

Abstract
Stepped wedge cluster randomized trials (SW-CRTs) have become increasingly popular and are used for a variety of interventions and outcomes, often chosen for their feasibility advantages. SW-CRTs must account for time trends in the outcome because of the staggered rollout of the intervention. Robust inference procedures and non-parametric analysis methods have recently been proposed to handle such trends without requiring strong parametric modeling assumptions, but these are less powerful than model-based approaches. We propose several novel analysis methods that reduce reliance on modeling assumptions while preserving some of the increased power provided by the use of mixed effects models. In one method, we use the synthetic control approach to find the best matching clusters for a given intervention cluster. Another method makes use of within-cluster crossover information to construct an overall estimator. We also consider methods that combine these approaches to further improve power. We test these methods on simulated SW-CRTs, describing scenarios in which these methods have increased power compared to existing non-parametric methods while preserving nominal validity when mixed effects models are misspecified. We also demonstrate theoretical properties of these estimators with less restrictive assumptions than mixed effects models. Finally, we propose avenues for future research on the use of these methods; motivation for such research arises from their flexibility, which allows the identification of specific causal contrasts of interest, their robustness, and the potential for incorporating covariates to further increase power. Investigators conducting SW-CRTs might well consider such methods when common modeling assumptions may not hold
Keywords: Stepped wedge, cluster randomized trials, mixed effects models, permutation tests, synthetic control
1. BACKGROUND
Cluster randomized trials (CRTs) have become a popular form of randomized trial, with many practical benefits, reflecting the necessity of implementing some interventions on clusters of individuals, and statistical benefits, such as accounting for interference between individuals.1–3 The causal estimand of interest and the overall risk-benefit profile of the trial can also affect the choice to use cluster randomization.4–6 While parallel-arm CRTs are the most common, stepped wedge CRTs (SW-CRTs) have also become more common, being used for a variety of interventions.7–14 In SW-CRTs, each cluster begins in the control arm. At designated time points, a cluster or clusters “cross over” to the intervention arm and remain in that arm for the duration of the study. The order in which clusters cross over to the intervention is randomized.15,16
SW-CRTs are especially valuable when the intervention cannot be implemented in a large number of clusters simultaneously due to practical constraints.4,7,8,17 They can also be useful when the communities who will participate in the trial wish to ensure that all clusters receive the intervention before the end of the trial.7,8,17,18 In particular, the design can be useful for assessing complex health interventions and for evaluating effectiveness of implementation.19,20 There are, however, drawbacks to the design, and some of the benefits of the design may be achieved with parallel-arm CRT designs as well.21 Ethical arguments both for and against SW-CRTs have been made in various contexts, including arguments about the role of clinical equipoise.7,22,23 And while the design may yield increased power over parallel-arm CRTs, this depends on both a large number of measurements over time and a statistically valid analysis method that controls for confounding of the treatment effect by time.16,20–22,24,25 Because fewer clusters are assigned to the intervention at the beginning of the trial, and more clusters are assigned to the intervention at later time points, the effect of time on the outcome must be accounted for in order to obtain unbiased or consistent treatment effects.10,22,26 Additionally, SW-CRTs with a relatively small number of clusters can be underpowered to detect effects, at least without making strong modeling assumptions.27
The most common method for analyzing SW-CRTs is the use of a linear or generalized linear mixed effects model. As described by Hussey and Hughes, this model can include a random intercept for each cluster and a fixed effect for time periods.15 This form of the model assumes that the additive effect for each time period is the same across clusters. A more general model proposed by Hooper et al. adds an independent random intercept for cluster-period;28 however, this approach still assumes that the time trend does not vary systematically among clusters. In addition, both models require the specification of the distribution of these random intercepts. Misspecified random effects distributions can affect inference on the fixed effect estimators (i.e., the treatment effect estimator), although the effect on fixed effect estimates themselves is unclear and context-dependent.27,29–34 Finally, for the relatively small number of clusters in many SW-CRTs, asymptotic inference based on the assumption of normally distributed random effects—as is frequently made for analysis using mixed effects models—can lead to inflated Type I Error and poor confidence interval coverage.35,36
Various methods have been proposed to remedy these issues. One approach, proposed by Wang and De Gruttola and by Ji et al., uses permutation tests to ensure nominal Type I Error and accurate inference, even for small numbers of clusters, as long as the effect estimate is unbiased.35,36 In the longitudinal context more generally, linear and generalized linear mixed effects models have been proposed that allow for flexible semi-parametric specification of the random effects distributions.37–39 The operating characteristics of these different approaches to robust mixed effect model fitting have not been well-studied for SW-CRTs. Scott et al. have proposed the use of generalized estimating equations with finite-sample corrections to avoid the need to specify random effects distributions.40 Thompson et al. recently proposed a non-parametric analysis method that uses within-period (“vertical”) comparisons.41 They propose conducting inference by permutation tests as well to ensure nominal Type I Error and confidence interval coverage. They demonstrate through simulation that this method has no or low bias and nominal Type I Error and coverage.41 Finally, Hughes et al. have proposed a robust inference method for SW-CRTs using vertical comparisons that gives a closed-form standard deviation estimate.42 However, both of these vertical methods can suffer from greatly reduced power compared to the parametric mixed effects models. Because SW-CRTs often have relatively few clusters, this can result in analyses that are highly underpowered to detect meaningful treatment effects.
In Section 2, we propose novel non-parametric methods to analyze SW-CRTs. In the first method, we, like Thompson et al., use within-period comparisons to avoid the problem of misspecification of time effects and cluster random intercept distributions. We incorporate the synthetic control procedure to match treated clusters with untreated clusters that are likely to be most similar. Synthetic controls are a relatively new but increasingly popular method for causal inference most common in the econometrics literature.43–45 The approach is generally used when there is one treated cluster and a “donor pool” of untreated clusters, with outcome data both before and after the treatment began. The method finds the linear combination of untreated clusters that most closely matches the pre-treatment outcomes of the treated cluster. The causal effect estimate is then some contrast of the treated cluster’s post-treatment outcomes and that linear combination of the outcomes of the untreated clusters in the same period.44 We use this approach, somewhat akin to matching or covariate adjustment in parallel-arm clinical trials, to improve the power of the analysis. The second method we propose uses the within-cluster between-period (“horizontal”) comparisons that are inherent in SW-CRT and other crossover designs to improve the power of non-parametric approaches.22,27 This crossover method compares the between-period effect of clusters crossing over to that of clusters in the control arm in both periods (or in the intervention arm in both periods). We also propose two ways of combining these methods. In one, we use synthetic controls to find the best-matching clusters for the crossover approach. In the other, we form an ensemble estimator by averaging the estimators obtained from the synthetic control and crossover methods.
In Section 3, we compare by simulation the operating characteristics of these novel methods, the mixed effects models with both asymptotic and permutation-based inference, and the non-parametric within-period model, for both risk difference and odds ratio effect scales. We also apply these novel methods to a SW-CRT on the effects of diagnostic tests on tuberculosis outcomes reported by Trajman et al.,46 and compare the results to those for existing methods. Finally, in Section 4, we discuss the implications of these results for those designing and analyzing SW-CRTs. We also propose future research directions to better understand the relative performance of the methods considered here, as well as to better understand in which settings a SW-CRT may or may not be a reasonable design.
2. METHODS
In this section, we propose several novel methods of analysis for SW-CRTs: a synthetic control-based method, a crossover-based method, a combination method, and an ensemble method. These methods have flexible weighting schemes that allow the method to be tailored to particular situations. These methods do not rely on any particular distribution of the outcome data and can be used to estimate any causal contrast of interest.
2.1. Setting and Notation
Consider a SW-CRT with I clusters with outcome measurements in each of J periods. Denote by Yi,j the mean outcome for all K measured individuals in cluster i in period j (K can be fixed or vary by cluster-period). Let Xi,j denote the intervention status of cluster i in period j, with Xi,j = 1 indicating that the cluster is on intervention and Xi,j = 0 indicating that the cluster is on control. For each period j, let I0,j = {i :Xi,j = Xi,j-1 = 0}, Ii,j= { i :Xi,j = 1, Xi,j-1, = 0}, and I2,j= { i :Xi,j = Xi,j-1 = 1}, the set of clusters on control in both periods j and j − 1, crossing over in period j, and on intervention in both periods j and j− 1, respectively. Denote the number of clusters in each of these sets by n0,j, n1,j, and n2,j, respectively. We assume that each cluster only crosses over once; once a cluster is on intervention, it remains so for the rest of the periods under study. We assume throughout that the order of crossover is determined randomly. For each cluster i, let ji be the last period for which it is on control (define ji = 0 if cluster i is on intervention in period 1); then ji + 1 is the first period on intervention for cluster i. For any period j, denote by Y.j the expected value of the outcome (marginal across clusters) in period j in the absence of intervention. That is, Y.j = E[Yi,j | Xi,j = 0] for any cluster i
Let g(y1,y2) be the contrast of interest. For example, for binary outcomes, the risk difference is given by g(y1,y2) = y1 − y2 and the log odds ratio is given by . Although binary outcomes are more common in SW-CRTs,10 contrasts of continuous and count outcomes may be specified as well.
2.2. Existing methods for comparison
We compare the performance of these novel analysis methods with that of three current approaches for the analysis of SW-CRTs: two mixed effects model specifications (each with both asymptotic and exact inference) and the non-parametric within-period method.
First, we consider the commonly-used mixed effects model with a random intercept for cluster and fixed effects for time:
| (1) |
where h is the link function, μ is the global mean under control in period 1, and θ1 = 0 for identifiability.15 Generalized linear mixed model theory can be used for asymptotic inference, and permutation tests (and associated confidence intervals) can be used for exact inference with this model.35,36
Second, we consider the mixed effects model with an additional cluster-period random intercept:
| (2) |
where h is the link function, μ is the global mean under control in period 1 , θ1 = 0 for identifiability, and for all i,j.28 Inference can proceed on an asymptotic or exact basis as above.35
Third, we consider the non-parametric within-period method. In this method, for each period j where there are clusters on control and on intervention, a period-specific effect estimate is calculated by comparing the mean outcome of clusters on intervention (i ∈ I1,j ∪ I2,j) to the mean outcome of clusters on control (i ∈ I0,j):
| (3) |
The period-specific effect estimates are combined using an inverse-variance weighted average to obtain an overall estimated intervention effect:
| (4) |
where , , and and are the empirical variances of the Yi,j values for clusters on control and on intervention, respectively, for period j.41 A schematic representation of this estimation method is given in Figure 1a. Exact inference can proceed using permutation tests.41
Figure 1.
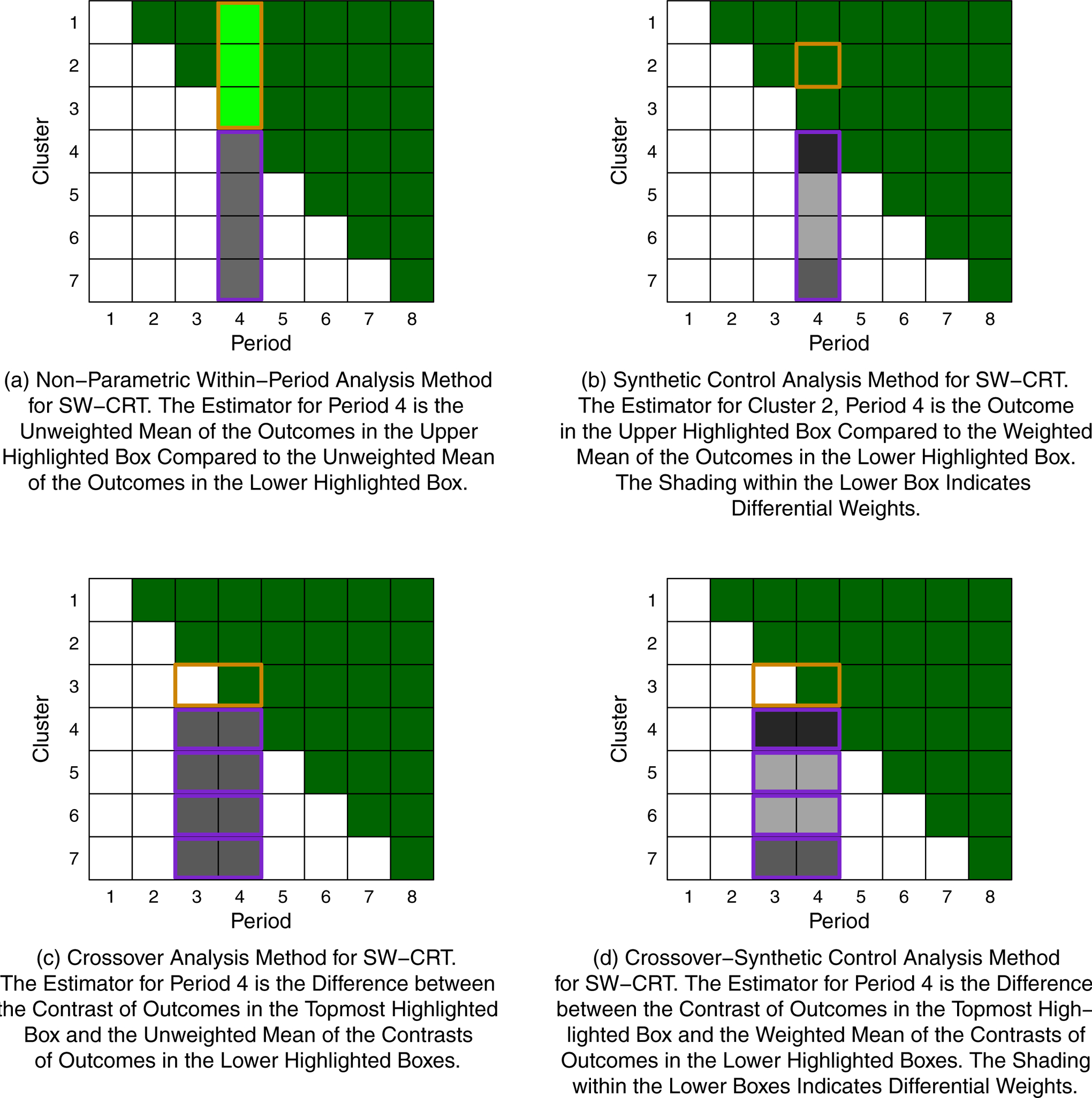
Schematic Representations of Several Existing and Novel Analysis Methods for a SW-CRT with Seven Clusters, Eight Periods, and One Crossover Per Period. Dark Green Boxes Indicate Cluster-Periods on Intervention and White/Gray Boxes Indicate Cluster-Periods on Control.
2.3. Synthetic control method
Our first proposed method uses the synthetic control procedure developed by Abadie et al. to estimate the effect of treatment for each intervention cluster-period.44 Similar to the non-parametric within-period method proposed by Thompson et al., this novel method constructs vertical comparisons and then uses a weighted average of these comparisons as an overall effect estimate.41
- For each period j where there are clusters on control and on intervention, for each cluster i on intervention (i ∈ I1,j ∪ I2,j), we construct a synthetic control estimator Zi,j, using the procedure outlined by Abadie et al.44 The synthetic control for cluster i in period j is a weighted average of the outcomes of the clusters on control in period , where are the clusters on control in period j. The weights, υi,j,n are selected by the synthetic control procedure to minimize the mean squared difference between the synthetic control for periods where cluster i was on control and the outcome for cluster i in that period subject to the constraints that the weights are nonnegative and for all i, j That is, they minimize:
See the proof of Theorem 1 in Appendix A for details. If specific cluster-level covariates are known, they can be included in estimation of the synthetic control as well.44 When the synthetic control procedure does not converge or there are no pre-intervention periods for this cluster, the unweighted mean of the outcomes of clusters on control in period j is used as Zij. In these cases, the period-specific effect estimator is the same as that for the non-parametric within-period method described above, and so the properties of that estimator hold.(5) - For each intervention cluster i for each period j where Xi,j = 1 and n0,j ≥1, we construct an estimator:
(6) - We find an overall estimator via a weighted average of these cluster-period-specific estimators:
where wi,j ≥ 0 and .(7)
A schematic representation of this estimation method is given in Figure 1b.
