

Abstract
Effect size indices are useful tools in study design and reporting because they are unitless measures of association strength that do not depend on sample size. Existing effect size indices are developed for particular parametric models or population parameters. Here, we propose a robust effect size index based on M-estimators. This approach yields an index that is very generalizable because it is unitless across a wide range of models. We demonstrate that the new index is a function of Cohen’s d, , and standardized log odds ratio when each of the parametric models is correctly specified. We show that existing effect size estimators are biased when the parametric models are incorrect (e.g., under unknown heteroskedasticity). We provide simple formulas to compute power and sample size and use simulations to assess the bias and standard error of the effect size estimator in finite samples. Because the new index is invariant across models, it has the potential to make communication and comprehension of effect size uniform across the behavioral sciences.
Keywords: M-estimator, Cohen’s d, R square, standardized log odds, semiparametric
Introduction
Effect sizes are unitless indices quantifying the association strength between dependent and independent variables. These indices are critical in study design when estimates of power are desired, but the exact scale of new measurement is unknown (Cohen, 1988), and in meta-analysis, where results are compiled across studies with measurements taken on different scales or outcomes modeled differently (Chinn, 2000; Morris and DeShon, 2002). With increasing skepticism of significance testing approaches (Trafimow and Earp, 2017; Wasserstein and Lazar, 2016; Harshman et al., 2016; Wasserstein et al., 2019), effect size indices are valuable in study reporting (Fritz et al., 2012) because they are minimally affected by sample size.
Effect sizes are also important in large open source datasets because inference procedures are not designed to estimate error rates of a single dataset that is used to address many different questions across tens to hundreds of studies. While effect sizes can have similar bias to p-values when choosing among multiple hypotheses, obtaining effect size estimates for parameters specified a priori may be more useful to guide future studies than hypothesis testing because, in large datasets, p-values can be small for clinically meaningless effect sizes.
There is extensive literature in the behavioral and psychological sciences describing effect size indices and conversion formulas between different indices (see e.g., Cohen, 1988; Borenstein et al., 2009; Hedges and Olkin, 1985; Ferguson, 2009; Rosenthal, 1994; Long and Freese, 2006). Cohen 1988 defined at least eight effect size indices for different models, different types of dependent and independent variables, and provided formulas to convert between the indices. For example, Cohen’s d is defined for mean differences, is used for simple linear regression, and standardized log odds ratio is used in logistic regression. Conversion formulas for some of these parametric indices are given in Table 1 and are widely used in research and software (Cohen, 1988; Borenstein et al., 2009; Lenhard and Lenhard, 2017).
Table 1.
Effect size conversion formulas based on derivations from the robust index under homoskedasticity.
| d | ||||
Each row denotes the input argument and the column denotes the desired output value. Robust versions of classical values can be obtained by computing them as a function of . and denote the population proportions of each group for a two sample comparison. d is Cohen’s d, is Cohen’s effect size for multiple regression, is the partial coefficient of determination, is the robust index. The variables without subscripts denote the value for the full model including covariates. Conversion formulas derived by the robust index match classical formulas (Cohen, 1988; Borenstein et al., 2009; Lenhard and Lenhard, 2017)
Several authors have proposed robust effect size indices based on sample quantiles (Zhang and Schoeps, 1997; Hedges and Olkin, 1984). These are robust in the sense that they do not assume a particular probability model; however, they are defined as parameters in the sense that they are a specific functional of the underlying distribution.
Despite the array of effect sizes, there are several limitations to the available indices: 1) there is no single unifying theory that links effect size indices; 2) as defined, many effect size indices do not accommodate nuisance covariates or multivariate outcomes; and 3) each index is specific to a particular population parameter. For example, Cohen’s d is designed for mean differences in the absence of covariates, correlation is specific to linear regression, and existing semiparametric indices are quantile estimators. For these reasons, these classical effect size indices are not widely generalizable because their scale is dependent on the type of parameter.
