

Abstract
Labeling training data is increasingly the largest bottleneck in deploying machine learning systems. We present Snorkel, a first-of-its-kind system that enables users to train state-of-the-art models without hand labeling any training data. Instead, users write labeling functions that express arbitrary heuristics, which can have unknown accuracies and correlations. Snorkel denoises their outputs without access to ground truth by incorporating the first end-to-end implementation of our recently proposed machine learning paradigm, data programming. We present a flexible interface layer for writing labeling functions based on our experience over the past year collaborating with companies, agencies, and research laboratories. In a user study, subject matter experts build models faster and increase predictive performance an average versus seven hours of hand labeling. We study the modeling trade-offs in this new setting and propose an optimizer for automating trade-off decisions that gives up to speedup per pipeline execution. In two collaborations, with the US Department of Veterans Affairs and the US Food and Drug Administration, and on four open-source text and image data sets representative of other deployments, Snorkel provides average improvements to predictive performance over prior heuristic approaches and comes within an average of the predictive performance of large hand-curated training sets.
Keywords: Machine learning, Weak supervision, Training data
Introduction
In the last several years, there has been an explosion of interest in machine learning-based systems across industry, government, and academia, with an estimated spend this year of $12.5 billion [61]. A central driver has been the advent of deep learning techniques, which can learn task-specific representations of input data, obviating what used to be the most time-consuming development task: feature engineering. These learned representations are particularly effective for tasks like natural language processing and image analysis, which have high-dimensional, high-variance input that is impossible to fully capture with simple rules or hand-engineered features [14, 18]. However, deep learning has a major upfront cost: these methods need massive training sets of labeled examples to learn from—often tens of thousands to millions to reach peak predictive performance [56].
Such training sets are enormously expensive to create, especially when domain expertise is required. For example, reading scientific papers, analyzing intelligence data, and interpreting medical images all require labeling by trained subject matter experts (SMEs). Moreover, we observe from our engagements with collaborators like research laboratories and major technology companies that modeling goals such as class definitions or granularity change as projects progress, necessitating re-labeling. Some big companies are able to absorb this cost, hiring large teams to label training data [12, 16, 35]. Other practitioners utilize classic techniques like active learning [53], transfer learning [38], and semi-supervised learning [9] to reduce the number of training labels needed. However, the bulk of practitioners are increasingly turning to some form of weak supervision: cheaper sources of labels that are noisier or heuristic. The most popular form is distant supervision, in which the records of an external knowledge base are heuristically aligned with data points to produce noisy labels [3, 7, 36]. Other forms include crowdsourced labels [41, 63], rules and heuristics for labeling data [47, 65], and others [33, 34, 34, 55, 64]. While these sources are inexpensive, they often have limited accuracy and coverage.
Ideally, we would combine the labels from many weak supervision sources to increase the accuracy and coverage of our training set. However, two key challenges arise in doing so effectively. First, sources will overlap and conflict, and to resolve their conflicts we need to estimate their accuracies and correlation structure, without access to ground truth. Second, we need to pass on critical lineage information about label quality to the end model being trained.
Example 1.1
In Fig. 1, we obtain labels from a high-accuracy, low-coverage Source 1, and from a low-accuracy, high-coverage Source 2, which overlap and disagree (split-color points). If we take an unweighted majority vote to resolve conflicts, we end up with null (tie-vote) labels. If we could correctly estimate the source accuracies, we would resolve conflicts in the direction of Source 1.
Fig. 1.
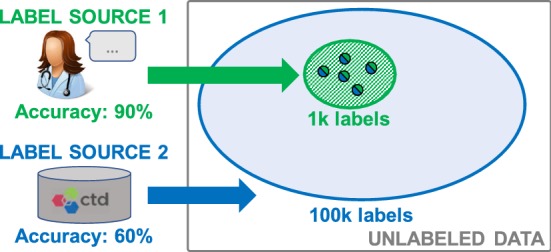
In Example 1.1, training data is labeled by sources of differing accuracy and coverage. Two key challenges arise in using this weak supervision effectively. First, we need a way to estimate the unknown source accuracies to resolve disagreements. Second, we need to pass on this critical lineage information to the end model being trained
We would still need to pass this information on to the end model being trained. Suppose that we took labels from Source 1 where available, and otherwise took labels from Source 2. Then, the expected training set accuracy would be —only marginally better than the weaker source. Instead we should represent training label lineage in end model training, weighting labels generated by high-accuracy sources more.
In recent work, we developed data programming as a paradigm for addressing both of these challenges by modeling multiple label sources without access to ground truth, and generating probabilistic training labels representing the lineage of the individual labels. We prove that, surprisingly, we can recover source accuracy and correlation structure without hand-labeled training data [5, 43]. However, there are many practical aspects of implementing and applying this abstraction that have not been previously considered.
We present Snorkel, the first end-to-end system for combining weak supervision sources to rapidly create training data (Fig. 2). We built Snorkel as a prototype to study how people could use data programming, a fundamentally new approach to building machine learning applications. Through weekly hackathons and office hours held at Stanford University over the past year, we have interacted with a growing user community around Snorkel’s open-source implementation.1 We have observed SMEs in industry, science, and government deploying Snorkel for knowledge base construction, image analysis, bioinformatics, fraud detection, and more. From this experience, we have distilled three principles that have shaped Snorkel’s design:
Bring All Sources to Bear The system should enable users to opportunistically use labels from all available weak supervision sources.
Training Data as the Interface to ML The system should model label sources to produce a single, probabilistic label for each data point and train any of a wide range of classifiers to generalize beyond those sources.
Supervision as Interactive Programming The system should provide rapid results in response to user supervision. We envision weak supervision as the REPL-like interface for machine learning.
Fig. 2.
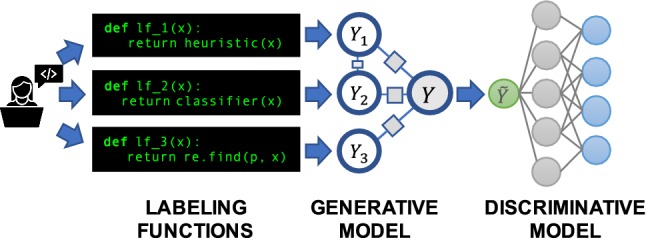
In Snorkel, rather than labeling training data by hand, users write labeling functions, which programmatically label data points or abstain. These labeling functions will have different unknown accuracies and correlations. Snorkel automatically models and combines their outputs using a generative model, then uses the resulting probabilistic labels to train a discriminative model
Our work makes the following technical contributions:
A Flexible Interface for Sources We observe that the heterogeneity of weak supervision strategies is a stumbling block for developers. Different types of weak supervision operate on different scopes of the input data. For example, distant supervision has to be mapped programmatically to specific spans of text. Crowd workers and weak classifiers often operate over entire documents or images. Heuristic rules are open ended; they can leverage information from multiple contexts simultaneously, such as combining information from a document’s title, named entities in the text, and knowledge bases. This heterogeneity was cumbersome enough to completely block users of early versions of Snorkel.
To address this challenge, we built an interface layer around the abstract concept of a labeling function (LF). We developed a flexible language for expressing weak supervision strategies and supporting data structures. We observed accelerated user productivity with these tools, which we validated in a user study where SMEs build models faster and increase predictive performance an average versus seven hours of hand labeling.
Trade-offs in Modeling of Sources Snorkel learns the accuracies of weak supervision sources without access to ground truth using a generative model [43]. Furthermore, it also learns correlations and other statistical dependencies among sources, correcting for dependencies in labeling functions that skew the estimated accuracies [5]. This paradigm gives rise to previously unexplored trade-off spaces between predictive performance and speed. The natural first question is: when does modeling the accuracies of sources improve predictive performance? Further, how many dependencies, such as correlations, are worth modeling?
We study the trade-offs between predictive performance and training time in generative models for weak supervision. While modeling source accuracies and correlations will not hurt predictive performance, we present a theoretical analysis of when a simple majority vote will work just as well. Based on our conclusions, we introduce an optimizer for deciding when to model accuracies of labeling functions, and when learning can be skipped in favor of a simple majority vote. Further, our optimizer automatically decides which correlations to model among labeling functions. This optimizer correctly predicts the advantage of generative modeling over majority vote to within accuracy points on average on our evaluation tasks, and accelerates pipeline executions by up to . It also enables us to gain 60–70% of the benefit of correlation learning while saving up to of training time ( minutes per execution).
First End-to-End System for Data Programming Snorkel is the first system to implement our recent work on data programming [5, 43]. Previous ML systems that we and others developed [65] required extensive feature engineering and model specification, leading to confusion about where to inject relevant domain knowledge. While programming weak supervision seems superficially similar to feature engineering, we observe that users approach the two processes very differently. Our vision—weak supervision as the sole port of interaction for machine learning—implies radically different workflows, requiring a proof of concept.
Snorkel demonstrates that this paradigm enables users to develop high-quality models for a wide range of tasks. We report on two deployments of Snorkel, in collaboration with the US Department of Veterans Affairs and Stanford Hospital and Clinics, and the US Food and Drug Administration, where Snorkel improves over heuristic baselines by an average . We also report results on four open-source datasets that are representative of other Snorkel deployments, including bioinformatics, medical image analysis, and crowdsourcing; on which Snorkel beats heuristics by an average and comes within an average of the predictive performance of large hand-curated training sets.
Snorkel architecture
Snorkel’s workflow is designed around data programming [5, 43], a fundamentally new paradigm for training machine learning models using weak supervision, and proceeds in three main stages (Fig. 3):
Writing Labeling Functions Rather than hand-labeling training data, users of Snorkel write labeling functions, which allow them to express various weak supervision sources such as patterns, heuristics, external knowledge bases, and more. This was the component most informed by early interactions (and mistakes) with users over the last year of deployment, and we present a flexible interface and supporting data model.
Modeling Accuracies and Correlations Next, Snorkel automatically learns a generative model over the labeling functions, which allows it to estimate their accuracies and correlations. This step uses no ground-truth data, learning instead from the agreements and disagreements of the labeling functions. We observe that this step improves end predictive performance over Snorkel with unweighted label combination, and anecdotally that it streamlines the user development experience by providing actionable feedback about labeling function quality.
Training a Discriminative Model The output of Snorkel is a set of probabilistic labels that can be used to train a wide variety of state-of-the-art machine learning models, such as popular deep learning models. While the generative model is essentially a re-weighted combination of the user-provided labeling functions—which tend to be precise but low-coverage—modern discriminative models can retain this precision while learning to generalize beyond the labeling functions, increasing coverage and robustness on unseen data.
Next, we set up the problem Snorkel addresses and describe its main components and design decisions.
Fig. 3.

An overview of the Snorkel system. (1) SME users write labeling functions (LFs) that express weak supervision sources like distant supervision, patterns, and heuristics. (2) Snorkel applies the LFs over unlabeled data and learns a generative model to combine the LFs’ outputs into probabilistic labels. (3) Snorkel uses these labels to train a discriminative classification model, such as a deep neural network
Setup Our goal is to learn a parameterized classification model that, given a data point , predicts its label , where the set of possible labels is discrete. For simplicity, we focus on the binary setting , though we include a multi-class application in our experiments. For example, x might be a medical image, and y a label indicating normal versus abnormal. In the relation extraction examples we look at, we often refer to x as a candidate. In a traditional supervised learning setup, we would learn by fitting it to a training set of labeled data points. However, in our setting, we assume that we only have access to unlabeled data for training. We do assume access to a small set of labeled data used during development, called the development set, and a blind, held-out labeled test set for evaluation. These sets can be orders of magnitudes smaller than a training set, making them economical to obtain.
