

Abstract
Smoking is one of the leading preventable threats to human health and a major risk factor for lung cancer, upper aero-digestive cancer, and chronic obstructive pulmonary disease. Estimating and forecasting the smoking attributable fraction (SAF) of mortality can yield insights into smoking epidemics and also provide a basis for more accurate mortality and life expectancy projection. Peto et al. (1992) proposed a method to estimate the SAF using the lung cancer mortality rate as an indicator of exposure to smoking in the population of interest. Here we use the same method to estimate the all-age SAF (ASAF) for both genders for over 60 countries. We document a strong and cross-nationally consistent pattern of the evolution of the SAF over time. We use this as the basis for a new Bayesian hierarchical model to project future male and female ASAF from over 60 countries simultaneously. This gives forecasts as well as predictive distributions that can be used to find uncertainty intervals for any quantity of interest. We assess the model using out-of-sample predictive validation, and find that it provides good forecasts and well calibrated forecast intervals, comparing favorably with other methods.
MSC 2010 subject classifications: Smoking attributable fraction, Peto-Lopez method, Bayesian hierarchical model, double logistic curve, probabilislic projection
1. Introduction.
Smoking is known to have adverse impacts on health and is one of the leading preventable causes of death (Peto et al., 1992; Bongaarts, 2014; Mons and Brenner, 2017). It is a major risk factor for lung cancer, chronic obstructive pulmonary disease (COPD), respiratory diseases, and vascular diseases, and tobacco use causes approximately 6 million deaths per year (Britton, 2017). For instance, tobacco use causes more than 480,000 deaths per year in the United States, accounting for about 20% of the total deaths of US adults, even though smoking prevalence in United States has declined from 42% in the 1960s to 14% in 2018 (Mons and Brenner, 2017).
The smoking attributable fraction (SAF) is the proportion by which mortality would be reduced if the population were not exposed to smoking. It is defined as
where nS is the number of smokers who died because of their smoking habit and nD is the total number of people who died. It can be shown that this is equivalent to
| (1.1) |
where p is the underlying prevalence of smoking in the population and r is the risk of dying of smokers divided by the risk of dying of nonsmokers in the population (Rosen, 2013).
Estimating and forecasting the SAF of mortality is essential for assessing how the smoking epidemic influences mortality measures from the past to the future. First of all, nonlinear patterns of increase in life expectancy over time are partially due to the smoking epidemic. Bongaarts (2006) used the SAF to calculate the non-smoking life expectancy, which turned out to evolve in a more linear fashion than overall life expectancy (including smoking effects). Janssen, van Wissen and Kunst (2013) used a similar technique to calculate the non-smoking attributable mortality, and showed that its decline is more linear than that of overall mortality.
Second, smoking partly accounts for regional variations in mortality. In most developed regions in the world including Western Europe, North America and some East Asian countries, the smoking epidemic among males started earlier than elsewhere, in the first half of the 20th century. The adverse effect of the smoking epidemic accumulated for several decades, leading to SAF peaking in these countries around the 1980s. With the continuous decline of male smoking prevalence in these countries due to anti-smoking movements and tobacco control, years of life lost due to smoking began to decrease in recent decades. In contrast, many developing countries are currently in the early stage of the smoking epidemic, with high and increasing smoking prevalence among males, even though tobacco control policies are in place.
Smoking also accounts for some subnational differences in mortality. For example, Fenelon and Preston (2012) found that smoking accounts for the southern mortality disadvantage relative to other regions of the United States. They showed that smoking explained 65% of the subnational variation in male mortality in 2004.
Third, changes in smoking mortality largely account for changes in the between-gender differences in mortality. The gap in mortality between males and females has tended to first widen and then narrow in most developed countries, and reduced between-gender differences in smoking largely explain the current closing of the between-gender mortality gap (Pampel, 2006; Preston and Wang, 2006). Indeed, in these countries the female smoking epidemic usually started one or two decades later than the male epidemic, and thereafter followed a similar pattern. In mid- to low-income countries, female smoking-related mortality remains low but still follows a similar rising-peaking-falling trend to the male one. The SAF for males and females clearly follows the same general increasing-peaking-decreasing trend but with different times of onset, times-to-peak and maximum values (see Figure 1).
Fig 1.
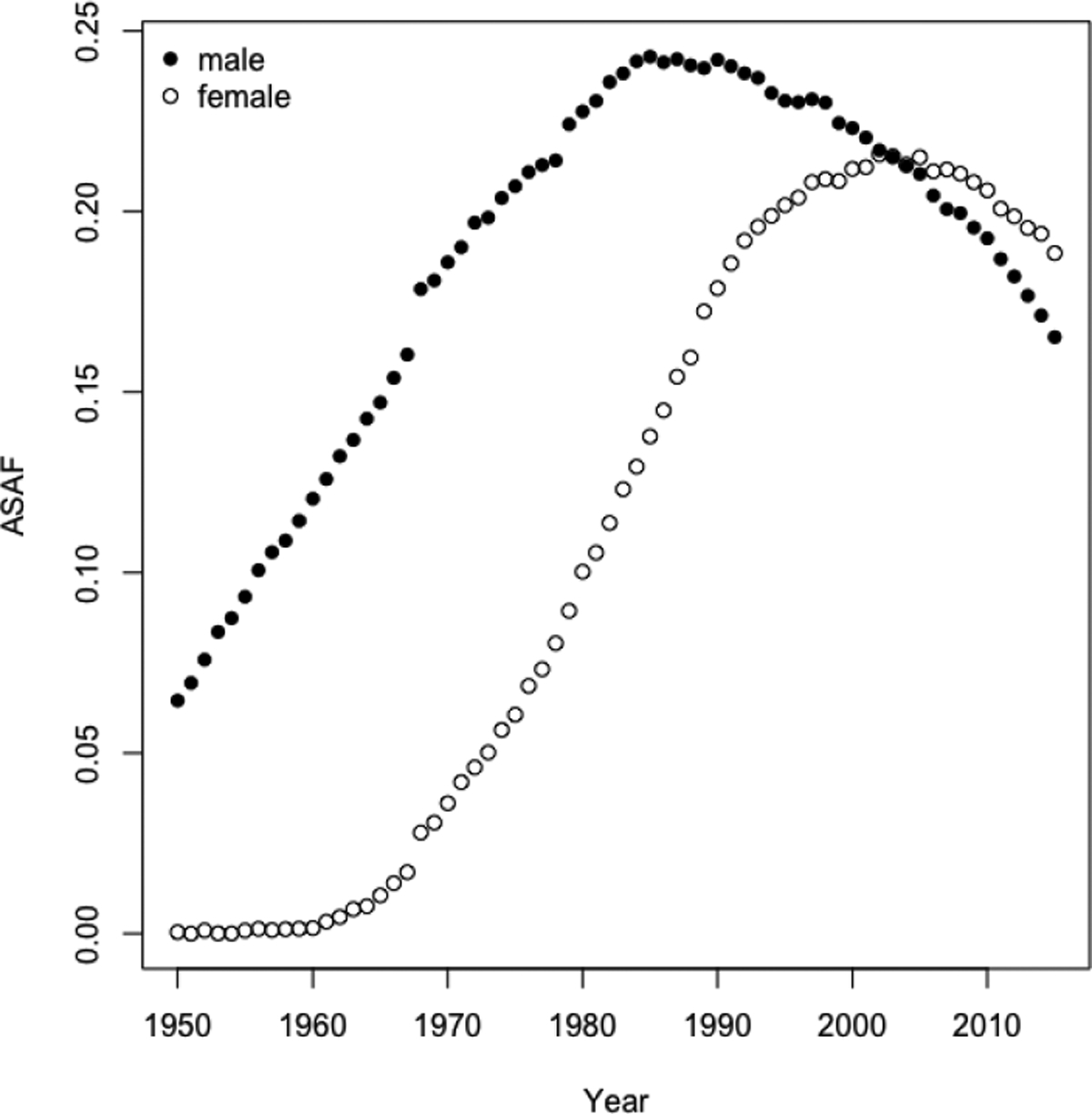
United States: All-age smoking attributable fractions of mortality for males and females from 1950 to 2015, estimated using the Peto-Lopez method.
Therefore, estimating and forecasting the SAF can help to improve mortality forecasts by taking the nonlinearity of mortality decline together with between-country and between-gender differentials into account (Bongaarts, 2006; Janssen, van Wissen and Kunst, 2013; Stoeldraijer et al., 2015). Here we propose a new Bayesian hierarchical model to project SAF that captures the observed increasing-peaking-declining trend so that it could be used for making better mortality forecasts.
Estimating the SAF is not easy for several reasons (Bongaarts, 2014; Tachfouti et al., 2014). First, the smoking habits of individuals can differ in terms of smoking intensity, smoking history, types of tobacco used, as well as firsthand or second-hand smoking, so that estimating the prevalence of smoking (p in Eq. 1.1) based on smoking behavior data is not straightforward. Secondly, to estimate the relative risk of smoking (r in Eq. 1.1) requires accurate cohort data. Such data are challenging to collect because smoking is not a direct killer but rather has a lifelong impact, with deaths occurring mostly at older ages. The American Cancer Society’s Cancer Prevention Study II (CPS-II), which began in 1982, is so far the largest study that collects such data (Tachfouti et al., 2014). Thirdly, the quality of registration and survey data varies across countries and between genders, which makes estimation and comparison of SAF across countries difficult.
Three categories of methods have been proposed to estimate SAF. The first is prevalence-based analysis in cohort studies (SAMMEC) (Levin, 1953). This uses estimated smoking prevalence from surveys and relative risk from CPS-II. The second method is prevalence-based analysis in case-control studies. This method is similar to the first one, except that the relative risk is estimated from a case-control study. It has been used for India (Gajalakshmi et al., 2003), Hong Kong (Lam et al., 2001), and China (Niu et al., 1998). The main drawback of prevalence-based methods is the scarcity of reliable historical data on smoking prevalence, especially for developing countries.
The third method, which overcomes this limitation, is an indirect method. It is called the Peto-Lopez method and was first proposed by Peto et al. (1992). This method estimates the proportion of the population exposed to smoking using lung cancer mortality data, since most lung cancer deaths are due to smoking in developed countries. According to Centers for Disease Control and Prevention (2019), cigarette smoking is associated with more than 80% of lung cancer deaths in the United States. Simonato et al. (2001) also concluded by case-control studies in 6 developed European countries that smoking is associated with over 90% of lung cancer cases. We use this method to estimate the SAF and we describe the procedure in Section 2.3.
Another indirect method, the PGW method of Preston, Glei and Wilmoth (2009), also uses lung cancer mortality rate as an indicator of the cumulative hazard of smoking. Instead of using relative risks from the CPS-II as the Peto-Lopez method does, the PGW method adopts a regression-based procedure. We discuss these two methods in Section 5.1. More comparisons among different estimation methods of SAF can be found in Pérez-Ríos and Montes (2008), Tachfouti et al. (2014), Kong et al. (2016), and Peters, Mackenbach and Nusselder (2016).
Figure 1 plots the estimated all-age SAF (ASAF) of males and females for the United States from 1950 to 2015. It can be seen that the evolution of SAF over time follows a remarkably strong pattern, first rising and then falling. Qualitatively very similar patterns were found in most countries that we studied, although in countries with less good data, higher levels of measurement error can be seen. It seems intuitive to expect that such a regular pattern could be used to obtain good forecasts. Here we describe our method for doing this. It turns out that, indeed, good forecasts can be obtained, thanks to the strong and consistent pattern of SAF over time. Here we propose a new probabilistic projection method for the SAF using a Bayesian hierarchical model. Our method will provide estimates and projections of the SAF for both genders jointly for more than 60 countries.
The paper is organized as follows. The data, the detailed SAF calculation based on the Peto-Lopez method, and the proposed Bayesian hierarchical model are described in Section 2. An out-of-sample validation experiment is reported in Section 3. We then discuss general estimation and forecasting results for all the countries considered in this work, with detailed case studies for four countries chosen from North America, South America, Asia, and Europe in Section 4. We conclude with a discussion in Section 5.
2. Method.
2.1. Notation.
We use the symbol y to denote the estimated (observed) all-age smoking attributable fraction (ASAF), which is defined as the smoking attributable fraction for all age groups combined, and we use the symbol h to denote the true (unobserved) ASAF. All of these quantities are indexed by country c, gender s, and year t. The quantities of interest are the unobserved true past and present ASAF together with their future projections. Here the estimation time period is 1950–2015 and the projection time period is 2015–2050. Section 2.3 describes the estimation procedure for ASAF using the Peto-Lopez method for all available countries. A Bayesian hierarchical model will be used to model the estimated ASAF. In the Bayesian hierarchical model, the country-specific parameter vector determining the time evolution pattern of ASAF for country c and gender s is denoted by θc,s, and the global parameters by ψ.
2.2. Data.
We use the annual death counts by country, age group, gender, and cause of death from the WHO Mortality Database (World Health Organization, 2017) which covers data from 1950 to 2015 for more than 130 countries and regions around the world. This dataset comprises death counts registered in national vital registration systems and is coded under the rules of the International Classification of Diseases (ICD). There are 5 raw datasets available by the most recent update on 11 April 2018. The first three datasets are labeled as ICD versions 7, 8, and 9 respectively, and the last two are labeled as ICD version 10.
Each version of ICD codes causes of death differently and a summary of the codes used for estimating ASAF in Section 2.3 is given in Table 1. For each country, the death counts data can differ by geographical coverage, number of years available and age group breakdown. Some countries such as China only have data from selected regions, and these countries will not be included here.
