

Abstract
The exceptional outbreaks of a number of epidemic diseases such as Ebola, SARS, Zika and H1N1 and their wide distribution over multiple regions calls for a reliable global health awareness system. This system is needed to achieve early detection of such emergencies. Furthermore, such health awareness system should be capable of predicting the outbreaks patterns to facilitate future countermeasure planning. This health awareness system should cover large scale regions that can be extended to multiple countries, continents and ultimately the globe. Many advanced and industrial countries are still struggling in building such system effectively even with the availability of resources and domain experts. The realization of a reliable health awareness system is accompanied with multiple challenges such as the availability of resources and experts, the global agreements about the system from the legislative and control point of view and the availability of the infrastructure that will support the system functionality with a reasonable cost. This paper presents a novel global health awareness system that overcomes the aforementioned challenges. The system is exploiting the emerging cloud computing services availability over the globe. To handle the large scale requirements, we introduce a multi-tier based cloud system that spans over four tiers starting from the monitored subjects to a centralized global cloud system. Also, we present a mixed integer optimization formulation to tackle the issues related to the latency of detecting outbreaks. Our results show that processing the data in multi-tier health awareness system will reduce the overall delay significantly and enable efficient health data sharing.
Keywords: Global health awareness system, Cloud computing, Multi-tier cloud, MapReduce, Processing delay
1. Introduction
With the frequent spreading and outbreaks of infectious diseases and human immunodeficiency viruses in the last few decades, the need for global health awareness system increased due to their importance in countering such emergencies. Many recent examples show the importance of building a global health awareness system for surveillance and disease control. The outbreak of Severe Acute Respiratory Syndrome (SARS) in 2003, the avian influenza H5N1 in 2005, the sudden emergence of H1N1 in 2009 and Ebola outbreak in March 2014 are just few examples [1], [2], [3], [4], [5]. The availability of health awareness system is crucial for the detection and prevention of emerging diseases. Actually, such awareness system is with great importance for all the countries in the worlds regardless of their health system status. Moreover, public health monitoring and awareness are considered as a major national security concerns for many countries. Such system can provide important health data in a timely manner allowing health organizations to prepare for encountering any sudden emergencies [6].
Emerging health care systems are using Wireless Body Area Network (WBAN) for their efficient data collection and communication. WBAN is a group of communicating sensors that are wearable or implanted on a human body is called. These sensors communicate wirelessly in order to collect the body's vital signs like heart rate, temperature, blood pressure and blood glucose [7]. Via Bluetooth, the collected data by the sensor nodes are transmitted to on-body smart phone or tablet PCs. The data is then forwarded using cellular or WiFi technology in real time routine to a public cloud provider in order to deliver the needed information to a healthcare service provider like clinic or hospital [8], [9]. WBAN infrastructure is considered as the basic block of our proposed global health awareness system. Fig. 1 shows the proposed healthcare data collection system using WBANs. The required information for the health service is generated in the cloud service provider and using the collected data from the monitored area of WBANs. It depends on the normality of the generated information. The healthcare service provider will take a necessary action if there is any abnormality in the collected information. Otherwise, the cloud service provider will delete the stored data after a certain period of time. The data is called abnormal if it is not within a range that is determined by National Institutes of Health (NIH) [8].
Fig. 1.
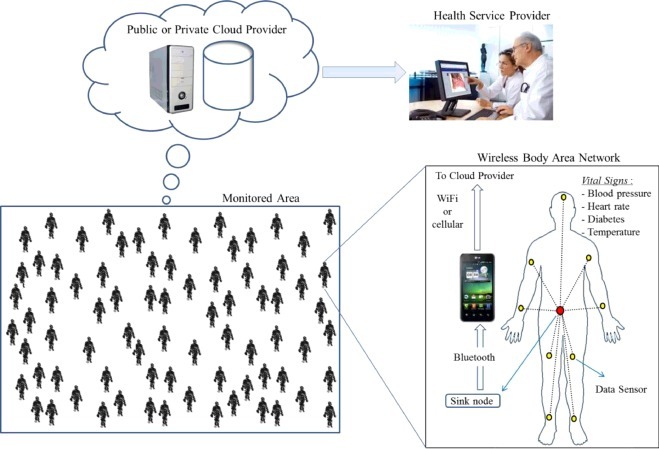
Healthcare data collection system using wireless body area networks.
