

Abstract
Virus replication requires specific interactions with host cells. The replication cycle begins with attachment of viral proteins to host cell receptors. The presence or absence of receptors is an important factor in determining if the cell is permissive for infection. The next step in the virus replication cycle is transfer of the genome into cytosol or nucleoplasm. Some viruses transport just their nucleic acid genomes into the cell while others deliver the entire virion. Once in the cell, virion proteins and genome interact with a variety of cell proteins, nucleic acids, and membranes. Productive replication requires synthesis of viral mRNAs, protein, and genomes. The details of these processes vary widely. However, to be successful a virus must be able to compete with host cell for building materials. For example, as the cell is constantly synthesizing proteins, viral mRNAs must be able to redirect ribosomes to their own mRNAs. Some viruses can shut down cellular transcription and translation to redirect those processes to the production of viral proteins. In contrast DNA viruses have developed methods to induce cell DNA replication and/or cell division to obtain materials necessary for genome synthesis. Viruses pack a lot of information into their relatively small genomes. Most do not have the complex promoters that drive cell transcription nor do they have long noncoding introns in their genes. Viruses that replicate in the nucleus often use alternative splicing to generate families of related mRNAs from a single precursor transcript. In other cases a single transcript may be used to produce multiple proteins by ribosome-mediated processes such as leaky scanning, stop codon suppression, and frame shifting. Once viral building blocks have been synthesized, new virions are assembled and must leave the cell. Again, the details of these processes can vary widely. Some of the simplest viruses can assemble in a test tube, from purified capsid proteins and genomes. More complex viruses use a variety of cell proteins and structures for assembly and release.
Keywords: Virus attachment, virus uncoating, endocytosis, membrane fusion, virus maturation, polarized cells, ribosomal frame-shifting, RNA-dependent RNA polymerase, reverse transcriptase
After studying this chapter, you should be able to:
-
•
List conditions that impact virus attachment.
-
•
Explain how to set up a synchronized infection in the laboratory.
-
•
Define “penetration” and “uncoating” as regards the virus replication cycle.
-
•
Describe the cellular machinery that viruses use to move through the cell.
-
•
Describe the general structure of a eukaryotic gene, including definitions of promoter, intron, and exon.
-
•
Explain the differences between DNA-dependent DNA polymerases, RNA-dependent RNA polymerases (RdRp), and reverse transcriptase (RT).
-
•
Explain why DNA virus replication is often linked to cell cycle.
This chapter examines the major steps in virus replication within the context of cellular structures and processes. The emphasis is on virus interactions with eukaryotic, primarily animal, cells. Recall that the major steps in virus replication are: (1) attachment, (2) penetration and uncoating, (3) synthesis of viral genomes and proteins, (4) assembly of new virions, (5) virion release and maturation.
Virus Interactions with the Cell
The Extracellular Space
Most animal cells are embedded in an extracellular matrix that helps form the architecture of tissues and organs. Much of the extracellular matrix is proteinaceous in nature; however, in the case of epithelial cells, the plasma membrane (PM) is surrounded by a coat of polysaccharides called the glycocalyx. Thus there are molecules outside of the cell that can interact with infectious agents such as viruses, before they reach the plasma membrane (PM). For example, the glycocalyx can serve as a barrier, but some viruses use the glycocalyx to their advantage by binding to its polysaccharides.
The Plasma Membrane
The PM is both a barrier to, and required for, virus attachment and entry. The PM is a selectively permeable lipid bilayer that contains many proteins; it is a complex and dynamic structure. Small molecules such as carbon dioxide and oxygen cross the PM by diffusion. Sugars and amino acids cross the PM using protein channels or transporters. Larger molecules must be endocytosed in order to enter the cell. PM-associated proteins include receptors, signaling molecules, enzymes, and adherence proteins. As shown in Fig. 3.1 , some proteins associated with the PM have cytoplasmic, membrane, and extracellular domains while others are embedded entirely with the bilayer. The proteins in the PM are mobile; they move laterally through the membrane, can reorganize and form complexes as the result of signaling. PM proteins are often glycosylated (carbohydrate chains are attached to the protein backbone). The lipids of the outer leaflet of the PM can also be glycosylated. Finally, the lipids within the PM not homogeneous; cholesterol can be found in discrete regions or microdomains called “rafts.” Specific proteins are associated with these lipid rafts.
Figure 3.1.
