

Abstract
The coverage problem is a fundamental problem for almost all applications in wireless sensor networks (WSNs). Many applications even impose the requirement of multilevel (k) coverage of the region of interest (ROI). In this paper, we consider WSNs with uncertain properties. More precisely, we consider WSNs under the probabilistic sensing model, in which the detection probability of a sensor node decays as the distance between the target and the sensor node increases. The difficulty we encountered is that there is no unified definition of k-coverage under the probabilistic sensing model. We overcome this difficulty by proposing a “reasonable” definition of k-coverage under such a model. We propose a sensor deployment scheme that uses less number of deployed sensor nodes while ensuring good coverage qualities so that (i) the resultant WSN is connected and (ii) the detection probability satisfies a predefined threshold , where . Our scheme uses a novel “zone 1 and zone 1–2” strategy, where zone 1 and zone 2 are a sensor node’s sensing regions that have the highest and the second highest detection probability, respectively, and zone 1–2 is the union of zones 1 and 2. The experimental results demonstrate the effectiveness of our scheme.
Keywords: sensor deployment, sensor coverage problem, network planning, probabilistic sensing model, wireless sensor network
1. Introduction
A wireless sensor network (WSN) has various applications in health-care, smart home, security, environmental exploration, and the military [1,2]. A sensor node (or simply node) is the basic component of a WSN. A WSN usually consists of numerous nodes deployed in a region of interest (ROI). Two nodes can communicate with each other if each is within the transmission range of the other, in which case we say that there is a link between them or that they are neighbors. Each node is able to collect data and process information and communicate with neighboring nodes.
Among various issues in WSNs, the coverage problem and the connectivity problem have been regarded as crucial foundations because many applications rely on them. Surveys for the coverage problem can be found in [3,4]. A good sensor deployment strategy should consider both coverage and connectivity. Sensor deployment not only determines the cost of constructing the network but also affects how well the given ROI will be monitored. This paper assumes that each node’s sensing region is of a disk shape (see Figure 1a) and all nodes have the same sensing range and communication range .
Figure 1.

(a) Disk shape. (b) Binary sensing model. (c) Probabilistic sensing model.
Let u be a location in the ROI, be a node in the WSN, and be the Euclidean distance between u and . Most of the past researches use the binary sensing model [5,6,7], where nodes are assumed to be accurate in detecting targets within their sensing ranges. More precisely, under the binary sensing model (see Figure 1b for an illustration), the detection probability of u by is defined as
In physical scenarios, the distance decay effect cannot be ignored. That is, the detection probability of a node decays as the distance between the target and the node increases. Based on this, the coverage problem under a more realistic model, called the probabilistic sensing model, has been investigated; see [7,8,9,10,11]. A survey for the coverage problem with uncertain properties can be found in [12]. Do notice that unlike the binary sensing model, which has a unified definition of , there is no unified definition of under the probabilistic sensing model; see Section 2 for details. We now give the definition of used in [7] and in this paper. Under the probabilistic sensing model (see Figure 1c for an illustration), the detection probability of u by is defined as
| (1) |
where is a sensor-dependent parameter.
Many real-world applications impose the requirement of multilevel coverage. For example, for military or surveillance applications, for positioning protocols using triangulation [13], conducting data fusion [14], and minimizing the impact of sensor failure [15]. Sensor deployment with multilevel (k) coverage have been discussed in [7,15,16,17].
Under the binary sensing model, an ROI is said to be k-covered if every location in the ROI can be detected by at least k nodes (i.e., every location in the ROI is within k nodes’ sensing regions). Unfortunately, to the best of our knowledge, there is no unified definition of k-coverage under the probabilistic sensing model. We now are ready to elaborate this issue. Let be the set of sensor nodes deployed in the ROI. In [7], a location u in the ROI is considered as k-covered if the probability that there are at least k nodes that can detect u is not smaller than a predefined threshold , where . More precisely, in [7], a location u in the ROI is said to be k-covered if
| (2) |
For clarity, we call this definition of k-coverage the k-threshold coverage. In [18], a location u in the ROI is said to be k-covered if
| (3) |
For clarity, we call this definition of k-coverage the k-expectation coverage. In both [7] and [18], the ROI is said to be k-covered if every location u inside the ROI is k-covered. The used in [18] is defined as (4), which is a generalization of (1) and is introduced in Section 2. By (3), the event of u detected by is independent of the event of u detected by for . Reference [18] proves that the ROI is k-covered by if, among all locations inside the ROI, the minimum expected number of nodes is k (there is a typo and k should be at leastk k).