The proposed system in Fig. 1 can be used to detect an epidemic disease in early stages before it spreads over a wide region, like a city or a country. The proposed system should be smart, efficient and working in a large scale manner, as we will discuss in Section 4. A large scale system for monitoring users with smart devices is proposed in this paper and as shown in Fig. 1. The vital signs of each user are collected and transmitted to the cloud provider [9] using an efficient big data collection model of WBANs system prototype. Having WBAN sensors installed with the textiles that users wear, the users need not worry about their operation. The user will only be required to carry a cell phone and when the system detects serious abnormalities, it will alert the cell phone, which in turn, will automatically call for help. The goal of this system is to provide early detection of dangerous diseases so that the patient will be given medical attention within the first few critical hours, thus greatly improving his or her chances of survival. Moreover, early detection of dangerous diseases will reduce diffusions of such outbreaks [10].
The combination of emerging computing models such as Internet of Things (IoT) and cloud computing in large scale applications, as in healthcare awareness, need to have unlimited storage space and processing power [11]. Recently, medical and health applications are showing an increasing momentum within the core of such phenomena, IoT and cloud models are delivering what is needed for such large scale applications. These needs for large scale storage are included in such models due to the increasing amount of generated data. Similarly, generated data needs to have a scalable storage and cost efficient computing capacity in order to provide the required quality of the needed services with minimum cost. Recently, applications with WBANs based healthcare present one of the most important requests for a high demands applications. The huge amount of collected data by WBANs needs to be on-demand, secure, scalable, powerful and high processing infrastructure. The integration of current computing paradigms, such as IoT and cloud, with current healthcare application of WBANs becomes a must to accomplish the WBANs healthcare applications. The proposed health awareness system will enable the end users to globally access the storage and processing infrastructure with minimum costs.
The proposed multi-tier system aims at reducing the total system resources usage with tolerable delay compared with using single-tier cloud system, where costly and unreliable communication systems are used. The multi-tier cloud system provides several benefits and advantages over other systems. First, it provides reliable cloud services supported by advances of cloud deployments and operations flexibility. Second, the proposed system provides scalability, by which it is capable to handle sudden increases (spikes) in demands in a timely manner. This is due to the fact that scaling in and out the resources is efficiently performed within the cloud system. Third, the proposed model facilities an effective data sharing with different stakeholder, such as health organizations and governments officials. Fourth, the system enjoys affordable and reasonable costs compared with deploying a similar system with conventional computing system. More details about our proposed multi-tier cloud system will be discussed in Sections 3 and 4.
The amount of data produced by the proposed health system needs efficient mechanisms for data processing and sharing. In our model we integrated MapReduce technique to handle this issue. MapReduce is a processing model used to manage data in a bulky based and large scale setting with distributed and parallel procedures [12]. A MapReduce model is composed of a Map process, that is used to filter and sort the data, and a Reduce process that is used to complete the actual operation. For customizing application data, a simple interface holds flexible components consisting of map and reduces process functions. There are many applications that are using MapReduce model, like web and graph traversal, search engines, document clustering, distributed sorting, machine learning, translation machines, cloud and mobile computing [13]. In our proposed health awareness system, the MapReduce model can be implemented in any cloud service provider in any tier, as we will discuss in Section 4 and Fig. 3.
Fig. 3.
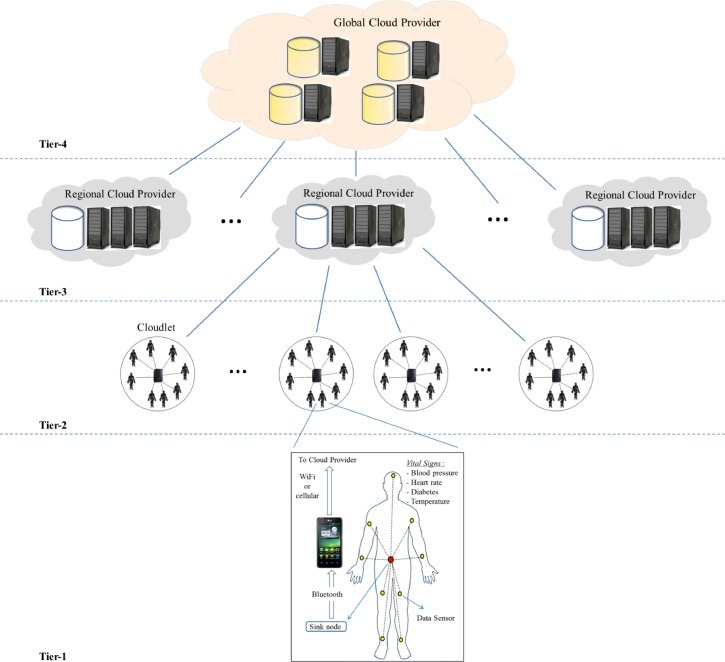
Proposed multi-tier health awareness system.
