

Abstract
Evaluating the joint significance of covariates is of fundamental importance in a wide range of applications. To this end, p-values are frequently employed and produced by algorithms that are powered by classical large-sample asymptotic theory. It is well known that the conventional p-values in Gaussian linear model are valid even when the dimensionality is a non-vanishing fraction of the sample size, but can break down when the design matrix becomes singular in higher dimensions or when the error distribution deviates from Gaussianity. A natural question is when the conventional p-values in generalized linear models become invalid in diverging dimensions. We establish that such a breakdown can occur early in nonlinear models. Our theoretical characterizations are confirmed by simulation studies.
Keywords: Nonuniformity, p-value, breakdown point, generalized linear model, high dimensionality, joint significance testing
1. Introduction
In many applications it is often desirable to evaluate the significance of covariates in a predictive model for some response of interest. Identifying a set of significant covariates can facilitate domain experts to further probe their causal relationships with the response. Ruling out insignificant covariates can also help reduce the fraction of false discoveries and narrow down the scope of follow-up experimental studies by scientists. These tasks certainly require an accurate measure of feature significance in finite samples. The tool of p-values has provided a powerful framework for such investigations.
As p-values are routinely produced by algorithms, practitioners should perhaps be aware that those p-values are usually based on classical large-sample asymptotic theory. For example, marginal p-values have been employed frequently in large-scale applications when the number of covariates p greatly exceeds the number of observations n. Those p-values are based on marginal regression models linking each individual covariate to the response separately. In these marginal regression models, the ratio of sample size to model dimensionality is equal to n, which results in justified p-values as sample size increases. Yet due to the correlations among the covariates, we often would like to investigate the joint significance of a covariate in a regression model conditional on all other covariates, which is the main focus of this paper. A natural question is whether conventional joint p-values continue to be valid in the regime of diverging dimensionality p.
It is well known that fitting the linear regression model with p > n using the ordinary least squares can lead to perfect fit giving rise to zero residual vector, which renders the p-values undefined. When p ≥ n and the design matrix is nonsingular, the p-values in the linear regression model are well defined and valid thanks to the exact normality of the least-squares estimator when the random error is Gaussian and the design matrix is deterministic. When the error is non-Gaussian, Huber (1973) showed that the least-squares estimator can still be asymptotically normal under the assumption of p = o(n), but is generally no longer normal when p = o(n) fails to hold, making the conventional p-values inaccurate in higher dimensions. For the asymptotic properties of M-estimators for robust regression, see, for example, Huber (1973); Portnoy (1984, 1985) for the case of diverging dimensionality p = o(n) and Karoui et al. (2013); Bean et al. (2013) for the scenario when the dimensionality p grows proportionally to sample size n.
We have seen that the conventional p-values for the least-squares estimator in linear regression model can start behaving wildly and become invalid when the dimensionality p is of the same order as sample size n and the error distribution deviates from Gaussianity. A natural question is whether similar phenomenon holds for the conventional p-values for the maximum likelihood estimator (MLE) in the setting of diverging-dimensional nonlinear models. More specifically, we aim to answer the question of whether p ~ n is still the breakdown point of the conventional p-values when we move away from the regime of linear regression model, where ~ stands for asymptotic order. To simplify the technical presentation, in this paper we adopt the generalized linear model (GLM) as a specific family of nonlinear models (McCullagh and Nelder, 1989). The GLM with a canonical link assumes that the conditional distribution of y given X belongs to the canonical exponential family, having the following density function with respect to some fixed measure
| (1) |
where X = (x1, ⋯ , xp) is an n × p design matrix with xj = (x1j, ⋯ , xnj)T, j = 1, ⋯ , p, y = (y1, ⋯ , yn)T is an n-dimensional response vector, β = (β1, ⋯ , βp)T is a p-dimensional regression coefficient vector, is a family of distributions in the regular exponential family with dispersion parameter ϕ ∈ (0, ∞), and θ = (θ1, ⋯ , θn)T = Xβ. As is common in GLM, the function b(θ) in (1) is implicitly assumed to be twice continuously differentiable with b″ (θ) always positive. Popularly used GLMs include the linear regression model, logistic regression model, and Poisson regression model for continuous, binary, and count data of responses, respectively.
The key innovation of our paper is the formal justification that the conventional p-values in nonlinear models of GLMs can become invalid in diverging dimensions and such a breakdown can occur much earlier than in linear models, which spells out a fundamental difference between linear models and nonlinear models. To begin investigating p-values in diverging-dimensional GLMs, let us gain some insights into this problem by looking at the specific case of logistic regression. Recently, Candès (2016) established an interesting phase transition phenomenon of perfect hyperplane separation for high-dimensional classification with an elegant probabilistic argument. Suppose we are given a random design matrix X ~ N(0, In ⊗ Ip) and arbitrary binary yi’s that are not all the same. The phase transition of perfect hyperplane separation happens at the point p/n = 1/2. With such a separating hyperplane, there exist some and such that for all cases yi = 1 and for all controls yi = 0. Let us fit a logistic regression model with an intercept. It is easy to show that multiplying the vector (−t, (β*)T)T by a divergence sequence of positive numbers c, we can obtain a sequence of logistic regression fits with the fitted response vector approaching y = (y1, ⋯ , yn)T as c → ∞. As a consequence, the MLE algorithm can return a pretty wild estimate that is close to infinity in topology when the algorithm is set to stop. Clearly, in such a case the p-value of the MLE is no longer justified and meaningful. The results in Candès (2016) have two important implications. First, such results reveal that unlike in linear models, p-values in nonlinear models can break down and behave wildly when p/n is of order 1/2; see Karoui et al. (2013); Bean et al. (2013) and discussions below. Second, these results motivate us to characterize the breakdown point of p-values in nonlinear GLMs with in the regime of α0 ∈ [0, 1/2). In fact, our results show that the breakdown point can be even much earlier than n/2.
It is worth mentioning that our work is different in goals from the limited but growing literature on p-values for high-dimensional nonlinear models, and makes novel contributions to such a problem. The key distinction is that existing work has focused primarily on identifying the scenarios in which conventional p-values or their modifications continue to be valid with some sparsity assumption limiting the growth of intrinsic dimensions. For example, Fan and Peng (2004) established the oracle property including the asymptotic normality for nonconcave penalized likelihood estimators in the scenario of p = o(n1/5), while Fan and Lv (2011) extended their results to the GLM setting of non-polynomial (NP) dimensionality. In the latter work, the p-values were proved to be valid under the assumption that the intrinsic dimensionality s = o(n1/3). More recent work on high-dimensional inference in nonlinear model settings includes van de Geer et al. (2014); Athey et al. (2016) under sparsity assumptions. In addition, two tests were introduced in Guo and Chen (2016) for high-dimensional GLMs without or with nuisance regression parameters, but the p-values were obtained for testing the global hypothesis for a given set of covariates, which is different from our goal of testing the significance of individual covariates simultaneously. Portnoy (1988) studied the asymptotic behavior of the MLE for exponential families under the classical i.i.d. non-regression setting, but with diverging dimensionality. In contrast, our work under the GLM assumes the regression setting in which the design matrix X plays an important role in the asymptotic behavior of the MLE . The validity of the asymptotic normality of the MLE was established in Portnoy (1988) under the condition of p = o(n1/2), but the precise breakdown point in diverging dimensionality was not investigated therein. Another line of work is focused on generating asymptotically valid p-values when p/n converges to a fixed positive constant. For instance, Karoui et al. (2013) and Bean et al. (2013) considered M-estimators in the linear model and showed that their variance is greater than classically predicted. Based on this result, it is possible to produce p-values by making adjustments for the inflated variance in high dimensions. Recently, Sur and Candès (2018) showed that similar adjustment is possible for the likelihood ratio test (LRT) for logistic regression. Our work differs from this line of work in two important aspects. First, our focus is on the classical p-values and their validity. Second, their results concern dimensionality that is comparable to sample size, while we aim to analyze the problem for a lower range of dimensionality and pinpoint the exact breakdown point of p-values.
The rest of the paper is organized as follows. Section 2 provides characterizations of p-values in low dimensions. We establish the nonuniformity of GLM p-values in diverging dimensions in Section 3. Section 4 presents several simulation examples verifying the theoretical phenomenon. We discuss some implications of our results in Section 5. The proofs of all the results are relegated to the Appendix.
2. Characterizations of P-values in Low Dimensions
To pinpoint the breakdown point of GLM p-values in diverging dimensions, we start with characterizing p-values in low dimensions. In contrast to existing work on the asymptotic distribution of the penalized MLE, our results in this section focus on the asymptotic normality of the unpenalized MLE in diverging-dimensional GLMs, which justifies the validity of conventional p-values. Although Theorems 1 and 4 to be presented in Sections 2.2 and A are in the conventional sense of relatively small p, to the best of our knowledge such results are not available in the literature before in terms of the maximum range of dimensionality p without any sparsity assumption.
