

Abstract
Magnetic resonance fingerprinting (MRF) is a relatively new imaging framework which allows rapid and simultaneous quantification of multiple tissue properties, such as T1 and T2 relaxation times, in one acquisition. To accelerate the data sampling in MRF, a variety of methods have been proposed to extract tissue properties from highly accelerated MRF signals. While these methods have demonstrated promising results, further improvement in the accuracy, especially for T2 quantification, is needed. In this paper, we present a novel deep learning approach, namely residual channel attention U-Net (RCA-U-Net), to perform the tissue quantification task in MRF. The RCA-U-Net combines the U-Net structure with residual channel attention blocks, to make the network focus on more informative features and produce better quantification results. In addition, we improved the preprocessing of MRF data by masking out the noisy signals in the background for improved quantification at tissue boundaries. Our experimental results on two in vivo brain datasets with different spatial resolutions demonstrate that the proposed method improves the accuracy of T2 quantification with MRF under high acceleration rates (i.e., 8 and 16) as compared to the state-of-the-art methods.
1. Introduction
Quantitative MR imaging, i.e., quantification of intrinsic tissue properties in human body, is desired in both clinics and medical research. Magnetic resonance fingerprinting (MRF) [5] is a relatively new imaging framework which allows accurate and simultaneous quantification of multiple tissue properties, e.g., T1 and T2 relaxation times, in one acquisition. With MRF, thousands of highly undersampled MR images with different contrast weightings are typically acquired to form an MRF signal evolution for tissue characterization. While MRF has demonstrated superior performance in acquisition speed as compared to conventional quantitative imaging methods, further acceleration with lower number of acquired images is desired for challenging patient populations, such as pediatric subjects, and to reduce scan time for high-resolution quantitative measurements.
Various methods have been previously proposed for tissue quantification in MRF. The conventional approaches are based on template matching [5,6], which matches the observed MRF signal evolution to a predefined dictionary to retrieve the corresponding tissue property values. Although these methods perform well on data with a sufficient number of sampling points, their accuracy is poor for MRF data with reduced number of images [2]. Recently, deep learning approaches have been developed for tissue quantification in MRF [1–3]. For example, Fang et al. [2] proposed a spatially-constrained quantification framework which achieves superior quantification accuracy in both T1 and T2 for accelerated data. However, the performance in T2 quantification still needs improvement, especially for high acceleration rates. Specifically, accurate quantification of T2 is often challenging in certain areas of the brain, such as the cerebrospinal fluid (CSF) and the brain boundary (cortical area). To overcome these issues, we propose a new deep learning approach for tissue quantification in MRF. Specifically, we introduce a new deep learning model called the residual channel attention U-Net (RCA-U-Net), which combines the U-Net structure [7] with residual channel attention blocks (RCAB) [8]. The RCAB includes two key components: (1) a channel attention module and (2) a residual skip connection. The channel attention module makes the network focus on more informative features for quantification of the desired tissue property by adaptively rescaling channel-wise feature maps. The residual connection allows more efficient flow of information in the network and boosts the training process. In addition, we also apply brain masking in the data preprocessing stage, which masks out the signals outside the head to eliminate their negative influence on the tissue quantification in the region of interest (ROI). Experimental results indicate that our proposed method achieves higher T2 quantification accuracy than the state-of-the-art methods for highly accelerated data in MRF. Notably, the quantification accuracy in challenging areas such as CSF and tissue boundary is improved. The application of the proposed method for high-resolution brain MRF is also evaluated.
2. Data
All the MRF datasets used in this study were acquired on a Siemens 3T Prisma scanner with a 32-channel head coil. The 2D MR images were acquired using fast imaging with steady state precession (FISP) sequence. For each slice, 2,304 MRF images (time points) were acquired.
Standard Dataset.
The 2D MRF data with 1.2 mm resolution were acquired from six normal subjects and 10~12 slices were obtained from each subject. One spiral arm was acquired for each time point as in the conventional MRF approach (reduction factor = 48). Other imaging parameters included: field of view (FOV), 30 cm; matrix size, 256 × 256; slice thickness, 5 mm; flip angle, 5°–12°. The acquisition time for each 2D slice was about 22 s.
