

It is what we think we know that keeps us from learning.
–Claude Bernard (1)
During the past 2 decades, imaging data has grown exponentially in both size and complexity. Paralleling this growth is the surge of electronic health information systems that can enable conducting research in real-world settings instead of controlled trials. Specifically, the amalgamation of cardiac imaging and clinical data may have profound ramifications on disease prognostications and survival predictions. Because human cognition to learn, understand, and process the data is finite, computer-based methods may aid standardized interpretation and recognition of important patterns from these stored data. To this end, Samad et al. (2), in this issue of iJACC, explore the idea of integrating a large dataset of standard clinical and echocardiographic data for prediction of all-cause mortality. Their analysis focuses on machine learning algorithms–an analytic field that lies at the intersection of mathematics, statistics, and computer science. There has been a growing enthusiasm among investigators worldwide with up to 1.2% of all papers published annually in PubMed during the past few years focused on machine learning techniques (3). The progress in computational methods has revolutionized the use of imaging techniques in diagnostic cardiology, yet the designs of clinical trials in cardiovascular imaging have only recently started adopting machine learning techniques for data-driven information discovery. Figure 1 shows the cumulative growth of use of machine learning techniques in cardiac imaging in published literature.
FIGURE 1. The Growth of Machine Learning Techniques for Cardiac Imaging.
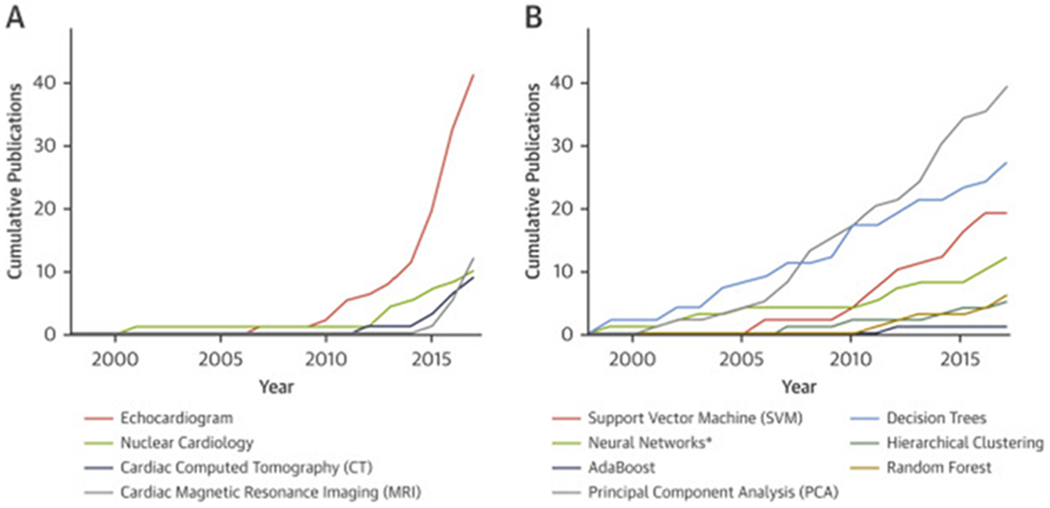
The data was collected using R package RISmed (6) to retrieve the publication data on cardiology imaging from PubMed between 1998 and 2017. (A) Cumulative usage of machine learning techniques in cardiac imaging publications (cardiac computed tomography, cardiac perfusion single-photon emission computed tomography or nuclear cardiology, echocardiography, and cardiac magnetic resonance imaging) from 1998 to 2017. (B) Cumulative publication counts for individual algorithm used in echocardiography from 1998 to 2017. Recently, interest in random forest has peaked, while SVM has plateaued. *Query for neural networks contains the keywords “artificial neural network,” “deep neural network,” and “deep learning.”
The traditional tenets of hypothesis-driven research are constructed using certain assumptions based on the underlying hypothesis and methods used to formalize understanding of the relationship between a limited set of variables for inference and hypothesis testing (4). Such approaches are specifically useful for choosing between alternative mechanisms that could explain an observed phenomenon (e.g., through a controlled experiment), but they are much less helpful for mapping out new areas of inquiry (e.g., the sequence of the human genome), predicting outcomes from relationships among different variables, or studying complex systems. In contrast, data-driven research is characterized as an iterative interplay among hypothesis-driven, question-driven, exploratory, and tool- and method-oriented research. As inquiry proceeds, initial questions are framed, while others are revised or give rise to new lines of research. In an effort to address these questions, new analytic techniques are often used and tested, frequently generating other sets of new questions and altering old ones. The study by Samad et al. (2) signifies this new paradigm of research that primarily addresses knowledge gaps by pursing a rather broad initial hypothesis. The authors broadly questioned whether nonlinear machine learning models with echocardiography measurements and clinical variables would have higher ability to predict mortality. They used a battery of analytic approaches to predict outcome using 331,317 echocardiographic studies from 171,510 unique patients. A mere 2-dimensional echocardiography database of 158 variables in such a database would produce 12,403 combinations to assess correlations of the variables. In the present study, random forest model was seen to outperform linear classifier in predicting all-cause mortality of the patients (with an area under the curve of 0.89). This is not surprising given the known applicability of random forest as an ensemble machine learning method that can train classification and regression decision trees effectively on a random subset of the data and can handle multiciass problems (5). These robust data once again underscore that new data-driven techniques, despite the broad hypothesis, can extract relevant features for understanding complex interactions and predicting clinical events.
