

Abstract
We investigate the effectiveness of health cards to assist decision making in Consumer Health Search (CHS). A health card is a concise presentation of a health concept shown along side search results to specific queries. We specifically focus on the decision making tasks of determining the health condition presented by a person and determining which action should be taken next with respect to the health condition. We explore two avenues for presenting health cards: a traditional single health card interface, and a novel multiple health cards interface. To validate the utility of health cards and their presentation interfaces, we conduct a laboratory user study where users are asked to solve the two decision making tasks for eight simulated scenarios. Our study makes the following contributions: (1) it proposes the novel multiple health card interface, which allows users to perform differential diagnoses, (2) it quantifies the impact of using health cards for assisting decision making in CHS, and (3) it determines the health card appraisal accuracy in the context of multiple health cards.
Introduction
It is common practice for people to search the Web for health advice and information about conditions, treatments, experiences and health services – we refer to these search activities as Consumer Health Search (CHS). CHS is a challenging domain where effective search is hindered by vocabulary mismatch and the users’ lack of domain exper tise. These issues affect both query formulation and result appraisal1. A study by Zeng et al.2 showed that, while the general public believes that they were effective in searching for medical advice online, 70% of the study’s participants were relying on incorrect advice. Furthermore, Fox & Duggan3 found that 38% of CHS users did not seek professional attention once they found medical advice online. This is problematic as in some cases incorrect medical diagnosis and treatment could lead to a fatal outcomes.
This study investigates the effectiveness of health cards to assist decision making in CHS (e.g., Figure 1). Health cards are a specific type of entity card that have recently been introduced by major web search engines to provide quicker access to trusted information relating to a specific health concept4. In general Web search, entity cards are effective in supporting user search activities by presenting heterogeneous information in a coherent way5. Yet, no previous work has thoroughly investigated the effectiveness of health cards to assist decision making in CHS.
Figure 1:

The middle and right panes of SERP with a single-card (Left) and multi-cards (Right) for scenario 1.
We specifically focus on the health decision making tasks of (A) determining the health condition presented by a person (self-diagnosis) and (B) determining which action should be taken next with respect to the health condition (e.g., consult a doctor, self-treat, etc.). To support users in making these decisions, we propose a novel interface that shows multiple health cards within a search engine result page (Figure 1 right) – we call this multi-cards – in place of traditional single health card interfaces (Figure 1 left). The multi-cards are inspired by interfaces for product comparison used within shopping websites6 (e.g., to compare laptops, shoes, etc.) where features of the compared products are summarised and presented side-by-side to assist the user in their purchase decisions. We believe that the multi-cards would allow CHS users to perform differential diagnoses by quickly, and with less effort, comparing their health observations with several probable conditions at once. In this context, we aim to address the following questions:
RQ1: How do single and multiple cards influence CHS users when making health decisions? The impact of health cards on CHS decisions is measured by: (1) the use of health cards as a source of information; (2) the correctness of decisions made on their basis; (3) the time needed to make decisions; (4) the number of web pages opened; (5) the rate of good abandonment7; and (6) the level of confidence in the decisions.
The multi-cards solution shows a set of health cards rather than a single card. This is useful in contexts where the search systems is unsure about which single relevant card should be shown to the user. The ability of showing multiple health cards increases the chance that the relevant (correct) health card is shown for the user’s condition. However, it is unclear whether users would be capable of identifying the correct card for their condition. We investigate this in our second question:
RQ2: How accurate are CHS users in appraising the correctness of health cards? Search results appraisal is challenging in CHS, and is affected by medical terminology, lack of prior knowledge, and cognitive biases8, among others. We investigate if this holds for the use of health cards by measuring how well CHS users identify the correct health cards for their health situation, in the context of a multi-cards interface.
To answer these questions, we conduct a study where 64 participants are presented with eight health scenarios and pre-formulated queries, and are asked to consider a search engine result page (SERP) containing health cards and search result snippets. Participants are then left to interact with the SERP and are asked to make two decisions: (A) What is the most likely health condition for the scenario? (B) What would you do next? Participants are rotated across two interfaces: one with a single health card, and one with the multi-cards.
Methods
A within-subjects user study was set up to answer the research questions presented above. Figure 2 depicts the activity flow of the user study. Participants were requested to complete eight health scenarios using two search interfaces and two correctness settings: (SC) with a correct single-card, (SN) with a incorrect single-card, (MC) with multi-cards, including a correct card, and (MN) with multi-cards, where none of the cards are correct. A health card is correct when it matches the known diagnosis of the scenario (see Table 2).
Figure 2:

The user study activity flow.
