

Abstract
Real-time simulation of a large-scale biologically representative spiking neural network is presented, through the use of a heterogeneous parallelization scheme and SpiNNaker neuromorphic hardware. A published cortical microcircuit model is used as a benchmark test case, representing ≈1 mm2 of early sensory cortex, containing 77 k neurons and 0.3 billion synapses. This is the first hard real-time simulation of this model, with 10 s of biological simulation time executed in 10 s wall-clock time. This surpasses best-published efforts on HPC neural simulators (3 × slowdown) and GPUs running optimized spiking neural network (SNN) libraries (2 × slowdown). Furthermore, the presented approach indicates that real-time processing can be maintained with increasing SNN size, breaking the communication barrier incurred by traditional computing machinery. Model results are compared to an established HPC simulator baseline to verify simulation correctness, comparing well across a range of statistical measures. Energy to solution and energy per synaptic event are also reported, demonstrating that the relatively low-tech SpiNNaker processors achieve a 10 × reduction in energy relative to modern HPC systems, and comparable energy consumption to modern GPUs. Finally, system robustness is demonstrated through multiple 12 h simulations of the cortical microcircuit, each simulating 12 h of biological time, and demonstrating the potential of neuromorphic hardware as a neuroscience research tool for studying complex spiking neural networks over extended time periods.
This article is part of the theme issue ‘Harmonizing energy-autonomous computing and intelligence’.
Keywords: neuromorphic, SpiNNaker, cortical microcircuit, real time, low-power, parallel programming
1. Introduction
Neural networks provide brains with the ability to perform cognitive tasks, motor control, and learn and memorize information. These circuits are robust, fault-tolerant and extremely efficient, with the human cerebral cortex consuming approximately 12 W [1]. However, understanding these systems is a complex task requiring consideration of cellular and circuit level behaviours. While experimental measurements are readily taken at the cellular scale, gathering data from large-scale circuits is more challenging. This has led to the use of computational models to simulate the response of circuit-scale spiking neural networks (SNNs) representing brain activity. In addition to the use of SNNs as a neuroscience research tool, there is a growing interest in harnessing their brain-like information processing to further the recent rapid progress in the field of deep learning and artificial neural networks. In addition to providing advanced computational capacity [2], the use of spike-based communication offers the potential to reduce significantly energy consumption, opening up potential for deployment of advanced inference/learning capabilities in edge computing devices [3], and in un-tethered/low-power neurorobotics applications [4]. However, execution of SNN models is a complex process on traditional computing machinery, particularly at scale, as the long-range connectivity and sparse temporal signals make traditional communication mechanisms inefficient. Communication costs therefore dominate performance, and scale nonlinearly with neural network size, slowing down simulations and increasing energy consumption of the underlying simulator.
This work presents a solution to this problem through the use of the digital neuromorphic platform SpiNNaker [5], together with software developments optimizing use of the massively parallel architecture. The target use case is a benchmark cortical microcircuit model from the literature [6], containing biologically representative numbers of neurons, connection topology and spiking activity. This paper builds on previous simulations of the model [7,8], providing an in-depth analysis of the required memory, processing and communication within the SNN, leading to a SpiNNaker implementation capable of simulating the model at biological real time: 10 s of simulation is executed in 10 s of wall-clock time—a feat not currently achievable using conventional HPC or GPU hardware. This opens up the potential to extend simulation times and computational neuroscience research to explore long-term effects in the brain, demonstrated here by successfully simulating in real time the target cortical microcircuit model continuously for 12 h. In addition to real-time processing, energy performance is improved by an order of magnitude relative to previous work [7], highlighting the benefits of neuromorphic computing in the quest for large-scale neural network simulation.
To demonstrate these achievements, the paper is structured accordingly: following this Introduction §2 highlights the main features of the target cortical circuitry, and explores the computational requirements of simulating such a model. Section 3 then explores how these requirements are mapped to SpiNNaker, and is followed by §4 detailing simulation correctness and performance. Finally, §5 comments on findings and makes suggestions for further improvements to the modelling process and future SNN simulator designs.
2. Background and motivation
(a). Use case: cortical microcircuit model
The focus of this work is the cortical microcircuit model developed by Potjans & Diesmann [6]. The model represents ≈1 mm2 of generic early sensory cortex, and contains 77 × 103 neurons and ≈0.3 × 109 synapses (see original publication [6] for a full description). Populations of neurons are arranged in layers, with each layer containing both excitatory and inhibitory neurons, with recurrent and inter-population connections as detailed in figure 1a. Synaptic weights are normally distributed, with mean±s.d. of 351.2 ± 35.32 pA for inhibitory source neurons, and 87.8 ± 8.78 pA for excitatory source neurons (except connections from layer 4 to 2/3 excitatory neurons, which have weights 175.6 ± 8.78 pA). Transmission delays are normally distributed and truncated to the nearest simulation time step Δt, with mean ± standard deviation of 1.5 ± 0.75 ms for excitatory sources, and 0.75 ± 0.375 ms for inhibitory neurons. Each population also receives background stimulation representing input from other brain regions. This input can either be in the form of direct current, injected directly into the neuron; or via Poisson input sources delivering synaptic input with population-dependent rates. Neurons are simulated with a single-compartment leaky integrate-and-fire unit, with current-based exponentially decaying synapses, as described by equation (2.1).
| 2.1 |
Membrane potential V, evolves with time constant τm, relative to a resting potential Vrest. Synaptic input current Isyn is increased on spike reception, and decays with time constant τsyn. This synaptic current is combined with direct input current IDC, and incorporated into the neuron membrane potential via membrane resistance R. When V exceeds the threshold potential Vθ, the neuron emits a spike, and its membrane potential is set to the reset potential Vreset. Simulations are performed for a total of 10 s with a simulation time step of Δt = 0.1 ms for accuracy of produced spike times. Simulation output is split into an initial transient followed by steady-state activity, with the first 1 s of results discarded when postprocessing to negate the effect of initial transient activity. Model performance is assessed from output spiketrains, and measured in terms of firing rates across each neuronal population, the coefficient of variation of inter-spike interval and the within-population activity correlation coefficient. These measures provide a quantitative analysis of a simulation and allow direct comparison of model results obtained under different initial conditions and from execution on a range of simulators.
Figure 1.

Cortical microcircuit model: (a) layered structure of excitatory and inhibitory neuron populations; (b) 0.4 s of steady-state output spikes (5% of total spikes plotted for clarity) and (c) layer-wise mean population firing rates. (Online version in colour.)
The cortical microcircuit model is a good test case for neuromorphic hardware, as it is an accepted standard across the field of computational neuroscience, and allows direct comparison between different software/hardware simulators. It demonstrates typical firing rates and peak synaptic fan-in/-out experienced in the brain, placing constraints on processing speed, communication and available synaptic memory. The model is also defined and built in a generic high-level way typically adopted by neuroscience researchers, here using the PyNN modelling language [9] (as opposed to bespoke simulator-specific coding). Synaptic connections are defined based on probability, representing a significant challenge as simplifying assumptions based on distance-dependence and proximity are unavailable to improve performance during routing and synaptic matrix generation/handling (routing must be all-to-all, encompassing all possibilities from short- to long-range connections). Successfully simulating this model is, therefore, a difficult challenge for neuromorphic hardware, but lays the foundations for scaling up and modelling additional and more complex brain regions in the future.
