


Abstract
The Standard European Vector Architecture 3.0 database (SEVA-DB 3.0, http://seva.cnb.csic.es) is the update of the platform launched in 2013 both as a web-based resource and as a material repository of formatted genetic tools (mostly plasmids) for analysis, construction and deployment of complex bacterial phenotypes. The period between the first version of SEVA-DB and the present time has witnessed several technical, computational and conceptual advances in genetic/genomic engineering of prokaryotes that have enabled upgrading of the utilities of the updated database. Novelties include not only a more user-friendly web interface and many more plasmid vectors, but also new links of the plasmids to advanced bioinformatic tools. These provide an intuitive visualization of the constructs at stake and a range of virtual manipulations of DNA segments that were not possible before. Finally, the list of canonical SEVA plasmids is available in machine-readable SBOL (Synthetic Biology Open Language) format. This ensures interoperability with other platforms and affords simulations of their behaviour under different in vivo conditions. We argue that the SEVA-DB will remain a useful resource for extending Synthetic Biology approaches towards non-standard bacterial species as well as genetically programming new prokaryotic chassis for a suite of fundamental and biotechnological endeavours.
INTRODUCTION
Plasmid vectors have been the key brokers of the recombinant DNA revolution initiated in the late 1970s of the last century (1). This has been followed three decades later by the not less spectacular and still ongoing development of Synthetic Biology, the ambition of which includes implementation of engineering in Biology not as a metaphor (as in traditional Genetic Engineering) but as an actual quantitative, design-oriented discipline (2). Despite spectacular advances in DNA synthesis (3,4), it is most likely that plasmids and related cloning vectors will remain for a considerable period of time the principal assets available to Synthetic Biologists and Molecular Biologists at large for both dissecting and building biological properties, especially in bacteria. Alas, the emphasis on standardization that characterizes Synthetic Biology has hardly reached beyond small communities. Even issues as simple as agreeing on fixed formats for plasmid vectors and other genetic tools has not widely succeeded to this day. Why? In reality, standards do limit flexibility but both boost interoperability of genetic devices among users, enable rigorous metrology of biological activities in time and space and enhance reproducibility (5,6). As Synthetic Biology moves from the Laboratory towards a range of applications in the Health sector, the industry and the environment, these last considerations acquire more importance and there is a growing demand of tackling Biological systems with standardized tools (7). In this context, the SEVA (Standard European Vector Architecture) database was created in 2013 as a web-based collection of plasmid vectors assembled with a simple, pre-formatted arrangement of functional DNA segments which eased the exchange of functional moieties (replication origins, antibiotic resistances and cargo modules) and allowed moving the resulting constructs among a suite of Gram-negative hosts (8,9; Figure 1). This release was followed in 2015 by a 2.0 SEVA-DB update (10) that apart of containing more plasmids it also incorporated some functionalities for virtual assembly and analysis of the vectors in the Web interface. Moreover, the SEVA 2.0 repository included what was called the SEVA-SIB collection (SIB = sibling) of plasmids that kept some features of the standards without adopting the format completely. Finally, the updated platform included an example of a description of an individual construct (pSEVA111) in SBOL (Synthetic Biology Open Language) format (11,12).
Figure 1.

The formatted structure of SEVA plasmids. The image show an interactive map with the organization of SEVA vectors as shown in the 3.0 version of the database. All plasmids contain three basic modules: a cargo, a replication origin and an antibiotic marker as indicated. Fixed restriction sites punctuate boundaries between modules in all constructs are indicated. Note the numbering position +1 of the DNA sequence is the first T of the unique PacI site. The preferred site(s) for inserting functional gadgets are indicated. See http://seva.cnb.csic.es for details.
In the last few years, the SEVA platform has consolidated itself as a popular source of vectors for unfolding engineered traits in a large variety of bacteria, with an increasing number of accessed and plasmids requests for running a large variety of projects. Experience has shown that the main value of the SEVA-DB is that of putting into action constructs in Gram-negative hosts or chassis other than Escherichia coli and enabling their portability among different type of bacteria. The last was made possible by the suite of broad host range replication origins available and by the default incorporation of an origin of transfer in all SEVA plasmids. The short oriT sequence, that is shared by all vectors (Figure 1) eases conjugal transfer of the engineered DNA among hosts of interest. It must be emphasized that the primary purpose of the platform is facilitating deployment of engineered functions, not the assembly of complex DNA segments—for which a whole suite of strategies and specialized vectors have been developed in recent years (13–16).