The user of Snorkel aims to generate training labels by providing a set of labeling functions, which are black-box functions, , that take in a data point and output a label where we use to denote that the labeling function abstains. Given unlabeled data points and labeling functions, Snorkel applies the labeling functions over the unlabeled data to produce a matrix of labeling function outputs . The goal of the remaining Snorkel pipeline is to synthesize this label matrix —which may contain overlapping and conflicting labels for each data point—into a single vector of probabilistic training labels, where . These training labels can then be used to train a discriminative model.
Next, we introduce the running example of a text relation extraction task as a proxy for many real-world knowledge base construction and data analysis tasks:
Example 2.1
Consider the task of extracting mentions of adverse chemical–disease relations from the biomedical literature (see CDR task, Sect. 4.1). Given documents with mentions of chemicals and diseases tagged, we refer to each co-occurring (chemical, disease) mention pair as a candidate extraction, which we view as a data point to be classified as either true or false. For example, in Fig. 1, we would have two candidates with true labels = True and = False: ![]()
Data Model A design challenge is managing complex, unstructured data in a way that enables SMEs to write labeling functions over it. In Snorkel, input data is stored in a context hierarchy. It is made up of context types connected by parent/child relationships, which are stored in a relational database and made available via an object-relational mapping (ORM) layer built with SQLAlchemy.2 Each context type represents a conceptual component of data to be processed by the system or used when writing labeling functions; for example a document, an image, a paragraph, a sentence, or an embedded table. Candidates—i.e., data points x—are then defined as tuples of contexts (Fig. 4).
Fig. 4.
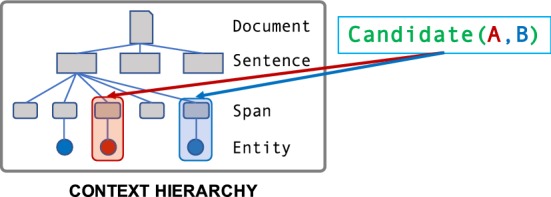
Labeling functions take as input a Candidate object, representing a data point to be classified. Each Candidate is a tuple of Context objects, which are part of a hierarchy representing the local context of the Candidate
Example 2.2
In our running CDR example, the input documents can be represented in Snorkel as a hierarchy consisting of Documents, each containing one or more Sentences, each containing one or more Spans of text. These Spans may also be tagged with metadata, such as Entity markers identifying them as chemical or disease mentions (Fig. 4). A candidate is then a tuple of two Spans.
A language for weak supervision
Snorkel uses the core abstraction of a labeling function to allow users to specify a wide range of weak supervision sources such as patterns, heuristics, external knowledge bases, crowdsourced labels, and more. This higher-level, less precise input is more efficient to provide (see Sect. 4.2) and can be automatically denoised and synthesized, as described in subsequent sections.
In this section, we describe our design choices in building an interface for writing labeling functions, which we envision as a unifying programming language for weak supervision. These choices were informed to a large degree by our interactions—primarily through weekly office hours—with Snorkel users in bioinformatics, defense, industry, and other areas over the past year.3 For example, while we initially intended to have a more complex structure for labeling functions, with manually specified types and correlation structure, we quickly found that simplicity in this respect was critical to usability (and not empirically detrimental to our ability to model their outputs). We also quickly discovered that users wanted either far more expressivity or far less of it, compared to our first library of function templates. We thus trade-off expressivity and efficiency by allowing users to write labeling functions at two levels of abstraction: custom Python functions and declarative operators.
Hand-Defined Labeling Functions In its most general form, a labeling function is just an arbitrary snippet of code, usually written in Python, which accepts as input a Candidate object and either outputs a label or abstains. Often these functions are similar to extract–transform–load scripts, expressing basic patterns or heuristics, but may use supporting code or resources and be arbitrarily complex. Writing labeling functions by hand is supported by the ORM layer, which maps the context hierarchy and associated metadata to an object-oriented syntax, allowing the user to easily traverse the structure of the input data.
Example 2.3
In our running example, we can write a labeling function that checks if the word “causes” appears between the chemical and disease mentions. If it does, it outputs True if the chemical mention is first and False if the disease mention is first. If “causes” does not appear, it outputs None, indicating abstention:  We could also write this with Snorkel’s declarative interface:
We could also write this with Snorkel’s declarative interface: ![]()
Declarative Labeling Functions Snorkel includes a library of declarative operators that encode the most common weak supervision function types, based on our experience with users over the last year. The semantics and syntax of these operators is simple and easily customizable, consisting of two main types: (i) labeling function templates, which are simply functions that take one or more arguments and output a single labeling function; and (ii) labeling function generators, which take one or more arguments and output a set of labeling functions (described below). These functions capture a range of common forms of weak supervision, for example:
Pattern-based Pattern-based heuristics embody the motivation of soliciting higher information density input from SMEs. For example, pattern-based heuristics encompass feature annotations [64] and pattern-bootstrapping approaches [19, 22] (Example 2.3).
Distant supervision Distant supervision generates training labels by heuristically aligning data points with an external knowledge base and is one of the most popular forms of weak supervision [3, 24, 36].
Weak classifiers Classifiers that are insufficient for our task—e.g., limited coverage, noisy, biased, and/or trained on a different dataset—can be used as labeling functions.
Labeling function generators One higher-level abstraction that we can build on top of labeling functions in Snorkel is labeling function generators, which generate multiple labeling functions from a single resource, such as crowdsourced labels and distant supervision from structured knowledge bases (Example 2.4).
Example 2.4
A challenge in traditional distant supervision is that different subsets of knowledge bases have different levels of accuracy and coverage. In our running example, we can use the Comparative Toxicogenomics Database (CTD)4 as distant supervision, separately modeling different subsets of it with separate labeling functions. For example, we might write one labeling function to label a candidate True if it occurs in the “Causes” subset, and another to label it False if it occurs in the “Treats” subset. We can write this using a labeling function generator, ![]() which creates two labeling functions. In this way, generators can be connected to large resources and create hundreds of labeling functions with a line of code.
which creates two labeling functions. In this way, generators can be connected to large resources and create hundreds of labeling functions with a line of code.
Interface Implementation Snorkel’s interface is designed to be accessible to subject matter expert (SME) users without advanced programming skills. All components run in Jupyter iPython notebooks,5 including writing labeling functions.6 Users can therefore write labeling functions as arbitrary Python functions for maximum flexibility (Fig. 5). We also provide a library of labeling function primitives and generators to more declaratively program weak supervision, and a viewer utility (Fig. 6) that displays candidates, and also supports annotation, e.g., for constructing a small held-out test set for end evaluation.
Fig. 5.
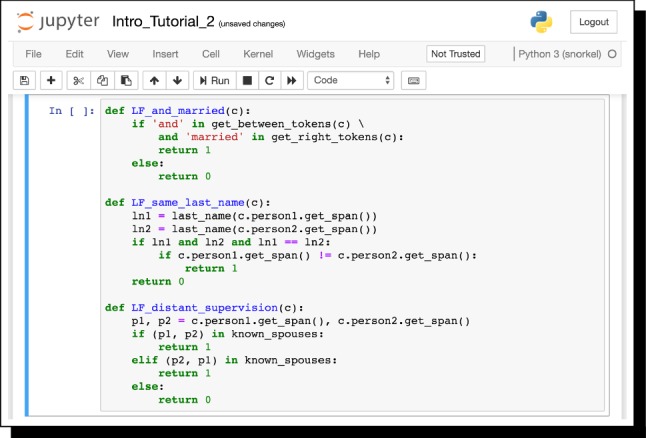
Labeling functions expressing pattern matching, heuristic, and distant supervision approaches, respectively, in Snorkel’s Jupyter notebook interface, for the Spouses example. Full code is available in Snorkel’s Intro tutorial. https://github.com/HazyResearch/snorkel/tree/master/tutorials/intro
Fig. 6.
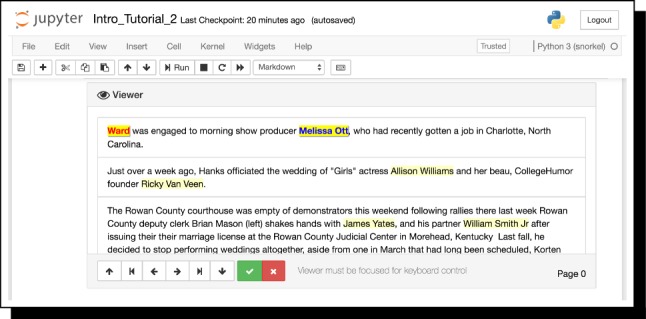
The data viewer utility in Snorkel, showing candidate spouse relation mentions from the Spouses example, composed of person–person mention pairs
Execution Model Since labeling functions operate on discrete candidates, their execution is embarrassingly parallel. If Snorkel is connected to a relational database that supports simultaneous connections, e.g., PostgreSQL, then the master process (usually the notebook kernel) distributes the primary keys of the candidates to be labeled to Python worker processes. The workers independently read from the database to materialize the candidates via the ORM layer, then execute the labeling functions over them. The labels are returned to the master process which persists them via the ORM layer. Collecting the labels at the master is more efficient than having workers write directly to the database, due to table-level locking.
Snorkel includes a Spark7 integration layer, enabling labeling functions to be run across a cluster. Once the set of candidates is cached as a Spark data frame, only the closure of the labeling functions and the resulting labels need to be communicated to and from the workers. This is particularly helpful in Snorkel’s iterative workflow. Distributing a large unstructured data set across a cluster is relatively expensive, but only has to be performed once. Then, as users refine their labeling functions, they can be rerun efficiently.
Generative model
The core operation of Snorkel is modeling and integrating the noisy signals provided by a set of labeling functions. Using the recently proposed approach of data programming [5, 43], we model the true class label for a data point as a latent variable in a probabilistic model. In the simplest case, we model each labeling function as a noisy “voter” which is independent—i.e., makes errors that are uncorrelated with the other labeling functions. This defines a generative model of the votes of the labeling functions as noisy signals about the true label.
We can also model statistical dependencies between the labeling functions to improve predictive performance. For example, if two labeling functions express similar heuristics, we can include this dependency in the model and avoid a “double counting” problem. We observe that such pairwise correlations are the most common, so we focus on them in this paper (though handling higher order dependencies is straightforward). We use our structure learning method for generative models [5] to select a set C of labeling function pairs to model as correlated (see Sect. 3.2).
Now we can construct the full generative model as a factor graph. We first apply all the labeling functions to the unlabeled data points, resulting in a label matrix , where . We then encode the generative model using three factor types, representing the labeling propensity, accuracy, and pairwise correlations of labeling functions:
For a given data point , we define the concatenated vector of these factors for all the labeling functions and potential correlations C as , and the corresponding vector of parameters . This defines our model:
where is a normalizing constant. To learn this model without access to the true labels , we minimize the negative log marginal likelihood given the observed label matrix :
We optimize this objective by interleaving stochastic gradient descent steps with Gibbs sampling ones, similar to contrastive divergence [23]; for more details, see [5, 43]. We use the Numbskull library,8 a Python NUMBA-based Gibbs sampler. We then use the predictions, , as probabilistic training labels.
