

Abstract
Prognostic tumor growth modeling via volumetric medical imaging observations can potentially lead to better outcomes of tumor treatment management and surgical planning. Recent advances of convolutional networks (ConvNets) have demonstrated higher accuracy than traditional mathematical models can be achieved in predicting future tumor volumes. This indicates that deep learning based data-driven techniques may have great potentials on addressing such problem. However, current 2D image patch based modeling approaches can not make full use of the spatio-temporal imaging context of the tumor’s longitudinal 4D (3D + time) patient data. Moreover, they are incapable to predict clinically-relevant tumor properties, other than the tumor volumes. In this paper, we exploit to formulate the tumor growth process through convolutional Long Short-Term Memory (ConvLSTM) that extract tumor’s static imaging appearances and simultaneously capture its temporal dynamic changes within a single network. We extend ConvLSTM into the spatio-temporal domain (ST-ConvLSTM) by jointly learning the inter-slice 3D contexts and the longitudinal or temporal dynamics from multiple patient studies. Our approach can incorporate other non-imaging patient information in an end-to-end trainable manner. Experiments are conducted on the largest 4D longitudinal tumor dataset of 33 patients to date. Results validate that the proposed ST-ConvLSTM model produces a Dice score of 83.2%±5.1% and a RVD of 11.2%±10.8%, both statistically significantly outperforming (p <0.05) other compared methods of traditional linear model, ConvLSTM, and generative adversarial network (GAN) under the metric of predicting future tumor volumes. Additionally, our new method enables the prediction of both cell density and CT intensity numbers. Last, we demonstrate the generalizability of ST-ConvLSTM by employing it in 4D medical image segmentation task, which achieves an averaged Dice score of 86.3%±1.2% for left-ventricle segmentation in 4D ultrasound with 3 seconds per patient case.
Index Terms-: Tumor growth prediction, Deep learning, Convolutional LSTM, Spatio-temporal Longitudinal Study, 4D Medical Imaging
I. INTRODUCTION
Tumor growth modeling using medical images of longitudinal studies is a challenging yet important problem in precision and predictive medicine, because it may potentially lead to better tumor treatment management and surgical planning for patients. For example, treatments of pancreatic neuroendocrine tumor (PanNET or PNET) include active surveillance, surgical intervention, and medical treatment. Active surveillance is undertaken if a PanNET does not reach 3 cm in diameter or a tumor-doubling time <500 days; otherwise the corresponding PanNET should be resected due to the high risk of metastatic disease [1]. Medical treatment (e.g., everolimus) is for the intermediate-grade (PanNETs with radiologic documents of progression within the previous 12 months), advanced or metastatic disease [2]. Therefore the patient-specific prediction of PanNET’s growth pattern at earlier stages is highly desirable, since it will assist decision making on different treatment strategies to better manage the undergoing treatment or surgical planning.
Conventionally, this task has been well exploited through complex and sophisticated mathematical modeling [3]–[9], which accounts for both cell invasion and mass-effect using reaction-diffusion equations and bio-mechanical models. From there the actual tumor growth can be predicted by personalizing the established model based on clinical imaging derived tumor physiological parameters, such as morphology, metabolic rate, and cell density. While these methods yield informative results, most of them have not been able to utilize the underlying statistical distributions of tumor growth patterns in the studied patient population. The number of mathematical model parameters is often very limited (e.g., 5 in [8]), which might not be sufficient to model the inherent complexities of the growing tumors.
Furthermore, two alternative approaches have been proposed to predict tumor growth. 1) Assuming that the future tumor growth pattern follows its past trend, optical flow computing can be used to estimate previous voxel-level tumor motions, and subsequently, to predict the future deformation field via an autoregressive model [10]. Therefore the entire future brain MR scan can be generated but the resulting tumor volume still needs to be measured manually. For slow- and fast-growing brain tumors, the method achieves 13.7% and 34.2% volumetric estimation errors, respectively. However this approach does not involve the tumor growth pattern in population trend, and may over-simplify the essential challenge because it only infers the future tumor imaging under a linear way. 2) To address this issue, machine learning principle is a potential solution to incorporate the population trend into tumor growth modeling. The pioneer study [11] attempts to model the glioma growth patterns as a pixel classification problem where traditional machine learning pipeline of hand-crafted feature extraction and selection and classifier training is applied. Although only moderate levels of accuracy (where both precision and recall values are 59.8% [11]) has been achieved, this data-driven statistical learning approach has shown its potential to tackle the highly changeling task of glioma (as a fast-growing tumor) growth prediction. Nevertheless the hand-crafted imaging features could be compromised by the limited understanding of tumor growth process, and may not generalize well for other tumors.
Recently, statistical and deep learning framework [12] and two-stream convolutional neural networks (ConvNets) [13] have shown more compelling and improved performance than the mathematical modeling approach [8] using the same pancreatic tumor dataset. More importantly, the later study [13] demonstrate the effectiveness of deep ConvNets in characterizing two fundamental processes of both cell invasion and mass-effect of tumor growth.
From [12], image patch based ConvNets extract deep image features that are late-fused with clinical factors, followed by a support vector machine (SVM) classifier using all features. Such a separated process may not fully exploit the inherent correlations between the deep image features and clinical factors. The two-stream ConvNet architecture [13] treats the prediction as a local patch-based classification task, which does not consider the global information of the tumor structure and its surrounding spatio-temporal context. Both methods make predictions based on 2D image slices whereas the tumor growth modeling is in fact a 4D (3D+time) problem. Additionally, [12], [13] cannot predict other clinically relevant properties, such as tumor cell density and radiodensity in Hounsfield units (HU). Last, due to the difficulties in collecting the longitudinal tumor data and the complexities of data preprocessing, both studies are only conducted and evaluated using a relatively small dataset consisting of ten patients.
In this paper, we propose a novel deep learning approach that incorporates both 3D spatial and temporal image properties and clinical information into one single deep neural network. Our main contributions are summarized as follows. (1) A novel spatio-temporal Convolutional Long Short-Term Memory (ST-ConvLSTM) network is proposed to jointly learn the intra-slice spatial structures, the inter-slice correlations in 3D contexts, and the temporal dynamics in time sequences. (2) Compared to previous machine (deep) learning based methods [11]–[13] that utilize 2D image patches and predict the future tumor volume only, our new model is holistic image-based and enables the predictions of future tumor imaging properties, i.e., future cell density and CT intensity numbers for relevant clinical diagnosis. (3) Other clinical information, such as time intervals can be fully integrated into our end-to-end trainable deep learning framework. (4) To the best of our knowledge, we construct the largest longitudinal pancreatic neuroendocrine tumor (which is a relatively slow-growing tumor) growth database to date (33 patients with serial CT imaging added), enriching our previous dataset by more than 3 times [12], [13]. (5) We demonstrate the effectiveness and high efficiency of employing 4D ST-ConvLSTM for a 3D+time left-ventricle ultrasound image segmentation task. Only a small subset of sparsely-annotated 3D ultrasound volumes per time sequence are required by ST-ConvLSTM.
II. RELATED WORK
In recent computer vision developments, the task of future image frame prediction (i.e., predicting a visual pattern of RGB raw pixels given a short video sequence) has attracted great research interests [14]–[19]. It is closely related to unsupervised feature learning and can enable intelligent agents to react to the environments. Table I briefly summarizes recent representative deep learning based approaches to tackle this problem. There are mainly four key technique components being exploited: convolutional LSTMs (ConvLSTM), generative adversarial network (GAN), encoder-decoder network, and motion (mostly optical flow) cues.
TABLE I.
DEEP LEARNING BASED FUTURE IMAGE FRAME PREDICTION METHODS AND THEIR KEY TECHNIQUES. CONVLSTM: CONVOLUTIONAL LONG SHORT-TERM MEMORY; GAN: GENERATIVE ADVERSARIAL NETWORK.
| ConvLSTM | GAN | Encoder-Decoder | Motion | |
|---|---|---|---|---|
| LSTM [20] | - | - | - | |
| ConvLSTM [21] | √ | - | - | - |
| BeyondMSE [22] | - | - | - | |
| Autoencoder [23] | √ | - | √ | √ |
| CDNA [24] | √ | - | - | √ |
| MCNet [14] | √ | - | √ | √ |
| PredNet [25] | √ | - | - | - |
| STNet [15] | √ | √ | √ | √ |
| VPN [16] | √ | - | √ | - |
| Hierarchical [26] | - | - | √ | - |
| S2S-GAN [27] | - | √ | - | - |
| DVF [28] | - | - | √ | √ |
| DM-GAN [17] | √ | √ | √ | √ |
| PredRNN [18] | √ | - | - | - |
| SNCCL [29] | - | √ | - | - |
| Two-stream [30] | - | - | √ | √ |
| Spatial-motion [19] | √ | √ | √ | √ |
LSTM [31] is designed for the next time-step status prediction in a temporal sequence, and can be naturally extended to predict the consequent frames from previous ones in a video [20]. Next, ConvLSTM [21] is proposed to preserve the spatial structure in both the input-to-state and state-to-state transitions. Subsequently, ConvLSTM becomes the backbone model of several video prediction approaches [14]–[19], [23]–[25], where each work is enhanced with additional improvements. For example, 1) optical flow is introduced in an encoder-ConvLSTM-decoder framework [23] to explicitly model the temporal dynamics; 2) ConvLSTM is reformulated to predict motions from the current pixels to the next pixels [24] with the goal of alleviating the blurry prediction images; 3) ConvLSTM is integrated in encoder-decoder networks to estimate the discrete joint distributions of the RGB pixels which archived the highest accuracy on the moving digits dataset [16]; 4) additionally, a new spatiotemporal LSTM unit [18] is designed to memorize both temporal and spatial representations, thus obtaining better performances than the conventional LSTM.
In addition to ConvLSTM, ConvNets integrated with GAN [22], [27], [29] based image generators represent the other thread of promising solutions, especially effective on sharpening blurry predictions. Encoder-decoder networks [14]–[17], [23], [26], [28] commonly serve as backbone deep learning architectures to achieve the image-to-image prediction that typically contain multiple convolutional layers for subsampling and several deconvolutional layers for upsampling. Comprehensive discussions of the above techniques are given in [15], [17], [19], where state-of-the-art quantitative performances are presented using video, vehicle and pedestrian datasets.
ConvLSTM has also been employed for 3D medical image segmentation, and is an effective way of treating the 3D volume as a sequence of 2D consecutive slices [32]–[34]. Compared to the 2D ConvNets-based segmentation, ConvLSTM tends to be more robust and consistent inter-slice wise since 3D contextual information is memorized and propagated in the z-direction.
