

Abstract
The Fine–Gray proportional subdistribution hazards model has been puzzling many people since its introduction. The main reason for the uneasy feeling is that the approach considers individuals still at risk for an event of cause 1 after they fell victim to the competing risk of cause 2. The subdistribution hazard and the extended risk sets, where subjects who failed of the competing risk remain in the risk set, are generally perceived as unnatural . One could say it is somewhat of a riddle why the Fine–Gray approach yields valid inference. To take away these uneasy feelings, we explore the link between the Fine–Gray and cause‐specific approaches in more detail. We introduce the reduction factor as representing the proportion of subjects in the Fine–Gray risk set that has not yet experienced a competing event. In the presence of covariates, the dependence of the reduction factor on a covariate gives information on how the effect of the covariate on the cause‐specific hazard and the subdistribution hazard relate. We discuss estimation and modeling of the reduction factor, and show how they can be used in various ways to estimate cumulative incidences, given the covariates. Methods are illustrated on data of the European Society for Blood and Marrow Transplantation.
Keywords: cause‐specific hazard, competing risks, cumulative incidence, proportional hazards, subdistribution hazard
1. INTRODUCTION
Competing risks are common in medical survival data, when patients can experience one of a number of mutually exclusive competing events. Examples are death of different causes, or recurrence of disease, when death is a competing risk (Prentice et al., 1978; Putter, Fiocco, & Geskus, 2007; Beyersmann, Allignol, & Schumacher, 2011; Andersen, Geskus, de Witte, & Putter, 2012; Geskus, 2015). When interest is in the effect of a covariate on an event of interest in the presence of competing risks, two main approaches are in use, both based on proportional hazards. The first approach imposes a proportional hazards assumption on the cause‐specific hazards. After estimating the regression coefficients and baseline hazards, probability calculations can be made to quantify the effect of the covariate on the probability scale, the cumulative incidence (Andersen et al., 2002). The situation can occur that, with an estimated positive regression coefficient for the cause‐specific hazard of interest, higher values of the covariate do not coincide with higher probabilities of the event of interest. The reason for this, perhaps unexpected, behaviour, is that the probability of occurrence of the event of interest depends on both cause‐specific hazards. Motivated by this complication, Fine and Gray (1999) developed their proportional subdistribution hazards model, nowadays commonly known as the Fine–Gray model.
The Fine–Gray model has been puzzling many people since its introduction. The main reason for the uneasy feeling is that the approach considers individuals still at risk for an event of cause 1 after they fell victim to cause 2 (the competing risk). The “explanation” is that the subdistribution is only interested in risk 1 and does not want any information about the occurrence of other competing events. The uneasiness is about not using the information that an individual is not at risk any more for other events if one particular event has occurred. One might say that in the extended risk sets of the Fine–Gray partial likelihood there is heterogeneity among the members of the risk set, one subgroup still can get the event, while the other subgroup cannot experience any further events. One might wonder whether this heterogeneity might introduce bias or lead to loss of efficiency. The subdistribution “hazard” and the extended risks sets of the Fine–Gray approach are perceived by most as unnatural concepts; the riddle is why the Fine–Gray approach works and why the partial likelihood based on the extended risk sets, and subsequent inference based on it is valid.
A related issue is that the cumulative incidence function that is directly estimated in the Fine–Gray approach cannot be used dynamically. In conditional (landmark) models one wants to condition on still being “alive” and not on not having experienced the event of interest. That explains why Cortese, Gerds, and Andersen (2013) have to compute separate Fine–Gray models for each landmark point they consider.
To take away these uneasy feelings our aim is to explore the link between the Fine–Gray and cause‐specific approaches in more detail. In Section 2, we study the relation between cause‐specific and subdistribution hazards, and we introduce the reduction factor. Section 3 discusses estimation and modeling of the reduction factor. Section 4 shows how the reduction factor can play a role in estimating cumulative incidence functions. Section 5 illustrates estimation of the reduction factor and its use in modeling cumulative incidence functions in a data set of CML patients. The paper ends with a discussion in Section 6.
2. ON THE RELATION BETWEEN THE CAUSE‐SPECIFIC AND SUBDISTRIBUTION HAZARD
2.1. Multistate description of the problem
To simplify the discussion we consider only two competing risks, risk 1 is the risk of interest and risk 2 is the union of all other competing risks. We can use a multistate model with the following three states to represent the competing risks problem:
-
State 0 (S0)
The initial state at ;
-
State 1 (S1)
The absorbing state of risk 1;
-
State 2 (S2)
The absorbing state of risk 2.
See Figure 1a for a graphical representation.
Figure 1.
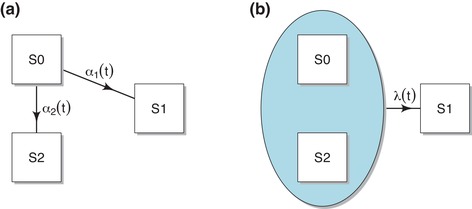
Graphical presentation of the (a) cause‐specific (multistate) approach and the (b) Fine–Gray approach
Let denote the multistate model process. The transition rates from state 0 to states 1 and 2 are the cause‐specific hazard rates, denoted by and . The state occupation probabilities are denoted by , and ; is the probability of being event‐free up to time t, and and are the cause‐specific cumulative incidences of cause 1 and 2, respectively. Assuming that the 's are continuous, the relation between and the cause‐specific hazards are given by
| (1) |
where is the cumulative cause‐specific hazard.
To explain the Fine–Gray approach for risk 1 we define , the complement of State 1. The Fine–Gray approach is based on directly modeling , the rate of moving from to State 1. See Figure 1b for a graphical presentation.