(b). SpiNNaker
(i). Hardware
SpiNNaker is a massively parallel digital neuromorphic platform for simulating SNNs. It comprises two key hardware components: the SpiNNaker chip and within that the SpiNNaker router. A SpiNNaker chip contains 18 cores, each comprising an ARM968 processor, direct memory access (DMA) controller, network interface and communications controllers, timer and other peripherals [10]. Cores have fast local Instruction and Data Tightly Coupled Memory (ITCM and DTCM), of 32 kB and 64 kB, respectively. Additional chip-level storage of 128 MB is provided in the form of SDRAM, with block transfer access available to all cores via their DMA controller. SpiNNaker chips are assembled onto boards, with inter-chip communication via small data packets (there is no shared memory between chips). The platform benefits from the SpiNNaker routing system: a dedicated message-passing fabric optimized for multicast transmission of many small data packets [11]. Each chip houses a hardware router containing a list of routing table entries, each of which describes what to do with a particular packet: transmit it to a neighbouring chip(s) on one (or more) of the six links (N, NE, E, S, SW, W), and/or deliver it to one (or more) of the cores on the current chip (cores 1–18). The routing system therefore enables efficient multicast communication from a single source to multiple destinations—much like action potential transmission and fan-out by a neuronal axon in biology.
(ii). Software
The sPyNNaker software package [12] provides a neural modelling framework for execution of SNNs on the SpiNNaker multicore hardware. SNN models are defined via the PyNN language [9], and interpreted via the Python-based SpiNNTools software package [13]. This host-based preprocessing performs model partitioning, mapping, place and route, and data generation. Model data defining neuron and synapse parameters and initial conditions, together with matrices defining synaptic connections are then loaded to the SpiNNaker machine, together with application binaries containing runtime code for execution on SpiNNaker cores.
SpiNNaker applications are programmed in C, and compiled into ARM instruction code. Each application is compiled against the SpiNNaker Application Runtime Kernel (SARK), providing access to low-level software and hardware components; and SpiN1API, a bespoke lightweight event-driven operating system. This allows linking of software callbacks to a range of hardware events, each with different priority, hence enabling construction of applications performing event-driven operations in real time. For example, during neural simulation periodic timer events are used to trigger callbacks performing regular state updates evolving neural dynamics, while the reception of spike packets is handled through high-priority packet-received events preempting all processing to ensure packet traffic is received as quickly as possible to reduce pressure on the network. Use of this operating system for neural simulation will be discussed in §3a; however, readers are referred to previous work [12] for detailed discussion and performance profiling of this event-based operating system in the context of neural simulation.
(c). Model assessment and previous work
In a recent study by Van Albada et al. [7], the cortical microcircuit model was ported to SpiNNaker, and performance compared to the HPC-based NEST simulator [14]. The SpiNNaker implementation distributed neurons 80 per core (80 individual sources per core for Poisson inputs), as this was the minimum number enabling the generation of routing tables satisfying hardware constraints. Machine allocation algorithms [13] calculated a total of 217 chips and 1924 cores were required for execution, resulting in allocation of a SpiNNaker machine consisting of six 48-chip boards, providing a potential 288 chips and 5174 cores, with unused boards turned off during simulation. To ensure neuron and spike processing was always completed within a given timer period, the interval between timer events was set to 400 000 clock cycles, yielding an effective 20 × slow-down relative to real time. With this configuration, the model was successfully executed with no system warnings or dropped packets, and results were in excellent agreement (both at the single neuron and network level) with the HPC simulator, which was able to execute the model at 3 × slow-down relative to real time. Energy per synaptic event for NEST and SpiNNaker was reported, respectively, at 5.8 μJ and 5.9 μJ, which is significantly higher than values reported previously for SpiNNaker: 20 nJ [15] and 110 nJ [16]. This reduced efficiency was explained by the simulation being sparsely distributed over the 6-board SpiNNaker machine, causing baseline power to be amortized across many fewer synaptic events [7], and, due to the simulation being slowed down by a factor of 20, causing the system to be powered for a longer period of time. A separate study explored the execution of this model on GPU hardware [8], using bespoke libraries optimized for SNN simulation [17]. The performance was evaluated on a range of GPUs with the best performance from a Tesla V100 achieving a processing speed of 2 × slow-down relative to real time, and an estimated 0.47 μJ per synaptic event. It is noted that a Jetson TX2 GPU was able to achieve superior energy consumption of 0.3 μJ per synaptic event; however, simulation processing speed dropped to 25 × slow-down relative to real time. It is also noted that performance was evaluated for simulation models which fit entirely within GPU memory, and hence these figures are unlikely to hold if simulations required multiple GPUs to be connected and data shared between them during execution.
While the cortical microcircuit model was executed successfully on SpiNNaker, performance of the neuromorphic hardware for this biological model was lower than expected. While this can be attributed in part to differences between the model and initial SpiNNaker design targets [5], certain parts of the simulation process were sub-optimal. This work therefore looks to understand how a model such as this can be better fit to the SpiNNaker hardware, and the lessons which can be learned in order to further the design of future neuromorphic systems. For example, exploring heterogeneous parallelization of neural computation as previously explored to handle synaptic plasticity [18], and understanding requirements of sub-millisecond time-step simulations [19]. A starting point for this research is therefore to quantify model requirements from the perspective of a simulation platform. Results from simulation of the cortical microcircuit model on the HPC-based NEST simulator (running in precise mode for maximum accuracy) are designated as the benchmark throughout, enabling performance comparison in terms of real-time execution and energy efficiency.
A fundamental requirement of hard real-time neural simulation is the processing of every simulation time step in the equivalent wall-clock time. This is in contrast to soft real-time simulation: where a section of simulation (containing many time steps) is executed within the equivalent total wall-clock time, but processing times of individual time steps can vary due to simulation activity. This is an important consideration when building an SNN simulator for interaction with external real-time systems, as unexpected behaviour may occur and information may be lost due to local variations in processing speeds causing phase shifts between the two systems. Such activity is demonstrated clearly by the cortical microcircuit model, when comparing mean firing rates to the variable instantaneous rates produced by network oscillations. For example, while figure 1c shows the mean layer-wise firing rates for the model, the total spikes produced for each simulation time step are plotted in figure 2 (both plots produced from baseline NEST simulation results). This demonstrates significant variations in counts of model spikes per time step from the initial transient phase of the simulation through to steady-state. Therefore, designing a system to cope with the mean rate may be sufficient to handle mean spike rates at soft real time; however, it will slow down or lose information during oscillation peaks of higher activity. Connectivity in the cortical microcircuit model obeys Dale’s Law [20], meaning all excitatory neurons make only excitatory connections, and inhibitory neurons only inhibitory connections. It is therefore interesting to split the total number of spikes produced per time step into excitatory and inhibitory counts. The right inset of figure 2 shows results from 1145 < t < 1170 ms, and demonstrates that population activity oscillations are typically in phase, but of different magnitude depending on neuron type. Mean activity in this period produces 17.0 excitatory and 8.3 inhibitory spikes per time step, with peaks of 55 and 38 spikes, respectively. The initial transient response of the model is extreme, with initial conditions causing the production of over 4000 spikes in the first time step. The SNN quickly damps this activity leading to steady-state behaviour after two subsequent regions of high spike output (figure 2, left inset).
Figure 2.

Analysis of cortical microcircuit output activity simulated with NEST: total, excitatory and inhibitory, spikes produced per simulation time step. Left inset shows an initial transient response, while right inset details steady-state oscillations. (Online version in colour.)
