

Abstract
Acronyms are an idiosyncratic part of our everyday vocabulary. Research in word processing has used acronyms as a tool to answer fundamental questions such as the nature of the word superiority effect (WSE) or which is the best way to account for word-reading processes. In this study, acronym naming was assessed by looking at the influence that a number of variables known to affect mainstream word processing has had in acronym naming. The nature of the effect of these factors on acronym naming was examined using a multilevel regression analysis. First, 146 acronyms were described in terms of their age of acquisition, bigram and trigram frequencies, imageability, number of orthographic neighbors, frequency, orthographic and phonological length, print-to-pronunciation patterns, and voicing characteristics. Naming times were influenced by lexical and sublexical factors, indicating that acronym naming is a complex process affected by more variables than those previously considered.
Keywords: Acronyms, Norms, Age of acquisition, Imageability, Acronym frequency, Acronym length
Introduction
Acronyms represent a significant and idiosyncratic part of our everyday vocabulary. The demands of a highly technical society have dramatically increased the proportion of acronyms encountered in everyday language. Acronyms are nowadays regularly found in scientific and nonscientific journals (e.g., DNA, EEG, CD-ROM, DVD, radar, sonar, VAT, CPI, OXO, NATO, NHS, etc.) and are actively used in text messages and e-mail communications (e.g., lol, MYOB, BW, etc.). The practice of abbreviating complex words is not new (e.g., INRI is an acronym that dates back to Roman times); however, their use has been relatively sparse until the second world war, when the formation of new acronyms escalated, since they were a convenient way of accelerating and encrypting communication. As an indication of the breathtaking expansion of acronyms in the language, the first edition (1960) of the Acronyms, Initialisms and Abbreviations Dictionary (AIAD) comprised 12,000 headwords, while the 16th edition (1992) included more than 520,000 headwords. The AIAD dictionary has been recognized as one of the most important books of reference by the American Library Association (1985), and its 43rd edition has just been made available to the public in June 2010. Strictly speaking, the term acronym refers to pronounceable abbreviations formed with the initial letters of a compound term, while initialism is the name for the same type of abbreviations that are “unpronounceable.” Despite this original distinction, the label initialism is rarely used, while acronym has extended its meaning to pronounceable and unpronounceable abbreviations. It is in this extended sense that the term acronym is going to be used here.
A distinctive characteristic of acronyms is that their configuration does not obey orthographic and/or phonological rules. They are often formed by a sequence of illegal letter strings that can become highly familiar to the language user (e.g., ABC, BBC, CNN, FBI, fm, HIV, KFC, pm, TV, USB, etc.). Due to this peculiar illegality, acronyms have recently been used in the study of two influential models of reading aloud: the triangle model and the dual-route cascade model (Laszlo & Federmeier, 2007b). An important discrepancy between these two models lies in the relative relevance given to the frequency of the word in contrast to its regularity when it is read aloud. One of the models under investigation in Laszlo and Federmeier (2007b) was the connectionist triangle model (Harm & Seidenberg, 2004; Seidenberg & McClelland, 1989). The model proposes a single processing system for reading all known words, irrespective of their frequency and regularity, and all unknown/novel words. This is achieved by means of a learning mechanism that extracts the statistically more reliable (frequent) spelling–sound relationships in English. Importantly, orthographic and/or phonological rules are redundant in the model, and therefore, they have not been specifically implemented. The other model investigated is the nonconnectionist dual-route cascade model (Coltheart, Curtis, Atkins, & Haller, 1993; Coltheart, Rastle, Perry, Langdon, & Ziegler, 2001). It proposes two reading routes or procedures: a lexical route and a nonlexical route. The lexical route entails direct connections between the mental representations of the written form of the word and the spoken form of the word and, also, detoured connections between written and spoken word forms with their corresponding conceptual representations in the semantic system. The nonlexical route converts letters into sounds applying the orthographic and phonologic rules of the language. The latter route is indispensable for reading novel words and nonwords, since no mental representation for them has been formed. Nonlexical processing will also give the correct pronunciation of regular words, although this is not the only reading pathway available to them. Correct reading of irregular words, however, needs to be accomplished via the lexical route, since these words do not stick to the pronunciation rules of the language.
Laszlo and Federmeier (2007b) tested these models by looking at the differential N400 repetition effect found for words (hat) and pseudowords (e.g., dawk) but not for orthographically illegal nonwords (mdtp). They argued that according to the dual-route model, the sensitivity of the N400 component to the repetition of legal letter strings, for both words and pseudowords (Deacon, Dynowska, Ritter, & Grose-Fifer, 2004; Rugg, 1990), could only reflect the performance of the nonlexical pathway, since this is the only route available for reading novel items such as the pseudowords. In consequence, no repetition effects in the N400 should be observed when acronyms are read, since their irregularity precludes the use of the nonlexical route. It is important to note that it is not clear how the predicted and reported absence of repetition effects for illegal letter strings fits into the argument, since illegal letter strings also make use of the nonlexical pathway. Connectionist models, alternatively, would predict repetition effects in the N400 for words, pseudowords, and acronyms, since the same process underpins the recognition of any type of letter string. Laszlo and Federmeier (2007b) found N400 repetition effects for words, pseudowords, and acronyms, but not for illegal nonwords. They concluded that this outcome could be accommodated only by the connectionist account for oral reading. However, Laszlo and Federmeier (2007b) failed to notice that pseudowords—in particular, pseudohomophones and those pseudowords extracted from high-frequency words—can generate activation in the lexical pathway (Coltheart, 2007). The lexical route will not produce the correct reading of pseudowords but can be, nevertheless, stimulated. Taking this into account, their results can be perfectly explained by the dual-route model through the activation of the lexical route by words, acronyms, and pseudowords. This explanation also reconciles better with the lexico-semantic processing found to be associated with the N400 component (Sheehan, Namy, & Mills, 2007; van Elk, van Schie, & Bekkering, 2010). Equivalent N400 amplitudes were found for words and acronyms in a subsequent study (Laszlo & Federmeier, 2008) in which the N400 sentence anomaly paradigm was used. The authors concluded that this pattern of results is not reconcilable with the dual-route model.
Acronyms have also played an important part in the investigation of the word superiority effect (WSE). Gibson, Bishop, Schiff, and Smith (1964), for example, investigated the relative contribution that meaningfulness and pronounceability had in the WSE. They devised two experimental conditions: one formed by meaningful but unpronounceable trigrams (these were all acronyms), and the other by meaningless but pronounceable trigrams (these were all pseudowords). They showed an advantage for acronyms in word recognition memory and recall, suggesting that meaning, rather than pronounceability, had a more powerful influence in these processes. Similar results were reported by Henderson (1974), who also manipulated meaning and pronounceability using acronyms and pseudowords. He found that participants were faster at judging pairs of items as being the same (e.g., FBI–FBI; BLI–BLI) or different (e.g., FBI–IMB; BLI–LSF) if a meaningful item or acronym was in the pair. A number of later studies have replicated the influence of meaning in the WSE, using acronyms in their experimental sets (Laszlo & Federmeier, 2007a; Noice & Hock, 1987; Staller & Lappin, 1981).
In sum, acronyms have been an integral part of experimental manipulations in a number of studies of word recognition and reading (Gibson et al., 1964; Henderson, 1974). The main reason for the use of acronyms has been their unusual combination of meaning and pronunciation, especially because the latter does not obey the standard spelling-to-sound correspondences of the language in use. The orthographic irregularity of acronyms, thus, has been paired with that of illegal letter strings, while their meaning and familiarity have been considered as equivalent to that of other words in the language. Although their meaning and peculiar pronounceability are indeed acronym characteristics, these might have been overemphasized to the detriment of other factors also known to be relevant in oral reading and word recognition processes. First, for example, not all acronyms comprise only consonants or all vowels, and those that do can be read by the application of a particular rule (i.e., letter naming). This rule might make acronyms somehow “regular” and different from other illegal letter strings. Second, acronyms tend to be items that are acquired during adulthood, and there is abundant evidence showing that late learned words are processed slower than early acquired words (for reviews, see Johnston & Barry, 2006; Juhasz, 2005). Third, acronyms are related to a more restricted number of familiar meanings than are conventional words, and words with few meanings tend to be processed more slowly than words with many meanings (Azuma & Van Orden, 1997; Ferraro & Hansen, 2002; Hino & Lupker, 1996; Klepousniotou & Baum, 2007). Another important difference is that orthographic and phonological length is often uncorrelated in acronyms. In contrast to conventional words, an acronym can often be orthographically short but phonologically long (e.g., HIV has only three letters but five sounds, ai-ch-eye-v-ee ). Finally, the number of orthographic neighbors associated to acronyms is generally much lower than those found in standard words. Orthographic neighborhood refers to all the words that can be formed by changing one letter from a target word while keeping constant the rest. Evidence shows that words with few orthographic neighbors take longer to be recognized (Alameda & Cuetos, 2000; Andrews, 1992; Perea, Acha, & Fraga, 2008; Whitney & Lavidor, 2005). All these properties (e.g., a late age of acquisition, short letter length, low number of meanings, etc.) make acronyms a very idiosyncratic material, possibly more than ever thought. More important, sets of acronyms and familiar words merely matched in letter length might not be easily comparable, and results from previous studies (Laszlo & Federmeier, 2007a, 2007b, 2008) could have been confounded with a number of uncontrolled variables.
Here, the authors present an investigation of 146 acronyms in relation to their orthographic illegality, peculiar pronunciation and six other lexico-semantic characteristics. Acronyms have generally been viewed as some kind of irregular word or even as a sort of “nonword with meaning.” However, the question of whether acronyms are processed as irregular words has never been tested. In order to address this question, the authors contrasted acronym-naming times against a number of lexical and semantic factors known to be relevant when mainstream words are read and manifestly overlooked in previous studies involving acronyms. The study is important since acronyms appear to be an effective material in the investigation of word recognition and reading aloud. Interestingly, in most word recognition and naming studies in which no acronyms but conventional words are used, a careful selection of the material is carried out to ensure that only the factor under investigation varies, while intercorrelated variables are controlled for. Normative data have proven useful in these studies of word recognition and production, yet there is a complete absence of norms for acronyms. This is in spite of the fact that acronyms are not only useful material to facilitate the experimental manipulations in word-processing research, but also a topic of scientific inquiry. Thus, a number of studies (Besner, Davelaar, Alcott, & Parry, 1984; Coltheart, 1978) have been concerned with the lexicality of acronyms, and attempts have been made to clarify whether acronyms enjoy the cognitive status of a word or a nonword. In the latest of these studies, Brysbaert, Speybroeck, and Vanderelst (2009) found that acronyms produced an associative priming effect equivalent to that generated by conventional words, and importantly, this effect was independent of case presentation. Brysbaert et al. (2009) concluded that acronyms are lexicalized items integrated in our mental lexicon.
In recognition of the growing interest of acronyms in psycholinguistic research and the imperative need of normative data for this type of stimuli, the authors present here an investigation of the lexico-semantic properties of 146 acronyms and their relationship with acronym-naming speed. The present norms will provide researchers with an inclusive database to enable appropriate experimental control in future research. The factors considered were age of acquisition (AoA), bigram frequency, trigram frequency, imageability, number of orthographic neighbors, number of letters, number of phonemes, number of syllables, acronyms’ print-to-pronunciation pattern, word frequency, word familiarity, and voicing. These norms will benefit research in acronyms and word reading in healthy and clinical populations. The authors start by describing the acronym characteristics considered in the present study in alphabetic order. Then the data collection for the norms and the acronym study are presented.
A secondary aim is to investigate the nature of acronym reading by inspecting how they are influenced by the factors included in the norms. The fact that acronyms are orthographically illegal does not necessarily mean that they are processed as irregular words. A major proportion of acronyms are pronounced by naming each constituent letter aloud, which endows acronyms with some kind of regularity that is a long way away from the sporadic grapheme-to-phoneme correspondences characteristic of irregular words. The potential regularity or irregularity of acronyms will be tested by contrasting the impact that a series of factors has on acronym naming and recognition speed and accuracy. Thus, for example, reduced or no AoA effects have been found when regular words are named. Robust AoA effects in acronym reading will indicate similarities between those processes governing acronym naming and irregular word naming. The factors under investigation, along with their specific predictions, are described below.
Acronym characteristics: What can they tell us?
The selection of acronym properties included was guided by those factors that have been shown to affect single-word processing (e.g., reading words aloud, distinguishing real words from invented words, or naming objects). Main findings related to each of the variables selected are briefly reviewed next, along with explicit hypotheses regarding their influence in acronym-naming times and accuracy. The selected variables are presented in alphabetic order.
Age of acquisition
AoA refers to the moment in time in which words, objects, and faces are first learned. Differences in order of learning or AoA have been shown to affect processing times, accuracy, amplitude of ERP components, eye fixation durations, and spatially distinctive brain regions (Cuetos, Barbón, Urrutia, & Dominguez, 2009; Ellis, Burani, Izura, Bromiley, & Venneri, 2006; Gilhooly & Logie, 1982; Juhasz & Rayner, 2006; Morrison & Ellis, 1995, 2000; Pérez, 2007; Weekes, Chan, & Tan, 2008). Evidence shows that early acquired material has an advantage over late acquired material in terms of processing time, accuracy, and resistance to brain damage (see reviews in Johnston & Barry, 2006; Juhasz, 2005).
Ratings have been the most common way of measuring AoA. Here, participants are asked to estimate, on 7-point or 9-point scales, the age at which they believe they learned a list of words. Although these estimations might seem too subjective, they have been shown to correlate highly with objective AoA values (Carroll & White, 1973; Gilhooly & Gilhooly, 1980; Pérez, 2007).
The relevance of the AoA effect in cognitive processes lies in the wide range of tasks, languages, and population samples influenced by it. Thus, AoA effects have been reported in lexical decision, word and object naming, word associate generation, semantic categorization, object and face recognition, written word production, and repetition priming (Barry, Johnston, & Wood, 2006; Bonin, 2005; Brysbaert, Van Wijnendaele, & De Deyne, 2000; Catling, Dent, & Williamson, 2008; Gerhand & Barry, 1999; Holmes, Fitch, & Ellis, 2006; J. Monaghan & Ellis, 2002; Richards & Ellis, 2008). Also, evidence shows that AoA influences performance of healthy and brain-damaged participants, bilingual speakers, and monolingual speakers of a variety of languages such as English, Chinese, Dutch, French, Icelandic, Italian, Spanish, and Turkish, among others (Alija & Cuetos, 2006; Bonin, Barry, Meot, & Chalard, 2004; Izura & Ellis, 2002; Liu, Hao, Shu, Tan, & Weekes, 2008; Menenti & Burani, 2007; Pind & Tryggvadottir, 2002; Raman, 2006).
The arbitrary mappings hypothesis is one of the current explanations for the AoA effect. According to this hypothesis, AoA is the result of arbitrary connections created between two representations in the learning process. Object naming is a good example of this type of unpredictable links, because there is no information in the shape or intrinsic meaning of the object that could possible predict its name. Conversely, when the mapping established between representations is consistent, AoA effects would not be noticeable, since late acquired material will benefit from the regularities extracted from the early acquired material. Research carried out on object and word naming supports the arbitrary mappings hypothesis, showing larger AoA effects in object than word naming, since the nature of the connections between orthography and phonology is more or less consistent in alphabetic languages (Brysbaert & Ghyselinck, 2006; Ghyselinck, Lewis, & Brysbaert, 2004).
The arbitrary mappings account for AoA effects allows the investigation of the assumed irregularity of acronyms. Thus, if acronym processing is similar to that of irregular words, AoA effects will be observed in acronym-naming times. However, if letter naming can be taken as a rule that confers acronyms with some kind of regularity, no AoA effects will be observable.
Bigram and trigram frequency
Bigram and trigram frequencies refer to the frequency at which a pair of letters or sets of three letters appear together in written words of any given length. Thus, from a word formed from n letters, n−1 bigrams and n−2 trigrams can be formed. Bigram and trigram frequencies are sublexical measures of what is known as orthographic redundancy or orthographic familiarity (Andrews, 1992; Graves, Desai, Humphries, Seidenberg, & Binder, 2010).
Anisfeld (1964) proposed bigram and trigram frequencies as an alternative explanation to the consistency effects found in word processing. He argued that it could be that consistent words are processed more efficiently not because of their “consistent pronounceability” but because they are formed by letters with higher bigram and trigram frequencies than are inconsistent words.
Bigram frequency has been reported to affect tasks involving word recognition (Conrad, Carreiras, Tamm, & Jacobs, 2009; Owsowitz, 1953; Rice & Robinson, 1975; Westbury & Buchanan, 2002). The effect of bigram frequency in these studies was such that words with low bigram frequencies facilitated recognition, whereas words formed by letters with high bigram frequencies were somehow slowed down.
As a consequence of the reported significance of bigram frequency in word recognition, many researchers in word naming have considered orthographic familiarity (bigram and/or trigram frequencies) as a relevant factor to have under control. However, the few studies that have investigated the influence of bigram frequency in word naming have reported no effects (Andrews, 1992; Bowey, 1990; Strain & Herdman, 1999).
Available evidence indicates a general absence of bigram and/or trigram frequency effects in standard word naming, but effects have been reported in word recognition. If acronym processing is similar to the processing of any other word in the language, bigram or trigram frequency effects are not predicted in acronym-naming speed.
Imageability
Imageability refers to the ease with which a word evokes a mental image (Paivio, Yuille, & Madigan, 1968). The lexical relevance of imageability emerged in the 1960s as an interpretation of the superiority of concrete over abstract nouns. This was supported by the fact that concrete words were rated as more imageable than abstract words (Paivio, 1965). Subsequent research has shown that highly imageable words are better recognized and memorised than low imageable words in tasks of lexical decision and cued and free recall (Balota, Cortese, Sergent-Marshall, Spieler, & Yap, 2004; Kennet, McGuire, Willis, & Schaie, 2000; Paivio 1965). The dual-code hypothesis (Paivio, 1971, 1991) accounts for the imageability effect, arguing that abstract words activate verbal codes, while concrete words activate verbal and imagery codes. The hypothesis states that the assistance of the imagery system facilitates the processing of concrete words.
