

ABSTRACT
Suppose we have a Bayesian model that combines evidence from several different sources. We want to know which model parameters most affect the estimate or decision from the model, or which of the parameter uncertainties drive the decision uncertainty. Furthermore, we want to prioritize what further data should be collected. These questions can be addressed by Value of Information (VoI) analysis, in which we estimate expected reductions in loss from learning specific parameters or collecting data of a given design. We describe the theory and practice of VoI for Bayesian evidence synthesis, using and extending ideas from health economics, computer modeling and Bayesian design. The methods are general to a range of decision problems including point estimation and choices between discrete actions. We apply them to a model for estimating prevalence of HIV infection, combining indirect information from surveys, registers, and expert beliefs. This analysis shows which parameters contribute most of the uncertainty about each prevalence estimate, and the expected improvements in precision from specific amounts of additional data. These benefits can be traded with the costs of sampling to determine an optimal sample size. Supplementary materials for this article, including a standardized description of the materials available for reproducing the work, are available as an online supplement.
KEYWORDS: Decision theory, Research prioritization, Uncertainty
1. Introduction
Bayesian modeling is a natural paradigm for decision making, in the presence of uncertainty, based on multiple sources of evidence. However, as more data sources, parameters, and assumptions are built into a model, it becomes harder to see the influence of each input or assumption. The modeling process should involve an investigation of where the weak parts of the model are, to identify which uncertainties in the model inputs contribute most to the uncertainty in the final result or decision (sensitivity analysis). We might then want to assess and compare the potential value of obtaining datasets of specific designs or sizes to strengthen different parts of the model. Furthermore, we may want to formally trade-off the costs of sampling with the resulting expected improvement to decision making.
Annual estimation of HIV prevalence in the United Kingdom has, for several years, been based on a Bayesian synthesis of evidence from various surveillance systems and other surveys (Goubar et al. 2008; Presanis et al. 2010; De Angelis et al. 2014; Kirwan et al. 2016). This is an example of a class of problems called multiparameter evidence synthesis (MPES) (e.g., Ades and Sutton 2006), where the quantities of interest cannot be estimated directly, but can be inferred from multiple indirect data sources linked through a network of model assumptions that can be expressed as a directed acyclic graph. Markov chain Monte Carlo (MCMC) is typically required to estimate the posterior. The HIV MPES model is used to inform health policies, thus it is crucial to be able to assess sensitivity to uncertain inputs and to indicate how the model could be strengthened with further data.
These dual aims can be achieved with value of information (VoI) analysis, a decision-theoretic framework based on expected reductions in loss from future information. The concepts of VoI were first set out in detail by Raiffa and Schlaifer (1961), while Parmigiani and Inoue (2009) give a more recent overview. The expected value of partial perfect information (EVPPI) is the expected reduction in loss if the exact value of a particular parameter or parameters were learnt, also interpreted as the amount of decision uncertainty that is due to . The expected value of sample information (EVSI) is the expected reduction in loss from a study of a specific design. The EVSI can be traded off with the costs of data collection to give the expected net benefit of sampling (ENBS). Therefore, as well as recommending a policy based on minimising expected loss under the current model and data, the decision-maker may also recommend collecting further data according to a design which minimises the ENBS.
These concepts have been applied in various forms in three distinct areas: health economics, computer modeling and Bayesian design. In health economic modeling, there is a large literature on calculation and application of VoI, see, for example, Felli and Hazen (1998); Willan and Pinto (2005); Claxton and Sculpher (2006); Welton et al. (2008). The model output is then the expected net benefit of each alternative policy, a known deterministic function of uncertain inputs , and the decision problem is the choice of policy that minimises . In computer modeling, see, for example, Oakley and O’Hagan (2004) and Saltelli et al. (2004), the influence of a particular element of is calculated as the expected reduction in , if we were to learn exactly. This is equivalent to the EVPPI for under a decision problem defined as point estimation of with quadratic loss (Oakley and O’Hagan 2004). The decision-theoretic view of Bayesian experimental design also has a long history, see, e.g. Lindley (1956); Bernardo and Smith (1994); Chaloner and Verdinelli (1995); Berger (2013), and a recent review of the computational challenges by Ryan et al. (2016).
However, the current tools in any one of these three areas cannot be applied directly to MPES. First of all, it is not always feasible or desirable to make a discrete decision with a quantifiable loss, as in health economic modeling. Instead, the aim of evidence synthesis is often to estimate one or more quantities. For a scalar quantity of interest, we might then define the “loss” as the posterior variance of this quantity, as Oakley and O’Hagan (2004) described in the computer modeling context. In computer modeling, however, tools to estimate the expected value of a proposed study to learn a particular more precisely have not been developed, and it is not clear what an appropriate loss for a vector of model outputs would be. Challenges also arise with computation. Current methods for computing the expected variance reduction in the computer modeling field (Sobol’ 2001; Saltelli et al. 2004) assume the output is an explicit function of the inputs, therefore do not apply in MPES, where this function is unknown and the outputs must be estimated by MCMC. For Bayesian design, Ryan et al. (2016) reviewed methods where evaluating the expected utility of a design (equivalent to the EVSI) is relatively inexpensive, so that maximizing the utility over a complex design space is feasible. However, this can again be difficult with MCMC. Given a sample from the posterior , potential future datasets under a specific design can be simulated cheaply from the posterior predictive distribution, but then to obtain the expected utility, the posterior needs to be repeatedly updated for different , which is feasible with Monte Carlo only for smaller problems (e.g., Han and Chaloner 2004).
Here, we use and extend methods from health economics, computer modeling, and Bayesian design to devise a new VoI framework for sensitivity analysis and research design in evidence syntheses based on graphical models fitted by MCMC. This is a broader class of models than those typically used in health economics or computer modeling, since the model “output” is not necessarily a known function of the inputs, but depends on the model parameters and observed data through a network of statistical models or deterministic functions, potentially with hierarchical relationships. We apply this new VoI framework to the part of the HIV prevalence estimation model that estimates prevalence in men who have sex with men (MSM), in London. Here, the decision problem is point estimation of a single scalar or a vector of parameters, followed by the choice of what extra data should be collected in the future. We use ideas from Bayesian design to choose appropriate loss functions in this context. We also generalize methods of computing EVPPI (Strong, Oakley, and Brennan 2014) and EVSI (Strong et al. 2015), developed for finite choices in health economics, to a broader class of decision problems, including point estimation. The method for computing EVSI enables the expected utility over all potential to be estimated cheaply without an additional level of simulation, assuming only that the information provided by can be represented as a low-dimensional sufficient statistic .
