

Abstract
The cerebellum exhibits both motor and reward-related signals. However, it remains unclear whether reward is processed independently from the motor command or might reflect the motor consequences of the reward drive. To test how reward-related signals interact with sensorimotor processing in the cerebellum, we recorded Purkinje cell simple spike activity in the cerebellar floccular complex while monkeys were engaged in smooth pursuit eye movement tasks. The color of the target signaled the size of the reward the monkeys would receive at the end of the target motion. When the tracking task presented a single target, both pursuit and neural activity were only slightly modulated by the reward size. The reward modulations in single cells were rarely large enough to be detected. These modulations were only significant in the population analysis when we averaged across many neurons. In two-target tasks where the monkey learned to select based on the size of the reward outcome, both behavior and neural activity adapted rapidly. In both the single- and two-target tasks, the size of the reward-related modulation matched the size of the effect of reward on behavior. Thus, unlike cortical activity in eye movement structures, the reward-related signals could not be dissociated from the motor command. These results suggest that reward information is integrated with the eye movement command upstream of the Purkinje cells in the floccular complex. Thus reward-related modulations of the simple spikes are akin to modulations found in motor behavior and not to the central processing of the reward value.
NEW & NOTEWORTHY Disentangling sensorimotor and reward signals is only possible if these signals do not completely overlap. We recorded activity in the floccular complex of the cerebellum while monkeys performed tasks designed to separate representations of reward from those of movement. Activity modulation by reward could be accounted for by the coding of eye movement parameters, suggesting that reward information is already integrated into motor commands upstream of the floccular complex.
Keywords: cerebellum, eye movements, kinematics, Purkinje cell, reward, smooth pursuit
INTRODUCTION
The cerebellum is crucial for implementing the transformation from sensory information to motor output. Theoretical and experimental studies of the cerebellum have examined the direct transformation of sensory input to motor output and the ways in which the cerebellum circuitry underlies motor learning (Albus 1971; Gilbert and Thach 1977; Herzfeld et al. 2015; Kennedy et al. 2014; Lisberger and Fuchs 1978; Marr 1969; McCormick and Thompson 1984; Nguyen-Vu et al. 2013; Shidara et al. 1993). In addition to implementation of direct sensorimotor information, reward-related signals in the cerebellum have been identified by recent research (Carta et al. 2019; Heffley et al. 2018; Kostadinov et al. 2019; Larry et al. 2019; Ramnani et al. 2004; Tanaka et al. 2004; Thoma et al. 2008; Wagner et al. 2017). Thus the corepresentation of reward and sensorimotor signals raises the question of whether and how these signals interact in the cerebellum.
The eye movement system and particularly the smooth pursuit system is an excellent model for testing the interaction between reward and sensorimotor signals in the cerebellum. Critical cerebellar areas for controlling pursuit movements such as the flocculus complex and oculomotor vermis have been identified (Krauzlis and Miles 1998; Lisberger and Fuchs 1978; Noda and Suzuki 1979; Takagi et al. 1998; Voogd et al. 2012); hence, the putative sites in which reward interacts with the sensorimotor processing are known. Eye kinematics is related to the neural activity in these sites (Dash et al. 2012; Medina and Lisberger 2007; Shidara et al. 1993); therefore we can study whether reward modifies the encoding properties of the neurons. Finally, the oculomotor areas of the cerebellum have been shown to be critical for motor learning and the underlying neural changes identified (Herzfeld et al. 2018; Medina and Lisberger 2008; Nguyen-Vu et al. 2013; Optican and Robinson 1980). This makes it possible to test whether the same mechanisms that are used in learning from sensory errors might also be engaged in learning from rewards in the cerebellum.
One of the main challenges in studying reward signals in the cerebellum and the motor system generally is to dissociate reward signals from the motor consequences of these reward signals. When the reward is already fully integrated into the motor command, all the reward-related modulations should be explained by the effect of reward on behavior. For example, in the motor periphery reward-related modulation should be equal to the behavioral effect. In other words, an identical reward and behavior modulation would suggest that the reward has been integrated with the motor processing upstream of the recording site. Alternatively, the reward could be represented differently or beyond behavior. These types of modulation have been found in the motor structures of the cerebral cortex and are suggestive of an interaction between reward and motor commands. For example, in the frontal eye field (FEF), reward is coded beyond eye speed and latency during smooth pursuit (Lixenberg and Joshua 2018) and saccade (Glaser et al. 2016).
To test whether reward is represented beyond behavior in the cerebellum, we recorded in the flocculus complex of monkeys when they were engaged in tasks in which we manipulated the expected reward size during smooth pursuit (Joshua and Lisberger 2012) and when we reversed the reward size in target selection tasks. We found that the reward modulations of the simple spike activity of Purkinje cells could be accounted for by the effect of reward on behavior. Unlike cerebral cortex activity (Hayden and Platt 2010; Lixenberg and Joshua 2018), reward did not multiplex with the motor representation. During reward reversal, learning changes in activity adhered closely to the changes in behavior. This contrasts with reports of learning from sensory errors in the cerebellum (Lisberger et al. 1994; Yang and Lisberger 2014) or during the learning of reward associations in other structures (Joshua et al. 2010; Williams and Eskandar 2006) in which the dynamics of the neural and behavior learning curves were found to be different. These results suggest that reward does not act at the level of the floccular complex to modulate eye movements but rather reward modulates activity upstream of the flocculus and propagates through the flocculus to drive behavior. The present results together with our previous research (Larry et al. 2019) highlight the gap in understanding how reward information in the climbing fibers is used for computations in the cerebellum.
MATERIALS AND METHODS
Data were collected from two male Macaca fascicularis monkeys (4–5 kg). All procedures were approved in advance by the Institutional Animal Care and Use Committees of The Hebrew University of Jerusalem and were in strict compliance with the National Institutes of Health Guide for the Care and Use of Laboratory Animals. To prepare the monkeys for the recording of eye movements, we implanted a head holder on the skull to allow us to restrain the monkeys’ head movements. The location of the eye was measured with a high-temporal resolution camera (1 kHz, EyeLink; SR Research) and collected for further analysis. In later surgery, we placed a recording cylinder stereotaxically over the ventral paraflocculus and flocculus (floccular complex). The center of the cylinder was placed above the skull targeted at 0 mm anterior and 11 mm lateral to the stereotaxic zero. We placed the cylinder at a backward angle of 26° and 20° for monkeys C and B, respectively.
Quartz-insulated tungsten electrodes were lowered into the floccular complex and neighboring areas to record neural activity with a Mini-Matrix System (Thomas Recording). Signals were digitized at a sampling rate of 40 kHz (Plexon Omniplex). For the detailed data analysis, we sorted the spikes off-line (Plexon). For sorting, we used principal component analysis and corrected manually for errors. We paid special attention to the isolation of spikes from single neurons, and we only included neurons for further analysis when they formed distinct clusters in the principal component analysis space. Sorted spikes were converted into timestamps with a time resolution of 1 ms and were inspected again visually to look for instability and obvious sorting errors.
Experimental design.
Visual stimuli were displayed on a monitor 45 cm from the monkeys’ eyes. The stimuli appeared on a dark background in a dimly lit room. A computer performed all real-time operations and controlled the sequences of target motion. The monkeys were trained to direct their gaze toward a still target and to track spots of light that moved across the video monitor. When the monkey tracked the spot successfully, it received liquid food (baby food mixed with water and infant formula).
The experiment was made up of three tasks: smooth pursuit in eight directions (directional task), smooth pursuit at different target speeds (speed task), and a target selection learning task (reward learning task). In the directional task the targets moved at 20°/s in one of eight directions. In the speed task the target moved at three speeds (5°/s, 10°/s, and 20°/s) in two directions corresponding to the preferred and null directions of the recorded neurons. The trials in the speed and directional tasks had the same temporal structure. Each trial started with a bright white target that appeared in the center of the screen. After 500 ms of presentation, in which the monkey was required to acquire fixation, the white target changed color. The color of the target signaled the size of the reward the monkey would receive if it tracked the target. For monkey B we used blue to signal a large reward (~0.2 mL) and red to signal a small reward (~0.05 mL); in monkey C we used yellow to signal a large reward and green to signal a small reward. The colored target appeared for 800–1,200 ms, during which time the monkeys continued to fixate on the target in the center of the screen; gaze shifts resulted in aborting of the trial. The targets stepped in one direction and then moved at a constant speed in the other direction (Rashbass 1961). The step size was set to minimize saccades and was 1°, 2°, and 4° for target speeds of 5°/s, 10°/s, and 20°/s. The target moved for 750 ms and then stopped and stayed still for an additional 500–700 ms. When the eye was within a 3° × 3° window around the target the monkey received a reward. In each task, different conditions of reward, target speed, and target direction were randomly interleaved.
In the selection task the monkeys were required to select one of two targets presented on the screen. The color of the targets signaled the size of the reward the monkey would receive if selected. One of the colors was associated with a large reward and the other with a small reward. Each trial began with a 500-ms fixation period, similar to the tasks described above. Then two additional colored spots appeared at a location 4° eccentric to the fixation target in orthogonal directions. The monkey was required to continue fixating on the white target in the middle of the screen. After a variable delay of 800–1,200 ms, the central target disappeared and the colored targets started to move toward the center of the screen at a constant speed of 20°/s. The monkeys typically initiated pursuit eye movement and after a variable delay made a saccade toward one of the targets. We detected these saccades online as an eye velocity that exceeded 80°/s. The target that was closer to the end point of the saccade remained in motion for up to 750 ms, and the more distant target disappeared. In cases where the monkey did not saccade until the end of the motion epoch, the target closer to the eye gaze at motion offset remained. The size of the reward was determined by the color of the remaining target. To avoid restricting selection behavior, there were no accuracy requirements from the initiation of target motion until we removed the unselected target. After this period, the monkeys were required to keep their gaze within a 3–4.5° invisible square window around the remaining target.
The selection task included trials in which we reversed the association between the color and the reward (learning trials) across sessions and trials in which the association between the color of the target and reward was constant across all experiments (base trials). The colors and the reward associated with them on the base trials were identical to the single-target task. For monkey C blue and red were used as learning colors and green and yellow for base trials, whereas in monkey B we reversed the colors. In each selection task we randomly interleaved the base and learning trials, thus enabling a direct comparison between them. We also randomly interleaved the direction of movement of the larger reward target in two orthogonal directions. For simplicity, in this report we present targets as though they were moving up and to the right, whereas in fact the exact directions were determined by the tuning of the cells. To align target direction to the first quadrant we multiplied the behavior by a rotation matrix. For example, when the targets moved to the left and down we rotated the behavior by 180°. This method allowed us to average the behavioral data across conditions.