2.1. Maximum likelihood estimation
For the GLM (1), the log-likelihood log fn(y; X, β) of the sample is given, up to an affine transformation, by
| (2) |
where b(θ) = (b(θ1), ⋯ , b(θn))T for . Denote by the MLE which is the maximizer of (2), and
| (3) |
A well-known fact is that the n-dimensional response vector y in GLM (1) has mean vector μ(θ) and covariance matrix ϕΣ(θ). Clearly, the MLE is given by the unique solution to the score equation
| (4) |
when the design matrix X is of full column rank p.
It is worth mentioning that for the linear model, the score equation (4) becomes the well-known normal equation XTy = XTXβ which admits a closed form solution. On the other hand, equation (4) does not admit a closed form solution in general nonlinear models. This fact due to the nonlinearity of the mean function μ(·) causes the key diffierence between the linear and nonlinear models. In future presentations, we will occasionally use the term nonlinear GLMs to exclude the linear model from the family of GLMs when necessary.
We will present in the next two sections some sufficient conditions under which the asymptotic normality of MLE holds. In particular, Section 2.2 concerns the case of fixed design and Section A deals with the case of random design. In addition, Section 2.2 allows for general regression coefficient vector β0 and the results extend some existing ones in the literature, while Section A assumes the global null β0 = 0 and Gaussian random design which enable us to pinpoint the exact breakdown point of the asymptotic normality for the MLE.
2.2. Conventional p-values in low dimensions under fixed design
Recall that we condition on the design matrix X in this section. We first introduce a deviation probability bound that facilitates our technical analysis. Consider both cases of bounded responses and unbounded responses. In the latter case, assume that there exist some constants M, υ0 > 0 such that
| (5) |
with (θ0,1, ⋯ , θ0,n)T = θ0 = Xβ0, where β0 = (β0,1, ⋯ , β0,p)T denotes the true regression coefficient vector in model (1). Then by Fan and Lv (2011, 2013), it holds that for any ,
| (6) |
where with c1 > 0 some constant, and ε ∈ (0, ∞) if the responses are bounded and ε ∈ (0, ‖a‖2/‖a‖∞] if the responses are unbounded.
For nonlinear GLMs, the MLE solves the nonlinear score equation (4) whose solution generally does not admit an explicit form. To address such a challenge, we construct a solution to equation (4) in an asymptotically shrinking neighborhood of β0 that meets the MLE thanks to the uniqueness of the solution. Specifically, define a neighborhood of β0 as
| (7) |
for some constant γ ∈ (0, 1/2]. Assume that for some α0 ∈ (0, γ) and let be a diverging sequence of positive numbers, where sn is a sequence of positive numbers that will be specified in heorem 1 below. We need some basic regularity conditions to establish the asymptotic normality of the MLE .
Condition 1
The design matrix X satisfies
| (8) |
| (9) |
with ∘ denoting the Hadamard product and derivatives understood componentwise. Assume that if the responses are unbounded.
Condition 2
The eigenvalues of n−1An are bounded away from 0 and ∞, , and , where An = XTΣ(θ0)X and (z1, ⋯ , zn)T = X.
Conditions 1 and 2 put some basic restrictions on the design matrix X and a moment condition on the responses. For the case of linear model, bound (8) becomes ‖(XTX)−1‖∞ = O(bn/n) and bound (9) holds automatically since b′′′ (θ) ≡ 0. Condition 2 is related to the Lyapunov condition.
Theorem 1 (Asymptotic normality)
Assume that Conditions 1–2 and probability bound (6) hold. Then
there exists a unique solution to score equation (4) in with asymptotic probability one;
- the MLE satisfies that for each vector with ‖u‖2 = 1 and ‖u‖1 = O(sn),
and specifically for each 1 ≤ j ≤ p,(10)
where An = XTΣ(θ0)X and denotes the jth diagonal entry of matrix .(11)
Theorem 1 establishes the asymptotic normality of the MLE and consequently justifies the validity of the conventional p-values in low dimensions. Note that for simplicity, we present here only the marginal asymptotic normality, and the joint asymptotic normality also holds for the projection of the MLE onto any fixed-dimensional subspace. This result can also be extended to the case of misspecified models; see, for example, Lv and Liu (2014).
As mentioned in the Introduction, the asymptotic normality was shown in Fan and Lv (2011) for nonconcave penalized MLE having intrinsic dimensionality s = o(n1/3). In contrast, our result in Theorem 1 allows for the scenario of p = o(n1/2) with no sparsity assumption in view of our technical conditions. In particular, we see that the conventional p-values in GLMs generally remain valid in the regime of slowly diverging dimensionality p = o(n1/2).
3. Nonuniformity of GLM P-values in Diverging Dimensions
So far we have seen that for nonlinear GLMs, the p-values can be valid when p = o(n1/2) as shown in Section 2, and can become meaningless when p ≥ n/2 as discussed in the Introduction. Apparently, there is a big gap between these two regimes of growth of dimensionality p. To provide some guidance on the practical use of p-values in nonlinear GLMs, it is of crucial importance to characterize their breakdown point. To highlight the main message with simplified technical presentation, hereafter we content ourselves with the specific case of logistic regression model for binary response. Moreover, we investigate the distributional property in (11) for the scenario of true regression coefficient vector β0 = 0, that is, under the global null. We argue that this specific model is sufficient for our purpose because if the conventional p-values derived from MLEs fail (i.e., (11) fails) for at least one β0 (in particular β0 = 0), then conventional p-values are not justified. Therefore, the breakdown point for logistic regression is at least the breakdown point for general nonlinear GLMs. This argument is fundamentally different from that of proving the overall validity of conventional p-values, where one needs to prove the asymptotic normality of MLEs under general GLMs rather than any specific model.
3.1. The wild side of nonlinear regime
For the logistic regression model (1), we have b(θ) = log(1 + eθ), and ϕ = 1. The mean vector μ(θ) and covariance matrix ϕΣ(θ) of the n-dimensional response vector y given by (3) now take the familiar form of and
with θ = (θ1, ⋯ , θn)T = Xβ. In many real applications, one would like to interpret the significance of each individual covariate produced by algorithms based on the conventional asymptotic normality of the MLE as established in Theorem 1. As argued at the beginning of this section, in order to justify the validity of p-values in GLMs, the underlying theory should at least ensure that the distributional property (11) holds for logistic regression under the global null. As we will see empirically in Section 4, as the dimensionality increases, p-values from logistic regression under the global null have a distribution that is skewed more and more toward zero. Consequently, classical hypothesis testing methods which reject the null hypothesis when p-value is less than the pre-specified level α would result in more false discoveries than the desired level of α. As a result, practitioners may simply lose the theoretical backup and the resulting decisions based on the p-values can become ineffective or even misleading. For this reason, it is important and helpful to identify the breakdown point of p-values in diverging-dimensional logistic regression model under the global null.
Characterizing the breakdown point of p-values in nonlinear GLMs is highly nontrivial and challenging. First, the nonlinearity generally causes the MLE to take no analytical form, which makes it di cult to analyze its behavior in diverging dimensions. Second, conventional probabilistic arguments for establishing the central limit theorem of MLE only enable us to see when the distributional property holds, but not exactly at what point it fails. To address these important challenges, we introduce novel geometric and probabilistic arguments presented later in the proofs of Theorems 2–3 that provide a rather delicate analysis of the MLE. In particular, our arguments unveil that the early breakdown point of p-values in nonlinear GLMs is essentially due to the nonlinearity of the mean function μ(·). This shows that p-values can behave wildly much early on in diverging dimensions when we move away from linear regression model to nonlinear regression models such as the widely applied logistic regression; see the Introduction for detailed discussions on the p-values in diverging-dimensional linear models.
Before presenting the main results, let us look at the specific case of logistic regression model under the global null. In such a scenario, it holds that θ0 = Xβ0 = 0 and thus Σ(θ0) = 4−1In, which results in
In particular, we see that when n−1XTX is close to the identity matrix Ip, the asymptotic standard deviation of the jth component of the MLE is close 2n−1/2 when the asymptotic theory in (11) holds. As mentioned in the Introduction, when p ≥ n/2 the MLE can blow up with excessively large variance, a strong evidence against the distributional property in (11). In fact, one can also observe inflated variance of the MLE relative to what is predicted by the asymptotic theory in (11) even when the dimensionality p grows at a slower rate with sample size n. As a consequence, the conventional p-values given by algorithms according to property (11) can be much biased toward zero and thus produce more significant discoveries than the truth. Such a breakdown of conventional p-values is delineated clearly in the simulation examples presented in Section 4.
3.2. Main results
We now present the formal results on the invalidity of GLM p-values in diverging dimensions.