2.3.1. Inferential procedure
A permutation test can be used for exact inference, as for mixed effects models and the non-parametric within-period method.35,41 The standard permutation test approach is used: P random permutations of the crossover order are generated and an estimate of the treatment effect is obtained from each permutation using the estimation procedure described above. The observed estimate is compared to these estimates and the p-value for the null hypothesis of no effect of treatment is given by the proportion of the P estimates for which . This approach matches inferential methods for synthetic control estimators, which rely on treatment of units and estimating placebo synthetic control estimators to derive the null distribution of the estimator.44,45,47 To obtain confidence intervals, the permutation test can be inverted in the standard way.
2.3.2. Computation
This procedure is implemented in the R code included in the Supplemental Material. The latest version of the code can be found at https://github.com/leekshaffer/SW-CRT-analysis This implementation uses the synth function from the Synth package to obtain the synthetic control weights υi,j,n.48 User-defined functions to implement this method can also be constructed in Stata using the Synth command to perform the synthetic control fits,48 and the swpermute command to permute clusters in a manner that preserves exchangeability.49 Implementations using either of these Synth commands rely on Synth for convergence. In R, Synth automatically runs with two starting values to improve the likelihood of convergence. However, for clusters that have extreme outcome values compared to the donor clusters, there is still no guarantee that the procedure will converge. This is most likely to occur when there are few donor clusters, i.e. later in the trial, or when the pattern of the target cluster is heterogeneous compared to the others.48
2.3.3. Properties of the estimator
In a SW-CRT with a randomized order of crossover, the synthetic control estimator Zi,j is an unbiased estimate of the expected outcome under control, Y.j, if the underlying cluster-level outcome distribution is symmetric around some global mean outcome vector across periods; see Theorem 1 in Appendix A. If the individual-level outcomes have cluster-conditional expectations that are symmetric around a global mean vector, the estimator is asymptotically unbiased as the number of subjects with measured outcomes per cluster increases; see Corollary 1. Thus, for any weights independent of the outcomes, the SC estimator using the risk difference is unbiased or asymptotically unbiased under these conditions if there is a common risk difference across cluster-periods. See Theorem 2 and Corollary 2. For a non-linear contrast function (e.g., risk ratio or odds ratio), the unbiasedness of Zi,j does not guarantee unbiasedness of the effect estimate. Depending on the contrast and the assumed data-generating process, it may be possible to show consistency of this estimate. Further research is needed on the effect of applying a non-linear contrast function to cluster-level outcomes, specifically on targeting marginal or cluster-specific parameters. Note that all of the assumptions of Corollary 2 are satisfied under the mixed effects models described in Section 2.2 with an identity link function as long as the random effects are independent and identically distributed following a normal (or any other symmetric) distribution. Hypothesis tests using the permutation test method consider the sharp null hypothesis that the treatment has no effect in any cluster.50 When the treatment effect varies by cluster—e.g., if there is a random cluster-by-treatment effect—the estimator will estimate some weighted average of the treatment effects and the permutation test may not guarantee nominal Type I Error and coverage rates, depending on the correlation of this variation with other parameters.
2.3.4. Selecting weights
The weights for combining the cluster-period-specific estimators, wi,j, can be selected on the basis of two primary goals: (1) minimizing the variance of the overall estimator or (2) estimating a specific causal contrast when treatment effects may not be equal across clusters and time periods.
For the first goal, a natural approach is to follow the synthetic control literature on evaluating the accuracy of the synthetic control estimator or combining multiple synthetic control estimators by using the inverse of the mean squared prediction error (MSPE) values for each synthetic control estimator.51–53 For cluster i in period j, the MSPE of the synthetic control fit is given by equation (5). In the SW-CRT setting, however, the MSPE values are not directly comparable as different synthetic control estimators have a different number of pre-intervention periods that contribute. By contrast, the MSPE values will be comparable for intervention clusters that begin treatment in the same period, as these clusters will always have the same number of pre-intervention periods, regardless of which of their intervention periods are being examined. We therefore propose to weight the values by the inverse-MSPE within each set of intervention clusters that cross over in the same period, and then weight across these sets equally. That is, for each (i,j) such that Xi,j= 1, set weights proportional to:
| (8) |
where MSPEi,j is the MSPE of the synthetic control estimation procedure that produces Zi,j. There may be other considerations that affect the variances of the cluster-period summaries. Most notably, if cluster sizes vary by period or cluster, it may be desirable to consider this in selecting the weights. All of the properties of the estimator hold for varying cluster sizes, provided that cluster sizes are large enough to assure asymptotic symmetry of the cluster-period summary, when that property is necessary.
For the second goal of weighting, the weighting approach will depend on the causal estimand of interest. If, for example, investigators are only interested in the effect of intervention in the first period of its introduction to any cluster, they may select as weights:
| (9) |
that is, only using the estimates for the first period on intervention for each cluster. We do not present results on this approach here, but further research is needed to understand the causal estimands that may be of interest when the treatment effect cannot be assumed to be constant across clusters and periods. In this way, the weights also aid interpretability of the estimator, as it is clear which clusters and periods are considered and how much weight is given to each.
2.4. Crossover method
The second novel method seeks to improve on the power of the non-parametric within-period method by incorporating horizontal comparisons at the time of crossover. There is substantial literature on the value of within-subject analysis methods and methods combining within- and between-subject analyses for individual randomized crossover trials, especially in the absence of anticipation, lag, or carryover effects of treatment.54–57 The method we propose for SW-CRTs compares the mean contrast between the last control period and the first intervention period for each cluster crossing over from one period to the next to the mean contrast in those same periods among clusters on control in both periods. Since standard mixed effects models give a large weight to horizontal comparisons,27 the crossover approach may recover some of the power of mixed effects models while preserving the robustness of non-parametric estimation. The procedure is as follows:
For each cluster i and period j > 1, define Di,j ≡ g(Yi,j, Yi,j-1) the contrast in outcomes in cluster i between consecutive periods. E.g., for a risk difference analysis, Di,j = Yi,j − Yi,j-1, the difference in outcomes between consecutive periods.
- For each period j > 1 with clusters on both intervention and control, estimate the treatment effect for period j by:
If the treatment effect is assumed to be constant across time, an alternate estimator is given by:(10)
This alternative compares the change in outcome for the clusters which cross over to the change for clusters which either remain on control in both periods or remain on intervention in both periods.(11) - Construct an overall estimator with a weighted average of period-specific estimators:
where and .(12)
A schematic representation of this estimation method is given in Figure 1c.
2.4.1. Inferential procedure
A permutation test can again be used for hypothesis testing and to obtain confidence intervals. The procedure is the same as the inferential procedure for the synthetic control estimator, detailed in Section 2.3.1.
2.4.2. Computation
This procedure is implemented in the R code included in the Supplemental Material. Again, a user-defined function to implement this method can also be constructed in Stata using the swpermute command to permute clusters in a manner that preserves exchangeability.49
2.4.3. Properties of the estimator
For the risk difference, g(y1,y2) = y1-y2 any of these crossover estimates are unbiased estimates of the true risk difference β, under a randomized crossover order and the assumption of a constant β across clusters and periods. See Theorem 3 in Appendix A. The controls-only estimator is unbiased for the intervention effect in the first period on intervention if that effect is constant across clusters. See Corollary 3 in Appendix A. As for the synthetic control estimator, there may be settings where consistency can be shown for non-linear contrast functions, although unbiasedness is not guaranteed. Again, non-linear link functions applied to cluster-level outcomes target specific causal estimands and further research is needed on the consequences of targeting marginal rather than cluster-specific estimands.
2.4.4. Selecting weights
As for the synthetic control estimator, the weights can be selected either to minimize the variance of the overall estimator or to ensure proper estimation of a specific causal estimand. For the latter, again, this will depend on the specific estimand of interest, e.g., to match a target population of clusters.
To minimize the variance of the overall estimator, the weights may depend on the variance of the cluster-level outcome for each cluster-period. If all of these variances are assumed to be the same (i.e., all have the same subject-level variance and the cluster sizes do not vary by cluster or period), then the weight should depend only on the number of clusters in each treatment condition in that period. That is, we weight each estimator by the harmonic mean of the number of clusters used to estimate the consecutive-period control effect and the number of clusters used to estimate the crossover effect. For where the clusters which were on intervention in both periods j and j – 1 are used as control crossovers as well, we weight by . Note that when the same number of clusters cross over at each time point, is constant across j, while wj decreases as j increases.
2.5. Crossover-synthetic control method
A third potential method combines these two approaches by finding a synthetic control for the horizontal crossover contrast and comparing the intervention horizontal contrast to this synthetic control. This may combine the benefits of using horizontal comparisons with the benefits of synthetic control-based matching between clusters.
For each cluster i and period j > 1, define Di,j ≡ g(Yi,j, Yi,j-1) the contrast in outcomes in cluster i between consecutive periods. E.g., for a risk difference analysis, Di,j = Yi,j − Yi,j-1, the difference in outcomes between consecutive periods.
For each cluster the set of clusters that begin intervention in a period after period 1 that has clusters on control, construct a synthetic control horizontal contrast estimator Ci, using the procedure outlined by Abadie et al.44 For cluster i, the synthetic control is a weighted average of the horizontal contrasts of the clusters on control in both periods ji and , where are the clusters on control in both periods. The weights are selected by the synthetic control procedure to minimize the mean squared difference between the synthetic control for periods j′ ≤ 1 where cluster i ∈ I0,j′ and the true horizontal contrast for cluster i in that period subject to the constraints that the weights are nonnegative and sum to one. When the synthetic control procedure does not converge or there are no pre-crossover consecutive period contrasts for this cluster, the unweighted mean of the values Di′,ji+1 for i′ ∈ I0,ji+1 is used as Ci
- For each cluster i ∈ I*, we construct an estimator using its crossover effect:
(13) - We find an overall estimator via a weighted average of these cluster-specific estimators:
where .(14)
A schematic representation of this estimation method is given in Figure 1d. Note that this procedure is the same as that for the synthetic control method, but using Di,j as the “outcomes” in place of Yi,j.
2.5.1. Inferential procedure
The inferential procedure for the synthetic control estimator, detailed in Section 2.3.1, can again be used here for exact inference.
2.5.2. Computation
This procedure is implemented in the R code included in the Supplemental Material. This implementation uses the synth function from the Synth package to obtain the synthetic control weights vi,n.48
2.5.3. Selecting weights
As for the synthetic control estimator, a natural approach to minimize the variance of the overall estimator is to use weights inversely proportional to the MSPE of the synthetic control fits. Again, though, because the number of pre-crossover periods varies, these are only comparable among clusters which cross over in the same period. So we propose to weight the values by the inverse-MSPE within each set of intervention clusters that cross over in the same period, and then weight across these sets equally. That is, for each i, set:
| (15) |
where MSPEi is the MSPE of the synthetic control estimation procedure that produces Zi.
2.6. Ensemble method
Finally, we consider an ensemble method that averages across the estimators of previously-described methods. For any unbiased and/or consistent estimators, a weighted average of those estimators with weights that do not depend on the data will also be unbiased/consistent. If the covariance of the estimators is small enough compared to the variances, it may also reduce the variance of the estimator. In Appendix B, we derive the variances and covariance of the non-parametric within-period and crossover estimators under a simplified data-generating process. We then demonstrate that in this setting, when the difference in the mean outcome between clusters is relatively small compared to the variability within clusters, a simple mean of the non-parametric within-period estimator and the crossover estimator has a lower variance than either estimator on its own.
No analytic formula is available for the variance of the synthetic control estimator, although we expect (and simulation results presented below suggest) the synthetic control estimator to have lower variance than the non-parametric within-period estimator when the synthetic control matching performs well. Since the synthetic control and non-parametric within-period estimators are both vertical methods of analysis, we consider here an ensemble estimator that is a simple mean of the synthetic control estimator and the crossover estimator. That is,
| (16) |
where is a synthetic control estimator and is a crossover estimator.
Note that many other ensemble estimators could be constructed using different analysis methods and different weights. In addition, within-period ensembles may be constructed and then combined across periods (e.g., take the average of the SC estimators within each period j and average those with the CO estimator for period j, and then combine across periods to target a specific causal estimand). We use this simple version here to demonstrate the concept of the ensemble method and show its potential to improve power, but different ensembles will have different operating characteristics and may perform better or worse, relative both to one another and to other methods, depending on the setting.
2.6.1. Inferential procedure
The inferential procedure for the synthetic control estimator, detailed in Section 2.3.1, can again be used here for exact inference.
2.6.2. Computation
This procedure is implemented in the R code included in the Supplemental Material. Other ensemble methods can be constructed by altering the weights and estimators used; a generic function is provided for this purpose in the R code.
3. RESULTS
We compare the performance of these novel methods with the existing methods under two simulation settings: the first using the risk difference contrast, g(y1,y2) = y1 – y2, and the second using the log odds ratio contrast, . As SW-CRTs most commonly have binary outcomes, we consider binary outcomes here; the methods, however, also work for continuous outcomes. Throughout we denote the methods considered as follows:
MEM denotes the mixed-effects model defined in equation (1).
CPI denotes the mixed-effects model with a cluster-period random effect defined in equation (2).
NPWP denotes the non-parametric within-period method defined in equations (3) and (4).
SC-1 denotes the synthetic control method defined in equations (6) and (7), with equal weights across cluster-period estimators.
SC-2 denotes the synthetic control method with inverse-MSPE weights as defined in equation (8). In this case, there is only one cluster crossing over per period, so the estimators are weighted by inverse-MSPE within each target cluster, and then equally weighted across clusters.
CO-1 denotes the crossover method defined in equations (10) and (12), using comparison data only from control clusters, with equal weights.
CO-2 denotes the crossover method defined in equations (10) and (12), using comparison data only from control clusters, with weights proportional to the harmonic mean of the number of control and crossover clusters.
CO-3 denotes the crossover method defined in equations (11) and (12), using comparison data from both control clusters and intervention clusters, with equal weights.
COSC-1 denotes the crossover-synthetic control method defined in equations (13) and (14) with equal weights across cluster-specific estimators.
COSC-2 denotes the crossover-synthetic control method with inverse-MSPE weights defined in equation (15).
ENS denotes the ensemble method defined in equation (16), using a simple mean of SC-2 and CO-2.
All inference is based on exact permutation tests, except for asymptotic inference using the MEM and CPI models, which is denoted by MEM-a and CPI-a. All permutation tests were conducted with 500 randomly-sampled permutations of the crossover order.
3.1. Simulation 1: risk difference
3.1.1. Setting and parameters
We consider a setting where the risk difference is the contrast of interest. There are I = 7 clusters and J = 8 time periods, with one cluster beginning treatment in each of periods 2 through 8. At each cluster-period, K = 100 individuals are sampled. The data are generated from a mixed effects model similar to that in equation (2) with μ = 0.30 and τ = 0.06, with an identity link. We consider four scenarios:
Fixed time effects θ = θ1 ≡ (0, 0.08, 0.18, 0.29, 0.30, 0.27, 0.20, 0.13) and no cluster-period effect (v = 0). The MEM model is correctly specified in this case.
Fixed time effects θ = θ1 and cluster-period effect with v = 0.01. The CPI model is correctly specified in this case.
Equal probability of each cluster having either the time effects θ1 or θ2 ≡ (0, 0.02, 0.03, 0.07, 0.13, 0.19, 0.27, 0.3). No cluster-period effect (v = 0). Neither MEM nor CPI is correctly specified in this case.
Equal probability of each cluster having either the time effects θ1or θ2. Cluster-period effect with v = 0.01. Neither MEM nor CPI is correctly specified in this case.
Note that all scenarios satisfy the conditions of Corollaries 1 and 2 and Theorem 3 in Appendix A, so the SC-1 estimator is asymptotically unbiased and the CO estimators are unbiased. Since SC-2 does not have equal weights, it does not meet the conditions of Theorem 2 or Corollary 2, so we cannot guarantee it is asymptotically unbiased. For scenarios 1 and 2, the global mean vector is Y.J = μ + θ1 For scenarios 3 and 4, the global mean vector is .
