

Abstract
Transfer learning using deep pre-trained convolutional neural networks is increasingly used to solve a large number of problems in the medical field. In spite of being trained using images with entirely different domain, these networks are flexible to adapt to solve a problem in a different domain too. Transfer learning involves fine-tuning a pre-trained network with optimal values of hyperparameters such as learning rate, batch size, and number of training epochs. The process of training the network identifies the relevant features for solving a specific problem. Adapting the pre-trained network to solve a different problem requires fine-tuning until relevant features are obtained. This is facilitated through the use of large number of filters present in the convolutional layers of pre-trained network. A very few features out of these features are useful for solving the problem in a different domain, while others are irrelevant, use of which may only reduce the efficacy of the network. However, by minimizing the number of filters required to solve the problem, the efficiency of the training the network can be improved. In this study, we consider identification of relevant filters using the pre-trained networks namely AlexNet and VGG-16 net to detect cervical cancer from cervix images. This paper presents a novel hybrid transfer learning technique, in which a CNN is built and trained from scratch, with initial weights of only those filters which were identified as relevant using AlexNet and VGG-16 net. This study used 2198 cervix images with 1090 belonging to negative class and 1108 to positive class. Our experiment using hybrid transfer learning achieved an accuracy of 91.46%.
Keywords: Cervical cancer screening, Deep learning, Transfer learning, Hybrid transfer learning, Machine learning, Medical image classification, Artificial intelligence
Introduction
Cervical cancer is one of the major reasons of illness and mortality among women worldwide [1]. It contributes to 12% of all cancers and is the second most common cause of death among women worldwide [1]. According to WHO report [2], almost 80% of deaths due to cervical cancer occur in developing countries. Pap smear is the most commonly used method for screening of cervical cancer. But it requires efficient networking between smear collection and cytology laboratories [3]. Also, it suffers from low sensitivity of 52% [4]. In addition to being an expensive test, results of this test are available approximately after 2 weeks. Hence, this approach cannot facilitate the screening and treatment in a single visit. VIA is demonstrated as a simple, cost-effective test that facilitates screen and treat approach [5, 6]. Application of 3–5% acetic acid turns the precancerous lesions white, called acetowhite (AW) regions. Typical cervix images prior to and after the application of acetic acid are shown in Fig. 1. Precancerous lesions, which have turned white, are marked as AW in Fig. 1b.
Fig. 1.

Typical cervix images. a Prior to the application of acetic acid. b After the application of acetic acid
These lesions can be destroyed instantly using cryotherapy [7]. This screen and treat approach can be performed in a single visit to the hospitals, which suppresses further development of cervical cancer.
Considerable training is required to discriminate between actual cancer lesions and lesions that are benign. The most important deciding features for VIA-positive lesions are intensity of acetowhitening, margin of AW lesions, and the rate at which AW lesions appear and disappear. Identification of these features requires considerable amount of skill. Hence, accuracy of this test depends on the skill level of the person who performs the test [8]. Blumenthal et al. [9] reported that health workers need to be trained well for successful implementation of VIA. This problem can be considered as a challenge in computer vision. Images of cervix during VIA examination can be acquired and analyzed using image processing algorithms. Deploying these algorithms in a cell phone or a comparable device with camera can be used as decision support system for the health workers during cervical cancer screening.
Related Work
State-of-the-art algorithms developed by various researchers used traditional machine learning method, which are based on the selection of hand-crafted features and classifying the images based on these features using a suitable classifier. These researchers tried to classify the images by extracting the features related to intensity of acetowhitening, margin of AW lesions, and the texture with in AW lesions. A few researchers [10–14] considered acetowhite feature for the classification of cervix images into VIA-positive and VIA-negative classes. Another group [15, 16] used texture within the aceotowhite lesion as feature. Claude et al. [17] and Raad et al. [18] used lesion margin feature. Identification of relevant features for detection of cervical cancer is a complex task. This problem can be overcome by using deep learning.
Deep learning is a rapidly growing field in machine learning for the analysis of images. It can be used for wide variety of image analysis tasks such as image classification, image segmentation, object detection, and image registration. Deep learning can be used for an image analysis task in two ways as shown in Fig. 2.
Fig. 2.