By building on the proven strengths of the earlier SEVA-DB versions, we present below an update that makes access to information easier to users, includes more plasmids (both canonical SEVA vectors and SEVA-SIB constructs) and additional information that allows them to be amenable to machine reading through descriptions in SBOL format. On these bases, we introduce SEVA-DB 3.0 as a useful, expandable and user-friendly resource that opens out Synthetic Biology strategies towards a large variety of bacterial species.
DATABASE DESCRIPTION
Database organization
As was the case with its predecessor, the updated SEVA database (SEVA-DB 3.0, http://seva.cnb.csic.es) serves primarily as an annotated and information-rich index of functional DNA sequences and constructs that are available to the community. The platform maintains a simple architecture, which consists of a relational database as the records storage layer, a series of modules and utilities that are hosted by an application server and a web-based presentation layer. The last is endowed with an explicit set of standards that apply to all constructs and can in most cases send the vector sequences to a remote analysis server. However, the outputs of the search for each vector are richer than the previous version of the database. Whereas SEVA 2.0 only allowed playing with the links to GenBank (or alternatively to an interim gb/gbk file of the plasmid), the SEVA 3.0 search tool provides the sequences in SBOL format as well as visual maps of each of the plasmids along with a number of matching resources for sequence analysis.
From the point of view of the user, the SEVA website has been altogether reworked for improving navigation and usability, as well as to enhance the position of the SEVA format as one of the most common standards for vector development in Europe and beyond. In brief, the new website has been developed in line with a modern graphic identity and features a homepage and five sections. The Structure section provides users with a basic description of the SEVA format as well as information about the steps needed for researchers to contribute to the standard. The Backbone module section constitutes one of the most significant advancement with respect to the previous version since it provides the user with an interactive and graphic tour through the different functional segments of the plasmids. With an easy click-and-play dynamic, web visitors can not only see but also copy all relevant sequences in the SEVA backbone and modules (Figure 2). The entire SEVA database can be browsed at the Find your plasmid section where an improved search box tool has been programmed. This utility allows users to filter available plasmids based on the antibiotic resistance, origin of replication and cargo, as well as the newly introduced category of gadgets. In order to allow for multiple visualization options, most canonical plasmids are linked to a Genbank sequence, a view in the LabGenius platform, the SBOL standard graphic format and a visual interactive map (powered by Doulix, see below). Finally, the website features two additional sections with information about the contributing Laboratories as well as contact forms for users to request their plasmids free of charge.
Figure 2.

Interactive maps of SEVA plasmids. By clicking in the corresponding segment of the vector scheme, user gets a roll-down list of choices for each of the available modules as well as their DNA sequence for further analysis or composition with other genetic parts.
These updates in the website are aligned with other communication efforts aimed at increasing the visibility of the SEVA-DB as a virtual and material platform of reference. To this end, the website homepage now contains an explanatory animation video (https://www.youtube.com/watch?v=I8gZjXDRQ2I) as well as a linked Twitter profile (https://twitter.com/SEVAplasmids) that opens a quick communication channel for updated information about the plasmid collection and its partial updates or amendments to its users.
New constructs
The SEVA-DB 3.0 hosts a significantly larger collection of plasmids and modules that follow rigorously the standard. This includes constructs with two new antibiotic resistances: trimethoprim (TmpR, a broad spectrum inhibitor of dihydrofolate reductase and thus of C1 metabolism) and apramycin (ApraR, an aminoglycoside that inhibits protein synthesis). The updated canonical list comprises a total of 31 cargoes (16 basic and 15 variants, Figure 4), among them a most useful broad host range thermoinducible system, an unstable variant of GFP and a specialized vector for assembling CRISPR arrays. We have also started to develop shuttle plasmids between Gram-negative and Gram-positive hosts that bear two separate origins of replication in their oriV module. As explained later, this has raised a new issue in the nomenclature of vectors. Owing to the feedback of users, the sequence of some modules has been corrected (e.g. the tetA gene in some SEVA plasmids). Also, note that combinations of modules that may not be available off-shelf can be easily generated by using the set of standardized primers and the strategy designed by (17).
Figure 4.

Updated numbering of core SEVA modules. The list of available modules for each position of the code shown in Figure 3 are shown.