The debate between hypothesis-driven and observation-based research is not new. Robert Boyle and Robert Hooke championed the use of hypotheses, whereas Francis Bacon and Isaac Newton opposed investigations that could be misled by bold proposals rather than working from available observations. The increasing availability of large datasets for many scientific disciplines is rekindling this philosophical divide. Specifically, given the treasure trove of data, complex patterns, and relationships existing in the growing electronic health and imaging records, it is logical to question whether we should restrict ourselves by creating rigid hypotheses and collect limited data with few parameters. Whereas the standards and methods for data collection are evolving, our proclivities for asserting relationships of features have lagged. The methods for scientific inquiry must be reformed. First, given the growth in imaging big data, researchers must be encouraged to avoid tunneling proposals into a misleading, linear research format. Rather, they must embrace a more realistic, nonlinear, iterative broad research trajectory. Certainly, hypothesis can continue to be important for unambiguous interpretation of the data, but curating a broad research question and hypothesis could improve likelihood for discovery. For example, some of the remarkable accidental observations such as the pacemaker and penicillin would not have been possible had the researchers focused solely on their hypotheses. Second, journals and editors should also be open to publications that are organized around a spectrum of methods addressing a knowledge gap rather than a specific linear-hypothesis testing approach. In addition, investigators should be encouraged to disseminate data and their analytic codes to the scientific community while receiving a credit in some form to establish broader generalizability and reproducibility of their approach. For example, the length of study by Samad et al. (2) over 19 years begets concerns for generalizability of the model. Therefore, provision of data codes and modeling equations could allow investigators to validate the observations in more contemporary settings. Finally, our education programs should focus on training a new breed of researcher to acquire a panoramic view of the data without a superlative opinion of their implicit knowledge to incorporate a dynamic hypothesis that lives and adapts with observations. This may help us circumvent bias that can creep into the analysis from the researchers’ intuition by following the data through exploration.
Despite the increasing availability of large dataset for many scientific disciplines, there are concerns that contemporary data-intensive research may be bad for science or that it will lead to poor methodology and unsubstantiated inferences in so-called fishing expeditions. How certain are we about such an assertion? We cannot continue to disregard the complex interactions of parameters in a complex disease space while fascinating scientific knowledge may be obfuscated by the inconspicuous underlying motif in heterogeneous diseases. Although our investigations remain assiduous in discovery of interventions and treatments for cardiac diseases, it is legitimate to assume that the first essential for unlocking the mechanistic underpinnings of an observation would be by producing a testable hypothesis. However, in the dynamic world, the traditional methods must also adapt. Limiting the exploration in small feature space may provide validation of what we perceive, but a leniency to explore in a broader landscape could augment a more contemporary quest. In the era of flourishing computational capabilities and growing data collection, the research question and hypothesis need to be broad and dynamic. Not only can salient relationships among high-dimensional complex data be accommodated by it, but also the future scientific discoveries may depend on it.
Acknowledgments
Dr. Sengupta has received personal fees from Heartsciences and Hitachi Aloka, Ltd. Mr. Shrestha has no relationships relevant to the content of this paper to disclose.
Footnotes
Editorials published in JACC: Cardiovascular Imaging reflect the views of the authors and do not necessarily represent the views of iJACC or the American College of Cardiology.
REFERENCES
- 1.A quote by Claude Bernard. Available at:https://www.goodreads.com/quotes/72482-it-s-what-we-think-we-know-that-keeps-us-from Accessed May 30, 2018.
- 2.Samad MD, Ulloa A, Wehner GJ, et al. Predicting survival from large echocardiography and electronic health record datasets: optimization with machine Learning. J Am Coll Cardiol Img 2019;12:681–9. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 3.Koohy H The rise and fall of machine learning methods in biomedical research [version 2; referees: 2 approved]. F1000Research 2017;6:2012. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 4.Bzdok D, Altman N, Krzywinski M. Points of significance: statistics versus machine learning. Nat Methods 2018;15:233–4. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 5.Li Y, Ho CP, Toulemonde M, et al. Fully automatic myocardial segmentation of contrast echocardiography sequence using random forests guided by shape model. IEEE Trans Med Imaging 2018;37:1081–91. [DOI] [PubMed] [Google Scholar]
- 6.Kovalchik S RISmed: Download Content from NCBI Databases. R package version 2.1.5. 2015. Available at: http://cran.r-project.org/package=RISmed Accessed November 20, 2018.