

Abstract
In this paper, we propose a novel and simple method for discovery of Granger causality from noisy time series using Gaussian processes. More specifically, we adopt the concept of Granger causality, but instead of using autoregressive models for establishing it, we work with Gaussian processes. We show that information about the Granger causality is encoded in the hyper-parameters of the used Gaussian processes. The proposed approach is first validated on simulated data, and then used for understanding the interaction between fetal heart rate and uterine activity in the last two hours before delivery and of interest in obstetrics. Our results indicate that uterine activity affects fetal heart rate, which agrees with recent clinical studies.
Index Terms—: Gaussian processes, Granger causality, cardiotocography, fetal heart rate, uterine activity
1. INTRODUCTION
The main goals of science are to understand Nature and, based on this understanding, predict how the world around us evolves. The identification of causal relationships is an important part of scientific research, since it provides us with insights about consequences for actions [1]. The gold standard for identifying causal relationships is using controlled randomized experiments. However, in many situations, these experiments are either impractical, unethical, or simply impossible [2]. The problem of inferring causal interactions from data has challenged scientists and philosophers for centuries [3] and many efforts have been made to solve it. [4].
Causal inference from time series is one important area of research in this domain, where many concepts and methods have been proposed. They include intervention causality [1, 5, 6], structural causality [7] and Granger causality [8,9] (see [10] for a detailed review). The Granger causality is probably the most prominent and most widely used concept although its usefulness is somewhat controversial [10].
In practice, when detecting Granger causality a (vector) autoregressive (AR) model is often used, and yet in reality, many causal relationships are likely to be nonlinear, this giving rise to doubts about the approach [11]. Further, it has been shown that non-linearity can be helpful in causal discovery [2]. Therefore, instead of using AR models, we adopt the use of Gaussian processes (GPs) for this purpose. They are more powerful for learning functions or mappings and moreover, they can accommodate prior knowledge and assumptions easily. A similar idea was proposed in [12], for testing Granger causality between time series using GPs. Unlike [12], instead of only relying on model evidence for casual discovery, we directly learn the mappings of possible causes and use cross-validation and model evidence for model selection. Further, we look into the hyper-parameters for causal discovery, which is more natural in the modeling sense and more robust to over-fitting.
In this paper, we are also interested in making inference about causality from cardiotocography (CTG). CTG is the most widely used technology for monitoring the well-being of fetuses during labor. CTG comprises of the fetal heart rate (FHR) and uterine activity (UA) signals, which are both recorded and visually inspected by clinicians. The interpretation of FHR recordings is a highly intricate and complex task with high inter- and intra-variable evaluations among obstetricians, notwithstanding the availability of various clinical guidelines from both the National Institute of Child Health and Human Development (NICHD) and the International Federation of Gynecology and Obstetrics (FIGO) [13–15]. In fact, the current guidelines for FHR evaluation have been criticized for simplistic interpretation [16]. The classification of CTG tracings by computerized systems remains a challenging problem [17]. For improved understanding of CTG recordings, the interactions between FHR tracings and UA is crucial, and especially establishing if there is causality between them. Interestingly, this issue has been largely overlooked in the literature of computerized analysis of CTG.
In the machine learning literature, Gaussian processes (GPs) provide data-efficient and flexible Bayesian machinery for learning functions or mappings from data. GPs have been successfully applied in both supervised and unsupervised learning tasks [18]. For example, in our previous work [19], we proposed a GP-based method that employs UA signals to recover missing samples of FHR recordings and had excellent results. This work also provided evidence that the UA signals contain information about fetal well-being. Also, there are many applications that exploit the hyper-parameters of GPs for making inference. For example, in [20, 21], the hyper-parameters are used for detecting change points, and in [22], for epilepsy detection from electroencephalograms.
In this paper, we propose a novel and simple method for discovery of Granger causality from noisy time series using GPs. Our approach to finding the possible causes and effects is based on the hyper-parameters of the GPs. Our hypothesis is that information about causality is encoded in the covariances of the GPs, and in particular in the characteristic length scales of the used features by the GPs. We use these length scales to define coefficients that reflect on the direction of causality. We tested the method based on these coefficients on simulated data and then applied it to CTG. The results indicate that the UA is a Granger cause of FHR. Our finding is consistent with recent clinical studies [23].
