

Abstract
Background
Sentiment analysis (SA) is a subfield of natural language processing whose aim is to automatically classify the sentiment expressed in a free text. It has found practical applications across a wide range of societal contexts including marketing, economy, and politics. This review focuses specifically on applications related to health, which is defined as “a state of complete physical, mental, and social well-being and not merely the absence of disease or infirmity.”
Objective
This study aimed to establish the state of the art in SA related to health and well-being by conducting a systematic review of the recent literature. To capture the perspective of those individuals whose health and well-being are affected, we focused specifically on spontaneously generated content and not necessarily that of health care professionals.
Methods
Our methodology is based on the guidelines for performing systematic reviews. In January 2019, we used PubMed, a multifaceted interface, to perform a literature search against MEDLINE. We identified a total of 86 relevant studies and extracted data about the datasets analyzed, discourse topics, data creators, downstream applications, algorithms used, and their evaluation.
Results
The majority of data were collected from social networking and Web-based retailing platforms. The primary purpose of online conversations is to exchange information and provide social support online. These communities tend to form around health conditions with high severity and chronicity rates. Different treatments and services discussed include medications, vaccination, surgery, orthodontic services, individual physicians, and health care services in general. We identified 5 roles with respect to health and well-being among the authors of the types of spontaneously generated narratives considered in this review: a sufferer, an addict, a patient, a carer, and a suicide victim. Out of 86 studies considered, only 4 reported the demographic characteristics. A wide range of methods were used to perform SA. Most common choices included support vector machines, naïve Bayesian learning, decision trees, logistic regression, and adaptive boosting. In contrast with general trends in SA research, only 1 study used deep learning. The performance lags behind the state of the art achieved in other domains when measured by F-score, which was found to be below 60% on average. In the context of SA, the domain of health and well-being was found to be resource poor: few domain-specific corpora and lexica are shared publicly for research purposes.
Conclusions
SA results in the area of health and well-being lag behind those in other domains. It is yet unclear if this is because of the intrinsic differences between the domains and their respective sublanguages, the size of training datasets, the lack of domain-specific sentiment lexica, or the choice of algorithms.
Keywords: sentiment analysis, natural language processing, text mining, machine learning
Introduction
Sentiment analysis (SA), also known as opinion mining, is a subfield of natural language processing (NLP) whose aim is to automatically classify the sentiment expressed in a free text. Its origins can be traced to the 1990s including methods for classifying the point of view [1], predicting the semantic orientation of adjectives [2], subjectivity classification [3], etc. However, its rapid growth is correlated with the advent of Web 2.0 and the increasing availability of user-generated data such as product and service reviews as well as the proliferation of social media communication channels.
SA has found practical applications across a wide range of societal contexts including marketing, economy, and politics [4-8]. This review focuses specifically on applications related to health, which is defined as “a state of complete physical, mental, and social well-being and not merely the absence of disease or infirmity” [9]. The well-being itself is considered to be a perceived or subjective state, that is, it can vary considerably across individuals with similar circumstances [10]. This makes well-being an ideal case study for SA. However, when it comes to matters of health, modern society tends to be preoccupied with the negative phenomena such as diseases, injuries, and disabilities [11], which makes SA in this domain challenging. For instance, for a patient with a chronic condition, having a good quality of life will not necessarily depend on the absence of associated symptoms, but rather on the extent to which they are managed and controlled. However, the negative connotation of health symptoms tends to skew the SA results toward the negative spectrum.
To establish the state of the art in SA related to health and well-being, we conducted a systematic review of the recent literature. To capture the perspective of those individuals whose health and well-being are affected, we focused specifically on spontaneously generated content and not necessarily that of health care professionals. This differentiates this review from others conducted on related topics. For example, Denecke and Deng [12] reviewed SA in medical settings, but focused on the word usage and sentiment distribution of clinical data, such as nurse letters, radiology reports, and discharge summaries, while public data shared by the likes of patients and caregivers were restricted to 2 websites. On the contrary, Gohil et al [13] dealt with user-generated data, but only considered Twitter, whereas we posed no restrictions on the platforms used to generate the data.
The remainder of the paper is organized as follows. The Methods explains the methodology of this systematic review in detail. Results presents the findings of the review, followed by a discussion. The final section summarizes the main findings of the review.
Methods
Guidelines
Our methodology is based on the guidelines for performing systematic reviews described by Kitchenham [14]. It is structured around the following steps:
Research questions define the scope, depth, and the overall aim of the review.
Search strategy is an organized process designed to identify all studies that are relevant to the research questions in an efficient and reproducible manner.
Inclusion and exclusion criteria define the scope of a systematic review.
Quality assessment refers to a critical appraisal of included studies to ensure that the findings of the review are valid.
Data extraction is the process of identifying the relevant information from the included studies.
Data synthesis involves critical appraisal and synthesis of evidence to support the findings of the review.
Research Questions
The overarching topic of this review is the SA of spontaneously generated narratives in relation to health and well-being. The main aim of this review was to answer the research questions given in Table 1.
Table 1.
Research questions.
| ID | Question |
| RQ1 | What are the major sources of data? |
| RQ2 | What is the originally intended purpose of spontaneously generated narratives? |
| RQ3 | What are the roles of their authors within health and care? |
| RQ4 | What are their demographic characteristics? |
| RQ5 | What areas of health and well-being are discussed? |
| RQ6 | What are the practical applications of SAa? |
| RQ7 | What methods have been used to perform SA? |
| RQ8 | What is the state-of-the-art performance of SA? |
| RQ9 | What resources are available to support SA related to health and well-being? |
aSA: sentiment analysis.
Search Strategy
To systematically identify articles relevant to SA related to health and well-being, we first considered relevant data sources: the Cochrane Library [15], MEDLINE [16], EMBASE [17], and CINAHL [18]. MEDLINE was chosen as the most diverse data source with respect to the topics covered and publication types. MEDLINE is a premier bibliographic database that contains more than 29 million references to articles in life sciences and biomedicine. Its coverage dates back to 1946, and its content is updated daily. It covers publications of various types, for example, journal articles, case reports, conference papers, letters, comments, guidelines, and clinical trials. Its content is systematically indexed by Medical Subject Headings (MeSH), a hierarchically organized terminology for cataloging biomedical information, to facilitate identification of relevant articles. For example, it defines the term natural language processing as “computer processing of a language with rules that reflect and describe current usage rather than prescribed usage.” Therefore, this term can be used to identify articles on this topic even when they use alternative terminology, for example, “sentiment analysis,” “information retrieval,” and “text mining.” We used PubMed, a multifaceted interface, to search MEDLINE.
Having chosen MEDLINE as the primary source of information, the next step in developing our search strategy was to define a search query that adequately describes the chosen topic—SA related to health and well-being. Given the MEDLINE’s focus on biomedicine, inclusion of terms related to health and well-being was considered redundant. Specifically, they could improve the precision of the search (ie, reduce the number of irrelevant articles retrieved), but could only decrease the recall (the number of relevant articles retrieved). Given the relative recency of research into SA and its applications in biomedicine, we expected a query focusing solely on SA to retrieve a manageable number of articles, which could then be reviewed manually. The search query was defined as follows:
((sentiment[Title] OR sentiments[Title] OR opinion[Title] OR opinions[Title] OR emotion[Title] OR emotions[Title] OR emotive[Title] OR affect[Title] OR affects[Title] OR affective[Title]) AND (“sentiment classification” OR “opinion mining” OR “natural language processing” OR NLP OR “text analytics” OR “text mining” OR “F-measure” OR “emotion classification”)) OR “sentiment analysis”
The search performed on January 24, 2019, retrieved a total of 299 articles. Notably, no articles published before 2011 were retrieved, which confirmed our hypothesis about the relative recency of research into SA and its applications in biomedicine.
Selection Criteria
To further refine the scope of this systematic review, we defined a set of inclusion and exclusion criteria (see Tables 2 and 3) to select the most appropriate articles from those matching the search query.
Table 2.
Inclusion criteria.
| ID | Criterion |
| IN1 | The input text represents spontaneously generated narrative. |
| IN2 | The input text discusses topics related to health and well-being. |
| IN3 | The input text captures the perspective of an individual personally affected by issues related to health and well-being (eg, patient or carer) rather than that of a health care professional. |
| IN4 | Sentiment is analyzed automatically using natural language processing. |
Table 3.
Exclusion criteria.
| ID | Criterion |
| EX1 | Sentiment analysis is performed in a language other than English. |
| EX2 | The article is written in a language other than English. |
| EX3 | The article is not peer reviewed. |
| EX4 | The article does not describe an original study. |
| EX5 | The article is published before January 1, 2000. |
| EX6 | The full text of the article is not freely available to academic community. |
Two annotators independently screened the retrieved articles against inclusion and exclusion criteria and achieved the interannotator agreement of 0.51 calculated using Cohen kappa coefficient [19]. Disagreements were resolved by the third independent annotator. A total of 95 articles were retained for further processing.
To ensure the rigorousness and credibility of selected studies, they were additionally evaluated against the quality assessment criteria defined in Table 4. A total of 9 studies were found not to match the given criteria. This further reduced the number of selected articles to 86. Figure 1 summarizes the outcomes of the 4 major stages in the systematic literature review.
Table 4.
Quality assessment criteria.
| ID | Criterion |
| QA1 | Are the aims of the research clearly defined? |
| QA2 | Is the study methodologically sound? |
| QA3 | Is the method explained in sufficient detail to reproduce the results? |
| QA4 | Were the results evaluated systematically? |
Figure 1.
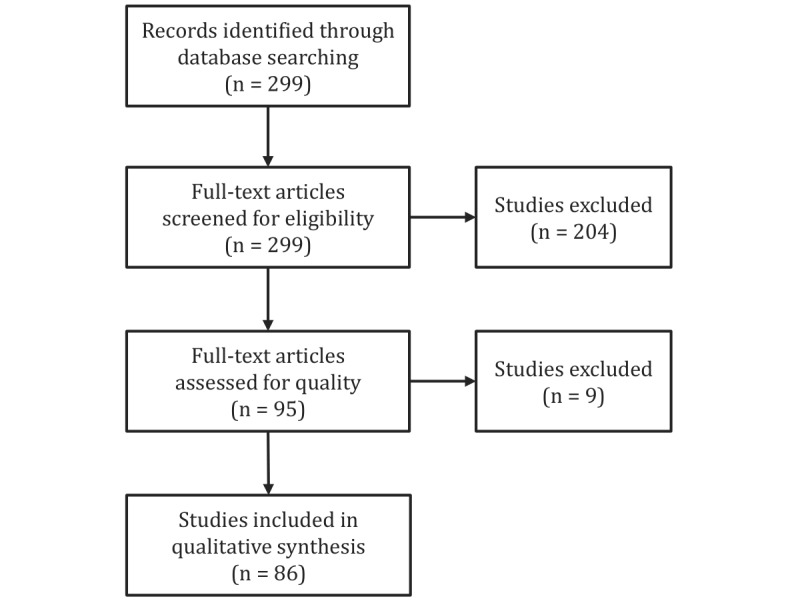
Flow diagram of the literature review process.
Data Extraction and Synthesis
Data extraction cards were designed to aid the collection of information relevant to the research questions. They included items described in Table 5. The selected articles were read in full to populate the data extraction cards, which were then used to facilitate narrative synthesis of the main findings.
Table 5.
Data extraction framework.
| Item | Description |
| Data | Provenance, purpose, selection criteria, size, and use. |
| Topic | General topic discussed in the given dataset including medical conditions and treatments. |
| Author | Author (data creator) demographics and their role in health care. |
| Application | Downstream application of SAa results. |
| Method | Type of SA method used, feature selection/extraction, and any resources used to support implementation of the method. |
| Evaluation | Measures used to evaluate the results, specific results reported, baseline method used, and improvements over the baseline (if any). |
aSA: Sentiment analysis.