In all tasks, trials in which monkeys did not match the precision requirements were aborted without reward and repeated until completed successfully. Repeating trials ensured that the monkeys could not deliberately abort trials with a small reward in order to expedite trials with a large reward. We confirmed that analyzing only trials that were preceded by a rewarded trial did not alter any of our conclusions.
After we isolated a neuron, the monkey was first administered the directional task. Neurons that seemed directionally tuned online were further tested on the speed task. We selected the direction of movement on the speed task to be the preferred and antipreferred directions of the neuron. If the neuron was still well isolated after the speed task, the monkey was administered the reward learning task. We aligned one of the directions of the target to be either the preferred or the antipreferred direction of the neuron and the other in an orthogonal direction. We used either the preferred or antipreferred direction to increase the likelihood that the direction would be the preferred direction of the complex spikes of the neuron, which is often opposite to the preferred direction of the simple spikes (Stone and Lisberger 1990). In the directional and speed tasks we used neurons that were recorded for at least 5 trials per condition. In the selection task we used neurons that were recorded in each learning condition for at least 40 trials.
Neural database.
Our goal was to focus on the interaction between reward and eye movement signals. We therefore only included neurons that were directionally tuned. This criterion further ensured that the cells we analyzed were comparable to cells that were previously considered to be in the flocculus and ventral paraflocculus (flocculus complex). Nevertheless, it is possible that some of the cells were from nearby areas such as the dorsal paraflocculus (Noda and Mikami 1986). On the directional and speed tasks, the effect of reward on behavior emerged mostly at motion onset before the first catch-up saccade. We therefore included neurons that were directionally tuned (α = 0.05, Kruskal–Wallis) during the first 300 ms of the movement. These criteria yielded 48 (out of 207; monkey B: 25, monkey C: 23) and 35 (out of 60; monkey B: 18, monkey C: 17) Purkinje cells in the directional and speed tasks. In the reward learning task the reward size affected behavior across all movements; hence, we used the full 750 ms of the movement to test for significance (α = 0.05, Kruskal–Wallis, across base and learning trials). This resulted in 28 Purkinje cells (out of 48; monkey B: 17, monkey C: 11) that met the inclusion criteria. We verified that using a longer time period for the directional and speed tasks or a shorter time period for the reward learning task did not alter any of the conclusions.
Purkinje cells were identified by the presence of complex spikes based on the distinct low and high frequencies of the extracellular signal (Zur and Joshua 2019). The analysis of the complex spikes of the neurons studied here and other cells that were not tuned to movement direction was reported elsewhere (Larry et al. 2019). In most of the cells, we were able to reliably isolate both the complex and simple spikes to confirm the presence of an ~10- to 20-ms pause in the simple spikes after a complex spike. We verified that the response properties of the cells in which we were able to isolate only simple spikes were similar. We mainly focused on collecting data from the Purkinje cells, but occasionally we collected data from cells without complex spikes, which we refer to as “non-PCs.” These included 30 (monkey B: 5, monkey C: 25), 11 (all from monkey C), and 2 (both from monkey C) neurons that were directionally tuned in the directional, speed, and learning tasks. Because of the small sample we do not report the activity of the non-PCs in the learning paradigm.
We compared the responses of the neurons recorded in the present study to neurons recorded from the FEF in a previous study (Lixenberg and Joshua 2018). Because of minor differences in the inclusion criteria of these studies, we reanalyzed and reported the FEF data with the same inclusion criteria we used for the cerebellar data, i.e., analysis was based on the first 300 ms after target motion onset (250 ms in Lixenberg and Joshua 2018). Overall, we reanalyzed 144 FEF neurons (monkey X: 56, monkey Y: 88). To ensure that the difference between the cerebellum and FEF data did not arise from the larger number of trials in the FEF recordings, we randomly pruned trials from the FEF to equal the number of trials in cerebellum recordings. The studies also differed in terms of the location of the cue that signaled the reward. Here the color cue appeared in the center of gaze, whereas in the FEF study we used eccentric cues. In discussion we return to the potential implications of these differences.
Data analysis.
All analyses were performed with MATLAB (MathWorks). We examined the time-varying properties of the spike density functions calculated from the spike times with a Gaussian kernel with a standard deviation (SD) of 20 ms. The baseline firing rate was defined as the average rate in the 500 ms before target motion onset across all recorded conditions. To calculate the tuning curves, we averaged the responses in the first 300 ms of the movement. We determined the preferred direction by taking the direction closest to the vector average of the responses (center of mass) of the neural activity.
Analysis of reward learning task.
To obtain the population learning curve we calculated the average behavior across sessions as a function of the number of trials. The selection was calculated as the fraction of sessions in which the monkeys selected the larger reward target. The pursuit angle was calculated as where vy and vx are the averages across sessions of eye velocities 100–300 ms after motion onset. We used this method and not the average of the angle on single trials because direction estimation from single trials can be noisy. This was most apparent in trials with late initiation, in which even slight noise could lead to large deviations in angle estimates.
In the learning sessions, for each neuron we defined the preferred condition as the condition in which the average firing rate across the 750 ms of movement was maximal during the base trials. The corresponding learning trial in which the larger reward target moved on the same axis was defined as the preferred learning condition. As a verification, defining the preferred learning condition as the condition in which at the end of the learning session the response was larger did not alter any of our conclusions.
In the analysis of the learning curve we focused on the population rather than on single neurons since constructing the single-neuron learning curve was too noisy. Because learning was rapid, we were unable to reduce the single trial variability by averaging across trials in a meaningful way. Even when we averaged across the population, the learning curves contained trial-by-trial fluctuations, probably reflecting noise and not true learning fluctuations at the population level. Therefore, we did not expect that the learning curve could be fully predicted by any model that did not consider these fluctuations. To estimate the best possible match given the degree of randomness in the data, we fitted an exponential function to estimate the learning curve. We then calculated the SD of the firing rate learning curve and the behavior-based predictor after learning had saturated (>20 trials per learning condition). We then added noise to the exponential fit with the same SD as we measured in the learning curves and predictor. We calculated the coefficient of determination of these two curves. We repeated this process 1,000 times and used the average to estimate the maximal amount of variability that could be explained by any model or predictor of the learning curve assuming the fluctuations were noise.
Associating firing rate with eye kinematics.
In the selection task we fit the population response to a vector to a linear weighted sum of the average eye movement components (Joshua and Lisberger 2014; Ono and Mustari 2009; Shidara et al. 1993). In this task the movement was not unidirectional; hence, we constructed a model that associated population neural activity to both the horizontal and vertical eye kinematic components as follows:
where and are the eye velocity and acceleration, the H and V subscripts correspond to the horizontal and vertical eye components, and ai are the parameters of the model. We focused on the first 300 ms of the movement; therefore, we did not use the eye position or temporal shift (Δt). The temporal shift was unnecessary for the population fit given the smoothness of the response and the fact that for the large range of shifts the quality of the fit was very similar. Position had very little effect on the firing rate at movement initiation since eye position changes were small during the first 300 ms after target motion (~1.5°) and the population position sensitivity of the neurons was small. We restricted this analysis to the initial movement because when we attempted to calculate the model across the full time course of selection trials it was unable to predict the average response. We suspect that this failure was due to the large intertrial saccades or the more complex nature of the pursuit movement in selection trials.
We also attempted to use a kinematic model to predict the effect of reward on single-target tasks. However, since the effect of reward on behavior and neural activity was small in these trials, the quality of the model fit was not sufficient to robustly compare reward modulation in neural activity to behavior. Instead, to compare behavior and neural activity in the single-target tasks we compared the effect of reward size on neural activity to that of eye speed. Identical effects of reward on neural activity and behavior would be expressed as . By rearranging terms, we get that . We therefore calculated the ratio between the eye speed in the small and large reward trials and multiplied this ratio by the modulation beyond baseline in the large reward. We compared this scaled response to the actual firing rate in the small reward condition. Similarity between the scaled and actual firing rates would suggest that reward modulates behavior and neural activity similarly. Calculating the scaled response on the population or individually for each cell and then averaging across cells did not alter any of our conclusions. The size of the behavioral effect in acceleration and velocity was similar; therefore, using either yielded similar conclusions.
For the single-cell analysis we used nonparametric tests because they were performed on spike counts in small time windows, which often leads to the violation of parametric test assumptions. In the population analysis we also used nonparametric tests to ensure that outliers did not bias the test.
RESULTS
Expectation of reward potentiates eye movement and activity of floccular complex neurons.
We recorded extracellularly from Purkinje cells in the floccular complex while the monkeys were engaged in a smooth pursuit task with reward size manipulations (Fig. 1A) (Joshua and Lisberger 2012; Lixenberg and Joshua 2018). Before target motion onset, the target changed color to indicate the size of the reward the monkey would receive upon successful tracking of the target (Fig. 1A). The monkeys initiated a smooth eye movement that was faster when they were expecting a large versus a small reward (Fig. 1B). We quantified the effect in a single session by calculating the average velocity 200–300 ms after target motion onset. Across sessions the eye moved consistently faster in the large versus small reward condition (Fig. 1C; signed-rank test, P = 3.7 × 10−8, n = 48 sessions). We initially focused the behavioral and neural analysis on the first 300 ms of motion since this period usually preceded the first corrective saccade, which made interpretation of both neural activity and behavior more complex.
Fig. 1.

Tasks, behavior, and examples of neural responses. A: the sequence of snapshots illustrates the structure of the behavioral task. The sizes of the 2 drops of water represent the amount of reward given at the end of the trials. B: average eye speed in the large (blue) and small (red) reward conditions across all recording sessions; gray bands show the SE. C: comparison of eye velocity for the large reward condition (x-axis) and the small reward condition (y-axis) 200–300 ms after motion onset. Each dot represents 1 session. D: examples of extracellular recordings from a Purkinje cell. Each trace shows the extracellular recording aligned to the time of a complex spike. The arrow at top marks the time of the complex spikes. E and F: raster plot (top) and peristimulus time histogram (bottom) of the example Purkinje cell for the large (blue) and small (red) reward conditions: data for motion in the preferred (E) and null (opposite to preferred; F) directions, which were determined by the center of mass (vector averaging) of the first 300 ms of responses in 8 directions.