A number of studies have also shown that high-imageable words are consistently better named by patients with a phonological impairment but some preservation of their reading ability (Hirsh & Ellis, 1994; Tree, Perfect, Hirsh, & Copstick, 2001; Weekes & Raman, 2008). Patients with better accuracy at naming abstract words also occur, although these cases have been reported less frequently (Papagno, Capasso, Zerboni, & Miceli, 2007; Reilly, Grossman, & McCawley, 2006). The influence of imageability in unimpaired oral reading, however, is uncertain. Strain, Patterson, and Seidenberg (1995) argued that the imageability influence shown in patients implies a relationship with reading. In Experiments 2 and 3, they found significant interactions between imageability and consistency for low-frequency words. This meant that significant longer times were required to read low-imageability and inconsistent words. In their view, translation from orthography to phonology is fast and efficient for words with regular/consistent spelling patterns (regardless of their frequency or imageability values) because orthography-to-phonology correspondences are assisted by the regular/consistent connections established by high-frequency words. However, low-frequency inconsistent words (e.g., dread, mischief) generate slow naming times, because neither the regularity of the word nor its frequency can aid in their pronunciation. As a consequence, the intervention of semantic information facilitates the reading processes of those inconsistent and low-frequency words with richer semantic representations or high imageability.
However, other studies (Gerhand, 1998; J. Monaghan & Ellis, 2002) have failed to observe imageability effects in word naming once AoA has been taken into account (J. Monaghan & Ellis, 2002).
Most acronyms can be considered inconsistent, and often they are also low frequency. Thus, imageability effects should be observable when acronyms are read and recognized, assuming that semantic intervention is necessary at the time of word/acronym recognition and low-frequency and inconsistent word reading.
Number of orthographic neighbors or neighborhood size (N)
The role of lexical similarity in the process of word recognition and naming has been the subject of extensive investigation. One of the fundamental questions under examination is how the system distinguishes the word to be recognized (e.g., word) from a set of similar candidates (e.g., ward, wore, warm, war). One way in which the lexical similarity of a word has been operationalized is counting the number of words formed by changing one letter from the given word while keeping constant the position and identity of the rest of the letters (Coltheart, Davelaar, Jonasson, & Besner, 1977). For example, the word peace produces four neighbors: peach, pence, pease , and place. It is often referred to as N, and it is the more commonly used measure in studies of lexical similarity. A common finding in word naming is that words with high N are named faster than words with low N (Andrews, 1989, 1992; Mathey, 2001; Sears, Hino, & Lupker, 1999).
A further concern, of relevance to the present study, relates to the locus from which the N-effect emerges. Andrews (1989) proposed an early origin, suggesting that the N-effect is a product of the interaction between letter and lexical units (neighbor words receive and feedback activation from and to their constituent letters, increasing the activation of the target letters and accelerating in this way the recognition of the correct word).
The word’s orthographic body is a structural characteristic of words that correlates with word rhyme, and N and has led to the suggestion of a late locus for the N-effect. In English, a great proportion of neighbors result from changing the first letter of the word. As a consequence, high-N words tend to share their orthographic body, and in addition, this orthographic body usually rhymes. This relationship between N, orthography, and phonology introduces the possibility that N-effects might be the consequence of phonological, rather than orthographic, computation. Adelman and Brown (2007) tested this hypothesis by analyzing the results from four existing megastudies of word recognition in English (Balota et al., 2000; Balota & Spieler, 1998; Spieler & Balota, 1997; Seidenberg & Waters, 1989). They conducted a series of regression analyses in which they included phonographic neighborhood, which refers to the number of words formed by changing one letter and phoneme from a given word, as a predictor variable. Other variables included in their analysis were word frequency, orthographic neighborhood size, first phoneme, number of letters, word regularity, number of friends, number of enemies, and rime consistency ratio. The results showed a significant facilitation of number of phonographic neighbors over and above the effects of regularity and rime consistency. Number of orthographic neighbors did not reliably predict reaction times in any of the four sets analyzed (apart from a small impact in the Seidenberg and Waters’s, 1989, data). Adelman and Brown (2007) concluded that neighborhood effects cannot be accounted for by orthographic processing only; instead, the conversion of print to sound is the more likely source of the effect.
In relation to acronym naming, N-effects are predicted only if they emerge from the early processing of their constituent letters. In contrast, if the N-effects derive from phonological similarity or from the interaction between orthography and phonology, the impact of N in acronym naming would be reduced or absent, since for most acronyms, the translation from letters into sounds will not correspond to that of its neighboring words in terms of single phonemes or rhyme units (e.g., as in EEG, leg, peg, beg, egg).
Orthographical and phonological length
Word length measured in terms of its orthographical (number of letters) or its phonological (number of syllables or phonemes) aspects shows a positive correlation with word-naming and recognition times (Balota et al., 2004; Hudson & Bergman, 1985). Phonological and orthographic measures of word length are also strongly intercorrelated in mainstream words, since increasing the number of syllables or phonemes inevitably increases the number of letters. Slower reaction times for words with many letters are a common finding in oral reading (Balota et al., 2004; Forster & Chambers, 1973; Frederiksen & Kroll, 1976; Spieler & Balota, 1997; Ziegler, Perry, Jacobs, & Braun, 2001). In addition, Balota et al. (2004) also observed an interaction between letter length and word frequency, with a greater influence of letter length over low-frequency words. However, null effects of letter length when skilled readers name words have also been reported (Bijeljac-Babic, Millogo, Farioli, & Grainger, 2004; Weekes, 1997).
A number of studies have also shown an influence of the number of syllables in oral reading times and accuracy. Number of syllables, like number of letters, also interacts with word frequency, with more pronounced length effects reported for multisyllabic low-frequency words (Ferrand, 2000; Jared & Seidenberg, 1990). Theoretically, length effects have been conceptualized as indicators of serial processing. Taking the dual-route model as the theoretical framework, the reported interaction between word length and frequency could be explained as the result of the rapid, parallel processing of high-frequency words via the lexical pathway (irrespective of word length) but the slow processing of low-frequency words by the same lexical route. The slowness in the lexical processing of low-frequency words makes the activity of the sublexical route more apparent, showing facilitation when short words are processed (Balota et al., 2004; Coltheart et al., 2001).
Number of letters and syllables were calculated for the acronyms included in the present study. The correlation between these variables was predicted to be low since, often, acronyms are short in number of letters but long in number of syllables (e.g., BBC, DVD, etc.). The disparity between letter and syllable length would help to reveal the relative contribution of orthographic and phonological length in acronym reading. In addition, since many acronyms are pronounced by naming each of the constituent letters aloud, a linear length effect was intuitively predicted in acronym-naming times.
Print-to-pronunciation patterns: Typicality and ambiguity
The spelling system of modern English is the result of a complex and rich language history that has produced a distinctive way of translating letters into sounds. The classification of the spelling regularities and, therefore, also inconsistencies, along with the examination of their influence on reading, has been profusely studied (Coltheart et al., 2001; Rastle & Coltheart, 1999; P. Monaghan & Ellis, 2010; Strain, Patterson, & Seidenberg, 2002; Zorzi, Houghton, & Butterworth, 1998). The difficulty of this enterprise is reflected in the fact that establishing the best classification method still is a bone of contention.
Venezky (1970) was one of the first to study the letter-to-sound patterns in English. He grouped the written representation of sounds into graphemes (letter or combination of letters equivalent to one sound) and established two types of grapheme-to-phoneme correspondences: major for those occurring with higher frequency and minor for those occurring with lower frequency. As an illustrative example of Venezky’s taxonomy, the pronunciation of ea as in seal was described as a major correspondence, while the pronunciations for ea in steak or bread were minor correspondences. Adhering to Venezky’s classification, Coltheart (1978) proposed a ruled-based mechanism for coding phonological information, known as the grapheme-to-phoneme correspondences (GPC) system. The application of the rules governing major correspondences, or the GPC system, allows the correct pronunciation of all the English regular words. However, a different but parallel lexical mechanism is required to allow for correct pronunciation of irregular words (those whose graphemes are converted to phonemic correspondences not embedded in the GPC system). The lexical and sublexical GPC mechanisms (also referred as routes) will produce the correct pronunciation for all regular words and nonwords. However, these two routes generate conflicting pronunciations for irregular words. The resolution of the conflict takes time, and this slows down responses. A common finding supporting the existence of these two routes for reading is that regular words are processed faster and more accurately than irregular words (Baron & Strawson, 1976; Gough & Cosky, 1977; Parkin, 1982; Stanovich & Bauer, 1978; Waters & Seidenberg, 1985).
An alternative word-reading account is based on the amount of features shared by the words in the vocabulary. Glushko (1979) showed that the pronunciation of a nonword could be achieved through a mechanism based on features shared with known words. According to Glushko, the most important characteristic when letters are translated into sounds is the consistency of the pronunciation of words with similar spelling. For example, the word body ade, as in wade, is pronounced in the same way in all similarly spelled words (e.g., bade and fade) and is, hence, described as consistent. In contrast, save is pronounced differently from have and is, therefore, an example of an inconsistent word. In Experiments 1 and 2, Glushko demonstrated that pseudowords created from words with irregular pronunciations (such as heaf from the irregular word deaf) were named slower than pseudowords based on words with regular spelling-to-sound correspondences (e.g., hean from dean). Glushko argued that the longer production latency for heaf over hean was the result of the eaf ending stemming from a group of exception words (e.g., deaf, leaf).
Glushko’s Experiment 3 indicated that words with regular grapheme–phoneme correspondences but inconsistent word bodies were named slower than regular words with consistent word bodies. Glushko argued that consistent words are named faster because the activation of neighboring nodes facilitates their processing. Cortese and Simpson (2000) and Jared (2002) also varied GPC regularity and word body consistency orthogonally in tests of word naming. Both studies indicated that consistency had an impact on production latency over and above any effects of regularity, as well as on the number of errors made by participants. These findings support the position that a hard and fast rule system might be insufficient for the conversion of words from print to sound. A rule system such as the grapheme–phoneme correspondences can only split words into two halves—those that follow the rules and those that violate them.
The problem of how the cognitive system deals with the translation of letters into sounds in English is complex and open to debate. Pronunciation of acronyms, however, might be less limited by the idiosyncrasies of the English language than are mainstream words. Neither of the two classification systems reviewed can be employed satisfactorily with acronyms. This is because the majority of the acronyms would be classified as inconsistent (e.g., in EEG, the word body -eg is common to leg, beg, and Meg, but the pronunciation is very different) and irregular (the application of GPC rules to acronym reading would produce either incorrect or impossible responses (e.g., HIV and BBC, respectively). However, most acronyms would be pronounced correctly by applying a simple rule: naming its letters.
Two features have been taken into account at the time of classifying the pronunciation of acronyms: pronunciation typicality and ambiguity. Acronyms named by spelling aloud each of their letters (e.g., DVD) have been classified as typically pronounced acronyms, while acronyms named following the spelling-to-sound correspondences of the language (e.g., DOS) have been classified as atypically pronounced acronyms. In addition, acronyms formed entirely by consonants or vowels (e.g., CNN, AOA) have an unambiguous pronunciation, naming each of its letters aloud, and have been considered as unambiguous. Acronyms containing a mixture of consonants and vowels have the potential of a “word-like” pronunciation (e.g., SARS, ROM).
However, this pronunciation potential is not always fulfilled (e.g., HIV, ISP), and that is why these acronyms have been classified as ambiguous. The combination of these features, pronunciation typicality and pronunciation ambiguity, provides three different types of acronym pronunciations: (1) ambiguous and typical (e.g., HIV), (2) ambiguous and atypical (e.g., ROM), and (3) typical and unambiguous (DVD). The definition of unambiguous pronunciation prevents the existence of atypical and unambiguous acronyms.
Word frequency and word familiarity
Word frequency refers to the number of times an individual encounters or uses a particular word. The intuition that frequency of occurrence could have an influence in word processing was first supported by Howes and Solomon’s (1951) findings, and its importance in word processing has been extensively demonstrated ever since. High-frequency words are recognized, produced, and recalled faster and with greater accuracy than low-frequency words (Connine, Mullinex, Shernoff, & Yelen, 1990; Oldfield & Wingfield, 1965; Whaley, 1978; Yonelinas, 2002).
Two main procedures have been employed to measure word frequency: statistical and rated estimations. Statistical valuations of frequency derived from corpora of written language have been commonly considered the objective measure of frequency. However, it has been observed that frequency norms generated from corpus of printed frequency might not be truly representative of the language in use (Brysbaert & New, 2009; Gernsbacher, 1984). This is because written language is edited, more diverse than spoken language, and fixed to the linguistic style of its time. Other sources of criticism come from the sample bias associated to statistical estimations. This bias is more pronounced in small corpuses where low-frequency words, in particular, lose discriminatory power (Burgress & Livesay, 1998; Zevin & Seidenberg, 2002). Brysbaert and New conducted a study looking at traditional and more contemporary frequency norms. They found that the bias for low-frequency words represents a concern only on corpuses sized below 16 million words. Brysbaert and New compared the predictive power of word frequency as obtained from six different frequency norms on word recognition times (as available from Balota et al., 2004). They showed that norms available from Internet discussion groups (Hyperspace Analogue to Language (HAL); Lund & Burgress, 1996) and subtitles (SUBTLEXus; Brysbaert & New, 2009) showed the highest correlations with word-processing variables.
The biases found in word frequency counts have prompted some researchers to study word recognition processes using frequency ratings (often in addition to written frequency measures: Balota et al., 2004; Connine et al., 1990; Gernsbacher, 1984). In order to obtain frequency ratings, participants are asked to estimate how many times they encounter and/or use a particular word. This measure of frequency is normally considered to be subjective and is often used interchangeably with the concept of word familiarity. In this study, a rated estimation of the subjective frequency/familiarity of a list of acronyms is presented along with a printed frequency measure for each acronym. Frequency corpuses tend to underrate the frequency of acronyms because they either avoid the inclusion of abbreviations (Zeno, Ivens, Millard, & Duvvuri, 1995) or are based on language samples where acronyms are scarcely represented (e.g. from subtitles SUBTLEXus). For this reason, acronyms’ printed frequency was calculated using three Internet search engines (www.altavista.com; www.google.co.uk; www.bing.com), as suggested by Blair, Urland, and Ma’s (2002) method. That is, each acronym was entered into the search function, and the number of hits returned was recorded as the measure of the acronym frequency. The validity of this method was provided by Blair et al. They compared frequency estimations based on two commonly used corpuses (i.e., the Kučera & Francis [1967] corpus and the Celex database [Baayen, Piepenbrock, & Gulikers, 1995]) with frequency calculations based on the number of hits returned by four Internet search engines (i.e., Alta Vista, Northern Light, Excite, and Yahoo). Frequencies from the search engines were collected at two points in time, with an interval of 6 months between them. Results showed high correlations between the frequency values provided by corpuses of written text and those generated by the search engines (e.g., Alta Vista frequencies correlated .81 with Kučera and Francis and .76 with Celex [Baayen et al., 1995]) and high test–retest reliabilities (r = .92). These correlations were based in a word sample of 382 words.
In the present study three different search engines were used in order to provide an indication of reliability. In addition, a rated estimation of each acronym subjective frequency/familiarity was also collected.
The importance researchers have assigned to word frequency is reflected in the fact that most models of word processing and word learning have incorporated word frequency in their operating architectures (Coltheart, 2001; Harm & Seidenberg, 2004; P. Monaghan & Ellis, 2010). Frequency effects in word naming tend to interact with word regularity and/or consistency (Ellis & Monaghan, 2002; Jared & Seidenberg, 1990; J. Monaghan & Ellis, 2002; Weekes, Castles, & Davies, 2006). This means that reading times are particularly slow and inaccurate for low-frequency inconsistent and/or irregular words. Considering the orthographic inconsistency/irregularity of acronyms and assuming that acronym naming exploits the same reading system as that used when mainstream words are named, large frequency effects are predicted in acronym-naming times and accuracy.
Word’s initial sound
A number of studies have shown that the acoustic characteristics of the word’s first phoneme influence the accuracy of voice key measurements. This is because voice keys are not reliable at detecting the acoustic onset of a word (Rastle & Davis, 2002). Rastle and Davis investigated the effects of onset complexity on reading times as captured by two different types of voice keys. The simple threshold voice key recorded the moment at which an amplitude value exceeded a predetermined threshold, and the integrative voice key was sensitive to the amplitude and, also, to the duration of the signal. Onset complexity had two levels that were operationalized as (1) words with two-phoneme onsets (e.g., /s/ followed by /p/ or /t/, as in spat or step) and (2) words with just one phoneme onset (e.g., /s/ as in sat). Results showed that the simple threshold voice key was triggered at the onset of voicing, which did not coincide with the real word’s onset, since all the words used started with the voiceless phoneme /s/.
In order to address voice key issues, some studies of word naming enter the characteristics of the initial phoneme of the words into their regression analyses. The procedure requires the transformation of each phonetic feature into a dummy variable that is then considered in the analyses (Balota et al., 2004; Treiman, Mullennix, Bijeljac-Babic, & Richmond-Welty, 1995). However, taking into account the phonetic features of the first phoneme of a word might not be enough, since voice key biases have been reported to emerge not only from the initial phoneme, but also from other consonants and vowels in the acoustic onset (Kessler, Treiman, & Mullennix, 2002; Rastle & Davis, 2002). Taking initial phoneme features plus complex consonant onsets into account requires adding an important number of variables (i.e., from 10 onward). These added variables do not pose a problem in multiple regression analyses comprising large number of stimuli (e.g., 2,428 words in Balota et al. [2004] and 1,329 words in Treiman et al. [1995]). However, ten or more new variables could be an excessive addition of factors in studies with a relatively small number of different stimuli.
In the present study, the aim was to investigate the characteristics of 146 acronyms. In order to keep a reasonable ratio of predictors and observations and in light of the results reported by Rastle and Davis (2002), the present study considered one of the phonetic characteristics of the acoustic onset: voicing. Thus, the sonority associated to the first phoneme of the acronyms (voiced or voiceless) is provided.
Norms
Method
Participants
One hundred twenty English native speakers, 34 males and 86 females, participated in the compilation of these norms. Each of the factors to be estimated—rated frequency, imageability, and AoA–was rated by a set of 40 participants. Participants were volunteers from Swansea University with a mean age of 24 years (range, 18–37). They all had normal or corrected-to-normal vision. None participated in the estimation of more than one factor, and all received course credit for their participation.