The rate is referred to as the subdistribution hazard. That term might cause confusion with the cause‐specific hazard and it can be considered the hazard only of something that violates the three principles of Andersen and Keiding (2012), but we will the term nevertheless because it is well‐established in the literature. It is given by
In principle there is also a subdistribution hazard of the competing risk, cause 2, but since the Fine–Gray model focuses on the cause of interest, cause 1, and F 1 depends only on one subdistribution hazard, we omit the subscript 1 from the notation of . The advantage of the approach is that the cumulative incidence function can be derived directly from , as . The subdistribution hazard can be estimated by partial likelihood using as the risk set. As stated in the introduction the uneasy elements are that the information about the occurrence of risk 2 is not used and that the risk set contains individuals that are only artificially at risk, because they already experienced the competing risk.
The link between and is given by
| (2) |
see also Latouche, Boisson, Chevret, and Porcher (2007) and Beyersmann and Scheike (2013), among others.
2.2. The reduction factor
The identity (2) is crucial for understanding the relation between the 's and λ. We call the reduction factor. It represents the proportion of subjects in the extended risk set that has not yet experienced a competing event, and can be expressed as
| (3) |
Observe that , , and that is decreasing. An explanation of the fact that is decreasing is that decreases and increases over time, as it is the fraction that experienced the competing event before time t. Mathematically, it follows from the fact that , which yields
| (4) |
Note that the term , coming from , is the subdistribution hazard . Notice also that implies that the subdistribution hazard and the cause‐specific hazard are identical at and will start diverging later on. The negative derivative of at equals α2(0); the larger the competing cause‐specific hazard, the larger the initial exponential decrease of . In some sense initially behaves like a survival function with cumulative hazard rate .
Figure 2 illustrates the behavior of for a number of choices of cause‐specific hazards from the Weibull family, with hazard rate , for . We choose three values of the shape parameter b, namely (a decreasing hazard), (constant hazard), and (increasing hazard) and choose the corresponding rate parameters a in such a way that , with the survival function corresponding to . This leads to the values 1.895, 1.198, and 0.479, for a, when , respectively. We consider a competing risks situation with two causes, where the cause‐specific hazards of cause 1 and 2 are both chosen from these three Weibull hazards, with and corresponding a values. We denote the hazard with as “Early risk,” with as “Middle risk,” and with as “Late risk.” The reduction factor was obtained by numerically solving the differential equation (4). The general behavior seen from Figure 2 is that decreases more rapidly when the competing cause‐specific hazard has an earlier risk. The effect of the shape of the cause‐specific hazards of the cause of interest is less pronounced.
Figure 2.
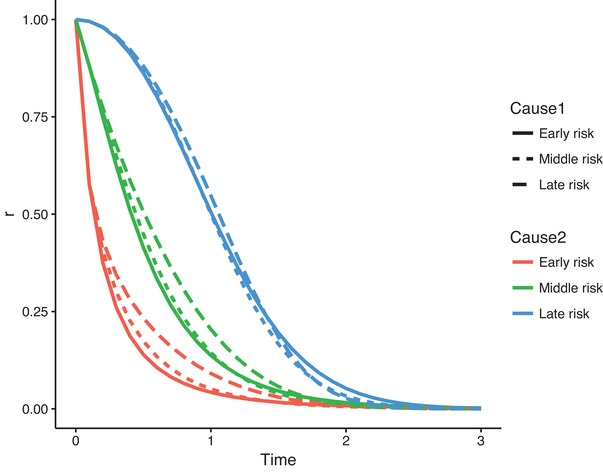
The reduction factor for different choices of Weibull hazards
Of course, the particular figure is highly dependent on the choice of parameters. The Supporting Information contains R code to reproduce the figure, and to change the settings of the parameters.
Remark 1
Equation (4) not only gives a formula for in terms of and , but also of in terms of and , and even of in terms of and . The usefulness of these relations will be discussed later.
2.3. The reduction factor and covariates
The reduction factor describes the relation between the subdistribution hazard and cause‐specific hazards. This implies that the dependence of the reduction factor on a covariate x gives information on how the effect of x on the cause‐specific and subdistribution hazards relate. To illustrate this point, suppose that the cause‐specific hazard is given by
and the subdistribution hazard by
Then the reduction factor has a similar form
with , and
| (5) |
Note that valid reduction factors have , so we must have and .
Equation (5) quantifies how the regression coefficients in a Fine–Gray model and in a cause‐specific hazards model differ. In particular, if and are time‐fixed, we get the simple relation . For this to really hold, in view of the above we must have . Cause‐specific and subdistribution hazards can typically not both fulfill the proportional hazards assumption at the same time, unless (Grambauer, Schumacher, & Beyersmann, 2010).
Figures 3 and 4 show the behaviour of and of the logarithm of in the case of proportional cause‐specific hazards models, for the Weibull hazards we used in Figure 2. The three choices of Weibull hazards (early, middle, and late risk) were used as baseline cause‐specific hazards for the competing risk, while for cause 1 the middle risk (constant hazard) was selected as baseline hazard. A single binary covariate x with mean was used with a proportional effect for both cause‐specific hazards; with regression coefficients β1 and , 0, 0.5, for cause 1 and 2, respectively. The solid curves in Figure 3 show the behaviour of implied by each of the nine different choices of β1 and β2 (referred to as beta1 and beta2 in the figure), for the case where the competing risk is “Early risk.” The dotted lines represent , which is time‐constant and trivially equals , 0 and 0.5 in the left, middle, and right column, respectively. Note that , and that initially increases if and initially decreases if . This can be explained from the fact that , which implies that here . Note also that is the only case when is time‐constant (and equal to 0). Figure 4 shows the resulting for and on a logarithmic scale, for each of the possibilities of β1 and β2, also for the case where the competing risk is “Early risk.” It is seen that the reduction curves behave like survival curves (they start in 1 and decrease monotonically). The main reason for showing the logarithmic scale is that the difference between the logarithms of and equals . Similar figures for “Middle risk” and “Late risk” can be obtained by running the code available in the Supporting Information. For later risk, both and start to diverge later.