SEVA-DB 3.0 also hosts a suite of vectors that largely keep features compatible with the canonical collection while failing to meet one of more criteria of the standard. The number of plasmids in the SEVA-SIB list has increased up to 129 new constructs kindly donated and deposited by a variety of contributors (see the Acknowledgements section and vector list). While the SEVA-DB curators will be distributing them upon request, note that specific details on their utilization may have to be requested to the original Authors' source.
Updating the nomenclature of SEVA modules
One feature that was not contemplated in the first versions of the database was that of double replication origins for proliferation of the same constructs in different hosts. SEVA 1.0 indeed contained a series of vectors with pRO1600 and ColE1 origins combined in a single module, which was given an oriV number (#4). While the host range of the 1.0 collection was intended to be just (or mostly) Gram-negative bacteria soon the necessity to move constructs among a wider variety of recipients became evident. To meet this development, the initial code for oriV modules has been updated as shown in Figure 3. Single origins beyond origin #9 are to be named by adding a capital letter (e.g. 9A, 9B etc). But in order to accommodate double origins the second position of the code must be added with a lower-case letter. This means that the code for the Gram-negative origin is kept but it should be complemented with a code letter for the Gram-positive (or other) counterparts. For example: a plasmid with RK2 and SCP2* origins at their oriV module should have at the replication module position the code 2b. In contrast, if the Gram-negative origin is beyond 9 (e.g. 9B), then its combination with an SCP2* would result in a code 9Bb. The codes of the core collection of replication origins, antibiotic resistance genes and cargoes available at this point are shown in Figure 4.
Figure 3.
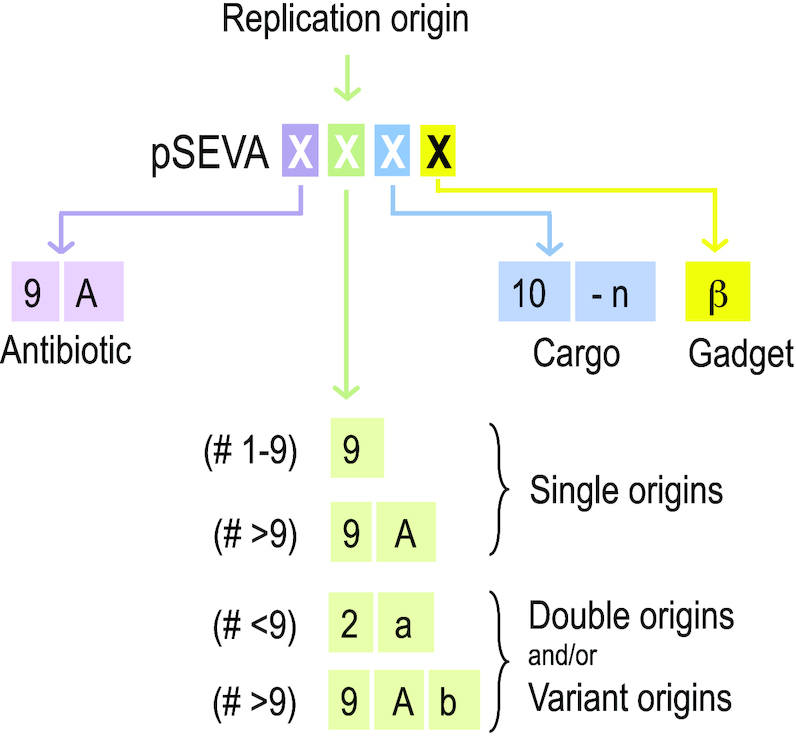
Updated nomenclature of SEVA vectors. The figure sketches the rules for naming each of the 4 positions available for shaping a complete SEVA code. Each of them is assigned to a code of four unequivocal positions in an alphanumeric cipher: The first position is for the antibiotic resistance. For the second position, the first nine origins of replication receive a sole numeric code 1 to 9 beyond which a capital letter will be added to ‘9’, starting with an A (9A) and following with 9B, 9C etc. In case of either variants or addition(s) of a second replication origin, a lower case letter is then added. The third position, each cargo is assigned a sole ordinal numeric code 1 to n (n being unlimited). Finally, the fourth position is for the gadgets, which are designated by lower case Greek letters (α to ω).
