

Abstract
Retrospective dietary exposure assessments were conducted for two groups of pesticides that have chronic effects on the thyroid: hypertrophy, hyperplasia and neoplasia of C‐cells, and hypothyroidism. The pesticides considered in this assessment were identified and characterised in the scientific report on the establishment of cumulative assessment groups of pesticides for their effects on the thyroid. The exposure assessments used monitoring data collected by Member States under their official pesticide monitoring programmes in 2014, 2015 and 2016, and individual food consumption data from 10 populations of consumers from different countries and from different age groups. Exposure estimates were obtained for each group of pesticides by means of a 2‐dimensional probabilistic model, which was implemented in SAS ® software. Results were validated against exposure estimates obtained by the Dutch National Institute for Public Health and the Environment (RIVM) using the Monte Carlo Risk Assessment (MCRA) software. Both tools produced nearly identical results and minor differences were mainly attributed to the random effect of probabilistic modelling. The exposure estimates obtained in this report are used in the final scientific report on the cumulative dietary risk characterisation of pesticides that have chronic effects on the thyroid. The latter combines the hazard assessment and exposure assessment into a consolidated risk characterisation including all uncertainties.
Keywords: cumulative exposure assessment, pesticide residues, chronic effects, thyroid, probabilistic modelling
Short abstract
This publication is linked to the following EFSA Supporting Publications article: http://onlinelibrary.wiley.com/doi/10.2903/sp.efsa.2019.EN-1707/full
This publication is linked to the following EFSA Journal articles: http://onlinelibrary.wiley.com/doi/10.2903/j.efsa.2019.5801/full
Summary
Retrospective dietary exposure assessments were conducted for two groups of pesticides that have chronic effects on the thyroid: hypertrophy, hyperplasia and neoplasia of C‐cells, and hypothyroidism. The pesticides considered in this assessment were identified and characterised in the scientific report on the establishment of cumulative assessment groups of pesticides for their effects on the thyroid.
The exposure calculations used monitoring data collected by Member States under their official monitoring programmes in 2014, 2015 and 2016 and individual food consumption data from 10 populations of consumers from different countries and from different age groups. Regarding the selection of relevant food commodities, the assessment included water, foods for infants and young children and 30 raw primary commodities of plant origin that are widely consumed within Europe.
Exposure estimates were obtained with SAS® software using a 2‐dimensional probabilistic method, which is composed of an inner‐loop execution and an outer‐loop execution. Variability within the population is modelled through the inner‐loop execution and is expressed as a percentile of the exposure distribution. The outer‐loop execution is used to derive 95% confidence intervals around those percentiles (reflecting the sampling uncertainty of the input data).
As agreed by risk managers in the Standing Committee on Plants, Animals, Food and Feed (SC PAFF), calculations were carried out according to a tiered approach. While the first‐tier calculations (Tier I) use very conservative assumptions for an efficient screening of the exposure with low risk for underestimation, the second‐tier assessment (Tier II) includes assumptions that are more refined but still intended to be conservative. For each scenario, exposure estimates were obtained for different percentiles of the exposure distribution and the total margin of exposure (MOET, i.e. the ratio of the toxicological reference dose to the estimated exposure) was calculated at each percentile. In accordance with the threshold agreed at the SC PAFF, further regulatory consideration would be required when the MOET calculated at the 99.9th percentile of the exposure distribution is below 100.
The lowest MOET estimates were obtained for pesticides associated with hypothyroidism. According to the Tier II scenario, MOET estimates at the 50th, 95th and 99th percentile of the exposure distribution were all well above 100. At the 99.9th percentile, estimates came near to 100, ranging from 103 to 201 in toddlers and other children. For adults, the MOETs were higher, ranging from 259 to 307. The exposure to this group of pesticides was predominantly driven by the occurrence of bromide ion. Other important drivers were propineb, thiabendazole, ziram, mancozeb, pyrimethanil, chlorpropham and cyprodinil.
For pesticides associated with hypertrophy, hyperplasia and neoplasia of C‐cells, MOETs calculated at the 99.9th percentile of the exposure distribution were higher, ranging from 1,480 to 3,400 in all populations. In this case, the difference between adults and children was less evident and the main drivers for the exposure were identified as thiram and ziram.
To ensure a rigorous validation of the methodology, exposure estimates obtained by the European Food Safety Authority (EFSA) were validated against those obtained by the Dutch National Institute for Public Health and the Environment (RIVM) using the Monte Carlo Risk Assessment (MCRA) software, version 8.3. Comparison of the results revealed that both tools produced nearly identical results and any observed differences are mainly attributed to the random effect of probabilistic modelling. It is acknowledged that the confidence intervals obtained through the SAS® program are slightly biased when the exposure estimates are driven by substances measured through an unspecific residue definition. This is the case for pesticides associated with hypertrophy, hyperplasia and neoplasia of C‐cells where the main contributing substances are measured as dithiocarbamates. These minor differences, however, do not impact on the outcome of the exposure assessment.
It is important to note that the calculations were conducted with conservative assumptions likely to overestimate the exposure, even in the more refined Tier II scenario. The most impactful assumptions are the random assignment of active substances to unspecific measurements (i.e. a measurement that may comprise multiple active substances) and the imputation of left‐censored data (i.e. measurements below the limit of quantification). If data on the use frequency of pesticides would be available at the European Union (EU) level, both these assumptions could be further refined. Another important overestimation of the exposure arises from the limited data on the effect of processing. When such data are missing, it is assumed that all pesticides in the raw primary commodity will reach the end consumer without any loss of residues. Sensitivity tests have demonstrated that, for pesticides associated with hypothyroidism, further data on the effect of processing might result in a fivefold increase of the MOET estimates in toddlers.
Uncertainties considered in this assessment, however, only refer to the exposure calculations and should still be considered in conjunction with other uncertainties that may apply to the hazard characterisation. Hence, together with the results obtained by RIVM, the exposure estimates presented in this report are used for the final scientific report on the cumulative dietary risk characterisation of pesticides that have chronic effects on the thyroid. The latter combines the hazard assessment and exposure assessment into a consolidated risk characterisation including all related uncertainties.
1. Introduction
Regulation (EC) No 396/2005 establishes the rules governing the setting of maximum residue levels (MRLs) for pesticides at European level. Article 14 of that Regulation stipulates that decisions on applications concerning MRLs shall take into account known cumulative and synergistic effects of pesticides when the methods to assess such effects are available. Likewise, Article 4 of Regulation (EC) No 1107/2009 further requires that the residues of the plant protection products shall not have any harmful effects on human health or animal health, taking into account known cumulative and synergistic effects where the scientific methods accepted by the Authority to assess such effects are available.
To support the implementation of cumulative risk assessment to pesticide residues, EFSA's Scientific Panel on Plant Protection Products and their Residues (PPR Panel) adopted two scientific opinions regarding the development of a tiered methodology for cumulative risk assessment to pesticide residues (EFSA PPR Panel, 2008, 2009) and two scientific opinions regarding the methodology to establish cumulative assessment groups (CAGs) for pesticides (EFSA PPR Panel, 2013a,b). A guidance document on the use of a probabilistic methodology for the dietary exposure assessment of pesticides, including cumulative exposure, was also adopted (EFSA PPR Panel, 2012). Aside from the general methodological principles, this guidance document also describes different scenarios for probabilistic modelling. First two basic modelling scenarios were proposed, i.e. optimistic and pessimistic. While the optimistic scenario is aimed at calculating the upper estimates of the true distribution of exposure, the pessimistic scenario is intended to obtain the lower estimates of that distribution. The outcome of both scenarios can then be used to determine whether further refinement of the exposure assessment is necessary.
Meanwhile, the European Commission funded the ACROPOLIS project under its 7th Framework Programme for Research (FP7). The main outcome of this project, coordinated by the Dutch National Institute for Public Health and the Environment (RIVM), was the release of the Monte Carlo Risk Assessment (MCRA) software, version 8. This is a web‐based software that allows performing higher tier exposure assessment to multiple pesticides. This software complies with the EFSA guidance document on the use of probabilistic methodologies for dietary exposure assessment to pesticides.
During the Standing Committee on Plants, Animals, Food and Feed (SC PAFF) of 11–12 June 2015, a discussion on related risk management aspects took place between the European Commission and Member States. The Standing Committee agreed on several parameters and assumptions that should be applied when assessing cumulative exposure to pesticide residues. The conclusion also included a change of approach, where the basic and refined modelling principles, as initially proposed by the European Food Safety Authority (EFSA) in its guidance document, were replaced by a tiered methodology (Tier I and Tier II).
EFSA therefore decided to consolidate the cooperation with RIVM by means of a Framework Partnership Agreement, which mainly aimed at testing and improving MCRA Software in view of its implementation in cumulative risk assessment to pesticide residues. In particular, the MCRA software was made scalable in order to handle large CAGs (van der Voet et al., 2016) and a proposal for a data model compliant with the MCRA software was also elaborated (Kruisselbrink et al., 2018). A pilot assessment of chronic cumulative exposure to pesticide residues was then performed with the adapted MCRA software, version 8.2. This version of MCRA integrated the tiered methodology as agreed by Member States.
For these pilot calculations RIVM relied on the preliminary CAGs that were available for the thyroid at that time (EFSA PPR Panel, 2013a). These CAGs, however, have been further refined and recently finalised by EFSA following a public consultation (EFSA, 2019a). The exposure calculations that used these preliminary data should therefore be revised accordingly. Furthermore, during the SC PAFF of 18–19 September 2018, Member States agreed on additional parameters and assumptions for the assessment of cumulative exposure to pesticide residues. Therefore, the European Commission, in its letter of 10 October 2018,1 asked EFSA to ensure that the newly agreed parameters would be used when calculating cumulative exposure to pesticides before publishing the assessments.
Due to these additional considerations, under a second Framework Partnership Agreement, EFSA and RIVM agreed to revise the MCRA software in order to handle the revised input data and integrate new functionalities addressing the assumptions and parameters agreed by Member States. RIVM was also requested by EFSA to revise the cumulative exposure assessment for pesticides affecting the thyroid using the new MCRA software (version 8.3). At the same time, EFSA initiated the process of repeating the cumulative exposure assessments internally using a different software that was available in‐house, i.e. SAS® software. By comparing results obtained with MCRA software and SAS® software, RIVM and EFSA will ensure a rigorous validation of the methodologies used for exposure assessment.
The current report presents the assessment of chronic cumulative exposure to pesticides affecting the thyroid using SAS® software. For these calculations, EFSA applied the main methodological principles described in the guidance document on probabilistic modelling of dietary exposure to pesticide residues (EFSA PPR Panel, 2012). Regarding the scenarios and assumptions, however, instead of using the basic and refined modelling described in the guidance document, EFSA relied on the tiered approach as agreed by Member States in 2018.1
Considering that the implementation of cumulative exposure assessment to pesticide residues is still in a pilot phase, it was decided to start with retrospective assessments for the reference period 2014–2016. Retrospective assessments refer to the post‐authorisation period of active substances and usually rely on the review of monitoring data. Retrospective assessments are therefore expected to better reflect actual exposure of consumers. Considering the complexity and resources required for this type of assessment, the calculations are limited to 10 dietary surveys that cover different age classes and geographical areas. Likewise, EFSA only considers the food consumption data for water, foods for infants and young children and 30 raw primary commodities (RPCs) of plant origin that are widely consumed within Europe. To ensure consistency with the exposure calculations carried out by RIVM using MCRA software, EFSA uses the same input data as those provided to RIVM.
Together with the reports prepared by RIVM, the results of this report will be used in the final scientific report on the cumulative dietary risk characterisation of pesticides that have chronic effects on the thyroid (EFSA, 2019b). The final report will assess all sources of uncertainty identified for either the exposure assessment or the establishment of the CAGs. All uncertainties will then be incorporated into a consolidated risk characterisation. Hence, the present report on exposure assessment does not consider the overall assessment of uncertainties or risks.
2. Data and methodologies
2.1. General principles
The cumulative exposure to pesticide residues was assessed in accordance with the guidance on probabilistic modelling of dietary exposure to pesticide residues (EFSA PPR Panel, 2012). Exposure estimates were obtained using a 2‐dimensional method where variability is modelled by means of an inner‐loop execution, and uncertainty is modelled through an outer‐loop execution (see Figure 1).
Figure 1.
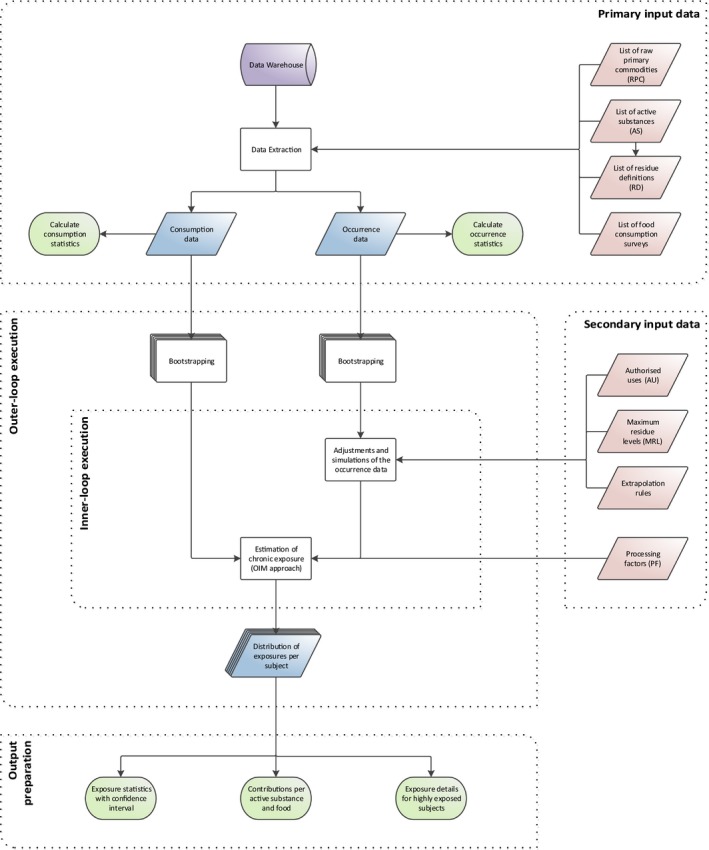
General process for calculating chronic cumulative exposure to pesticides
The primary input data required for modelling cumulative exposure to pesticide residues are occurrence data (i.e. the amounts of pesticide residue that are present in foods) and food consumption data (i.e. the types and amounts of those food consumed in a person's diet). These data are stored in the EFSA Data Warehouse. When the exposure calculations are initiated, the data for the relevant food commodities, active substances and dietary surveys are extracted.
Within the inner‐loop execution, occurrence data are subject to several simulations and imputations. These adjustments are intended to account for inaccuracies and missing information in the occurrence data set (e.g. unspecific measurements, measurements below the analytical limit of quantification, etc.). The consumption data and adjusted occurrence data are then used to estimate chronic dietary exposures using an empirical approach, referred to as the observed individual means (OIM) approach. This results in a distribution that represents the variability of chronic exposures within the population.
The different simulations performed during the inner‐loop execution require the use of additional data, referred to as secondary input data. This includes various types of data which can be used either for the adjustment of the occurrence data (e.g. authorisation status of the active substance) or for improvement of the exposure estimates (e.g. processing factors).
In order to quantify the uncertainties, the model uses an outer‐loop execution where the inner‐loop execution is repeated several times. Prior to each execution, the original consumption and occurrence data sets are modified by means of bootstrapping, a random resampling technique for quantifying sampling uncertainty. By repeating the inner‐loop execution multiple times (i.e. 100), the model produces multiple distributions of exposure. The differences between those distributions reflect the uncertainty around the true distribution of exposures.
During the output preparation, summary statistics (i.e. percentiles of exposure) are generated for the multiple distributions, resulting in multiple estimates for each percentile of exposure. From these multiple estimates, confidence intervals around each percentile are produced. Subsequently, in order to identify risk drivers, details on the highly exposed consumers are extracted (i.e. consumers with exposure exceeding the 99th percentile) and average contributions per food commodity and active substance are calculated.
According to the risk management principles agreed among Member States,1 the methodology describes above is applied in a tiered approach. While the first‐tier calculations (Tier I) use very conservative assumptions, the second‐tier assessment (Tier II) includes assumptions that are more refined but still intended to be conservative. Furthermore, in order to better understand the impact related to some of the assumptions and uncertainties, several sensitivity analyses were carried out.
