

Structured Abstract
OBJECTIVE(S):
To develop and assess AI algorithms to identify operative steps in laparoscopic sleeve gastrectomy (LSG).
BACKGROUND:
Computer vision, a form of artificial intelligence (AI), allows for quantitative analysis of video by computers for identification of objects and patterns, such as in autonomous driving.
METHODS:
Intraoperative video from LSG from an academic institution were annotated by two fellowship-trained, board-certified bariatric surgeons. Videos were segmented into the following steps: 1) port placement, 2) liver retraction, 3) liver biopsy, 4) gastrocolic ligament dissection, 5) stapling of the stomach, 6) bagging specimen, and 7) final inspection of staple line. Deep neural networks were used to analyze videos. Accuracy of operative step identification by the AI was determined by comparing to surgeon annotations.
RESULTS:
88 cases of LSG were analyzed. A random 70% sample of these clips were used to train the AI and 30% to test the AI’s performance. Mean concordance correlation coefficient for human annotators was 0.862, suggesting excellent agreement. Mean (±SD) accuracy of the AI in identifying operative steps in the test set was 82% ± 4% with a maximum of 85.6%.
CONCLUSIONS:
AI can extract quantitative surgical data from video with 85.6% accuracy. This suggests operative video could be used as a quantitative data source for research in intraoperative clinical decision support, risk prediction, or outcomes studies.
Mini-Abstract
The goal of this study was to develop and assess AI algorithms to identify operative steps in laparoscopic sleeve gastrectomy (LSG). 88 videos were analyzed. Mean accuracy of the algorithms was 82% ± 4% in identifying steps of LSG.
INTRODUCTION
The advent of minimally invasive surgery, particularly laparoscopy, improved the ease and quality of recording surgical cases. Video can subsequently be used for education – both for practicing surgeons and trainees – and for quality improvement purposes. For example, video-based coaching has been demonstrated to have value in assisting feedback to improve surgeon performance.1, 2 There has also been work that has investigated video as a form of operative documentation in conjunction with traditional operative reports.3
Despite the demonstrated utility of video recordings, analysis of video still requires timely (and, thus, costly) manual video review by human annotators. The use of crowd-sourced evaluations of video has had mixed results in identifying elements such as surgeon performance.4 Previous work by several groups has demonstrated the feasibility of utilizing different forms of artificial intelligence (AI) to automate some aspects of video review, such as identifying and tracking tools.5–7
Computer vision (CV), which can be considered a type of AI, is the field of study of machine-based understanding of images. Our group was interested in investigating whether CV could be utilized to help identify specific segments of an operation to help make video review more efficient. Thus, the aim of this study was to evaluate the performance of CV in analyzing operative video to identify steps of a laparoscopic sleeve gastrectomy (LSG). We hypothesized that CV could be utilized to automatically segment videos of LSG with greater than 70% accuracy.
METHODS
Institutional Approval
The protocol for this study was reviewed and approved by the Partners Healthcare Institutional Review Board (Protocol No: 2015P001161/PHS).
Video Dataset
The Department of Surgery at the Massachusetts General Hospital provides capabilities for surgeons to record their laparoscopic cases for education and quality improvement purposes, and patients consent to video recording of their cases as part of the standard consent form. Recording of cases is elective and made at the decision of the primary surgeon. Videos of laparoscopic sleeve gastrectomy from October 1, 2015 to September 1, 2018, were eligible for inclusion in this study. Eligibility criteria were as follows: 1) case was a laparoscopic sleeve gastrectomy, 2) Patient age >18 years, 3) video had the case recorded from the start of laparoscopy (at or just after insertion of trocars) to finish (just prior to removal of trocars). Eligible videos were downloaded to an encrypted hard drive. A 70/30 train/test split of the video dataset was utilized (i.e. 70% of video used to train the algorithms, and 30% used to test the algorithms).8 The data was split on a per-case level rather than at a per-frame level; thus, frames from a video in the training set did not appear in the test set.
Video Processing
Videos included in the study were de-identified by assigning a new filename that was not linked to a patient’s MRN or name. Videos were subsequently processed using ffmpeg 4.1 (www.ffmpeg.org) on a command line in macOS 10.13 (Apple, Cupertino, CA). Metadata such as date of recording and camera type was removed. Videos were screened to remove any segment of video at the start and end of the case that was extracorporeal and could show identifiers such as the surgeon, assistant, scrub tech, circulator, or other operating room personnel. Audio was removed from all videos that had audio recordings included.
