

Abstract
Adverse Drug Reaction (ADR) is a significant public health concern world-wide. Numerous graph-based methods have been applied to biomedical graphs for predicting ADRs in pre-marketing phases. ADR detection in post-market surveillance is no less important than pre-marketing assessment, and ADR detection with large-scale clinical data have attracted much attention in recent years. However, there are not many studies considering graph structures from clinical data for detecting an ADR signal, which is a pair of a prescription and a diagnosis that might be a potential ADR. In this study, we develop a novel graph-based framework for ADR signal detection using healthcare claims data. We construct a Drug-disease graph with nodes representing the medical codes. The edges are given as the relationships between two codes, computed using the data. We apply Graph Neural Network to predict ADR signals, using labels from the Side Effect Resource database. The model shows improved AUROC and AUPRC performance of 0.795 and 0.775, compared to other algorithms, showing that it successfully learns node representations expressive of those relationships. Furthermore, our model predicts ADR pairs that do not exist in the established ADR database, showing its capability to supplement the ADR database.
Keywords: ADR detection, Graph Neural Network, Large-scale clinical data
Introduction
An adverse drug reaction (ADR) is considered to be one of the significant causes of morbidity and mortality, estimated to be the fourth to sixth highest cause of death in the United States [8]. Most ADR detection research has been aimed to predict ADRs in pre-marketing phases, using biomedical information sources such as chemical structures, protein targets, and therapeutic indications. Especially, studies using graph-structured data have demonstrated the superiority of modeling biomedical interactions as graphs. Nevertheless, capturing potential ADRs from the entire population in post-marketing phases is also essential to fully establish the ADR profiles [5]. The potential causal relationship between an adverse event and a drug is called a ‘signal’ when the relation is previously unknown or incompletely documented. Traditional ADR signal detection research in post-marketing phases mainly counts on a spontaneous and voluntary reporting system that collects spontaneous reports of suspected drug-related events, such as the WHO Uppsala Monitoring Center [1, 2, 4]. However, the spontaneous reporting system has inherent limitations such as underreporting [3, 16], selective reporting [4], and the lack of drug usage data. Therefore, recent studies have attempted algorithmic approaches to detect ADR signals on large clinical databases such as electronic health records (EHR) and healthcare claims data [5, 14]. Many of these studies apply basic machine learning techniques such as random forest, support vector machines, and neural networks. However, fewer studies are using graph-based approaches on the clinical databases in the field of post-marketing ADR signal detection. Due to the complex polypharmacy and multiple relations among drugs and diseases, we expect that graph structure can provide insights to potential ADRs, which may not otherwise be apparent using disconnected structures.
In this study, we develop a novel graph-based framework for ADR signal detection using healthcare claims data to construct a Drug-disease graph. Specifically, we use National Health Insurance Service-National Sample Cohort (NHIS-NSC), the 12-year healthcare claims data that covers medical histories for one million population [10]. The constructed graph is a heterogeneous graph with drug and disease nodes, as it is depicted in Fig. 1. The nodes represent the medicine prescription codes and disease diagnosis codes derived from the healthcare claims data. To represent the relations among these codes, we define edge weights using information from the data. For example, l2-distance between two node embeddings, which are learned from the data, is used to define the drug-drug and disease-disease edge weights. Also, the conditional probability computed on the data is used for the drug-disease relationship. As Graph Neural Network (GNN) models have been demonstrated [7, 19] their power to solve many tasks with graph-structured data, showing state-of-the-art performances, we use GNN-based approach for ADR detection. We verify that GNNs can learn node representations that are indicative of various relations between drugs and diseases. Then our model makes a prediction on whether a drug node and a disease node will have an ADR relation based on the learned node representations.
Fig. 1.

Overview of the proposed ADR detection task pipeline. Drug and disease embeddings are learned using Skip-gram model on clinical data. Categorical embedding is extracted from the identifier codes of drug and diseases. Skip-gram and categorical embeddings are jointly used as input of node feature in the heterogeneous graph, and the graph is passed through GNN for ADR prediction.