Beyond the problems of 3D medical image segmentation (directly on 3D volumetric data scans) and natural video prediction (using 2D image+time sequences), tumor growth prediction is processed on 4D longitudinal volumetric patient imaging scans. Desirable prediction models should not only recall the temporal evolution trend, but also keep consistent with the tumor’s 3D spatial contexts. Motivated by this assumption, we propose a novel ST-ConvLSTM network to explicitly capture their dependencies among 2D image slices, through the recurrent analysis over spatial and temporal dimensions concurrently. An alternative way of extending ConvLSTM to 4D image is based on 3D ConvLSTM model [35]. However, given the computational complexity of both 3D convolution and LSTM, such a model is hard to train and get converged. Furthermore, due to the large GPU memory consumption, its input size is limited which potentially affects its performance.
4D medical image segmentation, such as the segmentation of 3D+time ultrasound volumes [36], is another application scenario of our ST-ConvLSTM model. Currently, 2D or 3D ConvNets are the main deep neural network models to solve 4D segmentation problem. Although well-designed 2D/3D ConvNets could produce promising accuracy, the 4th temporal dimension contains the time-consistency constraints and can potentially improve the 4D segmentation accuracy. However direct usage of 4D ConvNets for segmentation is extremely slow and less practical, mainly because of the large computational complexity and the lack of 4D labels (e.g., the manual segmentation annotations for all 3D image volumes per sequence).
III. METHODS
A. Construction of 4D Longitudinal Tumor Dataset
Our 4D longitudinal tumor imaging data set used in this study consists of dual-phase contrast-enhanced CT volumes at three time points for each patient. As shown in Fig. 1, for each pair of pre- and post-contrast (arterial phase) 3D CT volumes at the same time point, their organ (e.g., pancreas) regions are first roughly cropped and registered to post-contrast CT using the ITK1 implementation of mutual information based B-spline registration [37]. The segmentation is performed manually by a medical trainee using ITK-SNAP [38]2 on the post-contrast CT (as those tumors can be better evaluated in the arterial phase), under supervision of an experienced radiologist. Three image feature channels are derived: 1) intracellular volume fraction (ICVF) images representing the cell density that is normalized between [0 100] (more details about ICVF calculation can be referred to [7]); 2) post-contrast CT images in soft-tissue window [−100, 200HU] and linearly transformed to [0 255]; 3) binary tumor segmentation mask (0 or 255). A sequence of image patches of 32×32 pixels3 centered on the 3D tumor centroid is cropped to cover the entire tumor. The cropping is repeated for the three ICVF-CT-Mask channels (right panel in Fig. 1) and forms an RGB image as illustrated in Fig. 2. The dataset is prepared for every tumor volume at each time point, and imaging volumes at different times are aligned using the segmented 3D tumor centroids, to build the spatio-temporal sequence data set for training and testing. We acknowledge that there might be some bias of using simple tumor centroids for the longitudinal alignment, but this is a relatively (more) reliable approach compared to the image appearance based registration methods, based on our preliminary experiment and past studies (e.g., [8], [12], [13]).
Fig. 1.
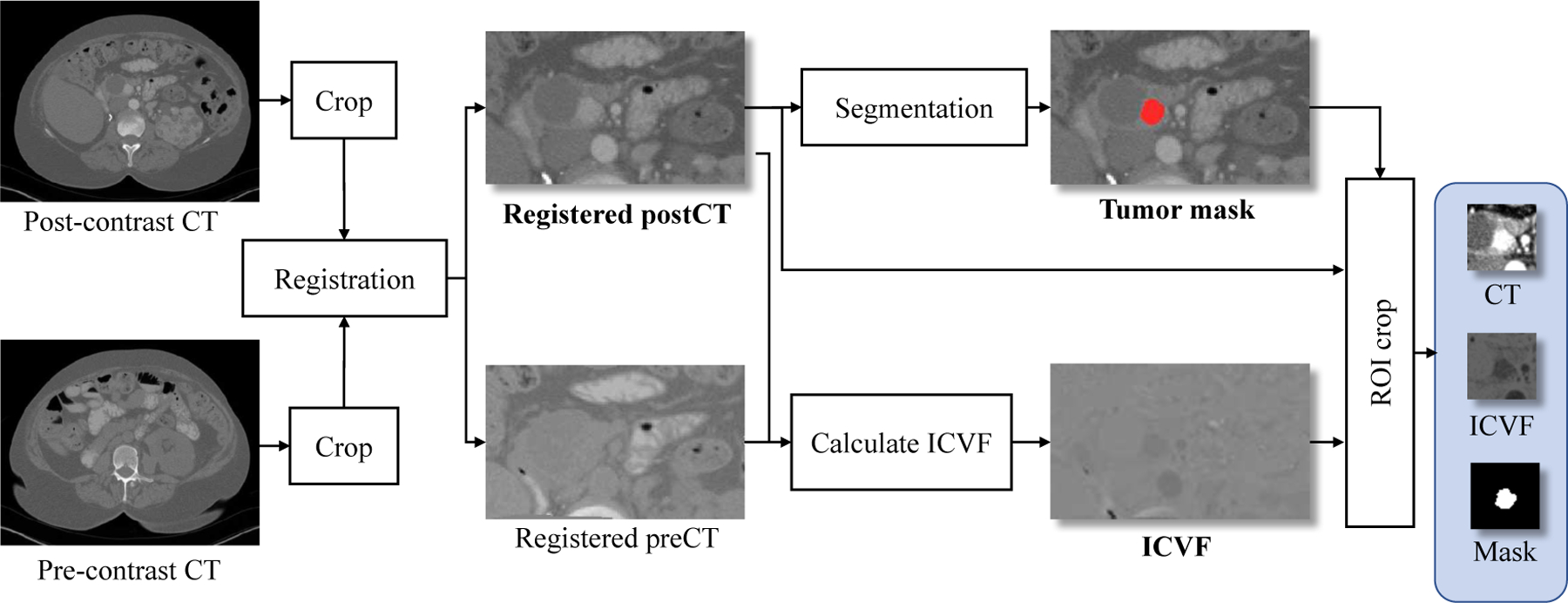
Image processing pipeline of constructing the tumor dataset for one time point.
Fig. 2. Left:
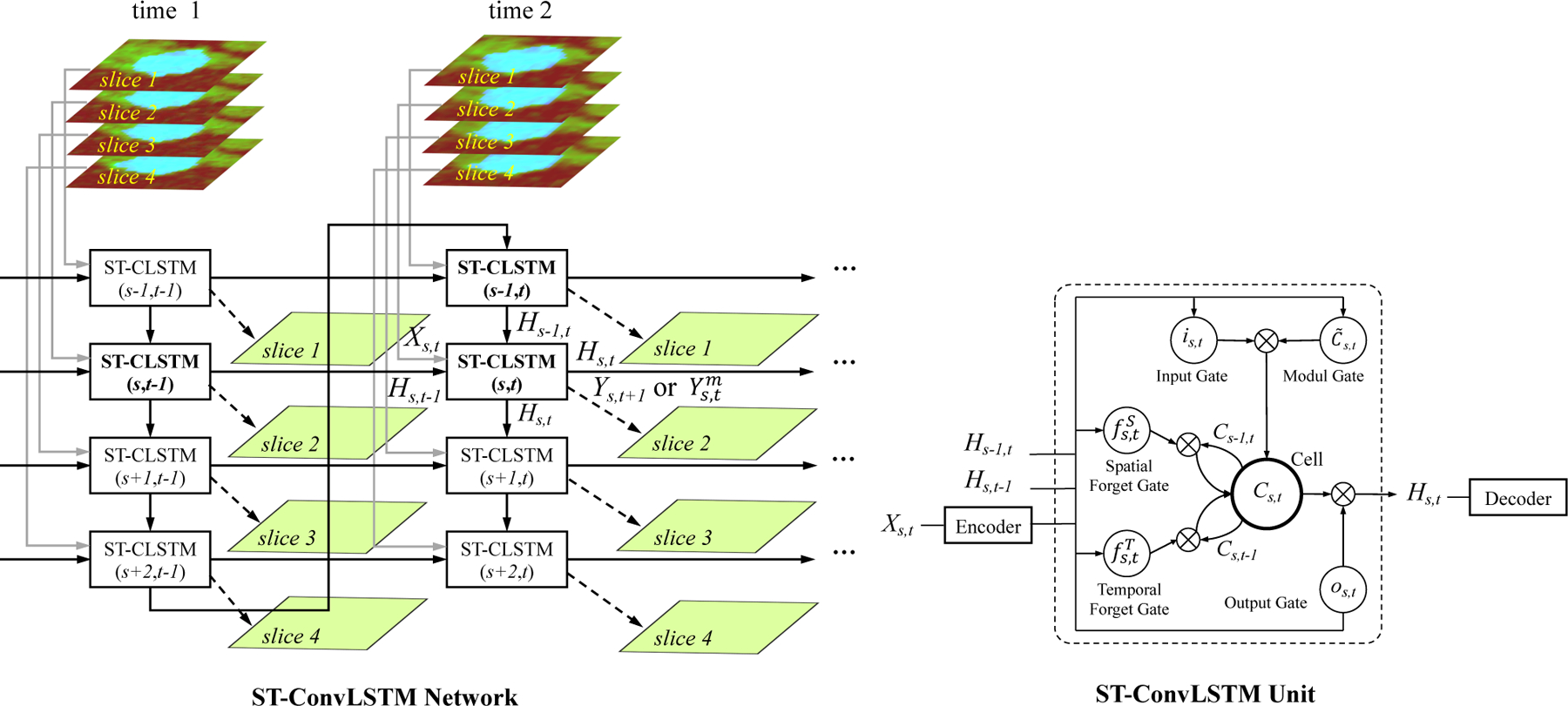
The proposed Spatio-Temporal Convolutional LSTM (ST-ConvLSTM, or ST-CLSTM) network for learning of 4D medical imaging representations to predict tumor growth or segment object. In this example, 2 time points (each with 4 spatially adjacent image slices and each slice is a 3-channel color image) are shown. This network model can be either used to predict tumor growth in 4D longitudinal data (i.e., to generate a future slice Ys,t+1) given the input Xs,t; or segment objects in 3D+time images (i.e., to compute the current segmentation mask frame Ys,t from an input ultrasound image Xs,t in Sec. IV-E). Right: The ST-ConvLSTM unit. The encoder-decoder architecture is depicted in Fig. 3.
