

Abstract
Human face-to-face communication is a complex multimodal signal. We use words (language modality), gestures (vision modality) and changes in tone (acoustic modality) to convey our intentions. Humans easily process and understand face-to-face communication, however, comprehending this form of communication remains a significant challenge for Artificial Intelligence (AI). AI must understand each modality and the interactions between them that shape the communication. In this paper, we present a novel neural architecture for understanding human communication called the Multi-attention Recurrent Network (MARN). The main strength of our model comes from discovering interactions between modalities through time using a neural component called the Multi-attention Block (MAB) and storing them in the hybrid memory of a recurrent component called the Long-short Term Hybrid Memory (LSTHM). We perform extensive comparisons on six publicly available datasets for multimodal sentiment analysis, speaker trait recognition and emotion recognition. MARN shows state-of-the-art results performance in all the datasets.
Introduction
Humans communicate using a highly complex structure of multimodal signals. We employ three modalities in a coordinated manner to convey our intentions: language modality (words, phrases and sentences), vision modality (gestures and expressions), and acoustic modality (paralinguistics and changes in vocal tones) (Morency, Mihalcea, and Doshi 2011). Understanding this multimodal communication is natural for humans; we do it subconsciously in the cerebrum of our brains everyday. However, giving Artificial Intelligence (AI) the capability to understand this form of communication the same way humans do, by incorporating all involved modalities, is a fundamental research challenge. Giving AI the capability to understand human communication narrows the gap in computers’ understanding of humans and opens new horizons for the creation of many intelligent entities.
The coordination between the different modalities in human communication introduces view-specific and cross-view dynamics (Zadeh et al. 2017). View-specific dynamics refer to dynamics within each modality independent of other modalities. For example, the arrangement of words in a sentence according to the generative grammar of the language (language modality) or the activation of facial muscles for the presentation of a smile (vision modality). Cross-view dynamics refer to dynamics between modalities and are divided into synchronous and asynchronous categories. An example of synchronous cross-view dynamics is the simultaneous co-occurrence of a smile with a positive sentence and an example of asynchronous cross-view dynamics is the delayed occurrence of a laughter after the end of sentence. For machines to understand human communication, they must be able to understand these view-specific and cross-view dynamics.
To model these dual dynamics in human communication, we propose a novel deep recurrent neural model called the Multi-attention Recurrent Network (MARN). MARN is distinguishable from previous approaches in that it explicitly accounts for both view-specific and cross-view dynamics in the network architecture and continuously models both dynamics through time. In MARN, view-specific dynamics within each modality are modeled using a Long-short Term Hybrid Memory (LSTHM) assigned to that modality. The hybrid memory allows each modality’s LSTHM to store important cross-view dynamics related to that modality. Cross-view dynamics are discovered at each recurrence time-step using a specific neural component called the Multi-attention Block (MAB). The MAB is capable of simultaneously finding multiple cross-view dynamics in each recurrence timestep. The MARN resembles the mechanism of our brains for understanding communication, where different regions independently process and understand different modalities (Kuzmanovic et al. 2012; Sergent and Signoret 1992) – our LSTHM – and are connected together using neural links for multimodal information integration (Jiang et al. 2012) – our MAB. We benchmark MARN by evaluating its understanding of different aspects of human communication covering sentiment of speech, emotions conveyed by the speaker and displayed speaker traits. We perform extensive experiments on 16 different attributes related to human communication on public multimodal datasets. Our approach shows state-of-the-art performance in modeling human communication for all datasets.
Related Work
Modeling multimodal human communication has been studied previously. Past approaches can be categorized as follows:
Non-temporal Models:
Studies have focused on simplifying the temporal aspect of cross-view dynamics (Poria et al. 2017; Pérez-Rosas, Mihalcea, and Morency 2013a; Wöllmer et al. 2013) in order to model co-occurrences of information across the modalities. In these models, each modality is summarized in a representation by collapsing the time dimension, such as averaging the modality information through time (Abburi et al. 2016). While these models are successful in understanding co-occurrences, the lack of temporal modeling is a major flaw as these models cannot deal with multiple contradictory evidences, eg. if a smile and frown happen together in an utterance. Furthermore, these approaches cannot accurately model long sequences since the representation over long periods of time become less informative.
Early Fusion:
Approaches have used multimodal input feature concatenation instead of modeling view-specific and cross-view dynamics explicitly. In other words, these approaches rely on generic models (such as Support Vector Machines or deep neural networks) to learn both view-specific and cross-view dynamics without any specific model design. This concatenation technique is known as early fusion (Wang et al. 2016; Poria et al. 2016). Often, these early fusion approaches remove the time factor as well (Zadeh et al. 2016; Morency, Mihalcea, and Doshi 2011). We additionally compare to a stronger recurrent baseline that uses early fusion while maintaining the factor of time. A shortcoming of these models is the lack of detailed modeling for view-specific dynamics, which in turn affects the modeling of cross-view dynamics, as well as causing overfitting on input data (Xu, Tao, and Xu 2013).
Late Fusion:
Late fusion methods learn different models for each modality and combine the outputs using decision voting (Wörtwein and Scherer 2017; Nojavanasghari et al. 2016). While these methods are generally strong in modeling view-specific dynamics, they have shortcomings for cross-view dynamics since these inter-modality dynamics are normally more complex than a decision vote. As an example of this shortcoming, if a model is trained for sentiment analysis using the vision modality and predicts negative sentiment, late fusion models have no access to whether this negative sentiment was due to a frowning face or a disgusted face.
Multi-view Learning:
Extensions of Hidden Markov Models (Baum and Petrie 1966) and Hidden Conditional Random Fields (Quattoni et al. 2007; Morency, Quattoni, and Darrell 2007) have been proposed for learning from multiple different views (modalities) (Song, Morency, and Davis 2012; 2013). Extensions of LSTMs have also been proposed in a multi-view setting (Rajagopalan et al. 2016).
MARN is different from the first category since we model both view-specific and cross-view dynamics. It is differs from the second and third category since we explicitly model view-specific dynamics using a LSTHM for each modality as well as cross-view dynamics using the MAB. Finally, MARN is different from the fourth category since it explicitly models view-specific dynamics and proposes more advanced temporal modeling of cross-view dynamics.