To examine how reward interacted with the encoding of eye movement by floccular complex neurons, we recorded the simple spike activity of Purkinje cells while the target moved in eight different directions (directional tuning task). We identified 48 neurons that were directionally tuned (Kruskal–Wallis, α = 0.05). We defined the preferred direction (PD) of the neuron as the direction that was closest to the vector average of the responses across directions (direction of the center of mass). Figure 1, D–F, show the activity of a sample Purkinje cell. The identification of a neuron as a Purkinje cell was based on the presence of a distinct extracellular signature of complex spikes (Fig. 1D). After target motion onset, the simple spike rate increased in the preferred direction (Fig. 1E) and slightly decreased in the null (opposite to PD) direction (Fig. 1F). In both directions, the responses to the large and small rewards were very similar, as indicated by the overlap of the red and blue lines. We found only a slight elevation of the rate for the larger reward condition at motion onset in the PD. Thus in this example cell activity was strongly modulated during eye movement but only slightly modulated by reward.
As we found for the example neuron, the average population activity in directions close to the preferred direction (PD and PD ± 45°) was also slightly larger for the larger versus small reward conditions (Fig. 2A). The overlap of the error bars, representing SE, indicates that the size of the effect was too small to reliably separate the average response in any specific time point. Nevertheless, for average activity in the first 300 ms after target motion onset we found a significant difference between large and small rewards (Fig. 2B; signed-rank test P = 0.03, n = 48 neurons). Thus both in behavior (Fig. 1, A–C) and in neural activity (Fig. 2) we found that reward size had a small but significant effect. To compare these neural and behavior effects, we used the size of the behavioral effect to scale the population activity in the large reward condition. We multiplied the population neural modulations in the large reward condition by the ratio of the eye velocities in the small to the large reward conditions (see materials and methods). This resulted in a trace that scaled the neural activity by the effect of eye velocity (Fig. 2A). The scaled trace closely matched actual activity in the small reward condition (Fig. 2A), indicating that the effect of reward size on neural activity and eye velocity was similar. Cell by cell comparison between the scaled and small reward traces was not significant (P = 0.32, n = 48 neurons, signed-rank test). Thus the slight reward-related modulations we found in directions close to the preferred directions were explained by behavior.
Fig. 2.
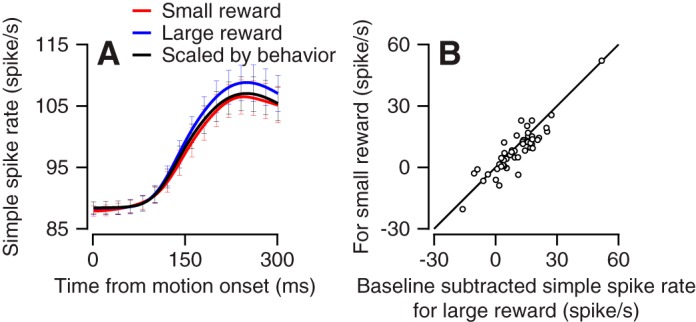
Population response of the Purkinje cells at movement initiation around the preferred direction. A: average activity of the population of neurons in the preferred direction and in directions rotated by 45°. The black line shows the prediction for the modulation in the small reward condition based on the large reward response and the behavioral effect. Error bars are presented at spacing of 20 ms and show the SE. B: cell-by-cell response to the large (x-axis) and small (y-axis) rewards. Each dot shows the average activity for the first 300 ms after target motion onset.
Reward interaction with direction tuning.
To calculate the effect of reward on directional tuning we aligned the responses of individual cells to their PD and averaged across the population. We found very minor differences between the pattern of responses for large and small rewards (Fig. 3A). The population pattern of responses for both large and small rewards was consistent with previous reports of the relationship between pursuit and flocculus complex activity (Medina and Lisberger 2007; Shidara et al. 1993). Close to the PDs, neurons increased their rate at motion onset and continued to fire beyond the prepursuit baseline during pursuit maintenance. At the end of the movement when the eye was directed eccentrically, activity returned close to the level before movement, indicating a slight population sensitivity to eye position (Joshua et al. 2013).
Fig. 3.

Directional tuning and reward modulations. A: population average of neural activity for the large and small reward conditions. Each plot corresponds to differences in the direction of motion from the preferred direction (PD) of the neurons. Solid lines show averages, and gray bands show the SE. B: the population tuning curve for large and small reward targets. Activity was averaged across the first 300 ms after motion onset. Error bars show the SE. C: the difference in tuning curves between the large and small rewards for the population of flocculus complex neurons (black) and for neurons in the frontal eye field (FEF) from our previous study (gray). D: the fraction of neurons that significantly encoded reward size as a function of the difference in motion direction from the PD. Black and gray bars show results for the cerebellum and FEF. FEF activity was reanalyzed to match the same number of trials and the time course (300 ms) we used for the analysis of cerebellar neurons.
To quantify the directional tuning at the initiation of movement, we calculated the tuning curve for each neuron in the first 300 ms after motion onset, aligned these curves by the PD, and averaged across the populations. This resulted in a population-directional tuning curve (Fig. 3B) for the large and small reward conditions. To highlight the effects of the reward on the tuning curve we calculated the differences between the large condition and the small condition (Fig. 3C). The neural activity in the PD and in directions rotated by 45° was slightly larger for the large versus small reward condition (Fig. 3, B and C), although it only reached significance for PD ± 45 (PD: P = 0.1, n = 48 responses, PD ± 45: P = 0.01, n = 96 responses, signed-rank test). In directions more remote from the PD, the responses to the large and small rewards were similar (P = 0.57, 0.85, and 0.5 for PD ± 90, 135, and 180, n = 96 responses for PD ± 90 and 135 and n = 48 responses for PD ± 180, signed-rank test). A larger reward modulation in directions where neurons encoded movement more strongly is expected if the reward-related modulations reflect encoding of the slightly faster movement. The observed population pattern differed from independent coding of behavior and reward (multiplexing) that has been observed, for example, in the anterior cingulate cortex. In this area, reward added a constant modulation to the directional tuning of the populations (Hayden and Platt 2010).
Similar population but distinct single-neuron reward modulation in flocculus complex and FEF.
Overall, the effect of reward size on the tuning curve of the population was similar for the cerebellum and the FEF. Figure 3C plots the results of the present study alongside the results of our previous study of FEF activity (Lixenberg and Joshua 2018). The pattern and magnitude of the population modulation in terms of reward were similar, as indicated by the overlaps in the difference between the large and small tuning curves in Fig. 3C. In the FEF modest population reward modulations were achieved despite substantial modulation at the level of the single neuron (Lixenberg and Joshua 2018). The population responses averaged out the single-cell modulations. This was exemplified by the large number of neurons that substantially encoded reward even in directions where the population was not modulated (Lixenberg and Joshua 2018 and Fig. 3D). Contrary to the neurons in the FEF, single-cell reward modulations were rarely significant in the cerebellum (Fig. 3D; 7% vs. 18%, P = 7 × 10−5, χ2 frequency test). Thus in both populations the pattern of reward modulation was similar (Fig. 3C) and matched the behavior (Fig. 2 and Lixenberg and Joshua 2018), but we only found substantial single-cell modulations in the FEF.
Target speed but not reward size substantially modulates neural activity and behavior.
In the directional tuning task, we found slight modulations as a function of reward that we were able to explain by the encoding of eye speed. To test whether neurons encoded reward beyond speed directly we recorded activity in the flocculus complex while manipulating both target speed and reward size. The target moved at one of three speeds (5°/s, 10°/s, and 20°/s), and, as above, the color of the target indicated the size of the reward. The monkeys initiated a smooth eye movement that increased with target velocity (Fig. 4A). At all three speeds the eye movement was faster for the large reward than for the small reward condition (P = 0.076, 4 × 10−4, and 3.5 × 10−4 for 5°/s, 10°/s, and 20°/s, n = 35 sessions, signed-rank test on average velocity between 200 and 300 ms after motion onset). Encoding of reward beyond the sensorimotor command would imply that the relationship between target or eye speed and neural activity should be substantially different for the large and small reward conditions. Alternatively, since the behavior modulations were small, if reward representation follows behavior we would expect either small or undetectable modulations in activity.
Fig. 4.

Population analysis of speed and reward modulations. A: average eye speed in the large (blue) and small (red) conditions for different speed targets. The key on right and dashed lines indicate the target speed of the corresponding trace. B and C: the population target (B) and eye (C) speed tuning for large and small reward targets in the preferred direction (PD) and the antipreferred direction (null). Error bars show the SE. The baseline firing rate was defined as the average rate at motion onset across all recorded conditions and was subtracted individually for each neuron. D–F: population average of the neural activity for the large and small reward conditions. Plots correspond to the different speed of target motion: 20°/s (D), 10°/s (E), and 5°/s (F).
We recorded neural activity from 35 neurons when the target moved in the preferred direction of the neuron and the direction opposite to the preferred direction (null). We calculated the population speed tuning by averaging the neural activity in the first 300 ms separately for each target speed condition. We did not find evidence for the encoding of reward beyond target speed (Fig. 4B). In the preferred and null directions, there was no significant difference between responses for the large and small rewards (P = 0.46 and P = 1 for PD and null direction, n = 35 neurons, signed-rank test on averages across target speeds). Calculating the eye speed rather than the target speed tuning did not reveal any consistent effect of the reward, either (Fig. 4C). We found a slight trend where the slope of the relationship between firing rate and eye speed was steeper for the small reward condition. However, the slopes for the large and small rewards were not significantly different (P = 0.19 and P = 0.52, for PD and null direction, signed-rank test on individual cell slopes, n = 35 neurons). Calculating both eye and target speed tuning could potentially dissociate target motion and eye movement representation (Krauzlis and Lisberger 1991). However, the behavioral effect of reward was small; therefore we were unable to use the differences between the tuning of the eye and target speed to dissociate motor and sensory signals. Analysis of the full movement time revealed that reward modulations were very small across the entire movement, as indicated by the overlap of the small and large reward population peristimulus time histograms (PSTHs) (Fig. 4, D–F).
Note that we were able to show that reward was significantly encoded on the directional task but not the speed task. This most likely does not represent a difference in the encoding of the reward since the structure of the directional and speed tuning tasks was the same. Directly testing for the difference between the reward encoding in neurons that were recorded during both the speed and directional tuning tasks did not reveal any difference (P = 0.95, n = 32 neurons that were recorded in both tasks, signed-rank test for the difference between large and small reward in the PD). Thus differences could arise from the differences in the number of cells, differences in the behavioral effect (and the corresponding rate), or random fluctuations. An additional possible interesting analysis would be to characterize the relationship between neural and behavioral variability, such as the neuron-behavior correlation (Joshua and Lisberger 2014; Medina and Lisberger 2007). However, in this study we did not have enough repeats to perform such analyses.