In this paper, we define a new robust effect size index based on M-estimators. M-estimators are parameter estimators that can be defined as the maximizer of an estimating equation. This approach has several advantages over commonly used indices: a) The generality of M-estimators makes the index widely applicable across many types of models that satisfy mild regularity conditions, including mean and quantile estimators, so this framework serves as a canonical unifying theory to link common indices; b) the sandwich covariance estimate of M-estimators is consistent under model misspecification (MacKinnon and White, 1985; White, 1980), so the index can accommodate unknown complex relationships between second moments of multiple dependent variables and the independent variable; c) the robust effect size index is directly related to the Wald-style sandwich chi-squared statistic and is formulaically related to common indices.
Here, we describe sufficient conditions for the new effect size index to exist, describe how it relates to other indices, and show that other estimators can be biased under model misspecification. In three examples, we show that the new index can be written as a function of Cohen’s d, , and standardized log odds ratio, demonstrating that it is related to indices that were developed using intuition for specific models. In addition, we describe how to obtain a simple estimate of the index and provide functions to compute power or sample size given an effect size index and degrees of freedom of the target parameter. Finally, we use simulations to assess the bias and standard error of the proposed index estimator. An R package to estimate the index is in development; the latest release is available at https://github.com/simonvandekar/RESI.
Notation
Unless otherwise noted, capital letters denote vectors or scalars and boldface letters denote matrices; lower and upper case greek letters denote vector and matrix parameters, respectively. Let be a sample of independent observations from with associated probability measure G and let H denote the conditional distribution of given . Here, denotes a combination of a potentially multivariate outcome vector with a multivariate covariate vector .
Let denote the full dataset and , be an estimating equation,
| 1 |
where is a known function. is a scalar-valued function that can be maximized to obtain the M-estimator . We define the parameter as the maximizer of the expected value of the estimating equation under the true distribution G,
| 2 |
and the estimator is
Assume,
| 3 |
where denotes a nuisance parameter, is the target parameter, and .
We define the matrices with j, kth elements
which are components of the asymptotic robust covariance matrix of .
A New Effect Size Index
Definition
Here, we define a robust effect size that is based on the test statistic for
| 4 |
is a reference value used to define the index. Larger distances from represent larger effect sizes. Under the regularity conditions in the Appendix,
| 5 |
This implies that the typical robust Wald-style statistic for the test of (4) is approximately chi-squared on degrees of freedom,
| 6 |
with noncentrality parameter , where is the asymptotic covariance matrix of , and can be derived from the covariance of (5) (Boos and Stefanski, 2013; Van der Vaart, 2000). We define the square of the effect size index as the component of the chi-squared statistic that is due to the deviation of from the reference value:
| 7 |
As we demonstrate in the examples below, the covariance serves to standardize the parameter so that it is unitless. The regularity conditions given in Appendix are sufficient for the index to exist. The robust index, , is defined as the square root of so that the scale is proportional to that used for Cohen’s d (see Example 1).
This index has several advantages: it is widely applicable because it is constructed from M-estimators; it relies on a robust covariance estimate; it is directly related to the robust chi-squared statistic; it is related to classical indices, and induces several classical transformation formulas (Cohen, 1988; Borenstein et al., 2009; Lenhard and Lenhard, 2017).
An Estimator
is defined in terms of parameter values and so must be estimated from data when reported in a study. Let be as defined in (6), then
| 8 |
is consistent for , which follows by the consistency of the components that make up (Van der Vaart, 2000; White, 1980). We use the factor to account for the estimation of m parameters.
is the square root of an estimator for the noncentrality parameters of chisquared statistic. There is a small body of literature on this topic (Saxena and Alam, 1982; Chow, 1987; Neff and Strawderman, 1976; Kubokawa et al., 1993; Shao and Strawderman, 1995; López-Blázquez, 2000). While the estimator (8) is inadmissable (Chow, 1987), it has smaller risk than the usual unbiased maximum likelihood estimator (MLE), , because the MLE is not bounded by zero. We assess estimator bias in Sect. 7.