Table 1.
ICD codes for different cause of death categories across versions.
| Causes | ICD-7 (A-list) | ICD-8 (A-list) | ICD-9 (09A, 09B) |
|---|---|---|---|
| Lung Cancer | A050 | A051 | B101 |
| Upper Aero-digestive Cancer | A044, A045, A040 | A045, A046, A050 | B08, B090, B100 |
| Other Cancer | rest of A044-A059 | rest of A045-A060 | rest of B08-B14 |
| COPD | A092, A093 | A093 | B323, B324, B325 |
| Other Respiratory | rest of A087-A097 | rest of A089-A096 | rest of B31-B32 |
| Vascular Disease | A079-A086 | A080-A088 | B25-B30 |
| Liver Cirrhosis | A105 | A102 | A347 |
| Other non-med | A138-A150 | A138-A150 | B47-B56 |
| Other medical | rest | rest | rest |
| All causes | A000 | A000 | B00 |
| Causes | ICD-9 (09N) | ICD-10 (101) | ICD-10 (103, 104, 10M) |
| Lung Cancer | B101 | 1034 | C33-C34 |
| Upper Aero-digestive Cancer | B08, B090, B100 | 1027, 1028, 1033 | C00-C15, C32 |
| Other Cancer | rest of CH02 | rest of 1027–1046 | rest of C00-C97 |
| COPD | B323, B324, B325 | 1076 | J40-J47 |
| Other Respiratory | rest of CH08 | rest of 1072 | J00-J99 |
| Vascular Disease | CH07 | 1064 | I00-I99 |
| Liver Cirrhosis | S347 | 1080 | K74, K70 |
| Other non-med | CH17 | 1095 | V00-Y89 |
| Other medical | rest | rest | rest |
| All causes | B00 | 1000 | AAA |
We use the quinquennial population by five-year age groups from the 2017 Revision of the World Population Prospects (United Nations, 2017) for each country, gender and age group. Since this dataset provides population estimates at five-year intervals, we use linear interpolation to obtain annual population estimates for each five-year age group.
2.3. ASAF Estimation.
We apply the original Peto-Lopez indirect method to estimate ASAF for male and female separately. This method uses the lung cancer mortality rate as an indicator of the accumulated hazard of smoking to estimate the proportion of population exposed to smoking. As commented in Peto et al. (1992), it is very rare to observe lung cancer cases among nonsmokers in developed countries, even in areas with pollution sources such as radon and asbestos. The original papers (Peto et al., 1992, 1994, 2006) applied the method to developed countries only, especially in Western Europe and North America. With the shift of global smoking pattern, and diffusion of smoking in middle- and low-income countries, this method has been extended to less developed countries (Ezzati and Lopez, 2003, 2004; Pampel, 2006).
For estimating ASAF using the Peto-Lopez method, we need first to estimate age- and cause-of-death-specific SAF. The age groups used for estimation are 0–34, 35–59, 60–64, 65–69, 70–74, 75–79, and 80+. For each age group, annual death counts of the following nine categories of causes of death are obtained from the five raw datasets of WHO Mortality Database: lung cancer, upper aero-digestive cancer, other cancers, COPD, other respiratory diseases, vascular diseases, liver cirrhosis, non-medical causes, and all other medical causes. A detailed list of codes from ICD 7, 8, 9, and 10 for these nine categories is provided in Table 1.
The ICD categorizes death count data according to availability using socalled sublists, which can be one of A-list or several others; see Table 1. The sublists we use are those satisfying the minimum requirements for ASAF calculation. More specifically, for ICD 7 and 8, only countries whose ICD sublist is A-list are used. For ICD 9, only those countries whose ICD sublist is 09A-, 09B-, or 09N-list are used. For ICD 10, countries whose ICD sublist is one of 101-, 103-, 104-, 10M-list are used. In addition, we only calculate age-specific SAF for countries whose age group breakdown is finer than the following age group breakdown: 0–34, 35–39, 40–44, 45–49, 50–54, 55–59, 6064, 65–69, 70–74, 75+. This corresponds to the age group format number 00, 01, 02, 03, 04 in the raw datasets.
To estimate the proportion of a population exposed to smoking, i.e., p in Eq. 1.1, the method compares the observed lung cancer mortality rate with the lung cancer mortality rate of smokers estimated from CPS-II. The estimated proportion, indexed by country c, age group a, gender s, and year t, is estimated by
where dc,a,s,t is the observed country-age-gender-year-specific lung cancer mortality rate, and and are age-gender-specific lung cancer mortality rates for smokers and nonsmokers from the CPS-II respectively. Here the observed lung cancer mortality rate dc,a,s,t is the observed lung cancer death count divided by the population estimated from the 2017 Revision of the World Population Prospects for country c, age group a, gender s, and year t.
The Peto-Lopez method uses the CPS-II to estimate the relative risk of dying for each cause of death for smokers and nonsmokers, i.e., r in Eq. 1.1. Specifically, the Cochran-Mantel-Haenszel method is used to estimate the relative risk for age group 35–59 by combining five sub-age groups (35–39, 40–44, 45–49, 50–54, 55–59). The relative risk is indexed by cause-of-death k, age group a, and gender s. Here k takes integer values 1–9 corresponding to the nine categories mentioned above.
The excess mortality rate attributable to smoking is denoted by erk,a,s for cause-of-death k, age group a, and gender s. For lung cancer, the excess mortality rate attributable to smoking is calculated as er1,a,s = r1,a,s − 1. For all other categories except liver cirrhosis (k = 7) and non-medical causes (k = 8), the excess risk is discounted by 50%, i.e., erk,a,s = 0.5(rk,a,s −1) for k = 2, 3, 4, 5, 6, 9, so as to control for confounding factors. The excess risks for liver cirrhosis and non-medical causes are set to 0, i.e., er7,a,s = er8,a,s = 0. The country-cause-age-gender-year-specific SAF, denoted by yc,k,a,s,t, is then
Any estimated negative values are set to zero.
Since the hazard due to smoking is accumulated across years and mostly causes deaths at older ages, the fraction of deaths due to smoking for ages 0–34 is typically very small and is set to 0. In addition, the SAF for ages 80+ is set to the same value as that for ages 75–79 since smoking data are unreliable for very old ages. Finally, the country-gender-year-specific ASAF, denoted by yc,s,t, is a weighted average of the age-specific smoking attributable fractions yc,k,a,s,t. Thus
where dc,k,a,s,t is the country-cause-age-gender-year-specific mortality rate.
We chose the Peto-Lopez method to estimate the ASAF because it has been validated and widely used (Preston, Glei and Wilmoth, 2009; Bongaarts, 2014; Tachfouti et al., 2014; Kong et al., 2016). Also, the data required for the estimation are cause- and age-specific death counts and population, which are provided with high quality by the WHO Mortality Database and the 2017 Revision of the World Population Prospects.
There are some variants of the Peto-Lopez method, which also assume that the lung cancer mortality rate is a good indicator for measuring smoking exposure. Some of the modifications include using different relative risk estimation instead of the CPS-II to extend the method to developing countries (Ezzati and Lopez, 2003) or using a regression-based approach (Preston, Glei and Wilmoth, 2009). Section 5.1 contains more detailed discussion and comparison of these methods.
2.4. Model.
We develop a four-level Bayesian hierarchical framework to model male and female ASAF jointly for multiple regions simultaneously.
Random walk with drift for the true ASAF.
The observed ASAF data show a strong and consistent pattern of increasing, then leveling, and then declining again for both genders (Stoeldraijer et al., 2015) (see Figure 1 for the example of United States). This pattern can be captured by the following five-parameter double logistic curve:
| (2.1) |
where t is the year of observation and θ is the double-logistic parameter vector, θ = (a1, a2, a3, a4, k).
Models based on the double logistic curve have been used quite widely for human population measures such as life expectancy and total fertility rates (Marchetti, Meyer and Ausubel, 1996; Raftery et al., 2013; Alkema et al., 2011)). Due to its natural scientific interpretability, the double logistic curve has also been used in other scientific fields such as hematology (Head and McCarty, 1987; Head et al., 2004), phenology (Yang et al., 2012), and agricultural science (Shabani et al., 2018). This function has also been used to describe social change, diffusion, and substitution processes (Grübler, Nakićenović and Victor, 1999; Fokas, 2007; Kucharavy and De Guio, 2011).
Most developed countries have had male smoking prevalence that started before 1950, and peaked around the 1950s or 1960s when the adverse impacts of smoking on health became known and tobacco control measures started being put in place. This led to a peak in smoking-related mortality a generation or so later, followed by a continuous decline since then. Pampel (2005) argued that the smoking epidemic involves diffusion from males to females, and from more developed countries to less developed ones. Hence, the strong increasing-peaking-decreasing trend of ASAF observed in most countries is a consequence of the smoking epidemic diffusion process, and the double logistic curve can naturally describe its dynamics.
For the five-parameter double logistic function in Eq. 2.1, a2 controls the first (left) inflection point of the curve and a4 controls the distance between the first (left) and the second (right) inflection points. The rates of change at these inflection points are controlled by a1 and a3 respectively. The parameter k is an upper bound for the maximum value of the curve. See the upper panel of Figure 2 for an illustration.
Fig 2.
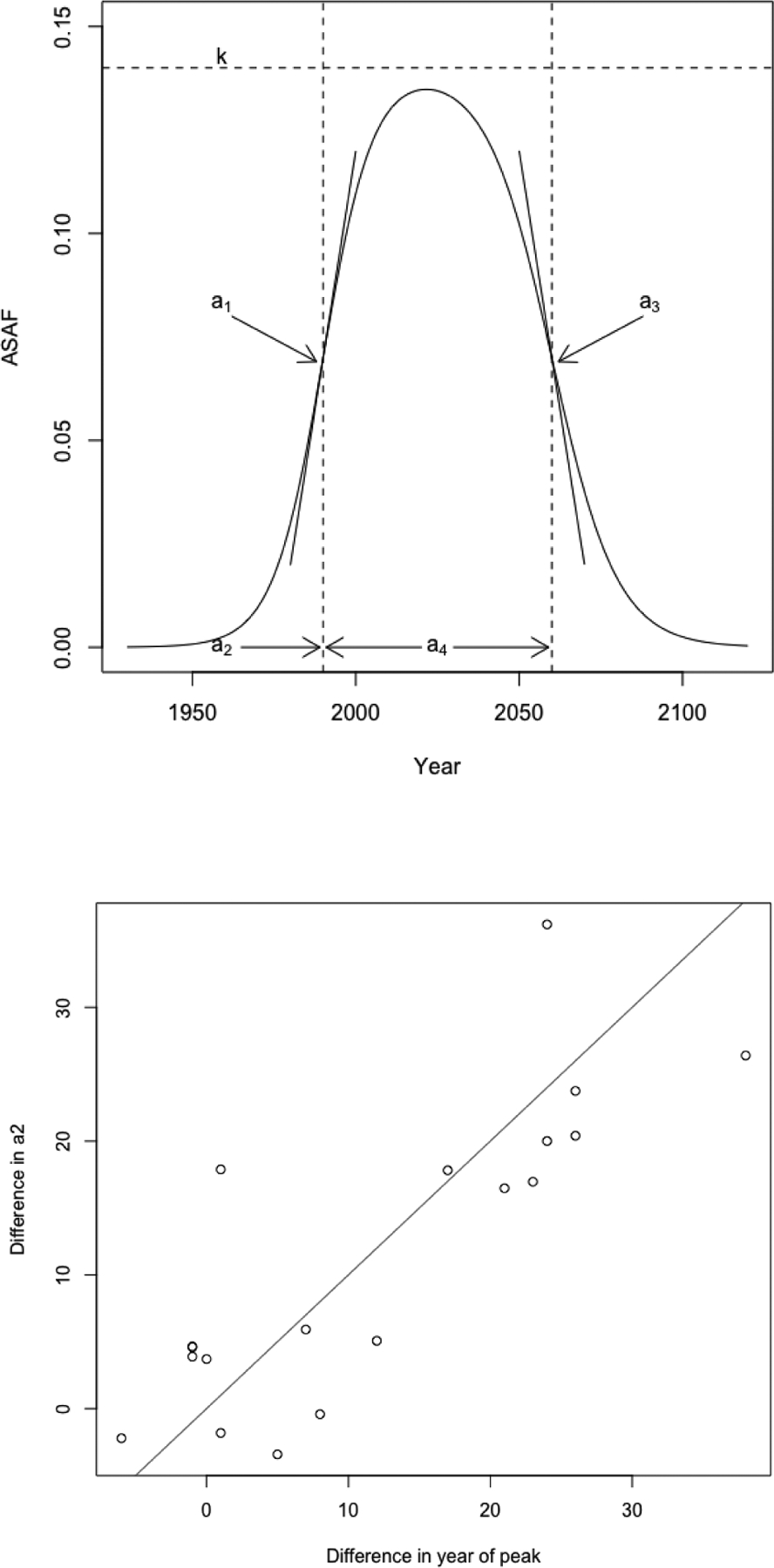
Upper: The five-parameter double logistic curve. a2 controls the left inflection point, a4 controls the distance between left and right inflections points, a1,a3 determine the rate of change at left and right inflection points, and k approximates the maximum value. Lower: The difference of country-specific and plotted against the difference between the country-specific peaks for males and females. The peak and a2 are estimated from the countries whose male and female ASAF have all passed the maximum by 2015, according to the results of the non-linear least squares estimation. The solid line is the 45 degree line.
