalized, with the sum of all weighting factors within a given voxel's neighborhood set to 1. The Bowsher prior sets the weighting factors for the k most similar voxels (determined by the Euclidean distance in feature space) within a spatial neighborhood to 1, and the others to 0:
| (17) |
The anato‐functional reconstruction methodology extends the MR‐guided Gaussian prior to include similarity weights from the current PET image update. The composite weighting factor is the product between the PET and MR Gaussian similarity kernels, where the PET similarity kernel is calculated from the image for each iteration update:
| (18) |
As the anato‐functional and HKEM priors rely on a previous activity estimate, no theoretical convergence guarantee can be provided for these adaptively weighted regularization methods. Although, our preliminary findings showed that empirically these reconstruction methods converge to a fixed point solution at which the objective function remains unchanged. All methods presented in both the kernel and MAP sections are based on the formation of similarity weights between voxels confined within a spatial neighborhood. These weights, or kernel basis function values, can be described through the general expression [Eq. (19)], based on a composite feature vector (z). Subsequently, the k most similar voxels to the central voxel (the k‐nearest neighbors) are identified, where the voxels' similarity can be assessed in terms of single voxel intensity, patch intensity, spatial position, or any alternative feature vector. Weighting factors (or basis function elements) that correspond to voxels that lie outside the central voxel’s k‐nearest neighbors are set to zero. All MR‐informed methods are expressed in this formulation in Table 1.
| (19) |
2.2. Simulation studies
A three‐dimensional‐simulated [18F]fluorodeoxyglucose (FDG) PET phantom was constructed with a voxel‐side length of 1 mm, based on the BrainWeb59 segmented MR database. The gray and white matter tissue classes were assigned intensities with the ratio of 4:1 in keeping with the expected uptake from an FDG tracer.30, 60, 61 Real PET images have more structural variation than the produced piecewise constant simulated phantom. To discourage overly piecewise constant images, Gaussian smoothed random structures were incorporated into the simulated PET phantom, in accordance with Eq. (20), producing more varied tissue structure:
| (20) |
where rand are uniformly distributed random numbers between 0 and 1 for each image voxel, G corresponds to convolution with a Gaussian kernel of width , and H is an amplitude parameter. Four high‐intensity structures (lesions) were added to the PET phantom (only). The two smaller lesions are located in the white matter, whereas the larger lesions are positioned across MR boundaries that differ (Fig. 2). Profiles through each of these PET‐unique regions are also shown in Fig. 2, with the intensity of tumors C and D equal to three times the intensity of the gray matter. The PET phantom was projected into span 11 sinograms using a reconstruction software which models the Siemens Biograph mMR PET‐MR scanner.62 A 4.5 mm point spread function (PSF) was applied in the forward model, to simulate the overall effects of photon acollinearity, positron range, and finite crystal width.63 The simulated sinograms were rescaled to high‐ and low‐count level datasets (108 and 107 prompts, respectively), each with a randoms fraction of 20% and a scatter fraction of 20%, prior to introducing Poisson noise. This was repeated for 10 noise realizations. The simulated sinograms were reconstructed at mMR resolution (voxel size of 2.09 × 2.09 × 2.03 mm3), with resolution modeling (PSF) included in the reconstruction.
Figure 2.
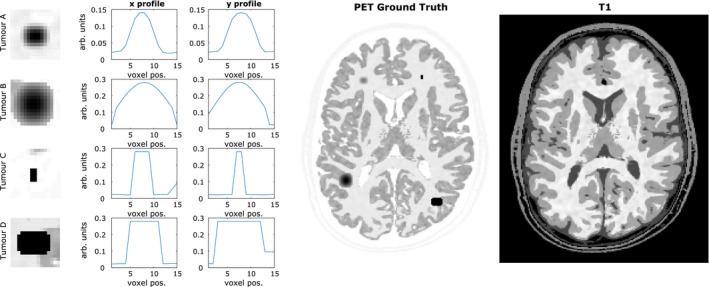
(Left) Simulated positron emission tomography (PET)‐unique high‐intensity regions (tumors A, B, C and D) that differ in structure to the corresponding regions in the T1 magnetic resonance (MR) phantom. (center) Simulated [18F]fluorodeoxyglucose (FDG) PET phantom based on the BrainWeb phantom, with the four PET‐unique high‐intensity regions added. (right) T1 image. All images are shown at MR resolution. The gray matter intensity value shown in the tumor profiles is approximately 0.1 arbitrary units. [Color figure can be viewed at http://wileyonlinelibrary.com]
2.2.1. Simulation studies parameter selection
All methods underwent a restricted grid search of the parameter range, for both the high‐count and low‐count simulated datasets. All images were reconstructed up to 300 iterations, with images resized to the original 1 mm resolution of the ground truth phantom for the calculation of the error metrics. The structural similarity index (SSIM)64 was used to determine the similarity between the reconstructed images and the ground truth, as is generally perceived to provide a closer numerical representation of visual perception. SSIM has previously been used in the PET and image processing literature to evaluate novel methodologies,54, 65, 66 and to assess structural similarity between multimodality images as part of a proposed methodology,17 among other uses. The simplified formulation of SSIM employed in this work is
| (21) |
where refers to the spatial local mean, refers to the local standard deviation, and is the cross‐covariance between the image and . C 1 and C 2 are constant values dependent on the dynamic range of the image. The parameters for each reconstruction method were compared for their ability to improve the SSIM metric, for regions where the PET and MR phantom notably differ (PET‐unique regions), and for the whole brain region. For each reconstruction method, the SSIM trade‐off curve that is positioned closest to the SSIM value of 1 for both the whole brain and PET‐unique regions, that is, produced the largest sum of the unique SSIM squared and whole brain SSIM squared, was selected. The chosen parameters for each reconstruction method are presented in Table 2. It should be noted that the performance of the PET‐MR‐informed methods of HKEM, and anato‐functional was found to be highly sensitive to the chosen parameters (in particular ) and the noise level of the PET image under reconstruction.
2.2.2. Simulation studies multiple noise realizations
The chosen parameter ranges for each reconstruction method were employed to reconstruct 10 noise realizations of the simulated data, for both the 108 and 107 count levels. The reconstructed images were assessed using a variety of error and image quality metrics for individual voxels and across regions of interest (ROI), to determine which MR‐informed method provided the best trade‐off between the reconstruction of the whole brain and PET‐unique regions. The values calculated for SSIM (Figs. 3 and 6) are now for multinoise realization data and were averaged across all noise realizations. The voxel‐wise metrics of mean, bias, and standard deviation (presented in the Appendix for tumor regions Figs. S2 and S3) are calculated across the multiple noise realizations (Nnoise) in accordance with the following equations:
| (22) |
| (23) |
| (24) |
Figure 3.
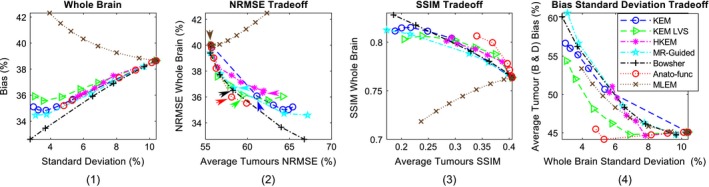
All the results shown are for the high counts (108) simulated dataset, over multiple noise realizations. (1) Bias vs standard deviation for the whole brain region. (2) Whole brain normalized root mean square error (NRMSE) vs the positron emission tomography (PET)‐unique region NRMSE (averaged over the four PET‐unique regions). (3) Whole brain structural similarity index (SSIM) vs the PET‐unique region SSIM (averaged over the four PET‐unique regions). (4) PET‐unique region bias (averaged over tumor regions B and D only) vs whole brain standard deviation. The methods investigated are shown for increasing β values (MAP) or k‐nearest neighbors (KEM). Maximum likelihood expectation maximization is shown for increasing levels of post reconstruction smoothing. [Color figure can be viewed at http://wileyonlinelibrary.com]
Figure 6.