All extractions, simulations, imputations and calculations described in the subsequent sections were programmed with SAS® Enterprise Guide 7.1 and SAS® Studio 3.71 (Enterprise Edition).
2.2. Primary input data
2.2.1. Raw primary commodities
To pilot the cumulative exposure assessment to pesticide residues, EFSA selected 30 RPCs of plant origin that are widely consumed in Europe (EFSA, 2015a). Water and foods specifically intended for infants and young children were integrated in the exposure assessment based on their importance in (certain) diets. The full list of the incorporated food commodities is provided in Annex A.1, Table A.1.02 and Annex A.2, Table A.2.02. Table 1 provides an overview of the variables contained in the list of food commodities.
Table 1.
Description of the variables contained in the list of raw primary commodities
| Name | Label | Description |
|---|---|---|
| prodCode | RPC code | Code of the raw primary commodity as defined by EFSA's harmonised terminology for scientific research (MATRIX catalogue; EFSA, 2019c) |
| prodName | RPC name | Name of the raw primary commodity as defined by EFSA's harmonised terminology for scientific research (MATRIX catalogue; EFSA, 2019c) |
RPC: raw primary commodity.
For the dietary surveys used in this assessment (see Section 2.2.5), the average contribution of the 30 RPCs to the total consumption of plant commodities (excluding sugar plants) ranges from 73% to 86%. Sugar plants and commodities of animal origin were not considered. As the occurrence of pesticide residues in these commodities is less frequent and at lower levels, their contribution to the dietary exposure is expected to be much lower than the contribution of plant commodities (EFSA, 2019b).
2.2.2. Active substances
Two CAGs were selected by EFSA to pilot the chronic cumulative risk assessment to pesticide residues. These CAGs include:
18 pesticides associated with hypertrophy, hyperplasia and neoplasia of C‐cells, i.e. affecting the parafollicular cells or the calcitonin system of the thyroid (CAG‐TCP);
124 pesticides associated with hypothyroidism, i.e. affecting the follicular cells and/or the hormone system of the thyroid (CAG‐TCF).
The methodology that was used to identify pesticide active substances affecting the thyroid system and the criteria that were applied to define the different assessment groups are described in a separate scientific report (EFSA, 2019a).
For each CAG, the list of active substances, which incorporates the key input data for cumulative exposure assessment, is presented in Annex A.1, Table A.1.01 and Annex A.2, Table A.2.01. The variables contained in the list of active substances are described in Table 2.
Table 2.
Description of the variables contained in the list of active substances
| Name | Label | Description |
|---|---|---|
| paramCode_AS | Substance code | Code of the active substance as defined by EFSA's harmonised terminology for scientific research (PARAM catalogue; EFSA, 2019c) |
| paramName_AS | Substance name | Name of the active substance as defined by EFSA's harmonised terminology for scientific research (PARAM catalogue; EFSA, 2019c) |
| NOAEL | NOAEL | No observed adverse effect level (NOAEL) of the active substance (EFSA, 2019a) |
| Mechanism | Mechanism of action | Short reference to the mechanism of action or to the mode of action, where available (EFSA, 2019a) |
| Study_type | Study type | Type of regulatory toxicity study required by Regulation (EC) No 1107/2009 from which the NOAEL has been derived (EFSA, 2019a) |
AS: active substance.
The toxicological potency of the active substances within each CAG is defined by means of the no observed adverse effect level (NOAEL). When an index compound is identified for the CAG, toxicological potency may also be expressed as a relative potency factor, i.e. the ratio of the NOAEL to that of the index compound (EFSA PPR Panel, 2012). This allows for the expression of exposure estimates in equivalents of the index compound. In this assessment, however, exposure estimates were normalised to a dimensionless number, referred to as the normalised exposure (see Section 2.4.2). Index compounds and relative potency factors were therefore no longer considered.
2.2.3. Residue definitions
While the CAGs are defined at the level of the pesticide active substances, the occurrence data reported to EFSA refer to a residue definition for enforcement purposes (see Section 2.2.4). As the residue definitions, defined by Regulation (EC) No 396/2005, may change over time, single active substances may be associated to multiple residue definitions throughout the reference period. EFSA therefore collected all the residue definitions that were applicable to the selected food commodities and active substances during the reference period 2014–2016. The residue definitions collected for CAG‐TCP and CAG‐TCF are presented in Annex A.1, Table A.1.03 and Annex A.2, Table A.2.03, respectively.
Depending on metabolism and availability of analytical methods, residue definitions may either be equal to the active substance, include additional metabolites, or even incorporate multiple active substances. When the residue definition includes additional metabolites, which are specific to the active substance, the residue definition is assigned to the active substance assuming that the metabolite will have the same toxicological potency as the parent compound (e.g. sum fipronil and its sulfone metabolite, expressed as fipronil). When the residue definition includes multiple active substances, however, the active substances may have different toxicological potencies (e.g. dithiocarbamates). The latter are referred to as unspecific residue definitions.
When active substances are associated to an unspecific residue definition (e.g. sum of MCPA, MCPB, their salts, esters and conjugates, expressed as MCPA), further distinction is made between exclusive and non‐exclusive associations.
Supposing that MCPA would be applied to the field, MCPA cannot be metabolised into MCPB and the measured residue would be attributed to MCPA only. In this case, the association is considered exclusive.
Supposing that MCPB would be applied to the field, MCPB would partially metabolise into MCPA. In this case, only a proportion of the measured residue would be attributed to MCPB and the remaining part would be attributed to MCPA. Hence, the association is not exclusive.
Data on the proportions, however, were not readily available to EFSA. Therefore, a default proportion of 0.5 (≈ 50%) was assumed for all associations that are not exclusive.
In order to allow for the correct allocation of active substances to the measured residues (see Section 2.4.1.1), this information was integrated in the list of residue definitions. Table 3 provides an overview of all relevant variables.
Table 3.
Description of the variables contained in the list of residue definitions
| Name | Label | Description |
|---|---|---|
| paramCode_RD | Residue code | Code of the residue definition as defined by EFSA's harmonised terminology for scientific research (PARAM catalogue; EFSA, 2019c) |
| paramName_RD | Residue name | Name of the residue definition as defined by EFSA's harmonised terminology for scientific research (PARAM catalogue; EFSA, 2019c) |
| paramCode_AS | Substance code | Code of the associated active substance(s) as defined by EFSA's harmonised terminology for scientific research (PARAM catalogue; EFSA, 2019c) |
| paramName_AS | Substance name | Name of the associated active substance(s) as defined by EFSA's harmonised terminology for scientific research (PARAM catalogue; EFSA, 2019c) |
| MW_factor | MW conversion factor | Multiplication factor used to convert the amount of measured residue into active substance. This factor is derived from the molecular weights (MW) of both compounds |
| Is_exclusive | Exclusive | Indicates whether the association between active substance and residue definition is exclusive |
| Proportion | Proportion | Estimated proportion of the active substance within the associated residue definition, only applicable when the association is not exclusive |
RD: residue definition; AS: active substance.
2.2.4. Occurrence data
The occurrence data collected under Article 31 of Regulation (EC) No 396/2005 are the most appropriate data available to EFSA for performing a retrospective exposure assessment to pesticide residues. These data are obtained from the official control activities carried out in the EU Member States, Iceland and Norway. These data are reported to EFSA using the Standard Sample Description (SSD) (EFSA, 2010, 2013). Although the occurrence data are collected at the level of individual measurements, the SSD allows identification of measurements associated to a single food sample (e.g. samples analysed for multiple pesticide residues). After validation by EFSA, the collected data are integrated in the EFSA Data Warehouse.
All occurrence data referring to the relevant food commodities (see Section 2.2.1) and residue definitions (see Section 2.2.3) were extracted from the Data Warehouse. Only measurements validated under the 2014, 2015 and 2016 EU reports on pesticide residues in food were included (EFSA, 2016, 2017, 2018).
According to the risk management principles agreed among Member States,1 the following additional criteria were applied to the extracted data.
Only samples resulting from the EU‐coordinated control programme (EUCP), national control programmes or a combination of those were selected (SSD codes K005A, K009A and K018A). Samples associated to increased control programmes or any other type of programme were excluded as they were not considered to be representative.
Only samples obtained through selective or objective sampling were retained (SSD codes ST10A and ST20A). Samples obtained through suspect sampling or any other type of sampling were not considered to be representative and therefore excluded.
As the food consumption data are reported for RPCs, samples for processed commodities were excluded from the assessment, except for foods for infants and young children. This means that for the 30 RPCs, only samples with a product treatment specified as ‘unprocessed’ or ‘freezing’ were selected (SSD codes T998A and T999A). Regarding foods for infants and young children, the product treatment ‘processed’ was considered implicit (SSD code T100A).
Only measurements reported as a numerical (i.e. quantifiable) value or as a non‐quantified value were considered useful for the assessment (SSD codes VAL and limit of quantification (LOQ)). Other result types were not considered valid and therefore excluded.
Only measurements reported for the full legal residue definition or for the most complete subset of the residue definition were used (SSD codes P004A and P005A). Measurements referring to a part of the residue definition were excluded from the assessment.
When the LOQ value for a measurement could not be reported by the Member States (i.e. for residue definitions composed of multiple components), the median LOQ of all measurements referring to the same combination of commodity and residue definition was assumed.
When several measurements with overlapping residue definitions were reported for the same sample, only the measurement referring to the most recent residue definition was retained for assessment.
Occurrence data from all EU Member States, Iceland and Norway were pooled into one single data set for each CAG. The key variables retained in the occurrence data set are summarised in Table 4.
Table 4.
Description of the variables contained in the occurrence data set
| Name | Label | Description |
|---|---|---|
| labSampCode | Sample code | Alphanumeric code of the analysed sample |
| prodCode | RPC code | Code of the raw primary commodity as defined by EFSA's harmonised terminology for scientific research (MATRIX catalogue; EFSA, 2019c) |
| prodName | RPC name | Name of the raw primary commodity as defined by EFSA's harmonised terminology for scientific research (MATRIX catalogue; EFSA, 2019c) |
| paramCode | Residue code | Code of the residue definition as defined by EFSA's harmonised terminology for scientific research (PARAM catalogue; EFSA, 2019c) |
| paramName | Residue name | Name of the residue definition as defined by EFSA's harmonised terminology for scientific research (PARAM catalogue; EFSA, 2019c) |
| resLOQ | Limit of quantification | The lowest quantifiable amount (in mg/kg) detectable by the laboratory's analytical system |
| resVal | Result value | Concentration of the measured residue (in mg/kg) within the analysed sample |
| resType | Result type | Indicates the type of result, whether it could be quantified/determined or not |
RPC: raw primary commodity.
Considering the size of the occurrence data sets, only the summary statistics per residue definition and food commodity are reported (see Annex A.1, Table A.1.09 and Annex A.2, Table A.2.09). Occurrence data for water were not available to EFSA and were therefore imputed according to the assumptions elaborated in Section 2.4.1.4.
2.2.5. Consumption data
The EFSA Comprehensive European Food Consumption Database (Comprehensive Database) provides a compilation of existing national information on food consumption at individual level. It was first built in 2010 (EFSA, 2011; Huybrechts et al., 2011; Merten et al., 2011). Details on how the Comprehensive Database is used are published in the Guidance of EFSA (EFSA, 2011). Data reported in the Comprehensive Database may either refer to RPCs, RPC derivatives (i.e. single‐component foods altered by processing) or composite foods (i.e. multicomponent). Consumption data for RPC derivatives and composite foods, however, cannot be used in exposure assessments when the occurrence data are reported for the RPCs.
To address the above issue, EFSA transformed the Comprehensive Database into a new RPC Consumption Database by means of the RPC model (EFSA, 2019d). This model converts the consumption data for composite foods or RPC derivatives into their equivalent quantities of RPCs. The RPC model was applied to the Comprehensive Database as of 31 March 2018, when it contained results from 51 different dietary surveys carried out in 23 different Member States covering 94,523 individuals.
In view of the current pilot project, the food consumption data extracted from the RPC Consumption Database were limited to the population classes and countries listed below.
Toddlers2: Denmark, the Netherlands and the United Kingdom;
Other children3: Bulgaria, France and the Netherlands;
Adults4: Belgium, the Czech Republic, Italy and Germany.
An overview of the selected dietary surveys is provided in Annex A.1, Table A.1.04 and Annex A.2, Table A.2.04.
For chronic exposure assessment, individuals who participated for only 1 day of the dietary survey were excluded because at least two survey days per individual are normally required to assess repeated exposure (EFSA, 2011). As a result, 65 individuals were excluded from the assessment, i.e. 64 from the Belgian survey and one from the Bulgarian survey.
Using the extraction criteria described above, a single consumption data set was obtained for chronic exposure assessment. Hence, the same data were used for assessment of both CAG‐TCP and CAG‐TCF. The key variables retained in the occurrence data set are summarised in Table 5. Summary statistics on the quantities of RPC consumed per country, survey and population class are reported (see Annex A.1, Table A.1.10 and Annex A.2, Table A.2.10).
Table 5.
Description of the variables contained in the food consumption data set
| Name | Label | Description |
|---|---|---|
| Country | Country | Country where the dietary survey took place as defined by EFSA's harmonised terminology for scientific research (COUNTRY catalogue; EFSA, 2019c) |
| Survey | Survey | Acronym of the dietary survey |
| PopClass | Population class | Participant's population class, based on age, as defined by EFSA's harmonised terminology for scientific research (AGECLS catalogue; EFSA, 2019c) |
| ORSUBID | Subject ID | A pseudonymised subject ID number generated by EFSA upon receipt of the data |
| Weight | Body weight | Bodyweight of the subject (in kg) |
| ndays | Number of survey days | Number of days on which the participant's consumption was surveyed |
| day | Survey day | Ordinal number of the day on which the participant's consumption was surveyed |
| prodCode | RPC code | Code of the raw primary commodity as defined by EFSA's harmonised terminology for scientific research (MATRIX catalogue; EFSA, 2019c) |
| prodName | RPC name | Name of the raw primary commodity as defined by EFSA's harmonised terminology for scientific research (MATRIX catalogue; EFSA, 2019c) |
| FoodEx2_Facets | Processing code | FoodEx2 facet code describing the processing technique, including additional descriptors such as qualitative information, part consumed or the nature of the food (EFSA, 2015b) |
| RPCD_amount | RPCD amount | Amount of raw primary commodity derivative (in grams) |
| RPC_amount | RPC amount | Amount of raw primary commodity (in grams) |
RPC: raw primary commodity; RPCD: raw primary commodity derivative.
2.3. Secondary input data
2.3.1. Maximum residue levels
Certain assumptions on the extrapolation of occurrence data (see Section 2.4.1.2) require information on the MRLs. An MRL is the upper legal level of a concentration for a pesticide residue in or on food or feed set in accordance with Regulation (EC) No 396/2005. This regulation also defines a procedure for the setting and modification of MRLs. MRLs may therefore have been modified throughout the 2014–2016 reference period. In order to obtain a single list of MRLs, EFSA decided to use the MRLs as of 31 December 2016 (i.e. the end of the current reference period). Hence, it was assumed that those MRLs were applicable during the entire reference period, regardless whether the MRL or residue definition may have changed during that period.
MRLs for the relevant food commodities (see Section 2.2.1) and residue definitions (see Section 2.2.3) were extracted from the EU Pesticides Database5 and organised in a data format that can be used directly for exposure assessment (see Annex A.1, Table A.1.05 and Annex A.2, Table A.2.05). Table 6 describes the variables that were part of this data format.
Table 6.
Description of the variables contained in the list of maximum residue levels
| Name | Label | Description |
|---|---|---|
| paramCode_RD | Residue code | Code of the residue definition as defined by EFSA's harmonised terminology for scientific research (PARAM catalogue; EFSA, 2019c) |
| paramName_RD | Residue name | Name of the residue definition as defined by EFSA's harmonised terminology for scientific research (PARAM catalogue; EFSA, 2019c) |
| prodCode | RPC code | Code of the raw primary commodity as defined by EFSA's harmonised terminology for scientific research (MATRIX catalogue; EFSA, 2019c) |
| prodName | RPC name | Name of the raw primary commodity as defined by EFSA's harmonised terminology for scientific research (MATRIX catalogue; EFSA, 2019c) |
| MRL | MRL (mg/kg) | Numerical value of the maximum residue level (MRL) as defined by Regulation (EC) No 396/2005, expressed in mg/kg |
| atLOQ | MRL at LOQ | Indicates whether the maximum residue level (MRL) is set at the analytical limit of quantification (LOQ). Under Regulation (EC) No 396/2005 such MRLs are marked with an asterisk (*) |
RPC: raw primary commodity; RD: residue definition.