Materials
A total of 269 acronyms were initially selected from the Oxford English Dictionary (2009) and from the Acronyms, Initialisms and Abbreviations Dictionary (Mossman, 1994). Acronyms were gathered if they were intuitively thought to be relatively familiar, and an effort was made to select acronyms from a diversity of domains, such as science, technology, business, industry, jargon, medicine, etc. The set of 269 acronyms originally chosen was randomized. The randomized list was subsequently split into two questionnaires of approximately equal lengths (131 and 138) for administration to participants. A randomised set of 20 acronyms were present in both lists to allow an assessment of reliability. This procedure increased the sizes of the lists to be rated to 141 and 148 acronyms each. Twenty acronyms were printed per page, in the same randomized order for the estimation of rated frequency or word familiarity, AoA, and imageability.
Care was taken to make sure that the selected acronym definitions (from Oxford English Dictionary and the Acronyms, Initialisms and Abbreviations Dictionary) corresponded to the more dominant meaning available to the participants tested in the present study. In order to accomplish this, a word association task was devised. Twenty participants (3 male, 17 female), none of whom had participated in any other acronym-related task and with a mean age of 21 years (SD = 1.997), were presented with each of the 269 acronyms using E-Prime (Schneider, Eschman, & Zuccolotto, 2002). They were instructed to say aloud the first thing that came to their mind in response to the acronym presented onscreen. A microphone placed approximately 10 cm away from the participant detected his/her vocal response. Then, the participant could type the word he/she had just said. Participant responses were then placed into five broad categories: semantic, orthographic, phonological, compound, and erratic. Semantic responses included those referring to the full term for the acronym, as well as semantic-related information (e.g., BBC–television). In order to establish the dominance of the acronym definition, only the semantic associations were taken into account. The full term listed here is the sense of the acronym that elicited the majority of semantic association responses.
The present database comprises 146 out of the original 269 acronyms. One hundred sixteen acronyms were excluded because they were reported to be unknown by more than 50% of the participants who completed the AoA questionnaire. A further 7 acronyms were deleted because they were unknown to more than 50% of the participants who completed the association task.
Acronyms were not included if they consisted of fewer than three letters (BA), contained lowercase letters (kJ), used numerical characters (4WD), or formed a mainstream word (AIDS).
Database variables
The list of 146 acronyms is presented in the Appendix, along with their definitions, the percentage of participants who gave an associated response semantically related to the definition provided, and their values for AoA, bigram and trigram frequencies, imageability, number of orthographic neighbors, number of letters, syllables, and phonemes, print-to-pronunciation patterns, rated frequency, printed frequencies, and voicing.
Procedure
Age of acquisition
The 141 and 148 acronym lists were presented to two groups of 20 participants (8 male, 32 female; mean age = 25 years, SD = 1.861), who were asked to estimate when they first had learned each of the acronyms in the lists by writing down the estimated age in a box located beside each acronym. This method has been used successfully in the past (Ghyselinck, De Moor, & Brysbaert, 2000; Izura, Hernandez-Muñoz, & Ellis, 2005). The method has greater flexibility to provide late age ranges, and this was thought particularly useful for generating AoA values of a material that might be learned relatively late. One hundred acronyms were presented per page in five equal columns. The estimated reliability (Cronbach’s alpha) for the group was .93. Since the ratio of male and female participants was considerably different, the average ratings for male and female were submitted to a t-test analysis. No significant differences were found, t(139) = −1.27, p > .1.
Bigram and trigram frequency
Bigram and trigram frequency values were obtained from the MCWord, an orthographic word form database (Medler & Binder, 2005). The unrestricted bigram and frequency values were used here. This measure simply counts the number of times that any bigram or trigram appears in the CELEX database (Baayen et al., 1995).
Imageability
Two groups of 20 participants (14 male, 26 female; mean age = 23 years, SD = 1.52) were presented with one of two lists of acronyms and were asked to estimate the imageability of each acronym on a 7-point scale. One list consisted of 141 acronyms, the other listed 148, and each was presented in a randomized order. The instructions and scale, adapted from Paivio et al. (1968) required participants to indicate the ease with which each of the acronyms evoked a mental image. Numbers in the scale were labeled to inform participants of the different degrees of image-evoking difficulty. These ranged from 1 (image aroused after long delay/not at all) to 7 (image aroused immediately). Twenty acronyms were presented per page. Twenty acronyms were included for rating by both of the groups of participants, and these ratings were correlated to assess interrater reliability. The internal reliability for the group, using Cronbach’s alpha, was .94. Since the ratio of male and female participants was different, the average ratings for male and female ratings were submitted to a t-test analysis. Ratings were significantly different, t(139) = 5.17, p < .001, with the females’ ratings being higher in imageability than the males’ ratings.
Number of orthographic neighbors
The number of orthographic neighbors was calculated by counting the number of words that differed in one letter with the target acronym while preserving the identity and position of the rest of the letters in the acronym. The calculation was based on the words listed in the CELEX database (Baayen et al., 1995). Where a word generated in this way was listed in the database more than once (e.g., as a verb and a noun), this was counted as only one neighbor.
Orthographic and phonological length
The length of each acronym was considered in terms of number of letters, number of syllables, and number of phonemes.
Printed frequency
Printed frequency estimates were generated following the procedure used by Blair et al. (2002). The number of hits returned by the Internet search engines (Google, Bing, and AltaVista) were computed as indexes of word frequency. All were advance searches restricted to the English language. The value presented here is the log transformation of the number of hits returned for each acronym.
Rated frequency/word familiarity
The two randomized lists of acronyms (141 and 148 items long, respectively) were each presented to a group of 20 participants for frequency rating (10 male, 30 female; mean age = 25 years, SD = 2.04). Each page consisted of 20 acronyms to be rated on how frequently they were used or encountered. Ratings were made using a 7-point Likert scale ranging from 1 (rarely/never) through to 7 (more than twice daily). Each page was headed with the same instructions detailing that responses were to be made by circling the appropriate number and that the full range of the scale could be used if it was felt appropriate. One page of acronyms was presented as part of both versions of the questionnaire. Interrater reliability (Cronbach’s alpha) was .91. Since the ratio of male and female participants was different, the average ratings for male and female ratings were submitted to a t-test analysis. No significant differences were found, t(139) = −.698, p > .1.
Results and discussion
The ratings collected were collapsed across lists for AoA, frequency, and imageability estimations. Descriptive statistics for each of the continuous variables considered in this study are shown in Table 1. The variable related to the voicing of the acronym’s initial sound was dichotomized in voiced (n = 116) or voiceless (n = 30) and was considered, therefore, as a categorical variable. Similarly, three additional categorical variables were created to account for the acronym print-to-pronunciation pattern. These were unambiguous pronunciation (n = 85), ambiguous but typically pronounced acronyms (n = 48), and ambiguous and atypically pronounced acronym (n = 13).
Table 1.
Descriptive statistics for each continuous variable
| M | SD | Min | Max | |
|---|---|---|---|---|
| Age of acquisition | 14.82 | 3.40 | 6.10 | 23.14 |
| Imageability | 5.09 | 1.06 | 1.85 | 6.90 |
| Number of letters | 3.32 | 0.57 | 3 | 6 |
| Number of phonemes | 5.84 | 1.52 | 3 | 14 |
| Number of syllables | 3.14 | 0.56 | 2 | 5 |
| Number of orthographic neighbors | 2.25 | 3.43 | 0 | 23 |
| Rated frequency | 2.79 | 0.86 | 1.4 | 5.85 |
| Log transformed: Google printed frequency | 7.26 | 0.81 | 5.18 | 9.11 |
| Log transformed: Bing printed frequency | 6.48 | 0.76 | 5.09 | 8.84 |
| Log transformed: AltaVista printed frequency | 7.74 | 0.71 | 6.12 | 9.67 |
| Log transformed: Bigram frequency | 3.33 | 0.93 | 0 | 4.57 |
| Log transformed: Trigram frequency | 0.91 | 1.06 | 0 | 4.17 |
M = mean; SD = Standard Deviation; Min = minimum; Max = maximum; Log = logarithm
Acronyms and all the normative values are presented alphabetically in the Appendix. The correlation matrix for all the continuous variables considered in this study is shown in Table 2. To ensure that the significance of the correlations reported was meaningful and valid, data were appropriately transformed to deal with skewed distributions. Thus, a logarithm transformation was applied to the printed frequency values obtained from the Google, Bing, and AltaVista search engines and also to rated frequency, number of syllables, number of phonemes, number of letters, and imageability. One unit was added before the logarithm transformation was applied to number of orthographic neighbors, bigram frequency, and trigram frequency. AoA ratings were normally distributed.
Table 2.
Correlation matrix for 12 variables and 146 acronyms
| Variable | 2 | 3 | 4 | 5 | 6 | 7 | 8 | 9 | 10 | 11 | 12 |
|---|---|---|---|---|---|---|---|---|---|---|---|
| 1. Number of letters | −0.24** | −0.24** | 0.44** | n.s. | n.s. | 0.34** | 0.38** | 0.34** | n.s. | −0.30** | −0.25** |
| 2. Number of syllables | - | 0.57** | n.s. | n.s. | n.s. | −0.23* | −0.26** | n.s. | n.s. | n.s. | n.s. |
| 3. Number of phonemes | - | −0.28* | n.s. | n.s. | −0.23** | −0.23* | −0.23** | n.s. | −0.42** | −0.36** | |
| 4. Number of orthographic neighbors | - | n.s. | n.s. | n.s. | 0.18* | n.s. | n.s. | 0.18* | n.s. | ||
| 5. Imageability | - | 0.63** | n.s. | 0.17* | n.s. | −0.57** | n.s. | n.s. | |||
| 6. Rated frequency | - | 0.36** | 0.30** | 0.32** | −0.18* | n.s. | n.s. | ||||
| 7. Printed frequency (Google) | - | 0.89** | 0.92** | n.s. | n.s. | n.s. | |||||
| 8. Printed frequency (Bing) | - | 0.86** | n.s. | n.s. | n.s. | ||||||
| 9. Printed frequency (AltaVista) | - | n.s. | n.s. | n.s. | |||||||
| 10. Age of acquisition | - | n.s. | n.s. | ||||||||
| 11. Bigram frequency | - | 0.61** | |||||||||
| 12. Trigram frequency | - |
A logarithm transformation was applied to number of letters, number of syllables, number of phonemes, rated frequency, all the printed frequency measures (Google, Bing, and AltaVista), and imageability. Number of orthographic neighbors, bigram frequency, and trigram frequency were the logarithm transformation of the original value plus one.
* p < .05
** p < .01
Some of the correlations in Table 2 are of particular importance. Interestingly, the number of letters shows a negative correlation with the number of syllables and the number of phonemes. Thus, shorter acronyms require more syllables and phonemes when pronounced (e.g., naming each letter aloud). It is also worth noting that the three acronym printed frequencies (from Google, Bing, and AltaVista) correlate significantly with rated frequency and are also highly intercorrelated, indicating a high level of reliability. However, they do not show the same pattern of correlations with the number of syllables, the number of orthographic neighbors, and imageability. All three printed frequencies correlate positively with the number of letters and negatively with the number of phonemes, meaning that high-frequency acronyms tend to have more letters but fewer phonemes. In addition, and in contrast to what is normally found with mainstream words, none of the printed frequencies showed a significant correlation with AoA. This lack of correlation is unusual in studies using common words (see Zevin & Seidenberg, 2002, 2004). This atypical relationship might reflect the fact that a number of newly introduced acronyms refer to technological devices, programs, organizations, and so forth that are becoming part of everyday live and language (e.g., DVD, GPS). The recent introduction of some of these acronyms means that they are learned late in life, despite their high frequency of appearance in print. AoA ratings showed significant and negative correlations with imageability and rated frequency, meaning that the later acquired the acronym, the lower its imageability and perceived frequency. These inverse relations of AoA with imageability and rated frequency have typically been found in studies using mainstream words (Morrison, Chappell, & Ellis, 1997; Stadthagen-Gonzalez & Davis, 2006). A linear correlation was found between rated frequencies and AoA ( r = −.18, p < .05; see Table 2), suggesting that the printed frequency estimations used in the present study overrated the perceived frequency of some acronyms—in particular, those at the higher end in the AoA scale. Thus, a number of late acquired acronyms appeared with greater printed than rated frequencies (e.g., PSP [play station personal], TFT [Thin Film Transition], MBA [Masters in Business Administration]).
It is also interesting to note that the number of orthographic neighbors correlates positively with the number of letters but negatively with the number of phonemes. That is, the more letters and fewer phonemes in the acronym, the greater the number of neighbors. This correlation departs from the correlations reported with mainstream words (see Adelman & Brown, 2007; Balota et al., 2004) and indicates that acronyms pronounced following grapheme-to-phoneme correspondences (e.g., those that have a few number of phonemes) tend to have a higher number of orthographic neighbors.
Word-naming experiment
Method
Participants
Twenty students from Swansea University with a mean age of 20 years (range, 18–24 years) participated in this experiment. None of them had collaborated in the collection of acronym associative responses, AoA, imageability, or frequency ratings, and they had not been involved in the completion of the acronym association task. The 15 female and 5 male participants were all native speakers of English, were nondyslexic, and had normal or corrected-to-normal vision. Course credit was offered as a reward for participation.
Procedure
Participants named the 146 acronyms with complete database entries for frequency, AoA, imageability, number of orthographic neighbors, and orthographic and phonological acronym length. Acronyms were presented one at a time in black capital letters on a white screen (19-in. monitor) in size 12, Times New Roman font. Each trial started with a fixation cross that appeared in the middle of the screen for 1,500 ms. Then an acronym appeared in the middle of the screen and remained there until the participant made a response. Participant responses were detected by a highly sensitive microphone (approximately 10 cm away from the participant’s mouth) attached to the computer. Activation of the microphone triggered the presentation of the next fixation cross. Trials were randomized for each participant. This was controlled by E-Prime (version 1.0.1, Psychology Software Tools, 1999) using a Dell computer with an Intel Pentium 4 1.5-GHz processor. The experimenter noted all the errors. In addition, the experimental sessions were audio recorded for further inspection of accuracy in the data. Following the completion of the naming task, participants were given a list with all the acronyms they had been asked to read and were required to indicate next to each acronym whether they knew it or not.
Results
Although the major purpose of this study was not to investigate the influence of acronym knowledge on acronym naming, it was thought interesting to examine participants’ accuracy when naming known and unknown acronyms. Once the acronym-naming task was finished, participants noted the acronyms they knew and those they did not know. The numbers of known and unknown acronyms were used to classify correct and incorrect responses in a two (known, unknown) by three (unambiguous, ambiguous typical, and ambiguous atypical) contingency table. Table 3 shows the percentage of correct and incorrect responses in each of the categories created.
Table 3.
Percentage of correct and incorrect responses to known and unknown acronyms
| Known | Unknown | |||
|---|---|---|---|---|
| Acronym Pronunciation | Correct | Incorrect | Correct | Incorrect |
| Unambiguous | 81.4 | 0.5 | 18.1 | 0 |
| Ambiguous typical | 78.2 | 1.6 | 19.8 | 0.4 |
| Ambiguous atypical | 84.2 | 9.2 | 2.7 | 3.8 |
Four Friedman’s ANOVAs were carried out with acronym’s print-to-pronunciation pattern as a between-subjects variable and number of responses as the dependent variable. The four analyses corresponded to the orthogonal manipulation of response accuracy (correct, incorrect) and acronym knowledge (known, unknown). Potential differences between the three types of acronyms (unambiguous, ambiguous typical, and ambiguous atypical) were examined in each of these four Friedman tests. Correct responses to unambiguous, ambiguous typical, and ambiguous atypical acronyms were not significantly different when the acronyms were known to the participants, χ 2(2) = 0.86, p > .1, or when the acronyms were unknown, χ 2(2) = 0.86, p > .1. However, significant differences among the three types of acronyms were detected for incorrect responses to known acronyms, χ 2(2) = 12.88, p < .001. This difference was further inspected using Wilcoxon tests. Bonferroni correction was applied, and, therefore, effects are reported at α/3 (i.e., .0167) level of significance. A significant difference was found between the errors produced when ambiguous typical and ambiguous atypical acronyms were named, T = 0, p < .01, r = −.36. The difference between erroneous responses to unambiguous and ambiguous atypical acronyms known to the participant approached significance, T = 6, p = .025, r = −.23. No significant differences were found between incorrect responses to unambiguous and ambiguous typical acronyms known to the participants. Finally, a main effect of acronym’s type was found for incorrect responses to unknown acronyms, χ 2(2) = 11.47, p < .01. Further inspection of this effect using Wilcoxon tests (Bonferroni correction applied at α/3 level of significance) showed a significant difference between ambiguous typical and ambiguous atypical acronyms, T = 0, p ≤ .016, r = −.29, and between unambiguous and ambiguous atypical acronyms, T = 0, p ≤ .016, r = −.23.
Thus, the results show that more errors occurred when ambiguous and atypical acronyms were read than when any of the other two types of acronyms were read. Interestingly, this higher error rate occurred when the acronym was known and when the acronym was unknown. The specific difficulty encountered by the participants when naming ambiguous atypical acronyms is likely to emerge from the shift in pronunciation patterns, since the orthographic configurations of ambiguous atypical acronyms and ambiguous typical acronyms are thought to be the same.
Reaction time analyses
Participant errors (2.12%), voice key malfunctions (3.94%), and response times that were 2.5 standard deviation above or below the mean (1.13%) were removed from the analyses of reaction times. Correlations between harmonic means of response times, percentage accuracy, and each of the numerical variables considered in this study are presented in Table 4.2
Table 4.
Correlations between predictor variables, reaction times, and errors
| Reaction Times | Percentage Errors | |
|---|---|---|
| Number of letters | .387** | .257** |
| Number of syllables | n.s. | −.336** |
| Number of phonemes | n.s. | −.305** |
| Number of orthographic neighbors | −.230** | n.s. |
| Imageability | −.249** | n.s. |
| Rated frequency | −.255** | n.s. |
| Printed frequency (Google) | −.281** | n.s. |
| Printed frequency (Bing) | −.308** | n.s. |
| Printed frequency (AltaVista) | −.289** | n.s. |
| Age of acquisition | .249** | n.s. |
| Bigram frequency | n.s. | n.s. |
| Trigram frequency | n.s. | n.s. |
Note. n.s. indicates that the correlation was not significant.
