

Abstract
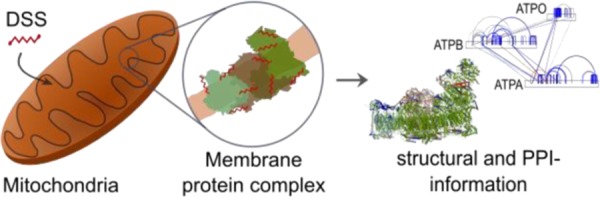
The field of structural biology is increasingly focusing on studying proteins in situ, i.e., in their greater biological context. Cross-linking mass spectrometry (CLMS) is contributing to this effort, typically through the use of mass spectrometry (MS)-cleavable cross-linkers. Here, we apply the popular noncleavable cross-linker disuccinimidyl suberate (DSS) to human mitochondria and identify 5518 distance restraints between protein residues. Each distance restraint on proteins or their interactions provides structural information within mitochondria. Comparing these restraints to protein data bank (PDB)-deposited structures and comparative models reveals novel protein conformations. Our data suggest, among others, substrates and protein flexibility of mitochondrial heat shock proteins. Through this study, we bring forward two central points for the progression of CLMS towards large-scale in situ structural biology: First, clustered conflicts of cross-link data reveal in situ protein conformation states in contrast to error-rich individual conflicts. Second, noncleavable cross-linkers are compatible with proteome-wide studies.
Keywords: cross-linking mass spectrometry, in situ large-scale structural biology, noncleavable DSS cross-linker, human mitochondria, comparative modeling
Introduction
Mitochondria are complex organelles that fulfill a wide set of essential cellular functions including energy metabolism in all eukaryotic cells.1 Damaged and dysfunctional mitochondria are implicated in several metabolic, cardiovascular, and neurological disorders and also cancer.1−5 To fully understand the molecular basis of mitochondrial physiology and its role in disease, it is essential to identify all of the relevant components and to reveal their structure and interactions. Human mitochondria have 1157 proteins currently annotated in MitoCarta 2.0;6 for fewer than 300 of these, we found structures deposited in the protein data bank (PDB), often only covering fragments of the proteins. Commonly used structural biological techniques usually require purification of proteins, which may compromise their structure, solubility, or stability.7−9 Ideally, structure elucidation is done in the protein’s native context. In situ techniques such as in-cell NMR,10−12 fluorescence microscopy,13,14 or cryo-electron tomography15,16 are developing quickly but still only target individual proteins or protein complexes of interest.
Cross-linking mass spectrometry (CLMS) is a technique that can provide in situ middle-resolution structural information for individual multiprotein complexes and can be scaled up to more complex samples such as entire organelles17 or bacterial cells.18−20 Distance restraints are generated by identifying which residues were cross-linked in a protein or between two interacting proteins and considering the length of the most extended conformation of the cross-linking reagent. Until recently, complex biological samples could only be tackled by the use of cross-linkers that cleave in the mass spectrometer19−23 or by the use of an isotope-labeled cross-linker, which create a special isotope pattern to aid in identifying cross-linked peptides.24,25 Two recent studies investigated murine mitochondria using MS-cleavable cross-linkers and reported 187622 and 277923 cross-linked residue pairs (excluding ambiguous cross-links, where one of the cross-linked peptides could have come from a number of proteins), respectively. These studies focused on the discovery of protein–protein interactions (PPIs) and partially on in situ protein structure analysis, while possible gains of systematic analysis of protein flexibility have been less explored.
Here, we use in situ CLMS to analyze protein structures in human mitochondria. Our cross-link-derived distance restraints combined with high-throughput comparative protein modeling reveal protein interactions and protein flexibility in their native environment. Due to the experimental error associated with single cross-links, we focus our analysis on systematic conflicts between structural models and our in situ distance restraints. This critically depends on data density, for which we designed a workflow around a standard cross-linker that combines sequential protein digestion,26 orthogonal peptide fractionation methods, and a decision-tree-based MS acquisition strategy.27 Importantly, our workflow demonstrates how the analysis of complex systems with non-MS-cleavable cross-linkers, including oxidative cross-linkers,28 photoactivatable amino acids,29,30 and photoactivatable cross-linkers,31,32 is now possible and the types of insights that such data add to our understanding of protein structures in situ.
Experimental Section
Reagents
Disuccinimidyl suberate (DSS) and trypsin were purchased from Thermo Scientific Pierce (Rockford, IL). The proteases GluC, chymotrypsin, and AspN were purchased from Promega (Madison, WI).
Cell Culture and Preparation of Human Mitochondria
K-562 cells (DSMZ, Cat# ACC-10) were grown at 37 °C under a humidified atmosphere containing 5% CO2 in Roswell Park Memorial Institute (RPMI) 1640 containing 10% fetal bovine serum. Four hundred million K-562 cells were collected by centrifugation and washed twice with phosphate-buffered saline (PBS). Cell lysis and mitochondria preparation were performed using a protocol adapted from Clayton and Shadel.33 Briefly, cell lysis was carried out in 5.5 mL of ice-cold RSB hypotonic buffer [10 mM N-(2-hydroxyethyl)piperazine-N′-ethanesulfonic acid (HEPES) pH 7.5, 10 mM NaCl, 1.5 mM MgCl2] using Dounce homogenization. Then, 4 mL of ice-cold 2.5× MS homogenization buffer [12.5 mM HEPES pH 7.5, 525 mM mannitol, 175 mM sucrose, 2.5 mM ethylenediaminetetraacetic acid (EDTA)] was added to obtain an isotonic solution. To clarify the cell lysate, it was centrifuged three times at 1300g (5 min, 4 °C). The mitochondria were pelleted by centrifugation at 12 360g (15 min, 4 °C) and washed once with 5 mL of ice-cold 1× MS homogenization buffer. The isolated mitochondria were resuspended in 20 mM sodium phosphate pH 8.0, and 150 mM NaCl. The protein concentration was estimated via the Bradford assay (BioRad). Aliquots of isolated mitochondria were frozen in liquid nitrogen and stored at −80 °C.
Cross-Linking Reaction, Tryptic In-Solution Digestion, and Peptide Purification
Isolated mitochondria were washed twice in ice-cold PBS and pelleted at 16 000g (5 min at 4 °C). Proteins (2 mg) were chemically cross-linked using 0.225 mM DSS in DMSO, which equals a protein-to-cross-linker ratio of 12:1 at a 1 mg/mL protein concentration in 2 × 1 mL in a 4 × 500 μL cross-linking reaction. Note that a DSS concentration optimization experiment was performed beforehand to find the proximate saturation point of the DSS-to-mitochondria ratio by sodium dodecyl sulfate-polyacrylamide gel electrophoresis (SDS-PAGE) and CLMS (for further details, see the supporting material, Figure S1). After 40 min incubation at 25 °C and gentle agitation, the cross-linking reaction was quenched by adding ammonium bicarbonate (ABC) to a final concentration of 50 mM (15 min at 25 °C). Samples were evaporated completely to minimize the volume for tryptic digestion. Cross-linked mitochondria (2 mg) were denatured using 6 M urea and 2 M thiourea in 50 mM ABC and reduced with 5 mM dithiothreitol (DTT) 20 min at 50 °C. To alkylate reduced disulfide bonds, 15 mM iodoacetamide (IAA) was added and incubated 30 min at 25 °C in the dark. After diluting with 50 mM ABC to a final concentration of 2 M urea/thiourea, trypsin was added at an enzyme-to-substrate ratio of 1:50 and incubated overnight at 37 °C with gentle agitation. The in-solution digestion was stopped by adding 10% (v/v) trifluoroacetic acid (TFA) until pH ≤ 2. Peptide desalting and purification were performed using Empore solid-phase extraction cartridges C-18-SD according to the manufacturer’s protocol. Afterward, the sample was divided in four portions of 500 μg tryptic peptides each.