These scenarios are designed to show the performance of the methods under the commonly-assumed mixed effects models, and under scenarios that are slightly more complex and thus have misspecified MEM and CPI models. Since the assumption of common or known time effects distributions are so key to the common mixed effects models, we focus on settings where that assumption does not hold. The difference in the two time effect vectors is set to be greater than the standard deviation of the random effects, so that it cannot be captured by that parameter. While there is heterogeneity in the size of SW-CRTs, many real and simulated studies have used 3–12 randomized treatment initiation times (“sequences” or “waves”) with one or more clusters per time.12–14,26,35,41,46 We chose seven initiation times with one cluster each to enable the varying time trends to have an effect on the outcomes while ensuring power was low enough in some scenarios to show variation between the methods and ensuring feasible computation time for a large number of simulations. We show results here for 100 individuals per cluster but found that using a higher number of individuals did not substantially affect the relative performance of different methods.
For each scenario, 1,000 data sets were simulated for each of three treatment effects: β = −0.2, β = −0.1, and β = 0. We do not present the results for the strong treatment effect (β = −0.2) here, as they are very similar to those for the moderate treatment effect (β = −0.1), but with such high power (all methods except NPWP over 90% in all scenarios) that it is hard to distinguish differences. A representative plot of cluster outcomes for each of the four scenarios with no treatment effect is given in Figure 2. If the probability of outcome for any cluster-period was less than 0 or greater than 1, it was truncated to 0 or 1, respectively. The number of simulations per scenario was chosen so that, for methods with a true Type I Error of 0.05, the empirical Type I Error will be between 0.037 and 0.064 with 95% probability. Similarly, for methods with a true confidence interval coverage of 95%, the empirical coverage will be between 93.6% and 96.3% with 95% probability. Code to generate and analyze the simulated data is available in the Supplemental Materials.
Figure 2.
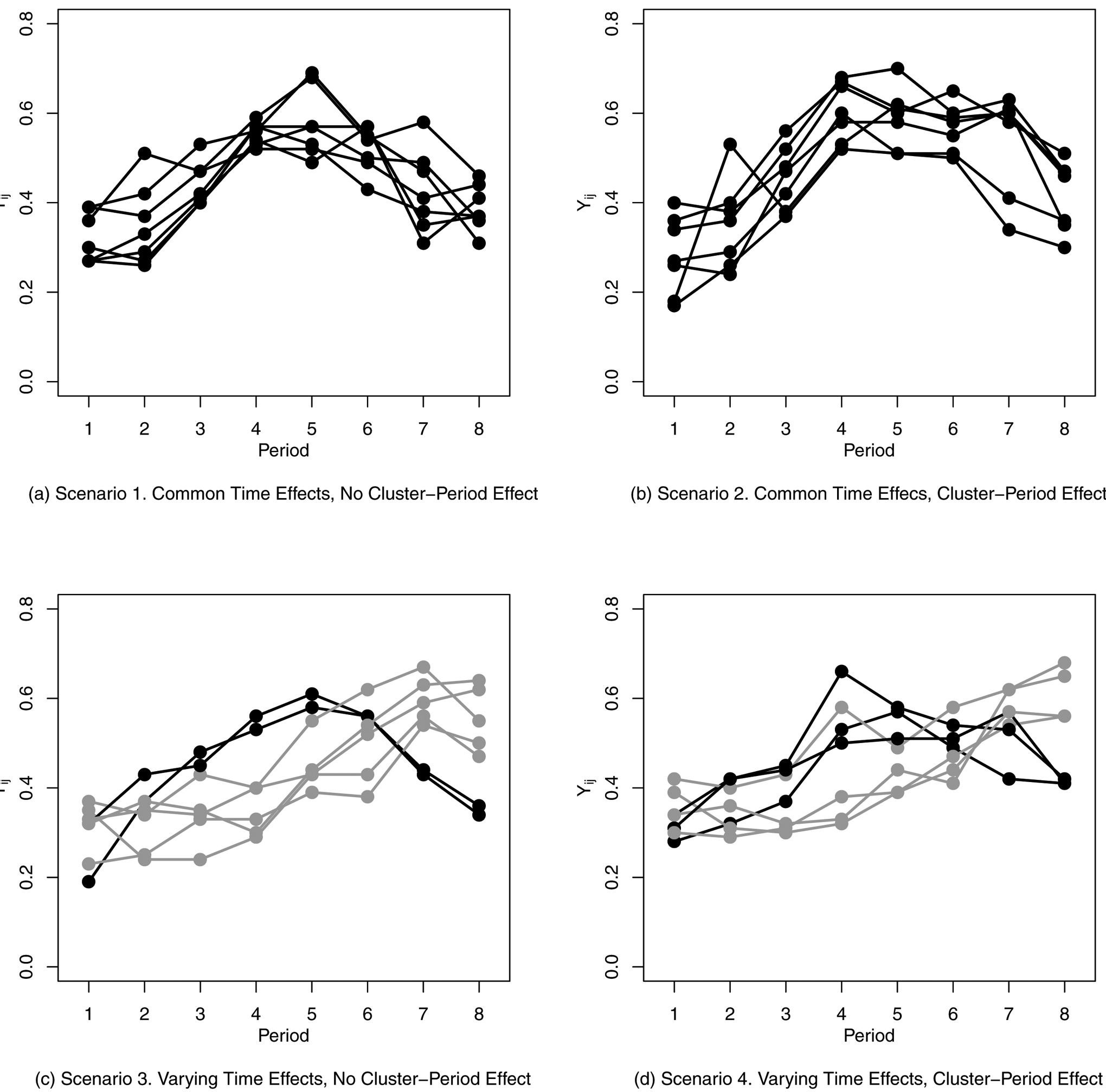
Sample Generated Data for Four Risk Difference Scenarios (Simulation 1) with No Treatment Effect. Each Line Represents the Simulated Cluster-Level Outcome for One Cluster over Eight Time Periods. Black Lines Represent Clusters with Time Effects θ = θ1 and Gray Lines Represent Clusters with Time Effects θ = θ2.
For each of the twelve scenarios, each data set was analyzed using the following methods: MEM, CPI, NPWP, SC-1, SC-2, CO-1, CO-2, CO-3, COSC, and ENS. Note that since only one cluster crosses over in each period, COSC-2 is equivalent to COSC-1; this is denoted COSC. The weights for SC-2 are calculated with inverse-MSPE weighting only within each intervention cluster but still differ from SC-1, which is equally weighted among all cluster-periods.
3.1.2. Simulation results
Figure 3 shows the mean effect estimate and 1/2-standard deviation of the effect estimates across the 1,000 simulations for each method for each scenario. The two subplots each show the scenarios for one treatment effect, with Scenario 1 at the top and Scenario 4 at the bottom of each plot. For all of the settings, all of the methods exhibit little overall bias, with the average estimate for each method within 0.005 of the true effect in each scenario. As expected given that all four scenarios meet the assumptions of Corollary 2 and Theorem 3, SC-1, CO-1, and CO-2 appear to be unbiased in the simulations. As noted by Thompson et al.,41 the nonparametric estimator NPWP must also be unbiased in all scenarios. Despite the misspecification of MEM and CPI in scenarios 3 and 4, they nonetheless result in unbiased estimators, albeit with wider empirical variance. And SC-2 appears unbiased in these simulations as well, despite its not meeting the conditions of Corollary 2. The variability of the effect estimates varies a great deal by method, with the MEM and CPI methods exhibiting the least variability when the time effects do not vary, and the CO and ENS methods exhibiting the least variability when the time effects do vary. Figure 4 shows the Type I Error (probability of finding a significant treatment effect when β = 0) for each analysis method under each scenario. All of the methods are close to the nominal Type I Error of 5% with the exception of asymptotic inference for the MEM and CPI methods when the time effects vary. All of the exact inference methods also achieve the nominal coverage in 95% confidence intervals, as shown in Figure 5. When the time effects do not vary, the MEM and CPI methods with asymptotic inference also achieve or nearly achieve the nominal coverage; when the time effects do vary, they both have less than 90% coverage. Even though MEM is misspecified in scenario 2, with fixed time effects but a non-zero random cluster-period effect, it still achieves nominal Type I Error and confidence interval coverage. This is likely due to the fact that the magnitude of the cluster-period effect is small compared to the treatment effect and random cluster effect. A model with a larger departure from the assumptions may lead to improper inference for this method.
Figure 3.
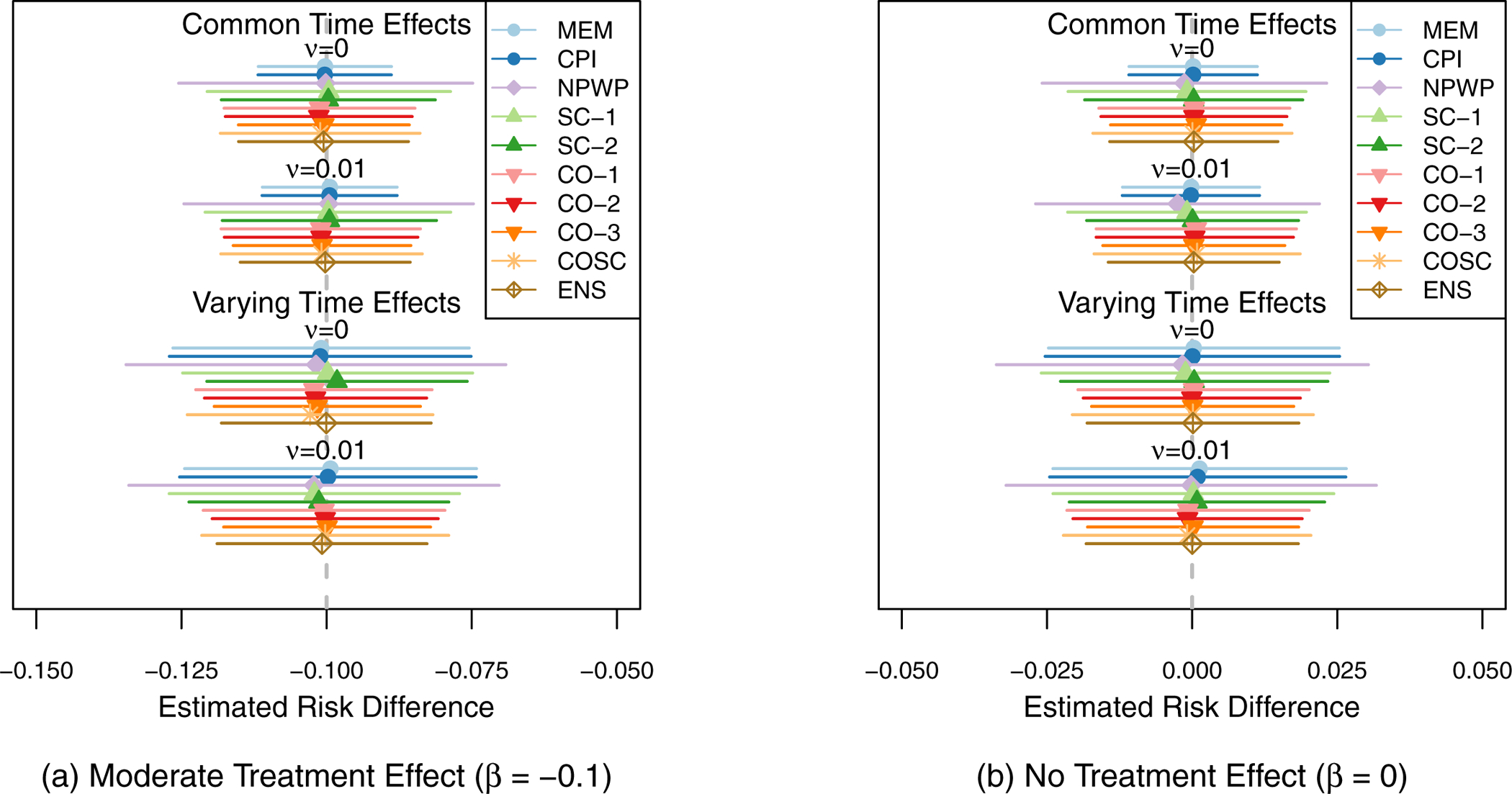
Mean Treatment Effect Estimates and 1/2-Standard Deviation of Estimates across 1,000 Simulations for Risk Difference Scenarios (Simulation 1) by Analysis Method.
Figure 4.
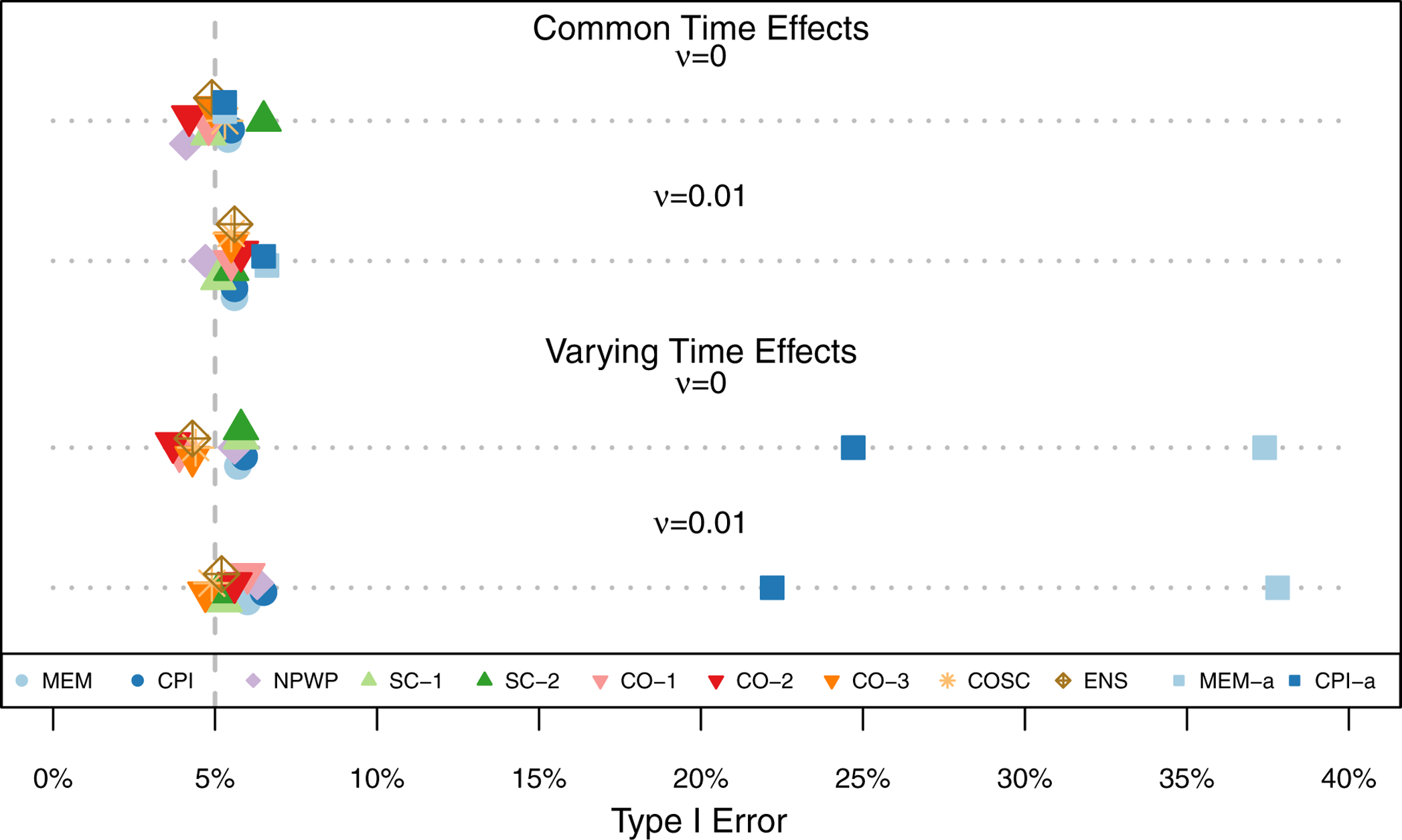
Type I Error Rate across 1,000 Simulations for Risk Difference Scenarios (Simulation 1) by Analysis Method.
Figure 5.
