

Abstract
Pharmacogenomics (PGx) clinical decision support integrated into the electronic health record (EHR) has the potential to provide relevant knowledge to clinicians to enable individualized care. However, past experience implementing PGx clinical decision support into multiple EHR platforms has identified important clinical, procedural, and technical challenges. Commercial EHRs have been widely criticized for the lack of readiness to implement precision medicine. Herein, we share our experiences and lessons learned implementing new EHR functionality charting PGx phenotypes in a unique repository, genomic indicators, instead of using the problem or allergy list. The Gen-Ind has additional features including a brief description of the clinical impact, a hyperlink to the original laboratory report, and links to additional educational resources. The automatic generation of genomic indicators from interfaced PGx test results facilitates implementation and long-term maintenance of PGx data in the EHR and can be used as criteria for synchronous and asynchronous CDS.
Keywords: precision medicine, pharmacogenetics, clinical decision support systems, electronic health record, medical informatics, delivery of health care, medication therapy management
INTRODUCTION
Pharmacogenomics (PGx), or pharmacogenetics, is defined as the study of the influence of individual genetic inheritance on medication response, including therapeutic effect and adverse drug reactions.1 Rapidly growing knowledge from basic science and clinical research has led to the translation of PGx knowledge into clinical practice guidelines, facilitating its implementation into clinical practice.2–4 This knowledge has the potential to help prescribing clinicians better identify individuals at risk for lack of therapeutic effect and significant or life-threatening adverse reactions. With PGx knowledge, clinicians can adjust the dose or drug to optimize efficacy and avoid adverse effects.
Despite these benefits, implementation of PGx in clinical practice has been very slow. A relatively small number of early adopters, usually large academic centers and members of research networks, have published their experience implementing PGx using diverse processes, PGx tests, and electronic tools.5–19 In general, they agree that the use of clinical decision support (CDS) integrated into the electronic health record (EHR) is critical for the implementation and adoption of PGx knowledge. However, commercial EHRs have been criticized for the slow response to these needs and the lack of tools to implement precision medicine.20–25 Current implementation of PGx uses EHR tools designed for other purposes such as the problem list, allergy list, PDF documents, and laboratory spreadsheets, which have significant limitations for PGx implementation. Some institutions have attempted to solve these problems by using homegrown applications within their EHR or standalone applications, but these solutions are not readily generalizable.16,17
New interest and attempts to solve these implementation challenges by commercial EHRs are welcome and very important. Commercial EHRs can facilitate generalizability of locally developed solutions and seamless information exchange among different institutions, which is indispensable for the long-term use of genetic data.
The aim of this work is to report our operational model implementing genomic indicators (Gen-Ind) and related CDS using new EHR functionality. Our intent is to facilitate cooperation and standardization, leading to large scale implementation of PGx.
IMPLEMENTATION MODEL
Clinical setting
PGx testing at the Mayo Clinic is performed by the Personalized Genomics Laboratory. All the PGx test results are electronically interfaced to the EHR as text reports (PDF) and structured data (genotype/phenotype). Clinicians may use outside laboratories, and the institution has electronic interfaces to receive structured results from some vendors. The institution used a multidisciplinary model to implement PGx-CDS in multiple EHRs since 2013.10 The model is organized into several components including leadership, clinical approval, education, laboratory results, knowledge translation, and EHR integration. Since 2018, the entire institution converted to a single instance of a commercial EHR (Epic, Verona, WI). There is also extensive PGx research, including collaboration with national networks to integrate genomic data in the EHR.26–29
Original implementation
An expert rules engine was used to identify new PGx test results and, by using a translation table, automatically document PGx phenotypes in the problem list, while the abacavir-HLA-B*57: 01 interaction was documented as an allergy. CDS pop-up alerts warned about potential drug-gene interactions or recommended genetic testing before the initiation of specific drug therapies. PGx-CDS evaluated patient data including the problem list (repository of the phenotypes), allergies, PGx genotype results and other biochemical laboratory results. PGx-CDS interventions were implemented for 21 drug-gene interactions.10
Pharmacogenomics genomic indicators
The new Gen-Ind functionality within the EHR can be used as a repository for storing patient-specific genomic data and can be managed with additional tools. This repository can be customized by the institution and replaces the problem list and the allergy list, which were previously used as repositories of PGx phenotypes in the EHR. Additional functionality includes easy access; clinician ability to add comments and security to control who can add, edit, delete, or view them; automatic documentation from PGx laboratory results; manual documentation; hyperlinks to access the original PGx lab report (PDF); and multiple links to additional educational information. The Gen-Ind can be used as criteria for CDS interventions in the same way as the problem and allergy lists, but, as Gen-Ind can be tailored more specifically, they are an improvement over these previously used repositories.