Table 2:
Topic description, correct diagnosis, triage-urgency, and user query string for each health scenario.
| Topic 1: Your 12-year-old daughter had a sudden severe abdominal pain with nausea, vomiting, and diarrhea. Her body temperature is 40C. | |
| Diagnosis (Urgency): Appendicitis (Emergency) | Query: child stomach ache vomiting diarrhea temperature |
| Topic 2: Your 18-year-old brother had sever headache and fever for the last 3 days. He also became very sensitive to lights and experienced neck stiffness. | |
| Diagnosis (Urgency): Meningitis (Emergency) | Query: migraine fever neck stiffness |
| Topic 3: Your 65-year-old aunt has had pain and swelling in the right leg for 5 days. She has a history of hypertension and recently hoptialised for pneumonia. After returning home from hospital, she had begun walking, but the right leg became painful, tender, red and swollen. | |
| Diagnosis (Urgency): Deep vein thrombosis (Emergency) | Query: hypertension pain swelling leg |
| Topic 4: Your 18-month-old toddler has had a runny nose, cough and nasal congestion for a week. She also became irritable, sleeping restlessly, and not eating well. She developed a fever overnight. She attends day care and both you and your partner smoke. | |
| Diagnosis (Urgency): Acute otitis media (Non-emergency) | Query: baby fever restless smoking |
| Topic 5: Your 35 year-old aunt experienced nasal congestion for the last 15 days. She also has had facial pain and green nasal discharge for the last 12 days. She has had no fever. She is otherwise healthy, except for mild obesity. She is on no medications, except for an over-the -counter decongestant. She has no drug allergies. | |
| Diagnosis (Urgency): Acute sinusitis (Non-emergency) | Query: obese nasal congestion over a week |
| Topic 6: Your 56-year-old aunt who has a history of smoking had shortness of breath and cough for several days. She also had runny nose since 3 days ago. Further, she mentioned to has a productive cough with white sputum. She denies getting chilled or weight-loss and has not received any relief from over-the-counter cough medicine. | |
| Diagnosis (Urgency): Chronic obstructive pulmonary disease (Non-emergency) | Query: white sputum coughing smoker |
| Topic 7: Your 61 year old mother has had a runny nose and cough productive of yellow sputum for 4 days. She initially had fever as high as 38C but those have now resolved. She is otherwise healthy except for high cholesterol. She has no drug allergies. | |
| Diagnosis: Acute bronchitis (Self-care) | Query: runny nose and fever yellow sputum |
| Topic 8: Your friend, a 30-year-old man, has had a painful, swollen right eye for the past day. He experienced minor pain on the eyelid but no any history of trauma, no crusting, and no change in vision. He has no history of allergies or any eye conditions and denies the use of any new soaps, lotions, or creams. His right eye had a localised tenderness and redness. | |
| Diagnosis: Stye (Self-care) | Query: swollen red tender eye |
The user study was performed in a usability laboratory with a PC equipped with eye tracking technology. To minimise fatigue bias, we rotated the eight scenarios and the four search interfaces using a Graeco-Latin square rotation9, resulting in 32 scenario–search interface combinations. Participants were principally university students. The study received Human Research Ethics Committee clearance (#2018002115). Next, we discuss each part of the user study.
Informed consent and demographic questionnaire
After consenting to participate, each participant was given a set of instructions presenting the elements of the interface and rules for the collection of evidence to answer the scenarios. Next, a demographic questionnaire collected information on the participant’s age group, highest level of education, education background, English proficiency* and the frequency of use of Web search engines. We used the responses to determine the participant’s eligibility.
Pre-task questionnaire
After completing the demographic questionnaire, participants completed pre-task questionnaires shown in Table 1 for all eight scenarios. We used the first three items to understand participants’ background knowledge for each health scenario and items 4 to 6 (adapted from Kelly et al.10) to understand the participant’s interest and background knowledge for each health scenario.
Table 1:
Pre-task questionnaire items.
| Pre-task Questionnaire Items (options) |
| 1. What is the most probable health condition for the scenario? (open answer) |
| 2. What would you do now? (1=Self-treat, 2=Contact an health professional, 3=Use an emergency service) |
| 3. How confident are you with your answers? (1=Very not confident to 5=Very confident) |
| 4. How interested are you to learn more about the topic of this scenario? (1=Very uninterested to 5=Very interested) |
| 5. How many times have you searched for information about the topic of this scenario? (1=Never, 2=1-2 times, 3=3-4 times, 4=≥ 5 times ) |
| 6. How much do you know about the topic of this scenario? (1=Nothing, 2=Little, 3=Some, 4=A great deal) |
Search scenarios
We selected eight scenarios of the 45 standardised patient vignettes used in a survey of symptoms checkers11. The vignettes were compiled from various clinical sources such as education material for health professionals and a medical resource website. Each vignette contained age, gender, symptoms, correct diagnosis and correct category of triage urgency for a given condition. They include both common and uncommon diagnoses (based on prevalence) from three categories of triage urgency: requiring emergency care, requiring non-emergency care, and self-care appropriate. We ensured that each diagnosis in the eight selected scenarios had a matching Google health card.