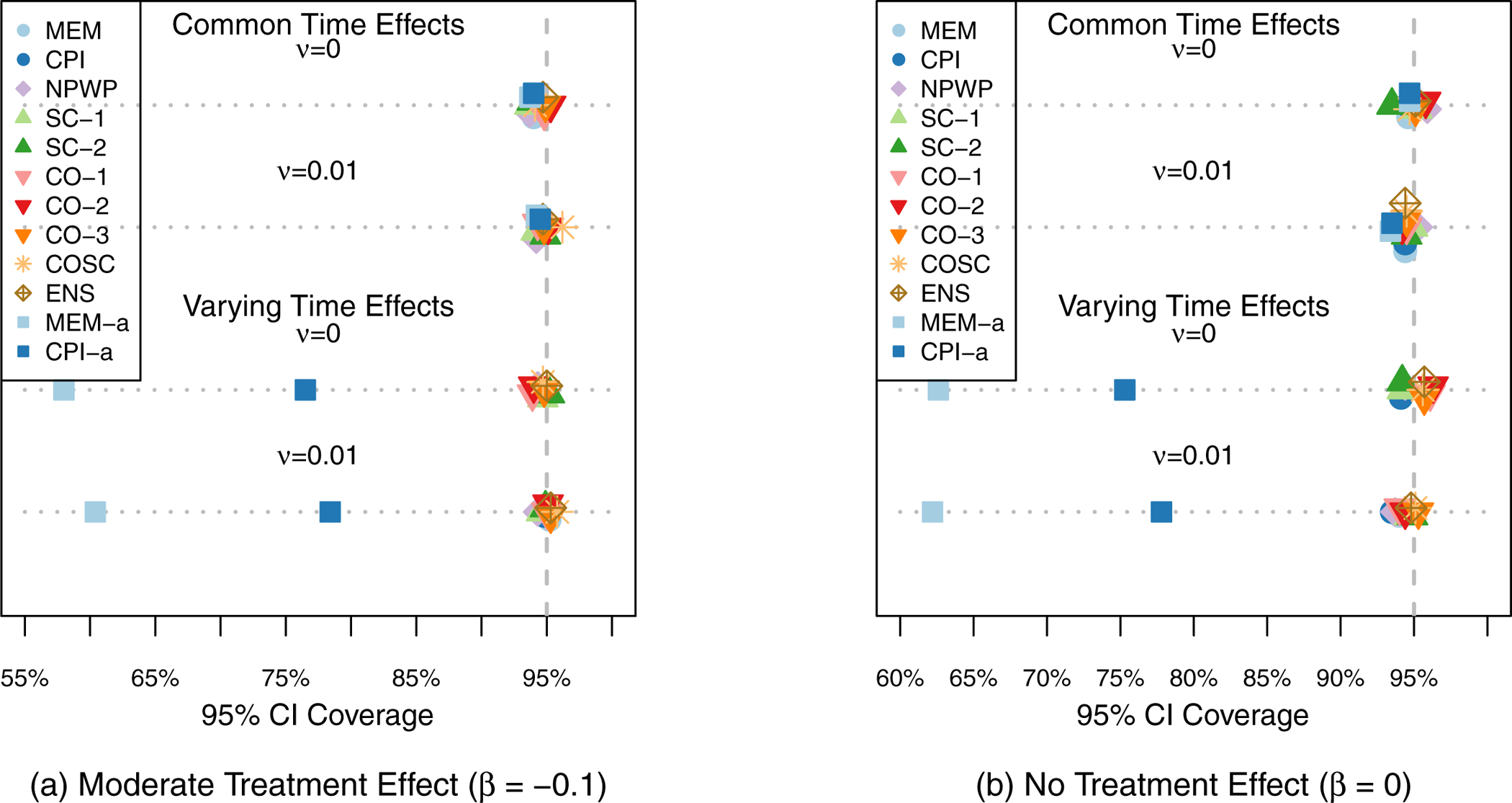
95% Confidence Interval Coverage Rate across 1,000 Simulations for Risk Difference Scenarios (Simulation 1) by Analysis Method.
Figure 6 shows the power (estimated probability of finding a significant treatment effect at the 5% significance level) for each analysis method under each scenario for the moderate treatment effect (β = −0.1). The asymptotic inference MEM and CPI results are not shown when the time effects vary as they have inflated Type I Error. The MEM and CPI (exact or asymptotic inference) methods have the highest power when the time effects do not vary. When the time effects do vary, the CO and ENS methods perform the best among the exact inference methods, followed by the COSC, SC, MEM, and CPI methods. The NPWP method has the least power. As expected with weights selected to reduce variance, CO-2 outperforms CO-1 and SC-2 outperforms SC-1. These differences, however, are smaller than the differences between classes of methods. These results are also shown in Table C1 in Appendix C.
Figure 6.
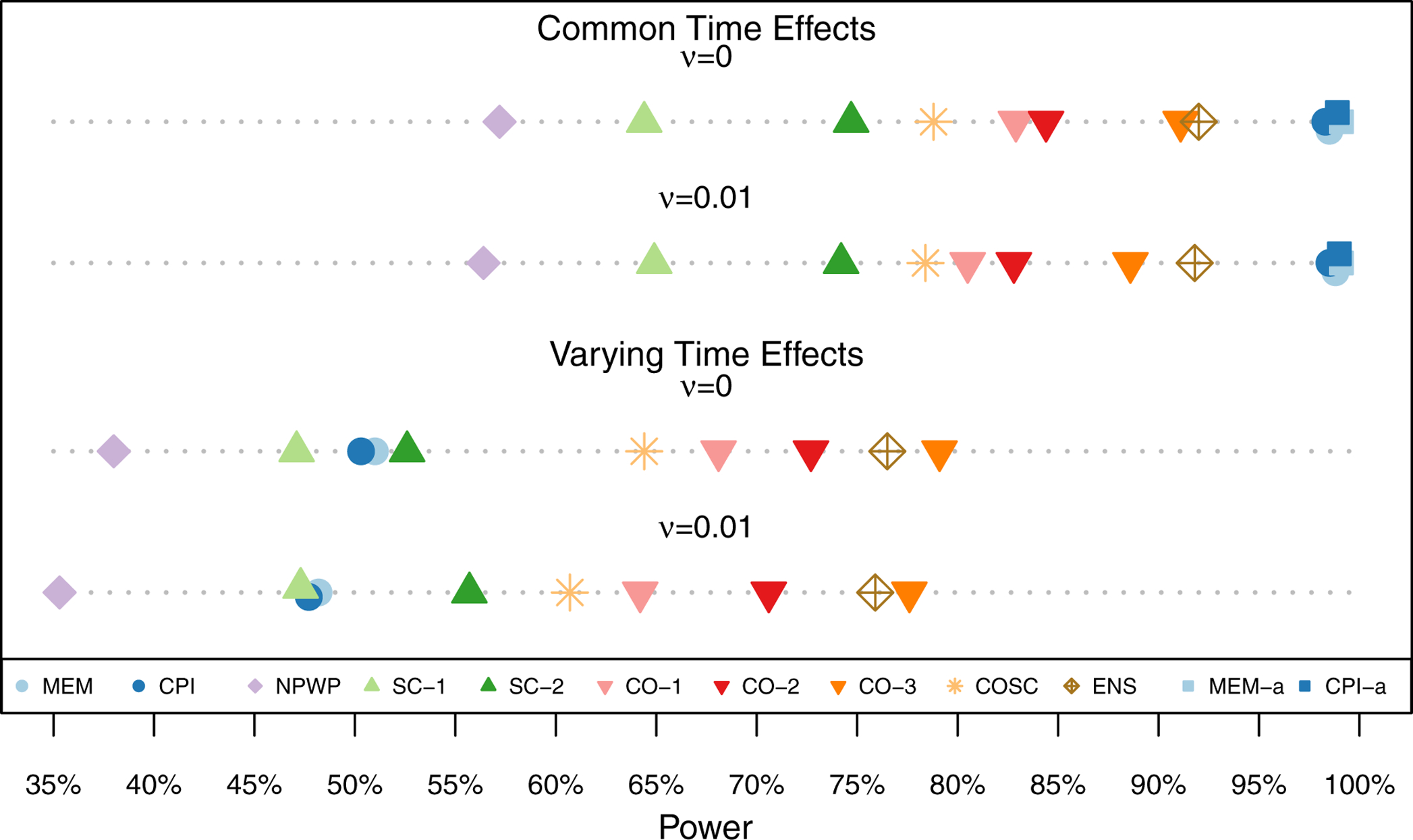
Power across 1,000 Simulations for Risk Difference Scenarios (Simulation 1) with Moderate Treatment Effect (β = −0.1) by Analysis Method.
3.2 |. Simulation 2: odds ratio
3.2.1 |. Setting and parameters
We consider now a setting where the odds ratio is the contrast of interest. There are again I = 7 clusters and J = 8 time periods, with one cluster beginning treatment in each of periods 2 through 8. At each cluster-period, K = 100 individuals are sampled. The data are generated from a mixed effects model similar to that in equation (2) with μ = logit(0.30) and τ = 0.1, with a logit link. We consider four scenarios:
Fixed time effects θ = θ1 ≡ log(1, 1.43, 2.15, 3.36, 3.50, 3.09, 2.33, 1.76) and no cluster-period effect (v = 0). The MEM model is correctly specified in this case.
Fixed time effects θ = θ1 and cluster-period effect with v = 0.01. The CPI model is correctly specified in this case.
Equal probability of each cluster having either the time effects θ1 or θ2 ≡ log(1, 1.10, 1.15, 1.37, 1.76, 2.24, 3.09, 3.50). No cluster-period effect (v = 0). Neither MEM nor CPI is correctly specified in this case.
Equal probability of each cluster having either the time effects θ1 or θ2. Cluster-period effect with ν = 0.01. Neither MEM nor CPI is correctly specified in this case.
For each scenario, 1,000 data sets were simulated for each of three treatment effects: β = log(0.50) ≈ −0.693, β = log(0.66) ≈ −0.416, and β = log(1) = 0. Again, we do not present the results for the strong treatment effect as they are very similar to those for the moderate treatment effect, but with such high power as to make comparisons difficult. These parameters were chosen to give similar outcome probabilities under control as in Simulation 1, but specified on the log-odds ratio scale. A representative plot of cluster outcomes for each of the four scenarios with no treatment effect is given in Figure 7. Code to generate and analyze the simulated data is available in the Supplemental Materials. For each of the twelve scenarios, each data set was analyzed using the same set of methods as in the previous section.
Figure 7.
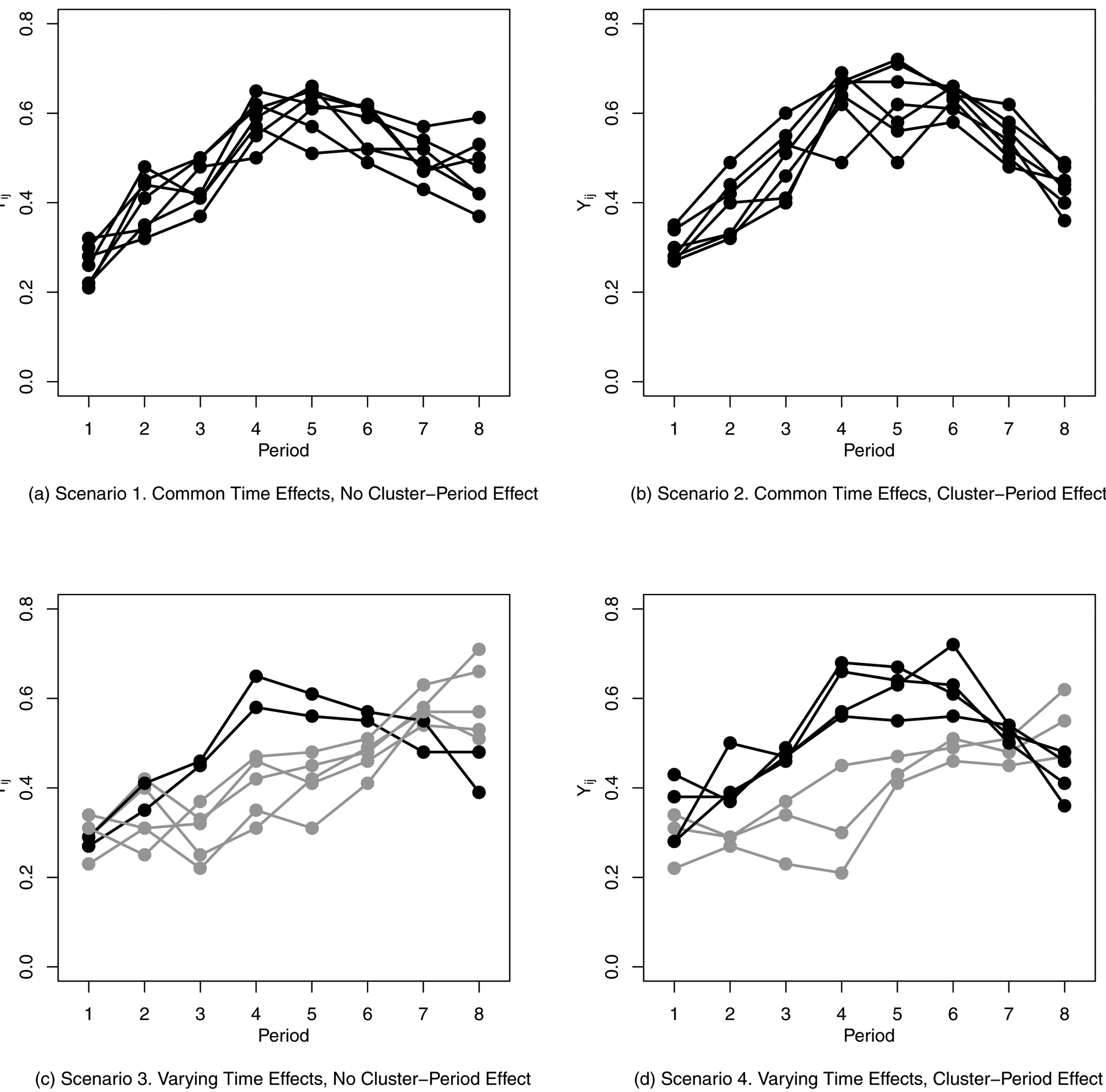
Sample Generated Data for Four Odds Ratio Scenarios (Simulation 2) with No Treatment Effect. Each Line Represents the Simulated Cluster-Level Outcome for One Cluster over Eight Time Periods. Black Lines Represent Clusters with Time Effects θ = θ1 and Gray Lines Represent Clusters with Time Effects θ = θ2
3.2.2. Simulation results
The same set of results are shown as for the risk difference simulations, in Figures 8, 9, 10, and 11, and in Table C2 in Appendix C. For all of the settings, all of the methods exhibit little overall bias, with the average estimate for each method within 0.01 of the true effect in each scenario. Thus, even without theoretical proofs of unbiasedness, in these simulated settings, the methods appear to give unbiased estimates. As in the risk difference setting, all of the methods are close to the nominal Type I Error of 5% and nominal 95% confidence interval coverage with the exception of asymptotic inference for the MEM and CPI methods when the time effects vary. Figure 11 shows the power for each analysis method under each scenario for the moderate treatment effect (β= log(0.66) ≈ −0.416). The asymptotic inference MEM and CPI results are not shown when the time effects vary as they have inflated Type I Error. The MEM and CPI (exact or asymptotic inference) methods have the highest power when the time effects do not vary, but there is relatively little loss of power for the ENS, SC, and CO-3 methods. When the time effects do vary, the ENS method performs the best among the exact inference methods, followed by the CO-3 method, the SC and other CO methods, and then the COSC method. The NPWP and exact inference MEM and CPI methods have the least power.
Figure 8.