Three main considerations in WSNs’ coverage are: maximizing coverage quality, maximizing network lifetime, and minimizing the number of deployed nodes. The coverage quality and lifetime are two conflict factors with respect to energy consumption. Reference [12] points out that the k-coverage requirement makes the problem more sophisticated because more nodes are needed; deploying less nodes by decreasing the overlap region and prolonging the network lifetime become complicated. The k-expectation coverage [18] has the drawback that the user cannot specify his/her preference for the threshold , meaning that the user cannot specify their desired coverage quality. Moreover, it is possible that the entire ROI is regarded as k-covered but some locations inside it are detected by a lot of nodes each with a small detection probability. The k-threshold coverage [7] has the drawback that it tends to use too many sensor nodes; we give the calculation details in Section 2. In short, Wang and Tseng [7] first calculate (notice that is denoted as in [7]) and then replace the original with in the deployment.
The objective of this paper is to propose a sensor deployment scheme to use less number of nodes while ensuring the following two important coverage qualities: (i) the resultant WSN is connected and (ii) the detection probability satisfies a predefined threshold , where . Although k-threshold coverage [7] achieves the same objective, we find that the nature of k-threshold coverage makes tend to become much smaller than the original . For example, suppose and m denotes meters. Then:
If and m, then for = 0.7, 0.8, 0.9 are 2.377 m, 1.487 m, and 0.702 m, respectively.
If and m, then for = 0.7, 0.8, 0.9 are 1.486 m, 0.929 m, and 0.439 m, respectively.
These very small ’s cause a large number of nodes to be deployed. Since the number of nodes is very large, the overall detection probability might be underestimated.
In this paper, we try to propose a “reasonable” solution to the k-coverage problem under the probabilistic sensing model. The main contributions of this paper are as follows.
We propose a “reasonable” definition of k-coverage under the probabilistic sensing model, called the k-layer coverage, and propose a scheme to achieve k-layer coverage.
We propose a novel “zone 1 and zone 1–2” strategy to fulfill k-layer coverage scheme and ensure good coverage quality. We propose an efficient algorithm to calculate the radius of zone 1, which takes at most 18 iterations when error tolerance .
Experimental results shows that our k-layer coverage scheme indeed uses less sensor nodes, thereby demonstrating the effectiveness of our scheme.
Our k-layer coverage scheme partitions the nodes into k subsets, each forming one layer of coverage, and ensures that for every location u inside the ROI, the detection probability for u by nodes in “each layer” is not smaller than . In particular, our k-layer coverage scheme ensures that every location u inside the ROI is within zone 1 of at least k nodes and within zone 1–2 of at least another nodes (zone 1 and zone 1–2 are defined in Section 4). When coverage quality is considered, our k-layer coverage scheme provides a good solution. Different from the k-threshold coverage [7], which replaces the original with , our k-layer coverage replaces the original with . We prove that as long as , we have , meaning that our k-layer coverage will use less nodes. When the number of nodes is considered, our k-layer coverage scheme also provides a good solution.
The rest of this paper is organized as follow. Section 2 introduces the related works. Section 3 gives preliminaries, assumptions, and objectives. Section 4 gives the basics of the k-layer coverage. Section 5 gives our k-layer coverage scheme. Section 6 illustrates experimental results. Concluding remarks are given in the final section.
2. Related Works
Recall that a good sensor deployment should consider both coverage and connectivity. Assuming that the ROI is a convex set, Zhang and Hou [19] investigate the relationship between coverage and connectivity and prove that is both necessary and sufficient to ensure that coverage implies connectivity. With such a proof, one can then focus only on the coverage problem. As long as , nodes can be deployed according to the regular triangular lattice pattern (triangular pattern for short; see Figure 2) so that both coverage and connectivity can be ensured [7,20]. Using the triangular pattern, neighboring nodes will be regularly separated by a distance of . A deployment using the triangular pattern is sometimes called an optimal deployment since it is asymptotically optimal in terms of the number of nodes needed to achieve full coverage of the ROI.
Figure 2.

Triangular pattern: (a) three neighboring nodes, (b) the general case.
In some applications, or may not hold. Wang and Tseng [7] therefore consider an arbitrary relationship between and , thus relaxing the limitations of existing results. In [7], for the the binary sensing model, two solutions to achieve k-coverage are proposed: the naive duplicate placement scheme (duplicate scheme for short) and the interpolating placement scheme (interpolating scheme for short). The idea of the duplicate scheme is to use a good sensor placement method to ensure 1-coverage and connectivity and then duplicate k nodes on each designated location. However, since the duplicate scheme may result in some regions in the ROI having a much higher coverage levels than k, the interpolation scheme is therefore being proposed to “reuse” these regions to generate a multilevel coverage. When or or ( and ), it is found that the interpolation scheme will not save nodes compared to the duplicate scheme, thereby adopting the duplicate scheme. For clarity, we summarize the schemes used in [7] in Table 1. Notice that the interpolation schemes used in the ()-case and the ()-case are different.