Theorem 2 (Uniform orthonormal design)1
Assume that n−1/2X is uniformly distributed on the Stiefel manifold consisting of all n × p orthonormal matrices. Then for the logistic regression model under the global null, the asymptotic normality of the MLE established in (11) fails to hold when p ~ n2/3, where ~ stands for asymptotic order.
Theorem 3 (Correlated Gaussian design)
Assume that X ~ N(0, In ⊗ Σ) with covariance matrix Σ nonsingular. Then for the logistic regression model under the global null, the same conclusion as in Theorem 2 holds.
Theorem 4 in Appendix A states that under the global null in GLM with Gaussian design, the p-value based on the MLE remains valid as long as the dimensionality p diverges with n at a slower rate than n2/3. This together with Theorems 2 and 3 shows that under the global null, the exact breakdown point for the uniformity of p-value is n2/3. We acknowledge that these results are mainly for theoretical interests because in practice one cannot check precisely whether the global null assumption holds or not. However, these results clearly suggest that in GLM with diverging dimensionality, one needs to be very cautious when using p-values based on the MLE.
The key ingredients of our new geometric and probabilistic arguments are demonstrated in the proof of Theorem 2 in Section B.3. The assumption that the rescaled random design matrix n−1/2X has the Haar measure on the Stiefel manifold greatly facilitates our technical analysis. The major theoretical finding is that the nonlinearity of the mean function μ(·) can be negligible in determining the asymptotic distribution of MLE as given in (11) when the dimensionality p grows at a slower rate than n2/3, but such nonlinearity can become dominant and deform the conventional asymptotic normality when p grows at rate n2/3 or faster. See the last paragraph of Section B.3 for more detailed in-depth discussions on such an interesting phenomenon. Furthermore, the global null assumption is a crucial component of our geometric and probabilistic argument. The global null assumption along with the distributional assumption on the design matrix ensures the symmetry property of the MLE and the useful fact that the MLE can be asymptotically independent of the random design matrix. In the absence of such an assumption, we may suspect that p-values of the noise variables can be affected by the signal variables due to asymmetry. Indeed, our simulation study in Section 4 reveals that as the number of signal variables increases, the breakdown point of the p-values occurs even earlier.
Theorem 3 further establishes that the invalidity of GLM p-values in high dimensions beyond the scenario of orthonormal design matrices considered in Theorem 2. The breakdown of the conventional p-values occurs regardless of the correlation structure of the covariates.
Our theoretical derivations detailed in the Appendix also suggest that the conventional p-values in nonlinear GLMs can generally fail to be valid when with α0 ranging between 1/2 and 2/3, which differs significantly from the phenomenon for linear models as discussed in the Introduction. The special feature of logistic regression model that the variance function b″ (θ) takes the maximum value 1/4 at natural parameter θ = 0 leads to a higher transition point of with α0 = 2/3 for the case of global null β0 = 0.
4. Numerical Studies
We now investigate the breakdown point of p-values for nonlinear GLMs in diverging dimensions as predicted by our major theoretical results in Section 3 with several simulation examples. Indeed, these theoretical results are well supported by the numerical studies.
4.1. Simulation examples
Following Theorems 2–3 in Section 3, we consider three examples of the logistic regression model (1). The response vector y = (y1, ⋯ , yn)T has independent components and each yi has Bernoulli distribution with parameter , where θ = (θ1, ⋯ ,θn)T = Xβ0. In example 1, we generate the n × p design matrix X = (x1, ⋯ , xp) such that n−1/2X is uniformly distributed on the Stiefel manifold as in Theorem 2, while examples 2 and 3 assume that X ~ N(0, In ⊗ Σ) with covariance matrix Σ as in Theorem 3. In particular, we choose Σ = (ρ|j−k|)1≤j,k≤p with ρ = 0, 0.5, and 0.8 to reflect low, moderate, and high correlation levels among the covariates. Moreover, examples 1 and 2 assume the global null model with β0 = 0 following our theoretical results, whereas example 3 allows sparsity s = ‖β0‖0 to vary.
To examine the asymptotic results we set the sample size n = 1000. In each example, we consider a spectrum of dimensionality p with varying rate of growth with sample size n. As mentioned in the Introduction, the phase transition of perfect hyperplane separation happens at the point p/n = 1/2. Recall that Theorems 2–3 establish that the conventional GLM p-values can become invalid when p ~ n2/3. We set with α0 in the grid {2/3 – 4δ, ⋯ , 2/3 – δ, 2/3, 2/3 + δ, ⋯ ,2/3 + 4δ, (log(n) – log(2))/log(n)} for δ = 0.05. For example 3, we pick s signals uniformly at random among all but the first components, where a random half of them are chosen as 3 and the other half are set as −3.
The goal of the simulation examples is to investigate empirically when the conventional GLM p-values could break down in diverging dimensions. When the asymptotic theory for the MLE in (11) holds, the conventional p-values would be valid and distributed uniformly on the interval [0, 1] under the null hypothesis. Note that the first covariate x1 is a null variable in each simulation example. Thus in each replication, we calculate the conventional p-value for testing the null hypothesis H0 : β0,1 = 0. To check the validity of these p-values, we further test their uniformity.
For each simulation example, we first calculate the p-values for a total of 1, 000 replications as described above and then test the uniformity of these 1, 000 p-values using, for example, the Kolmogorov–Smirnov (KS) test (Kolmogorov, 1933; Smirnov, 1948) and the Anderson–Darling (AD) test (Anderson and Darling, 1952, 1954). We repeat this procedure 100 times to obtain a final set of 100 new p-values from each of these two uniformity tests. Specifically, the KS and AD test statistics for testing the uniformity on [0, 1] are defined as
respectively, where is the empirical distribution function for a given sample .
4.2. Testing results
For each simulation example, we apply both KS and AD tests to verify the asymptotic theory for the MLE in (11) by testing the uniformity of conventional p-values at significance level 0.05. As mentioned in Section 4.1, we end up with two sets of 100 new p-values from the KS and AD tests. Figures 1–3 depict the boxplots of the p-values obtained from both KS and AD tests for simulation examples 1–3, respectively. In particular, we observe that the numerical results shown in Figures 1–2 for examples 1–2 are in line with our theoretical results established in Theorems 2–3, respectively, for diverging-dimensional logistic regression model under global null that the conventional p-values break down when with α0 = 2/3. Figure 3 for example 3 examines the breakdown point of p-values with varying sparsity s. It is interesting to see that the breakdown point shifts even earlier when s increases as suggested in the discussions in Section 3.2. The results from the AD test are similar so we present only the results from the KS test for simplicity.
Figure 1:
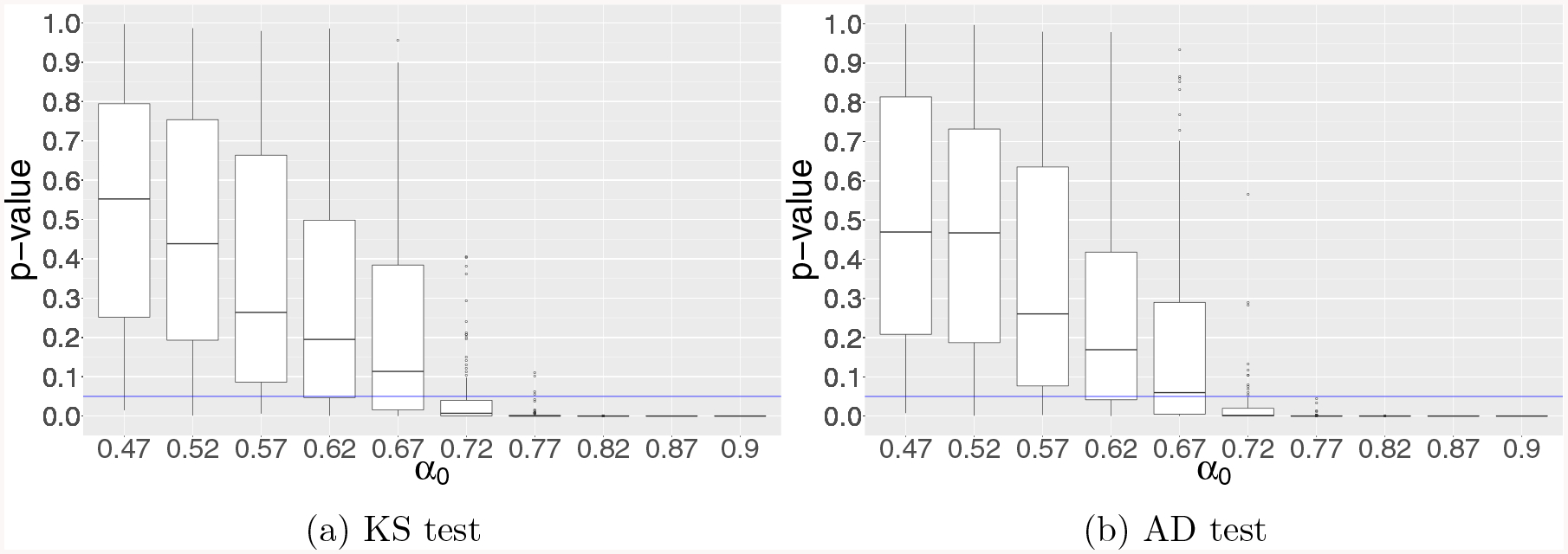
Results of KS and AD tests for testing the uniformity of GLM p-values in simulation example 1 for diverging-dimensional logistic regression model with uniform orthonormal design under global null. The vertical axis represents the p-value from the KS and AD tests, and the horizontal axis stands for the growth rate α0 of dimensionality p = [nα0].