To evaluate the performance of the proposed approaches, we conduct experiments with the newly generated dataset using the side effect resource database (SIDER). The empirical results demonstrate the superiority of our proposed model, which outperforms other alternative machine learning algorithms with a significant margin in terms of the area under the receiver operating characteristic (AUROC) score and the area under the precision-recall curve (AUPRC) score. Furthermore, our method unveils ADR candidates that are examined to be very useful information to the medical community. Our model uses only simple data processing and well-established medical terminologies. Therefore, our work does not demand case-by-case feature engineering that requires expertise.
Related Works
There have been numerous studies on ADR prediction in pre-marketing phases, attempting graph-based approaches on biomedical information sources [12, 15, 18, 22]. These studies predicted potential side-effects of drug candidate molecules based on their chemical structures [15] and additional biological properties [12]. Although such studies may play important roles in preventing ADRs in pre-marketing phases, capturing potential ADRs in real-world use cases has been considered very important.
A spontaneous and voluntary reporting system has been an important data source of the real world drug usages. Most of the traditional ADR signal detection research used voluntary reporting systems with disproportionality analysis (DA), which measures disproportionality of observed drug-adverse event pairs existing in data and the null expectations [1, 2, 4]. Recently, large-scale clinical databases such as EHR (Electronic Health Records) or healthcare claims data have gained popularity as an alternative or additive data source in ADR signal detection research. Much of the studies applied machine learning techniques such as support vector machine (SVM), random forest (RF), logistic regression (LR) and other statistical machine learning methods to model the decision boundary to detect ADR in post-marketing phases [5, 6, 11, 14, 21].
More recently, researchers explored neural network-based models over clinical databases. Shang et al. [17] combined graph structure with the memory network to recommend a personalized medication. The longitudinal electronic health records and drug-drug interaction information were embedded as a separate graph to be jointly considered for the recommendation. There also exists research for the recommendation, but the architectures are limited to the single use of instance symptoms [20, 23], or patient history [9]. However, none of these research explored graph neural network model for predicting the ADR reactions in the post-marketing phase.
The Proposed Framework
In this section, we formulate our problem and describe how we apply graph structures for the task. We also present the process of training and prediction.
Problem Formulation
The task is to predict the potential causal relationship between a given drug and a disease pair, which represents the prescription code and the diagnosis code in clinical data. To consider the various relationships between drugs and diseases, we convert our clinical data into a novel graph structure that consists of drug and disease nodes. The node representations and the edge weights are given according to the information retrieved from the clinical data NHIS-NSC in this study. We first learn a node embedding that reflects the temporal proximity between homogeneous nodes, i.e., drug-drug and disease-disease node pairs. In order to model the proximity between two codes, we form drug/disease sequences from patients’ records.
After the drug-disease graph is constructed, we build a GNN model that predicts the signal of side effects between any pairs of drug and disease. The side effect labels, which are taken from the SIDER database, are given to a subset of drug-disease pairs in graph G. We define the label function  as follows:
as follows:
 |
1 |
where  and
and  are the subsets of
are the subsets of  and
and  registered in the SIDER database respectively, and
registered in the SIDER database respectively, and  is the set of drug-disease pairs that are known to have side effect relation according to the SIDER database.
is the set of drug-disease pairs that are known to have side effect relation according to the SIDER database.
Code Embedding Learning with Skip-Gram Model
Most large-scale clinical databases including NHIS-NSC, are collected in the form of longitudinal visit records of the patients. In this section, we explain how we process the patient’s longitudinal records as sequential data and apply skip-gram model to learn the code embeddings.
Definition 1 (Drug/Disease Sequence). In the patient’s longitudinal records, each patient can be treated as a sequence of hospital visits  where n represents each patient in the data, and
where n represents each patient in the data, and  is the total number of visits of the patient. The
is the total number of visits of the patient. The 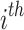 visit can be denoted as
visit can be denoted as  where
where 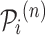 is the set of prescribed codes and
is the set of prescribed codes and 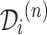 is the set of diagnosed codes in the
is the set of diagnosed codes in the  visit. Within a set of codes, codes are listed in arbitrary order. The size of each set is variable since the number of prescribed/diagnosed codes varies from visit to visit. With these sets of codes, we form a drug sequence
visit. Within a set of codes, codes are listed in arbitrary order. The size of each set is variable since the number of prescribed/diagnosed codes varies from visit to visit. With these sets of codes, we form a drug sequence 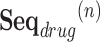 and a disease sequence
and a disease sequence 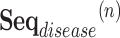 of
of  patient by listing each of the codes in a temporal order, as it is described below (Here, we leave out the symbol n):
patient by listing each of the codes in a temporal order, as it is described below (Here, we leave out the symbol n):
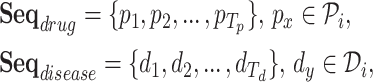 |
2 |
where 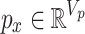 and
and 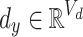 are the one-hot vectors representing each of the medical codes in the sequences.