Examples
In this section, we show that the robust index yields several classical effect size indices when the models are correctly specified. We demonstrate the interpretability of the effect size index through a series of examples. The following example shows that the robust index for a difference in means is proportional to Cohen’s d, provided that the parametric model is correctly specified; that is, the solution to the M-estimator is equal to the MLE.
Example 1
(Difference in means) In this example, we consider a two mean model, where and the conditional mean of given converges. That is,
| 9 |
for independent observations , where , , and we assume the limit (9) exists. In addition, we assume is known and that
Let , then
where . When (9) holds, then . Note that in this example is not defined as the derivative of a log-likelihood: It defines a single parameter that is a difference in means and does not require each observation to have the same distribution. Despite this general approach, we are still able to determine the asymptotic variance of ,
Then the robust effect size (7) is
| 10 |
For fixed sample proportions and , when , is proportional to the classical index of effect size for the comparison of two means, Cohen’s d (Cohen, 1988). However, is more flexible: It can accommodate unequal variance among groups and accounts for the effect that unequal sample proportions has on the power of the test statistic. Thus, S is an index that accounts for all features of the study design that will affect the power to detect a difference. The robust index is proportional to the absolute value of the large sample z-statistic that does not rely on the equal variance assumption. This is what we expect in large samples when the equal variance assumption is not necessary for “correct” inference. In this example, we did not explicitly assume an identical distribution for all , only that the mean of the variance of given converges in probability to a constant.
The following example derives the robust effect size for simple linear regression. This is the continuous independent variable version of Cohen’s d and is related to .
Example 2
(Simple linear regression) Consider the simple linear regression model
where and are unknown parameters, , and follows an unknown distribution with zero mean and conditional variance that can depend on , . Let . In this model
| 11 |
where
| 12 |
After some algebra, combining the formulas (11) and (12) gives
Then (7) is
| 13 |
The intuition of (13) is best understood by considering the homoskedastic case where for all . Then, . This is similar to , except that the denominator is the variance of conditional on instead of the marginal variance of . The denominator of (13) accounts for the possible dependence between and .
In the following example, we introduce two levels of complexity by considering logistic regression with multidimensional nuisance and target parameters.
Example 3
(Logistic regression with covariates) For logistic regression, we utilize the model
| 14 |
where is a Bernoulli random variable, is a row vector, and and are as defined in (3). Let and similarly define and . Let be the matrix with and for . Let be the matrix with and for . If (14) is correctly specified then . If this equality does not hold, then there is under or over dispersion.
To find the robust effect size, we first need to find the covariance matrix of . To simplify notation, we define the matrices
for . The block matrix of corresponding to the parameter is
| 15 |
Equation (15) is the asymptotic covariance of , controlling for , if model (14) is correctly specified.
The robust covariance for can be derived by finding the block matrix of corresponding to . In this general case, the asymptotic covariance matrix of is
If the model is correctly specified, , , then
| 16 |
The parameter (16) describes the effect of controlling for the collinearity of variables of interest , with the nuisance variables, . If the collinearity is high, then the diagonal of will be large and the effect size will be reduced.
Many suggestions have been made to compute standardized coefficients in the context of logistic regression (for a review see Menard, 2004, 2011). When , the square of the robust index in this context, under correct model specification, is the square of a fully standardized coefficient and differs by a factor of from the earliest proposed standardized index (Goodman, 1972). The index proposed by Goodman (1972) is simply a Wald statistic and was rightly criticized for its dependence on the sample size (Menard, 2011), despite that it correctly accounts for the fact that the variance of a binomial random variable is functions of its mean, through the use of the diagonal matrix in the matrix . The robust index remediates the dependence that Goodman’s standardized coefficient has on the sample size.
