

Abstract
According to the American Cancer Society's forecasts for 2019, there will be about 268,600 new cases in the United States with invasive breast cancer in women, about 62,930 new noninvasive cases, and about 41,760 death cases from breast cancer. As a result, there is a high demand for breast imaging specialists as indicated in a recent report for the Institute of Medicine and National Research Council. One way to meet this demand is through developing Computer-Aided Diagnosis (CAD) systems for breast cancer detection and diagnosis using mammograms. This study aims to review recent advancements and developments in CAD systems for breast cancer detection and diagnosis using mammograms and to give an overview of the methods used in its steps starting from preprocessing and enhancement step and ending in classification step. The current level of performance for the CAD systems is encouraging but not enough to make CAD systems standalone detection and diagnose clinical systems. Unless the performance of CAD systems enhanced dramatically from its current level by enhancing the existing methods, exploiting new promising methods in pattern recognition like data augmentation in deep learning and exploiting the advances in computational power of computers, CAD systems will continue to be a second opinion clinical procedure.
1. Introduction
Cancer is a disease that occurs when abnormal cells grow in an uncontrolled manner in a way that disregards the normal rules of cell division, which may cause uncontrolled growth and proliferation of the abnormal cells. This can be fatal if the proliferation is allowed to continue and spread in such a way that leads to metastasis formation. The tumor is called malignant or cancer if it invades surrounding tissues or spreads to other parts of the body [1]. Breast cancer forms in the same way and usually starts in the ducts that carry milk to the nipple or in the glands that make breast milk. Cells in the breast start to grow in an uncontrolled manner and form a lump that can be felt or detected using mammograms [2]. Breast cancer is the most prevalent cancer between women and the second cause of cancer-related deaths among them worldwide [3–5]. According to the American Cancer Society's forecasts for 2019, there will be about 268,600 new cases in the United States of invasive breast cancer diagnosed in women, about 62,930 new noninvasive cases, and about 41,760 death cases from breast cancer [3]. The death rates among women dropped 40% between 1989 and 2016, and since 2007, the death rates in younger women are steady and are steadily decreasing in older women due to early detection through screening, increased awareness, and better treatment [3, 6].
Mammography, which is performed at moderate X-ray photon energies, is commonly used to screen for breast cancer [7, 8]. If the screening mammogram showed an abnormality in the breast tissues, a diagnostic mammogram is usually recommended to further investigate the suspicious areas. The first sign of breast cancer is usually a lump in the breast or underarm that does not go after the period. Usually, these lumps can be detected by screening mammography long before the patient can notice them even if these lumps are very small to do any perceptible changes to the patient [9].
Several studies showed that using screening mammography as an early detection tool for breast cancer reduces breast cancer mortality [10–12]. Unfortunately, mammography has a low detection rate and 5% to 30% of false-negative results depending on the lesion type, the age of the patient, and the breast density [13–19]. Denser breasts are harder to diagnose as they have low contrast between the cancerous lesions and the background [20, 21]. The miss of classification in mammography is about four to six times higher in dense breasts than in nondense breasts [17, 20–24]. Dense breast reduces the test sensitivity (increases false-positive value), hence requiring unnecessary biopsy, and decreases test specificity (increases false-negative value), hence missing cancers [25].
Radiologists try to enhance the sensitivity and specificity of mammography by double reading the mammograms by different radiologists. Some authors reported that double reading enhances the specificity and sensitivity of mammography [26–28] but with extra cost on the patient. A recent study [29] and an older study [30] showed that the detection rate of double reading was not statistically different from the detection rate of a single reading in digital mammograms and hence the double reading is not a cost-effective strategy in digital mammography. The inconsistency in the results shows that there is a need for further studies in this area. Recently, Computer-Aided Diagnosis (CAD) systems are used to assist doctors in reading and interpreting medical images such as the location and the likelihood of malignancy in a suspicious lesion [7]. CADe and CADx schemes are used to differentiate between two strands of CAD systems. The main difference between CADe and CADx is that CADe stands for Computer-Aided Detection system, in which CADe systems do not present the radiological characteristics of tumors but help in locating and identifying possible abnormalities in the image and leaving the interpretation to the radiologist. On the other hand, CADx stands for Computer-Aided Diagnosis system, in which CADx serves as decision aids for radiologists to characterize findings from radiological images identified by either a radiologist or a CADe system. CADx systems do not have a good level of automation and do not detect nodules.
CAD helped the doctors to improve the interpretations of images in terms of accuracy in detection and productivity in time to read and interpret the images [31–37]. A study regarding CAD systems showed an increase in the radiologists' performance for those who used CAD systems [38]. Another study indicated that the detection rate for double reading was not significantly different from the detection rate of a single reading accompanied by a CAD system [23]. Typically, a CAD session starts with the radiologist reading the mammogram to look for suspicious patterns in it followed by the CAD system scanning the mammograms and looking for suspicious areas. Finally, the radiologist analyzes the prompts given by the CAD system about the suspicious areas [7].
The two main signs for malignancy are the microcalcification and masses [24, 39, 40]. Microcalcifications can be described in terms of their size, density, shape, distribution, and number [41]. Microcalcification detection in denser breasts is hard due to the low contrast between the microcalcification and the surrounding tissues [21]. A valuable study on how to enhance contrast, extraction, suppression of noise, and classification of microcalcification can be found in [42]. Masses, on the other hand, are circumscribed lumps in the breast and are categorized as benign or malignant. Masses can be described by shape, margin, size, location, and contrast. The shape can be further classified as round, lobular, oval, and irregular. Margin can also be further classified as obscured, indistinct, and spiculated. Masses are harder to detect by the radiologists than microcalcification because of their similarity to the normal tissues [43, 44]. Many studies presented the usage of CAD systems in mammography diagnosis such as [7, 45–50]. Like any other algorithm for a classification problem, the CAD system can be divided into three distinct areas: feature extraction, feature selection, and classification methodologies. On top of these three major areas, CAD systems depend heavily on an image enhancement step to prepare the mammogram for further analysis. Figure 1 shows a flowchart for a typical CAD system schema.
Figure 1.
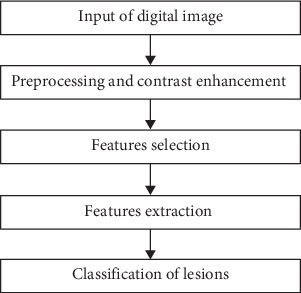
Flow chart for a typical CAD system.
In this study, we are presenting the developments of CAD methods used in breast cancer detection and diagnosis using mammograms, which include preprocessing and contrast enhancement, features extraction, features selection, and classification methods. The rest of the paper will be organized based on the schema in Figure 1 as follows: Section 2 presents the preprocessing and enhancement step, Section 3 discusses features selection and features extraction step, Section 4 is devoted to discussing classification through classifiers and combined classifiers, and Section 5 presents the conclusions.
2. Preprocessing and Contrast Enhancement
Mammograms do not provide good contrast between normal glandular breast tissues and malignant ones and between the cancerous lesions and the background especially in dense breasts [20–24, 51]. There are recognized poor contrast problems inherent to mammography images. According to the Beer-Lambert equation, the thicker the tissue is, the fewer the photons pass through it. This means that as the X-ray beam passes through normal glandular breast tissues and malignant ones in dense breast tissues, its attenuation will not differ much between the two tissues and hence there will be low contrast between normal glandular and malignant tissues [52]. Another well-known problem in mammograms is noise. Noise occurs in mammograms when the image brightness is not uniform in the areas that represent the same tissues as it supposes to be due to nonuniform photon distribution. This is called quantum noise. This noise reduces image quality especially in small objects with low contrast such as a small tumor in a dense breast. It is known that quantum noise can be reduced by increasing the exposure time. For health reasons, most of the time the radiologist prefers to decrease the exposure time for the patient at the expense of increasing the quantum noise, which will result in reducing the visibility of the mammogram. The presence of noise in a mammogram gives it a grainy appearance. The grainy appearance reduces the visibility of some features within the image especially for small objects with low contrast, which is the case for a small tumor in a dense breast [52, 53]. Because of this low-contrast problem, contrast enhancement techniques were proposed in the literature. A good review of conventional contrast enhancement techniques can be found in [54]. Unfortunately, there is no unified metrics for evaluating the performance of the preprocessing techniques to enhance the low-contrast problem and the existing evaluations are still highly subjective [55, 56].
Image enhancement usually is done by changing the intensity of the pixels for the input image [57]. The conventional histogram equalization technique for image enhancement is an attractive approach for its traceability and simplicity. The conventional histogram equalization starts by collecting statistics about the intensity of the image's pixels and formulating a histogram for the intensity levels and their frequency as in
| (1) |
where i is intensity index and fi is the frequency for intensity index i.
Using equation (1), a cumulative density function is defined as in
| (2) |
where L is the number of intensity levels and N is the total number of pixels in the image. A transformation function is defined based on equation (2) to give the output image Iout as follows:
| (3) |
where Imin and Imax are the minimum and the maximum intensity levels of the input image, respectively.
Unfortunately, the conventional histogram equalization tends to shift the output image brightness to the middle of the allowed intensity range. To overcome this problem, subimage based histogram equalization methods were proposed in the literature where the input image is divided into subimages and the intensity for each subimage is manipulated independently. A bi-histogram equalization method discussed in [58, 59] splits the image into two subregions of high and low mean brightness based on the average intensity of all pixels and then applies the histogram equalization to each subregion independently. The mathematics of bi-histogram equalization method starts by calculating the expected value for the intensity of the input image as in
| (4) |
Based on E[Iinp] , two subimages, Ilow and Ihigh, are created such that
| (5) |
Then Ilow and Ihigh are equalized using their corresponding range of intensities to produce two enhanced images Ilowenh and Ihighenh. The enhanced output image is then constructed as the union of these two subimages. The first limitation for this method is that the original brightness can be preserved only if the original image has a symmetric intensity histogram such that the number of pixels in Ilow is equal to the number of pixels in Ihigh. If the histogram is not symmetric, the mean tends to shift toward the long tail and hence the number of pixels in each subimage will not be equal. The second limitation arises when pixels intensities tend to concentrate in a narrow range. This will be shown as peaks in the histogram and hence will generate artifacts in the output image. A third limitation is that the image may suffer from overenhancement especially if the brightness dispersion in the image is high such that there are regions of very high and very low brightness.
To overcome the limitation generated from the unequal number of pixels in the subimages, dualistic subimage histogram equalization discussed in [60] incorporated the median value as the divider threshold in the process instead of the mean to have an equal number of pixels in each subimage. This method maximizes Shannon's entropy of the output image [61]. In this method, the input image is divided into two subimages just like with equal number pixels and hence the original brightness of the input image can be preserved to some extent. To overcome the limitation generated from pixels concentrated in a narrow range, the histogram peaks are clipped prior to cumulative density calculations [62]. The procedure used is similar to bi-histogram equalization method discussed earlier in which two subimages are created along with their histograms, but on the top of that, the mean values for the two subimages are calculated as the clipping limits for the subimages as in
| (6) |
The clipping limits are used to generate the histograms for the subimages as in equation (7) and the procedure continues after that as in the bi-histogram equalization method.
| (7) |
A difficulty that sometimes arises in this method is that the mean brightness for the resulting image is hard to calculate, as it sometimes does not have a closed-form expression to evaluate it [63].
An attempt to mitigate the limitation of overenhancement is by multiple division method proposed in [63] in which dynamic quadrants histogram equalization plateau limit method divides the image into four subimages. Another attempt is by median-mean based subimage clipped histogram equalization proposed in [64], which is an enhancement for the dynamic quadrants histogram equalization plateau limit method. In this method, the mean brightness of the input image was used first to divide the input image into subimages, these subimages are then further divided using the mean brightness for the subimages, and then the peaks of the subimage histogram were clipped using median values. The minimum mean brightness error bi-histogram equalization method was used in [65], which is an exhaustive search method, to determine the best separation threshold. This method, like the subimage based histogram equalization method, cannot guarantee a match between the input and the output brightness. Another drawback of this method is that it may need a considerable amount of computational time, as it is exhaustive in nature.
A dynamic stretching strategy is adopted in [63] for contrast enhancement instead of histogram equalization with the mean or median value for the separation threshold in which the efficient golden section search approach was used to find the optimal threshold, which preserves the mean brightness in the output image. Equation (8) gives the function used for the golden section search. The golden section search method is basically searching for the mean output image intensity E[Iout] that will minimize the absolute deviation between the output image mean intensity and the input image mean intensity E[Iinp].
| (8) |
There are many methods in literature to reduce the noise level in X-ray images. The traditional solution to reduce noise in X-rays images is to use a Wiener filter that computes a statistical estimate of the desired output image by filtering out the noise from the input image utilizing the second-order statistics of the Fourier decomposition [66, 67]. The Wiener filter minimizes the overall mean square error between the output image and the input image as in
| (9) |
By taking the derivatives of equation (9), the Fourier transformation, , of the constructed image can be derived as in
| (10) |
where f(x, y) is the original image, is the constructed image, H∗(u, v) is the complex conjugate of the Fourier transform of the degradation filter, H2(u, v) is the momentum square of the degradation filter, Sζ is the power spectrum of the noise, Sf is the power spectrum of the original image, G(u, v) is the observation, and (H∗(u, v)/(H2(u, v)+(Sζ/Sf))) is the Wiener filter. The output image is just the input image multiplied by the Wiener filter.
The Bayesian estimator is an extension to Wiener filter to exploit the higher-order statistics found in the point statistics of the subband decomposition of natural images, which cannot be captured by Fourier based techniques [68]. The Bayesian estimator needs to have the probability density function of the noise and the prior probability density function of the signal and hence usually parametrization model is needed to estimate the parameters for those functions. Let y be a scalar x with additive noise n such that y=x+n. The least-square estimator of x as a function of y can be derived using Bayes' rule as in
| (11) |
where Pn is the pdf for the noise, Px is the prior pdf for the signal, and the denominator is the pdf for the noise observations. Both probability density functions must be known to estimate the original signal x. A generalized Laplacian distribution was used by [69] as a parameterization model for these densities.