are the one-hot vectors representing each of the medical codes in the sequences. 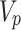 and
and 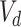 are the vocabulary size of the whole prescription and diagnosis codes within the data, respectively.
are the vocabulary size of the whole prescription and diagnosis codes within the data, respectively. 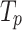 and
and 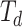 represent the total number of prescription/diagnosis codes of the patient’s record. In this way, we can build a corpus consisting of
represent the total number of prescription/diagnosis codes of the patient’s record. In this way, we can build a corpus consisting of  or
or 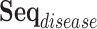 , in which the proximity-based code embedding learning can be implemented.
, in which the proximity-based code embedding learning can be implemented.
We use Skip-gram [13] model to learn the latent representation of medical codes in our data, in a way that captures the temporal proximity between them. With  or
or  , we use the context window size of 16, meaning 16 codes behind and 16 codes ahead, and apply the Skip-gram learning with negative sampling scheme. As a result, we project both diagnosis codes and prescription codes into the separate lower-dimensional spaces, where codes are embedded close to one another that are in close proximity to them. The trained Skip-gram vectors are then used as the proximity-based code embeddings.
, we use the context window size of 16, meaning 16 codes behind and 16 codes ahead, and apply the Skip-gram learning with negative sampling scheme. As a result, we project both diagnosis codes and prescription codes into the separate lower-dimensional spaces, where codes are embedded close to one another that are in close proximity to them. The trained Skip-gram vectors are then used as the proximity-based code embeddings.
Drug-Disease Graph Construction
Here, we describe how we construct our unique Drug-disease graph from NHIS-NSC. In Definition 2, we explain the concept of the Drug-disease graph. Then, we explain the node representations and edge connections.
Definition 2 (Drug-disease Graph). We construct a single heterogeneous graph 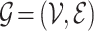 consisting of drug and disease nodes, where
consisting of drug and disease nodes, where 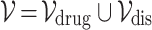 is the union of drug and disease nodes, and
is the union of drug and disease nodes, and  is the union of homogeneous edges
is the union of homogeneous edges  and
and 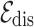 (i.e. consisting of same type of nodes) and heterogeneous edges
(i.e. consisting of same type of nodes) and heterogeneous edges 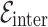 (i.e. consisting of different types of nodes).
(i.e. consisting of different types of nodes).
To represent  and
and  , we jointly use proximity-based node representation along with category-based node representation. Proximity-based node representation is obtained by initial Skip-gram code embedding as in Sect. 3.2. We denote a proximity-based drug node as
, we jointly use proximity-based node representation along with category-based node representation. Proximity-based node representation is obtained by initial Skip-gram code embedding as in Sect. 3.2. We denote a proximity-based drug node as  and a disease node as
and a disease node as 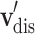 . Category-based node representation is designed to represent the categorical information of medical codes. We utilize the hierarchical structure of categorical codes (i.e. ATC and ICD-10 codes) by adopting the one-hot vector format. Since there are multiple categories for each code, the category-based node representation is shown as a concatenation of one-hot vectors, thus, a multi-hot vector. Finally, the initial node representation of the Drug-disease graph are represented as the concatenation of the proximity-based node embeddings and the category-based node embeddings. Following are the definitions for the drug and disease node representations.
. Category-based node representation is designed to represent the categorical information of medical codes. We utilize the hierarchical structure of categorical codes (i.e. ATC and ICD-10 codes) by adopting the one-hot vector format. Since there are multiple categories for each code, the category-based node representation is shown as a concatenation of one-hot vectors, thus, a multi-hot vector. Finally, the initial node representation of the Drug-disease graph are represented as the concatenation of the proximity-based node embeddings and the category-based node embeddings. Following are the definitions for the drug and disease node representations.