To represent this and also take account of the observed pattern of variability, we model changes in the true ASAF between adjacent time points using a random walk with drift given by the difference between the double logistic curve at the two points. This takes the form
| (2.2) |
where g(·|θc,s) (i.e., Eq. 2.1) quantifies the expected change of the true ASAF governed by the country- and gender-specific parameters , and are independent Gaussian noises. This random walk with drift model is designed to capture the variability of the true ASAF and allows the uncertainty of the forecast to increase when projecting further into the future.
Male-female joint model.
Since the female smoking epidemic usually starts one to two decades after the male one, the start of the increase in the female ASAF is also later than that of the male ASAF. For most countries, the observed female ASAF is still in the increasing or leveling phase up to 2015. However, as the smoking epidemic diffuses from the male to the female population, it is reasonable to assume that the female ASAF will follow the same trend of increasing-leveling-declining as that of the male ASAF. This has already been observed for several countries with early smoking epidemics, such as the United Kingdom, Denmark, and Japan (Pampel, 2005; Peto et al., 2006; Janssen, van Wissen and Kunst, 2013; Bongaarts, 2014; Stoeldraijer et al., 2015). For these countries, the female ASAF follows the same trend as that of the male ASAF, but differs mainly in terms of the rate of increase or decrease, the number of years taken to reach the peak, and the peak ASAF value.
For males, we need only estimate the rate of decline of the ASAF. For females, especially for those countries whose observed ASAF data have not levelled yet, one needs first to determine the time and value of leveling. By modeling male and female data jointly, the lower panel of Figure 2 shows that for countries whose male and female ASAF both passed the leveling period, the difference between the years of maximum of male and female is approximately the same as the difference in the a2 parameter estimated from Eq. 2.1. The a2 parameter represents the time point where the speed of the increasing part of the double logistic curve begins to slow down.
The difference between the times-to-peak of male and female ASAF also differs among countries. For example, the time-to-peak of the female ASAF in the United States is about 15 years later than that of the male ASAF, while the time-to-peak of the ASAF happened at about the same time for both genders in Hong Kong. To incorporate these observations, we model the difference between male and female country-specific using a Gaussian distribution:
| (2.3) |
where and are the country- and gender-specific values of a2, and is the country-specific difference between these two parameters with prior mean Δa2 and variance .
Moreover, since there are very few countries whose female ASAF have begun to decline by 2015, while the male ASAF has been declining for many years in most countries, we set the same global parameters for the gender-specific parameters and for each country, namely,
| (2.4) |
Except for , the other four country-specific parameters of the double logistic curve are conditioned on their own gender-specific global parameters.
Measurement error model for observed ASAF.
The observed country-gender-year-specific ASAF yc,s,t are modeled based on the true (unobserved) ASAF hc,s,t by incorporating measurement error due to the variability of data quality across different countries:
| (2.5) |
We assume that the variance of the observed ASAF for each country is time-and gender-invariant based on exploratory analyses that indicate that the data quality is consistent across time and between genders within the same country.
Summary of model.
We combine the Bayesian hierarchical model and measurement error model into a four-level Bayesian hierarchical model. We model the observed ASAF estimates using the measurement error model in Level 1, conditional on the true (unobserved) ASAF data which are modeled with a random walk with drift in Level 2, conditional on the country-specific parameters. Country-specific parameters are modeled in Level 3, where parameters for male and female ASAF are modelled jointly conditional on the global parameters, whose prior distributions are specified in Level 4.
The overall model is specified as follows:
-
Level 1:
-
Level 2:
-
Level 3:
-
Level 4:
Here, t0,c is the year of the first available ASAF data for country c, g denotes the five-parameter double logistic curve in Eq. 2.1, f denotes the conditional distribution of the country-specific parameters θc,s, and π denotes the hyperpriors for the global parameters ψ,ν,ρ2, . The country-specific parameters are gender-specific and the interaction between male and female parameters are governed by Eq. 2.3 and 2.4. The global parameters are also gender-specific except for . More information about the specification of the full model is given in the Appendix A.
Estimation and prediction.
Statistical analysis of the model is carried out in two phases, estimation and prediction. The goal of the estimation phase is to obtain the joint posterior distribution of the true ASAF hc,s,t during the estimation period 1950–2015 and the country-specific parameters for the underlying double-logistic curve. The aim of the prediction phase is to forecast the future ASAF of both genders for the prediction period 2015–2050 based on the observed ASAF for over 60 countries whose male ASAF data are classifed as clear-pattern (see Section 2.5 for the definition of clear-pattern).
The functional form of the prior distribution π(·) is assessed using results from non-linear least squares estimation based on clear-pattern countries (see Section 2.5 for details). Specifically, the priors for are based on non-linear least squares results from the male ASAF of over 60 clear-pattern countries, the prior for is estimated based on non-linear least squares results from the female ASAF of 52 clear-pattern countries, the priors for . are set to the same priors as their counterparts for males, while the priors for are estimated based on 19 countries for which both male and female ASAF have passed the leveling stage by 2015. The priors for ν,ρ2, are estimated by pooling male and female ASAF from all clear-pattern countries. A complete specification of the model is given in the Appendix A.
2.5. ASAF Categorization.
We categorize estimated ASAF for 127 countries and regions into two categories according to the data availability and quality: clear-pattern and non-clear-pattern. On one hand, the Peto-Lopez method is not guaranteed to produce reliable ASAF estimates for some less developed countries because of poor data quality. On the other hand, modeling only with clear-pattern countries can improve estimation and projection accuracy without introducing too much random noise.
The classification is based on non-linear least squares estimation of the following model for each country and gender separately:
where g(t|θ) is as in Eq. 2.1 and εt are independent standard Gaussian errors. Its fit to the data in a given country provides an indication of data quality for that country.
Our categorization is based on the number of observations, maximum of observed values, and the R2 value of the non-linear least squares fit. Due to the differences between the diffusion processes of smoking in the male and female populations (Pampel, 2006), we use different criteria for male and female data. For male data, we require that (1) the number of available annual observations up to 2015 be greater than 10; (2) at least one of the observations be greater than 0.05; and (3) that the R2 value be greater than 0.5.
For female data, since the smoking epidemic in general started one to two decades later than the male one, the onset and the value of the ASAF is later and smaller than that of the male epidemic (Pampel, 2005; Preston and Wang, 2006). The criteria for female data are that (1) the number of observations up to 2015 be greater than 10; (2) at least one of the observations be greater than 0.01; and (3) that the R2 value be greater than 0.6.
By these rules, there are over 60 countries whose male data are classifed as clear-pattern (2 in Africa, 16 in the Americas, 9 in Asia, 40 in Europe and 2 in Oceania), and 52 countries whose female data are classified as clear-pattern (12 in the Americas, 7 in Asia, 31 in Europe and 2 in Oceania).
2.6. Estimation.
Estimation is based on the male and female ASAF data from over 60 countries whose male ASAF is classified as clear-pattern for the period 1950–2015. The reason why we chose clear-pattern ASAF data is that non-clear-pattern data either have too few observations, very low values, or their shapes are not identifiable.
We used the Rstan package (Version 2.18.2) in R to obtain the joint posterior distributions of the parameters of interest (Carpenter et al., 2017). Rstan uses a No-U-turn sampler, which is an adaptive variant of Hamiltonian Monte Carlo (Neal, 2011; Hoffman and Gelman, 2014). We ran 3 chains with different initial values, each of length 10,000 iterations with a burn-in of 2,000 without thining. This yielded a final, approximately independent sample of size 8,000 for each chain. We monitored convergence by inspecting trace plots and using standard convergence diagnostics.
We also conducted a sensitivity analysis on the hyperparameters that specify the priors π(·) for the global parameters ψ, and concluded that the proposed model is not sensitive to the choice of hyperparameters. More information about the convergence diagnostics and the sensitivity analysis is given in the Supplementary Materials.
2.7. Projection.
We produce projections of future ASAF for the period 2015–2050 for over 60 countries whose male ASAF is classified as clear-pattern. The prediction of future ASAF for each country is based on past and present ASAF. We sample from the joint posterior distribution of the country-specific parameters θc,s and of the past, and present true ASAF hc,s,t. We then use Eq. 2.2 and 2.5 to generate a sample of trajectories of future true and observed ASAF respectively from their joint posterior predictive distribution. It is possible that the quantity generated by Eq. 2.2 and Eq. 2.5 is negative, and we set such values to zero. This yields a sample from the joint posterior predictive distribution of the future ASAF for over 60 countries, for both genders, taking account of uncertainty about the past observations as well as the future evolution. We include the plots of ASAF projections for over 60 countries and both genders in the Supplementary Materials.
3. Results.
We assess the predictive performance of our model using out-of-sample predictive validation.
3.1. Study Design.
The data we used for out-of-sample validation cover the period 1950–2015. We assess the quality of our model based on different choices of estimation and validation data from the observed data. Since the trend of increasing-leveling-declining pattern plays an important role for estimation and projection, assessing how the model works when only part of the trend has been observed is crucial. We consider different choices for estimation and validation periods, namely (1) 1950–2000 for estimation and 2000–2015 for validation; (2) 1950–2005 for estimation and 2005–2015 and for validation; and (3) 1950–2010 for estimation, 2010–2015 for validation. The countries used for validation in each time-split scenario are required to be clear-pattern countries based on the male ASAF, to contain more than 10 observations in the estimation period, and to have at least one observation in the prediction period. This results in 63, 66 and 66 countries used for validation under choices (1), (2) and (3), respectively.
Since we are making probabilistic projections, our evaluation is based on both accuracy of point prediction and calibration of prediction intervals. Our goal is not only to produce accurate point predictions, but also to account for variability of future predictions based on historic data, especially for those countries whose data in the estimation period reveal only part of the pattern. If the proposed model works well, we would expect the point predictor to have small gender-specific mean absolute error (MAE), which is defined as
| (3.1) |
where is the set of countries considered in the validation, is the set of country-year combinations used for validation, is the posterior median of the predictive distribution of ASAF at year t for country c and gender s, and N is the total number of data used for validation.
We wish the prediction to be well calibrated and sharp, i.e., the coverage of the prediction interval to be close to the nominal level with its half-width as short as possible. Thus, we include the empirical coverage and the half-width of the prediction interval in the validation. To assess the overall predictive performance, we also calculate the gender-specific continuous ranked probability score (CRPS) (Gneiting and Raftery, 2007), which is defined as
| (3.2) |
where Fc,s,t(y) is the predictive distribution of the future ASAF for country c, gender s, and time t, and 1(·) is equal to 1 if the condition in the parenthesis is satisfied and 0 otherwise. CRPS is a summary statistic measuring the quality of the probabilistic forecast, which evaluates model calibration and sharpness simultaneously. The smaller the CRPS, the closer the predictive distribution to the true data-generating distribution.
3.2. Out-of-sample Validation Results.
To our knowledge, no other method is available in the literature to produce probabilistic forecasts for male and female ASAF for developed and developing countries jointly. Janssen, van Wissen and Kunst (2013) and Stoeldraijer et al. (2015) developed methods for projection of age-specific SAF and age-standardized SAF, and their methods are based on age-period-cohort analysis, which cannot be trivially extended to ASAF. See Section 5.2 for more discussion of their procedures and comparison to the present ones.
As benchmarks against which to compare our method, we consider four other forecast procedures. The first one is the persistence forecast, which takes the last observed value as the forecast for the prediction period. The second method is the Bayesian thin plate regression spline method (Wood, 2003), implemented in the mgcv package (Version 1.8–27) in R. The third method is the Bayesian structural time series model (Harvey, 1990; Durbin and Koopman, 2012), implemented in the bsts package (Version 0.8.0) in R. Here we choose to use two state components — local linear trend and autocorrelation with lag 1 — to build the structural time series model. Our fourth comparison method is a non-hierarchical version of our proposed model, namely our proposed model without Level 4 (i.e., the global parameters). This is included to see whether the hierarchical structure is necessary.
We summarize the validation results in Table 2 for males and females separately. This shows the MAE, the coverage and half-width of the prediction intervals, and the continuous ranked probability score (CRPS). For males, our method improved the prediction accuracy for all three scenarios over the persistence forecast. For forecasting one and two five-year periods ahead, our method improved the MAE by 30% and 21% respectively. Since most male ASAF series had passed the peak by 2005 and had experienced declines for several years, the double logistic curve captures this trend well. For predictions three five-year periods into the future, during which the male ASAF series for some countries were just reaching the peak, our method still improved the MAE by 6%. For females, we observed similar improvements. Our method decreased the MAE by 22%, 17%, and 27% for predictions one, two, and, three five-year periods ahead compared to those of the persistence forecast.
Table 2.