Utilities for plasmid analysis and construct design
Plasmid analyses are facilitated in SEVA-DB 3.0 through the integration of the whole vector collection in the Doulix repository. This is a findable, accessible, interoperable and reusable (FAIR) platform in which each part and construct of the SEVA collection is associated to an unique persistent identifier registered at https://identifiers.org/ as DLXB https://doulix.com/collections/lrp/biomodules/ and DLXC (https://doulix.com/collections/lrp/constructs/) respectively. This ensures digital data integrity and traceability over time. SEVA sequences can be found either through organic web search or through public Application Programming Interfaces (API). Sequences are accessible through the Doulix sequence viewer for both registered and unregistered users—or directly through a public API. Doulix supports different formats to ensure interoperability including fasta, gb, gff3. Sequences are provided under the Creative Commons scheme as CC-BY-NC 4.0.
The 3.0 version of SEVA-DB also incorporates an advanced sequence editor through which design and validation of each SEVA vector and its derivatives can be easily carried out. Users can easily draft a new vector according to SEVA’s rules and syntax using the pSEVA template available in the Configuration step. The pSEVA template presents a modular architecture that consists of different placeholders; each placeholder hosts a different biological function (e.g. cargo, oriV, Selection marker) and is flanked by the rare restriction enzymes that punctuate the modules. Some placeholders are already pre-filled to simplify and speed up the design phase, where the user has only to choose the three major components of any plasmid vector: Origin of Replication, Selection Marker and the Business Cargo. In the drafting phase, users can easily manipulate the construct acting on individual placeholders by choosing a Biomodule among a list of hundreds of available parts. During drafting, Doulix algorithm ranks SEVA parts according to function and relevance to further assist users during the design process. The user has also the choice to upload its own sequence by creating a new biomodule directly within the sequence editor. In the advanced phase, the user has the option to manipulate the sequence at nucleotide level accessing advanced editing functions such as edit, mutate, replace, delete and annotate.
Finally, in order to ease virtual designs, SEVA-DB 3.0 includes the utility called SEVA Wizard (https://doulix.com/toolbox/create-pseva/), which is available within the Doulix's Toolbox. This tool guides the user step-by-step through the stages of designing pSEVA constructs complying with the standardized SEVA layout. To this end, the utility requires the user to (i) simply upload the DNA cargo as .FASTA or .gb or directly type in the sequence and (ii) name pSEVA construct. These two operations are the only prerequisites to let the Doulix server assemble the pSEVA construct carrying the user's Cargo sequence. Next, the user needs just to choose the Selection marker and the Replication Origin among hundreds of options. This choice is facilitated by the adoption of the SEVA nomenclature for all Biomodules belonging to the SEVA collection, so that their function can be easily inferred. SEVA Wizard supports the users also in the validation step of their pSEVA constructs. Once the Design step is completed, it helps avoiding most common flaws by returning a list of warnings that can be reviewed before moving to e.g. DNA synthesis—which is also offered as a choice. Finally, the user has the chance of explore different cloning protocols (e.g. Gibson, GoldenGate, SureVector) for assembling the pSEVA derivate at stake leveraging the Doulix cloning wizard (https://doulix.com/toolbox/from-fasta-to-synthesis). The SEVA Wizard thus aims at streamlining the entire process of construction of a new pSEVA vector or any derivative thereof from design to DNA synthesis.
SEVA sequences in SBOL format
In order to foster the sharing of information, all sequences in the new version of the SEVA database have been translated into the Synthetic Biology Open Language (12) (SBOL) format, a data standard for genetic circuit design. SBOL offers several advantages compared to existing formats of DNA sequence description. In the same way that GenBank upgrades FASTA in that the user is able to capture better-quality information (e.g. sequence annotations), SBOL upgrades the former by allowing for the representation of, among others, hierarchy, connectivity and modularity. It allows to represent not only DNA, but also other molecules such as regulators, and group them by functionality in a pre-defined hierarchical structure. The information about SEVA vectors is therefore fully standardized, which will hopefully foster the impact of the language in the development of given workflows (18,19). This will expectedly happen because of the ability of integrating and automating the design-build-test lifecycle, allowing for data (SBOL) and molecular (SEVA) standards proceed alongside.