Figure 3.
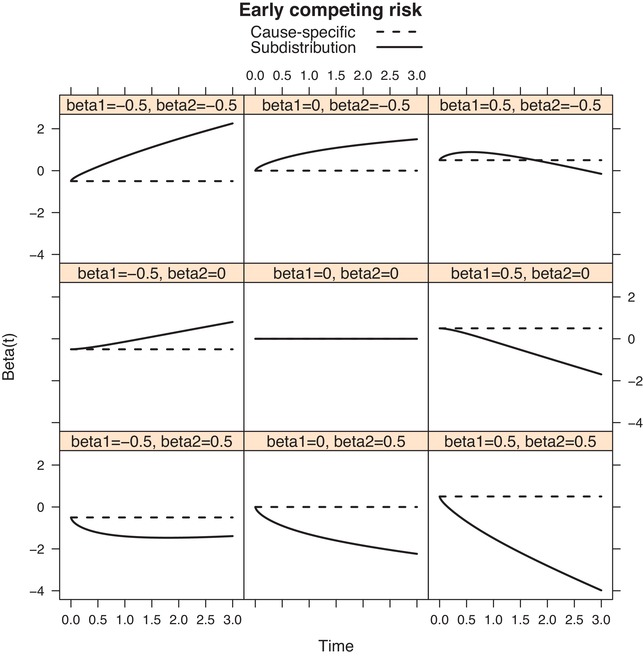
“Early” competing risk; the regression coefficients (dashed lines) and (solid lines) for the cause‐specific and subdistribution hazards respectively, for different choices of β1 and β2
Figure 4.
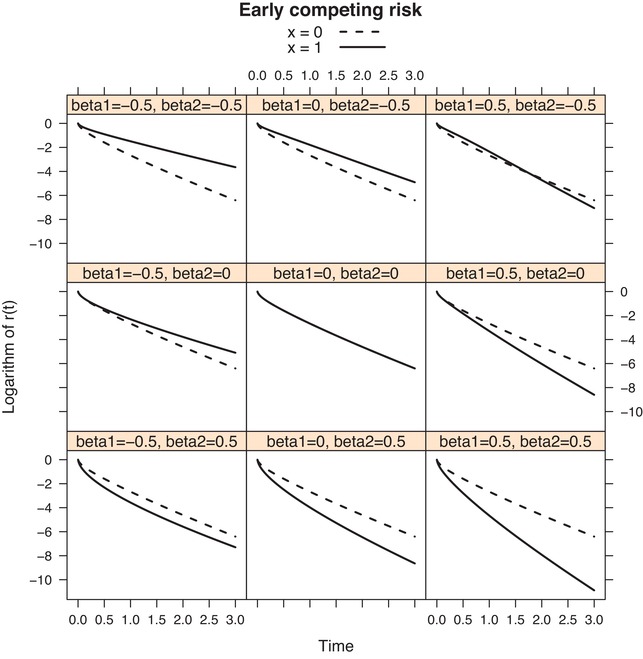
“Early” competing risk; the log reduction factor for different choices of β1 and β2
Equation (2) allows estimating the subdistribution hazard without using the partial likelihood on the extended risk set, the main cause of concern about the Fine–Gray approach. It needs a model for the reduction factor which is not a transition rate, but a ratio of the prevalent cumulative incidence functions that can be estimated through binomial models or empirical proportions. The drawback is that the resulting model for the subdistribution hazard will be far from simple. A simple model can be obtained by a little trick. Let the desired simple model for the subdistribution hazard be . From Equation (2), we can write
| (6) |
Equation (6) implies that, once has been estimated, can be estimated by fitting a model on the cause‐specific hazard, using the negative of as offset. Partial likelihood in the “proper” risk sets is used, although some programming is needed to handle the offset term. Note that using as offset is different from inverse probability weighting, although it has a similar flavour. Note also that, although the cause‐specific hazards model on the right hand side of Equation (6) looks like a proportional cause‐specific hazards model because of the presence of in the exponent, it is not because the offset term, although not associated with a parameter, is time‐dependent and depends on x. In the next section we show the remarkable fact that when x is a categorical covariate and the negative logarithm of the non‐parametric estimate of the reduction factor is used as offset in the partial likelihood for cause‐specific hazards, the resulting estimate equals the Fine–Gray estimate. In order to show this, we consider estimation and modeling of the reduction factor in the next section.
3. HAZARD REGRESSION MODELS AND THE REDUCTION FACTOR
3.1. Notation, risk sets, and partial likelihoods
We assume that there are no ties in the data and initially we also assume there is no censoring before the observation horizon, in other words we consider estimation before that horizon. Censoring will be discussed at the end of this section. For simplicity, we assume there are two competing risks, and we suppose again that cause 1 is the event of primary interest.
The data are given by realizations of , for , with the event or censoring time, and the type of event. In the case of right censoring, considered later, we have . Define as the set of all cause 1 event time points, that is, the distinct for which the corresponding equals 1. Denote the “usual” risk set at time t, used for inference on the cause‐specific hazards, by , and the extended Fine–Gray risk set by . In the absence of censoring, the Fine–Gray risk set can be obtained by replacing any by . In case of random censoring, more subtle inverse probability of censoring weighting has to be applied, which will be considered at the end of this section. Define the corresponding at risk indicators for subject i, and and their sums and .
A proportional hazards model for the cause‐specific hazards specifies, for instance for cause 1,
The regression coefficient estimate is found by maximizing the partial likelihood
where the product is over all cause 1 event time points . In practice this partial likelihood can be maximized by standard Cox software by censoring the competing events.