Predictive validation results for all-age smoking attributable fraction (ASAF). The first and second columns indicate the estimation and validation periods. The “Gender” and “n” columns indicate the gender and the number of countries used for the validation. In the “Model” column, “Bayes” represents the Bayesian hierarchcial model with measurement error and random walk with drift, “Bayes(S)” represents the same model as “Bayes” without the global parameters, “Persistence” represents the persistence forecast, “Spline” represents the Bayesian thin plate regression spline method, and “BSTS” represents the Bayesian structural time series method. The “MAE” column contains the mean absolute prediction error defined by Eq. 3.1. The “Coverage” columns show the proportion of validation observations contained in the 80%, 90%, 95% prediction intervals with their average half-widths in parentheses. The “CRPS” column contains the continuous ranked probability score defined by Eq. 3.2.
| Training | Test | n | Gender | Model | MAE | Coverage | CRPS | ||
|---|---|---|---|---|---|---|---|---|---|
| 80% | 90% | 95% | |||||||
| 1950–2010 | 2010–2015 | 66 | Male | Persistence | 0.010 | - | - | - | - |
| Bayes | 0.007 | 0.78 (0.011) | 0.86 (0.014) | 0.90 (0.017) | 0.00523 | ||||
| Bayes(S) | 0.007 | 0.86 (0.014) | 0.94 (0.018) | 0.97 (0.022) | 0.00505 | ||||
| Spline | 0.008 | 0.58 (0.009) | 0.65 (0.011) | 0.72 (0.013) | 0.00648 | ||||
| BSTS | 0.008 | 0.85 (0.015) | 0.94 (0.020) | 0.94 (0.025) | 0.00570 | ||||
| Female | Persistence | 0.009 | - | - | - | - | |||
| Bayes | 0.007 | 0.83 (0.012) | 0.93 (0.015) | 0.96 (0.018) | 0.00507 | ||||
| Bayes(S) | 0.008 | 0.88 (0.014) | 0.94 (0.018) | 0.97 (0.022) | 0.00538 | ||||
| Spline | 0.010 | 0.42 (0.007) | 0.52 (0.009) | 0.61 (0.011) | 0.00763 | ||||
| BSTS | 0.008 | 0.80 (0.013) | 0.89 (0.016) | 0.94 (0.020) | 0.00562 | ||||
| 1950–2005 | 2005–2015 | 66 | Male | Persistence | 0.014 | - | - | - | - |
| Bayes | 0.011 | 0.72 (0.014) | 0.83 (0.018) | 0.89 (0.022) | 0.00797 | ||||
| Bayes(S) | 0.010 | 0.85 (0.020) | 0.93 (0.027) | 0.97 (0.033) | 0.00795 | ||||
| Spline | 0.014 | 0.54 (0.014) | 0.65 (0.018) | 0.72 (0.021) | 0.01096 | ||||
| BSTS | 0.013 | 0.83 (0.026) | 0.90 (0.035) | 0.95 (0.043) | 0.00989 | ||||
| Female | Persistence | 0.012 | - | - | - | - | |||
| Bayes | 0.010 | 0.80 (0.015) | 0.90 (0.020) | 0.92 (0.025) | 0.00721 | ||||
| Bayes(S) | 0.011 | 0.88 (0.021) | 0.93 (0.028) | 0.95 (0.035) | 0.00808 | ||||
| Spline | 0.014 | 0.44 (0.011) | 0.51 (0.014) | 0.58 (0.016) | 0.01133 | ||||
| BSTS | 0.011 | 0.77 (0.017) | 0.88 (0.023) | 0.93 (0.029) | 0.00802 | ||||
| 1950–2000 | 2000–2015 | 63 | Male | Persistence | 0.017 | - | - | - | - |
| Bayes | 0.016 | 0.65 (0.020) | 0.76 (0.026) | 0.84 (0.031) | 0.01214 | ||||
| Bayes(S) | 0.018 | 0.84 (0.031) | 0.92 (0.042) | 0.95 (0.052) | 0.01278 | ||||
| Spline | 0.018 | 0.59 (0.019) | 0.69 (0.024) | 0.76 (0.029) | 0.01335 | ||||
| BSTS | 0.016 | 0.85 (0.039) | 0.93 (0.053) | 0.98 (0.068) | 0.01281 | ||||
| Female | Persistence | 0.015 | - | - | - | - | |||
| Bayes | 0.011 | 0.81 (0.021) | 0.90 (0.029) | 0.95 (0.037) | 0.00817 | ||||
| Bayes(S) | 0.012 | 0.88 (0.027) | 0.96 (0.039) | 0.98 (0.050) | 0.00887 | ||||
| Spline | 0.016 | 0.48 (0.014) | 0.59 (0.018) | 0.70 (0.022) | 0.01151 | ||||
| BSTS | 0.012 | 0.79 (0.022) | 0.89 (0.030) | 0.94 (0.039) | 0.00831 | ||||
Also, compared with other probabilistic forecast methods, our method produced shorter prediction intervals with empirical coverages close to the nominal level for one and two five-year predictions, while it produced predictive intervals with reasonably close to nomial for the three five-year predictions for the male ASAF. On the other hand, since most female ASAF series have not yet reached the peak, capturing the variability of future female ASAF is essential. The coverage of our method is close to the nominal level, indicating that our method is well calibrated.
Overall, our proposed BHM yielded the smallest CRPS among all methods in most cases for both the male and female epidemics. Among all five methods compared in the validation exercise, the Bayesian spline method was worst in terms of forecast accuracy, and tended to underestimate the variability of future values. The Bayesian structural time series model produced predictive interval close to the nominal level with slightly larger average half-width than our method. However, a significant drawback of the persistence forecast, the Bayesian spline method, and the Bayesian structural time series model is that they tend to produce unrealistic forecasts when all the observed data are before the peak, since they do not incorporate the increasing-peaking-decreasing information in the model. The left panel of Figure 3 indicates that the Bayesian thin plate spline method projected a monotonically increasing ASAF for United States female based on data before 2000, where the entire prediction interval missed the observed data after 2000. The right panel of Figure 3 shows that the Bayesian structural time series model did cover the data but with an unrealistically wide prediction interval.
Fig 3.
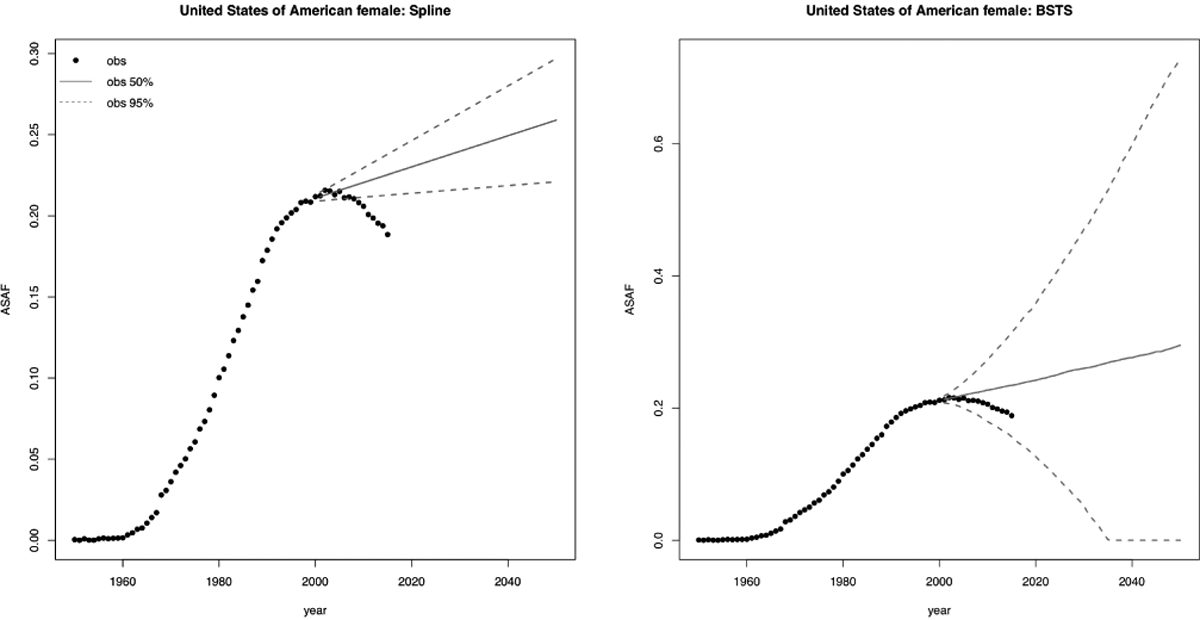
Forecast of US female ASAF based on data before 2000 using Bayesian spline method (left) and Bayesian structural time series method (right). Observed ASAF values are represented by black dots. The solid lines and dashed lines represent the posterior median and the 95% predictive interval, respectively.
The Bayesian model without the global level parameters produced results similar to those from our BHM for projecting short term male ASAF. When forecasting three five-year periods ahead, or the female ASAF, in both of which cases the peak has often not been reached, the Bayesian model without the global level parameters was worse in accuracy and CRPS. This indicates that the hierarchical structure did indeed improve the overall forecast when only part of the trend has been observed, by sharing information among all the countries.
Table 3 gives validation results for subgroups of countries, categorized by membership of the Organization for Economic Cooperation and Development (OECD). Most of the countries in the OECD are regarded as developed countries with high GDP and human development index (HDI). For male ASAF, our BHM improved most of the forecasts for OECD countries, especially the longer term projections. For OECD countries, the increasingpeaking-decreasing pattern is clearer and stronger, which fits with our modeling well. In contrast, our BHM performed less well among non-OECD countries.
Table 3.
Predictive validation results for all-age smoking attributable fraction (ASAF) for categories of countries. The “OECD” column represents whether the countries in the subgroup belong to the OECD. The number of countries in the subgroup used for the validation is in parentheses. All the other columns are the same as those in Table 2.
| Training | Test | Gender | OECD | Model | MAE | Coverage | CRPS | ||
|---|---|---|---|---|---|---|---|---|---|
| 80% | 90% | 95% | |||||||
| 1950–2010 | 2010–2015 | Male | Y(34) | Persistence | 0.011 | - | - | - | - |
| Bayes | 0.006 | 0.81 (0.011) | 0.90 (0.014) | 0.95 (0.016) | 0.00448 | ||||
| Bayes(S) | 0.006 | 0.88 (0.013) | 0.94 (0.017) | 0.99 (0.021) | 0.00459 | ||||
| Spline | 0.007 | 0.60 (0.008) | 0.67 (0.010) | 0.73 (0.012) | 0.00565 | ||||
| BSTS | 0.007 | 0.86 (0.014) | 0.95 (0.018) | 0.98 (0.022) | 0.00529 | ||||
| N(32) | Persistence | 0.008 | - | - | - | - | |||
| Bayes | 0.009 | 0.75 (0.011) | 0.81 (0.015) | 0.84 (0.018) | 0.00601 | ||||
| Bayes(S) | 0.008 | 0.85 (0.015) | 0.92 (0.019) | 0.94 (0.023) | 0.00554 | ||||
| Spline | 0.010 | 0.56 (0.010) | 0.63 (0.012) | 0.70 (0.015) | 0.00736 | ||||
| BSTS | 0.009 | 0.86 (0.017) | 0.95 (0.023) | 0.98 (0.028) | 0.00629 | ||||
| Female | Y(34) | Persistence | 0.009 | - | - | - | - | ||
| Bayes | 0.007 | 0.82 (0.011) | 0.92 (0.015) | 0.94 (0.018) | 0.00505 | ||||
| Bayes(S) | 0.008 | 0.86 (0.013) | 0.93 (0.017) | 0.96 (0.021) | 0.00560 | ||||
| Spline | 0.010 | 0.42 (0.007) | 0.51 (0.008) | 0.58 (0.010) | 0.00762 | ||||
| BSTS | 0.009 | 0.78 (0.012) | 0.85 (0.015) | 0.91 (0.019) | 0.00616 | ||||
| N(32) | Persistence | 0.008 | - | - | - | - | |||
| Bayes | 0.008 | 0.83 (0.012) | 0.95 (0.015) | 0.95 (0.018) | 0.00507 | ||||
| Bayes(S) | 0.007 | 0.89 (0.015) | 0.95 (0.019) | 0.98 (0.023) | 0.00516 | ||||
| Spline | 0.011 | 0.42 (0.008) | 0.54 (0.010) | 0.63 (0.012) | 0.00764 | ||||
| BSTS | 0.007 | 0.82 (0.013) | 0.89 (0.017) | 0.94 (0.021) | 0.00506 | ||||
| 1950–2005 | 2005–2015 | Male | Y(34) | Persistence | 0.016 | - | - | - | - |
| Bayes | 0.010 | 0.73 (0.014) | 0.85 (0.018) | 0.90 (0.021) | 0.00676 | ||||
| Bayes(S) | 0.010 | 0.84 (0.019) | 0.93 (0.025) | 0.97 (0.032) | 0.00717 | ||||
| Spline | 0.013 | 0.52 (0.012) | 0.61 (0.015) | 0.69 (0.018) | 0.01008 | ||||
| BSTS | 0.012 | 0.85 (0.028) | 0.91 (0.039) | 0.97 (0.049) | 0.01000 | ||||
| N(32) | Persistence | 0.011 | - | - | - | - | |||
| Bayes | 0.012 | 0.70 (0.014) | 0.81 (0.019) | 0.88 (0.022) | 0.00928 | ||||
| Bayes(S) | 0.011 | 0.87 (0.021) | 0.93 (0.029) | 0.96 (0.035) | 0.00879 | ||||
| Spline | 0.015 | 0.57 (0.016) | 0.68 (0.020) | 0.76 (0.024) | 0.01189 | ||||
| BSTS | 0.013 | 0.83 (0.026) | 0.90 (0.035) | 0.95 (0.043) | 0.00989 | ||||
| Female | Y(34) | Persistence | 0.012 | - | - | - | - | ||
| Bayes | 0.009 | 0.82 (0.015) | 0.92 (0.020) | 0.95 (0.025) | 0.00669 | ||||
| Bayes(S) | 0.010 | 0.88 (0.019) | 0.95 (0.025) | 0.96 (0.032) | 0.00736 | ||||
| Spline | 0.012 | 0.38 (0.008) | 0.45 (0.011) | 0.52 (0.013) | 0.00945 | ||||
| BSTS | 0.012 | 0.82 (0.019) | 0.90 (0.026) | 0.92 (0.033) | 0.00851 | ||||
| N(32) | Persistence | 0.013 | - | - | - | - | |||
| Bayes | 0.011 | 0.78 (0.015) | 0.88 (0.020) | 0.90 (0.025) | 0.00780 | ||||
| Bayes(S) | 0.012 | 0.88 (0.023) | 0.91 (0.031) | 0.93 (0.039) | 0.00885 | ||||
| Spline | 0.017 | 0.51 (0.013) | 0.58 (0.017) | 0.66 (0.020) | 0.01333 | ||||
| BSTS | 0.011 | 0.77 (0.017) | 0.88 (0.023) | 0.93 (0.029) | 0.00802 | ||||
| 1950–2000 | 2000–2015 | Male | Y(33) | Persistence | 0.018 | - | - | - | - |
| Bayes | 0.014 | 0.67 (0.020) | 0.79 (0.026) | 0.88 (0.032) | 0.01063 | ||||
| Bayes(S) | 0.017 | 0.83 (0.030) | 0.90 (0.040) | 0.95 (0.050) | 0.01221 | ||||
| Spline | 0.017 | 0.58 (0.015) | 0.68 (0.020) | 0.74 (0.023) | 0.01338 | ||||
| BSTS | 0.018 | 0.88 (0.035) | 0.93 (0.047) | 0.97 (0.060) | 0.01308 | ||||
| N(30) | Persistence | 0.017 | - | - | - | - | |||
| Bayes | 0.019 | 0.63 (0.020) | 0.72 (0.026) | 0.80 (0.031) | 0.01377 | ||||
| Bayes(S) | 0.018 | 0.86 (0.032) | 0.93 (0.042) | 0.95 (0.053) | 0.01341 | ||||
| Spline | 0.018 | 0.60 (0.022) | 0.71 (0.029) | 0.79 (0.034) | 0.01331 | ||||
| BSTS | 0.016 | 0.85 (0.045) | 0.94 (0.063) | 0.98 (0.082) | 0.01308 | ||||
| Female | Y(33) | Persistence | 0.016 | - | - | - | - | ||
| Bayes | 0.011 | 0.80 (0.021) | 0.89 (0.029) | 0.95 (0.037) | 0.00817 | ||||
| Bayes(S) | 0.013 | 0.84 (0.028) | 0.94 (0.038) | 0.97 (0.048) | 0.00981 | ||||
| Spline | 0.016 | 0.41 (0.012) | 0.54 (0.015) | 0.62 (0.018) | 0.01230 | ||||
| BSTS | 0.011 | 0.73 (0.016) | 0.86 (0.022) | 0.92 (0.027) | 0.00777 | ||||
| N(30) | Persistence | 0.013 | - | - | - | - | |||
| Bayes | 0.010 | 0.82 (0.017) | 0.92 (0.023) | 0.95 (0.030) | 0.00699 | ||||
| Bayes(S) | 0.010 | 0.93 (0.028) | 0.98 (0.040) | 0.99 (0.052) | 0.00784 | ||||
| Spline | 0.016 | 0.56 (0.017) | 0.66 (0.022) | 0.79 (0.026) | 0.01066 | ||||
| BSTS | 0.010 | 0.86 (0.022) | 0.94 (0.030) | 0.95 (0.039) | 0.00735 | ||||
Figure 4 shows validation results for the male ASAF of four countries or regions for predictions three five-year periods ahead. We see that our method works quite well for the United States and Hong Kong, and the prediction interval captures the variability of the male ASAF of Chile. Figure 5 shows the results from Scenario (1) where most female ASAF of countries among the examples have not reached the peak by the year 2000. We see that the posterior median of the predictive distribution captures the general trend of future female ASAF of the United States, the Netherlands, and Chile reasonably well. For countries or regions like Hong Kong whose female ASAF already passed the peak, our method also accurately estimates the rate of decline.