Annotation of Operative Steps and Normal/Abnormal Cases
To determine which steps of the operation should be annotated, a small focus group of four minimally invasive and bariatric surgeons was held. Starting with a framework from a published textbook,9 the surgeons discussed amongst themselves the major steps of LSG that were visible on a laparoscopic video. Consensus amongst the surgeons was reached, and each case was annotated into the following major steps: 1) port placement (if visible), 2) retraction of the liver, 3) biopsy of the liver (if present), 4) dissection of the gastrocolic ligament, 5) stapling of the stomach, 6) bagging of the gastric specimen, and 7) final inspection of the sleeve staple line. At our institution, it is customary for patients to undergo a biopsy of the liver during LSG; therefore, it was included as a step in the annotation process.
Two board-certified surgeons (EW, OM) who have completed a fellowship in minimally invasive and bariatric surgery underwent an annotation training protocol. Annotation training included discussion on the definition of each step, the definition of the start and end of each step, and a discussion on the classification of each case as normal or abnormal. Normal cases were defined as those containing a range of clinically acceptable, expected events in a straightforward, unremarkable LSG to each surgeon while abnormal cases were those that demonstrated events that could be specifically noted such as significant bleeding requiring multiple attempts at hemostasis, lysis of adhesions, or steps not typically included in a LSG (e.g. removal of a gastric band, repair of hiatal hernia). Normal/abnormal annotation was performed to assess for variability of the LSG cases included in the dataset. Each surgeon independently reviewed and annotated all videos included in the study. The Anvil Video Annotation Research Tool (http://www.anvil-software.org) was utilized to annotate videos.1
Inter-annotator reliability was compared using mean concordance correlation coefficient.
Computing
All work for the visual and temporal models was conducted in Anaconda 2018.12 (Anaconda, Inc., Austin, TX, USA) in Python 3.6. Visual and temporal model training utilized an NVIDIA (NVIDIA, Santa Clara, CA, USA) Titan XP graphics processing unit (GPU). Frequentist statistical testing on operative video length was performed in STATA 14IC (STATAcorp, College Station, TX, USA) with alpha=0.05.
Visual Model
As described in further detail in Hashimoto et al (2018) and Topol (2019), deep learning is a type of neural network that can be used to automate the extraction of visual features to optimize the performance of a given task, such as image-based identification of objects (Figure 1a).10, 11 While classical machine learning for computer vision involves human-based selection of features (e.g. detecting edges, corners, colors, etc.), also known as hand-crafted features, deep learning allows a network to self-select features that are most likely to contribute to improved performance. This study utilized a deep residual learning network, ResNet18, that was then trained to identify the operative steps of LSG (Figure 1b). The network was pretrained on general data as described by He et al (2016) with fine-tuning of the last three residual blocks based on our study’s training set of LSG videos.12 The pre-training was performed on the ImageNet 2012 classification database, a database of 1.28 million images of general objects such as animals, scenes (e.g. beach, mountain), food, etc.13