In Section 2, we describe the general MPES model, and define the expected VoI under different decision problems and loss functions, and in Section 3, we present methods to compute them. In Section 4, we describe the model for HIV prevalence estimation, and in Section 5, we use VoI to identify the areas of greatest uncertainty in this model and determine what specific data should be collected to improve the precision of the estimates of various subgroup-specific prevalences. Finally, we discuss potential extensions to the methods and application and the associated challenges.
2. Theory and Methods
2.1. Bayesian Graphical Modeling for Evidence Synthesis
In our motivating applications, the general model can be represented as a directed acyclic graph (Figure 1) in the standard way, see, for example, Lauritzen (1996). Nodes in the graph may represent scalar or vector quantities. A set of datasets is observed, most generally from n different sources. These data are assumed to arise from statistical models with parameters respectively, collectively denoted . The “founder nodes” of the graph are denoted and given a joint prior distribution which may also include substantive information. The full set of unknowns is denoted . Most simply, the could equal the or be related to the through deterministic functions, so that . More generally, some of the relationships in the graph could be stochastic, defining a hierarchical model, where the themselves arise from a distribution with parameters given by the or descendants of . The vector of unknowns would then comprise and the stochastic descendants of such as random effects.
Fig. 1.

Directed acyclic graph for Bayesian evidence synthesis.
We further denote as an intermediate node in the graph, the model “output,” which is used for decision making. This could be any unknown quantity, including one of the or , a function of these, or a prediction of new data. We may also plan to collect additional data, either from the same source as one of the existing datasets (e.g., y1 in Figure 1), or from a new source informing a parameter on which no direct data (y2) were available.
This DAG (Figure 1) is a generalization of the typical structure (Figure 2) used in computer modeling (Oakley and O’Hagan 2004) where the output is a known (usually complicated) deterministic function of uncertain model inputs , which are given substantive priors that may be derived separately from data.
Fig. 2.
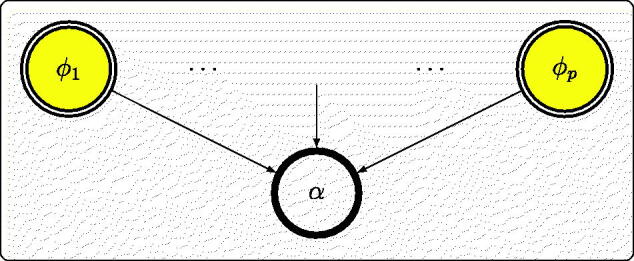
Graph representing a known deterministic model.
2.2. Expected VoI: Definitions
In a general decision-theoretic framework, the purpose of the model is to choose a decision or action d from a space of possible decisions , to minimise an expected loss , with the expectation taken with respect to the posterior distribution of . Let be the minimal subset or function of necessary to make the decision, so that , . For example, the purpose could be the choice of decision d among a finite set expected to minimize a loss defined as a function of the parameters, so that would be a vector with D components . This is the typical situation in health policy decisions (e.g., Claxton and Sculpher 2006), where a treatment d is chosen to maximize a measure of utility such as expected quality-adjusted survival. Alternatively, as in our examples, the decision could simply be the choice of a point estimate of some parameter , in which case the decision space is the support of (see Section 2.3). Alongside making a decision, we wish to also determine where further research should be prioritized to reduce the uncertainty about the decision, and given the costs of data collection, to determine the optimal design of further research (see Section 2.4).
For general decision problems, let be the optimal decision under current knowledge about , represented by the posterior distribution . Suppose now we are in a position to collect new information. Let be the optimal decision given further knowledge of a quantity (either parameters or potential data) that informs , so that the updated posterior would be . We define the following quantities.
-
The expected value of perfect information (EVPI) is the expected loss of the decision under current information, minus the expected loss for the decision we would make if we knew the true (Raiffa and Schlaifer 1961).
Since additional information is always expected to reduce the expected loss of the optimal decision (Parmigiani and Inoue 2009), the EVPI is an upper bound on the expected gains from any new information.
-
The expected value of partial perfect information (EVPPI) for a particular parameter is the expected reduction in loss if were to be learnt precisely. Since this precise value is not yet known, an expectation must be taken over all possible values.
(1) where is the optimal decision if were known. This is an upper bound on the potential value of data which inform only . In a graphical model, this means data that are conditionally independent of given , for example and in Figure 1.
- The expected value of sample information is the reduction in loss we would expect from collecting an additional dataset of a specific design
(2)
The inner expectation is now with respect to the updated posterior distribution of , after learning as well as the existing data , or “preposterior” (Berger 2013).
2.3. VoI in Different Decision Problems
Finite-Action Decisions
For a choice of d among a finite set with loss and , the expected loss with current information is , so (Raiffa and Schlaifer 1961)
| (3) |
Point estimation
When the decision is the choice of a point estimate of a vector of parameters , with quadratic loss
| (4) |
for a symmetric, positive-definite H, the optimal estimate with current information is the posterior mean, .
For a scalar and H = 1, the expected loss is under current information and zero under perfect information, so that and
| (5) |
| (6) |
the expected reduction in variance given new information. Expression (5) is used by Oakley and O’Hagan (2004) and Saltelli et al. (2004) as a measure of sensitivity of the output of a deterministic model to an uncertain input , termed the main effect of , but this has not been extended to the EVSI of potential data in a point estimation context.
When is a vector, the typical situation where a MPES of the form in Figure 1 is carried out, we could conduct independent VoI analyses for each component of . In more formal decision analyses, we may want a scalar loss for the overall vector . There are various alternatives based on generalizations of the variance, which can be used instead of the scalar variance in Equations (5) and (6) to define the expected VoI. These have been applied in the context of Bayesian study design, and we explain two examples that can be adopted for EVPPI and EVSI in our context as follows.
If in the quadratic loss (4), for some vector of weights , then the expected loss is , corresponding to optimal (under squared error loss) estimation of the weighted sum of the parameters, . For example, when the elements αs of are weighted equally, the goal is to minimise the sum of all elements (r, s) of the covariance matrix, , or, if the αs are also independent of each other, . The same absolute reductions in variance for different components of would then be valued equally. More generally, if is given a prior, then loss (4) also arises (see Chaloner and Verdinelli 1995 and references therein). Designs that minimize (4) are Bayesian analogs of classical A-optimal designs. See also Lamboni, Monod, and Makowski (2011) for similar measures of sensitivity for multivariate outputs in deterministic computer models.