The Fine–Gray approach is based on the wish to obtain a simple model for the cumulative incidence. It specifies a proportional hazards model for the subdistribution hazard, given by
| (7) |
The regression parameter is estimated using partial likelihood on the extended risk set, so including individuals that have experienced the competing event. The partial likelihood that is being maximized is given by
3.2. Non‐parametric estimation
In the multistate model, an estimate of is obtained implicitly from the models for and . Here, we explore the possibility of estimating it directly from the data. Some feeling for how this works can be obtained by looking at the simplest case where there are no covariates and one is only interested in estimating the cumulative incidence function. The non‐parametric estimates of and are defined at the same time points, namely the set of all cause 1 event time points, denoted by . Let . The Nelson–Aalen estimate of the cause‐specific hazard at that point (assuming no ties) is given by
The reduction factor can be estimated by
| (8) |
which, using the relation , leads to a Nelson–Aalen‐type estimator for the subdistribution hazard
So, in this situation the result is the same as a Nelson–Aalen estimator based directly on the Fine–Gray risk set. The only advantage is that the hazard estimate is based on the risk set where all individuals are at risk for the event and avoids the use of the risk set where it is known that some individuals cannot have the event because they already experienced the competing event.
Remark 2
As seen from (2), the subdistribution hazard depends on the past through and on the future through . That makes that is of no use in dynamic models where the conditioning is on and not on “ or a competing event having happened before time s.” Cause‐specific hazards are much more natural in this context; the conditional cumulative incidence function depends naturally on both cause‐specific hazards, between s and t, through
In terms of the subdistribution hazard, one would have to “forget” the competing risks that occurred before time s. One could work with
where (cf. Equation (2))
Dynamic modeling using subdistribution hazards would basically require reestimation of for all time points s where dynamic prediction probabilities are required. For dynamic modeling of cumulative incidence, it is more practical to use landmarking (Cortese & Andersen, 2010; Cortese et al., 2013), possibly combined with pseudo‐values (Nicolaie, van Houwelingen, de Witte, & Putter, 2013b) instead.
3.3. Covariates
In case of a categorical covariate x, the richest model for would be obtained by separate non‐parametric estimates for each possible value c of the covariate, as discussed above. If we let and denote the at risk indicators for subjects with covariate value equal to c, a saturated model for would have as estimate
| (9) |
for .
Remark 3
Interestingly, when x is a categorical covariate and when the estimate of the reduction factor is based on a saturated model, given by (9), it turns out that, in the absence of ties, the result of fitting a proportional hazards model on the cause‐specific hazard, using as offset, suggested at the end of Section 2, is identical to the estimate obtained by maximizing the partial likelihood of the Fine–Gray model. This can be seen by starting out from the Fine–Gray partial likelihood, separating the terms in the Fine–Gray risk set according to the value of the covariates, and applying (9). We obtain
(10) This sheds some light on the Fine–Gray riddle, in the sense that it shows that the Fine–Gray partial likelihood is not so unnatural as it may appear, and that it can be maximized based on the natural cause‐specific risk sets, using appropriate offsets.
Since has all the properties of a probability, an obvious way to start fitting more parsimonious models for is with a binomial GLM. Fix , and let be the extended risk set at . Within that set let . Then . For a given link function g, we can postulate the model
Models for the different risk sets can be joined by specifying a parametric function or using splines for the “baseline” . Depending on the choice of link function, time‐varying effects of the covariates can be incorporated by interactions of the covariates with (functions of) time. Practically, these models can be fitted using standard generalized estimating equations (GEE) software, where the risk sets, given by all time points where a cause 1 event occurs, are considered to be independent. Standard errors may be obtained by sandwiching.
Possible choices for link functions are , , and . It is useful to discuss the pro's and cons of different link functions in the context of what they imply for the subdistribution hazards, in relation to the models for the cause‐specific hazards. We already saw that the log link has the advantage that combining it with a proportional hazards model for the cause‐specific hazards leads to a proportional hazards model for the subdistribution hazard. The disadvantage of the log link is that it cannot deal with for t close to 0, because of the restriction that for all covariate values x. It would be advisable to use time‐dependent effects of the covariates, preferably with the restriction . The logit and cloglog links can deal with probabilities close to 1 for t close to 0. The disadvantage of the logit and cloglog links is that combining it with a proportional cause‐specific hazards model will lead to non‐proportional models for the subdistribution hazard.
Finally, as argued in Stijnen and van Houwelingen (1993), we can also estimate the regression coefficients in a GLM model by acting as if Y has a Poisson distribution. The Poisson model with log link will share the same advantages and disadvantages of the binomial GLM with log link. They may be easier to fit than binomial GLM with log link because also expected values higher than one are allowed.
3.4. Censoring
Right censoring complicates estimation in the Fine–Gray regression model, and also estimation of the reduction factor. The reason is that we do not know whether a censored observation will belong to the Fine–Gray risk set after the time of censoring. The potential observations of subject i are the pair , with the event time and the cause of failure. The event time is right censored by a censoring time , with censoring function . We now observe and the event indicator , which equals , in case , or 0, in case . We assume that C is stochastically independent of the pair and X. Alternatively, it can be assumed that T is independent of C, conditional on covariates. In that case the estimate of the censoring distribution below depends on X. Define . Following Fine and Gray (1999), we introduce time‐dependent weights for subject i at time t, where is the reverse Kaplan–Meier estimate of the censoring distribution (or a consistent estimate of G, given X). The idea behind the weighting is that the usable observations are upweighted to compensate for the censored ones; the weighted observations give a representation of what would be observed in the case of no censoring. By definition, we have , for .
In the case of categorical covariates, we redefine (9) as
| (11) |
The latter equality follows because for , we have , while for , we have . The GLM's can also be extended to incorporate these weights. Standard errors could be obtained using the methods outlined in the Appendix or through bootstrapping.