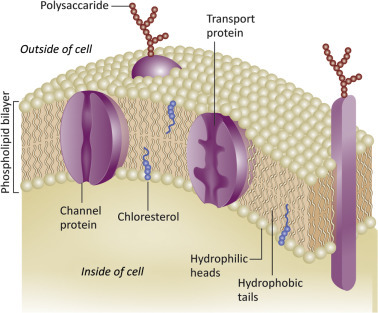
The PM is a selectively permeable lipid bilayer. Proteins associated with the PM include receptors, signaling molecules, enzymes, and adherence proteins.
Attachment Occurs at the Plasma Membrane
The first step in the virus replication cycle is attachment to PM-associated molecules. The process requires the interactions of receptor molecules on the host cell with attachment proteins on the infecting virus. Receptors are often proteins, but viruses also bind to the sugar residues found on glycoproteins or glycolipids on the cell surface. Influenza virus is an example of a virus that attaches to carbohydrate receptors. Naked (unenveloped) virions use capsid proteins for attachment while enveloped viruses use an envelope-associated protein.
Attachment is achieved by interactions of small subdomains of molecules. Interaction faces usually comprise just a few amino acids or sugar residues, and the interactions are usually electrostatic in nature. Thus the initial contacts between virus and receptor are weak and reversible. However, as multiple viral attachment proteins interact with multiple receptor molecules, binding becomes strong and irreversible. Thus it follows that cells with a higher density or number of receptors are more readily infected (Fig. 3.2 ). Because attachment is electrostatic, it can be affected by pH, ion concentration, and types of ions in the extracellular space. When we propagate viruses in the laboratory, the type of media used, and its pH, are important. Attachment does not require energy and can take place in the cold (4°C). A virus infection can be synchronized by allowing attachment to occur in the cold. Once sufficient time has passed the culture is quickly warmed up and the attached virions penetrate at the same time.
Figure 3.2.
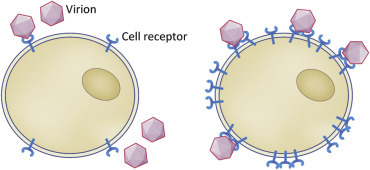
Receptor density and attachment. Cells with a higher density or number of receptors are more readily infected.
The presence or absence of receptors is a major host range determinant, as absence of receptors excludes viruses from a cell. Different cells within an organism display different surface molecules, thus one cell or tissue type may be permissive for virus attachment while others are not. Epithelial cells are an example of polarized cells. They display different molecules on their apical (facing the lumen) and basolateral (facing the inside) surfaces (Fig. 3.3 ). Receptor molecules may be expressed on only one surface of the polarized cell, such that passage through those cells is a one-way process.
Figure 3.3.
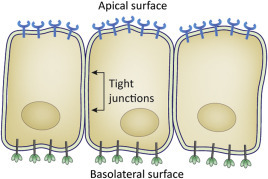
Polarized cells have discrete apical and basolateral surfaces. Apical surfaces face the outside (for example, the airspace in the lung or the lumen of the intestine) while basolateral surfaces face the inside of the body. Polarized cells display distinct proteins on their apical versus basolateral sides. Materials, such as viruses, can be transported directionally through polarized cells.
The receptors for many human and animal pathogens have been identified, but it is important to note that viruses adapted to cell cultures may use different receptors than those used during a natural infection. Even within an organism, a virus may utilize a variety of receptors. Attachment can also require interaction of the virus with more than one type of receptor molecule. An example is human immunodeficiency virus (HIV). The surface unit (SU) glycoprotein of HIV (also called gp120) attaches to the CD4 protein present on helper T-lymphocytes, macrophages, and dendritic cells. After initial interactions between SU and CD4, SU then binds to a second receptor, one of several chemokine receptors on the cell surface. The chemokine receptors are the coreceptors for HIV (Chapter 37: Replication and Pathogenesis of Human Immunodeficiency Virus).
Virus Penetration and Uncoating at the Plasma Membrane
Once a virus attaches to a cell, the next critical step is delivery of the viral genome into the cytoplasm or nucleoplasm. Different viruses exploit different strategies to accomplish this. The RNA genome of a picornavirus crosses the PM through a channel or pore formed by capsid proteins (Fig. 3.4 ). In the case of the reoviruses, the whole capsid crosses a channel through the PM.
Figure 3.4.
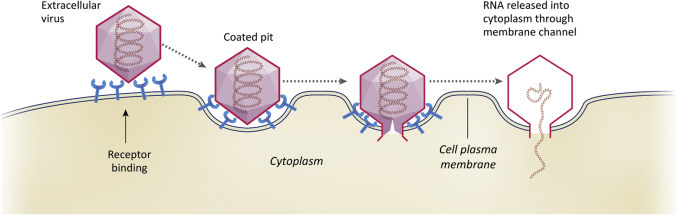
Illustration depicting the penetration of a viral genome across the PM. In this example the RNA genome of a picornavirus crosses the PM through a channel or pore formed by capsid proteins.