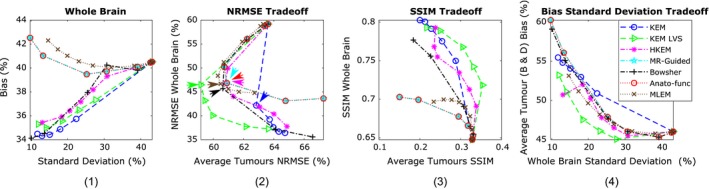
All the results shown are for the low counts (107) simulated dataset, using multiple noise realizations. (1) Bias vs standard deviation for the whole brain region. (2) Whole brain normalized root mean square error (NRMSE) vs the positron emission tomography (PET)‐unique region NRMSE (averaged over the four PET‐unique regions). (3) Whole brain structural similarity index (SSIM) vs the PET‐unique region SSIM (averaged over the four PET‐unique regions). (4) PET‐unique region bias (averaged over tumor regions B and D only) vs whole brain standard deviation. Each method is shown for increasing β values (MAP) or k‐nearest neighbors (KEM). Maximum likelihood expectation maximization is shown for increasing levels of post reconstruction smoothing. [Color figure can be viewed at http://wileyonlinelibrary.com]
ROI‐based error metrics of bias and standard deviation are also calculated across multiple noise realizations. These metrics are an extension of the metrics above; the metric value (squared) is now summed over each voxel within the ROI and is normalized according to the ground truth. ROI bias vs standard deviation curves are presented for the whole brain region, and each of the PET‐unique regions (Figs. 3, 6; Figs. S2 and S3).
| (25) |
| (26) |
Normalized root mean square error (NRMSE) as shown in Figs. 3 and 6, over a specific ROI can then be calculated as:
| (27) |
Alternative error metrics that only depend on a single noise realization are also included to allow direct comparison with the real data studies (Figs. 5, 8, 10 and 12). The tumor mean values were compared to the white matter standard deviation (calculated using an eroded ROI) to allow the trade‐off between the retention of PET‐unique features and noise suppression of each method to be assessed. These single noise realization error metrics are
| (28) |
| (29) |
Figure 5.
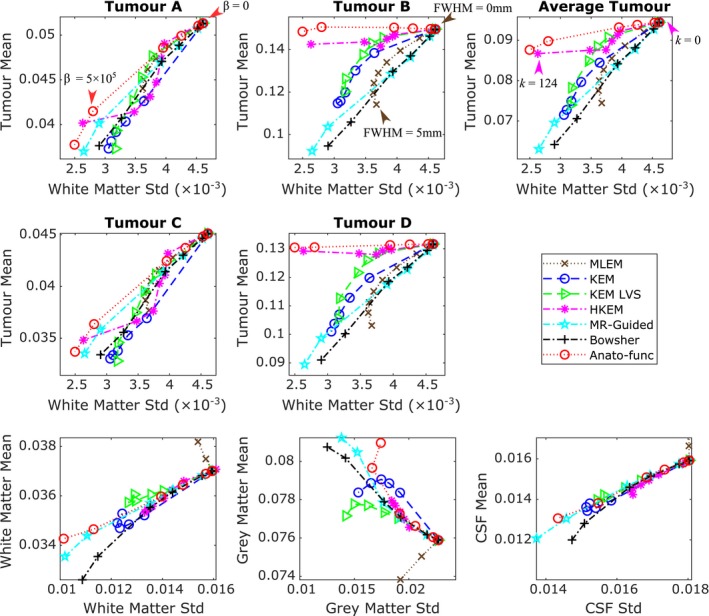
All the results shown are for the high counts (108) simulated dataset, averaged over the multiple noise realizations. (top and middle row) The tumor mean value vs white matter standard deviation, for all methods under consideration, for each positron emission tomography (PET)‐unique region. The mean and standard deviation values were calculated within the specified (eroded) regions of interest (ROIs) at PET resolution, and then averaged across the multiple noise realizations. The maximum likelihood expectation maximization (MLEM) noise‐free mean values for the different tumor regions are: 0.0624 for tumor A, 0.155 for tumor B, 0.0575 for tumor C and 0.137 for tumor D. (bottom row) Regional mean value vs regional standard deviation using the full ROI including edges. The expected trend for methods that reduce partial volume effects is a reduction in the white matter and cerebral spinal fluid mean, and an increase in the gray matter mean. The β (MAP) or k (KEM) parameter values are increased along each curve. MLEM is also shown for increasing level of postreconstruction smoothing. [Color figure can be viewed at http://wileyonlinelibrary.com]
Figure 8.
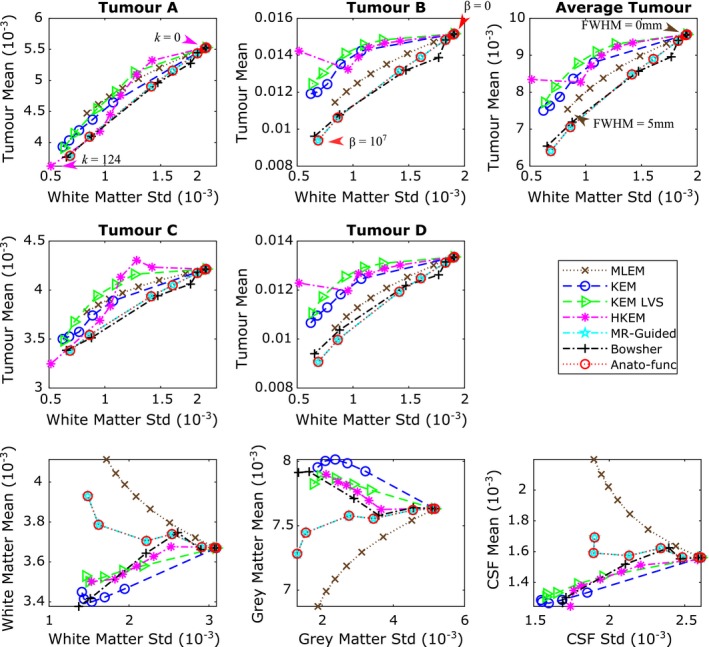
All the results shown are for the low counts (107) simulated dataset, averaged over multiple noise realizations. (top and middle row) The tumor mean value vs white matter standard deviation, for all methods under consideration, for each positron emission tomography (PET)‐unique region. The mean and standard deviation values were calculated within the specified regions of interests (ROIs) at PET resolution, and then averaged across the multiple noise realizations. The maximum likelihood expectation maximization (MLEM) noise‐free mean values for the different tumor regions are: 0.00624 for tumor A, 0.0155 for tumor B, 0.00575 for tumor C and 0.0137 for tumor D. (bottom row) Regional mean value vs regional standard deviation using the full ROI including edges. The expected trend for methods that reduce partial volume effects is a reduction in the white matter and cerebral spinal fluid mean, and an increase in the gray matter mean. β (MAP) or k (KEM) parameter values were increased along each curve. MLEM is also shown for increasing level of postreconstruction smoothing. [Color figure can be viewed at http://wileyonlinelibrary.com]
Figure 10.
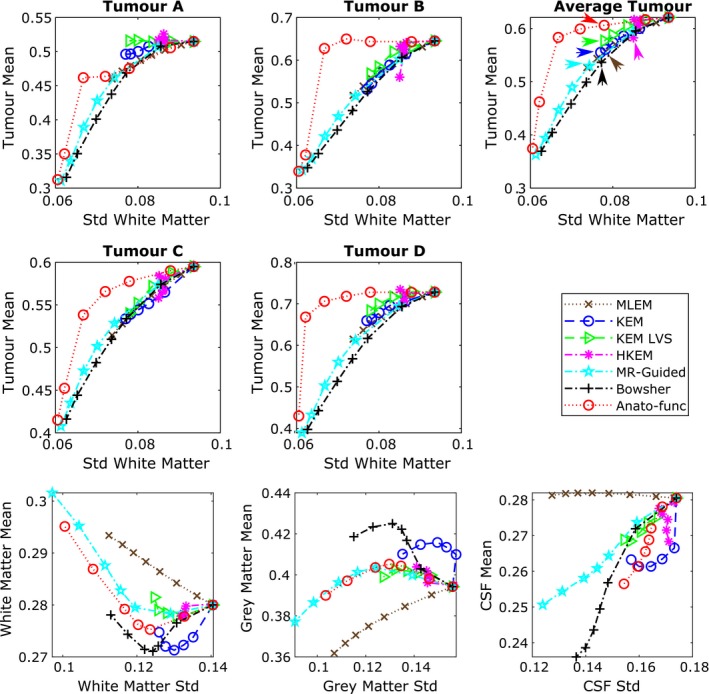
All results shown are for the 100% count level‐augmented real dataset. (top and middle rows) Tumor mean vs white matter (eroded mask) standard deviation. The arrows indicate the mean vs standard deviation trade‐off of the chosen parameters for the images shown in Fig. 11. (bottom row) Regional mean value vs regional standard deviation using the full regions of interest including edges. The expected trend for methods that reduce partial volume effects is a reduction in the white matter and cerebral spinal fluid mean, and an increase in the gray matter mean. [Color figure can be viewed at http://wileyonlinelibrary.com]
Figure 12.