Fractionation of Peptides by Strong Cation Exchange (SCX) Chromatography
The tryptic peptides were fractionated using strong cation exchange (SCX) chromatography (Figure 1A) as previously described.34 In our workflow, four aliquots of each 500 μg peptide were dried in a vacuum concentrator and resuspended in a 105 μL SCX buffer A [20 mM monopotassium phosphate pH 2.7, 30% (v/v) acetonitrile (ACN)]. Peptide samples (100 μL) were loaded onto a PolyLC PolySULFOETHYL A 100 × 2.1 mm2, 3 μm, 300 Å column operated by a Shimadzu high-performance liquid chromatography (HPLC) system. Peptides were fractionated by increasing the salt concentration [SCX buffer B: 20 mM monopotassium phosphate pH 2.7, 30% (v/v) ACN, 500 mM KCl] with the following settings: a constant flow rate of 0.2 mL/min, 0% B (0–5 min), 0–5% B (5–10 min), 5–20% B (10–14 min), 20–60% B (14–18 min), 60–70% B (18–21 min), and 70–100% B (21–25 min). Two minute fractions were collected, and seven selected fractions were partially pooled and evaporated completely, resulting in a total of five SCX fractions (14 + 15, 16, 17, 18, and 19 + 20 as that shown in Figure S2).
Figure 1.

Workflow, data density, and quality of cross-linking mass spectrometry analysis in human mitochondria. (A) Overview of cross-linking pipeline in human mitochondria. Sample preparation (upper panel): isolated mitochondria were cross-linked using the membrane-permeable cross-linker disuccinimidyl suberate (DSS). Proteins were digested with trypsin, and the resulting peptides were fractionated by strong cationic exchange (SCX) chromatography. Each fraction was then subjected to size exclusion chromatography (SEC), which enriches for cross-linked peptides in early fractions. SEC was conducted either directly or following an additional digestion step by either GluC, AspN, or chymotrypsin, which preferentially cleaves large peptides to enhance their detection during the subsequent mass spectrometric analysis.26,35 Data analysis (lower panel): the acquired tandem mass spectra (MS/MS) were searched against a sequence database using Xi.26 Cross-links were filtered to 5% false discovery rate (FDR) using xiFDR36 and used to analyze protein–protein interactions in xiNET37 and for protein structure modeling. (B) Majority of proteins detected with putative self-links are seen with multiple cross-links. Stress 70 protein (GRP75), malate dehydrogenase (MDHM), and 60 kDa heat shock protein (Hsp60) have more than 100 self-links. (C) Majority of protein pairs identified with cross-links are based on a single PPI-link. Protein–protein interactions between adenosine 5′-triphosphate (ATP) synthase subunits (ATPA, ATPB, ATPO) and prohibitin–prohibitin 2 (PHB–PHB2) are characterized by up to 20 unique PPI-links. (D) Localization of identified residue pairs of self-links within the human mitochondrion.
Sequential Digestion (SD) and Size Exclusion Chromatography (SEC)
Three of the four 500 μg peptide samples were sequentially digested using a second protease after SCX fractionation (Figure 1A) as previously described in Mendes et al.26 The protease amounts added were adjusted to the peptide content of each SCX fraction. The selected SCX fractions were resuspended in 50 μL of 50 mM ABC and digested using either GluC (1:50 protease-to-substrate ratio), chymotrypsin (1:50), or AspN (1:100). After overnight incubation (chymotrypsin at 25 °C, GluC and AspN at 37 °C), the protease digestion was stopped using 10% (v/v) TFA. Evaporated sequentially digested or tryptic digested samples were resuspended in a 40 μL SEC buffer [30% (v/v) ACN, 0.1% (v/v) TFA] and fractionated using SEC as previously described.38 In our workflow, peptides were fractionated using a Superdex Peptide 3.2/300 column (GE Healthcare) operated by a Shimadzu HPLC system at a flow rate of 0.05 mL/min in a 60 min isocratic gradient with SEC buffer. Two minute fractions were collected, and, depending on the sample amount, two up to six early eluting SEC fractions were selected (Figure S2). Due to the expectation that cross-linked peptides are overall larger than linear peptides, we selected only early SEC fractions for MS acquisitions. This entire workflow resulted in 88 different SCX–SD–SEC fractions, which were evaporated completely and resuspended in 4 μL of 0.1% (v/v) FA.
LC–MS/MS Acquisition
A total of 110 MS runs were analyzed as previously described27 using an UltiMate 3000 Nano LC system coupled to an Orbitrap Fusion Lumos Tribrid mass spectrometer (Thermo Fisher Scientific, San Jose). SCX–SD–SEC fractions with large sample amounts were injected as technical duplicates. Briefly, mobile phase A contained 0.1% (v/v) FA in water and mobile phase B contained 80% (v/v) ACN and 0.1% (v/v) FA in water. Fractionated peptides were injected onto a 500 mm C-18 EasySpray column (75 μm ID, 2 μm particles, 100 Å pore size) and separated using a constant flow rate of 250 nL/min. Depending on the sample amount per fraction, a linear gradient from 4 to 40% mobile phase B was employed for either 60 or 139 min for peptide elution. MS1 spectra were acquired at 120 000 resolution in the orbitrap with an AGC target of 2 × 105 ions and a maximum injection time of 50 ms. For fragmentation, precursor ions with charge states 3–8 and an intensity higher than 5 × 104 were isolated using an isolation window of 1.4 m/z (AGC target, 1–5 × 104; 60 ms max. injection time). Depending on the charge state and the m/z ratio, precursor ions were fragmented with energies based on the optimized data-dependent decision tree using HCD/EThcD fragmentation.27 MS2 spectra were recorded at 30 000 resolution in the orbitrap.