MARN Model
In this section we outline our pipeline for human communication comprehension: the Multi-attention Recurrent Network (MARN). MARN has two key components: Long-short Term Hybrid Memory and Multi-attention Block. Long-short Term Hybrid Memory (LSTHM) is an extension of the Long-short Term Memory (LSTM) by reformulating the memory component to carry hybrid information. LSTHM is intrinsically designed for multimodal setups and each modality is assigned a unique LSTHM. LSTHM has a hybrid memory that stores view-specific dynamics of its assigned modality and cross-view dynamics related to its assigned modality. The component that discovers cross-view dynamics across different modalities is called the Multi-attention Block (MAB). The MAB first uses information from hidden states of all LSTHMs at a timestep to regress coefficients to outline the multiple existing cross-view dynamics among them. It then weights the output dimensions based on these coefficients and learns a neural cross-view dynamics code for LSTHMs to update their hybrid memories. Figure 1 shows the overview of the MARN. MARN is differentiable end-to-end which allows the model to be learned efficiently using gradient decent approaches. In the next subsection, we first outline the Long-short Term Hybrid Memory. We then proceed to outline the Multi-attention Block and describe how the two components are integrated in the MARN.
Figure 1:
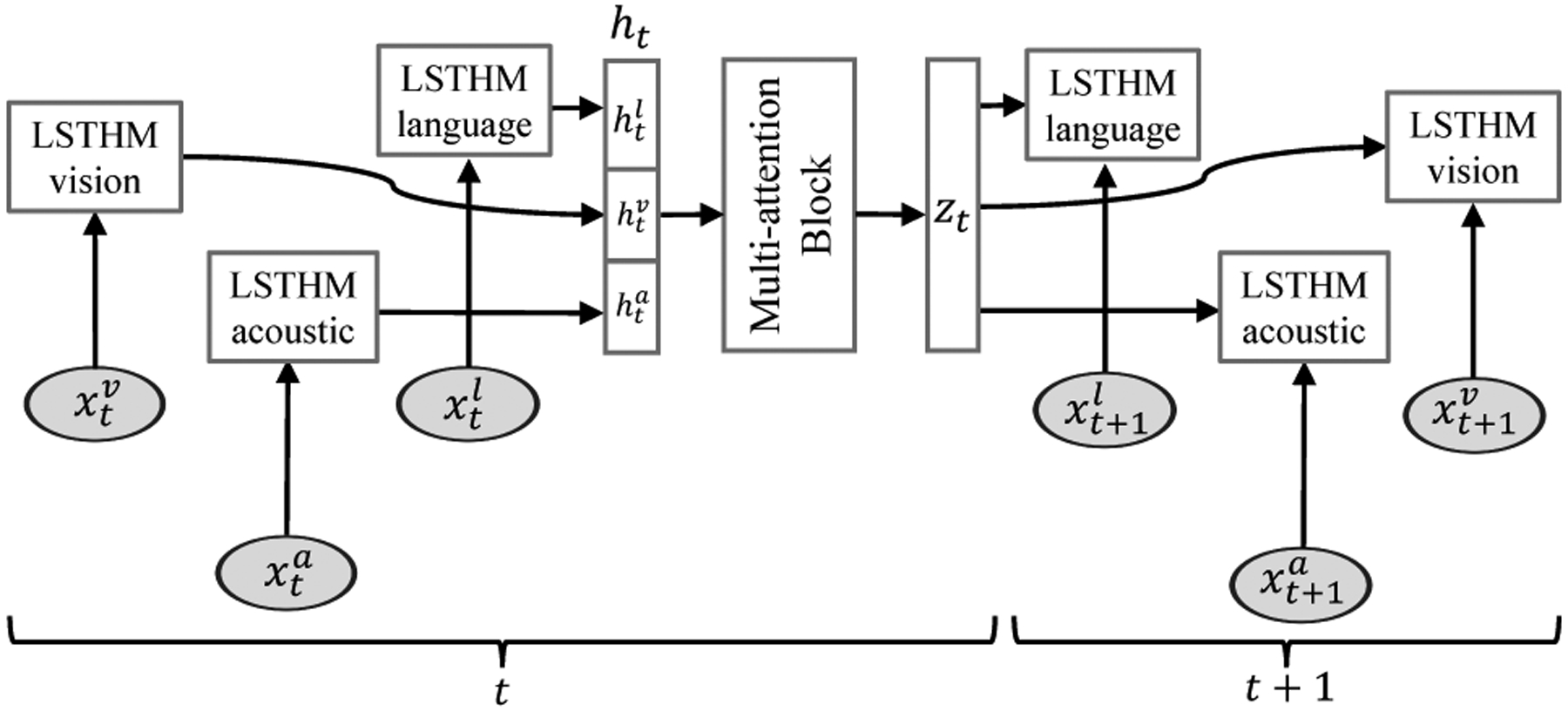
Overview of Multi-attention Recurrent Network (MARN) with Long-short Term Hybrid Memory (LSTHM) and Multi-attention Block (MAB) components, for M = {l; v; a} representing the language, vision and acoustic modalities respectively.
Long-short Term Hybrid Memory
Long-short Term Memory (LSTM) networks have been among the most successful models in learning from sequential data (Hochreiter and Schmidhuber 1997). The most important component of the LSTM is a memory which stores a representation of its input through time. In the LSTHM model, we seek to build a memory mechanism for each modality which in addition to storing view-specific dynamics, is also able to store the cross-view dynamics that are important for that modality. This allows the memory to function in a hybrid manner.
The Long-short Term Hybrid Memory is formulated in Algorithm 1. Given a set of M modalities in the domain of the data, subsequently M LSTHMs are built in the MARN pipeline. For each modality m ϵ M, the input to the mth LSTHM is of the form , where is the input at time t and is the dimensionality of the input of modality m. For example if m = l(language), we can use word vectors with at each time step is the dimensionality of the memory for modality m. σ is the (hard-)sigmoid activation function and tanh is the tangent hyperbolic activation function.⊕ denotes vector concatenation and ⊙denotes element-wise multiplication. Similar to the LSTM, i is the input gate, f is the forget gate, and o is the output gate. is the proposed update to the hybrid memory at time t. is the time distributed output of each modality.
The neural cross-view dynamics code zt is the output of the Multi-attention Block at the previous time-step and is discussed in detail in next subsection. This neural cross-view dynamics code zt is passed to each of the individual LSTHMs and is the hybrid factor, allowing each individual LSTHM to carry cross-view dynamics that it finds related to its modality. The set of weights , and respectively map the input of LSTHM , output of LSTHM , and neural cross-view dynamics code zt to each LSTHM memory space using affine transformations.
Multi-attention Block
At each timestamp t, various cross-view dynamics across the modalities can occur simultaneously. For example, the first instance can be the connection between a smile and positive phrase both happening at time t. A second instance can be the occurrence of the same smile at time t being connected to an excited voice at time t − 4, that was carried to time t using the audio LSTHM memory. In both of these examples, cross-view dynamics exist at time t. Therefore, not only do cross-view dynamics span across various modalities, they are scattered across time forming asynchronous cross-view dynamics.