Deep learning approaches
CNN is a deep learning algorithm used extensively to analyze images. They are mainly composed of different layers, namely convolutional layer, activation layer, pooling layer, and fully connected layer. CNNs can be employed for medical image classification in two ways. The first approach is to train the CNN from scratch which is called full training. Depending on the number of layers in the architectures, CNNs can be classified as deep layer CNN and shallow layer CNN. Full training of CNNs with deep architecture requires large amount of annotated data which are usually not available in the medical domain. Hence, the most popular deep CNNs [19–24] were trained with images of non-medical domain. Deep CNNs are capable of obtaining full representation of the training data. But requirement of large number of annotated data hinders its applicability in the analysis of images in medical domain. Hence, full training using shallow layered CNNs [25–29] was considered for image analysis in medical domain. To exploit the advantages of deep architecture of CNN on the limited dataset, another approach known as transfer learning was utilized. This approach facilitates the use of the knowledge acquired by pre-trained CNNs which were trained using large number of non-medical data. Transfer learning can be performed in two ways. First approach extracts the features from different layers after retraining them with small dataset [30–33]. The features extracted are classified using different classifiers. Second approach of transfer learning involves fine-tuning various layers of pre-trained CNNs to perform a different task [34–37]. It was demonstrated by these researchers that transfer learning is the best choice for the analysis of medical images, where large amount of annotated data is not available. A large number of filters present in the convolutional layers of pre-trained network facilitates extraction of wide variety of features. A very few features out of these features are useful for solving the problem in a different domain, while others are irrelevant, use of which reduces the efficacy of the network. However, by minimizing the number of filters required to solve the problem, the efficiency of the training the network can be improved. In this study, we consider identification of relevant filters using the pre-trained networks, namely AlexNet and VGG-16 net to detect cervical cancer from cervix images. This paper presents a novel hybrid transfer learning technique, in which a CNN is built and trained from scratch, with initial weights of only those filters which were identified as relevant using AlexNet and VGG-16 net.
Method
Data Collection and Ground Truth
The cervix images were collected from the Kasturba Medical College, Manipal, India. Ground truth for the study was provided by a Gynaecologic Oncology expert. A total of 231 images were collected of which 31 images were VIA positive. We also collected 1413 cervix images from the National Cancer Institute (NCI) and the National Institute of Health (NIH) archive. This consisted of 890 VIA-negative and 523 VIA-positive images. Combining both the datasets, we had 1644 images in total with 1090 VIA negative and 554 VIA positive. To increase the size of the dataset in VIA-positive class, we used data augmentation. We rotated the VIA-positive images by an angle of 90°. With data augmentation, we have 1108 VIA-positive images in this dataset consisting of 2198 images.
Hybrid Transfer Learning
We designed two shallow layer CNN architectures from scratch. We name them as CNN-1 and CNN-2 in this manuscript.
CNN-1
Architecture of CNN-1 is listed in Table 1. Number of filters in the convolutional layers of the CNN-1 was selected based on how many filters in the pre-trained networks highlight the specific features required.
Table 1.
Architecture of the CNN-1
| Layer type | Input size | Filter size | Number of filters | Stride | Pad | Output size |
|---|---|---|---|---|---|---|
| Data input | 227X227X3 | NA | NA | NA | NA | 227X227X3 |
| Convolution 1 | 227X227X3 | 5X5X3 | 23 | 4 | 0 | 57X57X23 |
| ReLU 1 | 57X57X23 | NA | NA | NA | NA | 57X57X23 |
| Max pool 1 | 57X57X23 | 3X3 | 1 | 2 | 0 | 28X28X23 |
| Convolution 2 | 28X28X23 | 5X5X23 | 28 | 1 | 2 | 28X28X28 |
| ReLU 2 | 28X28X28 | NA | NA | NA | NA | 28X28X28 |
| Max pool 2 | 28X28X28 | 3X3 | 1 | 2 | 0 | 13X13X28 |
| Fully connected 1 | 13X13X28 | NA | NA | NA | NA | 1024X1 |
| Fully connected 2 | 1024X1 | NA | NA | NA | NA | 512X1 |
| Fully connected 3 | 512X1 | NA | NA | NA | NA | 2X1 |
NA not applicable
Two pre-trained networks AlexNet and VGG-16 net were considered for visualizing the responses of different filters in convolutional layers. The main feature used for identification of cervical cancer is acetowhite feature. Further, margin of acetowhite region and texture within the acetowhite region are used to distinguish between various kinds of possible acetowhite regions. Filter responses were visualized for a few sample cervix images including VIA-positive and VIA-negative category. Responses of filter in the first and second convolutional layers of AlexNet and VGG-16 net were visualized. Responses of a few filters in the first convolutional layer of AlexNet for VIA-positive and VIA-negative images is shown in Fig. 3.
Fig. 3.

Responses of a few filters in the first convolutional layer of AlexNet for VIA-positive and VIA-negative images
Out of the 96 filters in the first convolutional layer of AlexNet, filters 10, 23, 32, 39, 40, 41, 77, 84, and 95 highlighted the whiteness features distinctly. Similarly, responses of a few filters in the first convolutional layer of VGG-16 net are shown in Fig. 4.
Fig. 4.