Cell identification based on complex spikes and spike train statistics.
Up to now we have analyzed the response of a subgroup of the recorded neurons in which we could identify complex spikes. In a subset of these cells (34/48 in the directional task and 26/35 in the speed task) we were able to simultaneously sort complex and simple spikes (Zur and Joshua 2019) to confirm that after a complex spike the simple spike rate was reduced (Fig. 5A). To further confirm that these two groups (sorted and unsorted complex spikes) were similar, we studied the statistics of the spike train of the neurons. If the neurons were from different groups, we would expect that the firing rate or variability of the cells would be different (Hensbroek et al. 2014; Van Dijck et al. 2013). We therefore calculated the average firing rate and the CV2 in the 500 ms before target motion onset. CV2 was calculated from interspike intervals (ISI) as the average of 2*| ISIn + 1 − ISIn |/(ISIn + 1 + ISIn) (Holt et al. 1996). We did not find a clear separation between groups, as indicated by the overlap of the clusters in the plot comparing the firing rate with CV2 (Fig. 5B). This further supports our assumption that the cells in which we could not sort complex spikes were Purkinje cells. By contrast, we found that the cells in which we did not observe complex spikes tended to have either a lower firing rate or a higher CV2 (Fig. 5B), suggesting that this group was distinct from the identified Purkinje cells (Hensbroek et al. 2014); we refer to these cells as non-PCs.
Fig. 5.
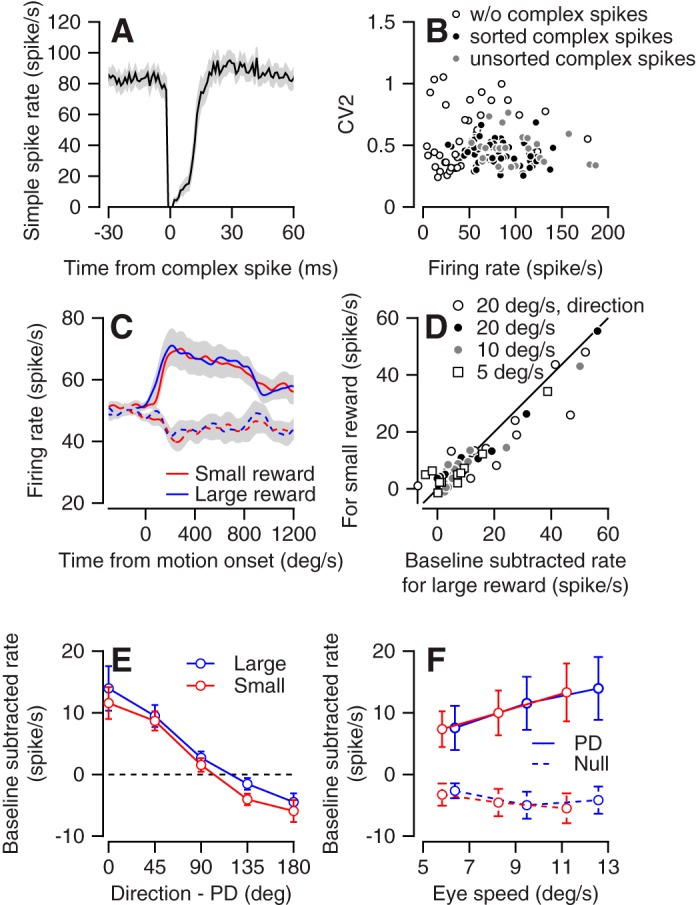
Cell identification and response of non-Purkinje cells (non-PCs). A: the simple spike firing rate (y-axis) aligned to the time from occurrence of a complex spike (x-axis). The solid line shows the average across all cells in which we identified both complex and simple spikes. B: the average firing rate (x-axis) and CV2 (y-axis) for the 500 ms before motion onset of all neurons in the study. Open, filled, and gray dots show cells in which we did not identify complex spikes, cells in which we identified and sorted complex spikes, and cells in which we identified complex spikes but were unable to sort them, respectively. C: population average activity of non-PCs in the preferred (solid) and null (dashed) directions in the large and small reward conditions in the direction tuning task. D: single-cell responses of the non-PCs in the preferred direction during the directional tuning task (direction) and at the 3 different speeds in the speed tuning task. Each symbol shows the average activity for the first 300 ms after motion onset for the large (x-axis) and small (y-axis) reward conditions. E: the population tuning curve for large and small reward targets. Activity was averaged across the first 300 ms after motion onset. PD, preferred direction. F: the population eye speed tuning for large (blue) and small (red) reward targets, in the PD and the antipreferred (null) direction. Error bars (E and F) and gray shading around traces (A and C) show the SE.
Non-Purkinje cells are also only slightly modulated by reward.
To further test whether the criteria we used to identify Purkinje cells might affect our conclusion we examined the response prosperities of the non-PCs. We recorded 30 and 11 non-PCs that were directionally tuned during the directional and speed tasks. Overall, the response properties of these cells were similar to those of the Purkinje cells. The population averages of the neurons in the large and small reward trials were similar, as demonstrated by the response of the neuron in the preferred and null directions (Fig. 5C). To demonstrate the similarity of the response to the large and small rewards for single neurons we calculated the average firing rate in the first 300 ms in the preferred direction (Fig. 5D). We found a slight tendency toward a larger response to the large reward (Fig. 5D), but this tendency did not reach significance (signed-rank test, P = 0.1, n = 63 responses).
As we found for the Purkinje cells, reward only slightly modulated the population directional and speed tuning of the neurons (Fig. 5E). One minor difference was that for Purkinje cells the activity was larger for the large reward condition close to the PD (Fig. 3, B and C) whereas for non-PCs the response was slightly larger for the large reward in all directions; however, a direct comparison between Purkinje and non-PCs was not significant in any of the directions (rank sum test between groups on large-small, P = 0.31, 0.14, 0.66, 0.07, and 0.49 for PD, PD ± 45, PD ± 90, PD ± 135, PD ± 180; n = 30 and 48 neurons). Larger data sets in behavioral paradigms designed to study this effect are needed to test whether Purkinje cells and non-PCs differ in terms of the reward modulation of their directional tuning. Finally, as we found for Purkinje cells, the reward modulation during speed tuning did not exceed the modulation expected by eye movements (Fig. 5F). In the preferred direction the neurons tended to fire more when the eye moved faster, but the relationship between eye speed and firing rate was similar for the large and small rewards as indicated by the overlap of the red and blue lines in the plot that shows the firing rate as a function of eye speed (Fig. 5F). Thus, overall, we found a very slight modulation by reward in both Purkinje and non-PCs, indicating that the selection of neuron for analysis did not bias our conclusions. Furthermore, the distinction in the firing properties suggests that indeed cells without complex spikes are not Purkinje cells. Thus these results suggest that in addition to the lack of reward encoding in the cerebellar cortex output (Purkinje cells), reward is not encoded in the intermediate processing stages.
Eye movement in reward learning task.
The results up to this point indicate that the signals that might be associated with reward expectations were small and when they reached significance could be explained by the encoding of eye movements. In the single-target paradigm we used so far, the behavioral effects were small. Studying the interaction between reward and behavior in this regime has the advantage of more clearly revealing the dissociation of reward modulations from the behavioral effect when they exist but has the disadvantage that if reward-related modulations reflect behavior they may be too small to be detected reliably. In fact, we were unable to reliably detect single-cell or even population reward modulations (Figs. 3–5). Thus, next we tested whether reward could be dissociated from behavior in reward-based reversal learning in a target selection paradigm. In this paradigm, reward modulates behavior beyond the effect it has on single targets (Joshua and Lisberger 2012; Raghavan and Joshua 2017). Therefore, if reward modulations reflect behavior, we would expect reward-related activity to be more robustly encoded in single-cell activity.
In addition to the representation of the expected reward (Wagner et al. 2017), the cerebellum is involved in reward-based learning (Sendhilnathan et al. 2020; Thoma et al. 2008). We probed whether and to what extent behavior and neural data were associated during reward learning. If reward learning is implemented upstream of the cerebellum, we would expect that the reward-dependent modulation would correspond directly to the change in behavior. Alternatively, during reward learning, activity modulations might not match the changes in behavior and the structure of the difference between the neural activity and behavior could constrain the implementation of reward learning. For example, the dynamics of neural changes could precede or follow behavior, thus indicating the distribution of reward learning across many areas (Williams and Eskandar 2006). The learning response might deviate from behavioral changes since plasticity might selectively enhance some pathways but not others in these networks (Lisberger 1988).
To determine the relationship between neural activity and behavior during reward learning we recorded activity in the floccular complex while the monkeys learned to select targets (Joshua and Lisberger 2012) based on reward information. At the beginning of each trial the monkeys fixated on a spot in the center of the screen while two colored dots appeared peripherally (Fig. 6A). After a variable delay, both dots moved toward the center of the screen at a constant speed. The monkey typically initiated a smooth eye movement and then performed a saccade to one of the targets. At the end of the saccade, the target closer to the gaze position remained and the other target disappeared. In cases where the monkey did not saccade until the end of the motion epoch, the target closer to the eye gaze at motion offset remained. We refer to the remaining target as the selected target.
Fig. 6.