The paper is organized as follows. In the next section, we provide a brief background on Granger causality and GPs. In Section 3, we present the details of our model. In Section 4, we describe our experiment results. Finally, we conclude with final remarks in Section 5.
2. BACKGROUND
2.1. Granger causality
Two principles are fundamental in Granger causality: (i) the effect does not precede its cause in time; (ii) the causal series contains unique information about the series being caused that is not available otherwise. The Granger causality is usually tested using an AR model or a vector autoregressive (VAR) model. For the bivariate case, given x1(t) and x2(t), the AR models are
| (1) |
where p is the order of the model, and e1(t) and e2(t) are perturbations. If the prediction error of x1(t) is reduced by using x2(t) or equivalently, the coefficients are jointly significantly different from zero, then x2(t) is a Granger cause of x1(t). A statistical test is often performed where the null hypothesis is that are jointly zero. Similarly, a test is performed on .
2.2. Gaussian Processes
By definition, a GP is a collection of random variables such that every finite collection of those random variables has a joint Gaussian distribution. This makes GPs suitable to model distributions over functions, and infinite dimensionality becomes a bless instead of a curse given their consistency property. To be more specific, if y denotes an output and x signifies a vector of input variables, and if y = f(x), where f(x) is a real-valued function, than a GP can be seen as the distribution of the function f(x). This GP is completely specified by its mean function m(x) and covariance function kf(xi,xj), which are defined by and . In machine learning, a GP is usually assumed to be zero mean, that is, m(x) = 0 for every x. It is also practical and common to assume the presence of observation noise i.e.,
| (2) |
where is additive white Gaussian noise.
In the GP regression framework, a prior distribution of the latent function can be directly placed in the function space. With the model and the Gaussian noise assumption, one can obtain tractable posteriors of the latent function and marginal likelihoods, which makes the GPs a powerful Bayesian non-parametric machinery for learning functions or mappings. Although the function f(x) is non-parameteric, the covariance function kf(xi,xj) is parameterized by its set of hyper-parameters θ.
Let denote the collection of all input vectors, and Kff the covariance matrix obtained by evaluating the covariance function for X, i.e., Kff = kf(X,X). Then the prior probability density function (pdf) of f given X is given by
| (3) |
The hyper-parameters θ are learned in the training stage by maximizing the marginal likelihood or model evidence,
| (4) |
If we have test inputs X*, the mean predictive distribution p(f*|X*,X,θ) will be Gaussian with a mean and covariance given by
| (5) |
| (6) |
In this work, we use the time variable as an input and we do not specify lengths of histories in the model. In other words, we model the time series simply as functions of time and do not make Markovian assumptions (as in AR processes). From (5), we see that the mean of the predictive distribution is a linear combination of all the previous observations.
2.3. Automatic Relevance Determination
The design of the covariance is of great importance, since it quantifies the distance or similarity between the inputs to the covariance between outputs. Thus, it encodes our prior knowledge or assumptions about the latent function, e.g., smoothness, periodicity, and stationarity. One of the most popular covariance functions is the radial basis function (RBF), which for the 1-D case has the form
| (7) |
where the characteristic length-scale l > 0 and the signal variance are its hyper-parameters. They also have interesting meanings; represents the variability of the function, and l affects the model complexity in that dimension. If l is small, a small change in the input distance will cause a large change in the covariance of the outputs and vice versa. This leads to another important interpretation of the characteristic length-scale, which is a measure of the importance or relevance of that dimension in the modeling. If l is small, the corresponding dimension is relevant. When x is a vector, we can compute the values for each dimension, where, e.g., each dimension could be a different feature, and then use them for feature selection. This is known as automatic relevance determination (ARD) [18], and is used in supervised learning and automatic dimensionality reduction in unsupervised learning [24–26].
3. MODEL DESCRIPTION
Given two time series xt and yt, we would like to determine their Granger causality. For each time series, as shown in Fig. 2, we can model it as a function of time and the history values of the other time series up to a certain length w, similar to the order of an AR model, i.e.,
| (8) |
| (9) |
where and are independent and additive white Gaussian noises, and the latent functions fx and fy are governed by two GPs, respectively, i.e.,
| (10) |
where the covariance functions kx and ky have the same form but each has a different set of hyper-parameters, and [.,.] denotes concatenation.