Two additional features compromising SpiNNaker performance in previous work [7] were the mechanisms handling network input and synaptic delays. Network input can be provided to the model in two ways: DC current injected into a neuron or Poisson generated spike-based input delivered to neurons through their synapses. When simulating the Poisson version of the model on SpiNNaker, individual cores are loaded with applications running a Poisson process, and sending packets targeting postsynaptic neurons (figure 3a). For the high rates of background activity present in the cortical microcircuit model, this resulted in certain cores receiving in excess of 300 spike packets per simulation time step, placing huge strain on both the SpiNNaker communications fabric and spike processing pipeline. Additional load was also introduced through handling of synaptic delays which exceeded the length of on-core synaptic input buffers. This caused spikes with synaptic delays of over 16Δt (1.6 ms) to be delivered to delay extension cores [7,12], which stored spikes for a given period before forwarding to postsynaptic cores at the appropriate time (figure 3a). As not all synapses required this delay, packets were routed directly between pre- and postsynaptic cores, in addition to via the delay extension core, greatly increasing network traffic and reducing efficiency as spike packets targeted fewer postsynaptic neurons on a single core. Together these features significantly increased the number of spike packets arriving at individual cores, with increases of over 300 spike packets relative to that shown in figure 2.
Figure 3.

Mapping of pre- and postsynaptic application cores to a SpiNNaker chip: (a) single neural application combining neuron and synapse processing (N&S), together with Poisson (P) and Delay Extension (D) cores, using entirely packet-based communication; (b) neural processing ensemble containing dedicated neuron (N), synapse (S) and Poisson cores (P), with local communication via shared memory. Monitor (M) and system (Sys) cores are required for correct chip/machine operation, but are not used directly by a simulation. (Online version in colour.)
The remainder of this work therefore explores how to improve the performance of the SpiNNaker implementation of the cortical microcircuit model, through better mapping to SpiNNaker hardware and an alternative formulation of neural processing software.
3. Methods
This section explores an alternative SpiNNaker software configuration to address the cortical microcircuit model requirements described and analysed in §2. A heterogeneous parallelization approach is presented, capable of scaling with the demands of large-scale biologically representative SNN simulation. This is followed by implementation of a board-to-board timer alignment protocol, and discussion of techniques for measuring system energy consumption.
(a). Parallelization of neural simulation
This section describes a heterogeneous parallelization of SNN operations, where ensembles of cores are used to address different neural processing tasks. It demonstrates how SpiNNaker hardware is assigned to parallelize neural processing operations, and how this alternative approach is integrated within the core SpiNNaker software stack. The programming model description includes mapping of processing tasks to the SpiNNaker chip, together with updated communication strategies; the different memory structures and how they are shared between cores; and real-time event-driven execution.
(i). Mapping and communication
A fundamental requirement of a hard real-time simulator targeting the cortical microcircuit model is handling of the peak spike rates presented in figure 2. The current SpiNNaker SNN simulation software sPyNNaker [12], maps a single neural sub-population to a single core (figure 3a). This core is responsible for updating the state of all its neurons, and processing all incoming spike packets delivering synaptic input. With this approach, the core must handle the incoming packet peaks associated with the ‘total’ curve in figure 2, in addition to spike packets from delay extension cores (representing synaptic events with delays too large to be handled by the postsynaptic core synaptic input buffers) and spike packets from Poisson sources representing background input. While it is possible to reduce the number of neurons simulated on a core to reduce the time required to update their state, this does not reduce significantly the number of incoming spike packets, which typically dominates core processing activity. Furthermore, reducing the number of neurons per core actually reduces spike processing efficiency, as the fixed costs of turning a spike into neural input are amortized over fewer individual neuron contributions [12].
This work therefore employs an alternative communication strategy, originally explored by Knight et al. [21], enabling parallelization of spike packet reception, and replacement of local packet-based communication with data transfer through shared SDRAM. This model is termed ‘heterogeneous parallelization’ as cores now act as part of a cooperative ensemble as shown in figure 3b. This ensemble is made up of: a neuron core (green) responsible for performing the neural state update; a Poisson input core (purple) providing background input and synapse cores for processing incoming spike packets (blue for excitatory, red for inhibitory). Synaptic and Poisson input is now transferred to neuron cores through shared SDRAM, greatly reducing the incoming spike packet traffic to a single core. Furthermore, incoming spike packets now target synapse cores based on their type, with inhibitory spikes arriving at inhibitory synapse cores, and vice versa for excitatory. Inhibitory synapse cores are therefore required to handle only the reduced peak spike rates marked ‘inhibitory’ in figure 2 (as opposed to those marked ‘total’), effectively parallelizing synaptic processing. This concept is extended for excitatory synapse cores, as the ‘excitatory’ peaks in figure 2 are effectively double the ‘inhibitory’ level. This load balancing is performed by routing spikes produced from the lower half of excitatory presynaptic populations to the lower excitatory synapse core (marked SL), and spikes from the upper half of excitatory presynaptic populations to the upper excitatory synapse core (marked SU). As neurons within a population are equally likely to emit spikes (there is no within-layer spatial information in the cortical microcircuit model) this mechanism effectively delivers half the peak ‘excitatory’ load from figure 2, to each excitatory synapse core, further parallelizing spike processing. This distribution of incoming packets between multiple receivers is a key difference to the previous sPyNNaker software implementation [12], and means that all spikes are no longer routed to every receiver. It is noted that this mechanism could be further extended, through the addition of extra synapse cores to the ensemble, to cater for SNN models with higher fan-in or peak spike rates.
Mapping and partitioning constraints are applied during the conversion of the high-level PyNN-defined network describing the structure in figure 1a, into a form suitable for loading to a SpiNNaker machine. These constraints ensure an ensemble of neural processing cores (dashed green box in figure 3b) are all mapped to the same chip, and can therefore share data through common SDRAM. Neuron-to-neuron communication is performed through multicast data packets, following the same approach described in [12]. These packets are source-routed based on the AER model [22], where spike packets carry only information about the source neuron, and are decoded at the receiving end to ascertain target synaptic contributions. Packets are transported around the SpiNNaker machine via the hardware routers present on each chip [11], which compare an incoming packet key with a predefined list of routing table entries defining actions to be taken on a match (see §2b). In this work, packet key generation is updated to assist processing on the postsynaptic core, and now follows the structure defined in figure 4. From least to most significant bits, a 32-bit key comprises 6 bits to define neuron ID between 0 and 63 within the presynaptic core; 9 bits to define the location of the sub-population within the global presynaptic population (allowing up to 512 64-neuron partitions, and hence PyNN-level populations of up to 32 768 neurons); and 17 routing bits, which the key generator is free to use to optimize route compression and hence minimize routing table entries. Note that use of the sub-population location to improve spike processing performance is discussed further in §3a(ii).
Figure 4.
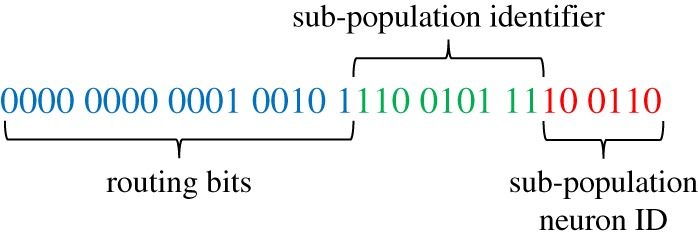
32-bit multicast packet key structure (no payload)—field sizes are representative and are adjusted based on source population size and target parallelization. (Online version in colour.)
(ii). Memory and processing
This section describes how an ensemble of cores cooperates to process neuron state updates and synaptic input. Shared data structures used at each stage of the process are presented, together with their locations and exchange mechanisms. SpiNNaker chip memory is allocated 64 kB per core (DTCM), with an additional chip-level 128 MB of shared memory (SDRAM). Owing to the highly connected cortical microcircuit topology, it is not possible to store synaptic matrices defining network connectivity within synapse core DTCM. These data structures are therefore kept in SDRAM, and retrieved on spike arrival as discussed in previous work [12].