B. Spatio-Temporal Convolutional LSTM
1). Convolutional LSTM:
LSTM [20] operates on temporal sequences of 1D vectors, and can reconstruct the input sequences or predict the future sequences. A LSTM unit contains a memory cell Ct, an input gate it, a forget gate ft, an output gate ot, and an output state Ht. Compared with the conventional LSTM, ConvLSTM is capable of modeling 2D spatio-temporal image sequences by explicitly encoding their 2D spatial structures (replacing LSTM’s fully connected transformations with spatial local convolutions in ConvLSTM) into the temporal domain [21], [33]. The main equations of ConvLSTM are as follows:
| (1) |
where σ and tanh are the sigmoid and hyperbolic tangent non-linearities, * is the convolution operator, and ⊙ is the Hadamard product. The input Xt, cell Ct, hidden states Ht, forget gate ft, input gate it, input-modulation gate , and output gate ot are all 3D tensors with the dimension of M × N × F (rows, columns, feature maps). The memory cell Ct is the key module, which acts as an accumulator of the state information controlled by the gates.
2). ST-ConvLSTM Network and Unit:
Given the ICVF-CT-Mask three-channel input maps at time 1 and time 2 (as , t ∈ {1, 2}, respectively), the aim is to predict the output ICVF-CT-Mask maps at time 3 (as , t = 3), shown in Fig. 2. Directly using ConvLSTM over temporal domain could discover the tumor 2D dynamics for its growth prediction. Furthermore, the spatial consistency in the 3D volume data and its form of sequential nature of 2D image slices make it possible to extend ConvLSTM to the 3D spatial domain.
Instead of simply concatenating the 2D CT slices, in order to learn simultaneously both the spatial consistency patterns among successive image slices and the temporal dynamics across different time points, we propose a new Spatio-Temporal Convolutional LSTM (ST-ConvLSTM) network as illustrated in Fig. 2 (left panel). In this network, each ST-ConvLSTM unit takes input from one image slice at one time point in the 4D space, and receives the hidden states from both the horizontal (the same slice locations at previous time) and vertical directions (previous adjacent slice at the current time). For example, the unit (s, t) in Fig. 2 (left panel) corresponds to the sth slice at time t, and receives the hidden states Hs,t-1 from unit (s, t - 1) and Hs-1,t from unit (s - 1, t). Along with the current input image slice , the ST-CLSTM unit (s, t) can predict the future slice , and generate its hidden state Hs,t. For the 4D ultrasound image segmentation task, the goal is from any current input raw image slice (e.g., Xs,t) to generate its output segmentation mask . In each ST-CLSTM unit (right in Fig. 2), since there are two different candidates generated from the spatial and temporal domains, respectively, two forget gates and are equipped for adding them to update the unit state. The activations of a ST-ConvLSTM at (s, t) are as follows:
| (2) |
where the input Xs,t, cell Cs,t, hidden states Hs-1,t and Hs,t-1, and gates , , is,t, , os,t are all 3D tensors with dimensions of M × N ×F (rows, columns, feature maps). More precisely, Xs,t in Eq. (1) and Eq. (2) represents the feature maps (i.e., 8 × 8 × 8 bottleneck in Fig. 3) after the convolutional encoder on the input image.
Fig. 3.
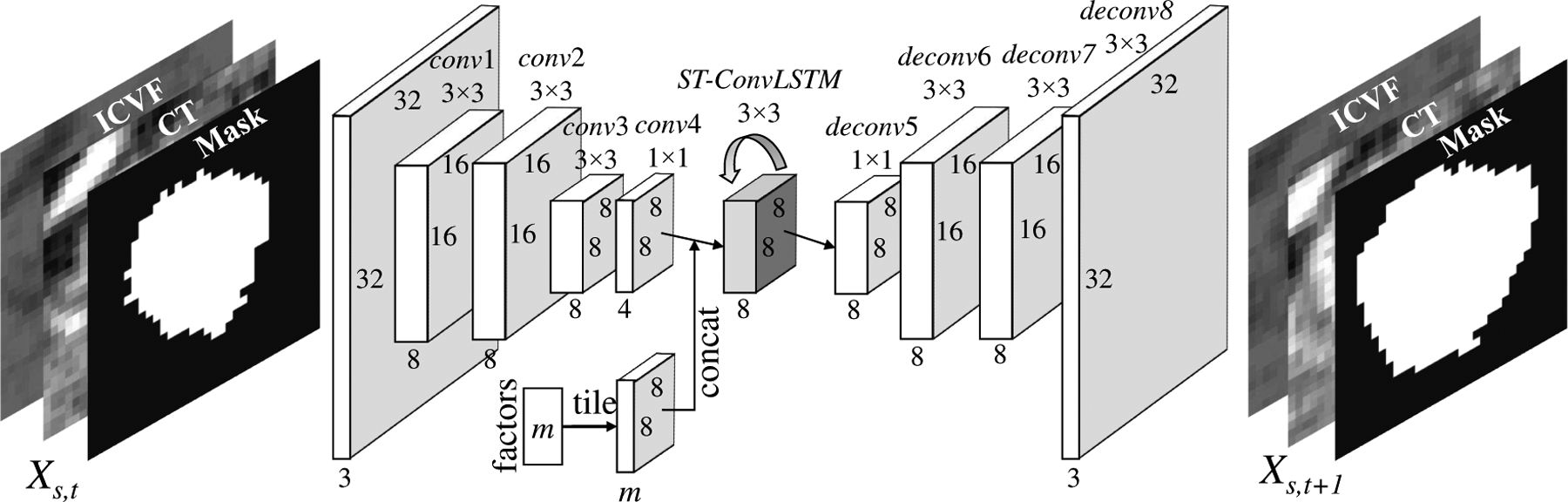
The end-to-end network architecture of our proposed encoder-ST-ConvLSTM-decoder for tumor growth prediction. For 4D segmentation task, the input is replaced with the raw (e.g., ultrasound) image, the output is its mask, no “factor” branch for other clinical properties, and network model channels are set to 1-8-16-32-64-64-64-32-16-1.
The unit of ST-ConvLSTM (1,1) does not have any preceding units in both the spatial and temporal directions, and units at time 1 level do not have the preceding units in their temporal direction. Zeros activations are fed into these units. The output hidden state of the last unit at time 1 level carries all the tumor information at time 1, thus bringing the global contexts to time 2 through the link connecting itself and the first unit at time 2. It is worth mentioning that the ST-ConvLSTM network is flexible that it can be easily extended to receive more numbers of input time points or to predict longer future steps by recursively applying the model. Moreover, for 3D+time segmentation task, only sparsely-labeled manual segmentations are required, e.g., representative volumes or even slices.
3). End-to-End Architecture:
We embed the ST-ConvLSTM unit in the encoder-decoder architecture [16], [24] to make the end-to-end predictions, as shown in Fig. 3 to replace the ST-ConvLSTM unit in Fig. 2. In other words, Fig. 3 happens in every ST-CLSTM unit in Fig. 2. Specifically, each frame Xs,t in the 4D spatio-temporal space is recurrently passed into the encoder which consists of four convolutional layers to encode a feature map. Along with the image features, clinical factors have non-neglectful influences on predicting the future image as well. We integrate the related factors into our model by spatially tiling the factors (i.e., m-dim vector) as a feature map with m-channels (m=1 in this paper, where only the time interval is added), which is then concatenated to the output of conv4 which possesses the smallest number of channels. The concatenated feature map is then fed into a standard ST-ConvLSTM unit (Fig. 2) with a 3×3 kernel and 8 hidden states for the spatio-temporal modeling. As such, the ST-ConvLSTM determines the future state by jointly considering or integrating the compact spatial information of the current slice, the states of slices from previous times and adjacent locations, and clinically relevant factor(s). After that, the decoder with four deconvolutional layers generates the future frame Ys,t+1. Because having a smaller transitional kernel helps ConvLSTM to capture smaller motions [21], we use a 3×3 convolutional kernel by taking into account the knowledge prior that the pancreatic tumor in our dataset is slow-growing. For fast-growing tumors, such as glioma, a larger convolutional kernel should be used.
4). Network Training and Testing:
For the tumor growth prediction task, during training, tumor image slices from time 1 and time 2 are fed as inputs into our network according to their corresponding spatio-temporal locations. Image slices from time 2 and time 3 are used to compute training loss. The objective function of our ST-ConvLSTM network is designed to minimize the ℓ2 loss between the predicted frames Y and the true future frames X at time 2 and time 3 (other losses, such as ℓ1 and GDL [22] have been tried, but ℓ2 produces empirically better results in our preliminary experiment):
| (3) |
where S is the spatial sub-sequence length (set to 5 in our current method). Note that minimizing the ℓ2 loss only at time 3 will have slightly lower performances, and more importantly, cannot maintain a reasonable performance on predicting time 2 which is not desired.
In testing, each spatial sequence (at time 1 and time 2) is divided to several sub-sequences, and fed into our model to generate predictions for time 3. These sub-sequences can be either overlapping or non-overlapping. In our preliminary experiment, no significantly differences are ever observed, so we use the non-overlapping sub-sequences for efficiency. In addition, our model is flexible to be extended to make prediction at an arbitrary later time point given the observational data of two previous time points, e.g., predicting time 4 based on time 1 and time 2, by directly setting the value of factor (as depicted in Fig. 3) as the time interval between time 2 and time 4. For the problem of 4D ultrasound image sequence segmentation, refer the network training and testing details to Sec. IV-E.
IV. EXPERIMENTS
A. Data and Protocol
Thirty-three patients (thirteen males and twenty females) each with a PanNET are collected from the von Hippel-Lindau (VHL) clinical trial at the National Institutes of Health. Each patient has at least three time points (eleven of these patients have the 4th time points) of dual-phase contrast-enhanced CT imaging, with the time interval of 398±90 days (average±std). The CT voxel sizes range between 0.60 × 0.60 × 1 mm3 - 0.98 × 0.98 × 1 mm3, and are resampled to 1 × 1 × 1 mm3 by trilinear interpolation. We did not include the modality of FDG-PET imaging as it only exists in a small portion of patients or time points. We acknowledge that the prediction performance may not be optimal without PET information. Nevertheless a CT-only predictive model can have wider application scenario (e.g., when more specific PET imaging is not available). The average age of patients and average volume of tumors at time 1 are 50±11 years and 1.7±1.7 cm3, respectively. Fig. 4 shows the trajectories of PanNET growth rates for different patients. The average information of all 33 patients is shown in Table II. These tumors keep slowly growing in general, but the growth speed is lower in the 2nd-3rd time period. From the 1st to 2nd time points, only one tumor shrinks. Such a number changes to twelve from the 2nd to 3rd time points. Only 11 patients have real imaging data and time interval information at time 4.
Fig. 4.