Fig. 2.
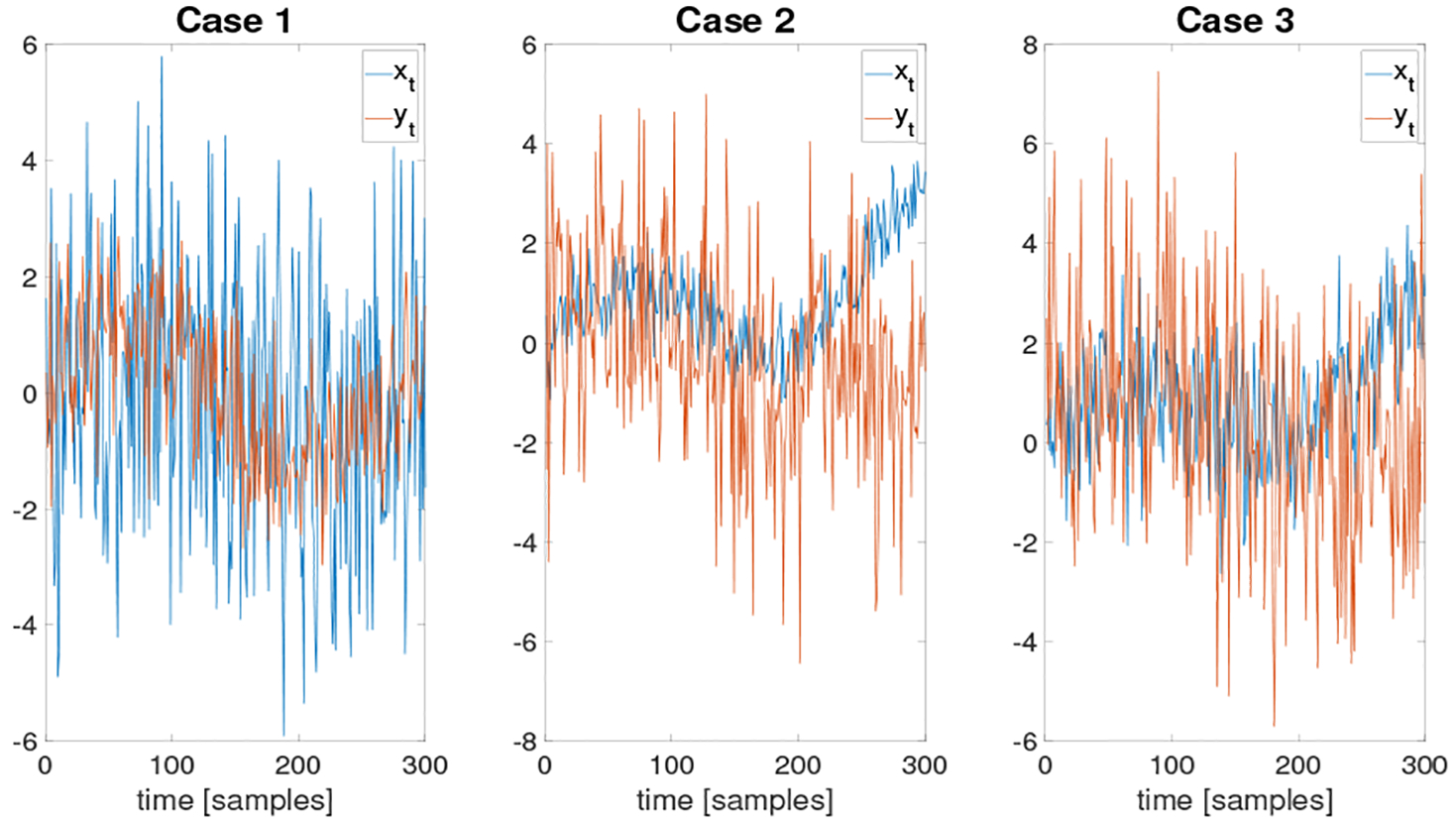
Simulated time series pairs in each simulation cases.