2.3.2. Authorised uses
In some cases, the imputations and simulations performed on the occurrence data rely on the authorisations for use of the active substance(s) (see Section 2.4.1). While the approval status of an active substance under Regulation (EC) No 1107/2009 is regulated at EU level, the authorisations for use of active substances on specific crops are delivered at national level within the EU Member States. A centralised database compiling these national authorisations is not yet available at EU level.
National authorisations can be reported to EFSA under Regulation (EC) No 396/2005, either for an MRL application under Article 10, or for an MRL review under Article 12. There is, however, no legal obligation to systematically report all national authorisations and the MRL review programme is still in progress. A comprehensive overview of all pesticide authorisation within the EU is therefore also not available to EFSA. Meanwhile, a tentative list of authorised uses was elaborated according to the following principles.
When the MRL for a given combination of active substance and RPC was not set at the LOQ (see Section 2.3.1), the active substance was assumed to be authorised for use on that specific commodity. This assumption also accounts for uses authorised outside the EU and for which treated products may be placed on the EU market.
For the group of dithiocarbamates, which comprises six active substances, Regulation (EC) No 396/2005 provides specific information on the active substances that were used for deriving the MRLs. Authorised uses for these active substances were identified accordingly.
For the remaining combinations of active substance and RPC (i.e. where the MRL was set at LOQ), EFSA screened the relevant reasoned opinions issued under Article 12 of Regulation (EC) No 396/2005 and the subsequent reasoned opinions issued under Article 10. Any authorised use reported in those reasoned opinions was recorded.
When the MRL was set at LOQ and a review under Article 12 of Regulation (EC) No 396/2005 had not been issued, it was assumed that the use was not authorised.
The authorised uses collected by EFSA were integrated in a data format that can be readily used for exposure assessment (see Annex A.1, Table A.1.06 and Annex A.2, Table A.2.06). Table 7 describes the variables of this data format.
Table 7.
Description of the variables contained in the list of authorised uses
| Name | Label | Description |
|---|---|---|
| paramCode_AS | Substance code | Code of the active substance as defined by EFSA's harmonised terminology for scientific research (PARAM catalogue; EFSA, 2019c) |
| paramName_AS | Substance name | Name of the active substance as defined by EFSA's harmonised terminology for scientific research (PARAM catalogue; EFSA, 2019c) |
| prodCode | RPC code | Code of the raw primary commodity as defined by EFSA's harmonised terminology for scientific research (MATRIX catalogue; EFSA, 2019c) |
| prodName | RPC name | Name of the raw primary commodity as defined by EFSA's harmonised terminology for scientific research (MATRIX catalogue; EFSA, 2019c) |
| Source | Source | Indicates the source of the information (i.e. MRL legislation, MRL review or MRL application) |
| Reference | Reference | EFSA Journal reference to the relevant reasoned opinion (i.e. when the information was retrieved from an MRL review or application) |
RPC: raw primary commodity; MRL: maximum residue level; AS: active substance.
2.3.3. Extrapolation rules
The extrapolation of occurrence data described in Section 2.4.1.2 is carried out in compliance with the guidelines on comparability, extrapolation, group tolerances and data requirements for setting MRLs (European Commission, 2017). These extrapolation rules depend on when the active substance is applied to the plant.
For the current assessment, available occurrence data do not provide any information on how the plant commodity was treated. Therefore, the most conservative extrapolation rules were applied, i.e. for treatments after formation of the edible plant parts. These extrapolation rules were integrated in a data format that can be readily used for exposure assessment (see Annex A.1, Table A.1.07 and Annex A.2, Table A.2.07). Table 8 describes the variables of this data format.
Table 8.
Description of the variables contained in the list of extrapolation rules
| Name | Label | Description |
|---|---|---|
| prodCode_from | RPC code (from) | Code of the raw primary commodity from which the extrapolated measurements are taken (i.e. source commodity). This code is compliant with EFSA's harmonised terminology for scientific research (MATRIX catalogue; EFSA, 2019c) |
| prodName_from | RPC name (from) | Name of the raw primary commodity from which the extrapolated measurements are taken (i.e. source commodity). This code is compliant with EFSA's harmonised terminology for scientific research (MATRIX catalogue; EFSA, 2019c) |
| prodCode_to | RPC code (to) | Code of the raw primary commodity to which the measurements are extrapolated (i.e. target commodity). This code is compliant with EFSA's harmonised terminology for scientific research (MATRIX catalogue; EFSA, 2019c) |
| prodName_to | RPC name (to) | Name of the raw primary commodity to which the measurements are extrapolated (i.e. target commodity). This code is compliant with EFSA's harmonised terminology for scientific research (MATRIX catalogue; EFSA, 2019c) |
RPC: raw primary commodity.
2.3.4. Processing factors
Occurrence data for pesticide residues are collected at the level of RPC (see Section 2.2.4). Food consumption data may be collected at the level of RPC, RPC derivative or composite food, but for the purpose of this assessment all consumption data for composite foods and RPC derivatives were converted into their equivalent quantities of RPCs (see Section 2.2.5). Combining occurrence and consumption data at the RPC level implies that all residues present in the RPC will reach the end consumer. This assumption, however, is conservative. In reality, these residues will most likely be altered through processing, such as peeling, washing, cooking, etc.
The effect of processing is usually addressed by means of processing factors. A processing factor is specific to each RPC, processing type and active substance, and it accounts for both the chemical alteration of the substance and weight change of the food. Processing factors are quantified by dividing the expected residue concentration in the processed commodity by the residue concentration in the raw commodity.
The European database on processing factors is the most recent and the most comprehensive compilation of processing factors currently available at EU level (Scholz et al., 2018). Processing factors for the active substances and RPCs under assessment were extracted from the database according to the following criteria.
For each active substance, RPC and processing technique only the median processing factor was extracted.
Only the processing factors indicated as reliable or indicative were extracted. Processing factors indicated as unreliable were excluded from the assessment.
Processing techniques reported in the processing factor database were then compared to the processing techniques reported in the RPC consumption data set. The processing techniques from both databases were matched according to the following principles:
When a generic processing technique was reported in the RPC consumption database (e.g. juice) while more specific processing techniques were reported in the processing factor database (e.g. pasteurised juice and unpasteurised juice), the specific processing technique with the highest processing factor was selected.
When a specific processing technique was reported in the RPC consumption database (e.g. mashed potato) while a more generic processing technique was reported in the processing factor database (e.g. boiled potato), the generic processing factor was applied to the specific processing techniques.
When a processing factor was reported for an isomeric mixture (e.g. benalaxyl), the processing factor was considered valid for any isomeric mixture that contained the same isomers (e.g. benalaxyl‐M).
Processing factors were extrapolated between raw primary commodities with similar properties (i.e. oranges and mandarins, apples and pears, table and wine grapes, wheat and rye grain).
Processing factors for peeling were applied to the corresponding fruit with inedible peel, even when the processing technique was not specified in the RPC consumption database (i.e. oranges, mandarins, bananas and melons).
By following these principles, lists of processing factors were obtained for the assessment of both CAG‐TCP and CAG‐TCF (see Annex A.1, Table A.1.08 and Annex A.2, Table A.2.08, respectively). Table 9 describes the variables contained in the list of processing factors.
Table 9.
Description of the variables contained in the list of processing factors
| Name | Label | Description |
|---|---|---|
| paramCode_AS | Substance code | Code of the active substance as defined by EFSA's harmonised terminology for scientific research (PARAM catalogue; EFSA, 2019c) |
| paramName_AS | Substance name | Name of the active substance as defined by EFSA's harmonised terminology for scientific research (PARAM catalogue; EFSA, 2019c) |
| prodCode | RPC code | Code of the raw primary commodity as defined by EFSA's harmonised terminology for scientific research (MATRIX catalogue; EFSA, 2019c) |
| prodName | RPC name | Name of the raw primary commodity as defined by EFSA's harmonised terminology for scientific research (MATRIX catalogue; EFSA, 2019c) |
| facetCode | Processing code | FoodEx2 facet code describing the processing technique, including additional descriptors such as qualitative information, part consumed or the nature of the food (EFSA, 2015b) |
| facetDesc | Processing description | Description of the processing code |
| procFac | Processing factor | Numerical value representing the expected residue concentration in the processed commodity divided by the residue concentration in the raw commodity |
| Source | Source | Indicates the source of the information (i.e. type of report) |
| Reference | Reference | Journal reference to the relevant report |
| Comment_PF | Comment | Indicates whether the processing factor relies on any type of assumption or extrapolation |
RPC: raw primary commodity; AS: active substance.
2.4. Inner‐loop execution
2.4.1. Adjustments and simulations on the occurrence data
2.4.1.1. Allocation of active substances to the occurrence data
While the CAGs are defined at the level of the pesticide active substances, the occurrence data reported to EFSA refer to residue definitions for enforcement purposes (see Section 2.2.4). Hence, the original occurrence data set obtained from the EFSA Data Warehouse is converted into a new intermediate data set where measurements are assigned to active substances instead of residue definitions.
Some of these residue definitions, however, referred to as unspecific residue definitions, may be associated to multiple active substances (see Section 2.2.3). Allocation of active substances to these unspecific residue definitions is performed in accordance with the risk management principles agreed among Member States.1
Under the Tier I assumptions, measurements for unspecific residue definitions are always assigned to the most potent active substance (i.e. the substance with the lowest NOAEL), regardless of its authorisation status. This approach is expected to overestimate the exposure because a less potent active substance may have been used. This overestimation may be even more substantial when the most potent active substance is not authorised for use on the relevant commodity.
A more likely scenario would be the use of a combination of more potent and less potent substances. Therefore, for the Tier II calculations, each measurement is randomly assigned to one of the active substances authorised on that commodity, regardless of whether the active substance is part of the CAG or not. If none of the active substances associated to the unspecific residue definition is authorised, any active substance is selected at random. Furthermore, special consideration is given to the active substances that may metabolise into another active substance, the non‐exclusive substances (see Section 2.2.3). If the measurement is assigned to a non‐exclusive substance (e.g. MCPB), the model assumes that the measurement is partially composed of the assigned active substance while the remaining fraction is attributed to the active substance into which it metabolises (e.g. MCPA), the exclusive substance.
A more detailed description of the methodologies used to allocate active substances to the occurrence data is provided in Appendix A.
Although the Tier II assumptions are expected to better reflect reality, some uncertainties related to this approach were still identified. Under ideal circumstances, the probability to select an active substance should be based on market share data for those active substances. Similarly, the proportion of the non‐exclusive substance should be derived from the available metabolism data. Both market share data and metabolism data, however, were not readily available. In the absence of these data, assumptions on equal probability and equal proportion are applied instead. It should be noted that these assumptions may either underestimate or overestimate the exposure.
An additional uncertainty derives from the assumption that measurements for unspecific residue definitions result from the use of single active substances. This assumption implies that other active substances associated to that unspecific residue definition are not present (i.e. implicit zero measurements). Although it is unlikely that substances with similar pesticidal activity are used on the same crop, this possibility cannot be excluded.
2.4.1.2. Extrapolation of occurrence data
For some active substances and food commodities, the number of measurements may be limited. Furthermore, for certain combinations, data may even be missing completely. In order to address the uncertainties related to those limited or missing data, extrapolation rules are integrated in the exposure model.
The extrapolations are carried out in compliance with the guidelines on comparability, extrapolation, group tolerances and data requirements for setting MRLs (European Commission, 2017). These extrapolation rules were developed and validated in view of extrapolating occurrence data from ‘data rich’ commodities (e.g. apples) to ‘data poor’ commodities (e.g. pears). However, there is currently no clear guidance on the number of measurements needed to perform a reliable probabilistic calculation. In the framework of this assessment, a minimum of 10 measurements per active substance and commodity is considered sufficient to perform a reliable probabilistic assessment.
Hence, only the combinations of food commodities and active substances with less than 10 measurements are extracted from the data set (i.e. the target combination). Measurements for the same active substance but a different commodity (i.e. source commodity) are then extrapolated to the target commodity provided that:
the extrapolation is compliant with the extrapolation rules reported in Section 2.3.3;
the MRLs are the same in both the source and target commodity;
the use of the active substance is authorised in both the source and target commodity; and
the number of measurements for the source commodity is higher than or equal to 10.
The extrapolated measurements are randomly assigned to the available target commodity samples, excluding samples where the active substance was already measured. The number of extrapolated measurements is reported in the final output (see Section 2.6).
The methodology used for extrapolation of occurrence data is independent of the Tier I or Tier II scenarios. A more detailed description is provided in Appendix B.
2.4.1.3. Imputation of left‐censored occurrence data
Over 95% of the occurrence data used for the current exposure assessment are left‐censored (see Section 2.2.4). Left‐censored data are measurements reported below the LOQ and for which an accurate value is not available. Some of these results may be low‐positive residues while others will be true zeroes (no‐residue situation).
In order to address the uncertainties resulting from the high proportion of left‐censored data, measurements below the LOQ were imputed in compliance with the risk management principles agreed among Member States.1
Under Tier I assumptions, left‐censored measurements were imputed with 1/2 LOQ when at least one positive result (i.e. above LOQ) was reported for a given substance‐commodity combination. Measurements for all remaining combinations were imputed with a zero (i.e. assuming a no‐residue situation).
For the Tier II assessment, use frequencies are estimated for each pesticide and each commodity, assuming that all samples were treated according to at least one agricultural use pattern (AUP).6 An AUP is the combination of pesticide uses applied to a single commodity or crop. The estimated use frequencies are then used to calculate a proportion of true zeros and the corresponding number of left‐censored measurements is then selected at random from the data set. While the selected measurements are imputed with zero, the remaining left‐censored measurements are imputed with ½ LOQ. A more detailed description of the methodology is provided in Appendix C.
As for the allocation of active substances (see Section 2.4.1.1), the Tier II assumption is expected to more refined compared to the Tier I assumption, which is a very conservative assumption. These Tier II calculations would be even more accurate if actual data on the use frequency of pesticides would be made available. In particular, for pesticides with unquantifiable residues the estimated use frequency will be 0% which is most likely an underestimation of the real use frequency. On the other hand, this scenario also assumes that the total AUP frequency is 100%, meaning that all commodities were treated according to at least one AUP. This tends to overestimate the exposure.
2.4.1.4. Imputation of occurrence data for water
Occurrence data for water are not available to EFSA (see Section 2.2.4). According to the risk management principles agreed among Member States,1 occurrence data for water are imputed for the five most potent active substances within the CAG.
For this purpose, the five substances with the lowest NOAEL are extracted from the list of active substances (see Section 2.2.1) and a measurement in water is added to the occurrence data set for each of these substances. These measurements are associated to a single fictitious sample code. While under the Tier I assessment, a result value of 0.001 mg/kg is assigned to each measurement, a result value of 0.0005 mg/kg is assigned under Tier II.
2.4.1.5. Calculation of mean occurrence values
Although individual residue measurements are required to enable bootstrapping and quantify the impact of sampling uncertainty, short‐term variability of residues between samples is not relevant when modelling chronic exposure (EFSA PPR Panel, 2012). Chronic exposure is therefore estimated using the average concentration for each active substance and commodity.
Hence, the occurrence data set obtained after imputation of the occurrence data for water (see Section 2.4.1.4) is used to calculate the average concentrations per active substance and food commodity. Under Tier II assumptions, the average concentrations also account for the implicit zero measurements resulting from the assignment of active substances to unspecific residue definitions (see Section 2.4.1.1).
2.4.2. Chronic exposure distribution
Chronic dietary exposure is modelled by means of an empirical approach, referred to as the OIM approach (EFSA PPR Panel, 2012). This method uses the mean consumption over the survey days of each individual to estimate the individuals’ long‐term consumption. Using the individuals’ bodyweight and the mean occurrence values obtained from Section 2.4.1.5, the individuals’ chronic exposures resulting from each food commodity and active substance are calculated. It should be noted, however, that, due to the limited duration of the dietary surveys, the OIM approach tends to overestimate upper tail exposures in chronic assessments.
In order to combine the different substances in a total chronic exposure estimate, the toxicological potency of each substance also needs to be accounted for. The use of relative potency factors has previously been suggested by EFSA (EFSA PPR Panel, 2012) but this method requires identification of an index compound for each CAG. Alternatively, the exposure estimates for the different active substances are divided by the corresponding NOAEL. The potency‐adjusted estimates can then be combined to obtain a total normalised exposure (NET) for each individual.