The equivalence, noted earlier (Remark 3), of the Fine–Gray partial likelihood estimator and the result of fitting a proportional hazards model on the cause‐specific hazard, using as offset for categorical covariates, remains valid in the presence of right censoring. In Equation (10), each contribution of and needs to be multiplied by , and the argument remains valid. Note that inverse probability of censoring weighting is only needed at the stage of estimation of the reduction factor, not when maximizing the partial likelihood.
4. MODELING THE EFFECT OF COVARIATES ON THE CUMULATIVE INCIDENCE FUNCTION
There are a number of ways of modeling the effect of covariates on the cumulative incidence of a given cause. In this section, we focus on models based on the cause‐specific hazards, subdistribution hazards, and/or reduction factor. Other approaches exist, such as vertical modeling (Nicolaie, van Houwelingen, & Putter, 2013a), but they fall outside the scope of this paper. Approaches 1 and 3 below are standard; approaches 2 and 4 are included to illustrate the use of the reduction factor. An extensive investigation of the relative performance of the estimators is outside the scope of this paper.
- Multistate approach (Multistate): Model both cause‐specific hazards by a proportional hazards model
for . Estimate the parameters β1 and β2, and the baseline cause‐specific hazards α10 and α20 by partial likelihood, using the cause‐specific hazards risk set. Using relation (1), the implied effect of the covariates on the cumulative incidence can be calculated. For given covariate values , using the estimates , , , , we obtain , , and finally
Since the cause‐specific hazards coincide with the transition hazards in the multistate model depicted in Figure 1a, this approach is known as the multistate approach to competing risks (Andersen, Abildstrom, & Rosthøj, 2002). It has been implemented in the multistate model package mstate (de Wreede, Fiocco, & Putter, 2010). The resulting effect of the covariates on the cumulative incidence may not always be increasing or decreasing in x. - Subdistribution implied by cause‐specific hazard and reduction factor (Subdistribution through ): Use the cause‐specific hazards risk set. Model by a proportional hazards model, estimate the parameters by partial likelihood using the cause‐specific hazards risk set, as in approach 1. Model by some GLM. Fit it by GEE or a similar approach. Calculate, for a given value of the covariates,
This approach has not been implemented in statistical software. Example code is provided in the Supporting Information. - Fine–Gray approach (Fine–Gray): The Fine–Gray model specifies a proportional hazards model for the subdistribution hazard, given by
After having estimated by maximizing the Fine–Gray partial likelihood, the cumulative incidence function is obtained by(12)
This approach has been implemented in the cmprsk package (Gray, 2014). -
Fine–Gray with cause‐specific hazards partial likelihood (Fine–Gray with CSH PL): The objective again is to have a simple relation for the subdistribution hazard, given by (12). The parameter is now estimated based on an initial estimate of , and subsequently based on maximizing the cause‐specific partial likelihood with as offset. By Remark 3, if x is categorical and the estimate of is based on a saturated model, then this approach yields the same estimate of as the Fine–Gray approach, and also the same cumulative incidence function for a given value of the covariates. If not, we obtain a different estimate of the same estimand . The cumulative incidence for fixed covariate value , , can be obtained from the estimates of Equation (6) and those of , by going back to Equation (2), and obtaining the subdistribution hazard as
for each event time point of the cause of interest, which, by Equation (6), yields
Since
we obtain
The cumulative incidence function is given by
where the sum is over all cause 1 event time points before time t.This approach has not been implemented in statistical software. Example code is provided in the Supporting Information.
5. ILLUSTRATION
We illustrate the different methods of Sections 3 and 4 on a data set of 1977 patients with chronic myeloid leukemia (CML), collected by the European Society for Blood and Marrow Transplantation (EBMT), and available in the mstate package (de Wreede et al., 2010) as data set ebmt1. After removing the children (age below 18) from the data, 1835 patients remain. The competing risks involved are relapse (421 events), and death before relapse (641 events), more commonly called non‐relapse mortality (NRM). The remaining 773 observations are right censored. The data contain ties, these have been broken for the analysis. The covariates that are used here for illustration are age (centered at 40, reported per decade for analysis) and the EBMT risk score, which is a grouping into “Low risk” (), “Medium risk” (), and “High risk” (). The age range was 18–64, with a median of 36. Figure 5 shows the (a) estimated cumulative hazards for relapse and (b) non‐relapse mortality, per risk group.
Figure 5.
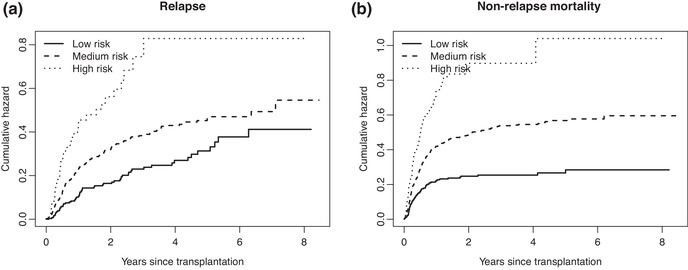
Non‐parametric estimates of the (a) cause‐specific hazards of relapse and (b) non‐relapse mortality, for each of the three EBMT risk score groups
They are comparable in terms of their values at the end of follow‐up and in terms of differences between the risk groups, but the shape of the cumulative hazards is somewhat different; those for non‐relapse mortality increase more steeply in the beginning, while those of relapse increase more gradually. In terms of the early, middle, and late risk terminology, used in Section 2, non‐relapse mortality would correspond to early risk and relapse would tend more toward middle risk. The EBMT risk score has comparable effects on both causes of failure. Proportional hazards models on the cause‐specific hazards yields, with age and risk group with “Low risk” as reference category, regression coefficients (standard errors) of 0.476 (0.149) and 1.139 (0.205) for “Medium risk” and “High risk,” respectively and 0.002 (0.053) for age (per decade) for relapse, and 0.658 (0.134), 1.206 (0.173) and 0.040 (0.043), again for “Medium risk,” “High risk” and age (per decade), respectively for non‐relapse mortality.