The wavelet transformation is a signal processing technique used to represent real-life nonstationary signals with high efficiency [70]. Continuous and discrete wavelet transformations are used extensively in image processing especially in microcalcification enhancement methods in mammograms [71].
Wavelet decomposes the signal into subbands using a mother wavelet function to generate other window functions. The mother wavelet function is a scaling and translation function of the form
| (12) |
where a is the scaling factor and b is the translation parameters. The mother wavelet function is applied to the original function f(x) as in
| (13) |
Images are 2D and hence a 2D discrete wavelet transform is needed, which can be computed using 2D wavelet filters followed by 2D downsampling operations for one level decomposition [72].
Microcalcification in mammograms was detected using a wavelet transformation with supervised learning through a cost function in [73]. The cost function represented the difference between the desired output image and the reconstructed image, which is obtained from the weighted wavelet coefficient for the mammogram under consideration. Then, a conjugate gradient algorithm was used to modify the weights for wavelet coefficients to minimize the cost function. In [74], the continuous wavelet transform was used to enhance the microcalcification in mammograms. In this method, a filter bank was constructed by discretizing a continuous wavelet transform. This discrete wavelet decomposition is designed in an optimal way to enhance the multiscale structures in mammograms. The advantage of this method is that it reconstructs the modified wavelet coefficients without the introduction of artifacts or loss of completeness.
Reference [75] presented a tumor detection system for fully digital mammography that detects the tumor with very weak contrast with its background using iris adaptive filter, which is very effective in distinguishing rounded opacities regardless of how weak its contrast with the background. The filter uses the orientation map of gradient vectors. Let Qi be any arbitrary pixel and let g be gradient vector toward the pixel of interest P; then, the convergence index can be expressed as
| (14) |
where θ is the orientation of the gradient vector g at Qi with respect to the ith half line. The average of convergence indexes over the length PQi, i.e., Ci is calculated by
| (15) |
The output of the iris filter C(x, y) at the pixel (x, y) is given by equation (16), where Cim is the maximum convergence degree deduced from equation (15):
| (16) |
Reference [54] lists a number of other contrast enhancement algorithms with their advantages and limitations. For example, manual intensity windowing is limited by its operator skill level. Histogram-based intensity windowing has the advantage of improving the visibility of the lesion edge but at the expense of losing the details outside the dense area of the image. Mixture-model intensity windowing enhances the contrast between the lesion borders and the fatty background but at the expense of losing mixed parenchymal densities near the lesion. Contrast-limited adaptive histogram equalization improves the visibility of the edges but at the expense of increasing noise. Unsharp masking improves visibility for lesion's borders but at the expense of misrepresenting indistinct masses as circumscribed. Peripheral equalization represents the lesion details well and keeps the peripheral details of the surrounding breast but at the expense of losing the details of the nonperipheral portions of the image. Trex processing increases visibility for lesion details and breast edges but at the expense of deteriorating image contrast.
3. Feature Selection and Feature Extraction
Pattern, as described in [76], is the opposite of chaos, i.e., regularities. Pattern recognition is concerned with automatic discovering of these regularities in data utilizing computer algorithms in order to take action like classification under supervised or unsupervised setup [77, 78]. Pattern recognition has been studied in various frameworks but the most successful framework is the statistical framework [79–82]. A good reference for discussing statistical tools for features selection and features extraction can be found in [83]. In a statistical framework, a pattern is described by a vector of d features in d-dimensional space. This framework aims to reduce the number of features used to allow the pattern vector, which belongs to different categories, to occupy compact and disjoint regions in m-dimensional feature space to improve classification, stabilize representation, and/or to simplify computations [78]. A preprocessing and contrast step, which includes outlier removal, data normalization, handling of missing data, and enhancing contrast, is usually performed before the selection and extraction step [84]. The effectiveness of the selection step is measured by how successful the different patterns can be separated [76]. The decision boundaries between the patterns are determined by the probability distributions of the patterns belonging to the corresponding class. These probability distributions can be either provided or learned [85, 86]. Because selecting an optimal subset of features is done offline, having an optimal subset of features is more important than execution time [85].
The selection step involves finding the most useful subset of features that best classifies the data into the corresponding categories by reducing the d-dimensional features vector into an m-dimensional vector such that m ≤ d [84]. This can be done by features selection in measurement space (i.e., features selection) or transformation from the measurements to lower-dimensional feature space (i.e., features extraction). Features extraction can be done through a linear or nonlinear combination of the features and can be done under supervision or no supervision [83]. The most important features that are usually extracted from the mammograms are spectral features, which correspond to the variations in the quality of color and tone in an image; Textural features, which describe the spatial distribution of the color and tone within an image, and contextual features, which contain the information from the area surrounding the interest region [67]. Textural features are very useful in mammograms and can be classified into fine, coarse, or smooth, rippled, molled, irregular, or lineated [67]. Several linear and nonlinear features extraction techniques based on textural features are used in mammograms analysis such as in [72, 87–95].
Considering M classes and corresponding feature vectors distributed as p(x|wi), the parametric likelihood functions, and the corresponding parameters vectors θi, we can find the corresponding probability density function p(x|θi). A maximum log-likelihood estimator, or other methods like Bayesian inference, can be used to estimate the unknown parameters giving the set of known feature vectors. The expected maximization algorithm can be used to handle missing data. Having the probability density functions for the data available, we can extract meaningful features from them.
Gray-level cooccurrence matrix (GLCM) proposed by [67] is a well-established method for texture features extraction and is used extensively in the literature [80, 96–104]. Fourteen features were extracted from GLCM by the same author who originally proposed it [105]. The basic idea of the GLCM is as follows: let I be an N-greyscale level image, and then the gray-level cooccurrence matrix G for I is an N square matrix with its entries being defined as the number of occasions a pixel with intensity i is adjacent (on its vertical, horizontal, right, or left diagonals) to a pixel with intensity j. The features are calculated on each possible combination of adjacency and then the average is taken. G can be normalized by dividing each element of G by the total number of cooccurrence pairs in G. For example, consider the following gray-level image:
| (17) |
If we apply the rule “1 pixel to the right and 1 pixel down,” the corresponding gray-level cooccurrence matrix is
| (18) |
For example, the first entry comes from the fact that there are 4 occasions where a 0 appears below and to the right of another 0, whereas the normalization factor (1/16) comes from the fact that there are 16 pairs entering into this matrix.
The 14 Haralick's texture features are contrast, correlation, sum of squares, homogeneity, sum average, sum variance, sum entropy, entropy, difference variance, difference entropy, information measure of correlation 1, information measure of correlation 2, and maximum correlation coefficient. Probably the most used are energy, entropy, contrast, homogeneity, and correlation [105].
Let P(i, j, d, θ) denote the probability of how often one gray-tone i in an N-greyscale level image will appear in a specified spatial relationship determined by the direction θ and the distance d to another gray-tone j in a mammogram. The probability can be calculated as
| (19) |
where C(i, j) are the values in cell (i, j).
This definition will be used to define five of the most commonly used measures of the 14 Haralick's texture features: energy, entropy, contrast, homogeneity, and correlation.
Energy, also known as angular second moment, measures the homogeneity of the image such that if the texture of the image is uniform, there will be very few dominant gray-tone transitions and hence the value of energy will be high. The energy can be calculated as
| (20) |
Entropy measures the nonuniformity in an image or complexity of an image. Entropy is strongly but inversely correlated to energy and can be calculated from the second-order histogram as
| (21) |
Contrast measures the variance of the gray level in the image, i.e., the local gray-level variations present in an image. It detects disorders in textures. For smooth images, the contrast value is low, and for coarse images, the contrast value is high.
| (22) |
Homogeneity, which is also known as inverse difference moment, is a measure of local homogeneity and it is inversely related to contrast such that if contrast is low, the homogeneity is high. Homogeneity is calculated as
| (23) |
Correlation is used to measure the linear dependencies in the gray-tone level between two pixels.
| (24) |
where μx is the mean value of pixel intensity i, σx is the standard deviation value of pixel intensity i, μy is the mean value of pixel intensity j, and σy is the standard deviation value of pixel intensity j.
Figure 2 shows the mdb028 mammogram (a) from the MIAS database [106] and the corresponding region of interest (b).
Figure 2.
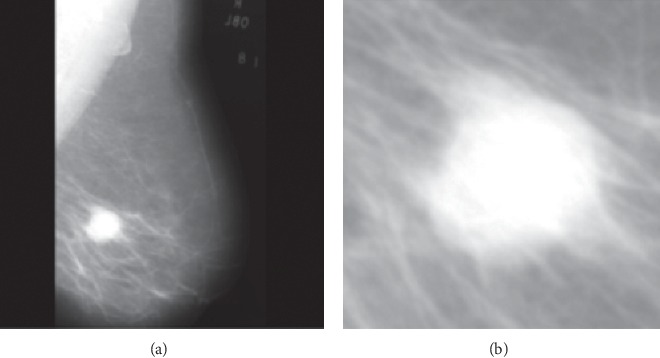
(a) Original mdb028 mammogram for a malignant patient. (b) The corresponding region of interest.
The corresponding contrast, correlation, energy, entropy, and homogeneity values calculated based on the GLCM matrix are 0.0813, 0.9617, 0.2656, 6.53, and 0.9594, respectively. One can see that this image has high homogeneity and low contrast as expected.
Gradient-based methods are widely used in analyzing mammograms [107–109]. The basic idea of the gradient is as follows: let Y be an ℝ-valued random variable, and then
| (25) |
where (X, Y) is a random vector such that X=(X1,…, Xm) ∈ ℝm, and B is a projection matrix, such that BTB=Id, into d-dimensional subspace such that d ≤ m. Equation (25) implies that the gradient ∂/∂xE[Y | X=x] at any x is contained in the effective direction for regression.
Traditional gradient methods often could not reveal a clear-cut transition or gradient information because malignant lesions usually fill a large area in the mammogram [110]. This limitation was addressed by [95] where directional derivatives were used to measure variations in intensities. This method is known as acutance, A, and is calculated as
| (26) |
where fmax and fmin are the local maximum and minimum pixel values in the region under consideration, respectively, N is the number of pixels along the boundary of the region, and fi(j), j=0,1,…, ni are (ni+1) number of perpendicular pixels available at the ith boundary point including the boundary point [110].
The evaluation of the spiculations of the tumor's edges through pattern recognition techniques is widely used among scholars to classify masses into malignant and benign [87, 89, 111–114]. Morphological features can help in distinguishing between benign and malignant masses. Benign masses are characterized by smooth, circumscribed, macrolobulated, and well-defined contours, while malignant masses are vague, irregular, microlobulated, and spiculated contours. Based on these morphological features of the mass, scholars defined certain measures and indicators to classify the masses into benign and malignant like the degree of compactness, the spiculation index, the fractional factor, and fractal dimension [115].
Differential analysis is also used to compare the prior mammographic image with the most current one to find if the suspicious masses have changed in size or shape. The relative gray level is also compared between the old mammogram and the current one to deduce the changes in the breast since the last mammogram by comparing the cumulative histograms of prior and current images [90]. The bilateral analysis is also used to compare the left and right mammograms to see any unusual differences between the left and right breasts [116].
The classification metrics for a classifier depends on the interrelation between sample size, number of features, and type of classifier [78]. For example, in naïve table-lookup, the number of training data points increases exponentially with the number of features [117]. This phenomenon is called the curse of dimensionality and it leads to another phenomenon. As [78] argued that as long as the number of training samples is arbitrarily large and representative of the underlying densities, the probability of misclassification of a decision rule does not increase as the number of features increases because under this condition the class-conditional densities are completely known. In practice, it has been observed that adding features will degrade the metrics of the classifier if the size of the training data used is small compared to the number of features. This inconsistent behavior is known as the peaking phenomenon [118–120]. The peaking phenomenon can be explained as follows: most of the parametric classifiers estimate the unknown parameters for the classifier and then plug them into the class-conditional densities. At the same sample size, as the number of features increases (consequently the number of unknown parameters increases), the estimation of the parameters degrades, and consequently, this will degrade the metrics of the classifier [78]. Because of the curse of dimensionality and peaking phenomena, features selection is an important step to enhance the overall metrics of the classifier. Many methods have been discussed in the literature for features selection [78, 83]. Class separability measure can help in a deep understanding of the data and in determining the separability criterion of various features classes along with suggestions for the appropriate classification algorithms.
Class separability measures are based on conditional probability. Given two classes Ci and Cj and a features vector v, Ci will be chosen if the ratio between P(Ci | v), and P(Cj | v) is more than 1. The distance Dij between Ci and Cj can be calculated as
| (27) |
And Dji can be calculated in the same way. The total distance dij is a measure of separability for multiclass problems. This distance is referred to as divergence or Kullback-Leibler distance measure. Kullback-Leibler distance can be calculated as discussed in [84, 121] as
| (28) |
Another well-known distance is Mahalanobis distance. Consider two Gaussian distributions with equal covariance matrices; then, the Mahalanobis distance is calculated as
| (29) |
where Σ is the covariance matrix for the two Gaussian distributions and μi and μj are their two means.
Class separability measures are important if many features are used. If up to 3 features, the analyst can see the class scatter. Three class separability measures are widely used: class scatter measure, Thornton's separability index, and direct class separability measure [122].
In class scatter measure, an unbounded measure J is defined as the ratio of the between-class scatter and the within-class scatter such that the larger the value of J is, the smaller the within-class scatter compared to the between-class scatter is. J can be calculated as
| (30) |
where C is the number of classes, ni is the number of instances in class i, mi is the mean of instances in class i, m is the overall mean of all classes, and xij is the jth instance in class i.