Enveloped viruses must transport their genomes across two sets of membranes, both the viral envelope and a cell membrane. The process sometimes occurs at the PM (Fig. 3.5 ). Unfavorable energetic barriers must be overcome to bring the two membranes into close enough proximity to allow formation of a pore (Box 3.1 ). If fusion occurs at the PM, viral envelope proteins remain on the cell surface.
Figure 3.5.
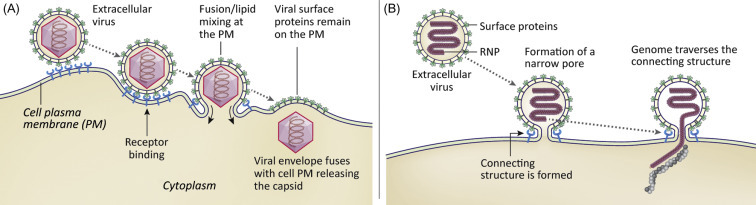
Illustration depicting the penetration of a viral genome after fusion of an enveloped virus with the PM. Panel A shows a process in which the viral envelope and PM become contiguous. Panel B shows a process in which a small pore is formed through the PM.
Box 3.1. Fusion Proteins.
Fusion of a viral membrane to a cellular membrane requires that the high kinetic barrier to membrane fusion be breached. Fusion proteins serve as the catalysts in this process. A hallmark of fusion proteins is that they undergo structural changes as a result of attachment and/or changes in pH (during endocytosis). Often these structural changes expose a hydrophobic segment called the fusion loop or fusion peptide whose function is to engage the target cell membrane. The fusion protein becomes a bridge between the two membranes, drawing them together (see Fig. 36.3). Viral fusion proteins are suicide enzymes that function only once.
Virus Penetration and Uncoating From Membrane Bound Vesicles
Many viruses exploit cell processes designed to bring cargo into cells via membrane bound vesicles. These processes include phagocytosis, macropinocytosis, and receptor-mediated endocytosis. There are different mechanisms by which endocytosis can occur, such as clatherin-dependent or caveolin-1-dependent pathways (Fig. 3.6 ). The environment inside of endosomes is distinct from the cell cytosol. Of importance to our discussion of viruses, endosomes become acidified as they mature and low pH often triggers penetration. As mentioned above, some picornaviruses form membrane channels at the PM upon attachment. However other picornaviruses are endocytosed, and low pH triggers the capsid rearrangements that form membrane channels. Enveloped viruses often use low pH to trigger rearrangement of their surface proteins, with the effect of releasing previously hidden hydrophobic (fusion) domains.
Figure 3.6.

Cellular uptake of macromolecules by phagocytosis, macropinocytosis, and various endocytic pathways.
Membrane Fusion
Membrane fusion results in lipid mixing or formation of a pore through both the viral envelope and a host cell membrane (Fig. 3.7 ). Key to the process, the viral envelope must be in very close proximity to the target cell membrane. Viruses use attachment and fusion proteins to accomplish this. To initiate fusion, hydrophobic portions of a viral protein are inserted into the target cell membrane. This triggers protein rearrangements that pull the two membranes into close proximity (within a few Å). Some viruses use discrete domains of a single protein to accomplish attachment and fusion. Influenza viruses have attachment and hydrophobic fusion domains in different regions of a single molecule, the hemagglutinin (HA) protein. Other viruses (for example, the paramyxoviruses) encode distinct attachment and fusion proteins. After fusion the viral nucleocapsids or cores are released into the cytosol or nucleoplasm (Fig. 3.8 ).
Figure 3.7.
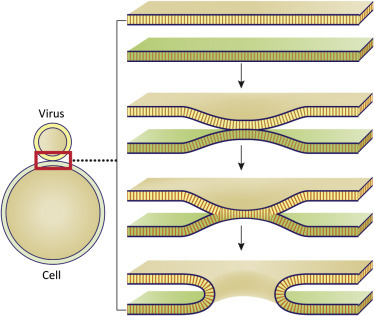
General illustration of the membrane fusion process. Membrane fusion or pore formation require membranes to be in very close proximity.
Figure 3.8.

Many viruses, both enveloped and unenveloped, are brought into cells by endocytosis. The low pH environment in the endosome triggers molecular rearrangements of capsid or envelope proteins. In this example an enveloped virus is fusing with an endosomal membrane to release the capsid into the cytosol.