Identification and Validation of Cross-Linked Peptides
MS raw data were converted to mgf format using msconvert, including a peak filter for the 20 most abundant peaks per 100 m/z window for further data analysis (Figure 1A). Resulting peak files were analyzed by Xi (version 1.6.731),26 using the following settings: MS tolerance 6 ppm, MS2 tolerance 20 ppm, potential missing monoisotopic peaks 3,39 enzyme dependent on respective single or sequential digestion (trypsin or trypsin + AspN, trypsin + GluC, trypsin + chymotrypsin), fixed modification carbamidomethylation of cysteine, variable modification oxidation on methionine, losses −CH3SOH, −H2O, and −NH3, and cross-linker BS3 (mass equivalent in cross-linked state, mass modification 138.06807 Da) with variable cross-linker modifications (“BS3-NH2” 155.0946 Da, “BS3-OH” 156.0786 Da). The DSS cross-linker was assumed to react primarily with lysine residues, but also with serine, threonine, tyrosine, or the protein N-terminus. Besides, precursor ions were the corresponding b- and y-fragment ions searched for HCD fragmentation; for EThcD, b-, c-, y-, and z-fragment ions were considered. Obtained peptide spectra were matched to a database constructed either from the MitoCarta 2.0 database of annotated human mitochondrial proteins (1157 protein IDs;6Table S1B) or including the most abundant proteins in all cross-linked and SCX–SD–SEC fractionated samples (1118 protein IDs, Table S1B; see the expanded material of linear MaxQuant Search in Table S1A). To filter for high confidence data, a false discovery rate (FDR) of 5% on link level was applied to the identified cross-linked peptides using xiFDR.36 Note that unlike other FDR calculations, our xiFDR groups identified peptides into putative self- or PPI-links to avoid an accumulation of false positives for self-links. Cross-links within one protein were calculated using the following settings: prefilter cross-links only, five amino acids as minimum peptide length. Cross-links between two different proteins were analyzed with the following parameters: prefilter cross-links only, Δ score 0.5, minimum number of fragments per peptide five, with eight amino acids as minimum peptide length.
Mitochondrial Protein Localization
The known localizations of 915 mitochondrial proteins were assigned according to the MitoCarta and UniProt subcellular location information (see Table S1B). The remaining mitochondrial proteins from MitoCarta were annotated as “other mitochondrial localization”.
Cross-Link Assessment Using Models from PDB
We investigated cross-links by mapping the residue pairs to all available PDB structures. For cross-links within the same protein, we mapped the cross-links on available monomeric structures and, where applicable, also on homomultimeric structures. For some proteins, there are several PDB structures or comparative models available, in which we mapped our self-links to the shortest distance in any given structure. Then, for each cross-linked residue pair, we calculated the Euclidean distance between the Cα atoms within the PDB structures. We consider a cross-link in agreement with the PDB model if the Cα–Cα distance is smaller than or equal to 30 Å.40 If not, we consider a cross-link to be a long-distance link. We use the SIFTS database41 to map the canonical UniProt sequences in our search database to available PDB structures. Note that for a unique, canonical UniProt42 sequence, there might be multiple PDB structures available. In this case, we calculate the distances for all PDB structures and take the shortest, including homooligomeric interfaces.
Protein Structure Modeling
We performed comparative modeling on 363 proteins with an unknown structure. The modeling procedure consists of four steps: first, we generate a sequence profile of the target sequence by searching for homologous sequences with HHblits 3.0.0.43 Second, we used the profiles to search the PDB70 database from February 2017 using HHSearch.44 We accept a template for a given protein sequence, if the negative logarithm of the HHSearch had a p-value ≥6.5,45 which corresponds to the threshold for a remote structure. If all templates for a protein do not satisfy this criterion, we do not model the structure because no reliable templates can be identified by HHsearch. Third, we used MODELER 9.1246 to generate 50 comparative models for each protein. Fourth, we used PROSA47 to select the top-scoring comparative model for each protein. We used normal mode analysis (NMA) to model dynamics using the web-based elNémo software48,49 and ProDy.50 During modeling, we use the template quality as a proxy to measure the quality of the resulting comparative models. HHsearch found template hits for 654 proteins for which we also identified cross-links, 363 of which had no experimental structure in humans. Swiss-model51 was used for the modeling of the ATP synthase, as well as for the complex III of the oxidative phosphorylation (OXPHOS) complex.
Structure Visualization and Protein Docking
Structures were visualized with UCSF Chimera52 and PyMol Molecular Graphics System, version 2.0 Schrödinger, LLC. During highlighting cross-linked amino acids in the Hsp60 protein complex (Figure 3B,C), the cross-linked K551 was not present in the PDB structure; therefore, the neighboring amino acids were modeled using MODELLER.46 For protein docking, we used the HADDOCK web service with default parameters.53,54 Cross-links between domains were set as unambiguous distance restraints with an upper limit of 30 Å in docking calculations. Center-of-mass restraints was enabled. To account for the peptide sequence between the domains, we imposed an upper limit of 35 Å.
Figure 3.

Protein–protein interaction analysis by CLMS. (A) Interaction network in human mitochondria. White circles represent proteins for which PPI-links were identified, and lines illustrate these interactions. Thickness of line scales with the number of PPI-links for each interaction. Lines are dashed when only one cross-link was detected. Lines are colored according to interactions found in STRING or BioGrid database (black) or not (red). Additional blue lines indicate that this particular protein–protein interaction was also identified by Schweppe et al. and/or Liu et al. (Table S3). The most dense interaction network in human mitochondria was observed in the complexes of the oxidative phosphorylation, mitochondrial heat shock proteins, and prohibitin. OMM: outer mitochondrial membrane, IMS: intermembrane space, and IMM: inner mitochondrial membrane. (B, C) Cross-linked amino acids in the 60 kDa heat shock protein complex, chain A. Residues being highlighted in green are located in the substrate channel, at the inside of the Hsp60 barrel. For example, Y223 cross-links to GLPK and K387 connects to protein–tyrosine phosphatase mitochondrial 1 (PTPM1). Furthermore, cross-link sites localize to the interface of the two heptameric Hsp60 ring structures, including K87/89/551 (highlighted in green) and the K31/91 (highlighted in blue). These amino acids cross-link to MDHM or Hsp70 (see Table S6 for further information). Cross-linked residues at the outside of the barrel are colored in pink.
Results and Discussion
Cross-Linking of Human Mitochondria Using a Noncleavable Cross-Linker
Human mitochondria were cross-linked using the homobifunctional and membrane-permeable reagent DSS (Figure 1A). Following tryptic digestion, peptides were fractionated using SCX chromatography into five fractions with enrichment of cross-linked peptides in higher salt fractions24,55 (Figure S2). The individual fractions were then subjected to our novel sequential digestion protocol (see Experimental Section for details; Figure 1A).26 The second digestion step preferentially shortens large and thus difficult-to-observe peptides, due to the proteases having a reduced cleavage efficiency for shorter peptides.26,35 All fractions were then subjected to SEC to further enrich for cross-linked peptides (Figure S2B).26,38,35 Only early SEC fractions, those enriched for cross-linked peptides, were analyzed by LC–MS/MS using a data-dependent decision tree of optimized fragmentation energies for cross-linked peptides.27 The database of protein sequences for cross-link search was generated by combining the most abundant 1000 proteins (Table S1A) in our mitochondrial preparations with all proteins listed in MitoCarta (total proteins 1660; Table S1B).