We propose to use the hyper-parameters of the GPs to determine Granger causality. In particular, we use the concept of relevance weights, which we define by r = 1/l. We measure the relevance of the history of yt when modeling xt with the maximum value of the relevance weight of the input yt−w:t−1, i.e., , where w is the history length, and is the relevance weight of the y sample with lag k. We denote the relevance weight of time, or equivalently xt, by . It represents the overall relevance of the history of xt when modelling xt. Finally, we normalize and by their sum for proper comparison, i.e.,
| (11) |
| (12) |
Similarly, we can define and , and their normalized versions and . The former metric measures the percentage of relevance of the history of yt on yt and the latter, the percentage of relevance of a window of history of xt on yt. An illustration of our model is shown in Fig 1.
Fig. 1.
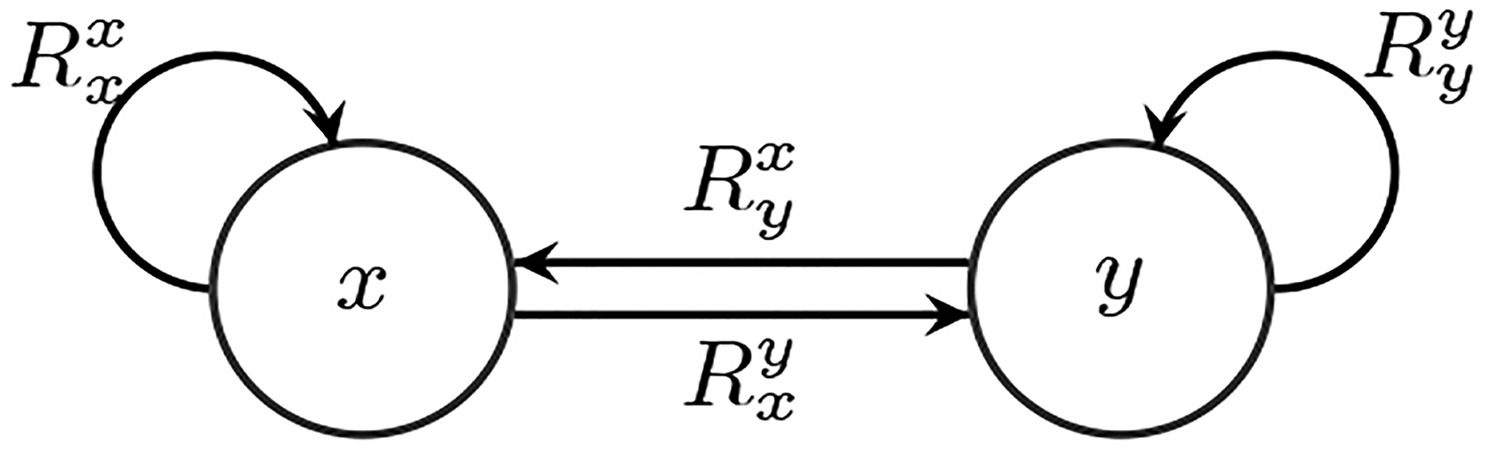
Illustration of our model, where the arrows stand for flow of information, and the normalized relevance weights indicate importance.
If the true direction of Granger causality is from xt to yt, then the relevance of the past values of xt in modeling of yt will be greater than the past values of yt in modeling xt. The reason is simple: the cause occurs before the effect and the change in cause entails a change in effect, and not the other way around. We note that from a machine learning perspective, the cause and effect are often viewed as a correlation only. Our interpretation of the values of , , , and is similar to that of the VAR model, which is that the information of Granger causality is encoded in the relevance weights of the GP models. Therefore, with our approach, if the true Granger causality is from xt to yt, this will be indicated as , and vice versa. Obviously, it is possible that the above analysis of the two time series can show that there is cause and effect in both directions. In principle, the determination of causality would require comparisons of the obtained normalized relevances with thresholds. Setting thresholds, however, is out of the scope of this paper.
If there is no Granger causality between the two time series, the information from the history of the other time-series will not benefit the modeling of the modeled time series. This will be encoded with small values of both and . We note that since our method is based on GP regression, if we have more prior knowledge about the interaction or relationship between the time series, e.g., in forms of superpositions and/or compositions, this can be included in the used model. In that case, the hyper-parameters will encode even richer information about the possible interactions. However, then the comparisons should be made more carefully, i.e., the relevance weights should also be normalized by the importance of the corresponding explanatory variables of the model.