Results
Data Provenance
This section discusses the main properties of data used as input for SA in relation to research questions RQ1 and RQ2. The majority of data were collected from the mainstream social multimedia and Web-based retailing platforms, which provide the most pervasive user base together with application programming interfaces (APIs) that can support large-scale data collection. Not surprisingly, 26 studies [20-45] used data sourced from Twitter, a social networking service on which users post messages restricted to 280 characters (previously 140). Twitter can be accessed via its API from a range of popular programming languages using libraries such as TwitterR [22], Twitter4J in Java [29,41], and Tweepy in Python [45].
Facebook, another social networking service, was used to collect user posts regarding Chron's disease [46] and depression and anxiety [47]. Comments posted on Instagram, a photo and video-sharing social networking service, were used to predict depression [48]. A total of 2 studies used data from YouTube, a video-sharing website, which allows users to share videos and comment on them. These studies collected comments on videos related to proanorexia [49] and Invisalign experience [50]. Reddit, a social news aggregation, Web content rating, and discussion website, was used to learn to differentiate between suicidal and nonsuicidal comments [51]. Amazon, a Web-based retailer, allows users to submit reviews of products. Customers may comment or vote on the reviews, much in the spirit of social networking websites. Amazon is the largest single source of consumer reviews on the internet. Amazon reviews were collected from the section of joint and muscle pain relief treatments [52].
Mainstream social media provide a generic platform to engage patients. One of their advantages in this context is that many patients are already active users of these platforms, thus effectively lowering barrier to entry to engaging patients online. However, the use of social media in the context of disclosing protected health information may raise ethical issues such as those related to confidence and privacy. The need to engage patients online while fully complying with data protection regulations has led to the proliferation of websites and networks developed specifically to provide a safe space for sharing health-related information online. This systematic review identified 10 platforms of this kind that have been utilized in 21 studies (see Table 6 for details).
Table 6.
Health-related websites and networks.
| Website | Description | Used in |
| RateMDs [55] | Allows users to post reviews about health care staff and services. | [56-58] |
| WebMD [59] | Publishes content about health and care topics, including fora that allow users to create or participate in support groups and discussions. | [23,60,61] |
| Ask a Patient [62] | Allows users to share their personal experience about drug treatments. | [61,63] |
| DrugLib.com [64] | Allows users to rate and review prescription drugs. | [23,61,63,65] |
| Breastcancer.org [66] | A breast cancer community of 218,615 members in 81 fora discussing 154,832 topics. | [67,68] |
| MedHelp [69] | Allows users to share their personal experiences and evidence-based information across 298 topics related to health and well-being. | [21,53,54,70,71] |
| DailyStrength [72] | A social networking service that allows users to create support groups across 34 categories related to health and well-being. | [23,27] |
| Cancer Survivors Network [73] | A social networking service that connects users whose lives have been affected by cancer and allows them to share personal experience and expressions of caring. | [74-76] |
| NHS website [77] (formerly NHS Choices) | The primary public facing website of the United Kingdom’s National Health Service (NHS) with more than 43 million visits per month. It provides health-related information and allows patients to provide feedback on services. | [78] |
| DiabetesDaily [79] | A social networking service that connects people affected by diabetes where they can trade advice and learn more about the condition. | [80] |
Due to ethical concerns, the data used in these studies are usually not released publicly to support further research and evaluation. Only one such dataset has been published. The eDiseases dataset used in 2 studies [53,54] contains patient data from the MedHelp website (see Table 6). The dataset contains 10 conversations from 3 patient communities, allergies, Crohn disease, and breast cancer, which according to a medical expert, exhibit high degree of heterogeneity with respect to health literacy and demographics. The conversations were selected randomly out of those that contained at least 10 user posts. Individual sentences were annotated with respect to their factuality (opinion, fact, or experience) and polarity (positive, negative, or neutral). Annotation was performed by 3 frequent users of health forums. With approximately 3000 annotated sentences with high degree of heterogeneity, this dataset represents a suitable testbed for evaluating SA in the health domain.
As illustrated by the studies discussed thus far, spontaneously generated narrative used in SA typically coincides with the user-generated content, that is, content created by a user of an online platform and made publicly available to other users. The fifth i2b2/VA/Cincinnati challenge in NLP for clinical data [81] represents an important milestone in SA research related to health and well-being. The challenge focused on the task of classifying emotions from suicide notes. The corpus used for this shared task contained 1319 written notes left behind by people who died by suicide. Individual sentences were annotated with the following labels: abuse, anger, blame, fear, guilt, hopelessness, sorrow, forgiveness, happiness, peacefulness, hopefulness, love, pride, thankfulness, instructions, and information. A total of 24 teams used these data to develop their classification systems and evaluate their performance, out of which 19 teams published their results [82-100].
As discussed above, the vast majority of data used in studies encompassed by this review represent user-generated content originating from online platforms. We can differentiate between 2 main types of user-generated content: customer reviews and user comments. A customer review is a review of a product or service made by someone who purchased, used, or had experience with the product or service. The main class of products reviewed in the datasets considered here are medicinal products. Product reviews were collected from Amazon, but also from specialized websites such as Ask a Patient and DrugLib.com. These reviews provide users with additional information about a product’s efficacy and possible side effects typically described in layman’s terms, thus lowering a barrier to participation in health care linked to health literacy and potentially providing better support for shared decision making. Other websites such as RateMDs and the National Health Service (NHS) website allow users to review health care services they received including health care professionals who provide such services. Service reviews can be used by health care providers to identify opportunities to improve the quality of care.
Web 2.0 gave rise to the publishing of one’s own content and commenting on other user’s content on online platforms that provide social networking services. On mainstream social media such as Twitter, Facebook, Instagram, YouTube, and Reddit, patients can organize their fora around groups, hashtags, or influencer users. The primary purpose of these conversations is to exchange information and provide social support online. More specialized websites such as those described in Table 6 serve the same purpose. Spontaneous narratives published on these media represent a valuable source for identifying patients’ needs, especially the unmet ones.
Data Authors
This section discusses the characteristics of those who authored the types of narratives discussed in the previous section. We first discuss their roles within health and care in relation to research questions RQ3 followed by their demographic characteristics in relation to question RQ4.
We have identified 5 roles with respect to health and well-being among the authors of the types of spontaneously generated narratives considered in this review: sufferer, addict, patient, carer, and suicide victim (see Table 7). Some of these roles may overlap, for example, a sufferer or an addict can also be a patient if they are receiving a medical treatment for their medical condition.
Table 7.
The roles of authors with respect to health and well-being.
| Role | Description | Studies |
| Sufferer | A person who is affected by a medical condition. | [21,23,27,46,53,54,60,61,63,65,67,68,70,71,74-76,101,102] |
| Addict | A person who is addicted to a particular substance. | [26,103-106] |
| Patient | A person receiving or registered to receive medical treatment. | [21,23,27,46,50,53,54,56-58,60,61,63,65,67,68,70,71,74-76,78,80,102,107,108] |
| Carer | A family member or friend who regularly looks after a sick or disabled person. | [23,56-58,60,61,74-76] |
| Suicide victim | A person who has committed suicide. | [51,82-100] |
Demographic factors refer to socioeconomic characteristics such as age, gender, education level, income level, marital status, occupation, and religion. Most studies involving clinical data summarize the demographics of study participants statistically to illustrate the extent to which its findings can be generalized. Our focus on spontaneously generated narratives implies that the corresponding studies could not mandate the collection of demographic factors. Instead, they can only rely on information provided by users in good faith. Different Web platforms may record different demographic factors, which may or may not be accessible to third parties. Nonmandatory user information will typically give rise to missing values. Moreover, demographic information is difficult to verify online, which raises the concerns over the validity of such information even when it is publicly available.
Table 8 states which demographic factors, if any, are recorded when a user registers an account on the given online services and which ones are accessible online. Only age and gender are routinely collected, but not necessarily shared publicly. Therefore, it should be noted when SA is used to analyze such data to address a clinical question, then the findings should be interpreted with caution as it may not be possible to generalize them across the relevant patient population. Out of 86 studies considered in this review, only 4 reported the demographics factors, [49,67,101,103]. Age was discussed in 3 studies [67,101,103], whereas gender was analyzed in 2 studies [49,103].
Table 8.
Recording and accessing demographic factors.
| Platform | Age | Gender | Education level | Income level | Marital status | Occupation | Religion | Used in |
| ?a/Ub | ?/Nc | Xd/N | X/N | X/N | X/N | X/N | [20-45] | |
| Me/U | M/U | ?/U | X/N | ?/U | ?/U | ?/U | [46,47] | |
| M/U | M/U | X/N | X/N | X/N | X/N | X/N | [48] | |
| YouTube | M/U | ?/U | X/N | X/N | X/N | X/N | X/N | [49,50] |
| X/N | X/N | X/N | X/N | X/N | X/N | X/N | [51] | |
| Amazon | X/N | X/N | X/N | X/N | X/N | X/N | X/N | [52] |
| RateMDs | X/N | X/N | X/N | X/N | X/N | X/N | X/N | [56-58] |
| WebMD | M/U | ?/U | X/N | X/N | X/N | X/N | X/N | [23,60] |
| Ask a Patient | M/Yf | M/Y | X/N | X/N | X/N | X/N | X/N | [61,63] |
| DrugLib.com | M/Y | M/Y | X/N | X/N | X/N | X/N | X/N | [23,61,63,65] |
| Breastcancer.org | M/U | ?/U | X/N | X/N | X/N | ?/U | X/N | [67,68] |
| MedHelp | ?/U | M/U | X/N | X/N | X/N | X/N | X/N | [21,53,54,70,71] |
| DailyStrength | M/U | M/U | X/N | X/N | X/N | X/N | X/N | [23,27] |
| Cancer Survivors Network | ?/U | ?/U | X/N | X/N | X/N | X/N | X/N | [74-76] |
| NHSg website | ?/U | ?/U | ?/U | X/N | X/N | X/N | X/N | [78] |
| DiabetesDaily | ?/U | ?/U | X/N | X/N | X/N | ?/U | X/N | [80] |
a? indicates optional recording.
bU: user-specific access.
cN: not accessible online.
dX: recording not available.
eM: recording mandatory.
fY: accessible online.
gNHS: National Health Service.
Areas and Applications
This section focuses on the areas of health and well-being encompassed by the given datasets in relation to research question RQ5. These areas provide context for the practical applications of SA, which are discussed in relation to question RQ6.
Support groups provide patients and carers with practical information and emotional support to cope with health-related problems. An ability to record these conversations online offers an opportunity to study and measure unmet needs of different health communities. These communities tend to form around health conditions with high severity and chronicity rates. Not surprisingly, SA has been used to study communities formed around cancer, mental health problems, chronic conditions from asthma to multiple sclerosis, pain associated with these conditions, eating disorders, and addiction (see Table 9 [109-112]). Studying the opinion expressed in spontaneous narratives offers an opportunity to improve health care services by taking into account unforeseen factors. For example, the content of social media can be used to continually monitor the effects of medications after they have been licensed to identify previously unreported adverse reactions [27]. Similarly, SA can be used to differentiate between suicidal and nonsuicidal posts, after which a real-time online counseling can be offered [51].
Table 9.
Health-related problems studied by sentiment analysis.
| Problem | Studied in |
| Cancer | [44,45,75,109], oral [110], lung [71], breast [53,54,67,68,70,71,74,76], cervical [110], prostate [21], colorectal [30,74,76], and cancer screening [38] |
| Mental health | [34], depression [47,48,111], suicide [51,82-100], and dementia [40] |
| Chronic condition | diabetes [41,43,44,60,71,80], Chron's disease [46,53,54], multiple sclerosis [22], and asthma [101] |
| Eating disorder | obesity [36] and anorexia [49] |
| Addiction | smoking [103-106] and cannabis [26] |
| Pain | [24,52], fibromyalgia [35] |
| Infectious diseases | Ebola [28] and latent infectious disease [37] |
| Quality of life | [29,42,112] |
The provision of health care services itself has been the subject of SA. Table 10 outlines different treatments and services discussed by patients whose opinions have been studied by means of SA. Patient reviews of specific medications can support their decision making but can also be explored to support shared decision making, ultimately influencing health outcomes and health care utilization. Patient reviews of health care services can reveal how the services are experienced in practice [20,56-58,78,107,108,113], help improve communication between patients and health care providers, and identify opportunities for service improvement, again influencing health outcomes and health care utilization. In terms of disease prevention, it is important to understand potential obstacles to population-based intervention approaches such as vaccination [25,32,33,110]. Patients’ opinions can help health practitioners gain insight into the reasons why some patients may opt for traditional and complementary medicine [109]. Alternatively, understanding patients’ experience with different treatments can support creation of personalized therapy plans [45]. SA can be used to continually monitor online conversations to automatically create alerts for community moderators when additional support is needed [60,74]. Practical support can be provided by making online health information more accessible [53,54]. In particular, such information can help carers provide better care to patients [70].