Relation to Other Indices
The new index can be expressed as a function of several common effect size indices for continuous or dichotomous dependent variables when there is homoskedasticity (Fig. 1; Table 1). The relations between effect sizes implied by the new index are equivalent to the classical conversion formulas between effect sizes (Borenstein et al., 2009; Selya et al., 2012). While the index is related to existing indices under correct model specification, the advantage of the robust index is that it is defined if the variance model is incorrectly specified. This is the case, for example, in linear regression when there is heteroskedasticity and the model assumes a single variance term for all subjects or in logistic regression when there is overdispersion. By using the formulas in Table 1, we can obtain robust versions of classical indices by writing them as functions of .
Fig. 1.
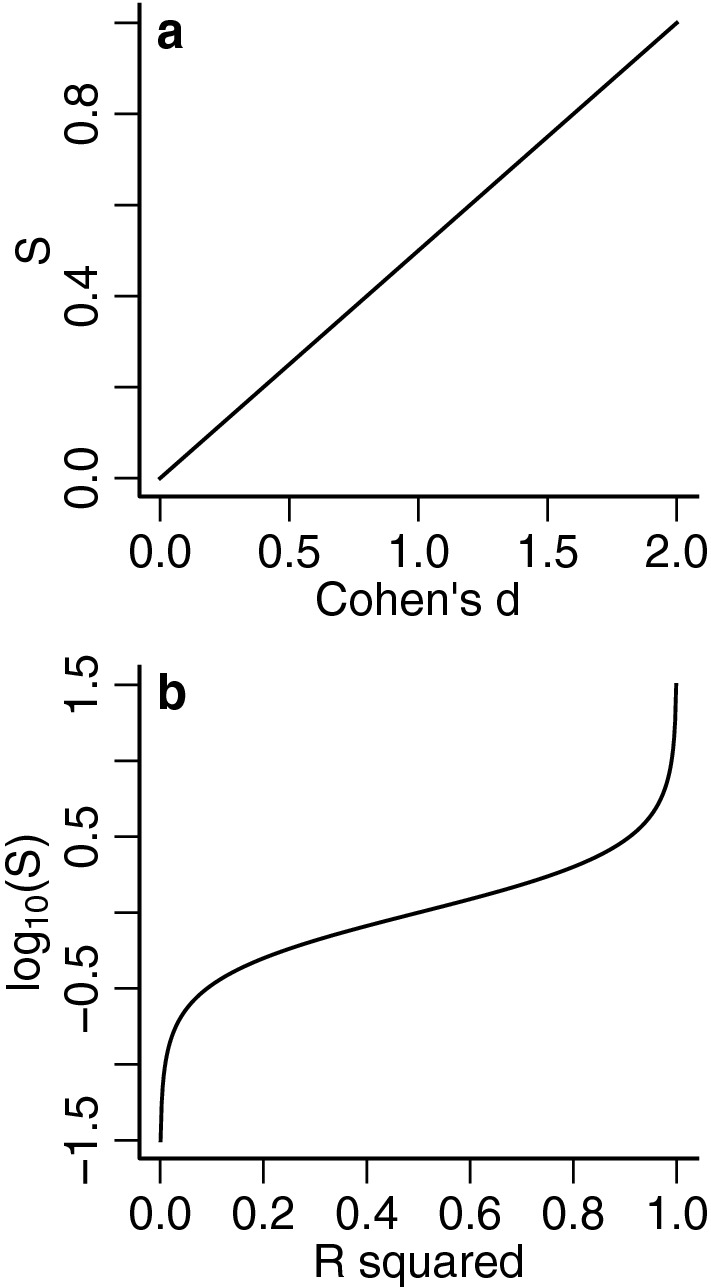
Graphs of the robust effect size as a function of some common effect size indices (see formulas in Table 1. a Cohen’s d, when and ; b .
Cohen (1988) defined ranges of meaningful effect sizes for the behavioral sciences (Table 2). These intervals can also be used to define similar regions for the robust index. These recommendations serve as a useful guide, however, ranges of meaningful effect sizes are field specific and should be based on clinical expertise and the effect an intervention could have if applied to the population of interest.
Table 2.