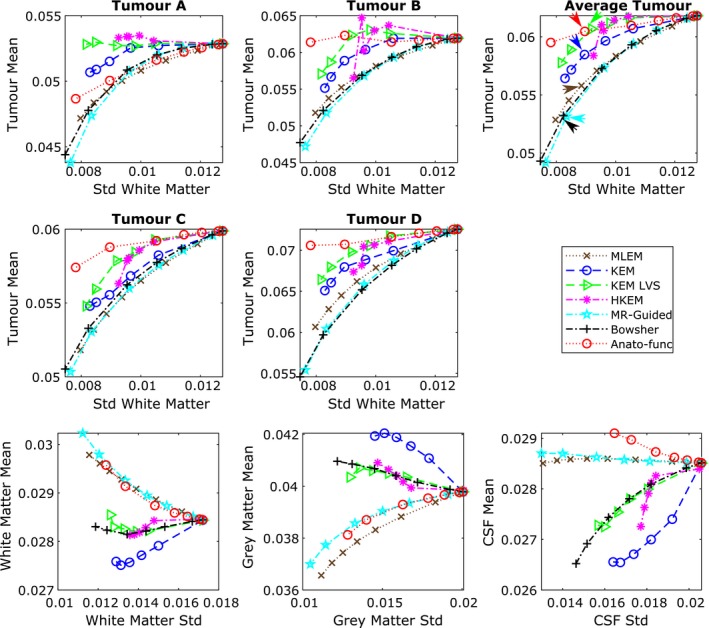
All results shown are for the 10% count level‐augmented real dataset. (top and middle row) Tumor mean vs white matter (eroded mask) standard deviation. The arrows indicate the mean vs standard deviation trade‐off of the chosen parameters for the images shown in Fig. 13. (bottom row) Regional mean value vs regional standard deviation using the full regions of interest including edges. The expected trend for methods that reduce partial volume effects is a reduction in the white matter and cerebral spinal fluid mean, and an increase in the gray matter mean. [Color figure can be viewed at http://wileyonlinelibrary.com]
However the tumor mean vs white matter standard deviation metric is incomplete and does not penalize the distortion of tumor regions, bias of the cortical regions, or the smoothing of different intensities across regional boundaries (PVEs). To address the issue of PVEs, the mean value of the white matter, gray matter, and cerebral spinal fluid (CSF) regions (using the full noneroded ROI including edges) is also examined. These regional mean values are plotted against their corresponding standard deviation values. The regional standard deviation values used for these plots are also calculated using the full noneroded ROI. Methods that reduce PVEs across these regional boundaries should result in a reduction in white matter and CSF mean values, and an increase in the gray matter mean value relative to unsmoothed MLEM, (while over‐smoothing methods will produce the converse trends). Improved reconstruction methods should therefore ideally lead to a fixed tumor mean relative to unsmoothed MLEM, reduced white matter standard deviation relative to unsmoothed MLEM, and follow the aforementioned regional mean trends.
2.3. Real data studies
2.3.1. FDG dataset
Real [18F]FDG data from a patient scan (Alzheimer's disease) was reconstructed using all seven methods previously considered. The dataset was acquired from the Siemens Biograph mMR simultaneous PET‐MR scanner, allowing simple acquisition of co‐registered PET‐MR data. The [18F]FDG scan had a total prompt count of 4.69 × 108 and a scan duration of 23 min. The tracer activity at time of injection (81 minutes prior to start of image acquisition) was 229 MBq. A T1 MPRAGE scan provided the anatomical image, which was resampled to the PET resolution (2.08626 mm × 2.08626 mm × 2.03125 mm) for use in anatomical guidance.
2.3.2. Augmented FDG dataset
Four simulated tumors were added to the FDG dataset to give known PET‐unique regions relative to the corresponding MR structure. The intensity profiles of the tumor regions are shown in Fig. 9 (the PET intensity of the gray matter is approximately 0.4 arb. units). This augmented dataset is reconstructed at the normal full (100%) count level and then also resampled to a lower count level of 10% (relative to the total prompt count level). The parameters used for the 100% and 10% count level‐augmented FDG real data studies were those chosen for the high‐ and low‐count simulation studies, respectively. However, the parameters employed by the anato‐functional method and HKEM were reselected for each count level, due to the dependence of on the PET image intensity. As previously evaluated in the simulated data studies, the mean value of each PET‐unique region was compared to the standard deviation of an eroded white matter region, in order to assess the ability of each method to simultaneously recover the PET‐unique region while suppressing noise in an (assumed) approximately uniform region. The white matter mask was extracted from the T1 image using FSL.67 The mean value of the white matter, gray matter, and cerebral spinal fluid (CSF) regions (using the full noneroded ROI including edges) is also examined for the real data studies, to help in investigating the PVE properties of each reconstruction method.
Figure 9.
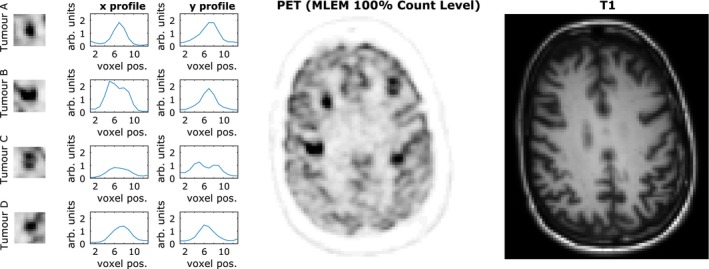
Real patient [18F]fluorodeoxyglucose (FDG) dataset, augmented with simulated tumor regions, to produce genuine regions of positron emission tomography (PET)‐magnetic resonance (MR) mismatch. (left) Tumor regions and profiles from the maximum likelihood expectation maximization (MLEM) reconstructed image for the 100% count level. (middle) MLEM reconstructed image of the whole brain region, shown at 300 iterations for the 100% count level. (right) T1 MPRAGE image. All images shown at PET resolution. The gray matter PET intensity value is approximately 0.4 arb. Units. [Color figure can be viewed at http://wileyonlinelibrary.com]
3. Results
3.1. Simulation Studies
For most of the figures presented (Figs. 3, 5, 6, 8; Figs. S2 and S3), either the regularization parameter is increased (for MAP methods), or the number of k‐nearest neighbors is increased (for kernel methods) along each curve. The original full neighborhood implementation of HKEM50, 51 is equivalent to the last point on each HKEM curve (kPET = 124). The popular reconstruction method of MLEM is also shown for comparison, at varying levels of postreconstruction smoothing.
3.1.1. Simulation Studies High Counts
Figure 3 shows a series of trade‐off curves for all reconstruction methods under investigation, applied to the 10 noise realizations of the high‐count (108) simulated dataset. The bias vs standard deviation plot for the whole brain region (Fig. 3 column 1) demonstrates the improvements of all regularized and reparameterized MR‐informed and PET‐MR‐informed reconstruction methods over postsmoothed MLEM, across the whole brain region where the majority of the MR structure matches the PET. The use of MR information in these methods enables smoothing across MR uniform regions (reducing noise), while preserving MR boundaries and reducing PVEs. Of particular interest in this work is the ability to maintain these positive attributes of MR‐informed methods, while also maintaining genuine high‐intensity features (tumor regions) present only in the PET data and not in the MR. To address this question, both NRMSE and SSIM curves are presented in Fig. 3 (columns 2 and 3 respectively), showing the trade‐off between the accurate reconstruction of the whole brain region vs the PET‐unique regions (averaged over the four PET‐unique regions). Both the NRMSE and SSIM curves (Fig. 3) show that the anato‐functional method achieves the best trade‐off relative to the other investigated methods, although the improvement is less apparent in terms of NRMSE. The KEM LVS and HKEM also perform well in terms of the SSIM trade‐off between the PET‐unique and whole brain regions, whereas if evaluated in terms of the NRMSE trade‐off, the Bowsher method performs more favorably. The PET‐unique region bias vs whole brain region standard deviation trade‐off curve (Fig. 3 column 4) also demonstrates the improved performance of the anato‐functional method and KEM LVS, both attaining a reduced bias (for the PET‐unique regions B & D) for a fixed whole brain standard deviation (image noise level) in comparison with postsmoothed MLEM.
The points indicated by arrows on the NRMSE curves (Fig. 3 column 2) indicate the parameters that produce approximately equivalent whole brain NRMSE. The corresponding images with fixed whole brain NRMSE are shown in Fig. 4, in which all MR‐informed methods can be seen to yield a sharper reconstruction of the regions with shared PET‐MR structure, in comparison with postsmoothed MLEM. Additionally, the anato‐functional method can be seen to perform favorably in reconstructing PET‐unique regions with a relatively high, constant intensity value and well‐defined boundaries (e.g., tumor D, Fig. 4 bottom row), whereas the MR‐guided and Bowsher MAP methods and KEM LVS perform better in the reconstruction of high‐intensity PET‐unique regions with a smoothed structure (e.g., tumor B).
Figure 4.