Fig 4.
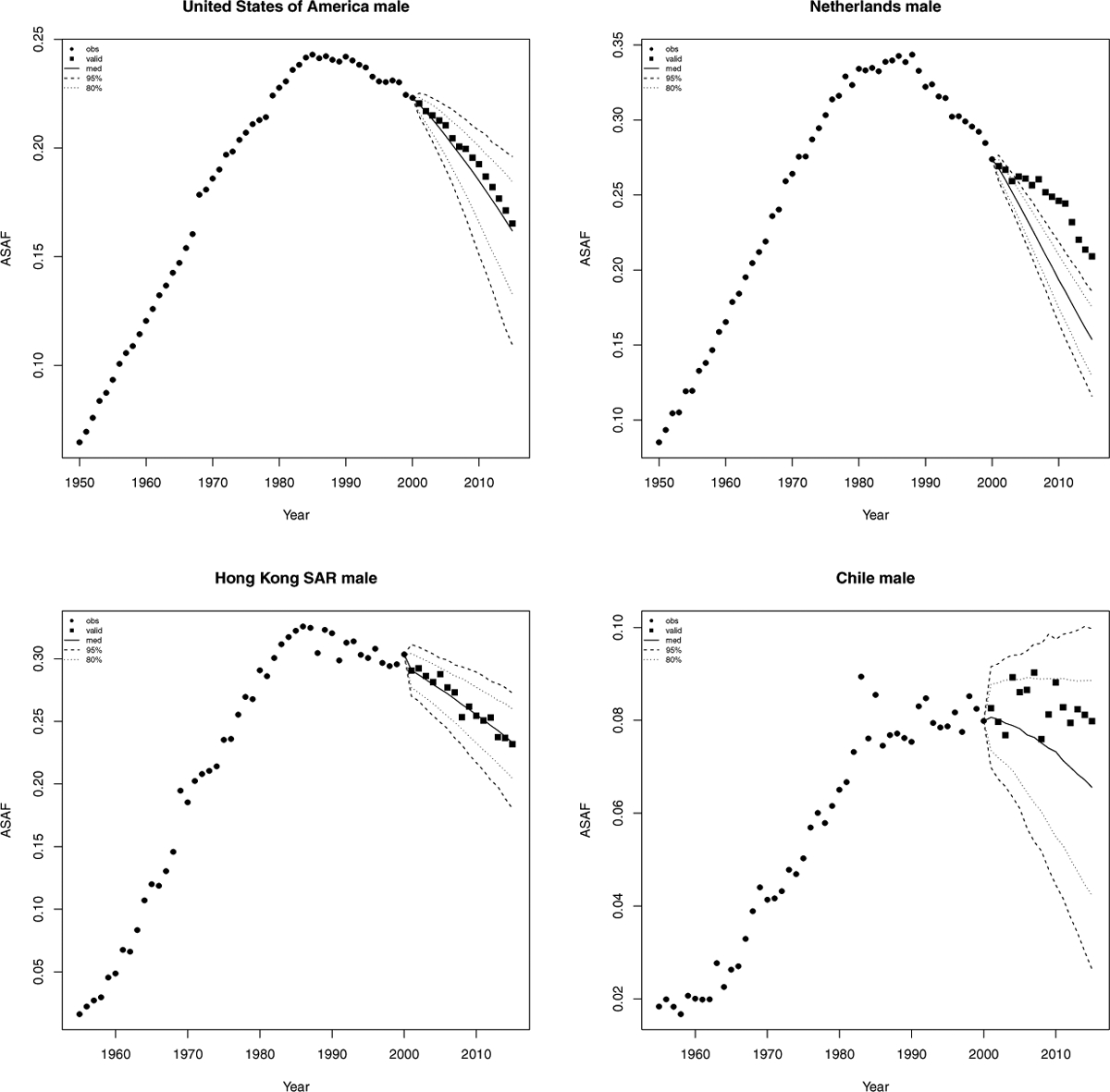
Validation of male all-age smoking attributable fraction for the United States, Netherlands, Hong Kong, and Chile. Past observed ASAF values are shown by black dots for 1950–2000 and by black squares for 2000–2015. The posterior median for 2000–2015 is shown by the solid line, and the 80% and 95% prediction intervals are shown by the dotted and dashed lines respectively.
Fig 5.
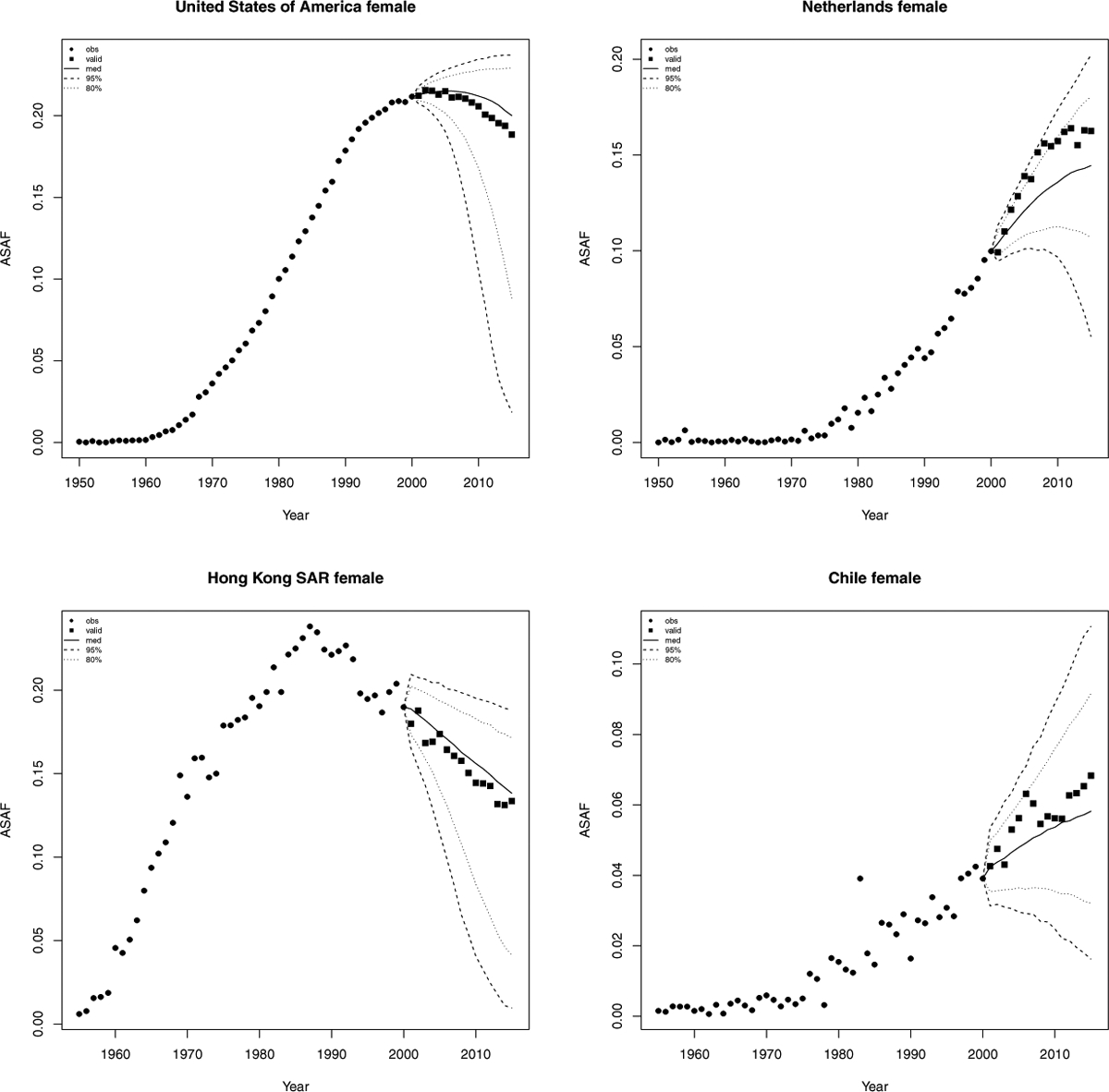
Validation of female all-age smoking attributable fraction for the United States, Netherlands, Hong Kong, and Chile. Past observed ASAF values are hown by black dots for 1950–2000 and by black squares for 2000–2015. The posterior median for 2000–2015 is shown by the solid line, and the 80% and 95% prediction intervals are shown by the dotted and dashed lines respectively.
4. Case Studies.
Probabilistic forecasts of ASAF to 2050 are given in the Supplementary Materials for over 60 countries. Broadly, the patterns in the OECD countries are similar, with male ASAF having declined from about 30% in the 1990s to around 15% in 2015, with further declines projected to 2050, reaching around 5%. The patterns vary more for females in OECD, and for both males and females in non-OECD countries because they are currently at different stages of the epidemic.
We now give four cases studies which illustrate various aspects of the proposed method for estimating and forecasting ASAF.
4.1. United States.
The annual ASAF for both male and female for the time period 1950–2015 is shown in Figure 1. The very clear pattern is due to the high quality of the data, reflecting the fact that the United States has one of the the best vital registration systems in the world.
The smoking epidemic in the male population in the United States started in the earlier 1900s, and there was a substantial decrease of smoking prevalence and lung cancer mortality rate after the 1950s. Smoking prevalence among US male adults was approximately 60% in 1950s, and went down to about 20% in the 1990s, and the general decline is still continuing (Burns et al., 1997; Islami, Torre and Jemal, 2015). The observed ASAF levelled around the 1990s and declined afterwards. We forecast that by 2050, the median observed ASAF for US males will be around 4.3% (with 95% prediction interval [0.0%, 8.3%]). Because the measurement error for the US is tiny, the projected true ASAF (long dashed line for posterior mean and dotted line for 95% predictive interval in Figure 6) for US males is almost equal to that of the observed ASAF.
Fig 6.