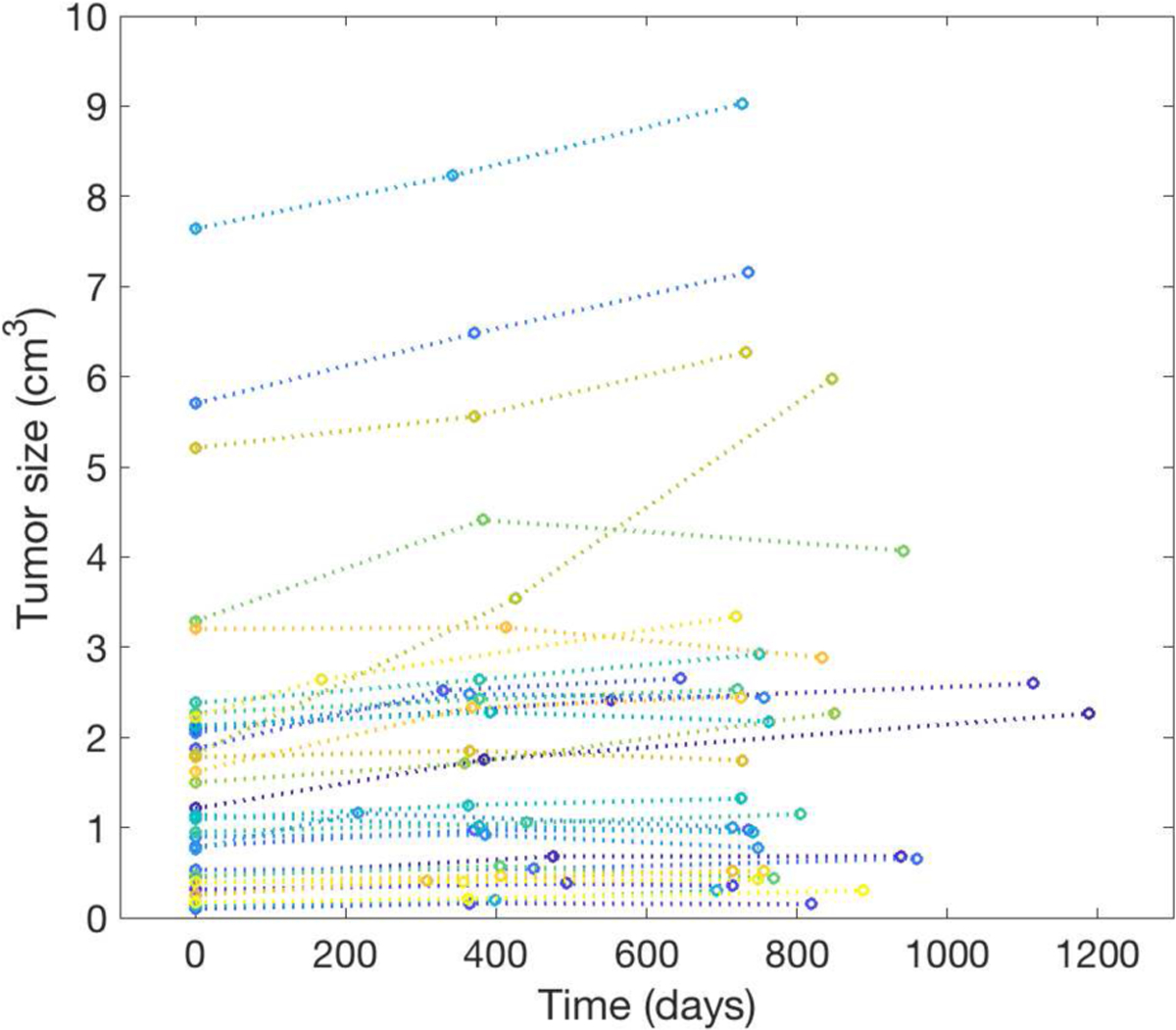
Longitudinal trajectories of PanNET tumor volumes over a population of 33 patients, from time 1 to time 3.
TABLE II.
STATISTICS OF TUMOR GROWTH AT THE 1ST, 2ND, AND 3RD TIME POINTS OF 33 PATIENTS.
| 1st-2nd | 2nd-3rd | ||||
|---|---|---|---|---|---|
| Days | Growth (%) | Days | Growth (%) | Size (cm3, 3rd) | |
| Average | 379±68 | 24.0±23.1 | 416±105 | 8.8±19.7 | 2.2±2.2 |
| [min,max] | [168,553] | [−10.5,95.6] | [221,804] | [−23.2,68.8] | [0.1,9.0] |
B. Experimental Design & Implementation Details
Training details:
Four data augmentation schemes are performed to enrich our dataset. Besides the original axial image slice sequences, we 1) reformat/reslice original volumes to obtain coronal and sagittal slices, 2) rotate (with 90 degree interval), 3) translate/shift (randomly 2 pixels in xy plane) for each 4D ICVF-CT-Mask volumetric sequence, and 4) reverse the slice order in spatial direction. Then, S=5 sub-sequences are cropped from the augmented sequences (the minimal-sized tumor in our dataset has about 5 slices), resulting in 172,296 training sub-sequences in total. Such methods add more variations into the generated or augmented dataset and improve the generalization capability. Note that we ensure the augmented sequences are still spatio-temporally aligned. We train our ST-ConvLSTM models for 5 epochs with the batch size of 16. Each data point has 5 slices at three time points. We use the ADAM optimizer [39] for neural network optimization with an initial learning rate of 10−3.
Testing details:
In the testing scenario, given any testing PanNET data including pre- and post-contrast CT scans from time 1 and time2 (, t ∈ {1, 2}), the preprocessing steps in Sec. III-A are applied to first obtain the aligned spatio-temporal ICVF-CT-Mask sequence pair. Next we divide the aligned data into several non-overlapping sub-sequence pairs: each sub-sequence image pair containing 5 consecutive slices from time 1 and their corresponding 5 from time 2. By feeding these sub-sequence pairs together with the time interval features as (time1-time2) and (time2-time3) into our model, the future (at time 3) consecutive data slices (, t = 3) can be predicted and produced. A thresholding value of 128 is applied upon the predicted probability map of mask channel to obtain a binary tumor mask Ym.
Comparison:
We implement the current clinical practice of a default linear growth model, the conventional ConvLSTM [21], and another major deep learning method for video prediction, i.e., BeyondMSE (GAN) [22], for model comparison. The linear growth model assumes that tumors would keep their past growing trend in the future. As detailed in [13], the past radial expansion/shrink distances on tumor boundaries are used to expand/shrink the current tumor boundary as future prediction. The ConvLSTM uses the same architecture as in Fig. 3 (but it only captures the temporal dependencies) and is trained with the same network optimization setting as ST-ConvLSTM. In the BeyondMSE framework, a multi-scale fully convolutional ConvNet is used as the future image generator, and a multi-scale ConvNet as the discriminator. The generator receives two past images as input and outputs one future image, while the discriminator receives all three images as input to classify whether they are real or fake. Our implementation uses the same network architecture and parameter setting as in [22]. Both ConvLSTM and BeyondMSE are trained for 5 epochs on the same augmented dataset as ST-ConvLSTM. All these aforementioned models are implemented in TensorFlow [40] and perform experiments on a DELL TOWER 7910 workstation with 2.40 GHz Xeon E5–2620 v3 CPU, 32 GB RAM, and a Nvidia TITAN X Pascal GPU of 12 GB of memory. Note that compared to previous machine (deep) learning based tumor growth model prediction methods [11]–[13] that merely utilize 2D image patches and only predict the future tumor volume, our new ST-ConvLSTM model is holistically 4D (volumetric+time) image-based and enables the predictions of future tumor imaging properties, such as future cell density and CT intensity numbers to assist relevant clinical diagnosis.
Predicting a later future:
In this experiment, we evaluate the problem of predicting a later time step 4 given only time 1 and time 2 available. For those 11 patients who have follow-up studies at time 4, we directly set the time interval between time 2 and time 4 as the feature in the trained predictive model. For the remaining 22 patients without the follow-up time step 4, we assume that their time 3 and time 4 have the equal time interval as the interval between their time 2 and time 3, in order to investigate the effectiveness of time interval feature in our predictive model on a larger patient cohort (of all 33 patient data).
C. Evaluation Methods
We evaluate our model using three-fold cross-validation. In each fold, 22 patients are used as training and the remaining 11 patients as testing data. The performance of tumor prediction is evaluated at the 3rd time point by the metrics of Dice coefficient and RVD (relative volume difference) [8], [12], [13] for tumor volume, RMSE (root-mean-squared error) for ICVF [8], and diff.HU (difference of average HU values) for CT value.
| (4) |
where TPV (true positive volume) is the overlapping volume between the predicted tumor volume Vpred and the ground truth tumor volume Vgt. icvf represents the ICVF value of a pixel. HU represents the average Hounsfield units within a volume. Both RMSE and diff.HU are evaluated within the TPV following [8], in which RMSE of ICVF prediction is assessed in the TPV. Paired t-tests are conducted to compare our new model and other previous methods.
We calculate the scatter plots of the ST-ConvLSTM predicted tumor volumes and the respective growth rates (Fig.6), in comparison with the ground truth. Based on the tumor growth rate, we also assess the performance of our method on another clinical relevant prediction task - prediction of tumor progression vs. regression at time 3. Specifically, the prediction results are divided in two groups comprising tumor progression (positive growth rate) and tumor regression (negative growth rate), where sensitivity and specificity are used as evaluation metrics. As an alternative solution, traditional machine learning methods are applied on this task by training binary classifiers and evaluating using the same three-fold cross-validation. Specifically, age, gender and tumor volume measures at time 1 and time 2, tumor volume changes between time 1 and time 2, are extracted as features for classification. Optimal feature combinations are experimented and assessed by several common classifiers including logistical regression, linear SVM, neural network (one hidden layer), and random forest.
Fig. 6.