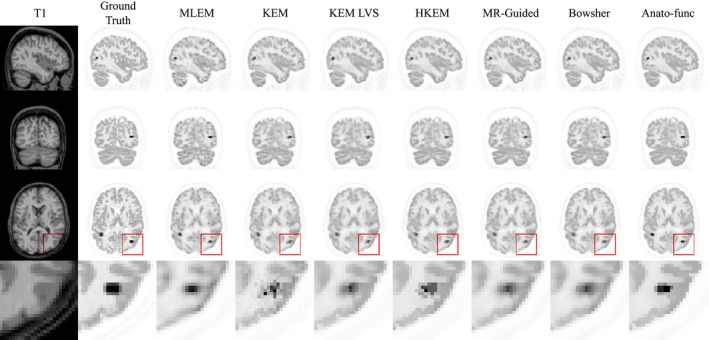
All the results shown are for the high counts (108) simulated dataset for a single noise realization, at positron emission tomography (PET) resolution. Reconstructed images for each of the methods under investigation. A zoomed in transverse region is shown along the bottom row. All magnetic resonance (MR)‐informed methods are shown at approximately fixed whole brain normalized root mean square error (NRMSE, as indicated by the arrows on the NRMSE curves, Fig. 3 column 2. [Color figure can be viewed at http://wileyonlinelibrary.com]
The ability of each reconstruction method to suppress image noise, without in turn suppressing the PET‐unique regions was also assessed through tumor mean vs white matter standard deviation curves (Fig. 5). These graphs show the improvement attained by the anato‐functional method, HKEM and to lesser extent, KEM LVS relative to the other MR(only)‐informed reconstruction methodologies for the high‐intensity tumor regions B and D. The anato‐functional method and HKEM can achieve mean values similar to that of unsmoothed MLEM for the high‐intensity PET‐unique regions, while markedly reducing the standard deviation across the white matter region. All MR‐informed and PET‐MR‐informed methods also lead to a reduction in the white matter mean and an increase in the gray matter mean in comparison with MLEM (Fig. 5, bottom row), as expected for methods that reduce the PVEs in these regions. This demonstrates the capability of MR‐informed methods to counteract PVEs that cause spill‐out effects for high‐intensity regions. The PET‐unique regions of A and C appear to have insufficient intensity to really benefit from the inclusion of PET information in the PET‐MR‐informed methods, with both the MR‐informed and PET‐MR‐informed methods producing similar tumor mean vs white matter standard deviation curves (Fig. 5, top and middle rows), as such, the information that can be drawn from the PET‐unique regions A and C is limited.
3.1.2. Simulation studies low counts
Figure 6 (columns 2 and 3) shows the NRMSE and SSIM trade‐off curves between the PET‐unique (averaged over the four PET‐unique regions) and whole brain regions, for the low count (107) simulated dataset. Both the NRMSE and SSIM plots show KEM LVS performing better than the other reconstruction methods, achieving both an improvement in whole brain and PET‐unique region image quality in comparison with unsmoothed MLEM. This trend can also be clearly seen in the bias (for tumor regions B and D) vs whole brain standard deviation plot (Fig. 6 column 4), with KEM LVS achieving the lowest tumor bias for a fixed whole brain noise level. The Bowsher method also performs well, when evaluated in terms of NRMSE trade‐off (Fig. 6 column 2), but less so if evaluated in terms of SSIM trade‐off (Fig. 6, column 3) or bias vs standard deviation trade‐off (Fig. 6, column 4) where instead the HKEM performs better than the other methods excluding KEM LVS.
The points indicated by arrows on the NRMSE curves (Fig. 6, column 2) correspond to the parameters that produce approximately equivalent whole brain NRMSE, with the reconstructed images shown in Fig. 7. In Fig. 7, KEM LVS and HKEM show a marginally sharper recovery of the PET‐unique regions in comparison with the remaining methods. Figure 8 shows the tumor mean vs white matter region standard deviation for the low count dataset, with KEM LVS and HKEM performing well in comparison to the other methods investigated. The two high‐intensity PET‐unique regions (B and D), particularly demonstrate the noise suppression abilities of the KEM LVS and HKEM methods, for a fixed tumor mean value. KEM also achieves a reduced white matter standard deviation for a relatively fixed PET‐unique region mean value in Fig. 8, despite visually its PET‐unique regions being more distorted than the corresponding KEM LVS and HKEM PET‐unique regions (as shown in Fig. 7). This highlights the limitations of using ROI‐based error metrics. Figure 8 (bottom row) shows an increase in the white matter mean value and a reduction in the gray matter mean value for the MR‐guided and anato‐functional methods due to an increased smoothing across the white–gray matter boundary (PVEs). Therefore, the MR‐guided and anato‐functional methods (with their low count chosen parameters) have lost their PVE correction capabilities that were demonstrated in the high counts simulation studies (Fig. 5).
Figure 7.
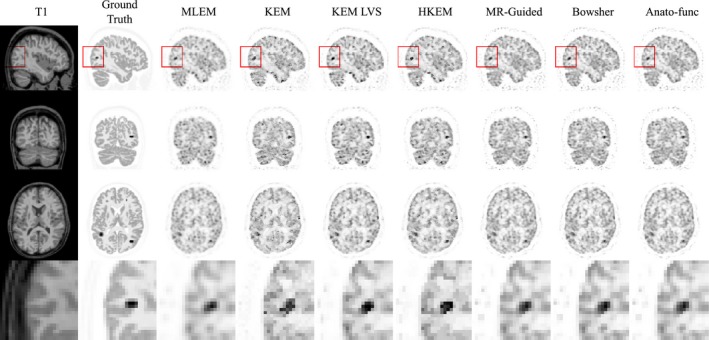
All the results shown are for the low counts (107) simulated dataset, for single noise realization, at positron emission tomography (PET) resolution. Reconstructed images for each of the methods under investigation. A zoomed in sagittal region is shown along the bottom row. All magnetic resonance‐informed methods are shown at approximately fixed whole brain normalized root mean square error (NRMSE), as indicated by arrows on the NRMSE curves, Fig. 6 column 2. MLEM is shown with post reconstruction smoothing with a FWHM of 3.5 mm. [Color figure can be viewed at http://wileyonlinelibrary.com]
3.2. Real data studies
3.2.1. 100% count level‐augmented FDG dataset
Figure 10 shows the tumor mean vs white matter standard deviation trade‐off plots (top and middle row) in addition to the white matter, gray matter, and CSF regional mean plots (bottom row), for the augmented FDG dataset (Fig. 9), at the 100% count level. The anato‐functional method is shown to perform well for the high‐count real data studies, achieving the lowest white matter standard deviation (noise level) for a fixed tumor mean value (for three out of the four tumor regions). The KEM LVS and HKEM methods also perform better than the remaining MR‐informed methods when evaluated in terms of tumor mean vs white matter standard deviation trade‐off (Fig. 10). Figure 10 (bottom row) shows that all MR‐informed methods produce images with a reduced white matter mean, and an increased gray matter mean for moderate levels of regularization (or reparameterization). These trends correspond to a reduction in PVEs, in particular for the KEM and Bowsher methods. Figure 11 shows the reconstructed images for each of the MR‐informed methods, with the parameters chosen to present an approximately fixed white matter standard deviation (as indicated by the arrowheads in Fig. 10). Figure 11 also shows the improved definition and delineation between the white and gray matter when using the Bowsher method and KEM.
Figure 11.
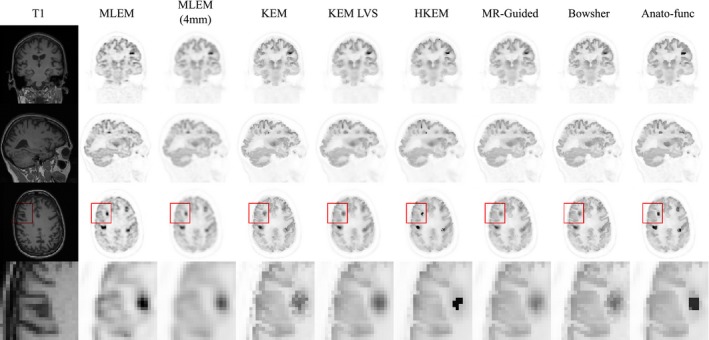
The reconstructed images are shown for each of the reconstruction methods investigated, applied to the 100% count level‐augmented real dataset. A zoomed in transverse region is shown along the bottom row. All magnetic resonance‐informed methods are shown at approximately fixed white matter standard deviation, as indicated by the arrows in Fig. 10. Maximum likelihood expectation maximization is shown with postreconstruction smoothing (FWHM 4 mm). [Color figure can be viewed at http://wileyonlinelibrary.com]
3.2.2. 10% count level‐augmented FDG dataset
Figure 12 shows the tumor mean values vs white matter standard deviation plots (top and middle row) in addition to the white matter, gray matter, and CSF regional mean plots (bottom row), for the augmented FDG dataset at the 10% count level. KEM LVS, HKEM and to a lesser extent, the anato‐functional method perform well in maintaining the mean value of the PET‐unique regions, while reducing the white matter standard deviation (Fig. 12, top and middle rows). Figure 12 (bottom row) shows that the anato‐functional and MR‐guided methods lead to an increase in white matter mean value and decrease in gray matter mean values. This trend demonstrates that the anato‐functional and MR‐guided methods have lost their PVE reduction capabilities that were demonstrated in the high‐count real data studies (Fig. 10). Figure 13 shows the reconstructed images for each of the MR‐informed methods, with the parameters chosen to present an approximately fixed white matter standard deviation (as indicated by the arrowheads in Fig. 12).