Responses of a few filters in the first convolutional layer of VGG-16 net for VIA-positive and VIA-negative images
Out of the 64 filters in the first convolutional layer of VGG-16 net, filters 2, 3, 9, 10, 13, 14, 16, 17, 20, 23, 24, 26, 30, and 53 distinctly highlighted the acetowhite feature in the image. We identified 23 filters which distinctly highlighted the acetowhite information in the image. These 23 filters were adapted into first convolutional layer of the proposed CNN-1. Size of filters in the first convolutional layer of AlexNet and VGG-16 net is 11X11X3 and 3X3X3 respectively. We resized the size of selected filters to 5X5X3, which is the size of the filters in the first convolutional layer of the proposed CNN. We also extracted the filter bias weights of the visualized filters and used them as the initial filter bias weights of the proposed CNN-1.
In the similar manner, we visualized responses of the filter in the second convolutional layer of AlexNet and VGG-16 net. Filters 15, 30, 48, 69, 112, 120, 140, 184, 232, and 248 of AlexNet and filters 2, 3, 9, 10, 11, 13, 16, 17, 19, 20, 23, 25, 26, 30, 42, 53, 55, and 60 of VGG-16 net distinctly highlighted the acetowhite features. Hence, 28 filters from second convolutional layers of pre-trained networks highlighted acetowhite feature. Thus, the second convolutional layer of the proposed CNN-1 has 28 filters. Filters were resized to 5X5X23. Since depth of the filters in the second convolutional layer is required to be 23, we randomly selected 23 slices of 64 slices from VGG-16 net. Similarly, from AlexNet, we randomly picked up 23 slices out of 48 slices. Bias weights of relevant filters in the second convolutional layer of pre-trained networks were used as the initial bias weights of the filters in the second convolutional layer of the proposed CNN-1. Two max pooling layers were used to reduce the dimensionality of the features. Finally, three fully connected layers were added whose weights were initialized randomly.
The CNN-1 was trained using cervix images. Dataset was divided as 85% for training, 7.5% for validation, and 7.5% for testing. Two hyperparameters, namely learning rate (LR) and batch size (BS), were varied and performance of CNN was observed. The parameter which provided the best performance was selected. The CNN was trained for 100 epochs.
We compared the performance of the proposed hybrid CNN-1 with the performance of proposed CNN-1 architecture by initializing the filter weights in the convolutional layers to random values.
CNN-2
Architecture of CNN-2 is shown in Fig. 5. As in the CNN-1 architecture, first convolutional layer (conv1 of Fig. 5) contains 23 filters weights of which were adapted from identified filters from AlexNet and VGG-16 net which highlighted acetowhite features. In the second convolutional layer of CNN-1, depth of the adapted filters was scaled to 23 by random selection of 23 slices. But in the second convolutional layer of CNN-2 (conv2a and conv2b of Fig. 5), the entire set of depths (48 in AlexNet and 64 inVGG-16 net) of adapted filters from the second convolutional layers of pre-trained networks was used. This is facilitated through the use of 1X1 convolutional layers (conv01 and conv02 of Fig. 5). Outputs of conv2a and conv2b layers are concatenated along the depth. The rest of the layers in CNN-2 after concatenation layer is the same as that of layers after conv2 layer of CNN-1. CNN-2 is trained in a similar manner as that of CNN-1. Initial learning rate was set to 0.001 and dropped by a factor of 0.1 in every 50 epochs to avoid overfitting.
Fig. 5.

Architecture of CNN-2
We compared the performance of the proposed hybrid transfer learning approach with traditional transfer learning approach. We fine-tuned pre-trained AlexNet and VGG-16 net using cervix images after replacing the final fully connected layers with a new fully connected layer with two neurons to suit the proposed two class problem.
Results
All the experiments were performed using system with Tesla K20Xm graphics card of 6GB memory. MATLAB R2019a was used to implement the network.
Performance of CNN-1 for different learning rates and batch sizes is shown in Fig. 6.
Fig. 6.

Performance of CNN-1 for different learning rates and batch sizes
It can be observed from Fig. 6 that for learning rate of 0.001 and batch size of 50, CNN-1 provides the best accuracy of 91.46%. Hence, we selected the learning rate as 0.001 and batch size as 50.
Accuracy, sensitivity, specificity, and AUC values for training, testing, and validation steps of CNN-1 for LR = 0.001 and batch size = 50 are listed in Table 2.
Table 2.
Performance of CNN-1 for LR = 0.001 and BS = 50
| Accuracy (%) | Sensitivity (%) | Specificity (%) | AUC | |
|---|---|---|---|---|
| Training | 97.16 | 95.75 | 98.6 | 0.97 |
| Testing | 91.46 | 89.16 | 93.83 | 0.92 |
| Validation | 84.85 | 77.11 | 92.68 | 0.85 |
A plot of training accuracy and validation accuracy for LR = 0.001 and BS = 50 is shown in Fig. 7.
Fig. 7.