Figure 3:
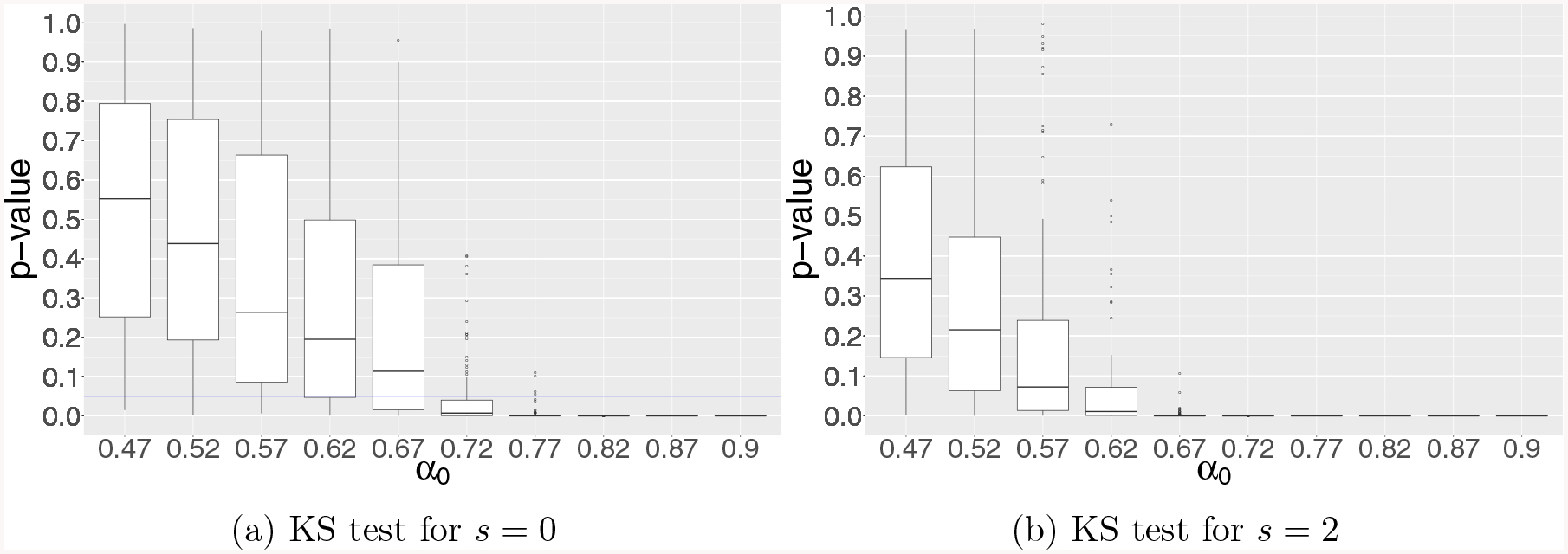
Results of KS test for testing the uniformity of GLM p-values in simulation example 3 for diverging-dimensional logistic regression model with uncorrelated Gaussian design under global null for varying sparsity s. The vertical axis represents the p-value from the KS test, and the horizontal axis stands for the growth rate α0 of dimensionality p = [nα0].
Figure 2:
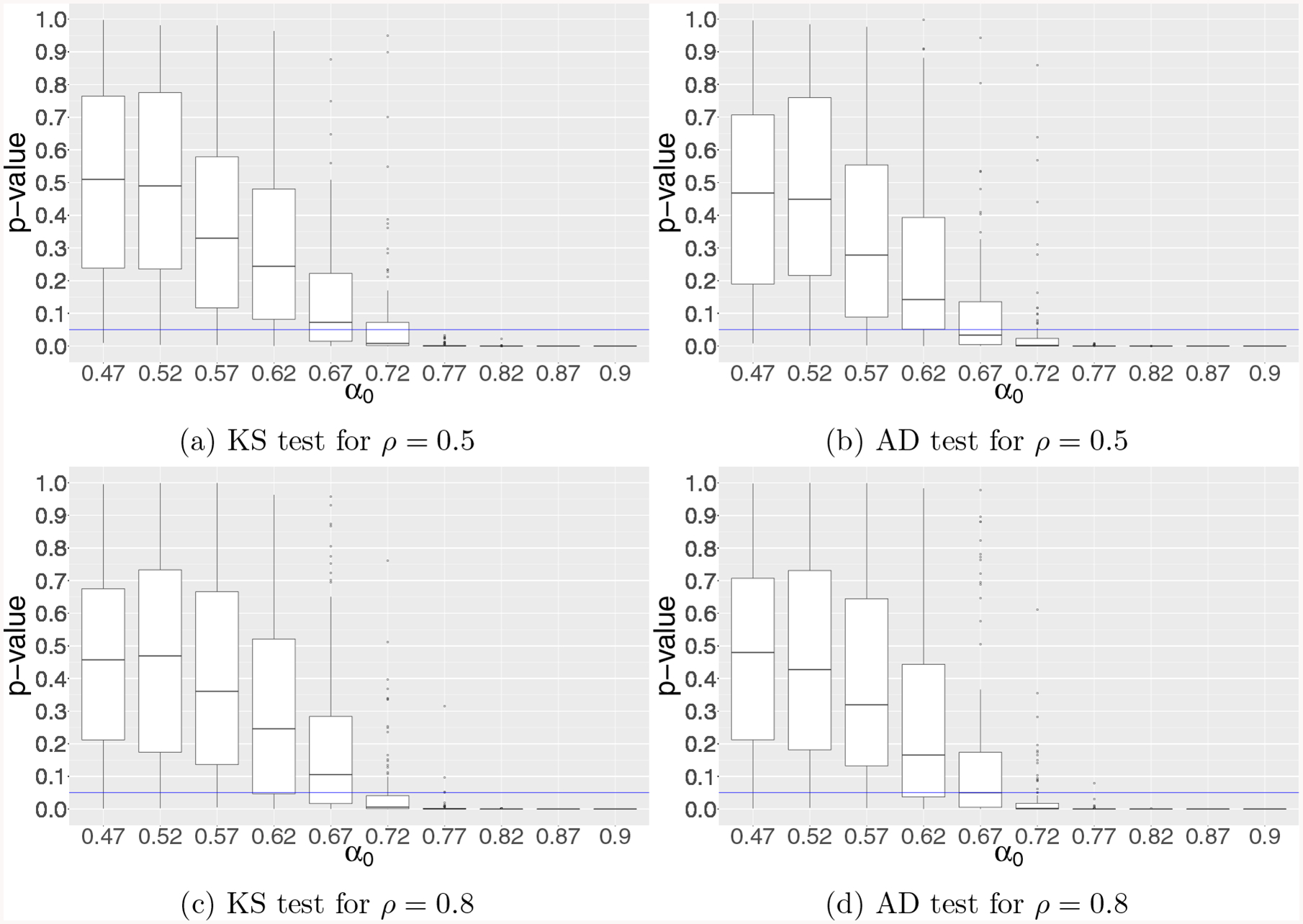
Results of KS and AD tests for testing the uniformity of GLM p-values in simulation example 2 for diverging-dimensional logistic regression model with correlated Gaussian design under global null for varying correlation level ρ. The vertical axis represents the p-value from the KS and AD tests, and the horizontal axis stands for the growth rate α0 of dimensionality p = [nα0].
To gain further insights into the nonuniformity of the null p-values, we next provide an additional figure in the setting of simulation example 1. Specifically, in Figure 4 we present the histograms of the 1,000 null p-values from the first simulation repetition (out of 100) for each value of α0. It is seen that as the dimensionality increases (i.e., α0 increases), the null p-values have a distribution that is skewed more and more toward zero, which is prone to produce more false discoveries if these p-values are used naively in classical hypothesis testing methods.