A Bayesian D-optimal design, on the other hand, minimizes the determinant (Chaloner and Verdinelli 1995; Ryan et al. 2016). This simplifies to the product of the when the αs are independent and equally weighted. Equivalently, a standardized version , where S is the number of components of , represents a geometric average variance of the αs, adjusted for their covariance.
Here, the same relative reductions in variance for different components of would then be valued equally, which would be more appropriate when the output of interest comprises quantities on very different scales and/or with different interpretations.
2.4. Maximising the Expected Net Benefit of Sampling
The EVSI measures the expected benefits from sampling. The costs of sampling should also be considered. The decision-maker can then choose the design and sample size for data to maximize the expected net benefit of sampling , where is the benefit and is the cost of obtaining data (Parmigiani and Inoue 2009). This requires benefits and costs to be measured on the same scale, which can be achieved in different ways. Improved precision of point estimates might be valued in monetary terms, as described below and illustrated in Section 5.4. Alternatively, the better knowledge given by the new data could lead to indirect benefits which could be valued, for example, improved health from better-informed health-related decision making, as discussed in Section 6. We will assume depends only on the design and sample size, thus is known in advance of observing , so that .
To directly translate improved precision to a monetary benefit, the decision-maker should specify the amount they are willing to pay to reduce the posterior variance by a certain amount. This willingness to pay may depend on the original posterior variance. Formally, the benefit function , specified by the decision-maker, places a value on a reduction in variance (or its multivariate analog as in Section 2.3) from to , the variance after collecting new data . For example, if any absolute variance reduction is valued the same way (as in A-optimal design, see Section 2.3), , where λ is the constant willingness-to-pay for one unit of variance reduction. The expected benefit is then , which equals using the quadratic loss function (4) multiplied by a constant λ. Alternatively, if the same relative gains are valued equally (as in D-optimal design), the decision-maker could specify λ as the amount they are willing to pay to (e.g.,) halve the variance, so that , for .
3. Computation of VoI
3.1. Partial Perfect Information
Computation of the EVPPI in general is not straightforward. Given a sample from the posterior distribution, the first term in Equation (1) can be calculated by a Monte Carlo mean. The double expectation in the second term is more challenging. While it can be evaluated using nested Monte Carlo, this is expensive. Strong, Oakley, and Brennan (2014) proposed a method for estimating the EVPPI in the special case of finite choice decisions (Equation 3) which uses only a single Monte Carlo loop. To estimate EVPPI (1) in a broader class of decision problems, which also includes point estimation, the method needs to be generalized.
Strong, Oakley, and Brennan (2014) estimated formula (3) by expressing
| (7) |
for each , where is an error term with mean zero. Then, is estimated by regression of αd on , fitted to a Monte Carlo sample of . If comprises p parameters that could be learned simultaneously, the regression will have p predictors. Since the functional form of will not be known in general, nonparametric regression methods are used. This produces a fitted value for each k, which allows the second term in Equation (3) to be estimated by a Monte Carlo mean
| (8) |
Our generalization of this approach computes EVPPI (Equation 1) in a broader class of decision problems defined as follows. Given a state of knowledge about the decision-relevant quantities represented by a distribution , the expected loss under the optimal decision should be a known function h of the mean of under that distribution
| (9) |
If is the current posterior, this is , and if we were to learn the value of , the expected loss would be . The method of Strong, Oakley, and Brennan (2014) only applies to the special case, where is a vector and . To estimate in more general problems, we use a similar principle to (7–8), by expressing
| (10) |
then fitting a regression model of on allows us to estimate
Point estimation problems are also a special case of Equation (9), for example, for estimation of a scalar α with quadratic loss, . Therefore to calculate EVPPI in this case (Equation (5)), we estimate by the squared residual , substitute this for and estimate as the mean, over k, of the squared residuals. Equivalently, we can estimate as the variance, over k, of the fitted values. Similarly, for vector and loss functions based on , we can fit regressions to get the marginal mean for each component αd, and calculate the empirical covariance matrix of the residuals.
Several methods of nonparametric regression have been suggested. For small p, Strong, Oakley, and Brennan (2014) used generalized additive models, with tensor products of splines to represent interactions between components of . Where included about p = 5 or more components, Gaussian process regression was recommended as a more efficient way of modeling interactions, though the resulting matrix computations rapidly become impractical as the MCMC sample size K increases. Heath, Manolopoulou, and Baio (2016) developed an integrated nested Laplace approximation for fitting Gaussian processes more efficiently where . For the application in Section 4 (with K = 150, 000, ), we have found multivariate adaptive regression splines (Friedman 1991) via the earth R package (Milborrow 2011) to be more efficient. Standard errors for the EVPPI estimates can be calculated in general by simulating from the asymptotic normal distribution of the regression coefficients (Mandel 2013).
3.2. Sample Information
The regression method above can also be used to estimate the expected value of sample information . This again requires a generalization of the approach described by Strong et al. (2015) from finite decision problems to any problem satisfying condition (9), including point estimation. The method requires that the information provided by the data can be expressed as a low-dimensional sufficient statistic , so that . This could be a point estimator of the parameter μ (as in Figure 1) that gives direct information on. As in (10), we can write
and estimate using a regression fitted to a Monte Carlo sample of , where are drawn from their posterior predictive distribution. Then, the fitted values enable the double expectation to be estimated as
Then, for example, for point estimation with quadratic loss, this is the estimated residual variance from the regression, as in Section 3.1.
4. The HIV Prevalence MPES Model
We consider the submodel of the full HIV burden model (De Angelis et al. 2014; Kirwan et al. 2016) that estimates HIV prevalence in men who have sex with men (MSM), in London. We define three subgroups of MSM: those who have attended a genitourinary medicine (GUM) clinic in the past year (GMSM), those who have not (NGMSM), and previous MSM (PMSM), men who no longer have sex with men. We denote the proportion of all men who are in these subgroups by ρG, ρN, and ρP respectively. For each group , we aim to estimate simultaneously these subgroup proportions ρg, prevalence of HIV in this group πg and the proportion of infections that are diagnosed, δg. Given these parameters, further important quantities are easily derived: the prevalence of diagnosed () and undiagnosed () infection; and the numbers of MSM living with diagnosed () and undiagnosed () infection, where is the number of men (MSM and non-MSM) living in London. Since the prevalence among PMSM is much lower, this subgroup is not examined in detail.