Then, we created a topic description based on each vignette. A topic description contains all symptoms as reported by the patient in the vignette, excluding clinical observations (since in a real setting, the user would not have such information). We also replaced medical terms with layman terms, where appropriate (e.g., “rhinorrhea” was replaced with “runny nose” and “acetaminophen” was replaced with “paracetamol” as “paracetamol” is a more commonly known term in Australia than “acetaminophen”). Finally, we asked research students in our team lab (who have no medical background and had English as first language) to formulate a search query for each topic description. Table 2 reports the topic description, diagnosis, urgency category, and search query for each health scenario.
To complete each scenario, we asked participants to first make a diagnosis then copy and paste the condition mention — either from the snippets, linked documents, or from the health cards. This protocol allowed us to track where participants found the relevant diagnosis mention and evidence for making their health decision (i.e., they could have found it across different information objects, but they made their final decision based on the copied one). Second, we asked participants to select the urgency condition for the scenario: requires emergency care (e.g., calling 911 or immediately going to hospital), requires non-emergency care (e.g., contacting GP or nurse help line), or self-care appropriate (e.g., taking over the counter drug or home-remedy, resting, performing activities to mitigate the condition). Finally, we asked participants to rate their confidence of the responses (1=Very not confident to 5=Very confident), and the quality of the presented health card(s) with respect to three dimensions: relevancy, understandability and trustworthiness (1=[neg], 2=Partially [pos] 3=[pos]; where [neg], [pos] labels were contextualised to the items; the partial option was only shown when multi-cards were shown).
User experience questionnaire and exit questionnaire
A user experience questionnaire captured the participants’ perceived difficulty, system effectiveness, satisfaction and workload. Finally, after completing all eight health scenarios (including the user experience questionnaire), participants reported their overall experience in completing the tasks and their previous experiences in searching online for health information, with specific attention to the use of health cards. Due to space constraints, the analysis of the user experience questionnaire and exit questionnaire are out of the scope of this paper, and are left to future work.
Search Interfaces
The search interfaces (Figure 1) contained three panes: left (not shown in Figure 1), middle, and right. The left pane displayed the topic, instructions, and tasks to be completed by participants. For the search interface with a single-card (Figure 1 left), the middle pane displayed the query string (disabled so a new query could not be entered) and the top ten search results (title, url, and snippet). The right pane of a single-card interface showed the health card. For the search interface with multi-cards (Figure 1 right), we merged the middle and the right panes to display the query string, the four health cards, and the top 10 search results. We designed the snippet list and the health cards following the Google search interface as it was the most popular search engine in Australia, i.e., where this study took place; thus, participants would be accustomed to the interface.
Search Results
To obtain the search results for each health scenario, we submitted the query to the Bing Web Search API† on February 2nd, 2019 and acquired the top 50 search results. To avoid problems with possible web pages and SERP updates, as noted by Jimmy et al.12, we archived all search results and source web pages. When a participant clicked on any link in the interface (either from the results or from a health card), we presented them with the archived web page. We then identified disease or syndrome concepts in the title and the snippets of each search result using QuickUMLS13, a tool for extracting Unified Medical Language System (UMLS, version 2018AA) medical thesaurus entities from free-text. We ranked the identified health concepts (i.e., disease or syndrome) based on how many of the top 50 search results contained each concept and we kept the five most frequent health concepts. We ensured the selected five concepts contained four incorrect health concepts and one correct health concept (there could not be more than one correct health concept for a scenario). If the top five concepts were all incorrect, we exchanged the lowest ranked with the correct concept. This was so that in the multi-cards interface we could display either four incorrect or three incorrect and one correct health cards. We only considered health concepts that matched a Google health card. Table 3 lists the five cards for each health scenario. Finally, we selected the two search results with the highest rank for each health concept, to make up in total 10 search results for each health scenario, to display in the SERP The 10 search results were ordered based on ranks from Bing.