High-Resolution Dataset.
The 2D MRF data with 0.8 mm resolution were acquired from five normal subjects and ten slices were acquired from each subject. To ensure the quality of quantitative tissue maps for such a high spatial resolution, four spiral arms instead of only one spiral arm were acquired for each time point (reduction factor = 12). A waiting time of 20 s was applied between sampling of different spiral arms to allow complete longitudinal relaxation for all brain tissues including CSF. Other imaging parameters included: FOV, 25 cm; matrix size, 304 × 304; slice thickness, 3 mm; flip angle, 5°–12°. The acquisition time for each slice was about 3 min.
MRF Dictionary and Reference Tissue Maps.
The MRF dictionary was simulated with 13,123 combinations of T1 (60–5000ms) and T2 (10–500ms). The reference tissue property maps were obtained by dictionary matching from all 2,304 time points. These maps are considered as ground truth in this work.
3. Method
Our proposed tissue quantification model consists of two networks, i.e., (1) a compression network for dimensionality reduction and feature extraction, and (2) a quantification network (i.e., RCA-U-Net) for tissue quantification. The workflow of our proposed method is shown in Fig. 1.
Fig. 1.

Overview of the proposed method for tissue quantification in magnetic resonance fingerprinting.
3.1. Head Masking
Because the MRF signals in the background (i.e., outside the head) are typically noise and can provide misleading spatial information for tissue quantification, we apply a head mask to the input MRF signals and set the signals outside the head as zero. The masks are generated from the raw MRF signal by following a three-step procedure below. First, an average image is generated by summing the images from all time points. Then, thresholding is applied to the average image to generate a binary image as a coarse mask of the head. Finally, the largest connected component is selected from the coarse mask, and morphological closing with disk-shaped kernel with a radius of 5 is further performed to generate the final mask.
3.2. Compression Network
We use a compression network to reduce the dimension of MRF signals and extract useful features for tissue quantification. The input of compression network is the high-dimensional MRF signal evolution at each pixel, and its output is a low-dimensional feature vector which is used as input for the subsequent quantification network. Specifically, the compression network consists of four fully-connected layers, where each layer has an output dimension of 64.
3.3. Quantification Network: Residual Channel Attention U-Net
We propose the residual channel attention U-Net (RCA-U-Net) to estimate tissue property maps from the output feature maps of the compression network. Figure 2 illustrates the structure of the proposed RCA-U-Net.
Fig. 2.
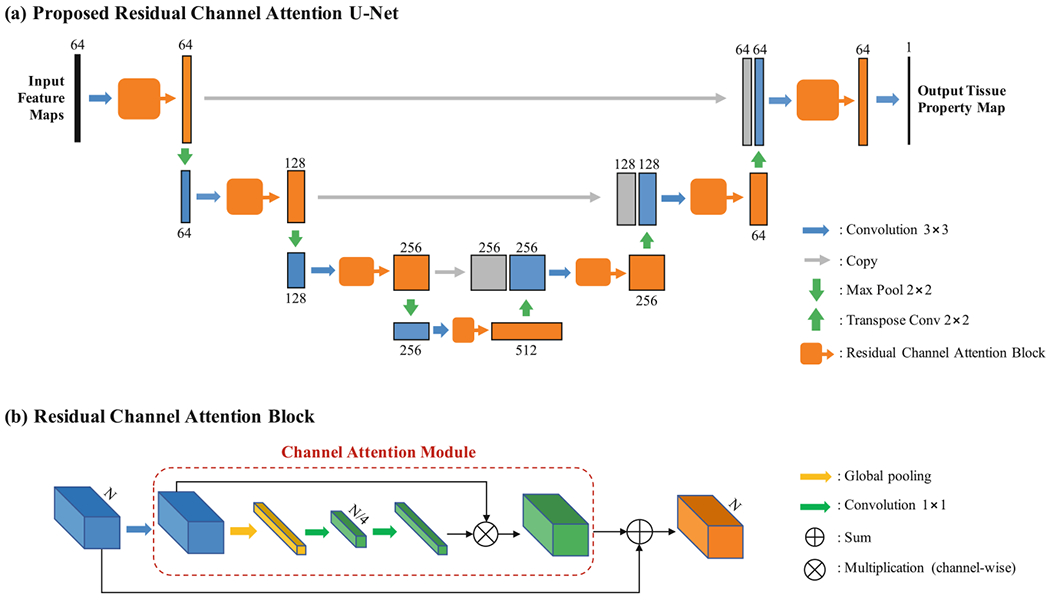
Illustration of (a) the framework of the proposed residual channel attention U-Net (RCA-U-Net) for tissue quantification and (b) the detailed configuration of residual channel attention block (RCAB).