The Multi-attention Block is a network that can capture multiple different, possibly asynchronous, cross-view dynamics and encode all of them in a neural cross-view dynamics code zt(see Figure 2). In the most important step of the Multi-attention Block, different dimensions of LSTHM outputs are assigned attention coefficients according to whether or not they form cross-view dynamics. These attention coefficients will be high if the dimension contributes to formation of a cross-view dynamics and low if they are irrelevant. The coefficient assignment is performed multiple times due to the existence of possibly multiple such cross-view dynamics across the outputs of LSTHM. The Multi-attention Block is formulated in Algorithm 1. We assume a maximum of K cross-view dynamics to be present at each timestamp t. To obtain the K attention coefficients, K softmax distributions are assigned to the concatenated LSTHM memories using a deep neural network with At each timestep t, the output of LSTHM is the set . takes the concatenation of LSTHM outputs , as input and outputs a set of K attentions with , . has a softmax layer at top of the network which takes the softmax activation along each one of the K dimensions of its output at. As a result, , which forms a probability distribution over the output dimensions. ht is then broadcasted (from to ) and element-wise multiplied by the at to produce attended outputs , denotes broadcasting by parameter K.
Figure 2:
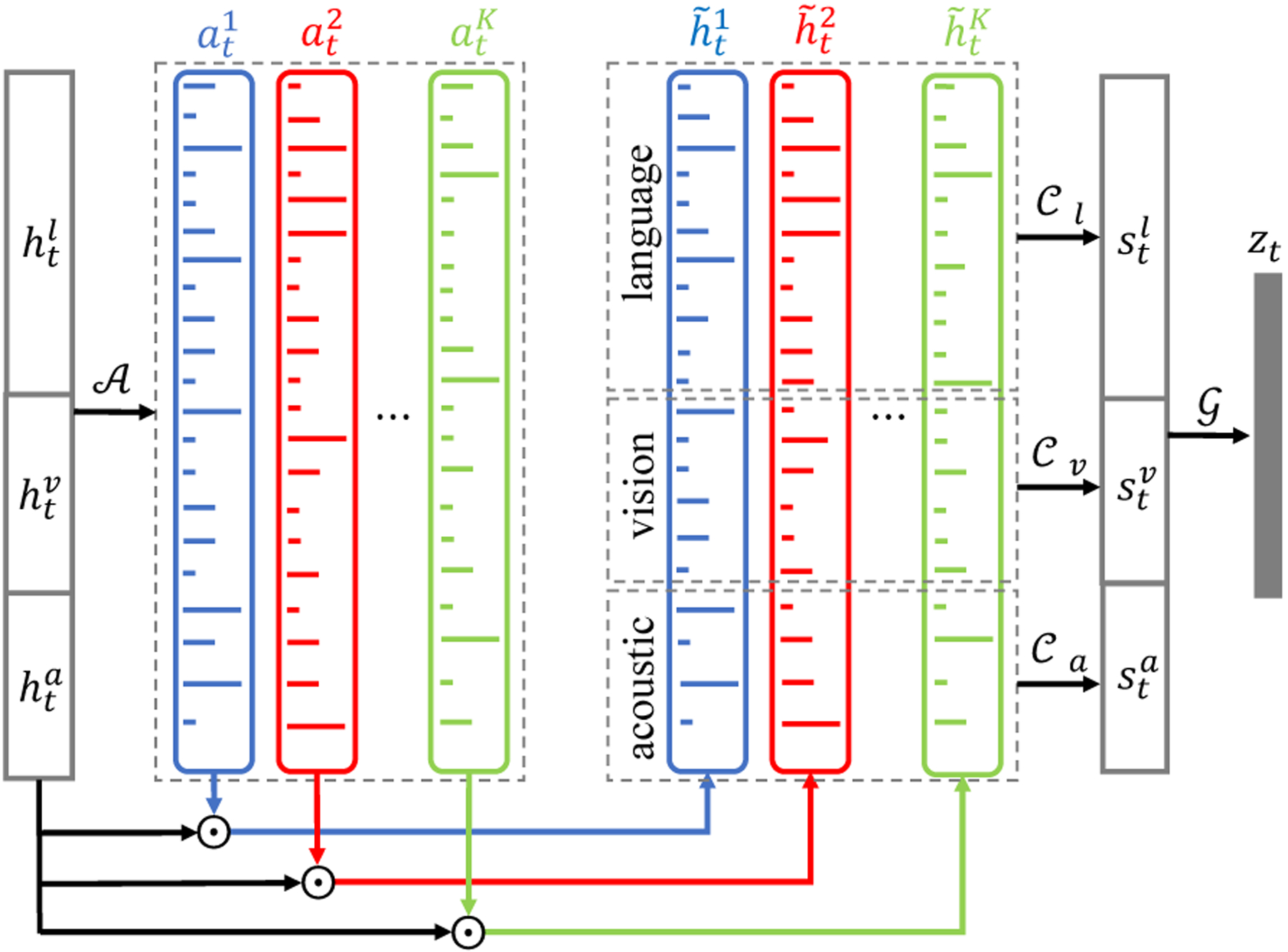
Overview of Multi-attention Block (MAB).
The first dimension of contains information needed for the first cross-view dynamic highlighted using , the second dimension of contains information for the second cross-view dynamic using , and so on until is high dimensional but ideally considered sparse due to presence of dimensions with zero value after element-wise multiplication with attentions. Therefore, is split into m different parts – one for each modality m – and undergoes dimensionality reduction using , ∀m ϵ M with as the target low dimension of each modality split in .The set of networks maps attended of modality to same vector space. This dimensionality reduction produces a dense code for the K times attended dimensions of each modality. Finally, the set of all M attended modality outputs, are passed into a deep neural network to generate the neural cross-view dynamics code zt at time t.
Experimental Methodology
In this paper we benchmark MARN’s understanding of human communication on three tasks: 1) multimodal sentiment analysis, 2) multimodal speaker traits recognition and 3) multimodal emotion recognition. We perform experimentations on six publicly available datasets and compare the performance of MARN with the performance of state-of-the-art approaches on the same datasets. To ensure generalization of the model, all the datasets are split into train, validation and test sets that include no identical speakers between sets, i.e. all the speakers in the test set are different from the train and validation sets. All models are re-trained on the same train/validation/test splits. To train the MARN for different tasks, the final outputs hT and neural cross-view dynamics code zT are the inputs to another deep neural network that performs classification (categorical cross-entropy loss function) or regression (mean squared error loss function). The code, hyperparameters and instruction on data splits are publicly available at https://github.com/A2Zadeh/MARN.
Following is the description of different benchmarks.
Multimodal Sentiment Analysis
CMU-MOSI The CMU-MOSI dataset (Zadeh et al. 2016) is a collection of 2199 opinion video clips. Each opinion video is annotated with sentiment in the range [−3,3]. There are 1284 segments in the train set, 229 in the validation set and 686 in the test set.