We construct a Bayesian model to link the unknown with the available evidence provided by various routinely-collected and survey datasets as well as expert belief. Figure 3 shows a directed acyclic graph representing this model, in the form of Figure 1, distinguishing founder nodes, observed data, and outputs of interest. The following sections explain in detail the quantities and relationships illustrated in Figure 3. All data and estimates refer to the year 2012 (unless indicated) and the Greater London area.
Fig. 3.

Directed acyclic graph for HIV prevalence estimation model.
4.1. Subgroup Membership
The total male population of London, , is informed by published data (Office for National Statistics 2012), assumed to be a Poisson count: . A log-normal prior for is assumed, . The number of people in each group g is estimated as . Estimates of the subgroup proportions ρg are informed by data from the National Survey of Sexual Attitudes and Lifestyles (Mercer et al. 2013): yG = 7, , out of men, which we assume to come from a multinomial distribution with probabilities given a uniform Dirichlet prior. Thus, the expected number of people with HIV (diagnosed or undiagnosed) in group g is .
4.2. Registry of Diagnosed Infections and Diagnosed Prevalence
Individuals diagnosed with HIV and accessing care in the UK are reported to the HIV and AIDS Reporting System (Kirwan et al. 2016). From the 2012 version of this dataset, known as SOPHID (Surveillance of Prevalent HIV Infections Diagnosed), we obtain the reported number of HIV diagnoses for MSM, , with yM = 8390. A reporting bias of unknown direction is assumed, through where , giving a prior 90% interval of about for the adjustment to the number of MSM HIV diagnoses μM. After adjustment, is the expected number of diagnoses among MSM, summed from the expected numbers of diagnoses among GMSM, NGMSM, and PMSM, respectively. The following sections explain where come from; μDP is modeled using similar techniques.
Since SOPHID did not record GUM clinic attendance, to strengthen the evidence on diagnosed prevalence in GMSM, we include data from the HIV and AIDS New Diagnoses and Deaths Database (HANDD) (Kirwan et al. 2016), recording how many of the yM prevalent diagnosed MSM were newly diagnosed in 2012 and reported to have been diagnosed initially in a GUM clinic. These new diagnoses, yH = 630, are modeled as , where pH is assumed to be a lower bound for the proportion of prevalent diagnosed MSM who have attended a GUM clinic in 2012. This bound is expressed through , where is the unknown probability that a prevalent diagnosed MSM who has attended a GUM clinic in 2012 was newly diagnosed that year. yH therefore gives us additional indirect information on μDG, the number of prevalent diagnosed GMSM.
The number of diagnosed infections is related to the total number of infections in each group g as . The proportion of infections that are diagnosed δg is not known, but given our inferences about the undiagnosed prevalence (explained in the subsequent sections), we can exploit the implicit constraint . Therefore, we define , with , and the diagnosed prevalence in each group follows.
4.3. Undiagnosed Prevalence Among GMSM
Information about undiagnosed infections in GMSM is obtained from GUMCAD (Genitourinary Medicine Clinic Activity Dataset) (Kirwan et al. 2016) a registry of attendance episodes in GUM clinics. HIV tests are offered routinely to previously undiagnosed patients. Thus, we have a sequence of observations gi, representing firstly the number of GUM clinic visitors () and then the number of patients with no previous HIV diagnosis (), HIV tests offered (), HIV tests accepted (), and HIV diagnoses made (). For , with priors and (see below). An HIV infection may therefore remain undiagnosed if either a test is not offered or the patient opts out of testing. We can then decompose the prevalence of undiagnosed infection into “unoffered” and “opt-out” components.
| (11) |
Both of those require strong prior assumptions to estimate, which will later be relaxed in a sensitivity analysis (Section 4.5). First, the prevalence of infection that remains undiagnosed due to an unoffered test is
where is the proportion of clinic attenders that are undiagnosed but not offered a test, and is the probability that a test would be positive for these people. We assume the prevalence in this group is between 0.5 and 1.5 times the prevalence in people actually tested, and , with
Secondly, the prevalence of infection remaining undiagnosed due to refusing a test is
where is the proportion of clinic attenders that are undiagnosed and offered a test but opt out. We assume this group has an underlying HIV prevalence higher than those given tests, but not more than 15%, so that the excess prevalence in this group is , where , and the prior on γ4 is truncated above at 0.15.
A small amount of additional evidence on is available from another dataset, GUM Anon (Public Health England, London 2012), a convenience survey of men not previously diagnosed with HIV who had attended a GUM clinic in the previous year. This gives direct information about the prevalence of HIV among previously undiagnosed GMSM,
| (12) |
where is the prevalence of newly diagnosed infection among clinic attenders. The data in GUM Anon are , where and .
4.4. Undiagnosed Prevalence Among NGMSM
To inform undiagnosed HIV prevalence in NGMSM, we use data from the Gay Men’s Sexual Health Survey (GMSHS) (Aghaizu et al. 2016), based on face-to-face interviews in selected venues where participants were offered anonymous HIV tests. While this group is likely to have a higher HIV prevalence than the general population of MSM, it is assumed that the relative odds of having HIV between NGMSM and GMSM is the same as in the general population. The GMSHS data provide the numbers out of previously undiagnosed people in group g who tested positive for HIV (20 out of 493 GMSM and 20 out of 452 NGMSM) so that , with . Defining the odds , we apply the resulting odds ratio to the baseline estimated from GUMCAD (Section 4.3), giving = .
4.5. Alternative Assumptions
The results presented in Section 5 are for the above model assumptions, unless specified otherwise. Two alternative assumptions are also explored.
-
Undiagnosed prevalence from GUM Anon only
To avoid the strong prior assumptions on prevalence among those not offered a test or refusing a test, which are necessary to use the GUMCAD data to infer , we could infer from GUM Anon alone. To construct this model, we replace Equation (11) by a U(0, 1) prior on , although the GUMCAD data are still used to estimate the parameters and γ1 relating the prevalence in GUM Anon to .
-
GUMCAD also informs diagnosed prevalence
Instead of being inferred indirectly through the graph, the diagnosed prevalence can be modeled directly as(13)
where is the probability of a previous diagnosis, and is the probability of a new diagnosis, in GUMCAD. This is not done in the base case due to concerns about inconsistencies in reporting between GUMCAD and SOPHID/HANDD.