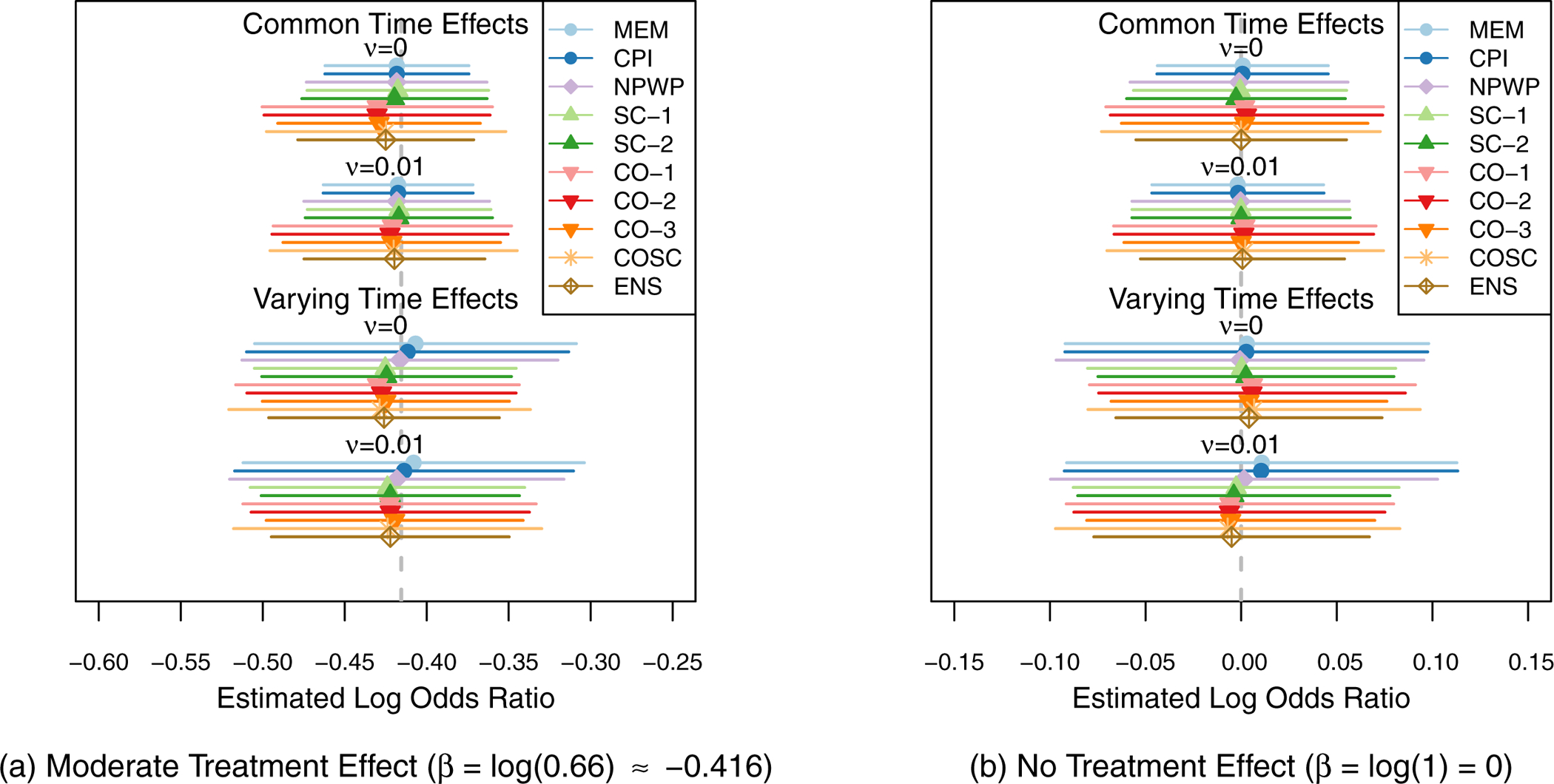
Mean Treatment Effect Estimates and 1/2-Standard Deviation of Estimates across 1,000 Simulations for Odds Ratio Scenarios (Simulation 2) by Analysis Method.
Figure 9.
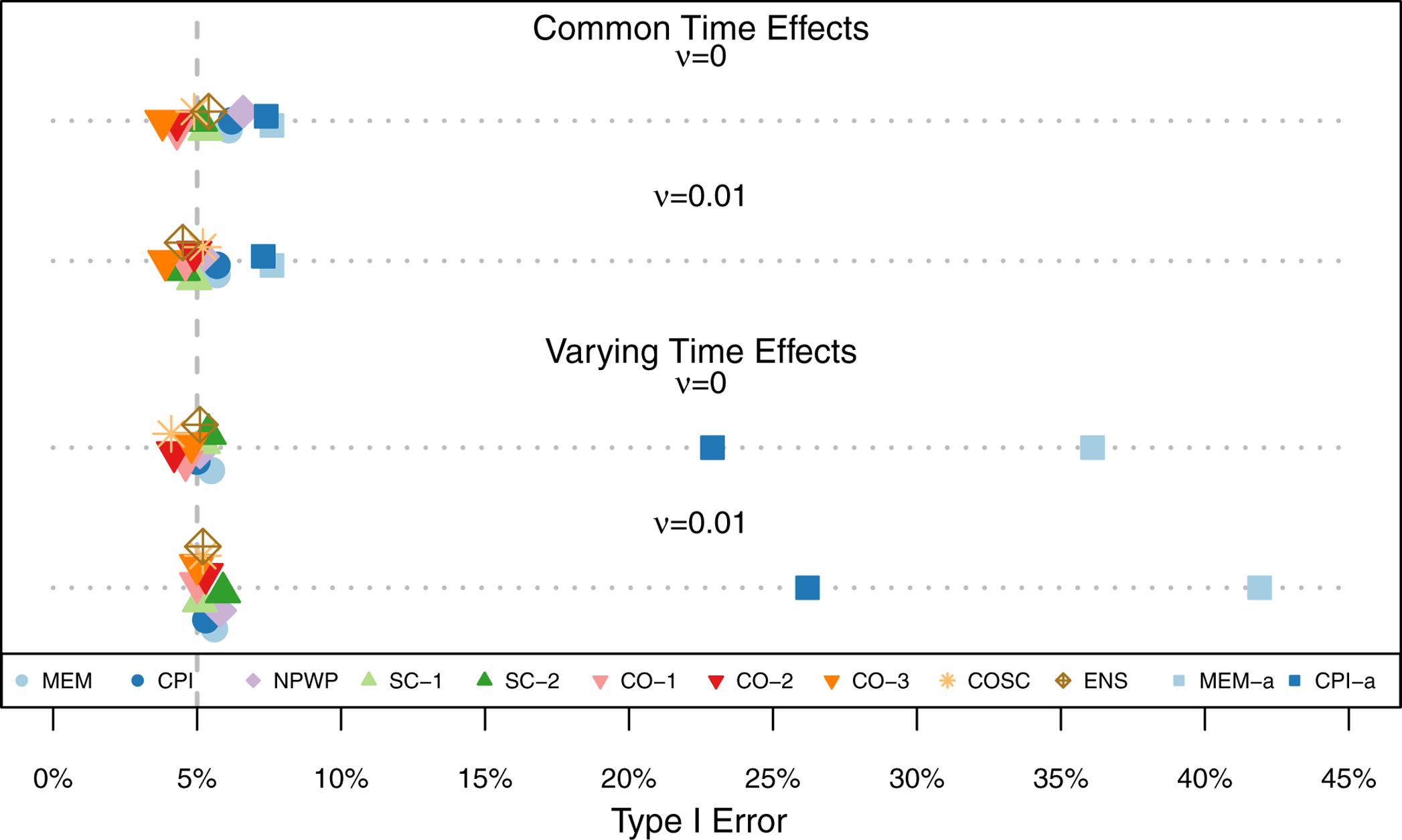
Type I Error Rate across 1,000 Simulations for Odds Ratio Scenarios (Simulation 2) by Analysis Method.
Figure 10.
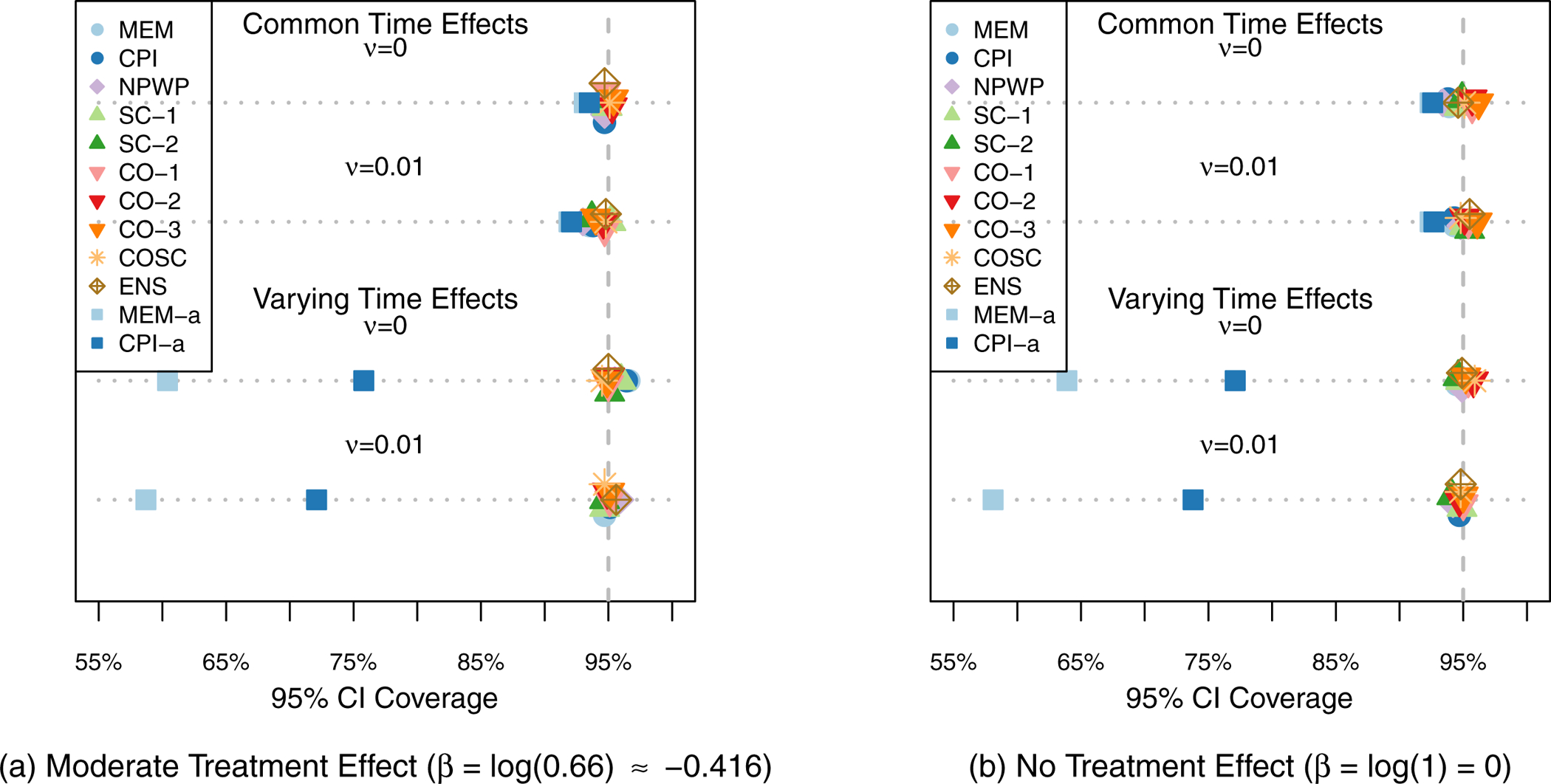
95% Confidence Interval Coverage Rate across 1,000 Simulations for Odds Ratio Scenarios (Simulation 2) by Analysis Method.
Figure 11.
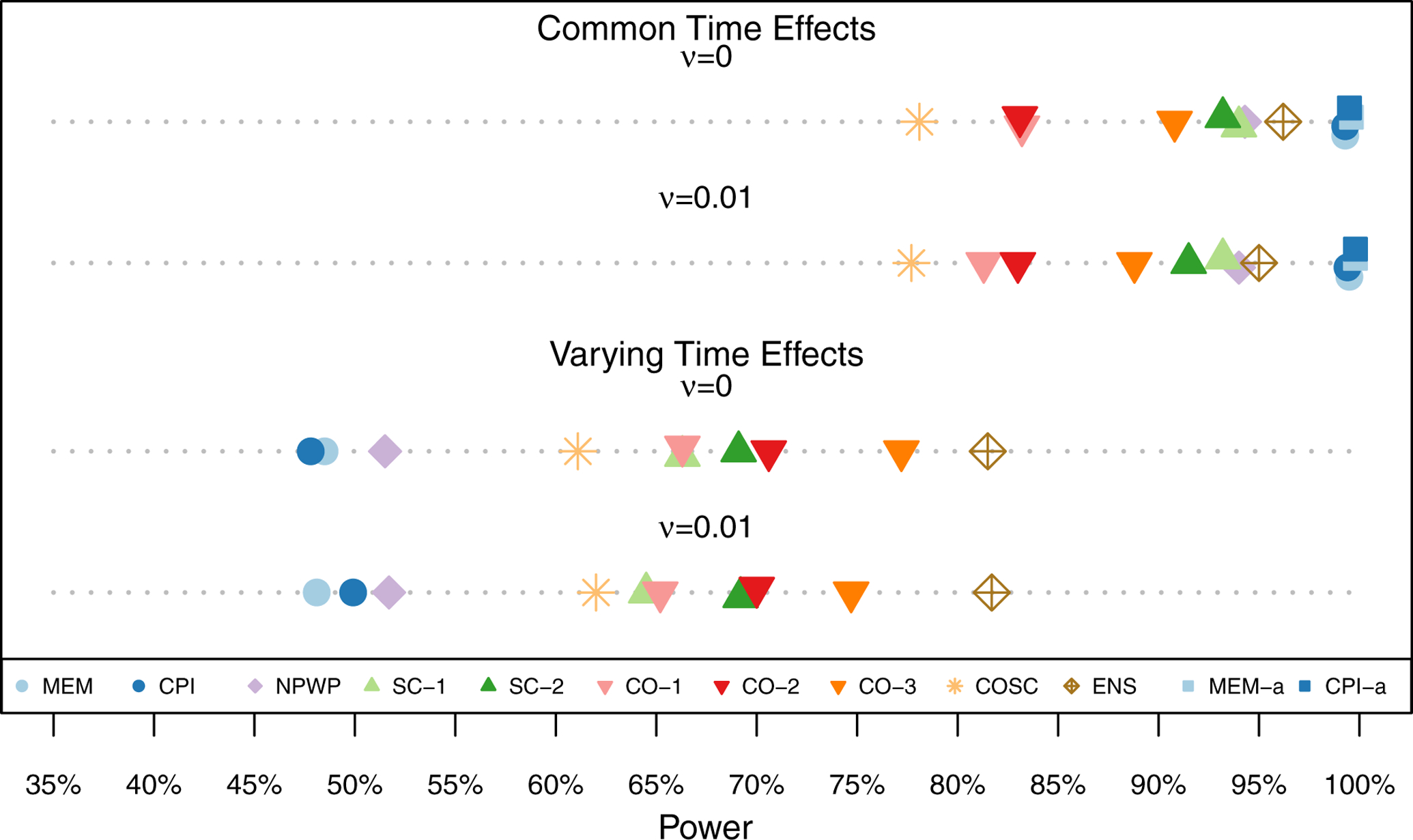
Power across 1,000 Simulations for Odds Ratio Scenarios (Simulation 2) with Moderate Treatment Effect (β = log(0.66) ≈ −0.416) by Analysis Method.
These results are largely similar to those seen in Simulation 1. This suggests that the contrast of interest is less important to the relative performance of these methods than the underlying distribution of the data.
3.3. Variance and covariance of estimators
To assess the variability between methods for a given instance of analysis, we determined the pairwise correlation for each pair of methods across the simulated settings. Within each data-generating setting, we found the correlation between methods across all 1,000 simulations. As a representative example of these correlations, we take scenario 4, the scenario with the most complex data-generating process, under the null hypothesis of no treatment effect, for both Simulation 1 and Simulation 2. The correlations are displayed in the heat map shown in Figure 12 for the risk difference (Simulation 1) and in Figure 13 for the odds ratio (Simulation 2).
Figure 12.