The above discussion is based on the assumption that we have properly selected the covariance function. If an inappropriate covariance function is used, the modeling and predictive performance will severely be deteriorated, which will most likely lead to unreliable conclusions. The choice of covariance function and window length of history w are model selection problems. Often this choice depends on how much we know about the addressed problem and the nature of the problem itself. One may use cross validation and exploit model evidence and predictive performance to select good covariance functions and window lengths. A tutorial on designing of covariance functions and model selection in GPs can be found in [18]. The window size w should not be very long, since this will increase the number of hyper-parameters in the model. Empirically, for determining Granger causality, we found that the model is robust with different choices of w.
4. EXPERIMENTS AND RESULTS
4.1. Simulations
In this section, we first provide a description of a test for our method. We simulated three pairs of time series (three cases), all shown in Fig. 2. The complexity of relationships between the time series was gradually increased as we moved from the first case to the third case. For each case, we wanted to discover the Granger causality. We used the RBF covariance function with ARD between two observed noisy time series xt and yt, each of length T = 300. The ground truth in the three simulations was that xt was a Granger cause of yt. For Case 2 and Case 3, we included nonlinear mappings and function composition to increase the complexity of the relationships. To remove bias, rather than using deterministic functions, we generated the mappings by GPs.
4.1.1. Case 1: A delayed function with additive noise
This simple simulation represents the case where we have a time series xt, which represents a sinusoid in noise, and another time series yt, which is generated by the same, but delayed, sinusoid. The time series yt also contained additive noise. More precisely, we generated the time series according to the following model:
| (13) |
| (14) |
where t was equally spaced in [0,2π], and where the additive Gaussian noises in xt and yt was white, and and , respectively, with and . The noises ϵx,t and ϵy,t were independent of each other.
4.1.2. Case 2: A noisy function with a nonlinear mapping
With the second simulation we generated more complicated relationship between the time series xt and yt. The time series xt was a superposition of two deterministic signals in additive Gaussian noise. The time series yt was composed of two parts, a function sampled from a GP that used xt as an input and a deterministic function of time. This time series also had zero mean additive Gaussian noise which was independent from the noise of xt. The exact generative model of the data is given by
| (15) |
| (16) |
| (17) |
where the noise variances were and .
4.1.3. Case 3: A delayed noisy function with two layers of function composition
In this simulation, we further complicated the previous case by introducing another layer of function composition and delay. We first generated a time series xt as in Case 2, and we used its delayed version as the input to a GP with an RBF covariance function. A function was then sampled from this GP and used as the input to another GP. This generative model is described by
| (18) |
| (19) |
| (20) |
| (21) |
where k1 and k2 are both RBF covariance functions but with different sets of hyper-parameters. The noises, as before, were independent and zero-mean Gaussian with variances and .
4.1.4. Results
The results of our method are summarized in Table. 1. The method correctly determined the causality in all three cases. We repeated the experiment five times, and correct decisions were made in each of them.
Table 1.
Simulation Results
| Granger causality | |||||
|---|---|---|---|---|---|
| Case 1 | 0.9931 | 0.0069 | 0.1566 | 0.8434 | xt Granger causes yt |
| Case 2 | 0.7914 | 0.2086 | 0.0008 | 0.9992 | xt Granger causes yt |
| Case 3 | 0.4029 | 0.5971 | 0.3986 | 0.6014 | xt Granger causes yt |
4.2. Real data: CTG segment
In our experiments with real CTG data, we used data records from an open access database that were acquired at the obstetrics ward of the University Hospital in Brno, Czech Republic. A detailed description of the database can be found in [27].
We applied the method on a real CTG segment of length 491 samples, as shown in Fig. 3, which corresponds to a duration of 2.04 minutes (the sampling rate for both FHR and UA signals was 4 Hz). We used the RBF covariance function with a window size of w = 4. The results are shown in Table 2. The values of the normalized relevance weights indicate that the UA is a Granger cause of FHR. This agrees with a recent clinical study [23].
Fig. 3.