Uncoating the Genome
Uncoating is the removal of viral proteins from the genome to allow for translation, transcription, and replication. For some viruses the processes of penetration and uncoating cannot be separated, but in other cases, uncoating requires additional steps. Some viral genomes are uncoated within the cytosol while in other cases uncoating occurs in the nucleus. Reoviruses are an interesting exception, their genomes are never uncoated but instead are transcribed within the capsid; mRNAs are released to the cytosol through pores in the capsid (Chapter 26: Family Reoviridae).
Cytoskeleton
Movement Through the Cell, Interactions With the Cytoskeleton
The cytosol is a dense network of filaments, organelles, and molecular assemblies (see Box 3.2 ). It is a highly viscous environment that restricts diffusion of molecules larger than 500 kDa or particles larger than 20 nm. (Recall that most viruses are larger than 20 nm.) Cells have evolved highly regulated processes to move and sort cargo in order to maintain the highly organized and complex environment of the cell. These processes can potentially inhibit virus movement and replication but are often exploited by viruses to enhance their replication. For example, viruses use actin filaments and microtubules to move through the cell as well as from cell to cell. To aid in their movement, viruses highjack the cellular molecular motors associated with actin filaments and microtubules. In fact specific interactions with the cell cytoskeleton are important in every step of the virus replication cycle, from attachment to replication to assembly to release.
Box 3.2. Cell Cytoskeleton.
The cytoskeleton is a dynamic and interconnected network of filaments. There are three major types of filaments. Actin filaments control cell shape, locomotion, and cytokinesis (separation of daughter cells after cell division). Intermediate filaments provide mechanical strength. Microtubules function in intracellular transport and chromosome segregation. Microtubules also control the position of organelles. The cytoskeleton is not static. It is constantly reorganizing via the assembly and disassembly of filaments. Regulation of the cytoskeleton is quite complex, requiring many molecular players. Molecular motors are key to moving materials along filaments. Members of the myosin superfamily of proteins are actin-based motors. For example, myosins facilitate movement of cargo along tracks of actin filaments and also move actin filaments relative to the PM.
Virus Assembly
Viruses assemble in the infected cell when the local concentrations of structural polypeptides and genomes are sufficiently high. Sometimes assembly takes place in discrete regions of the cell called “virus factories” containing high concentrations of capsid proteins and genomes. Cytoskeletal components and cellular organelles are often intimately involved in both virus assembly and release, although some very simple viruses can be assembled (albeit inefficiently) in the test tube.
There are two general ways to build a simple icosahedral capsid. In one scenario, capsid proteins form an empty shell into which the genome is inserted. Picornaviruses use this strategy and empty capsids can be seen in virus preparations. Empty particles are less dense than complete virions and can be separated from them by density centrifugation. In the second scenario, an encapsidation signal on the genome interacts with one or more capsid proteins, followed by recruitment of additional capsid proteins.
Most animal viruses with helical nucleocapsids are RNA viruses. They usually encode a basic protein (often called the nucleocapsid (N) protein) that interacts with viral RNA. Initial interactions are specific such that cellular RNAs are not packaged indiscriminately. Genome packaging signals often include sequences at both the 5′ and 3′ ends of the viral genomic RNA. This is a mechanism whereby genomic RNA can be “distinguished” from subgenomic mRNAs. In some cases the N protein surrounds the viral RNA, but in others (i.e., influenza viruses) it appears that the RNA winds around a protein core.
Virion Release
Mechanisms for virus release from cells include cell death (lysis), budding, and exocytosis. The cytoskeleton can present a barrier to release and some unenveloped viruses encode proteins that disrupt the cytoskeleton to allow dispersal of newly assembled virions. Enveloped viruses obtain their envelope by a budding process. A viral nucleocapsid interacts with a region of host cell membrane into which glycosylated viral envelope proteins have been inserted. The nucleocapsid “finds” the proper place to bud from the cell by forming specific interactions with the cytoplasmic tail(s) of the envelope proteins. Cell membranes that can serve as sites of budding include the PM, endosomal, and nuclear membranes. Viruses released by budding from the PM (for example, the HIV) are released individually (Fig. 3.9 ). Viruses with envelopes derived from endosomal or nuclear membranes may bud into vesicles that traffic to the PM and fuse, releasing their cargo of virions by a process called exocytosis (Fig. 3.10 ).
Figure 3.9.