Combining occurrence and consumption data at RPC level also implies that all residues present in the RPC will reach the end consumer, while alteration of residues is expected to occur when the RPCs are processed prior to consumption. This uncertainty, which is generally expected to overestimate exposure, is addressed by integrating processing factors where available (see Section 2.3.4). Considering, however, that processing factors account for both the chemical alteration of the substance and weight change of the food, occurrence values need to be combined with the consumed amount of processed food (i.e. RPC derivative) instead of the consumed amount of RPC. Furthermore, as the consumed amounts are expressed in grams and occurrence data are expressed in mg/kg, a correction factor of 1,000 needs to be considered.
Based on the considerations above, the NET is calculated for each individual according to the equations reported below.
where NETi is the total normalised exposure of individual i;
RPCidcp is the amount of commodity c with processing type p consumed by individual i on day d, expressed in kg of raw primary commodity per day;
RPCDidcp is the amount of commodity c with processing type p consumed by individual i on day d, expressed in kg of raw primary commodity derivative per day;
BWi is the body weight of individual i, expressed in kg;
Daysi is the number of survey days of individual i;
is the average concentration of substance s in commodity c, expressed in mg/kg;
PFcps is the processing factor for substance s in commodity c with processing type p;
NOAELs is the no observed adverse effect level for substance s, expressed in mg/kg bodyweight per day.
After having calculated the NET for each individual, empirical distributions of individual NETs are obtained. The distributions represent the variability of exposure within the different population groups.
The methodology used to derive the chronic exposure distribution is independent of the Tier I or Tier II scenarios, and a more detailed description is provided in Appendix D.
2.5. Outer‐loop execution
The consumption data used for this assessment are subject to sampling uncertainty and will not represent perfectly the true diets within the population. Likewise, the occurrence data will not perfectly reflect the true distribution of residue concentrations in food. These sampling uncertainties are addressed by repeating the inner‐loop execution multiple times, each time replacing the consumption and occurrence data sets with bootstrap data sets (EFSA PPR Panel, 2012). Bootstrap data sets are obtained by resampling, with replacement, the same number of observations from the original data sets. Each time the inner‐loop is executed with bootstrap data sets, a bootstrap distribution of NETs will be obtained. This shows how the distribution of NETs may have looked like if random sampling from the population would have generated different samples than those actually observed (Efron and Tibshirani, 1993).
It should be noted, however, that the both the consumption and occurrence data incorporate several multivariate patterns (e.g. association of foods and individuals’ characteristics, co‐occurrence of residues, etc.). These patterns need to be preserved in the bootstrap data sets.
Consumption data are, therefore, resampled at the individual level, i.e. selecting all consumption events and all survey days of the resampled individual. Hence, for each dietary survey, the bootstrap data sets contain the same number of individuals as the original data set.
Occurrence data, on the other hand, are resampled at the level of the laboratory sample, i.e. selecting all measurements obtained in the resampled laboratory sample. Hence, the bootstrap data sets contain for each food commodity the same number of laboratory samples as the original data set.
In the current exposure model, the inner‐loop execution is repeated 100 times. The first execution, also referred to as the nominal run, is performed with the original data sets. The remaining executions are performed with bootstrap data sets.
Although the outer‐loop execution is primarily intended to address the sampling uncertainty of the consumption and occurrence data, it also addresses uncertainty resulting from the probabilities applied in the model. This is particularly true for the Tier II scenarios where several simulations and imputations rely on the random selection of measurements (see Section 2.4.1).
2.6. Output preparation
Through the inner‐ and outer‐loop executions, multiple NET distributions are generated (i.e. 100 bootstrap distributions per dietary survey). To describe each bootstrap distribution, the following parameters are derived:
mean of the NET;
standard deviation of the NET;
percentiles of the NET (P2.5, P5, P10, P25, P50, P75, P90, P95, P97.5, P99, P99.9 and P99.99).
According to the risk management principles agreed among Member States,1 the parameters of the exposure distribution are expressed in total margin of exposure (MOET). The margin of exposure is normally calculated as the ratio of a toxicological reference dose (i.e. NOAEL) to the estimated exposure. Considering that the exposure is already normalised (see Section 2.4.2), the MOET is in this case the reciprocal value of the NET.
As a result, 100 MOET estimates are obtained for each parameter of the exposure distributions. These 100 estimates reflect the uncertainty distribution around the true value of those parameters. From these uncertainty distributions a 95% confidence interval is calculated for each parameter. The median of the uncertainty distribution is selected as the central estimate for the confidence interval.
To better understand the factors that influence the lowest MOETs (or the highest NETs), individuals with an MOET lower than the MOET calculated at the 99th percentile of the exposure distribution are extracted for each dietary survey and bootstrap distribution. The relevant information associated to those individuals is also retrieved (i.e. amounts of foods consumed and concentrations of active substances). Based on the individuals’ information, average contributions are calculated per dietary survey, active substance and food commodity.
Additional information is gathered throughout the calculation process to support the identification of missing information. These intermediate outputs mainly refer to the missing occurrence data and possible extrapolations (see Section 2.4.1.2). For the Tier II scenario, the estimated use frequencies are also reported (see Section 2.4.1.3).
The above reported percentiles were calculated using SAS® software, which provides five validated options for the definition of percentiles.7 For the purpose of this assessment, the following percentile definition was selected. Let n be the number of non‐missing values for a variable, let represent the ordered values of the variable and set . Then, the tth percentile is calculated as follows.
where y is the tth percentile;
j is the integer part of np;
g is the fractional part of np.
This definition was considered to be the most appropriate because it allows for the differentiation of percentiles, even when p > (n–1)/n. This is particularly useful for the dietary surveys with toddlers and children where a 99.9th percentile needs to be calculated even though the number of individuals is lower than 1,000. This method still contains an important bias because the calculated percentile will always be lower than or equal to the highest observation. For dietary surveys with a low number of individuals, it is not unlikely that the true percentile will be higher than the highest observation in the empirical distribution. However, estimation of percentiles beyond the highest observation would require parametric modelling of the exposure distribution which needs to be further investigated before being implemented in cumulative exposure assessment.
2.7. Tiers and sensitivity analyses
According to the risk management principles agreed among Member States,1 the exposure calculations are performed in a tiered approach:
The Tier I scenario uses very conservative assumptions that are less resourceful regarding data and computational capacity. This allows for an efficient screening of the exposure with low risk for underestimation of the real exposure to pesticide residues.
The Tier II scenario, which is more resourceful, includes more refined assumptions but it is still intended to be conservative.
Table 10 summarises the main assumptions and methodologies applied in the exposure model. The key differences between Tier I and Tier II are also highlighted. Although the methods and assumptions applied in the model were selected with the view of minimising the uncertainties, resources may sometimes be insufficient to allow for a more accurate assessment (e.g. use frequencies and processing factors). In order to assess how these additional data or improvement might impact on the exposure estimates, the following sensitivity analyses were also carried out:
Sensitivity analysis A assumes that left‐censored data are imputed at 1/2 LOQ when the use of the active substance is authorised.
Sensitivity analysis B assumes that all left‐censored data are imputed at zero.
Sensitivity analysis C assumes that residues will not be present in any processed food.
Sensitivity analysis D excludes all foods for infants and young children.
Table 10.
Overview of the main assumptions and methodological approaches used for assessing chronic cumulative exposure to pesticide residues
| Description | ||
|---|---|---|
| Consumption data | ||
| Number of surveys | 10 | |
| Population classes |
Adults (Belgium, Czech Republic, Germany and Italy) Other children (Bulgaria, France and Netherlands) Toddlers (Denmark, Netherlands and United Kingdom) |
|
| Food commodities |
30 raw primary commodities (includes conversion from foods as eaten) + 4 categories of foods for infants and young children + water |
|
| Other criteria | Individuals who participated only 1 day in the dietary survey were excluded | |
| Occurrence data (extraction) | ||
| Reference period | 2014–2016 (latest available 3‐year cycle) | |
| Food commodities |
30 raw primary commodities (unprocessed or frozen) + 4 categories of foods for infants and young children |
|
| Residue definitions | All residue definitions associated to CAG‐TCP and CAG‐TCF during the reference period (excl. overlapping residue definitions at sample level) | |
| Sampling framework | EU‐coordinated or national control programmes | |
| Sampling type | Objective or selective sampling only | |
| Occurrence data (simulations and imputations) | ||
| Unspecific residue definitions |
Tier I: Most potent active substance is allocated to each sample |
Tier II: Random allocation of authorised active substances to each sample* |
| Extrapolations | Extrapolation of measurements per active substance and commodity in accordance with guidance document SANCO 7525/VI/95 (European Commission, 2017), when MRL is equal and substance is authorised in both source (N ≥ 10) and target (N < 10) commodities | |
| Left‐censored data |
Tier I: Imputed at ½ LOQ for food‐substance combinations with quantifiable findings |
Tier II: Imputed at ½ LOQ based on estimated use frequencies (assuming 100% crop treatment) |
| Drinking water |
Tier I: Imputed at 0.1 μg/L for the 5 most potent active substances |
Tier II: Imputed at 0.05 μg/L for the 5 most potent active substances |
| Exposure calculations | ||
| Exposure model | Observed individual means approach (inner‐loop execution) | |
| Uncertainty model | Empirical bootstrapping (outer‐loop execution, n = 100) | |
| Processed foods | Processing factors obtained or extrapolated from the European database on processing factors for pesticides in food (Scholz et al., 2018) | |
CAG‐TCP: cumulative assessment group of pesticides associated with hypertrophy, hyperplasia and neoplasia of C‐cells; CAG‐TCF: cumulative assessment group of pesticides associated with hypothyroidism; MRL: maximum residue level; LOQ: limit of quantification.
* Accounts for substances that are not part of the CAG and for residue definitions that are not exclusive (see Section 2.4.1.1)
For these sensitivity analyses, only the impact on the 99.9th percentile of the exposure distribution (expressed in MOET) was assessed. Detailed results were in this case not provided.
3. Results
The results section summarises the chronic cumulative exposure estimates obtained from the calculations. Exposure estimates are presented for 2 CAGs (CAG‐TCP and CAG‐TCF), 2 different scenarios (Tier I and Tier II) and 10 different dietary surveys. More detailed results (including graphs and charts) are provided in the annexes.
Annex B.1 presents the results of the Tier I cumulative exposure calculations to CAG‐TCP.
Annex B.2 presents the results of the Tier I cumulative exposure calculations to CAG‐TCF.
Annex C.1 presents the results of the Tier II cumulative exposure calculations to CAG‐TCP.
Annex C.2 presents the results of the Tier II cumulative exposure calculations to CAG‐TCF.
All exposure estimates are expressed in MOET, which is the ratio of a toxicological reference dose (i.e. NOAEL) to the estimated exposure (see Section 2.6). Hence, an MOET below 1 implies that the estimated exposure exceeds the NOAEL. Likewise, an MOET of 100 means that the estimated exposure is 100 times lower than the NOAEL. The threshold for regulatory consideration agreed among Member States is an MOET of 100 at the 99.9th percentile of the exposure distribution.1 MOETs below this threshold may therefore trigger risk management decision by the European Commission and Member States.
It should be emphasised that results presented are exposure estimates based on the methods and assumptions listed in Section 2. These results do not estimate the actual risk of European consumers and do not account for all possible uncertainties. Although some uncertainties affecting the exposure estimates may already be highlighted in this report, the overall risk characterisation is addressed in a separate report (EFSA, 2019b). That report combines the assessment of all uncertainties related to both hazard assessment and exposure assessment into a consolidated risk characterisation.
3.1. Pesticides associated with hypertrophy, hyperplasia and neoplasia of C‐cells (CAG‐TCP)
3.1.1. Tier I
The results in Table 11 were obtained using the Tier I calculations. The largest margins of exposure were observed for adults, where MOET estimates at the 99.9th percentile ranged from 301 (Germany) to 447 (Italy). The margins of exposure for toddlers and other children were smaller. MOET estimates for these age classes ranged from 83.7 (Dutch toddlers) to 199 (French children).
Table 11.
Estimates of the total margin of exposure (MOET) and their corresponding 95% confidence intervals at the 50th, 95th, 99th and 99.9th percentiles of the exposure distribution for the Tier I scenario of CAG‐TCP
| Country | Population class | 50th percentile | 95th percentile | 99th percentile | 99.9th percentile |
|---|---|---|---|---|---|
| Belgium | Adults |
1,570 [1,380–1,730] |
691 [614–795] |
534 [425–619] |
359 [260–490] |
| Czech Republic | Adults |
2,000 [1,740–2,200] |
772 [680–857] |
562 [424–652] |
361 [270–425] |
| Germany | Adults |
1,490 [1,360–1,600] |
587 [539–638] |
421 [384–455] |
301 [255–324] |
| Italy | Adults |
1,370 [1,190–1,510] |
709 [623–796] |
557 [491–628] |
447 [345–503] |
| Bulgaria | Other children |
612 [522–685] |
278 [240–302] |
188 [134–230] |
130 [122–164] |
| France | Other children |
821 [718–896] |
393 [339–424] |
308 [211–344] |
199 [175–292] |
| Netherlands | Other children |
649 [576–702] |
299 [267–320] |
233 [199–254] |
164 [151–217] |
| Denmark | Toddlers |
582 [522–614] |
300 [276–321] |
221 [180–240] |
120 [82.5–180] |
| Netherlands | Toddlers |
489 [442–539] |
231 [209–251] |
172 [110–209] |
83.7 [64.1–180] |
| United Kingdom | Toddlers |
708 [624–756] |
343 [317–368] |
249 [216–280] |
180 [130–211] |
CAG‐TCP: cumulative assessment group of pesticides associated with hypertrophy, hyperplasia and neoplasia of C‐cells.
The main drivers of exposure were identified for the upper percentile of the distribution (see Annex B.1, Figure B.1.03 and Table B.1.02). Thiram made the greatest contribution to upper‐tail exposure (89.9‐93.3%); most of this contribution came from oranges (up to 46.5%), apples (up to 41.1%), wheat (up to 13.3%) and mandarins (up to 9.3%). In adults, thiram from wine grapes was an important and often predominant contributor (16.9‐43.3%). Other substances only played a minor role in overall exposure (not more than 3%).
Although MOET estimates below 100 were observed for Danish and Dutch toddlers, the Tier I calculations are by nature very conservative. This is clearly evidenced for CAG‐TCP, where thiram was identified as the main driver of exposure. Thiram is part of an unspecific residue definition, i.e. the dithiocarbamates group (see Annex A.1, Table A.1.03). According to the Tier I assumptions, all measurements for unspecific residues are assigned to the most potent substance. In this case, the most potent dithiocarbamate was thiram. Assignment of all dithiocarbamates to thiram, however, overestimated the exposure (i.e. underestimate MOET), as less potent dithiocarbamates may have been present. Furthermore, thiram is not expected to occur in oranges, wheat and mandarins, as the use of thiram is not authorised in these commodities (see Annex A.1, Table A.1.06). Yet, all three commodities are major contributors to thiram exposure in the Tier I CAG‐TCP calculations. These inaccuracies are accounted for under the Tier II assumptions.
3.1.2. Tier II
The results from the Tier II calculations are displayed in Table 12. As with the Tier I results, the largest margins of exposure at the 99.9th percentile were observed for adults; adult MOETs ranged from 2,290 (Germany) to 3,400 (Italy). The difference between the margins of exposure for other children and toddlers compared to adults, however, was much smaller than in the Tier I calculations; the MOETs for other children ranged from 1,760 (the Netherlands) to 3,870 (France) while the MOETs for toddlers ranged from 1,480 (the Netherlands) to 2,360 (the United Kingdom).
Table 12.