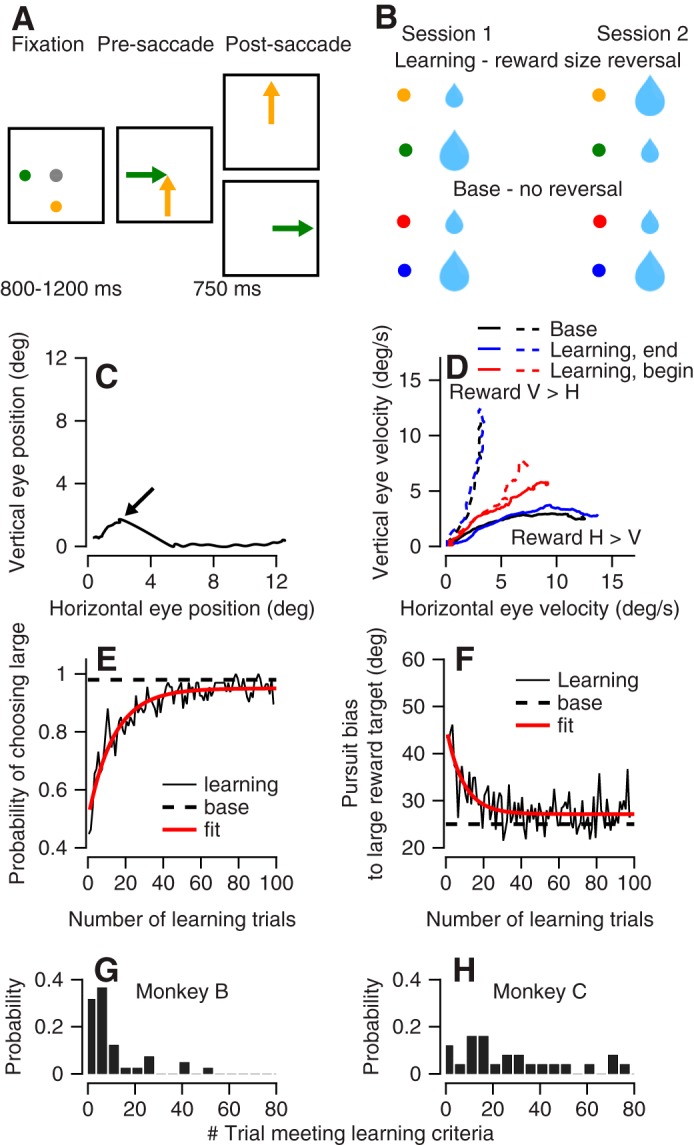
The reward learning paradigm and behavioral learning curves. A: the diagrams illustrate the temporal structure of the task. The gray dot represents the fixation target. The 2 colored dots represent targets associated with different amounts of reward (represented by the sizes of the drops). The arrows show the directions of target movement. B: structure of the learning sessions. Blue and red dots represent the trials in which the association with the reward size was constant across the learning session. Green and yellow dots represent the targets in which we reversed the association between color and reward size across sessions. C: the eye position during a sample trial. The arrow points to the eye position just before the saccade. D: eye velocity in the first 300 ms after target motion on the first 5 learning trials (red), the trials at the end of the learning session (blue), and the base trials (black). Solid and dashed traces show trials in which the larger reward target moved along the horizontal (H) and vertical (V) axes. E and F: the average across learning sessions of the % selection of the large reward target (E) and the pursuit bias toward the large reward target (F). The traces show data in the learning trials (solid black) and base trials (dashed black) and an exponential fit of the learning trials (red). G and H: histogram of the first of 10 consecutive trials in which the monkey (monkey B, G; monkey C, H) selected the larger reward target.
The color of the selected target determined the size of the reward the monkey received at the end of the trial. Two of the colors were the same as the colors used for the large and small rewards in the experiments with a single target (Figs. 1–5). The association between these colors and the size of the reward did not change across sessions. We refer to these as base trials (Fig. 6B, bottom). Two other colors were used for reward learning (Fig. 6B, top). Across sessions, we switched the association between the size of the reward and the color; we refer to these as learning trials. In each session we interleaved base and learning trials and interleaved trials in which the large reward target moved along either the horizontal or the vertical axis. Note that we present the targets as moving up and right, but they could have moved along other orthogonal directions (see materials and methods).
To demonstrate the flow of a trial, Fig. 6C shows the eye position in an example trial. In this plot, the trace shows the horizontal versus vertical eye position after motion onset. Time is not explicitly represented; rather, it begins with eye position at the origin. As time proceeds after the onset of target motion, eye position moves outward along the trace in the graph. After motion onset of the two targets, the eye initially moved in an oblique direction for 400 ms. At this time point (Fig. 6C) the monkey saccaded to the horizontal target. We detected the saccade online and determined that after the saccade the horizontal target was closer to the eye position; thus the vertical target was removed. The monkey continued to track the remaining horizontal target until the end of the trial and then received a reward determined by the color of remining target (i.e., horizontal target).
In the base trials, in 98% of trials eventually the large reward target was selected (as defined above). Furthermore, in base trials the presaccadic pursuit initiation was already biased toward the larger reward target (Joshua and Lisberger 2012; Raghavan and Joshua 2017). This bias is demonstrated in Fig. 6D by the tendency of the black solid trace to plot closer to the horizontal axis and the black dashed trace to plot closer to the vertical axis. This behavior is equivalent to a weighted vector averaging of the target speeds (Joshua and Lisberger 2012).
Reward learning was evident from comparisons of the eye velocity at the beginning and the end of the learning session. The average eye velocity on the first five learning trials was directed mostly in an oblique direction (Fig. 6D). At the end of the learning session the eye was strongly biased toward the larger reward target, similar to the bias in the base trials (Fig. 6D). To quantify the pursuit bias, we calculated the angle between the direction of motion of the large reward target and the eye movement. This angle quantifies how much of the initiation of pursuit was biased toward the larger reward target. An angle of 45° indicates that the eye moved exactly between targets. An angle of 0° indicates that the monkey only tracked the larger reward target. Intermediate values indicate a bias toward the large reward target.
The learning curve for target selection and pursuit bias showed that the monkeys rapidly learned the association between color and reward size. Figure 6, E and F, present the average learning curve across learning sessions for target selection and bias in pursuit. Across 100 learning trials the percentage of selection of the larger reward target increased from slightly below 50% to close to 100% (Fig. 6E). The pursuit bias in these trials dropped from close to 45° to around 25° (Fig. 6F). At the end of the learning session the bias in pursuit and the fraction of large reward choices were similar to the base trials (Fig. 6, E and F). The dynamics of the pursuit and selection learning curves were similar. The maximal amplitude of the correlation between the curves was achieved with zero lag (−0.71, where the negative sign indicates pursuit bias and choice of the same target), suggesting that a single process was driving both behaviors.
We found some variability in reward learning across monkeys and between sessions. To quantify reward learning in a single session we defined a learning criterion as the first trial that followed 10 consecutive selections of the large reward target. Monkey B reached this criterion after fewer trials than monkey C (Fig. 6, G and H; P = 0.0003, n = 25 and 42 sessions rank sum test). Very often, it took monkey B only a few trials to switch between targets, whereas monkey C would often persevere for more trials in each learning session. Note that because we interleaved trials in which the large reward target moved along the vertical or horizontal axis, selecting the large reward required the monkey to switch between selection of the horizontal and vertical targets. Therefore, the consecutive selection of the large reward target could not result from a decision to track in a single direction.
Activity in floccular neurons during reward learning task.
We recorded the activity of 48 neurons during the reward learning task. Of these, we further analyzed the activity of 28 neurons that discriminated significantly between task conditions (see materials and methods). Thus, in the selection task, manipulating the location of the large versus the small reward target led to a significant modulation of many neurons. For each neuron we defined the preferred condition in the base trials as the condition in which the activity of the neuron was the highest and the nonpreferred condition as the condition in which the larger reward target moved in the orthogonal direction. The corresponding learning trials in which the larger reward target moved on the same/different axis were defined as the preferred/nonpreferred learning conditions. We used a task design that interleaved learning trials in which the larger reward moved along an orthogonal direction and also interleaved base trials. This made two critical comparisons possible. First, we compared learning trials to identify the changes in activity associated with reward learning. Second, we compared learning and base trials to test whether activity during reward learning was modulated beyond the selection-related signals.
To test whether the population neural activity changed within a session, we calculated the population PSTH at the beginning of the learning session (first 5 trials) and toward the end of the learning session (after 30 learning trials from each learning condition). As found for behavior (Fig. 6), at the beginning of the session the difference in the PSTH between the preferred and nonpreferred learning conditions was small (Fig. 7A). At the end of the session there was a larger difference between learning conditions (Fig. 7A). To quantify these changes for single neurons across a learning session, for each neuron we compared the difference in the response in the preferred and nonpreferred learning conditions from the beginning of learning to the end of the learning session (Fig. 7B). Neurons tended to plot beneath the equality line (P = 0.002, n = 28 neurons, signed-rank test), indicating that the difference between the preferred and nonpreferred learning conditions increased throughout learning. Thus both behavior and neural activity changed during the learning sessions. The change in neural activity indicates that information about reward size can robustly drive cerebellar activity and lead to changes in behavior. These results also indicate that the site of reward learning cannot solely be downstream of the floccular complex.
Fig. 7.

Learned changes in neural activity. A: population peristimulus time histogram in the trials at the end of the learning session (blue, after 30th trial precondition), at the beginning of the learning session (red, first 5 trials), and on base trials (black). Preferred and nonpreferred conditions are presented with solid and dashed lines, respectively. B: the difference between the firing rate in the preferred and nonpreferred learning conditions at the end (x-axis) vs. the beginning (y-axis) of the learning session. Each dot shows data from a single cell. C: comparison of single-cell responses in the learning and base trials. Each dot shows the single-cell deviation from baseline activity at the end of learning (x-axis) vs. the base trials (y-axis) for the preferred or nonpreferred condition.
To test whether activity during reward learning was modulated beyond the selection-related signals, we compared activity at the end of the learning session and the base trials. The population PSTHs in the preferred and nonpreferred conditions on the learning trials were very similar to the corresponding PSTHs on the base trials (Fig. 7A). There was no significant difference in either the preferred conditions or the nonpreferred conditions between the responses in the learning and base trials (Fig. 7C; P = 0.83 and P = 0.92, for the preferred and nonpreferred conditions, n = 28 neurons, signed-rank test). Thus, as found for behavior, the rate modulations were similar at the end of the learning session and on base trials.
Linking neural activity and behavior during reward learning.
Both the population neural activity and behavior changed rapidly at the beginning of the learning session. Figure 8, A and B, illustrate the changes in population neural activity and behavior in a similar format, thus enabling a direct comparison. We calculated the population PSTH by averaging activity across the neurons as a function of the number of trials starting from the onset of the learning session. We quantified the learned component of the eye velocity as the difference between the velocity component in the direction of the large and small reward targets. In the first few trials both the population neural activity and the learned eye velocity remained low after motion onset, as indicated by the darker pixel colors at the top of Fig. 8, A and B. As the learning session proceeded, both neural activity and behavior increased and rapidly saturated, as indicated by the brighter pixels from approximately the 5–10th trials and onwards.
Fig. 8.