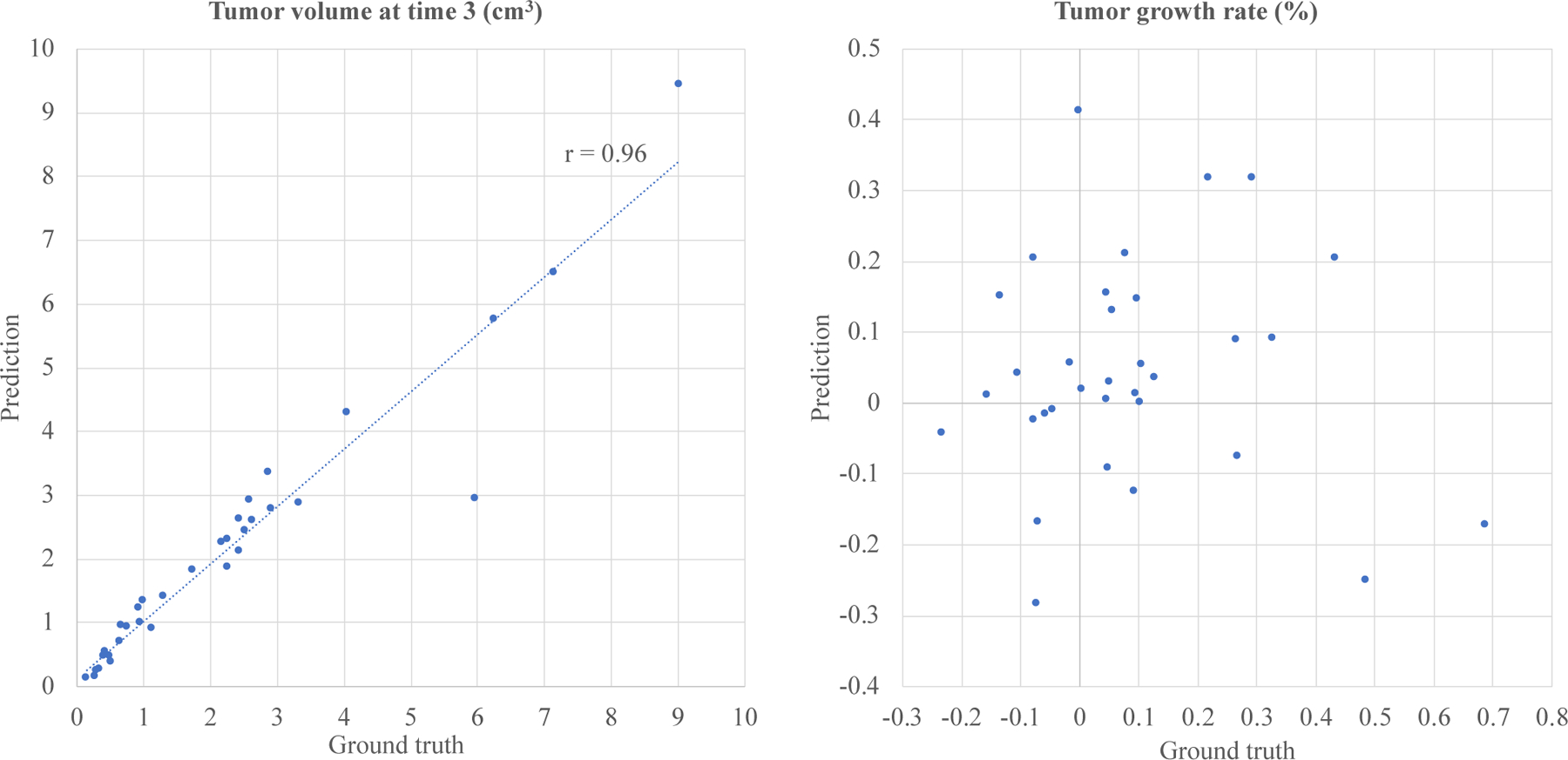
Scatter plots of ST-ConvLSTM predicted tumor volumes versus ground truth values (r is the linear correlation coefficient) (Left) and predicted tumor growth rates versus true rates (Right).
We examine the contribution of each input feature channel, by training with only one and predicting the corresponding future one: for example, from given previous CT scans to predict a future CT image. Note that RMSE and diff.HU reported here are also evaluated within the true positive volume.
D. Quantitative Results
The visual example in Fig. 5 shows the prediction results of future CT scan, tumor mask/volume, and ICVF obtained by ST-ConvLSTM (with time interval feature) and ConvLSTM. In this case, compared with the conventional ConvLSTM, our ST-ConvLSTM generates more spatially consistent prediction towards the actual tumor in terms of CT, mask and ICVF, and consequently, achieves better accuracies under all quantitative metrics (i.e., diff.HU, Dice, RVD and RMSE). Table III reports the overall performance of our ST-ConvLSTM model (with and without time interval feature) with that of ConvLSTM and the linear model on 33 patients. For the volume prediction, ST-ConvLSTM (w. time) produces a Dice score of 83.2% and a RVD of 11.2%. Both are significantly better than ConvLSTM (p <0.01 and p <0.05) and linear predictive model (p <0.001 and p <0.01). Furthermore, our model generates a RMSE of 14.0% for tumor cell density prediction, and a diff.HU of 10.2% for radiodensity prediction (no statistical significances are achieved on these two metrics in comparison to ConvLSTM). There is no significant difference between ST-ConvLSTM with and without time interval feature.
Fig. 5.
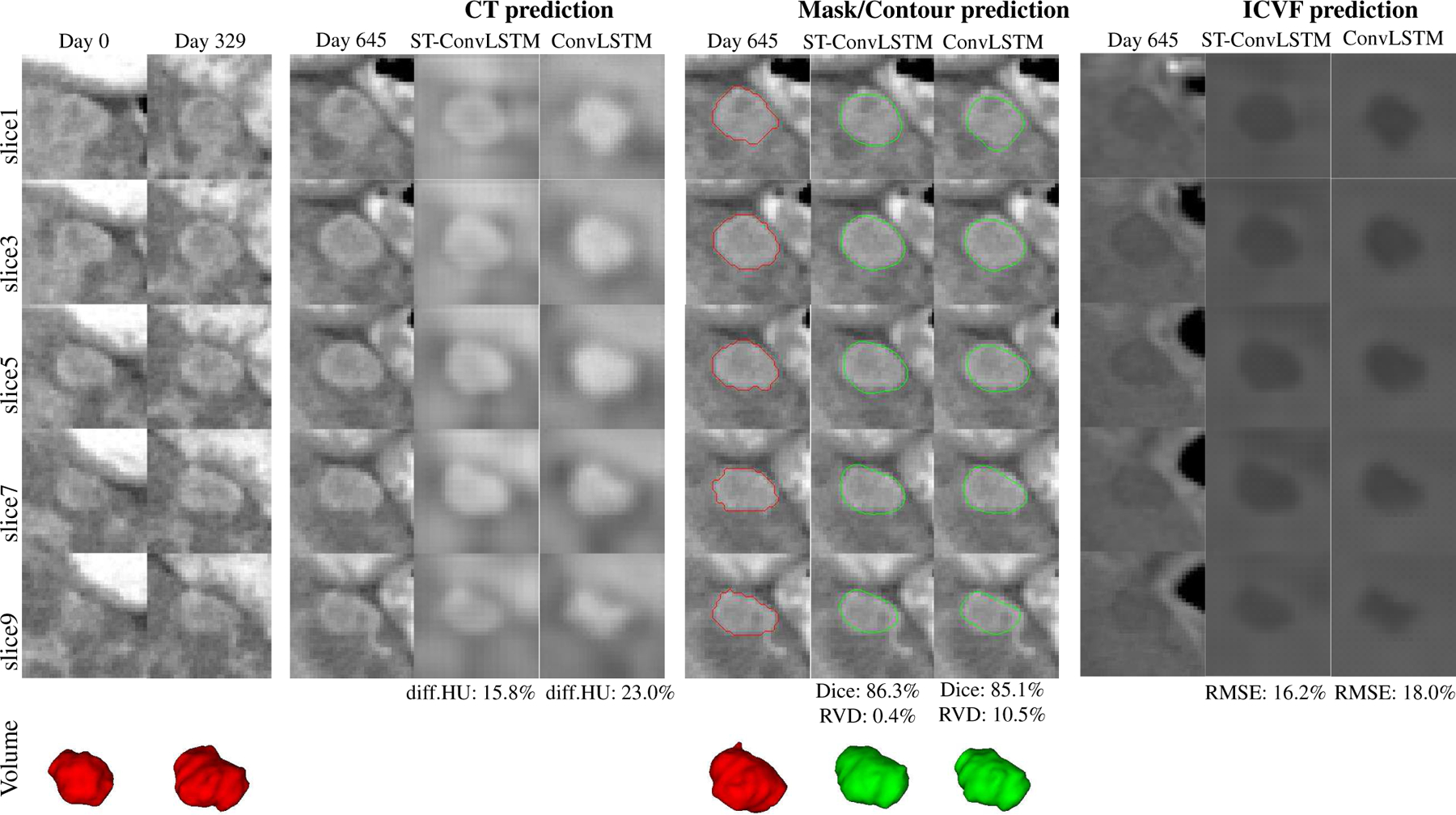
An illustrated example shows the prediction results of CT, mask/volume, and ICVF of a tumor by ST-ConvLSTM and ConvLSTM. Note that the tumor contours are superimposed on the ground truth CT images at time 3. Red: ground truth boundaries; Green: predicted tumor boundaries. In this example, consecutive image slices with the spatial interval of two slices are shown for better visualization of the spatial changes/differences.
TABLE III.
OVERALL QUANTITATIVE PERFORMANCE ON 33 PATIENTS UNDER 3-FOLD CROSS-VALIDATION - BASELINE LINEAR PREDICTIVE MODEL, CONVLSTM [21], AND OUR ST-CONVLSTM. RESULTS ARE REPORTED AS: MEAN ± STD [MIN, MAX].
| Volume-Dice (%) | Volume-RVD (%) | ICVF-RMSE (%) | CT-HUdiff. (%) | |
|---|---|---|---|---|
| Linear | 73.0±6.2 [60.2, 85.1] | 22.8±18.3 [5.1, 75.2] | - | - |
| ConvLSTM [21] | 82.1±5.8 [65.6, 90.4] | 14.1±12.4 [1.2, 50.4] | 13.7±8.4 [6.8, 42.4] | 10.4±8.3 [0.6, 32.4] |
| BeyondMSE (GAN) [22] | 79.3±5.7 [65.6, 90.4] | 20.9±14.4 [1.2, 50.4] | 19.7±12.0 [6.8, 42.4] | 10.7±8.1 [0.6, 32.4] |
| ST-ConvLSTM w/o. time | 83.1±4.9* [67.9, 91.1] | 12.6±9.0* [0.3, 48.6] | 13.9±7.9** [7.8, 43.5] | 10.0±7.3 [0.2, 26.3] |
| ST-ConvLSTM w. time | 83.2±5.1* [69.7, 91.1] | 11.2±10.8* [0.3, 46.5] | 14.0±8.5** [7.4, 41.4] | 10.2±8.5 [0.0, 35.0] |
OR
INDICATES A STATISTICALLY SIGNIFICANT DIFFERENCE OF OUR METHOD COMPARED TO OTHER METHODS AND BEYONDMSE (GAN), RESPECTIVELY. THERE IS NO SIGNIFICANT DIFFERENCE BETWEEN ST-CONVLSTM WITH AND WITHOUT TIME INTERVAL FEATURE.