Overall Structure.
As shown in Fig. 2(a), the proposed RCA-U-Net has a U-Net-like overall structure. With three downsampling (max pooling 2 × 2) layers and three upsampling (transpose convolution 2 × 2) layers, it extracts spatial information from three different scales. At each spatial scale, skip connections (copy) are used to combine global information with local details. Unlike the conventional U-Net, RCA-U-Net uses residual channel attention blocks (RCAB) to extract more informative features for improved tissue quantification.
Residual Channel Attention Block.
As shown in Fig. 2(b), the RCAB integrates a channel attention module into the conventional residual block. The channel attention module first applies global average pooling to each channel of the feature map to generate a channel descriptor. Then, two 1 × 1 convolution layers are used to exploit channel-wise dependencies for estimating channel-wise rescaling weights. Finally, the original feature map is rescaled by the weights through channel-wise multiplication, such that the features containing more information for the quantification of the desired tissue property are strengthened and those containing more noise and less information are weakened. The output of the channel attention module is then added to the input feature map by residual skip connection to generate the final output of RCAB.
3.4. Implementation Details
During training, we use the relative quantification error as the loss function:
| (1) |
where θx is the ground-truth tissue property at pixel x and is the estimated tissue property at pixel x. represents mathematic expectation. Adam optimizer [4] is used to train the networks with a batch size of 32 and patch size of 64 × 64. The network weights are initialized from a Gaussian distribution with zero mean and standard deviation of 0.02. The learning rate is initially set as 0.0002, kept the same for 200 epochs and linearly decayed to zero in the next 200 epochs. PyTorch is used to implement our proposed algorithm. A GeForce GTX TITAN XP GPU is used for training the networks.
4. Experiments and Results
Leave-one-out cross validation is used to evaluate the proposed method. Specifically, in each experiment, we use one subject as the test data and the remaining subjects as the training data. All the results reported in this section are evaluated on the test data. Relative quantification error, as defined in Eq. 1, is used as the quantitative evaluation metric.
In order to improve the MRF acquisition speed, data with fewer time points are used for tissue quantification in this study. For the standard dataset, we use an acceleration rate of 8, i.e., only the first 1/8 (i.e., 2304/8 = 288) time points are used to quantify tissue properties. For the high-resolution dataset, an acceleration rate of 16 is used, i.e., the first 1/4 (i.e., 2304/4 = 576) time points in the first spiral arm (out of a total of four arms) are applied.
4.1. Comparison with State-of-the-art Methods
To demonstrate the performance of the proposed method, we compare our results with four state-of-the-art methods, including: (1) dictionary template matching (DM) [5]; (2) SVD-based dictionary template matching (SDM) [6]; (3) temporal convolutional neural network (TCNN) [3]; and (4) two-stage spatially-constrained quantification network (SCQ) [2].