ICT-MMMO The ICT-MMMO dataset (Wöllmer et al. 2013) consists of online social review videos that encompass a strong diversity in how people express opinions, annotated at the video level for sentiment. The dataset contains 340 multimodal review videos, of which 220 are used for training, 40 for validation and 80 for testing.
YouTube The YouTube dataset (Morency, Mihalcea, and Doshi 2011) contains videos from the social media web site YouTube that span a wide range of product reviews and opinion videos. Out of 46 videos, 30 are used for training, 5 for validation and 11 for testing.
MOUD To show that MARN is generalizable to other languages, we perform experimentation on the MOUD dataset (Perez-Rosas, Mihalcea, and Morency 2013b) which consists of product review videos in Spanish. Each video consists of multiple segments labeled to display positive, negative or neutral sentiment. Out of 79 videos in the dataset, 49 are used for training, 10 for validation and 20 for testing.
Multimodal Speaker Trait Recognition
POM Persuasion Opinion Multimodal (POM) dataset (Park et al. 2014) contains movie review videos annotated for the following speaker traits: confidence, passion, dominance, credibility, entertaining, reserved, trusting, relaxed, nervous, humorous and persuasive. 903 videos were split into 600 were for training, 100 for validation and 203 for testing.
Multimodal Emotion Recognition
IEMOCAP The IEMOCAP dataset (Busso et al. 2008) consists of 151 videos of recorded dialogues, with 2 speakers per session for a total of 302 videos across the dataset. Each segment is annotated for the presence of 9 emotions (angry, excited, fear, sad, surprised, frustrated, happy, disappointed and neutral) as well as valence, arousal and dominance. The dataset is recorded across 5 sessions with 5 pairs of speakers. To ensure speaker independent learning, the dataset is split at the level of sessions: training is performed on 3 sessions (6 distinct speakers) while validation and testing are each performed on 1 session (2 distinct speakers).
Multimodal Computational Descriptors
All the datasets consist of videos where only one speaker is in front of the camera. The descriptors we used for each of the modalities are as follows:
Language All the datasets provide manual transcriptions. We use pre-trained word embeddings (glove.840B.300d) (Pennington, Socher, and Manning 2014) to convert the transcripts of videos into a sequence of word vectors. The dimension of the word vectors is 300.
Vision Facet (iMotions 2017) is used to extract a set of features including per-frame basic and advanced emotions and facial action units as indicators of facial muscle movement.
Acoustic We use COVAREP (Degottex et al. 2014) to extract low level acoustic features including 12 Mel-frequency cepstral coefficients (MFCCs), pitch tracking and voiced/unvoiced segmenting features, glottal source parameters, peak slope parameters and maxima dispersion quotients.
Modality Alignment To reach the same time alignment between different modalities we choose the granularity of the input to be at the level of words. The words are aligned with audio using P2FA (Yuan and Liberman 2008) to get their exact utterance times. Time step t represents the tth spoken word in the transcript. We treat speech pause as a word with vector values of all zero across dimensions. The visual and acoustic modalities follow the same granularity. We use expected feature values across the entire word for vision and acoustic since they are extracted at a higher frequency (30 Hz for vision and 100 Hz for acoustic).
Comparison Metrics
Different datasets in our experiments have different labels. For binary classification and multiclass classification we report accuracy AC where C denotes the number of classes, and F1 score. For regression we report Mean Absolute Error MAE and Pearson’s correlation r. For all the metrics, higher values denote better performance, except MAE where lower values denote better performance.
Baseline Models
We compare the performance of our MARN to the following state-of-the-art models in multimodal sentiment analysis, speaker trait recognition, and emotion recognition. All baselines are trained for datasets for complete comparison.
TFN (Tensor Fusion Network) (Zadeh et al. 2017) explicitly models view-specific and cross-view dynamics by creating a multi-dimensional tensor that captures unimodal, bimodal and trimodal interactions across three modalities. It is the current state of the art for CMU-MOSI dataset.
BC-LSTM (Bidirectional Contextual LSTM) (Poria et al. 2017) is a model for context-dependent sentiment analysis and emotion recognition, currently state of the art on the IEMOCAP and MOUD datasets.
MV-LSTM (Multi-View LSTM) (Rajagopalan et al. 2016) is a recurrent model that designates special regions inside one LSTM to different views of the data.
C-MKL (Convolutional Neural Network (CNN) with Multiple Kernel Learning) (Poria, Cambria, and Gelbukh 2015) is a model which uses a CNN for visual feature extraction and multiple kernel learning for prediction.
THMM (Tri-modal Hidden Markov Model) (Morency, Mihalcea, and Doshi 2011) performs early fusion of the modalities by concatenation and uses a HMM for classification.
SVM (Support Vector Machine) (Cortes and Vapnik 1995) a SVM is trained on the concatenated multimodal features for classification or regression (Zadeh et al. 2016; Perez-Rosas, Mihalcea, and Morency 2013b; Park et al. 2014). To compare to another strong non-neural baseline we use RF (Random Forest) (Breiman 2001) using similar multimodal inputs.
SAL-CNN (Selective Additive Learning CNN) (Wang et al. 2016) is a model that attempts to prevent identity-dependent information from being learned by using Gaussian corruption introduced to the neuron outputs.
EF-HCRF: (Hidden Conditional Random Field) (Quattoni et al. 2007) uses a HCRF to learn a set of latent variables conditioned on the concatenated input at each time step. We also implement the following variations: 1) EF-LDHCRF (Latent Discriminative HCRFs) (Morency, Quattoni, and Darrell 2007) are a class of models that learn hidden states in a CRF using a latent code between observed concatenated input and hidden output. 2) MV-HCRF: Multi-view HCRF (Song, Morency, and Davis 2012) is an extension of the HCRF for Multi-view data, explicitly capturing view-shared and view specific sub-structures. 3) MV-LDHCRF: is a variation of the MV-HCRF model that uses LDHCRF instead of HCRF. 4) EF-HSSHCRF: (Hierarchical Sequence Summarization HCRF) (Song, Morency, and Davis 2013) is a layered model that uses HCRFs with latent variables to learn hidden spatio-temporal dynamics. 5) MV-HSSHCRF: further extends EF-HSSHCRF by performing Multi-view hierarchical sequence summary representation. The best performing early fusion model is reported as EF-HCRF(⋆) while the best multi-view model is reported as MV-HCRF(⋆),where ⋆ ϵ {h, 1, s} to represent HCRF, and HSSCRF respectively.
DF (Deep Fusion) (Nojavanasghari et al. 2016) is a model that trains one deep model for each modality and performs decision voting on the output of each modality network.
EF-LSTM (Early Fusion LSTM) concatenates the inputs from different modalities at each time-step and uses that as the input to a single LSTM. We also implement the Stacked, (EF-SLSTM) Bidirectional (EF-BLSTM) and Stacked Bidirectional (EF-SBLSTM) LSTMs for stronger baselines. The best performing model is reported as EF-LSTM(⋆), ⋆ ϵ {−, s, b, sb} denoting vanilla stacked, bidirectional LSTMs respectively.