Figure 1.
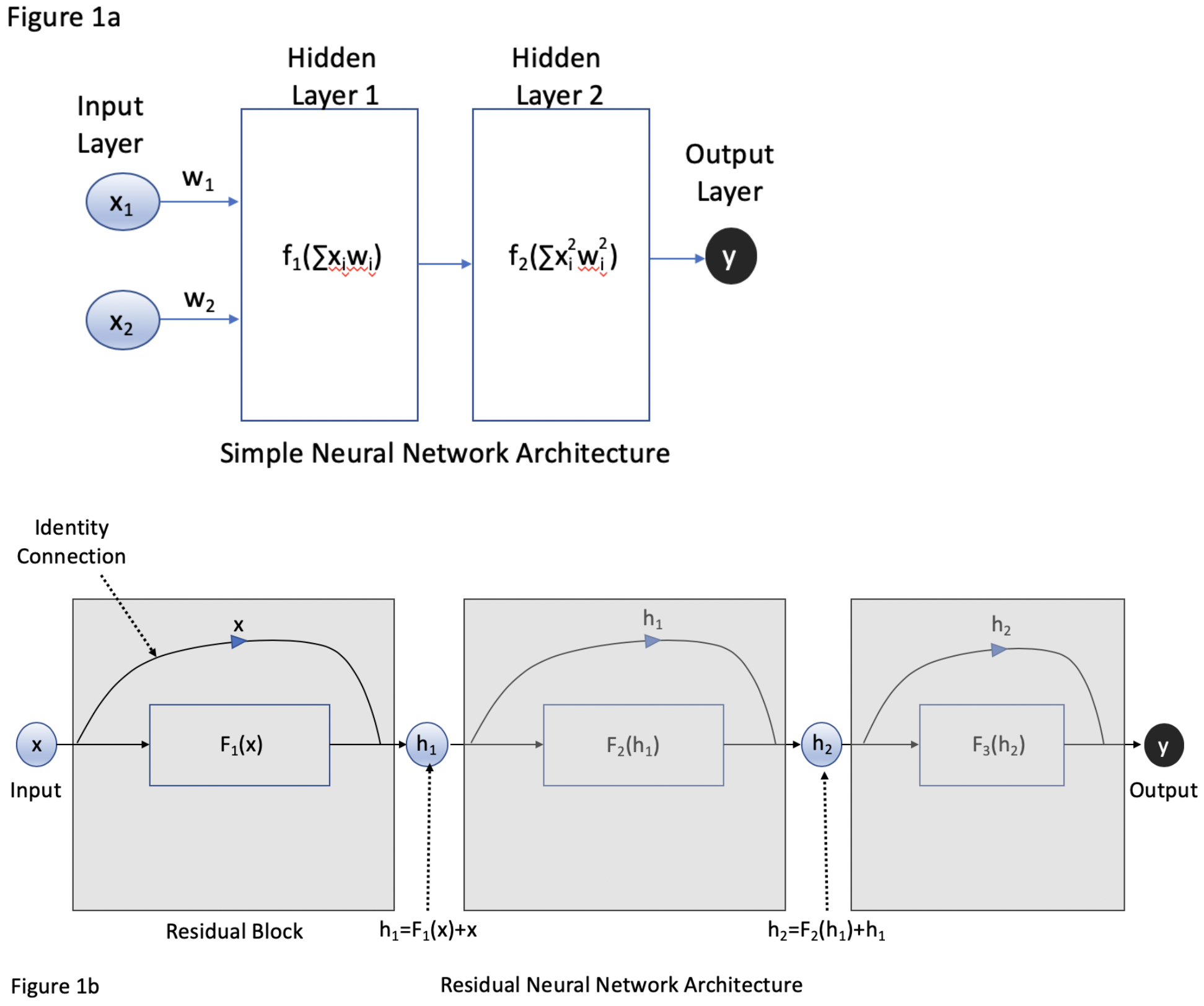
A) Traditional neural network architecture where x represents input and w represents the weight of that input within the network. Within each layer are neurons that contain an activation function that considers the sum of the products xi*wi in determining whether or not to “fire” and process further information. Each layer passes information sequentially to the next layer until an output is produced. With each successive layer, information can be lost as it is processed and re-weighted by the network. B) A residual neural network is comprised of residual blocks (grey boxes), where an input x can be processed by a layer with a function F to generate a hidden output h. An identity connection allows the input of that block to bypass F. This allows weak connections via F to have less of an impact on the information that is passed down to subsequent blocks with goal of generating an output y.
While operative step annotations were utilized by the visual model, normal/abnormal case annotations were not. Labeling of normal/abnormal cases was performed to ensure the dataset included cases that were somewhat heterogeneous (i.e. not all straight forward LSG). This study was not designed to detect whether a machine could identify normal versus abnormal cases.
Temporal Model
Temporal data can hypothetically help optimize classification accuracy by incorporating data about frame and procedure step sequence. For example, port placement must precede other steps of the operation so frames that are earliest in the case have a higher probability of being part of the “port placement” step. Long short-term memory (LSTM) neural networks are a specific type of recurrent neural network that allows for “memory” of data to persist within a neural network so that it can be used in other layers of a neural network.14
As an analogy to help explain why temporal relationships in data can be important, consider an example of a colonoscopy. As the endoscopist is inserting the endoscope, they may notice a polyp in the sigmoid colon and note to themselves the number of centimeters on the scope as a reminder to look for the lesion and perform a polypectomy after the cecum has been intubated. As the endoscopist is examining the colonic mucosa on withdrawal of the scope, they recall the initial polyp seen on intubation and ensure that they find it for polypectomy. Static neural networks may have difficulty efficiently propagating information from an earlier time frame of the data (e.g. seeing the polyp during intubation of the colon) to a later time frame of the data (e.g. upon mucosal inspection as the scope is being withdrawn). However, LSTMs can pass through data efficiently from one layer to the next (Figure 2).