Table 3:
Health cards for each scenario. [C] indicates the correct card.
| Id | Rank 1 | Rank 2 | Rank 3 | Rank 4 | Rank 5 |
| 1 | Septicemia | Stomach flu | Influenza | food poisoning | Appendicitis [C] |
| 2 | Migraine | Meningitis [C] | Encephalitis | Hypertensive disease | Pink eye |
| 3 | Hypertensive disease | Eclampsia | Type 2 diabetes | Venous ulcer | Deep Vein Thrombosis [C] |
| 4 | Anorexia | Common Cold | Roseola | Sinusitis | Otitis Media [C] |
| 5 | Sinusitis [C] | Upper respiratory in fection | Chronic obstructive pulmonary disease |
Perianal abscess | Common Cold |
| 6 | Acute Bronchitis | Pneumonia | bronchiolitis | Cheilitis | Chronic obstructive pul- monary disease [C] |
| 7 | Upper respiratory infec tion | Bronchitis [C] | Chronic obstructive pulmonary disease |
Seasonal allergies | Common Cold |
| 8 | Blepharitis | Pink eye | Stye [C] | Chapped lips | Chalazion |
Health Cards
Health cards were acquired from the Google search engine based on Table 3. Each health card contained a title, aliases (i.e., “also called”), if any, an image, a summary tab (i.e., about), a symptoms tab, and a treatments tab. Each tab contained a URL that links to the source information for the health card. In the acquired Google health cards, the word “critical” in bold would appear in the bottom part of the card if the associated condition requires emergency medical attention (e.g. “Appendicitis”): we maintained this feature. For health cards that had no image from the Google health cards, we obtained an image from other medical web pages that discuss the same condition. We fixed the health cards height to 600px and summarised the health cards content to ensure that all information fit the height setting. This was done to provide a similar look & feel for all search interfaces in the study.
Capturing Interaction Data
Throughout the user study, we captured participants interactions with the search interfaces using the Big Brother logging service‡. Big Brother records mouse movements (including anchored to containers, e.g., enter and leave the container), clicks, scroll, page loading (start and end), cut/copy/ paste, and window’s scroll position (mainly to align and validate eye-tracking data).
We used the Tobii Pro Spectrum eye tracker to acquire eye gaze data, set to operate at the frequency of 300Hz. The eye tracker was connected to a monitor with a resolution of 1920 x 1080 pixels. The eye tracker was calibrated for each participant at the start of the study using the method described by Blignaut14. We implemented the velocity-threshold identification algorithm15 to identify fixation points. We set the velocity radius threshold to 70 pixels following the size of the eye gazing point visualisation from the Tobii Pro Eye Tracker Manager. We set the minimum fixation duration threshold to 100ms as suggested by Blignaut14. Then, we mapped the fixation points to three areas-of-Interest (AOIs): scenario description (left pane), list of snippets, and health cards.
The eye gaze data was used to determine whether participants noticed the health cards, and how much time they spent on the health card, compared to the rest of the SERP or actual result web pages. Other analyses of the collected eye tracking data was regarded as being out of scope of this paper, and left to future work.
Participants
The study was advertised widely through The University of Queensland, a large public university in Australia, as well as through Facebook groups mainly tailored to students and alumni of this university. We did not enforce participants to be university students or affiliates (but we excluded research staff), and we allowed any member of the public to take part in the study. Nevertheless, the majority of the participants were university students. The following eligibility criteria for participation in the study were set and enforced: aged 18 years or above, no specific prior medical studies, experienced with using a web search engine on a daily basis, and proficient English readers and writers. Participants were told that the study would last approximately one hour and were given a AUD$15 gift card for their participation.
Experiment Results
From 64 participants, each performing eight scenarios, we collected 512 interaction data points. This gave us enough power for statistical analysis (power < 0.90 ), statistical tests using unpaired t-test adjusted with Bonferroni correction due to multiple comparisons in an analysis. Each of the 16 sequences of scenarios-search interface pairs was performed by three participants. Participants comprised 38 females and 26 males: 31 between 18-24 y.o., 23 between 25-34 y.o., 9 between 35-44 y.o. and 1 between 45-54. Their education background was: 20 Engineering/IT, 13 Business/Economics, 13 Science, 5 Psychology, 6 peripherally health related majors with no medical or diagnostic experience (e.g., personal trainer), 7 Humanities/Social Science. We confirmed that no participant had experience in the medical field and specifically in diagnosing health conditions. The highest level of completed education was: 13 high school, 13 diploma, 18 bachelor degree, 5 graduate diploma, and 15 postgraduate degree.
Participants considered the eight scenarios as interesting and unfamiliar. Overall, the participants’ average level of interest in the scenarios was moderately high ( 3.9 with, 1=very not interesting to 5=very interesting). Further, participants had no to little knowledge of the scenarios (M = 1.88) and never or rarely searched for information related to the scenarios (M = 1.42). We found very weak to no correlation between the participants’ level of interest, prior knowledge and prior search for the scenario on all six measurements; thus these had no systematic effect on results.