Estimates of the total margin of exposure (MOET) and their corresponding 95% confidence intervals at the 50th, 95th, 99th and 99.9th percentiles of the exposure distribution for the Tier II scenario of CAG‐TCP
| Country | Population class | 50th percentile | 95th percentile | 99th percentile | 99.9th percentile |
|---|---|---|---|---|---|
| Belgium | Adults |
23,900 [19,500–30,500] |
6,430 [3,110–11,400] |
4,570 [2,120–7,720] |
3,030 [1,150–5,040] |
| Czech Republic | Adults |
37,600 [31,700–45,500] |
8,170 [4,320–12,600] |
5,010 [2,260–7,990] |
2,620 [1,130–5,600] |
| Germany | Adults |
16,100 [13,000–20,200] |
4,950 [3,160–6,660] |
3,320 [1,900–4,490] |
2,290 [1,210–3,250] |
| Italy | Adults |
16,900 [12,300–22,700] |
6,520 [3,560–9,490] |
4,760 [2,440–6,970] |
3,400 [1,780–5,030] |
| Bulgaria | Other children |
13,400 [11,600–15,800] |
3,590 [2,950–4,290] |
2,590 [2,170–3,100] |
2,250 [1,840–2,760] |
| France | Other children |
14,300 [12,200–17,100] |
5,930 [4,870–6,860] |
4,370 [3,470–5,330] |
3,870 [3,100–4,460] |
| Netherlands | Other children |
9,020 [7,480–11,160] |
3,400 [2,600–4,440] |
2,350 [1,760–3,040] |
1,760 [1,340–2,300] |
| Denmark | Toddlers |
8,360 [7,240–9,850] |
3,670 [3,050–4,240] |
2,660 [2,220–3,110] |
2,080 [1,210–2,460] |
| Netherlands | Toddlers |
6,600 [5,450–8,050] |
2,680 [2,030–3,440] |
1,740 [1,280–2,390] |
1,480 [990–1,900] |
| United Kingdom | Toddlers |
11,500 [9,600–13,300] |
4,270 [3,560–4,870] |
3,060 [2,510–3,480] |
2,360 [1,810–2,940] |
CAG‐TCP: cumulative assessment group of pesticides associated with hypertrophy, hyperplasia and neoplasia of C‐cells.
The main drivers of exposures exceeding the 99th percentile were different from the Tier I calculations (see Annex C.1, Figure C.1.03 and Table C.1.02). Thiram remained a major contributor to exposure (74–87%) while ziram was a new major contributor (9–19%). The breakdown of commodities that made up the exposure from thiram also changed. Most thiram exposure came from apples (up to 44.1%), strawberries (up to 43.2%), peaches (up to 16.7%), lettuces (up to 14.3%), pears (up to 16%) and table grapes (up to 11.4%). On the other hand, ziram exposure mainly came from apples (up to 10.3%), pears (up to 3.9%) and table grapes (up to 2.8%). In adults only, wine grapes were another important contributor to exposure (29–53.6% for thiram and 0.02–15.8% for ziram). Other substances contributed for less than 11% of exposure.
The change in the main drivers of exposure was likely due to the different assumptions made in the Tier II calculations. Under this scenario, assignment of the active substances is restricted to authorised substances for a given crop. Measurements for dithiocarbamates in oranges, wheat and mandarins, which were major contributors in Tier I, are therefore no longer assigned to thiram. Furthermore, for the remaining contributing crops such as apples and table grapes, the active substances from the dithiocarbamates group are now assigned randomly rather than to the most potent substance. These assumptions had the most substantial influence on the increase in MOETs for CAG‐TCP. Aside from the assignment of active substances, left‐censored data are imputed with ½ LOQ based on estimated use frequencies in Tier II. In Tier I, even when only one quantifiable finding was identified, all left‐censored data are imputed with 1/2 LOQ. The dual effect of randomly assigning the active substances and different treatment of left‐censored data caused the MOETs to increase approximately 10‐fold from Tier I to Tier II.
Although Tier II calculations are expected to reflect a more refined scenario, this scenario is still subject to uncertainties. Some of these uncertainties were addressed through sensitivity analyses. A comparison between the MOETs obtained at the 99.9th percentile from the Tier II calculations and their corresponding sensitivity analyses is made in Table 13.
Table 13.
Estimates of the total margin of exposure (MOET) and their corresponding 95% confidence intervals at the 99.9th percentiles of the exposure distribution for the Tier II scenario of CAG‐TCP and several sensitivity analyses
| Country | Population class | Tier II | Sensitivity analysis Aa | Sensitivity analysis Bb | Sensitivity analysis Cc | Sensitivity analysis Dd |
|---|---|---|---|---|---|---|
| Belgium | Adults |
3,030 [1,150–5,040] |
729 [547–1,060] |
3,340 [1,140–6,970] |
7,320 [4,170–8,880] |
2,890 [1,220–4,610] |
| Czech Republic | Adults |
2,620 [1,130–5,600] |
713 [514–1,090] |
3,460 [1,170–7,830] |
6,910 [4,890–9,030] |
2,320 [894–4,220] |
| Germany | Adults |
2,290 [1,210–3,250] |
598 [524–668] |
2,530 [1,410–4,350] |
3,570 [2,020–4,550] |
2,220 [1,210–3,070] |
| Italy | Adults |
3,400 [1,780–5,030] |
760 [496–944] |
4,080 [2,060–6,700] |
5,520 [3,350–6,840] |
3,150 [1,660–4,890] |
| Bulgaria | Other children |
2,250 [1,840–2,760] |
298 [220–377] |
3,140 [2,030–4,040] |
2,880 [2,120–3,900] |
2,290 [1,770–2,730] |
| France | Other children |
3,870 [3,100–4,460] |
698 [504–983] |
5,570 [3,730–6,820] |
5,560 [4,190–7,890] |
3,890 [3,290–4,520] |
| Netherlands | Other children |
1,760 [1,340–2,300] |
365 [159–499] |
2,210 [1,160–2,960] |
2,480 [1,370–3,390] |
1,730 [1,400–2,180] |
| Denmark | Toddlers |
2,080 [1,210–2,460] |
371 [276–462] |
2,800 [1,280–3,600] |
3,100 [2,260–3,750] |
1,970 [1,160–2,520] |
| Netherlands | Toddlers |
1,480 [990–1,900] |
239 [191–425] |
1,940 [1,200–2,580] |
2,780 [2,020–3,930] |
1,480 [1,010–1,790] |
| United Kingdom | Toddlers |
2,360 [1,810–2,940] |
522 [462–628] |
3,350 [2,300–4,040] |
3,450 [2,790–4,270] |
2,410 [1,860–2,930] |
CAG‐TCP: cumulative assessment group of pesticides associated with hypertrophy, hyperplasia and neoplasia of C‐cells; LOQ: limit of quantification.
Sensitivity analysis assuming that left‐censored data are at 1/2 LOQ when the use of the active substance is authorised.
Sensitivity analysis assuming that all left‐censored data are at zero.
Sensitivity analysis assuming that residues will not be present in any processed food.
Sensitivity analysis excluding foods for infants and young children.
Sensitivity analyses A and B tested the uncertainty of imputing left‐censored data with 1/2 LOQ based on use frequencies. Sensitivity analysis A imputes all left‐censored data with 1/2 LOQ based on authorisation rather than use frequency. This is over‐conservative, as the commodities are not expected to be treated with all authorised substances at the same time. On the other hand, sensitivity analysis B imputes all left‐censored data with zero. This is not sufficiently conservative, as not all left‐censored data would be true zeros. In sensitivity analysis A, the MOETs dropped by 4–8 times. In sensitivity analysis B, the MOETs rose 1.1–1.4 times. Although the results from the Tier II calculations were in between the results from sensitivity analyses A and B, the margins of exposure obtained from Tier II were closer to those of sensitivity analysis B. Consequently, imputation of left‐censored data based on use frequency resulted primarily in zero values.
Sensitivity analysis C investigated the effect that missing processing factors might have on the margins of exposure. When no residues were assumed to be present in processed foods, the MOETs rose by a factor of 1.3–2.6. This change indicates that processing factors were not available for most of the major contributors to exposure. In this case, processing factors were only present for hexythiazox, imidiacloprid and ioxynil. Although including additional processing factors would likely not increase the margins of exposure to the extent suggested in sensitivity analysis C, more information on processing factors could substantially reduce the uncertainty.
Sensitivity analysis D investigated the effect of excluding foods for infants and young children in CAG‐TCP. There were no substantial changes in the margins of exposure when this assumption was made. This confirms previous findings of EFSA that exposure of toddlers to pesticide residues mainly comes from conventional foods (EFSA PPR Panel, 2018). This is due to the default MRL of 0.01 mg/kg, which applies to pesticide residues in foods for infants and young children.
Aside from the uncertainties that were tested through sensitivity analyses, several other uncertainties that were more difficult to quantify exist.
According to the risk management principles agreed among Member States,1 the MOET estimates were calculated at the 99.9th percentile of the exposure. The minimum number of subjects in a population needed to achieve reliable percentile estimates increases with the percentile to be computed. According to the guidance on the use of the comprehensive food consumption database, reliable estimates for the 95th and 99th percentiles can be achieved when n ≥ 59 and n ≥ 298, respectively (EFSA, 2011). Likewise, the number of subjects required to calculate a reliable 99.9th percentile is approximately 3,000. Although some of this uncertainty is partially captured by the confidence interval (see Section 2.5), it is acknowledged that also bootstrapping performs less well for small data sets (EFSA Scientific Committee, 2018), especially when the focus is on the tail of the variability distribution as is the case here (99.9th percentile). Therefore, the ratio of the 99.9th percentile to the median (50th percentile) was compared between surveys (EFSA, 2019b). Ratios were found to be within similar ranges, regardless of the number of subjects. Hence, for the surveys used in this assessment, it was concluded that the number of subjects was sufficient to derive reliable confidence intervals at the 99.9th percentile of the exposure distribution.
Another uncertainty is the limited availability of occurrence data for certain combinations of active substances and commodities (see Annex C.1, Table C.1.04). For CAG‐TCP, however, this only refers to combinations where the use of the active substance is neither authorised nor part of the CAG. This is therefore not expected to have any substantial impact on the outcome of the exposure assessment.
3.2. Pesticides associated with hypothyroidism (CAG‐TCF)
3.2.1. Tier I
Table 14 displays the results from the Tier I calculations. Similar to the CAG‐TCP, the largest MOETs were observed in adults, where MOET estimates at the 99.9th percentile were between 57.4 (Germany) and 70.4 (Italy). Likewise, the lowest MOETs were in toddlers and other children. MOET estimates in these population classes ranged from 15.1 (Dutch toddlers) to 34.3 (French other children).
Table 14.
Estimates of the total margin of exposure (MOET) and their corresponding 95% confidence intervals at the 50th, 95th, 99th and 99.9th percentiles of the exposure distribution for the Tier I scenario of CAG‐TCF
| Country | Population class | 50th percentile | 95th percentile | 99th percentile | 99.9th percentile |
|---|---|---|---|---|---|
| Belgium | Adults |
243 [231–257] |
124 [113–131] |
96.9 [85.7–104] |
69 [53–84.8] |
| Czech Republic | Adults |
288 [271–308] |
132 [121–140] |
97.4 [88–110] |
67.2 [59.4–79.3] |
| Germany | Adults |
246 [234–255] |
108 [102–113] |
78.6 [74.1–82.6] |
57.4 [52.9–61.1] |
| Italy | Adults |
212 [198–222] |
122 [112–129] |
95.6 [88.6–102] |
70.4 [60.3–87.8] |
| Bulgaria | Other children |
83.5 [76.1–89.1] |
42.7 [39–47.3] |
31.1 [24–35.8] |
21.9 [20.4–28.5] |
| France | Other children |
123 [115–129] |
62.4 [56.9–66.9] |
49.6 [36.4–55.2] |
34.3 [31.2–44.6] |
| Netherlands | Other children |
105 [98–112] |
53.1 [49.1–56.7] |
41 [37.2–44.5] |
32.1 [27.5–37.1] |
| Denmark | Toddlers |
87.5 [83.3–90.6] |
49.3 [46.5–52.5] |
37.4 [32–42.5] |
22.2 [16–32.1] |
| Netherlands | Toddlers |
79.4 [73.7–84.8] |
39.4 [35.8–44.3] |
31.8 [13.8–35.4] |
15.1 [11.9–31.4] |
| United Kingdom | Toddlers |
102 [96–107] |
54.3 [51.2–57.6] |
42.8 [37.9–46] |
30.3 [20.3–36.7] |
CAG‐TCF: cumulative assessment group of pesticides associated with hypothyroidism; LOQ: limit of quantification
The main contributors were identified for consumers with an exposure exceeding the 99th percentile of the distribution (see Annex B.2, Figure B.2.03 and Table B.2.02). Ziram was the predominant contributor to exposure (50.9–58.8%), most of this coming from oranges (up to 27.4%), apples (up to 18.5%), wheat (up to 9.6%) and mandarins (up to 6%). As with the CAG‐TCP, in adults, ziram from wine grapes was also an important contributor (0.04–12.9%). In addition to ziram, bromide ion (9–23.7%) and fipronil (6.5–30.6%) contributed substantially to exposure. Most bromide ion came from wheat (up to 8.7%), tomatoes (up to 5.3%) and potatoes (up to 2.8%) whilst most fipronil came from oranges (up to 9.5%) and potatoes (2.2%). Any other active substance contributed less than 21.2%.
While all the MOET estimates at the 99.9th percentile were below 100, several conservative assumptions were made to generate these results. As with thiram in the CAG‐TCP, ziram was the main driver for exposure in the CAG‐TCF. Ziram is the most potent substance in the dithiocarbamates group (see Annex A.2, Table A.2.03). According to Tier I assumptions, all dithiocarbamates are therefore assigned to ziram, although less potent dithiocarbamates might be present in practice. Ziram is also not authorised for use in oranges, wheat and mandarins. Assigning ziram to these commodities is therefore even more conservative. Furthermore, the contribution of fipronil in oranges and potatoes is driven by the high number of left‐censored data (99.9%). Under Tier I assumptions all these results were assumed to be 1/2 LOQ. This is most likely conservative considering that fipronil is not authorised for use in oranges and potatoes (see Annex A.2, Table A.2.06). These overestimations were accounted for in the Tier II calculations.
3.2.2. Tier II
Table 15 lists the results from the Tier II calculations. The largest margins of exposure at the 99.9th percentile were still observed in adults. The MOET estimates ranged from 259 (Germany) to 307 (Belgium). The lowest margins of exposure were seen in toddlers and other children. These ranged from 103 (Dutch toddlers) to 201 (French other children).
Table 15.
Estimates of the total margin of exposure (MOET) and their corresponding 95% confidence intervals at the 50th, 95th, 99th and 99.9th percentiles of the exposure distribution for the Tier II scenario of CAG‐TCF
| Country | Population class | 50th percentile | 95th percentile | 99th percentile | 99.9th percentile |
|---|---|---|---|---|---|
| Belgium | Adults |
984 [915–1048] |
507 [427–577] |
401 [317–481] |
307 [198–387] |
| Czech Republic | Adults |
1040 [980–1110] |
522 [452–586] |
377 [302–446] |
269 [186–366] |
| Germany | Adults |
1020 [960–1090] |
487 [423–546] |
362 [298–421] |
259 [205–313] |
| Italy | Adults |
776 [731–844] |
451 [394–506] |
362 [311–411] |
295 [252–330] |
| Bulgaria | Other children |
328 [307–356] |
193 [169–213] |
155 [131–166] |
127 [114–151] |
| France | Other children |
523 [492–556] |
292 [272–311] |
229 [203–270] |
201 [187–216] |
| Netherlands | Other children |
466 [436–501] |
265 [237–286] |
210 [183–234] |
176 [159–197] |
| Denmark | Toddlers |
328 [313–346] |
217 [202–227] |
183 [158–197] |
127 [102–175] |
| Netherlands | Toddlers |
360 [335–391] |
206 [184–225] |
160 [111–184] |
103 [86.3–165] |
| United Kingdom | Toddlers |
421 [394–448] |
238 [224–250] |
192 [172–209] |
124 [104–176] |
CAG‐TCF: cumulative assessment group of pesticides associated with hypothyroidism; LOQ: limit of quantification.
The main drivers of exposure at the upper bound of exposure were different in Tier II compared to Tier I (see Annex C.2, Figure C.2.03 and Table C.2.02). Although ziram remained a major contributor to exposure with a 4–22% contribution, bromide ion was the predominant contributor to exposure in Tier II (29–56%). Most bromide came from wheat (up to 31.2%), oat (up to 11.2%), rice (up to 8.5%) tomatoes (up to 7.0%) and rye (up to 6.9%). Unlike in Tier I, most of ziram's contribution came from wine grapes (up to 18.9%) consumed by adults but apples also contributed (up to 9.8%). In addition, propineb (6–25%), mancozeb (3–8.4%), thiabendazole (0.8–21.7%) and pyrimethanil (1.9–8.4%) now made major contributions to exposure. Most propineb came from wine grapes consumed by adults (up to 11.9%), and apples (up to 6.6%); most mancozeb, thiabendazole and pyrimethanil came from oranges (up to 6.5%, 18.8% and 7.0%, respectively). In some surveys, contribution of chlorpropham in potatoes (up to 6.4%) and cyprodinil in wine grapes (up to 5.1%) was also observed. Other substances contributed to less than 4% of exposure and fipronil no longer made a major contribution to exposure.