Figure 2.
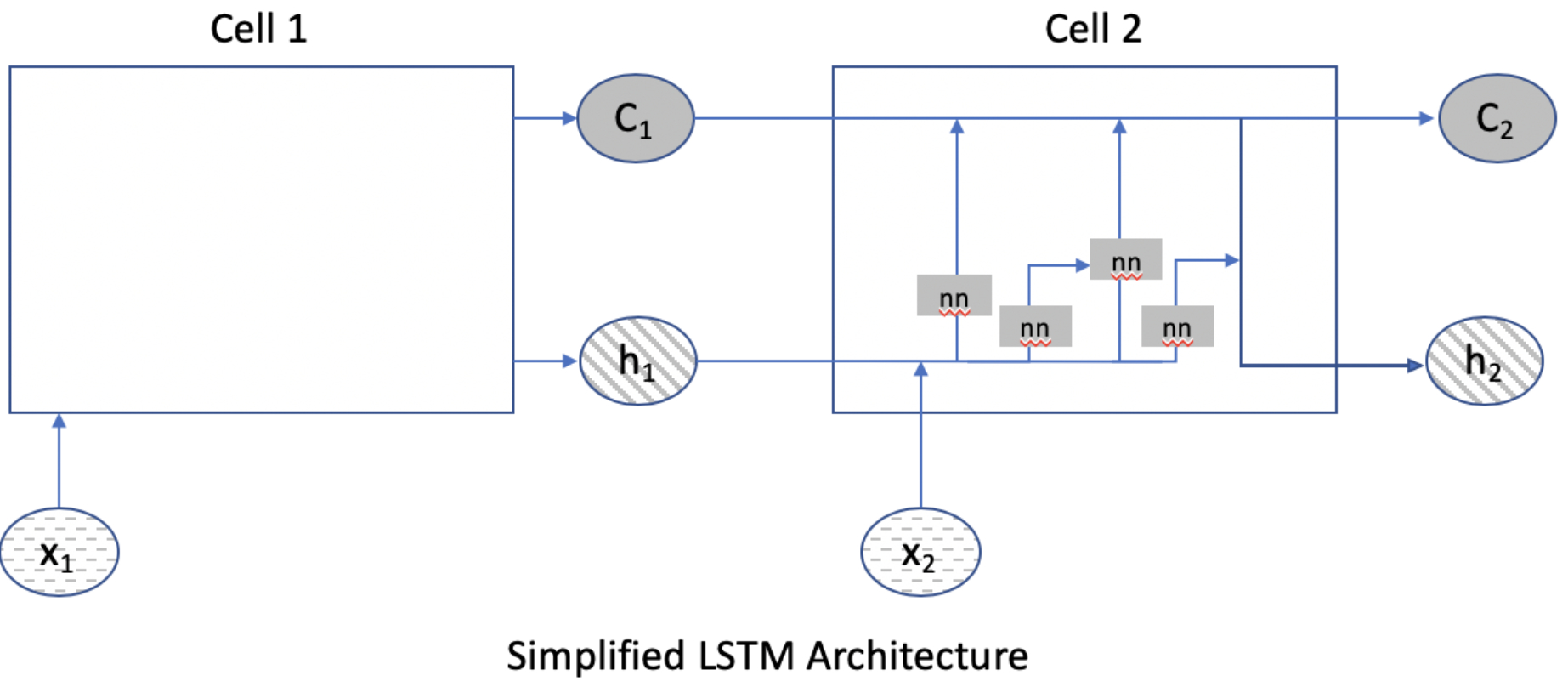
Simplified diagram of long short-term memory (LSTM) neural networks. LSTMs are comprised of cells. In this figure, Cell 2 provides more detail on the inner workings of a cell and will serve as the reference point. Cell 2 can receive input from the data as x2, from Cell 1’s state as C1, and from the hidden layer output of the prior cell h1. Within Cell 2, these inputs can undergo further processing to generate a new hidden output h2 or be passed through the cell along with data from x2 and h1 with relatively little processing into a new cell state C2. This allows information encountered early to be passed along the network as “memory” to assist in calculations later in the network.
Thus, LSTMs were used in this study to further process the output from the visual model to augment the identification of operative steps with temporal data from the video. The combined model of ResNet (visual model) and LSTMs (temporal model) that were trained for this study will be referred to as SleeveNet throughout the manuscript (Figure 3).
Figure 3.