Comparison of time courses for changes in neural activity and behavior during reward learning. A and B: the population peristimulus time histogram and corresponding learned eye velocity as a function of the number of learning trials (y-axis) in the preferred learning conditions. In A the color of each pixel corresponds to the average firing rate of the population. In B the color of each pixel corresponds to the difference between the eye velocity components in the direction of motion of the large and small reward targets. C: the population learning curve (black) and rate predictor (red) for the preferred (solid) and nonpreferred (dashed) learning conditions. x-Axis corresponds to the number of learning trials; y-axis corresponds to the difference between the average firing rate during 750 ms of target motion and the baseline rate before target motion. Gray bands show the SE. D: the average firing rate in the base trial (black) and the linear model fit (red). E: the population learning curve and behavioral predictor calculated from the first 350 ms of movement. Black traces show the rate learning curve. Red traces show the predictor based on the population rate and behavior. Blue traces show the predictor constructed individually for each cell and then averaged across the population. In C–E, solid and dashed traces show data for the preferred and nonpreferred learning directions. We preset the number of learning trials per condition; since conditions were randomly interleaved, the numbers presented are approximately half the number of the learning trials in the session.
To construct the neural learning curve, we calculated the average rate across the 750 ms of the target motion for the preferred and nonpreferred learning conditions (Fig. 8C). These curves also reveal the rapid changes across a small number of learning trials and the fast saturation of the neural activity. To test whether the changes in activity during reward learning could be predicted from the change in behavior, we combined behavior during reward learning with the neural modulation during the base trials to construct the predicted rate modulation. The assumption guiding this analysis was that if the activity during reward learning is equivalent to the representation of the eye movement, it should be similar to the activity during selection on the base trials. For each learning trial where the monkey selected the horizontal or vertical target, we constructed a rate predictor that was formulated as the activity on the adjacent base trial where the monkey also selected the same target. This analysis matched the base trial according to the behavior (direction of the selected target) and not the eventual reward. We then calculated the population predictor as the average across all the neurons. This predictor was a fairly good match with the actual rate, as indicated by the similarity of the black and red traces in Fig. 8C. The predictor explained 69% of the variance in the learning curve, whereas we estimated the maximal amount of variance that could be explained to be 77 ± 3% (mean and SD; see materials and methods). Thus the learning curve could be explained mostly by the activity in the base trial contingent on the selection.
The predictor constructed so far has the advantage of reducing the noise by averaging across the entire movement time; however, it ignores the specifics of the eye movement. As a complementary analysis, we constructed predictors based on the eye kinematics at pursuit initiation rather than on which target was selected. Neurons in the flocculus modulate their firing rate with the kinematics of the pursuit movement. To determine the extent to which the rate modulation depended on the kinematics, we expanded a linear model associating firing rate and eye kinematics (see materials and methods). We used the base trials to extract the parameters and then combined the parameters with behavior to predict the firing rate on the learning trials. Figure 8D depicts the average population firing rate in the first 350 ms on the base trials and the corresponding linear fit.
We combined this model with behavior observed during the learning trials to predict firing on the learning trials. We calculated the model either from the population activity or from single-cell data (Fig. 8E). As found for the analysis based on the full motion (Fig. 8C), the predictor coincided with the rate learning curve (Fig. 8E). The population and single-cell predictors explained 63% and 60% of the variance in the learning curve, whereas we estimated the corresponding maximal amount of variance that might be explained to be 68 ± 4.5% and 63 ± 5%. Thus, akin to our findings in the single target, when we focused the learning analysis on the initial motion and used the eye kinematics the reward learning-related modulations were mostly explained by behavior.
DISCUSSION
Reward-related signals are ubiquitous to nearly every cortical and subcortical area of the brain (Allen et al. 2019; Ding and Hikosaka 2006; Joshua et al. 2009; Ramkumar et al. 2016; Roesch and Olson 2003; Vickery et al. 2011; Wagner et al. 2017). One of the key questions is how these widespread reward representations are related to computations and transformations in different brain structures. When studying the effect of reward in the motor system, and in particular the cerebellum, the critical question is whether reward-related signals differ from motor commands. In the motor periphery, the reward information should be fully transformed to a motor command. In the shift from the periphery to central processing, more complex network representations of behavior and reward are likely to emerge. We found that in the floccular complex neurons responded as expected from a motor representation of reward. We suggest that information about the reward is combined with the sensorimotor signals upstream of the floccular complex and the signal then propagates through the cerebellum to drive eye movements. In this discussion we focus on the implications of the findings in terms of the ways in which reward interacts with smooth pursuit sensorimotor transformation and how reward is encoded in the cerebellum.
Reward signals in smooth pursuit eye movement system.
Information about reward drives vigorous eye movements and guides target selection (Joshua and Lisberger 2012; Takikawa et al. 2002). Our overall aim is to understand, at the implementation level, where and how reward acts on the sensorimotor signals that drive eye movements. The single-neuron reward modulations in the floccular complex are substantially different from the modulation in the frontal eye field (FEF). Unlike the neurons in the cerebellum, the reward-related modulation in the FEF cannot be completely accounted for by coding of eye movements (Glaser et al. 2016; Lixenberg and Joshua 2018).
In both the cerebellum and the FEF, organizing the population with respect to the preferred direction resulted in small rate modulations (Fig. 3). In the FEF this was achieved by averaging out reward modulation from the single cell. In the cerebellum the single-neuron reward modulations were mostly nonsignificant; thus the population effect was probably a result of the accumulation of small effects from many neurons. We previously hypothesized (Lixenberg and Joshua 2018) that decoders that average activity across neurons with a similar preferred direction could both explain how reward is modulated in the FEF beyond behavior at the single-cell level and be consistent with behavior at the population level.
The attenuation of reward signals might arise in the transformation from the FEF to the cerebellum. For example, the nucleus reticularis tegmenti pontis receives input from the FEF and projects to the flocculus complex (Langer et al. 1985b; Ono and Mustari 2009; Thier and Möck 2006). Other indirect polysynaptic pathways that connect the FEF to the cerebellum (Voogd et al. 2012) might also be organized by the preferred direction of the neurons. In this case, reward and behavior would already match at the level of input to the cerebellum. The lack of reward modulation in intermediate processing stages (Fig. 5) further supports the supposition that reward modulation is already averaged out in the input stages of the flocculus complex. However, it is possible that in the flocculus complex reward is encoded beyond behavior in granule cells (as was found for other cerebellar areas; see Wagner et al. 2017) and averaged out in the intermediate levels.
The difference between the FEF and the cerebellum probably is not a result of minor differences in task design. Specifically, in our previous FEF study the color cues appeared at eccentric locations and signaled the upcoming direction of movement. Eccentric versus central cues lead to differences in microsaccade behavior before target motion (Joshua et al. 2015) and to a slight decrease in pursuit latency. However, we expect that in the FEF reward would also be encoded beyond behavior with central cues since the FEF continued to code reward beyond behavior even after movement onset, when the differences between trials with eccentric and central cues were minimal. Other studies have reported the coding of reward beyond behavior in the FEF (Glaser et al. 2016) on different tasks, further supporting reward representation in the FEF beyond our specific task design.
Reward signals in cerebellum.
The cerebellum plays a notable role in the control of behavior beyond generating the final motor command. Diseases that affect the cerebellum often produce movement disorders; however, cerebellar patients can also suffer from cognitive and emotional impairments (Koziol et al. 2014; Schmahmann 2004; Thoma et al. 2008). Anatomically, the cerebellum is interconnected with the motor cortex as well as the prefrontal cortex (Kelly and Strick 2003). Functionally, cerebellar activity has been shown to relate to movement planning (Chabrol et al. 2019; Deverett et al. 2018; Gao et al. 2018) and represent reward-related information (Heffley et al. 2018; Kostadinov et al. 2019; Ramnani et al. 2004).
Given these properties of the cerebellum in processing rewards, our results suggest a functionally hierarchical organization of the cerebellum. In the floccular complex, which is disynaptically connected to the motoneurons (Langer et al. 1985a), information about reward is already fully transformed into motor commands. Other areas in the cerebellum such as the hemispheres that are connected to the frontal cortical areas (Kelly and Strick 2003) and the basal ganglia (Bostan and Strick 2018; Carta et al. 2019) could be part of the network that processes reward regardless of the exact motor parameters. Reward in these areas could be used to instruct learning of selection between targets (Sendhilnathan et al. 2020). A possible structure that might be midway between the eye movement motor signals of the flocculus and the cognitive signals is the vermis. Neurons in the vermis drive pursuit and saccadic eye movements (Krauzlis and Miles 1998; Raghavan and Lisberger 2017; Thier and Markanday 2019) but are also involved in movement planning (Kurkin et al. 2014). Future work should investigate the ocular vermis to determine how representations of reward and eye movements are distributed across the cerebellum.
Reward signals in complex spikes and simple spikes.
One potential way reward could modulate the input-output relationship in the cerebellum is through instructive signals from the climbing fibers. Climbing fiber activity can be detected by its manifestation as complex spikes in the Purkinje cells (Llinás and Sugimori 1980). Complex spike activity has been linked to the signaling of motor errors (Albus 1971; Gilbert and Thach 1977; Ito et al. 1982; Marr 1969) and recently also to reward (Heffley et al. 2018; Heffley and Hull 2019; Kostadinov et al. 2019; Larry et al. 2019). We also recorded complex spikes from the cells we analyzed in the present study and in other cells that did not respond to eye movements (Larry et al. 2019). The complex spikes encoded the expected reward size at the time of the color cue onset but not at reward delivery or during pursuit movement.
Several factors make it unlikely that the pattern of complex spikes drives the reward-related differences in simple spikes during movement. The complex spike signal during motion onset was not modulated by reward. The timing of the reward modulation in complex spikes was ∼1 s before we observed modulation in simple spikes. We would expect a tighter timing effect if the complex spikes were driving reward-related simple spike modulations (Suvrathan et al. 2016). Furthermore, if complex spikes drive the suppression of simple spike modulations, we would expect a link between the reward-related complex spike and simple spike modulation akin to the opposite directional tuning of complex and simple spikes. However, we did not find a correlation between reward modulation in simple and complex spikes (Larry et al. 2019). Furthermore, excluding cells that were modulated by complex spikes during the cue did not alter any of our conclusions. Finally, we did not find reward learning-related complex spike modulation (not shown), suggesting that the complex spike is not instructing reward learning. However, these modulations might be extremely hard to detect because of the low frequency of the complex spike response and the very fast learning in our paradigm. Overall, it is unlikely that reward-related modulation in the simple spike of the floccular complex emerges from complex spike-dependent plasticity.
In motor learning, a tight link has been established between the presence of a complex spike, trial-by-trial modulations in simple spikes, and behavior (Gilbert and Thach 1977; Medina and Lisberger 2008; Suvrathan et al. 2016). A similar link in reward paradigms would be especially intriguing since it would relate known mechanisms of plasticity in the cerebellum, neural activity, and the effect of reward on behavior. To date, our research (Larry et al. 2019) and other studies focusing on decision making or reward (Chabrol et al. 2019; Deverett et al. 2018; Sendhilnathan et al. 2019) have not found a similar trial-by-trial association between modulations in simple and complex spikes. Thus our studies in which we recorded and analyzed both complex and simple spikes highlight the gap in understanding how reward information in the climbing fibers is used for computations in the cerebellum.