5. VoI Results in the HIV Model
The model outputs of interest (as in Figures 1, 3) are ), the diagnosed and undiagnosed prevalences among both GMSM and NGMSM, and the corresponding absolute numbers of people living with HIV (or “case-counts”), and the total number of MSM with HIV . Samples from the posterior are generated using Hamiltonian Monte Carlo methods in the Stan software (Stan Development Team 2016). These are illustrated in Figure 4 along with the overall prevalence in each group g, and each of these quantities summed over the two groups g. The estimates of diagnosed prevalence in all MSM (top panel) are reasonably precise, while the corresponding estimates for NGMSM and GMSM are more uncertain. Estimates of undiagnosed prevalence are lower and more precise. Full results under the two alternative assumptions are presented in the supplementary figures.
Fig. 4.

Posterior distributions of HIV prevalence (top) and numbers of MSM living with HIV/AIDS (bottom), London 2012. Darkness within each strip proportional to posterior density, with 95% credible intervals indicated.
5.1. Partial Perfect Information (EVPPI) for Single Outputs
Defining the decision problem as point estimation of with quadratic loss, we use EVPPI formula (5) to determine which parameters contribute most to the uncertainty about each component of , thus which may be worth learning more precisely. We will take to include the founder nodes of the graph illustrated in Figure 3. Since they are related to the through a network of deterministic functions, perfect knowledge of these implies perfect knowledge of . Each of the are either directly informed by data or given a substantive prior distribution based on belief. In the former case, EVPPI measures the maximum potential value of collecting more data from the same source. In the latter case, it will not necessarily be feasible to collect data to improve the precision of the belief, but EVPPI is still useful as a measure of how much of the uncertainty in is explained by the uncertainty in the parameter.
The results are presented in Figure 5 as a grid whose r, s entry is colored according to , the proportion of variance in αs which would be reduced if we learnt . The lighter cells correspond to with greater EVPPI. Standard errors in these and all following EVPPI and EVSI estimates, arising from uncertainty in the coefficients of the regression (10), were negligible, at less than 1% of the EVPPI or EVSI estimates.
Fig. 5.

Expected value of partial perfect information in the HIV prevalence model.
The parameters and , governing the proportions of HIV infections that are diagnosed in each of the two groups, and the probability aH that a GMSM is newly diagnosed in a GUM clinic, explain most of the uncertainty in the diagnosed prevalences and the corresponding numbers of people diagnosed . Direct data on any of these parameters would be difficult to obtain. However, if we were willing to make the assumption in Equation (13), the estimates of diagnosed prevalence would become more precise, for example the posterior median (SD) of would change from 0.06 (0.13) to 0.051 (0.001), though the extent of uncertainty around would not change substantively.
For the undiagnosed prevalences and undiagnosed case count , Figure 5 shows that more GUM-Anon data (via ), more GMSHS data (via ) and more NATSAL data (via ), respectively, would give the greatest uncertainty reductions. These outcomes, however, are already precisely estimated in absolute terms (Figure 4). The number of NGMSM with undiagnosed HIV is more uncertain, with 95% CrI (279,1442), and more GMSHS data would be potentially valuable to reduce this uncertainty.
If were informed only from the 4 infections out of 85 people observed in GUM Anon (alternative assumption (a)), the estimates of undiagnosed prevalence or case counts become extremely uncertain, for example, increases from 3022 to 28722. We could reduce this uncertainty by collecting more GUM Anon data—since is of , more GUM Anon data could reduce to a minimum of (note that the square root of the expected variance after learning data is not the same as the expected standard deviation).
5.2. Partial Perfect Information for Multiple Outputs
Staying with alternative assumption (a), suppose we wish to calculate the maximum potential value of extra GUM Anon data for jointly reducing the uncertainty about the number of GMSM, NGMSM, and PMSM with undiagnosed HIV, so that is the vector . As described in Section 2.3, we could simply calculate the standard EVPPI based on a scalar output α redefined as their sum, , the total number of MSM with undiagnosed HIV, whose posterior median is 5149 (SD 3280). This would ensure that any data expected to reduce the variance of any of these three outputs by the same (additive) amount would be valued equally. From this, we find that extra GUM Anon data would be expected to reduce from 32802 to a minimum of 18012. Since μU is dominated by NGMSM (posterior median of is 4185), this is mostly explained by an expected reduction in from 28642 to a minimum of 17702.
Alternatively, suppose both the prevalences and the case counts are of interest, for example in NGMSM, so that . Since these two components are on very different scales, the Bayesian “D-optimality” criterion would be a preferable measure of overall expected loss due to uncertainty. We use this criterion to compare the maximum expected value of extra GUM Anon data and extra GMSHS data, which combine to estimate the outcomes for NGMSM as described in Section 4.4. The EVPPI is interpreted as the expected reduction in the product of and given by extra GUM Anon or GMSHS data, adjusted for their covariance. This is 425 and 135, respectively, favoring extra data from GUM Anon. Though in this example, examining expected reductions in or separately would lead to the same conclusion, since is defined as the proportion of NGMSM with HIV, and GUM Anon and GMSHS are not informative about the number rN of NGMSM, thus extra data informs entirely through information on (or vice versa).
5.3. Sample Information (EVSI)
We now estimate the expected value of data with specific sample sizes for improving the precision of the estimated number of people μU with undiagnosed HIV. Using the GUMCAD data and associated strong prior assumptions, the posterior median of μU is 804 (SD 320), compared to 5149 (SD 3280) with this information excluded (a). We compare the value of additional data from GUM Anon and additional data from GMSHS (on top of their original sample sizes of 85 and 945, respectively) for reducing these posterior standard deviations.
The EVSI is computed for a series of sample sizes n using the method in Section 3.2. For GUM Anon (Section 4.3), the sufficient statistic consists of the empirical HIV prevalence from an additional survey . For GMSHS (Section 4.4), given a sample size n, , where is the number of previously undiagnosed MSM in the future sample of n who attend GUM clinics (the equivalent of the observed ). Then and are the numbers of men out of denominators and (GMSM and NGMSM, respectively) who test positive for HIV, the equivalents of the observed . We take , a point estimator of the odds ratio, where is an estimator of the proportion of MSM in group g who have HIV. To avoid zeros in the denominator , we use a Bayesian estimator , the posterior mean of a binomial proportion under a Jeffreys Beta(0.5,0.5) prior, rather than the empirical proportion .