We first evaluate the performance on the standard MRF dataset, with quantification errors summarized in Table 1. Our method achieves higher accuracy for T2 quantification than the four state-of-the-art methods for the standard dataset. Compared to the template matching based approaches (DM and SDM), the deep learning based methods, including TCNN, SCQ and RCA-U-Net, generally achieve improved accuracy for T2 quantification, which demonstrates the advantage of deep learning based tissue quantification methods for highly accelerated MRF. Representative tissue property maps obtained from these methods are presented in Fig. 3, which further demonstrates the advantage of the proposed method. A slight increase in T1 quantification error is noticed with the proposed RCA-U-Net method as compared to SCQ, but both are better than other methods (Table 1).
Table 1.
Quantification errors of T1 and T2 relaxation times (mean(std), unit: %) yielded by the proposed RCA-U-Net and state-of-the-art methods (DM, SDM, TCNN, and SCQ). The values are obtained from all the subjects using leave-one-out cross validation.
| Data | Property | DM | SDM | TCNN | SCQ | Proposed |
|---|---|---|---|---|---|---|
| Standard | T1 | 3.88(1.00) | 4.67(1.11) | 2.25(0.38) | 1.86(0.26) | 2.02(0.32) |
| T2 | 61.26(6.21) | 60.84(5.78) | 11.69(2.37) | 8.63(1.29) | 8.09(1.42) | |
| High resolution | T1 | 7.60(1.76) | 8.25(1.96) | 6.20(1.17) | 4.86(0.60) | 4.34(0.67) |
| T2 | 20.41(0.88) | 27.08(1.31) | 9.08(1.07) | 10.86(0.83) | 7.50(0.64) |
Fig. 3.
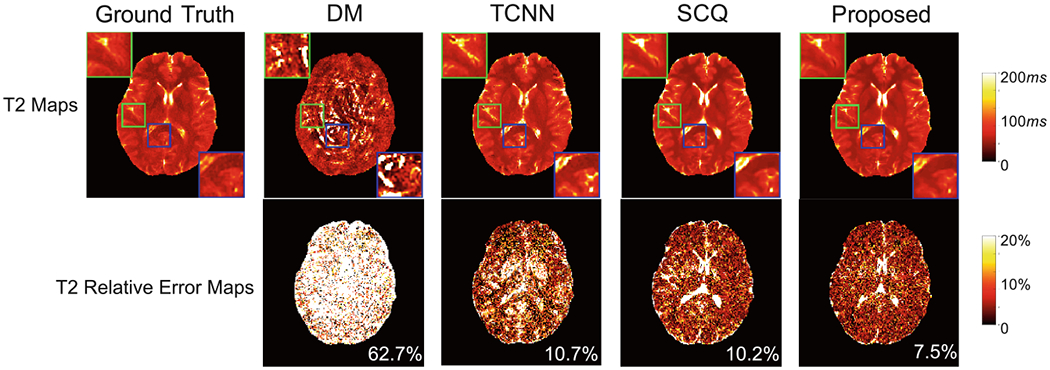
Quantitative T2 maps obtained using the proposed RCA-U-Net and three state-of-the-art methods (DM, TCNN, and SCQ), for a representative slice in the standard dataset. The average error is presented at the lower right corner of each error map.
4.2. Impact of Proposed Components
In this section, we conduct experiments to show the impact of each of two critical components in our proposed method, i.e., head masking and residual channel attention block, on the improvement of tissue quantification.
Impact of Head Masking.
To show the effectiveness of head masking (as described in Sect. 3.1), we compare the quantification results obtained with and without head mask (labeled as “RCA-U-Net with mask” and “RCA-U-Net without mask”, respectively) in Fig. 4. Improved T2 quantification, especially around brain boundaries is noticed (as indicated by the green arrows), which demonstrates the advantage of this preprocessing strategy.
Fig. 4.