Plot of training accuracy and validation accuracy for LR = 0.001 and BS = 50 for CNN-1
A plot of training loss and validation loss for CNN-1 for LR = 0.001 and BS = 50 is shown in Fig. 8.
Fig. 8.

Plot of training loss and validation loss for CNN-1 for LR = 0.001 and BS = 50
From Figs. 7 and 8, it can be observed that training and validation accuracy and loss curves are close to each other which indicate that the proposed CNN-1 is trained properly.
We also observed the performance of CNN-1 by initializing the weights of the filters in convolutional layers to random values. Figure 9 depicts the performance of CNN-1 by initializing the filter weights to random values.
Fig. 9.
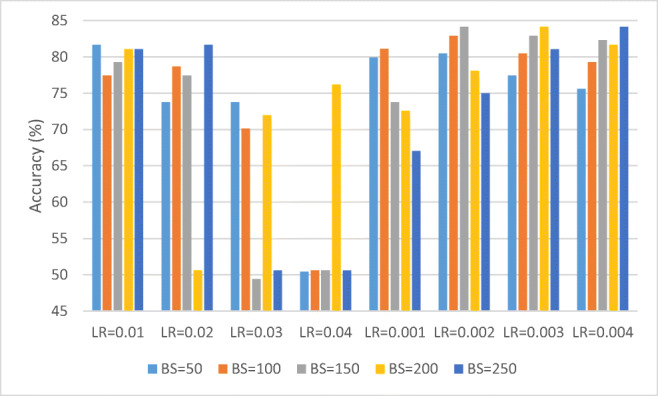
Performance of CNN-1 by initializing the filter weights to random values
From Fig. 9, it can be observed that the best accuracy of 84.15% was achieved for LR = 0.004 and BS = 250.
A plot of training and validation accuracy for LR = 0.004 and BS = 250 is shown in Fig. 10.
Fig. 10.

A plot of training and validation accuracy for LR = 0.004 and BS = 250 for CNN-1 when filter weights are initialized with random values
A plot of training and validation loss for CNN-1 when filter weights are initialized with random values is shown in Fig. 11.
Fig. 11.

Plot of training and validation loss for CNN-1 when filter weights are initialized with random values
By initializing the filter weights to random values, we obtained an accuracy of 84.15%, sensitivity of 83.13%, specificity of 85.19%, and AUC of 0.84.
To understand if the initialized filters from AlexNet and VGG-16 have improved after training, we visualized the filter outputs of CNN-1 and compared with the corresponding filter responses of AlexNet and VGG-16 net which were identified as relevant. Reponses of filters 10, 23, 32, 39, 40, 41, 77, 84, and 95 in the first convolutional layer of AlexNet for VIA-positive image (original image) depicted in Fig. 3 before training is shown in Fig. 12.
Fig. 12.

Responses of filters 10, 23, 32, 39, 40, 41, 77, 84, and 95 in the first convolutional layer of AlexNet before training
Responses of corresponding filters in CNN-1 after training are shown in Fig. 13.
Fig. 13.

Responses of corresponding filters in CNN-1 after training
It can be observed from Figs. 12 and 13 that filters 10, 23, and 32 do not highlight the acetowhite region distinctly after training, while in other filters, the acetowhite regions are more distinct after training when compared to their responses before training.
Reponses of filters 2, 3, 9, 10. 13, 14. 16, 17, 20, 23, 24, 26, 30, and 53 in the first convolutional layer of VGG-16 net for VIA-positive image before training is shown in Fig. 14.
Fig. 14.

Reponses of filters 2, 3, 9, 10. 13, 14, 16, 17, 20, 23, 24, 26, 30, and 53 in the first convolutional layer of VGG-16 net before training
Responses of corresponding filters in CNN-1 after training are shown in Fig. 15.
Fig. 15.

Responses of corresponding filters of VGG-16 net after training
From Figs. 14 and 15, it can be observed that filters 3, 16, 20, 30, and 53 do not highlight the acetowhite region distinctly after training, while in other filters, the acetowhite regions are more distinct or remained same after training when compared to their responses before training. In total, 5 filters out of 23 filters did not highlight the acetowhite feature after training.
Performance of CNN-2 for different batch sizes is shown in Fig. 16.
Fig. 16.