Figure 6 shows , the expected variance remaining after data collection, under the two alternative assumptions. With the strong priors, μU is relatively well informed, and extra data from GUM Anon at realistic sample sizes (1000 or less) would not noticeably reduce . GMSHS data would be more valuable, through improving the estimate of , the more uncertain contributor to . 1000 extra observations from GMSHS would be expected to reduce from 3202 to 2792.
Fig. 6.

EVSI: value of additional data from GUM Anon or GMSHS for reducing the variance of the total number of MSM with undiagnosed HIV, . The x-axis is on the log scale. The y-axis is the variance, with the labels as SD2.
Without the strong prior information, is substantially greater, and μU is only directly informed by the 85 observations from GUM Anon. Extra data from this source would be valuable, for example, another 500 observations would be expected to reduce this variance to 21842. Relative to these improvements, GMSHS data of the same size would be much less valuable. GMSHS data, however, would be expected to give around the same absolute reductions in , whether or not the strong priors are included.
5.4. Net Benefit of Sampling
The benefits from improved precision of estimates of μU must be traded off with the costs of data collection, to determine an optimal sample size for extra survey data. Consider the scenario which excluded the GUMCAD data and associated strong priors. In the GUM Anon survey, there was a cost of around £17 per participant, which is assumed to be the same for collecting further data from this source. The cost is illustrated against sample sizes of from 1 to 400 by the straight line in Figure 7. Suppose also that the decision-maker is willing to pay £5000 to reduce the variance of μU by , which in this case would reduce the standard deviation by 500, from 3271 to 2771. The willingness to pay per unit variance is then .
Fig. 7.

Expected cost, benefit, and net benefit of sampling up to 400 extra participants from GUM Anon, if we wish to reduce the variance of μU, the number of MSM with undiagnosed HIV. The optimal sample size is illustrated as a dotted line.
Collecting extra data will give an expected reduction in of , as illustrated in Figure 7. The resulting expected (monetary) benefit (Section 2.4) is shown to be a nonlinear function of the sample size of , with an asymptote representing the expected value of partial perfect information on . Hence, the expected net benefit of sampling is illustrated in the bottom panel of Figure 7. The expected benefits of sampling always exceed the costs, and the net benefit is maximized at a sample size of 166. Also illustrated are the benefit and net benefit that would result if the decision maker was willing to pay twice or half the original amount, or . The corresponding optimal sample sizes would be 315 or 81, respectively.
6. Summary and Potential Further Work
We have presented tools to find the most influential sources of uncertainty in MPES models and determine the expected value of extra data. We generalized methods, previously applied only in deterministic models, to complex graphical models, a class which also includes hierarchical models. We have shown how VoI methods developed for formal finite-choice decision problems can be extended to deal with estimation of single or multiple quantities.
While the purpose of our model was to estimate a quantity of interest to policy-makers, the same methods could be used for models to compare specific health policies. Sections 2.4 and 5.4 illustrated how the benefits from more precise estimates of HIV prevalence could be converted directly into a monetary value. An alternative approach would be to value the indirect health gains that would result from better data, through better-informed health policies. This would allow standard health economic principles to be used (see, e.g., Briggs, Sculpher, and Claxton 2006). For example, the National Institute for Health and Care Excellence in the UK recommends that a new health-care intervention is funded by the National Health Service if the cost per quality-adjusted life year (QALY) gained, compared to current practice, is less than around £20,000, implying a willingness to pay of λ per QALY. This is a choice between two actions “ intervention” (as in Section 2.3) with loss , where is the expected QALY and is the expected cost for a person under action d, from a health economic model with parameters θ. See, for example, Carmona, O’Rourke, and Robinson (2016); Baggaley et al. (2017), for how such models might be built for HIV testing interventions to increase the proportion δ of people who are diagnosed. Briefly, any QALY gains strongly depend on the underlying prevalence of HIV among the population receiving the intervention. Thus, improved estimates of prevalence will lead to more precise estimates of the QALY gains, and a better-informed decision about whether to implement the intervention, which may result in a better use of health service resources. VoI methods may then be used to decide whether further information should be collected to support the decision.
In the HIV application, we found that structural assumptions, such as whether to include a particular piece of information, were influential to both the parameter estimates and the VoI. Such uncertainties might be parameterized (see, e.g., Strong, Oakley, and Chilcott 2012), for example a particular prior or dataset of uncertain relevance could be discounted using an unknown weight (e.g., Neuenschwander, Branson, and Spiegelhalter 2009). The EVPPI of the extra parameter would then quantify this uncertainty in the context of all other uncertainties, referred to as the “expected value of model improvement” by Strong and Oakley (2014).
Note that VoI refers to the expected value of potential future information, which differs from the observed value of a dataset xi currently included in the model. The latter could be computed as the observed reduction in loss when the model is refitted without xi. This could demonstrate the value of past data to the policymaker responsible for funding the collection of future data of the same type. For surveys or longitudinal studies conducted at regular intervals, VoI might be used to determine the expected value of future surveys or follow-up, although a full analysis would require modeling the expected changes through time in the quantities, such as disease prevalence or incidence, informed by the data.
While our method is broadly applicable, the details of computation for different decision problems and loss functions may be different. We discussed finite-action decisions and point estimation. A more general decision problem is to estimate the entire uncertainty distribution of . The standard posterior is then optimal under a log scoring rule (Bernardo and Smith 1994), and (following Lindley 1956) standard Bayesian design theory aims to maximize the information gain from new data , which we can write as . Under linear models (Chaloner and Verdinelli 1995), this is equivalent to minimising , but more generally this is challenging to compute (Ryan et al. 2016).
Note that the VoI approach to sensitivity analysis is an example of the “global” approach, which examines the changes in model outputs given by varying parameters within the ranges of their belief distributions. The “local” approach is based on examining the posterior geometry resulting from small parameter perturbations around a base case, for example, Roos et al. (2015) assess the robustness of hierarchical models to prior assumptions in this way. While the global approach is easier to interpret, as discussed by Oakley and O’Hagan (2004) and Roos et al. (2015), it conditions on one particular prior specification, and parameterising all potential prior beliefs or structural assumptions would be impractical.
The regression method for VoI computation that we described requires only a MCMC sample from the joint distribution of parameters of interest and outputs . Additionally for EVSI it requires that the information in the new data can be condensed into an analytic sufficient statistic . Alternative methods which exploit particular analytic structures of , where α is a known function , thus avoiding a regression approximation, were discussed by Madan et al. (2014) for EVPPI and Ades et al. (2004) for EVSI. Menzies (2016) also presented an importance resampling method for EVSI computation which needs only a single MCMC sample and not a sufficient statistic.