Limitations of present study.
Our results constrain how reward may be encoded by neurons in the flocculus complex but do not completely eliminate the representation of reward beyond movement. It is possible that reward is represented in features of the data that we were unable to test. For example, reward could be coded in the trial-by-trial pattern of activity or in the properties of the spike train statistics. The instantaneous correlation between cells might be modulated beyond the expected relationship with variance in behavior. Finally, similar to previous work on the flocculus complex, we focused on cells that were modulated significantly with eye movements. Our results indicate that these cells did not encode reward beyond behavior. We cannot however unequivocally show that other cells that might encode reward but not eye movement are not part of the same network.
To sum up, in the present work we explored a cerebellar area that drives smooth pursuit eye movements to test how reward-related signals are combined with motor signals. We exploited the well-established relationship between eye movement and neural activity in the cerebellum to test whether reward is represented beyond eye movements. We found motor representations in reward-related signals, suggesting that reward is integrated with the motor command upstream of the flocculus complex.
GRANTS
This study was supported by a Human Frontiers Science Program (HFSP) career development award, the Israel Science Foundation, and the European Research Committee.
DISCLOSURES
No conflicts of interest, financial or otherwise, are declared by the authors.
AUTHOR CONTRIBUTIONS
M.J. conceived and designed research; A.L. and M.Y. performed experiments; A.L., Y.B., and M.J. analyzed data; A.L. and M.J. interpreted results of experiments; A.L. and M.J. prepared figures; A.L. and M.J. drafted manuscript; A.L. and M.J. edited and revised manuscript; M.J. approved final version of manuscript.
REFERENCES
- Albus JS. A theory of cerebellar function. Math Biosci 10: 25–61, 1971. doi: 10.1016/0025-5564(71)90051-4. [DOI] [Google Scholar]
- Allen WE, Chen MZ, Pichamoorthy N, Tien RH, Pachitariu M, Luo L, Deisseroth K. Thirst regulates motivated behavior through modulation of brainwide neural population dynamics. Science 364: 253, 2019. doi: 10.1126/science.aav3932. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Bostan AC, Strick PL. The basal ganglia and the cerebellum: nodes in an integrated network. Nat Rev Neurosci 19: 338–350, 2018. doi: 10.1038/s41583-018-0002-7. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Carta I, Chen CH, Schott AL, Dorizan S, Khodakhah K. Cerebellar modulation of the reward circuitry and social behavior. Science 363: eaav0581, 2019. doi: 10.1126/science.aav0581. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Chabrol FP, Blot A, Mrsic-Flogel TD. Cerebellar contribution to preparatory activity in motor neocortex. Neuron 103: 506–519.e4, 2019. doi: 10.1016/j.neuron.2019.05.022. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Dash S, Catz N, Dicke PW, Thier P. Encoding of smooth-pursuit eye movement initiation by a population of vermal Purkinje cells. Cereb Cortex 22: 877–891, 2012. doi: 10.1093/cercor/bhr153. [DOI] [PubMed] [Google Scholar]
- Deverett B, Koay SA, Oostland M, Wang SS. Cerebellar involvement in an evidence-accumulation decision-making task. eLife 7: e36781, 2018. doi: 10.7554/eLife.36781. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Ding L, Hikosaka O. Comparison of reward modulation in the frontal eye field and caudate of the macaque. J Neurosci 26: 6695–6703, 2006. doi: 10.1523/JNEUROSCI.0836-06.2006. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Gao Z, Davis C, Thomas AM, Economo MN, Abrego AM, Svoboda K, De Zeeuw CI, Li N. A cortico-cerebellar loop for motor planning. Nature 563: 113–116, 2018. doi: 10.1038/s41586-018-0633-x. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Gilbert PF, Thach WT. Purkinje cell activity during motor learning. Brain Res 128: 309–328, 1977. doi: 10.1016/0006-8993(77)90997-0. [DOI] [PubMed] [Google Scholar]
- Glaser JI, Wood DK, Lawlor PN, Ramkumar P, Kording KP, Segraves MA. Role of expected reward in frontal eye field during natural scene search. J Neurophysiol 116: 645–657, 2016. doi: 10.1152/jn.00119.2016. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Hayden BY, Platt ML. Neurons in anterior cingulate cortex multiplex information about reward and action. J Neurosci 30: 3339–3346, 2010. doi: 10.1523/JNEUROSCI.4874-09.2010. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Heffley W, Hull C. Classical conditioning drives learned reward prediction signals in climbing fibers across the lateral cerebellum. eLife 8: e46764, 2019. doi: 10.7554/eLife.46764. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Heffley W, Song EY, Xu Z, Taylor BN, Hughes MA, McKinney A, Joshua M, Hull C. Coordinated cerebellar climbing fiber activity signals learned sensorimotor predictions. Nat Neurosci 21: 1431–1441, 2018. doi: 10.1038/s41593-018-0228-8. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Hensbroek RA, Belton T, van Beugen BJ, Maruta J, Ruigrok TJ, Simpson JI. Identifying Purkinje cells using only their spontaneous simple spike activity. J Neurosci Methods 232: 173–180, 2014. doi: 10.1016/j.jneumeth.2014.04.031. [DOI] [PubMed] [Google Scholar]
- Herzfeld DJ, Kojima Y, Soetedjo R, Shadmehr R. Encoding of action by the Purkinje cells of the cerebellum. Nature 526: 439–442, 2015. doi: 10.1038/nature15693. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Herzfeld DJ, Kojima Y, Soetedjo R, Shadmehr R. Encoding of error and learning to correct that error by the Purkinje cells of the cerebellum. Nat Neurosci 21: 736–743, 2018. doi: 10.1038/s41593-018-0136-y. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Holt GR, Softky WR, Koch C, Douglas RJ. Comparison of discharge variability in vitro and in vivo in cat visual cortex neurons. J Neurophysiol 75: 1806–1814, 1996. doi: 10.1152/jn.1996.75.5.1806. [DOI] [PubMed] [Google Scholar]
- Ito M, Sakurai M, Tongroach P. Climbing fibre induced depression of both mossy fibre responsiveness and glutamate sensitivity of cerebellar Purkinje cells. J Physiol 324: 113–134, 1982. doi: 10.1113/jphysiol.1982.sp014103. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Joshua M, Adler A, Bergman H. Novelty encoding by the output neurons of the basal ganglia. Front Syst Neurosci 3: 20, 2010. doi: 10.3389/neuro.06.020.2009. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Joshua M, Adler A, Rosin B, Vaadia E, Bergman H. Encoding of probabilistic rewarding and aversive events by pallidal and nigral neurons. J Neurophysiol 101: 758–772, 2009. doi: 10.1152/jn.90764.2008. [DOI] [PubMed] [Google Scholar]
- Joshua M, Lisberger SG. Reward action in the initiation of smooth pursuit eye movements. J Neurosci 32: 2856–2867, 2012. doi: 10.1523/JNEUROSCI.4676-11.2012. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Joshua M, Lisberger SG. A framework for using signal, noise, and variation to determine whether the brain controls movement synergies or single muscles. J Neurophysiol 111: 733–745, 2014. doi: 10.1152/jn.00510.2013. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Joshua M, Medina JF, Lisberger SG. Diversity of neural responses in the brainstem during smooth pursuit eye movements constrains the circuit mechanisms of neural integration. J Neurosci 33: 6633–6647, 2013. doi: 10.1523/JNEUROSCI.3732-12.2013. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Joshua M, Tokiyama S, Lisberger SG. Interactions between target location and reward size modulate the rate of microsaccades in monkeys. J Neurophysiol 114: 2616–2624, 2015. doi: 10.1152/jn.00401.2015. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Kelly RM, Strick PL. Cerebellar loops with motor cortex and prefrontal cortex of a nonhuman primate. J Neurosci 23: 8432–8444, 2003. doi: 10.1523/JNEUROSCI.23-23-08432.2003. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Kennedy A, Wayne G, Kaifosh P, Alviña K, Abbott LF, Sawtell NB. A temporal basis for predicting the sensory consequences of motor commands in an electric fish. Nat Neurosci 17: 416–422, 2014. doi: 10.1038/nn.3650. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Kostadinov D, Beau M, Pozo MB, Häusser M. Predictive and reactive reward signals conveyed by climbing fiber inputs to cerebellar Purkinje cells. Nat Neurosci 22: 950–962, 2019. doi: 10.1038/s41593-019-0381-8. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Koziol LF, Budding D, Andreasen N, D’Arrigo S, Bulgheroni S, Imamizu H, Ito M, Manto M, Marvel C, Parker K, Pezzulo G, Ramnani N, Riva D, Schmahmann J, Vandervert L, Yamazaki T. Consensus paper: the cerebellum’s role in movement and cognition. Cerebellum 13: 151–177, 2014. doi: 10.1007/s12311-013-0511-x. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Krauzlis RJ, Lisberger SG. Visual motion commands for pursuit eye movements in the cerebellum. Science 253: 568–571, 1991. doi: 10.1126/science.1907026. [DOI] [PubMed] [Google Scholar]
- Krauzlis RJ, Miles FA. Role of the oculomotor vermis in generating pursuit and saccades: effects of microstimulation. J Neurophysiol 80: 2046–2062, 1998. doi: 10.1152/jn.1998.80.4.2046. [DOI] [PubMed] [Google Scholar]
- Kurkin S, Akao T, Fukushima J, Shichinohe N, Kaneko CR, Belton T, Fukushima K. No-go neurons in the cerebellar oculomotor vermis and caudal fastigial nuclei: planning tracking eye movements. Exp Brain Res 232: 191–210, 2014. doi: 10.1007/s00221-013-3731-x. [DOI] [PubMed] [Google Scholar]