Effect size thresholds suggested by Cohen (1988) on the scale of d and the robust index (), using the formula from Table 1 assuming equal sample proportions.
| Effect size | d | S |
|---|---|---|
| None-small | [0, 0.2] | [0, 0.1] |
| Small-medium | (0.2, 0.5] | (0.1, 0.25] |
| Medium-large | (0.5, 0.8] | (0.25, 0.4] |
Bias of Existing Indices Under Model Misspecification
To understand the bias of the classical estimators under model misspecification, we compare the asymptotic value of the classical estimators to the effect size formulas in Table 1. Under model misspecification, the existing parametric effect size indices can be biased.
The estimator for Cohen’s d using pooled variance converges to
Taking the ratio of this value to the robust value of Cohen’s d in Table 1 gives
A plot of this ratio with respect to and is given in Fig. 2. When or then there is no bias. When and Cohen’s d overestimates the effect size. When is small and Cohen’s d under underestimates the effect size. The plot is symmetric about the point (0, 1/2).
Fig. 2.
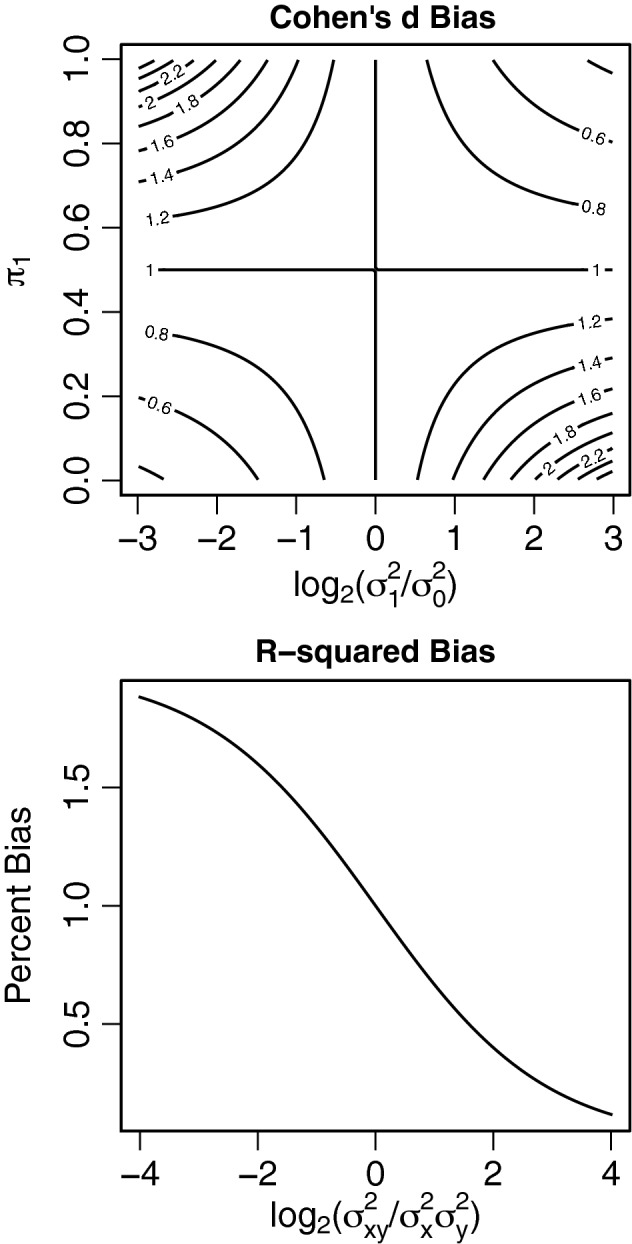
Percent bias for Cohen’s d and . When or the variances are equal the classical estimator of Cohen’s d is unbiased, it can be positively or negatively biased when the variances and sampling proportions are not equal. Similarly for , when is constant across subjects, there is no bias (because ), but when this is not true, the classical estimator can be positively or negatively biased depending on the relationship between the variances. Variables are as defined in (12).
The classical estimator for converges to
Taking the ratio of this value and the formula for given in Table 1 gives,
where variables are as defined in (12). Figure 2 plots the bias as a function of . When the variance is constant across subjects, , then the bias is zero. If not, then the direction of the bias of the classical estimator depends on the relationship between and .