The ST-ConvLSTM predicted tumor volumes achieve high correlations against the ground truth volumes (linear correlation coefficient r=0.96, the left panel in Fig. 6). However, the prediction of tumor growth rate is highly challenging (with r=0.04, the right panel in Fig. 6), especially for some extreme cases such as tumor shrink and aggressive progression (quadrants II and IV in the right panel in Fig. 6). Thus we assess the performance of a relatively more convenient binary prediction task: tumor progression (positive growth rate, 21 patients) versus regression (negative growth rate, 12 patients). As shown in Table IV, our method has a sensitivity of 76.2% and specificity of 50%, in compared to an optimized machine learning approach on this dataset that achieves a sensitivity of 61.9% and specificity of 50%. This result is obtained by a random forest classifier using the tumor volume at time 1 as the only feature (other feature combinations and classifiers are empirically worse than this performance). The overall available features and patient numbers for our studied problem are still limited.
TABLE IV.
PERFORMANCE OF PREDICTING TUMOR PROGRESSION VERSUS REGRESSION BY ST-CONVLSTM AND AN OPTIMIZED MACHINE LEARNING APPROACH ON THIS DATASET.
| Sensitivity (%) | Specificity (%) | |
|---|---|---|
| Time 1’s tumor volume + random forest | 61.9 | 50.0 |
| ST-ConvLSTM | 76.2 | 50.0 |
Figure 7 compares the prediction results of our ST-ConvLSTM with BeyondMSE (GAN) [22]. In this case, BeyondMSE has reported noticeably worse performance in predicting tumor volume, but generates less blurry CT and ICVF images (through visually observation). Table III lists the overall prediction performance of BeyondMSE, where the proposed method significantly outperforms BeyondMSE in terms of Dice, RVD, and ICVF-RMSE.
Fig. 7.

An example of image slices shows the prediction results of CT, mask/volume, and ICVF of a tumor by ST-ConvLSTM and BeyondMSE (GAN). Note that the tumor contours are superimposed on the ground truth CT images at time 3. Red: ground truth boundaries; Green: predicted tumor boundaries.
Fig. 8 shows the prediction results at an even later time step using ST-ConvLSTM for all 33 patients. As a result, 78.8% tumors are predicted to keep growing at later time points - the predicted volume at time 4 is larger than time 3. For the 11 tumors which have ground truth measures of tumor volume at time 4, our prediction produces a RVD of 37.2%±42.5%. Fig. 9 illustrates qualitative tumor visualization results upon changing the time interval feature, to examine the model’s predictions at future possible time steps. From Table V, when using the tumor mask as the single input channel, it produces statistically similar Dice and RVD measures as three input channels are utilized. However the three-channel ICVF-CT-Mask input configuration generates clearly better performance on RMSE and HUdiff. predictions.
Fig. 8.
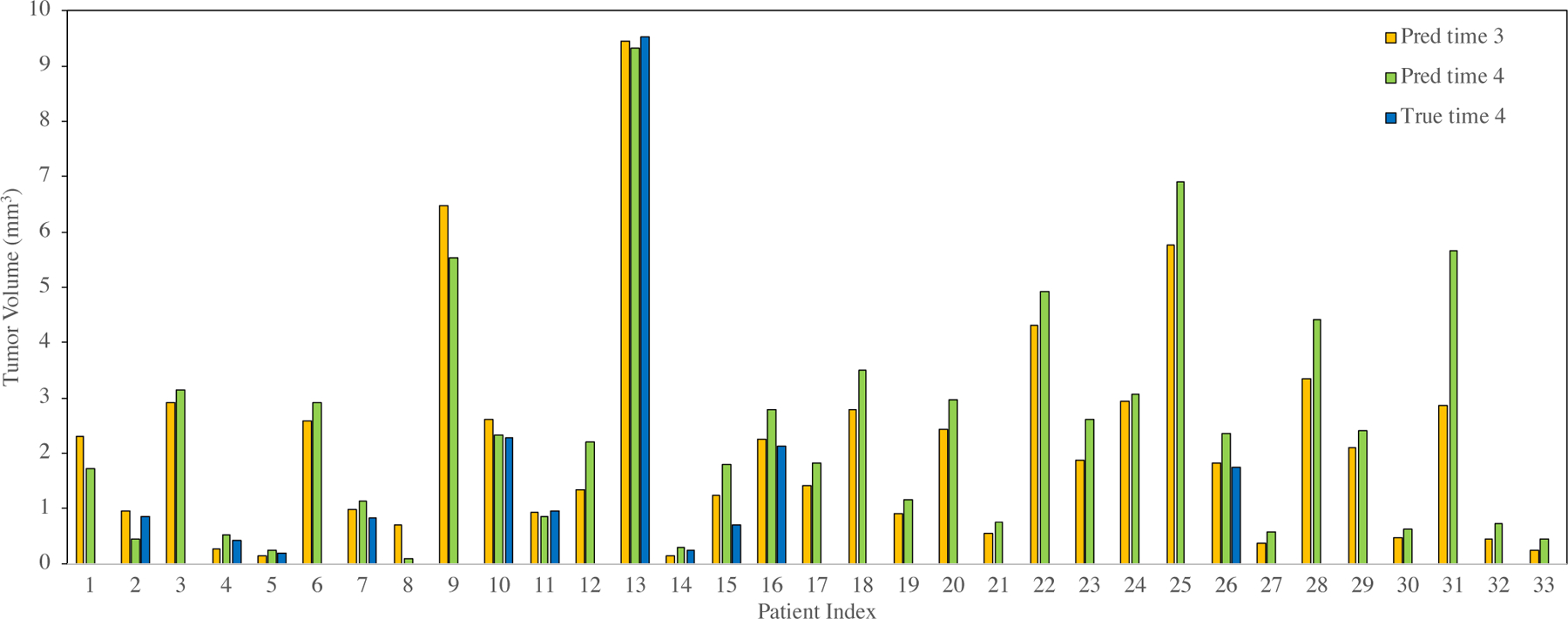
ST-ConvLSTM prediction results at an even later time point. Volume prediction results at time 4 based on time 1 and time 2 for all 33 patients. 26 out of 33 (78.8%) patients are predicted as tumor keeping growing (i.e., tumor size at time 4 larger than time 3).
Fig. 9.

One tumor example using ST-ConvLSTM predictions from time 1 (Day 0) and time 2 (Day 553), and at different later time points (Day 830, 1106, 1383, 1659). Note that the predicted tumor becomes larger when time interval grows.
TABLE V.
ABLATION STUDY SHOWING RESULTS FOR DIFFERENT INPUT FEATURE CHANNELS.
| Input channel | Dice (%) | RVD (%) | RMSE (%) | HUdiff. (%) |
|---|---|---|---|---|
| ICVF | - | - | 15.7±8.9 | - |
| CT | - | - | - | 12.1±10.8 |
| Mask | 83.6±4.7 | 13.7±11.9 | - | - |
| ICVF+CT+Mask | 83.1±4.9 | 12.6±9.0 | 13.9±7.9* | 10.0±7.3* |
INDICATES A STATISTICALLY SIGNIFICANT DIFFERENCE.
On average, our method takes ~ 1.2 hrs for training and 0.2 second for prediction per tumor. This performance is faster than the statistical and deep learning framework (~ 3.5 hrs training and 4.8 mins prediction [12]) in both training and inference; while faster than the two-stream ConvNets [13] in prediction but slower in training.
E. Segmentation in 3D+Time Ultrasound
To further demonstrate the feasibility of ST-ConvLSTM for 4D segmentation, the publicly available 3D+time ultrasound dataset CETUS [36] is used. The dataset is acquired from 15 patients where each patient containing 13–46 3D volumetric image sequences and each sequence with two volumes being manually segmented at the end-diastole (ED) and endsystole (ES) phases. We resample all 3D ultrasound scans to 1mm3 isotropic resolution. For facilitating ST-ConvLSTM training, the 4th dimension is downsampled to a constant length (i.e., 6 time points in our work), with image annotation/segmentation masks at the 1st and 6th time points. All image slices are resized to 96×96 pixels and pixel intensities are normalized to [0, 1].
2D ultrasound image slices are fed as inputs into the network according to their corresponding spatio-temporal locations to generate the corresponding segmentation masks, via a ℓ2 training loss computing only at two volumes from two time points (ED and ES phases). We train our model for 30 epochs with the batch size of 1. Each data instance has 10 image slices at 6 time points. We use ADAM optimizer [39] for the network optimization with an initial learning rate of 10−3. In testing, each sequence is divided to several sub-sequences and fed into our model to generate the segmentation mask at each time. The segmentation masks are post-processed with the largest connected-component selection. Five-fold cross-validation at the patient-level splitting is conducted.
Our method achieves the segmentation performance of Dice at 86.8%±2.1% and 85.9%±1.6% for ED and ES phase, respectively. Compared to the CETUS 2014 challenge winner (89.4%±4.1% and 85.6%±5.7%, using deformable model approach) [36], our method performs better for ES but worse for ED. Fig. 10 shows an example of our 4D segmentation result from ED to ES. Our method is efficient by taking ~ 6.5 hrs for training of 30 epochs and only 3 seconds for segmentation in testing per 4D sequence (6 ultrasound volumes in our setting).
Fig. 10.
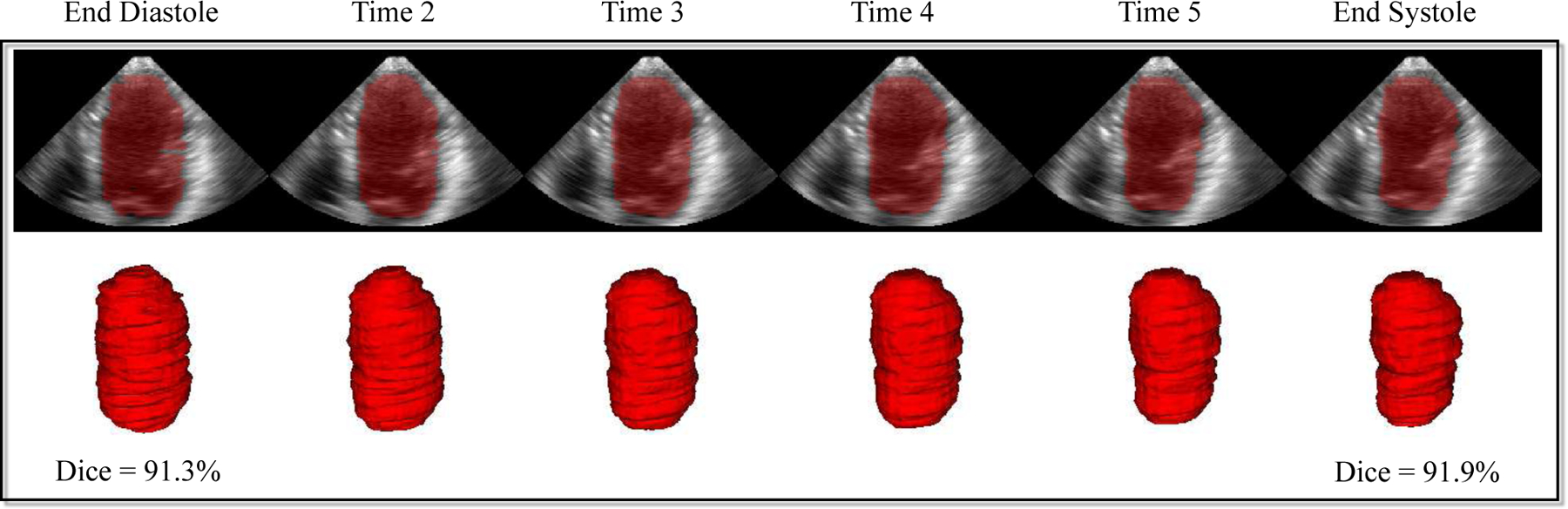
4D segmentation results of left ventricle in 3D+time ultrasound by ST-ConvLSTM.