Separability index (SI) reports the average number of instances that share the same class label as their nearest neighbors. SI is calculated as
| (31) |
Direct class separability DCSM takes into consideration the compactness of the class compared to its distance from the other class. DCSM can be calculated as
| (32) |
where xi and xj are the instances in classes i and j, respectively.
Class separability measures aim to choose the best set of features to increase the metrics of the classifier. Without this insight choice of features, two different datasets can look alike if the features were selected in the wrong way. This phenomenon is known as Ugly Duckling Theorem [123]. Many methods are used in literature to select features and can be categorized into three main methods: filter methods, wrapper methods, and hybrid methods (which is composed of both the filter and wrapper methods).
Filter methods assign ranks to the features to denote how useful each feature is for the classifier. Once these ranks are computed and assigned, the features set is then composed with the highest N rank features. Pearson's correlation coefficient method, as a filter method, looks at the strength of the correlation between the feature and the class of data [124]. If this correlation is strong, then this feature will be selected as it will help in separating the data and will be useful in classification. The mutual information method is another filter method. The mutual information method measures the shared information between a feature and the class of the labeled data. If there is a lot of shared information, then this feature is an important feature to distinguish between different classes in the data [125]. The relief method looks for the separation capability of randomly selected instances. It selects the nearest-class instant and the opposite-class instance and then calculates a weight for each feature. The weights are updated iteratively with each random instance. This method is known for its low computational time with respect to other methods [126]. Ensemble with the data permutation method is another filter method; the concept is to combine many weak classifiers to give a better classifier than any of the single classifiers used. The same concept is used to features selection where many weak rankings are combined to give much better ranking [127].
The general idea in wrapper methods is to calculate the efficacy for a certain set of features and to update this set until a stopping criterion is reached. A greedy forward search is an example of wrapper methods. This method calculates the efficacy of the set of features on hand and replaces the current set with this set only if its efficacy is better than the efficacy of the current set; otherwise, it keeps the current set. The greedy forward method starts with one feature and keeps adding features one at a time. The classifier is evaluated each time a new feature is added, and only if the efficacy of the classifier improved, the feature is maintained [128]. This method does not guarantee an optimal solution but it picks up the features that work best together. The exhaustive search method is considered a wrapper method. Exhaustive search features selection method, also known as the brute force method, looks for every possible combination of features and selects the combination that gives the best metrics for the classifier [128]. Of course, this can be only done within a reasonable computational time with a small number of features or if the number of possible combinations is reduced by searching certain combinations only. To see how large the number of possible combinations could be, consider a dataset with 300 features, and then the number of possible sets of features is 2300 ≈ 2 × 1090 which is a huge number. To reduce this number, we may specify that the number of features that we want is 20 features, and then the number of possible sets is 300C20=7.5 × 1030 (300 choice 20) which is much lower than the first case but still impractical in terms of computational time. If we are able somehow to reduce the 300 features into 50 features and we want to choose a set of 20 features out of them, the number of sets is 50C20=2.7 × 1013 which is still a very huge number. This illustration shows that the exhaustive search method for features selection works only when the method is highly constrained.
The principal component analysis is a widely used method for dimensionality reduction. The principal component analysis is a statistical procedure used to transfer a set of possibly correlated features into a set of linearly uncorrelated features by orthogonal transformation using eigenvalue decomposition on covariance matrices of the observed regions to determine their principal components. The transformation is carried out such that the first principal component has the highest variance, which means that it accounts for the largest amount of variability in the data, and the second principal component has the second highest variance under the constraint that it is orthogonal to all other components and so on. Principal component analysis reveals the internal structure of the data. It reveals how important each feature is in explaining the variability in the data. It simply shows the higher dimensional data space onto a shadow of lower-dimensional data space [127, 129–133].
Another method in dimensionality reduction is factor analysis. Factor analysis is a statistical method that describes variability in correlated observed factors (features) in terms of a lower number of unobserved new factors (new features). The principal component analysis is often confused with factor analysis. In fact, the two methods are slightly different. The principal component analysis does not involve any new features and it only ranks the features according to their importance in describing the data while the factor analysis involves creating new features by replacing a number of correlated features with a linear combination of them to create a new feature that does not exist originally [127].
4. Classification
Classification is the process of categorizing observations based on a training set of data. Classification predicts the value of a categorical variable, i.e., class of the observation, based on categorical and/or numerical variables, i.e., features. In mammograms, classification is used to predict the type of mass based on the extracted set of features. Classification algorithms can be grouped into four main groups according to their ways of calculations: frequency table based, covariance matrix based, similarity functions based, and others.
ZeroR classifier is the simplest type of frequency table classifiers that ignores the features and does classification based on the class only. The class of any observation is always the class of the majority [134, 135]. The ZeroR classifier is usually used as a baseline for benchmarking with other classifiers.
OneR classifier algorithm is another type of frequency table classifier. It generates a classification rule for each feature based on the frequency and then selects the feature that has the minimum classification error. This method is simple to construct and its accuracy is sometimes comparable to the more sophisticated classifiers with the advantage of easier results interpretation [136, 137].
Naïve Bayesian (NB) classifier is also a frequency classifier based on Bayes' theorem with a strong independence assumption between the features. NB classifier is especially useful for large datasets. Its performance sometimes outperforms the performance of the more sophisticated classifiers as discussed in [138–141]. Unlike ZeroR classifier that does not use any features in the prediction and OneR classifier that uses only one feature, the NB classifier uses all the features in the prediction.
NB classifier calculates the posterior probability of the class c given the set of features X={x1, x2,…, xn } as
| (33) |
where P(xi|c) is the probability of the feature xi given the class c and P(c) is the prior probability of the class [135]. Both probabilities can be estimated from the frequency table.
One problem facing the NB classifier is known as the zero-frequency problem. It happens when a combination of a feature and a class has zero frequency. In this case, one is added for every possible combination between features and classes, so no feature-class combination has a zero frequency.
The decision tree (DT) classifier is widely used in breast cancer classification [142–144]. The strength of DT is that it can be translated to a set of rules directly by mapping from the root nodes to the leaf nodes one by one and hence the decision-making process is easy to interpret. DT can be built based on a frequency table. It develops decision nodes and leaf nodes by repetitively dividing the dataset into smaller and smaller subsets until a stopping creation is reached or a pure class with single entry is reached. DTs can handle both categorical or numerical data. The core algorithm for DTs is called ID3, which is a top-down, greedy search algorithm with no backtracking that uses entropy and information gain to divide the subset with dependency assumption between the features [145].
Entropy was introduced in the context of features selection as one of Haralick's texture features earlier. In the ID3 algorithm, entropy has the same meaning as before and it is a measure of homogeneity in the sample. It has the same basic formula of
| (34) |
where S is the current dataset under consideration which changes at each step, X is the set of classes in S, and P(i) is the probability of class i, which can be estimated from the frequency table based on the dataset as the proportion of the number of elements in class x to the number of elements in S. A zero entropy for a dataset indicates a perfect classification.
Information gain is the change of entropy after a dataset is split based on a certain feature, i.e., the reduction of uncertainty in S after splitting it using the feature.
| (35) |
where T is the subsets created by splitting S with F such that S=∪t∈Tt and p(t) is the cardinality of t divided by the cardinality of S.
Overfitting is a significant problem in DTs. Overfitting is the problem of enhancing the prediction based on the training data on the expense of the prediction based on the test data. Prepruning and postpruning are used to avoid overfitting in DTs. In prepruning, the algorithm is stopped earlier before it classifies the training set perfectly while, in postpruning, the algorithm is allowed to perfectly classify the training data but then the tree is postpruned. Postpruning is more successful than prepruning because it is hard to know when exactly to stop the growth of the tree [146].
Linear Discriminant Analysis (LDA) is widely used in analyzing mammograms [51, 147] for breast cancer. LDA is a simple classifier that sometimes produces classification that is as good as the classification of the complex classifiers. It searches for a linear combination Z of features X that best separates two classes c1 and c2 such that
| (36) |
where βi is the coefficient corresponding to feature i and i=1, 2, …, d and d is the number of features. The coefficients are determined such that the score function S(β) in equation (37) is maximized.
| (37) |
where β is a vector of coefficients for the linear model given in equation (36) and can be calculated as
| (38) |
where μ1 and μ2 are the mean vectors of the two classes, and C is pooled covariance matrix given as
| (39) |
where C1, n1, C2, and n2 are covariance matrix for the first class, the number of elements in the first class, the covariance matrix for the second class, and the number of elements for the second class, respectively. A new point x is classified as C1, i.e., class 1, if the inequality (40) stands:
| (40) |
where P(C1) is the first-class probability and P(C2) is the probability of the second class. These probabilities can be estimated from the data.
The logistic regression classifier is another covariance classifier that is used to analyze mammograms for breast cancer prediction [148–151]. It can be used only with binary classification where there are only two classes just like classifying the masses into benign or malignant in a mammogram. It uses categorical and/or numerical features to predict a binary variable (the class either 0 or 1). Linear regression is not appropriate to predict a binary variable because the residuals will not be normal and the linear regression may predict values outside the permissible range, i.e., 0 to 1 while logistic regression can only produce values between 0 and 1 [152].
Logistic regression uses the natural logarithm of the odds of the class variable. The logistic regression equation is written in terms of the odd ration as in
| (41) |
where p is the logistic model predicted probability, and b0, b1,…, bn are the estimations of the coefficients in the logistic regression model for the n features, i.e., x's [151, 153]. The estimation of the model coefficients is carried out using maximum likelihood estimation. The predicted probability p by the logistic model can be calculated as
| (42) |
One way to do classification is to calculate p for the data instance, and if its probability is below 0.5, it will be assigned to class 1, and if it is above or equal to 0.5, it will be assigned to class 2.
K nearest neighbors (KNN) classifier is used in literature to diagnose mammograms [154–157]. This classifier is a type of majority vote and a nonparametric classifier based on a similarity function. It stores all available cases and then classifies a new data instance based on its similarity to other points in the nearest K classes measured by distance. If K=1, then the new data instance will be assigned to the nearest neighbor's class. Generally speaking, increasing the number of classes, i.e., the value of K, increases the precision as it reduces the overall noise. Cross-validation is one way to determine the best value of K by using an independent dataset to validate the value of K. Also, the cross-validation technique can reduce the variance in the test error estimate calculations. A good practice is to have K between 3 and 10.
There are three well-known distance functions used in KNN classifier [158] for continuous features: Euclidean, Manhattan, and Minkowski distance functions. Their equations are as in
| (43) |
where k is the number of features, xi is the value of feature i for object x, yi is the value of feature i for object y, and q is the order of the Minkowski metric.
These three distances are valid for continuous features only. If the features are categorical, the Hamming distance given in equation (44) is used, which basically measures the number of mismatches between two vectors.
| (44) |
If features are mixed, then numerical features should be standardized between 0 and 1 before the distance is calculated.
There are three types of classifiers that are not based on the frequency table, covariance matrix, or similarity functions. These classifiers are support vector machines, artificial neural networks, and recently deep learning.
Support vector machines (SVM) classifier is first proposed by [159] and is used extensively in breast cancer detection and diagnosis using mammograms [160–166].
A linear SVM classifies a linearly separable data by constructing a linear hyperplane in N-dimensional feature space (N is the number of features) to maximize the margin distance between two classes [160]. Figure 3 shows a linear hyperplane for 2-dimensional feature space, the support vectors, and the marginal width for a linear SVM [167].
Figure 3.
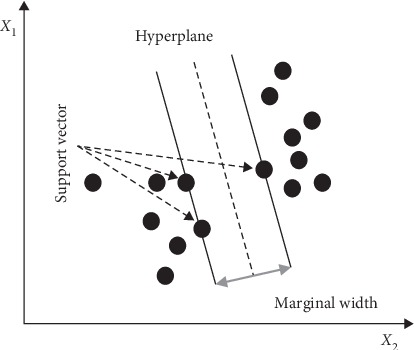
Support vectors, hyperplane, and marginal width with SVM [167].
If the data is not linearly separable, it is mapped into higher-dimensional feature space by various nonlinear mapping functions like sigmoid and radial basis functions. The strength of the SVM classifier is that it does not need to have a priori density functions between the input and the output like some other classifiers and this is very important because, in practice, these prior densities are not known and there are not enough data to estimate them precisely.
The linear SVM classifier uses the training data to find the weight vector w=[w1, w2, …, wn]T and the bias b for the decision function [161, 168] in
| (45) |
The optimal hyperplane is the hyperplane that satisfies d(X, w, b)=0.
In the testing phase, a vector y is created such that
| (46) |
Equation (46) is used to classify a new point Xnew such that if y(Xnew) is positive, then Xnew belongs to class 1 and to class 2 otherwise.
The weight vector w and the bias b are found by minimizing the following model:
| (47) |
where H is the Hessian matrix given by
| (48) |
and f is a unit vector. The values of α0i can be determined by solving the dual optimization problem in equation (47). These values are used to find the values of w and b as follows:
| (49) |
where N is the number of support vectors.
As mentioned before, for nonlinearly separable data, the data has to be mapped to a higher-dimensional feature space first using a suitable nonlinear mapping function φ(x). A kernel function K(xi, xj) that maps the data into a very high-dimensional feature space is defined as
| (50) |
and the hyperplane is defined as
| (51) |
The SVM produced in model (47) is called a hard margin classifier. Soft margin classifier can be produced with the same model (47) but with adding an additional constraint 0 ≤ αi ≤ C, where C is defined by the user. Soft margin SVM is preferred over the hard SVM to preserve the smoothness of the hyperplane [161].