As with the CAG‐TCP, the change in the assumptions made in the Tier II calculations resulted in a substantial increase of the MOETs. As active substances were assigned to authorised substances, ziram is no longer assumed to occur in oranges, wheat and mandarins. Furthermore, left‐censored data for fipronil in oranges and potatoes were no longer imputed with ½ LOQ. These combinations of commodities and active substances contributed up to 50% of a population's exposure in Tier I. The changes for these contributors were the predominant reason for the differences seen in MOETs.
Some of the uncertainties that were identified in Tier II were addressed through sensitivity analyses. A comparison between the MOETs obtained at the 99.9th percentile of exposure for Tier II and the sensitivity analyses is made in Table 16.
Table 16.
Estimates of the total margin of exposure (MOET) and their corresponding 95% confidence intervals at the 99.9th percentiles of the exposure distribution for the Tier II scenario of CAG‐TCF and several sensitivity analyses
| Country | Population class | Tier II | Sensitivity analysis Aa | Sensitivity analysis Bb | Sensitivity analysis Cc | Sensitivity analysis Dd |
|---|---|---|---|---|---|---|
| Belgium | Adults |
307 [198–387] |
95.6 [69.9–129] |
356 [212–482] |
991 [846–1160] |
314 [170–395] |
| Czech Republic | Adults |
269 [186–366] |
110 [78.8–127] |
314 [182–460] |
814 [592–1000] |
273 [176–346] |
| Germany | Adults |
259 [205–313] |
74.1 [66.2–82] |
307 [234–392] |
695 [525–815] |
263 [208–303] |
| Italy | Adults |
295 [252–330] |
113 [101–131] |
428 [330–502] |
710 [562–829] |
298 [266–332] |
| Bulgaria | Other children |
127 [114–151] |
36.8 [32.6–44.2] |
152 [132–191] |
292 [263–327] |
128 [113–152] |
| France | Other children |
201 [187–216] |
63.7 [58.4–70.6] |
254 [235–296] |
682 [612–801] |
198 [185–216] |
| Netherlands | Other children |
176 [159–197] |
41.1 [38–50.7] |
216 [187–252] |
481 [296–622] |
176 [160–198] |
| Denmark | Toddlers |
127 [102–175] |
32.5 [23.5–45.9] |
164 [114–226] |
409 [334–505] |
125 [103–151] |
| Netherlands | Toddlers |
103 [86.3–165] |
29.7 [24.8–40.8] |
121 [98.1–223] |
586 [525–649] |
100 [85.4–161] |
| United Kingdom | Toddlers |
124 [104–176] |
45.3 [32.6–56.4] |
224 [134–251] |
426 [333–503] |
128 [105–176] |
CAG‐TCF: cumulative assessment group of pesticides associated with hypothyroidism; LOQ: limit of quantification.
Sensitivity analysis assuming that left‐censored data are at 1/2 LOQ when the use of the active substance is authorised.
Sensitivity analysis assuming that all left‐censored data are at zero.
Sensitivity analysis assuming that residues will not be present in any processed food.
Sensitivity analysis excluding foods for infants and young children.
Sensitivity analyses A and B tested the uncertainty of imputing left‐censored data with 1/2 LOQ based on use frequency. When left‐censored data were imputed with ½ LOQ based on authorisation, the MOETs dropped by 3–4 times. When all left‐censored data were assumed to be at 0, the MOETs rose 1.1–1.8 times. As with the CAG‐TCP, the results in Tier II were between both sensitivity analyses but closer to the less conservative sensitivity analysis B. Therefore, imputation of left‐censored data based on use frequency mostly produced zero values.
Sensitivity analysis C investigated the effect that missing processing factors might have on the margins of exposure. The MOETs rose 2.3–5.7 times when no residues were assumed to be present in processed foods. This rise was larger than the one seen in CAG‐TCP because the main contributing commodities for CAG‐TCP referred to fruits and vegetables that are frequently consumed unprocessed (e.g. apples, pears, strawberries, table grapes and lettuce). The main drivers for CAG‐TCF, however, referred to citrus fruits or wine grapes, which are mostly processed (or at least peeled) prior to consumption. Therefore, collecting further information on processing factors is even more critical for reducing the uncertainty in CAG‐TCF.
Sensitivity analysis D investigated the effect of excluding foods for infants and young children in CAG‐TCP. Again, there were no substantial changes in the margins of exposure when this assumption was made. These results reinforce the observation made in Section 3.1.2. Due to the default MRL of 0.01 mg/kg, which applies to pesticide residues in foods for infants and young children, most dietary exposure of toddlers to pesticides comes from conventional foods (EFSA PPR Panel, 2018).
As for CAG‐TCP, additional uncertainties were identified which were more difficult to quantify.
Regarding the reliability of the 99.9th percentiles of the exposure distributions, the same considerations apply as for CAG‐TCP (see Section 3.1.2). Dietary surveys with 3,000 subjects would normally be required to produce reliable estimates at the 99.9th percentile for toddlers and other children, but parametric modelling of the exposure distributions may also be considered as an alternative solution for future assessments.
Compared to CAG‐TCP, the uncertainty resulting from the limited availability of occurrence data is more important for CAT‐TCF because a higher number of authorised substances‐commodity combinations were found to have missing data (see Annex C.2, Table C.2.04). Most of these missing data refer to 8‐hydroxyquinoline, penflufen, pyriofenone and thiencarbazone. Based on the MRLs in place for these active substances, however, residues for these active substances are expected to be low. Furthermore, NOAELs for these substances are all higher than or equal to 10 mg/kg bodyweight per day. It is therefore unlikely that the missing occurrence data would have a substantial impact on the outcome of this exposure assessment.
3.3. Comparison with Monte Carlo Risk Assessment software
Results of the calculations obtained by EFSA were compared with results obtained by the RIVM using the MCRA software version 8.3 (van Klaveren et al., 2019). Results of the Tier II scenarios obtained with both software for CAG‐TCP and CAG‐TCF are presented in Tables 17 and 18, respectively. This comparison is presented for the higher percentiles of the exposure distribution because these percentiles are considered most relevant for risk management purposes.
Table 17.
Estimates of the total margin of exposure (MOET) and their corresponding 95% confidence intervals obtained with two different software (SAS® and MCRA) at the 99th and 99.9th percentiles of the exposure distribution for the Tier II scenario of CAG‐TCP
| Country | Population class | SAS® | MCRA | ||
|---|---|---|---|---|---|
| 99th Percentile | 99.9th Percentile | 99th Percentile | 99.9th Percentile | ||
| Belgium | Adults |
4,570 [2,120–7,720] |
3,030 [1,150–5,040] |
4,388 [2,515–6,001] |
2,849 [1,389–4,592] |
| Czech Republic | Adults |
5,010 [2,260–7,990] |
2,620 [1,130–5,600] |
4,729 [2,638–6,553] |
2,532 [1,401–4,017] |
| Germany | Adults |
3,320 [1,900–4,490] |
2,290 [1,210–3,250] |
3,234 [2,267–4,117] |
2,241 [1,496–2,868] |
| Italy | Adults |
4,760 [2,440–6,970] |
3,400 [1,780–5,030] |
4,458 [2,787–6,193] |
3,401 [2,144–4,731] |
| Bulgaria | Other children |
2,590 [2,170–3,100] |
2,250 [1,840–2,760] |
2,626 [2,255–3,088] |
2,307 [1,860–2,627] |
| France | Other children |
4,370 [3,470–5,330] |
3,870 [3,100–4,460] |
4,427 [3,819–5,186] |
3,978 [3,337–4,430] |
| Netherlands | Other children |
2,350 [1,760–3,040] |
1,760 [1,340–2,300] |
2,458 [1,940–2,919] |
1,778 [1,491–2,187] |
| Denmark | Toddlers |
2,660 [2,220–3,110] |
2,080 [1,210–2,460] |
2,766 [2,236–3,098] |
2,072 [1,516–2,538] |
| Netherlands | Toddlers |
1,740 [1,280–2,390] |
1,480 [990–1,900] |
1,776 [1,407–2,190] |
1,468 [1,148–1,783] |
| United Kingdom | Toddlers |
3,060 [2,510–3,480] |
2,360 [1,810–2,940] |
3,122 [2,700–3,591] |
2,488 [2,077–2,913] |
CAG‐TCP: cumulative assessment group of pesticides associated with hypertrophy, hyperplasia and neoplasia of C‐cells.
Table 18.
Estimates of the total margin of exposure (MOET) and their corresponding 95% confidence intervals obtained with two different software (SAS® and MCRA) at the 99th and 99.9th percentiles of the exposure distribution for the Tier II scenario of CAG‐TCF
| Country | Population class | SAS® | MCRA | ||
|---|---|---|---|---|---|
| 99th Percentile | 99.9th Percentile | 99th Percentile | 99.9th Percentile | ||
| Belgium | Adults |
401 [317–481] |
307 [198–387] |
416 [349–461] |
316 [210–391] |
| Czech Republic | Adults |
377 [302–446] |
269 [186–366] |
394 [316–435] |
280 [200–349] |
| Germany | Adults |
362 [298–421] |
259 [205–313] |
367 [319–405] |
266 [228–302] |
| Italy | Adults |
362 [311–411] |
295 [252–330] |
365 [319–397] |
302 [274–335] |
| Bulgaria | Other children |
155 [131–166] |
127 [114–151] |
156 [142–166] |
130 [118–154] |
| France | Other children |
229 [203–270] |
201 [187–216] |
222 [204–267] |
200 [193–227] |
| Netherlands | Other children |
210 [183–234] |
176 [159–197] |
214 [190–229] |
177 [162–196] |
| Denmark | Toddlers |
183 [158–197] |
127 [102–175] |
185 [158–195] |
128 [110–172] |
| Netherlands | Toddlers |
160 [111–184] |
103 [86.3–165] |
159 [134–181] |
102 [89–160] |
| United Kingdom | Toddlers |
192 [172–209] |
124 [104–176] |
192 [172–212] |
149 [108–177] |
CAG‐TCF: cumulative assessment group of pesticides associated with hypothyroidism.
The results obtained with SAS® and MCRA were found to be very similar. For CAG‐TCP, most estimates calculated by EFSA showed less than 6% deviation compared to the estimates obtained by RIVM. For CAG‐TCF, the observed deviations generally remained below 5%. One single dietary survey (UK Toddlers) showed a substantial deviation of 20% on the estimate but the confidence intervals calculated for this dietary survey were nearly identical. These minor divergencies are attributed to random effects which are inherent to the probabilistic methodologies applied in the exposure assessment.
A more detailed comparison of the results, however, reveals that confidence intervals calculated by EFSA were slightly wider (i.e. 1.1–1.6 times) than those obtained by RIVM. This observation cannot be attributed to the random effects of the probabilistic model only. Therefore, the cause for these variances was further investigated by EFSA and RIVM. As a result, some minor methodological differences were identified, which may affect the width of the confidence intervals. These differences are summarised as follows:
Within the SAS® program the nominal run (i.e. the run based on the original data) was considered equivalent to any of the bootstrap runs, and uncertainty percentiles were based on all runs. In MCRA, uncertainty percentiles are based on the bootstrap runs only. Theoretically this may cause a difference because two randomly selected bootstrapped data sets will on average differ more from each other than each of them will differ from the original data set. However, when the calculations are performed with one nominal run and 99 bootstrap runs (SAS) or with 100 bootstrap runs (MCRA), the impact of this difference is anticipated to be very small in practice.
To reduce the computational time, calculations are handled through parallel computation. In MCRA, parallel computation is used within each bootstrap iteration, and bootstraps are handled sequentially. In the SAS® program, however, it was decided to handle the bootstraps in parallel. This approach caused a bias in the random assignment of active substances to unspecific residue definitions for the bootstrapped data (not for the nominal run), which could not be resolved by EFSA. Hence, the confidence interval calculated with SAS is biased (i.e. too wide) when the exposure is driven by substances coming from an unspecific residue definition.
Chronic exposure is estimated using the average concentration for each active substance and commodity (see Section 2.4.1.5). The average concentration depends on the relative frequencies of zeroes, left‐censored observations and positive measurements, and of course on the LOQ values and positive values. The uncertainty about the relative frequencies is handled in both MCRA and SAS by bootstrapping of the occurrence data. In addition, the program developed in SAS® generates in each iteration a set of samples using random imputations of individual sample concentrations at 1/2 LOQ, and subsequently estimates the mean concentration from the simulated set, ultimately leading to a wider confidence interval of the exposure estimates. Opinions were different regarding the most suitable approach, but the difference was not thought to have a substantial impact.
Based on the above considerations it is concluded that MCRA and the SAS® program elaborated by EFSA produce nearly identical results. The differences observed between both software are mainly attributed to the random effect of probabilistic modelling. It is acknowledged, however, that for CAG‐TCP, where the random assignment of active substances to unspecific residue definitions in the bootstrapped data is slightly biased, confidence intervals obtained with MCRA might be more realistic. For CAG‐TCF, the differences in width of the confidence intervals is mainly attributed to a different method for the calculation of the average concentrations in food. Yet, this does not impact greatly on the outcome of the assessment.
4. Conclusions
EFSA performed a retrospective assessment of cumulative exposure to pesticides affecting the thyroid for the reference period 2014–2016. Calculations included 10 dietary surveys that cover different age classes and geographical areas. In addition, EFSA only considered the food consumption data for water, foods for infants and young children and 30 raw primary commodities of plant origin that are widely consumed within Europe. All calculations were successfully executed using SAS® software.
As agreed by risk managers in the SC PAFF of 19 September 2018, calculations were carried out according to a tiered approach. While the Tier I scenario uses very conservative assumptions for an efficient screening of the exposure with low risk for underestimation, the Tier II scenario includes assumptions that are more refined but still intended to be conservative. For each scenario, exposure estimates were obtained for different percentiles of the exposure distribution and the total margin of exposure (MOET, i.e. the ratio of the toxicological reference dose to the estimated exposure) was calculated at each percentile. In accordance with the threshold agreed at the SC PAFF, further regulatory consideration would be required when the MOET calculated at the 99.9th percentile of the exposure distribution is below 100.
The lowest MOET estimates were obtained for pesticides associated with hypothyroidism. According to the Tier II scenario, MOET estimates at the 50th, 95th and 99th percentile of the exposure distribution were all well above 100. At the 99.9th percentile, estimates came near to 100, ranging from 103 to 201 in toddlers and other children. For adults, the MOETs were higher, ranging from 259 to 307. The exposure to this group of pesticides was predominantly driven by the occurrence of bromide ion. Other important drivers were propineb, thiabendazole, ziram, mancozeb, pyrimethanil, chlorpropham and cyprodinil.
For pesticides associated with hypertrophy, hyperplasia and neoplasia of C‐cells, MOETs calculated at the 99.9th percentile of the exposure distribution were higher, ranging from 1,480 to 3,400 in all populations. In this case, the difference between adults and children was less evident and the main drivers for the exposure were identified as thiram and ziram.
To ensure a rigorous validation of the methodology, exposure estimates obtained by EFSA were validated against those obtained by the RIVM using the MCRA software, version 8.3. Comparison of the results revealed that both tools produced nearly identical results and any observed differences are mainly attributed to the random effect of probabilistic modelling. It is acknowledged that the confidence intervals obtained through the SAS® program are slightly biased when the exposure estimates are driven by substances measured through an unspecific residue definition. This is the case for pesticides associated with hypertrophy, hyperplasia and neoplasia of C‐cells where the main contributing substances are measured as dithiocarbamates. These minor differences, however, do not impact on the outcome of the exposure assessment.
It is important to note that the calculations were conducted with conservative assumptions likely to overestimate the exposure, even in the more refined Tier II scenario. The most impactful assumptions are the random assignment of active substances to unspecific measurements (i.e. a measurement that may comprise multiple active substances) and the imputation of left‐censored data (i.e. measurements below the LOQ). If data on the use frequency of pesticides would be available at EU level, both these assumptions could be further refined. Another important overestimation of the exposure arises from the limited data on the effect of processing. When such data are missing, it is assumed that all pesticides in the raw primary commodity will reach the end consumer without any loss of residues. Sensitivity tests have demonstrated that, for pesticides associated with hypothyroidism, further data on the effect of processing might result in a fivefold increase of the MOET estimates in toddlers.