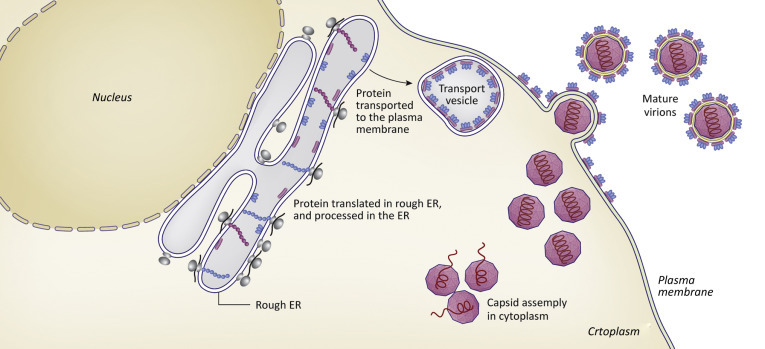
Illustration showing the process of assembly and budding of a virus particle from the PM.
Figure 3.10.

Illustration showing release of enveloped virions by exocytosis.
It is easy to assume that release always results in free virions escaping into the extracellular environment. And while this certainly does happen, virions can also be transmitted directly from one cell to another. Vaccinia virus (family Poxviridae) uses actin tails to move between cells. We can visualize this process using cells with fluorescent-tagged actin and virions tagged with a different fluorescent tag (Fig. 3.11 ).
Figure 3.11.

Actin projections (green) extending from a vaccinia virus infected cell. There is virus particle (red) at the tip of each projection.
From Figure 6 (panel F) of Cudmore, S., Reckmann, I., Griffiths, G., Way, M. 1996. Vaccinia virus: a model system for actin-membrane interactions. J. Cell Sci. 109, 1739–1747.
Virion Maturation
Maturation cleavages of virion proteins may occur after particle release, and these may be required to produce infectious virus (Fig. 3.9). Why do some viruses mature after release from a cell? The virion has two very different roles in the replication cycle: To assemble under conditions of favorable energy and to disassemble during the processes of attachment and penetration into a new cell. Maturation cleavages prepare the newly released virion to attach to a new cell and disassemble. For example, picornaviruses include in their capsids, an uncleaved precursor protein. The precursor is cleaved within the assembled capsid. If this cleavage is blocked, the capsid is unable to deliver the genome to a new cell. Retroviruses require a set of cleavages that convert long precursor polyproteins into individual structural proteins. The cleavages are made by a retroviral protease (Chapter 36: Family Retroviridae) and inhibitors of HIV protease activity are powerful antiviral drugs. Protease inhibitors are small molecules that interact with the HIV protease to prevent it from cleaving the polyproteins in the immature particle. For many enveloped viruses, maturation involves cleavage of glycoproteins that fuse the viral envelope to a host cell membrane.
Amplification of Viral Proteins and Nucleic Acids in the Context of the Infected Cell
After penetration and uncoating have been achieved, the next events in the viral replication cycle are the synthesis (amplification) of viral proteins and genomes. In the absence of successful amplification, the proteins and genomes needed to assemble new virions are not made. To better appreciate the processes used by viruses to synthesize mRNAs, genomes, and proteins let us review some of the most basic aspects of these processes in the host cell.
A Short Review of Transcription in the Eukaryotic Host Cell
Synthesis of cellular mRNAs (transcription) occurs in the nucleus of the eukaryotic cell. The enzyme that synthesizes mRNAs is RNA polymerase II (RNA polII). RNA polII is a DNA-dependent RNA polymerase (an enzyme that uses DNA as the template for synthesis of an RNA product). RNA polII forms protein complexes with other cellular proteins in order to be directed to specific genes. The regions of a eukaryotic gene that interact with the transcription complex are the promoter/enhancer sequences (Fig. 3.12 ). These can be quite long and complex as they allow graded cell responses to a variety of stimuli. The promoter/enhancer region of a gene defines the conditions under which a gene product will be synthesized. The promoter-enhancer sequences themselves are not transcribed.
Figure 3.12.

Organization of a eukaryotic gene showing a promoter region followed by introns and exons. The primary transcript is produced, followed by splicing to remove introns. After export to the cytoplasm, the capped and polyadenylated transcript is translated to produce the protein product of the gene.
Shortly after initiation of a transcript, the RNA is modified by addition of a 5′-methyl guanosine “cap.” The cap protects the 5′ end of the mRNA from degradation and also serves as the assembly site of the ribosome. Most eukaryotic genes have long regions, called introns that are not found in the mature mRNA. Instead, they are removed by a process called RNA splicing. Splicing is accomplished by an assemblies of small RNAs and proteins called the spliceosomes. Recall that the regions of the mRNA that are not removed (the protein coding regions) are called exons.