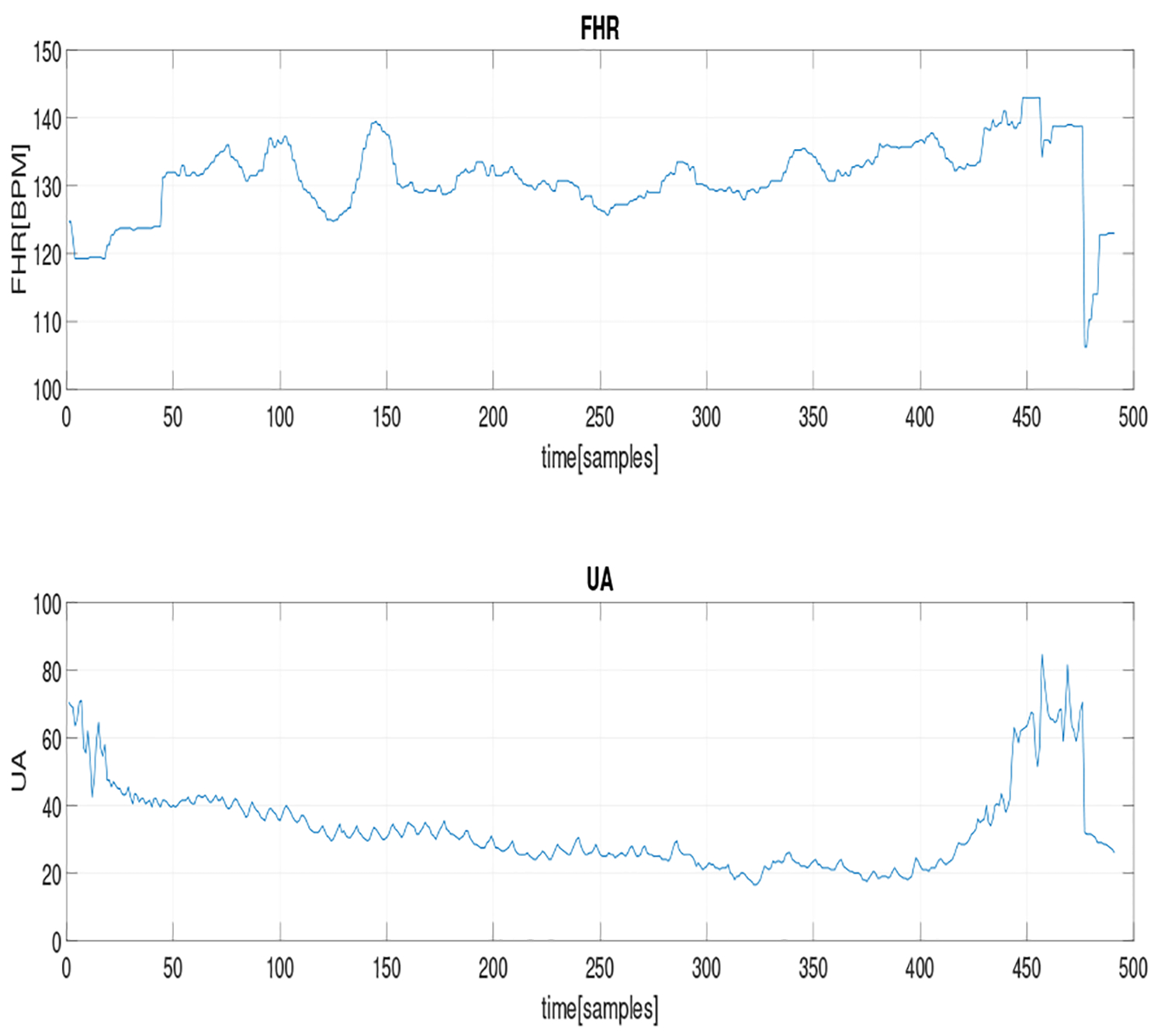
A segment of not-preprocessed (raw) FHR tracing and the corresponding UA signals.
Table 2.