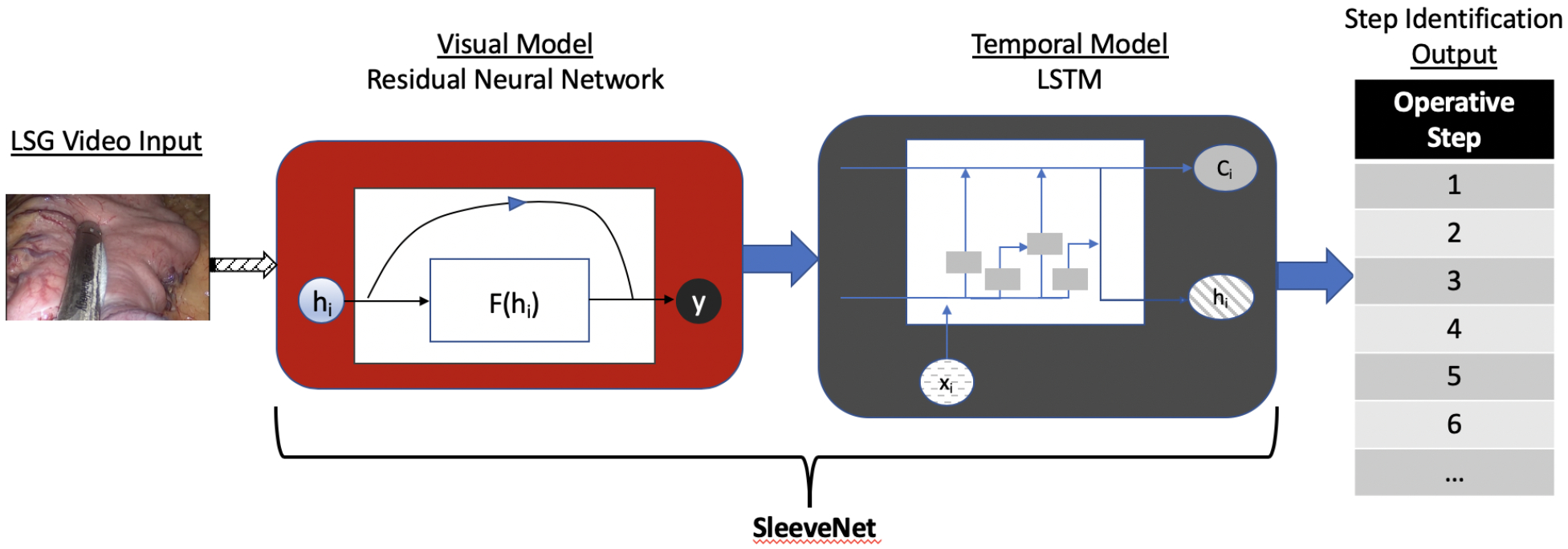
Simplified graphical representation of the architecture of SleeveNet.
Model Evaluation
Accuracy of the models’ identification of operative steps was defined as the ratio of correctly classified frames per operative step over the total number of analyzed frames. A correct classification was defined as matching the classification of at least one annotator. Accuracy was calculated for the visual model alone and for SleeveNet. For SleeveNet, six repetitions of cross validation tests were performed (i.e. six random 70/30 splits of the data were run to allow calculation of mean and standard deviation for accuracy of classification).
RESULTS
Eighty-eight videos of LSG met the criteria for inclusion in the study. Frame rate (i.e. the speed at which frames are displayed to generate a moving image) for videos analyzed in this study was between 24 to 30 frames per second (fps) based on the tower that was utilized during the operation. All videos were high definition with a minimum resolution of 1280×720 pixels (i.e. 720p) and an aspect ratio of 16:9. Between the two annotators, 176 annotation files were generated, two for each of the 88 videos included in the study. Mean concordance correlation coefficient for human annotators across all operative steps was 0.862, suggesting excellent agreement.
The mean ± SD length of all cases was 123.25 ± 23.5 minutes. Annotators marked 39 of the 88 cases (44.3%) as having some events that were abnormal. Table 1 summarizes the events and their frequencies. The mean±SD case length for all cases was 127.3 ± 23.5 minutes. Cases marked as normal were significantly shorter with mean ± SD case length of 119.8±15.2 minutes while those marked as abnormal had a mean ± SD length of 137±28.6 minutes (p<0.001).
Table 1.