An additional modification to the eukaryotic transcript is addition of nontemplated adenosines near the 3′ end, to produce the poly(A) tail. A short RNA sequence defines the polyA addition site. The transcript is cleaved at polyA addition site, followed by addition of the polyA tail (by an enzyme called polyA polymerase). The polyA tail controls degradation of the mRNA from the 3′ end and is also involved in initiating translation. The mature mRNA is now ready to be transported from the nucleus. In summary (Fig. 3.12):
-
•
Many eukaryotic genes have nontranscribed promoter/enhancer sequences.
-
•
The 5′ end of the mRNA is capped.
-
•
Many eukaryotic genes have introns that are removed from RNA by splicing.
-
•
The 3′ ends of mRNAs are cleaved and polyadenylated.
-
•
Capped, polyadenylated, spliced mRNAs are transported out of the nucleus.
-
•
The open reading frame or coding region of the mRNA is usually flanked by 5′ and 3′ nontranslated regions.
-
•
For the most part, one mRNA encodes one protein.
Transcription of Viral mRNAs
Do viruses follow the rules of gene organization, transcription and RNA processing used by the eukaryotic cell? Some do, but many do not. As we will see throughout this text, viruses use a variety of unique strategies to control synthesis of their mRNAs, as the abundance of an mRNA can directly impact the amount of protein product produced. Why have some viruses adopted unique strategies?
-
•
The coding capacity of many viruses is small because their genomes are small (compared to the host cell genome), thus they cannot have long complex promoter/enhancer regions and/or long nontranscribed introns.
-
•
Most RNA viruses transcribe their mRNAs in the cell cytoplasm, therefore have no access to spliceosomes or cellular RNA polII.
-
•
Many viruses inhibit host cell transcription and/or translation, therefore must use alternatives to “normal” cellular processes to produce viral proteins.
-
•
An infecting virus usually brings one copy of its genome into a very crowded cell. Viral mRNA synthesis and protein synthesis must be very efficient in order to compete for building materials.
Thus the organization and expression strategies of viral genes may differ from host genes:
-
•
Many viral genes have no introns.
-
•
Some viral mRNAs do not have 5′ caps.
-
•
Some viral mRNAs do not have poly(A) tails.
-
•
Some viral mRNAs have overlapping open reading frames such that more than one type of protein can be produced from a single transcript.
-
•
Viral transcripts with introns can be alternatively spliced to generate multiple, different mRNAs. (Obviously these must be viruses that are replicating in cell nucleus where the splicing machinery is present.)
-
•
Some viral mRNAs are not exact copies of the genome. In a process called RNA editing or pseudotemplated transcription, the polymerases of a few RNA viruses add nucleotides not present in the genome sequence. The term pseudotemplated suggests that there are some specific signals in the genome that instruct the addition of these extra residues.
A Short Review of Translation in the Eukaryotic Host Cell
Let us review a few basics of translation in the cell, focusing on initial interactions of the translation apparatus with the mRNA. Both the 5′ cap and the 3′ poly(A) tail are involved in translation initiation. The poly(A) tail is bound by polyA-binding protein (PAPB). A complex of initiation proteins (eIF4F complex) binds to the 5′ cap (Fig. 3.13 ) and interacts with PAPB. This is followed by association with a preinitiation complex that includes the 40S ribosomal subunit, tRNAmet, and other initiation factors. The preinitiation complex moves or scans along the untranslated region of the mRNA until it encounters an AUG codon with the appropriate surrounding sequences (Kozac sequence). Now the 60S subunit binds at the AUG codon to generate the 80S initiation complex with tRNAmet in the A site. A second tRNA enters the P site and a peptide bond is formed. The ribosome moves along the mRNA (translocates) one codon (3 nt) at a time. At the end of an open reading frame, a ribosome will encounter stop codons that trigger termination. In eukaryotes transcription termination is facilitated by two release factors (eRF1 and eRF3). eRF1 recognizes stop codons (UAA, UGA, or UAG) in the A site.
Figure 3.13.