Uncertainties considered in this assessment, however, only refer to the exposure calculations and should still be considered in conjunction with other uncertainties that may apply to the hazard characterisation. Hence, together with the results obtained by RIVM, the exposure estimates presented in this report are used for the final scientific report on the cumulative dietary risk characterisation of pesticides that have chronic effects on the thyroid. The latter combines the hazard assessment and exposure assessment into a consolidated risk characterisation including all related uncertainties.
5. Recommendation
In view of refining the exposure estimates, the following recommendations were derived by EFSA.
The assignment of active substances to unspecific residue definitions relies on the assumption that active substances are used with equal probability. The imputation of left‐censored data, on the other hand, uses the positive measurements observed in the occurrence data set to estimate the use frequencies. Considering that both assumptions have a strong impact on the exposure estimates, it is recommended that EFSA, the European Commission and Member States collect data on the use frequency of pesticides.
Due to the limited availability of processing factors for pesticide residues in food, the current calculations are expected to overestimate the exposure. It is therefore recommended that EFSA, the European Commission and Member States further elaborate the European Database on processing factors.
Validation of the SAS® program revealed that the confidence intervals are slightly biased when the exposure estimates are driven by substances measured through an unspecific residue definition. It is therefore recommended to investigate how the SAS® program can be adjusted in order to remove this bias.
Abbreviations
- AS
active substance
- AUP
agricultural use pattern, i.e. the combination of pesticide uses applied to a single commodity or crop
- BW
body weight
- CAG
cumulative assessment group
- CAG‐TCF
cumulative assessment group of pesticides associated with hypothyroidism
- CAG‐TCP
cumulative assessment group of pesticides associated with hypertrophy, hyperplasia and neoplasia of C‐cells
- EUCP
EU‐coordinated control programme
- FP7
7th Framework Programme for Research
- FoodEx2
multipurpose food classification and description system developed by EFSA, revision 2
- LOQ
limit of quantification
- MCRA
Monte Carlo Risk Assessment software
- MOE
margin of exposure, i.e. the ratio of a toxicological reference dose (i.e. NOAEL) to the estimated exposure
- MOET
total margin of exposure resulting from multiple chemicals and food commodities
- MRL
maximum residue level
- MW
molecular weight
- NE
normalised exposure, i.e. the ratio the estimated exposure to a toxicological reference dose (i.e. NOAEL)
- NET
total normalised exposure resulting from multiple chemicals and food commodities
- NOAEL
no observed adverse effect level
- OIM approach
observed individual means approach, i.e. an approach for estimating longer term exposures by taking each individual's observed mean consumption over the duration of a dietary survey
- PF
processing factor
- PPR Panel
EFSA Panel on Plant Protection Products and their Residues
- RD
residue definition
- RIVM
Dutch National Institute for Health and the Environment
- RPC
raw primary commodity, i.e. a single‐component food which is unprocessed or whose nature has not been changed by processing (e.g. apples)
- RPCD
raw primary commodity derivative, i.e. a single‐component food which has been physically changed by processing (e.g. apple juice)
- SC PAFF
Standing Committee on Plants, Animals, Food and Feed
- SSD
Standard Sample Description, i.e. a harmonised data model developed by EFSA for describing analytical measurements in food and feed samples
Appendix A – Procedure for the allocation of active substances to the measurements
1.
-
1
Select distinct combinations of raw primary commodity (RPC) and residue definition reported in the occurrence data set.
-
2
Identify the possible combinations of RPC, residue definition and active substance (AS) (by joining the information of the residue definitions table). Retain information on the molecular weight (MW) conversion factor, on whether this combination is exclusive or not, and on the proportion for the non‐exclusive combinations.
-
3
Add the relevant no observed adverse effect level (NOAEL) to each combination (join information from the AS table using the AS as the key).
-
4
Identify the authorisation status for each combination (join information from the authorisations table using the RPC and AS as the keys).
Tier I
-
5
There may now be combinations of RPC, residue definition and AS which refer to the same RPC and residue definition. Data are sorted by RPC, residue definition and NOAEL (ascending) and for each combination of RPC and residue definition, the first combination of RPC, residue definition and AS is retained, i.e. the one with the lowest NOAEL (most toxic AS).
-
6
For each measurement in the occurrence data set, the AS is assigned on the basis of the combinations derived at step 5 (using the RPC and the residue definition as keys).
Tier II
-
5
There may now be combinations of RPC, residue definition and AS which refer to the same RPC and residue definition. For each RPC and residue definition, only the combinations with authorised uses are retained. If none are authorised, all combinations are retained.
-
6
For each measurement in the occurrence data set, the AS is assigned on the basis of the combinations derived at step 5 (using the RPC and the residue definition as keys). If for a given measurement more than one AS could be assigned, only one AS is selected randomly using equal probability (regardless whether the AS is part of the cumulative assessment group).
-
7
For each measurement, it is verified whether the combination RPC, residue definition and AS assigned is exclusive or not. If it is not exclusive:
The residue value and the limit of quantification (LOQ) value are multiplied by the proportion specified in the residue definition table.
The exclusive AS of that residue definition is identified (from the residue definitions table).
A new measurement is generated for the same sample but for the exclusive AS identified above. The residue value and the LOQ value are also multiplied by a factor equal to (1 – proportion of the non‐exclusive substance).
Figure A.1.
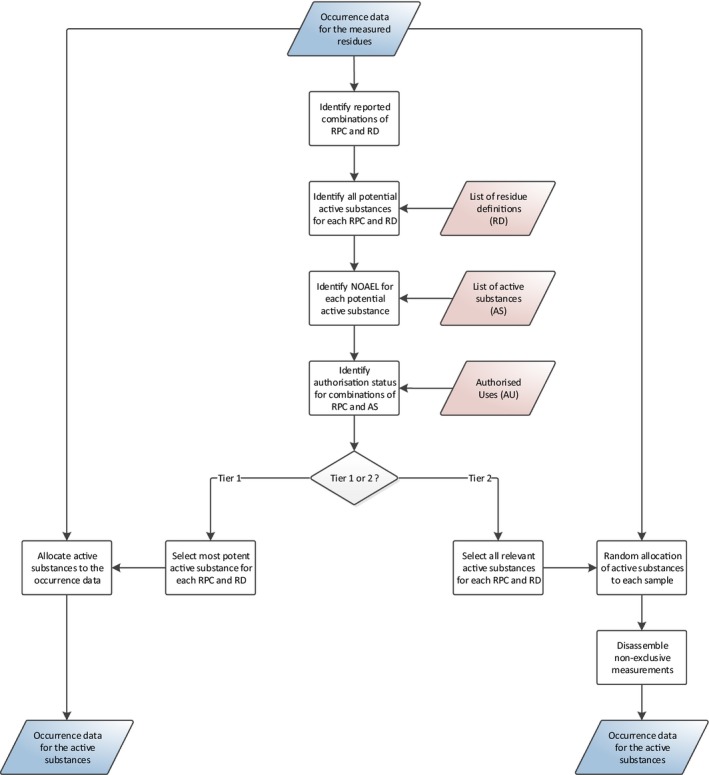
Flow chart for the allocation of active substances to the measurements
Appendix B – Procedure for the extrapolation of measurements
1.
-
1
Within the occurrence data set, count the number of observations per combination of active substance (AS) and raw primary commodity (RPC).
-
2
From the RPCs table and the ASs table, create a full matrix with all possible combinations of AS and RPC. Join this table with table created at step 1 to derive a complete list of missing and observed combination (using RPC and AS as keys).
-
3
Identify the maximum residue level (MRL) and the authorisation status of each of these combinations (using RPC and AS as keys). Since MRLs are defined at residue definition level, a preliminary step joins MRL table and residue definition table to associate MRL information to the active substances.
-
4
Identify for each combination all valid extrapolations on the basis of the extrapolation rule table. Extrapolations for a given AS and RPC are considered valid only when:
the number of observations for the FromFood is equal or above 10.
the number of observations for the ToFood is below 10.
MRL for FromFood and ToFood is equal.
Both FromFood and ToFood are authorised.
-
5
For each AS and for each valid extrapolation, the measurements in the FromFood are listed (can be positive or left‐censored).
-
6
For each AS and for each valid extrapolation, the samples of the ToFood that were not analysed for the AS are listed (i.e. the missing values). This implies indeed that no extrapolation will be done if there are no samples at all for a given food.
-
7
Random measurements (identified at step 7) are combined with random samples (identified at step 6). This is repeated until all the FromFood measurements or all the ToFood samples are assigned. Hence, if there are insufficient measurements in the FromFood, missing values in the ToFood will remain. If there are insufficient samples in the ToFood, some measurements in the FromFood will not be assigned.
-
8
Newly extrapolated values are added to the occurrence data set.
Figure B.1.
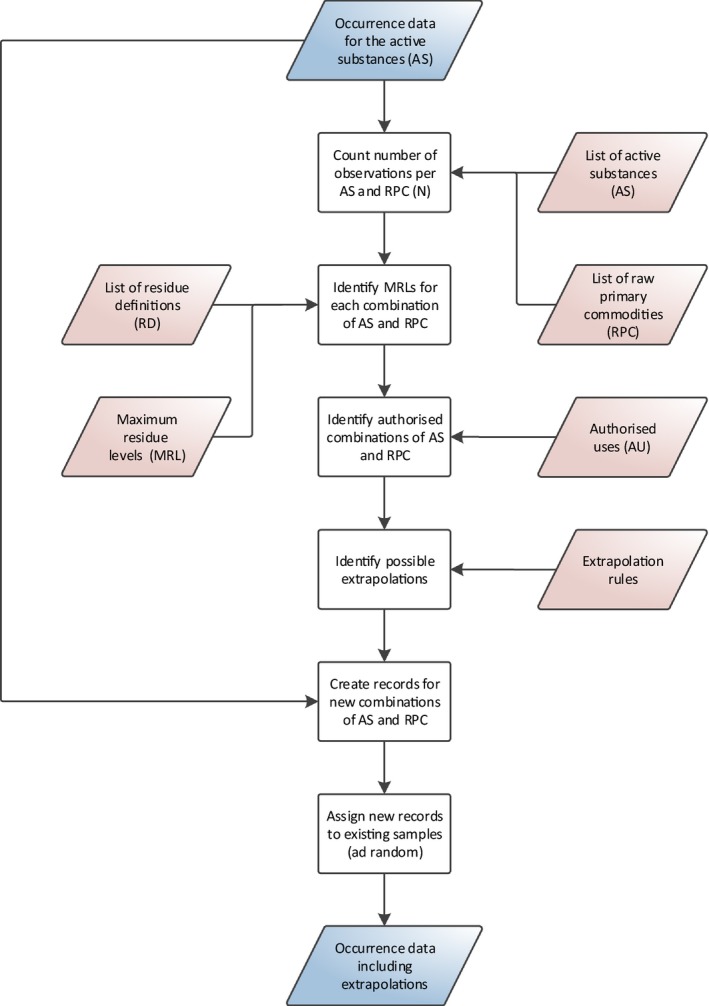
Flow chart for extrapolation of the occurrence data
Appendix C – Procedure for the imputation of left‐censored measurements
1.
Tier I
Retrieve from the occurrence data set all records which refer to a quantifiable result and identify distinct combinations of raw primary commodity (RPC) and active substance (AS). This results in a list of RPC/AS combinations where the non‐quantifiable results will be assumed to be at 1/2 limit of quantification (LOQ).
Identify in the occurrence data set all left‐censored records that refer to any of the combinations listed at step 1 (using RPC and AS as keys). Assign 1/2 LOQ as a result for those records.
Assign zero to all remaining left‐censored records in the occurrence data set.
Tier II
-
1
Define the list of agricultural use patterns (AUPs) observed in the data set. An AUP is the combination of AS quantified within a RPC. The list is derived as follows:
Retrieve from the occurrence data set all samples which have at least one quantifiable result.
Identify for each of the previous samples the AUP by concatenating the ASs quantified in each sample.
Select all the distinct AUPs and assign a identifier to each AUP.
Example : Among all apple samples, substances X, Y and Z were measured, and the following combinations were quantified within single samples: (X), (X‐Y‐Z), (Y), (X‐Y) and (Y‐Z). These combinations are now identified as AUP1, AUP2, AUP3, AUP4 and AUP5, respectively.
-
2
Count the number of samples for each AUP, i.e. the number of times that the AUP appears in the data set. Example : Number of apple samples where AUP1 was observed is 200; number of apple samples where AUP2 was observed is 23, etc.
-
3
Identify the analytical scope of each sample and, for each AUP, identify the number of samples where the AUP is covered by the analytical scope:
From the occurrence data set, identify for each sample the analytical scope by concatenating the ASs measured in each sample. Example : Samples were measured either for substance Y only (Scope1), for substances X and Y (Scope2), for substances X, Y and Z (Scope3) or for substances Y and Z (Scope4).
Count the number of samples for each analytical scope. Example : Number of samples where Scope1 was measured is 500; number of samples where Scope2 was measured is 250; number of samples where Scope3 was measured is 1,250; Number of samples where Scope4 was measured is 2,000.
For each AUP, identify the analytical scopes that include all ASs of that AUP. Example : AUP1 is covered by Scope2 and Scope3 only.
For each AUP, sum the number of samples for all analytical scopes identified at step 3c. Example : The number of samples where Scope2 and Scope3 were measured is 250 and 1,250. Hence, the total number of samples where AUP1 is covered by the analytical scope is 1,500.
-
4
Calculate frequency for each AUP (N samples AUP/N samples analytical scope). Example : Number of apple samples where AUP1 was observed is 200 (calculated at step 2). Number of apple samples where AUP1 is covered by the analytical scope is 1,500 (calculated at step 3). Hence, the frequency of AUP1 in apples is 13.3%.
-
5
Adjust frequencies for authorised AUPs (i.e. when all substances in the AUP are authorised) to obtain a total AUP frequency of 100% per RPC. This assumes that each sample in the occurrence data set was treated according to one AUP. Example : 5 AUPs were observed in apples and frequencies for each AUP were calculated: AUP1 (13.3%), AUP2 (2.3%), AUP3 (9.8%), AUP4 (1.2%) and AUP5 (0.2%). However, only AUP1, AUP3 and AUP4 include substances that are all authorised. Therefore, only these AUPs are adjusted to obtain a total number AUP frequency of 100%. Frequencies of AUP2 and AUP5 remain unchanged and the following adjusted frequencies are obtained: AUP1 (53.4%), AUP2 (2.3%), AUP3 (39.3%), AUP4 (4.8%) and AUP5 (0.2%).
-
6
Calculate use frequency for each combination of RPC and AS and identify the corresponding number of measurements that should be set to 1/2 LOQ:
For each combination of RPC and AS, calculate the use frequency by summing the AUP frequencies of all AUPs that contain the AS. Example : 5 AUPs were observed in apples and the following adjusted frequencies are obtained: AUP1 (53.4%), AUP2 (2.3%), AUP3 (39.3%), AUP4 (4.8%) and AUP5 (0.2%). Only AUP1, AUP2 and AUP4 include the use of substance X. Therefore, the estimated use frequency of substance X in apples is 60.5%.
For each combination of RPC and AS, calculate the percentage of true zeros (i.e. 100 – use frequency calculated at step 6a) Example: If the estimated use frequency of is 60.5%, the expected percentage of true zeros is 39.5%.
For each combination of RPC and AS, calculate the number of true zeros by multiplying the percentage of true zeros (calculated at step 6b) with number of measurements for that AS and RPC and divide by 100. Example: For substance X in apples, if the expected percentage of true zeros is 39.5% and the total number of measurements is 3,562, the estimated number of true zero measurements is 1,407.
For each combination of AS and RPC, count the total number of measurements. Subtract from this value the number of samples that already have a measured value and the number of true zeroes calculated at step 6c. This is the number of samples that should be set to 1/2 LOQ. If a negative number is obtained, set to 0. Example: For substance X in apples, if the total number of measurements is 3,562, the number of quantifiable measurements is 126 and the estimated number of true zero measurements is 1,407, the number of measurements to be imputed at ½ LOQ is 2029.
-
7
From the left‐censored data reported in the occurrence data set, randomly select for each RPC and AS the number of samples (as calculated above). Assign a residue value of 1/2 LOQ.
-
8
Assign zero to all remaining left‐censored records in the occurrence data set.
Figure C.1.