Granger causality in CTG
| CTG signal | 0.5090 | 0.4910 | 0.7917 | 0.2083 |
Another interpretation of the second principle of Granger causality is that if the UA Granger-causes the FHR, then past values of UA should contain information that helps in predicting future values of the FHR. With this information, the predictive performance of the method should be better than that of using information from past values of FHR alone. This is consistent with our observation in [19]. There we showed that adopting information from UA signals helps in recovering missing samples of FHR tracings.
We also used deep Gaussian processes [28] to see if FHR and UA signals have a common manifold. The results indicate that they cannot be generated from a common manifold, i.e., the FHR and UA encode different information about fetal well-being. This is also consistent with our observations in [29], where the performance of classification of FHR can be improved using features from UA.
5. CONCLUSIONS
In this paper, we proposed a Gaussian processes-based method for detecting Granger causality. We showed that the interaction or causal information can be extracted from the hyperparameters of the Gaussian processes. itemand real CTG recordings and found the results very promising. Although we used bivariate time series, this methodology can be easily extended to more than two time series. Furthermore, if we have additional prior knowledge about the time series and their interactions, it can be easily injected in the GP framework. After applying our method on real CTG recording, we found that uterine activity is a Granger cause of fetal heart rate, which agrees with recent clinical studies.
Acknowledgments
This work has been supported by NSF under Award CCF-1618999.
6. REFERENCES
- [1].Eichler M, “Causal inference in time series analysis,” Causality: Statistical perspectives and applications, pp. 327–354, 2012. [Google Scholar]
- [2].Hoyer PO, Janzing D, Mooij JM, Peters J, and Schölkopf B, “Nonlinear causal discovery with additive noise models,” in Advances in neural information processing systems, 2009, pp. 689–696. [Google Scholar]
- [3].Barnett L, Barrett AB, and Seth AK, “Granger causality and transfer entropy are equivalent for Gaussian variables,” Physical review letters, vol. 103, no. 23, p. 238701, 2009. [DOI] [PubMed] [Google Scholar]
- [4].Spirtes P and Zhang K, “Causal discovery and inference: concepts and recent methodological advances,” in Applied informatics, vol. 3, no. 1 SpringerOpen, 2016, p. 3. [DOI] [PMC free article] [PubMed] [Google Scholar]
- [5].Eichler M and Didelez V, “On Granger causality and the effect of interventions in time series,” Lifetime data analysis, vol. 16, no. 1, pp. 3–32, 2010. [DOI] [PubMed] [Google Scholar]
- [6].Berzuini C, Dawid P, and Bernardinell L, Causality: Statistical perspectives and applications. John Wiley & Sons, 2012. [Google Scholar]
- [7].White H and Lu X, “Granger causality and dynamic structural systems,” Journal of Financial Econometrics, vol. 8, no. 2, pp. 193–243, 2010. [Google Scholar]
- [8].Granger CW, “Investigating causal relations by econometric models and cross-spectral methods,” Econometrica: Journal of the Econometric Society, pp. 424–438, 1969. [Google Scholar]
- [9].Granger CW, “Testing for causality: a personal viewpoint,” Journal of Economic Dynamics and control, vol. 2, pp. 329–352, 1980. [Google Scholar]
- [10].Eichler M, “Causal inference with multiple time series: principles and problems,” Phil. Trans. R. Soc. A, vol. 371, no. 1997, p. 20110613, 2013. [DOI] [PubMed] [Google Scholar]
- [11].Chikahara Y and Fujino A, “Causal inference in time series via supervised learning.” in IJCAI, 2018, pp. 2042–2048. [Google Scholar]
- [12].Amblard P-O, Michel OJ, Richard C, and Honeine P, “A Gaussian process regression approach for testing Granger causality between time series data,” in Acoustics, Speech and Signal Processing (ICASSP), 2012 IEEE International Conference on IEEE, 2012, pp. 3357–3360. [Google Scholar]