Figure 4:
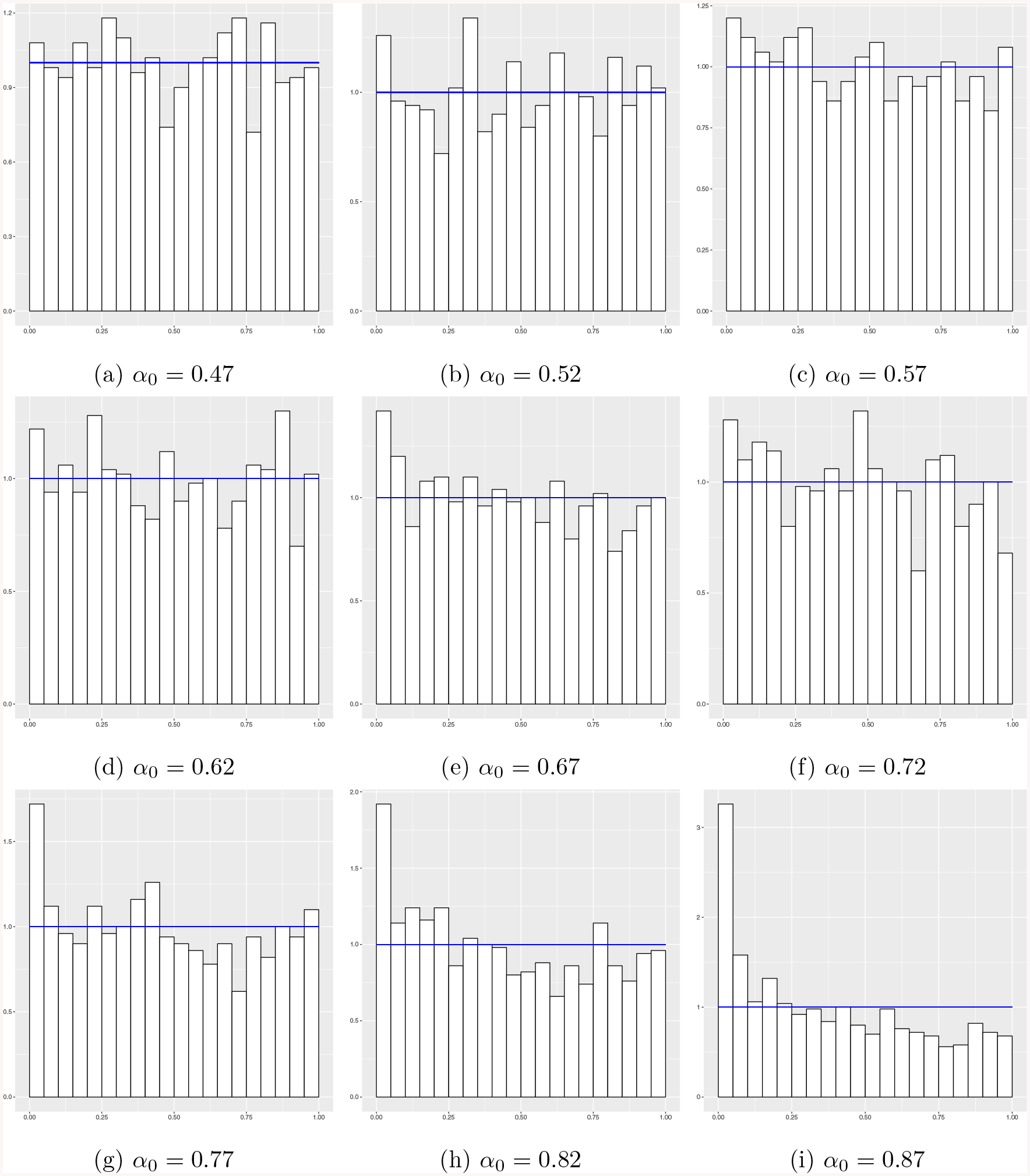
Histograms of null p-values in simulation example 1 from the first simulation repetition for different growth rates α0 of dimensionality p = [nα0].
To further demonstrate the severity of the problem, we estimate the probability of making type I error at significance level a, as the fraction of p-values below a. The means and standard deviations of the estimated probabilities are reported in Table 1 for a = 0.05 and 0.1. When the null p-values are distributed uniformly, the probabilities of making type I error should all be close to the target level a. However, Table 1 shows that when the growth rate of dimensionality α0 approaches or exceeds 2/3, these probabilities can be much larger than a, which again supports our theoretical findings. Also it is seen that when α0 is close to but still smaller than 2/3, the averages of estimated probabilities exceed slightly a, which could be the effect of finite sample size.
Table 1:
Means and standard deviations (SD) for estimated probabilities of making type I error in simulation example 1 with α0 the growth rate of dimensionality p = [nα0]. Two significance levels a = 0.05 and 0.1 are considered.
| α 0 | 0.10 | 0.47 | 0.57 | 0.67 | 0.77 | 0.87 | |
|---|---|---|---|---|---|---|---|
| a = 0.05 | Mean | 0.050 | 0.052 | 0.055 | 0.063 | 0.082 | 0.166 |
| SD | 0.006 | 0.007 | 0.007 | 0.007 | 0.001 | 0.011 | |
| a = 0.1 | Mean | 0.098 | 0.104 | 0.107 | 0.118 | 0.144 | 0.247 |
| SD | 0.008 | 0.010 | 0.009 | 0.011 | 0.012 | 0.013 |
5. Discussions
In this paper we have provided characterizations of p-values in nonlinear GLMs with diverging dimensionality. The major findings are that the conventional p-values can remain valid when p = o(n1/2), but can become invalid much earlier in nonlinear models than in linear models, where the latter case can allow for p = o(n). In particular, our theoretical results pinpoint the breakdown point of p ~ n2/3 for p-values in diverging-dimensional logistic regression model under global null with uniform orthonormal design and correlated Gaussian design, as evidenced in the numerical results. It would be interesting to investigate such a phenomenon for more general class of random design matrices.
The problem of identifying the breakdown point of p-values becomes even more complicated and challenging when we move away from the setting of global null. Our technical analysis suggests that the breakdown point can shift even earlier with α0 ranging between 1/2 and 2/3. But the exact breakdown point can depend upon the number of signals s, the signal magnitude, and the correlation structure among the covariates in a rather complicated fashion. Thus more delicate mathematical analysis is needed to obtain the exact relationship. We leave such a problem for future investigation. Moving beyond the GLM setting will further complicate the theoretical analysis.
As we routinely produce p-values using algorithms, the phenomenon of nonuniformity of p-values occurring early in diverging dimensions unveiled in the paper poses useful cautions to researchers and practitioners when making decisions in real applications using results from p-value based methods. For instance, when testing the joint significance of covariates in diverging-dimensional nonlinear models, the effective sample size requirement should be checked before interpreting the testing results. Indeed, statistical inference in general high-dimensional nonlinear models is particularly challenging since obtaining accurate p-values is generally not easy. One possible route is to bypass the use of p-values in certain tasks including the false discovery rate (FDR) control; see, for example, Barber and Candès (2015); Candès et al. (2018); Fan et al. (2018) for some initial efforts made along this line.
Acknowledgments
This work was supported by NIH Grant 1R01GM131407-01, NSF CAREER Award DMS-1150318, a grant from the Simons Foundation, and Adobe Data Science Research Award. The first and last authors sincerely thank Emmanuel Candès for helpful discussions on this topic. The authors would like to thank the Associate Editor and referees for their valuable comments that helped improve the article substantially.
Appendix A. Conventional P-values in Low Dimensions under Random Design
Under the specific assumption of Gaussian design and global null β0 = 0, we can show that the asymptotic normality of MLE continues to hold without previous Conditions 1–2.
Theorem 4
Assume that β0 = 0, the rows of X are i.i.d. from N(0, Σ), b(5)(·) is uniformly bounded in its domain, and y − μ0 has uniformly sub-Gaussian components. Then if p = O(nα) with some α ∈ [0, 2/3), we have the componentwise asymptotic normality
where all the notation is the same as in (11).
Theorem 4 shows that the conclusions of Theorem 1 continue to hold for the case of random design and global null with the major difference that the dimensionality can be pushed as far as p ~ n2/3. The main reasons for presenting Theorem 4 under Gausssian design are twofold. First, Gaussian design is a widely used assumption in the literature. Second, our results on the nonuniformity of GLM p-values in diverging dimensions use geometric and probabilistic arguments which require random design setting; see Section 3 for more details. To contrast more accurately the two regimes and maintain self-contained theory, we have chosen to present Theorem 4 under Gaussian design. On the other hand, we would like to point out that Theorem 4 is not for practitioners who want to justify the usage of classical p-values. The global null assumption of β0 = 0 restricts the validity of Theorem 4 in many practical scenarios.
Appendix B. Proofs of Main Results
We provide the detailed proofs of Theorems 1–3 in this Appendix.
B.1. Proof of Theorem 1
To ease the presentation, we split the proof into two parts, where the first part locates the MLE in an asymptotically shrinking neighborhood of the true regression coefficient vector β0 with significant probability and the second part further establishes its asymptotic normality.