Discriminative model
The end goal in Snorkel is to train a model that generalizes beyond the information expressed in the labeling functions. We train a discriminative model on our probabilistic labels by minimizing a noise-aware variant of the loss , i.e., the expected loss with respect to :
A formal analysis shows that as we increase the amount of unlabeled data, the generalization error of discriminative models trained with Snorkel will decrease at the same asymptotic rate as traditional supervised learning models do with additional hand-labeled data [43], allowing us to increase predictive performance by adding more unlabeled data. Intuitively, this property holds because as more data is provided, the discriminative model sees more features that co-occur with the heuristics encoded in the labeling functions.
Example 2.5
The CDR data contains the sentence, “Myasthenia gravis presenting as weakness after magnesium administration.” None of the 33 labeling functions we developed vote on the corresponding Causes(magnesium,myasthenia gravis) candidate, i.e., they all abstain. However, a deep neural network trained on probabilistic training labels from Snorkel correctly identifies it as a true mention.
Snorkel provides connectors for popular machine learning libraries such as TensorFlow [1], allowing users to exploit commodity models like deep neural networks that do not require hand-engineering of features and have robust predictive performance across a wide range of tasks.
Weak supervision trade-offs
We study the fundamental question of when—and at what level of complexity—we should expect Snorkel’s generative model to yield the greatest predictive performance gains. Understanding these performance regimes can help guide users and introduces a trade-off space between predictive performance and speed. We characterize this space in two parts: first, by analyzing when the generative model can be approximated by an unweighted majority vote, and second, by automatically selecting the complexity of the correlation structure to model. We then introduce a two-stage, rule-based optimizer to support fast development cycles.
Modeling accuracies
The natural first question when studying systems for weak supervision is, “When does modeling the accuracies of sources improve end-to-end predictive performance?” We study that question in this subsection and propose a heuristic to identify settings in which this modeling step is most beneficial.
Trade-off space
We start by considering the label density of the label matrix , defined as the mean number of non-abstention labels per data point. In the low-density setting, sparsity of labels will mean that there is limited room for even an optimal weighting of the labeling functions to diverge much from the majority vote. Conversely, as the label density grows, known theory confirms that the majority vote will eventually be optimal [31]. It is the middle-density regime where we expect to most benefit from applying the generative model. We start by defining a measure of the benefit of weighting the labeling functions by their true accuracies—in other words, the predictions of a perfectly estimated generative model—versus an unweighted majority vote:
Definition 1
(Modeling Advantage) Let the weighted majority vote of labeling functions on data point be denoted as , and the unweighted majority vote (MV) as , where we consider the binary classification setting and represent an abstaining vote as 0. We define the modeling advantage as the improvement in accuracy of over for a dataset:
In other words, is the number of times correctly disagrees with on a label, minus the number of times it incorrectly disagrees. Let the optimal advantage be the advantage using the optimal weights (WMV*).
Additionally, let:
be the average accuracies of the labeling functions. To build intuition, we start by analyzing the optimal advantage for three regimes of label density (see Fig. 7):
Fig. 7.
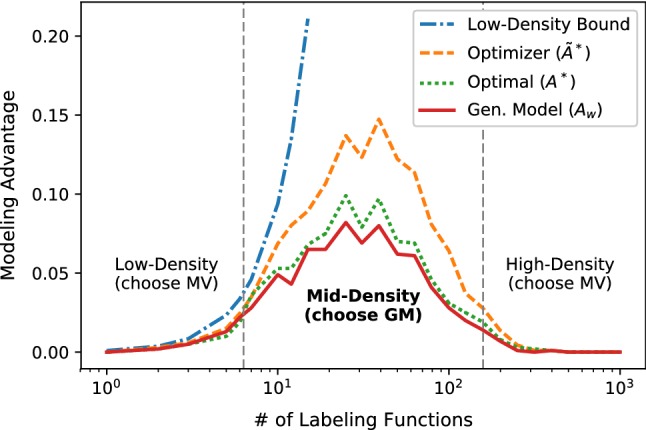
A plot of the modeling advantage, i.e., the improvement in label accuracy from the generative model, as a function of the number of labeling functions (equivalently, the label density) on a synthetic dataset.(We generate a class-balanced dataset of data points with binary labels, and independent labeling functions with average accuracy 75% and a fixed 10% probability of voting.) We plot the advantage obtained by a learned generative model (GM), ; by an optimal model ; the upper bound used in our optimizer; and the low-density bound (Proposition 1)
Low Label Density In this sparse setting, very few data points have more than one non-abstaining label; only a small number have multiple conflicting labels. We have observed this occurring, for example, in the early stages of application development. We see that with non-adversarial labeling functions (), even an optimal generative model (WMV*) can only disagree with MV when there are disagreeing labels, which will occur infrequently. We see that the expected optimal advantage will have an upper bound that falls quadratically with label density:
Proposition 1
(Low-Density Upper Bound) Assume that , and . Then, the expected label density is , and
| 1 |
Proof
We bound the advantage above by computing the expected number of pairwise disagreements; for details, see Appendix of extended online version.9
High Label Density In this setting, the majority of the data points have a large number of labels. For example, we might be working in an extremely high-volume crowdsourcing setting, or an application with many high-coverage knowledge bases as distant supervision. Under modest assumptions—namely, that the average labeling function accuracy is greater than 50%—it is known that the majority vote converges exponentially to an optimal solution as the average label density increases, which serves as an upper bound for the expected optimal advantage as well:
Proposition 2
(High-Density Upper Bound) Assume that , and that . Then:
| 2 |
Proof
This follows from an application of Hoeffding’s inequality; for details, see Appendix of extended version.
Medium Label Density In this middle regime, we expect that modeling the accuracies of the labeling functions will deliver the greatest gains in predictive performance because we will have many data points with a small number of disagreeing labeling functions. For such points, the estimated labeling function accuracies can heavily affect the predicted labels. We indeed see gains in the empirical results using an independent generative model that only includes accuracy factors (Table 1). Furthermore, the guarantees in [43] establish that we can learn the optimal weights, and thus approach the optimal advantage.
Table 1.
Modeling advantage attained using a generative model for several applications in Snorkel (Sect. 4.1), the upper bound used by our optimizer, the modeling strategy selected by the optimizer—either majority vote (MV) or generative model (GM)—and the empirical label density
| Dataset | (%) | (%) | Modeling strategy | |
|---|---|---|---|---|
| Radiology | 7.0 | 12.4 | GM | 2.3 |
| CDR | 4.9 | 7.9 | GM | 1.8 |
| Spouses | 4.4 | 4.6 | GM | 1.4 |
| Chem | 0.1 | 0.3 | MV | 1.2 |
| EHR | 2.8 | 4.8 | GM | 1.2 |
Automatically choosing a modeling strategy
The bounds in the previous subsection imply that there are settings in which we should be able to safely skip modeling the labeling function accuracies, simply taking the unweighted majority vote instead. However, in practice, the overall label density is insufficiently precise to determine the transition points of interest, given a user time-cost trade-off preference (characterized by the advantage tolerance parameter in Algorithm 1). We show this in Table 1 using our application data sets from Sect. 4.1. For example, we see that the Chem and EHR label matrices have equivalent label densities; however, modeling the labeling function accuracies has a much greater effect for EHR than for Chem.
Instead of simply considering the average label density , we instead develop a best-case heuristic based on looking at the ratio of positive to negative labels for each data point. This heuristic serves as an upper bound to the true expected advantage, and thus, we can use it to determine when we can safely skip training the generative model (see Algorithm 1). Let be the counts of labels of class y for , and assume that the true labeling function weights lie within a fixed range, and have a mean .10 Then, define:
where is the sigmoid function, is majority vote with all weights set to the mean , and is the predicted modeling advantage used by our optimizer. Essentially, we are taking the expected counts of instances in which a weighted majority vote could possibly flip the incorrect predictions of unweighted majority vote under best-case conditions, which is an upper bound for the expected advantage:
Proposition 3
(Optimizer Upper Bound) Assume that the labeling functions have accuracy parameters (log-odds weights) , and have . Then:
| 3 |
Proof Sketch:
We upper bound the modeling advantage by the expected number of instances in which WMV* is correct and MV is incorrect. We then upper bound this by using the best-case probability of the weighted majority vote being correct given .
We apply to a synthetic dataset and plot in Fig. 7. Next, we compute for the labeling matrices from experiments in Sect. 4.1 and compare with the empirical advantage of the trained generative models (Table 1).11 We see that our approximate quantity serves as a correct guide in all cases for determining which modeling strategy to select, which for the mature applications reported on is indeed most often the generative model. However, we see that while EHR and Chem have equivalent label densities, our optimizer correctly predicts that Chem can be modeled with majority vote, speeding up each pipeline execution by .
Accelerating initial development cycles
We find in our applications that the optimizer can save execution time especially during the initial cycles of iterative development. To illustrate this empirically, in Fig. 8 we measure the modeling advantage of the generative model versus a majority vote of the labeling functions on increasingly large random subsets of the CDR labeling functions. We see that the modeling advantage grows as the number of labeling functions increases, and that our optimizer approximation closely tracks it; thus, the optimizer can save execution time by choosing to skip the generative model and run majority vote instead during the initial cycles of iterative development.
Fig. 8.
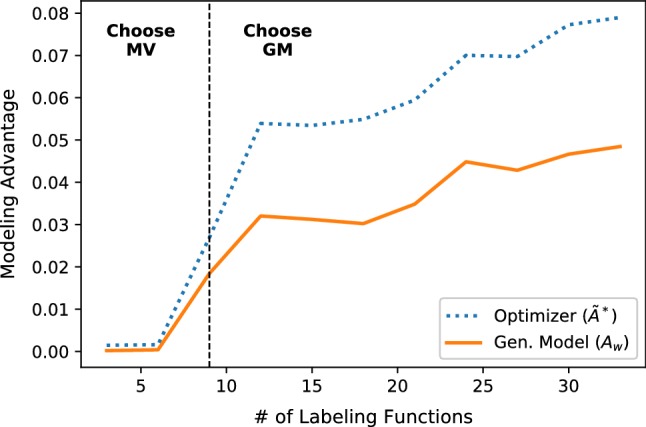
The predicted () and actual () advantage of using the generative labeling model (GM) over majority vote (MV) on the CDR application as the number of LFs is increased. At 9 LFs, the optimizer switches from choosing MV to choosing GM; this leads to faster modeling in early development cycles, and more accurate results in later cycles
Modeling structure
In this subsection, we consider modeling additional statistical structure beyond the independent model. We study the trade-off between predictive performance and computational cost, and describe how to automatically select a good point in this trade-off space.
Structure Learning We observe many Snorkel users writing labeling functions that are statistically dependent. Examples we have observed include:
Functions that are variations of each other, such as checking for matches against similar regular expressions.
Functions that operate on correlated inputs, such as raw tokens of text and their lemmatizations.
Functions that use correlated sources of knowledge, such as distant supervision from overlapping knowledge bases.
Modeling such dependencies is important because they affect our estimates of the true labels. Consider the extreme case in which not accounting for dependencies is catastrophic:
Example 3.1
Consider a set of 10 labeling functions, where 5 are perfectly correlated, i.e., they vote the same way on every data point, and 5 are conditionally independent given the true label. If the correlated labeling functions have accuracy and the uncorrelated ones have accuracy , then the maximum likelihood estimate of their accuracies according to the independent model is and .