Table 10.
Health care treatments studied by sentiment analysis
Methods Used for Sentiment Analysis
This section studies a range of methods and their implementations that have been used to perform SA in relation to research question RQ7. We also describe their classification performance to establish the state of the art in relation to question RQ8. SA requires an algorithm to classify sentiment associated with narrative text. Typically, sentiment is considered to be positive, negative, or neutral. Therefore, the problem of SA can be defined as that of multinomial classification. When an order can be imposed on the considered classes, then SA can be viewed as an ordinal regression problem.
Traditionally, lexicon-based SA methods classify the sentiment as a function of the predefined word polarities [28,31,37,43,50]. Lexicon-based methods are the simplest kind of rule-based methods. In general, rather than focusing on individual words, rule-based methods focus on more complex patterns, typically implemented using regular expressions [85,87,88,90,93-95,100,112]. Most often, these rules are used to extract features pertinent to SA, whereas the actual classification is based on machine learning algorithms. Table 11 provides information about specific machine learning algorithms used. Specific implementations of these algorithms that were used to support experimental evaluation are listed in Table 12.
Table 11.
Machine learning algorithms used in sentiment analysis related to health and well-being.
| Algorithm | Description | Used in |
| Support vector machine | Builds a classification model as a hyperplane that maximizes the margin between the training instances of 2 classes. | [25,26,32,33,47,53,67,76,78,82-89,91,92,95,97,98,106,107,110,114] |
| Naïve Bayes classifier | A probabilistic classifier based on Bayes theorem and an assumption that features are mutually independent. | [26,28,32,38,53,60,61,63,78,93,94,97,98,106,107,114] |
| Maximum entropy | A probabilistic classifier based on the principle of maximum entropy. | [61,63,67,96,98] |
| Conditional random fields | A method for labeling and segmenting structured data based on a conditional probability distribution over label sequences given an observation sequence. | [85,98] |
| Decision tree learning | A method that uses inductive inference to approximate a discrete-valued target function, which is represented by a decision tree. | [47,78,87,97,107,111] |
| Random forest | An ensemble learning method that fits multiple decision trees on various data samples and combines them to improve accuracy and control overfitting. | [32,53] |
| AdaBoost | AdaBoost combines multiple weak classifiers into a strong one by retraining and weighing the classifiers iteratively based on the accuracy achieved. | [67,74-76] |
| k-nearest neighbors | A nonparametric, instance-based learning algorithm based on the labels of the k nearest training instances. | [47,87] |
| Logistic regression | A method for modeling the log odds of the dichotomous outcome as a linear combination of the predictor variables. | [26,76,99,111] |
| Convolutional neural network | A feed-forward neural network that learns to extract salient features that are useful for the given prediction task. Convolutions are used to filter features by using nonlinear functions. Pooling can then be used to reduce the dimensionality. | [30] |
Table 12.
Implementations of machine learning algorithms.
| Library | Description | Used in |
| SVMlight [115] | An implementation of SVMsa in C. | [88,91,98] |
| PySVMLight [116] | A Python binding to the SVMlight (see above). | [83] |
| LIBLINEAR (LIBSVM) [117] | Integrated software for support vector classification, regression, and distribution estimation. It supports multiclass classification. | [32,76,82,84-86,89,95,118] |
| Weka [119] | A Java library that implements a collection of machine learning algorithms. | [20,23,32,53,54,56,60,76,78,93,94,118] |
| scikit-learn [120] | A Python library that implements a collection of machine learning algorithms. | [51,104,109] |
| Keras [121] | A high-level neural networks APIb written in Python. | [45] |
| TextBlob [122] | A Python library that supports NLPc and implements a collection of machine learning algorithms. | [45,51] |
aSVM: support vector machine.
bAPI: application programming interface.
cNLP: natural language processing.
To establish the state of the art, we summarized the performance of different classification algorithms in Tables 13 and 14. The results are provided in chronological order. Classification performance measures reported include accuracy (A), precision (P), recall (R), and F-measure, which are calculated using true positives (TP), true negatives (TN), false positives (FP), and false negatives (FN) in the following manner:
Table 13.
Classification performance.
| Study | Algorithma | Accuracy (%) | Precision (%) | Recall (%) | F-measure (%) |
| [110] | SVMb | 70 | —c | — | — |
| [82] | SVM | — | 55.72 | 54.72 | 55.22 |
| [83] | SVM | — | — | — | 53.31 |
| [84] | SVM | — | 49 | 46 | 47 |
| [85] | SVM + CRFd + rules | — | 60.1 | 36.8 | 45.6 |
| [86] | SVM | — | 51.9 | 48.59 | 50.18 |
| [87] | KNNe, DTf + SVM + rules | — | 49.92 | 50.55 | 50.23 |
| [88] | SVM + rules | — | 41.79 | 55.03 | 47.5 |
| [89] | SVM, rules | — | 53.8 | 53.9 | 53.8 |
| [90] | rules | — | 45.98 | 44.57 | 45.27 |
| [91] | SVM | — | 46 | 54 | 49.41 |
| [92] | SVM | — | 55.09 | 48.51 | 51.59 |
| [93] | NBg, rules, NB + rules | — | 57.09 | 55.74 | 56.4 |
| [94] | NB + rules | — | 54.96 | 51.81 | 53.34 |
| [95] | SVM, SVM + rules | — | — | — | 50.38 |
| [96] | ME | — | 57.89 | 49.61 | 53.43 |
| [97] | SVM + rules, NB, DT | — | 56 | 62 | 59 |
| [98] | SVM + NB + MEh + CRF + lexicon | — | 58.21 | 64.93 | 61.39 |
| [99] | LRi | — | 51.14 | 47.64 | 49.33 |
| [78] | SVM, NB, DT, bagging | 88.6 | — | — | 89 |
| [60] | NB | — | — | — | 54 |
| [74] | AdaBoost | 79.2 | — | — | — |
| [67] | SVM, AdaBoost, ME | 79.4 | — | — | — |
| [75] | AdaBoost | 79.2 | — | — | — |
| [61] | NB, ME, rules | — | 85.25 | 65 | 73.76 |
| [63] | NB, ME | — | 84.52 | 66.67 | 74.54 |
| [25] | SVM | 88.6 | — | — | — |
| [76] | SVM, LR, AdaBoost | 79.2 | — | — | — |
| [26] | SVM, NB, LR | — | 71.47 | 66.91 | 67.23 |
| [107] | SVM, NB, DT | — | — | — | 84 |
| [114] | SVM, NB | — | 63 | 82 | 73 |
| [28] | NB, lexicon-based | — | 75.8 | 74.3 | 73 |
| [30] | CNNj | 76.6 | 73.7 | 76.6 | 73.6 |
| [106] | SVM + NB | 82.04 | — | — | — |
| [32] | SVM, NB, RFk | — | 68.73 | 51.42 | 58.83 |
| [33] | SVM | — | 78.6 | 78.6 | 78.6 |
| [111] | LR, DT | 75 | 76.1 | — | — |
| [38] | NB | 80 | — | — | — |
| [41] | N-gram | — | 81.93 | 81.13 | 81.24 |
| [53] | SVM, NB, RF | — | — | — | 82.4 |
| [47] | SVM, KNN, DT | — | 58 | 99 | 73 |
aWhere multiple algorithms were compared, the performance of the best performing algorithm is indicated by italic typeset.
bSVM: support vector machine.
cNot applicable.
dCRF: conditional random fields.
ek-nearest neighbors
fDT: decision tree
gNB: naïve Bayes classifier.
hME: maximum entropy
iLR: logistic regression.
jCNN: convolutional neural network.
kRF: random forest.
Table 14.
Overall classification performance.
| Aggregated value | Accuracy (%) | Precision (%) | Recall (%) | F-measure (%) |
| Minimum | 70.00 | 41.79 | 36.8 | 45.27 |
| Maximum | 88.6 | 85.25 | 99 | 89 |
| Median | 79.20 | 57.89 | 54.87 | 54.81 |
| Mean | 79.80 | 61.54 | 60.23 | 61.52 |
| Standard deviation | 5.39 | 12.63 | 14.55 | 13.15 |
| A=(TP+TN)/(TP+FP+TN+FN), |
| P=TP/(TP+FP), R=TP/(TP+FN), F=2PR/(P+R) |
Although a wide range of methods was used, their performance was rarely systematically tested. According to the no free lunch theorem [123], there is no universally best learning algorithm. In other words, the performance of machine learning algorithms depends not only on a specific computational task at hand, but also on the properties of data that characterize the problem. SVMs proved to be the most popular choice (see Table 11), which outperformed naïve Bayes classifier (NB) [26,32,53,97,114,124] and random forest [32,51,53]. On occasion, it was outperformed by other methods, for example, NB [78,107], maximum entropy [67], and decision tree [47].
As it can be seen from Table 13, accuracy is not routinely reported, which makes it difficult to generalize the findings and compare them with SA performance in other domains. Nonetheless, we can observe that accuracy does not fall below 70%. On average, accuracy is around 80%. This is well below accuracy achieved in SA of movie reviews, which is typically well over 90% [125-128]. However, it is not straightforward to attribute these results to the intrinsic differences between the domains and their respective sublanguages because of the different choices in methods used. The methods tested on movie reviews are based on deep learning, whereas the methods tested on health narratives still feature traditional machine learning with only 2 studies using neural networks [30,45]. This may be due to the availability of data. Movie reviews are not only publicly available, but also come ready with annotations in the form of star rating. On the other side, health narratives may contain sensitive information and, therefore, cannot be routinely collected en masse. The fact that deep learning does require large amount of data for training may partly explain the preferences toward different types of methods.
Similarly, deep learning is commonly used to support SA of service and product reviews. However, in these domains, the results are closer to those in health and well-being with just over 80% for service reviews and just below 80% for product reviews [129-132]. The performance still lags behind the state of the art achieved in these 2 domains when measured by F-score, which was found to be below 60% on average and can go as low as 45%. F-measure achieved on service and product reviews was found to be in 70s and 80s, respectively [129,133-135]. In summary, the performance of SA of health narratives is much poorer than that in other domains, but it is yet unclear if this is because of nature of the domain, the size of training datasets, or the choice of methods. In addition to the choice of methods, their performance largely depends on the choice of features used to represent text. To support basic linguistic preprocessing, most studies used Stanford CoreNLP [136] (eg, [23,61,63,88,89,95,96,98,99,113]) and Natural Language Toolkit [137] (eg, [51,67,91,96,107,109]). Both libraries represent general purpose NLP tools, which may not be suitable for processing certain sublanguages [138]. It is worth noticing that only 4 studies explicitly stated the use of word embeddings [30,45,53,54].
Resources
In relation to research question RQ9, this section provides an overview of practical resources that can be used to support development of SA approaches in the context of health and well-being. Table 15 provides an overview of lexica that were utilized in studies covered by this systematic review. Apart from OpinionKB [61], none of the remaining lexica were developed specifically for applications to health or well-being. To determine how much of their content is specific to health and well-being, we cross-referenced against the Unified Medical Language System (UMLS) [139] using MetaMap Lite [140]. This analysis was limited to publicly available lexica that provide categorical labels of sentiment polarity. The results are shown in Figure 2. On average, 18.55% (with standard deviation of 0.0603) of each lexicon accounts for sentimentally polarized UMLS terms. In relative terms, this accounts for a significant portion of each lexicon given their general purpose. In absolute terms, the number of these terms ranges from as little as 330 in WordNet-Affect to as much as 11,687 in SentiWordNet. Knowing that the UMLS currently contains over 11 million distinct terms, we can observe that at most 1% of its content is covered by an individual lexicon referenced in Figure 2. This means that lexicon-based SA approaches will, by and large, ignore the terminology related to health and well-being.