Part 1: Existence of a unique solution to score equation (4) in under Condition 1 and probability bound (6). For simplicity, assume that the design matrix X is rescaled columnwise such that for each 1 ≤ j ≤ p. Consider an event
| (12) |
where ξ = (ξ1, ⋯ , ξp)T = XT [y − μ(θ0)]. Note that for unbounded responses, the assumption of in Condition 1 entails that . Thus by , probability bound (6), and Bonferroni’s inequality, we deduce
| (13) |
since for some α0 ∈ (0,γ) with γ ∈ (0, 1/2] by assumption. Hereafter we condition on the event defined in (12) which holds with significant probability.
We will show that for sufficiently large n, the score equation (4) has a solution in the neighborhood which is a hypercube. Define two vector-valued functions
and
Then equation (4) is equivalent to Ψ(β) = 0. We need to show that the latter has a solution inside the hypercube . To this end, applying a second order Taylor expansion of γ(β) around β0 with the Lagrange remainder term componentwise leads to
| (14) |
where r = (r1, ⋯ , rp)T and for each 1 ≤ j ≤ p,
with βj some p-dimensional vector lying on the line segment joining β and β0. It follows from (9) in Condition 1 that
| (15) |
Let us define another vector-valued function
| (16) |
where u = −[XTΣ(θ0)X]−1(ξ − r). It follows from (12), (15), and (8) in Condition 1 that for any ,
| (17) |
By the assumptions of with constant α0 ∈ (0, γ) and , We have
Thus in light of (16), it holds for large enough n that when ,
| (18) |
and when ,
| (19) |
where .
By the continuity of the vector-valued function , (18), and (19), Miranda’s existence theorem Vrahatis (1989) ensures that equation has a solution in . Clearly, also solves equation in view of (16). Therefore, we have shown that score equation (4) indeed has a solution in . The strict concavity of the log-likelihood function (2) by assumptions for model (1) entails that is the MLE.
Part 2: Conventional asymptotic normality of the MLE . Fix any 1 ≤ j ≤ p. In light of (16), we have , which results in
| (20) |
with having one for the jth component and zero otherwise. Note that since the smallest and largest eigenvalues of n−1An are bounded away from 0 and ∞ by Condition 2, it is easy to show that is of exact order n1/2. In view of (17), it holds on the event defined in (12) that
since by assumption. This leads to
| (21) |
It remains to consider the term , where . Clearly, the n random variables ηi’s are independent with mean 0 and
It follows from Condition 2 and the Cauchy–Schwarz inequality that
Thus an application of Lyapunov’s theorem yields
| (22) |
By Slutsky’s lemma, we see from (20)–(22) that
showing the asymptotic normality of each component of the MLE .
We further establish the asymptotic normality for the one-dimensional projections of the MLE . Fix an arbitrary vector with ‖u‖2 = 1 satisfying the L1 sparsity bound ‖u‖1 = O(sn). In light of (16), we have , which results in
| (23) |
Note that since the smallest and largest eigenvalues of n−1An are bounded away from 0 and ∞ by Condition 2, it is easy to show that is of exact order n1/2. In view of (17), it holds on the event defined in (12) that
since by assumption. This leads to
| (24) |
since ‖u‖1 = O(sn) by assumption.
It remains to consider the term with . Clearly, the n random variables ηi’s are independent with mean 0 and
It follows from Condition 2 and the Cauchy–Schwarz inequality that
Thus an application of Lyapunov’s theorem yields
| (25) |
By Slutsky’s lemma, we see from (23)–(25) that
showing the asymptotic normality of any L1-sparse one-dimensional projection of the MLE . This completes the proof of Theorem 1.
B.2. Proof of Theorem 4
The proof is similar to that for Theorem 1. Without loss of generality, we assume that Σ = Ip because under global null, a rotation of X yields standard normal rows. First let ξ = (ξ1, ⋯ , ξp)T = (XTX)−1XT[y − μ0], where μ0 = b′ (0)1 with because β0 = 0. Then y – μ0 has i.i.d. uniform sub-Gaussian components and is independent of . Define event
By Lemma 5, it is seen that . Furthermore, define the neighborhood
| (26) |
for some c3 > c2(b″ (0))−1. We next show that the MLE must fall into the region with probability at least 1 − O(p−a) following the similar arguments in Theorem 1.
First, we define
and
Applying a forth order Taylor expansion of γ(β) around β0 = 0 with the Lagrange remainder term componentwise leads to
where r = (r1, ⋯ , rp)T, s = (s1, ⋯ , sp)T, t = (t1, ⋯ , tp)T and for each 1 ≤ j ≤ p,
| (27) |
| (28) |
| (29) |
With some p-dimensional vector lying on the line segment joining β and β0.
Let us define another vector-valued function
| (30) |
where u = −(b″ (0))−1ξ + [b″ (0)XTX]−1(r + s + t). It follows from the above derivation that for any ,
Now, we bound the terms on the right hand side.
First note that on event ,
| (31) |
Then, we consider the next term: . We observe that
By Lemma 6, we have that . Lemmas 10, 11, 12 assert that
We combine last two bounds so that we have
| (32) |
with probability at least 1 − o(p−c) when p = O(nα) with α < 2/3.
Combining equations (31) and (32), we obtain that if p = O(nα) with α ∈ [0, 2/3), then
Thus, the MLE must fall into the region following the similar arguments in Theorem 1.
Next, we show the componentwise asymptotic normality of the MLE . By equation (30), we have . So, we can write
| (33) |
where . By Lemma 13 and Equation (32), both n1/2(b″ (0))−1T and converges to zero in probability. So, it is enough to consider the first summand in (33). Now, we show that is asymptotically normal. In fact, we can write where each summand xijyi is independent over i and has variance ϕb″ (0). Moreover, since |xij|3 and |yi|3 are independent and finite mean. So, we apply Lyapunov’s theorem to obtain . Finally, we know that in probability from the remark in Theorem 1. Thus, Slutsky’s lemma yields
| (34) |
This completes the proof of the theorem.
Lemma 5
Assume that the components of y − μ0 are uniform sub-Gaussians. That is, there exist a positive constant C such that P(|(y − μ0)i| > t) ≤ C exp {−Ct2} for all 1 ≤ i ≤ n. Then, it holds that, for some positive constant c2,
with asymptotic probability 1 − o(p−a).
Proof We prove the result by conditioning on X. Let E = n−1XTX − Ip. Then by matrix inversion,
Thus, it follows that
In the rest of the proof, we will bound η1, η2 and η3.
Part 1: Bound of η1.
First, it is easy to see that
We observe that each summand xij(y − μ0)i is the product of two subgaussian random variables, and so satisfies P(|xij(y − μ0)i| > t) ≤ C exp(−Ct) for some constant C > 0 by Lemma 1 in Fan et al. (2016). Moreover, E[xij(y − μ0)i] = 0 since xij and (y − μ0)i are independent and have zero mean. Thus, we can use Lemma 9 by setting Wij = xij(y − μ0)i and α = 1. So, we get
| (35) |
with probability 1 − O(p−c) for some positive constants c and c2.
Part 2: Bound of η2.
Now, we study η2 = ‖n−2XTXXT(y − μ0)‖∞. Let zk be the k-th column of X, that is zk = Xek. Direct calculations yield
Thus, it follows that
| (36) |
First, we consier . Lemma 14 shows that with probability 1 − O(p−c). We also have by equation (35). It follows that
| (37) |
Next, let and . Then it is easy to see that conditional on zk and y, aj ~ N(0, 1), bj ~ N(0, 1) and . By (E.6) of Lemma 7 in Fan et al. (2016), it can be shown that
where c1 is some large positive constant independent of zk and y. Moreover, we can choose c1 as large as we want by increasing c. Thus, it follows that
It follows from probability union bound that
Taking c1 > 1 yields that with probability at least 1 − o(p−a) for some a > 0,
By Lemma 14, we have . Therefore, by using the fact that , we have
| (38) |
| (39) |
Part 3: Bound of η3.
Finally, we study η3. We observe that . Lemma 7 proves that while equation (35) shows that with probability 1 − O(p−c). Putting these facts together, we obtain
| (40) |
where we use with α0 ∈ [0, 2/3).
Combining equations (35), (39), and (40), we obtain that with probability at least 1 − o(p−a),
■
Lemma 6
Under the assumptions of Theorem 4, ‖(n−1XTX)−1‖∞ ≤ 1 + O(pn−1/2) with probability 1 − O(p−c).
Proof Let E = n−1XTX − Ip. Then, ‖E‖2 ≤ C(p/n)1/2 for some constant C with probability 1 − O(p−c) by Theorem 4.6.1 in Vershynin (2016). Furthermore, by matrix inversion, we get
Now, we take the norm and use triangle inequalities to get
where we use the fact that p/n is bounded by a constant less than 1. ■
Lemma 7
In the same setting as Lemma 6, if E = n−1XTX−Ip then , with probability 1 − O(p−c).