Specifying a generative model to account for such dependencies by hand is impractical for three reasons. First, it is difficult for non-expert users to specify these dependencies. Second, as users iterate on their labeling functions, their dependency structure can change rapidly, like when a user relaxes a labeling function to label many more candidates. Third, the dependency structure can be dataset specific, making it impossible to specify a priori, such as when a corpus contains many strings that match multiple regular expressions used in different labeling functions. We observed users of earlier versions of Snorkel struggling for these reasons to construct accurate and efficient generative models with dependencies. We therefore seek a method that can quickly identify an appropriate dependency structure from the labeling function outputs alone.
Naively, we could include all dependencies of interest, such as all pairwise correlations, in the generative model and perform parameter estimation. However, this approach is impractical. For 100 labeling functions and 10,000 data points, estimating parameters with all possible correlations takes roughly 45 min. When multiplied over repeated runs of hyperparameter searching and development cycles, this cost greatly inhibits labeling function development. We therefore turn to our method for automatically selecting which dependencies to model without access to ground truth [5]. It uses a pseudolikelihood estimator, which does not require any sampling or other approximations to compute the objective gradient exactly. It is much faster than maximum likelihood estimation, taking 15 s to select pairwise correlations to be modeled among 100 labeling functions with 10,000 data points. However, this approach relies on a selection threshold hyperparameter which induces a trade-off space between predictive performance and computational cost.
Trade-off space
Such structure learning methods, whether pseudolikelihood or likelihood-based, crucially depend on a selection threshold for deciding which dependencies to add to the generative model. Fundamentally, the choice of determines the complexity of the generative model.12 We study the trade-off between predictive performance and computational cost that this induces. We find that generally there is an “elbow point” beyond which the number of correlations selected—and thus the computational cost—explodes, and that this point is a safe trade-off point between predictive performance and computation time.
Predictive Performance At one extreme, a very large value of will not include any correlations in the generative model, making it identical to the independent model. As is decreased, correlations will be added. At first, when is still high, only the strongest correlations will be included. As these correlations are added, we observe that the generative model’s predictive performance tends to improve. Figure 9, left, shows the result of varying in a simulation where more than half the labeling functions are correlated. After adding a few key dependencies, the generative model resolves the discrepancies among the labeling functions. Figure 9, middle, shows the effect of varying for the CDR task. Predictive performance improves as decreases until the model overfits. Finally, we consider a large number of labeling functions that are likely to be correlated. In our user study (described in Sect. 4.2), participants wrote labeling functions for the Spouses task. We combined all 125 of their functions and studied the effect of varying . Here, we expect there to be many correlations since it is likely that users wrote redundant functions. We see in Fig. 9, right, that structure learning surpasses the best performing individual’s generative model (50.0 F1).
Fig. 9.

Predictive performance of the generative model and number of learned correlations versus the correlation threshold . The selected elbow point achieves a good trade-off between predictive performance and computational cost (linear in the number of correlations). Left: simulation of structure learning correcting the generative model. Middle: the CDR task. Right: all user study labeling functions for the Spouses task
Computational Cost Computational cost is correlated with model complexity. Since learning in Snorkel is done with a Gibbs sampler, the overhead of modeling additional correlations is linear in the number of correlations. The dashed lines in Fig. 9 show the number of correlations included in each model versus . For example, on the Spouses task, fitting the parameters of the generative model at takes 4 min, and fitting its parameters with takes 57 min. Further, parameter estimation is often run repeatedly during development for two reasons: (i) fitting generative model hyperparameters using a development set requires repeated runs, and (ii) as users iterate on their labeling functions, they must re-estimate the generative model to evaluate them.
Automatically choosing a model
Based on our observations, we seek to automatically choose a value of that trades-off between predictive performance and computational cost using the labeling functions’ outputs alone. Including as a hyperparameter in a grid search over a development set is generally not feasible because of its large effect on running time. We therefore want to choose before other hyperparameters, without performing any parameter estimation. We propose using the number of correlations selected at each value of as an inexpensive indicator. The dashed lines in Fig. 9 show that as decreases, the number of selected correlations follows a pattern. Generally, the number of correlations grows slowly at first, then hits an “elbow point” beyond which the number explodes, which fits the assumption that the correlation structure is sparse. In all three cases, setting to this elbow point is a safe trade-off between predictive performance and computational cost. In cases where performance grows consistently (left and right), the elbow point achieves most of the predictive performance gains at a small fraction of the computational cost. For example, on Spouses (right), choosing achieves a score of 56.6 F1—within one point of the best score—but only takes 8 min for parameter estimation. In cases where predictive performance eventually degrades (middle), the elbow point also selects a relatively small number of correlations, giving an 0.7 F1 point improvement and avoiding overfitting.
Performing structure learning for many settings of is inexpensive, especially since the search needs to be performed only once before tuning the other hyperparameters. On the large number of labeling functions in the Spouses task, structure learning for 25 values of takes 14 min. On CDR, with a smaller number of labeling functions, it takes 30 s. Further, if the search is started at a low value of and increased, it can often be terminated early, when the number of selected correlations reaches a low value. Selecting the elbow point itself is straightforward. We use the point with greatest absolute difference from its neighbors, but more sophisticated schemes can also be applied [51]. Our full optimization algorithm for choosing a modeling strategy and (if necessary) correlations is shown in Algorithm 1.
Evaluation
We evaluate Snorkel by drawing on deployments developed in collaboration with users. We report on two real-world deployments and four tasks on open-source data sets representative of other deployments. Our evaluation is designed to support the following three main claims:
Snorkel outperforms distant supervision baselines In distant supervision [36], one of the most popular forms of weak supervision used in practice, an external knowledge base is heuristically aligned with input data to serve as noisy training labels. By allowing users to easily incorporate a broader, more heterogeneous set of weak supervision sources—for example, pattern matching, structure-based, and other more complex heuristics—Snorkel exceeds models trained via distant supervision by an average of .
Snorkel approaches hand supervision We see that by writing tens of labeling functions, we were able to approach or match results using hand-labeled training data which took weeks or months to assemble, coming within of the F1 score of hand supervision on relation extraction tasks and an average accuracy or AUC on cross-modal tasks, for an average across all tasks.
Snorkel enables a new interaction paradigm We measure Snorkel’s efficiency and ease of use by reporting on a user study of biomedical researchers from across the USA. These participants learned to write labeling functions to extract relations from news articles as part of a two-day workshop on learning to use Snorkel, and matched or outperformed models trained on hand-labeled training data, showing the efficiency of Snorkel’s process even for first-time users.
We now describe our results in detail. First, we describe the six applications that validate our claims. We then show that Snorkel’s generative modeling stage helps to improve the predictive performance of the discriminative model, demonstrating that it is more accurate when trained on Snorkel’s probabilistic labels versus labels produced by an unweighted average of labeling functions. We also validate that the ability to incorporate many different types of weak supervision incrementally improves results with an ablation study. Finally, we describe the protocol and results of our user study.
Applications
To evaluate the effectiveness of Snorkel, we consider several real-world deployments and tasks on open-source datasets that are representative of other deployments in information extraction, medical image classification, and crowdsourced sentiment analysis. Summary statistics of the tasks are provided in Tables 4 and 2.
Table 4.
Number of candidates in the training, development, and test splits for each dataset
| Task | # Train. | # Dev. | # Test |
|---|---|---|---|
| Chem | 65,398 | 1292 | 1232 |
| EHR | 225,607 | 913 | 604 |
| CDR | 8272 | 888 | 4620 |
| Spouses | 22,195 | 2796 | 2697 |
| Radiology | 3851 | 385 | 385 |
| Crowd | 505 | 63 | 64 |
Table 2.
Number of labeling functions, fraction of positive labels (for binary classification tasks), number of training documents, and number of training candidates for each task
| Task | # LFs | % Pos. | # Docs | # Candidates |
|---|---|---|---|---|
| Chem | 16 | 4.1 | 1753 | 65,398 |
| EHR | 24 | 36.8 | 47,827 | 225,607 |
| CDR | 33 | 24.6 | 900 | 8272 |
| Spouses | 11 | 8.3 | 2073 | 22,195 |
| Radiology | 18 | 36.0 | 3851 | 3851 |
| Crowd | 102 | – | 505 | 505 |
Discriminative Models One of the key bets in Snorkel’s design is that the trend of increasingly powerful, open-source machine learning tools (e.g., models, pre-trained word embeddings and initial layers, automatic tuners, etc.) will only continue to accelerate. To best take advantage of this, Snorkel creates probabilistic training labels for any discriminative model with a standard loss function.
In the following experiments, we control for end model selection by using currently popular, standard choices across all settings. For text modalities, we choose a bidirectional long short term memory (LSTM) sequence model [18], and for the medical image classification task we use a 50-layer ResNet [21] pre-trained on the ImageNet object classification dataset [14]. Both models are implemented in TensorFlow [1] and trained using the Adam optimizer [27], with hyperparameters selected via random grid search using a small labeled development set. Final scores are reported on a held-out labeled test set. See full version [42] for details.
A key takeaway of the following results is that the discriminative model generalizes beyond the heuristics encoded in the labeling functions (as in Example 2.5). In Sect. 4.1.1, we see that on relation extraction applications the discriminative model improves performance over the generative model primarily by increasing recall by on average. In Sect. 4.1.2, the discriminative model classifies entirely new modalities of data to which the labeling functions cannot be applied.
Data Set Details Additional information about the sizes of the datasets is included in Table 4. Specifically, we report the size of the (unlabeled) training set and hand-labeled development and test sets, in terms of number of candidates. Note that the development and test sets can be orders of magnitude smaller than the training sets. Labeled development and test sets were either used when already available as part of a benchmark dataset, or labeled with the help of our collaborators, limited to several hours of labeling time maximum. Note that test sets were labeled by individuals not involved with labeling function development to keep the test sets properly blinded.
Relation extraction from text
We first focus on four relation extraction tasks on text data, as it is a challenging and common class of problems that are well studied and for which distant supervision is often considered. Predictive performance is summarized in Table 3, and precision–recall curves are shown in Fig. 10. We briefly describe each task.
Table 3.
Evaluation of Snorkel on relation extraction tasks from text
| Task | Distant Supervision | Snorkel (Gen.) | Snorkel (Disc.) | Hand Supervision | ||||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| P | R | F1 | P | R | F1 | Lift | P | R | F1 | Lift | P | R | F1 | |
| Chem | 11.2 | 41.2 | 17.6 | 78.6 | 21.6 | 33.8 | + 16.2 | 87.0 | 39.2 | 54.1 | + 36.5 | – | – | – |
| EHR | 81.4 | 64.8 | 72.2 | 77.1 | 72.9 | 74.9 | + 2.7 | 80.2 | 82.6 | 81.4 | + 9.2 | – | – | – |
| CDR | 25.5 | 34.8 | 29.4 | 52.3 | 30.4 | 38.5 | + 9.1 | 38.8 | 54.3 | 45.3 | + 15.9 | 39.9 | 58.1 | 47.3 |
| Spouses | 9.9 | 34.8 | 15.4 | 53.5 | 62.1 | 57.4 | + 42.0 | 48.4 | 61.6 | 54.2 | + 38.8 | 47.8 | 62.5 | 54.2 |
Snorkel’s generative and discriminative models consistently improve over distant supervision, measured in F1, the harmonic mean of precision (P) and recall (R). We compare with hand-labeled data when available, coming within an average of 1 F1 point
Fig. 10.