F. Discussion
Deep learning based precision and predictive medicine is a new emerging research area, and has been shown to be capable of outperforming traditional mathematical modeling based methods for tumor growth prediction. This may suggest its great potential for solving this complicated but important problem. Because of the tremendous difficulties of collecting the longitudinal tumor data, most previous studies are evaluated on a relatively small sized dataset (i.e., < 10 patients). A statistically larger and more representative patient dataset is desired to evaluate the prediction performance. Our novel model, ST-ConvLSTM network, significantly differs from the most recent statistical and deep learning [12] and two-stream ConvNets [13] in several key aspects. Firstly, it uses a single recurrent neural network to explicitly and jointly model the temporal changes and spatial consistency (i.e., in 4D space), rather than separate invasion and expansion networks to model the temporal information only (i.e., 2D+time) [12], [13]. Secondly, it makes prediction at the holistic image-level instead of local image patch-level, integrating the global spatial context of tumor structure and meanwhile being more computationally efficient. Thirdly, it enables the prediction of both future images and the associated imaging properties, including CT scan, tumor cell density and radiodensity, as demonstrated in this paper. Fourthly, it uses an encoder-decoder deep neural network architecture that incorporates imaging feature and clinical factor (such as time interval) in an end-to-end learning framework, rather than a late feature fusion stage. Fifthly, we construct the largest longitudinal tumor dataset (33 patients) to date to the best of our knowledge, and comprehensive quantitative evaluation results against three other prediction methods using ConvLSTM [21] and GAN [22]. Finally, we extend our deep learning based method to make it capable of predicting any time point in a later future (beyond time point 3).
One of our main contributions is the novelty of proposed ST-ConvLSTM architecture. Compared to the previous state-of-the-art ConvLSTM [21] model for temporal modeling of 2D image sequences across different time points, we substantially extend the ConvLSTM into the spatio-temporal 4-dimensional space by jointly leaning both the temporal evolution of tumor growth and the spatial information of 3D consistency. Particularly, for the adjacent 2D CT slices, they are also modeled by ConvLSTM (slice-by-slice) to ensure their spatial consistency. In addition, the global contexts of previous time point are fed to the current time point. Therefore, each ST-ConvLSTM unit makes prediction not only based on its local spatial and temporal neighbors, but also from the whole information of past states. As a result, our ST-ConvLSTM is able to generate a sequence of images with better 4D properties than ConvLSTM, e.g., producing statistically higher accuracy in volume prediction, as shown in Table III. An illustrative example can be observed from Fig. 5. ST-ConvLSTM generates more consistent tumor morphology and structure for CT, mask, and ICVF predictions than ConvLSTM results (of irregular predictions for tumor morphology). An alternative option of using ConvLSTM for the 4D prediction task can simply stack 2D CT slices as different input channels and modeling the temporal relation using LSTM. However such a method cannot exploit either the inherent correlations of inter-slice correlations in 3D contexts, or temporal dynamics across time points. The simple linear predictive model performs the worst among all compared methods. This is in agreement with the fact that the pancreatic neuroendocrine tumors demonstrate nonlinear growth patterns [1], [41]. The ablation study shows that directly predicting the future tumor mask based on previous masks may perform comparably with the configuration of using all three information (ICVF, CT, mask). This is in accordance with the finding of a computer vision study [27] that segmentation-to-segmentation prediction generates no worse result than RGB+segmentation-to-segmentation prediction. Of course, the complete ICVF-CT-mask configuration offers better performance on RMSE and HUdiff. predictions, and more importantly, can compute the future tumor CT images (Fig. 9).
Beyond the tumor prediction task, our proposed novel ST-ConvLSTM architecture can be adapted conveniently for learning 4D medical image representations. We demonstrate its promising accuracy and high efficiency (e.g., 3 seconds to process per 4D imaging sequence) in 4D ultrasound image segmentation, while only requiring sparse image annotation masks (e.g., 2 out of 6 volumes per 4D sequence in our experiment) for training. Furthermore, it can also be applied to 4D classification task by changing the network output.
Besides ConvLSTM, BeyondMSE (GAN) [22] is another deep learning model for future frame prediction. Benefited from the ℓ1, image gradient based optimization and adversarial losses, GAN could generate less blurry future image predictions, as shown in Fig. 7. However GAN has much lower quantitative prediction performance than our method. One reason may be that GAN does not explicitly model the temporal dynamics, while LSTM has inherent temporal “memory” units though GAN-based tumor prediction can somewhat capture the tumor growing trend. For example, in Fig. 7, from time 1 to time 2, the tumor invasion happens mostly in its lower part so that GAN predicts the tumor to continue infiltrating to the below area at time 3. Nevertheless the tumor actually slows down its growing speed at time 3 in that direction. Our ST-ConvLSTM model learns the spatio-temporal information jointly and can leverage the current slice’s global and local neighbors’ information, which results in more robust prediction. On the other hand, the GAN-based method may have higher overfitting risk on our task. The network architectures used in [22] can be over-complicated for the relatively small-sized data studied in this work.
Using time-interval feature in the ST-ConvLSTM does not improve the prediction accuracy compared to without using such feature. This may be because for time 1–2 and time 2–3 in our data, 1) the time-intervals are similar (about 1 year) for different patients, and 2) the PanNet is slow-growing and can show different growing trend. Actually, recent studies show that time feature can be either helpful [42] or not helpful [43] in LSTM-based prediction on different medical data. More investigation is needed in this direction. Nevertheless, the time-interval feature is necessary for tumor growth prediction problem. For example, for the prospect of longer future prediction of tumor growth, the time-interval feature is effective to control our predictive model to generate sensible prediction results, as shown by the illustrative example in Fig. 9. Furthermore, our model predicts that 78.8% tumors keep growing at time 4. This is in accordance with the natural history of PanNET tumors, around 20% decreasing over a median follow-up duration of 4 years [41]. However, considering the missing of ground truths of 22 patients at time 4, the related results and discussions should be treated with caution. For the 11 patients with ground truths at time 4, the prediction accuracy at a longer future time point (i.e., RVD=37.2% at time 4) is much lower than that of the next predictable time step (i.e., RVD=15.7% at time 3). This is as expected since it is indeed harder to precisely predict the tumor growth trends and patterns after a longer period of time, for example, around two years later using our data. As a reference, a recent mathematical modeling based tumor growth prediction method [9] has the relative volume errors of later time predictions, ranging from 45% to 123% for breast carcinoma. Another solution for predicting further into the future is to recursively apply the two-time-input model as in [27], i.e., predicting the outcome of time 4 based on the time 2 and the predicted time 3 results.
There are some future directions which may further improve our method. First, the ℓ2 loss function used in our model is the major reason that causes blurry predictions. Adversarial training [22] can increase the sharpness of the predicted image and is straightforward to be incorporated into our ST-ConvLSTM network, through using a discriminator to determine whether the generated future image sequence is real or fake during training. Second, alternative network architectures, such as skip and residual connections [16], [24] may complement our current encoder-decoder network as the backbone. Third, testing time data augmentation may further improve the prediction performance, e.g., averaging prediction results along three reconstruction directions: axial, coronal, and sagittal. Fourth, predicting the tumor growth rate is challenge for the current model. This may be caused by the limited training data in which most tumors are slow-growing whereas our model is not trained to directly predict the tumor growth rate. Our deep model can scale well and perform better by incorporating more patient data when available in the future. Another potential solution is explicitly personalizing the predictive model as in our previous work [13]. Although obtaining much better result in predicting aggressive progression, we find that it decreases the overall volume prediction accuracy (increasing RVD difference from 11.2% to 13.1%) on our dataset. Nevertheless, our model shows competitive results on predicting tumor progression versus regression compared to traditional machine learning approaches.
V. CONCLUSION
In this paper, we have employed and substantially extended ConvLSTM [21] in the 4-dimensional spatio-temporal domain for the task of modeling 4D longitudinal tumor data. The novel ST-ConvLSTM network jointly learns the intra-slice structures, the inter-slice 3D contexts, and the temporal dynamics. Quantitative results of notably higher accuracies than the original ConvLSTM [21] are reported, using several metrics on predicting the future tumor volumes. Compared to the most recent 2D+time deep learning based tumor growth prediction models [12], [13], our new approach directly works on 4D imaging space and incorporates clinical factors in an end-to-end trainable manner. This method can also predict the tumor cell density and radiodensity. Our experiments are conducted on the largest longitudinal pancreatic tumor dataset (33 patients) to date and demonstrate the validity of our proposed method. In addition, ST-ConvLSTM enables efficient and effective 4D medical image segmentation with only sparse manual image annotations required. The presented ST-ConvLSTM model can potentially enable other applications of 4D medical imaging applications.
Acknowledgments
This work was supported by the Intramural Research Program at the NIH Clinical Center. The authors thank Nvidia for the TITAN X Pascal GPUs donation.
Footnotes
The majority part of work was performed when L. Zhang was with National Institutes of Health and Nvidia Corporation, L. Lu and J. Yao were with National Institutes of Health Clinical Center.
Most pancreatic tumors in our dataset are <3 cm (≈30 pixels) in diameter.
Contributor Information
Ling Zhang, PAII Inc., Bethesda, MD 20817, USA.
Le Lu, PAII Inc., Bethesda, MD 20817, and Johns Hopkins University, Baltimore, MD 21218, USA..
Xiaosong Wang, Nvidia Corporation, Bethesda, MD 20814, USA..
Jianhua Yao, Tencent Holdings Limited, Shenzhen 518057, China.