Proof Again, we use that ‖E‖2 ≤ C(p/n)1/2 for some constant C with probability 1 − O(p−c). By similar calculations as in Lemma 6, we deduce
■
Lemma 8
Let Wj be nonnegative random variables for 1 ≤ j ≤ p that are not necessarily independent. If P (Wj > t) ≤ C1 exp(−C2ant2) for some constants C1 and C2 and for some sequence an, then for any c > 0, with probability at least 1 − O(p−c).
Proof Using union bound, we get
Taking concludes the proof since then
■
Lemma 9
Let Wij be random variables which are independent over the index i. Assume that there are constants C1 and C2 such that with 0 < α ≤ 1. Then, with probability 1 − O(p−c),
for some positive constants c and C.
Proof We have by Lemma 6 of Fan et al. (2016) where C3 and C4 are some positive constants which only depend on C1 and C2. This probability bound shows that the assumption of Lemma 8 holds with an = nα. Thus, Lemma 8 finishes the proof. ■
Lemma 10
With probability 1 − O(p−c), the vector r defined in (27) satisfies the bound .
Proof We begin by observing that both xij and are standard normal variables. So, using Lemma 1 of Fan et al. (2016), we have for some constant C which does not depend β. It is easy to see that are independent random variables across i’s with mean 0. By Lemma 9, is of order O(n−1/3(log p)1/2). Moreover, when . Therefore,
since p = O(nα). ■
Lemma 11
With probability 1 − O(p−c), the vector s defined in (28) satisfies the bound .
Proof First, observe that for some constant C, . Moreover, the summands are independent over i and they satisfy the probability bound by Lemma 1 of Fan et al. (2016). Thus, by Lemma 9, we obtain
Now, we calculate the expected value of the summand . We decompose as where xi,−j and β−j are the vectors xi and β whose jth entry is removed. We use the independence of xi,−j and xij and get
Finally, we can combine the result of Lemma 9 and the expected value of . we bound ‖n−1s‖∞ as follows
Since , we have ‖β‖2 = O(p1/2n−1/2(log p)1/2) and ‖β‖∞ = O(n−1/2(log p)1/2). Thus, when p = O(nα). ■
Lemma 12
With probability 1 − O(p−c), the vector t defined in (29) satisfies the bound .
Proof The proof is similar to the proof of Lemma 11. Since b(5)(·) is uniformly bounded, for some constant C. We focus on the summands which are independent across i. Moreover, repeated application of Lemma 1 of Fan et al. (2016) yields for some constant C independent of β. We can bound the expected value of the summand by Cauchy-Schwartz: . So, by Lemma 9, we get
Finally, we can deduce that when p = O(nα). ■
Lemma 13
Let . Under the assumptions of Theorem 4, we have
| (41) |
Proof Since X and y are independent, expectation of T is clearly zero. Then, we consider the variance of T. To this end, we condition on X. We can calculate the conditional variance of T as follows
where we use var[y] = ϕb″ (0)In. When we define E = n−1XTX − Ip, simple calculations show that
Now, we can obtain the unconditional variance using the law of total variance.
Thus, using Lemma 7, we can show that var[T] = o(n−1). Finally, we use Chebyshev’s inequality P(|T| > n−1/2) ≤ nvar[T] = o(1). So, we conclude that T = o (n−1/2) ■
Lemma 14
Let xij be standard normal random variables for 1 ≤ i ≤ n and 1 ≤ j ≤ p. Then, with probability 1 − O(p−c) for some positive constant c. Consequently, when log p = O(nα) for some 0 < α ≤ 1, we have , for large enough n with probability 1 – O(p−c).
Proof Since xij is a standard normal variable, is subexponential random variable whose mean is 1. So, Lemma 9 entails that
with probability 1 − O(p−c). Thus, simple calculations yields
with probability 1 − O(p−c). ■
B.3. Proof of Theorem 2
To prove the conclusion in Theorem 2, we use the proof by contradiction. Let us make an assumption (A) that the asymptotic normality (11) in Theorem 1 which has been proved to hold when p = o(n1/2) continues to hold when p ~ nα0 for some constant 1/2 < α0 ≤ 1, where ~ stands for asymptotic order. As shown in Section 3.1, in the case of logistic regression under global null (that is, β0 = 0) with deterministic rescaled orthonormal design matrix X (in the sense of n−1XTX = Ip) the limiting distribution in (11) by assumption (A) becomes
| (42) |
where is the MLE.
Let us now assume that the rescaled random design matrix n−1/2X is uniformly distributed on the Stiefel manifold which can be thought of as the space of all n × p orthonormal matrices. Then it follows from (42) that
| (43) |
Based on the limiting distribution in (43), we can make two observations. First, it holds that
| (44) |
unconditional on the design matrix X. Second, is asymptotically independent of the design matrix X, and so is the MLE .
Since the distribution of n−1/2X is assumed to be the Haar measure on the Stiefel manifold , we have
| (45) |
where Q is any fixed p × p orthogonal matrix and stands for equal in distribution. Recall that the MLE solves the score equation (4), which is in turn equivalent to equation
| (46) |
since Q is orthogonal. We now use the fact that the model is under global null which entails that the response vector y is independent of the design matrix X. Combining this fact with (45)–(46) yields
| (47) |
by noting that Xβ = (XQ)(QT β). Since the distributional identity (47) holds for any fixed p × p orthogonal matrix Q, we conclude that the MLE has a spherical distribution on . It is a well-known fact that all the marginal characteristic functions of a spherical distribution have the same generator. Such a fact along with (44) entails that
| (48) |
To simplify the exposition, let us now make the asymptotic limit exact and assume that
| (49) |
The remaining analysis focuses on the score equation (4) which is solved exactly by the MLE , that is,
| (50) |
which leads to
| (51) |
Let us first consider the random variable ξ defined in (51). Note that 2[y − μ(0)] has independent and identically distributed (i.i.d.) components each taking value 1 or −1 with equal probability 1/2, and is independent of X. Thus since n−1/2X is uniformly distributed on the Stiefel manifold , it is easy to see that
| (52) |
where is a vector with all components being one. Using similar arguments as before, we can show that ξ has a spherical distribution on . Thus the joint distribution of ξ is determined completely by the marginal distribution of ξ. For each 1 ≤ j ≤ p, denote by ξj the jth component of ξ = 2−1n−1/2XT1 using the distributional representation in (52). Let X = (x1, ⋯ , xp) with each . Then we have
| (53) |
where . It follows from (53) and the concentration phenomenon of Gaussian measures that each ξj is asymptotically close to N(0, 4−1) and thus consequently ξ is asymptotically close to N(0, 4−1 Ip). A key fact (i) for the finite-sample distribution of ξ is that the standard deviation of each component ξj converges to 1/2 at rate Op(n−1/2) that does not depend upon the dimensionality p at all.
We now turn our attention to the second term η defined in (51). In view of (49) and the fact that n−1/2X is uniformly distributed on the Stiefel manifold , we can show that with significant probability,
| (54) |
for with α0 < 1. The uniform bound in (54) enables us to apply the mean value theorem for the vector-valued function η around β0 = 0, which results in
| (55) |
since n−1/2X is assumed to be orthonormal, where
| (56) |
Here, the remainder term is stochastic and each component rj is generally of order Op{p1/2n−1/2} in light of (49) when the true model may deviate from the global null case of β0 = 0.
Since our focus in this theorem is the logistic regression model under the global null, we can in fact claim that each component rj is generally of order Op{pn−1}, which is a better rate of convergence than the one mentioned above thanks to the assumption of β0 = 0. To prove this claim, note that the variance function b″(·) is symmetric in and takes the maximum value 1/4 at θ = 0. Thus in view of (54), we can show that with significant probability,
| (57) |
for all t ∈ [0, 1], where c > 0 is some constant and ≥ stands for the inequality for positive semidefinite matrices. Moreover, it follows from (49) and the fact that n−1/2X is uniformly distributed on the Stiefel manifold that with significant probability, all the n components of are concentrated in the order of p1/2n−1/2. This result along with (57) and the fact that n−1XTX = Ip entails that with significant probability,
| (58) |
where c* > 0 is some constant. Thus combining (56), (58), and (49) proves the above claim.
We make two important observations about the remainder term r in (55). First, r has a spherical distribution on . This is because by (55) and (51) it holds that
which has a spherical distribution on . Thus the joint distribution of r is determined completely by the marginal distribution of r. Second, for the nonlinear setting of logistic regression model, the appearance of the remainder term r in (55) is due solely to the nonlinearity of the mean function μ(·), and we have shown that each component rj can indeed achieve the worst-case order pn−1 in probability. For each 1 ≤ j ≤ p, denote by ηj the jth component of η. Then in view of (49) and (55), a key fact (ii) for the finite-sample distribution of η is that the standard deviation of each component ηj converges to 1/2 at rate OP{pn−1} that generally does depend upon the dimensionality p.