Precision–recall curves for the relation extraction tasks. The top plots compare a majority vote of all labeling functions, Snorkel’s generative model, and Snorkel’s discriminative model. They show that the generative model improves over majority vote by providing more granular information about candidates, and that the discriminative model can generalize to candidates that no labeling functions label. The bottom plots compare the discriminative model trained on an unweighted combination of the labeling functions, hand supervision (when available), and Snorkel’s discriminative model. They show that the discriminative model benefits from the weighted labels provided by the generative model, and that Snorkel is competitive with hand supervision, particularly in the high-precision region
Scientific Articles (Chem) With modern online repositories of scientific literature, such as PubMed13 for biomedical articles, research results are more accessible than ever before. However, actually extracting fine-grained pieces of information in a structured format and using this data to answer specific questions at scale remains a significant open challenge for researchers. To address this challenge in the context of drug safety research, Stanford and US Food and Drug Administration (FDA) collaborators used Snorkel to develop a system for extracting chemical reagent and reaction product relations from PubMed abstracts. The goal was to build a database of chemical reactions that researchers at the FDA can use to predict unknown drug interactions. We used the chemical reactions described in the Metacyc database [8] for distant supervision.
Electronic Health Records (EHR) As patients’ clinical records increasingly become digitized, researchers hope to inform clinical decision making by retrospectively analyzing large patient cohorts, rather than conducting expensive randomized controlled studies. However, much of the valuable information in electronic health records (EHRs)—such as fine-grained clinical details, practitioner notes, etc.—is not contained in standardized medical coding systems and is thus locked away in the unstructured text notes sections. In collaboration with researchers and clinicians at the US Department of Veterans Affairs, Stanford Hospital and Clinics (SHC), and the Stanford Center for Biomedical Informatics Research, we used Snorkel to develop a system to extract structured data from unstructured EHR notes. Specifically, the system’s task was to extract mentions of pain levels at precise anatomical locations from clinician notes, with the goal of using these features to automatically assess patient well-being and detect complications after medical interventions like surgery. To this end, our collaborators created a cohort of 5800 patients from SHC EHR data, with visit dates between 1995 and 2015, resulting in 500 K unstructured clinical documents. Since distant supervision from a knowledge base is not applicable, we compared against regular expression-based labeling previously developed for this task.
Chemical–Disease Relations (CDR) We used the 2015 BioCreative chemical–disease relation dataset [60], where the task is to identify mentions of causal links between chemicals and diseases in PubMed abstracts. We used all pairs of chemical and disease mentions co-occurring in a sentence as our candidate set. We used the Comparative Toxicogenomics Database (CTD) [37] for distant supervision, and additionally wrote labeling functions capturing language patterns and information from the context hierarchy. To evaluate Snorkel’s ability to discover previously unknown information, we randomly removed half of the relations in CTD and evaluated on candidates not contained in the remaining half.
Spouses Our fourth task is to identify mentions of spouse relationships in a set of news articles from the Signal Media dataset [10]. We used all pairs of person mentions (tagged with SpaCy’s NER module14) co-occurring in the same sentence as our candidate set. To obtain hand-labeled data for evaluation, we crowdsourced labels for the candidates via Amazon Mechanical Turk, soliciting labels from three workers for each example and assigning the majority vote. We then wrote labeling functions that encoded language patterns and distant supervision from DBpedia [30].
Cross-modal: images and crowdsourcing
In the cross-modal setting, we write labeling functions over one data modality (e.g., a text report, or the votes of crowdworkers) and use the resulting labels to train a classifier defined over a second, totally separate modality (e.g., an image or the text of a tweet). This demonstrates the flexibility of Snorkel, in that the labeling functions (and by extension, the generative model) do not need to operate over the same domain as the discriminative model being trained. Predictive performance is summarized in Table 5.
Table 5.
Evaluation on cross-modal experiments. Labeling functions that operate on or represent one modality (text, crowd workers) produce training labels for models that operate on another modality (images, text), and approach the predictive performance of large hand-labeled training datasets
| Task | Snorkel (Disc.) | Hand supervision |
|---|---|---|
| Radiology (AUC) | 72.0 | 76.2 |
| Crowd (Acc) | 65.6 | 68.8 |
Abnormality Detection in Lung Radiographs (Rad) In many real-world radiology settings, there are large repositories of image data with corresponding narrative text reports, but limited or no labels that could be used for training an image classification model. In this application, in collaboration with radiologists, we wrote labeling functions over the text radiology reports, and used the resulting labels to train an image classifier to detect abnormalities in lung X-ray images. We used a publicly available dataset from the OpenI biomedical image repository15 consisting of 3,851 distinct radiology reports—composed of unstructured text and Medical Subject Headings (MeSH)16 codes—and accompanying X-ray images.
Crowdsourcing (Crowd) We trained a model to perform sentiment analysis using crowdsourced annotations from the weather sentiment task from Crowdflower.17 In this task, contributors were asked to grade the sentiment of often-ambiguous tweets relating to the weather, choosing between five categories of sentiment. Twenty contributors graded each tweet, but due to the difficulty of the task and lack of crowdworker filtering, there were many conflicts in worker labels. We represented each crowdworker as a labeling function—showing Snorkel’s ability to subsume existing crowdsourcing modeling approaches—and then used the resulting labels to train a text model over the tweets, for making predictions independent of the crowd workers.
Effect of generative modeling
An important question is the significance of modeling the accuracies and correlations of the labeling functions on the end predictive performance of the discriminative model (versus in Sect. 3, where we only considered the effect on the accuracy of the generative model). We compare Snorkel with a simpler pipeline that skips the generative modeling stage and trains the discriminative model on an unweighted average of the labeling functions’ outputs. Table 6 shows that the discriminative model trained on Snorkel’s probabilistic labels consistently predicts better, improving on average. These results demonstrate that the discriminative model effectively learns from the additional signal contained in Snorkel’s probabilistic training labels over simpler modeling strategies.
Table 6.
Comparison between training the discriminative model on the labels estimated by the generative model, versus training on the unweighted average of the LF outputs. Predictive performance gains show that modeling LF noise helps
| Task | Disc. model on | ||
|---|---|---|---|
| Unweighted LFs | Disc. model | Lift | |
| Chem | 48.6 | 54.1 | + 5.5 |
| EHR | 80.9 | 81.4 | + 0.5 |
| CDR | 42.0 | 45.3 | + 3.3 |
| Spouses | 52.8 | 54.2 | + 1.4 |
| Crowd (Acc) | 62.5 | 65.6 | + 3.1 |
| Rad. (AUC) | 67.0 | 72.0 | + 5.0 |
Scaling with unlabeled data
One of the most exciting potential advantages of using a programmatic supervision approach as in Snorkel is the ability to incorporate additional unlabeled data, which is often cheaply available. Recently, proposed theory characterizing the data programming approach used predicts that discriminative model generalization risk (i.e., predictive performance on the held-out test set) should improve with additional unlabeled data, at the same asymptotic rate as in traditional supervised methods with respect to labeled data [43]. That is, with a fixed amount of effort writing labeling functions, we could then get improved discriminative model performance simply by adding more unlabeled data.
We validate this theoretical prediction empirically on three of our datasets (Fig. 11). We see that by adding additional unlabeled data—in these datasets, candidates from additional documents—we get significant improvements in the end discriminative model performance, with no change in the labeling functions. For example, in the EHR experiment, where we had access to a large unlabeled corpus, we were able to achieve significant gains (8.1 F1 score points) in going from 100 to 50 thousand documents. Further empirical validation of these strong unlabeled scaling results can be found in follow-up work using Snorkel in a range of application domains, including aortic valve classification in MRI videos [17], industrial-scale content classification at Google [4], fine-grained named entity recognition [45], radiology image triage [26], and others. Based on both this empirical validation, and feedback from Snorkel users in practice, we see this ability to leverage available unlabeled data without any additional user labeling effort as a significant advantage of the proposed weak supervision approach.
Fig. 11.
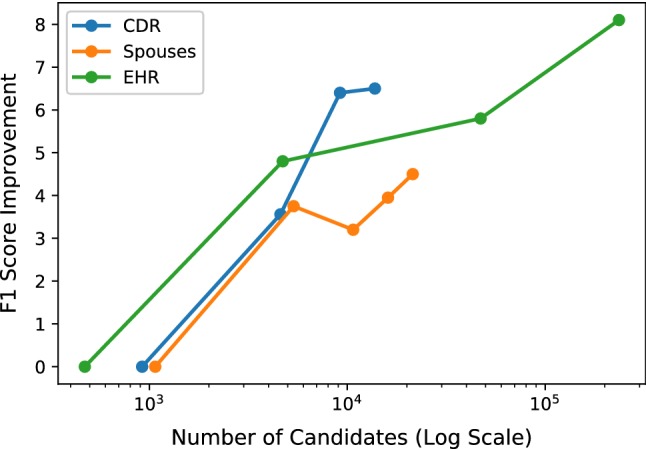
The increase in end model performance (measured in F1 score) for different amounts of unlabeled data, measured in the number of candidates. We see that as more unlabeled data is added, the performance increases
Labeling function type ablation
We also examine the impact of different types of labeling functions on end predictive performance, using the CDR application as a representative example of three common categories of labeling functions:
Text Patterns Basic word, phrase, and regular expression labeling functions.
Distant Supervision External knowledge bases mapped to candidates, either directly or filtered by a heuristic.
Structure-Based Labeling functions expressing heuristics over the context hierarchy, e.g., reasoning about position in the document or relative to other candidates.
We show an ablation in Table 7, sorting by stand-alone score. We see that distant supervision adds recall at the cost of some precision, as we would expect, but ultimately improves F1 score by 2 points; and that structure-based labeling functions, enabled by Snorkel’s context hierarchy data representation, add an additional F1 point.
Table 7.
Labeling function ablation study on CDR
| LF type | P | R | F1 | Lift |
|---|---|---|---|---|
| Text patterns | 42.3 | 42.4 | 42.3 | |
| + Distant supervision | 37.5 | 54.1 | 44.3 | + 2.0 |
| + Structure-based | 38.8 | 54.3 | 45.3 | + 1.0 |
Adding different types of labeling functions improves predictive performance
User study
We conducted a formal study of Snorkel to (i) evaluate how quickly subject matter expert (SME) users could learn to write labeling functions, and (ii) empirically validate the core hypothesis that writing labeling functions is more time-efficient than hand-labeling data. Users were given instruction on Snorkel, and then asked to write labeling functions for the Spouses task described in the previous subsection.
Participants
In collaboration with the Mobilize Center [28], an NIH-funded Big Data to Knowledge (BD2K) center, we distributed a national call for applications to attend a two-day workshop on using Snorkel for biomedical knowledge base construction. Selection criteria included a strong biomedical project proposal and little-to-no prior experience using Snorkel. In total, 15 researchers18 were invited to attend out of 33 team applications submitted, with varying backgrounds in bioinformatics, clinical informatics, and data mining from universities, companies, and organizations around the USA. The education demographics included 6 bachelors, 4 masters, and 5 Ph.D. degrees. All participants could program in Python, with 80% rating their skill as intermediate or better; 40% of participants had little-to-no prior exposure to machine learning; and 53-60% had no prior experience with text mining or information extraction applications (Table 8).
Table 8.