In total, we identified 12 664 unique cross-linked peptide pairs (excluding ambiguous cross-links; Table S2A), which correspond to 5518 unique residue pairs in 792 proteins (5% link-level FDR36). The majority of the proteins and protein–protein contacts were identified by multiple residue pairs (Figure 1B,C). Of these, 5366 are putative self-links (molecular interactions controlled vocabulary ID: 0898, Table S2B; from here referred to as “self-links” for simplicity). Self-links fall either within one or between two copies of the same protein. Some proteins such as malate dehydrogenase (MDHM), mitochondrial stress 70 protein (GRP75), and 60 kDa heat shock protein (Hsp60) were covered by more than 100 residue pairs (Figure 1B), which suggests the presence of abundant structural information in our data at least for some proteins. Overall, 4034 self-links were mapped to 513 (44% of 1157) proteins of MitoCarta (Figure 1D). The majority of identified links were identified on mitochondrial matrix proteins consistent with the DSS cross-linker passing through both mitochondrial membranes (54%; Figure 1D), although we cannot exclude the presence of fractured or lysed mitochondria. Furthermore, we identified 1335 cross-links in 255 proteins that are not included in MitoCarta. According to UniProt, some of these proteins are localized in mitochondria. However, the majority of these proteins are assigned to cytosolic cellular functions or belong to the endoplasmic reticulum, which is connected to the mitochondria and likely constitute the background of our purification. Nevertheless, our human mitochondria preparation was highly enriched. As one would expect, we identified cross-links exclusively in the more abundant proteins (Figure S3), while cross-links between proteins displayed an even higher bias toward highly abundant proteins. This underpins the general challenge of detecting cross-linked peptides. This also supports our decoy-based FDR approach for error assessment as random false identifications should not show an abundance bias.
Despite our departure from non-MS-cleavable cross-linkers, we identified more cross-links than previous studies using MS-cleavable cross-linkers (Figure S5A). There is a set of possible contributing factors: we countered some of the disadvantages of standard cross-linkers by optimized data acquisition27 and breakdown of the combinatorial search space.56 In contrast to others, our study employed sequential digestions,26 which boost our number of identifications up to 65% by shortening the average peptide length from 33 amino acids for cross-linked tryptic peptides to 22–24 amino acids for cross-linked sequentially digested peptides (Figure S4A,B). However, tryptic data contributed 4481 peptide pairs (Figure S4C), which still compares favorably to previous analyses of mitochondria, which yielded in total 242722 and 2779 peptide pairs.23 Note that although N-hydroxysuccinimide esters preferably cross-link primary amines such as those found in lysine side chains, there is a known side reaction with the hydroxyl groups of S/T/Y residues.57,58 These cross-links were not considered in the previously published studies, but they contributed to 3066 cross-linked peptide pairs (33%) in our full dataset (Figure S4D,E). Moreover, monoisotopic peak correction during database search39 makes up to 40% peptide spectrum matches in our full dataset (Figure S4F). However, a direct comparison of all three studies is hampered by many parameters that differ between them, including sample origin, digestion method, fractionation methods, fractionation depths, acquisition method and time, data analysis software, and finally FDR estimation with various filter settings and grouping of PPI- and self-links.36
CLMS Data Reveals Conformations Adopted by Proteins in Situ
We compared our self-links against experimental structures deposited in the PDB or, where none were available, to comparative models based on structures from other species (see Experimental Section). Cross-links (2,215; 41.3% of 5,366) were mapped on 343 proteins with human PDB structures (green subset in Figure S6A,C and Table S4A) and furthermore 1290 cross-links on 256 proteins with comparative models (blue subset in Figure S6A,D and Table S5A). Focusing on monomeric PDB structures, 219 cross-links (9.9%; Figure S6B) surpassed a 30 Å Cα–Cα distance, an empiric upper boundary for DSS cross-linking that is also supported by molecular dynamics simulations.40 By considering known homomultimerization, this reduced to 129 long-distance self-links in PDB entries (5.8%; Figure S6B,C). Thus, considering homomultimeric states resolved conflicts for 90 links. At least 66 of the remaining 129 long-distance self-links in 47 PDB entries will be rationalized below in the context of conformation changes, further reducing the apparent conflict between our self-links and PDB data to below 3% (Figure S6B and Table S4B). Additionally, we identified 68 cross-links with zero sequence separation (Table S2B), which cannot stem from the same protein molecule. These self-links may indicate homomultimerization but may also be artifacts due to the noncovalent association of the peptides during mass spectrometric measurement59 and thus were excluded from our structural analyses.
We investigated clusters of long-distance links to see whether they may reveal novel structural states in situ. As mentioned, homomultimerization resolved long-distance links. Some of these were clustered, for example, in the case of the β subunit of the methylcrotonoyl-CoA carboxylase as part of the MCCC complex. Fifteen self-links match the monomeric structure, while three were in conflict with it (Figure S7A, left panel). Using the oligomeric orthologous from Pseudomonas aeruginosa (PDB 3U9S) as a template for modeling harmonized these conflicts (Figure S7A, right structure), consistent with a homooligomeric structure also of the human MCCC2 complex.
Furthermore, we found several cases of clustered conflicts, which indicate protein flexibility in situ. The mitochondrial elongation factor Tu had six long-distance links (out of 57 self-links), which connect from different parts of the protein to the β sheet domain (shown at the bottom in Figure S7B, left panel). A normal mode analysis of our comparative model suggests a domain movement toward the core structure (indicated with an arrow in Figure S7B, right panel) that reduces all long-distance links. We find analogous protein flexibility in the mitochondrial OXPHOS supercomplex (complex I1III2IV1), which is critical for ATP production in mitochondria. Overall, we see an excellent agreement with previous structural data (PDB 5XTH; Figure S7C), but 20 out of 196 distance restraints (10.2%) exceed 30 Å Cα–Cα distance. Seven long-distance links clustered in complex I, involving the proteins reduced nicotinamide adenine dinucleotide (NADH) dehydrogenase [ubiquinone] 1 α subcomplex subunit 7 (NDUA7) and NADH dehydrogenase [ubiquinone] iron–sulfur proteins 2 and 3 (NDUS2, NDUS3). Especially NDUA7 consists of extensive unstructured protein segments (Figure S7C), which contributes to protein flexibility in this region of complex I. Extending in situ structural analysis to another OXPHOS complex, we visualized distance restraints also in ATP synthase (complex V). In the absence of a human structure, we mapped human protein sequences into the bovine structure, which is available in different states of the ATP production cycle.60 Resulting models and cross-links were in excellent agreement (187 out of 199 fall below 30 Å; Figure S7D). Cross-links fell within each of the major extra membrane domains of the ATP synthase (rotor, peripheral stator, and α3β3 core subunit). The 12 distance restraints that exceed our 30 Å cutoff did not cluster and were thus not used to propose conformational changes.
The two structurally solved domains of Hsp70 (PDB 4KBO, 3N8E) covered 60 of the identified 134 self-links and could be arranged using the full-length model of the Escherichia coli orthologue (PDB 2KHO, gray structure in Figure 2A, upper panel). However, cross-link data disagreed with the resulting interface of both domains (highlighted in orange, Figure 2A) for which also in E. coli, some flexibility has been reported.61 Docking the domains using cross-link restraints in HADDOCK53,54 resolved many conflicting cross-links (Figure 2A, lower panel). This previously undescribed arrangement proposed by CLMS might occur during protein regulation. In fact, cross-linking also captured the regulatory mitochondrial GrpE protein homologue 162 in the substrate-binding domain of Hsp70 (Table S6). Our CLMS data therefore suggest that negative regulation by GrpE may require a dramatic dynamic process of both Hsp70 domains (as indicated by an arrow in Figure 2A, lower panel).