One other classifier used extensively in detecting cancer in mammograms is the artificial neural network (ANN). This classifier is imitating the biological neural network, such as the brain. The biological neural network consists of a tremendous amount of connected neurons through a junction called synapses. Each neuron is connected to thousands of other neurons and receives signals from them. If the sum of these signals exceeds a certain threshold, a response is sent through the axon. ANN imitates this setup. In an ANN, the neurons are called nodes and these nodes are connected to each other. The strength of the connections is represented by weights such that the weight between two nodes represents the strength of the connection between them. Figure 4 shows the generic structure for ANN in mammography where the network receives the features at the input nodes and provides the predicted class at the output node [169].
Figure 4.
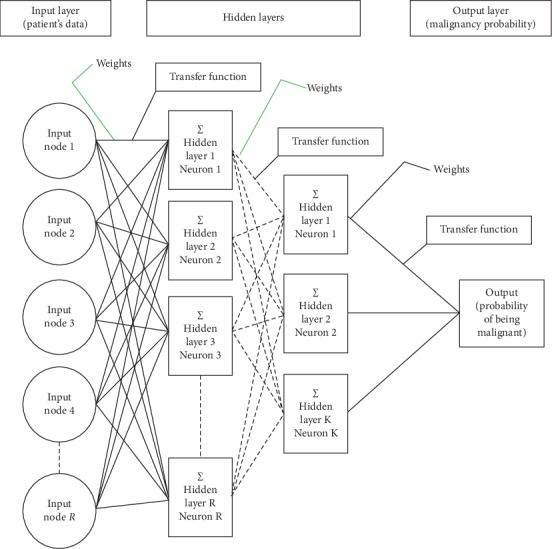
Structure of ANN for typical breast cancer detection using mammogram [169].
The inhabitation occurs when the weight is -1 and the excitation occurs when the weight is 1. Within each node's design, a transfer function is introduced [169]. The most used transfer functions are a unit step function, sigmoid function, Gaussian function, linear function, and a piecewise linear function. ANN usually has three layers of nodes: an input layer, a hidden layer, and an output layer.
ANNs have certain traits that make them suit breast cancer detection and diagnosis using mammograms. They are capable of learning complicated patterns [170, 171], they can handle missing data [172], and they are accurate classifiers [173–175]. In breast cancer detection and diagnosis using mammograms, the nodes of the input layer usually represent the features extracted from the region of interest (ROI) and the node in the output layer represents the class (either malignant or benign). The nodes of the input layer receive activation values as numeric information such that the higher the information, the greater the activation. The activation value is passed from node to node based on the weights and the transfer function such that each node sums the activation values that it receives and then modifies the sum based on its transfer function. The activation spread out in the network from the input layer nodes to the output layer node through the hidden layer where the output node represents the results in a meaningful way. The network learns through gradient descent algorithm where the error between the predicted value and the actual value is propagated backward by apportioning them to each node's weights according to the amount of this error the node is responsible for [176].
A deep learning (DL) or hierarchical learning classifier is a subset of machine learning that uses networks to simulate humanlike decision making based on the layers used in ANN. Unlike other machine learning techniques discussed until now, DL classifiers do not need features selection and extraction step as they adaptively learn the appropriate features extraction process from the input data with respect to the target output [177]. This is considered a big advantage for DL classifiers as the features selection and extraction step is challenging in most cases. For an image classification problem, the DL classifier needs three things to work properly: a large number of labeled images, neural network structure with many layers, and high computational power. It can reach high classification accuracy [178]. The most common type of DL architecture used to analyze images is Convolution Neural Network (CNN).
Different types of CNN were proposed recently to deal with breast cancer detection and diagnosis using mammograms problem [20, 166, 179–186]. For example, the VGG16 network is a deep CNN used to detect and diagnose lesions in mammograms. VGG16 consists of 16 layers with the final layer capable of detecting two kinds of lesions (benign and malignant) in the mammogram [186, 187]. VGG16 encloses each detected lesion with a box and attaches a confidence level in the predicted class for each detected lesion. Faster R-CNN is also a deep CNN used in breast cancer detection and diagnosis using mammograms. The basic Faster R-CNN is based on a convolutional neural network with an additional layer on the last convolutional layer called Region Proposal Network to detect, localize, and classify lesions. It uses various boxes with different sizes and aspect ratios to detect objects with different sizes and shapes [185]. A fast microcalcification detection and segmentation procedure utilizing two CNNs was developed in [186]. One of the CNNs was used for quick detection of candidate regions of interest and the other one was used to segment them. A context-sensitive deep neural network (DNN) is another CNN for detecting and diagnosing breast cancer using mammograms [188]. DNN takes into consideration both the local image features of a microcalcification and its surrounding tissues such that the DNN classifier automatically extracts the relevant features and the context of the mammogram. Handcraft descriptors and deep learning descriptors were used to characterize the microcalcification in mammograms [189]. The results showed that the deep learning descriptors outperformed the handcraft features. Pretrained ResNet-50 architecture and Class Activation Map technique along with Global Average Pooling for object localization were used in [190] to detect and diagnose breast cancer in mammograms. The results showed an area under the ROC of 0.96. A recent comprehensive technical review on the convolutional neural network applied to breast cancer detection and diagnosis using mammograms is found in [191].
To overcome the problem of overfitting in machine learning techniques such as DL and CNN, data augmentation techniques were used to generate artificial data by applying several transformations techniques to the actual data such as flipping, rotations, jittering, and random scaling to the actual data. Data augmentation is a very powerful method for overcoming overfitting. The augmented data represents a more complete set of data points. This will minimize the variance between the training and validation sets and any future testing sets. Data augmentation has been used in many studies along with DL and CNN such as [192–196].
It is well established among the scholars who work on the problem of breast cancer detection and diagnosis using mammograms and on classification problems in general that there is no “one size fits all” classifier. The classifier who is trained on a certain dataset and certain features space may not work with the same efficacy on other datasets. This problem is rooted in the “No Free Lunch Theorem” coined in [197]. “No Free Lunch Theorem” showed that there are no a priori differences between learning algorithms when it comes to an off-training-set error in a noise-free scenario where the loss function is the misclassification rate [197]. Therefore, each classifier has its own advantages and disadvantages based on the feature space and dataset used for learning [198]. For example, the features come in different representations like continuous, categorical, or binary variables and the features may have different physical meanings like energy, entropy, or size. Lump sums these diverse features into one features vector and then uses a single classifier that requires normalizing these features first, which is a tedious job. It may be easier to aggregate those features that share the same characteristics in terms of representation and physical meaning into several homogenous features vectors and then apply a different classifier to each vector separately. Moreover, even if the features are homogeneous in terms of representation and physical meaning but the number of features is large with a small number of training data points, then the estimation of the classifier parameters degrades as a result of the curse of dimensionality and peaking phenomena discussed earlier [118–120].
Because of this, scholars can improve their classification accuracy by combining outputs from different classifiers through a combining schema. From an implementation point of view, combination topologies can be categorized into multiple, conditional, hierarchical, or hybrid topologies [199]. For a thorough discussion of combinational topologies, one can consult [200, 201]. A combining schema includes a rule to determine when a certain classifier should be invoked and how each classifier interacts with other classifiers in the combination [78, 202]. The majority votes and weighted majority votes are two widely used combining schemas in literature. In majority votes, all classifiers have the same vote weight and the test instance will have the class that has the highest number of votes from different classifiers, i.e., the class that is predicted by the majority of the classifiers used in the combination. In majority votes, the classifiers have to be independent [78] as it has been shown that using majority votes with a combination of dependent classifiers will not improve the overall classification performance [203]. In weighted majority votes, each classifier has its own weight that will be changed according to its efficacy such that the weight will be decreased every time the classifier has a wrong class. The test instance will be classified according to the highest weighted majority class [203, 204].
Boosting and Bagging are also used to improve the accuracy of classification results. They were used successfully to improve the accuracy of the classifiers, like the DT classifier, by combining several classification results from the training data. Bagging combines classification results from different classifiers or from the same classifier using different subsets of training data, which is usually generated by bootstrapping. The main advantage of bootstrapping is to reduce the number of training datasets used. Bootstrapping resamples the same training dataset to create different training datasets that can be used with different classifiers or the same classifier. Bagging uses bootstrapping to create different datasets from one dataset. Bagging can be viewed as a voting combining technique and it has been implemented with majority voting or weighted majority voting such that the prediction is the class that has the majority votes or the weighted majority votes from different classifiers (or same classifier) with different training subsets. Bagging was used in the context of breast cancer detection using mammograms in several manuscripts like [205, 206]. Boosting technique attaches weights to different instances of training data such that lower weights are given to instances that were frequently classified correctly and higher weights for those who were frequently misclassified; therefore, these classes will be selected more frequently in the resampling to improve their performance. This is followed by another iteration of computing weights and this sequence is repeated until a termination condition is reached. The most popular version of boosting techniques is AdaBoost (stands for Adaptive Boosting) algorithm [207–209] which classifies the data instance as a weighted sum of the output of other weak classifiers. It is considered adaptive because the weights of the weak classifiers are changed adaptively based on their performance.
Table 1 shows a list of some common classifiers and their performance measures by the area under the receiver operating characteristic ROC curve registered in the respective papers where they were proposed/used.
Table 1.
The area under the ROC for some common classification techniques for mammograms.
| Method | Area under ROC |
|---|---|
| Binary decision tree [210] | 0.90 |
| Linear classifier [210] | 0.90 |
| PCA–LS SVM [211] | 0.94 |
| ANN [212] | 0.88 |
| Multiple expert system [213] | 0.79 |
| Texture measure with ANN [214] | 0.87 |
| Multiresolution texture analysis [215] | 0.86 |
| Subregion Hotelling observers [216] | 0.94 |
| Logistic regression [217] | 0.81 |
| KNN [218] | 0.82 |
| NB [219] | 0.56 |
| DL [190] | 0.96 |
| Genetic algorithms with SVM [220] | 0.97 |
For the sake of completeness, Table 2 shows a list of common databases used in CAD-related techniques. It should be noticed that the acquisition protocol of these databases normally must be rigorous and they are expensive.
Table 2.
List of common databases used in CAD-related techniques.
5. Conclusions
In this study, we shed some light on CAD methods used in breast cancer detection and diagnosis using mammograms. We reviewed the different methods used in literature in the three major steps of the CAD system, which include preprocessing and enhancement, feature extraction, and selection and classification.
Studies reviewed in this article have shown that computer-aided detection and diagnosis of breast cancer from mammograms is limited by the low contrast between normal glandular breast tissues and malignant ones and between the cancerous lesions and the background, especially in dense breasts tissue. Moreover, quantum noise also reduces mammogram quality especially for small objects with low contrast such as a small tumor in a dense breast. The presence of noise in a mammogram gives it a grainy appearance, which reduces the visibility of some features within the image especially for small objects with low contrast. A wide range of histogram equalization techniques, among other techniques, were used in many articles for image enhancement to reduce the effect of low contrast by changing the intensity of the pixels for the input image. Different filters were proposed and used to reduce noises in mammograms such as Wiener filter and Bayesian estimator.
Morphological features were widely used by scholars to distinguish between benign and malignant masses. Benign masses are characterized by smooth, circumscribed, macrolobulated, and well-defined contours, while malignant masses are vague, irregular, microlobulated, and spiculated contours. Differential analysis was also used to compare the prior mammographic image with the most current one to find if the suspicious masses have changed in size or shape. The bilateral analysis is also used to compare the left and right mammograms to see any unusual differences between the left breast and right breast.
Table 1 gives a rough estimation of the average performance of the different CAD methods used and measured as the area under the ROC curve, which is about 0.86. This performance is encouraging but still not reliable enough to accept CAD systems as a standalone clinical procedure to detect and diagnose breast cancer using mammograms. Moreover, many results that were reported in the literature with excellent performance in cancer detection using CAD systems cannot be generalized as their analyses were conducted and tuned using a specific dataset. Therefore, unless a higher performance is reached with CAD systems by exploiting new promising methods like deep learning and higher computational power systems, CAD systems can only be used as a second opinion clinical procedure.
Acknowledgments
The author is grateful to the German Jordanian University, Mushaqar, Amman, Jordan, for the financial support granted to this research.
Conflicts of Interest
The author declares that there are no conflicts of interest regarding the publication of this paper.
References
- 1.Hejmadi M. Introduction to Cancer Biology. 2nd. London, UK: Bookboon; 2010. [Google Scholar]
- 2.American Cancer Society. Breast Cancer Facts and Figures 2017-2018. Atlanta, GA, USA: American Cancer Society; 2017. [Google Scholar]
- 3.American Cancer Society. Breast Cancer Facts and Figures 2019. Atlanta, GA, USA: American Cancer Society; 2019. [Google Scholar]
- 4.Ginsburg O., Bray F., Coleman M. P., et al. The global burden of women’s cancers: a grand challenge in global health. The Lancet. 2017;389(10071):847–860. doi: 10.1016/s0140-6736(16)31392-7. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 5.Eric J., Wun L. M., Boring C. C., Flanders W., Timmel J., Tong T. The lifetime risk of developing breast cancer. Journal of the National Cancer Institute. 1993;85(11):892–897. doi: 10.1093/jnci/85.11.892. [DOI] [PubMed] [Google Scholar]
- 6.Sirovich B. E., Sox H. C. Breast cancer screening. Surgical Clinics of North America. 1999;79(5):961–990. doi: 10.1016/S0039-6109(05)70056-6. [DOI] [PubMed] [Google Scholar]
- 7.Rangayyan R. M., Ayres F. J., Leo Desautels J. E. A review of computer-aided diagnosis of breast cancer: toward the detection of subtle signs. Journal of the Franklin Institute. 2007;344(3-4):312–348. doi: 10.1016/j.jfranklin.2006.09.003. [DOI] [Google Scholar]
- 8.Helms R. L., O’Hea E. L., Corso M. Body image issues in women with breast cancer. Psychology, Health and Medicine. 2008;13(3):313–325. doi: 10.1080/13548500701405509. [DOI] [PubMed] [Google Scholar]
- 9.“Mayo clinic. 2019. https://www.mayoclinic.org/diseases-conditions/breast-cancer/diagnosis-treatment/drc-20352475.