Events occurring in cases annotated as abnormal
| Event | Frequency (%) |
|---|---|
| Bleeding | 21 (23.9%) |
| Lysis of adhesions | 7 (8%) |
| Additional steps (e.g. hiatal hernia repair, Nissen takedown) | 15 (17%) |
| Other event (staple misfire) | 1 (1.1%) |
Convergence for training of the visual model was achieved after 1.2 hours with a training set classification of 81.9%. Convergence for training of the temporal model was achieved after 7 hours with a training set classification of 85.7%.
On the test set, the visual model alone demonstrated a maximum overall classification accuracy of 82.4%. SleeveNet demonstrated a mean classification accuracy of 82% ± 4% with a minimum classification accuracy of 73% and a maximum classification accuracy of 85.6%.
DISCUSSION
Improvement in computing technology such as the use of graphical processing units (GPUs) for parallel processing, the accessibility of types of big data, and the resurgence of interest in neural networks and other machine learning approaches has led to significant recent advances in AI both broadly in society and, more specifically, in healthcare.10, 11 Our study demonstrates that techniques in computer vision and machine learning – residual neural networks and LSTM neural networks together – can identify the operative steps of a LSG with a fairly high degree of accuracy (85.6%).
The findings in this study contribute to the field a deep learning model with high accuracy in automatically identifying the steps of LSG in an operative video. Previous work by our group utilized classical machine learning techniques (i.e. support vector machines) with hand-crafted features to achieve best performance of 92.9% accuracy in identifying steps of LSG on a small set of 12 cases. However, this approach would not have scaled well to other cases as the hand-crafted features selected in that study may not have translated to other types of operations.15
Tiwanda et al (2017) demonstrated their approach to identification of operative steps in laparoscopic cholecystectomy, using a convolutional neural network known as EndoNet. Their approach was a combination of tool tracking (i.e. automating identification of tools being used in each step of the cholecystectomy) and operative step identification. They used the self-learned feature output of the convolutional neural network in addition to hand-crafted features and performed additional training using support vector machines and hidden Markov models to further boost the classification accuracy with best demonstrated performance between 86% and 92.2%, with higher accuracy demonstrated when tool tracking was used to augment the identification of the operative step.16 In the current study, we achieved similar accuracy results in LSG without the need for hand-crafting of features; thus, opening the opportunity to explore self-learning of features with deep learning alone. The ability to rely on self-learning of features alone suggests the potential to scale to a greater number and variety of cases.
Similar to Tiwanda et al (2017)16, our results demonstrated that classification accuracy improved when the temporal model was deployed in addition to the visual model alone. These results are not surprising. Surgery occurs as a sequence of events that together define the operative course for a patient. A single image alone may be insufficient to provide the appropriate anatomic and clinical context to a human observer; thus, one can hypothesize that a computer vision system would similarly require additional information for context (in this case, to improve its accuracy in identifying operative steps).
Implications for Video-Based Analysis in Surgery
Our work has implications especially in surgical education. Video-based coaching has been demonstrated to lead to improvements in surgical skill in residents17–19, and the technology we describe can expand automated indexing of surgical cases to LSG (similar to automated indexing of laparoscopic cholecystectomy that has been demonstrated by the CAMMA research group at the University of Strasbourg). This approach could be expanded to other cases as well to allow automated indexing of a variety of laparoscopic cases. Residents who are interested in reviewing an attending’s case prior to scrubbing with them could quickly and easily search a database of cases to identify relevant portions of a procedure to review. Postoperatively, a video could be quickly indexed to allow faculty members to review and provide feedback on key sections of a case with trainees.
While it was beyond the scope of this study to assess for prediction of events such as postoperative complications, mortality, readmission, etc., the results of this study demonstrate a proof of concept that computer analysis of operative video is feasible and accurate in identifying the steps of LSG. While humans perceive images from the videos presented on our screens and summarize events that occur throughout a video through language, computers are able to “perceive” and store these images and events as quantitative data. This opens the possibility of using data derivatives from these types of video-based analyses as variables in other models that are designed to predict risk and outcomes. Furthermore, automated identification of steps provides the foundation on which more specific identification of events and structures can be performed. As work in this field progresses, identification of operative steps could provide the operative context for a system to then identify or predict potential errors as well.