We customized the Gen-Ind using the following parameters:
Name: <PGx gene name> <PGx phenotype>. The phenotype includes the new and old terminology, that is, “CYP2D6 Normal (Extensive) metabolizer.” For genes that can be associated with multiple drugs, the drugs are not part of the name. The drug-gene interaction is mentioned in the description section or is handled by the CDS interventions. For genes or panels of genes that are specific to a drug, the drug name can be part of the name, that is, “Warfarin Panel: High warfarin sensitivity.”
Overview: information about the creation of the Gen-Ind including specific genotype, that is, *1/*2. It can also report changes from the original report due to updated knowledge.
Linked Results: a hyperlink to the original full PGx test result report, usually a PDF file with extensive information.
About This Indicator: a brief description of the potential clinical meaning of the phenotype that could include specific drugs and clinical interactions.
References: Links to additional information, including the Clinical Pharmacogenetics Implementation Consortium guidelines and our internal educational resources.
There is additional functionality as well, including date of creation, author name, search function, sorting, summary display of the phenotypes, and patient portal access. Figure 1 shows an example of a Gen-Ind.
Figure 1.

Example of a pharmacogenomics genomic indicator.
Gen-Ind can be entered manually, but with the rapid growth in the number of patients getting testing and the number of genes tested in a panel, this option is impractical and error-prone. It is an option for special cases of high risk results available only as a paper report or PDF file. Documentation of a Gen-Ind can protect the patient from the use of contraindicated drugs by triggering a CDS alert. However, the best option to document a Gen-Ind is with the genomic translation engine, which allows automatic documentation based on structured PGx test results. This option requires electronic interfaces between the laboratories and the EHR, and a PGx translation table that is still institutionally owned and maintained. A set of electronic tools allows maintenance in groups. For example, if a specific genotype is reclassified to a different phenotype with a different level of risk (ie, from normal to intermediate metabolizer), these tools can find all the records with the old definition and change them to the new phenotype and document the reason for the change. The laboratory generally will not change the original report because it reflects correct information at the time of testing and updating the report poses a large logistical challenge, but the Gen-Ind can be updated and used to explain the changes.
Using genomic indicators to implement clinical decision support
Figure 2 describes the overall model for implementing PGx-CDS using Gen-Ind. Electronic interfaces with the genomic laboratories are critical and the most challenging technical step of the process. Currently, there is limited standardization, and the laboratories do not always disclose their methodology of determining genotypes and phenotypes.30 Reporting differences can be standardized using institutional criteria in the translation table and the genomic translation engine. However, this translation is still local and may not always follow Clinical Pharmacogenetics Implementation Consortium guidelines.
Figure 2.