Majority performs majority voting for classification tasks, and predicts the expected label for regression tasks. This baseline is useful as a lower bound of model performance.
Human performance is calculated for CMU-MOSI dataset which offers per annotator results. This is the accuracy of human performance in a one-vs-rest classification/regression.
Finally, MARN indicates our proposed model. Additionally, the modified baseline MARN (no MAB) removes the MAB and learns no dense cross-view dynamics code z. This model can be seen as three disjoint LSTMs and is used to investigate the importance of modeling temporal cross-view dynamics. The next modified baseline MARN (no ) removes the deep network and sets all K attention coefficients This comparison shows whether explicitly outlining the cross-view dynamics using the attention coefficients is required. For MARN and MARN (no ), K is treated as a hyperparamter and the best value of K is indicated in parenthesis next to the best reported result.
Experimental Results
Results on CMU-MOSI dataset
We summarize the results on the CMU-MOSI dataset in Table 1. We are able to achieve new state-of-the-art results for this dataset in all the metrics using the MARN. This highlights our model’s capability in understanding sentiment aspect of multimodal communication.
Table 1:
Sentiment prediction results on CMU-MOSI test set using multimodal methods. Our model outperforms the previous baselines and the best scores are highlighted in bold.
| Binary | Multiclass | Regression | |||
|---|---|---|---|---|---|
| Method | A2 | F1 | A7 | MAE | Corr |
| Majority | 50.2 | 50.1 | 17.5 | 1.864 | 0.057 |
| RF | 56.4 | 56.3 | 21.3 | - | - |
| SVM-MD | 71.6 | 72.3 | 26.5 | 1.100 | 0.559 |
| THMM | 50.7 | 45.4 | 17.8 | - | - |
| SAL-CNN | 73.0 | - | - | - | - |
| C-MKL | 72.3 | 72.0 | 30.2 | - | - |
| EF-HCRF(⋆) | 65.3(h) | 65.4(h) | 24.6(l) | - | - |
| MV-HCRF(⋆) | 65.6(s) | 65.7(s) | 24.6(l) | - | - |
| DF | 72.3 | 72.1 | 26.8 | 1.143 | 0.518 |
| EF-LSTM(⋆) | 73.3(sb) | 73.2(sb) | 32.4(−) | 1.023(−) | 0.622(−) |
| MV-LSTM | 73.9 | 74.0 | 33.2 | 1.019 | 0.601 |
| BC-LSTM | 73.9 | 73.9 | 28.7 | 1.079 | 0.581 |
| TFN | 74.6 | 74.5 | 28.7 | 1.040 | 0.587 |
| MARN (no MAB) | 76.5 | 76.5 | 30.8 | 0.998 | 0.582 |
| MARN (no ) | 59.3(3) | 36.0(3) | 22.0(3) | 1.438(5) | 0.060(5) |
| MARN | 77.1 (4) | 77.0 (4) | 34.7 (3) | 0.968 (4) | 0.625 (5) |
| Human | 85.7 | 87.5 | 53.9 | 0.710 | 0.820 |
Results on ICT-MMMO, YouTube, MOUD Datasets
We achieve state-of-the-art performance with significant improvement over all the comparison metrics for two English sentiment analysis datasets. Table 2 shows the comparison of our MARN with state-of-the-art approaches for ICT-MMMO dataset as well as the comparison for YouTube dataset. To assess the generalization of the MARN to speakers communicating in different languages, we compare with state-of-the-art approaches for sentiment analysis on MOUD, with opinion utterance video clips in Spanish. The final third of Table 2 shows these results where we also achieve significant improvement over state-of-the-art approaches.
Table 2:
Sentiment prediction results on ICT-MMMO, YouTube and MOUD test sets. Our model outperforms the previous baselines and the best scores are highlighted in bold.
| ICT-MMMO Binary | YouTube Multiclass | MOUD Binary | ||||
|---|---|---|---|---|---|---|
| Method | A2 | F1 | A3 | F1 | A2 | F1 |
| Majority | 40.0 | 22.9 | 42.4 | 25.2 | 60.4 | 45.5 |
| RF | 70.0 | 69.8 | 49.3 | 49.2 | 64.2 | 63.3 |
| SVM | 68.8 | 68.7 | 42.4 | 37.9 | 60.4 | 45.5 |
| THMM | 53.8 | 53.0 | 42.4 | 27.9 | 58.5 | 52.7 |
| C-MKL | 80.0 | 72.4 | 50.2 | 50.8 | 74.0 | 74.7 |
| EF-HCRF(⋆) | 81.3(l) | 79.6(l) | 45.8(l) | 45.0(l) | 54.7(h) | 54.7(h) |
| MV-HCRF(⋆) | 81.3(l) | 79.6(l) | 44.1(s) | 44.0(s) | 60.4(l) | 47.8(l) |
| DF | 77.5 | 77.5 | 45.8 | 32.0 | 67.0 | 67.1 |
| EF-LSTM(⋆) | 80.0(sb) | 78.5(sb) | 44.1(−) | 43.6(−) | 67.0(−) | 64.3(−) |
| MV-LSTM | 72.5 | 72.3 | 45.8 | 43.3 | 57.6 | 48.2 |
| BC-LSTM | 70.0 | 70.1 | 47.5 | 47.3 | 72.6 | 72.9 |
| TFN | 72.5 | 72.6 | 47.5 | 41.0 | 63.2 | 61.7 |
| MARN (no MAB) | 82.5 | 82.4 | 47.5 | 42.8 | 75.5 | 72.9 |
| MARN (no ) | 80.0(5) | 79.1(5) | 44.1(5) | 29.3(5) | 63.2(5) | 61.9(5) |
| MARN | 86.3 (2) | 85.9 (2) | 54.2 (6) | 52.9 (6) | 81.1 (2) | 81.2 (2) |
Results on POM Dataset
We experiment on speaker traits recognition based on observed multimodal communicative behaviors. Table 3 shows the performance of the MARN on POM dataset, where it achieves state-of-the-art accuracies on all 11 speaker trait recognition tasks including persuasiveness and credibility.