Table 15.
Lexical resources for sentiment analysis.
| Resource | Description | Used in |
| Affective Norms for English Words [141,142] | A set of normative emotional ratings for a large number of words in terms of pleasure, arousal, and dominance. | [48,52,89] |
| AFINN [143,144] | A list of 2477 words and phrases manually rated for valence with an integer between –5 (negative) and 5 (positive). | [24,52,70] |
| Harvard General Inquirer [145,146] | A lexicon attaching syntactic, semantic, and pragmatic information to words. It includes 1915 positive and 2291 negative words. | [53,54] |
| LabMT 1.0 [147,148] | A list 10,222 words, their average happiness evaluations according to users on Mechanical Turk. | [31,48] |
| Multi-Perspective Question Answering [149,150] | A subjectivity lexicon that provides polarity scores for approximately 8000 words. | [27,88,95,105] |
| Emotion Lexicon (also called EmoLex) [151,152] | A list of words and their associations with 8 basic emotions (anger, fear, anticipation, trust, surprise, sadness, joy, and disgust) and 2 sentiments (negative and positive). The annotations were done manually by crowdsourcing. | [27] |
| OpinionKB [61,153] | A knowledge base of indirect opinions about drugs represented by quadruples (e, a, r, p), where e refers to the effective entity, a refers to the affected entity, r is the effect of e on a, and p is the opinion polarity. | [61] |
| Opinion Lexicon [5,154] | A list of around 6800 positive and negative opinion words. | [22,27,68,94,112] |
| SentiSense [155,156] | A lexicon attaching emotional category to 2190 WordNet synsets, which cover a total of 5496 words. | [53,54] |
| SentiWordNet [157,158] | An extension of WordNet that associates each synset 3 sentiment scores: positivity, negativity, and objectivity. | [23,41,61,63,65,71,83,94,102,113] |
| WordNet-Affect [159,160] | An extension of WordNet that correlates a subset of synsets suitable to represent affective concepts with affective words. Its hierarchical structure was modelled on the WordNet hyponymy relation. | [85,88,92,94] |
Figure 2.
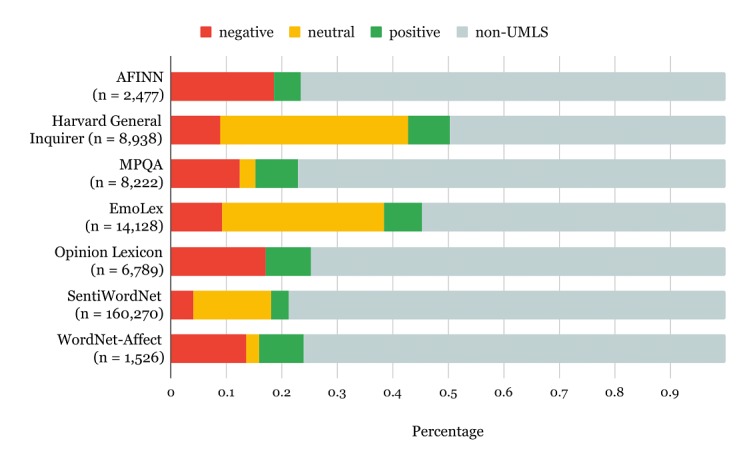
The representation of the UMLS in sentiment lexica.
Extending the UMLS by including sentiment polarity would address this gap, but this problem is nontrivial as lexicon acquisition has been known to be a major bottleneck for SA. Lessons can be learnt from existing research that focuses on automatic acquisition of sentiment lexicons. These approaches can be divided into 2 basic categories: corpus- and thesaurus-based approaches. Corpus-based approaches operate on a hypothesis that words with the same polarity cooccur in a discourse. Therefore, their polarity may be determined from their cooccurrence with the seed words of known polarity [2,161-163]. In this context, MEDLINE [16] would be an obvious source for assembling a large corpus. Similarly, thesaurus-based approaches exploit the structure of a thesaurus (eg, WordNet [164]) to infer polarity of unknown words from their relationships to the seed words of known polarity [165-169]. They rely on a hypothesis that synonyms (eg, trauma and injury) have the same polarity, whereas antonyms (eg, ill and healthy) have the opposite polarity. Starting with the seed words, the network of lexical relationships is crawled to propagate the known polarity in a rule-based approach. The structure of the UMLS could be exploited in a similar manner to infer the sentiment of its terms.
Discussion
Principal Findings
The overarching topic of this review is the SA of spontaneously generated narratives in relation to health and well-being. Specifically, this systematic review was conducted with the aim of answering research questions specified in Table 1. It identified a total of 86 relevant studies, which were used to support the findings, which are summarized here.
What Are the Major Sources of Data?
The majority of data were collected from the mainstream social multimedia and Web-based retailing platforms. Mainstream social media provide a generic platform to engage patients. However, their use of social media in the context of disclosing protected health information may raise ethical issues. The need to engage patients online while fully complying with data protection regulations has led to the proliferation of websites and networks developed specifically to provide a safe space for sharing health-related information online. This systematic review identified 10 such platforms (see Table 6 for details). In addition to user-generated content, the fifth i2b2/VA/Cincinnati challenge in NLP for clinical data [81] represents an important milestone in SA research related to health and well-being. The corpus used for this shared task contained 1319 written notes left behind by people who died by suicide. This is one of the few datasets that have been made available to research community. Owing to ethical concerns, the data used in the studies included in this systematic review are usually not released publicly to support further research and evaluation. This makes it difficult to benchmark the performance of SA in health and well-being, and test the portability of methods developed. In addition, the lack of sufficiently large datasets prevents the use of state-of-the-art methods such as deep learning (see Tables 12 and 13).
What Is the Originally Intended Purpose of Spontaneously Generated Narratives?
Web 2.0 gave rise to the self-publishing and commenting on other user’s content on online platforms. On mainstream social media such as Twitter, Facebook, Instagram, YouTube, and Reddit, patients can self-organize around groups, hashtags, and influencer users. The primary purpose of these conversations is to exchange information and provide social support online. More specialized websites such as those described in Table 6 serve the same purpose.
What Are the Roles of Their Authors Within Health and Care?
We identified 5 roles with respect to health and well-being among the authors of the types of spontaneously generated narratives considered in this review: a sufferer (a person who is affected by a medical condition), an addict (a person who is addicted to a particular substance), a patient (a person receiving or registered to receive medical treatment), a carer (a family member or friend who regularly looks after a sick or disabled person), and a suicide victim (a person who has committed suicide). Some of these roles may overlap, for example, a sufferer or an addict can also be a patient if they are receiving a medical treatment for their medical condition.
What Are Their Demographic Characteristics?
Our focus on spontaneously generated narratives implies that the corresponding studies could not mandate the collection of demographic factors. Different Web platforms may record different demographic factors, which may not be accessible to third parties. Demographic information is also difficult to verify online, which raises the concerns over the validity of such information even when it is publicly available. Table 8 states which demographic factors, if any, are recorded when a user registers an account on the given online services and which ones are accessible online. Only age and gender are routinely collected, but not necessarily shared publicly. Therefore, any findings resulting from these data should be interpreted with caution as it may not be possible to generalize them across the relevant patient population. Out of 86 studies considered in this review, only 4 reported the demographic characteristics.
What Areas of Health and Well-Being Are Discussed?
Online communities tend to form around health conditions with high severity and chronicity rates. Not surprisingly, SA has been used to study communities formed around cancer, mental health problems, chronic conditions from asthma to multiple sclerosis, pain associated with these conditions, eating disorders, and addiction (see Table 9). The provision of health care services itself has been the subject of SA. Different treatments and services discussed by patients whose opinions have been studied by means of SA include medications, vaccination, surgery, orthodontic services, individual physicians, and health care services in general.
What Are the Practical Applications of Sentiment Analysis?
Analyzing the sentiment expressed in spontaneous narratives offers an opportunity to improve health care services by taking into account unforeseen factors. For example, social media can be used to continually monitor the effects of medications to identify previously unknown adverse reactions. Similarly, SA can be used to differentiate between suicidal and nonsuicidal posts, after which a real-time online counseling can be offered. Patient reviews of specific medications can support their decision making but can also be explored to support shared decision making, ultimately influencing health outcomes and health care utilization. Patient reviews of health care services can help identify opportunities for service improvement, thus influencing health outcomes and health care utilization. In terms of disease prevention, patients’ opinions can help health practitioners understand potential obstacles to population-based intervention approaches such as vaccination. Understanding patients’ experience with different treatments can support creation of personalized therapy plans.
What Methods Have Been Used to Perform Sentiment Analysis?
A wide range of methods have been used to perform SA. Most common choices include SVMs, naïve Bayesian learning, decision trees, logistic regression, and adaptive boosting. Other approaches include maximum entropy, conditional random fields, random forests, and k-nearest neighbors. The findings show strong bias toward traditional machine learning. A single study used deep learning. This is in stark contrast with general trends in SA research.
What Is the State-of-the-Art Performance of Sentiment Analysis?
On average, accuracy is around 80%, and it does not fall below 70%. This is well below accuracy achieved in SA of movie reviews, which is typically well over 90%. In SA of service and product reviews, the results are closer to those in health and well-being with just more than 80% for service reviews and just below 80% for product reviews. However, the performance still lags behind the state of the art achieved in these 2 domains when measured by F-score, which was found to be below 60% on average. F-measure achieved on service and product reviews is found to be above 70% and 80%, respectively. In summary, the performance of SA of health narratives is much poorer than that in other domains.
What Resources Are Available to Support Sentiment Analysis Related to Health and Well-Being?
A wide range of lexica were utilized in studies covered by this systematic review (see Table 15. Notably, out of 11 lexica, only 1 was developed specifically for a domain related to health or well-being. The lack of domain-specific lexicons may partly explain the poorer performance recorded in this domain.
Conclusions
In summary, this review has uncovered multiple opportunities to advance research in SA related to health and well-being. Keeping in mind the no free lunch theorem, researchers in this area need to put more effort in systematically exploring a wide range of methods and testing their performance. Community efforts to create and share a large, anonymized dataset would enable not only rigorous benchmarking of existing methods but also exploration of new approaches including deep learning. This should help the field catch up with the most recent developments in SA. The creation of domain-specific sentiment lexica stands to further improve the performance of SA related to health and well-being. Although many studies have dealt with automatic construction of domain-specific sentiment lexica using methods such as random walks, no such studies have been identified in this systematic review. Finally, health-related applications of SA require systematic collection of demographic data to illustrate the extent to which the findings can be generalized.
Acknowledgments
This work is part of a PhD project funded by Cardiff University via Vice-Chancellor’s International Scholarships for Research Excellence. The scholarship has been awarded to AŽ, and her project is supervised by IS and PC.
Abbreviations
- API
application programming interface
- NB
naïve Bayes classifier
- NLP
natural language processing
- SA
sentiment analysis
- SVM
support vector machine
- UMLS
Unified Medical Language System
Footnotes
Authors' Contributions: IS designed the study. AŽ conducted the search and data extraction. All authors were responsible for critical evaluation, analysis, and presentation of the results. AŽ and IS drafted the manuscript. PC critically evaluated the article. All authors approved the final version before submission.
Conflicts of Interest: None declared.