The goal of this paper is to develop a global health awareness system using a multi-tier cloud system infrastructure. The core objective of the system is to detect any abnormality in the collected vital signs data for an epidemic disease in wide infected area. The proposed system computes the end-to-end delay in real-time manner. The end-to-end delay of the proposed system is modeled as a mixed integer optimization problem and integrated with MapReduce model in order to minimize the processing delay. The integration with the MapReduce model facilities the processing of the large amount of data from WBANs and accelerate the decision generation. While reducing end-to-end data energy, the proposed system is minimizing the data processing delay by choosing different cloud providers in different tiers, so that the overall delay is minimized. The performance of the proposed system is evaluated analytically using theoretical models and experimentally using extended MCC simulator [14] to show the impact of processing the collected data in different tiers.
2. Related work
Currently with the growth of healthcare service technologies, people need to access all the resources of health service almost everywhere. In this context, human subjects can take advantage of this fact, in terms of WBAN, eHealth, deploying Cloud-based solutions on eHealth services. On the other hand, the growth of eHealth data, health service providers need a global health awareness system with advanced techniques and resources in terms of process, store, share and transfer capabilities.
The use of cloud computing in healthcare has been introduced by the authors in [15] as a tool to monitor patients, maintain vital records, and efficiently handle diseases by analyzing the collected data and cooperating with peers. A cloud computing application with eHealth services was implemented by authors in [16] in order to expose the issues, benefits, requisites and challenges for the needed eHealth services. In this paper the authors proposed two scenarios for eHealth and cloud based solutions. Then, an Electronic Health Records (EHRs) management system is proposed to provide a large scale primary care centers, as in clinic or hospital. The process of vital sign data collection from patients was proposed by authors in [17]. The authors in this paper improve the data collection process by automating it through attaching sensors to the present medical equipment that are connected to the patient and to exchange the medical service. In these proposed works, the authors did not take in consideration the sharing of collected data in large scale setting or the processing time complexity of such data.
Scalability and cost are two important goals that need to be considered when we talk about processing of big data. Authors in [18] presented replication, partitioning, caching and distributed control as four levels for multi-tier database application. These architectures can be seen in applications like in Google and Azure and with small modules bases. However, the proposed architectures do not serve in data processes as big data collection as in eHealth applications. The authors in [19] presented automatic virtual machine configuration for database workloads in order to share a common pool of data for running and management occurrences in the lower tiers without considering the scalability and the cost of the collected data.
Intercloud, or what is called cloud of clouds, is an interconnected global network of networks (an extension of the Internet) [20]. Intercloud is used for federation of cloud computing environments in utility oriented base, and it should support scalable applications in different tiers [21]. The first published work on Intercloud was few years ago after the spread of cloud computing infrastructure in many aspects [22], [23], [24], [25]. In this context we should differentiate between two terms, Multi-Cloud and Federation. Multi-Cloud indicates when a client uses independent and multiple clouds without implying volunteer sharing and interconnection of providers’ infrastructures. While a federation indicates when there are a set of interconnected volunteer cloud providers sharing of resources among each other [25]. None of the above works integrated data processing, storing, sharing and transmitting with Intercloud as part of global health awareness system, and as a coupled with of MapReduce model in multi-tiers cloud provider.
Compared with the above proposed works, the novelty of this paper comes from the following. First, the authors in the literature did not take in consideration the sharing of collected data in large scale setting or the processing time complexity of such data. Second, none of the above works integrate both MapReduce framework and the DBMS to be the concentration of the proposed paradigm, so that the advantages of both frameworks can be realized in this paper. Third, none of the above works integrate data processing, storing, sharing and transmitting with Intercloud as part of global health awareness system, and as a coupled with MapReduce model in multi-tiers cloud provider. In this paper we present a novel global health awareness system with multi-tier cloud provider. Using analytical implemented model, the proposed system optimizes data processing time in multiple tiers in the presence of scalable data collection. In this system three tiers of data processing were proposed, namely, cloudlet, regional cloud and global cloud providers. To analyze and processing big data, we present MapReduce framework in order to schedule, map and reduce the big data in parallel and to reduce the processing time in the different tiers. To the best of our knowledge, the novelty of the proposed work has never been addressed in any previous studies. Moreover, MapReduce in multi-tier scales were never proposed on a large scale as it is fully supported by our proposed MapReduce cloud-based WBANs system. While most of the previous proposed solutions were mainly targeting health related issues, our proposed solution provide a holistic solution that can be deployed in different environments which are not limited to the healthcare systems. Examples of these applications are military, students in school or university, where the deployment of the local cloud depends on the clustering of the users in these applications.