Figure 5, details memory use for an ensemble of neural processing cores, together with interactions with specific neural processing tasks. The lower right-hand side of figure 5, shows an inhibitory spike packet arriving at the inhibitory synapse core, triggering the spike processing pipeline. This triggers a software callback (see §3a(iii)) which uses the packet key (figure 4) in a binary search of the master population table (see [12] for details). This look-up results in the start address in SDRAM of the appropriate synaptic matrix—here for the L6I population. The synaptic matrix is row-indexed by presynaptic neuron, with individual rows comprising multiple synaptic words, each characterizing a single connection from the presynaptic neuron to a single postsynaptic neuron. In an update from previous work [12], the packet-key neuron ID and sub-population identifier fields are combined to calculate a memory jump to the target row in the population-level synaptic matrix. This mechanism removes the need of an individual master population table entry for each sub-population partition, reducing the length of the master population table (and hence binary search times performed on the arrival of every spike packet) from more than 1000 to four entries (corresponding to the four source excitatory PyNN populations on excitatory synapse cores, and the four source inhibitory PyNN populations on inhibitory synapse cores). Once a target row has been located, its contents are copied via DMA to synapse core DTCM for processing. Each synaptic word is decomposed into target neuron ID, synapse type, synaptic delay and weight (figure 5). Synaptic input buffers, organized one per neuron and containing 255 slots, allow for accumulation of synaptic input for delivery over the next 255Δt = 25.5 ms. The separation of neural processing into neuron and synapse cores frees DTCM memory for synapse cores, facilitating these extended buffers and the removal of delay extension cores used previously [7]. This greatly reduces spike packet traffic, improving system efficiency and spike processing capacity. At the end of the timer period marking a simulation time step, slots for each neuron containing input for time step t + Δt for all synaptic input buffers are transferred to SDRAM via DMA B, and pointers updated incrementing the buffers one slot forward in time.
Figure 5.

On-chip memory use and data structures for SNN simulation. Cores use shared memory for transfer of local information within a neural processing ensemble. Bold capital letters mark DMA transfers corresponding to the same labels in figure 6. (Online version in colour.)
Poisson background input is delivered to all neurons in the cortical microcircuit, each with model-defined rates and weights. In the approach presented here, this input is generated by a dedicated core (top right of figure 5), and transferred to the neuron via SDRAM. As this input is intended to be delivered through a synapse, undergoing accumulation and decay according to equation (2.1), this input is generated and copied to SDRAM (DMA C) in a similar manner to a synapse core. The Poisson core maintains a 16-bit Poisson input buffer for each associated neuron (totalling 64 per Poisson core for the implementation presented here), along with a Poisson source following a Poisson process as described in previous work [12]. In parallel with a neuron core performing its state update, the Poisson core updates the state of each Poisson source, and determines whether it should emit a spike, and if so how many. This count is then used to add a weight value (scaled according to synaptic weights) to the Poisson input buffer for this source. On completing the update the entire buffer is copied to SDRAM, and then cleared ready for use in the next time step. This mechanism for handling Poisson input through shared memory greatly reduces spike packet traffic, without compromising the functionality or flexibility of the system.
The left-hand side of figure 5 shows a neuron state update, where the synaptic and Poisson inputs for this time step for all neurons are transferred from SDRAM to neuron core DTCM (DMA D), and used to update the synaptic state and membrane potential dynamics of each individual neuron (using equation (2.1), as discussed in [12]). Neuron cores must therefore hold in DTCM the state variables and parameters defining the neuron and synapse models, together with recording buffers. Compared to previous approaches [12], the splitting of synapse and neuron cores splits memory requirements, leaving additional capacity on both cores. While this was used to model extended synaptic delays on synapse cores, it could be used to increase neuron capacity on neuron cores. However, as discussed in §3a(iii), the system is currently processor constrained, setting capacity at 64 neurons per core. On state update completion, user-requested neuron state variables are recorded to SDRAM (DMA E), for subsequent extraction via the host-based software described in [13]. Note that for SpiNNaker simulations of the cortical microcircuit recorded data comprises output spike times of all model neurons.
(iii). Real-time event-driven processing
This section details real-time operation of neural simulation, including how the communication through packets and shared memory described in the previous sections fits within the event-based processing framework. Figure 6 shows the ensemble of cores from figure 3, along with how their respective operations are distributed in time. Black vertical lines and associated coloured rectangles correspond, respectively, to hardware events and software callbacks. The system is clock-driven, with each core working off its own timer, but with all timers on the same SpiNNaker board effectively aligned due to sharing the same crystal source (see §3b). Each core responds to a periodic timer event, through an associated timer callback, as described in previous work [12]. For real-time processing, with a simulation time step of Δt = 0.1 ms, the timer period is also tp = 0.1 ms, giving 20 000 clock cycles between timer events on the 200 MHz SpiNNaker ARM968. This timer provides the alignment necessary for performing DMAs A–E as demonstrated by figure 6 and detailed below.
Figure 6.

Event-based real-time execution of a neural processing ensemble. Bold capital letters mark DMA transfers corresponding to the same labels in figure 5. (Online version in colour.)
Neuron core immediately requests DMA D at the beginning of its timer callback (pale blue region in figure 6), transferring the Poisson and synaptic input required for the subsequent synapse and neuron state updates. These updates constitute the remainder of the software callback (dark blue bar in figure 6), and on completion updated state variables are recorded in SDRAM (DMA E), marking the end of the callback. Above-threshold neurons emit spike packets as they are updated, with packet keys constructed using the neuron ID (figure 4), and packets sent via the NoC to the chip router for transmission to all target synapse cores across the SpiNNaker machine. Individual neuron updates are measured at 1.05 μs per neuron, with the initial DMA read of 512 bytes taking a maximum of 2.68 μs. This measurement assumes the Poisson version of the cortical microcircuit, and mapping of three ensembles (and hence three neuron cores) to a SpiNNaker chip. These measurements specify that 64 neurons can be simulated on a neuron core with 100 μs timer period. This ensures all neurons will have updated their state and sent any spike packets before 70 μs of the timer period have elapsed, ensuring all spike packets are delivered to postsynaptic synapse cores within the spike processing window ts,proc.
Poisson core uses its timer callback to update the state of all Poisson sources, and add the appropriate multiple of the associated scaled synaptic weight to the Poisson input buffer slot. Sources in the cortical microcircuit model have rates in the range 12.8 ≤ f ≤ 23.2 kHz, meaning they are likely to produce multiple spikes per simulation time step. At these frequencies, the average update time for 64 Poisson sources, combined with the buffer transfer time to SDRAM is 63.81 μs. This transfer (DMA C) is indicated by the pale purple region in figure 6, and occurs approximately mid-way through the timer period, minimizing SDRAM contention with reads/writes by other cores in the ensemble. Note that for the DC version of the model, this core is omitted from the ensemble, and the buffer is not transferred into the neuron core within DMA D.
Synapse cores use their timer callback to schedule a second timer event at a fixed distance in time from the end of the timer period. This event triggers a software callback responsible for transferring the latest synaptic input buffer to SDRAM (DMA B). There is some core-to-core variation in SDRAM access times across the SpiNNaker chip, as multiple cores contend for SDRAM write bandwidth (potentially nine synapse cores writing per chip—figure 5), with mean (max) DMA times for writing 128 bytes measured at approximately 5 (7.2) μs. This second timer event is therefore scheduled 10 μs before the end of the timer period, ensuring DMA B is complete before the associated neuron core reads this memory during its next timer callback. The window between the neuron core beginning the neuron state update (after completing DMA D) and the synapse core writing these data (DMA B) therefore determines ts,proc, the time available for processing incoming spikes (figure 6). If at the end of this window there are unprocessed entries in the input spike buffer, the second timer callback interrupts spike processing (due to elevated priority), and flushes the incoming spike buffer discarding any unprocessed spikes. This ensures real-time execution is honoured regardless of SNN activity, guaranteeing hard real-time simulation at the expense of lost information during periods of high activity. To monitor performance, the maximum number of spikes flushed in a single time step is recorded throughout a simulation.