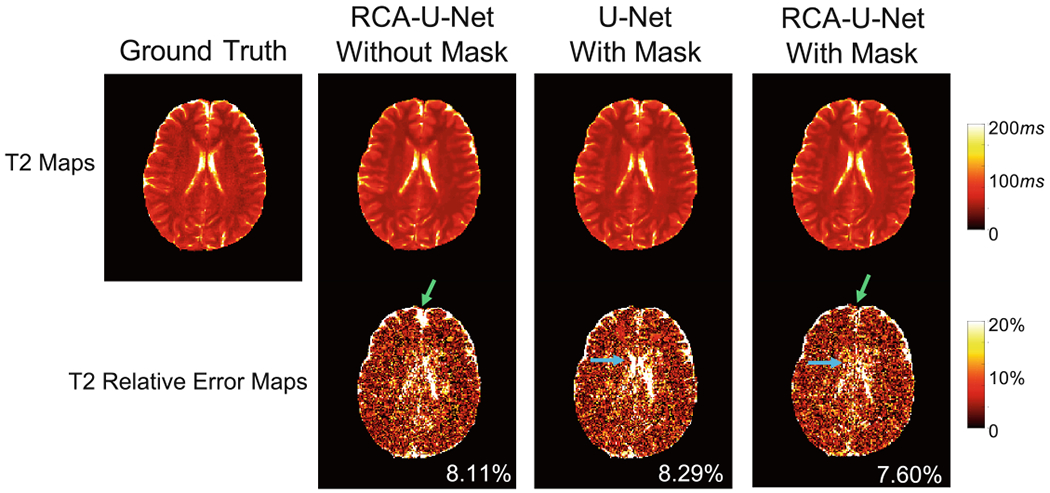
Effect of head masking and residual channel attention block (RCAB) in the quantification of T2. Results are obtained from the standard dataset. Improved T2 quantification due to head masking is noted for brain boundaries, as indicated by the green arrows. Improved T2 quantification due to RCAB is noted for CSF regions, as indicated by the blue arrows. (Color figure online)
Impact of Residual Channel Attention Block.
To demonstrate the impact of residual channel attention blocks (RCAB), we compare the result of the proposed RCA-U-Net (labeled as “RCA-U-Net with mask”) with the result of the conventional U-Net (labeled as “U-Net with mask”) in Fig. 4. As shown in the figure, RCA-U-Net yields lower quantification error than the conventional U-Net. Specifically, RCA-U-Net achieves better results in the CSF area (as indicated by the blue arrows), which is often challenging in highly accelerated MRF.
4.3. Validation on High-Resolution Dataset
High-resolution quantitative imaging is critical for pediatric imaging, but time consuming even with the standard MRF method. In this study, we further evaluate the potential of applying the proposed method for acceleration of submillimeter MRF. Representative T1 and T2 maps acquired with a 0.8 mm inplane resolution are shown in Fig. 5. The results obtained with the standard MRF approach with 2304 time points and dictionary template matching are also presented for comparison (label as “DM”). With only 25% of the time points, improved quantification in both T1 and T2 is achieved with the proposed method as compared to the standard MRF approach. This enables rapid data acquisition of 7.5 s per slice for high-resolution MRF, which makes pediatric imaging feasible. Table 1 summarizes the quantification errors for high-resolution dataset. Compared with the state-of-the-art methods, improved performance in both T1 and T2 quantification is noted with the proposed method.
Fig. 5.