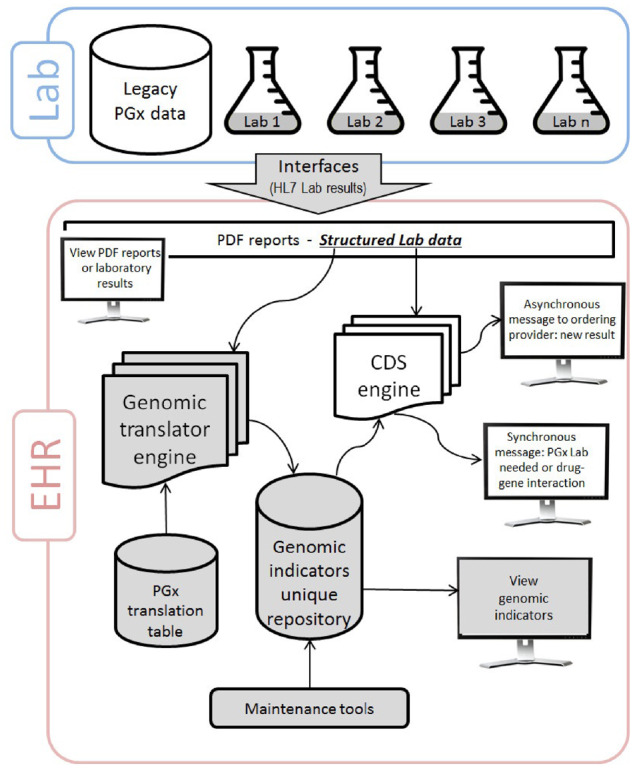
Implementation of genomic indicators and related clinical decision support. The structure laboratory (lab) data are interfaced to the electronic health record (EHR) and can be viewed by the clinicians. The genomic translation engine uses the lab data and the pharmacogenomics (PGx) translation table to define and storage the genomic indicators which can be viewed by the clinicians. Maintenance tools are available to update the genomic indicators as needed. The clinical decision support (CDS) engine can access the lab data and the genomic indicators to send asynchronous and synchronous alerts to the clinicians. The monitors represent clinician access. HL7: health level 7.
The CDS engine can use the Gen-Ind as criteria to trigger synchronous and asynchronous CDS interventions that may include:
Alerting prescribers of a significant drug-gene interaction
Alerting providers if PGx testing is required before a specific drug is prescribed
Notifying providers of PGx test result(s) with actionable variant(s) or unreadable results (ie, uncharacterized variant or report error)
A link to additional online educational resources
A link to the Gen-Ind
A warfarin dose calculator
OUTCOME OF THE IMPLEMENTATION
Our implementation consisted of transferring structured PGx data from 3 legacy EHRs to the new system and processing new data from 3 laboratory interfaces. These laboratories evaluate a total of 35 PGx genes as single gene tests or as a panel. However, only 16 of these genes have been approved for translation as Gen-Ind based on available clinical evidence.
As of April 2019, the EHR had a total of 20 816 patients with structured PGx test results and at least one Gen-Ind. A patient could have from one to 15 Gen-Ind with a total of 190, 433 active Gen-Ind (Table 1). After the initial data load, approximately 15 504 errors were detected and corrected by retransmitting the laboratory result interface message. Approximately 4681 (0.15%) errors remained and were corrected manually. The most common errors were related to unexpected text in the result field (ie, “See comment,” “mail in specimen,” extra text, or extra spaces). Some errors were related to discordant phenotypes from 2 different test results and truly novel alleles or newly defined phenotypes.
Table 1.