- 10.Njor S., Nyström L., Moss S., et al. Breast cancer mortality in mammographic screening in Europe: a review of incidence-based mortality studies. Journal of Medical Screening. 2012;19(1_suppl):33–41. doi: 10.1258/jms.2012.012080. [DOI] [PubMed] [Google Scholar]
- 11.Morrell S., Taylor R., Roder D., Dobson A. Mammography screening and breast cancer mortality in Australia: an aggregate cohort study. Journal of Medical Screening. 2012;19(1):26–34. doi: 10.1258/jms.2012.011127. [DOI] [PubMed] [Google Scholar]
- 12.Independent UK Panel on Breast Cancer Screening. The benefits and harms of breast cancer screening: an independent review. The Lancet. 2012;380(9855):1778–1786. doi: 10.1016/s0140-6736(12)61611-0. [DOI] [PubMed] [Google Scholar]
- 13.Pisano E. D., Gatsonis C., Hendrick E., et al. Diagnostic performance of digital versus film mammography for breast-cancer screening. New England Journal of Medicine. 2005;353(17):1773–1783. doi: 10.1056/NEJMoa052911. [DOI] [PubMed] [Google Scholar]
- 14.Carney P. A., Miglioretti D. L., Yankaskas B. C., et al. Individual and combined effects of age, breast density, and hormone replacement therapy use on the accuracy of screening mammography. Annals of Internal Medicine. 2003;138(3):168–175. doi: 10.7326/0003-4819-138-3-200302040-00008. [DOI] [PubMed] [Google Scholar]
- 15.Woodard D. B., Gelfand A. E., Barlow W. E., Elmore J. G. Performance assessment for radiologists interpreting screening mammography. Statistics in Medicine. 2007;26(7):1532–1551. doi: 10.1002/sim.2633. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 16.Cole E. B., Pisano E. D., Kistner E. O., et al. Diagnostic accuracy of digital mammography in patients with dense breasts who underwent problem-solving mammography: effects of image processing and lesion type. Radiology. 2003;226:153–160. doi: 10.1148/radiol.2261012024. [DOI] [PubMed] [Google Scholar]
- 17.Boyd N. F., Guo H., Martin L. J., et al. Mammographic density and the risk and detection of breast cancer. New England Journal of Medicine. 2007;356(3):227–236. doi: 10.1056/NEJMoa062790. [DOI] [PubMed] [Google Scholar]
- 18.Bird R. E., Wallace T. W., Yankaskas B. C. Analysis of cancers missed at screening mammography. Radiology. 1992;184(3):613–617. doi: 10.1148/radiology.184.3.1509041. [DOI] [PubMed] [Google Scholar]
- 19.Kerlikowske K., Carney P. A., Geller B., et al. Performance of screening mammography among women with and without a first-degree relative with breast cancer. Annals of Internal Medicine. 2000;133(11):855–863. doi: 10.7326/0003-4819-133-11-200012050-00009. [DOI] [PubMed] [Google Scholar]
- 20.Ertosun M. G., Rubin D. L. Probabilistic visual search for masses within mammography images using deep learning. Proceedings of the IEEE International Conference on Bioinformatics and Biomedicine (BIBM); November 2015; Washington, DC, USA. [Google Scholar]
- 21.Nunes F. L., Schiabel H., Goes C. E. Contrast enhancement in dense breast images to aid clustered microcalcifications detection. Journal of Digital Imaging. 2007;20(1):53–66. doi: 10.1007/s10278-005-6976-5. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 22.Maskarinec G., Pagano I., Chen Z., Nagata C., Gram I. T. Ethnic and geographic differences in mammographic density and their association with breast cancer incidence. Breast Cancer Research and Treatment. 2007;104(1):47–56. doi: 10.1007/s10549-006-9387-5. [DOI] [PubMed] [Google Scholar]
- 23.Nelson H. D., Tyne K., Naik A., et al. Screening for breast cancer: an update for the US preventive services task force. Annals of Internal Medicine. 2009;151(10):727–737. doi: 10.7326/0003-4819-151-10-200911170-00009. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 24.Sampat M. P., Markey M. K., Bovik A. C. Handbook of Image and Video Processing. London, UK: Elsevier; 2003. Computer-aided detection and diagnosis in mammography. [Google Scholar]
- 25.Jesneck J. L., Lo J. Y., Baker J. A. Breast mass lesions: computer-aided diagnosis models with mammographic and sonographic descriptors. Radiology. 2007;244(2):390–398. doi: 10.1148/radiol.2442060712. [DOI] [PubMed] [Google Scholar]
- 26.Dinnes J., Moss S., Melia J., Blanks R., Song F., Kleijnen J. Effectiveness and cost-effectiveness of double reading of mammograms in breast cancer screening: findings of a systematic review. The Breast. 2009;10(6):455–463. doi: 10.1054/brst.2001.0350. [DOI] [PubMed] [Google Scholar]
- 27.Warren R., Duffy W. Comparison of single reading with double reading of mammograms, and change in effectiveness with experience. The British Journal of Radiology. 1995;68(813):958–962. doi: 10.1259/0007-1285-68-813-958. [DOI] [PubMed] [Google Scholar]
- 28.Blanks R. G., Wallis M. G., Moss S. M. A comparison of cancer detection rates achieved by breast cancer screening programmes by number of readers, for one and two view mammography: results from the UK National Health Service breast screening programme. Journal of Medical Screening. 1998;5(4):195–201. doi: 10.1136/jms.5.4.195. [DOI] [PubMed] [Google Scholar]
- 29.Posso M., Carles M., Rué M., Puig T., Bonfill X. Cost-effectiveness of double reading versus single reading of mammograms in a breast cancer screening programme. PLoS One. 2016;11(7) doi: 10.1371/journal.pone.0159806.e0159806 [DOI] [PMC free article] [PubMed] [Google Scholar]
- 30.Gur D., Sumkin J. H., Rockette H. E., et al. Changes in breast cancer detection and mammography recall rates after the introduction of a computer-aided detection system. JNCI Journal of the National Cancer Institute. 2004;96(3):185–190. doi: 10.1093/jnci/djh067. [DOI] [PubMed] [Google Scholar]
- 31.Doi K. Computer-aided diagnosis in medical imaging: achievements and challenges. Proceedings of the World Congress on Medical Physics and Biomedical Engineering; 2009; Munich, Germany. [Google Scholar]
- 32.Balleyguier C., Kinkel K., Fermanian J., et al. Computer-aided detection (CAD) in mammography: does it help the junior or the senior radiologist? European Journal of Radiology. 2005;54(1):90–96. doi: 10.1016/j.ejrad.2004.11.021. [DOI] [PubMed] [Google Scholar]
- 33.Sanchez Gómez S., Torres Tabanera M., Vega Bolivar A., et al. Impact of a CAD system in a screen-film mammography screening program: a prospective study. European Journal of Radiology. 2011;80(3):e317–e321. doi: 10.1016/j.ejrad.2010.08.031. [DOI] [PubMed] [Google Scholar]
- 34.Malich A., Azhari T., Böhm T., Fleck M., Kaiser W. Reproducibility—an important factor determining the quality of computer aided detection (CAD) systems. European Journal of Radiology. 2000;36(3):170–174. doi: 10.1016/s0720-048x(00)00189-3. [DOI] [PubMed] [Google Scholar]
- 35.Marx C., Malich A., Facius M., et al. Are unnecessary follow-up procedures induced by computer-aided diagnosis (CAD) in mammography? Comparison of mammographic diagnosis with and without use of CAD. European Journal of Radiology. 2004;51(1):66–72. doi: 10.1016/s0720-048x(03)00144-x. [DOI] [PubMed] [Google Scholar]
- 36.Giger M. L., Karssemeijer N., Armato S. G. Computer aided diagnosis in medical imaging. IEEE Transactions on Medical Imaging. 2001;20(12):1205–1208. doi: 10.1109/tmi.2001.974915. [DOI] [PubMed] [Google Scholar]
- 37.Giger M. L. Computer-aided diagnosis of breast lesions in medical images. Computer Science & Engineering. 2000;2(5):39–45. [Google Scholar]
- 38.Freer T. W., Ulissey M. J. Screening mammography with computer-aided detection: prospective study of 12,860 patients in a community breast center. Radiology. 2001;220(3):781–786. doi: 10.1148/radiol.2203001282. [DOI] [PubMed] [Google Scholar]
- 39.Sampat M. P., Markey M. K., Bovik A. C. Handbook of Image and Video Processing. Vol. 2. Cambridge, MA, USA: Academic Press; 2005. Computer-aided detection and diagnosis in mammography; pp. 1195–1217. [Google Scholar]
- 40.Zhang W., Doi K., Giger M. L., Wu Y., Nishikawa R. M., Schmidt R. A. Computerized detection of clustered microcalcifications in digital mammograms using a shift-invariant artificial neural network. Medical Physics. 1994;21(4):517–524. doi: 10.1118/1.597177. [DOI] [PubMed] [Google Scholar]
- 41.Mousa R., Munib Q., Moussa A. Breast cancer diagnosis system based on wavelet analysis and fuzzy-neural. Expert Systems with Applications. 2005;28(4):713–723. doi: 10.1016/j.eswa.2004.12.028. [DOI] [Google Scholar]
- 42.Rizzi M., D’Aloia M., Castagnolo B. Health care CAD systems for breast microcalcification cluster detection. Journal of Medical and Biological Engineering. 2012;32:147–156. [Google Scholar]
- 43.Islam M. J., Ahmadi M., Sid-Ahmed M. A. Computer-aided detection and classification of masses in digitized mammograms using artificial neural network. Proceedings of the Advances in Swarm Intelligence: First International Conference, ICSI 2010; 2010; Beijing, China. pp. 327–334. [DOI] [Google Scholar]
- 44.Kozegar E., Soryani M., Minaei B., Domingues I. Assessment of a novel mass detection algorithm in mammograms. Journal of Cancer Research and Therapeutics. 2013;9(4):592–600. doi: 10.4103/0973-1482.126453. [DOI] [PubMed] [Google Scholar]
- 45.Jalalian A., Mashohor S., Mahmud R., Karasfi B., Saripan M. I. B., Ramli A. R. B. Foundation and methodologies in computer-aided diagnosis systems for breast cancer detection. EXCLI Journal. 2017;16:113–137. doi: 10.17179/excli2016-701. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 46.Oliver A., Freixenet J., Martí J., et al. A review of automatic mass detection and segmentation in mammographic images. Medical Image Analysis. 2010;14(2):87–110. doi: 10.1016/j.media.2009.12.005. [DOI] [PubMed] [Google Scholar]
- 47.Pisano E. D., Yaffe M. J., Kuzmiak C. M. Digital Mammography. Philadelphia, PA, USA: Lippincott Williams and Wilkins; 2004. [Google Scholar]
- 48.Peitgen H. O. Digital mammography. Proceedings of the IWDM 2002-6th International Workshop on Digital Mammography; 2003; Bremen, Germany. Springer-Verlag; [Google Scholar]
- 49.Doi K., MacMahon H., Katsuragawa S., Nishikawa R. M., Jiang Y. Computer-aided diagnosis in radiology: potential and pitfalls. European Journal of Radiology. 1999;31(2):97–109. doi: 10.1016/s0720-048x(99)00016-9. [DOI] [PubMed] [Google Scholar]
- 50.Vyborny C. J., Giger M. L., Nishikawa R. M. Computer aided detection and diagnosis of breast cancer. Radiologic Clinics of North America. 2000;38(4):725–740. doi: 10.1016/s0033-8389(05)70197-4. [DOI] [PubMed] [Google Scholar]
- 51.Suhail Z., Denton E. R. E., Zwiggelaar R. Classification of micro-calcification in mammograms using scalable linear fisher discriminant analysis. Medical & Biological Engineering & Computing. 2018;56(8):1475–1485. doi: 10.1007/s11517-017-1774-z. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 52.Scharcanski J., Jung C. R. Denoising and enhancing digital mammographic images for visual screening. Computerized Medical Imag. Graphics. 2006;30(4):243–254. doi: 10.1016/j.compmedimag.2006.05.002. [DOI] [PubMed] [Google Scholar]
- 53.The web-based edition of the physical principles of medical imaging. 2019. http://www.sprawls.org/ppmi2/
- 54.Pisano E. D., Cole E. B., Hemminger B. M., et al. Image processing algorithms for digital mammography: a pictorial essay. Radiographics. 2000;20(5):1479–1491. doi: 10.1148/radiographics.20.5.g00se311479. [DOI] [PubMed] [Google Scholar]