Determining Effect Sizes, Sample Sizes, and Power
A convenient aspect of the robust index is that it makes asymptotic power calculations easy. The formula is the same for every parameter that is a solution to an estimating equation, such as (2). For a fixed sample size and rejection threshold, power can be determined from the robust index and degrees of freedom of the chi-squared test using (6). The explicit formula for power can be written
| 17 |
where and denote the type 1 and type 2 error rates, respectively, df denotes the degrees of freedom of the test statistic, denotes the cumulative distribution function of a noncentral chi-squared distribution with noncentrality parameter , and is as defined in (7). Equation (17) can be easily solved for sample size, power, error rate, or effect size, using basic statistical software with fixed values of the other variables (Fig. 3). Because the robust index is not model dependent, power curves are effectively model-free and applicable for any fixed sample size, rejection threshold, and degrees of freedom.
Fig. 3.

Power curves as a function of the sample size for several values of the robust index (S) and degrees of freedom (df), for a rejection threshold of . The curves are given by formula (17) and are not model dependent.
Simulation Analysis
We used 1,000 simulations to assess finite sample bias and standard errors of the estimator (8). Covariates of row vectors, , were generated from a multivariate normal distribution , where,
with , , and . Here, and denote the identity matrix and a vector of ones in , respectively. This distribution implies that the total correlation between the nuisance covariates and target covariates is equal to . Samples of , for of size were generated with mean
where was determined such that . We used a gamma distribution with shape parameter and rate equal to to generate heteroskedastic errors for . For each simulation, we compute bias of the estimator (8). Only a subset of the results are reported here; however, code to run the simulations and the saved simulation results are published with this paper.
Bias and standard error of the estimator is presented for , for , and all values of S considered in the simulations (Fig. 4). Results demonstrate the effect size estimator is biased upwards in small samples, but the bias is close to zero for sample sizes over 500. Because the effect size is defined conditional on covariates, the existence of covariates does not affect estimation bias. The standard error of the estimator is larger in small samples and for larger values of S. When the sample size is small, , the standard error can be larger than the value of .
Fig. 4.

Bias and standard error of when the data generating distribution has skew0.63 with two nuisance covariates (). tends to be positively biased across values of S. The standard error is proportional to S and is quite large in small samples. Rhosq denotes the total squared correlation of nuisance covariates with the target variables. Rhosq does not affect the bias, standard error, or value of the effect size index because S is defined conditionally on the covariates.
Discussion
We proposed a robust effect size index that utilizes an M-estimator framework to define an index that is generalizable across a wide range of models. The robust index provides a unifying framework for formulaically relating effect sizes across different models. The proposed index is robust to model misspecification, has an easily computable estimator, and is related to classical effect size indices. We showed that classical estimators can be asymptotically biased when the covariance model is misspecified.
The relationship between the robust index and indices based on correctly specified models (such as Cohen’s d and ) is appealing because it follows intuition from other areas of robust covariance estimation. That is, when the estimating equation is proportional to the log-likelihood, then the robust index is a function of classical definitions derived from likelihood-based models. The new framework also generalizes classical indices by easily accommodating nuisance covariates and sandwich covariance estimators that are robust to heteroskedasticity. The robust index puts effect sizes for all models on the same scale so that asymptotically accurate power analyses can be performed for model parameters using a single framework.
One important feature of the proposed index is that it is defined conditional on covariates. While the effect size lies on a standardized scale that is related directly to the power of the test, the inclusion of covariates affects the interpretation of the index because it is defined conditional on the covariates. For this reason, careful consideration of the target parameter is necessary for accurate interpretation and comparison across studies that present the robust index. Marginal estimators (without conditioning on covariates) should be considered if the investigator is interested in the general effect across a given population.