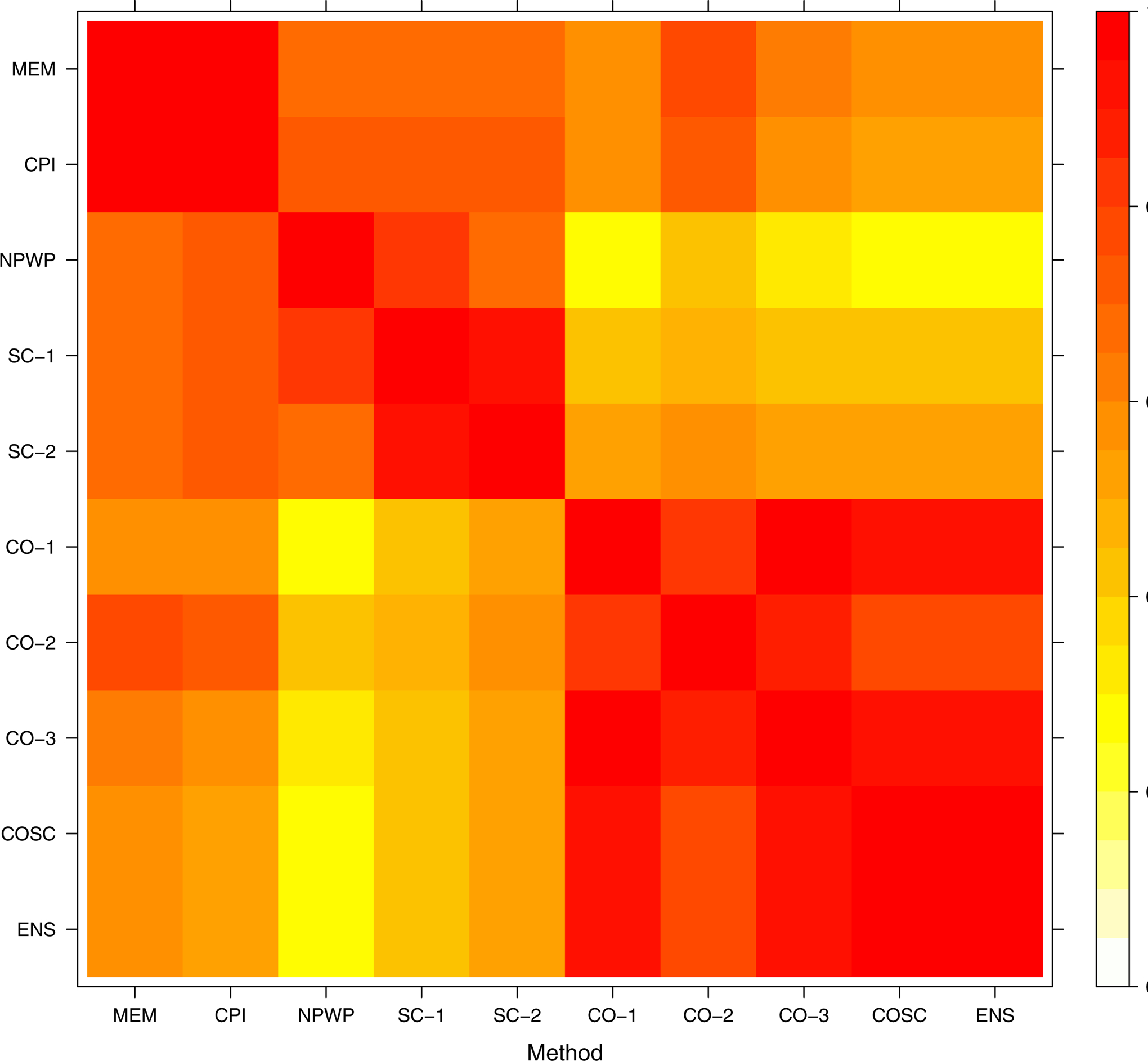
Pairwise Correlations between Effect Estimates from Different Methods: Simulation 1 (Risk Difference), Scenario 4, No Treatment Effect.
Figure 13.
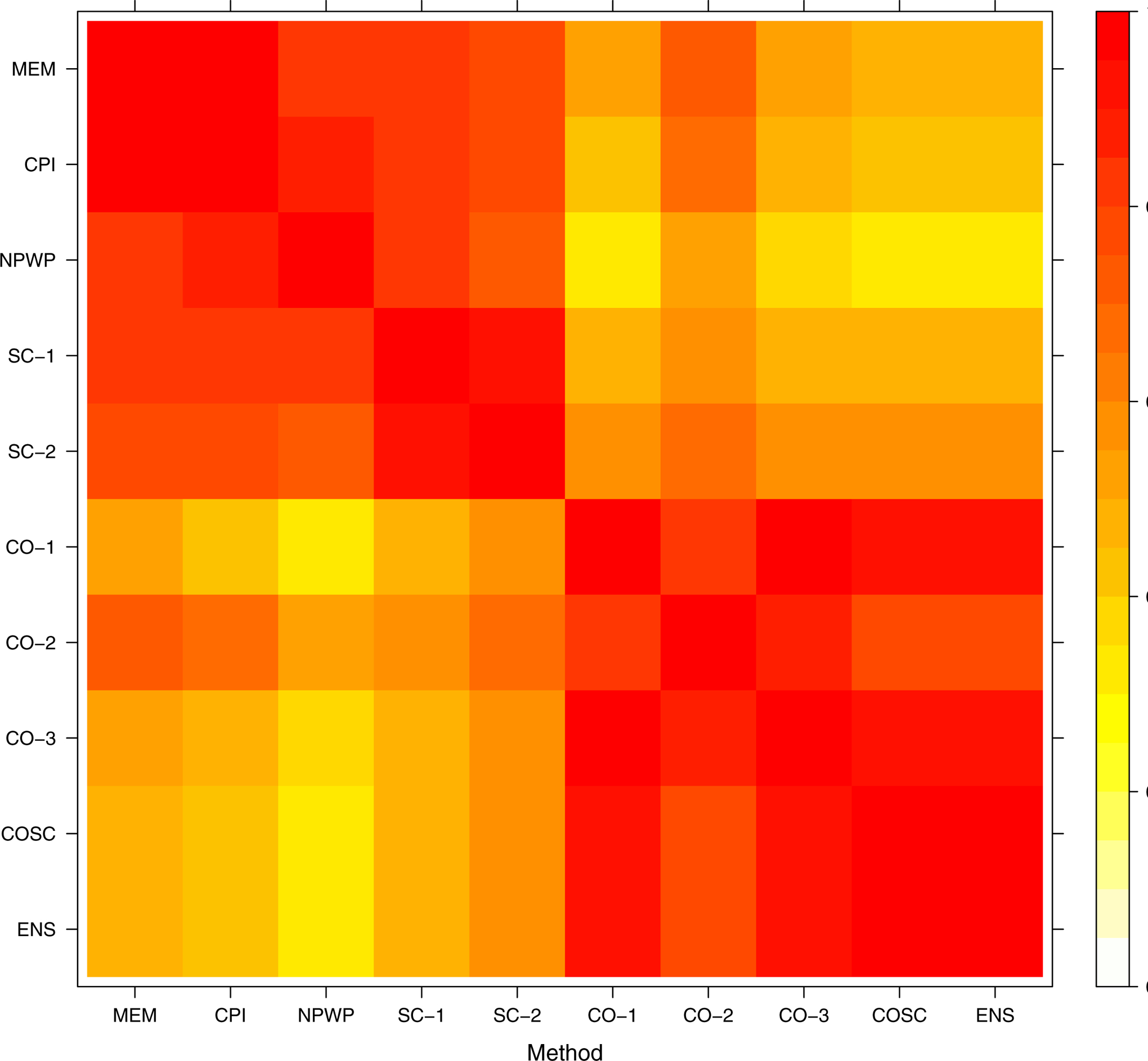
Pairwise Correlations between Effect Estimates from Different Methods: Simulation 2 (Odds Ratio), Scenario 4, No Treatment Effect.
These results indicate rather high correlations within classes of methods; that is, the mixed effects model methods are highly correlated with one another, the synthetic control methods are highly correlated with one another, and the crossover methods (including COSC) are highly correlated with one another. NPWP is correlated with the mixed effects model methods and the SC methods.
The least correlation occurs between the NPWP method and any of the CO-based methods, followed by the correlations between any mixed effects or SC method and the CO methods. This suggests that using an ensemble method combining an SC method and a CO method is indeed valuable here as the low correlation may lead to a covariance that is lower than the variance of either method individually. This corresponds with the increased power for the ENS method compared with SC-2 and CO-2 seen in the previous sections. Multiplying by the square root of the empirical variances gives the covariance; the ENS method has relatively low, equal covariance with the other methods. This suggests there is little to be gained in this setting by more complex ensemble methods.
3.4. Application to tuberculosis SW-CRT
We applied the methods discussed here to a SW-CRT that assessed the effect of a tuberculosis (TB) diagnostic test on reducing unsuccessful (non-cure) outcomes of adults on TB treatment.46 Note that this is the same trial re-analyzed by Thompson et al. using the within-period methods they proposed.41
3.4.1. Trial description
In this study, Trajman et al. conducted a SW-CRT in fourteen laboratories in the Brazilian cities of Rio de Janeiro and Manaus. While in the control arm, the labs diagnosed TB using two-sample sputum smear microscopy; in the intervention arm, diagnosis and first-line evaluation of potential drug resistance was by a single sputum sample XpertMTB/RIF assay. Data were collected on individuals diagnosed with TB in eight months in 2012 in the clinics associated with these laboratories. In the first month, all labs were in the control arm. In each subsequent month, two labs were switched to the intervention arm. In the final month, all labs were in the intervention arm.58
The outcome of interest was the proportion of unfavorable TB treatment outcomes, where unfavorable outcomes are defined as: loss to follow-up, TB-attributed death, death from other causes, change of diagnosis, transfer out (including to specialized clinics for management of drug-resistant TB or drug intolerance), and suspicion of drug resistance. In total, the trial analyzed the intervention and outcome status of 3,924 patients.46
3.4.2. Goodness of fit of mixed effects models
Before analyzing these data using non-parametric approaches, we consider the goodness of fit of the mixed effects models. We fit both the MEM and CPI models, as usual assuming independent normally-distributed random effects. In this case, the CPI model yields nearly the same fitted values as the MEM model, so we consider only the MEM model from this point. A variety of methods have been proposed to assess the assumption of independent normally-distributed random effects.59–65 We use several of these methods to assess the assumption in this case; details are in Appendix D. Some methods indicate a violation of the assumption and others do not, but caution should be exercised in interpreting these results as diagnostic tests may not be powerful or reliable for such a small number of clusters.66 Because of the potential of model misspecification, we proceed with the non-parametric analyses.
3.4.3. Results
The primary analysis conducted by Trajman et al., which did not adjust for time effects, found a decrease in the number of events (unsuccessful outcomes) in the intervention arm compared to the control arm, although this decrease was not statistically significant at the 0.05 level.46 Re-analyzing the data using the NPWP method, Thompson et al. found a statistically significant decrease on both the odds ratio and risk difference scales.41
We analyzed these data using all of the methods described here using both the risk difference and log odds ratio contrasts; all exact inference methods use 500 permutations. Note that the NPWP method corresponds to that used by Thompson et al. for the risk difference scale. There is a slight discrepancy on the odds ratio scale, since Thompson et al. estimate the within-period contrast by comparing the mean log odds among the intervention clusters to the mean log odds among the control clusters, while we estimate that contrast by applying the log odds ratio contrast to the mean cluster-level outcome among the intervention clusters and among the control clusters.41 In both cases, inference may differ slightly because of the stochasticity in the permutation-based inference. This stochasticity, as well as the difference of calculating under the alternative hypothesis rather than the null, can also lead to confidence intervals including the null when the hypothesis test rejects the null and vice versa. Also note that since there are two clusters which cross over at each time period, COSC-1 and COSC-2 yield different results. The results, reported on the risk difference scale and the odds ratio scale, are summarized in Table 1.
TABLE 1.
Results from SW-CRT of diagnostic method on rates of unfavorable TB treatment outcomes in Brazil, by analysis method
| Risk Difference | Odds Ratio | |||||
|---|---|---|---|---|---|---|
| Method | Estimate | 95% Conf. Int. | p | Estimate | 95% Conf. Int. | p |
| MEM/CPI | −3.59% | (−8.9%, 1.4%) | 0.126 | 0.835 | (0.66, 1.07) | 0.104 |
| MEM/CPI-a | −3.59% | (−8.4%, 1.1%) | 0.105 | 0.835 | (0.66, 1.05) | 0.091 |
| NPWP | −4.83% | (−10.1%, 0.1%) | 0.050 | 0.794 | (0.61, 0.99) | 0.046 |
| SC-1 | −7.28% | (−18.2%, 1.0%) | 0.084 | 0.703 | (0.44, 1.04) | 0.066 |
| SC-2 | −8.29% | (−18.3%, 1.1%) | 0.080 | 0.675 | (0.43, 1.07) | 0.082 |
| CO-1 | −7.34% | (−14.5%, 0.5%) | 0.064 | 0.703 | (0.49, 1.04) | 0.046 |
| CO-2 | −6.97% | (−14.0%, 0.5%) | 0.052 | 0.717 | (0.50, 1.03) | 0.054 |
| CO-3 | −7.00% | (−14.0%, 0.0%) | 0.050 | 0.721 | (0.51, 1.00) | 0.036 |
| COSC-1 | −7.01% | (−15.5%, 1.1%) | 0.078 | 0.728 | (0.49, 1.10) | 0.118 |
| COSC-2 | −5.12% | (−14.7%, 4.5%) | 0.242 | 0.784 | (0.50, 1.18) | 0.222 |
| ENS | −7.63% | (−15.0%, −0.6%) | 0.036 | 0.696 | (0.49, 0.95) | 0.032 |
The novel methods identify a stronger treatment effect than do the model-based and NPWP methods. As Thompson et al. show, the NPWP method here places a large amount of weight on the contrast in the fifth period, which has a modest (−2.23%) effect.27 This attenuates the effect compared to, for example, CO-1, which equally weights contrasts in different periods. It also, however, reduces the variance of the overall estimator, thus yielding a lower p-value for the NPWP method than the CO methods which use the control crossovers only. The COSC methods do not appear to give more precision than the CO methods, but yield similar effect estimates. On both scales, the ENS method yields the lowest p-values, as it detects a strong effect and has more precision than the other novel methods. All of the results suggest a protective effect of the intervention, with the novel methods detecting a larger effect but with more uncertainty, and the NPWP method estimating a narrower confidence interval of smaller effect sizes. This example clearly shows how the choice of analysis method can have a substantial impact on the estimation and inference made on a given data set, based on the assumptions of the methods and their operating characteristics in the specific data-generating setting.
4. DISCUSSION
These results demonstrate the potential of analytic methods for SW-CRTs that do not rely on parametric modeling of secular trends for validity. These methods achieve greater power than the purely vertical within-period method by using the history of outcomes within each cluster inherently collected in a SW-CRT to match the most similar clusters or by using horizontal, within-cluster information. In the simulation settings used here, when the mixed effects models were misspecified, an ensemble method that averaged the crossover method and the synthetic control method had the highest power to detect a true treatment effect, followed by the crossover method. Further research is needed to determine in which settings each of these methods is likely to perform the best, and which of the possible ensemble methods may perform the best in which settings. These results demonstrate that this simple ensemble method may in some settings perform better, but not uniformly; nor is it necessarily the most powerful ensemble method in any setting. The potential for incorporating measured covariates or stratified randomization into the SC method may also lead to increased power in some situations.
While these methods are valuable and in general rely on weaker assumptions than do mixed effects methods for unbiasedness, they are still not as powerful as parametric mixed effects methods when the modeling assumptions are met. Investigators and analysts must assess when assumptions are likely to be met; additional research is needed to ascertain when non-parametric methods are required to accommodate secular trends that may arise in particular research settings. Additionally, further work on using regression diagnostics to identify violations of modeling assumptions would be very valuable. Investigators should consider exact inference on parametric methods when the modeling assumptions of mixed effects methods are likely to nearly hold and the non-parametric methods when the secular trends are unknown or the modeling assumptions methods are likely to be strongly violated. Caution should be exercised regarding the SC methods as well when the underlying data distribution is unlikely to be symmetric or asymptotically symmetric.
As can be seen in variability in estimates across methods, with relatively few clusters, the estimation can be very sensitive to the analysis method and even to the selection of the weighting scheme. The performance of any method in one particular analysis of a trial may not reflect its overall operating characteristics. The specific settings where the estimators depend heavily on certain cluster-periods and the impact that has on operating characteristics deserve more scrutiny. Again, this is an area where methods that equally weight clusters or periods, including specifically constructed ensemble methods, may prove useful in mitigating high dependence on specific cluster-periods by certain methods.