Figure 13.
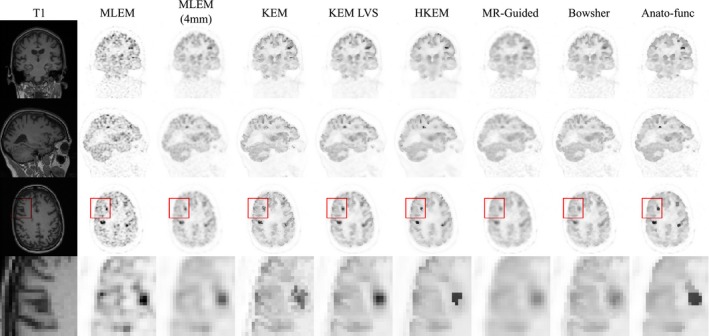
The reconstructed images are shown for each of the reconstruction methods investigated, applied to the 10% count level‐augmented real dataset. A zoomed in transverse region is shown along the bottom row. All magnetic resonance‐informed methods are shown at approximately fixed white matter standard deviation, as indicated by arrows in, Fig. 12. Maximum likelihood expectation maximization is shown with postreconstruction smoothing (FWHM 4 mm). [Color figure can be viewed at http://wileyonlinelibrary.com]
4. Discussion
4.1. Simulation studies high count
The results from the high‐count simulation studies show that the anato‐functional method excels in concurrently improving the reconstruction of the whole brain and PET‐unique regions, when assessed via the majority of metrics presented in Figs. 3, 4, 5. The KEM LVS and HKEM also perform well in terms of the SSIM trade‐off (Fig. 3) between the PET‐unique and whole brain regions, and achieve a reduced white matter standard deviation for a fixed tumor mean value (Fig. 5). The Bowsher method achieves the lowest whole brain NRMSE (Fig. 3) and notably reduces PVEs, however it clearly suppresses the mean values of the PET‐unique regions (Fig. 5). The remaining MR‐informed methods are not the foremost method in respect to any of the presented metrics.
The superior performance of the anato‐functional method over HKEM can be attributed to the added flexibility provided by tuning the β regularization parameter. This is important due to the lack of PET structure present in the reconstructed PET image at low iterations, as such, the weighting factors (for the anato‐functional method) and basis functions (for HKEM) will be strongly influenced by the MR structure only, producing reconstructions similar to MR‐informed methods. Thus, a low level of regularization for the anato‐functional method is beneficial for high‐count datasets to prevent PET‐unique features being suppressed at low iterations. For HKEM, fewer voxels can be selected to contribute to the basis function (lower kNN) to prevent PET‐unique features being suppressed. As can be seen in Fig. 3 column 4, HKEM performs similarly to the anato‐functional method for kNN = 5, however for larger values of kNN the tumor regions are generally more biased. Therefore, the added flexibility of the regularised anato‐functional method improves its recovery of PET‐unique regions as well as the shared PET‐MR regions, in comparison with HKEM. Although for high regularization levels (high β), the anato‐functional methods will also suppress the PET‐unique regions.
Despite the beneficial attributes of the anato‐functional method over MR(only)‐informed methods, it should be noted that the inclusion of PET information for both HKEM and anato‐functional does degrade their noise reduction ability for regions with differing PET and MR structures as shown in the standard deviation images and bias vs standard deviation trade‐off plots for the PET‐unique regions (Fig. S2). In addition, the effective reduction in regularization that occurs for these PET‐MR‐informed methods at the PET‐unique regions may leave the corresponding reconstructed images more vulnerable to Gibbs like artefacts.68, 69 This is clearly a downside of the PET‐MR‐informed methods, however the increase in standard deviation (noise) is only observed in these particular regions (where the PET and MR structures differ) and at large β values. Both improvements in the noise reduction properties of PET‐MR‐informed methods, and more effective suppression of Gibbs like artefacts can be achieved through selecting a larger parameter (as done for the low count simulations), resulting in broader PET similarity kernels. However, this will impair the discussed PET‐MR‐informed methods capability of reconstructing PET‐unique regions.
4.2. Low‐count simulation studies
The results from the low‐count simulation studies show that KEM LVS performs better than the other investigated methods in terms of the majority of metrics evaluated, such as NRMSE trade‐off, SSIM trade‐off (Fig. 6 columns 2 and 3) and tumor bias vs tumor standard deviation trade‐off (Fig. S3). The lack of dependence of KEM LVS on PET data helps to suppress the noise in the image, while the compactness of the basis functions enables improved recovery of the PET‐unique regions (relative to the other MR‐informed methods). HKEM also performs well when evaluated in terms of SSIM trade‐off, tumor bias vs whole brain standard deviation trade‐off (Fig. 6, columns 3 and 4), or tumor mean vs white matter standard deviation (Fig. 8). Both KEM and Bowsher methods lead to large reductions in whole brain NRMSE (Fig. 6, columns 2) and PVEs (Fig. 8, bottom row), however this is at the expense of suppression and possible deformation of the tumor regions (as shown in Fig. 7 and Fig. S3 bias‐std trade‐off and profiles). In contrast to the high‐count simulation studies, the anato‐functional method performs poorly in terms of the all the metrics presented (Fig. 6, 7, 8) for the low‐count simulation studies.
The noise present in the low‐count dataset clearly has a negative impact on the anato‐functional method, which fails to outperform the rival methods as it did for the high‐count dataset, (Figs. 6 vs 3). For the anato‐functional method, to preserve PET only edges requires the value of to be relatively small. However, for noisy PET data, most of the PET voxel values will be quite different to the central voxel value, leading to most of the weighting factors going to zero. This limits the extent of regularization for the anato‐functional method resulting in noisy reconstructed images. This problem can be resolved by using a larger value of (as chosen for the low count simulations), but this limits the influence of the PET update image, and hence the recovery of PET‐unique regions. By comparison, HKEM uses the kNN sparsification to select voxel to contribute to the basis function, based on their PET voxel value. The kNN sparsification allows PET features to be extracted, while allowing a large value to be selected. Therefore, a fixed number of voxels are selected to contribute to each basis function, effectively fixing the level of regularization (irrespective of the noise present in the PET image). This allows HKEM to achieve an improved trade‐off in comparison to the anato‐functional method.
A further comparison of the high‐ and low‐count simulation studies (Figs. 4 vs 7) shows a major change in the MR‐guided (and anato‐functional) method's capability to delineate white and gray matter regions. This is due to the different values selected (as shown in Table 1), for the different count levels. For the high counts dataset, a smaller value of is selected (in comparison to the low count dataset value), emphasizing differences in MR voxel values, and thus enhancing edges in the reconstructed PET image. Whereas, for the low counts dataset, a larger value of was selected, leading to similar weighting values for all MR voxels as differences in the MR voxels are effectively ignored, producing spatially smooth PET images. This trend is also observed for the high‐ and low‐count real data studies, where the same parameters are used as in the corresponding simulation study.
4.3. Augmented FDG dataset
For the high‐count simulation and real data studies similar trends are observed. In both studies, the anato‐functional method followed by KEM LVS and HKEM perform better than the remaining MR‐informed methods when evaluated in terms of tumor mean vs white matter standard deviation trade‐off (Figs. 5 and 10). In particular, the anato‐functional method achieves the lowest white matter standard deviation for a fixed tumor mean for three out of the four tumor regions assessed (Figs. 5 and 10, top and middle row), while reducing PVEs with respect to postsmoothed MLEM (Figs. 5 and 10, bottom row). Therefore, the inclusion of PET information into the reconstruction process via the anato‐functional method (and HKEM) appears to be beneficial in the high‐count simulated and real patient datasets investigated. All MR‐informed methods investigated also demonstrate improved PVE correction for both simulation and real data studies, in comparison to postsmoothed MLEM. Visual support of the improved gray–white matter delineation is shown in Fig. 11.