Table 3:
Speaker personality trait recognition results on POM test set. Our model outperforms the previous baselines and the best scores are highlighted in bold.
| Task | Confident | Passionate | Dominant | Credible | Entertaining | Reserved | Trusting | Relaxed | Nervous | Persuasive | Humorous |
|---|---|---|---|---|---|---|---|---|---|---|---|
| Method | A7 | A7 | A7 | A7 | A7 | A5 | A5 | A5 | A5 | A7 | A5 |
| Majority | 19.2 | 20.2 | 18.2 | 21.7 | 19.7 | 29.6 | 44.3 | 39.4 | 24.1 | 20.7 | 6.9 |
| SVM | 26.6 | 20.7 | 35.0 | 25.1 | 31.5 | 34.0 | 50.2 | 49.8 | 41.4 | 28.1 | 36.0 |
| RF | 26.6 | 27.1 | 26.1 | 23.2 | 26.1 | 34.0 | 53.2 | 40.9 | 36.0 | 25.6 | 40.4 |
| THMM | 24.1 | 15.3 | 29.1 | 27.6 | 12.3 | 22.7 | 31.0 | 31.5 | 27.1 | 17.2 | 24.6 |
| DF | 25.6 | 24.1 | 34.0 | 26.1 | 29.6 | 30.0 | 53.7 | 50.2 | 42.4 | 26.6 | 34.5 |
| EF-LSTM(⋆) | 25. l(b) | 30.5(sb) | 36.9(s) | 29.6(b) | 33.5(b) | 33.5(sb) | 52.7(sb) | 48.3(−) | 44.8(sb) | 25.6(sb) | 39.4(b) |
| MV-LSTM | 25.6 | 28.6 | 34.5 | 25.6 | 29.1 | 33.0 | 52.2 | 50.7 | 42.4 | 26.1 | 38.9 |
| BC-LSTM | 26.6 | 26.6 | 33.0 | 27.6 | 29.6 | 33.0 | 52.2 | 47.3 | 36.0 | 27.1 | 36.5 |
| TFN | 24.1 | 31.0 | 34.5 | 24.6 | 29.1 | 30.5 | 38.9 | 35.5 | 42.4 | 27.6 | 33.0 |
| MARN (no MAB) | 26.1 | 27.1 | 35.5 | 28.1 | 30.0 | 32.0 | 55.2 | 50.7 | 42.4 | 29.1 | 33.5 |
| MARN (no ) | 24.6(6) | 32.0(5) | 34.0(5) | 24.6(6) | 29.6(6) | 32.5(6) | 53.2(6) | 49.3(6) | 42.4(5) | 29.6(6) | 42.4(4) |
| MARN | 29.1 (2) | 33.0 (6) | 38.4 (6) | 31.5 (2) | 33.5 (3) | 36.9 (1) | 55.7 (1) | 52.2 (6) | 47.3 (5) | 31.0 (3) | 44.8 (5) |
Results on IEMOCAP Dataset
Our results for multimodal emotion recognition on IEMOCAP dataset are reported in Table 4. Our approach achieves state-of-the-art performance in emotion recognition: both emotion classification as well as continuous emotion regression except for the case of correlation in dominance which our results are competitive but not state of the art.
Table 4:
Emotion recognition results on IEMOCAP test set using multimodal methods. Our model outperforms the previous baselines and the best scores are highlighted in bold.
| Task | Emotions | Valence | Arousal | Dominance | ||||
|---|---|---|---|---|---|---|---|---|
| Method | A9 | F1 | MAE | Corr | MAE | Corr | MAE | Corr |
| Majority | 21.2 | 7.4 | 2.042 | −0.02 | 1.352 | 0.01 | 1.331 | 0.17 |
| SVM | 24.1 | 18.0 | 0.251 | 0.06 | 0.546 | 0.54 | 0.687 | 0.42 |
| RF | 27.3 | 25.3 | - | - | - | - | - | - |
| THMM | 23.5 | 10.8 | - | - | - | - | - | - |
| C-MKL | 34.0 | 31.1 | - | - | - | - | - | - |
| EF-HCRF(⋆) | 32.0(s) | 20.5(s) | - | - | - | - | - | - |
| MV-HCRF(⋆) | 32.0(s) | 20.5(s) | - | - | - | - | - | - |
| DF | 26.1 | 20.0 | 0.250 | −0.04 | 0.613 | 0.27 | 0.726 | 0.09 |
| EF-LSTM(⋆) | 34.1(s) | 32.3(s) | 0.244(−) | 0.09(−) | 0.512(b) | 0.62(−) | 0.669(s) | 0.51(sb) |
| MV-LSTM | 31.3 | 26.7 | 0.257 | 0.02 | 0.513 | 0.62 | 0.668 | 0.52 |
| BC-LSTM | 35.9 | 34.1 | 0.248 | 0.07 | 0.593 | 0.40 | 0.733 | 0.32 |
| TFN | 36.0 | 34.5 | 0.251 | 0.04 | 0.521 | 0.55 | 0.671 | 0.43 |
| MARN (no MAB) | 31.2 | 28.0 | 0.246 | 0.09 | 0.509 | 0.63 | 0.679 | 0.44 |
| MARN (no ) | 23.0(3) | 10.9(3) | 0.249(5) | 0.05(5) | 0.609(4) | 0.29(4) | 0.752(4) | 0.21(5) |
| MARN | 37.0 (4) | 35.9 (4) | 0.242 (6) | 0.10 (5) | 0.497 (3) | 0.65 (3) | 0.655 (1) | 0.50 (5) |
Discussion
Our experiments indicate outstanding performance of MARN in modeling various attributes related to human communication. In this section, we aim to better understand different characteristics of our model.
Properties of Attentions
To better understand the effects of attentions, we pose four fundamental research questions (RQ) in this section as RQ1: MARN (no MAB): whether the cross-view dynamics are helpful. RQ2: MARN (no ): whether the attention coefficients are needed. RQ3: MARN: whether one attention is enough to extract all cross-view dynamics. RQ4: whether different tasks and datasets require different numbers of attentions.
-
RQ1:
MARN (no MAB) model can only learn simple rules among modalities such as decision voting or simple co-occurrence rules such as Tensor Fusion baseline. Across all datasets, MARN (no MAB) is outperformed by MARN. This indicates that continuous modeling of cross-view dynamics is crucial in understanding human communication.
-
RQ2:
Whether or not the presence of the coefficients at are crucial is an important research question. From the results tables, we notice that the MARN (no ) baseline severely under-performs compared to MARN. This supports the importance of the attentions in the MAB.Without these attentions, MARN is not able to accurately model the cross-view dynamics.
-
RQ3:
In our experiments the MARN with only one attention (like conventional attention models) under-performs compared to the models with multiple attentions. One could argue that the models with more attentions have more parameters, and as a result their better performance may not be due to better modeling of cross-view dynamics, but rather due to more parameters. However we performed extensive grid search on the number of parameters in MARN with one attention. Increasing the number of parameters further (by increasing dense layers, LSTHM cellsizes etc.) did not improve performance. This indicates that the better performance of MARN with multiple attentions is not due to the higher number of parameters but rather due to better modeling of cross-view dynamics.
-
RQ4:
Different tasks and datasets require different number of attentions. This is highly dependent on each dataset’s nature and the underlying interconnections between modalities.