References
- 1.Wiebe J, Bruce R. Probabilistic classifiers for tracking point of view. Progress in communication sciences. 1995:125–42. https://pdfs.semanticscholar.org/033e/414b82a6c20f6ed7e0b5232a1ae36d54e7b3.pdf. [Google Scholar]
- 2.Hatzivassiloglou V, McKeown KR. Predicting the Semantic Orientation of Adjectives. Proceedings of the 35th Annual Meeting of the Association for Computational Linguistics and Eighth Conference of the European Chapter of the Association for Computational Linguistics; ACL'98/EACL'98; July 7-12, 1997; Madrid, Spain. 1997. pp. 174–81. https://www.aclweb.org/anthology/P97-1023/ [DOI] [Google Scholar]
- 3.Wiebe JM, Bruce RF, O'Hara TP. Development and Use of a Gold-standard Data Set for Subjectivity Classifications. Proceedings of the 37th annual meeting of the Association for Computational Linguistics on Computational Linguistics; ACL'99; June 20-26, 1999; College Park, Maryland, USA. 1999. pp. 246–53. https://www.aclweb.org/anthology/P99-1032/ [DOI] [Google Scholar]
- 4.Hu M, Liu B. Mining Opinion Features in Customer Reviews. Proceedings of the 19th national conference on Artifical intelligence; AAAI'04; July 25 - 29, 2004; San Jose, California, USA. 2004. pp. 755–60. https://dl.acm.org/citation.cfm?id=1597269. [Google Scholar]
- 5.Hu M, Liu B. Mining and Summarizing Customer Reviews. Proceedings of the tenth ACM SIGKDD international conference on Knowledge discovery and data mining; KDD'04; August 22 - 25, 2004; Seattle, Washington, USA. 2004. pp. 168–77. https://dl.acm.org/citation.cfm?id=1014073. [DOI] [Google Scholar]
- 6.Bollen J, Mao H, Zeng X. Twitter mood predicts the stock market. J Comput Sci. 2011;2(1):1–8. doi: 10.1016/j.jocs.2010.12.007. [DOI] [Google Scholar]
- 7.Efron M. Cultural orientation: Classifying subjective documents by cociation analysis. Proceedings of the AAAI Fall Symposium on Style and Meaning in Language, Art, and Music; AAAI'04; July 25-29, 2004; San Jose, California. 2004. pp. 41–8. [Google Scholar]
- 8.Ramteke J, Shah S, Godhia D, Shaikh A. Election Result Prediction Using Twitter Sentiment Analysis. Proceedings of the 2016 International Conference on Inventive Computation Technologies; ICICT'16; August 26-27, 2016; Coimbatore, India. 2016. pp. 1–5. [DOI] [Google Scholar]
- 9.World Health Organisation. Geneva, Switzerland: World Health Organisation; 2006. [2019-11-12]. Constitution of the World Health Organisation https://www.who.int/governance/eb/who_constitution_en.pdf. [Google Scholar]
- 10.Huber M, Knottnerus JA, Green L, van der Horst H, Jadad AR, Kromhout D, Leonard B, Lorig K, Loureiro MI, van der Meer JW, Schnabel P, Smith R, van Weel C, Smid H. How should we define health? Br Med J. 2011 Jul 26;343:d4163. doi: 10.1136/bmj.d4163. [DOI] [PubMed] [Google Scholar]
- 11.Berg O. Health and quality of life. Acta Sociologica. 1975;18(1):3–22. doi: 10.1177/000169937501800102. [DOI] [Google Scholar]
- 12.Denecke K, Deng Y. Sentiment analysis in medical settings: new opportunities and challenges. Artif Intell Med. 2015 May;64(1):17–27. doi: 10.1016/j.artmed.2015.03.006. [DOI] [PubMed] [Google Scholar]
- 13.Gohil S, Vuik S, Darzi A. Sentiment analysis of health care tweets: review of the methods used. JMIR Public Health Surveill. 2018 Apr 23;4(2):e43. doi: 10.2196/publichealth.5789. https://publichealth.jmir.org/2018/2/e43/ [DOI] [PMC free article] [PubMed] [Google Scholar]
- 14.Kitchenham B. Procedures for performing systematic reviews. Keele University, Keele. 2004;33(2004):1–26. http://www.inf.ufsc.br/~aldo.vw/kitchenham.pdf. [Google Scholar]
- 15.Cochrane Library: Cochrane Reviews. [2019-11-12]. https://www.cochranelibrary.com/
- 16.National Library of Medicine. [2019-11-12]. MEDLINE: Description of the Database https://www.nlm.nih.gov/bsd/medline.html.
- 17.Embase. [2019-11-12]. https://www.embase.com.
- 18.EBSCO Health. [2019-11-12]. CINAHL Database https://health.ebsco.com/products/the-cinahl-database.
- 19.Cohen J. A Coefficient of Agreement for Nominal Scales. Educ Psychol Meas. 1960;20(1):37–46. doi: 10.1177/001316446002000104. [DOI] [Google Scholar]
- 20.Yoon S, Bakken S. Methods of knowledge discovery in tweets. NI 2012 (2012) 2012;2012:463. http://europepmc.org/abstract/MED/24199142. [PMC free article] [PubMed] [Google Scholar]
- 21.Mishra MV, Bennett M, Vincent A, Lee OT, Lallas CD, Trabulsi EJ, Gomella LG, Dicker AP, Showalter TN. Identifying barriers to patient acceptance of active surveillance: content analysis of online patient communications. PLoS One. 2013;8(9):e68563. doi: 10.1371/journal.pone.0068563. http://dx.plos.org/10.1371/journal.pone.0068563. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 22.Ramagopalan S, Wasiak R, Cox AP. Using Twitter to investigate opinions about multiple sclerosis treatments: a descriptive, exploratory study. F1000Res. 2014;3:216. doi: 10.12688/f1000research.5263.1. https://f1000research.com/articles/10.12688/f1000research.5263.1/doi. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 23.Wiley MT, Jin C, Hristidis V, Esterling KM. Pharmaceutical drugs chatter on Online Social Networks. J Biomed Inform. 2014 Jun;49:245–54. doi: 10.1016/j.jbi.2014.03.006. https://linkinghub.elsevier.com/retrieve/pii/S1532-0464(14)00063-X. [DOI] [PubMed] [Google Scholar]
- 24.Tighe PJ, Goldsmith RC, Gravenstein M, Bernard HR, Fillingim RB. The painful tweet: text, sentiment, and community structure analyses of tweets pertaining to pain. J Med Internet Res. 2015 Apr 2;17(4):e84. doi: 10.2196/jmir.3769. https://www.jmir.org/2015/4/e84/ [DOI] [PMC free article] [PubMed] [Google Scholar]
- 25.Zhou X, Coiera E, Tsafnat G, Arachi D, Ong M, Dunn AG. Using social connection information to improve opinion mining: identifying negative sentiment about HPV vaccines on Twitter. Stud Health Technol Inform. 2015;216:761–5. doi: 10.3233/978-1-61499-564-7-761. [DOI] [PubMed] [Google Scholar]
- 26.Daniulaityte R, Chen L, Lamy FR, Carlson RG, Thirunarayan K, Sheth A. 'When 'Bad' is 'Good'': identifying personal communication and sentiment in drug-related tweets. JMIR Public Health Surveill. 2016 Oct 24;2(2):e162. doi: 10.2196/publichealth.6327. https://publichealth.jmir.org/2016/2/e162/ [DOI] [PMC free article] [PubMed] [Google Scholar]
- 27.Korkontzelos I, Nikfarjam A, Shardlow M, Sarker A, Ananiadou S, Gonzalez GH. Analysis of the effect of sentiment analysis on extracting adverse drug reactions from tweets and forum posts. J Biomed Inform. 2016 Aug;62:148–58. doi: 10.1016/j.jbi.2016.06.007. https://linkinghub.elsevier.com/retrieve/pii/S1532-0464(16)30050-8. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 28.Ofoghi B, Mann M, Verspoor K. Towards early discovery of salient health threats: a social media emotion classification technique. Pac Symp Biocomput. 2016;21:504–15. doi: 10.1142/9789814749411_0046. http://psb.stanford.edu/psb-online/proceedings/psb16/abstracts/2016_p504.html. [DOI] [PubMed] [Google Scholar]
- 29.Palomino M, Taylor T, Göker A, Isaacs J, Warber S. The online dissemination of nature-health concepts: lessons from sentiment analysis of social media relating to 'Nature-deficit disorder'. Int J Environ Res Public Health. 2016 Jan 19;13(1):pii: E142. doi: 10.3390/ijerph13010142. http://www.mdpi.com/resolver?pii=ijerph13010142. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 30.Bian J, Zhao Y, Salloum RG, Guo Y, Wang M, Prosperi M, Zhang H, Du X, Ramirez-Diaz LJ, He Z, Sun Y. Using social media data to understand the impact of promotional information on laypeople's discussions: a case study of lynch syndrome. J Med Internet Res. 2017 Dec 13;19(12):e414. doi: 10.2196/jmir.9266. https://www.jmir.org/2017/12/e414/ [DOI] [PMC free article] [PubMed] [Google Scholar]
- 31.Davis MA, Zheng K, Liu Y, Levy H. Public response to Obamacare on Twitter. J Med Internet Res. 2017 May 26;19(5):e167. doi: 10.2196/jmir.6946. https://www.jmir.org/2017/5/e167/ [DOI] [PMC free article] [PubMed] [Google Scholar]
- 32.Du J, Xu J, Song H, Liu X, Tao C. Optimization on machine learning based approaches for sentiment analysis on HPV vaccines related tweets. J Biomed Semantics. 2017 Mar 3;8(1):9. doi: 10.1186/s13326-017-0120-6. https://jbiomedsem.biomedcentral.com/articles/10.1186/s13326-017-0120-6. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 33.Du J, Xu J, Song H, Tao C. Leveraging machine learning-based approaches to assess human papillomavirus vaccination sentiment trends with Twitter data. BMC Med Inform Decis Mak. 2017 Jul 5;17(Suppl 2):69. doi: 10.1186/s12911-017-0469-6. https://bmcmedinformdecismak.biomedcentral.com/articles/10.1186/s12911-017-0469-6. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 34.Gruebner O, Lowe SR, Sykora M, Shankardass K, Subramanian SV, Galea S. A novel surveillance approach for disaster mental health. PLoS One. 2017;12(7):e0181233. doi: 10.1371/journal.pone.0181233. http://dx.plos.org/10.1371/journal.pone.0181233. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 35.Haghighi PD, Kang Y, Buchbinder R, Burstein F, Whittle S. Investigating subjective experience and the influence of weather among individuals with fibromyalgia: a content analysis of Twitter. JMIR Public Health Surveill. 2017 Jan 19;3(1):e4. doi: 10.2196/publichealth.6344. https://publichealth.jmir.org/2017/1/e4/ [DOI] [PMC free article] [PubMed] [Google Scholar]
- 36.Kang Y, Wang Y, Zhang D, Zhou L. The public's opinions on a new school meals policy for childhood obesity prevention in the US: a social media analytics approach. Int J Med Inform. 2017 Jul;103:83–8. doi: 10.1016/j.ijmedinf.2017.04.013. [DOI] [PubMed] [Google Scholar]
- 37.Lim S, Tucker CS, Kumara S. An unsupervised machine learning model for discovering latent infectious diseases using social media data. J Biomed Inform. 2017 Feb;66:82–94. doi: 10.1016/j.jbi.2016.12.007. https://linkinghub.elsevier.com/retrieve/pii/S1532-0464(16)30181-2. [DOI] [PubMed] [Google Scholar]