Self-reported skill levels—no previous experience (New), beginner (Beg.), intermediate (Int.), and advanced (Adv.)—for all user study participants
| Subject | New | Beg. | Int. | Adv. |
|---|---|---|---|---|
| Python | 0 | 3 | 8 | 4 |
| Machine learning | 5 | 1 | 4 | 5 |
| Info. extraction | 2 | 6 | 5 | 2 |
| Text mining | 3 | 6 | 4 | 2 |
Protocol The first day focused entirely on labeling functions, ranging from theoretical motivations to details of the Snorkel API. Over the course of 7 hours, participants were instructed in a classroom setting on how to use and evaluate models developed using Snorkel. Users were presented with 4 tutorial Jupyter notebooks providing skeleton code for evaluating labeling functions, along with a small labeled development candidate set, and were given 2.5 hours of dedicated development time in aggregate to write their labeling functions. All workshop materials are available online.19
Baseline To compare our users’ performance against models trained on hand-labeled data, we collected a large hand-labeled dataset via Amazon Mechanical Turk (the same set used in the previous subsection). We then split this into 15 datasets representing 7 hours worth of hand-labeling time each—based on the crowdworker average of 10 s per label—simulating the alternative scenario where users skipped both instruction and labeling function development sessions and instead spent the full day hand-labeling data. Partitions were created by drawing a uniform random sample of 2500 labels from the total Amazon Mechanical Turk-generated Spouse dataset. For 15 such random samples, the mean F1 score was 20.9 (min:11.7, max: 29.5). Scaling to 55 random partitions, the mean F1 score was 22.5 (min:11.7, max: 34.1).
Results Our key finding is that labeling functions written in Snorkel, even by SME users, can match or exceed a traditional hand-labeling approach. The majority (8) of subjects matched or outperformed these hand-labeled data models. The average Snorkel user’s score was 30.4 F1, and the average hand-supervision score was 20.9 F1. The best performing user model scored 48.7 F1, 19.2 points higher than the best supervised model using hand-labeled data. The worst participant scored 12.0 F1, 0.3 points higher that the lowest hand-labeled model. The full distribution of scores by participant, and broken down by participant background, compared against the baseline models trained with hand-labeled data are shown in Figs. 12, 13 and 14 respectively.
Fig. 12.
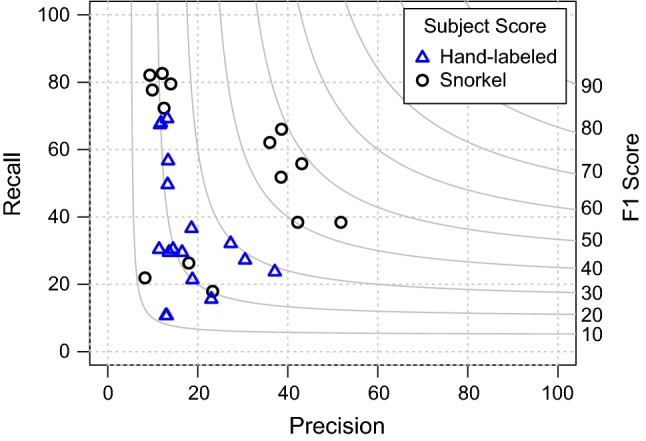
Predictive performance attained by our 14 user study participants using Snorkel. The majority (57%) of users matched or exceeded the performance of a model trained on 7 h (2500 instances) of hand-labeled data
Fig. 13.
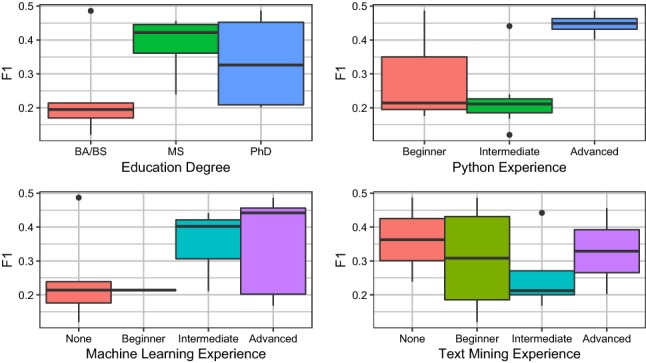
The profile of the best performing user by F1 score was a MS or Ph.D. degree in any field, strong Python coding skills, and intermediate to advanced experience with machine learning. Prior experience with text mining added no benefit
Fig. 14.
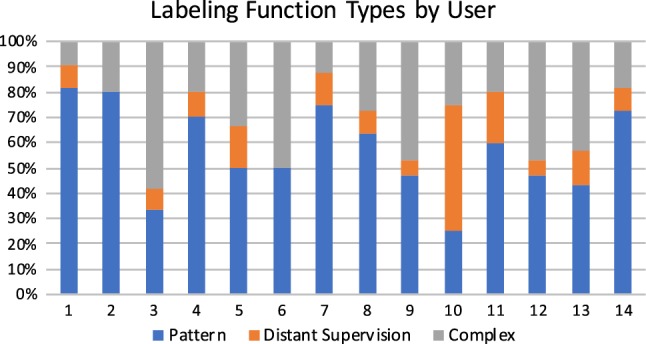
We bucketed labeling functions written by user study participants into three types—pattern-based, distant supervision, and complex. Participants tended to mainly write pattern-based labeling functions, but also universally expressed more complex heuristics as well
Additional Details We note that participants only needed to create a fairly small set of labeling functions to achieve the reported performances, writing a median of 10 labeling functions (with a minimum of 2, and a maximum of 15). In general, these labeling functions had simple form; for example, two from our user study: 
Participant labeling functions had a median length of 2 lines of Python code (min:2, max:12). We grouped participant-designed functions into three types:
Pattern-based (regular expressions, small term sets)
Distant Supervision (interacts with a knowledge base)
Complex (misc. heuristics, e.g., counting PERSON named entity tags, comparing last names of a pair of PERSON entities)
On average, 58% of participant’s labeling functions where pattern-based (min:25%, max: 82%). The best labeling function design strategy used by participants appeared to be defining small term sets correlated with positive and negative labels. Participants with the lowest F1 scores tended to design labeling functions with low coverage of negative labels. This is a common difficulty encountered when designing labeling functions, as writing heuristics for negative examples is sometimes counter-intuitive. Users with the highest overall F1 scores wrote 1-2 high-coverage negative labeling functions and several medium-to-high-accuracy positive labeling functions.
We note that the best single participant’s pipeline achieved an F1 score of 48.7, compared to the authors’ score of 54.2. User study participants favored pattern-based labeling functions; the most common design was creating small positive and negative term sets. Author labeling functions were similar, but were more accurate overall p (e.g., better pattern matching).
Extensions and next steps
In this section, we briefly discuss extensions and use cases of Snorkel that have been developed since its initial release, as well as next steps and future directions more broadly.
Extensions for real-world deployments
Since its release, Snorkel has been used at organizations such as the Stanford Hospital, Google, Intel, Microsoft, Facebook, Alibaba, NEC, BASF, Toshiba, and Accenture; in the fight against human trafficking as part of DARPA’s MEMEX program; and in production at several large technology companies. Deploying Snorkel in these real-world settings has often involved productionizing around various key aspects. With various teams at the Stanford School of Medicine, we have worked to extend the cross-modal radiology application described in Sect. 4 to a range of other similar cross-modal medical problems, which has involved building robust interfaces for various multi-modal clinical data and formats [26]. In collaboration with several teams at Google, we recently developed a new version of Snorkel, Snorkel DryBell, to interface with Google’s organizational weak supervision resources and compute infrastructure, and enable weak supervision at industrial scale [4]. Another focus has been extending Snorkel to handle richly-formatted data, defined in [62] as data with multi-modal, semi-structured components such as PDF forms, tables, and HTML pages. Support for this rich but challenging data type has been implemented in a system built on top of Snorkel, Fonduer [62], which has been applied to domains such as anti-human trafficking efforts via DARPA’s MEMEX project and extraction of genome-wide association (GWA) studies from the scientific literature [29].
Ascending the code-as-supervision stack
The goal of Snorkel is to enable users to program the modern machine learning stack, by labeling training data with labeling functions rather than manual annotation. This code-as-supervision approach can then inherit the traditional advantages of code such as modularity, debuggability, and higher-level abstraction layers. In particular, enabling this last element—even higher-level, more declarative ways of specifying labeling functions—has been a major motivation of the Snorkel project.
Since Snorkel’s release, various extensions have explored higher-level, more declarative interfaces for labeling training data by building on top of Snorkel (Fig. 15). One idea, motivated by the difficulty of writing labeling functions directly over image or video data, is to first compute a set of features or primitives over the raw data using unsupervised approaches, and then write labeling functions over these building blocks [58]. For example, if the goal is to label instances of people riding bicycles, we could first run an off-the-shelf pre-trained algorithm to put bounding boxes around people and bicycles, and then write labeling functions over the dimensions or relative locations of these bounding boxes.20 In medical imaging tasks, anatomical segmentation masks provide a similarly intuitive semantic abstraction for writing labeling functions over. For example, in a large collection of cardiac MRI videos from the UK Biobank, creating segmentations of the aorta enabled a cardiologist to define labeling functions for identifying rare aortic valve malformations [17].
Fig. 15.
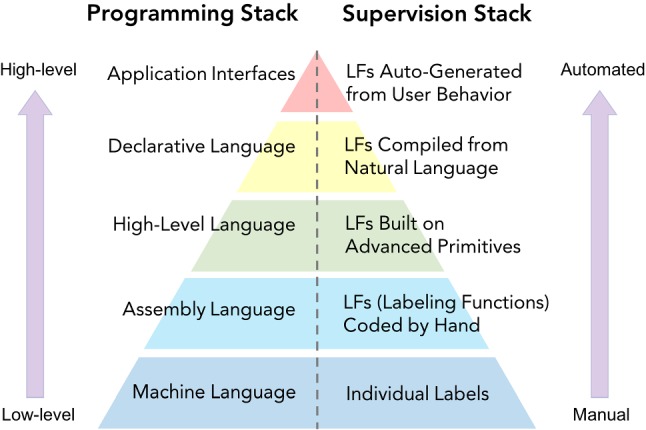
In a traditional programming stack, progressively higher-level languages and abstractions provide increasingly simple and declarative interfaces. Similarly, we envision a code-as-supervision stack built on top of the basic unit of labeling functions, allowing users to label training data in increasingly higher-level ways. Figure from [46]
An even higher-level interface is natural language. The Babble Labble project [20] accepts natural language explanations of data points and then uses semantic parsers to parse these explanations into labeling functions. In this way, users without programming knowledge have the capability to write labeling functions just by explaining reasons why data points have specific labels. Another related approach is to use program synthesis techniques, combined with a small set of labeled data points, to automatically generate labeling functions [59].
Multi-task weak supervision
Many real-world use cases of machine learning involve multiple related classification tasks—both because there are multiple tasks of interest, and because available weak supervision sources may in fact label different related tasks. Handling this multi-task weak supervision setting has been the focus of recent work on a new version of Snorkel, Snorkel MeTaL,21 which handles labeling functions that label different tasks, and in turn can be used to supervise popular multi-task learning (MTL) discriminative models [44, 45]. For example, we might be aiming to train a fine-grained named entity recognition (NER) system which tags specific types of people, places, and things, and have access to both fine-grained labeling functions—e.g., that label doctors versus lawyers—and coarse-grained ones, e.g., that label people versus organizations. By representing these as different logically-related tasks, we can model and combine these multi-granularity labeling functions using this new multi-task version of Snorkel.