Frequency of the genomic indicators by gene or gene panel (N = 190 433)
| Genomic indicators by gene | Number | Proportion (%) | Associated drug(s) |
|---|---|---|---|
| Carbamazepine panel (HLA-B*15: 02, HLA-A*31: 01) | 11 847 | 6.22 | carbamazepine, oxcarbazepine |
| CYP1A2 | 13 259 | 6.96 | |
| CYP2C19 | 15 443 | 8.11 | citalopram, clopidogrel, escitalopram |
| CYP2C9 | 13 305 | 6.99 | warfarin |
| CYP2D6 | 15 928 | 8.36 | codeine, fluoxetine, fluvoxamine, paroxetine, tamoxifen, tramadol, venlafaxine |
| CYP3A4 | 13 660 | 7.17 | |
| CYP3A5 | 13 560 | 7.12 | tacrolimus |
| DPYD | 13 414 | 7.04 | fluorouracil, capecitabine |
| HLA-B*57: 01 | 12 555 | 6.59 | abacavir |
| HLA-B*58: 01 | 12 310 | 6.46 | allopurinol |
| NUDT15 | 2973 | 1.56 | azathioprine, mercaptopurine, thioguanine |
| SLCO1B1 | 13 314 | 6.99 | simvastatin |
| TPMT | 14 221 | 7.47 | azathioprine, mercaptopurine, thioguanine |
| UGT1A1 | 12 095 | 6.35 | belinostat |
| Warfarin panel (CYP2C9, VKORC1) | 12 549 | 6.59 | warfarin |
DISCUSSION
The clinicians can now have multiple options for reviewing PGx test results in the EHR and can use these data in their decision making. We believe that the use of the Gen-Ind repository is practical, user-friendly and easy to access before prescribing medications. They can help clinical workflows by clearly displaying the PGx phenotype and actionable knowledge about potential risks. They can also facilitate access to more comprehensive education and guidelines as needed by clinicians. These are significant improvements when compared with previous options using the problem list, allergy list, or PDF reports. Furthermore, this new functionality can be complementary to the efforts of national research networks (ie, eMERGE, CSER, IGNITE)5–7 when developing, standardizing, and sharing best practice to integrate genomic medicine in the EHR. There are also important technical advantages. Automatic documentation of PGx phenotypes from new genetic results using a translation engine is more efficient and easier to maintain than previous options. The phenotypes are less likely to be deleted by providers. Availability of electronic tools allows error detection and regular updates based on changing PGx knowledge. During our initial implementation, these tools were widely used to automatically resolve a large number of errors. They were also used to find and update Gen-Ind due to changes in the interpretation of CYP2D6*2A.
There were important lessons learned from our implementation. The new functionality works well for a small number of PGx tests. With the development of genetic testing panels, increasing number of known PGx genes, and multigene drug interactions, the ability to filter and sort the phenotypes will become critical. The lack of standardization among the PGx laboratory reports represents an important challenge. New efforts to standardize are underway, but it is not clear when or if laboratories will implement standardized reporting.31–33
The new functionality requires specific configuration of the records to be evaluated by the genomic translation engine, and the discrete results must post to a specific order record field. It is important to anticipate resolution strategies for novel variants, newly defined phenotypes, and errors in data that are unreadable by the translation engine. Legacy PGx results and instances of patients with more than 1 result or discordant results represent special challenges. We created a series of business rules to detect these errors, and they trigger a manual review process that works well with a limited number of errors.
Not all the PGx genes currently reported by some laboratories have strong clinical evidence to support their implementation. Clinical experts are needed to guide decisions related to which PGx tests should be configured as Gen-Ind and if should trigger CDS interventions. A complementary multidisciplinary group is very important for helping with knowledge translation, clinical approval and education. It is important to recognize that Gen-Ind are new for clinicians. They are familiar with reviewing the problems and allergies but not the Gen-Ind. Special attention is needed to enhance visibility and provide ongoing educational opportunities for the healthcare team, especially prescribers and pharmacists. Finally, current utilities and tools to build and maintain the new functionality are helpful but are new, and there is still room for improvement.
In conclusion, the automation of a unique repository of PGx phenotypes facilitates the integration and maintenance of PGx test results in the EHR and may provide a mechanism for further standardization and exchange among organizations. Despite the challenges, this new approach is a step forward to improve implementation and long-term maintenance of precision medicine in daily clinical practice.
FUNDING
This work was supported in part by NIH grant U01HG006379, Center for Individualized Medicine and Center for the Science of Health Care Delivery at Mayo Clinic. Dr. Caraballo is additionally funded by grants NSF 1602198 and LM 11972.