Definition 3 (Node Representations)
 |
3 |
where 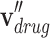 is a category-based drug node,
is a category-based drug node, 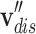 is a category-based disease node,
is a category-based disease node, 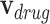 is an initial drug node,
is an initial drug node,  is an initial disease node, and || is a vector concatenation function. Each
is an initial disease node, and || is a vector concatenation function. Each 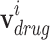 represents the each level in the ATC code structure and
represents the each level in the ATC code structure and 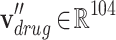 . Because the ATC code structure is represented in 5 levels, a drug node vector is also represented as the concatenation of 5 one-hot vectors. Similarly, each
. Because the ATC code structure is represented in 5 levels, a drug node vector is also represented as the concatenation of 5 one-hot vectors. Similarly, each 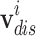 represents each of the first two levels in the ICD-10 code structure and
represents each of the first two levels in the ICD-10 code structure and  . We only use two classification levels of the ICD-10 code structure, therefore, the disease node vector is represented as the concatenation of 2 one-hot vectors.
. We only use two classification levels of the ICD-10 code structure, therefore, the disease node vector is represented as the concatenation of 2 one-hot vectors.
For homogeneous edges like 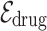 and
and 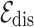 , we view the relationships between homogeneous nodes as the temporal proximity of two entities, meaning that two nodes are likely to be close together in the records. Therefore, using the proximity-based node embeddings, we compute l2-distance between two node embeddings to estimate the temporal proximity. For heterogeneous edges, which are the edges connecting drug nodes and disease nodes, are given as the conditional probability of drug prescription given the diagnosed disease. The definitions of the two types of edges are given as follows:
, we view the relationships between homogeneous nodes as the temporal proximity of two entities, meaning that two nodes are likely to be close together in the records. Therefore, using the proximity-based node embeddings, we compute l2-distance between two node embeddings to estimate the temporal proximity. For heterogeneous edges, which are the edges connecting drug nodes and disease nodes, are given as the conditional probability of drug prescription given the diagnosed disease. The definitions of the two types of edges are given as follows:
Definition 4 (Homogeneous Edges). For any node 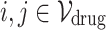 (or
(or 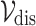 ), the edge weight
), the edge weight 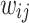 between two nodes are defined using Gaussian weighting function as follows:
between two nodes are defined using Gaussian weighting function as follows:
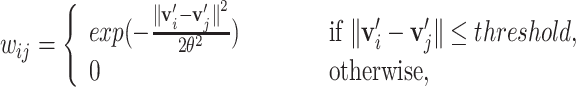 |
4 |
for some parameters threshold and  .
.  and
and  are the proximity-based node embeddings of two nodes i and j. Later, we additionally use edge-forming thresholds to control the sparsity of the graph.
are the proximity-based node embeddings of two nodes i and j. Later, we additionally use edge-forming thresholds to control the sparsity of the graph.
Definition 5 (Heterogeneous Edges). For any drug node  and any disease node
and any disease node  , the edge weight
, the edge weight 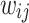 between two nodes are given as:
between two nodes are given as:
 |
5 |
where 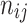 is number of patients’ histories in the NHIS-NSC database that is recorded with a diagnosis j and a prescription i in tandem.
is number of patients’ histories in the NHIS-NSC database that is recorded with a diagnosis j and a prescription i in tandem.  is the number of patients’ histories with the diagnosis j.
is the number of patients’ histories with the diagnosis j.
A GNN-Based Method for Learning Graph Structure
We aggregate neighborhood information of each drug/disease node from the constructed graph using the Graph Neural Network (GNN) framework. In each layer of GNN, the weighted sum of neighboring node features in the previous layer is computed to serve as the node features (after applying a RELU nonlinearity 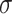 ) as follows:
) as follows:
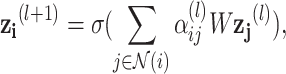 |
6 |
where  denotes the set of neighbors of
denotes the set of neighbors of  node,
node, 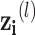 denotes feature vector of
denotes feature vector of 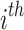 node at
node at 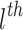 layer, W denotes a learnable weight matrix and
layer, W denotes a learnable weight matrix and 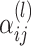 denotes the normalized edge weight between
denotes the normalized edge weight between 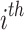 and
and 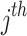 nodes at the
nodes at the 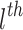 layer. In the first layer, the initial drug/disease node representations are each passed through a nonlinear projection function to match their dimensions.
layer. In the first layer, the initial drug/disease node representations are each passed through a nonlinear projection function to match their dimensions.