- 38.Metwally O, Blumberg S, Ladabaum U, Sinha SR. Using social media to characterize public sentiment toward medical interventions commonly used for cancer screening: an observational study. J Med Internet Res. 2017 Jun 7;19(6):e200. doi: 10.2196/jmir.7485. https://www.jmir.org/2017/6/e200/ [DOI] [PMC free article] [PubMed] [Google Scholar]
- 39.Noll D, Mahon B, Shroff B, Carrico C, Lindauer SJ. Twitter analysis of the orthodontic patient experience with braces vs Invisalign. Angle Orthod. 2017 May;87(3):377–83. doi: 10.2319/062816-508.1. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 40.Oscar N, Fox PA, Croucher R, Wernick R, Keune J, Hooker K. Machine learning, sentiment analysis, and tweets: an examination of Alzheimer's disease stigma on Twitter. J Gerontol B Psychol Sci Soc Sci. 2017 Sep 1;72(5):742–51. doi: 10.1093/geronb/gbx014. [DOI] [PubMed] [Google Scholar]
- 41.Salas-Zárate MD, Medina-Moreira J, Lagos-Ortiz K, Luna-Aveiga H, Rodríguez-García MA, Valencia-García R. Sentiment analysis on tweets about diabetes: an aspect-level approach. Comput Math Methods Med. 2017;2017:5140631. doi: 10.1155/2017/5140631. doi: 10.1155/2017/5140631. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 42.Cao X, MacNaughton P, Deng Z, Yin J, Zhang X, Allen JG. Using Twitter to better understand the spatiotemporal patterns of public sentiment: a case study in Massachusetts, USA. Int J Environ Res Public Health. 2018 Feb 2;15(2):pii: E250. doi: 10.3390/ijerph15020250. http://www.mdpi.com/resolver?pii=ijerph15020250. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 43.Gabarron E, Dorronzoro E, Rivera-Romero O, Wynn R. Diabetes on Twitter: a sentiment analysis. J Diabetes Sci Technol. 2019 May;13(3):439–44. doi: 10.1177/1932296818811679. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 44.Pai RR, Alathur S. Assessing mobile health applications with Twitter analytics. Int J Med Inform. 2018 May;113:72–84. doi: 10.1016/j.ijmedinf.2018.02.016. [DOI] [PubMed] [Google Scholar]
- 45.Zhang L, Hall M, Bastola D. Utilizing Twitter data for analysis of chemotherapy. Int J Med Inform. 2018 Dec;120:92–100. doi: 10.1016/j.ijmedinf.2018.10.002. [DOI] [PubMed] [Google Scholar]
- 46.Roccetti M, Marfia G, Salomoni P, Prandi C, Zagari RM, Kengni FL, Bazzoli F, Montagnani M. Attitudes of Crohn's disease patients: infodemiology case study and sentiment analysis of Facebook and Twitter posts. JMIR Public Health Surveill. 2017 Aug 9;3(3):e51. doi: 10.2196/publichealth.7004. https://publichealth.jmir.org/2017/3/e51/ [DOI] [PMC free article] [PubMed] [Google Scholar]
- 47.Islam MR, Kabir MA, Ahmed A, Kamal AR, Wang H, Ulhaq A. Depression detection from social network data using machine learning techniques. Health Inf Sci Syst. 2018 Dec;6(1):8. doi: 10.1007/s13755-018-0046-0. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 48.Ricard BJ, Marsch LA, Crosier B, Hassanpour S. Exploring the utility of community-generated social media content for detecting depression: an analytical study on Instagram. J Med Internet Res. 2018 Dec 6;20(12):e11817. doi: 10.2196/11817. https://www.jmir.org/2018/12/e11817/ [DOI] [PMC free article] [PubMed] [Google Scholar]
- 49.Oksanen A, Garcia D, Sirola A, Näsi M, Kaakinen M, Keipi T, Räsänen P. Pro-anorexia and anti-pro-anorexia videos on YouTube: sentiment analysis of user responses. J Med Internet Res. 2015 Nov 12;17(11):e256. doi: 10.2196/jmir.5007. https://www.jmir.org/2015/11/e256/ [DOI] [PMC free article] [PubMed] [Google Scholar]
- 50.Livas C, Delli K, Pandis N. 'My Invisalign experience': content, metrics and comment sentiment analysis of the most popular patient testimonials on YouTube. Prog Orthod. 2018 Jan 22;19(1):3. doi: 10.1186/s40510-017-0201-1. http://europepmc.org/abstract/MED/29354889. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 51.Aladağ AE, Muderrisoglu S, Akbas NB, Zahmacioglu O, Bingol HO. Detecting suicidal ideation on forums: proof-of-concept study. J Med Internet Res. 2018 Jun 21;20(6):e215. doi: 10.2196/jmir.9840. https://www.jmir.org/2018/6/e215/ [DOI] [PMC free article] [PubMed] [Google Scholar]
- 52.Adams DZ, Gruss R, Abrahams AS. Automated discovery of safety and efficacy concerns for joint & muscle pain relief treatments from online reviews. Int J Med Inform. 2017 Apr;100:108–20. doi: 10.1016/j.ijmedinf.2017.01.005. [DOI] [PubMed] [Google Scholar]
- 53.Carrillo-de-Albornoz J, Vidal JR, Plaza L. Feature engineering for sentiment analysis in e-health forums. PLoS One. 2018;13(11):e0207996. doi: 10.1371/journal.pone.0207996. http://dx.plos.org/10.1371/journal.pone.0207996. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 54.Carrillo-de-Albornoz J, Aker A, Kurtic E, Plaza L. Beyond opinion classification: extracting facts, opinions and experiences from health forums. PLoS One. 2019;14(1):e0209961. doi: 10.1371/journal.pone.0209961. http://dx.plos.org/10.1371/journal.pone.0209961. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 55.RateMDs. [2019-11-12]. https://www.ratemds.com/
- 56.Alemi F, Torii M, Clementz L, Aron DC. Feasibility of real-time satisfaction surveys through automated analysis of patients' unstructured comments and sentiments. Qual Manag Health Care. 2012;21(1):9–19. doi: 10.1097/QMH.0b013e3182417fc4. [DOI] [PubMed] [Google Scholar]
- 57.Wallace BC, Paul MJ, Sarkar U, Trikalinos TA, Dredze M. A large-scale quantitative analysis of latent factors and sentiment in online doctor reviews. J Am Med Inform Assoc. 2014;21(6):1098–103. doi: 10.1136/amiajnl-2014-002711. http://europepmc.org/abstract/MED/24918109. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 58.Hopper AM, Uriyo M. Using sentiment analysis to review patient satisfaction data located on the internet. J Health Organ Manag. 2015;29(2):221–33. doi: 10.1108/JHOM-12-2011-0129. [DOI] [PubMed] [Google Scholar]
- 59.WebMD - Better information. Better health. [2019-11-12]. https://www.webmd.com/
- 60.Huh J, Yetisgen-Yildiz M, Pratt W. Text classification for assisting moderators in online health communities. J Biomed Inform. 2013 Dec;46(6):998–1005. doi: 10.1016/j.jbi.2013.08.011. https://linkinghub.elsevier.com/retrieve/pii/S1532-0464(13)00139-1. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 61.Noferesti S, Shamsfard M. Resource construction and evaluation for indirect opinion mining of drug reviews. PLoS One. 2015;10(5):e0124993. doi: 10.1371/journal.pone.0124993. http://dx.plos.org/10.1371/journal.pone.0124993. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 62.Ask a Patient. [2019-11-12]. https://www.askapatient.com/
- 63.Noferesti S, Shamsfard M. Using Linked Data for polarity classification of patients' experiences. J Biomed Inform. 2015 Oct;57:6–19. doi: 10.1016/j.jbi.2015.06.017. https://linkinghub.elsevier.com/retrieve/pii/S1532-0464(15)00127-6. [DOI] [PubMed] [Google Scholar]
- 64.DrugLib. [2019-11-12]. http://www.druglib.com/
- 65.Asghar MZ, Ahmad S, Qasim M, Zahra SR, Kundi FM. SentiHealth: creating health-related sentiment lexicon using hybrid approach. Springerplus. 2016;5(1):1139. doi: 10.1186/s40064-016-2809-x. http://europepmc.org/abstract/MED/27504237. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 66.Breast Cancer Information and Support. [2019-11-12]. https://www.breastcancer.org/
- 67.Zhang S, Bantum E, Owen J, Elhadad N. Does sustained participation in an online health community affect sentiment? AMIA Annu Symp Proc. 2014;2014:1970–9. http://europepmc.org/abstract/MED/25954470. [PMC free article] [PubMed] [Google Scholar]
- 68.Cabling ML, Turner JW, Hurtado-de-Mendoza A, Zhang Y, Jiang X, Drago F, Sheppard VB. Sentiment analysis of an online breast cancer support group: communicating about tamoxifen. Health Commun. 2018 Sep;33(9):1158–65. doi: 10.1080/10410236.2017.1339370. http://europepmc.org/abstract/MED/28678549. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 69.MedHelp. [2019-11-12]. https://medhelp.org/
- 70.Yang FC, Lee AJ, Kuo SC. Mining health social media with sentiment analysis. J Med Syst. 2016 Nov;40(11):236. doi: 10.1007/s10916-016-0604-4. [DOI] [PubMed] [Google Scholar]
- 71.Lu Y, Wu Y, Liu J, Li J, Zhang P. Understanding health care social media use from different stakeholder perspectives: a content analysis of an online health community. J Med Internet Res. 2017 Apr 7;19(4):e109. doi: 10.2196/jmir.7087. https://www.jmir.org/2017/4/e109/ [DOI] [PMC free article] [PubMed] [Google Scholar]
- 72.DailyStrength. https://www.dailystrength.org/
- 73.Cancer Survivor Network. [2019-11-12]. http://csn.cancer.org/
- 74.Portier K, Greer GE, Rokach L, Ofek N, Wang Y, Biyani P, Yu M, Banerjee S, Zhao K, Mitra P, Yen J. Understanding topics and sentiment in an online cancer survivor community. J Natl Cancer Inst Monogr. 2013 Dec;2013(47):195–8. doi: 10.1093/jncimonographs/lgt025. [DOI] [PubMed] [Google Scholar]
- 75.Zhao K, Yen J, Greer G, Qiu B, Mitra P, Portier K. Finding influential users of online health communities: a new metric based on sentiment influence. J Am Med Inform Assoc. 2014 Oct;21(e2):e212–8. doi: 10.1136/amiajnl-2013-002282. http://europepmc.org/abstract/MED/24449805. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 76.Bui N, Yen J, Honavar V. Temporal causality analysis of sentiment change in a cancer survivor network. IEEE Trans Comput Soc Syst. 2016 Jun;3(2):75–87. doi: 10.1109/TCSS.2016.2591880. http://europepmc.org/abstract/MED/29399599. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 77.National Health Service. [2019-11-12]. https://www.nhs.uk/
- 78.Greaves F, Ramirez-Cano D, Millett C, Darzi A, Donaldson L. Use of sentiment analysis for capturing patient experience from free-text comments posted online. J Med Internet Res. 2013 Nov 1;15(11):e239. doi: 10.2196/jmir.2721. https://www.jmir.org/2013/11/e239/ [DOI] [PMC free article] [PubMed] [Google Scholar]
- 79.DiabetesDaily. [2019-11-12]. https://www.diabetesdaily.com.