3. Cloud computing in multi-tier system
The expansion in exploiting cloud computing services to handle different large scale applications, such as climate change monitoring and distance learning applications open the doors for new applications to benefit from these enormous computing resources. Globally oriented health awareness systems are becoming an urgent need with the increase in epidemic diseases that are not contained within the regions of a single country or even a single continent. These health awareness systems are based on large scale monitoring for the infected areas with different sizes.
Achieving efficient health monitoring on a large scale should be accompanied with reliable computing infrastructures that facilitate data sharing and storage in a timely manner. The availability of the computing resources cannot be guaranteed, many infected areas and countries are suffering from a shortage in advanced computing and communication systems. This computing infrastructure should span from the end user data collection system in one location all the way to the global decision making system that covers the entire globe. This will require collective efforts from different parties such as the governments, health organizations, and computing and communication service providers. In this paper we are focusing on the latter one.
Cloud computing provides a viable solution to handle the construction of reliable and cost efficient health monitoring system to support the holistic health awareness concepts. Cloud computing deployment flexibility can support our proposed system in different levels (i.e. user level, cloudlet level, regional cloud provider and the centralized global cloud), as we will discuss in Section 4. In the following, we investigate different concepts that support the construction of our proposed system. We will discuss public cloud as storage provider, Cloud Federation and Cloud Coordinator, Global and Regional–based Cloud.
3.1. Public cloud provider
To achieve one of the core advantages of our proposed system for being cost effective, we built our system based on exploiting the available public cloud service providers. The public cloud service providers provide their cloud services such as computing capacity, applications and storage to the general public users who are able to access the cloud system service over the internet. The cloud services are offered to the users in similar way as other utilities, such water and electricity. A Service Level Agreement (SLA) between the cloud service provider and the users is used to control the usage mechanism, Quality of Service (QoS) and the incurred cost [26]. Public clouds [27], [28] have several advantages over proprietary or private cloud systems [29], [30], [31]. These advantages include (i) the agility of service deployments in which the services are up and running when we need them, (ii) the low cost of deployment as there is no need to own the hardware or to maintain the system operations and (iii) the widespread availability of such systems in most of the world. Public cloud facilities for data storage and data sharing are needed to support our proposed model. Cloud storage model provides flexibility in storing huge amount of data that is easy to be accessed by different parties from different locations. The access is provided using predefined portals. The cloud storage can be leased from cloud service providers and controlled by SLA. Similar to the computing resources, it can be scaled in and out based on the demands.
3.2. Cloud federation and cloud coordinator
The basic idea of cloud federation (i.e. "cloud of clouds") is to connect set of cloud service providers together in one platform aiming at collaborating to provide cloud services with high QoS standards to the customers [21]. This can be achieved by load balancing the user's workload especially during the demand spikes. The cloud federation enables the cloud service providers to provide better services quality with less resource by pretending that it owns more resources than it actually has. In our model we are extending the cloud federation one step further to facilitate data processing and data aggregation scheduling in different levels based on the extended geographical footprints, as we will discuss in Section 4, beside the basic objective of resources pooling. The federation is used to reach important data for our awareness model at their sources of generation (e.g. WBANs or Cloudlets) to enable what we call Processing at the Edge. Processing at the edge is similar to the emerging fog computing [32], [33], which enables moving the processing and storage of the data to the edge of the network. In the proposed system, the MapReduce processing model is implemented in WBANs, Cloudlets, Regional Cloud Provider or in Global Cloud Provider, as we will discuss in Section 4. This can be accomplished by redefining the cloud coordinator responsibilities to facilitate centralized and semi-centralized control of different cloud service providers. Cloud coordinator is one of the main enabling mechanisms for cloud federation.