SBOL data is stored in an instance of SynBioHub (20) (synbiohub.org) that was installed under the domain http://sevahub.es i.e. the SEVA hub repository. SynBioHub is as an open-source software project aiming at facilitating the hosting of information about genetic designs, and specifically developed to exploit the benefits of the SBOL format. At SEVAhub, the user can interact with SEVA data. Users can download the SBOL description (also its GenBank/FASTA version) for entire plasmids (e.g. pSEVA111) or single components within them (e.g. terminator T0), which shows the modularity in which SBOL data is structured. This is, all markers, cargoes and origins of replication, along with sequence details as scars (i.e., unexpected bases after assembly) or restriction sites can be searched for and downloaded independently. A more advanced use of the SEVAhub repository would be to use computer-aided design (CAD) tools, as for instance iBioSim (21), to fetch genetic parts from SEVAhub, or to use programmatic software libraries (22) to edit SBOL data on demand. This repository is associated with what we termed the web-of-registries, a cooperation between SynBioHub instances making SBOL data from different sources accessible. Currently, it is not possible for the user to open an account at SEVAhub in order to upload genetic designs – this option was disabled on purpose for the sake of maintaining consistency between the wet and the in silico collections. Only those SEVA vectors listed in http://seva.cnb.csic.es are, for the time being, included in SEVAhub. Future planned upgrades will target the visualisation of SBOL data in SEVAhub by improving SBOLvisual (23) support, the addition of a user-friendly application (within SEVAhub) to allow users edit SBOL data, and the development of an SBOL interface within Doulix's design application aiming at closing the loop from design to implementation.
Non-canonical vector collections based on or related to the SEVA-DB 3.0 list
Since the launch of the SEVA-DB 2.0 platform a number of constructs for diverse genetic engineering transactions can be found in the literature which—while non following the standard—have incorporated some features for specialized used in given types of bacteria. These include single copy repABC—shuttle vectors for Sinorhizobium meliloti (24), streamlined plasmids for Agrobacterium tumefaciens-mediated transformation of fungi (25), derivatives designed as assembly and integrative vectors for Bacillus subtilis (26) and plasmids modified for easing assembly of multiple DNA segments (27). Some of the constructs are available in the SEVA-SIB entry of the 3.0 platform, but all the others have been developed independently and are thus neither available through our repository nor guaranteed to follow the rules of assembly and open source availability—let alone their sequences cannot be analysed through the SEVA-DB 3.0 utilities already described. Potential users are thus encouraged to request these constructs directly from the Authors and clarifying with them the terms of use.
Availability of materials stocked in the SEVA repository
At the time of writing this article > 2,100 plasmids from the SEVA collection have been distributed to 37 countries and the articles describing platforms 1.0 and 2.0 have received > 390 citations. At the time of writing this update, the three most solicited plasmids in the collection are: pSEVA221, pSEVA251 and pSEVA224. The repository has also been instrumental for circulation of 164 SEVA-SIB plasmids. As was declared in previous editions of the database, all materials posted in SEVA-DB 3.0 can be requested on line and free of charge following the instructions indicated in the corresponding section of the webpage and under the terms of disclaiming carrier liability thereby specified. While a moderate number of requests can be shipped for free from the central repository of the collection at the National Center of Biotechnology (Madrid, Spain), note that larger orders may have to be handed over to an accredited handling company and thus subject to a fee. Those willing to get familiar with the SEVA platform can also order a starter kit free of charge with a selection of 10 most frequently requested plasmids containing a wide combination of antibiotic selection markers, replication origins and cargoes (pSEVA111, pSEVA224, pSEVA2313, pSEVA331, pSEVA427, pSEVA551, pSEVA631, pSEVA242, pSEVA228, pSEVA236).
OUTLOOK
Since its beginning, the SEVA platform has ambitioned to contribute to the ongoing push towards standardization in Synthetic Biology, Molecular Microbiology and Biotechnology as a whole (7). In line with the early ethos of Synthetic Biology, access to the plasmids of the collection is entirely cost-free and intellectual property issues are handed over to end-using scenarios rather than raising them upfront. We expect being able to maintain this state of affairs during the whole lifetime of the SEVA-DB 3.0 and hopefully the next editions as well. But what could be the novelties that can be envisioned in such future versions?