- 80.Akay A, Dragomir A, Erlandsson B. A novel data-mining approach leveraging social media to monitor consumer opinion of sitagliptin. IEEE J Biomed Health Inform. 2015 Jan;19(1):389–96. doi: 10.1109/JBHI.2013.2295834. [DOI] [PubMed] [Google Scholar]
- 81.Pestian JP, Matykiewicz P, Linn-Gust M, South B, Uzuner O, Wiebe J, Cohen KB, Hurdle J, Brew C. Sentiment analysis of suicide notes: a shared task. Biomed Inform Insights. 2012 Jan 30;5(Suppl 1):3–16. doi: 10.4137/bii.s9042. http://europepmc.org/abstract/MED/22419877. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 82.Cherry C, Mohammad SM, de Bruijn B. Binary classifiers and latent sequence models for emotion detection in suicide notes. Biomed Inform Insights. 2012;5(Suppl. 1):147–54. doi: 10.4137/BII.S8933. http://europepmc.org/abstract/MED/22879771. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 83.Desmet B, Hoste V. Combining lexico-semantic features for emotion classification in suicide notes. Biomed Inform Insights. 2012;5(Suppl 1):125–8. doi: 10.4137/BII.S8960. http://europepmc.org/abstract/MED/22879768. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 84.Dzogang F, Lesot M, Rifqi M, Bouchon-Meunier B. Early fusion of low level features for emotion mining. Biomed Inform Insights. 2012;5(Suppl 1):129–36. doi: 10.4137/BII.S8973. http://europepmc.org/abstract/MED/22879769. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 85.Liakata M, Kim J, Saha S, Hastings J, Rebholz-Schuhmann D. Three hybrid classifiers for the detection of emotions in suicide notes. Biomed Inform Insights. 2012;5(Suppl 1):175–84. doi: 10.4137/BII.S8967. http://europepmc.org/abstract/MED/22879774. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 86.Luyckx K, Vaassen F, Peersman C, Daelemans W. Fine-grained emotion detection in suicide notes: a thresholding approach to multi-label classification. Biomed Inform Insights. 2012;5(Suppl 1):61–9. doi: 10.4137/BII.S8966. http://europepmc.org/abstract/MED/22879761. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 87.McCart JA, Finch DK, Jarman J, Hickling E, Lind JD, Richardson MR, Berndt DJ, Luther SL. Using ensemble models to classify the sentiment expressed in suicide notes. Biomed Inform Insights. 2012;5(Suppl 1):77–85. doi: 10.4137/BII.S8931. http://europepmc.org/abstract/MED/22879763. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 88.Nikfarjam A, Emadzadeh E, Gonzalez G. A hybrid system for emotion extraction from suicide notes. Biomed Inform Insights. 2012;5(Suppl 1):165–74. doi: 10.4137/BII.S8981. http://europepmc.org/abstract/MED/22879773. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 89.Pak A, Bernhard D, Paroubek P, Grouin C. A combined approach to emotion detection in suicide notes. Biomed Inform Insights. 2012;5(Suppl 1):105–14. doi: 10.4137/BII.S8969. http://europepmc.org/abstract/MED/22879766. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 90.Pedersen T. Rule-based and lightly supervised methods to predict emotions in suicide notes. Biomed Inform Insights. 2012;5(Suppl 1):185–93. doi: 10.4137/BII.S8953. http://europepmc.org/abstract/MED/22879775. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 91.Read J, Velldal E, Ovrelid L. Labeling emotions in suicide notes: cost-sensitive learning with heterogeneous features. Biomed Inform Insights. 2012;5(Suppl 1):99–103. doi: 10.4137/BII.S8930. http://europepmc.org/abstract/MED/22879765. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 92.Roberts K, Harabagiu SM. Statistical and similarity methods for classifying emotion in suicide notes. Biomed Inform Insights. 2012;5(Suppl 1):195–204. doi: 10.4137/BII.S8958. http://europepmc.org/abstract/MED/22879776. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 93.Sohn S, Torii M, Li D, Wagholikar K, Wu S, Liu H. A hybrid approach to sentiment sentence classification in suicide notes. Biomed Inform Insights. 2012;5(Suppl 1):43–50. doi: 10.4137/BII.S8961. http://europepmc.org/abstract/MED/22879759. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 94.Spasić I, Burnap P, Greenwood M, Arribas-Ayllon M. A naïve Bayes approach to classifying topics in suicide notes. Biomed Inform Insights. 2012;5(Suppl 1):87–97. doi: 10.4137/BII.S8945. http://europepmc.org/abstract/MED/22879764. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 95.Wang W, Chen L, Tan M, Wang S, Sheth AP. Discovering fine-grained sentiment in suicide notes. Biomed Inform Insights. 2012;5(Suppl 1):137–45. doi: 10.4137/BII.S8963. http://europepmc.org/abstract/MED/22879770. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 96.Wicentowski R, Sydes MR. Emotion detection in suicide notes using maximum entropy classification. Biomed Inform Insights. 2012;5(Suppl 1):51–60. doi: 10.4137/BII.S8972. http://europepmc.org/abstract/MED/22879760. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 97.Xu Y, Wang Y, Liu J, Tu Z, Sun J, Tsujii J, Chang E. Suicide note sentiment classification: a supervised approach augmented by web data. Biomed Inform Insights. 2012;5(Suppl 1):31–41. doi: 10.4137/BII.S8956. http://europepmc.org/abstract/MED/22879758. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 98.Yang H, Willis A, de Roeck A, Nuseibeh B. A hybrid model for automatic emotion recognition in suicide notes. Biomed Inform Insights. 2012;5(Suppl 1):17–30. doi: 10.4137/BII.S8948. http://europepmc.org/abstract/MED/22879757. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 99.Yeh E, Jarrold W, Jordan J. Leveraging psycholinguistic resources and emotional sequence models for suicide note emotion annotation. Biomed Inform Insights. 2012;5(Suppl 1):155–63. doi: 10.4137/BII.S8979. http://europepmc.org/abstract/MED/22879772. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 100.Yu N, Kübler S, Herring J, Hsu Y, Israel R, Smiley C. LASSA: emotion detection via information fusion. Biomed Inform Insights. 2012;5(Suppl. 1):71–6. doi: 10.4137/BII.S8949. http://europepmc.org/abstract/MED/22879762. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 101.Mammen JR, Java JJ, Rhee H, Butz AM, Halterman JS, Arcoleo K. Mixed-methods content and sentiment analysis of adolescents' voice diaries describing daily experiences with asthma and self-management decision-making. Clin Exp Allergy. 2019 Mar;49(3):299–307. doi: 10.1111/cea.13250. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 102.Asghar MZ, Khan A, Ahmad S, Qasim M, Khan IA. Lexicon-enhanced sentiment analysis framework using rule-based classification scheme. PLoS One. 2017;12(2):e0171649. doi: 10.1371/journal.pone.0171649. http://dx.plos.org/10.1371/journal.pone.0171649. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 103.Cobb NK, Mays D, Graham AL. Sentiment analysis to determine the impact of online messages on smokers' choices to use varenicline. J Natl Cancer Inst Monogr. 2013 Dec;2013(47):224–30. doi: 10.1093/jncimonographs/lgt020. [DOI] [PubMed] [Google Scholar]
- 104.Cohn AM, Amato MS, Zhao K, Wang X, Cha S, Pearson JL, Papandonatos GD, Graham AL. Discussions of alcohol use in an online social network for smoking cessation: analysis of topics, sentiment, and social network centrality. Alcohol Clin Exp Res. 2019 Jan;43(1):108–14. doi: 10.1111/acer.13906. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 105.Chu KH, Valente TW. How different countries addressed the sudden growth of e-cigarettes in an online tobacco control community. BMJ Open. 2015 May 21;5(5):e007654. doi: 10.1136/bmjopen-2015-007654. http://bmjopen.bmj.com/cgi/pmidlookup?view=long&pmid=25998038. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 106.Chen Z, Zeng DD. Mining online e-liquid reviews for opinion polarities about e-liquid features. BMC Public Health. 2017 Jul 7;17(1):633. doi: 10.1186/s12889-017-4533-z. https://bmcpublichealth.biomedcentral.com/articles/10.1186/s12889-017-4533-z. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 107.Doing-Harris K, Mowery D, Daniels C, Chapman W, Conway M. Understanding patient satisfaction with received healthcare services: a natural language processing approach. AMIA Annu Symp Proc. 2016;2016:524–33. http://europepmc.org/abstract/MED/28269848. [PMC free article] [PubMed] [Google Scholar]
- 108.Alemi F, Jasper H. An alternative to satisfaction surveys: let the patients talk. Qual Manag Health Care. 2014;23(1):10–9. doi: 10.1097/QMH.0000000000000014. [DOI] [PubMed] [Google Scholar]
- 109.Diorio C, Afanasiev M, Salena K, Marjerrison S. 'A world of competing sorrows': a mixed methods analysis of media reports of children with cancer abandoning conventional treatment. PLoS One. 2018;13(12):e0209738. doi: 10.1371/journal.pone.0209738. http://dx.plos.org/10.1371/journal.pone.0209738. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 110.Corley C, Mihalcea R, Mikler A, Sanfilippo A. Predicting individual affect of health interventions to reduce HPV prevalence. In: Arabnia H, Tran QN, editors. Software Tools and Algorithms for Biological Systems. New York, New York, USA: Springer; 2011. pp. 181–90. [DOI] [PubMed] [Google Scholar]
- 111.Jung H, Park H, Song T. Ontology-based approach to social data sentiment analysis: detection of adolescent depression signals. J Med Internet Res. 2017 Jul 24;19(7):e259. doi: 10.2196/jmir.7452. https://www.jmir.org/2017/7/e259/ [DOI] [PMC free article] [PubMed] [Google Scholar]
- 112.Chen L, Gong T, Kosinski M, Stillwell D, Davidson RL. Building a profile of subjective well-being for social media users. PLoS One. 2017;12(11):e0187278. doi: 10.1371/journal.pone.0187278. http://dx.plos.org/10.1371/journal.pone.0187278. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 113.Rastegar-Mojarad M, Ye Z, Wall D, Murali N, Lin S. Collecting and analyzing patient experiences of health care from social media. JMIR Res Protoc. 2015 Jul 2;4(3):e78. doi: 10.2196/resprot.3433. https://www.researchprotocols.org/2015/3/e78/ [DOI] [PMC free article] [PubMed] [Google Scholar]
- 114.Liu R, Zhang X, Zhang H. Web-video-mining-supported workflow modeling for laparoscopic surgeries. Artif Intell Med. 2016 Nov;74:9–20. doi: 10.1016/j.artmed.2016.11.002. [DOI] [PubMed] [Google Scholar]
- 115.SVM light. [2019-11-12]. http://svmlight.joachims.org/
- 116.Cauchois B. pysvmlight. [2019-11-12]. https://bitbucket.org/wcauchois/pysvmlight.