In conclusion, the consideration of future evidence requirements is an often-neglected part of statistical analysis. The VoI methods we have presented provide a practicable set of tools for achieving this aim in the context of Bayesian evidence synthesis.
Supplementary Materials
A supplementary document provides estimates of HIV prevalence and expected value of partial perfect information under the alternative assumptions described in Section 4.5.
Supplementary Material
Funding Statement
This work was funded by the Medical Research Council, grant code U105260566, and from Public Health England (funding DDA and SC).
Acknowledgments
The authors are grateful to the HIV department of Public Health England for providing the data and permission to use the example, to the NATSAL team for providing data, and Louise Logan for advice on costs of data collection in GUM Anon.
References
- Ades, A., Lu, G., and Claxton, K. (2004), “Expected Value of Sample Information Calculations in Medical Decision Modeling,” Medical Decision Making, 24, 207–227. DOI: 10.1177/0272989X04263162. [DOI] [PubMed] [Google Scholar]
- Ades, A. E., and Sutton, A. J. (2006), “Multiparameter Evidence Synthesis in Epidemiology and Medical Decision-Making: Current Approaches,” Journal of the Royal Statistical Society, Series A, 169, 5–35. DOI: 10.1111/j.1467-985X.2005.00377.x. [DOI] [Google Scholar]
- Aghaizu, A., Wayal, S., Nardone, A., Parsons, V., Copas, A., Mercey, D., Hart, G., Gilson, R., and Johnson, A. (2016), “Sexual Behaviours, HIV Testing, and the Proportion of Men at Risk of Transmitting and Acquiring HIV in London, UK, 2000–13: A Serial Cross-Sectional Study,” The Lancet HIV, 3, e431–e440. DOI: 10.1016/S2352-3018(16)30037-6. [DOI] [PubMed] [Google Scholar]
- Baggaley, R. F., Irvine, M. A., Leber, W., Cambiano, V., Figueroa, J., McMullen, H., Anderson, J., Santos, A. C., Terris-Prestholt, F., Miners, A., Hollingsworth, D., and Griffiths, C. J. (2017), “Cost-effectiveness of Screening for HIV in Primary Care: A Health Economics Modelling Analysis,” The Lancet HIV, 4, e465–e474. DOI: 10.1016/S2352-3018(17)30123-6. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Berger, J. O. (2013), Statistical Decision Theory and Bayesian Analysis, New York, NY: Springer. [Google Scholar]
- Bernardo, J. M., and Smith, A. F. M. (1994), Bayesian Theory, Chichester: Wiley. [Google Scholar]
- Briggs, A., Sculpher, M., and Claxton, K. (2006), Decision Modelling for Health Economic Evaluation, Handbooks in Health Economic Evaluation. Oxford: Oxford University Press. [Google Scholar]
- Carmona, C., O’Rourke, D., and Robinson, S. (2016), “HIV Testing: Increasing Uptake Among People Who May Have Undiagnosed HIV. Evidence Review on the Most Cost Effective Ways to Increase the Uptake of HIV Testing to Reduce Undiagnosed HIV Among People Who May Have Been Exposed to It,” available at https://www.nice.org.uk/guidance/ng60/documents/evidence-review-5
- Chaloner, K., and Verdinelli, I. (1995), “Bayesian Experimental Design: A Review,” Statistical Science, 273–304. DOI: 10.1214/ss/1177009939. [DOI] [Google Scholar]
- Claxton, K. P., and Sculpher, M. J. (2006), “Using Value of Information Analysis to Prioritise Health Research,” Pharmacoeconomics, 24, 1055–1068. DOI: 10.2165/00019053-200624110-00003. [DOI] [PubMed] [Google Scholar]
- De Angelis, D., Presanis, A. M., Conti, S., and Ades, A. E. (2014), “Estimation of HIV Burden Through Bayesian Evidence Synthesis,” Statistical Science, 29, 9–17. DOI: 10.1214/13-STS428. [DOI] [Google Scholar]
- Felli, J. C., and Hazen, G. B. (1998), “Sensitivity Analysis and the Expected Value of Perfect Information,” Medical Decision Making, 18, 95–109. DOI: 10.1177/0272989X9801800117. [DOI] [PubMed] [Google Scholar]
- Friedman, J. H. (1991), “Multivariate Adaptive Regression Splines,” The Annals of Statistics, 19, 1–67. DOI: 10.1214/aos/1176347963. [DOI] [Google Scholar]
- Goubar, A., Ades, A. E., DeAngelis, D., McGarrigle, C. A., Mercer, C. H., Tookey, P. A., Fenton, K., and Gill, O. N. (2008), “Estimates of Human Immunodeficiency Virus Prevalence and Proportion Diagnosed Based on Bayesian Multiparameter Synthesis of Surveillance Data,” Journal of the Royal Statistical Society, Series A, 171, 541–580. DOI: 10.1111/j.1467-985X.2007.00537.x. [DOI] [Google Scholar]
- Han, C., and Chaloner, K. (2004), “Bayesian Experimental Design for Nonlinear Mixed-Effects Models With Application to HIV Dynamics,” Biometrics, 60, 25–33. DOI: 10.1111/j.0006-341X.2004.00148.x. [DOI] [PubMed] [Google Scholar]
- Heath, A., Manolopoulou, I., and Baio, G. (2016), “Estimating the Expected Value of Partial Perfect Information in Health Economic Evaluations Using Integrated Nested Laplace Approximation,” Statistics in Medicine, 35, 4264–4280. DOI: 10.1002/sim.6983. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Kirwan, P., Chau, C., Brown, A., Gill, O., Delpech, V., and contributors (2016), “HIV in the UK — 2016 Report,” Technical report, Public Health England, London.