REFERENCES
- [1].Keutgen XM, Hammel P, Choyke PL, Libutti SK, Jonasch E, and Kebebew E, “Evaluation and management of pancreatic lesions in patients with von hippel-lindau disease,” Nature Reviews Clinical Oncology, vol. 13, no. 9, pp. 537–549, 2016. [DOI] [PubMed] [Google Scholar]
- [2].Yao JC, Shah MH, Ito T, Bohas CL, Wolin EM, Van Cutsem E, Hobday TJ, Okusaka T, Capdevila J, De Vries EG et al. , “Everolimus for advanced pancreatic neuroendocrine tumors,” New England Journal of Medicine, vol. 364, no. 6, pp. 514–523, 2011. [DOI] [PMC free article] [PubMed] [Google Scholar]
- [3].Swanson KR, Alvord E, and Murray J, “A quantitative model for differential motility of gliomas in grey and white matter,” Cell Proliferation, vol. 33, no. 5, pp. 317–329, 2000. [DOI] [PMC free article] [PubMed] [Google Scholar]
- [4].Clatz O, Sermesant M, Bondiau P-Y, Delingette H, Warfield SK, Malandain G, and Ayache N, “Realistic simulation of the 3D growth of brain tumors in MR images coupling diffusion with biomechanical deformation,” TMI, vol. 24, no. 10, pp. 1334–1346, 2005. [DOI] [PMC free article] [PubMed] [Google Scholar]
- [5].Hogea C, Davatzikos C, and Biros G, “An image-driven parameter estimation problem for a reaction-diffusion glioma growth model with mass effects,” Journal of Mathematical Biology, vol. 56, no. 6, pp. 793–825, 2008. [DOI] [PMC free article] [PubMed] [Google Scholar]
- [6].Menze BH, Van Leemput K, Honkela A, Konukoglu E, Weber M-A, Ayache N, and Golland P, “A generative approach for image-based modeling of tumor growth,” in IPMI. Springer, 2011, pp. 735–747. [DOI] [PMC free article] [PubMed] [Google Scholar]
- [7].Liu Y, Sadowski S, Weisbrod A, Kebebew E, Summers R, and Yao J, “Patient specific tumor growth prediction using multimodal images,” Medical Image Analysis, vol. 18, no. 3, pp. 555–566, 2014. [DOI] [PMC free article] [PubMed] [Google Scholar]
- [8].Wong KCL, Summers RM, Kebebew E, and Yao J, “Pancreatic tumor growth prediction with elastic-growth decomposition, image-derived motion, and FDM-FEM coupling,” TMI, vol. 36, no. 1, pp. 111–123, 2017. [DOI] [PMC free article] [PubMed] [Google Scholar]
- [9].Roque T, Risser L, Kersemans V, Smart S, Allen D, Kinchesh P, Gilchrist S, Gomes AL, Schnabel JA, and Chappell MA, “A DCE-MRI driven 3-D reaction-diffusion model of solid tumor growth,” TMI, vol. 37, no. 3, pp. 724–732, 2018. [DOI] [PubMed] [Google Scholar]
- [10].Weizman L, Ben-Sira L, Joskowicz L, Aizenstein O, Shofty B, Constantini S, and Ben-Bashat D, “Prediction of brain MR scans in longitudinal tumor follow-up studies,” in MICCAI. Springer, 2012, pp. 179–187. [DOI] [PubMed] [Google Scholar]
- [11].Morris M, Greiner R, Sander J, Murtha A, and Schmidt M, “Learning a classification-based glioma growth model using MRI data,” Journal of Computers, vol. 1, no. 7, pp. 21–31, 2006. [Google Scholar]
- [12].Zhang L, Lu L, Summers RM, Kebebew E, and Yao J, “Personalized pancreatic tumor growth prediction via group learning,” in MICCAI, 2017, pp. 424–432. [Google Scholar]
- [13].--, “Convolutional invasion and expansion networks for tumor growth prediction,” TMI, vol. 37, no. 2, pp. 638–648, 2018. [DOI] [PMC free article] [PubMed] [Google Scholar]
- [14].Villegas R, Yang J, Hong S, Lin X, and Lee H, “Decomposing motion and content for natural video sequence prediction,” in ICLR, 2017. [Google Scholar]
- [15].Lu C, Hirsch M, and Schölkopf B, “Flexible spatio-temporal networks for video prediction,” in CVPR, 2017, pp. 6523–6531. [Google Scholar]
- [16].Kalchbrenner N, Oord A. v. d., Simonyan K, Danihelka I, Vinyals O, Graves A, and Kavukcuoglu K, “Video pixel networks,” in ICML, 2017. [Google Scholar]
- [17].Liang X, Lee L, Dai W, and Xing EP, “Dual motion GAN for future-flow embedded video prediction,” in ICCV, 2017. [Google Scholar]
- [18].Wang Y, Long M, Wang J, Gao Z, and Philip SY, “Predrnn: Recurrent neural networks for predictive learning using spatiotemporal LSTMs,” in NIPS, 2017, pp. 879–888. [Google Scholar]
- [19].Liu W, Luo W, Lian D, and Gao S, “Future frame prediction for anomaly detection-a new baseline,” in CVPR, 2018, pp. 6536–6545. [Google Scholar]
- [20].Srivastava N, Mansimov E, and Salakhudinov R, “Unsupervised learning of video representations using LSTMs,” in ICML, 2015, pp. 843–852. [Google Scholar]
- [21].Shi X, Chen Z, Wang H, Yeung D-Y, Wong W-K, and Woo W.-c., “Convolutional LSTM network: A machine learning approach for precipitation nowcasting,” in NIPS, 2015, pp. 802–810. [Google Scholar]
- [22].Mathieu M, Couprie C, and LeCun Y, “Deep multi-scale video prediction beyond mean square error,” in ICLR, 2016. [Google Scholar]
- [23].Patraucean V, Handa A, and Cipolla R, “Spatio-temporal video autoencoder with differentiable memory,” in ICLR Workshop, 2016. [Google Scholar]
- [24].Finn C, Goodfellow I, and Levine S, “Unsupervised learning for physical interaction through video prediction,” in NIPS, 2016, pp. 64–72. [Google Scholar]
- [25].Lotter W, Kreiman G, and Cox D, “Deep predictive coding networks for video prediction and unsupervised learning,” in ICLR, 2017. [Google Scholar]
- [26].Villegas R, Yang J, Zou Y, Sohn S, Lin X, and Lee H, “Learning to generate long-term future via hierarchical prediction,” in ICLR, 2017. [Google Scholar]
- [27].Luc P, Neverova N, Couprie C, Verbeek J, and LeCun Y, “Predicting deeper into the future of semantic segmentation,” in ICCV, vol. 1, 2017. [Google Scholar]
- [28].Liu Z, Yeh RA, Tang X, Liu Y, and Agarwala A, “Video frame synthesis using deep voxel flow.” in ICCV, 2017, pp. 4473–4481. [Google Scholar]
- [29].Bhattacharjee P and Das S, “Temporal coherency based criteria for predicting video frames using deep multi-stage generative adversarial networks,” in NIPS, 2017, pp. 4268–4277. [Google Scholar]
- [30].Jin X, Xiao H, Shen X, Yang J, Lin Z, Chen Y, Jie Z, Feng J, and Yan S, “Predicting scene parsing and motion dynamics in the future,” in NIPS, 2017, pp. 6915–6924. [Google Scholar]
- [31].Hochreiter S and Schmidhuber J, “Long short-term memory,” Neural Computation, vol. 9, no. 8, pp. 1735–1780, 1997. [DOI] [PubMed] [Google Scholar]
- [32].Chen J, Yang L, Zhang Y, Alber M, and Chen DZ, “Combining fully convolutional and recurrent neural networks for 3D biomedical image segmentation,” in NIPS, 2016, pp. 3036–3044. [Google Scholar]
- [33].Cai J, Lu L, Xie Y, Xing F, and Yang L, “Improving deep pancreas segmentation in CT and MRI images via recurrent neural contextual learning and direct loss function,” in MICCAI, 2017. [Google Scholar]
- [34].Tseng K-L, Lin Y-L, Hsu W, and Huang C-Y, “Joint sequence learning and cross-modality convolution for 3D biomedical segmentation,” in CVPR, 2017, pp. 3739–3746. [Google Scholar]
- [35].Yang D, Xiong T, Xu D, Zhou SK, Xu Z, Chen M, Park J, Grbic S, Tran TD, Chin SP et al. , “Deep image-to-image recurrent network with shape basis learning for automatic vertebra labeling in large-scale 3D CT volumes,” in MICCAI. Springer, 2017, pp. 498–506. [Google Scholar]
- [36].Bernard O, Bosch JG, Heyde B, Alessandrini M, Barbosa D, Camarasu-Pop S, Cervenansky F, Valette S, Mirea O, Bernier M et al. , “Standardized evaluation system for left ventricular segmentation algorithms in 3D echocardiography,” TMI, vol. 35, no. 4, pp. 967–977, 2015. [DOI] [PubMed] [Google Scholar]
- [37].Rueckert D, Sonoda LI, Hayes C, Hill DL, Leach MO, and Hawkes DJ, “Nonrigid registration using free-form deformations: application to breast MR images,” TMI, vol. 18, no. 8, pp. 712–721, 1999. [DOI] [PubMed] [Google Scholar]
- [38].Yushkevich PA, Piven J, Hazlett HC, Smith RG, Ho S, Gee JC, and Gerig G, “User-guided 3D active contour segmentation of anatomical structures: significantly improved efficiency and reliability,” NeuroImage, vol. 31, no. 3, pp. 1116–1128, 2006. [DOI] [PubMed] [Google Scholar]
- [39].Kingma DP and Ba J, “Adam: A method for stochastic optimization,” in International Conference for Learning Representations, 2015. [Google Scholar]
- [40].Abadi M, Agarwal A, Barham P, Brevdo E, Chen Z, Citro C, Corrado GS, Davis A, Dean J et al. , “TensorFlow: Large-scale machine learning on heterogeneous systems,” 2015. [Online]. Available: https://www.tensorflow.org/ [Google Scholar]
- [41].Weisbrod AB, Kitano M, Thomas F, Williams D, Gulati N, Gesuwan K, Liu Y, Venzon D, Turkbey I, Choyke P et al. , “Assessment of tumor growth in pancreatic neuroendocrine tumors in von hippel lindau syndrome,” Journal of the American College of Surgeons, vol. 218, no. 2, pp. 163–169, 2014. [DOI] [PMC free article] [PubMed] [Google Scholar]
- [42].Baytas IM, Xiao C, Zhang X, Wang F, Jain AK, and Zhou J, “Patient subtyping via time-aware LSTM networks,” in ACM SIGKDD Conference on Knowledge Discovery and Data Mining (KDD). ACM, 2017, pp. 65–74. [Google Scholar]
- [43].Li Y, Du N, and Bengio S, “Time-dependent representation for neural event sequence prediction,” in ICLR Workshop, 2018. [Google Scholar]