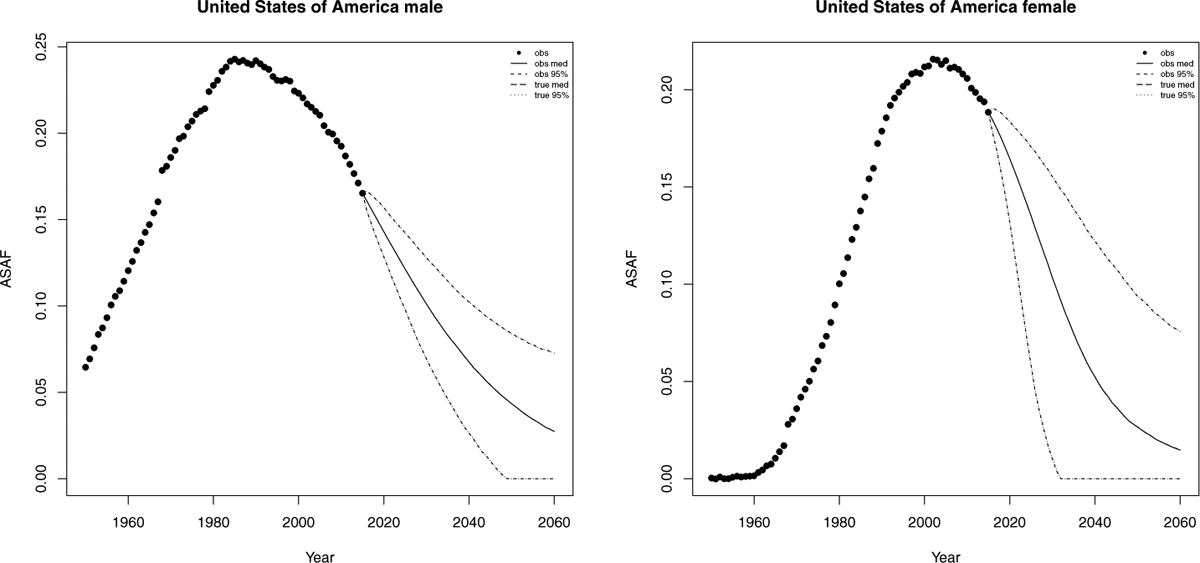
United States: The left and right panels show the projection of ASAF up to 2050 under the proposed model for male and female respectively. The solid and long dashed lines show the posterior median of projected observed ASAF and true ASAF respectively. The dashed and dotted lines represent 95% prediction intervals for observed ASAF and true ASAF respectively.
The female smoking epidemic started two decades later than the male one and the maximum prevalence was around 30% in the 1960s, and then declined to about 20% in the 1990s (Burns et al., 1997). The pattern of smoking prevalence among US females is similar to that for males, but around 20 years behind (Burns et al., 1997; Islami, Torre and Jemal, 2015). The female ASAF started to rise around the 1960s and reached its peak of 23% around 2005. We forecast that by 2050, the median observed ASAF for US females will be around 2.7% (with 95% prediction interval [0.0%, 9.3%]). Similarly, the projected US female true ASAF follows closely with that of the observed ASAF. Figure 6 shows the historical records of the observed male and female ASAF during the time period 1950–2015, along with projections up to 2050 with posterior median and prediction intervals.
4.2. The Netherlands.
The Netherlands is a high-income western Europe country whose smoking epidemic started relatively early. Smoking prevalence reached 90% in the 1950s and dropped to 30% in the 2010s. The male observed ASAF in Netherlands passed its maximum ASAF around the 1990s and we project that it will go down to around 5.7% (with 95% prediction interval [1.4%, 9.7%]) in 2050.
For females, smoking prevalence is also relatively high, and reached its peak of about 40% in the 1970s and dropped to 24% in the 2010s (Stoeldraijer et al., 2015). The female ASAF in Netherlands is among the few that is already experiencing the leveling stage. By our projection, the median year-to-peak for the female ASAF will be around 2020, which is about 30 years after the male peak, and will reach 16.6% (with 95% prediction interval [12.4%, 18.5%]). By 2050, the median observed female ASAF will be 4.7% (with 95% prediction interval [0.0%, 19.3%]). Similarly to the case of US, the projected true ASAF follows that of the observed ASAF closely, due to the small measurement error. Figure 7 shows the historical records of the observed male and female ASAF during time period 1950–2015, and projections are given up to 2050 with posterior median and prediction intervals for both observed and true ASAF.
Fig 7.
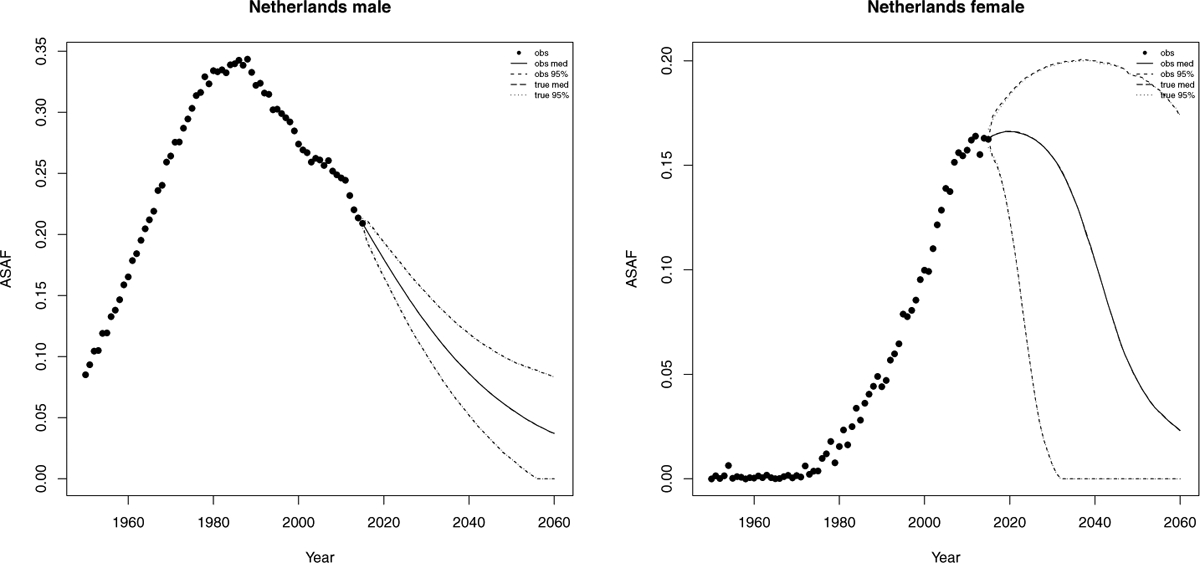
Netherlands: The left and right panels show the projection of ASAF up to 2050 under the proposed model for male and female respectively. The solid and long dashed lines show the posterior median of projected observed ASAF and true ASAF respectively. The dashed and dotted lines represent 95% prediction intervals for observed ASAF and true ASAF respectively.
4.3. Hong Kong.
Hong Kong has an advanced smoking epidemic, but had a decrease in male smoking prevalence from about 40% in the 1980s to 22% in 2000. A decline has also been observed in female smoking prevalence, from 5.6% to 3.3% (Au et al., 2004). Like Japan, Singapore, and South Korea, both male and female ASAF have passed the leveling stage and have been declining for two decades. Unlike in most western developed countries, the time trend of the ASAF has been almost identical for males and females in Hong Kong, with similar times of onset and times-to-peak. Au et al. (2004) showed that the time trends of lung cancer incidence were similar for both genders.
By our projection, the observed ASAF will reach 9.7% for males (with 95% prediction interval [4.9%, 14.3%]) and 4.1% for females (with 95% prediction interval [0.0%, 8.1%]) by 2050. Compared with US and the Netherlands, the projected true ASAF of Hong Kong will have narrower predictor intervals than those of the observed ASAF due to larger measurement error exhibited in the historical data. However, the difference becomes less and less since the majority uncertainty of the future ASAF will be account mainly by the variance from the random walk model of the true ASAF.
As discussed by Lam et al. (2001), Hong Kong may be a good indicator for the future development of the smoking epidemic and its impact on mortality in mainland China and other developing countries. Figure 8 shows the historical records of the observed male and female ASAF during time period 1950–2015, along with projections up to 2050 with posterior median and prediction intervals.
Fig 8.
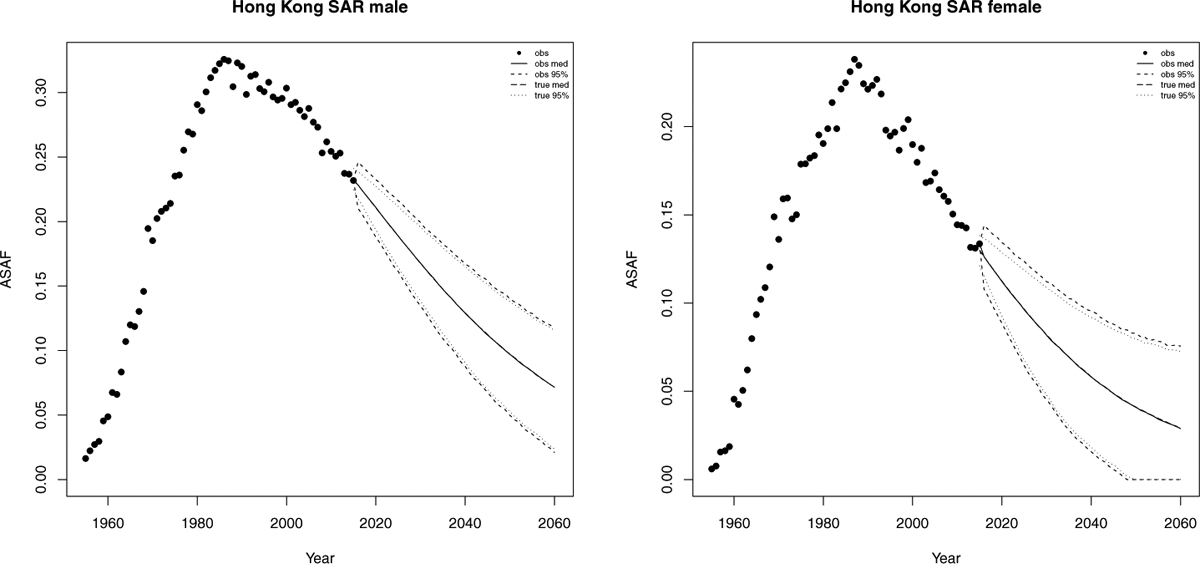
Hong Kong: The left and right panels show the projection of ASAF up to 2050 under the proposed model for male and female respectively. The solid and long dashed lines show the posterior median of projected observed ASAF and true ASAF respectively. The dashed and dotted lines represent 95% prediction intervals for observed ASAF and true ASAF respectively.
4.4. Chile.
Chile is one of the South America countries that have clear-pattern ASAF data for both males and females. It also has relatively high smoking prevalence. A decline in prevalence among males and females has been observed in recent years but is modest compared to the decline in the United States (Islami, Torre and Jemal, 2015). Also, female smoking prevalence is far behind that of males.
Our method projects that the male ASAF will decline gradually. By 2050, the projected median observed ASAF for the male population will be 4.3% (with 95% prediction interval [0.0%, 9.1%]). For females, we expect an increase for another 10 years with the median observed ASAF reaching the maximum 7.6% (with 95% prediction interval [2.0%, 11.8%]) by 2030. By 2050, the median observed female ASAF be 5.36% (with 95% prediction interval [0.0%, 15.2%]); see Figure 9. Similarly to Hong Kong, Chile also has larger measurement error and the pattern is less clear, so that the projected true ASAF has wider predictive intervals compared with previous cases and the difference between true and observed projections also appears in the short term.
Fig 9.
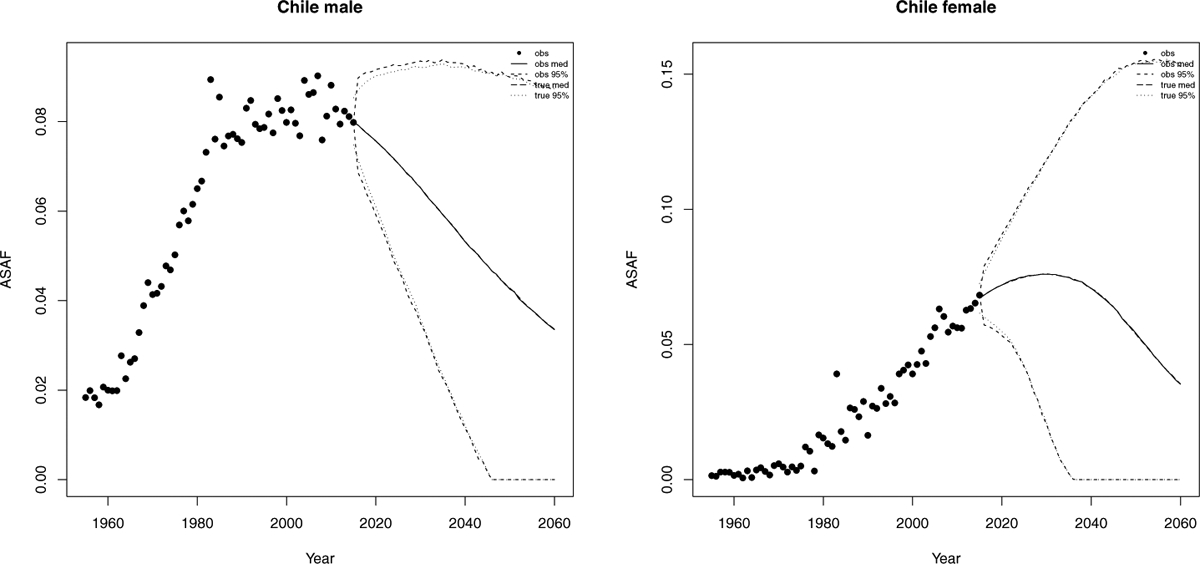
Chile: The left and right panels show the projection of ASAF up to 2050 under the proposed model for male and female respectively. The solid and long dashed lines show the posterior median of projected observed ASAF and true ASAF respectively. The dashed and dotted lines represent 95% prediction intervals for observed ASAF and true ASAF respectively.