- 55.Jamal N., Ng K. H., McLean D. A study of mean glandular dose during diagnostic mammography in Malaysia and some of the factors affecting it. The Bristish Journal of Radiology. 2003;76(904):238–245. doi: 10.1259/bjr/66428508. [DOI] [PubMed] [Google Scholar]
- 56.Jamal N., Ng K.-H., McLean D., Looi L.-M., Moosa F. Mammographic breast glandularity in Malaysian women derived from radiographic data. American Journal of Roentgenology. 2004;182:713–717. doi: 10.2214/ajr.182.3.1820713. [DOI] [PubMed] [Google Scholar]
- 57.Gonzalez R. C., Woods R. E. Digital Image Processing. 2nd. Upper Saddle River, NJ, USA: Prentice-Hall; 2002. [Google Scholar]
- 58.Kim Y.-T. Contrast enhancement using brightness preserving bi-histogram equalization. IEEE Transactions on Consumer Electronics. 1997;43:1–8. [Google Scholar]
- 59.Zuo C., Chen Q., Sui X. Range limited bi-histogram equalization for image contrast enhancement. Optik. 2013;124(5):425–431. doi: 10.1016/j.ijleo.2011.12.057. [DOI] [Google Scholar]
- 60.Wang Y., Chen Q., Zhang B. Image enhancement based on equal area dualistic subimage histogram equalization method. IEEE Transactions on Consumer Electronics. 1999;45:68–75. [Google Scholar]
- 61.Shannon C. A mathematical theory of communication. The Bell System Technical Journal. 1948;27(3):379–423. [Google Scholar]
- 62.Ooi C. H., Kong N., Ibrahim H. Bi-histogram equalization with a plateau limit for digital image enhancement. IEEE Transactions on Consumer Electronics. 2009;55(4):2072–2080. doi: 10.1109/tce.2009.5373771. [DOI] [Google Scholar]
- 63.Ooi C. H., Isa N. Adaptive contrast enhancement methods with brightness preserving. IEEE Transactions on Consumer Electronics. 2010;56(4):2543–2551. doi: 10.1109/tce.2010.5681139. [DOI] [Google Scholar]
- 64.Singh K., Kapoor R. Image enhancement via median-mean based sub-image-clipped histogram equalization. Optik—International Journal for Light and Electron Optics. 2014;125(17):4646–4651. doi: 10.1016/j.ijleo.2014.04.093. [DOI] [Google Scholar]
- 65.Chen S.-D., Ramli A. R. Minimum mean brightness error bi-histogram equalization in contrast enhancement. IEEE Transactions on Consumer Electronics. 2003;49(4):1310–1319. doi: 10.1109/tce.2003.1261234. [DOI] [Google Scholar]
- 66.Lerski R. A., Straughan K., Schad L. R., Boyce D., Bluml S., Zuna I. MR image texture analysis—an approach to tissue characterization. Magnetic Resonance Imaging. 1993;11(6):873–887. doi: 10.1016/0730-725x(93)90205-r. [DOI] [PubMed] [Google Scholar]
- 67.Haralick R. M., Shanmugan K., Dinstein I. Textural features for image classification. IEEE transactions on systems: man, and cybernetics SMC. 1973;3(6):610–621. [Google Scholar]
- 68.Simoncelli E. P., Adelson E. H. Noise removal via bayesian wavelet coring. Proceedings of 3rd IEEE International Conference on Image Processing; September 1996; Lausanne, Switzerland. pp. 379–382. [DOI] [Google Scholar]
- 69.Mallat S. G. A theory for multiresolution signal decom-position: the wavelet representation. IEEE Transactions on Pattern Analysis and Machine Intelligence. 1989;11:674–693. [Google Scholar]
- 70.Mozammel Hoque Chowdhury M., Khatun A. Image compression using discrete wavelet transform. IJCSI International Journal of Computer Science. 2012;9(1) [Google Scholar]
- 71.Dhawan A. P., Chitre Y., Kaiser-Bonasso C. Analysis of mammographic microcalcifications using gray-level image structure features. IEEE Transactions on Medical Imaging. 1996;15(3):246–259. doi: 10.1109/42.500063. [DOI] [PubMed] [Google Scholar]
- 72.Minarno A. E., Munarko Y., Kurniawardhani A., Bimantoro F., Suciati N. Texture feature extraction using co-occurrence matrices of sub-band image for batik image classification. Proceedings of the 2014 2nd International Conference on Information and Communication Technology (ICoICT); 2014; Bandung, Indonesia. pp. 249–254. [Google Scholar]
- 73.Yoshida H., Wei Z., Cai W., Doi K., Nishikawa R. M., Giger M. L. Optimizing wavelet transform based on supervised learning for detection of microcalcifications in digital mammograms. Proceedings of the International Conference Image Processing; October 1995; Washington, DC, USA. pp. 152–155. [DOI] [Google Scholar]
- 74.Heinlein P., Drexl J., Schneider W. Integrated wavelets for enhancement of microcalcifications in digital mammography. IEEE Transactions on Medical Imaging. 2003;22(3):402–413. doi: 10.1109/TMI.2003.809632. [DOI] [PubMed] [Google Scholar]
- 75.Kobatake H., Murakami M., Takeo H., Nawano S. Computerized detection of malignant tumors on digital mammograms. IEEE Transactions on Medical Imaging. 1999;18(5):369–378. doi: 10.1109/42.774164. [DOI] [PubMed] [Google Scholar]
- 76.Watanabe S. Pattern Recognition: Human and Mechanical. New York, NY, USA: Wiley; 1985. [Google Scholar]
- 77.Bishop C. M. Pattern Recognition and Machine Learning. Berlin, Germany: Springer; 2006. [Google Scholar]
- 78.Jain A. K., Duin R. P. W., Mao J. C. Statistical pattern recognition: a review. IEEE Transactions on Pattern Analysis and Machine Intelligence. 2000;22(1):4–37. doi: 10.1109/34.824819. [DOI] [Google Scholar]
- 79.Sameti M., Ward R. K., Morgan-Parkes J., Palcic B. Image feature extraction in the last screening mammography prior to detection of breast cancer. IEEE Journal of Selected Topics in Signal Processing. 2011;3(1):46–52. [Google Scholar]
- 80.Hupes R., Karssemeijer N. Use of normal tissue context in computer-aided detection of masses in mammograms. IEEE Transactions on Medical Imaging. 2010;28(12):2033–2041. doi: 10.1109/TMI.2009.2028611. [DOI] [PubMed] [Google Scholar]
- 81.Lambrou A., Papadopoulos H., Gammerman A. Evolutionary conformal prediction for breast cancer diagnosis. Proceedings of the IEEE 9th International Conference on Information Technology and Applications in Biomedicine; 2011; Los Alamitos, CA, USA. pp. 1–4. [Google Scholar]
- 82.Gao X., Wang Y., Li X., Tao D. On combining morphological component analysis and concentric morphology model for mammographic mass detection. IEEE Transactions on Information Technology in Biomedicine. 2011;14(2):266–273. doi: 10.1109/TITB.2009.2036167. [DOI] [PubMed] [Google Scholar]
- 83.Webb A. R. Statistical Pattern Recognition. 2nd. New York, NY, USA: Wiley; 2002. [Google Scholar]
- 84.Theodoridis S., Koutroumbas K. Pattern Recognition. 3rd. New Providence, NJ, USA: Elsevier; 2006. [Google Scholar]
- 85.Devroye L., Gyorfi L., Lugosi G. A Probabilistic Theory of Pattern Recognition. Berlin, Germany: Springer-Verlag; 1996. [Google Scholar]
- 86.Duda R. O., Hart P. E. Pattren Classification and Scene Analysis. New York, NY, USA: John Wiley & Sons; 1973. [Google Scholar]
- 87.Karssemeijer N., Te Brake G. Detection of stellate distortions in mammograms. IEEE Transactions on Medical Imaging. 1996;15(10):611–619. doi: 10.1109/42.538938. [DOI] [PubMed] [Google Scholar]
- 88.Fan G., Xia X.-G. Wavelet-based texture analysis and synthesis using hidden markov models. IEEE Transactions on Circuits and Systems I: Fundamental Theory and Applications. 2003;50(1):106–120. [Google Scholar]
- 89.Kok S. L., Brady J. M., Tarassenko L. The detection of abnormalities in mammograms. Proceedings of the 2nd International Workshop on Digital Mammography; 1994; York, UK. pp. 261–270. [Google Scholar]
- 90.Timp S., Varela C., Karssemeijer N. Temporal change analysis for characterization of mass lesions in mammography. IEEE Transactions on Medical Imaging. 2007;26(7):945–953. doi: 10.1109/TMI.2007. [DOI] [PubMed] [Google Scholar]
- 91.Sidhu S., Raahemifar K. Texture classification using wavelet transform and support vector machines. Proceedings of the 2005 Canadian Conference on Electrical and Computer Engineering; May 2005; Saskatoon, Canada. IEEE; pp. 941–944. [Google Scholar]
- 92.Amroabadi S. H., Ahmadzadeh M. R., Hekmatnia A. Mass detection in mammograms using GA based PCA and Haralick features selection. Proceedings of the 19th Iranian Conference on Electrical Engineering (ICEE); 2011; Tehran, Iran. p. p. 1. [Google Scholar]
- 93.Ke L., Mu N., Kang Y. Mass computer-aided diagnosis method in mammogram based on texture features. Proceedings of the 3rd International Conference on Biomedical Engineering and Informatics (BMEI); 2010; Yantai, China. pp. 354–357. [DOI] [Google Scholar]
- 94.Guliato D., Rangayyan R. M., Carnielli W. A., Zuffo J. A., Desautels J. E. L. Segmentation of breast tumors in mammograms by fuzzy region growing. Proceedings of the 20th Annual International Conference on IEEE Engineering Medicine Biology Society; 1998; Hong Kong, China. [Google Scholar]
- 95.Rangayyan R. M., El-Faramawy N. M., Desautels J. E. L., Alim O. A. Measures of acutance and shape for classification of breast tumours. IEEE Transactions on Medical Imaging. 1997;16(12):799–810. doi: 10.1109/42.650876. [DOI] [PubMed] [Google Scholar]
- 96.Ojala T., Pietikainen M., Maenpaa T. Multiresolution gray-scale and rotation invariant texture classification with local binary patterns. IEEE Transactions on Pattern Analysis and Machine Intelligence. 2002;24(7):971–987. doi: 10.1109/tpami.2002.1017623. [DOI] [Google Scholar]
- 97.Bharati M. H., Liu J., MacGregor J. F. Image texture analysis: methods and comparisons. Chemometrics and intelligent laboratory Systems. 2004;72(1):57–71. doi: 10.1016/j.chemolab.2004.02.005. [DOI] [Google Scholar]
- 98.Zhang J., Tan T. Brief review of invariant texture analysis methods. Pattern Recognition. 2002;35(3):735–747. doi: 10.1016/s0031-3203(01)00074-7. [DOI] [Google Scholar]
- 99.Tou J. Y., Tay Y. H., Lau P. Y. Recent trends in texture classification: a review. Proceedings Symposium on Progress on Information and Communication Technology 2009 (SPICT 2009); 2009; Kuala Lumpur, Malaysia. pp. 63–68. [Google Scholar]
- 100.Mudigonda N. R., Rangayyan R. M., Desautels J. E. L. Gradient and texture analysis for the classification of mammographic masses. IEEE Transactions on Medical Imaging. 2000;19(10):1032–1043. doi: 10.1109/42.887618. [DOI] [PubMed] [Google Scholar]
- 101.Weszka S., Dyer C. R., Rosenfeld A. A comparative study of texture measures for terrain classification. IEEE Transactions on Systems, Man, and Cybernetics. 1976;SMC-6(4):269–285. doi: 10.1109/tsmc.1976.5408777. [DOI] [Google Scholar]
- 102.Siew L. H., Hodgson R. H., Wood E. J. Texture measures for carpet wear asessment. IEEE Transactions on Pattern Analysis and Machine Intelligence. 1988;10(1):92–105. doi: 10.1109/34.3870. [DOI] [Google Scholar]
- 103.Chan H.-P., Sahiner B., Helvie M. A. Improvement of radiologists’ characterization of mammographic masses by using computer-aided diagnosis: an ROC study. Radiology. 1999;212(3):817–827. doi: 10.1148/radiology.212.3.r99au47817. [DOI] [PubMed] [Google Scholar]
- 104.Sahiner B., Heang-Ping C., Petrick N., et al. Classification of mass and normal breast tissue: a convolution neural network classifier with spatial domain and texture images. IEEE Transactions on Medical Imaging. 1996;15(5):598–610. doi: 10.1109/42.538937. [DOI] [PubMed] [Google Scholar]
- 105.Haralick R. M. Statistical and structural approaches to texture. Proceedings of IEEE. 1979;67(5):786–804. doi: 10.1109/proc.1979.11328. [DOI] [Google Scholar]
- 106.Suckling J., Parker J., Dance D., et al. Mammographic image analysis society (MIAS) database v1.21 [dataset] 2015. https://www.repository.cam.ac.uk/handle/1810/250394.