We use two weighting schemes for 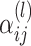 . The first variant follows the definition in [7], and the weight is defined as follows:
. The first variant follows the definition in [7], and the weight is defined as follows:
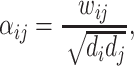 |
7 |
where 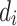 and
and 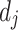 are the degree of nodes i and j respectively, and
are the degree of nodes i and j respectively, and 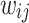 are the edge weights defined in Sect. 3.3. The weights are fixed for all layers. The second weighting scheme instead learns the weighting scheme using attention mechanism [19] as follows:
are the edge weights defined in Sect. 3.3. The weights are fixed for all layers. The second weighting scheme instead learns the weighting scheme using attention mechanism [19] as follows:
 |
8 |
where g is a single fully-connected layer with LeakyReLU nonlinearity that takes a pair of node features as input. In the rest of this paper, we call the network with the first weighting scheme as GCN and the network with the second scheme as GAT.
We predict the ADR signal of a drug-disease pair using the learned embeddings from the GNN model with a single bilinear layer as follows:
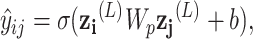 |
9 |
where  , b are the learnable weights, and
, b are the learnable weights, and  ,
,  are the node features of drug node i and disease node j at the last GNN layer. The whole model is trained by minimizing the cross-entropy loss.
are the node features of drug node i and disease node j at the last GNN layer. The whole model is trained by minimizing the cross-entropy loss.
Experiments
Data Preprocessing
As we get the labels from the SIDER database and the edge weight from the NHIS-NSC database, we retrieve the drug and disease nodes over the joint set of two databases. The resulting dataset is composed of 607 drugs and 556 diseases, and the number of positive samples, indicating the drug-side effect relationships, are 28,746 pairs. A negative sample is defined as a combination of drugs and diseases over the dataset, where the known 28,746 positive samples are excluded. We randomly select negative samples, setting the size of negative samples same as the size of positive samples.
Experimental Settings
Since we extract those combinations from the SIDER database, it is plausible to believe that they have not been reported as ADRs. Although the labels are only given to the drug-disease pairs over the joint set of two databases, we make use of all the drugs and diseases in NHIS-NSC as graph nodes to utilize the relations among the drugs and diseases.
To predict the link between the drugs and diseases, we split drug-disease pairs from the ADR dataset into training, validation, and test sets, ensuring that the classes of diseases included in each set do not overlap. The reason we split the data without overlapping disease classes is to increase the usability of the ADR signal detection model. It is also because only a few classes of diseases exist in our dataset, and therefore there could be a data leakage if the same disease class exists in both training and validation. The class of disease means the classification up to the third digit of ICD-10 codes. Note that we make the inference very difficult by not letting the model know which classes of diseases are linked with drugs as ADRs. We use 80% of data for training, 10% for validation, and the remaining 10% for testing.
To control the sparsity of a graph, we build two types of graphs where the edge-forming threshold is either low or high. When the edge-forming threshold is low, the graph has more edges, having more information as a result. We examine whether it is beneficial or detrimental to have more edge information. We distinguish two graphs by setting the thresholds for  differently. The summary statistics of the constructed graphs and datasets are provided in Table 1.
differently. The summary statistics of the constructed graphs and datasets are provided in Table 1.
Table 1.
Summary statistics of the constructed graph and datasets
| Edge-forming threshold | Low | High |
|---|---|---|
| # Drug nodes | 1,201 | |
| # Labeled drug-dis pairs in train | 37,016 | |
| # Labeled drug-dis pairs in test | 6,092 | |
| # Disease nodes | 10,117 | |
| # Drug2drug-Edges | 19,918 | 7,199 |
| # Drug2dis-Edges | 1,306 | |
| # Dis2dis-Edge | 401,801 | |
Evaluations
To verify the performance of the GCN-based approach, we compare GCN-based models with non-graph-based ML techniques. We apply vanilla GCN and its variants to examine the effect of considering the edge types. The followings are the models used for the graph embedding learnings. All the neural-network based models use two layers with a hidden dimension of 300.