Then, we investigated whether fatigue may have had a systematic effect on results. We did this by correlating the sequence of scenarios and the results from the six measurements used in RQ1. We found that there was a weak negative correlation between the scenario sequence and duration taken to complete a scenario (corr=-0.21): this may have been due to fatigue or acquired familiarity with the search tasks and interface. Further, we found very weak to no correlation between the scenario sequence and the other five measurements: health card usage rate (corr=0.02), correct diagnosis rate (corr=-0.05), correct urgency score (corr=0.06), number of page read (corr=0.04), good abandonment rate (corr=0.00), and confidence rate (corr=-0.13). This indicates that the results are comparable across scenario sequences. Next, we investigated the impact of presenting single and multi-cards on decision making behaviour.
The multi-cards interface was found to drive users’ attention toward the health cards (as opposed to the search results). When the multi-cards were shown, most participants spent more time on health cards (M = 82%) than on snippets (M = 18%). However, when only a single-card was shown, participants spent equal amounts of time on snippets and on health cards (M = 51% vs. M = 49%). These findings were observed by measuring which AOI (i.e., snippets vs. health cards) participants paid attention to when health cards were displayed. (We removed eye tracker data associated to other display areas, e.g., the instructions pane.) Since the time taken by each session varied, we normalised durations, and present results with respect to the progress in the session. Figure 3 reports the percentage of participants that paid attention to each AOI throughout the session. These findings are understandable since when the single-card is shown, there is more information to process in snippets and the display area containing the snippets is larger. On the other hand, the multi-cards occupy most of the initial display and only the top three snippets are visible without scrolling. Participants may have also found most of the information they required among the multi-cards.
Figure 3:

Percentage of participants’ that paid attention to snippets vs. health cards overtime.
Participants often considered health cards earlier in their session: There is a moderate to strong negative correlation between attention on health cards (according to eye tracking) and time point in the session when both single-card (corr=-0.50) and multi-cards (corr=-0.90) were shown. Interestingly, regardless of the declining attention overtime, we found that the attention on health cards increased at the end of the session for both interfaces. We speculate that although health cards were prioritised at the beginning of the session, participants may have felt the health cards did not contain enough information to make the final decision, and went on examining snippets throughout the SERP. Participants may have felt that information from the snippets was still not sufficient to complete the scenario, hence, they re-considered the health cards at the end of the session.
Results for RQ1: How do single and multiple health cards influence CHS users when making health decisions?
Regardless of the search interfaces, participants perceived health cards as relevant (M = 0.8203), trustworthy (M = 2.5762) and easy to understand (M = 2.703). We measured health cards’ relevance as binary where 0=not relevant and 1=relevant (Note that a health card that was considered as relevant, was not necessarily considered as correct). We speculate that participants may have considered an incorrect health card as relevant since it helped participants to rule out a condition. Trustworthiness and understandability were measured on a 1 to 3 scale (3 being most trustwothy/un- derstandable). Next, we contrast the influence of single and multiple health cards on CHS decision making based on results on the key metrics reported in Table 4.
Table 4:
The impact of single and multi cards on CHS users in making health decisions. Search interface: (SC) single correct card, (SN) single incorrect card, (MC) multi cards with a correct card, (MN) multi cards with incorrect card. The superscripts indicate statistical significance (unpaired t-test) between the result and the result from the condition associated with the superscript (lower cases refer to α < 0.05 and upper cases refer to α < 0.01 ). Higher results are better for measurements 1, 2, 5 and 6. Vice versa for measurements 3 and 4.