**p < .01
Acronym-naming times show a negative correlation with number of orthographic neighbors, imageability, and all the frequency measures considered here (rated and printed), indicating that highly imageable and high-frequency acronyms with a high number of orthographic neighbors were named faster than low-imageability and low-frequency acronyms with a low number of orthographic neighbors. Reaction time correlations with N, imageability and frequency are also characteristically found in word-naming studies (Barca, Burani, & Arduino, 2002; Morrison & Ellis, 2000). Similarly, and in line with other word-naming studies (Balota et al., 2004), number of letters shows a correlation with acronym-naming times and accuracy, meaning that long acronyms were named slower and with more errors. In contrast to what has been found in other word-naming studies (Balota et al., 2004; Morrison & Ellis, 2000), the number of syllables and the number of phonemes showed negative correlations with accuracy, indicating that phonologically long words produced smaller numbers of errors.
Having looked at the relationships between the dependent variables (naming times and accuracy) and independent variables (number of letters, number of syllables, number of phonemes, number of orthographic neighbors, imageability, rated frequency, printed frequencies, AoA, bigram frequency, and trigram frequency), the predictive power of each independent factor was examined. The particular technique used here to analyze the data is known as the multilevel or hierarchical model (Miles & Shevlin, 2001). Multilevel models are linear regressions in which variation of groups can be modeled at different levels (Gelman & Hill, 2007). For the purpose of this study, the data were structured hierarchically with a three-level hierarchy: one corresponding to the participants, and the other two to the predictor variables. One of the advantages of this model over classical regression is that it allows an examination of the predictive power of independent variables while accounting for systematic unexplained variation among the group of participants. For the purpose of all the analyses reported here, acronym-naming times were log transformed to reduce skew. The software used in all analyses was SPSS (16.0).
The three measures of acronym printed frequency were examined first in order to select the measure with greater predictive power for final analyses. Thus, the logarithm transformations of the printed frequencies as derived from the Google, Bing, and AltaVista search engines were compared. The three measures provided a significant change in the proportion of variance explained when included in the last step of the multilevel model (Altavista, ΔR 2 = .004; Google, ΔR 2 = .002; Bing, ΔR 2 = .003). The log transformation of the printed frequencies derived from the AltaVista search engine accounted for the greater proportion of variance, and therefore, this was the measure selected for subsequent analyses.
A series of four multilevel regression analyses was carried out as the result of alternating the submission of only one of the measures of phonological word length (number of syllables or number of phonemes) and one of the letter frequencies (bigram or trigram frequencies). Acronym’s print-to-pronunciation pattern, number of letters, number of phonemes, number of orthographic neighbors, imageability, rated frequency, and AoA were entered as predictors in all the analyses. The curvilinear relationships of two predictors (i.e., imageability and number of letters) with reaction times violated the regression assumption of linearity. The quadratic term of imageability and number of letters was introduced into the analysis as a procedure that tackles this problem (Kline, 2005). In these cases, variable Y (i.e., reaction times) is regressed on both X (i.e., imageability) and X 2 (i.e., imageability2). The presence of the squared variable adds a curvature to the regression line, and its regression coefficient indicates the influence of the quadratic aspect of imageability on reaction times.
The four analyses carried out yielded very similar results. A summary of the results from the analyses that accounted for the greatest proportion of the variance can be seen in Table 5.
Table 5.
Standard errors and t values for an analysis carried out on acronym RTs
| SE | t | |
|---|---|---|
| Step 2 | ||
| Ambiguous typical | .004 | −1.329 |
| Ambiguous atypical | .008 | 5.429** |
| Step 3 | ||
| Voicing | 0.005 | 5.693** |
| Number of letters | 0.615 | 4.128** |
| Number of letters2 | 0.539 | −3.495** |
| Number of orthographic neighbors | 0.007 | 2.494* |
| Imageability | 0.200 | −1.591 |
| Imageability2 | 0.152 | 0.623 |
| Rated frequency | 0.032 | 2.34* |
| Printed frequency | 0.005 | −3.317** |
| Age of acquisition (AoA) | 0.001 | −2.173* |
| Bigram frequency | 0.003 | −5.022** |
| Number of syllables | 0.050 | 0.335 |
| AoA × ambiguous typical | 0.001 | 4.247** |
| AoA × ambiguous atypical | 0.004 | 0.850 |
| Rated frequency × ambiguous typical | 0.047 | −1.657† |
| Rated frequency × ambiguous atypical | 0.104 | 1.610 |
| Printed frequency × ambiguous typical | 0.007 | 2.844** |
| Printed frequency × ambiguous atypical | 0.014 | 2.205* |
| Imageability × ambiguous typical | 0.061 | 3.184** |
| Imageability × ambiguous atypical | 0.211 | −1.083 |
| R 2 | .248 | |
† p < .1
* p < .05
** p < .01
In order to ensure that multicollinearity did not add noise in the precision of the estimations, the condition number (k), and the variance inflation factor (VIF) were examined in each of the four analyses. VIF values were within a tolerable range (ranging from 1.13 to 7.99), and the condition number k (ranging from 8.21 in one analysis to 13.71 in another analysis) indicated the presence of medium but not potentially harmful collinearity (k > 30).
Four potential interactions were also assessed. These were acronym’s print-to-pronunciation characteristics with word frequency (printed and rated), with AoA, and also with imageability. An interaction term was created by centering the continuous variables (printed and rated frequency, AoA, and imageability) and multiplying the result by each of the dummy variables representing acronym print-to-pronunciation characteristics.
In order to introduce the three types of acronym print-to-pronunciation patterns (unambiguous, ambiguous typical, ambiguous atypical) into the analyses, two of the dummy variables, ambiguous typical and ambiguous atypical, were included in the analyses, while unambiguous acronyms worked as the reference category. Both dummy variables were entered in step 2 of each analysis so the results could be meaningfully compared with the reference category.
The analysis explaining the greatest percentage of the variance associated to acronym naming times included bigram frequency and number of syllables as predictor variables (see Table 5). Consistent main effects were found across the analyses for voicing, number of letters, printed and letter frequency, AoA, and letter frequency (bigram or trigram). The main effect of number of orthographic neighbors was significant only when the bigram frequency was in the analyses. The number of phonemes emerged as significant predictor in the analysis with trigram frequency and approached significance in the analysis with bigram frequency. Imageability did not emerge as a significant predictor in any of the analyses. In terms of interactions, the printed frequency showed significant interaction in all the analyses with both types of ambiguous acronyms (typical and atypical). AoA and imageability also showed an interaction in all the analyses with ambiguous typical acronyms. Finally, the interaction between rated frequency and ambiguous typical acronyms approached significance in all but one analysis. In order to inspect the nature of these interactions a bit further, a regression line was fitted for each type of acronym in terms of their reaction times and printed frequency (see Fig. 1), AoA (see Fig. 2), and imageability (see Fig. 3). Thus, in relation to acronyms’ frequency, high-frequency typical acronyms (ambiguous or unambiguous) were named faster than low-frequency typical acronyms. However, high-frequency atypical acronyms were named slower than low-frequency atypical acronyms. The same interaction pattern was revealed when rated, instead of printed, frequency was used.
Fig. 1.
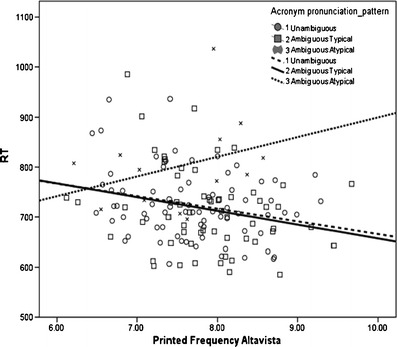
Regression lines between reaction times and printed frequencies for the different types of acronyms
Fig. 2.

Regression lines between reaction times and age of acquisition for the different types of acronyms
Fig. 3.
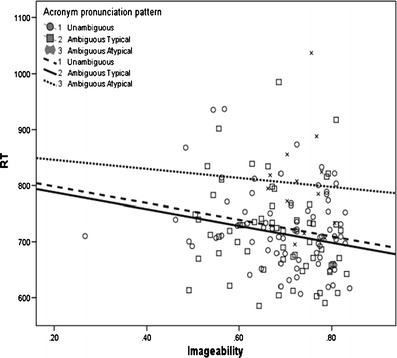
Regression lines between reaction times and imageability for the different types of acronyms
Another interaction observed in all analyses was between AoA and ambiguous typical acronyms. Again, a regression line for each acronym type was plotted against their naming times and AoA values (see Fig. 2). Early acquired typical acronyms (ambiguous and unambiguous) were named faster than late acquired typical acronyms. However, the slope for atypical acronyms shows an inverse relation between reaction times and AoA, with slower RTs for early acquired acronyms.
Finally, the interaction between imageability and ambiguous but typically pronounced acronyms is depicted in Fig. 3. High-imageability acronyms were named faster than low-imageability acronyms. The imageability effect was stronger for typically pronounced acronyms (ambiguous or unambiguous) than for atypically pronounced acronyms.
Another series of multilevel regression analyses were carried out in order to assess the individual contribution of each predictor variable over and above the other factors. The procedure was the same as explained above, with the addition of a fourth step in the regression analysis in which the variable under consideration was assessed.3 Results are shown in Table 6.
Table 6.
Unique acronym-naming variance for each variable as explained when entered in the last step of the multilevel hierarchical analysis
| R 2 change | t | |
|---|---|---|
| Voicing | .011 | 6.37** |
| Number of letters | .010 | 3.2** |
| Number of orthographic neighbors | .003 | 3.24** |
| Imageability | .000 | −0.47 |
| Rated frequency | .001 | 2.27** |
| Printed frequency | .003 | −3.44** |
| Age of acquisition | .004 | −2.67** |
| Trigram frequency | .003 | −3.39** |
| Bigram frequency | .005 | −4.31** |
| Number of syllables | .000 | 0.05 |
| Number of phonemes | .001 | 0.22 |
** p < .01
Errors analyses
Four logistic multilevel hierarchical analyses were conducted with accuracy as the dependent variable. The multilevel technique allowed taking into account the accuracy of each participant for each acronym, and therefore, accuracy was registered as a dummy variable (correct responses coded as 0, incorrect responses as 1). As in the analyses of reaction times, data was structured hierarchically with a three-level hierarchy: one corresponding to the participants, and the other two to the predictor variables. The main effects of voicing and number of orthographic neighbors were found significant across the four analyses. The main effects of imageability and rated frequency approached significance across all the analyses. The main effect of printed acronym frequency was found in one of the analysis only (i.e., with the number of syllables and bigram frequency included; see Table 7), and bigram frequency had an effect only in one out of the four analyses (i.e., with the number of phonemes in). None of the interactions was significant, although the interaction between rated frequency and ambiguous atypical acronym pronunciation approached significance in two out of the four analyses. A summary of the results from one of the analyses can be seen in Table 7.
Table 7.
Wald statistic: A multilevel analyses carried out on acronym accuracy
| Step 2 | |
| Ambiguous typical | 0.001 |
| Ambiguous atypical | 57.57** |
| Step 3 | |
| Voicing | 8.655** |
| Number of letters | 0.378 |
| Number of letters2 | 0.307 |
| Number of orthographic neighbors | 11.695** |
| Imageability | 3.669† |
| Imageability2 | 3.856* |
| Rated frequency | 2.919† |
| Printed frequency | 0.424* |
| Age of acquisition (AoA) | 0.200 |
| Bigram frequency | 3.183† |
| Number of syllables | 0.577 |
| AoA × ambiguous typical | 0.797 |
| AoA × ambiguous atypical | 0.188 |
| Rated frequency × ambiguous typical | 1.890 |
| Rated frequency × ambiguous atypical | 0.016 |
| Printed frequency × ambiguous typical | 0.037 |
| Printed frequency × ambiguous atypical | 0.185 |
| Imageability × ambiguous typical | 2.195 |
| Imageability × ambiguous atypical | 0.065 |
† p < .1
* p ≤ .05
**p ≤ .01
General discussion
One of the aims of the present study was to investigate the processing features of acronyms by conducting a detailed examination of acronyms’ characteristics and an evaluation of the manner in which they intercorrelate.
The study started collecting values for acronyms in a series of selected variables. Thus, questionnaires were created to rate acronyms in terms of their frequency of occurrence, AoA, and imageability. Acronyms voicing and phonological and orthographic length were computed by hand, while number of orthographic neighbors were extracted from a program based on the CELEX database (Baayen et al., 1995). Bigram and trigram frequencies were also considered and derived from the MCWord, an orthographic word form database (Medler & Binder, 2005). Print-to-pronunciation patterns in acronyms were divided into three categories: unambiguous pronunciation pattern (e.g., BBC), ambiguous but typical pronunciation pattern (e.g. ,HIV), and ambiguous atypical pronunciation pattern (e.g., SCUBA). Acronyms’ print-to-pronunciation patterns were considered as a further variable of interest in the study.
The way in which acronym characteristics were correlated resembled, to a certain extent, the correlations reported among standard words. For example, AoA correlated negatively with imageability and rated frequency, meaning that early acquired acronyms were more imageable and familiar (Morrison et al., 1997; Stadthagen-Gonzalez & Davis, 2006). However, some correlations conflicted with what is normally found with mainstream words. For example, the negative correlations found between letter length and syllable length and, between letter length and number of phonemes show an inverse relationship between orthographic and phonological length not present in mainstream words. For the acronyms studied here, as orthographic length increased, phonological length decreased. This is possibly the result of the variety of print-to-pronunciation patterns observed in acronyms. Short acronyms tend to be pronounced naming each of their constituent letters (e.g., DVD), but long acronyms are more likely to include vowels and be pronounced following grapheme-to-phoneme correspondences (e.g., SCUBA).
Other peculiar relationships are the positive correlations of orthographic length with printed frequencies and with the number of orthographic neighbors but the negative correlations of phonological length in terms of the number of phonemes with printed frequencies and with the number of orthographic neighbors. This means, the more letters and fewer phonemes in the acronym, the higher its frequency and N. Longer acronyms are more likely to be formed by a mixture of consonants and vowels. These structures are more likely to be akin to other words and, therefore, produce a high number of orthographic neighbors. In addition, vowels require fewer phonemes to be named aloud than consonants (e.g., /ae/ for a vs. /eich/ for h).
The results of the second step of the hierarchical multilevel analysis of reaction times showed that ambiguous atypical acronyms were read significantly slower (760 ms) than unambiguous acronyms (689 ms). This difference should be interpreted with caution, due to the low amount of ambiguous atypical acronyms present in the study. However, the difference could be the result of a contextual effect. That is, in the context of naming lists of acronyms, participants found it particularly difficult to produce those acronyms whose pronunciation is atypical for acronyms, albeit common for mainstream words. This account is supported by the fact that naming times did not differ for ambiguous typical (679 ms) and unambiguous (689 ms) acronyms by definition pronounced in a typical acronym manner.
The contribution of the selected set of predictor variables and interactions on acronym naming times were examined in the third step of the analyses. Acronyms initial sound, number of letters, printed and rated word frequency, AoA, and letter frequencies (bigram and trigram) successfully predicted naming times in all the analyses carried out. The number of orthographic neighbors emerged as a significant predictor only when the bigram frequency was in the analyses. Imageability interacted with typically pronounced acronyms, indicating that its influence was stronger in this type of acronyms than in atypically pronounced acronyms.
As was predicted, number of letters affected acronym-naming times reflecting the general serial nature of acronym naming. From the phonological measures of word length, only number of phonemes had an influence on reaction times. Bigram frequency affected reaction times and accuracy, while trigram frequency made a significant contribution to naming times only. Studies of standard word naming have struggled to find bigram frequency effects once other variables such as N, onsets, and rimes are taken into account (Andrews, 1992; Bowey, 1990; Strain & Herdman, 1999). The fact that a particular variable does not show an effect on a particular behavior (e.g., reaction time or accuracy) does not mean that the processes associated to that behavior are free from its influence. Although bigram frequency effects are not commonly found in measures of word-naming performance, its influence has been detected when measuring brain activity (Binder, Medler, Westbury, Liebenthal, & Buchanan, 2006; Hauk, Davis, Ford, Pulvermüller & Marslen-Wilson, 2006; Hauk, Patterson et al., 2006). The number of orthographic neighbors (N) exerted an influence in acronym-naming times (analyses with bigram frequency) and accuracy. This result can only support Andrews’s (1989) proposal of an early origin for the N-effect as a product of the interaction between letter and lexical units. This is because the translation from letters to sounds in acronyms does not correspond, in the great majority of the cases, to that of the neighboring words in relation to single phonemes or rhyme units (e.g., EEG and leg, peg, beg, egg).
The clear influence of orthography (i.e., number of letters, N, bigram and trigram frequency) in acronym naming might indicate that the most compelling difference between acronyms and standard words lies in their orthographic assembly, highly arbitrary in acronyms and somehow more predictable or frequent in mainstream words.
In this study, printed and rated word frequency showed significant main effects in acronym-naming times, along with significant interactions with ambiguous typical acronyms and with ambiguous atypical acronyms, indicating different frequency effects for the three types of acronyms. The regression lines plotted in Fig. 3 showed that high-frequency unambiguous acronyms and high-frequency ambiguous typical acronyms were named faster than their low-frequency counterparts. However, high-frequency ambiguous and atypical acronyms were named slower than low-frequency ambiguous and atypical acronyms. This reversed frequency effect is interpreted as a result of the reading context. In the context of naming acronyms (pronouncing most of them by naming each letter aloud), reading aloud acronyms following grapheme-to-phoneme correspondences is slowed down because this pronunciation mechanism conflicts with a letter-by-letter naming mechanism more frequently used in this particular task context. The higher the frequency of the acronym pronounced following grapheme-to-phoneme correspondences, the greater the conflict and the time needed to resolve it. The same kind of argument can be applied to the significant interaction found between AoA and ambiguous typical acronyms. Figure 2 shows the usual difference between naming early and late acquired typical acronyms, with faster naming for early learned acronyms than for later learned acronyms. However, early learned ambiguous atypical acronyms are named much slower than late acquired ambiguous atypical acronyms. As with printed frequency, the “reversed” AoA effect might be due to a conflict between pronunciation mechanisms. This conflict is not normally encountered, since naming acronyms is infrequent in comparison with naming mainstream words.4
The arbitrary mapping hypothesis (Ellis & Lambon Ralph, 2000) argues that AoA effects emerge only when the knowledge of the material learned first cannot be applied to material learned some time later. Word reading is a good example of this differential effect. AoA effects are particularly large when participants read aloud irregular words, but tiny or no effects have been reported when regular words are named. The difference here is that while the pronunciation of late acquired regular words (e.g., groin) can be inferred from the pronunciation of other early acquired words (e.g., coin). The pronunciation of irregular late acquired words (e.g., suave) cannot be derived from the pronunciation of any other word learned earlier (regular or irregular).