LR is a logistic regression (LR) approach with information of the graph topology. The vector composed of initial node representations of the node itself and its neighbor nodes are input to the LR model. The number of neighbors is limited to 10.
NN is a 2-layer fully-connected neural network which is solely based on the initial node representations.
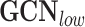 is a graph convolution network, a representative GNN model that uses graph convolutions [7].
is a graph convolution network, a representative GNN model that uses graph convolutions [7].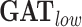 is a GNN that applies the attention mechanism on the node embeddings. Here we use GAT with two layers, where the number of heads are (4,4) for each layer.
is a GNN that applies the attention mechanism on the node embeddings. Here we use GAT with two layers, where the number of heads are (4,4) for each layer.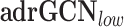 is an adapted version of GCN, that uses separate GCN layers according to the edge types and then aggregate them.
is an adapted version of GCN, that uses separate GCN layers according to the edge types and then aggregate them.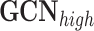 ,
, 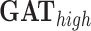 ,
,  are the graph-based models applied to the sparser graph, i.e. the edge-forming threshold is high.
are the graph-based models applied to the sparser graph, i.e. the edge-forming threshold is high.
As shown in Table 2, the proposed graph-based approaches surpass all the non-graph-based approaches. The best AUROC performance is achieved when GCN is applied with the low edge-forming threshold. The results show that the GCN model efficiently leverages the information from sufficiently selected edges. To see the robustness of the proposed method, we also examine whether our model works well for the infrequent drug-ADR pairs. We evaluate model performance for the infrequent drug-ADR pairs, which are labeled as ‘rare’ or ‘post-marketing’ in SIDER. As a result, the best average test accuracy in infrequent drug-ADR pairs is achieved with  (0.746), demonstrating that using multiple GCNs according to the edge types is useful to detect rare symptoms. According to the SIDER database, the ADRs with ‘rare‘ or ‘post-marketing‘ labels are reported with frequencies under 0.01.
(0.746), demonstrating that using multiple GCNs according to the edge types is useful to detect rare symptoms. According to the SIDER database, the ADRs with ‘rare‘ or ‘post-marketing‘ labels are reported with frequencies under 0.01.
Table 2.
Model AUROC and AUPRC performances (including 95% CI)
| Model | AUROC | AUPRC |
|---|---|---|
| LR | 0.631 ± 0.006 | 0.585 ± 0.007 |
| NN | 0.739 ± 0.005 | 0.701 ± 0.006 |
GCN
|
0.795 ± 0.006 | 0.775 ± 0.006 |
GAT
|
0.732 ± 0.005 | 0.686 ± 0.009 |
adrGCN
|
0.755 ± 0.008 | 0.726 ± 0.009 |
GCN
|
0.784 ± 0.006 | 0.761 ± 0.008 |
GAT
|
0.733 ± 0.008 | 0.692 ± 0.009 |
adrGCN
|
0.756 ± 0.004 | 0.732 ± 0.006 |
Newly-Described ADR Candidates
To verify the power of the graph-based approach to discover ADR candidates which are unseen in the dataset, we extract the drug-disease pairs which are predicted to be positive with high probability—over 0.97 but labeled as negative (false positive). To demonstrate the genuine power of graph-based methods, we exclude the candidates that are also positively predicted by the baseline neural network, which does not use relational information. As a result, clinical experts (M.D.) confirm that there exist pairs that are clearly considered to be real ADRs. The pairs are listed in Table 3.
Table 3.
Newly-described drug-ADR pairs which are predicted, by the proposed method, to be positive with high probability.
| Drug name | ADR symptom | Probability |
|---|---|---|
| Dasatinib | Cardiac murmur | 0.985 |
| Hydroxycarbamide | Abnormal reflex | 0.981 |
| Alendronic acid | Tetany | 0.978 |
| Ibandronic acid | Unspecified edema | 0.976 |
| Etidronic acid | Abnormal reflex | 0.972 |
Many of the discovered pairs, including umbrella terms like edema, are rather symptoms and signs than diseases. This can be explained by the fact that the SIDER database is less comprehensive to cover all the specific symptoms, that can be induced by taking medicine. Especially, cardiac murmur and abnormal reflex are frequent symptoms, but it is reasonable to say that the suggested pairs are ADRs. For example, Dasatinib is used to treat leukemia and can have significant cardiotoxicity, which can lead to cardiac murmurs. Hydroxycarbamide is a cytotoxic drug used for certain types of cancer, and it is known that cytotoxic medications can cause electrolyte imbalance leading to abnormal reflex.