Figure 6 shows the (a) estimated cumulative incidence curves for relapse and (b) non‐relapse mortality, separately for each risk group.
Figure 6.
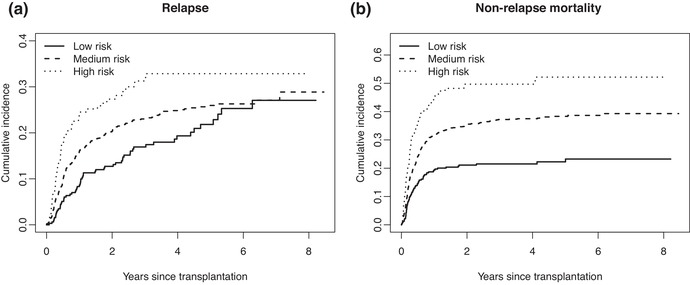
Non‐parametric estimates of the (a) cumulative incidences of relapse and (b) non‐relapse mortality, for each of the three EBMT risk score groups
Relapse seems to be more affected by the competing risk NRM than reversely; the effect of the EBMT risk score is now seen to be smaller for relapse than for NRM. Fine–Gray regression with age and risk group yields regression coefficients (standard errors) of 0.287 (0.147), 0.619 (0.208), and −0.012 (0.056) for “Medium risk,” “High risk,” and age (decade), respectively for relapse, and 0.584 (0.135), 1.004 (0.174), and 0.041 (0.042), again for “Medium risk,” “High risk” and age (decade), respectively for non‐relapse mortality. The fact that, compared to the cause‐specific log hazard ratios, the Fine–Gray estimates for relapse are much more reduced than those for NRM, can be understood by noting that relapse tends more toward later risk than NRM.
To model the reduction factor we fitted, separately for event time point of the cause of interest, a Poisson GLM model with
with defined (with all subjects in the Fine–Gray risk set at ) as 1 if also in the cause‐specific hazards risk set at and 0 otherwise, x 1 and x 2 the dummy variables for medium and high risk scores (compared to low risk) and x 3 age, centered by 40, by decade. Inverse probability of censoring weights, described in Section 3, have been used in this analysis. Figure 7 shows the estimates of (Intercept), and of (Medium risk / Low risk), (High risk / Low risk) and (Age) for relapse (a) and non‐relapse mortality (b).
Figure 7.
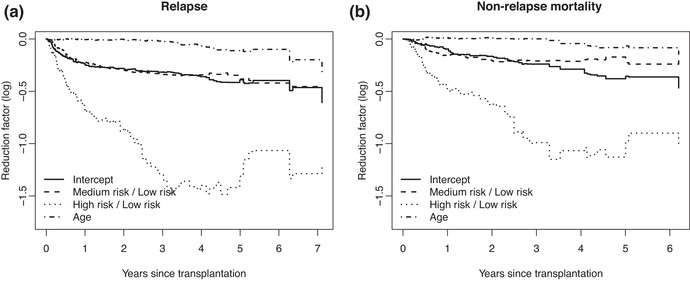
Estimates of the baseline and effects of score and age on the log reduction factor for (a) relapse and (b) non‐relapse mortality
Recalling Equation (5), the fact that for instance the for High risk / Low risk is quite negative implies that the Fine–Gray regression coefficient will be lower than the corresponding regression coefficient for the cause‐specific hazards for this factor.
Finally, Figure 8 shows the estimates of the cumulative incidences of (a) relapse and (b) non‐relapse mortality for the two extreme risk groups (the middle one was omitted because no real differences could be seen) and age equal to 40, based on the four modeling approaches of Section 4.
Figure 8.
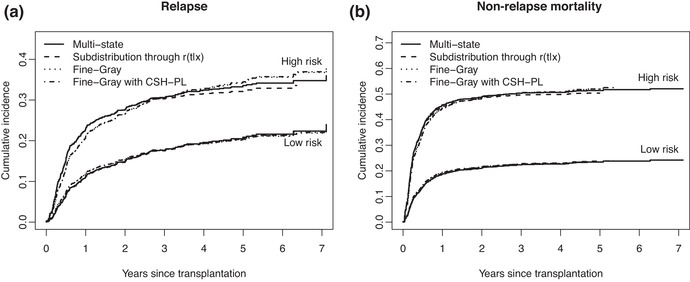
Estimates of the cumulative incidences of (a) relapse and (b) non‐relapse mortality for the low and high risk groups and age equal to 40, based on four modeling approaches
Note that the model we used for estimating the reduction factor was almost saturated (it would be if age was not included), since we have full interactions of all covariates with time. This causes the curves for Fine–Gray (method 3) and “Fine–Gray with CSH‐PL” (method 4) to be almost indiscernible. The regression coefficients for “Fine–Gray with CSH‐PL” were almost identical to Fine–Gray (results can be seen in the Supporting Information). The underlying assumptions for Fine–Gray (and “Fine–Gray with CSH‐PL”) and “Multistate” (method 1) are different. Both assume proportional hazards, but Fine–Gray assumes proportional hazards on the subdistribution hazards, while “Multistate” assumes proportional hazards on the cause‐specific hazards. The difference in the shape of the cumulative incidence curves for the high risk group can be clearly seen. Looking at Figures 5 and 6a, one could question the validity of the proportional hazards assumption, both for the cause‐specific hazards and for the subdistribution hazard of relapse. Despite the apparent violation of the proportional hazards assumption for the cause‐specific hazard and subdistribution hazard of relapse, we chose to retain the proportional models, because it illustrates the influence of the proportional hazards assumptions on the estimated cumulative incidences. The “Subdistribution through ” method (method 2) is close to the proportional subdistribution hazards approach, in terms of assumptions. The cause‐specific hazards have been estimated based on a proportional hazards assumption on the cause‐specific hazards, but subsequently subdistribution hazards are obtained by multiplying with an estimate of the reduction factor, where this estimate does not make that assumption (nor of proportionality on the subdistribution hazard).