Table 1.
Scheme used by [7]: “k” means “to make the ROI k-covered”, “duplicate” means “duplicate scheme”, “interpolation” means “interpolation scheme”, and “tri. pattern” means “triangular pattern”.
| k | Case | Case | Case | Case |
|---|---|---|---|---|
| duplicate | duplicate | duplicate | duplicate and tri. pattern | |
| duplicate | duplicate | duplicate | duplicate and tri. pattern | |
| interpolation | interpolation | duplicate | duplicate and tri. pattern |
Wang and Tseng [7] adapt the schemes of the binary sensing model to the probabilistic sensing model. Set (★) = ( and ) for convenience. We now use the (★)-case as an illustration to show how [7] performs the adaption. According to Table 1 (shown in Section 2), under the binary sensing model, [7] will use the duplicate scheme and triangular pattern in the (★)-case. Under the probabilistic sensing model, in the (★)-case, [7] first calculates (notice that is denoted as in [7]). Then, [7] replaces the original with in the deployment to ensure that every location inside the ROI is k-covered under the probabilistic sensing model. Since the duplicate scheme places k nodes on each designated location, [7] calculates by
and
where u is a location in the ROI having the minimum k-covered probability and u is detected by a set of k nodes placed at a designated location with distance to u.
Let u, , , and be defined as in Section 1. In [11,18,21,22], four parameters are used to specify a probabilistic sensing model and is defined as
| (4) |
where and are sensor-dependent parameters (see Figure 3). That is, if , then a target at u will definitely be detected by ; if , then the detection probability will be too small and will be totally ignored. If , then the behavior of the detection probability obeys the function . By taking and , (4) coincides with (1).
Figure 3.

(a) and . (b) The generalized probabilistic sensing model.
Notice that besides the binary sensing model and the probabilistic sensing model, some researchers consider the evidence-based sensor coverage model and use the theory of belief functions to solve the coverage problem; see [23,24,25,26]. Notice that [23,24,25,26] consider 1-coverage and their ROI is assumed as a two- or three-dimensional grid of points. In this paper, we consider k-coverage and our ROI contains every location inside it. Some other references related to k-coverage can also be found in [27,28,29,30,31]. Before ending this section, for clarity, we summarize our most related works in Table 2.
Table 2.
Definitions of k-coverage: is the set of sensor nodes deployed in the ROI and “det. prob.” means “detection probability”.
3. Preliminaries, Assumptions, and Objectives
Typical types of coverage are target coverage, area coverage, and barrier coverage. The purpose of target coverage is to cover (monitor) a set of specific targets (or points), that of area coverage is to cover the entire ROI, and that of barrier coverage is to detect intruders who intend to cross a long belt region. In a WSN, nodes are deployed in ad-hoc or pre-planned manner. In pre-planned deployment, nodes are placed to designated locations in the ROI so that fewer nodes can provide satisfactory coverage with lower network maintenance and management cost. Area coverage is usually more difficult and can be solved by ad-hoc or pre-planned deployment, depending on the application scenario.
This paper discusses “area coverage” by “pre-planned deployment”; the following assumptions are made:
The ROI is of a rectangular shape.
Sensor nodes are homogeneous, i.e., with the same sensing range and communication range .
.
The application that we are interested in allows nodes to be deployed in pre-planned manner.
The detection probability, of u by , used in this paper is (1).
The objective of this paper is to propose a “reasonable” definition of k-coverage under the probabilistic sensing model and to develop a sensor deployment scheme that uses less number of nodes while ensuring the following two coverage qualities: (i) the resultant WSN is connected and (ii) the detection probability satisfies a predefined threshold , where .
4. Basics of the k-Layer Coverage
4.1. The Definition of k-Layer Coverage
Definition 1.
Given an ROI and a set of a finite number of nodes deployed in the ROI, a location u in the ROI is k-layer covered (or k-covered for short) if can be partitioned into k subsets such that
(5) for a predefined threshold , where . The ROI is k-layer covered (or k-covered for short) if every location inside it is k-layer covered.