There are also significant pairs such as alendronic acid and tetany in the third row. Severe and transient hypocalcemia is a well-known side-effect of bisphosphonates, which can lead to symptoms of tetany. Alendronic acid is classified as bisphosphonates, and therefore, tetany can be described as ADR of alendronic acid. Ibandronic acid and etidronic acid in the last two rows are also bisphosphonates, and the paired symptoms are relevant to the usage of bisphosphonates. Unspecified edema may signify bone marrow edema caused by bisphosphonate use, and electrolyte imbalance, which can lead to abnormal reflex, can be caused by etidronic acid use. All these explanations show that the ADR pairs we extract are based on various relations among drugs and diseases.
Conclusion
In this study, we propose a novel graph-based approach for ADR detection by constructing a graph from the large-scale healthcare claims data. Our model can capture various relations among drugs and diseases, showing improved performance in predicting drug-ADR pairs. Furthermore, our model even predicts drug-ADR pairs that do not exist in the established ADR database, showing that it is capable of supplementing the ADR database. The explanation by clinical experts verifies that the graph-based method is valid for ADR detection. In this study, we only make inferences within the labeled dataset, yet we plan to make inferences on unlabeled data to discover unknown ADR pairs, which will be a huge breakthrough in ADR detection.
Acknowledgements
K. Jung is with Automation and Systems Research Institute (ASRI), Seoul National University. This work was supported by the National Research Foundation of Korea (NRF) grant funded by the Korea government (No. 2016R1A2B2009759).
Contributor Information
Hady W. Lauw, Email: hadywlauw@smu.edu.sg
Raymond Chi-Wing Wong, Email: raywong@cse.ust.hk.
Alexandros Ntoulas, Email: antoulas@di.uoa.gr.
Ee-Peng Lim, Email: eplim@smu.edu.sg.
See-Kiong Ng, Email: seekiong@nus.edu.sg.
Sinno Jialin Pan, Email: sinnopan@ntu.edu.sg.
Heeyoung Kwak, Email: hykwak88@snu.ac.kr.
Minwoo Lee, Email: minwoolee@snu.ac.kr.
Seunghyun Yoon, Email: mysmilesh@snu.ac.kr.
Jooyoung Chang, Email: joomyjoo@gmail.com.
Sangmin Park, Email: smpark.snuh@gmail.com.
Kyomin Jung, Email: kjung@snu.ac.kr.
References
- 1.Bate A, Lindquist M, Edwards IR, Orre R. A data mining approach for signal detection and analysis. Drug Saf. 2002;25(6):393–397. doi: 10.2165/00002018-200225060-00002. [DOI] [PubMed] [Google Scholar]
- 2.Hauben M, Bate A. Decision support methods for the detection of adverse events in post-marketing data. Drug Discov. Today. 2009;14(7–8):343–357. doi: 10.1016/j.drudis.2008.12.012. [DOI] [PubMed] [Google Scholar]
- 3.Hazell L, Shakir SA. Under-reporting of adverse drug reactions. Drug Saf. 2006;29(5):385–396. doi: 10.2165/00002018-200629050-00003. [DOI] [PubMed] [Google Scholar]
- 4.Hochberg A, Hauben M. Time-to-signal comparison for drug safety data-mining algorithms vs. traditional signaling criteria. Clin. Pharmacol. Ther. 2009;85(6):600–606. doi: 10.1038/clpt.2009.26. [DOI] [PubMed] [Google Scholar]
- 5.Jeong E, Park N, Choi Y, Park RW, Yoon D. Machine learning model combining features from algorithms with different analytical methodologies to detect laboratory-event-related adverse drug reaction signals. PloS One. 2018;13(11):1–15. doi: 10.1371/journal.pone.0207749. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 6.Karlsson I, Zhao J, Asker L, Boström H. Predicting adverse drug events by analyzing electronic patient records. In: Peek N, Marín Morales R, Peleg M, editors. Artificial Intelligence in Medicine; Heidelberg: Springer; 2013. pp. 125–129. [Google Scholar]