For additional work in this field to advance, it is necessary to collect and annotate large amounts of data to achieve high levels of accuracy, as reinforced by previous work demonstrating that increasing the sample size of operative videos in cholecystectomy from 10 to 40 to 80 cases can result in improvement in accuracy from 65.9% to 75.2% to 92%.16 Our own group has advocated for the creation of a national or international dataset of surgical video – the “collective surgical consciousness” – that can be confidentially linked to outcomes data, such as data collected by the American College of Surgeons National Safety and Quality Improvement Program (NSQIP).10 This would provide researchers the opportunity to use a common and expansive dataset of video to test models and algorithms that can quantitatively explore the effects of intraoperative events, techniques, and decisions on patient outcomes. Such an opportunity would be in addition to the other benefits of recordings operations as outlined by Langerman and Grantcharov (2017) and Dimick and Scott (2019).20, 21
This study has several limitations. It is a single institution study on cases performed by surgeons within one department of surgery. Certainly, there is a concern that our models as currently trained may not generalize to videos of LSG performed at other institutions, and future work should assess the results of our trained models on an external dataset of LSG from other institutions. While we did not quantify the amount of time necessary to annotate the cases in this study, we do note that having board-certified surgeons review video for the purposes of annotation is costly and time-consuming and may not necessarily be feasible at every institution. Furthermore, the annotation structure for this study was limited to the major, straight forward steps of LSG rather than focusing on more granular sub-steps or techniques (e.g. more specific elements such as how the gastrocolic dissection was performed at each bite of a dissecting instrument such as an ultrasonic scalpel or bipolar vessel sealer). If more granular elements of an operation were to be analyzed, the number of potential features that would need to be modeled would increase, thus necessitating an increase in the sample size to appropriately power the analysis. More granular analysis of steps would also require more granular annotation of the training cases. However, previous research has suggested that cognitive task analysis (CTA) can help elucidate the more granular steps of an operation that are of clinical importance to experienced surgeons22–24, and CTAs could be utilized to further guide development of annotation protocols for future studies.
Despite the limitations of this study, the accuracy of SleeveNet in automatically identifying the steps of LSG suggests the promise of utilizing operative video in surgical education and research without the need for extensive manual review. However, more work is necessary to both collect the necessary video data needed to advance this type of research and to further develop the technology to achieve clinically relevant future applications of this work.
CONCLUSION
The results of this study suggest that deep learning can be utilized to automatically identify steps of LSG from operative video with a high degree of accuracy. As advances in AI may translate to healthcare applications and reduce the need for costly manual review of video, surgeons should consider saving their operative video as a potential data source for future analyses of surgical cases, quality improvement, and education.
ACKNOWLEDGMENTS
Daniel Hashimoto was partly funded for this work by NIH grant T32DK007754–16A1 and the MGH Edward D. Churchill Research Fellowship.
Footnotes
DISCLOSURES
Daniel Hashimoto, Guy Rosman, Ozanan Meireles, and Daniela Rus have a patent pending on technology derived from the work presented in this manuscript.
Daniel Hashimoto, Guy Rosman, Ozanan Meireles, Allison Welton, Caitlin Stafford, and Daniela Rus receive research support from Olympus Corporation. Daniel Hashimoto is a consultant for Verily Life Sciences, Johnson & Johnson Institute, and Gerson Lehrman Group. Ozanan Meireles and David Rattner are consultants for Olympus Corporation. Daniela Rus and Guy Rosman receive research support from Toyota Research Institute (TRI). No commercial funding or support was received for this project. The content is solely the responsibility of the authors and does not necessarily represent the official views of the NIH, TRI, or any other entity.
Elan Witkowski and Keith Lillemoe have no conflicts of interest to disclose.