For convenience, we call each one “layer” and call the above coverage the k-layer coverage. See Figure 4 for an illustration. The k-layer coverage ensures that the detection probability for u contributed by each layer (i.e., each ) is not smaller than . Thus, u is k-layer covered if and only if it is 1-layer covered by each , . Consequently, the ROI is k-layer covered if and only if it is 1-layer covered by each , .
Figure 4.

The concept of k-layer coverage.
4.2. “Zone 1 and Zone 1–2” Strategy
We regard each node’s sensing region as the composition of three concentric circular zones: zone 1, zone 2, and zone 3, as shown in Figure 5. We denote by the radius of zone 1 and , the outer contour radius of zone 2, where . We take so that the calculations can be greatly simplified. Zone 1 has a higher detection probability than zone 2 which further has a higher detection probability than zone 3. Zone 3 might be empty and our coverage scheme will not take it into account. For convenience, denote by zone 1–2 the union of zones 1 and 2.
Figure 5.
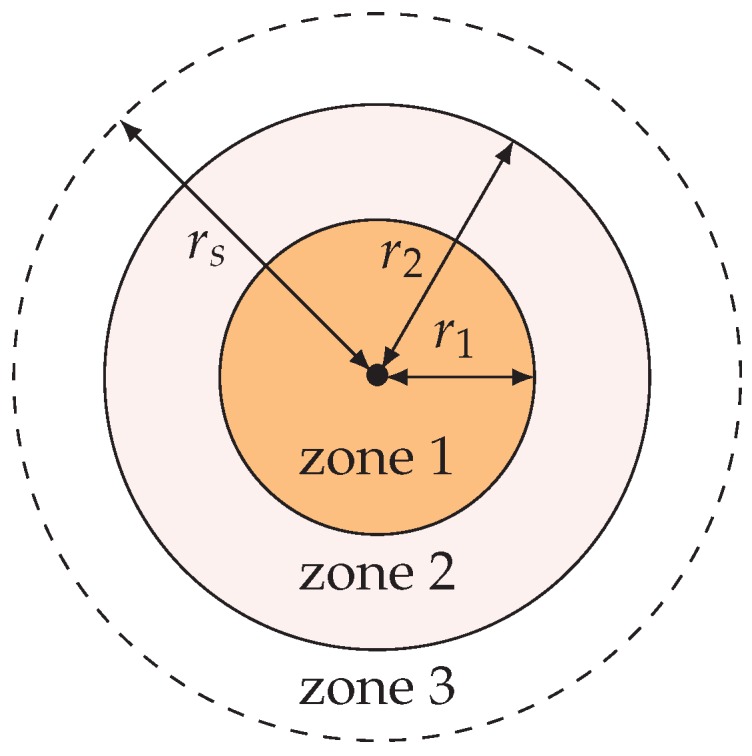
Zone 1, zone 2, zone 3, , , and . We take .
The following theorem states the “zone 1 and zone 1–2” strategy used in our k-layer coverage scheme, whose proof is in Section 5.
Theorem 1.
Our k-layer coverage scheme ensures that for each , every location inside the ROI is within zone 1 of one node in and within zones 1–2 of at least another two nodes in .
4.3. An Algorithm for Calculating the Radius of Zone 1
To use the “zone 1 and zone 1–2” strategy, we need to calculate . Let u be an arbitrary location inside the ROI. By Theorem 1, there exist three distinct nodes , , and in such that u is within zone 1 of and zones 1–2 of and . By (5), we have
On the one hand, to minimize the number of nodes, should be as large as possible. On the other hand, to ensure coverage quality, cannot be too large because the following inequality is needed:
| (6) |
Therefore, we should find the largest possible that satisfies (6). The following algorithm finds such an and we now briefly describe the idea behind our algorithm.
Since the detection probability of any target outside is defined as zero, and must satisfy . Since we take , the largest possible is therefore . Substituting by into (6), we have
Thus, our k-layer coverage has an unavoidable lower bound of , which is defined as
This unavoidable lower bound is due to the system assumption that the detection probability of any target outside is zero. If , then our algorithm enlarges to be and returns for . In the remaining part of this paragraph, we assume and show how to calculate when . Since
we have
| (7) |
For convenience, denote by the the largest possible that satisfies (6) under the assumption that . We say that a value is an ϵ-approximation of if it satisfies (6) and satisfies a given error tolerance . The following method finds either or an -approximation of by using (7). Substituting for in (7), we have
Thus
Hence
By using , we can obtain an approximate . Since is a lower bound of , let
By using , we can obtain another approximate . Since is an upper bound of , let
By keeping
when our algorithm stops, it finds either or an -approximation of . Our full algorithm is now shown in Algorithm 1.
| Algorithm 1: |
|
Input:, , and , where is the threshold, is the sensing range, and is the sensor-dependent parameter given in (1). Output: if ; or an -approximation of if .
|
Theorem 2.