Visualization of Attentions
We visually display how each attention is sensitive to different dimensions of LSTHM outputs in Figure 3. Each column of the figure denoted by ak shows the behavior of the kth attention on a sample video from CMU-MOSI. The left side of ak is t = 1 and the right side is t = 20, since the sequence has 20 words. The y axis shows what modality the dimension belongs to. Dark blue means high coefficients and red means low coefficients. Our observations (O) are detailed below:
-
O1:
By comparing each of the attentions together, they show diversity on which dimensions they are sensitive to, indicating that each attention is sensitive to different cross-view dynamics.
-
O2:
Some attention coefficients are not active (always red) throughout time. These dimensions carry only view-specific dynamics needed by that modality and not other modalities. Hence, they are not needed for cross-view dynamics and will carry no weight in their formation.
-
O3:
Attentions change their behaviors across time. For some coefficients, these changes are more drastic than the others. We suspect that the less drastic the change in an attention dimension over time, the higher the chances of that dimension being part of multiple cross-view dynamics. Thus more attentions activate this important dimension.
-
O4:
Some attentions focus on cross-view dynamics that involve only two modalities. For example, in a3, the audio modality has no dark blue dimensions, while in a1 all the modalities have dark blue dimensions. The attentions seem to have residual effects. a1 shows activations over a broad set of variables while a4 shows activation for fewer sets, indicating that attentions could learn to act in a complementary way.
Figure 3:
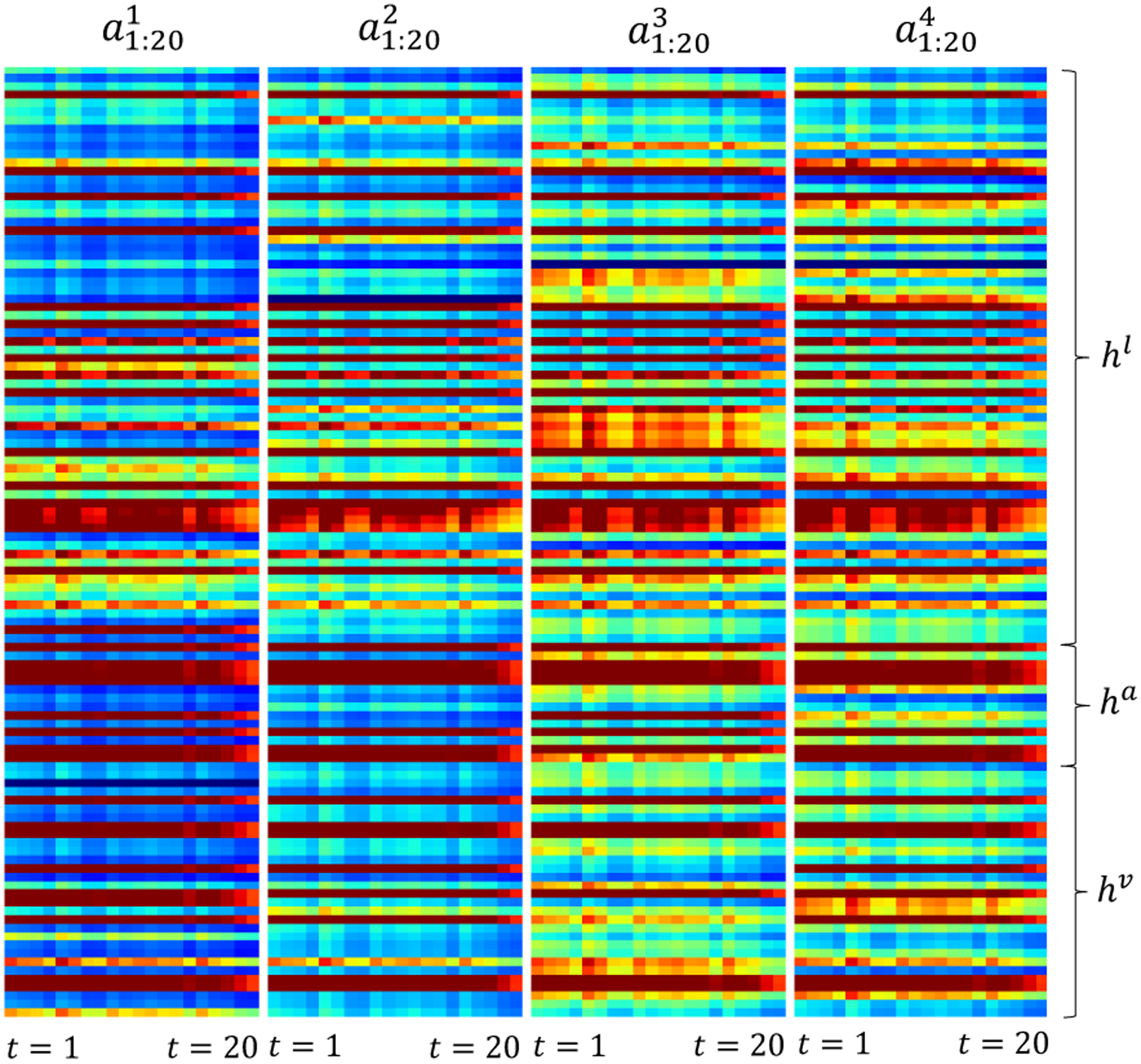
Visualization of attention units throughout time. Blue: activated attentions and red: non-activated attentions. The learned attentions are diverse and evolve across time.
Conclusion
In this paper we modeled multimodal human communication using a novel neural approach called the Multi-attention Recurrent Network (MARN). Our approach is designed to model both view-specific dynamics as well as cross-view dynamics continuously through time. View-specific dynamics are modeled using a Long-short Term Hybrid Memory (LSTHM) for each modality. Various cross-view dynamics are identified at each time-step using the Multi-attention Block (MAB) which outputs a multimodal neural code for the hybrid memory of LSTHM. MARN achieves state-of-the-art results in 6 publicly available datasets and across 16 different attributes related to understanding human communication.
Acknowledgements
This project was partially supported by Oculus research grant. We thank the reviewers for their valuable feedback.
Contributor Information
Amir Zadeh, Carnegie Mellon University, USA.
Paul Pu Liang, Carnegie Mellon University, USA.
Soujanya Poria, NTU, Singapore.
Prateek Vij, NTU, Singapore.
Erik Cambria, NTU, Singapore.
Louis-Philippe Morency, Carnegie Mellon University, USA.