- 7.Kipf, T.N., Welling, M.: Semi-supervised classification with graph convolutional networks. arXiv preprint arXiv:1609.02907 (2016)
- 8.Lazarou J, Pomeranz BH, Corey PN. Incidence of adverse drug reactions in hospitalized patients: a meta-analysis of prospective studies. JAMA. 1998;279(15):1200–1205. doi: 10.1001/jama.279.15.1200. [DOI] [PubMed] [Google Scholar]
- 9.Le, H., Tran, T., Venkatesh, S.: Dual memory neural computer for asynchronous two-view sequential learning. In: Proceedings of the 24th ACM SIGKDD, pp. 1637–1645. ACM (2018)
- 10.Lee J, Lee JS, Park SH, Shin SA, Kim K. Cohort profile: the national health insurance service-national sample Cohort (NHIS-NSC), South Korea. Int. J. Epidemiol. 2016;46(2):e15. doi: 10.1093/ije/dyv319. [DOI] [PubMed] [Google Scholar]
- 11.Liu M, et al. Comparative analysis of pharmacovigilance methods in the detection of adverse drug reactions using electronic medical records. JAMIA. 2012;20(3):420–426. doi: 10.1136/amiajnl-2012-001119. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 12.Liu M, et al. Large-scale prediction of adverse drug reactions using chemical, biological, and phenotypic properties of drugs. J. Am. Med. Inform. Assoc. 2012;19(e1):e28–e35. doi: 10.1136/amiajnl-2011-000699. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 13.Mikolov, T., Sutskever, I., Chen, K., Corrado, G.S., Dean, J.: Distributed representations of words and phrases and their compositionality. In: Advances in Neural Information Processing Systems, pp. 3111–3119 (2013)
- 14.Park MY, et al. A novel algorithm for detection of adverse drug reaction signals using a hospital electronic medical record database. Pharmacoepidemiol. Drug Saf. 2011;20(6):598–607. doi: 10.1002/pds.2139. [DOI] [PubMed] [Google Scholar]
- 15.Pauwels E, Stoven V, Yamanishi Y. Predicting drug side-effect profiles: a chemical fragment-based approach. BMC Bioinform. 2011;12(1):169. doi: 10.1186/1471-2105-12-169. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 16.Sarker A, et al. Utilizing social media data for pharmacovigilance: a review. J. Biomed. Inform. 2015;54:202–212. doi: 10.1016/j.jbi.2015.02.004. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 17.Shang, J., Xiao, C., Ma, T., Li, H., Sun, J.: GAMENet: graph augmented memory networks for recommending medication combination. In: Proceedings of the AAAI, vol. 33, 1126–1133 (2019)
- 18.Su C, Tong J, Zhu Y, Cui P, Wang F. Network embedding in biomedical data science. Brief. Bioinform. 2018;21:1–16. doi: 10.1093/bib/bby117. [DOI] [PubMed] [Google Scholar]
- 19.Veličković, P., Cucurull, G., Casanova, A., Romero, A., Lio, P., Bengio, Y.: Graph attention networks. In: ICLR (2018)
- 20.Wang, M., Liu, M., Liu, J., Wang, S., Long, G., Qian, B.: Safe medicine recommendation via medical knowledge graph embedding. arXiv:1710.05980 (2017)
- 21.Yoon D, Park M, Choi N, Park BJ, Kim JH, Park R. Detection of adverse drug reaction signals using an electronic health records database: comparison of the laboratory extreme abnormality ratio (clear) algorithm. Clin. Pharmacol. Ther. 2012;91(3):467–474. doi: 10.1038/clpt.2011.248. [DOI] [PubMed] [Google Scholar]
- 22.Yue, X., et al.: Graph embedding on biomedical networks: methods, applications, and evaluations. arXiv preprint arXiv:1906.05017 (2019) [DOI] [PMC free article] [PubMed]
- 23.Zhang, Y., Chen, R., Tang, J., Stewart, W.F., Sun, J.: LEAP: learning to prescribe effective and safe treatment combinations for multimorbidity. In: Proceedings of the 23rd ACM SIGKDD, pp. 1315–1324. ACM (2017)