References
- 1.Hu YY, Mazer LM, Yule SJ, et al. Complementing Operating Room Teaching With Video-Based Coaching. JAMA Surg 2017; 152(4):318–325. [DOI] [PubMed] [Google Scholar]
- 2.Greenberg CC, Ghousseini HN, Pavuluri Quamme SR, et al. A Statewide Surgical Coaching Program Provides Opportunity for Continuous Professional Development. Ann Surg 2018; 267(5):868–873. [DOI] [PubMed] [Google Scholar]
- 3.van de Graaf FW, Lange MM, Spakman JI, et al. Comparison of Systematic Video Documentation With Narrative Operative Report in Colorectal Cancer Surgery. JAMA Surg 2019. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 4.Deal SB, Stefanidis D, Telem D, et al. Evaluation of crowd-sourced assessment of the critical view of safety in laparoscopic cholecystectomy. Surgical Endoscopy 2017:1–7. [DOI] [PubMed] [Google Scholar]
- 5.Franke S, Meixensberger J, Neumuth T. Multi-perspective workflow modeling for online surgical situation models. J Biomed Inform 2015; 54:158–66. [DOI] [PubMed] [Google Scholar]
- 6.Quellec G, Lamard M, Cochener B, et al. Real-time task recognition in cataract surgery videos using adaptive spatiotemporal polynomials. IEEE Trans Med Imaging 2015; 34(4):877–87. [DOI] [PubMed] [Google Scholar]
- 7.Maktabi M, Neumuth T. Online time and resource management based on surgical workflow time series analysis. International journal of computer assisted radiology and surgery 2017; 12(2):325–338. [DOI] [PubMed] [Google Scholar]
- 8.Langford J Tutorial on practical prediction theory for classification. Journal of machine learning research 2005; 6(Mar):273–306. [Google Scholar]
- 9.Schirmer BD. Surgical Treatment of Morbid Obesity and Type 2 Diabetes In: Zinner MJ, Ashley SW, Hines OJ, eds. Maingot’s Abdominal Operations, 13e. New York, NY: McGraw-Hill Education; 2019. [Google Scholar]
- 10.Hashimoto DA, Rosman G, Rus D, et al. Artificial Intelligence in Surgery: Promises and Perils. Ann Surg 2018; 268(1):70–76. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 11.Topol EJ. High-performance medicine: the convergence of human and artificial intelligence. Nature Medicine 2019; 25(1):44–56. [DOI] [PubMed] [Google Scholar]
- 12.He K, Zhang X, Ren S, et al. Deep residual learning for image recognition. Proceedings of the IEEE conference on computer vision and pattern recognition, 2016. pp. 770–778. [Google Scholar]
- 13.Russakovsky O, Deng J, Su H, et al. Imagenet large scale visual recognition challenge. International journal of computer vision 2015; 115(3):211–252. [Google Scholar]
- 14.Hochreiter S, Schmidhuber J. Long short-term memory. Neural computation 1997; 9(8):1735–1780. [DOI] [PubMed] [Google Scholar]
- 15.Volkov M, Hashimoto DA, Rosman G, et al. Machine learning and coresets for automated real-time video segmentation of laparoscopic and robot-assisted surgery. IEEE International Conference on Robotics and Automation (ICRA), 2017. pp. 754–759. [Google Scholar]
- 16.Twinanda AP, Shehata S, Mutter D, et al. EndoNet: A Deep Architecture for Recognition Tasks on Laparoscopic Videos. IEEE Trans Med Imaging 2017; 36(1):86–97. [DOI] [PubMed] [Google Scholar]
- 17.Rindos NB, Wroble-Biglan M, Ecker A, et al. Impact of Video Coaching on Gynecologic Resident Laparoscopic Suturing: A Randomized Controlled Trial. J Minim Invasive Gynecol 2017; 24(3):426–431. [DOI] [PubMed] [Google Scholar]
- 18.Soucisse ML, Boulva K, Sideris L, et al. Video Coaching as an Efficient Teaching Method for Surgical Residents-A Randomized Controlled Trial. J Surg Educ 2017; 74(2):365–371. [DOI] [PubMed] [Google Scholar]
- 19.Alameddine MB, Englesbe MJ, Waits SA. A Video-Based Coaching Intervention to Improve Surgical Skill in Fourth-Year Medical Students. J Surg Educ 2018; 75(6):1475–1479. [DOI] [PubMed] [Google Scholar]
- 20.Langerman A, Grantcharov TP. Are We Ready for Our Close-up?: Why and How We Must Embrace Video in the OR. Annals of Surgery 2017. [DOI] [PubMed] [Google Scholar]
- 21.Dimick JB, Scott JW. A Video Is Worth a Thousand Operative Notes. JAMA Surg 2019. [DOI] [PubMed] [Google Scholar]
- 22.Hashimoto DA, Axelsson CG, Jones CB, et al. Surgical procedural map scoring for decision-making in laparoscopic cholecystectomy. Am J Surg 2019; 217(2):356–361. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 23.Pugh CM, DaRosa DA. Use of cognitive task analysis to guide the development of performance-based assessments for intraoperative decision making. Mil Med 2013; 178(10 Suppl):22–7. [DOI] [PubMed] [Google Scholar]
- 24.Pugh CM, Santacaterina S, DaRosa DA, et al. Intra-operative decision making: more than meets the eye. J Biomed Inform 2011; 44(3):486–96. [DOI] [PubMed] [Google Scholar]