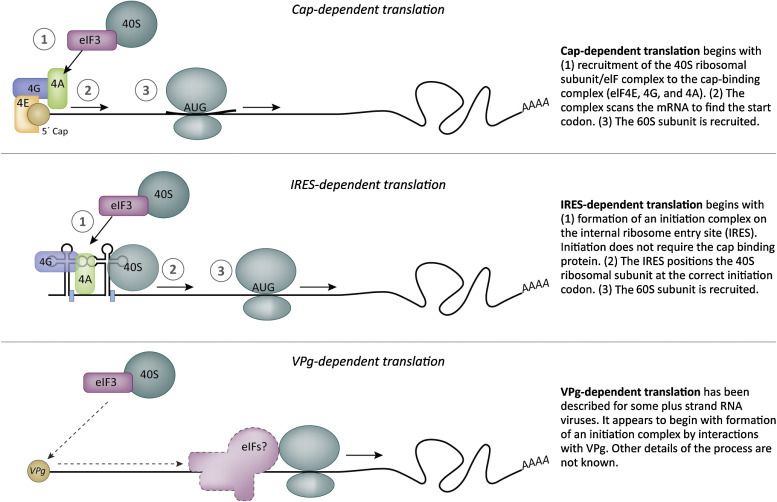
Methods of translation initiation. Most cellular transcripts have a 5′ cap and a 3′ poly(A) sequence that are key players in ribosome assembly. Many types of viruses adhere to this host cell strategy. However, several positive strand RNA viruses use cap-independent translation. Picornaviruses and some flaviviruses use an RNA structure called the internal ribosome entry site (IRES) to direct ribosome assembly. Another strategy is ribosome assembly directed by a viral protein (VpG) covalently linked to an RNA transcript (see Ch. 12: Family Caliciviridae).
Translation of Viral Proteins
We noted above that most eukaryotic mRNAs code for a single protein. But one hallmark of viruses is their ability to efficiently exploit a small genome. So it is not uncommon for individual viral mRNAs to encode different versions of a protein, or two or more completely different proteins. Common strategies are illustrated in Fig. 3.14 and include:
-
•
Use of alternative start codons, a process often called leaky scanning.
-
•
Suppression of stop codons to produce a longer protein product.
-
•
Frame-shifting moves a ribosome to another reading frame to produce a longer protein product.
-
•
Termination-reinitiation or stop-start.
Figure 3.14.

Viruses use a number of strategies to produce more than one protein from a transcript.
These mechanisms all function at the level of the ribosome and serve to control relative amounts of protein products. For example, use of alternate start codons will result in production of a greater amount of the protein with the best Kozak sequence and lesser amounts of proteins that initiate at alternative start codons. In the case of ribosomal frame-shifting, folding of the mRNA into structures called pseudoknots modifies the translation process (Fig. 3.15 ) (See Box 3.3 ).
Figure 3.15.

An RNA pseudo-knot directs ribosomal frame shifting.
Box 3.3. Ribosomal Frame-Shifting and Stop Codon Suppression.
Ribosomal frame-shifting is common among retroviruses and coronaviruses. It is a process whereby the ribosome moves from one reading frame (protein 1) to a second reading frame (protein 2). Ribosomes frame-shift when they stall during protein synthesis. They stall at specific sites on viral mRNAs called “pseudoknots.” The pseudoknot forms as a result of base pairing within the mRNA. In most cases the pseudoknot causes frame-shifting about 20% of the time. A surprisingly efficient process!
Suppression of a stop codon is a process whereby a ribosome fails to terminate protein synthesis at a stop codon. Most eukaryotic genes terminate with multiple stop codons, but if there is a single stop codon, an amino acid can be inserted into the growing polypeptide and translation continues. This is estimated to occur as often as 20% of the time. Thus a protein coding sequence downstream of a pseudoknot or a single stop codon will be synthesized at a lower quantity (~20%) than the protein encoded when the signal is ignored (~80% of the time).
Many RNA viruses produce polyproteins that are cleaved by viral proteases to generate smaller, functional proteins (Fig. 3.16 ). The process is exemplified by picornaviruses. The picornaviral genome contains a single, long open reading frame that is translated to produce a large precursor polyprotein. Protease domains within the polyprotein are enzymatically active immediately after being translated and work to quickly cleave the large precursor into mature products. The proteolytic cleavages occur in an ordered sequence. Intermediate cleavage products may have activities distinct from those of the final cleavage products.
Figure 3.16.

Proteolytic cleavage of a viral polyprotein.
As viruses must use the host cell translational apparatus, their viral mRNAs must complete with cellular mRNAs for ribosomes and amino acids. One way to compete is simply to inhibit synthesis of host cell transcription and/or translation. (This also limits the ability of the cell to respond to infection.) Another strategy is to efficiently compete for the translational machinery. Some viruses use a combination of both methods. But how can a virus inhibit translation of host proteins without effecting viral protein synthesis? An example is provided in Box 3.4 .
Box 3.4. Poliovirus (PV) and Cap-Independent Translation.