| Measurements | Num. Cards Shown | Correct Card Present | Search Interface | |||||
| Singlea | Multib | Yesa | Nob | SCa | SNb | MCc | MNd | |
| 1. Health cards usage | 0.3711B | 0.6875A | 0.5664 | 0.4922 | 0.4062CD | 0.3359CD | 0.7266AB | 0.6484AB |
| 2.A Correct diagnosis | 0.3789B | 0.2461A | 0.4922B | 0.1328A | 0.5781BCD | 0.1797AC | 0.4062ABD | 0.0859AC |
| 2.B Urgency score | 0.543b | 0.4453a | 0.543b | 0.4453a | 0.5977d | 0.4883 | 0.4883 | 0.4023a |
| 3. Duration (sec.) | 157 | 158 | 150 | 165 | 148 | 166 | 152 | 164 |
| 4. Num. of page opened | 2.4844B | 1.3438A | 1.7812 | 2.0469 | 2.2656Cd | 2.7031CD | 1.2969AB | 1.3906aB |
| 5. Good abandonment | 0.2344B | 0.4727A | 0.3789 | 0.3281 | 0.2578CD | 0.2109CD | 0.5AB | 0.4453AB |
| 6. Confidence | 3.6875 | 3.8359 | 3.8125 | 3.7109 | 3.7031 | 3.6719 | 3.9219 | 3.75 |
Multi-cards were preferred as a source of information. This is evident from the probability that the information in health cards was selected for making the health decisions. When multi-cards were presented, in fact, most participants preferred to select information from one of the health cards to complete the scenario (68.75% of 256 scenarios), while when the traditional single-card was presented, the organic search results were preferred more than the health card (only 37.11% of 256 scenario show information selected from the health card). This was regardless of the correctness of the health cards, and differences are strongly statistically significant.
In terms of diagnosis correctness, the single-card was more effective than the multi-cards in leading participants to identify the correct diagnosis (37.89% vs. 24.61%): these differences are strongly statistically significant. Similarly, for the level of urgency correctness, we also found that the average correctness score of the submitted urgency was significantly higher when a single-card was shown (0.543) than when multi-cards were shown (0.4453). To determine the correctness score of the submitted urgency, we computed score = 1 — (lΔurgencyl * p) where Δurgency = correct urgency — submitted urgency and the possible level of urgency are: 1= self-treat, 2= contact a health professional, and 3= use an emergency service. Lastly, p models the penalty for an incorrect urgency decision. We set the penalty for incorrect decisions so as to greatly penalise urgency decisions that put the well-being of the person at risk (e.g., decided to self-treat when the correct urgency was to use an emergency service). For this study, we set p = 1 when Δurgency > 0 and p = 0.5 when Δurgency 0.
The multi-cards interface, on average, lead participants to identify lower levels of urgency (not the correctness score). In fact, a significantly higher level of urgency was recorded when a single-card was shown (M = 1.9258) than when multi-cards were shown (M = 1.7813). Yet, the mean of the submitted level of urgency from both settings were lower than the mean of the correct level of urgency (2.125). This suggests that participants were more likely to make incorrect “what to do” decisions that could have put the person in the scenario at risk.
The interface type did not influence the session duration (no significant difference, M = 158seconds); however the multi-cards required less efforts (clicking and browsing web pages) from participants than the single-card interface (this difference is statistically significant). In fact, regardless of the presence of a correct card, users opened significantly less result pages when provided with multi-cards. Furthermore, results also show that multi-cards were more likely to lead participants to good abandonment7, compared to the single-card (difference is statistically significant). Note that good abandonment occurs when a scenario is completed without clicking on links from the SERP. Interestingly, although not statistically significant, we found that the likelihood of participants submitting a correct diagnosis was higher when good abandonment occurred (35.36% of 181 scenarios) than when clicking on links (29%). Of the 181 good abandonment occurrences, 83.43% of the decisions were made by selecting information from health cards.
Finally, we found that there were no significance differences in the level of confidence in the decisions made across all search interfaces. Interestingly, inline with Zeng et al.’s findings2, we found no correlation between the level of confidence in the user decisions and the user decisions’ correctness (both diagnosis correctness and urgency score). The majority of the diagnosis decisions (66%) submitted with (very) confidence were incorrect.
Of the six measurements, only the diagnosis decisions’ correctness suggests that the multi-cards are significantly less useful than the single-cards for assisting decision making in CHS. In fact, the highest probability of making a correct diagnosis (57.81%) and the highest average urgency correctness score (0.5977) were found when single correct cards were shown. Nevertheless, determining the single-card that is relevant to a user’s query is not trivial for a search system. A search system may identify the single-card to show by relying on the top search result; alternatively it could rely on ranking cards according to the popularity of the underlying concept within the search results. However, if a system based on a single card interface was to follow any of these two methods, then it would display the correct card for only 1 of the 8 queries in Table 2 (thus, probability of single correct card shown: P(SC) = 0.125). This is unlike for a multi-cards interface, for which the probability of correct card shown: P(MC) = 0.5. Overall, the probabilities that a correct diagnosis is made depending on the two interfaces can be compared:
The result above suggests that, if the probability of the system showing a correct health card was accounted for, then the multi-cards interface is more likely to lead to correct diagnoses.
Results for RQ2: How accurate are CHS users in appraising the correctness of health cards?