For the low count simulation and real data studies, similar trends are also observed in terms of accurately reconstructing PET‐unique regions, while concurrently suppressing noise, with KEM LVS and to a lesser extent, HKEM performing better than the other methods investigated. In both simulated and real data studies, KEM LVS and HKEM achieve similar PVE reduction and noise suppression properties (Figs. 8 and 12, bottom row) to the Bowsher method, while reconstructing the PET‐unique regions with an increased mean value (Figs. 8 and 12, top and middle row) relative to Bowsher. The performance of the anato‐functional method, however, does differ slightly between the simulation and real data studies, with the anato‐functional method achieving an improved tumor mean vs white matter standard deviation trade‐off in the real data study (Figs. 8 vs 12). This change can be attributed to the parameter, which was reselected for the real data studies. Excluding the anato‐functional method, a similar trend is observed between the simulated and real data studies for the remaining MR‐informed methods in terms of tumor mean vs white matter standard deviation (Figs. 8 and 12, top and middle row). The regional mean values for the MR‐informed methods also show similar results between the simulated and real data studies (Figs. 8 and 12, bottom row). In both cases, KEM provides the best reduction in PVEs (reducing the white matter mean and increasing the gray matter mean), whereas the anato‐functional and MR‐guided methods show the converse trend due to increased PVEs. The over‐smoothing of the MR‐guided and anato‐functional methods, in comparison with the other MR‐informed methods investigated (such as Bowsher) can be seen in Fig. 13.
5. Limitations
This study has used the image quality measures of NRMSE and SSIM to evaluate the proposed methods, which are useful for representing the performance of quantification tasks. However, the ability to interpret such error metrics as potential changes in patient diagnosis and management is limited. The ultimate evaluation of medical image quality is through task‐based observer studies, using either a human observer or a representative mathematical observer. Two popular means for undertaking such task‐based observer studies include receiver operating characteristic (ROC) curves and the use of the Hotelling observer.70, 71, 72, 73 For the presented comparison study, the use of human observers (radiologists in the case of PET‐MR images) would be very time‐consuming given the evaluation required of multiple patients and reconstruction methodologies. Ideally each scan would also be read by multiple radiologists to account for inter‐person variation in the reading of PET scans. In related work, a preliminary task‐based observer study has been undertaken, in which a reduced number of MR methods are evaluated for the diagnosis of Alzheimer's disease or temporal lobe epilepsy from reduced count PET images.74 Automating the task‐based observer process is still an area of active research within medical imaging, even for the relatively simple task of tumor detection.75, 76.
6. Conclusions
Three regularized and three reparameterized MR‐informed PET reconstruction methodologies have been compared. The capability of each method to reduce PVEs and the noise present in the reconstructed image without biasing the recovery of genuine high‐intensity PET‐MR mismatched regions was investigated.
For the high‐count dataset, the anato‐functional method provided the best SSIM and NRMSE whole brain to PET‐unique region trade‐off relative to the other methods investigated. The inclusion of the current PET image through the calculation of the weighting factors, as presented by the anato‐functional MAP method, enables PVE correction and noise suppression to be attained in regions of matching PET‐MR structure, while also reconstructing PET‐unique regions with a similar bias to unsmoothed MLEM.
For the low count simulated dataset, the use of spatially compact basis functions (KEM LVS) achieved the best SSIM and NRMSE trade‐off for the reconstruction of PET‐unique and whole brain regions, outperforming the other methods investigated. HKEM also performed well for the simulated and real datasets in terms of tumor mean vs white matter standard deviation, relative to the remaining MR‐informed methods. The presence of noise in the low count dataset (of similar intensity to the PET‐unique regions) leads to the inclusion of noise in the reconstructed PET image for the anato‐functional (and the HKEM to a lesser extent) method if certain parameters values were selected. Therefore, at low count levels the inclusion of PET information into the reconstruction process could be more beneficial if integrated in an alternative manner.
To conclude, for the reconstruction of noisy data, multiple MR‐informed methods produce favorable whole brain vs PET‐unique region trade‐off curves, very comfortably outperforming the whole brain denoising of postsmoothed MLEM, for a fixed PET‐unique region SSIM.
Supporting information
Appendix S1: Appendix A: Comparison of KEM and KEM LVS basis functions.
Appendix B. Extended evaluation of simulated dataset.
Fig. S1: Basis functions derived using either the conventional kernel method (KEM) method or the KEM largest value sparsification (LVS) method. The impact of the different implementations on basis function shape is shown for a uniform (top row) and structured (bottom row) magnetic resonance (MR) region. Only the proposed KEM LVS can deliver compact basis functions in uniform MR regions and also structured basis functions in detail containing MR regions for the same fixed set of parameters.
Fig. S2: All the results shown are for the high counts (108) simulated dataset, using multiple noise realizations. Bias Images: bias images for each of the positron emission tomography (PET)‐unique regions, shown for increasing level of β (MAP) or k (KEM) for each reconstruction method. Std Images: standard deviation images for each of the PET‐unique regions, shown for increasing level of β or k for each reconstruction method. Bias‐Std Trade‐off: Bias vs standard deviation plots for each of the PET‐unique regions, for increasing levels of β (MAP) or k (KEM) along each curve. Tumor Profiles: tumor profiles through the mean image (averaged across noise realizations) of each reconstruction method (approximately fixed normalized root mean square error), for each PET‐unique region.
Fig. S3: All the results shown are for the low counts (107) simulated dataset, using multiple noise realizations. Bias Images: bias images for each of the positron emission tomography (PET)‐unique regions, shown for increasing level of β (MAP) or k (KEM) for each reconstruction method. Std Images: standard deviation images for each of the PET‐unique regions, shown for increasing level of β or k for each reconstruction method. Bias‐Std Trade‐off: bias vs standard deviation plots for each of the PET‐unique regions, for increasing levels of β (MAP) or k (KEM) along each curve. Tumor profiles: tumor profiles through the mean image of each reconstruction method (the selected parameters for which correspond to an approximately fixed whole brain normalized root mean square error, for each PET‐unique region. The maximum likelihood expectation maximization (MLEM) profile has been taken from the mean image of MLEM with post reconstruction smoothing applied (FWHM 3.5 mm).
Acknowledgments
This work was funded by the King’s College London and Imperial College London EPSRC Centre for Doctoral Training in Medical Imaging (EP/L015226/1) and supported by the Wellcome EPSRC Centre for Medical Engineering at King’s College London (WT 203148/Z/16/Z) and by the EPSRC grant number EP/M020142/1. According to the EPSRC's policy framework on research data, figures and data supporting this study are openly available at https://doi.org/10.5281/zenodo.3372337.