If , then Algorithm 1 returns in time. If , then Algorithm 1 returns either or an ϵ-approximation of for after at most 18 iterations.
Proof.
The first statement is obvious. Assume that and consider the second statement. Then, Algorithm 1 returns either or . Consider the former case. In this case, . By lines 9∼10, . Thus is exactly . Now, consider the latter case. In this case, . Hence
Thus satisfies (6). The execution of the while-loop ensures that satisfies the error tolerance . Therefore is an -approximation of . We now prove that when , Algorithm 1 takes at most 18 iterations. Set for easy writing. Since , we have . By line 5, initially . By line 6, initially . Therefore, initially . Let . The function achieves its maximum value when , which occurs when
Note that . Moreover, each iteration of the while-loop cuts the search space by half. Thus after the execution of i-th iteration of the while-loop,
When (i.e., when ), Algorithm 1 terminates its while-loop. Since , we have . Thus Algorithm 1 takes at most 18 iterations. □
The following corollary follows from the proof of the above theorem.
Corollary 1.
For an arbitrary error tolerance ϵ, Algorithm 1 takes at most iterations. In particular, when , where x is a positive integer, Algorithm 1 takes at most iterations.
Suppose m denotes meters. Algorithm 1 obtains:
If , m, then for are 15.685m, 12.391m, and 8.749m, respectively.
If , m, then for are 9.801m, 7.743m, and 5.468m, respectively.
To handle the probabilistic sensing model, Wang and Tseng [7] replace the original with in their deployment. To handle the probabilistic sensing model, we replace the original with . The relationship between and is given in the following lemma.
Lemma 1.
If and , then
Proof.
Since , it is true that . Now assume that satisfies the assumption of this lemma. Then,
Hence . □
5. Our k-Layer Coverage Scheme
5.1. The Case
Our 1-layer coverage scheme deploys nodes according to a “pseudo” triangular pattern deployment, in which neighboring nodes will be regularly separated by a distance of (i.e., ) except that some of them will be separated by a distance of or and these exceptions only occur at the boundary of the ROI. See Figure 6 for an illustration.
Figure 6.

Sensor placement in 1-layer coverage scheme; notice that only zone 1 of each node is shown in this figure. This ROI has and and therefore no adjustment for rows .
Let L and H be the length and the height of the ROI, respectively. We assume that the ROI’s lower left corner is located at coordinate . Then, the coordinates (i.e., locations) of nodes will be calculated row-by-row, with row 1 containing , and row ℓ containing the upper boundary of the ROI. Our full 1-layer coverage scheme is shown in Algorithm 2. Since all nodes have to be within the ROI, we may need to adjust the locations of the following nodes:
the first node in each even-numbered row (handled by line 6 of Algorithm 2),
the last node in each row (handled by line 9 of Algorithm 2), and
all nodes in row ℓ (handled by lines 11–18 of Algorithm 2).
| Algorithm 2: |
|
Input: The derived by Algorithm 1, the length L of the ROI, and the height H of the ROI. Output: The designated locations of nodes.
|
Let ℓ, , and denote the number of rows, the number of nodes deployed in an odd-numbered row, and the number of nodes deployed in an even-numbered row by Algorithm 2, respectively. Three claims are made.
Claim 1..
Proof.
This claim follows from the fact that the distance between row i and row , , is exactly , and the distance between row and row ℓ is . □
Claim 2..
Proof.
Consider an arbitrary odd-numbered row and let node 1, node 2, …, node be nodes in this row. Then, the distance between node i and node , , is exactly , and the distance between node and node is . Hence the claim. □
Claim 3..
Proof.
Consider an arbitrary even-numbered row and let node 1, node 2, …, node be nodes in this row. Then, the distance between node 1 and node 2 is , the distance between node i and node , , is exactly , and that between node and node is . Hence the claim. □
We now are ready to prove Theorem 1.
Proof.
It can be easily observed from Figure 6 that every location inside the ROI is within zone 1 of at least one node. Thus, to prove this theorem, it suffices to prove that every location inside the ROI is within zones 1–2 of at least three nodes. This assertion can be easily verified by using Figure 7 and hence we have this theorem. □
Figure 7.

Sensor placement in 1-layer coverage scheme; notice that only zone 1–2 of each node is shown in this figure.