- [13].Ayres-de Campos D, Spong CY, Chandraharan E, and F. I. F. M. E. C. Panel, “FIGO consensus guidelines on intrapartum fetal monitoring: Cardiotocography,” International Journal of Gynecology & Obstetrics, vol. 131, no. 1, pp. 13–24, 2015. [Online]. Available: 10.1016/j.ijgo.2015.06.020 [DOI] [PubMed] [Google Scholar]
- [14].Macones GA, Hankins GD, Spong CY, Hauth J, and Moore T, “The 2008 National Institute of Child Health and Human Development workshop report on electronic fetal monitoring: Update on definitions, interpretation, and research guidelines,” Journal of Obstetric, Gynecologic, & Neonatal Nursing, vol. 37, no. 5, pp. 510–515, 2008. [DOI] [PubMed] [Google Scholar]
- [15].Dash S, Quirk JG, and Djurić PM, “Learning dependencies among fetal heart rate features using Bayesian networks,” in Engineering in Medicine and Biology Society (EMBC), 2012 Annual International Conference of the IEEE IEEE, 2012, pp. 6204–6207. [DOI] [PubMed] [Google Scholar]
- [16].Ugwumadu A, “Are we (mis) guided by current guidelines on intrapartum fetal heart rate monitoring? case for a more physiological approach to interpretation,” BJOG: An International Journal of Obstetrics & Gynaecology, vol. 121, no. 9, pp. 1063–1070, 2014. [DOI] [PubMed] [Google Scholar]
- [17].Steer P, “Commentary on ‘antenatal cardiotocogram quality and interpretation using computers’,” BJOG: An International Journal of Obstetrics & Gynaecology, vol. 121, no. s7, pp. 9–13, 2014. [DOI] [PubMed] [Google Scholar]
- [18].Rasmussen CE, Gaussian Processes for Machine Learning. Citeseer, 2006. [Google Scholar]
- [19].Feng G, Quirk JG, and Djurić PM, “Recovery of missing samples in fetal heart rate recordings with Gaussian processes,” in Signal Processing Conference (EUSIPCO), 2017 25th European IEEE, 2017, pp. 261–265. [Google Scholar]
- [20].Roberts S, Osborne M, Ebden M, Reece S, Gibson N, and Aigrain S, “Gaussian processes for time-series modelling,” Phil. Trans. R. Soc. A, vol. 371, no. 1984, p. 20110550, 2013. [DOI] [PubMed] [Google Scholar]
- [21].Saatçi Y, Turner RD, and Rasmussen CE, “Gaussian process change point models,” in Proceedings of the 27th International Conference on Machine Learning (ICML-10) Citeseer, 2010, pp. 927–934. [Google Scholar]
- [22].Faul S, Gregorcic G, Boylan G, Marnane W, Lightbody G, and Connolly S, “Gaussian process modeling of EEG for the detection of neonatal seizures,” IEEE Transactions on Biomedical Engineering, vol. 54, no. 12, pp. 2151–2162, 2007. [DOI] [PubMed] [Google Scholar]
- [23].Sletten J, Kiserud T, and Kessler J, “Effect of uterine contractions on fetal heart rate in pregnancy: a prospective observational study,” Acta obstetricia et gynecologica Scandinavica, vol. 95, no. 10, pp. 1129–1135, 2016. [DOI] [PubMed] [Google Scholar]
- [24].Lawrence ND, “Gaussian process latent variable models for visualisation of high dimensional data,” in Advances in neural information processing systems, 2004, pp. 329–336. [Google Scholar]
- [25].Damianou A, Ek C, Titsias M, and Lawrence N, “Manifold relevance determination,” arXiv preprint arXiv:1206.4610, 2012. [Google Scholar]
- [26].Damianou AC, Titsias MK, and Lawrence ND, “Variational inference for latent variables and uncertain inputs in Gaussian processes,” The Journal of Machine Learning Research, vol. 17, no. 1, pp. 1425–1486, 2016. [Google Scholar]
- [27].Chudáček V, Spilka, Buša M, Janků P, Hruban L, Huptych M, and Lhotská L, “Open access intrapartum CTG´ database,” BMC pregnancy and childbirth, vol. 14, no. 1, p. 16, 2014. [DOI] [PMC free article] [PubMed] [Google Scholar]
- [28].Damianou A and Lawrence N, “Deep Gaussian processes,” in Artificial Intelligence and Statistics, 2013, pp. 207–215. [Google Scholar]
- [29].Feng G, Quirk JG, and Djurić PM, “Supervised and unsupervised learning of fetal heart rate tracings with deep Gaussian processes,” in 14th Symposium on Neural Networks and Applications, 2018. [Google Scholar]