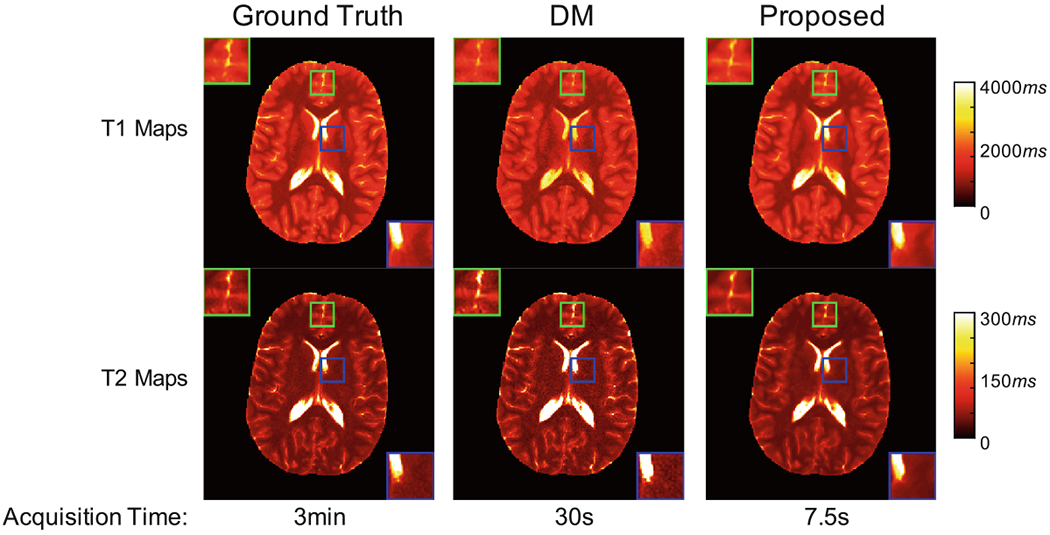
Quantification results on high resolution dataset. From left to right: result of dictionary template matching using 2304 time points in all four spiral arms (i.e., ground truth); result of dictionary template matching using 2304 time points in the first spiral arm; result of the proposed method using 576 time points in the first spiral arm. The time needed for data acquisition is presented at the bottom of each figure.
5. Conclusion
In this paper, we have presented a new deep learning approach for tissue quantification in highly accelerated magnetic resonance fingerprinting (MRF). A novel deep learning model, namely residual channel attention U-Net (RCA-U-Net), is proposed, which leads to more adaptive and informative feature extraction and better tissue quantification results. A preprocessing strategy with head masking is also added to eliminate noisy background signals for improved quantification accuracy. Our experimental results demonstrate that the proposed method achieves superior tissue quantification results for highly accelerated MRF data and has the potential to enable rapid high-resolution MRF for pediatric imaging.
Acknowledgement.
This work was supported in part by NIH grant EB006733.
References
- 1.Cohen O, Zhu B, Rosen MS: MR fingerprinting deep reconstruction network (drone). Magn. Reson. Med 80(3), 885–894 (2018) [DOI] [PMC free article] [PubMed] [Google Scholar]
- 2.Fang Z, et al. : Deep learning for fast and spatially-constrained tissue quantification from highly-accelerated data in magnetic resonance fingerprinting. IEEE Trans. Med. Imaging (2019). 10.1109/TMI.2019.2899328 [DOI] [PMC free article] [PubMed] [Google Scholar]
- 3.Hoppe E, et al. : Deep learning for magnetic resonance fingerprinting: accelerating the reconstruction of quantitative relaxation maps. In: Proceedings of the 26th Annual Meeting of ISMRM, Paris, France (2018) [Google Scholar]
- 4.Kingma DP, Ba JL: Adam: a method for stochastic optimization. In: International Conference on Learning Representations (ICLR), pp. 1–15 (2015) [Google Scholar]
- 5.Ma D, et al. : Magnetic resonance fingerprinting. Nature 495(7440), 187 (2013) [DOI] [PMC free article] [PubMed] [Google Scholar]
- 6.McGivney DF, et al. : SVD compression for magnetic resonance fingerprinting in the time domain. IEEE Trans. Med. Imaging 33(12), 2311–2322 (2014) [DOI] [PMC free article] [PubMed] [Google Scholar]
- 7.Ronneberger O, Fischer P, Brox T: U-Net: convolutional networks for biomedical image segmentation In: Navab N, Hornegger J, Wells WM, Frangi AF (eds.) MICCAI 2015. LNCS, vol. 9351, pp. 234–241. Springer, Cham: (2015). 10.1007/978-3-319-24574-4_28 [DOI] [Google Scholar]
- 8.Zhang Y, Li K, Li K, Wang L, Zhong B, Fu Y: Image super-resolution using very deep residual channel attention networks. In: Proceedings of the European Conference on Computer Vision (ECCV), pp. 286–301 (2018) [Google Scholar]