Individual spike processing is pipelined according to methods described in previous work [12]. Spike packet arrival triggers a high-priority packet-received event linked to a fast packet-received callback, which buffers the packet key for subsequent processing (‘MC Packet Received CB’ in figure 6). If a packet arrives while the spike processing pipeline is inactive, a software callback is scheduled to initiate spike processing (‘Software CB’ in figure 6). This instigates look-up of the spike key in the Master Population Table, and transfer to core DTCM of the synaptic matrix target row from SDRAM (as described in §3a(iii)). On completion of the DMA, synaptic words are extracted from the row, and converted into synaptic input buffer contributions as demonstrated in figure 5. Once the row has been processed, the input spike buffer is checked to see if subsequent spike packets have arrived while processing the first, and the row retrieval and processing loop is repeated until the buffer is empty (continuation of solid yellow block in figure 6 inset). At this point, the pipeline becomes inactive, and the core idles until interrupted (either by subsequent packet-received or timer events). Readers are invited to review previous work [12], for an in-depth description and performance analysis of this processing pipeline.
Several updates to the spike processing pipeline are introduced in this work to optimize performance and increase spike-processing capacity. First, due to reduced processing requirements of a synapse core in the heterogeneous parallelization approach relative to a single neural application (ensemble structure shown in figure 3), it is possible to simplify callback priorities and structure. Here spike processing is treated as a background task, freeing up the need to use an interrupt-based response to DMA completion when transferring synaptic data. After requesting a synaptic row (DMA A in figure 5), the synapse core polls its DMA controller status bit to check for transfer completion. This simplification not only removes hazards, but improves performance as the interrupt service routine no longer needs to be processed—a costly operation considering it must be processed once for every received spike. The heterogeneous programming model also removes the need for queuing of multiple DMAs by a single core, simplifying the API for interacting with the controller as no software queue needs to be maintained or managed. This reduces latency on software functions triggering the DMA, and improves performance without compromising functionality. Several additional optimizations have been made to the framework for software routing: the process whereby a packet key is converted into the target synaptic row address in SDRAM. As discussed previously, the updated packet key structure of figure 4, enables significant reductions in size of the master population table, greatly reducing average binary search times. However, through recognition of the cortical microcircuit structure and topology, it is possible to further optimize performance. For example, while the sPyNNaker software package can handle a generic SNN model with multiple projections between populations, the cortical microcircuit model has only a single receiving projection between each population. This information is used to simplify code handling address look-up, acknowledging the fact that only a single address will be returned, and removing multiple loops and conditional statements accordingly. Overall these updates enable a single spike targeting a single neuron to be processed in 3.55 μs, a 31% reduction relative to previously published results [12]. It is useful to contrast this number with the spike processing window, which effectively begins when neurons start sending spike packets, and ends when the second timer event is triggered, giving it range: 3.73 μs < ts,proc < 90 μs.
(b). SpiNNaker machine clock alignment
SpiNNaker machines comprise multiple 48-chip SpiNNaker boards, with board-to-board communication via data packets. All cores on the same board share a common crystal governing clock speed, and therefore have aligned timers. However, crystal manufacturing variability leads to small differences in clock speed between boards, and hence cores on different boards may have slightly different timer speeds. When running a timer-driven simulation, these variations can lead to significant clock drift between boards, particularly when running long-duration simulations. The heterogeneous programming model of §3a is sensitive to this drift, as spike packets emitted by neuron cores on one board may arrive relatively late/early at synapse cores on another, reducing time available for their processing or causing their arrival within the wrong time step.
A master-slave beacon alignment protocol is therefore employed to alleviate board-to-board clock drift. The monitor core on every chip (see ‘M’ core in figure 3) participates in the synchronization, and instructs all neighbouring cores on the same chip how to adjust their clocks. A single master core sends a beacon packet to each of the slave cores every 2 s, with payload detailing the time of sending. Slave cores use this information, together with the packet arrival time and compare the inter-beacon interval to the period elapsed on their timer. This allows each slave core to calculate a correction factor in terms of clock cycles, which is subsequently written to chip-level shared memory (SRAM). Each application core then reads this parameter and updates its timer period accordingly. Correction factors are typically small (less than a single clock cycle), and hence for accuracy corrections can be accumulated over multiple timer periods before being applied. While this mechanism accounts for clock drift, it does not ensure timers are in phase across the machine. When beginning a simulation, a start signal is sent from host to the SpiNNaker machine root monitor core (monitor core on chip (0, 0)), which then propagates this signal to the rest of the system. As the signal is routed from chip to chip, a small transmission time is encountered by each router (500 ns) and board-to-board link (900 ns), meaning chips farthest from the machine origin will receive the start signal latest. Furthermore, spike packets transmitted during simulation will encounter a similar transit time across the machine, meaning a spike sent at the beginning of the timer period by a core at the far edge of a machine will arrive at a core close to the origin with a relative delay of double the transit time. While the transit time is relatively small on the SpiNNaker machines discussed here (as it is proportional to machine size), in the extreme case this feature can cause packets to arrive during the wrong simulation time step, and hence lead to unpredictable results. Phase alignment is therefore achieved using the start signal together with a chip-specific delay, which is calculated during boot and is proportional to the distance from the chip(s) with the largest start-signal transit time. For example, the chip at the origin receives the start signal instantaneously on beginning a simulation, but delays execution until the start signal has propagated to chips on the farthest edge of the machine. Conversely, a chip on the farthest edge of the machine acknowledges its location, and starts immediately on receiving the signal, hence causing all cores to start in phase.
Measurements from the 12-board SpiNNaker system employing these alignment mechanisms found that core timers were aligned across boards to within 5 μs. This ensures correctness in real-time SNN simulations using the discussed API, together with a timer period of tp = 100 μs (a requirement resulting from real-time execution of models with a simulation time step of Δt = 0.1 ms).
(c). Energy and performance profiling
A key target of neuromorphic computing is emulation of the low-power computational abilities of the brain. It is therefore useful to measure energy consumed during simulation execution, to contrast with both the brain and other computing platforms such as HPC and GPUs. Target measures characterizing performance are energy to solution (energy consumed during the state propagation phase of simulation), and energy per synaptic event (where a synaptic event is defined as a single spike arriving at the synapse of an individual postsynaptic neuron). Recording such measures is a challenge due to the low power consumption of neuromorphic hardware, along with achieving consistency between measurements of different hardware platforms. While power monitoring equipment has been included on dedicated SpiNNaker boards for measurements from individual cores/chips, there are currently no instrumented large multi-board systems. In this work, a technique used in previous work [7] is replicated, whereby an energy meter is used to record wall-socket power of the entire SpiNNaker system: SpiNNaker boards, communications switch, power supplies and cooling fans. The meter provides a reading accurate to 0.01 kWh. A software-controlled camera is instructed to take readings at the beginning and end of simulation, the difference between readings then defines the total energy consumed. This energy to solution is then converted into energy per synaptic event by dividing by the total model synaptic events, and assuming constant power consumption throughout the simulation period.