5. Discussion.
5.1. Comparison between SAF Estimation Methods.
In Section 1, we briefly described three categories of estimation methods for SAF. Prevalence-based methods depend heavily on smoking prevalence history. Since the lag between smoking prevalence and SAF is usually around two or three decades, in order to use smoking prevalence to estimate and predict SAF, especially for those countries whose onset of SAF is before 1950, one needs data at least back to the 1920s or 1930s. However, such smoking prevalence history is not available for most countries, and reconstruction of such data is challenging. Ng et al. (2014) provided estimates of smoking prevalence for many countries only from 1980 onwards.
Insufficient historical data is a major obstacle to using smoking prevalence for estimation and projection of SAF, and with currently available historical data, the predictive power using smoking prevalence data is not very high. In addition, smoking prevalence only reveals one aspect of the smoking epidemic, which cannot capture other aspects such as smoking intensity and duration and thus has been argued to be a poor indicator of the smoking exposure of the population (Shibuya, Inoue and Lopez, 2005; Luo et al., 2018). Prevalence-based estimation and projection have generally been applied only to specific countries on an individual basis, and examples include Taiwan (Wen et al., 2005) and the United States (Ma et al., 2018).
There are two main indirect methods used widely in the literature, which both use the lung cancer mortality rate as an indicator for the accumulated hazard of smoking. The first one is the Peto-Lopez method which we have used here. This has been widely used in the demographic literature, in part because its data requirements are relatively modest. It has been validated in many studies (Preston, Glei and Wilmoth, 2009; Kong et al., 2016).
One drawback of the Peto-Lopez method is that it uses the CPS-II to estimate the relative risk. Since the CPS-II was conducted in 1982 with volunteer participants only from the United States and most of them were middle-class, the CPS-II might not be fully representative and may potentially underestimate lung cancer mortality in nonsmokers (Tachfouti et al., 2014). Moreover, the Peto-Lopez method assumes that the relative risk is constant over time and homogeneous across nations. Mehta and Preston (2012), Teng et al. (2017), and Lariscy, Hummer and Rogers (2018) have shown that the risks from smoking are changing over time. Also, in China and India, the lung cancer mortality rate among nonsmokers is higher than that of the developed countries such as that in the CPS-II (Liu et al., 1998; Gajalakshmi et al., 2003). Another issue is that the original Peto-Lopez paper reduced the smoking excess risk of each cause-of-death except lung cancer by 50% to control for other confounders. As stated in their paper, this reduction is somewhat arbitrary. To avoid some of these issues, here we have used only data from clear-pattern countries, which avoids some countries for which the Peto-Lopez method may not give good estimates.
Some variants of the Peto-Lopez method have been proposed. For example, Ezzati and Lopez (2003) reduced the correction factor for excess risk from 50% to 30% for all countries and extended this method to less developed countries by estimating the non-smoker lung cancer mortality rate based on household use of coal in poorly-vented stoves. They also provided an analysis of uncertainty. Mackenbach et al. (2004) used a simplified version which only used the all-cause relative risk in the CPS-II study and avoided calculations for the nine disease categories separately. Janssen, van Wissen and Kunst (2013) used this version to calculate age-specific SAF to partition mortality into smoking and non-smoking attributable parts, and projected them separately.
Muszyńska, Fihel and Janssen (2014) and Stoeldraijer et al. (2015) used the same method to calculate an age-standardized SAF, whose purposes are to compare the role of smoking in different regions of Poland, and to estimate and compare smoking attributable fraction of mortality among England & Wales, Denmark and the Netherlands, respectively. While age-standardization is used mainly to compare SAF among different populations, ASAF provides the all-cause SAF with all age-groups aggregated and is the main quantity reported in the iterature, e.g., Peto et al. (1992, 1994, 2006); Preston, Glei and Wilmoth (2009).
Based on these concerns about the Peto-Lopez method, Preston, Glei and Wilmoth (2009) and Preston, Glei and Wilmoth (2011) came up with the PGW method, which used a regression-based method to connect lung cancer mortality rate with other causes of death mortality rate instead of using the CPS-II. The PGW method avoids the relative risk problem faced by the Peto-Lopez method and provides estimates of uncentainty. However, its authors stated that the Peto-Lopez method might work better for countries where the cause-of-death structure is very different from that observed in developed countries, such as tropical African countries. They also pointed out that both methods would not work well for countries whose lung cancer mortality rate is also influenced largely by some other factors such as air pollution. As discussed by Preston, Glei and Wilmoth (2009), the PGW method produces similar estimates to the Peto-Lopez method in general for both males and females.
5.2. Projection Methodology.
To our knowledge, there are only two other methods available for projecting SAF based on the Peto-Lopez method. Janssen, van Wissen and Kunst (2013) proposed the first method to forecast age-specific SAF and to our knowledge it has so far been applied only to the Netherlands. For projecting male age-specific SAF, a constant decline rate (−1.5%) based on the current trend of all-age combined SAF is applied for each age group. For females, it first estimates the time-to-peak and value of peak of female SAF. It uses age-period-cohort (APC) analysis to find the cohort with the highest lung cancer mortality rate and then adds 68, which is the average age of dying from lung cancer, to that cohort to estimate the year which the all-age combined female SAF would reach the maximum. Then the difference between year-to-peak of male and female SAF with all ages combined is estimated and applied to get the time-to-peak and thus the age-specific female SAF. Finally, the rate of decline of female age-specific SAF is set to the same as that of the male.
The other method proposed for projecting SAF is to first estimate and project lung cancer mortality rate by considering the cohort effect, and use it to calculate the age-specific SAF. Stoeldraijer et al. (2015) used an APC model to estimate and forecast the lung cancer mortality rate of three countries: England & Wales, Denmark, and the Netherlands. For female data, they first estimated the time-to-peak for each age group by assuming that the time-to-peak of age-specific lung cancer mortality rate for females is when it reaches the corresponding rate for males. By assuming that the female lung cancer mortality will follow the same increasing-leveling-declining time trend as that for males for each age group, the authors argued that their method could provide long-term projections of lung cancer mortality rate, while previous work which only used historic trends in APC analysis could only provide short-term projections.
APC analysis is widely used, but it is also plagued by the unidentifiability issue resulting from the perfect linear relationship between the three effects. To resolve this requires extra constraints on the parameter space, many of which are not desirable (Luo, 2013; Smith and Wakefield, 2016). Also, projection of the future lung cancer mortality rate also requires the projection of age, period, and cohort effects, which introduces additional projection error, even more so for young cohorts for which historical data are not available.
Another way to resolve the unidentifiability issue in APC analysis is by introducing cohort explanatory variables (Smith and Wakefield, 2016). Cohort smoking history is one such powerful tool for estimating and projecting mortality. Preston and Wang (2006) and Wang and Preston (2009) used the average year of smoking before 40 of a cohort as a covariate to explain the mortality differences between genders and forecasted mortality of United States for both genders up to 2035. Shibuya, Inoue and Lopez (2005) and Luo et al. (2018) used APC anlaysis with selected smoking covariates such as cigarette tar exposure to estimate and project the lung cancer mortality rate. Cohort smoking history is a powerful tool, but it requires additional data (Burns et al., 1997) that are not available for many of the countries we considered.
5.3. China and India.
According to Reitsma et al. (2017), China and India are the two countries that have seen the largest percentage increase in smoking prevalence. As a result, the ASAF for these two countries is important for understanding and projecting the world trend of the effect of smoking on mortality since the diffusion of the smoking epidemic from developed countries to developing countries has already started.
Parascandola and Xiao (2019) found that smoking-related health issues in China have increased over the past two decades, and the trend resembles the early pattern observed in high income countries such as the US and Japan. Smoking prevalence among Chinese men has remained high (around 60%) since the 1980s, with a modest decrease to 52% by 2015. Smokers born after 1970 tended to start smoking earlier and more intensely than those born before 1970.
Chen et al. (2015) analyzed two nationwide prospective cohort studies on smoking conducted in China during 1991–99 and 2006–14. They found that the excess risk among smokers almost doubled over the 15-year period. They reported that the SAF of males aged 40–79 increased from 11% in the first study to 18% in the second study, and they predicted that it would be over 20% in the mid-2010s.
In contrast, female smoking prevalence decreased from 7% in the 1980s to 3% in 2015 (Parascandola and Xiao, 2019). However, second-hand smoking remains high among Chinese females. Zheng et al. (2018) estimated that 65% of Chinese female non-smokers were exposed to second hand smoking in 2012. Nonetheless, the SAF for Chinese females aged 40–79 years was around 3% in 2006–14.
There are also substantial geographic differences in smoking prevalence. In big cities like Beijing and Shanghai, smoking control measures have developed more rapidly than in other areas.
India has become the country with the second largest cigarette consumption in the world, after China. Smoking, including manufactured cigarettes, bidis, and chewing tobacco is one of the major causes of death for middle-aged Indians. Mishra et al. (2016) estimated that smoking prevalence among male Indians aged 15–69 years declined modestly from 27% in 1998 to 24% in 2010, while smoking prevalence among young adults aged 15–29 years rose.
We have not included these two countries in our analysis for the following two reasons. Firstly, we do not have enough data to estimate the ASAF for China and India. Even though there are some records of lung cancer death count data in the WHO Mortality Database for China (World Health Organization, 2017), these are only regional data and so could be biased. India has a reasonably good vital registration system but it also has lung cancer mortality data only for selected regions and locations.
Secondly, as pointed out by Preston, Glei and Wilmoth (2009), neither the Peto-Lopez original method nor the PGW method will provide reliable estimates of SAF for countries like China since smoking is not the only major factor that can cause lung cancer. The main assumptions of the Peto-Lopez and PGW methods are that lung cancer mortality is primarily caused by smoking and that the lung cancer mortailty rate is very low among nonsmokers. Therefore, as proposed by Ezzati and Lopez (2003) and others, some extra covariates such as household use of coal in poorly-vented stoves are used to adjust the estimates. Incorporating China and India in the joint model could be feasible in the future if better ASAF estimation methods and related data become available.
5.4. Decision-making and covariates.
A main purpose of our method is to help improve mortality forecasts. One could also ask whether our approach could be used directly for policy-making. One possible use would be to provide a baseline forecast of what would happen with a continuation of current trends in general health, development and tobacco control measures. This could help to assess the effectiveness of additional policies in accelerating the decline of smoking-related mortality. This could be done retrospectively, by considering a time point in the past at which a new tobacco control policy was introduced, and then comparing the probabilistic forecast based on data up to that point with what actually happened.
To do this prospectively would require the addition of covariates to the model. This is challenging, and would be a good topic for further research. A difficulty with forecasting using covariates is that the covariates themselves need to be forecast, and the covariates can be harder to forecast than the quantity being forecast. This is especially the case when, as here, the quantity being forecast has a strong time trend, and thus may well itself be easier to forecast than the covariates. In this situation, adding covariates can lead to forecasts that are noisier. This is one reason why, after decades of research, the majority of demographic studies do not use covariates in forecasting demographic quantities.
Supplementary Material
ACKNOWLEDGEMENTS
The authors thank John Bongaarts for helpful discussions.
Supported by NIH grants R01 HD054511 and R01 HD070936, and the Center for Advanced Research in the Behavioral Sciences at Stanford University.
APPENDIX A: FULL BAYESIAN HIERARCHICAL MODEL
The details of the four-layer Bayesian Hierarchical model described in Section 2.4 are as follows. Here represents a normal distribution with mean a and variance b truncated at interval [l, u] (l(u) is omitted if it takes value −∞ (∞)). Gamma(a, b) represents a Gamma distribution with shape a and rate b. Lognormal(a, b) represents a log-normal distribution with parameters a, b. InvGamma(a, b) represents a inverse-Gamma distribution with shape a and scale b.
-
Level 1:
-
Level 2:
-
Level 3:
-
Level 4:
where , , , , , , , , , , , , , , , , , , , , , , , , , , , , αν = −10.414,βν = 1.1862, , , , .
Footnotes
SUPPLEMENTARY MATERIAL
Supplementary material for “Estimating and Forecasting the Smoking-Attributable Mortality Fraction for Both Genders Jointly in Over 60 Countries”
(doi: COMPLETED BY THE TYPESETTER; .pdf). The supplementary material includes two sections: 1: MCMC convergence diagnostics; 2: All-age smoking attributable fraction projection for over 60 countries for both genders up to 2050.