3.3. Regional-based cloud
Cloud service providers focus on reaching every single country in the world to extend their market share. The extended cloud deployments and their availability in most of the world regions is the key enabling factor in our model. In our model, the country based cloud provider system is called Regional Cloud provider and presents regional cloud tier of our model. The Regional Cloud provider is a public cloud provider who is included in the cloud federation and it is enabled to support the cloud coordinator requirements. The centralized cloud system is shown in Fig. 2 . Regional Cloud system has larger computing and storage capacity than the cloudlet in lower tier. In the model, the regional cloud tier receives the data from the cloudlet tier, as we will discuss in Section 4. The regional cloud has the capability to process, store, share and transfer the data to a third party of global cloud.
Fig. 2.
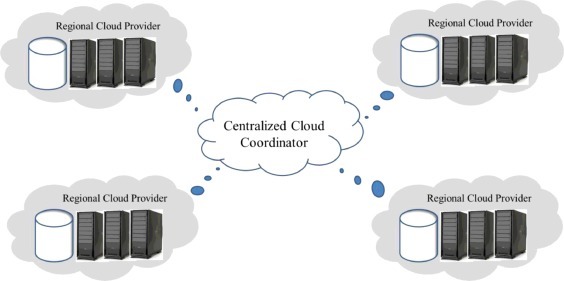
Centralized cloud coordinator infrastructure.
3.4. Global-based cloud
In our proposed model, the Global Cloud system represents the top tier. It has two different functionalities which are data processing and the overall system operations control (other tiers mainly perform data processing and transfer only). The Global Cloud is a high capacity system with the ability to process large amounts of data aggregated from the lower tiers. It is connected directly to the regional cloud system through a high speed backbone network to reduce data transfer latency. Moreover, it should have long term storage capacity for the data future usage. Handling the control operations should not impact the system processing capacity. The Global Cloud system should be a platform as service model which is more flexible and faster in deployment the required services.
4. Global health awareness system using multi-tier clouds
The objective of this section is to develop our proposed global health awareness system. The system is efficiently handling large scale data collection and processes the data to detect if there is any abnormality in these data. Processing large amount of data from different regions, and deciding if there is any epidemic disease, is considered as the core challenge for many health and non-health applications. The challenge is increased when we talk about the amount of time that it needs to come up with any epidemic conclusion. This is mainly due to the accumulated delay due to the fact that data collection and processing are performed on a huge number of human subjects, as well as the fact that these data are collected from faraway regions. The data collection from the sources can be in the field or in an area suffered from an epidemic disease while the processing can be in a data center that maybe thousands of kilometers far from the data sources, from where a decision can be taken. Another major challenge in this type of applications is how to map the data of interest (i.e. abnormal data) precisely to its exact sources in the field, especially in large scale monitored area. In this work, we introduced an end to end data management framework that efficiently handles these challenges for medical and health applications.
4.1. Multi-tier health awareness system
Fig. 3 shows the top level overview of our proposed health awareness system. The system is composed of four data centers or tiers. These tiers from low to top are WBAN or Monitored Subject, Cloudlet, Regional and Global tiers.
-
•
WBAN tier or Monitored Subject (MS): Wireless body area network is representing human being within the area under monitoring. This can also represent other subjects, other than humans, such as animals and plants. The MSs are equipped with on-body data collection sensors and communication capabilities using mobile device. Such mobile device has the ability to communicate with cloud using Cloudlet, Regional Cloud Provider and Global Cloud Provider infrastructures using WiFi or 3G technologies. The number of MSs can be ranged from hundreds to millions, depending on the regions and the density of the monitored area. The size of the monitored area depends on the number of MSs, the covered area by Cloudlet or Regional Cloud Providers [9], [34].
-
•
Cloudlet tier: It is composed of a local cloud system, which represents inexpensive, resource efficient, easy to deploy and moveable computing system with communication capabilities with MSs and other computing facilities on Regional tier. A Cloudlet consumes less amount of power for processing and communication with an acceptable quality of service compared with Regional and Global Cloud providers [9]. The number of Cloudlets in this tier depends on the size of the monitored area and the number of users. Each Cloudlet can handle data from tens or may be hundreds of MSs in the covered area. The covered area of the Cloudlet is determined by the transmission range of the WiFi technology, as we will discuss in Section 5. At the same time, the Cloudlet has the capability of running MapReduce operations to extract the abnormal data in the covered area, as we will study in Section B.