Figure 9 shows pointwise standard errors of the four model‐based cumulative incidence curves of relapse, also for the low and high risk groups and age equal to 40. They are quite similar, with the exception of the cumulative incidence curves for relapse for high risk based on the multistate model, which shows lower standard errors than the other curves from one year after stem cell transplantation onward.
Figure 9.
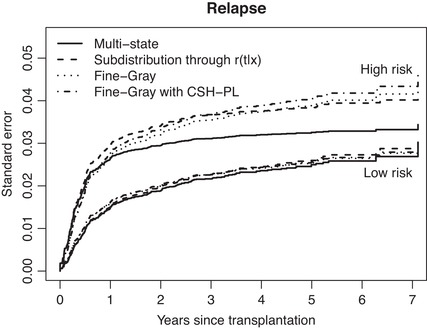
Estimates of the standard errors of the cumulative incidences of relapse for the low and high risk groups and age equal to 40, based on four modeling approaches
6. DISCUSSION
Our primary aim in this paper was to study the relation between the cause‐specific hazards and the subdistribution hazard. For this purpose, we defined the reduction factor as the ratio between subdistribution hazard and cause‐specific hazard. The effect of a covariate on the log reduction factor (possibly time‐varying) quantifies the difference between the regression coefficients obtained by Fine–Gray regression and Cox regression on the cause‐specific hazard.
Estimating and modeling the reduction factor offers alternative ways of modeling the cumulative incidence function as a function of covariates. One attractive approach is to model both the cause‐specific hazard and the reduction factor and obtain the subdistribution hazard as the product of these. It is not quite clear at present what are the properties of this estimator, especially in situations where the proportional hazards assumption on cause‐specific hazard and/or subdistribution hazard is violated. In general we recommend making the models for the reduction factor rich, as we did in the application, for instance separate Poisson GLM's for each time point. Although the target for estimation is very different, the modeling approach resembles that for additive hazards. Reasons for the recommendation of making rich models are given in the following two paragraphs.
We showed that a Fine–Gray‐type coefficient can be obtained by using the negative logarithm of the estimated reduction factor as time‐dependent offset in a cause‐specific hazards model. For a single categorical covariate, when the model for the reduction factor is fully saturated, in other words when separate non‐parametric estimates of the reduction factor for each level of the covariate are used, maximizing the partial likelihood of the cause‐specific hazard with the negative logarithm of this estimated reduction factor as offset, yields exactly the Fine–Gray estimator, maximizing the Fine–Gray partial likelihood. Thus, in a sense this solves the Fine–Gray riddle: the reduction factor is also the adjustment factor needed to justify the Fine–Gray likelihood.
In the Appendix, we outline how to obtain standard errors for the estimators of cumulative incidence functions given covariates, for the four methods discussed in Section 4. Methods 2 and 4 use an initial estimate of the reduction factor , given the covariates. We derive standard errors of the cumulative incidences given covariates, ignoring the uncertainty in the estimate of . Despite our recommendation to make the models for very rich, we think that as far as the standard errors of the estimates of the parameters of the reduction factor are concerned, the uncertainty in these estimates can be ignored in practice, but this requires further study. Using standard Cox software for the cause‐specific hazards with the negative logarithm of the reduction factor as offset, we obtain very similar (although not exactly identical) estimates of the standard errors of the Fine–Gray coefficients, compared to the results from Fine–Gray, see Supporting Information. The situation is not unlike marginal structural models or propensity score matching, where models for inverse probability weights and propensity scores are also advised to be sufficiently rich, and where uncertainty in these intermediate models is negligible for the end results where the results of these models are used for weighting or adjusting/matching. More research is needed to assess the behaviour of the estimators of the cumulative incidence functions and their estimated standard errors, in terms of accuracy and coverage.
CONFLICT OF INTEREST
The authors have declared no conflict of interest.
Supporting information
Supporting Information
ACKNOWLEDGMENTS
The authors are grateful to Jan Beyersmann for fruitful discussions, two anonymous referees for comments which have improved the presentation of the paper, and the European Society for Blood and Marrow Transplantation for providing the data.
In this appendix, we outline how asymptotic standard errors of the cumulative incidence for given covariates x can be obtained, for the four methods in Section 4. We do not discuss the first approach (multistate) in detail, since asymptotic theory for this approach can be found in textbooks (Beyersmann et al., 2011; Geskus, 2015) and has been implemented in mstate (de Wreede et al., 2010). Calculation of the standard errors in the other three cases follows a very similar structure that is well known (Andersen, Borgan, Gill, & Keiding, 1993; Therneau & Grambsch, 2000; van Houwelingen & Putter, 2012). Throughout, we ignore the uncertainty in the estimation of the reduction factor , see Discussion. We also do not specify how is modeled, but we assume that the model is correctly specified and that is consistently estimated for all x. Key for all three remaining methods is to derive the asymptotic variance of
the sum being over all cause 1 event time points before time t. These can be used to construct confidence intervals for on the log‐scale, or on the probability scale, after applying the delta method, which yields
The estimates of are obtained in different ways for the three remaining methods, leading to slightly different ways of deriving the asymptotic variance of .
Subdistribution through
Denote the estimate of in the proportional hazards model for the cause‐specific hazard of cause 1 as . The subdistribution rate is estimated as the product of and .
Define as a weighted average of the x's in the risk set , that is
The Fisher information of the partial likelihood, assuming no ties, is given by , with
the weighted covariance matrix in the risk set at event time . The asymptotic variance of may now be estimated consistently by
with
Fine–Gray
The Fine–Gray model is based on the partial likelihood of the Fine–Gray risk set, using inverse probability of censoring weighting to account for the censoring. Recall the time‐dependent weights for subject i at time t, where is the reverse Kaplan–Meier estimate of the censoring distribution. Let be the Fine–Gray estimate of the effect of x on the cumulative incidence of cause 1. The formulas need to be adjusted in the following way.