Next, we only focus on the MC interface to investigate the users ability in identifying the correct health card. We tied the correctness of the appraisal of an information object (cards, snippets) to the diagnosis decision that participants made based on the information object, which is identified by the source of information measurement. That is, a correct appraisal of a health card, for example, occurs when a correct decision is made and information from that health card is selected in their answer.
We found that the majority of participants were not able to assess the correctness of a health card within the MC interface. In fact, of all decisions taken using this interface, 39.1% were taken based on incorrect health cards (and which lead to incorrect diagnoses), while 33.6% were taken based on correct health cards. This situation is however better than when users attempted to assess snippets. In this case, in fact, the majority of decisions taken using snippets lead to incorrect diagnoses (20.3%), while only 7.0% were correct. Remember that in every SERP, a minimum of two out of 10 snippets contained the correct diagnosis.
In summary, the appraisal of health cards by users is still a challenge, but health cards are more likely to be correctly appraised than search results snippets.
Discussion
Diagnosis correctness was found to be dependent on the correctness of the presented health cards, in line with findings of Pogacar et al.16 for SERPs. Regardless of the interface (single vs. multi-cards), the correctness of the diagnosis was statistically significantly higher when a correct card was presented (0.4922) than when no correct card was presented (0.1328). The highest level of correctness was found when only the correct health card was presented.
Participants consistently underestimated the necessary level of urgency (e.g., decide to self-treat when they should have gone to the Emergency); this finding is independent of the correctness of the diagnosis. Figure 4 shows that, before searching, 51% of 512 tasks have been assigned the wrong level of urgency. Of these, 57% (43%) were underestimated (overestimated). In fact, search activities lead to a strongly significantly increase in number of correct diagnoses (4% correct diagnoses prior to search VS. 38% (single-card) and 25% (multi-cards) post search). However, the number of correctly estimated urgency levels are comparable prior (49%) and post search (50% for singlecard; 44% for multi-cards). Of the incorrectly estimated levels of urgency post search, 67% (single-card) and 76% (multi-card) of the times these were underestimated. When considering decisions for which a correct diagnosis was identified, 43% of these had an incorrect urgency level (73% of which were underestimated).
Figure 4:
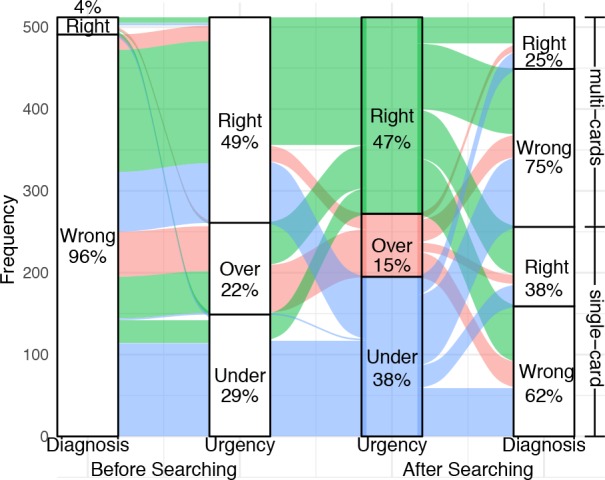
Diagnosis and urgency decisions before and after searching
Conclusions
We investigated the influence of health cards to assist decision making in consumer health search. Specifically, we presented eight health scenarios and asked 64 participants to make two decisions: determining the portrait health condition and determining the follow up action that should be taken (level of urgency). The experiment was conducted in a laboratory using two search interfaces: one with a traditional single card and one with a novel multi-cards design. Regardless of the search interfaces, health cards were perceived as relevant, trustworthy and easy to understand.
We found that showing a correct single card leads to the highest probability of identifying a correct diagnosis and level of urgency. However, determining the correct single card that is relevant to a user’s query is not trivial for a search system, and errors are made when an incorrect card is presented instead. If the probability of the system showing a correct health card is accounted for, then the multi-cards interface (which is more likely to show a correct card) leads to a higher number of correct diagnosis decisions than the single-card interface. We also found that participants consistently underestimated urgency across settings: this is of particular concerns because, while an incorrect diagnosis can be rectified by a clinician, this would not happen if users do not seek medical attention.
Furthermore, we found that the multi-cards interface enables users to make health decisions with significantly less effort than the the single card interface. When multi-cards were shown, in fact, participants clicked significantly less links, and completed significantly more scenarios without clicking on links from the SERP (i.e., good abandonment), than when they were presented with a single-card.
The multi-cards were the most preferred source of information, compared to the traditional single cards and the search results snippets. From the eye-gazing data, in fact, we found that when a single-card was shown, participants spent a comparable amount of time considering the health cards and the snippets. On the other hand, when multi-cards were shown, participants spent significantly more time considering the health cards, compared to the snippets.