As already mentioned, the rising ease and low cost of chemical or enzymatic DNA synthesis (3,4) may make the use of plasmids and associated DNA assembly methods less appealing in the future, specially for well established bacterial models. Self-replicating vectors will however be still necessary for a significant period of time for bringing genetic engineering to a growing number of isolates and species with interesting properties but for which few or little tools are not at hand. To this end, the SEVA-DB 3.0 collection does contain (whether in the canonical or the SEVA-SIB lists) a number of constructs that can be used off-the-shelf for CRISPR/Cas9 applications and double stranded (ds), single stranded (ss) DNA recombineering in different types of bacteria and a compilation of inducible heterologous expression systems.
On the basis of the core collection currently available we anticipate various developments of interest. One is the possibility of designing SEVA cargoes compatible with advanced DNA composition strategies such as Molecular Cloning (MoClo; 28). In this way, assembly and deployment can be done in the same construct without the limitations imposed by the fixed restriction sites of the multiple cloning site of the existing cargoes. Note that a SEVA-inspired vector collection has been recently published to this end (27), including variants for use in Gram-positive bacteria (26). While surely useful, they do not follow the SEVA format and thus they cannot be considered as standardized tools. Fortunately, reshaping SEVA vectors for MoClo is relatively straightforward and we expect to see soon an extension of the standardized platform adapted to this end. Furthermore, efforts are under way to make different assembly and deployment vector platforms compatible (29). The same is true for harmonizing the SEVA standard with the wealth of functional DNA segments deposited in the iGEM-based Registry of Biological Parts (http://parts.igem.org; Damalas et al., in preparation). These developments will be accounted for—and whenever possible incorporated—in future editions of the SEVA platform.
Another possible development that has not escaped out notice is that the diversity of broad host range origins of replication and antibiotic resistances of the SEVA-DB 3.0 allow testing the large collection of the genetically-encoded logic gates that shape the CELLO operative system (30). While the original set of constructs was developed and optimized for E. coli, the SEVA vectors enable studies on their interoperability among strains of the same species and/or among different species, an issue that is currently under investigation in our Laboratory.
Finally, we will be pursuing the development of a SEVA-compatible standard for engineering mobile genetic elements e.g. transposons and transposon-vectors (31) as well as formatted replicons for easy transfer of constructs and complex assemblies between yeast and non-E. coli bacteria. Ultimately, we ambition SEVA to serve the Synthetic Biology community by offering an open and user-friendly collection of genetic tools that meets a whole range of needs from very simple students' projects all the way to industrial applications.
ACKNOWLEDGEMENTS
Authors are indebted to all members of the Molecular Environmental Microbiology in Madrid (ttp://www.cnb.csic.es/∼synbio) for their enthusiastic assistance in the preservation and expansion of the SEVA repository. The laboratories of F. Lombó (Oviedo, Spain), P. Nikel (Lyngby, Denmark), E. Santero (Seville, Spain), J. Nogales (Madrid, Spain), S. Rosser (Edinburgh, UK), T. Mascher (Munich, Germany), A. Becker (Marburg, Germany), S. Müller (Leipzig, Germany), A.T. Nielsen (Lyngby, Denmark), L. Blank (Aachen, Germany), Csaba Pal (Szeged, Hungary) and J. Kroemer (Leipzig, Germany) are gratefully acknowledged for their valuable contributions to the collection.
FUNDING
The SEVA repository has been developed with funds of the SETH Project of the Spanish Ministry of Science [RTI 2018-095584-B-C42, MADONNA (H2020-FET-OPEN-RIA-2017-1-766975), BioRoboost (H2020-NMBP-BIO-CSA-2018), SYNBIO4FLAV (H2020-NMBP/0500) and LIAR (H2020-EU.1.2.1-686585)]; Contracts of the European Union and the S2017/BMD-3691 InGEMICS-CM funded by the Comunidad de Madrid (European Structural and Investment Funds) and the UK Engineering and Physical Science Research Council [EP/R019002/1]. Work at Raytheon was supported by the Air Force Research Laboratory (AFRL) and DARPA under contract FA875017CO184. Any opinions, findings and conclusions or recommendations expressed in this material are those of the author(s) and do not necessarily reflect the views of the AFRL and DARPA.This document does not contain technology or technical data controlled under either U.S. International Traffic in Arms Regulation or U.S. Export Administration Regulations. Funding for open access charge: H2020-NMBP-BIO-CSA-2018.
Conflict of interest statement. None declared.