Most acronyms adhere to typical acronym-naming rules (letter naming). According to the arbitrary mapping hypothesis AoA should not affect acronym reading, because late acquired acronyms should be able to exploit the early learned rule to facilitate processing of late acronyms, just as happens when regular words are read aloud.
However, it could be the case that the main effect of AoA observed here was due to the semantic intervention in acronym reading. The interaction found between imageability and acronym print-to-pronunciation patterns supports this argument, showing a greater effect of imageability on those typically pronounced acronyms. In addition, the acquisition of meaning and form occurs simultaneously for acronyms, while the concepts of many irregular and late acquired words are known and familiar to the individual well before he/she finds it in print for the first time.
An aim of this study was to provide data regarding the characteristics of acronyms, such that the use of acronyms as experimental stimuli could be subject to the same degree of control as stimuli for word-reading tasks. The normative values collected here will allow for the design of strictly controlled studies using acronyms.
Acronyms have, thus far, been considered to be similar to irregular words (Laszlo & Federmeier, 2007a, 2007b). However, most acronyms can be named following the simple rule of naming each of their constituent letters aloud. This could make acronyms somehow regular in the way print is translated into sound. The question of the relative regularity of acronyms in relation to the factors that affect acronym naming remains unanswered. Results showed a mixed influence of variables commonly related to regular and irregular word reading (e.g., number of letters, orthographic familiarity, printed frequency, AoA, imageability, etc.). These results might indicate the peculiar nature of acronyms, whose processing is not as straightforward as regular or irregular words but a complex mixture of both.
Acronyms might even have a processing mechanism of their own, since the rules that need to be applied to acronyms in order to name most of them correctly (letter naming) are very different from those that need to be applied to regular word reading (grapheme-to-phoneme conversions). It might be the case that acronym reading requires a mechanism for reading in which letters are processed individually. There is a precedent for this claim in the literature concerning letter-by-letter dyslexics. As Howard (1991) noted, patients with acquired dyslexia will often name each letter of a written word in turn before producing a whole-word pronunciation. It has been argued that this strategy is used because there is an obstacle to processing the letters of a word in parallel. In cases where letter naming is preserved while whole-word recognition is impaired, it is possible to argue that there are disparate routes for the two processes. It could be that rather than this capability developing to overcome a specific deficit, the mechanism is available to all readers. In normal readers, the letter-naming rule system is applied only when it is necessary or efficient to do so, such as in acronym reading. Letter-by-letter readers may be forced to rely on this system in all instances. Further evidence for this claim could be provided in future research by using acronyms as stimuli in examinations of impaired reading performance, particularly in cases where the lexico-semantic system is specifically affected or in designs tailored to preclude lexical reading.
The present study shows that number of letters and orthographic familiarity are only two of the several acronym characteristics that need to be taken into account in future studies involving acronyms. The researchers propose that models need to be adapted to allow for correct acronym reading, since although acronyms constitute only a relatively small proportion of language usage, they are becoming more predominant in scientific and popular literature and seem to pose a few problems for the reader.
Author Note
We express our gratitude for the speed and competence with which Ian Paterson proofread the manuscript and to all the individuals who kindly participated in the data collection for this study.
Appendix
Table 8.
Acronyms and norms in alphabetical order
| Acronym | Acronym Definition | Ass | V | Pronun Un:1 | Freq | Freq | Freq | Log (x + 1) | Log (x + 1) | |||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| Sem | Ved: 0 | Am Typ:2 | No. | No. | No. | Rated | Log | Log | Log | Big | Trig | |||||
| Rel (%) | Vless: 1 | Am Atyp:3 | Lett | Syll | Phon | N | Imag | Freq | Bing | AltaVista | AoA | Freq | Freq | |||
| ABBA | Anni-Frid, Bjorn, Benny and Agnetha (music group) | 95 | 0 | 3 | 4 | 2 | 3 | 0 | 6.10 | 2.20 | 7.04 | 7.21 | 7.53 | 8.42 | 3.67 | 1.91 |
| ACDC | Alternating Current Direct Current (music group) | 94 | 0 | 2 | 4 | 4 | 7 | 0 | 5.3 | 2.60 | 6.61 | 7.06 | 7.40 | 14.24 | 3.66 | 0.00 |
| ADHD | Attention Deficit Hyperactivity Disorder | 100 | 0 | 2 | 4 | 4 | 8 | 0 | 5.75 | 3.30 | 7.23 | 7.02 | 7.94 | 15.31 | 3.73 | 1.00 |
| AGM | Annual General Meeting | 69 | 0 | 2 | 3 | 3 | 5 | 4 | 3.6 | 1.80 | 6.82 | 6.71 | 7.65 | 16.33 | 3.52 | 1.68 |
| AOL | America Online | 94 | 0 | 2 | 3 | 3 | 4 | 5 | 5.25 | 2.70 | 8.20 | 8.25 | 8.70 | 18.19 | 3.71 | 0.00 |
| APR | Annual Percentage Rate | 67 | 0 | 2 | 3 | 3 | 4 | 3 | 3.6 | 2.50 | 8.87 | 8.53 | 9.17 | 16.44 | 3.93 | 1.84 |
| ASAP | As Soon As Possible | 100 | 0 | 2 | 4 | 2 | 6 | 0 | 5.3 | 4.25 | 7.84 | 7.11 | 6.12 | 10.49 | 4.20 | 2.16 |
| ASBO | Anti-Social Behavior Order | 100 | 0 | 3 | 4 | 2 | 4 | 0 | 5.5 | 2.65 | 5.95 | 5.15 | 6.55 | 20.25 | 4.13 | 0.87 |
| ATM | Automated Teller Machine | 87 | 0 | 2 | 3 | 3 | 5 | 3 | 6.3 | 3.85 | 7.66 | 7.16 | 8.12 | 15.84 | 4.36 | 2.13 |
| AWOL | Absent Without Leave | 62 | 0 | 3 | 4 | 2 | 4 | 0 | 4.6 | 2.20 | 6.24 | 6.36 | 7.03 | 13.62 | 3.87 | 1.25 |
| BAFTA | British Academy of Film and Television Arts | 100 | 0 | 3 | 5 | 5 | 5 | 0 | 6.4 | 2.10 | 6.34 | 5.73 | 7.09 | 14.67 | 3.82 | 2.71 |
| BBC | British Broadcasting Corporation | 100 | 0 | 1 | 3 | 3 | 6 | 0 | 6.2 | 5.85 | 8.29 | 7.63 | 8.72 | 6.74 | 2.45 | 1.34 |
| BHS | British Home Stores | 94 | 0 | 1 | 3 | 3 | 7 | 1 | 5.9 | 2.70 | 6.61 | 6.37 | 7.12 | 11.68 | 2.42 | 0.00 |
| BLT | Bacon Lettuce and Tomato | 100 | 0 | 1 | 3 | 3 | 6 | 4 | 6.25 | 3.40 | 6.51 | 6.34 | 7.29 | 13.45 | 3.75 | 0.00 |
| BMI | Body Mass Index | 56 | 0 | 1 | 3 | 3 | 5 | 0 | 4.95 | 3.02 | 7.21 | 6.98 | 7.79 | 17.65 | 3.67 | 1.58 |
| BMW | Bavarian Motor Works | 94 | 0 | 1 | 3 | 3 | 9 | 1 | 6.45 | 3.90 | 8.23 | 7.90 | 8.63 | 9.83 | 1.54 | 0.00 |
| BNP | British National Party | 83 | 0 | 1 | 3 | 3 | 6 | 1 | 4.9 | 2.20 | 6.85 | 6.36 | 7.50 | 18.10 | 1.79 | 0.00 |
| BOGOF | Buy One Get One Free | 83 | 0 | 3 | 5 | 2 | 5 | 0 | 5.3 | 3.30 | 5.18 | 5.09 | 6.21 | 16.55 | 4.09 | 0.86 |
| BPM | Beats Per Minute | 80 | 0 | 1 | 3 | 3 | 6 | 1 | 3.65 | 1.90 | 7.11 | 6.97 | 7.68 | 15.21 | 2.18 | 0.00 |
| BPS | British Psychological Society | 58 | 0 | 1 | 3 | 3 | 6 | 1 | 3.95 | 2.75 | 7.12 | 6.57 | 7.42 | 18.26 | 3.00 | 0.00 |
| BRB | Be Right Back | 50 | 0 | 1 | 3 | 3 | 6 | 5 | 6.75 | 4.15 | 6.51 | 5.80 | 6.82 | 11.93 | 3.36 | 0.00 |
| BSE | Bovine Spongiform Encephalography | 62 | 0 | 1 | 3 | 3 | 5 | 3 | 4.15 | 1.90 | 6.75 | 6.62 | 7.58 | 16.07 | 4.16 | 2.43 |
| BST | British Summer Time | 81 | 0 | 1 | 3 | 3 | 6 | 4 | 3.1 | 2.10 | 7.92 | 6.78 | 8.04 | 15.16 | 4.24 | 2.31 |
| BTW | By The Way | 65 | 0 | 1 | 3 | 3 | 9 | 1 | 6.45 | 3.95 | 8.09 | 7.26 | 8.24 | 12.67 | 3.19 | 0.00 |
| BYOB | Bring Your Own Bottle | 50 | 0 | 2 | 4 | 4 | 7 | 2 | 3.6 | 1.75 | 6.16 | 5.63 | 7.06 | 18.36 | 3.76 | 0.06 |
| CBT | Cognitive Behavioral Therapy | 63 | 1 | 1 | 3 | 3 | 6 | 3 | 4.65 | 2.65 | 6.78 | 7.08 | 7.20 | 19.38 | 2.31 | 0.00 |
| CCTV | Closed Circuit Television | 100 | 1 | 1 | 4 | 4 | 8 | 0 | 6.4 | 4.15 | 7.76 | 6.70 | 8.00 | 14.44 | 3.61 | 0.00 |
| CEO | Chief Executive Officer | 79 | 1 | 2 | 3 | 3 | 4 | 1 | 4.7 | 2.30 | 8.26 | 7.67 | 8.82 | 17.74 | 4.01 | 0.32 |
| CIA | Criminal Intelligence Agency | 88 | 1 | 2 | 3 | 3 | 4 | 1 | 5.65 | 2.65 | 7.63 | 7.26 | 8.12 | 13.43 | 3.81 | 3.26 |
| CJD | Creutzfeld-Jakob Disease | 80 | 1 | 1 | 3 | 3 | 6 | 3 | 3.05 | 1.45 | 6.00 | 5.79 | 6.44 | 16.89 | 0.00 | 0.00 |
| CNN | Cable News Network | 100 | 1 | 1 | 3 | 3 | 6 | 3 | 5.35 | 3.20 | 7.97 | 7.49 | 8.54 | 15.23 | 3.06 | 0.00 |
| CPU | Central Processing Unit | 80 | 1 | 1 | 3 | 3 | 5 | 0 | 4.55 | 2.80 | 8.10 | 7.68 | 8.35 | 16.42 | 3.21 | 0.00 |
| CSI | Crime Scene Investigation | 100 | 1 | 1 | 3 | 3 | 5 | 1 | 5.3 | 3.40 | 7.68 | 6.96 | 8.12 | 18.11 | 3.90 | 0.47 |
| DHL | Dalsey, Hillblom and Lynn (Delivery Company) | 63 | 0 | 1 | 3 | 3 | 7 | 0 | 4.7 | 2.65 | 6.97 | 6.75 | 7.64 | 16.59 | 2.34 | 0.00 |
| DIY | Do It Yourself | 100 | 0 | 2 | 3 | 3 | 5 | 9 | 6.55 | 3.80 | 8.24 | 7.20 | 8.69 | 10.44 | 3.79 | 0.13 |
| DNA | Deoxyribonucleic Acid | 100 | 0 | 1 | 3 | 3 | 5 | 0 | 6 | 3.10 | 8.08 | 7.48 | 8.44 | 13.83 | 3.60 | 1.34 |
| DOA | Dead On Arrival | 58 | 0 | 2 | 3 | 3 | 4 | 0 | 4.25 | 2.35 | 6.98 | 6.40 | 8.21 | 14.55 | 3.68 | 0.00 |
| DOB | Date Of Birth | 100 | 0 | 2 | 3 | 3 | 5 | 23 | 6.15 | 3.50 | 6.90 | 6.60 | 7.35 | 10.15 | 3.72 | 0.34 |
| DUI | Driving Under the Influence | 69 | 0 | 2 | 3 | 3 | 4 | 6 | 3.4 | 2.05 | 7.33 | 6.63 | 8.00 | 17.51 | 3.52 | 0.74 |
| DVD | Digital Versatile Disc | 100 | 0 | 1 | 3 | 3 | 6 | 3 | 6.6 | 5.45 | 8.96 | 8.73 | 9.29 | 17.30 | 2.45 | 0.00 |
| DVLA | Driver and Vehicle Licensing Authority | 100 | 0 | 1 | 4 | 4 | 7 | 0 | 6.25 | 3.00 | 5.98 | 5.22 | 6.71 | 17.89 | 3.70 | 0.00 |
| DVT | Deep Vein Thrombosis | 46 | 0 | 1 | 3 | 3 | 6 | 1 | 4.25 | 1.90 | 6.63 | 6.15 | 6.83 | 16.54 | 2.45 | 0.00 |
| ECG | Electrocardiogram (Heart Monitor) | 85 | 0 | 1 | 3 | 3 | 5 | 5 | 4.60 | 2.10 | 7.05 | 6.48 | 7.22 | 15.08 | 3.80 | 0.11 |
| EEG | Electroencephalogram | 73 | 0 | 2 | 3 | 3 | 4 | 8 | 4.95 | 2.90 | 6.86 | 6.26 | 8.61 | 18.09 | 3.97 | 0.07 |
| ENT | Ear, Nose and Throat | 27 | 0 | 2 | 3 | 3 | 5 | 4 | 3.45 | 2.50 | 7.75 | 7.28 | 8.05 | 17.24 | 4.57 | 4.17 |
| ESP | Extra Sensory Perception | 50 | 0 | 2 | 3 | 3 | 5 | 1 | 4.3 | 1.95 | 7.65 | 6.89 | 8.02 | 14.52 | 4.32 | 3.01 |
| ESRC | Economic and Social Research Council | 50 | 0 | 1 | 4 | 4 | 7 | 0 | 3.5 | 2.35 | 5.80 | 6.03 | 6.65 | 23.14 | 4.12 | 0.03 |
| ETA | Estimated Time of Arrival | 45 | 0 | 2 | 3 | 3 | 4 | 1 | 4.75 | 2.45 | 7.87 | 7.09 | 7.72 | 16.43 | 4.16 | 2.80 |
| FAO | For the Attention Of | 50 | 1 | 2 | 3 | 3 | 4 | 8 | 4 | 3.00 | 7.37 | 6.49 | 7.49 | 15.38 | 3.47 | 0.00 |
| FAQ | Frequently Asked Question | 94 | 1 | 2 | 3 | 3 | 5 | 7 | 5.65 | 4.00 | 9.08 | 8.84 | 9.67 | 14.21 | 3.47 | 0.00 |
| FBI | Federal Bureau of Investigation | 94 | 1 | 1 | 3 | 3 | 5 | 1 | 6.1 | 2.80 | 7.72 | 7.52 | 8.15 | 11.93 | 3.19 | 1.03 |
| FIFA | Federation of International Football Associations | 94 | 1 | 3 | 4 | 2 | 4 | 1 | 5.85 | 3.25 | 8.07 | 7.21 | 8.29 | 11.80 | 3.84 | 1.99 |
| FYI | For Your Information | 78 | 1 | 1 | 3 | 3 | 5 | 0 | 4.7 | 3.80 | 7.23 | 6.91 | 7.90 | 16.24 | 2.90 | 1.86 |
| GBH | Grievous Bodily Harm | 100 | 0 | 1 | 3 | 3 | 7 | 0 | 5.15 | 2.25 | 6.06 | 5.84 | 6.57 | 14.31 | 1.22 | 0.00 |
| GCSE | General Certificate of Secondary Education | 100 | 0 | 1 | 4 | 4 | 7 | 0 | 5.6 | 3.15 | 6.68 | 6.53 | 7.54 | 13.23 | 3.98 | 0.00 |
| GMT | Greenwich Mean Time | 88 | 0 | 1 | 3 | 3 | 6 | 4 | 4.65 | 3.20 | 8.55 | 8.05 | 8.99 | 13.83 | 1.81 | 0.09 |
| GPA | Grade Point Average | 50 | 0 | 1 | 3 | 3 | 5 | 1 | 1.85 | 1.40 | 7.19 | 6.67 | 7.60 | 16.97 | 3.66 | 0.00 |
| GPS | Global Positioning Satellite | 82 | 0 | 1 | 3 | 3 | 6 | 1 | 4.85 | 3.70 | 8.41 | 7.65 | 8.84 | 20.30 | 3.00 | 0.00 |