Finally, we found that the appraisal of search results is still an issue, even within the multi-cards interface (MC). In fact, only 33.6% of decisions taken in this context and using the health cards lead to a correct diagnosis. However, this was better than when using snippets only (7.0%).
Our findings suggest that, from a search engine designer’s perspective, the provision of health cards (in addition to organic search results) should generally be preferred to the display of search results only. However, care should be taken in selecting the health cards to display, as their correctness influences the correctness of health decisions (both in terms of diagnosis and urgency). To address this aspect, in future work we plan to investigate and advance the effectiveness of current entity-oriented retrieval methods to identify and rank health cards.
A limitation of our study is that participants were recruited from a university campus and this may not be representative of the real diversity of users (e.g., our sample of users was biased towards young people). In future work we plan to overcome this limitation by considering other means of participant recruitment and by increasing the sample size.
Acknowledgments.
Jimmy is sponsored by the Indonesia Endowment Fund for Education (Lembaga Pengelola Dana Pendidikan / LPDP) (20151022014644). Dr. Guido Zuccon is the recipient of an Australian Research Council DECRA Research Fellowship (DE180101579) and a Google Faculty Award; both these grants funded this study.
Footnotes
We verified participants English proficiency by checking whether they: (1) spoke English as first language, or (2) achieved IELTS overall test score of at least 5.0 with a score of at least 4.5 in each of the four test components. These are the minimum English proficiency to work in Australia.
https://azure.microsoft.com/en-us/services/cognitive-services/bing-web-search-api/
https://github.com/hscells/bigbro
Figures & Table
References
- 1.Zuccon G, Koopman B, Palotti J. Diagnose this if you can. In ECIR’15. 2015 [Google Scholar]
- 2.Zeng QT, Kogan S, Plovnick RM, Crowell J, Lacroix EM, Greenes RA. Positive attitudes and failed queries: an exploration of the conundrums of consumer health information retrieval. IJMI. 2004;73(1) doi: 10.1016/j.ijmedinf.2003.12.015. [DOI] [PubMed] [Google Scholar]
- 3.Fox S, Duggan M. Health online 2013. Technical report, Pew Research Center. 2013 [Google Scholar]
- 4.Gabrilovich E. Cura te ipsum: answering symptom queries with question intent. In Second WebQA workshop, SIGIR 2016 (invited talk) 2016 [Google Scholar]
- 5.Bota H, Zhou K, Jose JM. Playing your cards right: the effect of entity cards on search behaviour and workload. In CHIIR’2016. 2016 [Google Scholar]
- 6.Spenke M, Beilken C, Berlage T. Focus: the interactive table for product comparison and selection. In UIST’96. 1996 ACM. [Google Scholar]
- 7.Li J, Huffman S, Tokuda A. Good abandonment in mobile and pc internet search. In SIGIR’09. 2009 ACM. [Google Scholar]
- 8.White RW, Horvitz E. Cyberchondria: studies of the escalation of medical concerns in web search. TOIS. 2009;27(4) [Google Scholar]
- 9.Kelly D. Methods for evaluating interactive information retrieval systems with users. FTIR. 2009;3(1–2) [Google Scholar]
- 10.Kelly D, Arguello J, Edwards A, Wu W. Development and evaluation of search tasks for iir experiments using a cognitive complexity framework. In ICTIR’15. 2015 [Google Scholar]
- 11.Semigran HL, Linder JA, Gidengil C, Mehrotra A. Evaluation of symptom checkers for self diagnosis and triage: audit study. BMJ. 2015;351 doi: 10.1136/bmj.h3480. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 12.Jimmy, Zuccon G, Demartini G. On the volatility of commercial search engines and its impact on information retrieval research. In SIGIR’18. 2018 [Google Scholar]
- 13.Soldaini L, Goharian N. Quickumls: a fast, unsupervised approach for medical concept extraction. In MedIR workshop, SIGIR. 2016 [Google Scholar]
- 14.Blignaut P. Fixation identification: the optimum threshold for a dispersion algorithm. Attention, Perception, & Psychophysics. 2009;71(4) doi: 10.3758/APP.71.4.881. [DOI] [PubMed] [Google Scholar]
- 15.Salvucci DD G JH. Identifying fixations and saccades in eye-tracking protocols. In ETRA’00. 2000 [Google Scholar]
- 16.Frances A Pogacar, Ghenai Amira, Smucker Mark D, Clarke Charles LA. The positive and negative influence of search results on people’s decisions about the efficacy of medical treatments. ICTIR’17. 2017 ACM. [Google Scholar]