Future directions
In addition to working on the core directions outlined—real-world deployment, higher-level interfaces, and multi-task supervision—several other directions are natural and exciting extensions of Snorkel. One is the extension to other classic machine learning settings, such as structured prediction, regression, and anomaly detection settings. Another direction is extending the possible output signature of labeling functions to include continuous values, probability distributions, or other more complex outputs. The extension of the core modeling techniques—for example, learning labeling function accuracies that are conditioned on specific subsets of the data, or jointly learning the generative and discriminative models—also provide exciting avenues for future research.
Another practical and interesting direction is exploring integrations with other complementary techniques for dealing with the lack of hand-labeled training data (see Other Forms of Supervision in Sect. 6). One example is active learning [53], in which the goal is to intelligently sample data points to be labeled; in our setting, we could intelligently select sets of data points to show to the user when writing labeling functions—e.g., data points not labeled by existing labeling functions—and potentially with interesting visualizations and graphical interfaces to aid and direct this development process. Another interesting direction is formalizing the connection between labeling functions and transfer learning [38], and making more formal and practical connections to semi-supervised learning [9].
Limitations
To be applicable in a problem domain, Snorkel requires three main ingredients: first, a set of labeling functions that users can write; second, a discriminative model to train; and third, a preferably large amount of unlabeled data. While there are many current and exciting future directions for enabling users to more easily write labeling functions in a more diverse set of circumstances, as discussed in this section, there are some tasks or datasets where this will remain a gating limitation. Next, Snorkel’s ease of use implicitly relies on easily available discriminative models, such as the increasingly commoditized architectures available in the open-source today, e.g., text, image, and other data types; however, this is not the case in every domain. Finally, Snorkel benefits from settings where unlabeled data is readily available, as demonstrated empirically in this paper and theoretically in prior work [43], which is not always the case.
Related work
This section is an overview of techniques for managing weak supervision, many of which are subsumed in Snorkel. We also contrast it with related forms of supervision.
Combining Weak Supervision Sources The main challenge of weak supervision is how to combine multiple sources. For example, if a user provides two knowledge bases for distant supervision, how should a data point that matches only one knowledge base be labeled? Some researchers have used multi-instance learning to reduce the noise in weak supervision sources [24, 49], essentially modeling the different weak supervision sources as soft constraints on the true label, but this approach is limited because it requires using a specific end model that supports multi-instance learning.
Researchers have therefore considered how to estimate the accuracy of label sources without a gold standard with which to compare—a classic problem [13]—and combine these estimates into labels that can be used to train an arbitrary end model. Much of this work has focused on crowdsourcing, in which workers have unknown accuracy [11, 25, 66]. Such methods use generative probabilistic models to estimate a latent variable—the true class label—based on noisy observations. Other methods use generative models with hand-specified dependency structures to label data for specific modalities, such as topic models for text [3] or denoising distant supervision sources [50, 57]. Other techniques for estimating latent class labels given noisy observations include spectral methods [39]. Snorkel is distinguished from these approaches because its generative model supports a wide range of weak supervision sources, and it learns the accuracies and correlation structure among weak supervision sources without ground truth data.
Other Forms of Supervision Work on semi-supervised learning considers settings with some labeled data and a much larger set of unlabeled data, and then leverages various domain- and task-agnostic assumptions about smoothness, low-dimensional structure, or distance metrics to heuristically label the unlabeled data [9]. Work on active learning aims to automatically estimate which data points are optimal to label, thereby hopefully reducing the total number of examples that need to be manually annotated [54]. Transfer learning considers the strategy of repurposing models trained on different datasets or tasks where labeled training data is more abundant [38]. Another type of supervision is self-training [2, 52] and co-training [6], which involves training a model or pair of models on data that they labeled themselves. Weak supervision is distinct in that the goal is to solicit input directly from SMEs, however at a higher level of abstraction and/or in an inherently noisier form. Snorkel is focused on managing weak supervision sources, but combing its methods with these other types of supervision is straightforward.
Related Data Management Problems Researchers have considered related problems in data management, such as data fusion [15, 48] and truth discovery [32]. In these settings, the task is to estimate the reliability of data sources that provide assertions of facts and determine which facts are likely true. Many approaches to these problems use probabilistic graphical models that are related to Snorkel’s generative model in that they represent the unobserved truth as a latent variable, e.g., the latent truth model [67]. Our setting differs in that labeling functions assign labels to user-provided data, and they may provide any label or abstain, which we must model. Work on data fusion has also explored how to model user-specified correlations among data sources [40]. Snorkel automatically identifies which correlations among labeling functions to model.
Conclusion
Snorkel provides a new paradigm for soliciting and managing weak supervision to create training data sets. In Snorkel, users provide higher-level supervision in the form of labeling functions that capture domain knowledge and resources, without having to carefully manage the noise and conflicts inherent in combining weak supervision sources. Our evaluations demonstrate that Snorkel significantly reduces the cost and difficulty of training powerful machine learning models while exceeding prior weak supervision methods and approaching the quality of large, hand-labeled training sets. Snorkel’s deployments in industry, research laboratories, and government agencies show that it has real-world impact, offering developers an improved way to build models.
Acknowledgements
Alison Callahan and Nigam Shah of Stanford, and Nicholas Giori of the US Dept. of Veterans Affairs developed the electronic health records application. Emily Mallory, Ambika Acharya, and Russ Altman of Stanford, and Roselie Bright and Elaine Johanson of the US Food and Drug Administration developed the scientific articles application. Joy Ku of the Mobilize Center organized the user study. Nishith Khandwala developed the radiograph application. We thank the contributors to Snorkel including Bryan He, Theodoros Rekatsinas, and Braden Hancock. We gratefully acknowledge the support of DARPA under Nos. N66001-15-C-4043 (SIMPLEX), FA8750-17-2-0095 (D3M), FA8750-12-2-0335, and FA8750-13-2-0039, DOE 108845, NIH U54EB020405, ONR under Nos. N000141210041 and N000141310129, the Moore Foundation, the Okawa Research Grant, American Family Insurance, Accenture, Toshiba, the Stanford Interdisciplinary Graduate and Bio-X fellowships, and members of the Stanford DAWN project: Intel, Microsoft, Teradata, and VMware. The US Government is authorized to reproduce and distribute reprints for Governmental purposes notwithstanding any copyright notation thereon. Any opinions, findings, and conclusions or recommendations expressed in this material are those of the authors and do not necessarily reflect the views, policies, or endorsements, either expressed or implied, of DARPA, DOE, NIH, ONR, or the US Government.
Footnotes
Note that all code is open source and available—with tutorials, blog posts, workshop lectures, and other material—at http://snorkel.stanford.edu/.
We fix these at defaults of , which corresponds to assuming labeling functions have accuracies between 62 and 82%, and an average accuracy of 73%.
Note that in Sect. 4, due to known negative class imbalance in relation extraction problems, we default to a negative value if majority vote yields a tie-vote label of 0. Thus, our reported F1 score metric hides instances in which the generative model learns to correctly (or incorrectly) break ties. In Table 1, however, we do count such instances as improvements over majority vote, as these instances have an effect on the training of the end discriminative model (they yield additional training labels).
Specifically, is both the coefficient of the regularization term used to induce sparsity, and the minimum absolute weight in log scale that a dependency must have to be selected.
One participant declined to write labeling functions, so their score is not included in our analysis.
See the image tutorial at http://snorkel.stanford.edu/.
Publisher's Note
Springer Nature remains neutral with regard to jurisdictional claims in published maps and institutional affiliations.
Contributor Information
Alexander Ratner, Email: ajratner@cs.stanford.edu.
Stephen H. Bach, Email: bach@cs.stanford.edu
Henry Ehrenberg, Email: henryre@cs.stanford.edu.
Jason Fries, Email: jfries@cs.stanford.edu.
Sen Wu, Email: senwu@cs.stanford.edu.
Christopher Ré, Email: chrismre@cs.stanford.edu.