Define as a weighted average of the x's in the risk set , that is
The Fisher information of the partial likelihood, assuming no ties, is given by , with
the weighted covariance matrix in the risk set at event time . The asymptotic variance of may now be estimated consistently by
with
Fine–Gray with CSH PL
Define as a weighted average of the x's in the risk set , accounted for the offset, that is
The Fisher information of the partial likelihood, assuming no ties, is given by , with
the weighted covariance matrix in the risk set at event time . The asymptotic variance of may now be estimated consistently by
with
Putter H, Schumacher M, van Houwelingen HC. On the relation between the cause‐specific hazard and the subdistribution rate for competing risks data: The Fine–Gray model revisited. Biometrical Journal. 2020;62:790–807. 10.1002/bimj.201800274
REFERENCES
- Andersen, P. K. , Abildstrom, S. Z. , & Rosthøj, S. (2002). Competing risks as a multi‐state model. Statistical Methods in Medical Research, 11(2), 203–215. [DOI] [PubMed] [Google Scholar]
- Andersen, P. K. , Borgan, O. , Gill, R. D. , & Keiding, N. (1993). Statistical models based on counting processes. New York: Springer. [Google Scholar]
- Andersen, P. K. , Geskus, R. B. , de Witte, T. , & Putter, H. (2012). Competing risks in epidemiology: Possibilities and pitfalls. International Journal of Epidemiology, 41(3), 861–870. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Andersen, P. K. , & Keiding, N . (2012). Interpretability and importance of functionals in competing risks and multistate models. Statistics in Medicine, 31, 1074–1088. [DOI] [PubMed] [Google Scholar]
- Beyersmann, J. , Allignol, A. , & Schumacher, M. (2011). Competing risks and multistate models with R. New York: Springer. [Google Scholar]
- Beyersmann, J. , & Scheike, T. (2013). Classical regression models for competing risks In Klein John P., van Houwelingen Hans C., Ibrahim Joseph G. & Scheike Thomas H. (Eds.), Handbook of Survival Analysis (pp. 153–172). Boca Raton, FL: Chapman & Hall/CRC. [Google Scholar]
- Cortese, G. , & Andersen, P. K . (2010). Competing risks and time‐dependent covariates. Biometrical Journal, 52, 138–158. [DOI] [PubMed] [Google Scholar]
- Cortese, G. , Gerds, T. A. , & Andersen, P. K . (2013). Comparing predictions among competing risks models with time‐dependent covariates. Statistics in Medicine, 32, 3089–3101. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Fine, J. P. , & Gray, R. J . (1999). A proportional hazards model for the subdistribution of a competing risk. Journal of the American Statistical Association, 94, 496–509. [Google Scholar]
- Geskus, R. B. (2015). Data analysis with competing risks and intermediate states. Boca Raton, FL: Chapman and Hall/CRC. [Google Scholar]
- Grambauer, N. , Schumacher, M. , & Beyersmann, J . (2010). Proportional subdistribution hazards modeling offers a summary analysis, even if misspecified. Statistics in Medicine, 29, 875–884. [DOI] [PubMed] [Google Scholar]
- Gray, B. (2014). cmprsk: Subdistribution analysis of competing risks [R package version 2.2‐7]. Retrieved from https://CRAN.R-project.org/package=cmprsk [Google Scholar]
- van Houwelingen, H. , & Putter, H. (2012). Dynamic prediction in clinical survival analysis. Boca Raton, FL: CRC Press. [Google Scholar]
- Latouche, A. , Boisson, V. , Chevret, S. , & Porcher, R . (2007). Misspecified regression model for the subdistribution hazard of a competing risk. Statistics in Medicine, 26, 965–974. [DOI] [PubMed] [Google Scholar]
- Nicolaie, M. A. , van Houwelingen, J. C. , & Putter, H . (2013a). Vertical modeling: A pattern mixture approach for competing risks modeling. Statistics in Medicine, 29, 1190–1205. [DOI] [PubMed] [Google Scholar]
- Nicolaie, M. A. , van Houwelingen, J. C. , de Witte, T. M. , & Putter, H . (2013b). Dynamic pseudo‐observations: A robust approach to dynamic prediction in competing risks. Biometrics, 69, 1043–1052. [DOI] [PubMed] [Google Scholar]
- Prentice, R. L. , Kalbfleisch, J. D. , Peterson, A. V., Jr. , Flournoy, N. , Farewell, V. T. , & Breslow, N. E. (1978). The analysis of failure times in the presence of competing risks. Biometrics, 34(4), 541–554. [PubMed] [Google Scholar]
- Putter, H. , Fiocco, M. , & Geskus, R. B. (2007). Tutorial in biostatistics: Competing risks and multi‐state models. Statistics in Medicine, 26(11), 2389–2430. [DOI] [PubMed] [Google Scholar]
- Stijnen, T. , & van Houwelingen, H. C . (1993). Relative risk, risk difference and rate difference models for sparse stratified data: A pseudo likelihood approach. Statistics in Medicine, 12, 2285–2303. [DOI] [PubMed] [Google Scholar]
- Therneau, T. M. , & Grambsch, P. M. (2000). Modeling survival data: Extending the cox model. New York: Springer. [Google Scholar]
- de Wreede, L. C. , Fiocco, M. , & Putter, H. (2010). The mstate package for estimation and prediction in non‐ and semi‐parametric multi‐state and competing risks models. Computer Methods and Programs in Biomedicine 99, 261–274. [DOI] [PubMed] [Google Scholar]
Associated Data
This section collects any data citations, data availability statements, or supplementary materials included in this article.
Supplementary Materials
Supporting Information