Performance of CNN-2 for different batch sizes
At batch size of 150 CNN performance was better in terms of accuracy and sensitivity. Accuracy, sensitivity, specificity, and AUC values for training, testing, and validation steps of CNN-2 for batch size = 150 are listed in Table 3.
Table 3.
Performance of CNN-2 for BS = 150
| Accuracy (%) | Sensitivity (%) | Specificity (%) | AUC | |
|---|---|---|---|---|
| Training | 86.41 | 79.72 | 93.20 | 0.86 |
| Testing | 85.37 | 86.75 | 83.95 | 0.85 |
| Validation | 78.18 | 75.90 | 80.49 | 0.78 |
A plot of training and validation accuracy and loss for BS = 150 for CNN-2 is shown in Fig. 17.
Fig. 17.

Plot of training and validation accuracy and loss for BS = 150 for CNN-2
Performance of traditional transfer learning approach using fine-tuning pre-trained AlexNet, VGG-16 net, and performance of proposed CNNs is listed in Table 4.
Table 4.
Performance of fine-tuning AlexNet and VGG-16 net
| Accuracy (%) | Sensitivity (%) | Specificity (%) | Training time (s) | Learnable parameters (millions) | |
|---|---|---|---|---|---|
| AlexNet | 84.31 | 93.50 | 75.00 | 5079.32 | 61 |
| VGG-16 | 84.15 | 83.13 | 85.18 | 62,479.52 | 138 |
| CNN-1 | 91.46 | 89.16 | 93.83 | 1506.08 | 5.4 |
| CNN-2 | 85.37 | 86.75 | 83.95 | 661.84 | 5.4 |
From Table 4, it can be observed that proposed CNN-1 and CNN-2 perform equally well when compared to the performance of traditional transfer learning with lesser training time and learnable parameters.
Discussions
One of the principal challenges in deep learning is overfitting, as an overfit model is not generalizable to unseen data. Overfitting of a CNN on training data is usually identified by monitoring the loss and accuracy on the training and validation datasets. In the case if the model performs well only on the training set compared to the validation set, then the model has likely been overfit to the training data. As per statistical learning theory [38], large number of learnable parameters in a predictor make the model hard to train in the case of limited data samples. As per Zhang et al. [39], with 2n + d number of parameters, a simple neural network with two-layers is capable of perfectly fitting any dataset of n samples of dimension d. However, the pre-trained networks used in transfer learning have much more than 2n + d parameters which may lead to overfitting. Also, it requires more computational resources and training time as shown in Table 4. There have been a few techniques proposed to limit overfitting, for example, regularization with dropout, batch normalization, data augmentation, and early stopping. In spite of these efforts, there is still a concern of overfitting. The best solution for reducing overfitting is to obtain more training data. A model trained on a larger dataset typically generalizes better, though that is not always attainable in medical imaging. Wu et al. [40] in their experimentation of classifying Tiny ImageNet data using deep and shallow pre-trained CNNs concluded that benefits of going deeper in the case of small data is limited. Hence, solution is reducing architectural complexity. This is achieved in the proposed hybrid transfer learning approach. Along with having simple architecture, since weights of filters in the convolutional layers have been adapted from learnt filters, this provides comparable performance to the state-of-the-art transfer learning method with lesser training time, learning parameters, and memory requirements. This type of transfer learning can be used for classification when number of available data are small as in healthcare. Drawback of this type of hybrid transfer learning is that it can be performed only on color images as the ImageNet dataset consists of color images having red, green, and blue channels. It cannot be applied to healthcare aspects which has gray scale images as in the case of radiology. A comparison of performance of proposed method with that of state-of-the-art traditional methods for classification of cervix images as listed in Table 5 reveals that proposed method performs equally well and in some cases even better than state-of-the-art methods in spite of larger data compared to the number of data used by state-of-the-art methods.
Table 5.
Comparison of performance of proposed method with that of state-of-the-art traditional methods
| Authors | Features | Classifier | Number of images | Performance |
|---|---|---|---|---|
| Park et al. [10] | RGB intensity values, ratios, gray scale values | KNN, SVM | 29 |