Several limitations may inspire future research topics: Like p-values, estimates of effect size indices can be subject to bias by data dredging. Also, the estimator can be biased in small samples because the index is based on asymptotic results. Thus, methods for bias adjustment or low mean squared error estimators could be considered to adjust the effects of data dredging or small sample sizes. Here, we considered an M-estimator framework, but a semiparametric or robust likelihood framework may have useful properties as well (Royall and Tsou, 2003; Blume et al., 2007). We believe this index serves as a first step in constructing a class of general robust effect size estimators that can make communication of effect sizes uniform across models in the behavioral sciences.
Acknowledgements
We are grateful to three anonymous reviewers whose comments substantially improved the quality of this paper.
Appendix
The following regularity conditions are required for the asymptotic normality of (Van der Vaart, 2000)
Funding
National Institutes of Health grants: (5P30CA068485-22 to S.N.V.).
Footnotes
Publisher's Note
Springer Nature remains neutral with regard to jurisdictional claims in published maps and institutional affiliations.
Change history
11/16/2020
The original version of this article unfortunately contained a typographical mistake in one of the main formula.
References
- Blume JD, Su L, Olveda RM, McGarvey ST. Statistical evidence for GLM regression parameters: A robust likelihood approach. Statistics in Medicine. 2007;26(15):2919–2936. doi: 10.1002/sim.2759. [DOI] [PubMed] [Google Scholar]
- Boos DD, Stefanski LA. Essential statistical inference: Theory and methods. New York: Springer Texts in Statistics. Springer; 2013. [Google Scholar]
- Borenstein, M., Hedges, L. V., Higgins, J. P., & Rothstein, H. R. (2009). Converting Among Effect Sizes. In Introduction to Meta-Analysis (pp. 45–49). West Sussex, UK: John Wiley & Sons Ltd.
- Chinn S. A simple method for converting an odds ratio to effect size for use in meta-analysis. Statistics in Medicine. 2000;19(22):3127–3131. doi: 10.1002/1097-0258(20001130)19:22<3127::AID-SIM784>3.0.CO;2-M. [DOI] [PubMed] [Google Scholar]
- Chow MS. A complete class theorem for estimating a noncentrality parameter. The Annals of Statistics. 1987;15(2):800–804. doi: 10.1214/aos/1176350375. [DOI] [Google Scholar]
- Cohen J. Statistical power analysis for the behavioral sciences. Hillsdale, NJ: Erlbaum Associates; 1988. [Google Scholar]
- Ferguson CJ. An effect size primer: A guide for clinicians and researchers. Professional Psychology: Research and Practice. 2009;40(5):532–538. doi: 10.1037/a0015808. [DOI] [Google Scholar]
- Fritz CO, Morris PE, Richler JJ. Effect size estimates: Current use, calculations, and interpretation. Journal of Experimental Psychology: General. 2012;141(1):2–18. doi: 10.1037/a0024338. [DOI] [PubMed] [Google Scholar]
- Goodman LA. A modified multiple regression approach to the analysis of dichotomous variables. American Sociological Review. 1972;37(1):28–46. doi: 10.2307/2093491. [DOI] [Google Scholar]
- Harshman, R. A., Raju, N. S., & Mulaik, S. A. (2016). There is a time and a place for significance testing. In What if there were no significance tests?, (pp. 109–154). Routledge.
- Hedges LV, Olkin I. Nonparametric estimators of effect size in meta-analysis. Psychological Bulletin. 1984;96(3):573. doi: 10.1037/0033-2909.96.3.573. [DOI] [Google Scholar]
- Hedges LV, Olkin I. Statistical methods for meta-analysis. London, UK: Elsevier; 1985. [Google Scholar]
- Kubokawa T, Robert CP, Saleh AKME. Estimation of noncentrality parameters. The Canadian Journal of Statistics / La Revue Canadienne de Statistique. 1993;21(1):45–57. doi: 10.2307/3315657. [DOI] [Google Scholar]
- Lenhard, W., & Lenhard, A. (2017). Calculation of Effect Sizes. https://www.psychometrica.de/effect_size.html. Accessed: 2019-08-12.