-
•
Regional Cloud tier: It is composed of a regional cloud system, which represents cloud resources that are specific to a zone, or a region, which can only be accessed by clients or users in the same zone or region. As we discussed in Section 3, the cloud provider in this tier can reach every single country in the world to extend their market share. The cloud provider can handle hundreds of deployed cloudlets in the region. The extended cloud deployments and its availability in most of the world regions is the key enabling factor in our model. In our model, the country based cloud provider system is called Regional cloud provider and presents regional cloud tier of our model, as seen in Fig. 3. The Regional cloud provider is a public cloud provider who is included in the cloud federation and it is enabled to support the cloud coordinator requirements. Regional cloud system has larger computing and storage capacity than the cloudlet in lower tier. In the model, the regional cloud tier receives the data from the cloudlet tier. It has the capability to process, store, share and transfer the data to a third party, like Global Cloud provider.
-
•
Global Cloud tier: It is composed of a Global Cloud system, which is the core processing and coordinator system that aims to process the collected data from different regional cloud provider in large scale to generate useful facts, observations, in order to find abnormal phenomena within the monitored data, or to detect or predict any epidemic disease in global field. Then, a control decision can be taken by the health service provider against that epidemic. The Global Cloud tier represents the top one in the proposed system. Global Cloud tier has two different functionalities, data processing and the overall system operations control (other tiers mainly perform data processing and transfer only). As we discussed in Section 3, the Global Cloud is a high capacity system with the ability to process large amounts of data aggregated from the lower tiers. It is connected directly to the regional cloud system through a high speed backbone network to reduce data transfer latency.
4.2. Data processing model
In this section we discuss the integration of the MapReduce model proposed in Section 1 with data processing line in cloud service provider in the multi-tier system that is shown in Fig. 3. The MapReduce model can be implemented to process the collected data in any of Tier-2, Tier-3 and Tier-4. The data is collected from MSs in Tier-1 and the implementation of the MapReduce model will be on top of Cloudlet, Regional and Global Cloud service providers. In this paper we did not consider processing the data in a user level of Tier-1 or in WBAN because of the limited power resources in WBAN [35], a problem which is out of scope of this paper.
MapReduce data processing model is shown in Fig. 4 , which is similar to the model proposed in [36] and it is composed of the following components:
-
•
Data collector: This component is responsible for data collection from the lower tier, where the MSs data can be processed in either Cloudlet, Regional or Global Cloud providers in order to detect any abnormality in the data or any epidemic disease. The abnormal data and the observations are delivered to the health service provider through the Global provider in order to take any action. In each cloud service provider, data will be first stored in a shared storage system that can be used by different processing elements. Then data will be split into a number of slices that are feeding the MapReduce model discussed in Section 1. In the MapReduce model, the following modules and processing entity are used in order to extract the intermediate pairs of abnormal data from data collector.
-
•
Tasks scheduler: This component is responsible for the data flow and processing assignments for the MapReduce system. It also provides an interface to deploy user defined functions on the data. These user defined functions reflect the objectives of processing the data (e.g. detecting the abnormal data).
-
•
Map phase operations: The Map phase is the first part of the MapReduce processing model. The mappers are a set of high capacity processing elements that receive their input data from the Enterprise cloud (EP) data collector (i.e. usually one slice per mapper). Then, each mapper performs a set of commands (e.g. set of user defined functions) provided by the task scheduler. The mapper also generates a classified data with a predefined set of objectives (i.e. map the input data to these objectives). A map function is used in order to specify a relation between pair of inputs and outputs. The output of the Map phase will be used as input to the Reduce phase for further processing.
-
•
Reduce phase operations: The aim of this phase is to reduce the amount of data that will be used to generate the useful facts or the one to be examined by humans (e.g. physicians, scientists, etc.). The reduce operations are also user defined functions that can be defined by the task scheduler (abnormal data in our case).
-
•
Cloud service provider: It consists of data analyst, decision maker, etc. The cloud service provider receives its input from Global Cloud provider in Tier-4 that is built on top of the health awareness system.
Fig. 4.