Figure 2.

In situ determined self-links contain structural information. (A) Full-length modeling of stress 70 protein. Positioning two human Hsp70 domain structures (PDBs 4KBO/4N8E shown in cyan in the upper structure) using the Hsp70 structure in E. coli (PDB 2KHO shown in gray) as a template. The majority of conflict restraints are at the domain interface, which are indicated in the structure. Docking with the CLMS restraints resolved most of the long-distance links at the interface and suggests an alternative domain arrangement of Hsp70 (lower structure, shown in yellow). Histograms show the length distribution of all distance restraints on these protein structures before and after docking. (B) In situ flexibility within the mitochondrial chaperonin complex. The PDB structure 4PJ1 (shown in gray) portrays the heptameric 60 and 10 kDa heat shock protein complexes. Identified cross-links were matched to a single ring structure at the shortest distance between the cross-linked residues. (C) Assessment of human cross-links in the context of an E. coli homologue. When mapping the human in situ CLMS distance restraints on GroEL (PDB 4AAQ), half of the conflicting restraints were resolved.
The most striking conflict with the established structures was observed for the 60 kDa heat shock protein (Hsp60). We identified 291 self-links, including 61 long-distance cross-links, almost all of which indicate a compression of the heptameric Hsp60 ring (PDB 4PJ1; Figure 2B). The orthologous chaperonin GroEL/GroES system in E. coli has flexible apical domains that can be attributed to the ability of chaperonin to bind different substrates or to the involvement of the apical domains in substrate unfolding processes.63−65 In comparison, the human chaperonin structure shows more intense asymmetric movements within the Hsp60 ring subunits, which were previously suggested not to be concerted.66 In contrast, our in situ CLMS data show clustered long-distance restraints with anchor points on the opposite side of the heptameric Hsp60 ring structure (Figure 2B). This indicates a compression-like movement of Hsp60 in situ (indicated with an arrow in Figure 2B). Therefore, we also mapped our distance restraints to the GroEL structure (PDB 4AAQ), which has a narrow structure (Figure 2C). This solved nearly half of the conflicting distance restraints. The remaining conflicts suggest an even higher degree of protein flexibility. Consequently, substrate binding and/or unfolding might require directed movements within the human chaperonin ring similar to but possibly exceeding those described for the ATP-dependent E. coli GroEL/GroES system.64,65
In Situ Protein–Protein Interactions Revealed by CLMS
In addition to self-links, we identified 152 protein–protein interaction links (PPI-links between two proteins; Table S2C). Our interaction network comprised 134 cross-links between mitochondrial proteins (Figure 3A). This included known interactors such as the respiratory chain complexes, ATP synthase, mitochondrial heat shock proteins, and prohibitin–prohibitin 2 interaction. We also identified 26 protein–protein interactions, which are not yet annotated for human mitochondria in STRING or BioGrid databases (highlighted red in Figure 3A). Some could be explained as possible substrates for mitochondrial heat shock proteins (see Hsp60 results described below). Others describe interactions between subunits of the respiratory chain complexes I, III, IV, and V (ATP synthase) like the interaction between NADH dehydrogenase [ubiquinone] 1 α subcomplex subunits 5 and 7 (NDUA5 and NDUA7), which lacked experimental evidence in humans so far but is known in putative homologues. Notably, multiple cross-links (Table S2C) support the interaction between ATPase family AAA domain-containing proteins 3A and 3B (ATD3A and ATD3B). Using loss- and gain-of-function approaches, Merle et al.67 showed that the association of ATD3B with the ubiquitous ATD3A protein negatively regulates the interaction of ATD3A with matrix nucleoid complexes and contributes to mitochondrial homeostasis and metabolism specific in embryonic stem cells. We here found evidence for these heterodimers also in mature K-562 cells.
We identified a much lower fraction of PPI-links (2.8% of all cross-links; Figure S5A) than the previous studies, Schweppe et al. (29%) and Liu et al. (64%). As a plausible contributing factor, we investigated different ways of FDR calculation employed by these studies. In contrast to Schweppe et al.22 and Liu et al.,23 we separate PPI- and self-links for FDR analysis, due to a large prior probability that self-links are correct.36 If we do not separate these for FDR estimation, we see a substantial increase in PPI-links (on our tryptic subset, 16% up from 3.3%; Figure S5B). Unfortunately, many of these additional PPI-links are likely false; we gain 53 PPI-links but also 22 PPI-link decoys, i.e., FDR 42%. Also, self-links decrease 3.4-fold, from 2620 to 767. The need for separating PPI- and self-links for FDR analysis is further supported by all three studies seeing the majority of self-links supported by multiple peptide pairs (Figure S5C). However, this is only the case for PPI-links if a separate FDR estimation is performed (Figure S5D). Taken together, this reveals a large dependency of PPI-links on the FDR method and suggests that the field needs to find a standardized and carefully tested agreement here.
Nevertheless, different mitochondrial study approaches can corroborate each other by independently identifying novel interactions. We compared protein–protein interactions identified in our study to orthologous interactions found in murine mitochondria by Schweppe et al.22 and Liu et al.23 Here, 8 out of 14 protein–protein interactions revealed by a single PPI-link (our least statistically confident protein pairs) in our data were also found in mouse (Table S3). For example, ATP synthase subunits α (ATPA) and d (ATP5H) were observed with multiple links in both mouse studies. Additionally, this approach also supported 6 (blue lines in Figure 3A and Table S3) out of 26 protein–protein interactions that were not reported for human mitochondria in STRING or BioGrid (red lines in Figure 3A).
The presence of an Hsp60 structure allowed a closer look at the 17 PPI-links involving Hsp60 and other proteins. Importantly, 5 out of the 11 Hsp60 residues were involved in these links located in the substrate channel at the inside of the Hsp60 ring structure, indicating that the proteins linked to those are likely substrates (Figure 3B and Table S6). This includes a kinase, the mitochondrial glycerol kinase (GLPK) and a phosphatase, mitochondrial phosphatidylglycerophosphatase, and protein–tyrosine phosphatase mitochondrial 1 (PTPM1). Previous studies have shown that the E. coli GroEL/GroES system folds a wide spectrum of proteins including certain kinases and phosphatases68,69 but chaperonin substrates in the human system remain mostly unknown.
Conclusions
In summary, these results support the use of CLMS as an in situ structural analysis method to gain new insights into multimerization and protein flexibility occurring in situ. Most of the proteome-wide CLMS studies to date focus on protein–protein interactions. We add a systematic view on clustered conflicts of long-distance cross-links within proteins. We show that large-scale CLMS, even by using a standard noncleavable cross-linker, generates sufficient data to start informing protein structure analysis across an entire cellular organelle. This workflow releases constraints for novel cross-linker designs and opens complex mixture CLMS to other cross-linker chemistries such as oxidative cross-linking or the use of photoactivatable cross-linkers and amino acids. By further maturation of proteome-wide CLMS analysis, there will be more over-length conflicts, which can be explained in a biological context. This will extend our structural knowledge in a unique way, being complementary to traditional structure elucidation methods.