References
- 1. Somayajula S, Panagiotou C, Rangarajan A, Li Q, Arridge SR, Leahy RM. PET image reconstruction using information theoretic anatomical priors. IEEE Trans Med Imaging. 2011;30:537–549. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 2. Cheng‐Liao J, Qi J. PET image reconstruction with anatomical edge guided level set prior. Phys Med Biol. 2011;56:6899–6918. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 3. Nguyen Van‐Giang, Lee S‐J. Incorporating anatomical side information into PET reconstruction using nonlocal regularization. IEEE Trans Image Process. 2013;22:3961–3973. [DOI] [PubMed] [Google Scholar]
- 4. Tang J, Rahmim A. Bayesian PET image reconstruction incorporating anato‐functional joint entropy. Phys Med Biol. 2009;54:7063–7075. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 5. Bowsher JE, Yuan H, Hedlund LW, et al. Utilizing MRI Information to Estimate F18‐FDG Distributions in Rat Flank Tumors. IEEE Symp Conf Rec Nucl Sci. 2004;4:2488–2492. [Google Scholar]
- 6. Baete K, Nuyts J, Van Paesschen W, Suetens P, Dupont P. Anatomical‐based FDG‐PET reconstruction for the detection of hypo‐metabolic regions in epilepsy. IEEE Trans Med Imaging. 2004;23:510–519. [DOI] [PubMed] [Google Scholar]
- 7. Ardekani BA, Braun M, Hutton BF, Kanno I, Iida H. Minimum cross‐entropy reconstruction of PET images using prior anatomical information Minimum cross‐entropy reconstruction of PET images using prior anatomical information. Phys Med Biol. 1996;41:2497–2517. [DOI] [PubMed] [Google Scholar]
- 8. Hero AO, Piramuthu R, Fessier JA, Titus SR. Minimax emission computed tomography using high‐resolution anatomical side information and B‐spline models. IEEE Trans Inf Theory. 1999;45:920–938. [Google Scholar]
- 9. Wang G, Qi J. PET image reconstruction using kernel method. IEEE Trans Med Imaging. 2015;34:61–71. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 10. Hutchcroft W, Wang G, Chen KT, Catana C, Qi J. Anatomically‐aided PET reconstruction using the kernel method. Phys Med Biol. 2016;61:6668–6683. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 11. Bland J, Belzunce MA, Ellis S, McGinnity CJ, Hammers A, Reader AJ. Spatially‐compact MR‐guided kernel EM for PET image reconstruction. IEEE Trans Radiat Plasma Med Sci. 2018;2:470–482. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 12. Ellis S, Reader AJ. Kernelised EM Image Reconstruction for Dual‐Dataset PET Studies. 2016 IEEE Nucl Sci Symp Med Imaging Conf October 2016:1‐3. 10.1109/NSSMIC.2016.8069450 [DOI]
- 13. Bland J, Mehranian A, Belzunce MA, et al. MR‐guided kernel EM reconstruction for reduced dose PET imaging. IEEE Trans Radiat Plasma Med Sci. 2017;2:235–243. 10.1109/TRPMS.2017.2771490. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 14. Spencer B, Qi J, Badawi RD, Wang G. Dynamic PET Image reconstruction for parametric imaging using the HYPR kernel method. 2017 SPIE Med Imaging Proc 2017;10132. 10.1117/12.2254497. [DOI]
- 15. Hofmann T, Scholkopf B, Smola AJ. Kernel methods in machine learning. Ann Stat. 2008;36:1171–1220. [Google Scholar]
- 16. Zhao Y, Baikejiang R, Li C.Application of kernel method in fluorescence molecular tomography. In: Azar FS, Intes X, eds. Proc. SPIE 10057, Multimodal Biomedical Imaging XII. Vol 100570P. International Society for Optics and Photonics; 2017. doi: 10.1117/12.2252782. [DOI]
- 17. Gong K, Cheng‐Liao J, Wang G, Chen KT, Catana C, Qi J. Direct patlak reconstruction from dynamic PET data using the kernel method with MRI information based on structural similarity. IEEE Trans Med Imaging. 2017;37:955–965. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 18. Novosad P, Reader AJ. MR‐guided dynamic PET reconstruction with the kernel method and spectral temporal basis functions. Phys Med Biol. 2016;61:4624–4644. [DOI] [PubMed] [Google Scholar]
- 19. High WG. Temporal‐resolution dynamic PET image reconstruction using a new spatiotemporal kernel method. IEEE Trans Med Imaging. 2018;38:664–674. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 20. Baikejiang R, Zhao Y, Fite BZ, Ferrara KW, Li C. Anatomical image‐guided fluorescence molecular tomography reconstruction using kernel method. J Biomed Opt. 2017;22:055001. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 21. Baikejiang R, Zhang W, Li C.Gaussian kernel based anatomically‐aided diffuse optical tomography reconstruction. In: Tromberg BJ, Yodh AG, Sevick‐Muraca EM, Alfano RR, eds. Proc. SPIE 10059, Optical Tomography and Spectroscopy of Tissue XII. Vol 1005912. International Society for Optics and Photonics; 2017:1005912. 10.1117/12.2252786 [DOI]
- 22. Jiao J, Markiewicz P, Burgos N, et al. Detail‐preserving PET reconstruction with sparse image representation and anatomical priors. Inf Process Med Imaging. 2015;24:540–551. [DOI] [PubMed] [Google Scholar]
- 23. Tahaei MS, Reader AJ. Patch‐based image reconstruction for PET using prior‐image derived dictionaries. Phys Med Biol. 2016;61:6833–6855. [DOI] [PubMed] [Google Scholar]
- 24. Elad M, Milanfar P, Rubinstein R . Analysis versus synthesis in signal priors. In: European Signal Processing Conference; 2006. 10.1088/0266-5611/23/3/007. [DOI]
- 25. Levitan E, Herman GT. A maximum a posteriori probability expectation maximization algorithm for image reconstruction in emission tomography. IEEE Trans Med Imaging. 1987;6:185–192. [DOI] [PubMed] [Google Scholar]
- 26. Hebert T, Leahy R. A generalized EM algorithm for 3‐D Bayesian reconstruction from poisson data using gibbs priors. IEEE Trans Med Imaging. 1989;8:194–202. [DOI] [PubMed] [Google Scholar]
- 27. Nuyts J, Beque D, Dupont P, et al. A concave prior penalizing relative differences for maximum‐a‐posteriori reconstruction in emission tomography. IEEE Trans Nucl Sci. 2002;49:56–60. [Google Scholar]
- 28. Lange K. Convergence of EM image reconstruction algorithms with Gibbs smoothing. IEEE Trans Med Imaging. 1990;9:439–446. [DOI] [PubMed] [Google Scholar]
- 29. Kaipio JP, Kolehmainen V, Vauhkonen M, Somersalo E. Inverse problems with structural prior information. Inverse Probl. 1999;15:713–729. [Google Scholar]
- 30. Schramm G, Holler M, Rezaei A, et al. Evaluation of parallel level sets and Bowsher's method as segmentation‐free anatomical priors for time‐of‐flight PET reconstruction. IEEE Trans Med Imaging. 2017;37:590–603. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 31. Kazantsev D, Ourselin S, Hutton BF, et al. A novel technique to incorporate structural prior information into multi‐modal tomographic reconstruction. Inverse Probl. 2014;30:065004. [Google Scholar]
- 32. Wang G, Qi J. Penalized likelihood PET image reconstruction using patch‐based edge‐preserving regularization. IEEE Trans Med Imaging. 2012;31:2194–2204. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 33. Bai B, Li Q, Leahy RM. Magnetic resonance‐guided positron emission tomography image reconstruction. Semin Nucl Med. 2013;43:30–44. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 34. Vunckx K, Atre A, Baete K, et al. Evaluation of three MRI‐based anatomical priors for quantitative PET brain imaging. IEEE Trans Med Imaging. 2012;31:599–612. [DOI] [PubMed] [Google Scholar]
- 35. Nuyts J, Baete K, Beque D, Dupont P. Comparison between MAP and post‐processed ML for incorporating anatomical knowledge in emission tomography. 2005;24(5). 10.1109/nssmic.2003.1352274 [DOI] [PubMed]
- 36. Shepp LA, Vardi Y. Maximum likelihood reconstruction for emission tomography. IEEE Trans Med Imaging. 1982;1:113–122. [DOI] [PubMed] [Google Scholar]
- 37. Hudson HM, Larkin RS. Accelerated image reconstruction using ordered subsets of projection data. IEEE Trans Med Imag. 1994;13:601–609. [DOI] [PubMed] [Google Scholar]
- 38. Wang H, Fei B. An MR image‐guided, voxel‐based partial volume correction method for PET images. Med Phys. 2012;39:179–194. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 39. Belzunce MA, Mehranian A, Reader AJ. Enhancement of partial volume correction in MR‐guided PET image reconstruction by using MRI voxel sizes. IEEE Trans Radiat Plasma Med Sci. 2018;3:315–326. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 40. Nahmias C, Garnett ES, Firnau G, Lang A. Striatal dopamine distribution in Parkinsonian patients during life. J Neurol Sci. 1985;69:223–230. [DOI] [PubMed] [Google Scholar]
- 41. Chang IC, Lue KH, Hsieh HJ, Liu SH, Kao CHK. Automated striatal uptake analysis of 18F‐FDOPA PET images applied to Parkinson’s disease patients. Ann Nucl Med. 2011;25:796–803. [DOI] [PubMed] [Google Scholar]
- 42. Klunk WE, Price JC, Mathis CA, et al. Amyloid deposition begins in the striatum of presenilin‐1 mutation carriers from two unrelated pedigrees. J Neurosci. 2007;27:6174–6184. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 43. Mosconi L, McHugh PF. FDG‐ and amyloid‐PET in Alzheimer’s disease: Is the whole greater than the sum of the parts? Q J Nucl Med Mol Imaging. 2011;55:250–264. [PMC free article] [PubMed] [Google Scholar]