- Lamboni, M., Monod, H., and Makowski, D. (2011), “Multivariate Sensitivity Analysis to Measure Global Contribution of Input Factors in Dynamic Models,” Reliability Engineering & System Safety, 96, 450–459. DOI: 10.1016/j.ress.2010.12.002. [DOI] [Google Scholar]
- Lauritzen, S. L. (1996), Graphical Models (Vol. 17), Oxford, UK: Clarendon Press. [Google Scholar]
- Lindley, D. V. (1956), “On a Measure of the Information Provided by an Experiment,” The Annals of Mathematical Statistics, 986–1005. DOI: 10.1214/aoms/1177728069. [DOI] [Google Scholar]
- Madan, J., Ades, A. E., Price, M., Maitland, K., Jemutai, J., Revill, P., and Welton, N. J. (2014), “Strategies for Efficient Computation of the Expected Value of Partial Perfect Information,” Medical Decision Making, 34, 327–342. DOI: 10.1177/0272989X13514774. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Mandel, M. (2013), “Simulation-based Confidence Intervals for Functions With Complicated Derivatives,” The American Statistician, 67(2), 76–81. DOI: 10.1080/00031305.2013.783880. [DOI] [Google Scholar]
- Menzies, N. A. (2016), “An Efficient Estimator for the Expected Value of Sample Information,” Medical Decision Making, 36, 308–320. DOI: 10.1177/0272989X15583495. [DOI] [PubMed] [Google Scholar]
- Mercer, C., Tanton, C., Prah, P., Erens, B., Sonnenberg, P., Clifton, S., Macdowall, W., Lewis, R., Field, N., Datta, J., Copas, A., Phelps, A., Wellings, K., and Johnson, A. (2013), “Changes in Sexual Attitudes and Lifestyles in Britain Through the Life Course and Over Time: Findings From the National Surveys of Sexual Attitudes and Lifestyles (Natsal),” Lancet, 382, 1781–1794. DOI: 10.1016/S0140-6736(13)62035-8. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Milborrow, S. (2011), earth: Multivariate Adaptive Regression Splines. R package. Derived from mda:mars by T. Hastie and R. Tibshirani. Available at http://CRAN.R-project.org/package=earth
- Neuenschwander, B., Branson, M., and Spiegelhalter, D. J. (2009), “A Note on the Power Prior,” Statistics in Medicine, 28, 3562–3566. DOI: 10.1002/sim.3722. [DOI] [PubMed] [Google Scholar]
- Oakley, J. E., and O’Hagan, A. (2004), “Probabilistic Sensitivity Analysis of Complex Models: A Bayesian Approach,” Journal of the Royal Statistical Society, Series B, 66, 751–769. DOI: 10.1111/j.1467-9868.2004.05304.x. [DOI] [Google Scholar]
- Office for National Statistics (2012), “Mid-year Population Estimates,” available at https://www.ons.gov.uk/peoplepopulationandcommunity/populationandmigration/populationestimates
- Parmigiani, G., and Inoue, L. (2009), Decision Theory: Principles and Approaches, Chichester, UK: Wiley. [Google Scholar]
- Presanis, A. M., Gill, O. N., Chadborn, T. R., Hill, C., Hope, V., Logan, L., Rice, B. D., Delpech, V. C., Ades, A. E., and De Angelis, D. (2010), “Insights Into the Rise in HIV Infections, 2001 to 2008: A Bayesian Synthesis of Prevalence Evidence,” AIDS (London, England), 24, 2849–2858. DOI: 10.1097/QAD.0b013e32834021ed. [DOI] [PubMed] [Google Scholar]
- Public Health England, London (2012), “UA Survey of Genitourinary Medicine (GUM) Clinic Attendees (GUM Anon Survey),” available at https://www.gov.uk/guidance/hiv-overall-prevalence\#ua-survey-of-genitourinary-medicine-gum-clinic-attendees-gum-anon-survey
- Raiffa, H., and Schlaifer, R. (1961), Applied Statistical Decision Theory, Cambridge, MA: Harvard University. [Google Scholar]
- Roos, M., Martins, T. G., Held, L., and Rue, H. (2015), “Sensitivity Analysis for Bayesian Hierarchical Models,” Bayesian Analysis, 10, 321–349. DOI: 10.1214/14-BA909. [DOI] [Google Scholar]
- Ryan, E. G., Drovandi, C. C., McGree, J. M., and Pettitt, A. N. (2016), “A Review of Modern Computational Algorithms for Bayesian Optimal Design,” International Statistical Review, 84, 128–154. DOI: 10.1111/insr.12107. [DOI] [Google Scholar]
- Saltelli, A., Tarantola, S., Campolongo, F., and Ratto, M. (2004), Sensitivity Analysis in Practice: A Guide to Assessing Scientific Models, Chichester, UK: Wiley. [Google Scholar]
- Sobol’, I. M. (2001), “Global Sensitivity Indices for Nonlinear Mathematical Models and Their Monte Carlo Estimates,” Mathematics and Computers in Simulation, 55, 271–280. [Google Scholar]
- Stan Development Team (2016), Stan Modeling Language Users Guide and Reference Manual, Version 2.14.0. Available at http://mc-stan.org
- Strong, M., and Oakley, J. E. (2014), “When is a Model Good Enough? Deriving the Expected Value of Model Improvement Via Specifying Internal Model Discrepancies,” SIAM/ASA Journal on Uncertainty Quantification, 2, 106–125. DOI: 10.1137/120889563. [DOI] [Google Scholar]
- Strong, M., Oakley, J., and Chilcott, J. (2012), “Managing Structural Uncertainty in Health Economic Decision Models: A Discrepancy Approach,” Journal of the Royal Statistical Society, Series C, 61, 25–45. DOI: 10.1111/j.1467-9876.2011.01014.x. [DOI] [Google Scholar]
- Strong, M., Oakley, J. E., and Brennan, A. (2014), “Estimating Multiparameter Partial Expected Value of Perfect Information From a Probabilistic Sensitivity Analysis Sample: A Nonparametric Regression Approach,” Medical Decision Making, 34, 311–326. DOI: 10.1177/0272989X13505910. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Strong, M., Oakley, J. E., Brennan, A., and Breeze, P. (2015), “Estimating the Expected Value of Sample Information Using the Probabilistic Sensitivity Analysis Sample: A Fast, Nonparametric Regression-based Method,” Medical Decision Making, 35, 570–83. DOI: 10.1177/0272989X15575286. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Welton, N., Ades, A., Caldwell, D., and Peters, T. (2008), “Research Prioritization Based on Expected Value of Partial Perfect Information: A Case-Study on Interventions to Increase Uptake of Breast Cancer Screening,” Journal of the Royal Statistical Society, Series A, 171, 807–841. DOI: 10.1111/j.1467-985X.2008.00558.x. [DOI] [Google Scholar]
- Willan, A. R., and Pinto, E. M. (2005), “The Value of Information and Optimal Clinical Trial Design,” Statistics in Medicine, 24, 1791–1806. DOI: 10.1002/sim.2069. [DOI] [PubMed] [Google Scholar]
Associated Data
This section collects any data citations, data availability statements, or supplementary materials included in this article.