Acknowledgments
The authors thank Andrea Graziadei for the technical support for protein modeling and helpful discussions. The authors thank Dr. Philipp Selenko for the opportunity of using the cell culture and lab equipment for mitochondria isolation at the FMP, Berlin. The authors thank Dr. Janine Kirstein for valuable discussion and comments on their data on heat shock proteins. Furthermore, the authors thank Drs. James E. Bruce and Juan Chavez for critically reading the manuscript. This work was supported by the Einstein Foundation, the DFG (RA 2365/4-1, SFB-740 1-5000019-01-TP), and the Wellcome Trust through a Senior Research Fellowship to J.R. (103139) and a multiuser equipment grant (108504). The Wellcome Centre for Cell Biology is supported by core funding from the Wellcome Trust (203149).
Supporting Information Available
The Supporting Information is available free of charge at https://pubs.acs.org/doi/10.1021/acs.jproteome.9b00541.
DSS concentration optimization experiment (Figure S1); coupled SCX and SEC fractionation of tryptic peptides (Figure S2); protein abundance of linear identifications in comparison to proteins with identified self- and PPI-links (Figure S3); detailed peptide pair analysis of our identified cross-links (Figure S4); comparison of three different CLMS mitochondria studies (Figure S5); assessment of PDB structures and comparative models using in situ CLMS data (Figure S6); in situ determined self-links containing structural information (Figure S7) (PDF)
MaxQuant search output table of cross-linked and fractionated mitochondria samples originated from all sequential digestion datasets (Table S1A); protein IDs of the most abundant proteins in cross-linked and fractionated sample and protein IDs of MitoCarta (Table S1B); list of all identified unique peptide pairs after 5% FDR calculation on link level (Table S2A); list of all identified putative self-cross-links after 5% FDR calculation on link level (Table S2B); list of all identified PPI-links after 5% FDR calculation on link level (Table S2C); auxiliary cross-link identifications in human and murine mitochondrial proteins (Table S3); self-links mapped on available human monomeric PDB structures (Table S4A); candidates with systematic mismatches within monomeric PDB models (Table S4B); self-links mapped on comparative models (Table S5A); candidates for systematic mismatches in comparative models (Table S5B); list of identified cross-links that indicate protein–protein interaction to human heat shock proteins like Hsp60 (Table S6) (XLSX)
Author Contributions
P.S.J.R. and J.R. developed the study; M.S. performed cell culture and mitochondria isolation; P.S.J.R. and L.B. performed sample preparation and chromatographic fractionation in cooperation with L.S.; P.S.J.R. and M.M.L.M. performed LC–MS analysis; P.S.J.R., M.B.-S., L.F., S.L., F.J.O., and J.R. performed data analysis; M.B.-S., S.L., and P.S.J.R. performed structural modeling; P.S.J.R., M.B.-S., F.J.O., and J.R. wrote the article with critical input from all authors.
The authors declare no competing financial interest.
Notes
The mass spectrometry proteomics data have been deposited to the ProteomeXchange Consortium via the PRIDE70 partner repository with the dataset identifier PXD014675. Other data supporting the findings of this study are available from the corresponding authors upon reasonable request.
Notes
§ M.B.-S. performed this work before joining Amazon.
Supplementary Material
References
- Duchen M. R. Mitochondria in health and disease: perspectives on a new mitochondrial biology. Mol. Aspects Med. 2004, 25, 365–451. 10.1016/j.mam.2004.03.001. [DOI] [PubMed] [Google Scholar]
- Cadonic C.; Sabbir M. G.; Albensi B. C. Mechanisms of Mitochondrial Dysfunction in Alzheimer’s disease. Mol. Neurobiol. 2016, 53, 6078–6090. 10.1007/s12035-015-9515-5. [DOI] [PubMed] [Google Scholar]
- Gorman G. S.; et al. Mitochondrial diseases. Nat. Rev. Dis. Primers 2016, 2, 16080. 10.1038/nrdp.2016.80. [DOI] [PubMed] [Google Scholar]
- Vyas S.; Zaganjor E.; Haigis M. C. Mitochondria and Cancer. Cell 2016, 166, 555–566. 10.1016/j.cell.2016.07.002. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Tahrir F. G.; Langford D.; Amini S.; Mohseni Ahooyi T.; Khalili K. Mitochondrial quality control in cardiac cells: Mechanisms and role in cardiac cell injury and disease. J. Cell. Physiol. 2019, 234, 8122–8133. 10.1002/jcp.27597. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Calvo S. E.; Clauser K. R.; Mootha V. K. MitoCarta2.0: an updated inventory of mammalian mitochondrial proteins. Nucleic Acids Res. 2016, 44, D1251–D1257. 10.1093/nar/gkv1003. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Acharya K. R.; Lloyd M. D. The advantages and limitations of protein crystal structures. Trends Pharmacol. Sci. 2005, 26, 10–14. 10.1016/j.tips.2004.10.011. [DOI] [PubMed] [Google Scholar]
- Wang H.-W.; Wang J.-W. How cryo-electron microscopy and X-ray crystallography complement each other. Protein Sci. 2017, 26, 32–39. 10.1002/pro.3022. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Carroni M.; Saibil H. R. Cryo electron microscopy to determine the structure of macromolecular complexes. Methods 2016, 95, 78–85. 10.1016/j.ymeth.2015.11.023. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Li H.; Sun H. In-cell NMR: an emerging approach for monitoring metal-related events in living cells. Metallomics 2014, 6, 69–76. 10.1039/C3MT00224A. [DOI] [PubMed] [Google Scholar]
- Freedberg D. I.; Selenko P. Live cell NMR. Annu. Rev. Biophys. 2014, 43, 171–192. 10.1146/annurev-biophys-051013-023136. [DOI] [PubMed] [Google Scholar]
- Rhodes C. J. Magnetic resonance spectroscopy. Sci. Prog. 2017, 100, 241–292. 10.3184/003685017X14993478654307. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Heintzmann R.; Huser T. Super-Resolution Structured Illumination Microscopy. Chem. Rev. 2017, 117, 13890–13908. 10.1021/acs.chemrev.7b00218. [DOI] [PubMed] [Google Scholar]
- Li W.; Geng C.; Liu B. Visualization of synaptic vesicle dynamics with fluorescence proteins. Folia Neuropathol. 2018, 56, 21–29. 10.5114/fn.2018.74656. [DOI] [PubMed] [Google Scholar]
- Wagner J.; Schaffer M.; Fernández-Busnadiego R. Cryo-electron tomography-the cell biology that came in from the cold. FEBS Lett. 2017, 591, 2520–2533. 10.1002/1873-3468.12757. [DOI] [PubMed] [Google Scholar]