| HDTV | High Definition Television | 85 | 0 | 1 | 4 | 4 | 9 | 0 | 5.95 | 3.45 | 8.03 | 7.23 | 8.34 | 14.50 | 1.75 | 0.00 |
| HGV | Heavy Goods Vehicle | 83 | 0 | 1 | 3 | 3 | 7 | 0 | 5.3 | 2.75 | 6.16 | 5.73 | 6.75 | 15.62 | 0.32 | 0.00 |
| HIV | Human Immunodeficiency Virus | 100 | 0 | 2 | 3 | 3 | 6 | 6 | 5.55 | 2.95 | 7.76 | 7.58 | 8.36 | 13.34 | 4.27 | 1.62 |
| HMO | Health Management Organization | 50 | 0 | 1 | 3 | 3 | 6 | 0 | 3.95 | 1.95 | 7.09 | 6.59 | 7.39 | 18.46 | 3.77 | 0.40 |
| HMS | His/Her Majesty's Ship | 53 | 0 | 1 | 3 | 3 | 7 | 2 | 5.25 | 2.70 | 6.89 | 6.65 | 7.41 | 12.58 | 3.18 | 0.88 |
| HMV | His Master's Voice (trademark in the music business) | 100 | 0 | 1 | 3 | 3 | 7 | 0 | 6.6 | 3.60 | 6.86 | 6.46 | 7.35 | 12.20 | 2.09 | 0.00 |
| HRT | Hormone Replacement Therapy | 56 | 0 | 1 | 3 | 3 | 7 | 5 | 4.5 | 2.20 | 6.76 | 6.32 | 7.19 | 18.06 | 3.82 | 0.00 |
| HSBC | Hong Kong and Shanghai Banking Corporation | 89 | 0 | 1 | 4 | 4 | 9 | 0 | 5.95 | 3.60 | 7.18 | 6.48 | 7.83 | 18.70 | 2.41 | 0.00 |
| IBM | International Business Machines Corporation | 79 | 0 | 2 | 3 | 3 | 5 | 0 | 4.5 | 2.50 | 8.03 | 7.94 | 8.47 | 15.28 | 3.10 | 0.00 |
| IBS | Irritable Bowel Syndrome | 85 | 0 | 2 | 3 | 3 | 5 | 1 | 4.85 | 2.20 | 6.67 | 6.48 | 7.53 | 13.80 | 3.26 | 1.22 |
| ICT | Information and Communication Technology | 65 | 0 | 2 | 3 | 3 | 5 | 4 | 6.50 | 3.05 | 7.61 | 6.93 | 8.04 | 8.67 | 4.15 | 2.93 |
| IMDB | Internet Movie Database | 81 | 0 | 2 | 4 | 4 | 7 | 0 | 3.75 | 2.50 | 8.36 | 6.72 | 8.55 | 20.56 | 3.57 | 0.00 |
| IRA | Irish Republican Army | 100 | 0 | 2 | 3 | 3 | 4 | 7 | 5.75 | 2.05 | 7.60 | 7.24 | 7.96 | 12.73 | 4.14 | 2.40 |
| ISP | Internet Service Provider | 72 | 0 | 2 | 3 | 3 | 5 | 0 | 3.8 | 2.90 | 7.44 | 7.55 | 8.10 | 19.81 | 4.30 | 2.56 |
| ITN | Independent Television News | 83 | 0 | 2 | 3 | 3 | 5 | 3 | 5.85 | 3.85 | 6.75 | 5.84 | 7.21 | 10.47 | 4.29 | 1.79 |
| ITV | Independent Television | 79 | 0 | 2 | 3 | 3 | 5 | 1 | 5.95 | 4.75 | 7.15 | 6.57 | 7.72 | 8.42 | 4.28 | 0.64 |
| IVF | In Vitro Fertilization | 100 | 0 | 2 | 3 | 3 | 5 | 1 | 5.2 | 2.95 | 6.58 | 6.23 | 7.20 | 16.08 | 3.58 | 0.00 |
| KFC | Kentucky Fried Chicken | 100 | 0 | 1 | 3 | 3 | 6 | 0 | 6.4 | 3.05 | 6.90 | 6.30 | 7.61 | 11.17 | 1.65 | 0.00 |
| LBW | Leg Before Wicket | 63 | 0 | 1 | 3 | 3 | 10 | 2 | 3.15 | 2.05 | 6.06 | 5.82 | 6.69 | 13.03 | 1.77 | 0.39 |
| LCD | Liquid Crystal Display | 78 | 0 | 1 | 3 | 3 | 6 | 3 | 4.9 | 2.70 | 8.31 | 7.72 | 8.71 | 16.45 | 2.08 | 0.00 |
| LMAO | Laughing My Ass Off | 75 | 0 | 1 | 4 | 4 | 6 | 0 | 6.45 | 4.95 | 7.45 | 6.48 | 7.71 | 13.61 | 3.76 | 1.19 |
| LSD | Lysergic Acid Diethylamide (psychedelic drug) | 95 | 0 | 1 | 3 | 3 | 6 | 3 | 5.4 | 2.35 | 6.98 | 6.89 | 7.40 | 13.98 | 3.32 | 0.72 |
| MBA | Masters in Business Administration | 58 | 0 | 1 | 3 | 3 | 5 | 1 | 3.1 | 2.05 | 7.69 | 7.33 | 8.18 | 20.19 | 3.61 | 2.22 |
| MDMA | Methylenedioxymethamphetamine (ecstasy, psychedelic drug) | 60 | 0 | 1 | 4 | 4 | 7 | 1 | 4.25 | 2.15 | 6.21 | 5.98 | 6.67 | 17.92 | 3.74 | 1.14 |
| MGM | Metro Goldwyn Mayer | 58 | 0 | 1 | 3 | 3 | 6 | 2 | 4.2 | 2.25 | 7.25 | 7.03 | 7.73 | 14.62 | 1.70 | 0.00 |
| MMR | Measles Mumps Rubella | 44 | 0 | 1 | 3 | 3 | 6 | 1 | 4.95 | 2.45 | 6.62 | 6.15 | 7.09 | 15.31 | 3.25 | 0.00 |
| MRI | Magnetic Resonance Imaging | 100 | 0 | 1 | 3 | 3 | 5 | 0 | 5.2 | 2.70 | 7.28 | 6.75 | 7.82 | 17.88 | 4.02 | 0.00 |
| MRSA | Methicillin Resistant Staphylococcus Aureus | 100 | 0 | 1 | 4 | 4 | 7 | 1 | 5 | 2.70 | 6.55 | 5.59 | 7.25 | 22.38 | 3.89 | 2.45 |
| MSN | Microsoft Network | 90 | 0 | 1 | 3 | 3 | 6 | 5 | 6.90 | 4.70 | 8.55 | 8.17 | 8.70 | 11.26 | 3.20 | 0.00 |
| MTV | Music television | 95 | 0 | 1 | 3 | 3 | 6 | 0 | 6.2 | 3.20 | 8.06 | 7.51 | 8.34 | 12.67 | 1.58 | 0.00 |
| NASA | North American Space Agency | 100 | 0 | 3 | 4 | 2 | 4 | 0 | 5.9 | 2.60 | 8.51 | 7.35 | 8.37 | 10.66 | 4.22 | 1.98 |
| NASCAR | National Association for Stock Car Auto Racing | 75 | 0 | 3 | 6 | 2 | 5 | 1 | 4.65 | 1.80 | 7.94 | 7.56 | 8.57 | 14.00 | 4.27 | 2.79 |
| NATO | North American Trade Organization | 79 | 0 | 3 | 4 | 2 | 4 | 0 | 5.05 | 2.45 | 7.56 | 7.16 | 7.99 | 15.56 | 4.49 | 3.14 |
| NBA | National Basketball Association | 86 | 0 | 1 | 3 | 3 | 5 | 0 | 4.4 | 1.80 | 8.30 | 7.80 | 8.78 | 15.92 | 3.44 | 0.92 |
| NCIS | Naval Criminal Intelligence Service | 50 | 0 | 1 | 4 | 4 | 7 | 0 | 3.5 | 2.25 | 7.16 | 5.59 | 7.50 | 20.57 | 4.24 | 2.85 |
| NHS | National Health Service | 94 | 0 | 1 | 3 | 3 | 7 | 0 | 6.35 | 4.30 | 8.04 | 6.94 | 8.05 | 10.68 | 2.57 | 0.82 |
| NSPCC | National Society for the Prevention of Cruelty to Children | 100 | 0 | 1 | 5 | 5 | 10 | 0 | 5.95 | 2.75 | 5.76 | 5.42 | 6.49 | 13.26 | 3.69 | 1.97 |
| NYPD | New York Police Department | 95 | 0 | 1 | 4 | 4 | 8 | 0 | 5.90 | 2.20 | 6.40 | 6.33 | 7.33 | 12.40 | 3.16 | 0.17 |
| OAP | Old Age Pensioner | 100 | 0 | 2 | 3 | 3 | 4 | 16 | 6.35 | 3.20 | 6.15 | 6.59 | 6.67 | 11.40 | 3.60 | 1.44 |
| OBE | Officer of the Order of the British Empire (British title) | 71 | 0 | 2 | 3 | 3 | 4 | 4 | 4.95 | 2.20 | 6.76 | 6.78 | 7.07 | 14.89 | 4.08 | 2.28 |
| OCD | Obsessive Compulsive Disorder | 88 | 0 | 2 | 3 | 3 | 5 | 2 | 5.45 | 3.35 | 6.67 | 6.36 | 7.42 | 16.48 | 3.32 | 0.00 |
| OCR | Oxford Cambridge and RSA Examinations | 62 | 0 | 2 | 3 | 3 | 5 | 2 | 3.25 | 2.00 | 7.40 | 7.07 | 7.58 | 16.81 | 3.64 | 2.29 |
| OHP | Over Head Projector | 75 | 0 | 2 | 3 | 3 | 6 | 3 | 3.80 | 1.75 | 6.11 | 5.79 | 6.85 | 10.08 | 2.52 | 0.00 |
| PAYE | Pay As You Earn | 92 | 1 | 2 | 4 | 4 | 6 | 8 | 4.85 | 2.60 | 6.28 | 5.78 | 6.88 | 17.28 | 3.88 | 2.55 |
| PDA | Personal Digital Assistant | 41 | 1 | 2 | 3 | 3 | 5 | 1 | 3.2 | 2.25 | 8.09 | 7.66 | 8.45 | 20.77 | 3.38 | 0.81 |
| Portable Document Format | 93 | 1 | 1 | 3 | 3 | 6 | 0 | 6.15 | 5.35 | 9.03 | 8.34 | 9.22 | 19.50 | 1.74 | 0.00 | |
| PGCE | Post Graduate Certificate in Education | 73 | 1 | 1 | 4 | 4 | 7 | 2 | 5.3 | 3.00 | 5.83 | 5.43 | 6.55 | 19.00 | 3.79 | 0.15 |
| PSP | Playstation Personal | 72 | 1 | 1 | 3 | 3 | 6 | 6 | 4.15 | 2.25 | 8.25 | 6.88 | 8.67 | 21.61 | 3.58 | 0.00 |
| PTA | Parent Teacher Association | 83 | 1 | 1 | 3 | 3 | 5 | 1 | 4.7 | 2.15 | 6.92 | 6.61 | 7.55 | 14.38 | 3.94 | 2.21 |
| PTO | Please Turn Over | 80 | 1 | 1 | 3 | 3 | 5 | 2 | 6.20 | 2.60 | 6.82 | 6.56 | 7.34 | 9.56 | 4.32 | 1.67 |
| PTSD | Post Traumatic Stress Disorder | 63 | 1 | 1 | 4 | 4 | 8 | 0 | 3.7 | 2.45 | 6.51 | 6.23 | 7.41 | 17.73 | 3.61 | 1.65 |
| PVC | Polyvinyl Chloride (thermoplastic material) | 65 | 1 | 1 | 3 | 3 | 6 | 0 | 6.2 | 2.65 | 7.66 | 7.35 | 8.18 | 12.40 | 0.46 | 0.22 |
| QVC | Quality, Value, Convenience (multinational corporation) | 69 | 1 | 1 | 3 | 3 | 6 | 0 | 4.9 | 1.90 | 6.54 | 6.36 | 7.24 | 17.36 | 0.41 | 0.00 |
| RAF | Royal Air Force | 100 | 0 | 2 | 3 | 3 | 5 | 9 | 6.25 | 2.90 | 7.28 | 6.91 | 7.67 | 9.53 | 3.99 | 2.28 |
| RBS | Royal Bank of Scotland | 27 | 0 | 1 | 3 | 3 | 6 | 0 | 4.45 | 2.20 | 6.72 | 6.25 | 7.55 | 15.86 | 2.95 | 1.47 |
| REM | Rapid Eye Movement (music group) | 100 | 0 | 3 | 3 | 3 | 3 | 8 | 5.25 | 2.55 | 7.54 | 7.06 | 7.62 | 14.59 | 4.54 | 3.20 |
| RNIB | Royal National Institute for the Blind | 56 | 0 | 2 | 4 | 4 | 7 | 0 | 4.05 | 1.90 | 5.57 | 5.71 | 6.26 | 14.74 | 3.74 | 2.63 |
| RNLI | Royal National Lifeboat Institute | 67 | 0 | 1 | 4 | 4 | 7 | 0 | 4.1 | 1.85 | 5.77 | 5.50 | 6.68 | 14.86 | 3.96 | 1.95 |
| RPG | Role Playing Game | 78 | 0 | 1 | 3 | 3 | 6 | 3 | 3.55 | 1.75 | 7.86 | 7.37 | 8.26 | 17.76 | 2.71 | 0.00 |
| RRP | Recommended Retail Price | 63 | 0 | 1 | 3 | 3 | 6 | 3 | 3.65 | 3.15 | 7.26 | 6.80 | 7.94 | 15.51 | 3.38 | 0.00 |
| RSPB | Royal Society for the Protection of Birds | 87 | 0 | 1 | 4 | 4 | 8 | 0 | 5.3 | 2.40 | 6.12 | 6.32 | 6.85 | 14.16 | 3.80 | 1.33 |
| RSPCA | Royal Society for the Protection of Cruelty to Animals | 100 | 0 | 1 | 5 | 5 | 9 | 0 | 5.9 | 2.80 | 6.20 | 5.82 | 6.89 | 10.66 | 3.94 | 1.13 |
| RSVP | Repondez S'il Vous Plait | 100 | 0 | 1 | 4 | 4 | 8 | 0 | 6.75 | 2.80 | 7.25 | 6.77 | 8.12 | 10.16 | 3.65 | 0.09 |
| SAE | Stamped Addressed Envelope | 87 | 0 | 2 | 3 | 3 | 4 | 11 | 4.8 | 2.35 | 7.06 | 6.58 | 7.53 | 12.42 | 3.66 | 0.00 |
| SAS | Special Air Services | 71 | 0 | 2 | 3 | 3 | 5 | 13 | 5.65 | 2.30 | 7.62 | 7.17 | 8.01 | 13.15 | 4.32 | 1.92 |
| SCUBA | Self-Contained Underwater Breathing Apparatus | 90 | 1 | 3 | 5 | 2 | 5 | 0 | 5.05 | 1.50 | 7.41 | 7.31 | 8.03 | 10.27 | 3.60 | 2.22 |
| SMS | Short Messaging Service | 100 | 0 | 1 | 3 | 3 | 6 | 1 | 5.1 | 4.95 | 8.46 | 8.19 | 8.63 | 18.17 | 3.40 | 1.64 |
| SPSS | Statistical Package for the Social Sciences | 87 | 0 | 1 | 4 | 4 | 8 | 2 | 4.8 | 3.40 | 7.10 | 6.88 | 7.32 | 19.66 | 3.81 | 0.83 |
| STD | Sexually Transmitted Disease | 89 | 0 | 1 | 3 | 3 | 6 | 3 | 5.3 | 2.60 | 7.63 | 7.33 | 8.10 | 14.59 | 4.23 | 0.13 |
| TBA | To Be Announced | 64 | 1 | 1 | 3 | 3 | 5 | 1 | 4.45 | 2.90 | 7.18 | 6.97 | 7.83 | 15.77 | 3.45 | 1.69 |
| TBC | To Be Confirmed | 73 | 1 | 1 | 3 | 3 | 6 | 2 | 4.3 | 2.80 | 6.71 | 6.28 | 7.36 | 15.76 | 1.86 | 0.00 |
| TCP | Trichlorophenymlmethyliodosalicyl (antiseptic) | 71 | 1 | 1 | 3 | 3 | 6 | 4 | 4.6 | 2.00 | 7.42 | 7.36 | 7.79 | 12.03 | 2.84 | 0.00 |
| TFT | Thin Film Transistor | 57 | 1 | 1 | 3 | 3 | 6 | 7 | 2.9 | 2.10 | 7.42 | 7.30 | 7.89 | 20.82 | 3.25 | 0.00 |
| TLC | Tender Loving Care | 95 | 1 | 1 | 3 | 3 | 6 | 4 | 6.40 | 2.30 | 7.31 | 6.90 | 7.81 | 10.12 | 3.32 | 0.00 |
| TNT | Trinitrotoluene (explosive) | 67 | 1 | 1 | 3 | 3 | 6 | 5 | 5.85 | 2.05 | 7.39 | 7.07 | 7.83 | 13.99 | 4.17 | 0.15 |
| UCAS | University and College Admission System | 100 | 0 | 3 | 4 | 2 | 4 | 0 | 6 | 2.85 | 6.15 | 5.84 | 6.79 | 17.30 | 4.25 | 2.86 |
| UEFA | Union of European Football Associations | 94 | 0 | 3 | 4 | 3 | 4 | 0 | 5.7 | 3.00 | 7.91 | 7.14 | 7.95 | 13.88 | 3.67 | 1.17 |
| UFC | Ultimate Fighting Championship | 24 | 0 | 2 | 3 | 3 | 5 | 0 | 3.25 | 2.00 | 7.78 | 6.11 | 8.17 | 14.64 | 2.46 | 0.00 |
| UFO | Unidentified Flying Object | 100 | 0 | 2 | 3 | 3 | 4 | 0 | 6.45 | 2.35 | 7.37 | 7.18 | 7.92 | 9.72 | 3.90 | 0.26 |
| UHF | Ultra High Frequency | 50 | 0 | 2 | 3 | 3 | 6 | 0 | 3.65 | 2.10 | 6.73 | 6.55 | 7.34 | 17.20 | 1.61 | 0.05 |
| USA | United States of America | 100 | 0 | 2 | 3 | 3 | 4 | 2 | 6.80 | 4.45 | 9.11 | 8.84 | 9.45 | 6.10 | 4.10 | 2.43 |
| USB | Universal Serial Bus | 100 | 0 | 2 | 3 | 3 | 5 | 1 | 6.6 | 5.40 | 8.44 | 7.90 | 8.76 | 20.18 | 3.91 | 2.22 |
| USSR | Union of Soviet Socialist Republics | 100 | 0 | 2 | 4 | 4 | 7 | 1 | 5.15 | 1.80 | 7.26 | 6.95 | 7.64 | 11.73 | 3.97 | 2.36 |
| VCR | Video Cassette Recorder | 95 | 0 | 1 | 3 | 3 | 6 | 1 | 6.40 | 2.85 | 6.74 | 7.55 | 7.77 | 7.20 | 3.35 | 0.00 |
| VHS | Video Home System | 80 | 0 | 1 | 3 | 3 | 7 | 2 | 6.15 | 2.05 | 8.64 | 8.05 | 8.13 | 9.93 | 2.41 | 0.00 |
| VIP | Very Important Person | 84 | 0 | 2 | 3 | 3 | 5 | 14 | 5.75 | 3.20 | 8.34 | 7.64 | 8.53 | 10.96 | 3.67 | 0.44 |
| WWF | World Wild Fund | 47 | 0 | 1 | 3 | 3 | 14 | 0 | 6 | 2.35 | 6.93 | 7.32 | 7.47 | 11.63 | 1.59 | 0.00 |
| YMCA | Young Men's Christian Association | 65 | 0 | 1 | 4 | 4 | 7 | 0 | 6 | 2.70 | 7.11 | 6.84 | 7.69 | 11.66 | 3.73 | 0.11 |
Ass. Sem. Rel (%) = percentage of associative responses semantically related to the acronym definition. V = voicing. Ved = voiced. Vless = voiceless. Pronun = pronunciation. Un = unambiguous. Am Typ = ambiguous typical. Am Atyp = ambiguous atypical. No lett = number of letters. No Syll = number of syllables. No Phon = number of phonemes. N = number of orthographic neighbours. Imag = imageability. Freq = frequency. Log = logarithm transformation. AoA = age of acquisition. Big = bigram. Trig = Trigram
Footnotes
The participants involved in the ratings and naming data in the present study constitute a sample of undergraduate students. As such, their ages ranged from 18 to 27 years, and the gender ratio was skewed towards females. Therefore, generalizations beyond the evidence shown for this group would have to be made with caution.