5.2. The General Case
To achieve k-layer coverage for , we begin with the 1-layer coverage and duplicate k sensor nodes on each designated location of the 1-layer coverage. See Figure 8 for an illustration. See also Appendix A and Figure A1 for possible improvements. The following corollary follows from Claims 1∼3.
Figure 8.

(a) 2-layer coverage. (b) 3-layer coverage.
Corollary 2.
The number N of nodes deployed by our k-layer coverage scheme equals to
6. Experimental Results
Our experimental results are obtained by using Visual C++ programming language under the environment of a 64-bit personal computer with win 10 operating system. Parameters used in our experimental results are listed in Table 3.
Table 3.
Parameters used: m denote meters.
| Size of the ROI | 1000 m × 1000 m |
| sensing range | 30 m |
| error tolerance used in Algorithm 1 | |
| sensor-dependent parameter used in (1) | either 0.05 or 0.08 |
Our experimental results are shown in Table 4, Table 5 and Table 6. These results demonstrate used in k-threshold coverage [7] and used in our k-layer coverage. Recall that both and are served as a substitution radius for the original sensing radius . As can be observed in Table 4, Table 5 and Table 6, is much smaller than and is more reasonable. Table 4, Table 5 and Table 6 also demonstrate the number of nodes required by k-threshold coverage [7] and our k-layer coverage. It is not difficult to see that the number of nodes required by k-threshold coverage [7] is quite large, especially when k is large. On the other hand, the number of nodes required by our k-layer coverage is much less.
Table 4.
The number of nodes for coverage: “# nodes” means “the number of nodes required”.
Table 5.
The number of nodes for coverage: “# nodes” means “the number of nodes required”.
Table 6.
The number of nodes for coverage: “# nodes” means “the number of nodes required”.
7. Concluding Remarks
This paper considers the multilevel (k) coverage problem in WSNs with uncertain properties (i.e., under the probabilistic sensing model). We find that the nature of the previous k-threshold coverage [7] makes its substitution radius tend to be much smaller than the original sensing range and therefore will use too many nodes. We thus try to propose a more reasonable solution and yield the k-layer coverage. In k-layer coverage, each node’s sensing region is regarded as the composition of zone 1, zone 2, and zone 3. Although regarding each node’s sensing region as the composition of several zones has been proposed in the literature, to the best of our knowledge, we are the first ones to use the “zone 1 and zone 1–2” strategy to solve the probabilistic multilevel (k) coverage problem. By using such a “zone 1 and zone 1–2” strategy, our k-layer coverage achieves a better coverage quality and uses less nodes. A preliminary version of this paper was in [32]; see also [33]. One future work for this research is to extend k-layer coverage to the probabilistic sensing model in (4) and to more realistic regions of interest. Another future work is to explore the relationship between coverage and energy consumption.
Acknowledgments
The authors would like to thank Yu-Chee Tseng for his valuable comments that greatly improve the presentation of this paper. The authors would also like to express their deepest gratitude to the anonymous reviewers for their constructive comments and time spent to analyze this paper.
Appendix A. Appendix: Balanced k-Layer Coverage
In Figure 8, some locations in the ROI get a much higher coverage than the other locations. We show how to obtain a more balanced k-layer coverage. Let denote the 1-layer coverage obtained by Algorithm 2. The balanced 1-layer coverage is . Instead of duplicating each node twice, the balanced 2-layer coverage is together with a shift of ; see Figure A1a. Instead of duplicating each node thrice, the balanced 3-layer coverage is together with two shifts and of ; see Figure A1b. Notice that some nodes have to be added to (respectively, ) (all of these nodes are close to the ROI’s boundary) so that (respectively, ) can ensure a 1-layer coverage; we omit the details. For , let and . The balanced k-layer coverage is applying the balanced 3-layer coverage q times and applying the balanced r-layer coverage once. For example, if , then apply the balanced 3-layer coverage once and the balanced 2-layer coverage once.
Figure A1.

(a) The balanced 2-layer coverage. (b) The balanced 3-layer coverage. consists of all nodes colored black, consists of all nodes colored yellow, and consists of all nodes colored green.
Author Contributions
Conceptualization, Y.-N.C. and C.C.; methodology, Y.-N.C. and C.C.; validation, Y.-N.C., W.-H.L. and C.C.; investigation, Y.-N.C., W.-H.L. and C.C.; data curation, Y.-N.C.; writing–original draft preparation, Y.-N.C. and C.C.; writing–review and editing, W.-H.L. and C.C.; supervision, C.C.; project administration, C.C.; funding acquisition, W.-H.L. and C.C. All authors have read and agreed to the published version of the manuscript.