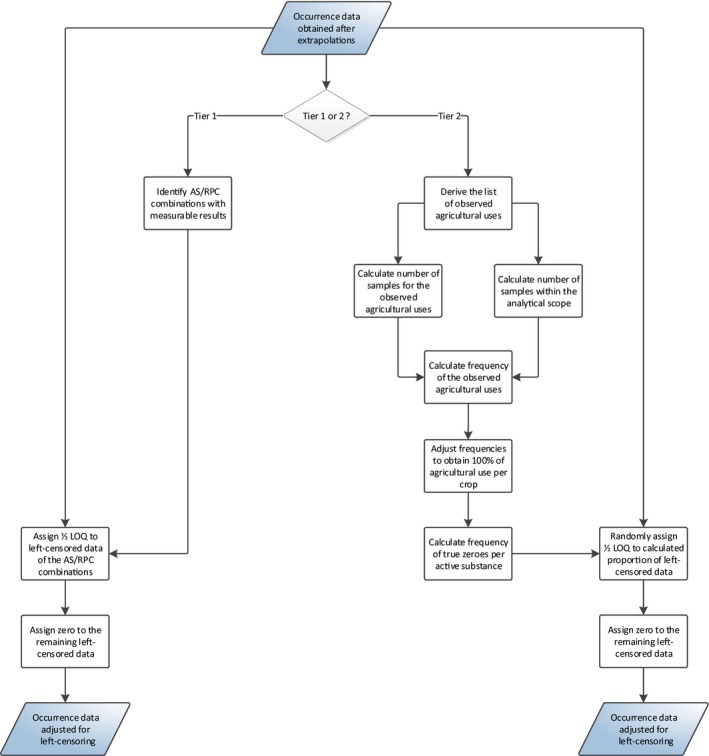
Flow chart for the imputation of left‐censored measurements
Appendix D – Procedure for deriving the chronic exposure distribution
1.
Calculate average concentrations for each active substance and RPC. Under Tier II assumptions, the average concentrations also account for the implicit zero measurements resulting from the assignment of active substances to unspecific residue definitions. Assign to each consumption record mean occurrence value of active substances in RPC by joining consumption data with occurrence data (using the RPC as a key).
Assign processing factors (PFs) to the relevant records of data set created at step 1 by joining information from the PFs table (using the RPC, active substance and FoodEx2 facet as the keys). If no PF is available for a specific combination, then a missing value is assigned to the PF.
Calculate normalised exposure (NE) for each record using formula described in Section 2.4.2 to obtain NE per subject, RPC and active substance.
Sum all normalised exposures of RPCs and active substances per subject to obtain a total normalised exposure (NET) for each subject.
Figure D.1.
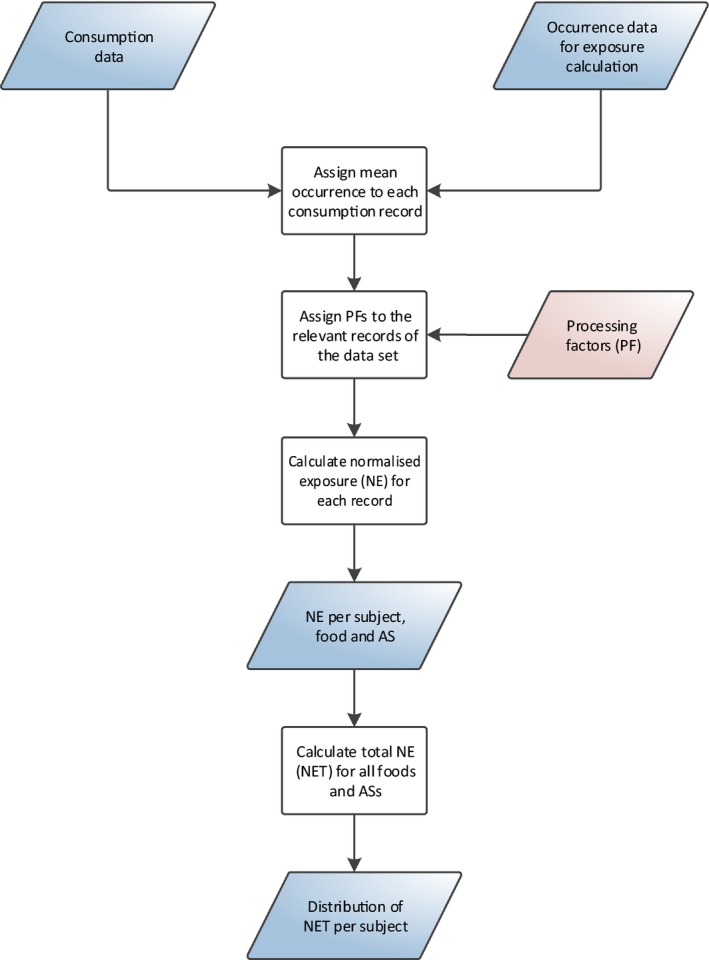
Flow chart for the calculation of chronic exposure
Annex A.1 – Input data for the exposure assessment of CAG‐TCP
1.
Annex A.1 can be found online on EFSA's knowledge junction: https://doi.org/10.5281/zenodo.3338152
Annex A.2 – Input data for the exposure assessment of CAG‐TCF
1.
Annex A.2 can be found online on EFSA's knowledge junction: https://doi.org/10.5281/zenodo.3338152
Annex B.1 – Output data from the Tier I exposure assessment of CAG‐TCP
1.
Annex B.1 can be found online on EFSA's knowledge junction: https://doi.org/10.5281/zenodo.3338152
Annex B.2 – Output data from the Tier I exposure assessment of CAG‐TCF
1.
Annex B.2 can be found online on EFSA's knowledge junction: https://doi.org/10.5281/zenodo.3338152
Annex C.1 – Output data from the Tier II exposure assessment of CAG‐TCP
1.
Annex C.1 can be found online on EFSA's knowledge junction: https://doi.org/10.5281/zenodo.3338152
Annex C.2 – Output data from the Tier II exposure assessment of CAG‐TCF
1.
Annex C.2 can be found online on EFSA's knowledge junction: https://doi.org/10.5281/zenodo.3338152
Suggested citation: EFSA (European Food Safety Authority) , Dujardin B and Bocca V, 2019. Scientific Report on the cumulative dietary exposure assessment of pesticides that have chronic effects on the thyroid using SAS® software. EFSA Journal 2019;17(9):5763, 49 pp. 10.2903/j.efsa.2019.5763
Requestor: EFSA
Question number: EFSA‐Q‐2018‐00482
Acknowledgements: EFSA wishes to thank the following for the support provided to this scientific output: Stefano Dellacasagrande, Florence Gerault, Alexandra Mienné, Luc Mohimont, Ti Kian Seow, Jan Dirk te Biesebeek, Hilko van der Voet, Gerda van Donkersgoed and Jacob van Klaveren. EFSA wishes to acknowledge all European competent institutions, Member State bodies and other organisations that provided data for this scientific output.
Adopted: 28 June 2019
This publication is linked to the following EFSA Supporting Publications article: http://onlinelibrary.wiley.com/doi/10.2903/sp.efsa.2019.EN-1707/full
This publication is linked to the following EFSA Journal articles: http://onlinelibrary.wiley.com/doi/10.2903/j.efsa.2019.5801/full
Notes
The population class ‘toddlers’ refers to participants from ≥ 12 months to < 36 months old.
The population class ‘other children’ refers to participants from ≥ 36 months to < 10 years old.
The population class ‘adults’ refers to participants from ≥ 18 years to < 65 years old.
http://ec.europa.eu/food/plant/pesticides/eu-pesticides-database/public/?event=homepage&language=EN
The method described is an interpretation of ‘Option 5’ defined by the risk management principles on cumulative risk assessment (http://www.efsa.europa.eu/sites/default/files/SANTE_CRA_Mandate.pdf).
References
- Efron B and Tibshirani R, 1993. An Introduction to the Bootstrap. Chapman & Hall. [Google Scholar]
- EFSA (European Food Safety Authority), 2010. Guidance of EFSA on the standard sample description in food and feed. EFSA Journal 2010;8(1):1457, 54 pp. 10.2903/j.efsa.2010.1457 [DOI] [Google Scholar]
- EFSA (European Food Safety Authority), 2011. Guidance of EFSA on the use of the EFSA Comprehensive European Food Consumption Database in Intakes Assessment. EFSA Journal 2011;9(3):2097, 34 pp. 10.2903/j.efsa.2011.2097 [DOI] [Google Scholar]
- EFSA (European Food Safety Authority), 2013. Guidance of EFSA on the standard sample description ver. 2.0. EFSA Journal 2013;11(10):3424, 114 pp. 10.2903/j.efsa.2013.3424 [DOI] [Google Scholar]
- EFSA (European Food Safety Authority), 2015a. Scientific report on the pesticide monitoring program: design assessment. EFSA Journal 2015;13(2):4005, 52 pp. 10.2903/j.efsa.2015.4005 [DOI] [Google Scholar]
- EFSA (European Food Safety Authority), 2015b. The food classification and description system FoodEx2 (revision2). EFSA Supporting Publication 2015:EN‐804, 90 pp. 10.2903/sp.efsa.2015.en-804 [DOI]
- EFSA (European Food Safety Authority), 2016. The 2014 European Union report on pesticide residues in food. EFSA Journal 2016;14(10):4611, 139 pp. 10.2903/j.efsa.2016.4611 [DOI] [PMC free article] [PubMed] [Google Scholar]
- EFSA (European Food Safety Authority), 2017. The 2015 European Union report on pesticide residues in food. EFSA Journal 2017;15(4):4791, 134 pp. 10.2903/j.efsa.2017.4791 [DOI] [PMC free article] [PubMed] [Google Scholar]
- EFSA (European Food Safety Authority), 2018. The 2016 European Union report on pesticide residues in food. EFSA Journal 2018;16(7):5348, 139 pp. 10.2903/j.efsa.2018.5348 [DOI] [PMC free article] [PubMed] [Google Scholar]
- EFSA (European Food Safety Authority), 2019a. Scientific report on the establishment of cumulative assessment groups of pesticides for their effects on the thyroid. EFSA Journal 2019;17(9):5801, 61 pp. 10.2903/j.efsa.2019.5801 [DOI] [PMC free article] [PubMed] [Google Scholar]
- EFSA (European Food Safety Authority), 2019b. Scientific report on the cumulative dietary risk characterisation of pesticides that have chronic effects on the thyroid (draft submitted for public consultation on 17 September 2019). Available online: https://www.efsa.europa.eu/en/consultations/call/public-consultation-scientific-report-cumulative
- EFSA (European Food Safety Authority), 2019c. Harmonized terminology for scientific research [Data set]. Zenodo. 10.5281/zenodo.2554064 [DOI]
- EFSA (European Food Safety Authority), 2019d. Technical report on the raw primary commodity (RPC) model: strengthening EFSA's capacity to assess dietary exposure at different levels of the food chain, from raw primary commodities to foods as consumed. EFSA Supporting Publication 2019:EN‐1532, 30 pp. 10.2903/sp.efsa.2019.en-1532 [DOI]
- EFSA PPR Panel (European Food Safety Authority Panel on Plant Protection Products and their Residues), 2008. Scientific Opinion on the suitability of existing methodologies and, if appropriate, the identification of new approaches to assess cumulative and synergistic risks from pesticides to human health with a view to set MRLs for those pesticides in the frame of Regulation (EC) 396/2005. EFSA Journal 2008;6(5):704, 85 pp. 10.2903/j.efsa.2008.704 [DOI] [Google Scholar]
- EFSA PPR Panel (European Food Safety Authority Panel on Plant Protection Products and their Residues), 2009. Scientific Opinion on risk assessment for a selected group of pesticides from the triazole group to test possible methodologies to assess cumulative effects from exposure throughout food from these pesticides on human health. EFSA Journal 2009;7(9):1167, 104 pp. 10.2903/j.efsa.2009.1167 [DOI] [Google Scholar]
- EFSA PPR Panel (European Food Safety Authority Panel on Plant Protection Products and their Residues), 2012. Guidance on the use of probabilistic methodology for modelling dietary exposure to pesticide residues. EFSA Journal 2012;10(10):2839, 95 pp. 10.2903/j.efsa.2012.2839 [DOI] [Google Scholar]
- EFSA PPR Panel (European Food Safety Authority Panel on Plant Protection Products and their Residues), 2013a. Scientific Opinion on the identification of pesticides to be included in cumulative assessment groups on the basis of their toxicological profile. EFSA Journal 2013;11(7):3293, 131 pp. 10.2903/j.efsa.2013.3293 [DOI] [Google Scholar]
- EFSA PPR Panel (European Food Safety Authority Panel on Plant Protection Products and their Residues), 2013b. Scientific Opinion on relevance of dissimilar mode of action and its appropriate application for cumulative risk assessment of pesticides residues in food. EFSA Journal 2013;11(12):3472, 40 pp. 10.2903/j.efsa.2013.3472 [DOI] [Google Scholar]
- EFSA PPR Panel (European Food Safety Authority Panel on Plant Protection Products and their Residues), 2018. Scientific opinion on pesticides in foods for infants and young children. EFSA Journal 2018;16(6):5286, 75 pp. 10.2903/j.efsa.2016.5286 [DOI] [PMC free article] [PubMed] [Google Scholar]
- EFSA Scientific Committee , 2018. Scientific Opinion on the principles and methods behind EFSA's Guidance on Uncertainty Analysis in Scientific Assessment. EFSA Journal 2018;16(1):5122, 235 pp. 10.2903/j.efsa.2018.5122 [DOI] [PMC free article] [PubMed] [Google Scholar]
- European Commission , 2017. Appendix D. Guidelines on comparability, extrapolation, group tolerances and data requirements for setting MRLs. 7525/VI/95‐rev.10.3, June 2017.
- Huybrechts I, Sioen I, Boon PE, Ruprich J, Lafay L, Turrini A, Amiano P, Hirvonen T, De Neve M, Arcella D, Moschandreas J, Westerlund A, Ribas‐Barba L, Hilbig A, Papoutsou S, Christensen T, Oltarzewski M, Virtanen S, Rehurkova I, Azpiri M, Sette S, Kersting M, Walkiewicz A, Serra‐Majem L, Volatier J‐L, Trolle E, Tornaritis M, Busk L, Kafatos A, Fabiansson S, De Henauw S and Van Klaveren JD, 2011. Dietary exposure assessments for children in Europe (the EXPOCHI project): rationale, methods and design. Archives of Public Health, 69, 4 10.1186/0778-7367-69-4 [DOI] [PMC free article] [PubMed] [Google Scholar]
- van Klaveren JD, Kruisselbrink JW, de Boer WJ, van Donkersgoed G, te Biesebeek JD, Sam M and van der Voet H 2019. Cumulative dietary exposure assessment of pesticides that have chronic effects on the thyroid using MCRA software. EFSA supporting publication 2019:EN‐1707, 89 pp. 10.2903/sp.efsa.2019.en-1707 [DOI]
- Kruisselbrink JW, van der Voet H, van Donkersgoed G and van Klaveren J, 2018Proposal for a data model for probabilistic cumulative dietary exposure assessments of pesticides in line with the MCRA software. EFSA supporting publication 2018:EN‐1375, 35 pp. 10.2903/sp.efsa.2018.en-1375 [DOI]
- Merten C, Ferrari P, Bakker M, Boss A, Hearty A, Leclercq C, Lindtner O, Tlustos C, Verger P, Volatier JL and Arcella D, 2011. Methodological characteristics of the national dietary surveys carried out in the European Union as included in the European Food Safety Authority (EFSA) Comprehensive European Food Consumption Database. Food Additives and Contaminants: Part A, 28, 975–995. 10.1080/19440049.2011.576440. [DOI] [PubMed] [Google Scholar]
- Scholz R, van Donkersgoed G, Hermann M, Kittelmann A, von Schledorn M, Graven C, Mahieu K, van der Velde‐Koerts T, Anagnostopoulos C, Bempelou E and Michalski B, 2018. Database of processing techniques and processing factors compatible with the EFSA food classification and description system FoodEx 2. Objective 3: European database of processing factors for pesticides in food. EFSA supporting publication 2018:EN‐1510, 50 pp. 10.2903/sp.efsa.2018.en-1510 [DOI]
- van der Voet H, de Boer WJ, Kruisselbrink JW, van Donkersgoed G and van Klaveren J, 2016. MCRA made scalable for large cumulative assessment groups. EFSA supporting publication 2016:EN‐910, 38 pp. 10.2903/sp.efsa.2016.en-910 [DOI]