- 44. Jagust WJ, Bandy D, Chen K, et al. The Alzheimer’s disease neuroimaging initiative positron emission tomography core. Alzheimer's Dement. 2010;6:221–229. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 45. Zhu A, Lee D, Shim H. Metabolic PET imaging in cancer detection and therapy response. Semin Oncol. 2012;38:55–69. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 46. Al‐Ibraheem A, Buck A, Krause BJ, Scheidhauer K, Schwaiger M. Clinical applications of FDG PET and PET/CT in head and neck cancer. J Oncol. 2009;2009:1–13. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 47. Wong RJ. Current status of FDG‐PET for head and neck cancer. J Surg Oncol. 2008;97:649–652. [DOI] [PubMed] [Google Scholar]
- 48. Mehranian A, Belzunce MA, Niccolini F, et al. PET image reconstruction using multi‐parametric anato‐functional priors. Phys Med Biol. 2017;62:5975–6007. [DOI] [PubMed] [Google Scholar]
- 49. Kazantsev D, Bousse A, Pedemonte S, Arridge SR, Hutton BF, Ourselin S. Edge preserving bowsher prior with nonlocal weighting for 3D spect reconstruction. Proc ‐ Int Symp Biomed Imaging 2011:1158–1161. 10.1109/ISBI.2011.5872607 [DOI]
- 50. Deidda D, Karakatsanis NA, Robson PM, et al. Hybrid PET-MR list-mode kernelized expectation maximization reconstruction. Inverse Probl. 2019;35 10.1088/1361-6420/ab013f. [DOI] [Google Scholar]
- 51. Deidda D, Member S, Karakatsanis N, et al. Effect of PET‐MR inconsistency in the kernel image reconstruction method. IEEE Trans Radiat Plasma Med Sci. 2018;3:400–409. 10.1109/TRPMS.2018.2884176 [DOI] [PMC free article] [PubMed] [Google Scholar]
- 52. Reeder BJ, Svistunenko DA, Wilson MT. Lipid binding to cytoglobin leads to a change in haem co‐ordination: a role for cytoglobin in lipid signalling of oxidative stress. Biochem J. 2011;434:483–492. [DOI] [PubMed] [Google Scholar]
- 53. Nuyts J. The use of mutual information and joint entropy for anatomical priors in emission tomography. In: 2007 IEEE Nuclear Science Symposium Conference Record IEEE; 2007:4149–4154. 10.1109/NSSMIC.2007.4437034 [DOI]
- 54. Ehrhardt MJ, Arridge SR. Vector‐valued image processing by parallel level sets. IEEE Trans Image Process. 2014;23:9–18. [DOI] [PubMed] [Google Scholar]
- 55. Ehrhardt MJ, Thielemans K, Pizarro L, et al. Joint reconstruction of PET‐MRI by exploiting structural similarity. Inverse Probl. 2015;31:015001. [Google Scholar]
- 56. Dempster AP, Laird NM, Rubin DB. Maximum likelihood from incomplete data via the EM algorithm. J R Stat Soc Ser B Methodol. 1977;39:1–38. [Google Scholar]
- 57. De Pierro AR. Modified expectation maximization algorithm for penalized likelihood estimation in emission tomography. IEEE Trans Med Imaging. 1995;14:132–137. [DOI] [PubMed] [Google Scholar]
- 58. Ellis S, Mallia A, McGinnity CJ, Cook GJR, Reader AJ. Multi‐tracer guided PET image reconstruction. IEEE Trans Radiat Plasma Med Sci. 2018;2:499–509. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 59. Cocosco C, Kollokian V, Kwan RK, Pike GB, Evans AC. BrainWeb: Online Interface to a 3D MRI Simulated Brain Database. 3‐rd Int Conf Funct Mapp Hum Brain; 1997;5(4):S425. https://doi.org/10.1.1.51.3917
- 60. Ellis S, Reader AJ. Penalized maximum likelihood simultaneous longitudinal PET image reconstruction with difference‐image priors. Med Phys. 2018;45:3001–3018. [DOI] [PubMed] [Google Scholar]
- 61. Liu C‐C, Qi J. Higher SNR PET image prediction using a deep learning model and MRI image. Phys Med Biol. 2019;64:115004. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 62. Belzunce MA, Reader AJ. Assessment of the impact of modeling axial compression on PET image reconstruction. Med Phys. 2017;44:5172–5186. [DOI] [PubMed] [Google Scholar]
- 63. Belzunce MA, Mehranian A, Chalampalakis Z, Reader AJ. Evaluation of shift‐invariant image‐space PSFs for the Biograph mMR PET Scanner. In: PSMR Conference, Lisbon; 2017.
- 64. Wang Z, Bovik AC, Sheikh HR, Simoncelli EP. Image quality assessment: from error visibility to structural similarity. IEEE Trans Image Process. 2004;13:600–612. [DOI] [PubMed] [Google Scholar]
- 65. Rasch J, Brinkmann EM, Burger M. Joint reconstruction via coupled Bregman iterations with applications to PET‐MR imaging. Inverse Probl. 2018;34:014001. [Google Scholar]
- 66. Yan J, Lim JC‐S, Townsend DW. MRI‐guided brain PET image filtering and partial volume correction. Phys Med Biol. 2015;60:961–976. [DOI] [PubMed] [Google Scholar]
- 67. Smith SM, Woolrich MW, Jbabdi S, et al. Bayesian analysis of neuroimaging data in FSL. NeuroImage. 2008;45:S173–S186. [DOI] [PubMed] [Google Scholar]
- 68. Nuyts J. Unconstrained image reconstruction with resolution modelling does not have a unique solution. EJNMMI Phys. 2014;1:98 http://www.ejnmmiphys.com/content/1/1/98. Accessed June 16, 2017. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 69. Stute S, Comtat C. Practical considerations for image‐based PSF and blobs reconstruction in PET. Phys Med Biol. 2013;58:3849–3870. [DOI] [PubMed] [Google Scholar]
- 70. Metz CE. ROC methodology in radiologic imaging. Invest Radiol. 1986;21:720–733. [DOI] [PubMed] [Google Scholar]
- 71. Myers KJ, Barrett HH. Addition of a channel mechanism to the ideal‐observer model. J Opt Soc Am A. 1987;4:2447. [DOI] [PubMed] [Google Scholar]
- 72. Metz CE. Basic Principles of ROC Analysis. Semin Nucl Med. 1978;8:283–298. http://www.umich.edu/~ners580/ners-bioe_481/lectures/pdfs/1978-10-semNucMed_Metz-basicROC.pdf [DOI] [PubMed] [Google Scholar]
- 73. Barrett HH, Yao J, Rolland JP, Myers KJ. Model observers for assessment of image quality. Proc Natl Acad Sci USA. 1993;90:9758–9765. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 74. Mehranian A, Bland J, McGinnity CJ, Hammers A, Reader AJ. Clinical assessment of MR‐assisted PET image reconstruction algorithms for low‐dose brain PET imaging. In: IEEE Nuclear Science Symposium Conference Record; 2019.
- 75. Schwyzer M, Ferraro DA, Muehlematter UJ, et al. Automated detection of lung cancer at ultralow dose PET/CT by deep neural networks – initial results. Lung Cancer. 2018;126:170–173. [DOI] [PubMed] [Google Scholar]
- 76. Lakshmanaprabu SK, Mohanty SN, Shankar K, Arunkumar N, Ramirez G. Optimal deep learning model for classification of lung cancer on CT images. Futur Gener Comput Syst. 2019;92:374–382. [Google Scholar]
Associated Data
This section collects any data citations, data availability statements, or supplementary materials included in this article.
Supplementary Materials
Appendix S1: Appendix A: Comparison of KEM and KEM LVS basis functions.
Appendix B. Extended evaluation of simulated dataset.
Fig. S1: Basis functions derived using either the conventional kernel method (KEM) method or the KEM largest value sparsification (LVS) method. The impact of the different implementations on basis function shape is shown for a uniform (top row) and structured (bottom row) magnetic resonance (MR) region. Only the proposed KEM LVS can deliver compact basis functions in uniform MR regions and also structured basis functions in detail containing MR regions for the same fixed set of parameters.
Fig. S2: All the results shown are for the high counts (108) simulated dataset, using multiple noise realizations. Bias Images: bias images for each of the positron emission tomography (PET)‐unique regions, shown for increasing level of β (MAP) or k (KEM) for each reconstruction method. Std Images: standard deviation images for each of the PET‐unique regions, shown for increasing level of β or k for each reconstruction method. Bias‐Std Trade‐off: Bias vs standard deviation plots for each of the PET‐unique regions, for increasing levels of β (MAP) or k (KEM) along each curve. Tumor Profiles: tumor profiles through the mean image (averaged across noise realizations) of each reconstruction method (approximately fixed normalized root mean square error), for each PET‐unique region.
Fig. S3: All the results shown are for the low counts (107) simulated dataset, using multiple noise realizations. Bias Images: bias images for each of the positron emission tomography (PET)‐unique regions, shown for increasing level of β (MAP) or k (KEM) for each reconstruction method. Std Images: standard deviation images for each of the PET‐unique regions, shown for increasing level of β or k for each reconstruction method. Bias‐Std Trade‐off: bias vs standard deviation plots for each of the PET‐unique regions, for increasing levels of β (MAP) or k (KEM) along each curve. Tumor profiles: tumor profiles through the mean image of each reconstruction method (the selected parameters for which correspond to an approximately fixed whole brain normalized root mean square error, for each PET‐unique region. The maximum likelihood expectation maximization (MLEM) profile has been taken from the mean image of MLEM with post reconstruction smoothing applied (FWHM 3.5 mm).