Funding
This research was partially supported by the Ministry of Science and Technology of Taiwan under grants MOST-108-2115-M-009-006 and MOST-108-2115-M-009-013.
Conflicts of Interest
The authors declare no conflict of interest.
References
- 1.Akyildiz I.F., Su W., Sankarasubramaniam Y., Cayichi E. Wireless sensor network: A survey. Comput. Netw. 2002;38:393–422. doi: 10.1016/S1389-1286(01)00302-4. [DOI] [Google Scholar]
- 2.Huo H., Xu Y., Zhang H., Chuang Y.H., Wu T.C. Wireless-sensor-networks-based healthcare system: A survey on the view of communication paradigms. Int. J. Ad Hoc Ubiquitous Comput. 2011;8:135–154. doi: 10.1504/IJAHUC.2011.042348. [DOI] [Google Scholar]
- 3.Farsi M., Elhosseini M.A., Badawy M., Ali H.A., Eldin H.Z. Deployment techniques in wireless sensor networks, coverage and connectivity: A survey. IEEE Access. 2019;7:28940–28954. doi: 10.1109/ACCESS.2019.2902072. [DOI] [Google Scholar]
- 4.Wang B. Coverage problems in sensor networks: A survey. ACM Comput. Surv. 2011;43:32. doi: 10.1145/1978802.1978811. [DOI] [Google Scholar]
- 5.Mini S., Udgata S., Sabat S. Sensor deployment and scheduling for target coverage problem in wireless sensor networks. IEEE Sens. J. 2014;14:636–644. doi: 10.1109/JSEN.2013.2286332. [DOI] [Google Scholar]
- 6.Rebai M., Snoussi H., Hnaien F., Khoukhi L. Sensor deployment optimization methods to achieve both coverage and connectivity in wireless sensor networks. Comput. Oper. Res. 2015;59:11–21. doi: 10.1016/j.cor.2014.11.002. [DOI] [Google Scholar]
- 7.Wang Y.C., Tseng Y.C. Distributed deployment scheme for mobile wireless sensor networks to ensure multilevel coverage. IEEE Trans. Parallel Distrib. Syst. 2008;19:1280–1294. doi: 10.1109/TPDS.2007.70808. [DOI] [Google Scholar]
- 8.Dhillon S.S., Chakrabarty K. Sensor placement for effective coverage and surveillance in distributed sensor networks; Proceedings of the IEEE Wireless Communications and Networking Conference (WCNC’03); New Orleans, LA, USA. 16–20 March 2003; pp. 1609–1614. [Google Scholar]
- 9.Yang Q., He S., Li J., Chen J., Sun Y. Energy-efficient probabilistic area coverage in wireless sensor networks. IEEE Trans. Veh. Technol. 2015;64:367–377. doi: 10.1109/TVT.2014.2300181. [DOI] [Google Scholar]
- 10.Yun Z., Bai X., Xuan D., Lai T.H., Jia W. Optimal deployment patterns for full coverage and k-connectivity wireless sensor networks. IEEE/ACM Trans. Netw. 2010;18:934–947. [Google Scholar]
- 11.Zou Y., Chakrabarty K. Sensor deployment and target localization based on virtual forces; Proceedings of the IEEE Infocom Conference (INFOCOM 2003); San Francisco, CA, USA. 30 March–3 April 2003; pp. 1293–1303. [Google Scholar]
- 12.Wang Y., Wu S., Chen Z., Gao X., Chen G. Coverage problem with uncertain properties in wireless sensor networks: A survey. Comput. Netw. 2017;123:200–232. doi: 10.1016/j.comnet.2017.05.008. [DOI] [Google Scholar]
- 13.Nicules D., Nath B. Ad-hoc positioning system (APS) using AoA; Proceedings of the IEEE International Conference on Computer Communications (INFOCOM’03); Dallas, TX, USA. 30 March–3 April 2003; pp. 1734–1743. [Google Scholar]
- 14.Klein L.A. A Boolean algebra approach to multiple sensor voting fusion. IEEE Trans. Aerosp. Electron. Syst. 1993;29:317–327. doi: 10.1109/7.210070. [DOI] [Google Scholar]
- 15.Sun T., Chen L.J., Han C.C., Gerla M. Reliable sensor networks for planet exploration; Proceedings of the IEEE International Conference on Networking, Sensing, and Control (ICNSC’05); Tucson, AZ, USA. 19–22 March 2005; pp. 816–821. [Google Scholar]
- 16.Chakrabarty K., Iyengar S.S., Qi H., Cho E. Grid coverage for surveillance and target location in distributed sensor networks. IEEE Trans. Comput. 2002;51:1448–1453. doi: 10.1109/TC.2002.1146711. [DOI] [Google Scholar]