- 117.LIBSVM -- A Library for Support Vector Machines. [2019-11-12]. https://www.csie.ntu.edu.tw/~cjlin/libsvm/
- 118.Dashtipour K, Poria S, Hussain A, Cambria E, Hawalah AY, Gelbukh A, Zhou Q. Multilingual sentiment analysis: state of the art and independent comparison of techniques. Cognit Comput. 2016;8:757–71. doi: 10.1007/s12559-016-9415-7. http://europepmc.org/abstract/MED/27563360. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 119.Department of Computer Science: University of Waikato. [2019-11-12]. https://www.cs.waikato.ac.nz/ml/weka/
- 120.scikit-learn. [2019-11-12]. https://scikit-learn.org/
- 121.Keras Documentation. [2019-11-12]. https://keras.io/
- 122.TextBlob: Simplified Text Processing. [2019-11-12]. https://textblob.readthedocs.io/en/dev/
- 123.Wolpert DH. The lack of a priori distinctions between learning algorithms. Neural Comput. 1996;8(7):1341–90. doi: 10.1162/neco.1996.8.7.1341. doi: 10.1162/neco.1996.8.7.1341. [DOI] [Google Scholar]
- 124.Hutto C, Gilbert E. Vader: A parsimonious rule-based model for sentiment analysis of social media text. Proceedings of Eighth International AAAI Conference on Weblogs and Social Media; ICWSM-14; June 1–4, 2014; Ann Arbor, Michigan, USA. 2014. [Google Scholar]
- 125.Yang Z, Dai Z, Yang Y, Carbonell J, Salakhutdinov R, Le QV. XLNet: Generalized autoregressive pretraining for language understanding. arXiv. 2019 https://arxiv.org/abs/1906.08237. [Google Scholar]
- 126.Howard J, Ruder S. Universal Language Model Fine-tuning for Text Classification. Proceedings of the 56th Annual Meeting of the Association for Computational Linguistics; ACL'18; July 15-20, 2018; Melbourne, Australia. 2018. pp. 328–39. [DOI] [Google Scholar]
- 127.Gray S, Radford A, Kingma DP. GPU kernels for block-sparse weights. arXiv. 2017 https://www.semanticscholar.org/paper/GPU-Kernels-for-Block-Sparse-Weights-Gray-Radford/a07609c2ed39d049d3e59b61408fb600c6ab0950. [Google Scholar]
- 128.Johnson R, Zhang T. Supervised and Semi-supervised Text Categorization Using LSTM for Region Embeddings. Proceedings of the 33rd International Conference on International Conference on Machine Learning - Volume 48; ICML'16; June 19 - 24, 2016; New York, New York, USA. 2016. pp. 526–34. https://arxiv.org/abs/1602.02373. [Google Scholar]
- 129.Xu H, Liu B, Shu L, Yu PS. BERT Post-training for review reading comprehension and aspect-based sentiment analysis. Proceedings of the 2019 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, Volume 1; NAACL'19; June 3-5, 2019; Minneapolis, USA. 2019. pp. 2324–35. https://arxiv.org/abs/1904.02232. [Google Scholar]
- 130.Huang B, Ou Y, Carley K. Aspect Level Sentiment Classification With Attention-over-attention Neural Networks. International Conference on Social Computing, Behavioral-Cultural Modeling and Prediction and Behavior Representation in Modeling and Simulation; SBP-BRiMS'18; July 10-13, 2018; Washington, DC, USA. 2018. pp. 197–206. https://arxiv.org/abs/1804.06536. [DOI] [Google Scholar]
- 131.Li X, Bing L, Lam W, Shi B. Transformation Networks for Target-oriented Sentiment Classification. Proceedings of the 56th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers); ACL'18; July 15-20, 2018; Melbourne, Australia. 2018. pp. 946–56. https://arxiv.org/abs/1805.01086. [DOI] [Google Scholar]
- 132.Chen P, Sun Z, Bing L, Yang W. Recurrent Attention Network on Memory for Aspect Sentiment Analysis. Proceedings of the 2017 Conference on Empirical Methods in Natural Language Processing; the Conference on Empirical Methods in Natural Language Processing; September 7–11, 2017; Copenhagen, Denmark. 2017. pp. 452–61. https://www.aclweb.org/anthology/D17-1047/ [DOI] [Google Scholar]
- 133.Xu H, Liu B, Shu L, Yu P. Double Embeddings and CNN-based Sequence Labeling for Aspect Extraction. Proceedings of the 56th Annual Meeting of the Association for Computational Linguistics (Volume 2: Short Papers); ACL'18; July 15-20, 2018; Melbourne, Australia. 2018. pp. 592–8. https://www.aclweb.org/anthology/P18-2094/ [DOI] [Google Scholar]
- 134.Li X, Lam W. Deep Multi-task Learning for Aspect Term Extraction With Memory Interaction. Proceedings of the 2017 Conference on Empirical Methods in Natural Language Processing; EMNLP'17; September 7–11, 2017; Copenhagen, Denmark. 2017. pp. 2886–92. https://www.aclweb.org/anthology/D17-1310/ [DOI] [Google Scholar]
- 135.Wang W, Pan S, Dahlmeier D, Xiao X. Recursive Neural Conditional Random Fields for Aspect-based Sentiment Analysis. Proceedings of the 2016 Conference on Empirical Methods in Natural Language Processing; EMNLP'16; November 1–5, 2016; Austin, Texas, USA. 2016. pp. 616–26. https://www.aclweb.org/anthology/D16-1059/ [DOI] [Google Scholar]
- 136.Manning C, Surdeanu M, Bauer J, Finkel J, Bethard S, McClosky D. The Stanford CoreNLP natural language processing toolkit. Proceedings of 52nd Annual Meeting of the Association for Computational Linguistics: System Demonstrations; ACL'14; June 22-27, 2014; Baltimore, Maryland, USA. 2014. pp. 55–60. https://www.aclweb.org/anthology/P14-5010/ [DOI] [Google Scholar]
- 137.Bird S. NLTK: The Natural Language Toolkit. Proceedings of the COLING/ACL on Interactive presentation sessions; COLING-ACL'06; July 17 - 18, 2006; Sydney, Australia. 2006. pp. 69–72. https://www.aclweb.org/anthology/P06-4018/ [DOI] [Google Scholar]
- 138.Friedman C, Kra P, Rzhetsky A. Two biomedical sublanguages: a description based on the theories of Zellig Harris. J Biomed Inform. 2002 Aug;35(4):222–35. doi: 10.1016/s1532-0464(03)00012-1. https://linkinghub.elsevier.com/retrieve/pii/S1532-0464(03)00012-1. [DOI] [PubMed] [Google Scholar]
- 139.Bodenreider O. The Unified Medical Language System (UMLS): integrating biomedical terminology. Nucleic Acids Res. 2004 Jan 1;32(Database issue):D267–70. doi: 10.1093/nar/gkh061. http://europepmc.org/abstract/MED/14681409. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 140.Demner-Fushman D, Rogers WJ, Aronson AR. MetaMap Lite: an evaluation of a new Java implementation of MetaMap. J Am Med Inform Assoc. 2017 Jul 1;24(4):841–4. doi: 10.1093/jamia/ocw177. http://europepmc.org/abstract/MED/28130331. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 141.Bradley MM, Lang PJ. The University of Vermont. 1999. [2019-11-12]. Affective Norms for English Words (ANEW): Instruction Manual and Affective Ratings https://www.uvm.edu/pdodds/teaching/courses/2009-08UVM-300/docs/others/everything/bradley1999a.pdf.
- 142.Center for the Study of Emotion and Attention. [2019-11-12]. ANEW Message https://csea.phhp.ufl.edu/media/anewmessage.html.
- 143.Nielsen FA. A new ANEW: Evaluation of a word list for sentiment analysis in microblogs. Proceedings of the ESWC 2011 Workshop on 'Making Sense of Microposts': Big things come in small packages; ESWC'11; 2011; Heraklion, Greece. 2011. pp. 93–8. https://arxiv.org/abs/1103.2903. [Google Scholar]
- 144.AFINN. [2019-11-12]. http://www2.imm.dtu.dk/pubdb/views/publication_details.php?id=6010.
- 145.Stone PJ, Dunphy DC, Smith MS, Ogilvie DM. General Inquirer: A Computer Approach to Content Analysis. Cambridge, Massachusetts, USA: MIT Press; 1966. [Google Scholar]
- 146.Harvard General Inquirer. [2019-11-12]. http://www.wjh.harvard.edu/~inquirer/homecat.htm.
- 147.Dodds PS, Harris KD, Kloumann IM, Bliss CA, Danforth CM. Temporal patterns of happiness and information in a global social network: hedonometrics and Twitter. PLoS One. 2011;6(12):e26752. doi: 10.1371/journal.pone.0026752. http://dx.plos.org/10.1371/journal.pone.0026752. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 148.Language Assessment by Mechanical Turk (labMT) Sentiment Words. [2019-11-12]. https://trinker.github.io/qdapDictionaries/labMT.html.
- 149.Wilson T, Wiebe J, Hoffmann P. Recognizing Contextual Polarity in Phrase-level Sentiment Analysis. Proceedings of the conference on Human Language Technology and Empirical Methods in Natural Language Processing; HLT'05; October 06 - 08, 2005; Vancouver, Canada. 2005. pp. 347–54. https://dl.acm.org/citation.cfm?id=1220619. [DOI] [Google Scholar]
- 150.MPQA. [2019-11-12]. http://mpqa.cs.pitt.edu/
- 151.Mohammad SM, Turney PD. Crowdsourcing a word-emotion association lexicon. Comput Intel. 2013;29(3):436–65. doi: 10.1111/j.1467-8640.2012.00460.x. https://arxiv.org/abs/1308.6297. [DOI] [Google Scholar]
- 152.NRC Emotion Lexicon. [2019-11-12]. http://sentiment.nrc.ca/lexicons-for-research/
- 153.OpinionKB. [DOI]
- 154.Opinion Lexicon. [2019-11-12]. https://www.cs.uic.edu/~liub/FBS/sentiment-analysis.html#lexicon.
- 155.de Albornoz JC, Plaza L, Gervás P. SentiSense: An easily scalable concept-based affective lexicon for sentiment analysis. Proceedings of the Eighth International Conference on Language Resources and Evaluation; LREC'12; May 21-27, 2012; Istanbul, Turkey. 2012. pp. 3562–7. https://www.aclweb.org/anthology/L12-1089/ [Google Scholar]
- 156.SentiSense Affective Lexicon. [2019-11-12]. http://nlp.uned.es/~jcalbornoz/SentiSense.html.
- 157.Baccianella S, Esuli A, Sebastiani F. SentiWordNet 3.0: An Enhanced Lexical Resource for Sentiment Analysis and Opinion Mining. Proceedings of the Seventh International Conference on Language Resources and Evaluation; LREC'10; May 17-23, 2010; Valletta, Malta. 2010. pp. 2200–4. https://www.aclweb.org/anthology/L10-1531/ [Google Scholar]
- 158.SentiWordNet. [2019-11-12]. http://sentiwordnet.isti.cnr.it/
- 159.Strapparava C, Valitutti A. WordNet Affect: An Affective Extension of WordNet. Proceedings of the Fourth International Conference on Language Resources and Evaluation; LREC’04; May 26-28, 2004; Lisbon, Portugal. 2004. https://www.aclweb.org/anthology/L04-1208/ [Google Scholar]
- 160.WordNet Domains. [2019-11-12]. WordNet-Affect http://wndomains.fbk.eu/wnaffect.html.
- 161.Turney PD, Littman ML. Measuring praise and criticism: Inference of semantic orientation from association. ACM Trans Inf Syst. 2003;21(4):315–46. doi: 10.1145/944012.944013. [DOI] [Google Scholar]
- 162.Taboada M, Anthony C, Voll K. Methods for Creating Semantic Orientation Dictionaries. Proceedings of the Fifth International Conference on Language Resources and Evaluation; LREC’06; May 22-28, 2006; Genoa, Italy. 2006. pp. 427–32. https://www.aclweb.org/anthology/L06-1250/ [Google Scholar]
- 163.Du W, Tan S, Cheng X, Yun X. Adapting Information Bottleneck Method for Automatic Construction of Domain-oriented Sentiment Lexicon. Proceedings of the third ACM international conference on Web search and data mining; WSDM'10; February 4 - 6, 2010; New York, New York, USA. 2010. pp. 111–20. https://dl.acm.org/citation.cfm?id=1718502. [DOI] [Google Scholar]
- 164.Miller GA. WordNet: a lexical database for English. Commun ACM. 1995;38(11):39–41. doi: 10.1145/219717.219748. https://dl.acm.org/citation.cfm?id=219748. [DOI] [Google Scholar]
- 165.Kim S, Hovy E. Determining the Sentiment of Opinions. Proceedings of the 20th international conference on Computational Linguistics; COLING'04; August 23 - 27, 2004; Geneva, Switzerland. 2004. https://www.aclweb.org/anthology/C04-1200/ [DOI] [Google Scholar]
- 166.Kamps J, Marx M, Mokken R, Rijke M. Using WordNet to Measure Semantic Orientations of Adjectives. Proceedings of the Fourth International Conference on Language Resources and Evaluation; LREC’04; May 26-28, 2004; Lisbon, Portugal. 2004. pp. 1115–8. https://www.aclweb.org/anthology/L04-1473/ [Google Scholar]
- 167.Hassan A, Radev D. Identifying Text Polarity Using Random Walks. Proceedings of the 48th Annual Meeting of the Association for Computational Linguistics; ACL'10; July 11 - 16, 2010; Uppsala, Sweden. 2010. pp. 395–403. https://www.aclweb.org/anthology/P10-1041/ [Google Scholar]
- 168.Dragut E, Yu C, Sistla P, Meng W. Construction of a Sentimental Word Dictionary. Proceedings of the 19th ACM international conference on Information and knowledge management; CIKM'10; October 26 - 30, 2010; Toronto, Canada. 2010. pp. 1761–4. [DOI] [Google Scholar]
- 169.Lu Y, Castellanos M, Dayal U, Zhai C. Automatic Construction of a Context-aware Sentiment Lexicon: An Optimization Approach. Proceedings of the 20th international conference on World wide web; WWW'11; March 28 - April 1, 2011; Hyderabad, India. 2011. pp. 347–56. https://dl.acm.org/citation.cfm?id=1963456. [DOI] [Google Scholar]