REFERENCES
- 1. Balbás P., Soberón X., Merino E., Zurita M., Lomeli H., Valle F., Flores N., Bolivar F.. Plasmid vector pBR322 and its special-purpose derivatives—a review. Gene. 1986; 50:3–40. [DOI] [PubMed] [Google Scholar]
- 2. Church G.M., Elowitz M.B., Smolke C.D., Voigt C.A., Weiss R.. Realizing the potential of synthetic biology. Nat. Rev. Mol. Cell Biol. 2014; 15:289. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 3. Venetz J.E., Del Medico L., Wölfle A., Schächle P., Bucher Y., Appert D., Tschan F., Flores-Tinoco C.E., van Kooten M., Guennoun R. et al.. Chemical synthesis rewriting of a bacterial genome to achieve design flexibility and biological functionality. Proc. Nat. Acad. Sci. U.S.A. 2019; 116:8070–8079. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 4. Ceze L., Nivala J., Strauss K.. Molecular digital data storage using DNA. Nat. Rev. Genet. 2019; 20:456–466. [DOI] [PubMed] [Google Scholar]
- 5. Endy D. Foundations for engineering biology. Nature. 2005; 438:449–453. [DOI] [PubMed] [Google Scholar]
- 6. Canton B., Labno A., Endy D.. Refinement and standardization of synthetic biological parts and devices. Nat. Biotechnol. 2008; 26:787–793. [DOI] [PubMed] [Google Scholar]
- 7. de Lorenzo V., Schmidt M.. Biological standards for the Knowledge-Based BioEconomy: what is at stake. New Biotechnol. 2018; 40:170–180. [DOI] [PubMed] [Google Scholar]
- 8. Silva-Rocha R., Martinez-Garcia E., Calles B., Chavarria M., Arce-Rodriguez A., de Las Heras A., Paez-Espino A.D., Durante-Rodriguez G., Kim J., Nikel P.I. et al.. The Standard European Vector Architecture (SEVA): a coherent platform for the analysis and deployment of complex prokaryotic phenotypes. Nucleic Acids Res. 2013; 41:D666–D675. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 9. Durante-Rodriguez G., de Lorenzo V., Martinez-Garcia E.. The Standard European Vector Architecture (SEVA) plasmid toolkit. Methods Mol. Biol. 2014; 1149:469–478. [DOI] [PubMed] [Google Scholar]
- 10. Martínez-García E., Aparicio T., Goñi-Moreno A., Fraile S., de Lorenzo V.. SEVA 2.0: an update of the Standard European Vector Architecture for de-/re-construction of bacterial functionalities. Nucleic Acids Res. 2014; 43:D1183–D1189. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 11. Galdzicki M., Clancy K.P., Oberortner E., Pocock M., Quinn J.Y., Rodriguez C.A., Roehner N., Wilson M.L., Adam L., Anderson J.C. et al.. The Synthetic Biology Open Language (SBOL) provides a community standard for communicating designs in synthetic biology. Nat. Biotechnol. 2014; 32:545–550. [DOI] [PubMed] [Google Scholar]
- 12. Madsen C., Moreno A.G., Umesh P., Palchick Z., Roehner N., Atallah C., Bartley B., Choi K., Cox R.S., Gorochowski T.. Synthetic biology open language (SBOL) version 2.3. J. Integr. Bioinf. 2018; 16:doi:10.1515/jib-2019-0025. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 13. Moore S.J., Lai H.-E., Kelwick R.J., Chee S.M., Bell D.J., Polizzi K.M., Freemont P.S.. EcoFlex: a multifunctional MoClo kit for E. coli synthetic biology. ACS Synth. Biol. 2016; 5:1059–1069. [DOI] [PubMed] [Google Scholar]
- 14. Storch M., Casini A., Mackrow B., Ellis T., Baldwin G.S.. Synthetic DNA. 2017; Springer; 79–91. [DOI] [PubMed] [Google Scholar]
- 15. Cavaleiro A.M., Kim S.H., Seppala S., Nielsen M.T., Nørholm M.H.. Accurate DNA assembly and genome engineering with optimized uracil excision cloning. ACS Synth. Biol. 2015; 4:1042–1046. [DOI] [PubMed] [Google Scholar]
- 16. Juhas M., Ajioka J.W.. High molecular weight DNA assembly in vivo for synthetic biology applications. Crit. Revs. Biotechnol. 2017; 37:277–286. [DOI] [PubMed] [Google Scholar]