- 107.Wang S. A review of gradient-based and edge-based feature extraction methods for object detection. Proceedings of the 11th IEEE International Conference on Computer and Information Technology, CIT 2011; August 2011; Pafos, Cyprus. pp. 277–282. [DOI] [Google Scholar]
- 108.Hristache M., Juditsky A., Polzehl J., Spokoiny V. Structure adaptive approach for dimension reduction. The Annals of Statistics. 2001;29(6):1537–1566. doi: 10.1214/aos/1015345954. [DOI] [Google Scholar]
- 109.Samarov A. M. Exploring regression structure using nonparametric functional estimation. Journal of the American Statistical Association. 1993;88(423):836–847. doi: 10.1080/01621459.1993.10476348. [DOI] [Google Scholar]
- 110.Ganesan K., Acharya U. R., Chua C. K., Min L. C., Abraham K. T., Ng K. Computer-aided breast cancer detection using mammograms: a review. IEEE Reviews in Biomedical Engineering. 2012;6:77–98. doi: 10.1109/RBME.2012.2232289. [DOI] [PubMed] [Google Scholar]
- 111.Guliato D., Rangayyan R. M., Carvalho J. D., Santiago S. A. Spiculation-preserving polygonal modeling of contours of breast tumors. Proceedings of the 28th International Conference of the IEEE Engineering in Medicine and Biology Society; August 2006; New York, NY, USA. pp. 2791–2794. [DOI] [PubMed] [Google Scholar]
- 112.Cheikhrouhou I., Djemal K., Sellami D., Maaref H., Derbel N. New mass description in mammographies. Proceedings of the Image Processing Theory, Tools and Applications; 2008. [Google Scholar]
- 113.Feig S. A., Yaffe M. J. Digital Mammography, Computer-Aided Diagnosis and Telemammography, The Radiologic Clinics of North America. Vol. 33. Breast Imaging Press; 1995. [PubMed] [Google Scholar]
- 114.Domínguez A. R., Nandi A. K. Toward breast cancer diagnosis based on automated segmentation of masses in mammograms. Pattern Recognition. 2009;42(6):1138–1148. doi: 10.1016/j.patcog.2008.08.006. [DOI] [Google Scholar]
- 115.Rangayyan R. M., Nguyen T. M. Pattern classification of breast masses via fractal analysis of their contours. International Congress Series. 2005;1281:1041–1046. doi: 10.1016/j.ics.2005.03.329. [DOI] [Google Scholar]
- 116.Rangayyan M., Rangaraj, Ferrari R., Frère A. Analysis of bilateral asymmetry in mammograms using directional, morphological, and density features. Journal of Electronic Imaging. 2007;16(1) doi: 10.1117/1.2712461.013003 [DOI] [Google Scholar]
- 117.Bishop C. M. Neural Networks for Pattern Recognition. Oxford, UK: Oxford Calrendon Press; 1995. [Google Scholar]
- 118.Jain A. K., Chandrasekaran B. Handbook of Statistics. Vol. 2. Amsterdam, Netherlands: Elsevier; 1982. Dimensionality and sample size considerations in pattern recognition practice; pp. 835–855. [DOI] [Google Scholar]
- 119.Raudys S. J., Pikelis V. On dimensionality, sample size, classification error, and complexity of classification algorithm in pattern recognition. IEEE Transactions on Pattern Analysis and Machine Intelligence. 1980;2(3):242–252. doi: 10.1109/tpami.1980.4767011. [DOI] [PubMed] [Google Scholar]
- 120.Raudys S. J., Jain A. K. Small sample size effects in statistical pattern recognition: recommendations for practitioners. IEEE Transactions on Pattern Analysis and Machine Intelligence. 1991;13(3):252–264. doi: 10.1109/34.75512. [DOI] [Google Scholar]
- 121.Kulback S., Liebler R. A. On information and sufficiency. The Annals of Mathematical Statistics. 1951;22(1):79–86. doi: 10.1214/aoms/1177729694. [DOI] [Google Scholar]
- 122.Mthembu L., Greene J. A comparison of three class separability measures. Proceedings of the 15th Annual Symposium of the Pattern Recognition Association of South Africa; November 2004; Grabouw, South Africa. pp. 63–67. [Google Scholar]
- 123.Watanabe S. Pattern Recognition: Human and Mechanical. New York, NY, USA: Wiley; 1995. [Google Scholar]
- 124.“Mutual information. 2019. http://en.wikipedia.org/wiki/Mutual_information.
- 125.“Pearson product. 2019. http://en.wikipedia.org/wiki/Pearson_product_moment_correlation_coefficient.
- 126.Kira K., Rendell L. A. A practical approach to feature selection. ML92 Proceedings of the 9th International Workshop on Machine Learning; 1992; [DOI] [Google Scholar]
- 127.Saeys Y., Abeel T., de Peer Y. V. Machine Learning and Knowledge Discovery in Databases. Berlin, Germany: 2008. Robust feature selection using ensemble feature selection techniques; pp. 313–325. [DOI] [Google Scholar]
- 128.Guyon I., Elissee A. An introduction to variable and feature selection. Journal of Machine Learning Research. 2003;3:1157–1180. [Google Scholar]
- 129.Luo J., Hu B., Ling X.-T., Liu R.-W. Principal independent component analysis. IEEE Transactions on Neural Networks. 1999;10(4) doi: 10.1109/72.774259. [DOI] [PubMed] [Google Scholar]
- 130.Comon P. Independent component analysis, a new concept? Signal Processing. 1994;36:287–314. [Google Scholar]
- 131.Oja E. Espoo, Finland: Helsinki University of Technology; 1995. The nonlinear PCA learning rule and signal separation mathematical analysis. Technical report A26. [Google Scholar]
- 132.Oja E., Karhunen J., Wang L., Vigario R. Principal and independent components in neural networks—recent developments. Proceedings of the 7th Italian Workshop on Neural Nets WIRN’95; May 1995; Vietri sulMare, Italy. [Google Scholar]
- 133.Christoyianni I., Koutras A., Dermatas E., Kokkinakis G. Computer aided diagnosis of breast cancer in digitized mammograms. Computerized Medical Imaging and Graphics. 2002;26(5):309–319. doi: 10.1016/S0895-6111(02)00031-9. [DOI] [PubMed] [Google Scholar]
- 134. http://chem-eng.utoronto.ca/%7Edatamining/dmc/zeror.htm, 2019.
- 135.Nasa C., Suman S. Evaluation of different classification techniques for web data. International Journal of Computer Applications. 2012;52(9):34–40. doi: 10.5120/8233-1389. [DOI] [Google Scholar]
- 136.Buddhinath G., Derry D. A Simple Enhancement to One Rule Classification. Melbourne, Australia: Department of Computer Science & Software Engineering University of Melbourne; 2006. [Google Scholar]
- 137.Parsania V., Jani N. N., Bhalodiya N. Applying naïve bayes, BayesNet, PART, JRip and OneR algorithms on hypothyroid database for comparative analysis. IJDI-ERET. 2014;3 [Google Scholar]
- 138.Maron M. E. Automatic indexing: an experimental inquiry. Journal of the ACM. 1961;8(3):404–417. doi: 10.1145/321075.321084. [DOI] [Google Scholar]
- 139.Rennie J., Shih L., Teevan J., Karger D. Tackling the poor assumptions of Naive Bayes classifiers. Proceedings of the 20th International Conference on Machine Learning; 2003; Washington, DC, USA. [Google Scholar]
- 140.Rish I. An empirical study of the naive Bayes classifier. Proceedings of the 2001 IJCAI Workshop on Empirical Methods in AI; 2001; New York, NY, USA. [Google Scholar]
- 141.Yuan L. An improved naive Bayes text classification algorithm in Chinese information processing. Proceedings of the 3rd International Symposium on Computer Science and Computational Technology; 2010; Jiaozhou, China. pp. 14–15. [Google Scholar]
- 142.Vibha L., Harshavardhan G. M., Pranaw K., Shenoy P. D., Venugopal K. R., Patnaik L. M. Classification of mammograms using decision trees. Proceedings of the 2006 10th International Database Engineering and Applications Symposium (IDEAS’06); December 2006; Delhi, India. pp. 263–266. [Google Scholar]
- 143.Mohanty A. K., Senapati M. R., Beberta S., Lenka S. K. Texture-based features for classification of mammograms using decision tree. Neural Computing & Applications. 2013;23(3-4):1011–1017. doi: 10.1007/s00521-012-1025-z. [DOI] [Google Scholar]
- 144.Polat K., Güneş S. A novel hybrid intelligent method based on C4.5 decision tree classifier and one-against-all approach for multi-class classification problems. Expert Systems with Applications. 2009;36(2):1587–1592. doi: 10.1016/j.eswa.2007.11.051. [DOI] [Google Scholar]
- 145.Quinlan J. R. Induction of decision trees. Machine Learning. 1986;1(1):81–106. doi: 10.1007/BF00116251. [DOI] [Google Scholar]
- 146.Mitchell T. M. Machine Learning. New York, NY, USA: McGraw-Hill; 1997. [Google Scholar]
- 147.Chan H.-P., Wei D., Helvie M. A., et al. Computer-aided classification of mammographic masses and normal tissue: linear discriminant analysis in texture feature space. Physics in Medicine and Biology. 1995;40(5):857–876. doi: 10.1088/0031-9155/40/5/010. [DOI] [PubMed] [Google Scholar]
- 148.Chhatwal J., Alagoz O., Lindstrom M. J., Kahn C. E., Shaffer K. A., Burnside E. S. A logistic regression model based on the national mammography database format to aid breast cancer diagnosis. American Journal of Roentgenology. 2009;192(4):1117–1127. doi: 10.2214/ajr.07.3345. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 149.Barlow W. E., White E., Ballard-Barbash R., et al. Prospective breast cancer risk prediction model for women undergoing screening mammography. JNCI: Journal of the National Cancer Institute. 2006;98(17):1204–1214. doi: 10.1093/jnci/djj331. [DOI] [PubMed] [Google Scholar]
- 150.Zhou X., Liu K. Y., Wong S. T. C. Cancer classification and prediction using logistic regression with Bayesian gene selection. Journal of Biomedical Informatics. 2004;37(4):249–259. doi: 10.1016/j.jbi.2004.07.009. [DOI] [PubMed] [Google Scholar]
- 151.Samanta B., Bird G. L., Kuijpers M., et al. Prediction of periventricular leukomalacia. Part I: selection of hemodynamic features using logistic regression and decision tree algorithms. Artificial Intelligence in Medicine. 2009;46(3):201–215. doi: 10.1016/j.artmed.2008.12.005. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 152.Hosmer D. W., Lemeshow S. Applied Logistic Regression. New York, NY, USA: Wiley; 2000. [Google Scholar]
- 153.Hosmer D. W., Lemeshow S. Applied Logistic Regression. New York, NY, USA: Wiley; 1989. [Google Scholar]
- 154.Nusantara A. C., Purwanti E., Soelistiono S. Classification of digital mammogram based on nearest-neighbor method for breast cancer detection. International Journal of Technology. 2016;7(1):p. 71. doi: 10.14716/ijtech.v7i1.1393. [DOI] [Google Scholar]
- 155.Prathibha B. N., Sadasivam V. Multi-resolution texture analysis of mammograms using nearest neighbor classification techniques. International Journal of Information Acquisition. 2010;7(2):109–118. doi: 10.1142/s0219878910002105. [DOI] [Google Scholar]
- 156.Alpaslan N., Kara A., Zenci̇r B., Hanbay D. Classification of breast masses in mammogram images using KNN. Proceedings of the 2015 23rd Signal Processing and Communications Applications Conference (SIU); 2015; Malatya, Turkey. pp. 1469–1472. [DOI] [Google Scholar]
- 157.Rodriguez V., Sharma K., Walker D. Breast cancer prediction with K-nearest neighbor algorithm using different distance measurements. 2018.
- 158.Prasath V. B., Arafat Abu Alfeilat H., Lasassmeh O., Hassanat A. B. A. Distance and similarity measures effect on the performance of k-nearest neighbor classifier—a review. 2017. https://arxiv.org/pdf/1708.04321.pdf. [DOI] [PubMed]
- 159.Vapnik V. The Nature of Statistical Learning Theory. New York, NY, USA: Springer-Verlag; 1995. [Google Scholar]
- 160.Kecman V. Learning and Soft Computing: Support Vector Machines, Neural Networks, and Fuzzy Logic Models. Cambridge, MA, USA: MIT Press; 2001. [Google Scholar]
- 161.Sakr G., Elhajj I., Huijer H. A.-S. Support vector machines to define and detect agitation transition. IEEE Transactions on Affective Computing. 2010;1(2):98–108. doi: 10.1109/T-AFFC.2010.2. [DOI] [Google Scholar]
- 162.Lesniak J. M., Hupse R., Blanc R., Karssemeijer N., Székely G. Comparative evaluation of support vector machine classification for computer aided detection of breast masses in mammography. Physics in Medicine and Biology. 2012;57(16):5295–5307. doi: 10.1088/0031-9155/57/16/5295. [DOI] [PubMed] [Google Scholar]
- 163.El-Naqa I., Yang Y., Wernick M., Galatsanos N., Nishikawa R. A support vector machine approach for detection of microcalcifications. IEEE Transactions on Medical Imaging. 2002;21(12):1552–1563. doi: 10.1109/tmi.2002.806569. [DOI] [PubMed] [Google Scholar]
- 164.Wei J., Chan H. P., Zhou C., et al. Computer-aided detection of breast masses: four-view strategy for screening mammography. Medical Physics. 2011;38(4):1867–1876. doi: 10.1118/1.3560462. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 165.Land W. H., Mckee D., Velazquez R., Wong L., Lo J. Y., Anderson F. R. Application of support vector machines to breast cancer screening using mammogram and clinical history data. Proceedings of SPIE—Medical Imaging 2003: Image Processing; 2003; San Diego, CA, USA. [DOI] [Google Scholar]
- 166.Prabhpreet K., Gurvinder S., Parminder K. Intellectual detection and validation of automated mammogram breast cancer images by multi-class SVM using deep learning classification. Informatics in Medicine Unlocked. 2019;16 doi: 10.1016/j.imu.2019.01.001.100151 [DOI] [Google Scholar]
- 167. https://www.saedsayad.com/support_vector_machine.htm, 2019.
- 168. https://www.saedsayad.com/images/SVM_2.png, 2019.
- 169.Ayer T., Chen Q., Burnside E. Artificial neural networks in mammography interpretation and diagnostic decision making. Computational and Mathematical Methods in Medicine. 2013;2013:10. doi: 10.1155/2013/832509.832509 [DOI] [PMC free article] [PubMed] [Google Scholar]
- 170.Ayer T., Chhatwal J., Alagoz O., Kahn C. E., Woods R. W., Burnside E. S. Comparison of logistic regression and artificial neural network models in breast cancer risk estimation. Radiographics. 2010;30(1):13–22. doi: 10.1148/rg.301095057. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 171.Dayhoff J. E., DeLeo J. M. Artificial neural networks: opening the black box. Cancer. 2001;91(8):1615–1635. doi: 10.1002/1097-0142(20010415)91:8+<1615::aid-cncr1175>3.0.co;2-l. [DOI] [PubMed] [Google Scholar]
- 172.Markey M. K., Tourassi G. D., Margolis M., DeLong D. M. Impact of missing data in evaluating artificial neural networks trained on complete data. Computers in Biology and Medicine. 2006;36(5):516–525. doi: 10.1016/j.compbiomed.2005.02.001. [DOI] [PubMed] [Google Scholar]
- 173.Stafford R. G., Beutel J., Mickewich D. J., Albers S. L. Application of neural networks to computer-aided pathology detection in mammography. Proceedings of SPIE. 1993;1896:341–352. [Google Scholar]
- 174.Lawrence J. Introduction to Neural Networks. Nevada City, CA, USA: California Scientific Software; 1993. [Google Scholar]
- 175.Maren A. J., Harston C. T., Pap R. M. Handbook of Neural Computing Applications. San Diego, CA, USA: Academic Press; 1990. [Google Scholar]
- 176. https://www.saedsayad.com/artificial_neural_network.htm, 2019.