All simulations and measurements reported here were executed on a 24-board SpiNNaker system, with machines allocated depending on simulation requirements. The cortical microcircuit model requires 6.6 boards for the DC input version, and 8.4 boards for the Poisson version, both of which result in allocation of a 12-board SpiNNaker machine. During simulation, unused chips remain in a booted but idle state, while unallocated boards (not part of the 12-board machine) remain powered off. In order to understand background power consumption relative to that of the SNN simulation, measurements are taken across three machine states: powered off; booted but idle and actively running a simulation. In all cases, readings are measured over a 12 h period in order to minimize error introduced through the energy meter resolution.
4. Results
The cortical microcircuit model described in §2 was simulated on the SpiNNaker platform using the approach described in §3. The following results document model and system performance in terms of real-time execution, accuracy and energy consumption.
(a). Real-time execution
The cortical microcircuit model was executed for 10 s of biological simulation time, with each 0.1 ms time step evaluated in 0.1 ms CPU time, resulting in a wall-clock simulation time of 10 s, and hard real-time execution. Results for the Poisson version of this simulation are shown in figure 7. Model initial conditions are relaxed from previous implementations [7] to avoid excessive firing in the first simulation time step due to neurons being initialized above threshold (figure 2). Neuron membrane potentials are instead initialized to give population firing dynamics over the first simulation time steps similar to steady-state activity. Figure 7 shows that these initial conditions do not affect the steady-state behaviour of the network, with good agreement observed between figures 7 and 1.
Figure 7.

Results from hard real-time simulation of cortical microcircuit model with Poisson input on SpiNNaker. Here (a) 0.4 s of output spikes (5% of total spikes plotted for clarity) and (b) layer-wise mean population firing rates. (Online version in colour.)
To understand how the simulator coped with real-time execution, it is useful to examine the synapse cores as these are the only part of the ensemble to experience variable load during simulation. Profiling output from an upper excitatory synapse core from the L23E population is shown in figure 8 (core active in simulation results presented in figures 7 and 9). A window of activity 1.0 s ≤ t ≤ 1.2 s is displayed, detailing the breakdown of incoming spikes to the core. The total spikes produced by the model which target this core is plotted by the dashed grey line; however, this is difficult to view as it is obscured by the solid red line which details the total spikes handled by the core. This demonstrates correct operation of the neural ensemble throughout the simulation, as all spikes are accounted for in the appropriate time step. The solid red line is made up of the total flushed spikes (orange curve) and processed spikes (blue curve). For the majority of the simulation, no spikes are flushed, indicating good load balancing between the two excitatory synapse cores. However, the right inset in figure 8 shows that during certain model oscillations incoming spike rates exceed the processing capacity of the core, and a number of spikes are flushed—e.g. around t = 1190 ms. Here the blue and red curves deviate from one another, demonstrating the peak processing capacity of the core to be approximately 26 spikes per time step. Much larger flushes are observed during the initial time step of the model (figure 8, left inset), as despite the improved initial conditions over 100 spikes are delivered to upper excitatory synapse cores in the first time step. The core is able to handle this extreme load, and maintains hard real-time execution (see §2c) by flushing unprocessed spikes and proceeding to the following time step. Also shown in figure 8 are curves detailing the number of spike packets targeting zero neurons on this particular synapse core (dashed crimson curve), and the number of times the spike processing pipeline was kick-started within a particular time step (dashed green curve). The pipeline is often kick-started multiple times within a timer period, indicating that spike packets are received throughout the ts,proc window. It is also noted that the time penalty of pipeline kick-starts rarely impacts peak spike processing capacity, as when large numbers of spikes arrive within a timer period they automatically keep the pipeline active. However, spikes which target no neurons on the postsynaptic core do impact performance, particularly as the processing pipeline has already spent significant effort to discover this. While for L23E synapse cores this is not detrimental to performance, for postsynaptic populations receiving connections based on low probabilities, spikes not targeting any neurons can make up approximately half the spike traffic arriving at synapse cores. It is noted that this issue could be exacerbated in large models containing sparse long-range connections. However, there are a number of mechanisms which could be employed to remove this wasted effort, including increasing the neuron density per chip, and using hardware/software routing strategies to stop zero-target spike packets arriving at a synapse core, and/or minimizing the effort required in their processing.
Figure 8.

Synapse core profiling during simulation of the Poisson input cortical microcircuit. Total spike packets received per time step plotted, together with total processed and flushed spikes: left inset details response around initial transient; while right inset details handling of extreme peak spike rates during steady-state oscillations. (Online version in colour.)
Figure 9.

Comparison of spiking output from last 10 s of cortical microcircuit simulations with Poisson input, executed using SpiNNaker in real time, and NEST at 3 × slow-down (all averaged over last 9 s of simulation): (a) single neuron firing rates; (b) coefficient of variation of inter-spike interval and (c) correlation coefficient between binned spiketrains. (Online version in colour.)
(b). Simulation accuracy
While the cortical microcircuit model produced correct results when executed in hard real time, the flushing of unprocessed spikes on saturated synapse cores means information is lost. Table 1 details the total synaptic events processed during real-time SpiNNaker simulations, with 9.135 × 109 and 9.343 × 109 reported for DC and Poisson input versions of the cortical microcircuit, respectively. This compares with 9.416 × 109 synaptic events in the NEST simulation with Poisson input, representing synaptic event losses within DC and Poisson SpiNNaker simulations of 2.98% and 0.76%, respectively. It is thought that increased flushes occur during simulation of the DC version of the model, due mapping causing increased neuron density per chip in this configuration. This results in additional synapse cores on each chip, which in turn increases the chance of contention during synaptic row fetches (DMA A), extending transfer times and reducing spike processing capacity. While this effect is relatively minor, it highlights the holistic nature of distributed systems design and the need for further research to optimize make-up of neural processing ensembles.
Table 1.
Energy measurements from 24-board SpiNNaker system used to execute cortical microcircuit simulations.
| configuration | wall-clock time | total energy (kWh) | synaptic events | energy per synaptic event (μJ/syn-event) |
|---|---|---|---|---|
| system only | 12 h | 0.93 | — | — |
| 12 booted boards | 12 h | 4.93 | — | — |
| cortical microcircuit, DC input, real-time | 12 h | 6.59 | — | — |
| cortical microcircuit, Poisson input, real-time | 12 h | 7.11 | — | — |
| cortical microcircuit, DC input, real-time | 10 s | 0.001525a | 9.135 × 109 | 0.601 |
| cortical microcircuit, Poisson input, real-time | 10 s | 0.001646a | 9.343 × 109 | 0.628 |
aQuantity estimated from extended duration simulation.
To understand the effect of lost synaptic events, statistical analysis is performed on output spiketrains to compare quantitatively results with baseline NEST simulations. Resulting spiketrains are postprocessed to extract the within-population distribution of firing rates; coefficients of variation of inter-spike interval and correlation coefficients for binned spike trains. Analysis is performed with the Elephant toolbox [23], and, where necessary, spiketrains are binned according to the Freedman–Diaconis rule. Results are displayed in figure 9, for the real-time Poisson input SpiNNaker simulation (blue), together with corresponding results from the NEST simulator running at 3 × slow-down (yellow). Good correlation between SpiNNaker and NEST results is observed across all metrics. The most significant variation is between the distributions of firing rates in the inhibitory layer five population, however, this is in common with observations in previous work when changing simulator random number generator seeds [7]. The results therefore confirm the model is executing correctly, and simulation accuracy has been preserved within the real-time heterogeneous parallelization.