Recent evidence has shown that gender has an effect in the way in which language is processed (Ullman, Miranda, and Travers, 2008). Gender differences have been shown to be particularly relevant in episodic memory and verbal fluency tasks. Although the present study did not involve any such tasks, potential gender differences were investigated correlating male response times and female response times with the rest of the variables. No differences between the two groups were found.
A further two multilevel analyses (one for males [n = 5] and one for females [n = 15]) were carried out to explore the possibility of gender differences. Results showed the same predictor variables affecting both groups. Only number of orthographic neighbors differed across groups, emerging as a significant predictor of acronym-naming times for the group of males, but not for the group of females. This disparity might be due to the idiosyncratic way in which the genders rely on the declarative and procedural systems, as was suggested by Ullman, Miranda, and Travers (2008).
Analyses similar to those reported were carried out excluding those ambiguous and atypical acronyms. The results were very similar to those reported, indicating that overall, the impact of these groups of acronyms was not major.
References
- Adelman JS, Brown GDA. Phonographic neighbors, not orthographic neighbors, determine word naming latencies. Psychonomic Bulletin & Review. 2007;24:455–459. doi: 10.3758/BF03194088. [DOI] [PubMed] [Google Scholar]
- Alameda JR, Cuetos F. Incidencia de la vecindad ortográfica en el reconocimiento de palabras. Revista de Psicologica General y Aplicada. 2000;53:85–107. [Google Scholar]
- Alija M, Cuetos F. Effects of the lexical-semantic variables in visual word recognition. Psicothema. 2006;18:485–491. [PubMed] [Google Scholar]
- Andrews S. Frequency and neighbourhood effects on lexical access: Activation or search? Journal of Experimental Psychology: Learning, Memory, and Cognition. 1989;15:802–814. doi: 10.1037/0278-7393.15.5.802. [DOI] [Google Scholar]
- Andrews S. Frequency and neighbourhood effects on lexical access: Lexical similarity or orthographic redundancy? Journal of Experimental Psychology: Learning, Memory, and Cognition. 1992;18:234–254. doi: 10.1037/0278-7393.18.2.234. [DOI] [Google Scholar]
- Anisfeld, E. (1964). A comparison of the cognitive function of monolinguals and bilinguals. Unpublished doctoral thesis. McGill University.
- Azuma T, Van Orden GC. Why SAFE is better than FAST: The relatedness of a word’s meanings affects lexical decision times. Journal of Memory and Language. 1997;36:484–504. doi: 10.1006/jmla.1997.2502. [DOI] [Google Scholar]
- Baayen RH, Piepenbrock R, Gulikers L. The CELEX Lexical Database (Version 2) (CD-ROM) Philadelphia: University of Pennsylvania, Linguistic Data Consortium; 1995. [Google Scholar]
- Balota, D. A., Cortese, M. J., Hutchison, K. A., Neely, J. H., Nelson, D., Simpson, G. B., & Treiman, R. (2000). The English Lexicon Project: A Web-based repository of descriptive and behavioral measures for 40,481 English words and nonwords.Available at elexicon.wustl.edu.
- Balota DA, Cortese MJ, Sergent-Marshall SD, Spieler DH, Yap MJ. Visual word recognition of single-syllable words. Journal of Experimental Psychology. General. 2004;133:283–316. doi: 10.1037/0096-3445.133.2.283. [DOI] [PubMed] [Google Scholar]
- Balota DA, Spieler DH. The utility of item-level analyses in model evaluation: A reply to Seidenberg and Plaut. Psychological Science. 1998;9:238–240. doi: 10.1111/1467-9280.00047. [DOI] [Google Scholar]
- Barca L, Burani C, Arduino LS. Word naming times and psycholinguistic norms for Italian nouns. Behavior Research Methods. 2002;34:424–434. doi: 10.3758/bf03195471. [DOI] [PubMed] [Google Scholar]
- Baron J, Strawson C. Use of orthographic and word-specific knowledge in reading aloud. Journal of Experimental Psychology. Human Perception and Performance. 1976;2:386–393. doi: 10.1037/0096-1523.2.3.386. [DOI] [Google Scholar]
- Barry C, Johnston RA, Wood RF. Effects of age of acquisition, age and repetition priming on object naming. Visual Cognition. 2006;13:911–927. doi: 10.1080/13506280544000101. [DOI] [Google Scholar]
- Besner D, Davelaar E, Alcott D, Parry P. Wholistic reading of alphabetic print: Evidence from the FDM and the FBI. In: Henderson L, editor. Orthographies and reading: Perspectives from cognitive psychology, neuropsychology and linguistics. Hillsdale, NJ: Erlbaum; 1984. pp. 121–135. [Google Scholar]
- Bijeljac-Babic R, Millogo V, Farioli F, Grainger J. A developmental investigation of word length effects in reading using a new on-line word identification paradigm. Reading and Writing. 2004;17:411–431. doi: 10.1023/B:READ.0000032664.20755.af. [DOI] [Google Scholar]
- Binder JR, Medler DA, Westbury CF, Liebenthal E, Buchanan L. Tuning of the human left fusiform gyrus to sublexical orthographic structure. NeuroImage. 2006;33:739–748. doi: 10.1016/j.neuroimage.2006.06.053. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Blair IV, Urland GR, Ma JE. Using Internet search engines to estimate word frequency. Behavior Research Methods. 2002;34:286–290. doi: 10.3758/bf03195456. [DOI] [PubMed] [Google Scholar]
- Bonin P. Comment accè-t-on à un mot en production verbale écrite? [Lexical access in written word production] Psychologie Française. 2005;50:323–338. doi: 10.1016/j.psfr.2005.05.003. [DOI] [Google Scholar]
- Bonin P, Barry C, Meot A, Chalard M. The influence of age of acquisition in word reading and other tasks: A never ending story? Journal of Memory and Language. 2004;50:456–476. doi: 10.1016/j.jml.2004.02.001. [DOI] [Google Scholar]
- Bowey JA. Orthographic onsets and rimes as functional units of reading. Memory & Cognition. 1990;18:419–427. doi: 10.3758/BF03197130. [DOI] [PubMed] [Google Scholar]
- Brysbaert M, Ghyselinck M. The effect of age-of-acquisition: Partly frequency-related, partly frequency-independent. Visual Cognition. 2006;13:992–1011. doi: 10.1080/13506280544000165. [DOI] [Google Scholar]
- Brysbaert M, New B. Moving beyond Kučera and Francis: A critical evaluation of current word frequency norms and the introduction of a new and improved word frequency measure for American English. Behavior Research Methods. 2009;41:977–990. doi: 10.3758/BRM.41.4.977. [DOI] [PubMed] [Google Scholar]
- Brysbaert M, Speybroeck S, Vanderelst D. Is there room for the BBC in the mental lexicon? On the recognition of acronyms. Quarterly Journal of Experimental Psychology. 2009;62:1832–1842. doi: 10.1080/17470210802585471. [DOI] [PubMed] [Google Scholar]
- Brysbaert M, Van Wijnendaele I, De Deyne S. Age of acquisition effects in semantic tasks. Acta Psychologica. 2000;104:215–226. doi: 10.1016/S0001-6918(00)00021-4. [DOI] [PubMed] [Google Scholar]
- Burgress C, Livesay K. The effect of corpus size in predicting reaction time in a basic word recognition task: Moving on from Kučera & Francis. Behavior Research Methods, Instruments, & Computers. 1998;30:272–277. doi: 10.3758/BF03200655. [DOI] [Google Scholar]
- Carroll JB, White MN. Word frequency and age of acquisition as determiners of picture naming latency. Quarterly Journal of Experimental Psychology. 1973;25:85–95. doi: 10.1080/14640747308400325. [DOI] [Google Scholar]
- Catling JC, Dent K, Williamson S. Age of acquisition, not word frequency affects object recognition: Evidence from the effects of visual degradation. Acta Psychologica. 2008;129:130–137. doi: 10.1016/j.actpsy.2008.05.005. [DOI] [PubMed] [Google Scholar]
- Coltheart M. Lexical access in simple reading tasks. In: Underwood G, editor. Strategies of information processing. New York: Academic Press; 1978. pp. 151–216. [Google Scholar]
- Coltheart M. Assumptions and methods in cognitive neuropsychology. In: Rapp B, editor. Handbook of cognitive neuropsychology. Philadelphia: Psychology Press; 2001. pp. 3–21. [Google Scholar]
- Coltheart M. Modelling reading: The dual-route approach. In: Snowling MJ, Hulme C, editors. The science of reading: A handbook. Malden, MA: Blackwell; 2007. pp. 6–23. [Google Scholar]
- Coltheart M, Curtis B, Atkins P, Haller M. Models of reading aloud: Dual-route and parallel-distributed-processing approaches. Psychological Review. 1993;100:589–608. doi: 10.1037/0033-295X.100.4.589. [DOI] [Google Scholar]
- Coltheart M, Davelaar E, Jonasson JT, Besner D. Access to the internal lexicon. In: Dornic S, editor. Attention and performance VI. Hillsdale, NJ: Erlbaum; 1977. pp. 535–555. [Google Scholar]
- Coltheart M, Rastle K, Perry C, Langdon R, Ziegler J. DRC: A dual route cascaded model of visual word recognition and reading aloud. Psychological Review. 2001;108:204–256. doi: 10.1037/0033-295X.108.1.204. [DOI] [PubMed] [Google Scholar]
- Connine CM, Mullenix J, Shernoff E, Yelen J. Word familiarity and frequency in visual and auditory word recognition. Journal of Experimental Psychology: Learning, Memory, and Cognition. 1990;16:1084–1096. doi: 10.1037/0278-7393.16.6.1084. [DOI] [PubMed] [Google Scholar]
- Conrad M, Carreiras M, Tamm S, Jacobs AM. Syllables and bigrams: Orthographic redundancy and syllabic units affect visual word recognition at different processing levels. Journal of Experimental Psychology. Human Perception and Performance. 2009;35:461–479. doi: 10.1037/a0013480. [DOI] [PubMed] [Google Scholar]
- Cortese MJ, Simpson GB. Regularity effects in word naming: What are they? Memory & Cognition. 2000;28:1269–1276. doi: 10.3758/BF03211827. [DOI] [PubMed] [Google Scholar]
- Cuetos F, Barbón A, Urrutia M, Dominguez A. Determining the time course of lexical frequency and age of acquisition using ERP. Clinical Neurophysiology. 2009;120:285–294. doi: 10.1016/j.clinph.2008.11.003. [DOI] [PubMed] [Google Scholar]
- Deacon D, Dynowska A, Ritter W, Grose-Fifer J. Repetition and semantic priming of nonwords: Implications for theories of N400 and word recognition. Psychophysiology. 2004;41:60–74. doi: 10.1111/1469-8986.00120. [DOI] [PubMed] [Google Scholar]
- Ellis AW, Burani C, Izura C, Bromiley A, Venneri A. Traces of vocabulary acquisition in the brain: Evidence from covert object naming. NeuroImage. 2006;33:958–968. doi: 10.1016/j.neuroimage.2006.07.040. [DOI] [PubMed] [Google Scholar]
- Ellis A. W., Lambon Ralph M. A. Age of acquisition effects in adult lexical processing reflect loss of plasticity in maturing systems: insights from connectionist networks. Journal of Experimental Psychology: Learning, Memory and Cognition. 2000;26:1103–1123. doi: 10.1037//0278-7393.26.5.1103. [DOI] [PubMed] [Google Scholar]
- Ellis AW, Monaghan J. Reply to Strain, Patterson, and Seidenberg (2002) Journal of Experimental Psychology: Learning, Memory, and Cognition. 2000;28:215–220. doi: 10.1037/0278-7393.28.1.215. [DOI] [PubMed] [Google Scholar]
- Ferrand L. Reading aloud polysyllabic words and nonwords: The syllabic length effect reexamined. Psychonomic Bulletin & Review. 2000;7:142–148. doi: 10.3758/BF03210733. [DOI] [PubMed] [Google Scholar]
- Ferraro FR, Hansen CL. Orthographic neighborhood size, number of word meanings, and number of higher frequency neighbors. Brain and Language. 2002;82:200–205. doi: 10.1016/S0093-934X(02)00016-0. [DOI] [PubMed] [Google Scholar]
- Forster KI, Chambers SM. Lexical access and naming. Journal of Verbal Learning and Verbal Behavior. 1973;12:627–635. doi: 10.1016/S0022-5371(73)80042-8. [DOI] [Google Scholar]
- Frederiksen JR, Kroll JF. Spelling and sound: Approaches to the internal lexicon. Journal of Experimental Psychology. Human Perception and Performance. 1976;2:361–379. doi: 10.1037/0096-1523.2.3.361. [DOI] [Google Scholar]
- Gelman A, Hill J. Data analysis using regression and multilevel/hierarchical models. Cambridge: Cambridge University Press; 2007. [Google Scholar]
- Gerhand, S. (1998). Age of acquisition effects in normal reading and in deep dyslexia. Unpublished doctoral dissertation, University of Cardiff, Cardiff, Wales.