- Langer T, Fuchs AF, Chubb MC, Scudder CA, Lisberger SG. Floccular efferents in the rhesus macaque as revealed by autoradiography and horseradish peroxidase. J Comp Neurol 235: 26–37, 1985a. doi: 10.1002/cne.902350103. [DOI] [PubMed] [Google Scholar]
- Langer T, Fuchs AF, Scudder CA, Chubb MC. Afferents to the flocculus of the cerebellum in the rhesus macaque as revealed by retrograde transport of horseradish peroxidase. J Comp Neurol 235: 1–25, 1985b. doi: 10.1002/cne.902350102. [DOI] [PubMed] [Google Scholar]
- Larry N, Yarkoni M, Lixenberg A, Joshua M. Cerebellar climbing fibers encode expected reward size. eLife 8: e46870, 2019. doi: 10.7554/eLife.46870. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Lisberger SG. The neural basis for learning of simple motor skills. Science 242: 728–735, 1988. doi: 10.1126/science.3055293. [DOI] [PubMed] [Google Scholar]
- Lisberger SG, Fuchs AF. Role of primate flocculus during rapid behavioral modification of vestibuloocular reflex. I. Purkinje cell activity during visually guided horizontal smooth-pursuit eye movements and passive head rotation. J Neurophysiol 41: 733–763, 1978. doi: 10.1152/jn.1978.41.3.733. [DOI] [PubMed] [Google Scholar]
- Lisberger SG, Pavelko TA, Bronte-Stewart HM, Stone LS. Neural basis for motor learning in the vestibuloocular reflex of primates. II. Changes in the responses of horizontal gaze velocity Purkinje cells in the cerebellar flocculus and ventral paraflocculus. J Neurophysiol 72: 954–973, 1994. doi: 10.1152/jn.1994.72.2.954. [DOI] [PubMed] [Google Scholar]
- Lixenberg A, Joshua M. Encoding of reward and decoding movement from the frontal eye field during smooth pursuit eye movements. J Neurosci 38: 10515–10524, 2018. doi: 10.1523/JNEUROSCI.1654-18.2018. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Llinás R, Sugimori M. Electrophysiological properties of in vitro Purkinje cell somata in mammalian cerebellar slices. J Physiol 305: 171–195, 1980. doi: 10.1113/jphysiol.1980.sp013357. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Marr D. A theory of cerebellar cortex. J Physiol 202: 437–470, 1969. doi: 10.1113/jphysiol.1969.sp008820. [DOI] [PMC free article] [PubMed] [Google Scholar]
- McCormick DA, Thompson RF. Neuronal responses of the rabbit cerebellum during acquisition and performance of a classically conditioned nictitating membrane-eyelid response. J Neurosci 4: 2811–2822, 1984. doi: 10.1523/JNEUROSCI.04-11-02811.1984. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Medina JF, Lisberger SG. Variation, signal, and noise in cerebellar sensory-motor processing for smooth-pursuit eye movements. J Neurosci 27: 6832–6842, 2007. doi: 10.1523/JNEUROSCI.1323-07.2007. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Medina JF, Lisberger SG. Links from complex spikes to local plasticity and motor learning in the cerebellum of awake-behaving monkeys. Nat Neurosci 11: 1185–1192, 2008. doi: 10.1038/nn.2197. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Nguyen-Vu TD, Kimpo RR, Rinaldi JM, Kohli A, Zeng H, Deisseroth K, Raymond JL. Cerebellar Purkinje cell activity drives motor learning. Nat Neurosci 16: 1734–1736, 2013. doi: 10.1038/nn.3576. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Noda H, Mikami A. Discharges of neurons in the dorsal paraflocculus of monkeys during eye movements and visual stimulation. J Neurophysiol 56: 1129–1146, 1986. doi: 10.1152/jn.1986.56.4.1129. [DOI] [PubMed] [Google Scholar]
- Noda H, Suzuki DA. The role of the flocculus of the monkey in fixation and smooth pursuit eye movements. J Physiol 294: 335–348, 1979. doi: 10.1113/jphysiol.1979.sp012933. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Ono S, Mustari MJ. Smooth pursuit-related information processing in frontal eye field neurons that project to the NRTP. Cereb Cortex 19: 1186–1197, 2009. doi: 10.1093/cercor/bhn166. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Optican LM, Robinson DA. Cerebellar-dependent adaptive control of primate saccadic system. J Neurophysiol 44: 1058–1076, 1980. doi: 10.1152/jn.1980.44.6.1058. [DOI] [PubMed] [Google Scholar]
- Raghavan RT, Joshua M. Dissecting patterns of preparatory activity in the frontal eye fields during pursuit target selection. J Neurophysiol 118: 2216–2231, 2017. doi: 10.1152/jn.00317.2017. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Raghavan RT, Lisberger SG. Responses of Purkinje cells in the oculomotor vermis of monkeys during smooth pursuit eye movements and saccades: comparison with floccular complex. J Neurophysiol 118: 986–1001, 2017. doi: 10.1152/jn.00209.2017. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Ramkumar P, Dekleva B, Cooler S, Miller L, Kording K. Premotor and motor cortices encode reward. PLoS One 11: e0160851, 2016. doi: 10.1371/journal.pone.0160851. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Ramnani N, Elliott R, Athwal BS, Passingham RE. Prediction error for free monetary reward in the human prefrontal cortex. Neuroimage 23: 777–786, 2004. doi: 10.1016/j.neuroimage.2004.07.028. [DOI] [PubMed] [Google Scholar]
- Rashbass C. The relationship between saccadic and smooth tracking eye movements. J Physiol 159: 326–338, 1961. doi: 10.1113/jphysiol.1961.sp006811. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Roesch MR, Olson CR. Impact of expected reward on neuronal activity in prefrontal cortex, frontal and supplementary eye fields and premotor cortex. J Neurophysiol 90: 1766–1789, 2003. doi: 10.1152/jn.00019.2003. [DOI] [PubMed] [Google Scholar]
- Schmahmann JD. Disorders of the cerebellum: ataxia, dysmetria of thought, and the cerebellar cognitive affective syndrome. J Neuropsychiatry Clin Neurosci 16: 367–378, 2004. doi: 10.1176/jnp.16.3.367. [DOI] [PubMed] [Google Scholar]
- Sendhilnathan N, Ipata A, Goldberg ME. Complex spikes encode reward expectation signals during visuomotor association learning (Preprint). bioRxiv 841858, 2019. doi: 10.1101/841858. [DOI]
- Sendhilnathan N, Ipata AE, Goldberg ME. Neural correlates of reinforcement learning in mid-lateral cerebellum. Neuron pii: S0896-6273(19)31098-0, 2020. doi: 10.1016/j.neuron.2019.12.032. [DOI] [PubMed] [Google Scholar]
- Shidara M, Kawano K, Gomi H, Kawato M. Inverse-dynamics model eye movement control by Purkinje cells in the cerebellum. Nature 365: 50–52, 1993. doi: 10.1038/365050a0. [DOI] [PubMed] [Google Scholar]
- Stone LS, Lisberger SG. Visual responses of Purkinje cells in the cerebellar flocculus during smooth-pursuit eye movements in monkeys. II. Complex spikes. J Neurophysiol 63: 1262–1275, 1990. doi: 10.1152/jn.1990.63.5.1262. [DOI] [PubMed] [Google Scholar]
- Suvrathan A, Payne HL, Raymond JL. Timing rules for synaptic plasticity matched to behavioral function. Neuron 92: 959–967, 2016. [Erratum in Neuron 97: 248–250, 2018.] doi: 10.1016/j.neuron.2016.10.022. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Takagi M, Zee DS, Tamargo RJ. Effects of lesions of the oculomotor vermis on eye movements in primate: saccades. J Neurophysiol 80: 1911–1931, 1998. doi: 10.1152/jn.1998.80.4.1911. [DOI] [PubMed] [Google Scholar]
- Takikawa Y, Kawagoe R, Itoh H, Nakahara H, Hikosaka O. Modulation of saccadic eye movements by predicted reward outcome. Exp Brain Res 142: 284–291, 2002. doi: 10.1007/s00221-001-0928-1. [DOI] [PubMed] [Google Scholar]
- Tanaka SC, Doya K, Okada G, Ueda K, Okamoto Y, Yamawaki S. Prediction of immediate and future rewards differentially recruits cortico-basal ganglia loops. Nat Neurosci 7: 887–893, 2004. doi: 10.1038/nn1279. [DOI] [PubMed] [Google Scholar]
- Thier P, Markanday A. Role of the vermal cerebellum in visually guided eye movements and visual motion perception. Annu Rev Vis Sci 5: 247–268, 2019. doi: 10.1146/annurev-vision-091718-015000. [DOI] [PubMed] [Google Scholar]
- Thier P, Möck M. The oculomotor role of the pontine nuclei and the nucleus reticularis tegmenti pontis. Prog Brain Res 151: 293–320, 2006. doi: 10.1016/S0079-6123(05)51010-0. [DOI] [PubMed] [Google Scholar]
- Thoma P, Bellebaum C, Koch B, Schwarz M, Daum I. The cerebellum is involved in reward-based reversal learning. Cerebellum 7: 433–443, 2008. doi: 10.1007/s12311-008-0046-8. [DOI] [PubMed] [Google Scholar]
- Van Dijck G, Van Hulle MM, Heiney SA, Blazquez PM, Meng H, Angelaki DE, Arenz A, Margrie TW, Mostofi A, Edgley S, Bengtsson F, Ekerot CF, Jörntell H, Dalley JW, Holtzman T. Probabilistic identification of cerebellar cortical neurones across species. PLoS One 8: e57669, 2013. doi: 10.1371/journal.pone.0057669. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Vickery TJ, Chun MM, Lee D. Ubiquity and specificity of reinforcement signals throughout the human brain. Neuron 72: 166–177, 2011. doi: 10.1016/j.neuron.2011.08.011. [DOI] [PubMed] [Google Scholar]
- Voogd J, Schraa-Tam CK, van der Geest JN, De Zeeuw CI. Visuomotor cerebellum in human and nonhuman primates. Cerebellum 11: 392–410, 2012. doi: 10.1007/s12311-010-0204-7. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Wagner MJ, Kim TH, Savall J, Schnitzer MJ, Luo L. Cerebellar granule cells encode the expectation of reward. Nature 544: 96–100, 2017. doi: 10.1038/nature21726. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Williams ZM, Eskandar EN. Selective enhancement of associative learning by microstimulation of the anterior caudate. Nat Neurosci 9: 562–568, 2006. doi: 10.1038/nn1662. [DOI] [PubMed] [Google Scholar]
- Yang Y, Lisberger SG. Role of plasticity at different sites across the time course of cerebellar motor learning. J Neurosci 34: 7077–7090, 2014. doi: 10.1523/JNEUROSCI.0017-14.2014. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Zur G, Joshua M. Using extracellular low frequency signals to improve the spike sorting of cerebellar complex spikes. J Neurosci Methods 328: 108423, 2019. doi: 10.1016/j.jneumeth.2019.108423. [DOI] [PubMed] [Google Scholar]