(c). SpiNNaker machine mapping and energy
The model was executed on a 12-board SpiNNaker machine, with 576 chips (with dimensions 24 chips wide by 24 chips high) and 10 085 cores (total reduced from theoretical maximum due to failed cores present on active chips). This size of machine is provided by the SpiNNaker allocation software, which assigns square machines with dimensions incrementing by three boards with growing machine size. Mapping of the cortical SNN model populations to the SpiNNaker machine is detailed in figure 10, where (x, y) chip coordinates are coloured according to the assigned population. This shows that while a 12-board machine is allocated by preprocessing software, the DC version of the model is mapped to 6.6 boards (a total of 4840 cores over 318 chips—figure 10a), while the Poisson version requires 8.4 boards (a total of 6050 cores over 404 chips—figure 10b). This is an increase in cores of 25%, due to the addition of a Poisson core to the neural processing ensemble. Note that for DC simulations, four ensembles can be mapped to a single chip, giving a neuron density of 256 neurons per chip. The Poisson input version of the model maps three ensembles to a chip, leading to a neuron density of 192 neurons per chip.
Figure 10.

Mapping of cortical microcircuit layer-wise excitatory and inhibitory populations to chip coordinates of the SpiNNaker machine: (a) DC input version and (b) Poisson input version. (Online version in colour.)
The 12-board machine is allocated from a self-contained 24-board system, which is configured with wrap-around connectivity at its top and bottom edges, reducing the shortest path length for spike packets traversing the machine. This machine continuity at top and bottom edges is visible in figure 10, where a radial placer is used to map partitioned model populations to SpiNNaker chips, resulting in the outward spiralling of populations from the machine origin (chip (0,0)). This arrangement works favourably in terms of spike packet distribution to all synapse processing cores, due to the interleaving of excitatory and inhibitory populations. This ensures that spike packets from adjacent neuron cores arrive quickly, while packets from distant neuron cores will arrive later, thus helping kick-start the spike processing pipeline early in the timer period, and helping it remain active as further packets arrive.
Energy use was measured according to the methods described in §3c, and is reported for a range of configurations in table 1. The first three configurations report the energy required to power the system for 12 h, enabling precision in power recording equipment through accumulation of readings over long time windows. The ‘System Only’ configuration details the base power of the machine with all SpiNNaker boards powered off, and therefore represents auxiliary system components including cooling fans, communication switch, and rack power supplies. The ‘12 boards booted’ configuration captures the energy used by the 12-board SpiNNaker machine in its powered on and booted state, demonstrating an increase of 5.3 × relative to the powered-off machine. Results for both the DC and Poisson input versions of the cortical microcircuit simulation are then reported (also executed for 12 h). The DC version consumes 1.34 × more energy than the booted but idle SpiNNaker system, demonstrating that total energy consumption contributed by SNN simulation is approximately 25%. The Poisson version of the model consumes 1.44 × more energy than the booted but idle configuration, a slight increase relative to the DC version due to the additional chips/cores used, demonstrating that 30% of total energy consumed is used by the SNN simulation with Poisson input.
The bottom two rows of table 1 show estimated energy consumption of 10 s cortical microcircuit simulations with DC and Poisson input. This value is then used, together with the recorded synaptic events from each simulation, to estimate energy per synaptic event. This is calculated at 0.601 μJ and 0.628 μJ per synaptic event for the respective DC and Poisson simulations. This represents an order of magnitude reduction relative to previous results for both SpiNNaker and HPC (5.9 μJ and 5.8 μJ per synaptic event, respectively [7]). It also demonstrates how the relatively low-tech SpiNNaker processors, based on a 130 nm CMOS technology much older than that used in the comparator HPC or GPU systems, compete favourably with a range of modern GPUs running optimized SNN libraries (0.3–2.0 μJ/syn-event [8]).
5. Conclusion
This work presents the first real-time execution of a published large-scale cortical microcircuit model. This result surpasses previously published results in terms of processing speed, with optimal performance relative to real time reported at 3 × slow-down for an HPC-based simulator [7], and 2 × slow-down for GPUs running optimized SNN libraries [8]. Real-time processing was achieved through the use of SpiNNaker neuromorphic hardware, together with a heterogeneous programming model mapping neural processing to an ensemble of cores, each tackling different simulation operations. This approach enabled parallelization of incoming spike traffic, and hence additional synapse-focused cores to be added to the ensemble to handle simulation requirements. Energy use for the proposed approach is measured at 0.628 μJ/syn-event, surpassing published HPC performance figures by an order of magnitude [7], and giving comparable consumption to modern GPU hardware [8].
Neuron density per chip is reduced significantly from initial SpiNNaker design targets (256 neurons per chip for DC version, and 192 for Poisson version of the model); however, the model specification is also increased in complexity from initial design targets, containing an order of magnitude more synaptic connections per neuron, and requiring simulation time steps of Δt = 0.1 ms—also an order of magnitude less than original predictions. Energy consumption figures therefore stand to be improved dramatically by further research and software optimizations, which could allow simulation of increased numbers of neurons per chip, and mapping of the cortical microcircuit to a much smaller SpiNNaker machine. Likely candidates for optimization include speeding up of neuron state updates, and combining of Poisson input source code into neuron core applications, freeing up multiple cores per chip to run additional neural processing ensembles. However, it should be highlighted that SpiNNaker simulations are already operating across multiple boards, and hence have overcome the communication bottleneck limiting further performance gains from HPC and GPUs. The parallelization of spike communication presented here, therefore, not only improves speed and energy efficiency at this scale of model, but stands to scale further with model size and the use of additional SpiNNaker hardware, preserving both real-time processing and energy per synaptic event levels.
System correctness and robustness is also demonstrated, with all spikes accounted for within the spike processing pipeline, and multiple 12 h simulations performed successfully. This deterministic and predictable nature, coupled with extended duration simulations executed in real time, opens the door for a new paradigm in neuroscience research. Neuromorphic hardware now offers the potential to study long-term effects in spiking neural network models representing brain activity, both at the same speed as they occur in biology, and at scales not measurable through physical experiments. It also opens the door to deploying large-scale SNNs in real-time neurorobotics applications, and exploring applications of large-scale brain-inspired artificial intelligence.
Acknowledgements
The authors thank Hanjia Jiang, Sacha van Albada and Marcus Diesman of FZ Jülich, Germany, for providing NEST simulation results of the cortical microcircuit model, and with assistance in generating the updated initial conditions used in neuromorphic simulations reported here. We also thank Mantas Mikaitis and Robert James of the Advanced Processor Technologies group at the University of Manchester, for assistance with optimization of SpiNNaker application code, and discussions on synaptic parallelization and improving performance in large-scale SNNs.
Data accessibility
The data and code used to generate the results presented in this paper are available from the SpiNNaker software stack: https://github.com/SpiNNakerManchester, using branches realtime_cortical_ microcircuit.
Authors' contributions
L.P. co-designed and built the SpiNNaker software implementation of the heterogeneous programming model. A.D.R. implemented the improved synaptic matrix generation and access, along with the board-to-board drift alignment protocol. A.G. implemented the Poisson application delivering neuron input through shared memory. L.A.P. implemented the board-to-board phase alignment, and assisted with low-level SpiNNaker application code and hardware interfaces. C.B. implemented the updated packet key structure and key generation mechanisms. S.B.F. leads the SpiNNaker group and supervised the research. O.R. conceived the study, performed the analysis of the cortical microcircuit model, co-designed the SpiNNaker software implementation of the heterogeneous programming model, ran the simulations and drafted the manuscript. All authors read, commented and approved the final manuscript.
Competing interests
S.B.F. is a founder, director and shareholder of Cogniscience Ltd, which owns SpiNNaker IP. L.A.P. and A.G.D.R. are shareholders of Cogniscience Ltd.