Sensitivity, 79% Specificity, 88% |
| Li et al. [11] | G component of RGB color space, contrast feature | K-means | 99 |
Sensitivity, 94% Specificity,87% |
| Kim et al. [12] | Pyramid color histogram in CIE Lab space (PLAB), pyramid histogram of oriented gradients (PHOG) | SVM | 2000 |
Sensitivity, 73% Specificity, 77% |
| Xu et al. [13] | PHOG, PLAB, and pyramid histogram of local binary pattern (PLBP) | AdaBoost | 345 |
Sensitivity, 86.4% Specificity,74.2% Accuracy, 80.3% |
| Kudva et al. [14] |
Color, SGLDM, NGTDM NGLDM, wavelet, LBP |
SVM | 102 |
Sensitivity, 99.05% Specificity, 97.16% Accuracy, 97.94% |
| Ji et al. [15] | 24 texture features such as joint entropy, angle entropy, energy, contrast, etc. | Minimum-distance classifier | 300 | Accuracy, 87.03% |
| Claude et al. [17] | Contour features | Multilayer perceptron | 30 | Accuracy, 95.8% |
| Proposed method | Hybrid transfer learning | CNN | 2198 |
Sensitivity, 91.46% Specificity, 89.16% Accuracy, 93.83% |
Considering only acetowhite feature of images in the filters, we were able to achieve a classification accuracy of 91.46%. Performance of the network may be improved by having more filters in the convolutional layers which highlight the margin of acetowhite region and texture within the acetowhite region.
Conclusion
A novel hybrid transfer learning approach for cervix image classification was reported in this paper. Two shallow layer CNNs were designed and initial weights of the filters were adapted from pre-trained AlexNet and VGG-16 net which highlight the acetowhite features. These networks were trained to classify cervix images. It provided a classification accuracy of 91.46%. Performance of the network may be improved by having more filters in the convolutional layers which highlight the margin of acetowhite regions and texture within the acetowhite region.
Acknowledgments
This publication is made possible by a sub-agreement from the Consortium for Affordable Medical Technologies (CAMTech) at Massachusetts General Hospital with funds provided by the generous support of the American people through the United States Agency for International Development (USAID grant number 224581). We would like to acknowledge the support of Mark Schiffman, M.D, M.P.H., Division of Cancer Epidemiology and Genetics, National Cancer Institute, USA, for providing us with cervix images. We would like to acknowledge the support of Dr. Suma Nair, Associate Professor, Community Medicine Department, Kasturba Medical College, Manipal, for facilitating the acquisition of images during the screening programs conducted.
Compliance with Ethical Standards
Disclaimer
The contents are the responsibility of Manipal Academy of Higher Education and do not necessarily reflect the views of Massachusetts General Hospital, USAID or the United States Government.
Footnotes
Publisher’s Note
Springer Nature remains neutral with regard to jurisdictional claims in published maps and institutional affiliations.
Contributor Information
Vidya Kudva, Email: vidyakudva@nitte.edu.in.
Keerthana Prasad, Email: Keerthana.prasad@manipal.edu.
Shyamala Guruvare, Email: shyamala.g@manipal.edu.
References
- 1.J. Ferlay, I. Soerjomataram, M. Ervik, R. Dikshit, S. Eser, C. Mathers, M. Rebelo, D. M. Parkin, D. Forman and F. Bray 2013 GLOBOCAN 2012 v1.0, Cancer incidence and mortality worldwide: IARC CancerBase No. 11, Lyon, France: IARC [internet]. Available from:http://globocan.iarc.fr, . Last accessed on 28-07-2018.
- 2.World Health Organization 2002 Cervical cancer screening in developing countries: Report of a WHO consultation. Program on Cancer Control. Last accessed on 28-03-2018.
- 3.Fahey MT, Irwiq L, Macaskill P. Meta-analysis of pap test accuracy. American Journal of Epidemiology. 1995;141(7):680–689. doi: 10.1093/oxfordjournals.aje.a117485. [DOI] [PubMed] [Google Scholar]
- 4.Bhattacharyya AK, Nath JD, Deka H. Comparative study between pap smear and Visual Inspection with Acetic acid (VIA) in screening of CIN and early cervical cancer. Journal of Mid-life Health. 2015;6(2):53–58. doi: 10.4103/0976-7800.158942. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 5.Sankaranarayanan R, Wesley R, Thara S, Dhakad N, Chandralekha B, Sebastian P, Chithrathara K, Parkin DM, Nair MK. Test characteristics of visual inspection with 4% acetic acid and Lugol’s Iodine in cervical cancer screening in Kerala. India. International Journal of Cancer. 2003;106(3):404–408. doi: 10.1002/ijc.11245. [DOI] [PubMed] [Google Scholar]