The methods presented here also provide advantages in interpretability and flexibility. When the treatment effect is not constant across clusters or across time periods, the mixed effects model estimate for nonlinear link functions is a conditional parameter, and its interpretation can be unclear.67 For linear link functions, the mixed effects model estimate is a weighted average intervention effect that depends on the form of the treatment effect, including any treatment-time interactions or random treatment-by-cluster effects.26 With the non-parametric methods, using equal weighting across clusters and periods, the estimate is easily interpreted as an average treatment effect across cluster-periods in the study. Other causal effects can be estimated using weights chosen to match the target parameter, depending on the effect of interest and assumptions the investigators are willing to make about generalizability to a separate target population. More work is needed to determine how to select weights that maximize efficiency for specific causal parameters that may be of common interest. For instance, if the effect of time on the intervention effect is known or a parametric form can be assumed, there may be an efficiency-maximizing weighting scheme.
When treatment effects are not instantaneous—common in settings where treatment effects vary over time—methods must be modified. Throughout this article, we have assumed that the full effect of treatment occurs during the first period of treatment and that there are no anticipation effects prior to that point. In practice, it may be desirable to account for a lag in, or gradual onset of, treatment effects resulting from logistical complexity in reaching everyone in the cluster or for the effect to reach its full strength.8,16 This can be incorporated into the SC methods by taking as the time of start of the intervention the time of completion of such a transition period. It can be incorporated into the CO methods by taking as the “crossover effect” the contrast between the first period after the transition and the last period prior to any anticipation effects. Achieving the same efficiency as would be achieved with a similar trial with no transition period may require more clusters or more time between successive cluster crossovers. All SW-CRT methods are sensitive to properly accounting for the transition period, but the CO methods are particularly sensitive because of their focus on the horizontal comparison. If the transition period length is unknown or likely to vary across clusters, the CO methods may not be appropriate.
The synthetic control method allows for additional flexibility and the potential for increased power and use in a wider variety of settings. As mentioned above, it can be useful when lagged treatment effects or time-varying treatment effects make a specific causal estimand more desirable as a target for inference. It also, as shown in the simulations here, can be a valuable part of an ensemble method that improves the power of an estimator. And for trials with more periods, or a longer pre-intervention history, the SC method itself may perform better. In general, it provides many of the advantages of the non-parametric within-period method while using a matching-like procedure to increase power. For the COSC method, the relatively poor performance in these simulation settings may stem from the fact that one period of history is lost by using the crossover estimator. With few periods, that can have a large effect on the power. Again, a longer pre-intervention history may improve the value of this method.
Additionally, more advanced techniques can be used to improve synthetic control matching and thus potentially improve the power of the SC and COSC methods. Synthetic controls can incorporate measured covariates to improve the matching.44,68 Moreover, new synthetic control algorithms and methodologies may also be useful in improving the matching and designing efficiency-maximizing weighting schemes. These include Bayesian synthetic control approaches,69,70 flexible non-parametric synthetic control,71 generalized synthetic control,72 and augmented synthetic control.73 The SC method, potentially incorporating these approaches to improve the causal inference component, may also provide a path for analysis of non-randomized studies that mimic stepped wedge trials, as the synthetic control may address confounding of treatment initiation. Further work is needed in this area to determine whether the stepped wedge trial design can be used as a target trial for causal inference from observational studies.74,75
More research, with specific simulation settings derived from representative trials in various domains, is necessary to determine the relative performance of these methods across a wide variety of settings. Various data-generating processes and assumptions about those processes—including specific non-normal random effects, different correlation structures, and treatment effects that vary by time or cluster—have been proposed in prior research on SW-CRTs.26,27,36,76 Some of these may be more reasonable in some individual fields than in others, and so research to determine which methods are best suited to specific SW-CRT settings, considering the outcome, cluster, and intervention of interest, would be very valuable. In addition, future work should consider appropriate sample size and power calculation approaches for these new methods. While the MEM method in the scenario where it is correctly specified here gives empirical power that matches the power predicted by analytic methods,15 this power calculation is clearly inadequate for the other methods and data scenarios, as they all suffer reduced power compared to the correctly specified MEM. Analytic formulae for specific common data-generating processes and simulation-based explorations of the power of these approaches are necessary future steps to improve the usability of novel and existing methods in a wider variety of settings. Understandings of sample size and power will also contribute to future work on the optimal design of SW-CRTs to be analyzed using different methods.77,78 For example, all of the novel methods presented here make use of information from the initial control period, while the NPWP method does not. This suggests that while the initial control period may be inefficient for existing methods,77,78 it may in fact be an efficient use of resources for novel methods.
These methods increase the number of analysis options available to investigators conducting stepped wedge cluster randomized trials. The SC method provides a semi-parametric option that relies on weaker assumptions about the underlying data-generating process than mixed effects models, while increasing power compared to the NPWP method, and it can be improved with advanced methods or with additional pre-intervention data. The CO method provides a non-parametric option with greatly improved power, although it relies on a constant treatment effect that appears very soon after treatment initiation. Variations of these methods and ensemble methods can also be used to target specific causal parameters and improve power in certain circumstances. Careful consideration is still required, however, to determine which analysis method is most appropriate for each individual circumstance, and more work is needed to clarify how to make that determination a priori or in a systematic way. Moreover, careful selection of analysis method does not alleviate all of the drawbacks and concerns about SW-CRTs and, as mentioned above, does not ensure ideal performance of any single analysis. Investigators should continue to select the appropriate trial design for each study, taking into account analysis methods, the target estimand, and power considerations, along with issues of logistical feasibility, ethics, risk-benefit profiles, and generalizability.
Supplementary Material
ACKNOWLEDGMENTS
The authors wish to thank the reviewers and editor for their helpful comments in improving this article. The authors also wish to thank Professor Michael D. Hughes for his valuable comments and feedback on the research at various stages. Finally, the authors wish to thank Professor Anete Trajman for making the data available from the stepped wedge cluster randomized trial described in Section 3.4, and Professor Jennifer Thompson for making the code available from her analysis of that trial.
Financial disclosure
Research reported in this publication was supported by the National Institute of Allergy and Infectious Diseases under Award Numbers 5T32AI007358-28 and 1F31AI147745 (for L.K.S.), and R3751164 (for V.d.G.); and National Institute of General Medical Sciences Award Number U54GM088558 (for M.L.).
Funding: National Institute of Allergy and Infectious Diseases Award Numbers 5T32AI007358-28 and 1F31AI147745 (for L.K.S.), and R3751164 (for V.d.G.); and National Institute of General Medical Sciences Award Number U54GM088558 (for M.L.).
APPENDIX
A. PROOFS OF THEOREMS
Theorem 1. Suppose that for each cluster i, denoting by ji the last period for which cluster i is on control, E[(Yi,1, Yi,2 …,Yi,j,i)] = (Y.1, Y.2, …, Y.ji) ≡ Y.ji and that the distribution of (Yi,1, Yi,2 … Yi,j,i) is symmetric about Y.ji. Suppose further that the cluster-level outcomes from two different clusters are uncorrelated conditional on the full vector of expected outcomes, Y.j, and the treatment effect β. Then, for any cluster i* in any period j* where that cluster is on intervention (j*>ji*), the synthetic control estimator Zi*,j* is an unbiased estimate of the marginal (across clusters) expectation for an untreated cluster in period j*. That is, E[Zi*,j*] = Y.j*.
Proof. Consider a target cluster i* and period j* such that Xi*,j* = 1. Let m1… ,mn* index the n* ≡ n0,j* clusters on control (“donor clusters”) in period j*. For any cluster i, define Yi,ji* ≡(Yi,1,…, Yi,ji*)T, where ji* is the last period for which cluster i* is on control (and thus ji* < j*). Denote the ji × n* matrix of pre-intervention donor cluster outcomes by Y ≡ (Ym1,ji*,…, Ymn*,ji*). Construct a ji* × n* matrix of pre-intervention target cluster outcomes by repeating the vector Yi*,ji* n* times Yi* ≡(Yi*,ji*,…, Yi*,ji*).
By definition of the synthetic control estimator, Zi*,j* The vector of these weights is denoted νi*,j* and lies in the set:
Note that for all Then We can Write
| (A1) |
where the difference matrix is :
By the symmetry and independence assumptions, for any n = 1, … ,n*, the distribution of Yi*,ji* are independent and both are symmetrically distributed with a common mean Y,ji*. Thus, each column of is symmetrically distributed with expectation 0 and hence the matrix is symmetrically distributed with expectation 0.
Moreover, for any n = 1, … ,n*, the distribution of Ymn,j* is only correlated with the nth column of Since is symmetrically distributed about (0, …, 0), the distribution of conditional on for any constants aj is equal to the distribution of conditional on Hence:
| (A2) |
for any difference matrix A
For any difference matrix A and any donor cluster mn, then:
| (A3) |
By equation (A1) and since for all is correlated with the outcome vector only through the element wise absolute value of . Hence, for any n =1,…,n*:
| (A4) |
And thus, denoting by νi*,j*,n the nth component of the vector vi*,j*:
| (A5) |
Corollary 1. Suppose that for each control cluster-period (i,j), the individual outcomes Yi,j,k are independent and identically distributed, conditional on the cluster and period, with expectation Y′i,j and finite variance. Suppose further that the Y′i,j values satisfy the conditions in Theorem 1; that is, they are symmetrically distributed about some common expectation vector Y.J and each cluster’s values are independent of the values from all other clusters. Then the synthetic control estimator Zi*j* for any cluster i* in any period j* where that cluster is on intervention is an asymptotically (with respect to the number of individuals in each cluster) unbiased estimate of Y.j*.
Proof. If the individual outcomes are independent and identically distributed with expectation Y′i,j, and finite variance, then, by the Central Limit Theorem, the mean outcome Yi,j, for each control cluster-period is asymptotically (with respect to the number of individuals in each cluster) normally distributed with expectation Y′i,j and finite variance. Thus, for any cluster i, we can write the distribution of the vector of pre-intervention cluster-level outcomes, as:
| (A6) |
where for some finite , and the Bi,j are mutually independent. Since the Bi,j are normally (and hence symmetrically) distributed, the limiting distribution of (Yi,1,…,Yi,j,i) is symmetric about (Y1,…,Yji) by the assumption on Y′i,j. Moreover, since the individual outcomes are independent conditional on the cluster-period mean and the cluster means are independent by assumption for any i ≠ i′.
Because of this asymptotic symmetry, for any target cluster-period (i*,j*) where Xi*,j*= 1, for any difference matrix A:
| (A7) |
where . Additionally, by this symmetry, for any donor cluster mn ∈ {m1,…,mn*}(defined as in Theorem 1):
| (A8) |
Thus, for any difference matrix A:
And so for any difference matrix A for any n = 1, … ,n*:
| (A9) |
Following the steps in the proof of Theorem 1, and using the properties of convergence, then, for any n= 1, … ,n*:
| (A10) |
and thus, using that :
| (A11) |
Hence, for any cluster i*and period j* where Xi*,j*= 1, Zi,j is an asymptotically unbiased estimate of Y.j*.
Theorem 2. Assume that the assumptions of Theorem 1 are met and that for any intervention cluster-period (i,j), E[Yi,j]= Y.j + β Then for the risk difference function, g(y1,y2) = y1–y2, the synthetic control estimator with weights wi,j independent of the outcomes is an unbiased estimate of β
Proof. By Theorem 1, for any target cluster-period (i,j) such that Xi,j= 1, E[Zi,j] = Y.j (note that we have dropped the i*,j* notation for simplicity). Thus:
| (A12) |
Corollary 2. Assume that the assumptions of Corollary 1 are met and that for any intervention cluster-period (i,j), E[Yi,j]= Y.j + β Then for the risk difference function, g(y1,y2) = y1–y2, the synthetic control estimator β with weights wi,j independent of the outcomes is an asymptotically (with respect to the number of individuals in each cluster) unbiased estimate of β.
Proof. By Corollary 1, for any target cluster-period (i,j) such that Xi,j= 1, (again dropping the i*, j* notation). Thus:
| (A13) |
Thus is an asymptotically unbiased estimate of β.
Theorem 3. Assume that there is a constant risk difference β due to treatment across clusters and periods; that is, E[Yi,j|Xi,j =1]=E[Yi,j | Xi,j = 0] + β for all i,j Then for any weights wj that are independent of th e outcomes Yi,j, the crossover estimators and using the risk difference function, g(y1,y2),= y1 – y2 are unbiased estimates of β. That is
Proof. We denote by Y.j the expectation (marginal across clusters) of the outcome of any cluster on control in period j. By the assumptions, for all j > 1:
| (A14) |
| (A15) |
| (A16) |
Define θ′j = Y.j − Y.j-1 for all j > 1. Then:
| (A17) |
| (A18) |
Now, for any weights wjthat are independent of the outcomes:
| (A19) |
| (A20) |
So as desired,
Corollary 3. Assume that there is a constant risk difference β due to treatment in the first period on treatment across clusters; that is E[Yi,j| Xi,j = 1 ⋂ Xi,j-1 = 0] = E[Yi,j| Xi,j = 0] +β for all i,j Then for any weights w,j that are independent of the outcomes Yi,j, the crossover estimator using the risk difference function, g(y1,y2),= y1 – y2, is an unbiased estimate of β. That is,
Proof. Again, we denote by Y.j the expectation (marginal across clusters) of the outcome of any cluster on control in period j. By the assumptions, for all j > 1:
| (A21) |
| (A22) |
Define θ′j = Y.j Y.j-1 for all j > 1. Then:
| (A23) |
Now, for any weights wj that are independent of the outcomes, by equation (A23):
| (A24) |
So as desired, .
Remark 1. Since depends only on E[Di,j| i ∈ I1,j] and E[Di,j| i ∈ I0,j] it requires only the weaker assumption of Corollary 3 to be unbiased, while requires the stronger assumption given in Theorem 3.
Remark 2. Specifically, equal weighting and the weights wj and w′j given in Section 2.4.4 are independent of the outcomes Yi,j and thus result in unbiased estimates if the other conditions of Theorem 3 are met.
Footnotes
Conflict of interest
The authors declare no potential conflicts of interest.
Data availability
R code that implements the methods detailed in this article is available in the online Supporting Information. This code is being updated to improve usability and reduce computing time. The latest version is available at https://github.com/leekshaffer/SW-CRT-analysis. The data for the analysis in Section 3.4 is from Trajman et al. 2015 and was provided to the authors of this article by Professor Trajman.46
Supporting information
The following supporting information is available as part of the online article:
Appendix B. Variance and covariance of estimates.
Appendix C. Tables of simulation results.
Appendix D. Goodness of fit measures of the mixed effects models for the data analysis.
SW-CRT Analysis Methods.R. R program to implement the methods detailed in this article.
Simulations.R R program to replicate the simulations used in this article.
Figures.R R program to generate the figures and data tables based on simulated data presented in this article.