- Koning R. I.; Koster A. J.; Sharp T. H. Advances in cryo-electron tomography for biology and medicine. Ann. Anat. 2018, 217, 82–96. 10.1016/j.aanat.2018.02.004. [DOI] [PubMed] [Google Scholar]
- O’Reilly F. J.; Rappsilber J. Cross-linking mass spectrometry: methods and applications in structural, molecular and systems biology. Nat. Struct. Mol. Biol. 2018, 25, 1000–1008. 10.1038/s41594-018-0147-0. [DOI] [PubMed] [Google Scholar]
- Zheng C.; et al. Cross-linking measurements of in vivo protein complex topologies. Mol. Cell. Proteomics 2011, 10, M110.006841 10.1074/mcp.M110.006841. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Weisbrod C. R.; et al. In vivo protein interaction network identified with a novel real-time cross-linked peptide identification strategy. J. Proteome Res. 2013, 12, 1569–1579. 10.1021/pr3011638. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Navare A. T.; et al. Probing the protein interaction network of Pseudomonas aeruginosa cells by chemical cross-linking mass spectrometry. Structure 2015, 23, 762–773. 10.1016/j.str.2015.01.022. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Chavez J. D.; Weisbrod C. R.; Zheng C.; Eng J. K.; Bruce J. E. Protein interactions, post-translational modifications and topologies in human cells. Mol. Cell. Proteomics 2013, 12, 1451–1467. 10.1074/mcp.M112.024497. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Schweppe D. K.; et al. Mitochondrial protein interactome elucidated by chemical cross-linking mass spectrometry. Proc. Natl. Acad. Sci. U.S.A. 2017, 1732. 10.1073/pnas.1617220114. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Liu F.; Lössl P.; Rabbitts B. M.; Balaban R. S.; Heck A. J. R. The interactome of intact mitochondria by cross-linking mass spectrometry provides evidence for coexisting respiratory supercomplexes. Mol. Cell. Proteomics 2018, 17, 216–232. 10.1074/mcp.RA117.000470. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Rinner O.; et al. Identification of cross-linked peptides from large sequence databases. Nat. Methods 2008, 5, 315–318. 10.1038/nmeth.1192. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Yang B.; et al. Identification of cross-linked peptides from complex samples. Nat. Methods 2012, 9, 904–906. 10.1038/nmeth.2099. [DOI] [PubMed] [Google Scholar]
- Mendes M. L.; et al. An integrated workflow for cross-linking/mass spectrometry. Mol. Syst. Biol. 2019, e8994 10.15252/msb.20198994. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Kolbowski L.; Mendes M. L.; Rappsilber J. Optimizing the Parameters Governing the Fragmentation of Cross-Linked Peptides in a Tribrid Mass Spectrometer. Anal. Chem. 2017, 89, 5311–5318. 10.1021/acs.analchem.6b04935. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Cline E. N.; et al. A novel crosslinking protocol stabilizes amyloid β oligomers capable of inducing Alzheimer’s-associated pathologies. J. Neurochem. 2019, 148, 822–836. 10.1111/jnc.14647. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Suchanek M.; Radzikowska A.; Thiele C. Photo-leucine and photo-methionine allow identification of protein-protein interactions in living cells. Nat. Methods 2005, 2, 261–267. 10.1038/nmeth752. [DOI] [PubMed] [Google Scholar]
- Lössl P.; et al. Analysis of nidogen-1/laminin γ1 interaction by cross-linking, mass spectrometry, and computational modeling reveals multiple binding modes. PLoS One 2014, 9, e112886 10.1371/journal.pone.0112886. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Belsom A.; Schneider M.; Fischer L.; Brock O.; Rappsilber J. Serum Albumin Domain Structures in Human Blood Serum by Mass Spectrometry and Computational Biology. Mol. Cell. Proteomics 2016, 15, 1105–1116. 10.1074/mcp.M115.048504. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Tanaka Y.; Bond M. R.; Kohler J. J. Photocrosslinkers illuminate interactions in living cells. Mol. Biosyst. 2008, 4, 473–480. 10.1039/b803218a. [DOI] [PubMed] [Google Scholar]
- Clayton D. A.; Shadel G. S. Isolation of mitochondria from cells and tissues. Cold Spring Harbor Protoc. 2014, 2014, db.top074542 10.1101/pdb.top074542. [DOI] [PubMed] [Google Scholar]
- Fritzsche R.; Ihling C. H.; Götze M.; Sinz A. Optimizing the enrichment of cross-linked products for mass spectrometric protein analysis. Rapid Commun. Mass Spectrom. 2012, 26, 653–658. 10.1002/rcm.6150. [DOI] [PubMed] [Google Scholar]
- Dau T.; Gupta K.; Berger I.; Rappsilber J. Sequential digestion with Trypsin and Elastase in cross-linking/mass spectrometry. Anal. Chem. 2019, 91, 4472–4478. 10.1021/acs.analchem.8b05222. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Fischer L.; Rappsilber J. Quirks of Error Estimation in Cross-Linking/Mass Spectrometry. Anal. Chem. 2017, 89, 3829–3833. 10.1021/acs.analchem.6b03745. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Combe C. W.; Fischer L.; Rappsilber J. xiNET: cross-link network maps with residue resolution. Mol. Cell. Proteomics 2015, 14, 1137–1147. 10.1074/mcp.O114.042259. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Leitner A.; Walzthoeni T.; Aebersold R. Lysine-specific chemical cross-linking of protein complexes and identification of cross-linking sites using LC-MS/MS and the xQuest/xProphet software pipeline. Nat. Protoc. 2014, 9, 120–137. 10.1038/nprot.2013.168. [DOI] [PubMed] [Google Scholar]
- Lenz S.; Giese S. H.; Fischer L.; Rappsilber J. In-Search Assignment of Monoisotopic Peaks Improves the Identification of Cross-Linked Peptides. J. Proteome Res. 2018, 17, 3923–3931. 10.1021/acs.jproteome.8b00600. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Merkley E. D.; et al. Distance restraints from crosslinking mass spectrometry: mining a molecular dynamics simulation database to evaluate lysine-lysine distances. Protein Sci. 2014, 23, 747–759. 10.1002/pro.2458. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Velankar S.; et al. SIFTS: Structure Integration with Function, Taxonomy and Sequences resource. Nucleic Acids Res. 2013, 41, D483–D489. 10.1093/nar/gks1258. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Poux S.; et al. On expert curation and scalability: UniProtKB/Swiss-Prot as a case study. Bioinformatics 2017, 33, 3454–3460. 10.1093/bioinformatics/btx439. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Remmert M.; Biegert A.; Hauser A.; Söding J. HHblits: lightning-fast iterative protein sequence searching by HMM-HMM alignment. Nat. Methods 2012, 9, 173–175. 10.1038/nmeth.1818. [DOI] [PubMed] [Google Scholar]