- 6.Belinson J, Pretorius R, Zhang W, Wu LY, Qiao YL, Elson P. Cervical cancer screening by simple visual inspection after acetic acid. Obstetrics & Gynecology. 2001;98(3):441–444. doi: 10.1016/s0029-7844(01)01454-5. [DOI] [PubMed] [Google Scholar]
- 7.Chumworathayi B, Blumenthal PD, Limpaphayom KK, Kamsa-Ard S, Wongsena M, Supaatakorn P. Effect of single-visit VIA and cryotherapy cervical cancer prevention program in Roi Et, Thailand: a preliminary report. Journal of Obstetrics and Gynaecology Research. 2010;36(1):79–85. doi: 10.1111/j.1447-0756.2009.01089.x. [DOI] [PubMed] [Google Scholar]
- 8.Sangwa-Lugoma G, Mahmud S, Nasr SH, Liaras J, Patrick KK, Tozin RR, Drouin P, Lorincz A, Ferenczy A, Franco EL. Visual inspection as a cervical cancer screening method in a primary health-care setting in Africa. International Journal of Cancer. 2006;119(6):1389–1395. doi: 10.1002/ijc.21972. [DOI] [PubMed] [Google Scholar]
- 9.Blumenthal P, Lauterbach M, Sellors J, Sankaranarayanan R. Training for cervical cancer prevention programs in low-resource settings: Focus on visual inspection with acetic acid and cryotherapy. International Journal of Gynecology & Obstetrics. 2005;89(2):S30–S37. doi: 10.1016/j.ijgo.2005.01.012. [DOI] [PubMed] [Google Scholar]
- 10.Park SY, Follen M, Milbourne A, Rhodes H, Malpica A, MacKinnon N, MacAulay C, Markey MK, Richards-Kortum R. Automated image analysis of digital colposcopy for the detection of cervical neoplasia. Journal of Biomedical Optics. 2008;13(1):014029. doi: 10.1117/1.2830654. [DOI] [PubMed] [Google Scholar]
- 11.Li W, Venkataraman S, Gustafsson U, Oyama JC, Ferris DG, Lieberman RW. Using acetowhite opacity index for detecting cervical intraepithelial neoplasia. Journal of Biomedical Optics. 2009;14(1):014020. doi: 10.1117/1.3079810. [DOI] [PubMed] [Google Scholar]
- 12.Kim E, Huang X. A Data Driven Approach to Cervigram Image Analysis and Classification. In: Celebi M, Schaefer G, editors. Color Medical Image Analysis. Lecture Notes in Computational Vision and Biomechanics. Dordrecht: Springer; 2013. [Google Scholar]
- 13.T. Xu, E. Kim and X. Huang 2015 Adjustable AdaBoost classifier and pyramid features for image-based cervical cancer diagnosis. In Proc. IEEE 12th International Symposium on Biomedical Imaging, pages 281–285, New York, NY, USA
- 14.Kudva V, Prasad K, Guruvare S. Andriod Device-Based Cervical Cancer Screening for Resource-Poor Settings. Journal of Digital Imaging. 2018;31(5):646–654. doi: 10.1007/s10278-018-0083-x. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 15.Ji Q, Engel J, Craine E. Texture analysis for classification of cervix lesions. IEEE Transactions on Medical Imaging. 2000;19(11):1144–1149. doi: 10.1109/42.896790. [DOI] [PubMed] [Google Scholar]
- 16.Song D, Kim E, Huang X, Patruno J, Munoz-Avila H, Hein J. Multimodal entity coreference for cervical dysplasia diagnosis. IEEE Transactions on Medical Imaging. 2015;34(1):229–245. doi: 10.1109/TMI.2014.2352311. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 17.I. Claude, R. Winzenrieth, P. Pouletaut and J. C. Boulanger. Contour features for colposcopic images classification by articial neural networks. In Proc. 16th International Conference on Pattern Recognition, pages 771–774, Quebec City, Quebec, Canada, 2002.
- 18.V. V. Raad, Z. Xue and H. Lange. Lesion margin analysis for automated classification of cervicalcancer lesions. In Proc. SPIE Medical Imaging: Image Processing, volume 6144, pages 1–13, San Diego, California, United States, 2006.
- 19.Y. Jia, E. Shelhamer, J. Donahue, S. Karayev, J. Long, R. Girshick, S. Guadarrama and T. Darrell 2014 CAFFE: Convolutional Architecture for Fast Feature Embedding. arXiv:1408.5093. Last accessed on 28-03-2018.
- 20.A. Krizhevsky, I. Sutskever and G. E. Hinton. ImageNet classification with deep convolutional neural networks. In Proc. 25th International Conference on Neural Information Processing Systems, volume 1, page 1097–1105, Lake Tahoe, Nevada, 2012.
- 21.LeCun Y, Bottou L, Bengio Y, Haner P. Gradient-based learning applied to document recognition. Proceedings of the IEEE. 1998;86(11):2278–2324. [Google Scholar]
- 22.P. Sermanet, D. Eigen, X. Zhang, M. Mathieu, R. Fergus and Y. LeCun. Over-Feat: Integrated recognition, localization and detection using convolutional networks. In Proc. International Conference on Learning Representations (ICLR2014), arXiv:1312.6229, 2014. Last accessed on 28-03-2018.