- Long JS, Freese J. Regression models for categorical dependent variables using Stata. 2. College Station: Stata press; 2006. [Google Scholar]
- López-Blázquez F. Unbiased estimation in the non-central chi-square distribution. Journal of Multivariate Analysis. 2000;75(1):1–12. doi: 10.1006/jmva.2000.1898. [DOI] [Google Scholar]
- MacKinnon JG, White H. Some heteroskedasticity–consistent covariance matrix estimators with improved finite sample properties. Journal of econometrics. 1985;29(3):305–325. doi: 10.1016/0304-4076(85)90158-7. [DOI] [Google Scholar]
- Menard S. Six approaches to calculating standardized logistic regression coefficients. The American Statistician. 2004;58(3):218–223. doi: 10.1198/000313004X946. [DOI] [Google Scholar]
- Menard S. Standards for standardized logistic regression coefficients. Social Forces. 2011;89(4):1409–1428. doi: 10.1093/sf/89.4.1409. [DOI] [Google Scholar]
- Morris SB, DeShon RP. Combining effect size estimates in meta-analysis with repeated measures and independent-groups designs. Psychological Methods. 2002;7(1):105–125. doi: 10.1037/1082-989X.7.1.105. [DOI] [PubMed] [Google Scholar]
- Neff N, Strawderman WE. Further remarks on estimating the parameter of a noncentral chi-square distribution. Communications in Statistics—Theory and Methods. 1976;5(1):65–76. doi: 10.1080/03610927608827332. [DOI] [Google Scholar]
- Rosenthal R. Parametric measures of effect size. The Handbook of Research Synthesis. 1994;621:231–244. [Google Scholar]
- Royall R, Tsou T-S. Interpreting statistical evidence by using imperfect models: Robust adjusted likelihood functions. Journal of the Royal Statistical Society: Series B (Statistical Methodology) 2003;65(2):391–404. doi: 10.1111/1467-9868.00392. [DOI] [Google Scholar]
- Saxena KML, Alam K. Estimation of the non-centrality parameter of a chi squared distribution. The Annals of Statistics. 1982;10(3):1012–1016. doi: 10.1214/aos/1176345892. [DOI] [Google Scholar]
- Selya, A. S., Rose, J. S., Dierker, L. C., Hedeker, D., & Mermelstein, R. J. (2012). A Practical Guide to Calculating Cohen’s f2, a Measure of Local Effect Size, from PROC MIXED. Frontiers in Psychology, 3(111). [DOI] [PMC free article] [PubMed]
- Shao PYS, Strawderman WE. Improving on the positive part of the umvue of a noncentrality parameter of a noncentral chi-square distribution. Journal of Multivariate Analysis. 1995;53(1):52–66. doi: 10.1006/jmva.1995.1024. [DOI] [Google Scholar]
- Trafimow D, Earp BD. Null hypothesis significance testing and Type I error: The domain problem. New Ideas in Psychology. 2017;45:19–27. doi: 10.1016/j.newideapsych.2017.01.002. [DOI] [Google Scholar]
- Van der Vaart AW. Asymptotic Statistics. Cambridge: Cambridge University Press; 2000. [Google Scholar]
- Wasserstein RL, Lazar NA. The ASA’s statement on p-values: Context, process, and purpose. The American Statistician. 2016;70(2):129–133. doi: 10.1080/00031305.2016.1154108. [DOI] [Google Scholar]
- Wasserstein RL, Schirm AL, Lazar NA. Moving to a world beyond “p 0.05”. The American Statistician. 2019;73(sup1):1–19. doi: 10.1080/00031305.2019.1583913. [DOI] [Google Scholar]
- White, H. (1980). A heteroskedasticity–consistent covariance matrix estimator and a direct test for heteroskedasticity. Econometrica: Journal of the Econometric Society, (pp. 817–838).
- Zhang Z, Schoeps N. On robust estimation of effect size under semiparametric models. Psychometrika. 1997;62(2):201–214. doi: 10.1007/BF02295275. [DOI] [Google Scholar]