Finally, we are ready to compare the two random variables ξ and η on the two sides of equation (51). Since equation (51) is a distributional identity in , naturally the square root of the sum of varξj’s and the square root of the sum of varηj’s are expected to converge to the common value 2−1p1/2 at rates that are asymptotically negligible. However, the former has rate p1/2OP(n−1/2) = Op{p1/2n−1/2}, whereas the latter has rate p1/2OP{pn−1} = OP{p3/2n−1}. A key consequence is that when for some constant the former rate is , while the latter rate becomes which is now asymptotically diverging or nonvanishing. Such an intrinsic asymptotic difference is, however, prohibited by the distributional identity (51) in , which results in a contradiction. Therefore, we have now argued that assumption (A) we started with for 2/3 ≤ α0 < 1 must be false, that is, the asymptotic normality (11) which has been proved to hold when p = o(n1/2) generally would not continue to hold when with constant 2/3 ≤ α0 ≤ 1. In other words, we have proved the invalidity of the conventional GLM p-values in this regime of diverging dimensionality, which concludes the proof of Theorem 2.
B.4. Proof of Theorem 3
By assumption, X ~ N(0, In ⊗ Σ) with covariance matrix Σ nonsingular. Let us first make a useful observation. For the general case of nonsingular covariance matrix Σ, we can introduce a change of variable by letting and correspondingly . Clearly, and the MLE for the transformed parameter vector is exactly , where denotes the MLE under the original design matrix X. Thus to show the breakdown point of the conventional asymptotic normality of the MLE, it suffices to focus on the specific case of X ~ N(0, In ⊗ Ip).
Hereafter we assume that X ~ N(0, In ⊗ Ip) with p = o(n). The rest of the arguments are similar to those in the proof of Theorem 2 in Section B.3 except for some modifications needed for the case of Gaussian design. Specifically, for the case of logistic regression model under global null (that is, β0 = 0), the limiting distribution in (11) becomes
| (59) |
since n−1XTX → Ip almost surely in spectrum and thus in probability as n → ∞. Here, we have used a claim that both the largest and smallest eigenvalues of n−1XTX converge to 1 almost surely as n → ∞ for the case of p = o(n), which can be shown by using the classical results from random matrix theory (RMT) Geman (1980); Silverstein (1985); Bai (1999).
Note that since X ~ N(0, In ⊗ Ip), it holds that
| (60) |
where Q is any fixed p × p orthogonal matrix and stands for equal in distribution. By X ~ N(0, In ⊗ Ip), it is also easy to see that
| (61) |
where is a vector with all components being one. In view of (49) and the assumption of X ~ N(0, In ⊗ Ip), we can show that with significant probability,
| (62) |
for with constant α0 < 1. It holds further that with significant probability, all the n components of are concentrated in the order of p1/2n−1/2. This result along with (57) and the fact that n−1XTX → Ip almost surely in spectrum entails that with asymptotic probability one,
| (63) |
where c* > 0 is some constant. This completes the proof of Theorem 3.
Footnotes
For completeness, we present Theorem 4 in Appendix A which provides a random design version of Theorem 1 under global null and a partial converse of Theorems 2 and 3.
Contributor Information
Yingying Fan, Data Sciences and Operations Department, University of Southern California, Los Angeles, CA 90089, USA.
Emre Demirkaya, Business Analytics & Statistics, The University of Tennessee, Knoxville, Knoxville, TN 37996-4140, USA.
Jinchi Lv, Data Sciences and Operations Department, University of Southern California, Los Angeles, CA 90089, USA.
References
- Anderson TW and Darling DA. Asymptotic theory of certain “goodness-of-fit” criteria based on stochastic processes. Annals of Mathematical Statistics, 23:193–212, 1952. [Google Scholar]
- Anderson TW and Darling DA. A test of goodness-of-fit. Journal of the American Statistical Association, 49:765–769, 1954. [Google Scholar]
- Athey Susan, Imbens Guido W., and Wager Stefan. Efficient inference of average treatment effects in high dimensions via approximate residual balancing. arXiv preprint arXiv:1604.07125, 2016. [Google Scholar]
- Bai ZD. Methodologies in spectral analysis of large dimensional random matrices, a review. Statist. Sin, 9:611–677, 1999. [Google Scholar]
- Barber Rina Foygel and Candès Emmanuel J.. Controlling the false discovery rate via knockoffs. Ann. Statist, 43:2055–2085, 2015. [Google Scholar]
- Bean Derek, Bickel Peter J., Karoui Noureddine E., and Yu Bin. Optimal M-estimation in high-dimensional regression. Proceedings of the National Academy of Sciences of the United States of America, 110:14563–14568, 2013. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Candès EJ. Private communication. 2016.
- Candès Emmanuel, Fan Yingying, Janson Lucas, and Lv Jinchi. Panning for gold: ‘model-X’ knockoffs for high dimensional controlled variable selection. Journal of the Royal Statistical Society Series B, 80:551–577, 2018. [Google Scholar]
- Fan J and Peng H. Nonconcave penalized likelihood with diverging number of parameters. Ann. Statist, 32:928–961, 2004. [Google Scholar]
- Fan Jianqing and Lv Jinchi. Nonconcave penalized likelihood with NP-dimensionality. IEEE Transactions on Information Theory, 57:5467–5484, 2011. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Fan Y and Lv J. Asymptotic equivalence of regularization methods in thresholded parameter space. Journal of the American Statistical Association, 108:1044–1061, 2013. [Google Scholar]
- Fan Yingying, Kong Yinfei, Li Daoji, and Lv Jinchi. Interaction pursuit with feature screening and selection. arXiv preprint arXiv:1605.08933, 2016. [Google Scholar]
- Fan Yingying, Demirkaya Emre, Li Gaorong, and Lv Jinchi. RANK: large-scale inference with graphical nonlinear knockoffs. Journal of the American Statistical Association, to appear, 2018. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Geman S. A limit theorem for the norm of random matrices. Ann. Probab, 8:252–261, 1980. [Google Scholar]
- Guo Bin and Chen Song Xi. Tests for high dimensional generalized linear models. J. R. Statist. Soc. B, 78:1079–1102, 2016. [Google Scholar]
- Huber PJ. Robust regression: Asymptotics, conjectures and Monte Carlo. The Annals of Statistics, 1:799–821, 1973. [Google Scholar]
- Karoui Noureddine E., Bean Derek, Bickel Peter J., Lim Chinghway, and Yu Bin. On robust regression with high-dimensional predictors. Proceedings of the National Academy of Sciences of the United States of America, 110:14557–14562, 2013. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Kolmogorov A. Sulla determinazione empirica di una legge di distribuzione. G. Ist. Ital. Attuari, 4:83–91, 1933. [Google Scholar]
- Lv J and Liu JS. Model selection principles in misspecified models. Journal of the Royal Statistical Society Series B, 76:141–167, 2014. [Google Scholar]
- McCullagh P and Nelder JA. Generalized Linear Models. Chapman and Hall, London, 1989. [Google Scholar]
- Portnoy S. Asymptotic behavior of M-estimators of p regression parameters when p2/n is large. i. consistency. The Annals of Statistics, 12:1298–1309, 1984. [Google Scholar]
- Portnoy S. Asymptotic behavior of M-estimators of p regression parameters when p2/n is large; ii. normal approximation. The Annals of Statistics, 13:1403–1417, 1985. [Google Scholar]
- Portnoy S. Asymptotic behavior of likelihood methods for exponential families when the number of parameters tends to infinity. The Annals of Statistics, 16:356–366, 1988. [Google Scholar]
- Silverstein JW. The smallest eigenvalue of a large dimensional wishart matrix. Ann. Probab, 13:1364–1368, 1985. [Google Scholar]
- Smirnov N. Table for estimating the goodness of fit of empirical distributions. Annals of Mathematical Statistics, 19:279–281, 1948. [Google Scholar]
- Sur Pragya and Candès Emmanuel J. A modern maximum-likelihood theory for high-dimensional logistic regression. arXiv preprint arXiv:1803.06964, 2018. [DOI] [PMC free article] [PubMed] [Google Scholar]
- van de Geer Sara, Bühlmann Peter, Ritov Ya’acov, and Dezeure Ruben. On asymptotically optimal confidence regions and tests for high-dimensional models. Ann. Statist, 42:1166–1202, 2014. [Google Scholar]
- Vershynin Roman. High-dimensional probability. An Introduction with Applications, 2016. [Google Scholar]
- Vrahatis Michael N. A short proof and a generalization of Miranda’s existence theorem. Proceedings of the American Mathematical Society, 107:701–703, 1989. [Google Scholar]