REFERENCES
- Alkema L, Raftery AE, Gerland P, Clark SJ, Pelletier F, Buettner T and Heilig GK (2011). Probabilistic projections of the total fertility rate for all countries. Demography 48 815–839. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Au JS, Mang OW, Foo W and Law SC (2004). Time trends of lung cancer incidence by histologic types and smoking prevalence in Hong Kong 1983–2000. Lung Cancer 45 143–152. [DOI] [PubMed] [Google Scholar]
- Bongaarts J (2006). How long will we live? Population and Development Review 32 605–628. [Google Scholar]
- Bongaarts J (2014). Trends in causes of death in low-mortality countries: implications for mortality projections. Population and Development Review 40 189–212. [Google Scholar]
- Britton J (2017). Death, disease, and tobacco. The Lancet 389 1861–1862. [DOI] [PubMed] [Google Scholar]
- Burns DM, Lee L, Shen LZ, Gilpin E, Tolley HD, Vaughn J, Shanks TG et al. (1997). Cigarette smoking behavior in the United States. Changes in cigarette-related disease risks and their implication for prevention and control. Smoking and Tobacco Control Monograph 8 13–42. [Google Scholar]
- Carpenter B, Gelman A, Hoffman MD, Lee D, Goodrich B, Betancourt M, Brubaker M, Guo J, Li P and Riddell A (2017). Stan: A probabilistic programming language. Journal of Statistical Software 76. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Chen Z, Peto R, Zhou M, Iona A, Smith M, Yang L, Guo Y, Chen Y, Bian Z, Lancaster G et al. (2015). Contrasting male and female trends in tobacco-attributed mortality in China: evidence from successive nationwide prospective cohort studies. The Lancet 386 1447–1456. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Durbin J and Koopman SJ (2012). Time series analysis by state space methods. Oxford University Press. [Google Scholar]
- Ezzati M and Lopez AD (2003). Estimates of global mortality attributable to smoking in 2000. The Lancet 362 847–852. [DOI] [PubMed] [Google Scholar]
- Ezzati M and Lopez AD (2004). Regional, disease specific patterns of smoking-attributable mortality in 2000. Tobacco Control 13 388–395. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Fenelon A and Preston SH (2012). Estimating smoking-attributable mortality in the United States. Demography 49 797–818. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Fokas N (2007). Growth functions, social diffusion, and social change. Review of Sociology 13 5–30. [Google Scholar]
- Centers for Disease Control and Prevention (2019). What Are the Risk Factors for Lung Cancer? Last accessed: Oct. 19, 2019 https://www.cdc.gov/cancer/lung/basic_info/risk_factors.htm.
- Gajalakshmi V, Peto R, Kanaka TS and Jha P (2003). Smoking and mortality from tuberculosis and other diseases in India: retrospective study of 43000 adult male deaths and 35000 controls. The Lancet 362 507–515. [DOI] [PubMed] [Google Scholar]
- Gneiting T and Raftery AE (2007). Strictly proper scoring rules, prediction, and estimation. Journal of the American Statistical Association 102 359–378. [Google Scholar]
- Grübler A, Nakićenović N and Victor DG (1999). Dynamics of energy technologies and global change. Energy Policy 27 247–280. [Google Scholar]
- Harvey AC (1990). Forecasting, structural time series models and the Kalman filter. Cambridge University Press. [Google Scholar]
- Head GA and McCarty R (1987). Vagal and sympathetic components of the heart rate range and gain of the baroreceptor-heart rate reflex in conscious rats. Journal of the Autonomic Nervous System 21 203–213. [DOI] [PubMed] [Google Scholar]
- Head GA, Lukoshkova EV, Mayorov DN and van den Buuse M (2004). Non-symmetrical double-logistic analysis of 24-h blood pressure recordings in normotensive and hypertensive rats. Journal of Hypertension 22 2075–2085. [DOI] [PubMed] [Google Scholar]
- Hoffman MD and Gelman A (2014). The No-U-turn sampler: adaptively setting path lengths in Hamiltonian Monte Carlo. Journal of Machine Learning Research 15 1593–1623. [Google Scholar]
- Islami F, Torre LA and Jemal A (2015). Global trends of lung cancer mortality and smoking prevalence. Translational Lung Cancer Research 4 327. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Janssen F, van Wissen LJ and Kunst AE (2013). Including the smoking epidemic in internationally coherent mortality projections. Demography 50 1341–1362. [DOI] [PubMed] [Google Scholar]
- Kong KA, Jung-Choi K-H, Lim D, Lee HA, Lee WK, Baik SJ, Park SH and Park H (2016). Comparison of prevalence-and smoking impact ratio-based methods of estimating smoking-attributable fractions of deaths. Journal of Epidemiology 26 145–154. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Kucharavy D and De Guio R (2011). Logistic substitution model and technological forecasting. Procedia Engineering 9 402–416. [Google Scholar]
- Lam T, Ho S, Hedley A, Mak K and Peto R (2001). Mortality and smoking in Hong Kong: case-control study of all adult deaths in 1998. BMJ 323 361. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Lariscy JT, Hummer RA and Rogers RG (2018). Cigarette smoking and all-cause and cause-specific adult mortality in the United States. Demography 55 1855–1885. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Levin ML (1953). The occurrence of lung cancer in man. Acta Unio Int Contra Cancrum 9 531–941. [PubMed] [Google Scholar]
- Liu B-Q, Peto R, Chen Z-M, Boreham J, Wu Y-P, Li J-Y, Campbell TC and Chen J-S (1998). Emerging tobacco hazards in China: 1. Retrospective proportional mortality study of one million deaths. BMJ 317 1411–1422. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Luo L (2013). Assessing Validity and Application Scope of the Intrinsic Estimator Approach to the Age-Period-Cohort Problem (with Discussion). Demography 50 1945–1988. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Luo Q, Yu XQ, Wade S, Caruana M, Pesola F, Canfell K and O’Connell DL (2018). Lung cancer mortality in Australia: Projected outcomes to 2040. Lung Cancer 125 68–76. [DOI] [PubMed] [Google Scholar]
- Ma J, Siegel RL, Jacobs EJ and Jemal A (2018). Smoking-attributable Mortality by State in 2014, US. American Journal of Preventive Medicine 54 661–670. [DOI] [PubMed] [Google Scholar]
- Mackenbach JP, Huisman M, Andersen O, Bopp M, Borgan J-K, Borrell C, Costa G, Deboosere P, Donkin A, Gadeyne S et al. (2004). Inequalities in lung cancer mortality by the educational level in 10 European populations. European Journal of Cancer 40 126–135. [DOI] [PubMed] [Google Scholar]
- Marchetti C, Meyer PS and Ausubel JH (1996). Human population dynamics revisited with the logistic model: how much can be modeled and predicted? Technological Forecasting and Social Change 52 1–30. [DOI] [PubMed] [Google Scholar]
- Mehta N and Preston SH (2012). Continued increases in the relative risk of death from smoking. American Journal of Public Health 102 2181–2186. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Mishra S, Joseph RA, Gupta PC, Pezzack B, Ram F, Sinha DN, Dikshit R, Patra J and Jha P (2016). Trends in bidi and cigarette smoking in India from 1998 to 2015, by age, gender and education. BMJ Global Health 1 e000005. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Mons U and Brenner H (2017). Demographic ageing and the evolution of smoking-attributable mortality: the example of Germany. Tobacco Control 26 455–457. [DOI] [PubMed] [Google Scholar]
- Muszyńska MM, Fihel A and Janssen F (2014). Role of smoking in regional variation in mortality in P oland. Addiction 109 1931–1941. [DOI] [PubMed] [Google Scholar]
- United Nations (2017). World Population Prospects. United Nations, New York, N.Y. Accessed: Oct. 15, 2018 http://population.un.org/wpp/Download/Standard/Population/. [Google Scholar]
- Neal RM (2011). MCMC using Hamiltonian dynamics. Handbook of Markov Chain Monte Carlo 2 2. [Google Scholar]
- Ng M, Freeman MK, Fleming TD, Robinson M, Dwyer-Lindgren L, Thomson B, Wollum A, Sanman E, Wulf S, Lopez AD et al. (2014). Smoking prevalence and cigarette consumption in 187 countries, 1980–2012. Journal of the American Medical 311 183–192. Dataset last assess: Oct. 15, 2018 http://www.healthdata.org/data-tools. [DOI] [PubMed] [Google Scholar]
- Niu S-R, Yang G-H, Chen Z-M, Wang J-L, Wang G-H, He X-Z, Schoepff H, Boreham J, Pan H-C and Peto R (1998). Emerging tobacco hazards in China: 2. Early mortality results from a prospective study. BMJ 317 1423–1424. [DOI] [PMC free article] [PubMed] [Google Scholar]
- World Health Organization (2017). Mortality Database. Last accessed: Oct. 15, 2018 http://www.who.int/healthinfo/statistics/mortality_rawdata/en/.
- Pampel F (2005). Forecasting sex differences in mortality in high income nations: The contribution of smoking. Demographic Research 13 455. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Pampel FC (2006). Global patterns and determinants of sex differences in smoking. International Journal of Comparative Sociology 47 466–487. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Parascandola M and Xiao L (2019). Tobacco and the lung cancer epidemic in China. Translational Lung Cancer Research 8 S21. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Pérez-Ríos M and Montes A (2008). Methodologies used to estimate tobacco-attributable mortality: a review. BMC public health 8 22. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Peters F, Mackenbach J and Nusselder W (2016). Do life expectancy projections need to account for the impact of smoking. Netspar Design Papers 2016 1–54. [Google Scholar]
- Peto R, Boreham J, Lopez AD, Thun M and Heath C (1992). Mortality from tobacco in developed countries: indirect estimation from national vital statistics. The Lancet 339 1268–1278. [DOI] [PubMed] [Google Scholar]
- Peto R, Lopez AD, Boreham J, Thun M and Heath C (1994). Mortality from smoking in developed countries 1950–2000. Indirect estimates from national statistics. [Google Scholar]
- Peto R, Lopez AD, Boreham J and Thun M (2006). Mortality from smoking in developed countries. Population 673290 300245. [Google Scholar]
- Preston SH, Glei DA and Wilmoth JR (2009). A new method for estimating smoking-attributable mortality in high-income countries. International Journal of Epidemiology 39 430–438. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Preston SH, Glei DA and Wilmoth JR (2011). Contribution of smoking to international differences in life expectancy In International Differences in Mortality at Older Ages: Dimensions and Sources (Crimmins EM, Preston SH and Cohen B, eds.) 105–31. The National Academies Press, Washington, DC. [PubMed] [Google Scholar]
- Preston SH and Wang H (2006). Sex mortality differences in the United States: The role of cohort smoking patterns. Demography 43 631–646. [DOI] [PubMed] [Google Scholar]
- Raftery AE, Chunn JL, Gerland P and Ševčíková H (2013). Bayesian probabilistic projections of life expectancy for all countries. Demography 50 777–801. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Reitsma MB, Fullman N, Ng M, Salama JS, Abajobir A, Abate KH, Abbafati C, Abera SF, Abraham B, Abyu GY et al. (2017). Smoking prevalence and attributable disease burden in 195 countries and territories, 1990–2015: a systematic analysis from the Global Burden of Disease Study 2015. The Lancet 389 1885–1906. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Rosen L (2013). An intuitive approach to understanding the attributable fraction of disease due to a risk factor: the case of smoking. International Journal of Environmental Research and Public Health 10 2932–2943. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Shabani A, Sepaskhah A, Kamgar-Haghighi A and Honar T (2018). Using double logistic equation to describe the growth of winter rapeseed. The Journal of Agricultural Science 156 37–45. [Google Scholar]
- Shibuya K, Inoue M and Lopez AD (2005). Statistical modeling and projections of lung cancer mortality in 4 industrialized countries. International Journal of Cancer 117 476–485. [DOI] [PubMed] [Google Scholar]
- Simonato L, Agudo A, Ahrens W, Benhamou E, Benhamou S, Boffetta P, Brennan P, Darby SC, Forastiere F, Fortes C et al. (2001). Lung cancer and cigarette smoking in Europe: an update of risk estimates and an assessment of inter-country heterogeneity. International Journal of Cancer 91 876–887. [DOI] [PubMed] [Google Scholar]
- Smith TR and Wakefield J (2016). A review and comparison of age–period–cohort models for cancer incidence. Statistical Science 31 591–610. [Google Scholar]
- Stoeldraijer L, Bonneux L, van Duin C, van Wissen L and Janssen F (2015). The future of smoking-attributable mortality: the case of England & Wales, Denmark and the Netherlands. Addiction 110 336–345. [DOI] [PubMed] [Google Scholar]
- Tachfouti N, Raherison C, Obtel M and Nejjari C (2014). Mortality attributable to tobacco: review of different methods. Archives of Public Health 72 22. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Teng A, Atkinson J, Disney G, Wilson N and Blakely T (2017). Changing smoking-mortality association over time and across social groups: National census-mortality cohort studies from 1981 to 2011. Scientific Reports 7 11465. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Wang H and Preston SH (2009). Forecasting United States mortality using cohort smoking histories. Proceedings of the National Academy of Sciences 106 393–398. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Wen C, Tsai S, Chen C, Cheng T, Tsai M and Levy D (2005). Smoking attributable mortality for Taiwan and its projection to 2020 under different smoking scenarios. Tobacco Control 14 i76–i80. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Wood SN (2003). Thin plate regression splines. Journal of the Royal Statistical Society: Series B (Statistical Methodology) 65 95–114. [Google Scholar]
- Yang X, Mustard JF, Tang J and Xu H (2012). Regional-scale phenology modeling based on meteorological records and remote sensing observations. Journal of Geophysical Research: Biogeosciences 117. [Google Scholar]
- Zheng Y, Ji Y, Dong H and Chang C (2018). The prevalence of smoking, second-hand smoke exposure, and knowledge of the health hazards of smoking among internal migrants in 12 provinces in China: a cross-sectional analysis. BMC Public Health 18 655. [DOI] [PMC free article] [PubMed] [Google Scholar]
Associated Data
This section collects any data citations, data availability statements, or supplementary materials included in this article.