- 177.LeCun Y., Bengio Y., Hinton G. Deep learning. Nature. 2015;521(7553):436–444. doi: 10.1038/nature14539. [DOI] [PubMed] [Google Scholar]
- 178.Hamidinekoo A., Denton E., Rampun A., Honnor K., Zwiggelaar R. Deep learning in mammography and breast histology, an overview and future trends. Medical Image Analysis. 2018;47:45–67. doi: 10.1016/j.media.2018.03.006. [DOI] [PubMed] [Google Scholar]
- 179.Carneiro G., Nascimento J., Bradley A. P. Unregistered multiview mammogram analysis with pre-trained deep learning models. Proceedings of the International Conference on Medical Image Computing and Computer-Assisted Intervention; October 2015; Munich, Germany. pp. 652–660. [Google Scholar]
- 180.Huynh B. Q., Li H., Giger M. L. Digital mammographic tumor classification using transfer learning from deep convolutional neural networks. Journal of Medical Imaging. 2016;3(3) doi: 10.1117/1.jmi.3.3.034501.034501 [DOI] [PMC free article] [PubMed] [Google Scholar]
- 181.Krizhevsky A., Sutskever I., Hinton G. E. Advances in Neural Information Processing Systems. Berlin, Germany: Springer; 2012. Im-agenet classification with deep convolutional neural networks; pp. 1097–1105. [Google Scholar]
- 182.Jiao Z., Gao X., Wang Y., Li J. A deep feature based framework for breast masses classification. Neurocomputing. 2016;197:221–231. doi: 10.1016/j.neucom.2016.02.060. [DOI] [Google Scholar]
- 183.Arevalo J., González F. A., Ramos-Pollán R., Oliveira J. L., Lopez M. A. G. Representation learning for mammography mass lesion classification with convolutional neural networks. Computer Methods and Programs in Biomedicine. 2016;127:248–257. doi: 10.1016/j.cmpb.2015.12.014. [DOI] [PubMed] [Google Scholar]
- 184.Ribli D., Horváth A., Unger Z., Pollner P., Csabai I. Detecting and classifying lesions in mammograms with deep learning. Scientific Reports. 2018;8(1):p. 4165. doi: 10.1038/s41598-018-22437-z. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 185.Ren S., He K., Girshick R., Sun J. Advances in Neural Information Processing Systems. Berlin, Germany: Springer; 2015. Faster R-CNN: towards real-time object detection with region proposal networks; pp. 91–99. [Google Scholar]
- 186.Simonyan K., Zisserman A. Very deep convolutional networks for large-scale image recognition. 2014. https://arxiv.org/abs/1409.1556.
- 187.Valvano G., Santini G., Martini N., et al. Convolutional neural networks for the segmentation of microcalcification in mammography imaging. Journal of Healthcare Engineering. 2019;2019:9. doi: 10.1155/2019/9360941.9360941 [DOI] [PMC free article] [PubMed] [Google Scholar]
- 188.Wang J., Yang Y. A context-sensitive deep learning approach for microcalcification detection in mammograms. Pattern Recognition. 2018;78:12–22. doi: 10.1016/j.patcog.2018.01.009. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 189.Cai H., Huang Q., Rong W., et al. Breast microcalcification diagnosis using deep convolutional neural network from digital mammograms. Computational and Mathematical Methods in Medicine. 2019;2019:10. doi: 10.1155/2019/2717454.2717454 [DOI] [PMC free article] [PubMed] [Google Scholar]
- 190.Fathy W., Ghoneim A. A deep learning approach for breast cancer mass detection. International Journal of Advanced Computer Science and Applications. 2019;10(1) doi: 10.14569/IJACSA.2019.0100123. [DOI] [Google Scholar]
- 191.Zou L., Yu S., Meng T., Zhang Z., Liang X., Xie Y. A technical review of convolutional neural network-based mammographic breast cancer diagnosis. Computational and Mathematical Methods in Medicine. 2019;2019:16. doi: 10.1155/2019/6509357.6509357 [DOI] [PMC free article] [PubMed] [Google Scholar]
- 192.Abdelhafiz D., Yang C., Ammar R., Nabavi S. Deep convolutional neural networks for mammography: advances, challenges and applications. BMC Bioinformatics. 2019;20:p. 281. doi: 10.1186/s12859-019-2823-4. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 193.Dhungel N., Carneiro G., Bradley A. P. The automated learning of deep features for breast mass classification from mammograms. Proceedings of the International Conference on Medical Image Computing and Computer-Assisted Intervention; 2016; Athens, Greece. Springer; pp. 106–114. [Google Scholar]
- 194.Chougrad H., Zouaki H., Alheyane O. Convolutional neural networks for breast cancer screening: transfer learning with exponential decay. 2017. https://arxiv.org/abs/1711.10752. [DOI] [PubMed]
- 195.Jadoon M. M., Zhang Q., Haq I. U., Butt S., Jadoon A. Three-class mammogram classification based on descriptive CNN features. BioMed Research International. 2017;2017:11. doi: 10.1155/2017/3640901.3640901 [DOI] [PMC free article] [PubMed] [Google Scholar]
- 196.Kooi T., Gubern-Merida A., Mordang J. J., Mann R., Pijnappel R., Schuur K. A comparison between a deep convolutional neuralnetwork and radiologists for classifying regions of interest in mammography. Proceedings of the 2016 International Workshop on Digital Mammography; June 2016; Malmö, Sweden. Springer; pp. 51–56. [Google Scholar]
- 197.Wolpert D. H., Macready W. G. No free lunch theorems for optimization. IEEE Transactions on Evolutionary Computation. 1997;1(1):67–82. doi: 10.1109/4235.585893. [DOI] [Google Scholar]
- 198.Wei L., Yang Y., Nishikawa R. M., Jiang Y. A study on several machine-learning methods for classification of malignant and benign clustered microcalcifications. IEEE Transactions on Medical Imaging. 2005;24(3):371–380. doi: 10.1109/TMI.2004.842457. [DOI] [PubMed] [Google Scholar]
- 199.Lam L. Multiple Classifier Systems. Vol. 1857. Berlin, Germany: Springer; 2000. Classifier combinations: implementations and theoretical issues. [Google Scholar]
- 200.Powalka R. K., Sherkat N., Whitrow R. J. Multiple recognizer combination topologies. In: Simner M. L., Leedham C. G., Thomasson A. J. W. M., editors. Handwriting and Drawing Research: Basic and Applied Issues. Amsterdam, Netherlands: IOS Press; 1996. pp. 329–342. [Google Scholar]
- 201.Rahman A. F. R., Fairhurst M. C. An evaluation of multi-expert configurations for the recognition of handwritten numerals. Pattern Recognition. 1998;31(9):1255–1273. doi: 10.1016/s0031-3203(97)00161-1. [DOI] [Google Scholar]
- 202.Lam L. Multiple Classifier Systems. Vol. 1857. Cagliari, Italy: Springer; 2000. Classifier combinations: implementations and theoretical issues; pp. 78–86. [DOI] [Google Scholar]
- 203.Kuncheva L. I., Whitaker C. J., Shipp C. A., Duin R. P. W. Limits on the majority vote accuracy in classifier fusion. Pattern Analysis & Applications. 2003;6(1):22–31. doi: 10.1007/s10044-002-0173-7. [DOI] [Google Scholar]
- 204.Ruta D., Gabrys B. Classifier selection for majority voting. Information Fusion. 2005;6(1):63–81. doi: 10.1016/j.inffus.2004.04.008. [DOI] [Google Scholar]
- 205.Breiman L. Bagging predictors. Machine Learning. 1996;24(2):123–140. doi: 10.1007/bf00058655. [DOI] [Google Scholar]
- 206.Wolpert D. Stacked generalization. Neural Networks. 1992;5(2):241–259. doi: 10.1016/s0893-6080(05)80023-1. [DOI] [Google Scholar]
- 207.Freund Y., Schapire R. E. Experiments with a new boosting algorithm. Proceedings of the 13th International Conference on Machine Learning; 1996; Lanzhou, China. pp. 148–156. [Google Scholar]
- 208.Zhang X. A new ensemble learning approach for microcalcification clusters detection. Journal of Software. 2009;4(9):1014–1021. doi: 10.4304/jsw.4.9.1014-1021. [DOI] [Google Scholar]
- 209.Friedman J., Hastie T., Tibshirani R. Additive logistic regression: a statistical view of boosting (with discussion and a rejoinder by the authors) The Annals of Statistics. 2000;28(2):337–407. doi: 10.1214/aos/1016218223. [DOI] [Google Scholar]
- 210.Woods K. S., Doss C. C., Bowyer K. W., Solka J. L., Priebe C. E., Kegelmeyer W. P. Comparative evaluation of pattern recognition techniques for detection of microcalcifications in mammography. International Journal on Pattern Recognition and Artificial Intelligence. 1993;7(6):1417–1436. doi: 10.1142/s0218001493000698. [DOI] [Google Scholar]
- 211.Devos A., Simonetti A. W. V., Graaf M., et al. The use of multivariate MR imaging intensities versus metabolic data from MR classification. Journal of Magnetic Resonance. 2005;173(2):218–228. doi: 10.1016/j.jmr.2004.12.007. [DOI] [PubMed] [Google Scholar]
- 212.Kim J. K., Park J. M., Song K. S., Park W. Detection of clustered microcalcifications on mammograms using surrounding region dependence method and artificial neural network. Journal on VLSI Signal Process. 1998;18:251–262. [Google Scholar]
- 213.Alolfe M. A., Mohamed W. A., Youssef A.-B. M., Mohamed A. S., Kadah Y. M. Computer aided diagnosis in digital mammography using support vector machine and linear discriminant analysis classification. Proceedings of the 16th IEEE International Conference on Image Processing (ICIP); November 2009; Cairo, Egypt. pp. 2609–2612. [DOI] [Google Scholar]
- 214.Chitre Y., Dhawan A. P., Moskowitz M. Artificial neural network based classification of mammographic microcalcifications using image structure features. International Journal of Pattern Recognition and Artificial Intelligence. 1993;7(12):1377–1402. doi: 10.1142/s0218001493000674. [DOI] [Google Scholar]
- 215.Wei D., Chan H. P., Helvie M. A., et al. Classification of mass and normal breast tissue on digital mammograms: multiresolution texture analysis. Medical Physics. 1995;22(9):1501–1513. doi: 10.1118/1.597418. [DOI] [PubMed] [Google Scholar]
- 216.Baydush A. H., Catarious D. M., Abbey C. K., Floyd C. E. Computer aided detection of masses in mammography using subregion hotelling observers. Medical Physics. 2003;30(7):1781–1787. doi: 10.1118/1.1582011. [DOI] [PubMed] [Google Scholar]
- 217.Wang Y., Aghaei F., Zarafshani A., Qiu Y., Qian W., Zheng B. Computer-aided classification of mammographic masses using visually sensitive image features. Journal of X-Ray Science and Technology. 2016;25(1):171–186. doi: 10.3233/XST-16212. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 218.Khuzi A. M., Besar R., Wan Zaki W. M. D., Ahmad N. N. Identification of masses in digital mammogram using gray level co-occurrence matrices. Biomedical Imaging and Intervention Journal. 2009;5(3):p. e17. doi: 10.2349/biij.5.3.e17. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 219.Marina M., Dragan J., Aleksandar P. Comparative analysis of breast cancer detection in mammograms and thermograms. Biomedical Engineering/Biomedizinische Technik. 2015;60(1):49–56. doi: 10.1515/bmt-2014-0047. [DOI] [PubMed] [Google Scholar]
- 220.Ramadan S., El-Banna M. Breast cancer diagnosis in digital mammography images using automatic detection for region of interest. Current Medical Imaging Formerly Current Medical Imaging Reviews. 2019;15 doi: 10.2174/1573405615666190717112820. [DOI] [PubMed] [Google Scholar]
- 221.Suckling J. The mammographic image analysis society digital mammogram database exerpta medica. International Congress Series. 1994;1069:375–378. [Google Scholar]
- 222.Heath M., Bowyer K., Kopans D., Moore R., Philip Kegelmeyer W. The digital database for screening mammography. In: Yaffe M. J., editor. Proceedings of the 5th International Workshop on Digital Mammography; June 2000; Toronto, Canada. Medical Physics Publishing; pp. 212–218. [Google Scholar]
- 223.Lawrence Livermore National Library/UCSF Digital Mammogram Database. Center for Health Care Technologies Livermore. Livermore, CA, USA: Lawrence Livermore National Library; 2010. http://gdo-biomed.ucllnl.org/pub/mammo-db/ [Google Scholar]
- 224.Amendolia S. R., Bisogni M. G., Bottigli U. The CALMA project. Nuclear Instruments and Methods in Physics Research Section A: Accelerators, Spectrometers, Detectors and Associated Equipment. 2001;461(1–3):428–429. doi: 10.1016/S0168-9002(00)01266-3. [DOI] [Google Scholar]
- 225.PROENG. Image processing and image analysis applied to mastology. 2012. http://visual.ic.uff.br/en/proeng/