References
- 1.Abadi, M., Barham, P., Chen, J., Chen, Z., Davis, A., Dean, J., Devin, M., Ghemawat, S., Irving, G., Isard, M., et al.: TensorFlow: A system for large-scale machine learning. In: USENIX Symposium on Operating Systems Design and Implementation (OSDI) (2016)
- 2.Agrawala AK. Learning with a probabilistic teacher. IEEE Trans. Infom. Theory. 1970;16:373–379. [Google Scholar]
- 3.Alfonseca, E., Filippova, K., Delort, J.-Y., Garrido, G.: Pattern learning for relation extraction with a hierarchical topic model. In: Meeting of the Association for Computational Linguistics (ACL) (2012)
- 4.Bach, S., Rodriguez, D., Liu, Y., Luo, C., Shao, H., Xia, C., Sen, S., Ratner, A., Hancock, B., Alborzi, H., Kuchhal, R., Ré C, Snorkel, Malkin, R.: drybell: A case study in deploying weak supervision at industrial scale. Arxiv (2019) [DOI] [PMC free article] [PubMed]
- 5.Bach, S.H., He, B., Ratner, A., Ré, C.: Learning the structure of generative models without labeled data. In: International Conference on Machine Learning (ICML) (2017) [PMC free article] [PubMed]
- 6.Blum, A., Mitchell, T.: Combining labeled and unlabeled data with co-training. In: Workshop on Computational Learning Theory (COLT) (1998)
- 7.Bunescu, R.C., Mooney, R.J.: Learning to extract relations from the Web using minimal supervision. In: Meeting of the Association for Computational Linguistics (ACL) (2007)
- 8.Caspi R, Billington R, Ferrer L, Foerster H, Fulcher CA, Keseler IM, Kothari A, Krummenacker M, Latendresse M, Mueller LA, Ong Q, Paley S, Subhraveti P, Weaver DS, Karp PD. The MetaCyc database of metabolic pathways and enzymes and the BioCyc collection of pathway/genome databases. Nucleic Acids Res. 2016;44(D1):D471–D480. doi: 10.1093/nar/gkv1164. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 9.Chapelle, O., Schölkopf, B., Zien, A. (eds.): Semi-Supervised Learning. Adaptive Computation and Machine Learning, MIT Press (2009)
- 10.Corney, D., Albakour, D., Martinez, M., Moussa, S.: What do a million news articles look like? In: Workshop on Recent Trends in News Information Retrieval (2016)
- 11.Dalvi, N., Dasgupta, A., Kumar, R., Rastogi, V.: Aggregating crowdsourced binary ratings. In: International World Wide Web Conference (WWW) (2013)
- 12.Davis, P.A. et al.: A CTD–Pfizer collaboration: Manual curation of 88,000 scientific articles text mined for drug–disease and drug–phenotype interactions. em Database (2013) [DOI] [PMC free article] [PubMed]
- 13.Dawid AP, Skene AM. Maximum likelihood estimation of observer error-rates using the EM algorithm. J. R. Stat. Soc. C. 1979;28(1):20–28. [Google Scholar]
- 14.Deng, J., Dong, W., Socher, R., Li, L.-J., Li, K., Fei-Fei, L.: Imagenet: A large-scale hierarchical image database. In: IEEE Conference on Computer Vision and Pattern Recognition (CVPR) (2009)
- 15.Dong, X.L., Srivastava, D.: Big Data Integration. Synthesis Lectures on Data Management. Morgan and Claypool Publishers (2015)
- 16.Eadicicco, L.: (2017) Baidu’s Andrew Ng on the future of artificial intelligence. Time [Online; posted 11-January-2017]
- 17.Fries, J.A., Varma, P., Chen, V.S., Xiao, K., Tejeda, H., Saha, P., Dunnmon, J., Chubb, H., Maskatia, S., Fiterau, M., Delp, S., Ashley, E., Ré, C., Priest, J.: Weakly supervised classification of rare aortic valve malformations using unlabeled cardiac mri sequences. bioRxiv (2018) [DOI] [PMC free article] [PubMed]
- 18.Graves A, Schmidhuber J. Framewise phoneme classification with bidirectional LSTM and other neural network architectures. Neural Netw. 2005;18(5):602–610. doi: 10.1016/j.neunet.2005.06.042. [DOI] [PubMed] [Google Scholar]
- 19.Gupta, S., Manning, C.D.: Improved pattern learning for bootstrapped entity extraction. In: CoNLL (2014)
- 20.Hancock, B., Varma, P., Wang, S., Bringmann, M., Liang, P., Ré, C.: Training classifiers with natural language explanations (2018) [PMC free article] [PubMed]
- 21.He, K., Zhang, X., Ren, S., Sun, J.: Deep residual learning for image recognition. CoRR, arXiv:1512.03385 (2015)
- 22.Hearst, A.M.: Automatic acquisition of hyponyms from large text corpora. In: Meeting of the Association for Computational Linguistics (ACL) (1992)
- 23.Hinton GE. Training products of experts by minimizing contrastive divergence. Neural Comput. 2002;14(8):1771–1800. doi: 10.1162/089976602760128018. [DOI] [PubMed] [Google Scholar]
- 24.Hoffmann, R., Zhang, C., Ling, X., Zettlemoyer, L., Weld, D.S.: Knowledge-based weak supervision for information extraction of overlapping relations. In: Meeting of the Association for Computational Linguistics (ACL) (2011)
- 25.Joglekar, M., Garcia-Molina, H., Parameswaran, A.: Comprehensive and reliable crowd assessment algorithms. In: International Conference on Data Engineering (ICDE) (2015)
- 26.Khandwala, N., Ratner, A., Dunnmon, J., Goldman, R., Lungren, M., Rubin, D., Ré, C.: Cross-modal data programming for medical images. NIPS ML4H Workshop (2017) [DOI] [PMC free article] [PubMed]
- 27.Kingma, D., Ba, J.: Adam: A method for stochastic optimization (2014) arXiv preprintarXiv:1412.6980
- 28.Ku JP, Hicks JL, Hastie T, Leskovec J, Ré C, Delp SL. The Mobilize center: an NIH big data to knowledge center to advance human movement research and improve mobility. J. Am. Med. Inf. Assoc. 2015;22(6):1120–1125. doi: 10.1093/jamia/ocv071. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 29.Kuleshov, V., Hancock, B., Ratner, A., Ré C, Batzaglou, S., Snyder, M.: A machine-compiled database of genome-wide association studies. NIPS ML4H Workshop (2016) [DOI] [PMC free article] [PubMed]
- 30.Lehmann, J., Isele, R., Jakob, M., Jentzsch, A., Kontokostas, D., Mendes, P., Hellmann, S., Morsey, M., van Kleef, P., Auer, S., Bizer, C.: DBpedia–A large-scale, multilingual knowledge base extracted from Wikipedia. Semantic Web Journal (2014)
- 31.Li, H., Yu, B., Zhou, D.: Error rate analysis of labeling by crowdsourcing. In: ICML Workshop: Machine Learning Meets Crowdsourcing. Atalanta, Georgia, USA (2013)
- 32.Li Y, Gao J, Meng C, Li Q, Su L, Zhao B, Fan W, Han J. A survey on truth discovery. SIGKDD Explor. Newsl. 2015;17(2):1–6. [Google Scholar]
- 33.Liang, P., Jordan, M.I., Klein, D.: Learning from measurements in exponential families. In: International Conference on Machine Learning (ICML) (2009)
- 34.Mann GS, McCallum A. Generalized expectation criteria for semi-supervised learning with weakly labeled data. J. Mach. Learn. Res. 2010;11:955–984. [Google Scholar]
- 35.Metz, C.: Google’s hand-fed AI now gives answers, not just search results. Wired [Online; posted 29-November-2016] (2016)
- 36.Mintz, M., Bills, S., Snow, R., Jurafsky, D.: Distant supervision for relation extraction without labeled data. In: Meeting of the Association for Computational Linguistics (ACL) (2009)
- 37.Davis AP, Grondin CJ, Johnson RJ, Sciaky D, King BL, McMorran R, Wiegers J, Wiegers T, Mattingly CJ. The comparative toxicogenomics database: update 2017. Nucleic Acids Res. 2016;45:D972–D978. doi: 10.1093/nar/gkw838. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 38.Pan SJ, Yang Q. A survey on transfer learning. IEEE Trans. Knowl. Data Eng. 2010;22(10):1345–1359. [Google Scholar]
- 39.Parisi F, Strino F, Nadler B, Kluger Y. Ranking and combining multiple predictors without labeled data. Proc. Natl. Acad. Sci. USA. 2014;111(4):1253–1258. doi: 10.1073/pnas.1219097111. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 40.Pochampally, R., Das Sarma, A., Dong, X.L., Meliou, A., Srivastava, D.: Fusing data with correlations. In: ACM SIGMOD International Conference on Management of Data (SIGMOD) (2014)
- 41.Quinn, A.J., Bederson, B.B.: Human computation: A survey and taxonomy of a growing field. In: ACM SIGCHI Conference on Human Factors in Computing Systems (CHI) (2011)
- 42.Ratner, A., Bach, S.H., Ehrenberg, H.R., Fries, J.A., Wu, S., Ré, C.: Snorkel: Rapid training data creation with weak supervision (2017) CoRR, arXiv:1711.10160 [DOI] [PMC free article] [PubMed]
- 43.Ratner, A., De Sa, C., Wu, S., Selsam, D., Ré, C.: Data programming: Creating large training sets, quickly. In: Neural Information Processing Systems (NIPS) (2016) [PMC free article] [PubMed]
- 44.Ratner, A., Hancock, B., Dunnmon, J., Goldman, R., Ré, C.: Snorkel metal: Weak supervision for multi-task learning. In: Proceedings of the Second Workshop on Data Management for End-To-End Machine Learning, page 3. ACM (2018) [DOI] [PMC free article] [PubMed]
- 45.Ratner, A., Hancock, B., Dunnmon, J., Sala, F., Pandey, S., Ré, C.: Training complex models with multi-task weak supervision. AAAI (2019) [DOI] [PMC free article] [PubMed]
- 46.Ratner, A., Hancock, B., Ré, C.: The role of massively multi-task and weak supervision in software 2.0. In: Conference on Innovative Data Systems Research (2019)
- 47.Rekatsinas T, Chu X, Ilyas IF, Ré C. HoloClean: Holistic data repairs with probabilistic inference. PVLDB. 2017;10(11):1190–1201. [Google Scholar]
- 48.Rekatsinas, T., Joglekar, M., Garcia-Molina, H., Parameswaran, A., Ré, C.: SLiMFast: Guaranteed results for data fusion and source reliability. In: ACM SIGMOD International Conference on Management of Data (SIGMOD) (2017)
- 49.Riedel Sebastian, Yao Limin, McCallum Andrew. Machine Learning and Knowledge Discovery in Databases. Berlin, Heidelberg: Springer Berlin Heidelberg; 2010. Modeling Relations and Their Mentions without Labeled Text; pp. 148–163. [Google Scholar]
- 50.Roth, B., Klakow, D.: Combining generative and discriminative model scores for distant supervision. In: Conference on Empirical Methods on Natural Language Processing (EMNLP) (2013)
- 51.Satopaa, V., Albrecht, J., Irwin, D., Raghavan, B.: Finding a “kneedle” in a haystack: Detecting knee points in system behavior. In: International Conference on Distributed Computing Systems Workshops (2011)
- 52.Scudder HJ. Probability of error of some adaptive pattern-recognition machines. IEEE Trans. Infom. Theory. 1965;11:363–371. [Google Scholar]
- 53.Settles, B.: Active learning literature survey. Technical report, University of Wisconsin-Madison Department of Computer Sciences (2009)
- 54.Settles, B.: Active Learning. Synthesis Lectures on Artificial Intelligence and Machine Learning. Morgan and Claypool Publishers (2012)
- 55.Stewart, R., Ermon, S.: Label-free supervision of neural networks with physics and other domain knowledge. In: AAAI Conference on Artificial Intelligence (AAAI) (2017)
- 56.Sun, C., Shrivastava, A., Singh, S., Gupta, A.: Revisiting unreasonable effectiveness of data in deep learning era (2017) arXiv preprintarXiv:1707.02968
- 57.Takamatsu, S., Sato, I., Nakagawa, H.: Reducing wrong labels in distant supervision for relation extraction. In: Meeting of the Association for Computational Linguistics (ACL) (2012)
- 58.Varma, P., He, B., Bajaj, P., Khandwala, N., Banerjee, I., Rubin, D., Ré, C.: Inferring generative model structure with static analysis. In: Proceedings of NIPS (2017) [PMC free article] [PubMed]
- 59.Varma, P., Ré, C.: Snuba: Automating weak supervision to label training data. In: Proceedings of VLDB (2019) [DOI] [PMC free article] [PubMed]
- 60.Wei, C.-H., Peng, Y., Leaman, R., P, D.A., Mattingly, C.J., Li, J., Wiegers, T., Lu, Z.: Overview of the BioCreative V chemical disease relation (CDR) task. In: BioCreative Challenge Evaluation Workshop (2015)
- 61.Worldwide semiannual cognitive/artificial intelligence systems spending guide. Technical report, International Data Corporation (2017)
- 62.Wu, S., Hsiao, L., Cheng, X., Hancock, B., Rekatsinas, T., Levis, P., Ré, C.: Fonduer: Knowledge base construction from richly formatted data. In: Proceedings of the 2018 International Conference on Management of Data, pp. 1301–1316. ACM (2018) [DOI] [PMC free article] [PubMed]
- 63.Yuen, M.-C., King, I., Leung, K.-S.: A survey of crowdsourcing systems. In: Privacy, Security, Risk and Trust (PASSAT) and International Conference on Social Computing (SocialCom) (2011)
- 64.Zaidan, O.F., Eisner, J.: Modeling annotators: A generative approach to learning from annotator rationales. In: Conference on Empirical Methods in Natural Language Processing (EMNLP) (2008)
- 65.Zhang C, Ré C, Cafarella M, De Sa C, Ratner A, Shin J, Wang F, Wu S. DeepDive: Declarative knowledge base construction. Commun. ACM. 2017;60(5):93–102. [PMC free article] [PubMed] [Google Scholar]
- 66.Zhang Y, Chen X, Zhou D, Jordan MI. Spectral methods meet EM: a provably optimal algorithm for crowdsourcing. J. Mach. Learn. Res. 2016;17:1–44. [Google Scholar]
- 67.Zhao B, Rubinstein BI, Gemmell J, Han J. A Bayesian approach to discovering truth from conflicting sources for data integration. PVLDB. 2012;5(6):550–561. [Google Scholar]