- Söding J. Protein homology detection by HMM-HMM comparison. Bioinformatics 2005, 21, 951–960. 10.1093/bioinformatics/bti125. [DOI] [PubMed] [Google Scholar]
- Kamisetty H.; Ovchinnikov S.; Baker D. Assessing the utility of coevolution-based residue-residue contact predictions in a sequence- and structure-rich era. Proc. Natl. Acad. Sci. 2013, 110, 15674–15679. 10.1073/pnas.1314045110. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Webb B.; Sali A. Protein Structure Modeling with MODELLER. Methods Mol. Biol. 2017, 39–54. 10.1007/978-1-4939-7231-9_4. [DOI] [PubMed] [Google Scholar]
- Sippl M. J. Recognition of errors in three-dimensional structures of proteins. Proteins: Struct., Funct., Genet. 1993, 17, 355–362. 10.1002/prot.340170404. [DOI] [PubMed] [Google Scholar]
- Suhre K.; Sanejouand Y.-H. ElNémo: a normal mode web server for protein movement analysis and the generation of templates for molecular replacement. Nucleic Acids Res. 2004, 32, W610–W614. 10.1093/nar/gkh368. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Suhre K.; Sanejouand Y. H. On the potential of normal-mode analysis for solving difficult molecular-replacement problems. Acta Crystallogr., Sect. D: Biol. Crystallogr. 2004, 60, 796–799. 10.1107/S0907444904001982. [DOI] [PubMed] [Google Scholar]
- Bakan A.; Meireles L. M.; Bahar I. ProDy: protein dynamics inferred from theory and experiments. Bioinformatics 2011, 27, 1575–1577. 10.1093/bioinformatics/btr168. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Waterhouse A.; et al. SWISS-MODEL: homology modelling of protein structures and complexes. Nucleic Acids Res. 2018, 46, W296–W303. 10.1093/nar/gky427. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Pettersen E. F.; Goddard T. D.; Huang C. C.; et al. UCSF Chimera—a visualization system for exploratory research and analysis. J. Comput. Chem. 2004, 25, 1605–1612. 10.1002/jcc.20084. [DOI] [PubMed] [Google Scholar]
- Dominguez C.; Boelens R.; Bonvin A. M. J. J. HADDOCK: a protein-protein docking approach based on biochemical or biophysical information. J. Am. Chem. Soc. 2003, 125, 1731–1737. 10.1021/ja026939x. [DOI] [PubMed] [Google Scholar]
- van Zundert G. C. P.; et al. The HADDOCK2.2 Web Server: User-Friendly Integrative Modeling of Biomolecular Complexes. J. Mol. Biol. 2016, 428, 720–725. 10.1016/j.jmb.2015.09.014. [DOI] [PubMed] [Google Scholar]
- Chen Z. A.; et al. Architecture of the RNA polymerase II–TFIIF complex revealed by cross-linking and mass spectrometry. EMBO J. 2010, 29, 717–726. 10.1038/emboj.2009.401. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Giese S. H.; Fischer L.; Rappsilber J. A Study into the Collision-induced Dissociation (CID) Behavior of Cross-Linked Peptides. Mol. Cell. Proteomics 2016, 15, 1094–1104. 10.1074/mcp.M115.049296. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Chen F.; Nielsen S.; Zenobi R. Understanding chemical reactivity for homo- and heterobifunctional protein cross-linking agents. J. Mass Spectrom. 2013, 48, 807–812. 10.1002/jms.3224. [DOI] [PubMed] [Google Scholar]
- Müller M. Q.; Dreiocker F.; Ihling C. H.; Schäfer M.; Sinz A. Fragmentation behavior of a thiourea-based reagent for protein structure analysis by collision-induced dissociative chemical cross-linking. J. Mass Spectrom. 2010, 45, 880–891. 10.1002/jms.1775. [DOI] [PubMed] [Google Scholar]
- Giese S. H.; Belsom A.; Sinn L.; Fischer L.; Rappsilber J. Noncovalently Associated Peptides Observed during Liquid Chromatography-Mass Spectrometry and Their Effect on Cross-Link Analyses. Anal. Chem. 2019, 91, 2678–2685. 10.1021/acs.analchem.8b04037. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Zhou A.; et al. Structure and conformational states of the bovine mitochondrial ATP synthase by cryo-EM. eLife 2015, 4, e10180 10.7554/eLife.10180. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Bertelsen E. B.; Chang L.; Gestwicki J. E.; Zuiderweg E. R. P. Solution conformation of wild-type E. coli Hsp70 (DnaK) chaperone complexed with ADP and substrate. Proc. Natl. Acad. Sci. U.S.A. 2009, 106, 8471–8476. 10.1073/pnas.0903503106. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Choglay A. A.; Paul Chapple J.; Blatch G. L.; Cheetham M. E. Identification and characterization of a human mitochondrial homologue of the bacterial co-chaperone GrpE. Gene 2001, 267, 125–134. 10.1016/S0378-1119(01)00396-1. [DOI] [PubMed] [Google Scholar]
- Braig K.; Adams P. D.; Brünger A. T. Conformational variability in the refined structure of the chaperonin GroEL at 2.8 Å resolution. Nat. Struct. Mol. Biol. 1995, 2, 1083. 10.1038/nsb1295-1083. [DOI] [PubMed] [Google Scholar]
- Wang J.; Boisvert D. C. Structural basis for GroEL-assisted protein folding from the crystal structure of (GroEL-KMgATP)14 at 2.0A resolution. J. Mol. Biol. 2003, 327, 843–855. 10.1016/S0022-2836(03)00184-0. [DOI] [PubMed] [Google Scholar]
- Clare D. K.; et al. ATP-Triggered Conformational Changes Delineate Substrate-Binding and -Folding Mechanics of the GroEL Chaperonin. Cell 2012, 149, 113–123. 10.1016/j.cell.2012.02.047. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Nisemblat S.; Yaniv O.; Parnas A.; Frolow F.; Azem A. Crystal structure of the human mitochondrial chaperonin symmetrical football complex. Proc. Natl. Acad. Sci. U.S.A. 2015, 112, 6044–6049. 10.1073/pnas.1411718112. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Merle N.; et al. ATAD3B is a human embryonic stem cell specific mitochondrial protein, re-expressed in cancer cells, that functions as dominant negative for the ubiquitous ATAD3A. Mitochondrion 2012, 12, 441–448. 10.1016/j.mito.2012.05.005. [DOI] [PubMed] [Google Scholar]
- Houry W. A.; Frishman D.; Eckerskorn C.; Lottspeich F.; Hartl F. U. Identification of in vivo substrates of the chaperonin GroEL. Nature 1999, 402, 147–154. 10.1038/45977. [DOI] [PubMed] [Google Scholar]
- Kerner M. J.; et al. Proteome-wide analysis of chaperonin-dependent protein folding in Escherichia coli. Cell 2005, 122, 209–220. 10.1016/j.cell.2005.05.028. [DOI] [PubMed] [Google Scholar]
- Perez-Riverol Y.; et al. The PRIDE database and related tools and resources in 2019: improving support for quantification data. Nucleic Acids Res. 2019, 47, D442–D450. 10.1093/nar/gky1106. [DOI] [PMC free article] [PubMed] [Google Scholar]
Associated Data
This section collects any data citations, data availability statements, or supplementary materials included in this article.