Funding
The design and construction of the SpiNNaker machine was supported by EPSRC(the UK Engineering and Physical Sciences Research Council) under grant nos. EP/D07908X/1 and EP/G015740/1, in collaboration with the universities of Southampton, Cambridge and Sheffield and with industry partners ARM Ltd, Silistix Ltd and Thales. Ongoing development of the software, including the work reported here, is supported by the EU ICT Flagship Human Brain Project (H2020 785907), in collaboration with many university and industry partners across the EU and beyond. A.G.D.R. is part-funded by the Helmholtz Association Initiative and Networking Fund under project no. SO-092 (Advanced Computing Architectures, ACA). L.P. is funded by an EPSRC DTA studentship in the Department of Computer Science.
Reference
- 1.Herculano-Houzel S. 2011. Scaling of brain metabolism with a fixed energy budget per neuron: implications for neuronal activity, plasticity and evolution. PLoS ONE 6, e17514 ( 10.1371/journal.pone.0017514) [DOI] [PMC free article] [PubMed] [Google Scholar]
- 2.Maass W, Markram H. 2004. On the computational power of circuits of spiking neurons. J. Comput. Syst. Sci. 69, 593–616. ( 10.1016/j.jcss.2004.04.001) [DOI] [Google Scholar]
- 3.Shi W, Cao J, Zhang Q, Li Y, Lanyu X. 2016. Edge computing: vision and challenges. IEEE Internet Things J. 3, 637–646. ( 10.1109/JIOT.2016.2579198) [DOI] [Google Scholar]
- 4.Bing Z, Meschede C, Knoll AC. 2018. A survey of robotics control based on learning-inspired spiking neural networks. Front. Neurorobotics 12, 35 ( 10.3389/fnbot.2018.00035) [DOI] [PMC free article] [PubMed] [Google Scholar]
- 5.Furber SB, Lester DR, Plana LA, Garside JD, Painkras E, Temple S, Brown AD. 2013. Overview of the SpiNNaker system architecture. IEEE Trans. Comput. 62, 2454–2467. ( 10.1109/tc.2012.142) [DOI] [Google Scholar]
- 6.Potjans TC, Diesmann M. 2014. The cell-type specific cortical microcircuit: relating structure and activity in a full-scale spiking network model. Cereb. Cortex 24, 785–806. ( 10.1093/cercor/bhs358) [DOI] [PMC free article] [PubMed] [Google Scholar]
- 7.van Albada SJ, Rowley AG, Senk J, Hopkins M, Schmidt M, Stokes AB, Lester DR, Diesmann M, Furber SB. 2018. Performance comparison of the digital neuromorphic hardware SpiNNaker and the neural network simulation software NEST for a full-scale cortical microcircuit model. Front. Neurorobotics 12, 291 ( 10.3389/fnins.2018.00291) [DOI] [PMC free article] [PubMed] [Google Scholar]
- 8.Knight JC, Nowotny T. 2018. GPUs outperform current HPC and neuromorphic solutions in terms of speed and energy when simulating a highly-connected cortical model. Front. Neurorobotics 12, 941 ( 10.3389/fnins.2018.00941) [DOI] [PMC free article] [PubMed] [Google Scholar]
- 9.Davison AP, Brüderle D, Eppler J, Kremkow J, Muller E, Pecevski D, Perrinet L, Yger P. 2008. PyNN: a common interface for neuronal network simulators. Front. Neurorobotics 2, 11 ( 10.3389/neuro.11.011.2008) [DOI] [PMC free article] [PubMed] [Google Scholar]
- 10.Painkras E, Plana LA, Garside J, Temple S, Galluppi F, Patterson C, Lester DR, Furber SB. 2013. SpiNNaker: a 1-W 18-core system-on-chip for massively-parallel neural network simulation. IEEE J. Solid-State Circuits 48, 1943–1953. ( 10.1109/jssc.2013.2259038) [DOI] [Google Scholar]
- 11.Navaridas J, Luján M, Plana LA, Temple S, Furber SB. 2013. SpiNNaker: enhanced multicast routing. J. Parallel Comput. 45, 49–66. ( 10.1016/j.parco.2015.01.002) [DOI] [Google Scholar]
- 12.Rhodes O. et al. 2018. sPyNNaker: a software package for running PyNN simulations on SpiNNaker. Front. Neurorobotics 12, 816 ( 10.3389/fnins.2018.00816) [DOI] [PMC free article] [PubMed] [Google Scholar]
- 13.Rowley AGD. et al. 2019. SpiNNTools: the execution engine for the SpiNNaker platform. Front. Neurorobotics 13, 231 ( 10.3389/fnins.2019.00231) [DOI] [PMC free article] [PubMed] [Google Scholar]
- 14.Gewaltig MO, Diesmann M. 2007. NEST neural simulation tool. Scholarpedia 2, 1430 ( 10.4249/scholarpedia.1430) [DOI] [Google Scholar]
- 15.Stromatias E, Galluppi F, Patterson C, Furber S. 2013. Power analysis of large-scale, real-time neural networks on SpiNNaker. In Proc. of The 2013 Int. Joint Conf. on Neural Networks (IJCNN), Dallas, TX, 4–9 August, pp. 1–8. Piscataway, NJ: IEEE.
- 16.Sharp T, Galluppi F, Rast A, Furber S. 2012. Power-efficient simulation of detailed cortical microcircuits on SpiNNaker. J. Neurosci. Methods 210, 110–118. ( 10.1016/j.jneumeth.2012.03.001) [DOI] [PubMed] [Google Scholar]
- 17.Yavuz E, Turner J, Nowotny T. 2016. GeNN: a code generation framework for accelerated brain simulations. Nature: Sci. Rep. 6, 18854 ( 10.1038/srep18854) [DOI] [PMC free article] [PubMed] [Google Scholar]
- 18.Galluppi F, Lagorce X, Stromatias E, Pfeiffer M, Plana LA, Furber SB, Benosman RB. 2015. A framework for plasticity implementation on the SpiNNaker neural architecture. Front. Neurorobotics 8, 429 ( 10.3389/fnins.2014.00429) [DOI] [PMC free article] [PubMed] [Google Scholar]
- 19.Lagorce X, Stromatias E, Galluppi F, Plana LA, Liu S, Furber SB, Benosman RB. 2015. Breaking the millisecond barrier on SpiNNaker: implementing asynchronous event-based plastic models with microsecond resolution. Front. Neurorobotics 9, 206 ( 10.3389/fnins.2015.00206) [DOI] [PMC free article] [PubMed] [Google Scholar]
- 20.Strata P, Harvey R. 1999. Dale’s principle. Brain Res. Bull. 50, 349–350. ( 10.1016/S0361-9230(99)00100-8) [DOI] [PubMed] [Google Scholar]
- 21.Knight JC, Furber SB. 2016. Synapse-centric mapping of cortical models to the SpiNNaker neuromorphic architecture. Front. Neurorobotics 10, 420 ( 10.3389/fnins.2016.00420) [DOI] [PMC free article] [PubMed] [Google Scholar]
- 22.Mead C. 1989. Analog VLSI and neural systems. Reading, MA: Addison-Wesley. [Google Scholar]
- 23.Yegenoglu A, Davidson A, Holstein D, Muller E, Torre E, Sprenger J. 2016. Elephant–open-source tool for the analysis of electrophysiological data sets. In Proc. INM Retreat 2015, Jülich. See http://juser.fz-juelich.de/record/255984.
Associated Data
This section collects any data citations, data availability statements, or supplementary materials included in this article.
Data Availability Statement
The data and code used to generate the results presented in this paper are available from the SpiNNaker software stack: https://github.com/SpiNNakerManchester, using branches realtime_cortical_ microcircuit.