- 23.K. Simonyan and A. Zisserman 2014 Very deep convolutional networks for large-scale image recognition. arXiv:1409.1556. Last accessed on 28-03-2018.
- 24.C. Szegedy, W. Liu, Y. Jia, P. Sermanet, S. Reed, D. Anguelov, D. Erhan, V. Vanhoucke and A. Rabinovich 2015 Going deeper with convolutions. In Proc. IEEE Conference on Computer Vision and Pattern Recognition, pages 1–9, Boston, MA, USA.
- 25.Zhanga W, Lia R, Dengb H, Wangc L, Lind W, Jia S, Shenc D. Deep convolutional neural networks for multi-modality isointense infant brain image segmentation. NeuroImage. 2015;108:214–224. doi: 10.1016/j.neuroimage.2014.12.061. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 26.Gao Z, Wang L, Zhou L, Zhang J. HEp-2 cell image classification with deep convolutional neural networks. IEEE Journal of Biomedical and Health Informatics. 2017;21(2):416–428. doi: 10.1109/JBHI.2016.2526603. [DOI] [PubMed] [Google Scholar]
- 27.Lequan Y, Hao C, Dou Q, Qin J, Heng PA. Automated melanoma recognition in dermoscopy images via very deep residual networks. IEEE Transactions on Medical Imaging. 2017;36(4):994–1004. doi: 10.1109/TMI.2016.2642839. [DOI] [PubMed] [Google Scholar]
- 28.Sharma H, Zerbe N, Klempert I, Hellwich O, Hufnagl P. Deep convolutional neural networks for automatic classification of gastric carcinoma using whole slide images in digital histopathology. Computerized Medical Imaging and Graphics. 2017;61:2–13. doi: 10.1016/j.compmedimag.2017.06.001. [DOI] [PubMed] [Google Scholar]
- 29.Kudva V, Prasad K, Guruvare S. Automation of Detection of Cervical Cancer Using Convolutional Neural Networks. Critical Reviews in Biomedical Engineering. 2018;46(2):135–145. doi: 10.1615/CritRevBiomedEng.2018026019. [DOI] [PubMed] [Google Scholar]
- 30.Ribeiro E, Andreas U, Wimmer G, Hafner M. Exploring deep learning and transfer learning for colonic polyp classification. Computational and Mathematical Methods in Medicine. 2016;2016:1–16. doi: 10.1155/2016/6584725. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 31.Abdolmanafi A, Duong L, Dahdah N, Cheriet F. Deep feature learning for automatic tissue classification of coronary artery using optical coherence tomography. Biomedical Optics Express. 2017;8(2):1203–1220. doi: 10.1364/BOE.8.001203. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 32.Abbas Q, Fondon I, Sarmiento A, Jiménez S, Alemany P. Automatic recognition of severity level for diagnosis of diabetic retinopathy using deep visual features. Medical & Biological Engineering & Computing. 2017;55(11):1959–1974. doi: 10.1007/s11517-017-1638-6. [DOI] [PubMed] [Google Scholar]
- 33.Beevi KS, Madhu SN, Bindu GR. Automatic mitosis detection in breast histopathology images using Convolutional Neural Network based deep transfer learning. Biocybernetics and Biomedical Engineering. 2019;39:214–223. [Google Scholar]
- 34.Chen H, Ni D, Qin J, Li S, Yang X, Wang T, Heng PA. Standard plane localization in fetal ultrasound via domain transferred deep neural networks. IEEE Journal of Biomedical and Health Informatics. 2015;19(5):1627–1636. doi: 10.1109/JBHI.2015.2425041. [DOI] [PubMed] [Google Scholar]
- 35.Tajbakhsh N, Shin JY, Gurudu SR, Hurst RT, Kendall CB, Gotway MB, Liang J. Convolutional neural networks for medical image analysis: Full training or fine tuning? IEEE Transactions on Medical Imaging. 2016;35(5):1299–1312. doi: 10.1109/TMI.2016.2535302. [DOI] [PubMed] [Google Scholar]
- 36.Paras L. Deep convolutional neural networks for endotracheal tube position and X-ray image classification: Challenges and opportunities. Journal of Digital Imaging. 2017;30(4):460–468. doi: 10.1007/s10278-017-9980-7. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 37.Phillip MC, Malhi HS. Transfer learning with convolutional neural networks for classification of abdominal ultrasound images. Journal of Digital Imaging. 2017;30(2):234–243. doi: 10.1007/s10278-016-9929-2. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 38.V. Vapnik 2013 The nature of statistical learning theory. Springer science & business media.
- 39.C. Zhang, S. Bengio and M. Hardt. Understanding deep learning requires rethinking generalization. arXiv:1611.03530v2 [cs.LG] 26 Feb 2017. Available online at https://arxiv.org/pdf/1611.03530.pdf. Last accessed on 15.06.2019
- 40.J. Wu, Q. Zhang and G. Xu. Tiny ImageNet challenge. Technical report, Stanford University, 2017. Available online at http://cs231n.stanford.edu/reports/2017/pdfs/930.pdf. Last accessed on 14-06-2019.