- 17. Kim S.H., Cavaleiro A.M., Rennig M., Nørholm M.H.. SEVA linkers: a versatile and automatable DNA backbone exchange standard for synthetic biology. ACS Synth. Biol. 2016; 5:1177–1181. [DOI] [PubMed] [Google Scholar]
- 18. Goñi-Moreno A., Carcajona M., Kim J., Martínez-García E., Amos M., de Lorenzo V.. An implementation-focused bio/algorithmic workflow for synthetic biology. ACS Synth. Biol. 2016; 5:1127–1135. [DOI] [PubMed] [Google Scholar]
- 19. Myers C.J., Beal J., Gorochowski T.E., Kuwahara H., Madsen C., McLaughlin J.A., Mısırlı G., Nguyen T., Oberortner E., Samineni M.. A standard-enabled workflow for synthetic biology. Biochem. Soc. Trans. 2017; 45:793–803. [DOI] [PubMed] [Google Scholar]
- 20. McLaughlin J.A., Myers C.J., Zundel Z., Mısırlı G.k., Zhang M., Ofiteru I.D., Gonñi-Moreno A., Wipat A.. SynBioHub: a standards-enabled design repository for synthetic biology. ACS Synth. Biol. 2018; 7:682–688. [DOI] [PubMed] [Google Scholar]
- 21. Watanabe L., Nguyen T., Zhang M., Zundel Z., Zhang Z., Madsen C., Roehner N., Myers C.. iBioSim 3: a tool for model-based genetic circuit design. ACS Synth. Biol. 2018; 8:1560–1563. [DOI] [PubMed] [Google Scholar]
- 22. Bartley B.A., Choi K., Samineni M., Zundel Z., Nguyen T., Myers C.J., Sauro H.M.. pySBOL: a python package for genetic design automation and standardization. ACS Synth Biol. 2018; 8:1515–1518. [DOI] [PubMed] [Google Scholar]
- 23. Beal J., Nguyen T., Gorochowski T.E., Goñi-Moreno A., Scott-Brown J., McLaughlin J.A., Madsen C., Aleritsch B., Bartley B., Bhakta S.. Communicating structure and function in synthetic biology diagrams. ACS Synth. Biol. 2019; 8:1818–1825. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 24. Dohlemann J., Wagner M., Happel C., Carrillo M., Sobetzko P., Erb T.J., Thanbichler M., Becker A.. A family of single copy repABC-type shuttle vectors stably maintained in the alpha-proteobacterium sinorhizobiummeliloti. ACS Synth. Biol. 2017; 6:968–984. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 25. Nora L.C., Gonçales R.A., Martins-Santana L., Ferreira B.H., Rodrigues F., Silva-Rocha R.. Synthetic and minimalist vectors for Agrobacteriumtumefaciens-mediated transformation of fungi. Gen. Mol. Biol. 2019; 42:395–398. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 26. Radeck J., Meyer D., Lautenschläger N., Mascher T.. Bacillus SEVA siblings: a Golden Gate-based toolbox to create personalized integrative vectors for Bacillus subtilis. Sci. Rep. 2017; 7:14134. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 27. Geddes B.A., Mendoza-Suárez M.A., Poole P.S.. A bacterial expression vector archive (BEVA) for flexible modular assembly of golden gate-compatible vectors. Front. Microbiol. 2018; 9:3345. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 28. Weber E., Engler C., Gruetzner R., Werner S., Marillonnet S.. A modular cloning system for standardized assembly of multigene constructs. PLoS One. 2011; 6:e16765. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 29. Valenzuela-Ortega M., French C.. Joint Universal Modular Plasmids (JUMP): a flexible and comprehensive platform for synthetic biology. 2019; bioRxiv doi:10 October 2019, preprint: not peer reviewed 10.1101/799585. [DOI] [PMC free article] [PubMed]
- 30. Nielsen A.A., Der B.S., Shin J., Vaidyanathan P., Paralanov V., Strychalski E.A., Ross D., Densmore D., Voigt C.A.. Genetic circuit design automation. Science. 2016; 352:aac7341. [DOI] [PubMed] [Google Scholar]
- 31. Martinez-Garcia E., Aparicio T., de Lorenzo V., Nikel P.. New transposon tools tailored for metabolic engineering of Gram-negative microbial cell factories. Front. Bioeng. Biotechnol. 2015; 2:46. [DOI] [PMC free article] [PubMed] [Google Scholar]