References
- 1.Halloran ME, Longini IM, Struchiner CJ. Design and Analysis of Vaccine Studies Statistics for Biology and Health. New York: Springer; 2010. [Google Scholar]
- 2.Eldridge S, Kerry S. A Practical Guide to Cluster Randomised Trials in Health Services Research Statistics in Practice. Chichester, UK: John Wiley & Sons; 2012. [Google Scholar]
- 3.Hayes RJ, Moulton LH. Cluster Randomised Trials 2nd ed. Chapman & Hall/CRC Interdisciplinary Statistics Series. Boca Raton, FL: CRC Press; 2017. [Google Scholar]
- 4.Kahn R, Rid A, Smith PG, Eyal N, Lipsitch M. Choices in vaccine trial design in epidemics of emerging infections. PLoS Med. 2018; 15(8): e1002632. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 5.Hitchings MDT, Lipsitch M, Wang R, Bellan SE. Competing effects of indirect Ppotection and clustering on the power of cluster-randomized controlled vaccine trials. Am. J. Epidemiol. 2018; 187(8): 1763–1771. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 6.Bellan SE, Eggo RM, Gsell PS, et al. An online decision tree for vaccine efficacy trial design during infectious disease epidemics: the InterVax-Tool. Vaccine 2019; 37(31): 4376–4381. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 7.Brown CA, Lilford RJ. The stepped wedge trial design: a systematic review. BMC Med. Res. Methodol 2006; 6(1): 54. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 8.Hemming K, Haines TP, Chilton PJ, Girling AJ, Lilford RJ. The stepped wedge cluster randomised trial: rationale, design, analysis, and reporting. BMJ 2015; 350: h391. [DOI] [PubMed] [Google Scholar]
- 9.Beard E, Lewis JJ, Copas A, et al. Stepped wedge randomised controlled trials: systematic review of studies published between 2010 and 2014. Trials 2015; 16: 353. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 10.Davey C, Hargreaves J, Thompson JA, et al. Analysis and reporting of stepped wedge randomised controlled trials: synthesis and critical appraisal of published studies, 2010 to 2014. Trials 2015; 16: 358. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 11.Barker D, McElduff P, D’Este C, Campbell MJ. Stepped wedge cluster randomised trials: a review of the statistical methodology used and available. BMC Med. Res. Methodol 2016; 16(1): 69. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 12.Golden MR, Kerani RP, Stenger M, et al. Uptake and population-level impact of expedited partner therapy (EPT) on Chlamydia trachomatis and Neisseria gonorrhoeae: the Washington State community-level randomized trial of EPT. PLoS Med 2015; 12(1): e1001777. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 13.Sharp AL, Hu YR, Shen E, et al. Improving antibiotic stewardship: a stepped-wedge cluster randomized trial. Am. J. Manag. Care 2017; 23(11): e360–e365. [PubMed] [Google Scholar]
- 14.Lenguerrand E, Winter C, Siassakos D, et al. Effect of hands-on interprofessional simulation training for local emergencies in Scotland: the THISTLE stepped-wedge design randomised controlled trial. BMJ Qual. Saf 2019. doi: 10.1136/bmjqs-2018-008625. Accessed Nov. 23, 2019. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 15.Hussey MA, Hughes JP. Design and analysis of stepped wedge cluster randomized trials. Contemp. Clin. Trials 2007; 28(2): 182–191. [DOI] [PubMed] [Google Scholar]
- 16.Copas AJ, Lewis JJ, Thompson JA, Davey C, Baio G, Hargreaves JR. Designing a stepped wedge trial: three main designs, carry-over effects and randomisation approaches. Trials 2015; 16: 352. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 17.Prost A, Binik A, Abubakar I, et al. Logistic, ethical, and political dimensions of stepped wedge trials: critical review and case studies. Trials 2015; 16: 351. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 18.Tugwell P, Knottnerus JA. Stepped wedge designs are coming of age in clinical epidemiology. J. Clin. Epidemiol 2019; 107: vi–viii. [DOI] [PubMed] [Google Scholar]
- 19.Mdege ND, Man MS, Taylor CA, Torgerson DJ. Systematic review of stepped wedge cluster randomized trials shows that design is particularly used to evaluate interventions during routine implementation. J. Clin. Epidemiol 2011; 64(9): 936–948. [DOI] [PubMed] [Google Scholar]
- 20.Keriel-Gascou M, Buchet-Poyau K, Rabilloud M, Duclos A, Colin C. A stepped wedge cluster randomized trial is preferable for assessing complex health interventions. J. Clin. Epidemiol 2014; 67(7): 831–833. [DOI] [PubMed] [Google Scholar]
- 21.Kotz D, Spigt M, Arts ICW, Crutzen R, Viechtbauer W. Use of the stepped wedge design cannot be recommended: a critical appraisal and comparison with the classic cluster randomized controlled trial design. J. Clin. Epidemiol 2012; 65(12): 1249–1252. [DOI] [PubMed] [Google Scholar]
- 22.Hargreaves JR, Copas AJ, Beard E, et al. Five questions to consider before conducting a stepped wedge trial. Trials 2015; 16: 350. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 23.Eyal N, Lipsitch M. Vaccine testing for emerging infections: the case for individual randomisation. J. Med. Ethics 2017; 43(9): 625–631. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 24.Mdege ND, Kanaan M. Response to Keriel-Gascou et al. Addressing assumptions on the stepped wedge randomized trial design. J. Clin. Epidemiol 2014; 67(7): 833–834. [DOI] [PubMed] [Google Scholar]
- 25.Viechtbauer W, Kotz D, Spigt M, Arts ICW, Crutzen R. Response to Keriel-Gascou et al.: higher efficiency and other alleged advantages are not inherent to the stepped wedge design. J. Clin. Epidemiol 2014; 67(7): 834–836. [DOI] [PubMed] [Google Scholar]
- 26.Nickless A, Voysey M, Geddes J, Yu LM, Fanshawe TR. Mixed effects approach to the analysis of the stepped wedge cluster randomised trial—Investigating the confounding effect of time through simulation. PLoS One 2018; 13(12): e0208876. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 27.Thompson JA, Fielding KL, Davey C, Aiken AM, Hargreaves JR, Hayes RJ. Bias and inference from misspecified mixed-effect models in stepped wedge trial analysis. Stat. Med 2017; 36(23): 3670–3682. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 28.Hooper R, Teerenstra S, Hoop E, Eldridge S. Sample size calculation for stepped wedge and other longitudinal cluster randomised trials. Stat. Med 2016; 35(26): 4718–4728. [DOI] [PubMed] [Google Scholar]
- 29.Hartford A, Davidian M. Consequences of misspecifying assumptions in nonlinear mixed effects models. Comput. Stat. Data Anal 2000; 34(2): 139–164. [Google Scholar]
- 30.Heagerty PJ, Kurland BF. Misspecified maximum likelihood estimates and generalised linear mixed models. Biometrika 2001; 88(4): 973–985. [Google Scholar]
- 31.Agresti A, Caffo B, Ohman-Strickland P. Examples in which misspecification of a random effects distribution reduces efficiency, and possible remedies. Comput. Stat. Data Anal 2004; 47(3): 639–653. [Google Scholar]
- 32.Litière S, Alonso A, Molenberghs G. Type I and type II error under random-effects misspecification in generalized linear mixed models. Biometrics 2007; 63(4): 1038–1044. [DOI] [PubMed] [Google Scholar]
- 33.Litière S, Alonso A, Molenberghs G. The impact of a misspecified random-effects distribution on the estimation and the performance of inferential procedures in generalized linear mixed models. Stat. Med 2008; 27(16): 3125–3144. [DOI] [PubMed] [Google Scholar]
- 34.McCulloch CE, Neuhaus JM. Prediction of random effects in linear and generalized linear models under model misspecification. Biometrics 2011; 67(1): 270–279. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 35.Wang R, De Gruttola V. The use of permutation tests for the analysis of parallel and stepped-wedge cluster-randomized trials. Stat. Med 2017; 36(18): 2831–2843. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 36.Ji X, Fink G, Robyn PJ, Small DS. Randomization inference for stepped-wedge cluster-randomized trials: an application to community-based health insurance. Ann. Appl. Stat 2017; 11(1): 1–20. [Google Scholar]
- 37.Davidian M, Gallant AR. The Nonlinear Mixed Effects Model with a Smooth Random Effects Density. Biometrika 1993; 80(3): 475–488. [Google Scholar]
- 38.Zhang D, Davidian M. Linear mixed models with flexible distributions of random effects for longitudinal data. Biometrics 2001; 57(3): 795–802. [DOI] [PubMed] [Google Scholar]
- 39.Chen J, Zhang D, Davidian M. A Monte Carlo EM algorithm for generalized linear mixed models with flexible random effects distribution. Biostatistics 2002; 3(3): 347–360. [DOI] [PubMed] [Google Scholar]
- 40.Scott JM, deCamp A, Juraska M, Fay MP, Gilbert PB. Finite-sample corrected generalized estimating equation of population average treatment effects in stepped wedge cluster randomized trials. Stat. Methods Med. Res 2017; 26(2): 583–597. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 41.Thompson JA, Davey C, Fielding K, Hargreaves JR, Hayes RJ. Robust analysis of stepped wedge trials using cluster-level summaries within periods. Stat. Med 2018; 37(16): 2487–2500. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 42.Hughes JP, Heagerty PJ, Xia F, Ren Y. Robust Inference for the Stepped Wedge Design. Biometrics 2019. 10.1111/biom.13106. Accessed Nov. 23, 2019. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 43.Abadie A, Gardeazabal J. The economic costs of conflict: a case study of the Basque Country. Am. Econ. Rev 2003; 93(1): 113–132. [Google Scholar]
- 44.Abadie A, Diamond A, Hainmueller J. Synthetic control methods for comparative case studies: estimating the effect of California’s tobacco control program. J. Am. Stat. Assoc 2010; 105(490): 493–505. [Google Scholar]
- 45.Abadie A, Diamond A, Hainmueller J. Comparative Politics and the Synthetic Control Method. Am. J. Pol. Sci 2015; 59(2): 495–510. [Google Scholar]
- 46.Trajman A, Durovni B, Saraceni V, et al. Impact on patients’ treatment outcomes of XpertMTB/RIF implementation for the diagnosis of tuberculosis: follow-up of a stepped-wedge randomized clinical trial. PLoS One 2015; 10(4): e0123252. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 47.Gautier PA, Siegmann A, Van Vuuren A. Terrorism and attitudes towards minorities: the effect of the Theo van Gogh murder on house prices in Amsterdam. J. Urban Econ 2009; 65(2): 113–126. [Google Scholar]
- 48.Abadie A, Diamond A, Hainmueller J. Synth: an R package for synthetic control methods in comparative case studies. J. Stat. Softw 2011; 42(13): 1–17. [Google Scholar]
- 49.Thompson J, Davey C, Hayes R, Hargreaves J, Fielding K. Permutation tests for stepped-wedge cluster-randomized trials. Stata J 2019. https://researchonline.lshtm.ac.uk/id/eprint/4654957. Accessed Nov. 23, 2019. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 50.Gail MH, Mark SD, Carroll RJ, Green SB, Pee D. On design considerations and randomization-based inference for community intervention trials. Stat. Med 1996; 15(11): 1069–1092. [DOI] [PubMed] [Google Scholar]
- 51.Dube A, Zipperer B. Pooling multiple case studies using synthetic controls: an application to minimum wage policies . Tech. Rep. 8944, Institution for the Study of Labor; 2015. https://papers.ssrn.com/sol3/papers.cfm?abstract_id=2589786. Accessed Nov. 23, 2019. [Google Scholar]
- 52.Donohue JJ, Aneja A, Weber KD. Right-to-carry laws and violent crime: a comprehensive assessment using panel data and a state-level synthetic control analysis. J. Empir. Leg. Stud 2019; 16(2): 198–247. [Google Scholar]
- 53.Powell D. Synthetic control estimation beyond case studies: does the minimum wage reduce employment? Tech. Rep. WR-1142, RAND Labor & Population; 2017. https://papers.ssrn.com/sol3/papers.cfm?abstract_id=2791789. Accessed Nov. 23, 2019. [Google Scholar]
- 54.Everitt BS. The analysis of repeated measures: a practical review with examples. J. R. Stat. Soc. Ser. D The Statistician 1995; 44(1): 113–135. [Google Scholar]
- 55.Jones B, Donev AN. Modelling and design of cross-over trials. Stat. Med 1996; 15(13): 1435–1446. [DOI] [PubMed] [Google Scholar]
- 56.Omar RZ, Wright EM, Turner RM, Thompson SG. Analysing repeated measurements data: a practical comparison of methods. Stat. Med 1999; 18(13): 1587–1603. [DOI] [PubMed] [Google Scholar]
- 57.Fitzmaurice GM. Applied longitudinal analysis 2nd ed. Wiley series in probability and statistics. Hoboken, N.J.: Wiley; 2011. [Google Scholar]
- 58.Durovni B, Saraceni V, van den Hof S, et al. Impact of replacing smear microscopy with XpertMTB/RIF for diagnosing tuberculosis in Brazil: a stepped-wedge cluster-randomized trial. PLoS Med 2014; 11(12): e1001766. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 59.Alonso A, Litière S, Molenberghs G. A family of tests to detect misspecifications in the random-effects structure of generalized linear mixed models. Comput. Stat. Data Anal 2008; 52(9): 4474–4486. [Google Scholar]
- 60.Huang X. Diagnosis of random-effect model misspecification in generalized linear mixed models for binary response. Biometrics 2009; 65(2): 361–368. [DOI] [PubMed] [Google Scholar]
- 61.Verbeke G, Molenberghs G. The gradient function as an exploratory goodness-of-fit assessment of the random-effects distribution in mixed models. Biostatistics 2013; 14(3): 477–490. [DOI] [PubMed] [Google Scholar]
- 62.Meintanis SG, Allison JS, Santana L. Diagnostic tests for the distribution of random effects in multivariate mixed effects models. Commun. Stat. Theory Methods 2016; 45(1): 201–215. [Google Scholar]
- 63.Drikvandi R. Nonlinear mixed-effects models for pharmacokinetic data analysis: assessment of the random-effects distribution. J. Pharmacokinet. Pharmacodyn 2017; 44(3): 223–232. [DOI] [PubMed] [Google Scholar]
- 64.Singer JM, Nobre JS, Rocha FMM. Diagnostic and treatment for linear mixed models. In: Proceedings of the 59th ISI World Statistics Congress, August; 2013: 25–30. [Google Scholar]
- 65.Ritz C. Goodness-of-fit tests for mixed models. Scand. Stat. Theory Appl 2004; 31(3): 443–458. [Google Scholar]
- 66.Yap BW, Sim CH. Comparisons of various types of normality tests. J. Stat. Comput. Simul 2011; 81(12): 2141–2155. [Google Scholar]
- 67.Hubbard AE, Ahern J, Fleischer NL, et al. To GEE or not to GEE: comparing population average and mixed models for estimating the associations between neighborhood risk factors and health. Epidemiology 2010; 21(4): 467–474. [DOI] [PubMed] [Google Scholar]
- 68.Botosaru I, Ferman B. On the role of covariates in the synthetic control method. Econom. J 2019; 22(2): 117–130. [Google Scholar]
- 69.Bruhn CAW, Hetterich S, Schuck-Paim C, et al. Estimating the population-level impact of vaccines using synthetic controls. Proc. Natl. Acad. Sci. U. S. A 2017; 114(7): 1524–1529. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 70.Kim S, Lee C, Gupta S. Bayesian synthetic control methods. Tech. Rep. 3382359, SSRN; 2019. https://papers.ssrn.com/sol3/papers.cfm?abstract_id=3382359. Accessed Nov. 23, 2019. [Google Scholar]
- 71.Cerulli G. A flexible synthetic control method for modeling policy evaluation. Econ. Lett 2019; 182: 40–44. [Google Scholar]
- 72.Xu Y. Generalized synthetic control method: causal inference with interactive fixed effects models. Polit. Anal 2017; 25(1): 57–76. [Google Scholar]
- 73.Ben-Michael E, Feller A, Rothstein J. The augmented synthetic control method. arXiv Preprint 2018. https://arxiv.org/abs/1811.04170. Accessed Nov. 23, 2019.
- 74.Hernán MA, Sauer BC, Hernández-Díaz S, Platt R, Shrier I. Specifying a target trial prevents immortal time bias and other self-inflicted injuries in observational analyses. J. Clin. Epidemiol 2016; 79: 70–75. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 75.García-Albéniz X, Hsu J, Hernán MA. The value of explicitly emulating a target trial when using real world evidence: an application to colorectal cancer screening. Eur. J. Epidemiol 2017; 32(6): 495–500. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 76.Kasza J, Hemming K, Hooper R, Matthews JNS, Forbes AB. Impact of non-uniform correlation structure on sample size and power in multiple-period cluster randomised trials. Stat. Methods Med. Res 2019; 28(3): 703–716. [DOI] [PubMed] [Google Scholar]
- 77.Girling AJ, Hemming K. Statistical efficiency and optimal design for stepped cluster studies under linear mixed effects models. Stat. Med 2016; 35(13): 2149–2166. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 78.Thompson JA, Fielding K, Hargreaves J, Copas A. The optimal design of stepped wedge trials with equal allocation to sequences and a comparison to other trial designs. Clin. Trials 2017; 14(6): 639–647. [DOI] [PMC free article] [PubMed] [Google Scholar]
Associated Data
This section collects any data citations, data availability statements, or supplementary materials included in this article.