PV inhibits cap-dependent translation in the infected host cell. It does so by cleaving the eukaryotic initiation factor 4G (eIF-4G). A function of eIF-4G is to interact with both the 5′-cap on the mRNA and the 40S ribosomal subunit, thereby bringing mRNA and ribosome together. A protease encoded by PV cuts eIF-4G into two pieces. One piece binds to eIF-3 on the 40S subunit and the other piece binds to the cap-binding protein eIF-4E. As the two business ends of eIF-4G are now separate polypeptides, the 40S subunit cannot bind the cap. PV RNA is not capped so the cleavage does not interfere with viral protein synthesis. PV uses a cap-independent mechanism for ribosome assembly onto its mRNA.
Synthesis of Viral Genomes
As noted in Chapter 1, Introduction to Animal Viruses, viruses can be placed into one of three major groups based on genome type/genome replication strategy. The groups are (1) DNA viruses, (2) RNA viruses, and (3) viruses that use RT.
There are many families of DNA viruses. The genomes of DNA viruses range from 3000 nt to well over 1 million base pairs. Some DNA viruses have circular genomes, others linear. But all DNA viruses use a DNA-dependent DNA polymerase to synthesize additional genome copies. Some DNA viruses use a cellular DNA polymerase but others encode their own DNA polymerases for genome synthesis. There is also obviously a need for a sufficient pool of dNTPs. Eukaryotic DNA synthesis is a highly regulated process. Some types of animal cells divide regularly (for example, epithelial cells) but others are quiescent, seldom dividing except in response to damage (for example, hepatocytes (liver cells)). Nondividing cells have limited DNA replication machinery and very limited dNTP pools. Strict regulation of cell division causes a problem for some DNA viruses. Some can only replicate in mitotically active cells. But others can stimulate quiescent cells to divide (see Chapter 28: Introduction to DNA Viruses). Some large DNA viruses encode enzymes required for dNTP synthesis, thereby increasing the cellular pools of these building blocks in nondividing cells. Animal DNA viruses (with the exception of the poxviruses) replicate their genomes in the nucleus.
RNA viruses were originally defined as viruses with an RNA genome packaged within the virion. But more critical to the definition is that the RNA genome found in the virion is used as the template for the synthesis of additional RNA genomes. Animal RNA viruses encode an RdRp for genome synthesis. The RdRp is also called the “replicase.” The RdRp is used both for genome synthesis and transcription. The RNA viruses never use a host-encoded RNA polymerase to replicate their genomes. As all living cells continuously produce RNAs for “housekeeping” purposes, the synthesis of viral RNA genomes can occur in dividing or nondividing cells.
Members of the families Retroviridae and Hepadnaviridae use a polymerase called reverse transcriptase (RT) to synthesize their genomes. Retroviruses package an RNA genome while hepadnaviruses package a DNA genome. Both virus families use the enzyme RT to make a DNA copy of an RNA molecule. The RNA genome of a reverse transcribing virus is an mRNA, transcribed from the viral DNA genome by host cell RNA polII. (In the case of retroviruses the DNA form of the viral genome is integrated into the cell DNA)
In this chapter we have learned that:
-
•
Virus attachment requires specific host receptors and the process is influenced by receptor density, pH, and ions.
-
•
Attachment does not require energy, thus can occur in the cold. Adding virions to cells in the cold is a way to synchronize a viral infection. Penetration is an energy-requiring step that occurs only after the culture has been warmed to physiologic temperature (37°C for most animal cells).
-
•
In order to penetrate into the host cell, a virion or genome must cross a lipid membrane. This can occur at the PM or after endocytosis.
-
•
Uncoating is a process that can occur during or after penetration. Uncoating provides the viral genome access to cytoplasm or nucleoplasm.
-
•
Enveloped viruses use fusion proteins to overcome the kinetic barriers to membrane fusion. Fusion proteins are suicide enzymes that catalyze membrane fusion.
-
•
The cell has a complex and dynamic cytoskeletal system that is often highjacked by viruses.
-
•
Eukaryotic genes are large. They are preceded by untranscribed promoter regions and most have large introns. RNA polII transcribes cellular mRNAs. Cellular mRNAs are highly processed in the nucleus, undergoing capping, splicing (removal of introns), and polyadenylation.
-
•
Viruses maximize use of small genomes by minimizing the size of promoters and encoding multiple proteins from a single mRNA. Some viruses make extensive use of alternative splicing. Some viruses modulate the process of translation by inducing ribosomal frame-shifting and suppression of stop codons.
-
•
DNA viruses use cellular or virally encoded DNA-dependent DNA polymerases for genome replication. Most DNA viruses require that the cellular DNA synthesis machinery be active to provide adequate dNTP pools.
-
•
RNA viruses use virally encoded RdRp to transcribe mRNAs and to replicate genomes. RNA viruses can replicate in dividing or nondividing cells.