- 17.Huang C.F., Tseng Y.C. The coverage problem in a wireless sensor network. Mob. Netw. Appl. 2005;10:519–528. doi: 10.1007/s11036-005-1564-y. [DOI] [Google Scholar]
- 18.Wang H.L., Chung W.H. The generalized k-coverage under probabilistic sensing model in sensor networks; Proceedings of the IEEE Wireless Communications and Networking Conference: Mobile and Wireless Networks (WCNC); Shanghai, China. 1–4 April 2012; pp. 1737–1742. [Google Scholar]
- 19.Zhang H., Hou J.C. Maintaining sensing coverage and connectivity in large sensor networks. Ad Hoc Sens. Wirel. Netw. 2005;1:89–124. [Google Scholar]
- 20.Kershner R. The number of circles covering a set. Am. J. Math. 1939;61:665–671. doi: 10.2307/2371320. [DOI] [Google Scholar]
- 21.Zou Y., Chakrabarty K. Uncertainty-aware and coverage-oriented deployment for sensor networks. J. Parallel Distrib. Comput. 2004;64:788–798. doi: 10.1016/j.jpdc.2004.03.019. [DOI] [Google Scholar]
- 22.Zou Y., Chakrabarty K. A distributed coverage- and connectivity-centric technique for selecting active nodes in wireless sensor networks. IEEE Trans. Comput. 2005;54:978–991. doi: 10.1109/TC.2005.123. [DOI] [Google Scholar]
- 23.Senouci M.R., Mellouk A., Oukhellou L., Aissani A. Uncertainty-aware sensor network deployment; Proceedings of the IEEE Globecom; Houston, TX, USA. 5–9 December 2011; pp. 1–5. [Google Scholar]
- 24.Senouci M.R., Mellouk A., Oukhellou L., Aissani A. An evidence-based sensor coverage model. IEEE Commun. Lett. 2012;16:1462–1465. doi: 10.1109/LCOMM.2012.070512.120999. [DOI] [Google Scholar]
- 25.Senouci M.R., Mellouk A., Oukhellou L., Aissani A. Efficient uncertainty-aware deployment algorithms for wireless sensor networks; Proceedings of the IEEE Wireless Communications and Networking Conference: Mobile and Wireless Networks; Paris, France. 1–4 April 2012; pp. 2163–2167. [Google Scholar]
- 26.Senouci M.R., Mellouk A., Oukhellou L., Aissani A. WSNs deployment framework based on the theory of belief functions. Comput. Netw. 2015;88:12–26. doi: 10.1016/j.comnet.2015.05.014. [DOI] [Google Scholar]
- 27.Ammari H.M., Das S.K. Centralized and clustered k-coverage protocols for wireless sensor networks. IEEE Trans. Comput. 2012;61:118–133. doi: 10.1109/TC.2011.82. [DOI] [Google Scholar]
- 28.Elhoseny M., Tharwat A., Farouk A., Hassanien A.E. K-coverage model based on genetic algorithm to extend WSN lifetime. IEEE Sens. Lett. 2017;1:7500404. doi: 10.1109/LSENS.2017.2724846. [DOI] [Google Scholar]
- 29.Liu Q. K-coverage reliability evaluation for wireless sensor networks using 2 dimensional k / r×s / m×n:F system; Proceedings of the 2018 12th International Conference on Reliability, Maintainability, and Safety (ICRMS); Shanghai, China. 17–29 October 2018; pp. 83–87. [Google Scholar]
- 30.Özdağ R. The solution of the k-coverage problem in wireless sensor networks; Proceedings of the 2016 24th Signal Processing and Communication Application Conference (SIU); Zonguldak, Turkey. 16–19 May 2016; pp. 873–876. [Google Scholar]
- 31.Rezaee A.A., Zahedi M.-H., Dehghan Z. Coverage optimization in wireless sensor networks using gravitational search algorithm. J. Soft Comput. Inf. Technol. (JSCIT) 2019;8:20–31. [Google Scholar]
- 32.Chen Y.-N. Master’s Thesis. National Chiao Tung University; Hsinchu, Taiwan: Jun, 2019. Multilevel (k) Coverage Based on Probabilistic Sensing Model in Wireless Sensor Networks. [Google Scholar]
- 33.Chen Y.-N., Chen C. Sensor deployment under probabilistic sensing model; Proceedings of the 2nd High Performance Computing and Cluster Technologies Conference (HPCCT); Beijing, China. 22–24 June 2018; pp. 33–36. [Google Scholar]