AUTHOR CONTRIBUTIONS
All the authors contributed with the design and implementation of the system. JAS led the technical implementation. JAS and PJC collected the data and designed the figures. The paper was drafted by PJC and reviewed, critically edited and approved by all the authors.
ACKNOWLEDGMENTS
The authors would like to recognize Kelly Wix, Amen Amusan, Mary Karow, Dustin Basel, Razan El Melik, and Eric Matey for their participation in the implementation of the genomic indicators and Lucy Hodge for help with manuscript preparation.
CONFLICT OF INTEREST STATEMENT
None declared.
References
- 1. Weinshilboum RM, Wang L.. Pharmacogenetics and pharmacogenomics: development, science, and translation. Annu Rev Genom Hum Genet 2006; 7 (1): 223–45. [DOI] [PubMed] [Google Scholar]
- 2.Clinical Pharmacogenetics Implementation Consortium (CPIC). 2019. https://cpicpgx.org/ Accessed May 6, 2019.
- 3. Relling M, Klein T.. CPIC: clinical pharmacogenetics implementation consortium of the pharmacogenomics research network. Clin Pharmacol Ther 2011; 89 (3): 464–7. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 4. Relling MV, Evans WE.. Pharmacogenomics in the clinic. Nature 2015; 526 (7573): 343–50. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 5.Electronic Medical Records and Genomics (eMERGE) network. 2019. https://emerge.mc.vanderbilt.edu/ Accessed May 6, 2019.
- 6.Clinical Sequencing Evidence-Generating Research (CSER) consortium. 2019. https://cser-consortium.org/ Accessed May 6, 2019.
- 7.Implementing Genomics in Practice (IGNITE) consortium. 2019. https://gmkb.org/ Accessed May 6, 2019.
- 8. Arwood MJ, Chumnumwat S, Cavallari LH, Nutescu EA, Duarte JD.. Implementing pharmacogenomics at your institution: establishment and overcoming implementation challenges. Clin Transl Sci 2016; 9 (5): 233–45. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 9. Bell GC, Crews KR, Wilkinson MR, et al. Development and use of active clinical decision support for preemptive pharmacogenomics. J Am Med Inform Assoc 2014; 21 (e1): e93–9. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 10. Caraballo PJ, Hodge LS, Bielinski SJ, et al. Multidisciplinary model to implement pharmacogenomics at the point of care. Genet Med 2017; 19 (4): 421–9.. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 11. Dunnenberger HM, Crews KR, Hoffman JM, et al. Preemptive clinical pharmacogenetics implementation: current programs in five US medical centers. Annu Rev Pharmacol Toxicol 2015; 55 (1): 89–106. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 12. Gottesman O, Scott SA, Ellis SB, et al. The CLIPMERGE PGx program: clinical implementation of personalized medicine through electronic health records and genomics-pharmacogenomics. Clin Pharmacol Ther 2013; 94 (2): 214–7. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 13. Hicks JK, Stowe D, Willner MA, et al. Implementation of clinical pharmacogenomics within a large health system: from electronic health record decision support to consultation services. Pharmacotherapy 2016; 36 (8): 940–8. [DOI] [PubMed] [Google Scholar]
- 14. Hoffman JM, Haidar CE, Wilkinson MR, et al. PG4KDS: a model for the clinical implementation of pre-emptive pharmacogenetics. Am J Med Genet C Semin Med Genet 2014; 166C (1): 45–55. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 15. Johnson JA, Elsey AR, Clare-Salzler MJ, Nessl D, Conlon M, Nelson DR.. Institutional profile: University of Florida and Shands Hospital Personalized Medicine Program: clinical implementation of pharmacogenetics. Pharmacogenomics 2013; 14 (7): 723–6. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 16. O'Donnell P, Bush A, Spitz J, et al. The 1200 patients project: creating a new medical model system for clinical implementation of pharmacogenomics. Clin Pharmacol Ther 2012; 92 (4): 446–9. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 17. Peterson JF, Bowton E, Field JR, et al. Electronic health record design and implementation for pharmacogenomics: a local perspective. Genet Med 2013; 15 (10): 833–41. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 18. Pulley JM, Denny JC, Peterson JF, et al. Operational implementation of prospective genotyping for personalized medicine: the design of the Vanderbilt PREDICT project. Clin Pharmacol Ther 2012; 92 (1): 87–95. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 19. Shuldiner AR, Palmer K, Pakyz RE, et al. Implementation of pharmacogenetics: The University of Maryland personalized anti‐platelet pharmacogenetics program. Am J Med Genet 2014; 166 (1): 76–84. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 20. Caraballo PJ, Bielinski SJ, St Sauver JL, Weinshilboum RM.. Electronic medical record-integrated pharmacogenomics and related clinical decision support concepts. Clin Pharmacol Ther 2017; 102 (2): 254–64. [DOI] [PubMed] [Google Scholar]
- 21. Hoffman MA. The genome-enabled electronic medical record. J Biomed Inform 2007; 40 (1): 44–6. [DOI] [PubMed] [Google Scholar]
- 22. Kimball BC, Nowakowski KE, Maschke KJ, McCormick JB.. Genomic data in the electronic medical record: perspectives from a biobank community advisory board. J Empir Res Hum Res Ethics 2014; 9 (5): 16–24. [DOI] [PubMed] [Google Scholar]
- 23. Kullo IJ, Jarvik GP, Manolio TA, Williams MS, Roden DM.. Leveraging the electronic health record to implement genomic medicine. Genet Med 2013; 15 (4): 270–1. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 24. Roden DM, Xu H, Denny JC, Wilke RA.. Electronic medical records as a tool in clinical pharmacology: opportunities and challenges. Clin Pharmacol Ther 2012; 91 (6): 1083–6. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 25. Wilke RA, Xu H, Denny JC, et al. The emerging role of electronic medical records in pharmacogenomics. Clin Pharmacol Ther 2011; 89 (3): 379–86. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 26. Aronson S, Babb L, Ames D, et al. Empowering genomic medicine by establishing critical sequencing result data flows: the eMERGE example. J Am Med Inform Assoc 2018; 25 (10): 1375–81. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 27. Bielinski SJ, Olson JE, Pathak J, et al. Preemptive genotyping for personalized medicine: design of the right drug, right dose, right time-using genomic data to individualize treatment protocol. Mayo Clin Proc 2014; 89 (1): 25–33. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 28. Kullo IJ, Olson J, Fan X, et al. The Return of Actionable Variants Empirical (RAVE) study, a Mayo clinic genomic medicine implementation study: design and initial results. Mayo Clin Proc 2018; 93 (11): 1600–10. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 29. St Sauver JL, Bielinski SJ, Olson JE, et al. Integrating pharmacogenomics into clinical practice: promise vs reality. Am J Med 2016; 129 (10): 1093–9.e1. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 30. Moyer AM, Rohrer Vitek CR, Giri J, Caraballo PJ.. Challenges in ordering and interpreting pharmacogenomic tests in clinical practice. Am J Med 2017; 130 (12): 1342–4. [DOI] [PubMed] [Google Scholar]
- 31. Pratt VM, Cavallari LH, Del Tredici AL, et al. Recommendations for clinical CYP2C9 Genotyping allele selection: a joint recommendation of the association for molecular pathology and College of American Pathologists. J Mol Diagn 2019; 21 (5): 746–55. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 32. Pratt VM, Del Tredici AL, Hachad H, et al. Recommendations for clinical CYP2C19 genotyping allele selection: a report of the association for molecular pathology . J Mol Diagn 2018; 20 (3): 269–76. [DOI] [PubMed] [Google Scholar]
- 33. Shabo A. Clinical genomics data standards for pharmacogenetics and pharmacogenomics. Pharmacogenomics 2006; 7 (2): 247–53. [DOI] [PubMed] [Google Scholar]