- Gerhand S, Barry C. Age-of-acquisition and frequency effects in speeded naming. Cognition. 1999;73:B27–B36. doi: 10.1016/S0010-0277(99)00052-9. [DOI] [PubMed] [Google Scholar]
- Gernsbacher MA. Resolving 20 years of inconsistent interactions between lexical familiarity and orthography, concreteness, and polysemy. Journal of Experimental Psychology. General. 1984;113:254–281. doi: 10.1037/0096-3445.113.2.256. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Ghyselinck M, De Moor W, Brysbaert M. Age-of-acquisition ratings on 2816 Dutch four- and five-letter nouns. Psychologica Belgica. 2000;40:77–98. [Google Scholar]
- Ghyselinck M, Lewis MB, Brysbaert M. Age of acquisition and the cumulative frequency hypothesis: A review of the literature and a new multitask investigation. Acta Psychologica. 2004;115:43–67. doi: 10.1016/j.actpsy.2003.11.002. [DOI] [PubMed] [Google Scholar]
- Gibson EJ, Bishop CH, Schiff W, Smith J. Comparisons of meaningfulness and pronunciability as grouping principles in the perception and retention of verbal material. Journal of Experimental Psychology. 1964;67:173–182. doi: 10.1037/h0044124. [DOI] [PubMed] [Google Scholar]
- Gilhooly KJ, Gilhooly MLM. The validity of age-of-acquisition ratings. British Journal of Psychology. 1980;71:105–110. doi: 10.1111/j.2044-8295.1980.tb02736.x. [DOI] [Google Scholar]
- Gilhooly KJ, Logie RH. Word age-of-acquisition and lexical decision making. Acta Psychologica. 1982;50:21–34. doi: 10.1016/0001-6918(82)90048-8. [DOI] [Google Scholar]
- Glushko RJ. The organization and activation of orthographic knowledge in reading aloud. Journal of Experimental Psychology. Human Perception and Performance. 1979;5:674–691. doi: 10.1037/0096-1523.5.4.674. [DOI] [Google Scholar]
- Gough P, Cosky M. One second of reading again. In: Castellan N, Pisoni D, Potts G, editors. Cognitive theory. Hillsdale, NJ: Erlbaum; 1977. pp. 271–288. [Google Scholar]
- Graves WW, Desai R, Humphries C, Seidenberg MS, Binder JR. Neural systems for reading aloud: A multiparametric approach. Cerebral Cortex. 2010;20:1799–1815. doi: 10.1093/cercor/bhp245. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Harm MW, Seidenberg MS. Computing the meanings of words in reading: Cooperative division of labor between visual and phonological processes. Psychological Review. 2004;111:662–720. doi: 10.1037/0033-295X.111.3.662. [DOI] [PubMed] [Google Scholar]
- Hauk O, Davis MH, Ford M, Pulvermüller F, Marslen-Wilson WD. The time course of visual word recognition as revealed by linear regression analysis of ERP data. NeuroImage. 2006;30:1383–1400. doi: 10.1016/j.neuroimage.2005.11.048. [DOI] [PubMed] [Google Scholar]
- Hauk O, Patterson K, Woollams A, Watling L, Pulvermüller F, Rogers TT. [Q:] When would you prefer a SOSSAGE to a SAUSAGE? [A:] At about 100 msec. ERP correlates of orthographic typicality and lexicality in written word recognition. Journal of Cognitive Neuroscience. 2006;18:818–832. doi: 10.1162/jocn.2006.18.5.818. [DOI] [PubMed] [Google Scholar]
- Henderson L. A word superiority effect without orthographic assistance. Quarterly Journal of Experimental Psychology. 1974;20:301–311. doi: 10.1080/14640747408400416. [DOI] [Google Scholar]
- Hino Y, Lupker SJ. Effects of polysemy in lexical decision and naming: An alternative to lexical access accounts. Journal of Experimental Psychology. Human Perception and Performance. 1996;22:1331–1356. doi: 10.1037/0096-1523.22.6.1331. [DOI] [Google Scholar]
- Hirsh KW, Ellis AW. Age of acquisition and aphasia: A case study. Cognitive Neuropsychology. 1994;11:435–458. doi: 10.1080/02643299408251981. [DOI] [Google Scholar]
- Holmes S, Fitch J, Ellis AW. Age of acquisition affects object recognition and naming in patients with Alzheimer's disease. Journal of Clinical and Experimental Neuropsychology. 2006;28:1010–1022. doi: 10.1080/13803390591004392. [DOI] [PubMed] [Google Scholar]
- Howard D. Letter by letter readers: Evidence for parallel processing. In: Besner D, Humphreys GW, editors. Basic processes in reading: Visual word recognition. Hillsdale, NJ: Erlbaum; 1991. pp. 34–76. [Google Scholar]
- Howes DH, Solomon RL. Visual threshold as a function of word-probability. Journal of Experimental Psychology. 1951;41:401–410. doi: 10.1037/h0056020. [DOI] [PubMed] [Google Scholar]
- Hudson PTW, Bergman MW. Lexical knowledge in word recognition: Word length and word frequency in naming and lexical decision tasks. Journal of Memory and Language. 1985;24:46–58. doi: 10.1016/0749-596X(85)90015-4. [DOI] [Google Scholar]
- Izura C, Ellis AW. Age of acquisition effects in word recognition and production in first and second languages. Psicologica. 2002;23:245–281. [Google Scholar]
- Izura C, Hernandez-Muñoz N, Ellis AW. Category norms for 500 Spanish words in five semantic categories. Behavior Research Methods. 2005;37:385–397. doi: 10.3758/BF03192708. [DOI] [PubMed] [Google Scholar]
- Jared D. Spelling–sound consistency and regularity effects in word naming. Journal of Memory and Language. 2002;46:723–750. doi: 10.1006/jmla.2001.2827. [DOI] [Google Scholar]
- Jared D, Seidenberg MS. Naming multisyllabic words. Journal of Experimental Psychology. Human Perception and Performance. 1990;16:92–105. doi: 10.1037/0096-1523.16.1.92. [DOI] [PubMed] [Google Scholar]
- Johnston RA, Barry C. Age of acquisition and lexical processing. Visual Cognition. 2006;13:789–845. doi: 10.1080/13506280544000066. [DOI] [Google Scholar]
- Juhasz BJ. Age of acquisition effects in word and picture identification. Psychological Bulletin. 2005;131:684–712. doi: 10.1037/0033-2909.131.5.684. [DOI] [PubMed] [Google Scholar]
- Juhasz BJ, Rayner K. The role of age of acquisition and word frequency in reading: Evidence from eye fixation durations. Visual Cognition. 2006;13:846–863. doi: 10.1080/13506280544000075. [DOI] [Google Scholar]
- Kennet J, McGuire L, Willis SL, Schaie KW. Memorability functions in verbal memory: A longitudinal approach. Experimental Ageing Research. 2000;26:121–137. doi: 10.1080/036107300243597. [DOI] [PubMed] [Google Scholar]
- Kessler B, Treiman R, Mullenix J. Phonetic biases in voice key response time measurements. Journal of Memory and Language. 2002;47:145–171. doi: 10.1006/jmla.2001.2835. [DOI] [Google Scholar]
- Klepousniotou E, Baum SR. Disambiguating the ambiguity advantage effect in word recognition: An advantage for polysemous but not homonymous words. Journal of Neurolinguistics. 2007;20:1–24. doi: 10.1016/j.jneuroling.2006.02.001. [DOI] [Google Scholar]
- Kline RB. Principles and practice of structural equation modelling. 2. New York: Guildford; 2005. [Google Scholar]
- Kučera H, Francis WN. Computational analysis of present day American English. Providence, RI: Brown University Press; 1967. [Google Scholar]
- Laszlo S, Federmeier KD. The acronym superiority effect. Psychonomic Bulletin & Review. 2007;14:1158–1163. doi: 10.3758/BF03193106. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Laszlo S, Federmeier KD. Better the DVL you know: Acronyms reveal the contribution of familiarity to single-word reading. Psychological Science. 2007;18:122–126. doi: 10.1111/j.1467-9280.2007.01859.x. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Laszlo S, Federmeier KD. Minding the PS, queues and PXQs: Uniformity of semantic processing across multiple stimulus types. Psychophysiology. 2008;45:458–466. doi: 10.1111/j.1469-8986.2007.00636.x. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Liu YY, Hao ML, Shu H, Tan L-H, Weekes BS. Age of acquisition effects on oral reading in Chinese. Psychonomic Bulletin & Review. 2008;15:344–350. doi: 10.3758/PBR.15.2.344. [DOI] [PubMed] [Google Scholar]
- Lund K, Burgress C. Producing high-dimensional semantic spaces from lexical co-occurrence. Behavior Research Methods, Instruments, & Computers. 1996;28:203–208. doi: 10.3758/BF03204766. [DOI] [Google Scholar]
- Mathey S. L’influence du voisinage orthographique lors de la reconnaisance des mots écrits [The influence of orthographic neighbourhood on visual word recognition] Revue Canadienne de Psychologie Expérimentale/Canadian Journal of Experimental Psychology. 2001;55:1–23. doi: 10.1037/h0087349. [DOI] [PubMed] [Google Scholar]
- Medler, D. A., & Binder, J. R. (2005). MCWord: An on-line orthographic database of the English language. Retrieved from http://www.neuro.mcw.edu/mcword/
- Menenti L, Burani C. What causes the effect of age of acquisition in lexical processing? Quarterly Journal of Experimental Psychology. 2007;60:652–660. doi: 10.1080/17470210601100126. [DOI] [PubMed] [Google Scholar]
- Miles J, Shevlin M. Applying regression and correlation: A guide for students and researchers. London: Sage; 2001. [Google Scholar]
- Monaghan J, Ellis AW. What exactly interacts with spelling–sound consistency in word naming? Journal of Experimental Psychology: Learning, Memory, and Cognition. 2002;28:183–206. doi: 10.1037/0278-7393.28.1.183. [DOI] [PubMed] [Google Scholar]
- Monaghan P, Ellis AW. Modeling reading development: Cumulative, incremental learning in a computational model of word naming. Journal of Memory and Language. 2010;63:506–525. doi: 10.1016/j.jml.2010.08.003. [DOI] [Google Scholar]
- Morrison CM, Chappell TD, Ellis AW. Age of acquisition norms for a large set of object names and their relation to adult estimates and other variables. Quarterly Journal of Experimental Psychology. 1997;50A:528–559. [Google Scholar]
- Morrison CM, Ellis AW. The roles of word frequency and age of acquisition in word naming and lexical decision. Journal of Experimental Psychology: Learning, Memory, and Cognition. 1995;21:116–133. doi: 10.1037/0278-7393.21.1.116. [DOI] [Google Scholar]
- Morrison CM, Ellis AW. Real age of acquisition effects in word naming and lexical decision. British Journal of Psychology. 2000;91:167–180. doi: 10.1348/000712600161763. [DOI] [PubMed] [Google Scholar]
- Mossman J, editor. Acronyms, initialisms and abbreviations dictionary. Detroit, MI: Gale Cengage; 1994. [Google Scholar]
- Noice H, Hock HS. A word superiority effect with nonorthographic acronyms: Testing for unitized visual codes. Perception & Psychophysics. 1987;42:485–490. doi: 10.3758/BF03209756. [DOI] [PubMed] [Google Scholar]
- Oldfield RC, Wingfield A. Response latencies in naming objects. Quarterly Journal of Experimental Psychology. 1965;17:273–281. doi: 10.1080/17470216508416445. [DOI] [PubMed] [Google Scholar]
- Owsowitz, S. E. (1953). The effect of word familiarity and letter structure familiarity on the perception of words. Rand Corporation Publications, No. P-2820, 1963.
- Oxford English dictionary. (2009). Oxford: Oxford University Press.
- Paivio A. Abstractness, imagery, and meaningfulness in paired-associate learning. Journal of Verbal Learning and Verbal Behavior. 1965;4:32–38. doi: 10.1016/S0022-5371(65)80064-0. [DOI] [Google Scholar]
- Paivio A. Imagery and verbal processes. New York: Holt, Rinehart, and Winston; 1971. [Google Scholar]
- Paivio A. Dual coding theory: Retrospect and current status. Canadian Journal of Psychology. 1991;45:255–287. doi: 10.1037/h0084295. [DOI] [Google Scholar]
- Paivio A, Yuille JC, Madigan SA. Concreteness, imagery, and meaningfulness values for 925 nouns. Journal of Experimental Psychology. 1968;76:1–25. doi: 10.1037/h0025327. [DOI] [PubMed] [Google Scholar]
- Papagno C, Capasso R, Zerboni H, Miceli G. A reverse concreteness effect in a subject with semantic dementia. Brain and Language. 2007;103:90–91. doi: 10.1016/j.bandl.2007.07.059. [DOI] [Google Scholar]
- Parkin AJ. Phonogical recoding in lexical decision: Effects of spelling-to-sound regularity depend on how regularity is defined. Memory & Cognition. 1982;10:43–53. doi: 10.3758/BF03197624. [DOI] [PubMed] [Google Scholar]
- Perea M, Acha J, Fraga I. Lexical competition is enhanced in the left hemisphere: Evidence from different types of orthographic neighbors. Brain and Language. 2008;105:199–210. doi: 10.1016/j.bandl.2007.08.005. [DOI] [PubMed] [Google Scholar]
- Pérez MA. Age of acquisition persists as the main factor in picture naming when cumulative word frequency and frequency trajectory are controlled. Quarterly Journal of Experimental Psychology. 2007;60:32–42. doi: 10.1080/17470210600577423. [DOI] [PubMed] [Google Scholar]
- Pind J, Tryggvadottir HB. Determinants of picture naming times in Icelandic. Scandinavian Journal of Psychology. 2002;43:221–226. doi: 10.1111/1467-9450.00290. [DOI] [PubMed] [Google Scholar]
- Raman I. On the age-of-acquisition effects in word naming and orthographic transparency: Mapping specific or universal? Visual Cognition. 2006;13:1044–1053. doi: 10.1080/13506280500153200. [DOI] [Google Scholar]
- Rastle K, Coltheart M. Serial and strategic effects in reading aloud. Journal of Experimental Psychology. Human Perception and Performance. 1999;25:482–503. doi: 10.1037/0096-1523.25.2.482. [DOI] [PubMed] [Google Scholar]
- Rastle K, Davis M. On the complexities of measuring naming. Journal of Experimental Psychology. Human Perception and Performance. 2002;28:307–314. doi: 10.1037/0096-1523.28.2.307. [DOI] [PubMed] [Google Scholar]
- Reilly J, Grossman M, McCawley MC. Concreteness effects in lexical processing of semantic dementia. Brain and Language. 2006;99:157–158. doi: 10.1016/j.bandl.2006.06.088. [DOI] [Google Scholar]
- Rice GA, Robinson DO. The role of bigram frequency in the perception of words and nonwords. Memory & Cognition. 1975;3:513–518. doi: 10.3758/BF03197523. [DOI] [PubMed] [Google Scholar]
- Richards RM, Ellis AW. Mechanisms of identity and gender decisions to faces: Who rocked in 1986? Perception. 2008;37:1700–1719. doi: 10.1068/p6023. [DOI] [PubMed] [Google Scholar]
- Rugg MD. Event-related brain potentials dissociate repetition effects of high- and low-frequency words. Memory & Cognition. 1990;18:367–379. doi: 10.3758/BF03197126. [DOI] [PubMed] [Google Scholar]
- Schneider W, Eschman A, Zuccolotto A. E-Prime 1.0. Pittsburgh: Psychological Software Tools; 2002. [Google Scholar]
- Sears CR, Hino Y, Lupker SJ. Orthographic neighbourhood effects in parallel distributed processing models. Canadian Journal of Experimental Psychology. 1999;53:220–229. [Google Scholar]
- Seidenberg MS, McClelland JL. A distributed, developmental model of word recognition and naming. Psychological Review. 1989;96:523–568. doi: 10.1037/0033-295X.96.4.523. [DOI] [PubMed] [Google Scholar]
- Seidenberg MS, Waters GS. Word recognition and naming: A mega study. Bulletin of the Psychonomic Society. 1989;27:489. [Google Scholar]
- Sheehan EA, Namy LL, Mills DL. Developmental changes in neural activity to familiar words and gestures. Brain and Language. 2007;101:246–259. doi: 10.1016/j.bandl.2006.11.008. [DOI] [PubMed] [Google Scholar]
- Spieler DH, Balota DA. Bringing computational models of word naming down to the item level. Psychological Science. 1997;8:411–416. doi: 10.1111/j.1467-9280.1997.tb00453.x. [DOI] [Google Scholar]
- Stadthagen-Gonzalez H, Davis CJ. The Bristol norms for age of acquisition, imageability, and familiarity. Behavior Research Methods. 2006;38:598–605. doi: 10.3758/BF03193891. [DOI] [PubMed] [Google Scholar]
- Staller JD, Lappin JS. Visual detection of multi-letter patterns. Journal of Experimental Psychology. Human Perception and Performance. 1981;7:1258–1272. doi: 10.1037/0096-1523.7.6.1258. [DOI] [PubMed] [Google Scholar]
- Stanovich KE, Bauer DW. Experiments on the spelling-to-sound regularity effect in word recognition. Memory & Cognition. 1978;6:410–415. doi: 10.3758/BF03197473. [DOI] [PubMed] [Google Scholar]
- Strain E, Herdman CM. Imageability effects in word naming: An individual differences analysis. Canadian Journal of Experimental Psychology. 1999;53:347–359. doi: 10.1037/h0087322. [DOI] [PubMed] [Google Scholar]
- Strain E, Patterson KE, Seidenberg MS. Semantic effects in single-word naming. Journal of Experimental Psychology: Learning, Memory, and Cognition. 1995;21:1140–1154. doi: 10.1037/0278-7393.21.5.1140. [DOI] [PubMed] [Google Scholar]
- Strain E, Patterson KE, Seidenberg MS. Theories of word naming interact with spelling–sound consistency. Journal of Experimental Psychology: Learning, Memory, and Cognition. 2002;28:207–214. doi: 10.1037/0278-7393.28.1.207. [DOI] [PubMed] [Google Scholar]
- Tree JJ, Perfect TJ, Hirsh KW, Copstick S. Deep dysphasic performance in non-fluent progressive aphasia: A case study. Neurocase. 2001;7:473–488. doi: 10.1093/neucas/7.6.473. [DOI] [PubMed] [Google Scholar]
- Treiman R, Mullennix J, Bijeljac-Babic R, Richmond-Welty ED. The special role of rimes in the description, use, and acquisition of English orthography. Journal of Experimental Psychology. General. 1995;124:107–136. doi: 10.1037/0096-3445.124.2.107. [DOI] [PubMed] [Google Scholar]
- Ullman MT, Miranda RA, Travers ML. Sex differences in the neurocognition of language. In: Becker JB, Berkley KJ, Gearyet N, Hampson E, Herman SP, Young E, editors. Sex on the brain: From genes to behavior. New York: Oxford University Press; 2008. pp. 291–310. [Google Scholar]
- van Elk M, van Schie HT, Bekkering H. The N400-concreteness effect reflects the retrieval of semantic information during the preparation of meaningful actions. Biological Psychology. 2010;85:134–142. doi: 10.1016/j.biopsycho.2010.06.004. [DOI] [PubMed] [Google Scholar]
- Venezky R. The structure of English orthography. The Hague: Mouton; 1970. [Google Scholar]
- Waters GS, Seidenberg MS. Spelling–sound effects in reading: Time course and decision criteria. Memory & Cognition. 1985;13:557–572. doi: 10.3758/BF03198326. [DOI] [PubMed] [Google Scholar]
- Weekes BS. Differential effects of number of letters on word and nonword naming latency. Quarterly Journal of Experimental Psychology. 1997;50A:439–456. [Google Scholar]
- Weekes BS, Castles AE, Davies RA. Effects of consistency and age of acquisition on reading and spelling among developing readers. Reading and Writing. 2006;19:133–169. doi: 10.1007/s11145-005-2032-6. [DOI] [Google Scholar]
- Weekes BS, Chan AHD, Tan LH. Effects of age of acquisition on brain activation during Chinese character recognition. Neuropsychologia. 2008;46:2086–2090. doi: 10.1016/j.neuropsychologia.2008.01.020. [DOI] [PubMed] [Google Scholar]
- Weekes BS, Raman I. Bilingual deep dysphasia. Cognitive Neuropsychology. 2008;25:411–436. doi: 10.1080/02643290802057311. [DOI] [PubMed] [Google Scholar]
- Westbury C, Buchanan L. The probability of the least likely non-length-controlled bigram affects lexical decision reaction times. Brain and Language. 2002;81:66–78. doi: 10.1006/brln.2001.2507. [DOI] [PubMed] [Google Scholar]
- Whaley CP. Word–nonword classification time. Journal of Verbal Learning and Verbal Behavior. 1978;17:143–154. doi: 10.1016/S0022-5371(78)90110-X. [DOI] [Google Scholar]
- Whitney C, Lavidor M. Facilitative orthographic neighborhood effects: The SERIOL model account. Cognitive Psychology. 2005;51:179–213. doi: 10.1016/j.cogpsych.2005.07.001. [DOI] [PubMed] [Google Scholar]
- Yonelinas AP. The nature of recollection and familiarity: A review of 30 years of research. Journal of Memory and Language. 2002;46:441–517. doi: 10.1006/jmla.2002.2864. [DOI] [Google Scholar]
- Zeno SM, Ivens SH, Millard RT, Duvvuri R. The educator's word frequency guide. Brewster, NY: Touchstone Applied Science Associates; 1995. [Google Scholar]
- Zevin JD, Seidenberg M. Age-of-acquisition effects in word reading and other tasks. Journal of Memory and Language. 2002;47:1–29. doi: 10.1006/jmla.2001.2834. [DOI] [Google Scholar]
- Zevin JD, Seidenberg M. Age-of-acquisition effects in reading aloud: Tests of cumulative frequency and frequency trajectory. Memory & Cognition. 2004;32:31–38. doi: 10.3758/BF03195818. [DOI] [PubMed] [Google Scholar]
- Ziegler J, Perry C, Jacobs A, Braun M. Identical words are read differently in different languages. Psychological Science. 2001;12:379–384. doi: 10.1111/1467-9280.00370. [DOI] [PubMed] [Google Scholar]
- Zorzi M, Houghton G, Butterworth B. Two routes or one in reading aloud? A connectionist dual-route model. Journal of Experimental Psychology. Human Perception and Performance. 1998;24:1131–1161. doi: 10.1037/0096-1523.24.4.1131. [DOI] [Google Scholar]