References
- Abburi H; Prasath R; Shrivastava M; and Gangashetty SV 2016. Multimodal sentiment analysis using deep neural networks. In International Conference on Mining Intelligence and Knowledge Exploration, 58–65. Springer. [Google Scholar]
- Baum LE, and Petrie T 1966. Statistical inference for prob-abilistic functions of finite state markov chains. The Annals of Mathematical Statistics 37(6):1554–1563. [Google Scholar]
- Breiman L 2001. Random forests. Mach. Learn 45(1):5–32. [Google Scholar]
- Busso C; Bulut M; Lee C-C; Kazemzadeh A; Mower E; Kim S; Chang J; Lee S; and Narayanan SS 2008. Iemocap: Interactive emotional dyadic motion capture database. Journal of Language Resources and Evaluation 42(4):335–359. [Google Scholar]
- Cortes C, and Vapnik V 1995. Support-vector networks. Mach. Learn 20(3):273–297. [Google Scholar]
- Degottex G; Kane J; Drugman T; Raitio T; and Scherer S 2014. Covarepa collaborative voice analysis repository for speech technologies. In Acoustics, Speech and Signal Processing (ICASSP), 2014 IEEE International Conference on, 960–964. IEEE. [Google Scholar]
- Hochreiter S, and Schmidhuber J 1997. Long short-term memory. Neural computation 9(8):1735–1780. [DOI] [PubMed] [Google Scholar]
- iMotions. 2017. Facial expression analysis.
- Jiang J; Dai B; Peng D; Zhu C; Liu L; and Lu C 2012. Neural synchronization during face-to-face communication. Journal of Neuroscience 32(45):16064–16069. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Kuzmanovic B; Bente G; von Cramon DY; Schilbach L; Tittgemeyer M; and Vogeley K 2012. Imaging first impressions: Distinct neural processing of verbal and nonverbal social information. NeuroImage 60(1):179–188. [DOI] [PubMed] [Google Scholar]
- Morency L-P; Mihalcea R; and Doshi P 2011. Towards multimodal sentiment analysis: Harvesting opinions from the web. In Proceedings of the 13th international conference on multimodal interfaces, 169–176. ACM. [Google Scholar]
- Morency L-P; Quattoni A; and Darrell T 2007. Latent-dynamic discriminative models for continuous gesture recognition. In Computer Vision and Pattern Recognition, 2007. CVPR’07. IEEE Conference on, 1–8. IEEE. [Google Scholar]
- Nojavanasghari B; Gopinath D; Koushik J; Baltrušaitis T; and Morency L-P 2016. Deep multimodal fusion for persuasiveness prediction. In Proceedings of the 18th ACM International Conference on Multimodal Interaction, ICMI 2016, 284–288. New York, NY, USA: ACM. [Google Scholar]
- Park S; Shim HS; Chatterjee M; Sagae K; and Morency L-P 2014. Computational analysis of persuasiveness in social multimedia: A novel dataset and multimodal prediction approach. In Proceedings of the 16th International Conference on Multimodal Interaction, ICMI ‘14, 50–57. New York, NY, USA: ACM. [Google Scholar]
- Pennington J; Socher R; and Manning CD 2014. Glove: Global vectors for word representation. In EMNLP, volume 14, 1532–1543. [Google Scholar]
- Pérez-Rosas V; Mihalcea R; and Morency L-P 2013a. Utterance-level multimodal sentiment analysis. In ACL (1), 973–982. [Google Scholar]
- Perez-Rosas V; Mihalcea R; and Morency L-P 2013b. Utterance-Level Multimodal Sentiment Analysis. In Association for Computational Linguistics (ACL). [Google Scholar]
- Poria S; Chaturvedi I; Cambria E; and Hussain A 2016. Convolutional mkl based multimodal emotion recognition and sentiment analysis. In Data Mining (ICDM), 2016 IEEE 16th International Conference on, 439–448. IEEE. [Google Scholar]
- Poria S; Cambria E; Hazarika D; Majumder N; Zadeh A; and Morency L-P 2017. Context-dependent sentiment analysis in user-generated videos. In Proceedings of the 55th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), volume 1, 873–883. [Google Scholar]
- Poria S; Cambria E; and Gelbukh AF 2015. Deep convolutional neural network textual features and multiple kernel learning for utterance-level multimodal sentiment analysis. In Proceedings of the 2015 Conference on Empirical Methods in Natural Language Processing, EMNLP 2015, Lisbon, Portugal, September 17–21, 2015, 2539–2544. [Google Scholar]
- Quattoni A; Wang S; Morency L-P; Collins M; and Darrell T 2007. Hidden conditional random fields. IEEE Trans. Pattern Anal. Mach. Intell 29(10):1848–1852. [DOI] [PubMed] [Google Scholar]
- Rajagopalan SS; Morency L-P; Baltrušaitis T; and Roland G 2016. Extending long short-term memory for multi-view structured learning. In European Conference on Computer Vision. [Google Scholar]
- Sergent J, and Signoret J-L 1992. Processing the facial image - functional and anatomical decomposition of face processing: evidence from prosopagnosia and pet study of normal subjects. Philosophical Transactions of the Royal Society of London B: Biological Sciences 335(1273):55–62. [DOI] [PubMed] [Google Scholar]
- Song Y; Morency L-P; and Davis R 2012. Multi-view latent variable discriminative models for action recognition. In Computer Vision and Pattern Recognition (CVPR), 2012 IEEE Conference on, 2120–2127. IEEE. [Google Scholar]
- Song Y; Morency L-P; and Davis R 2013. Action recognition by hierarchical sequence summarization. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, 3562–3569. [Google Scholar]
- Wang H; Meghawat A; Morency L-P; and Xing EP 2016. Select-additive learning: Improving cross-individual generalization in multimodal sentiment analysis. arXiv preprint arXiv:1609.05244. [Google Scholar]
- Wöllmer M; Weninger F; Knaup T; Schuller B; Sun C; Sagae K; and Morency L-P 2013. Youtube movie reviews: Sentiment analysis in an audio-visual context. IEEE Intelligent Systems 28(3):46–53. [Google Scholar]
- Wörtwein T, and Scherer S 2017. What really matters – an information gain analysis of questions and reactions in automated ptsd screenings. In Affective Computing and Intelligent Interaction. [Google Scholar]
- Xu C; Tao D; and Xu C 2013. A survey on multi-view learning. arXiv preprint arXiv:1304.5634. [Google Scholar]
- Yuan J, and Liberman M 2008. Speaker identification on the scotus corpus. Journal of the Acoustical Society of America 123(5):3878. [Google Scholar]
- Zadeh A; Zellers R; Pincus E; and Morency L-P 2016. Multimodal sentiment intensity analysis in videos: Facial gestures and verbal messages. IEEE Intelligent Systems 31(6):82–88. [Google Scholar]
- Zadeh A; Chen M; Poria S; Cambria E; and Morency L-P 2017. Tensor fusion network for multimodal sentiment analysis. In Proceedings of the 2017 Conference on Empirical Methods in Natural Language Processing, 1114–1125. [Google Scholar]