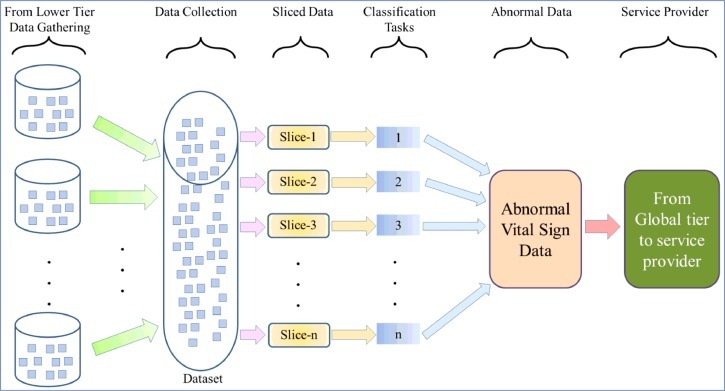
Data processing model for global health awareness system.
4.3. Modeling of multi-tier data processing
In this section, an optimization problem is formulated using mixed integer-linear programming to address the problem of determining the best processing level for a large scale health awareness system in order to handle the large amount of collected data by the system and to reduce the total system delay. The computed strategy may include processing the collected data in a decentralized fashion which we called computing at the edge or processing at the edge. In this strategy, the collected data is processed in the lower tiers closer to its sources of WBAN. By doing that, we are proposing new innovation method of simulating a large scale data in parallel and using mixed integer-linear programming. In this case the transferred data size is less while the processing delay is larger as we are using a cloud system with lower capacity in the lower tiers.
In another approach, we used a centralized strategy in which the data will be transferred from its sources all the way to the global cloud system. The data processing will take place in one centralized location. The global cloud system is a very powerful system compared with other tiers and data processing should not cost a lot of time, however, the delay incurred by the amount of data and the data transfer will contribute the largest share of the total system delay. The proposed model achieves its goal by calculating the total delay incurred for processing and transferring the data from its source of generation to its final destination in the globe cloud system and health service provider. Fig. 4 represents our system model that we are going to present in this section.
The main contribution of the proposed global health awareness system is to minimize the computation delay, from the source of the collected data in WBAN sensors to the global cloud or health service provider. Let's define D S, U, D U, CL, D CL, CP and D CP, G to be the computation delay of the collected data in the user level, cloudlet, regional and global cloud providers, respectively. The goal is to minimize the overall delay of D S, U + D U, CL + D CL, CP + D CP, G. Now, let's define the data collected from the sensor system in WBAN by:
| (1) |
with fraction of F0, which represents the delivery ratio of the collected data SN by using each sensor s in a set of S sensors in WBAN of user u using cloudlet c, and during time h and service provider r. The amount of collected data from users in Tier-1 in cloudlets of Tier-2 can be defined as:
| (2) |
where F1 denotes the collection fraction of data in cloudlets c from u users in a set of U discrete users, and u ∈ U and using the WiFi data transmission technology. On the other hand, the amount of collected data from cloudlets in Tier-2 in regional cloud of Tier-3 can be defined as:
| (3) |
Here F2 denotes to the collected fraction of data in regional clouds r from c cloudlets in a set of CL, where c ∈ CL. The amount of collected data in global cloud can be represented by:
| (4) |
where F3 denotes to the collected fraction of data in global cloud from r regional clouds in a set of CP, where r ∈ CP.
The total amount of consumed power can be divided into four types: the consumed power in WBANs (or Tier-1), the consumed power in cloudlets (or Tier-2), the consumed power in regional cloud providers (or Tier-3) and the consumed power in the global cloud center (or Tier-4). The consumed power at any point of time t can be expressed as:
| (5) |
where Ps, Pc, Pr and Pg in Eq. (5) are the consumed power in Tier-1, Tier-2, Tier3 and Tier-4, respectively. T1, T2, T3 and T4 represent the tier power weights where the data will be processed. For example, T1 represents a user-defined power weight by which the wearable sensors on WBAN will consume, where studying the amount of this power is out of scope of the paper. Notice that, at any time the data will be processed in only one of the four tiers that we have in the system.
In each tier, the total consumed power can be divided into two types. Power is consumed by the IT equipment devices, such as servers, routers, etc., or power consumed by non-IT equipment devices, like the ones that are used for conversation, lighting, cooling, etc. Let's define Eusage to be the total consumed powers in the server to the consumed power by the IT devices. Eusage is used as a metric for datacenter Power Usage Efficiency (PUE), and it is in the range of 1 ≤ E usage ≤ 2, which is usually 1.14. To compute the consumed power at the server, let us define Pidle be the average consumed power when the server is idle and Ppeak when it is handling a service request. Equations from (6)–(8) are used to compute the power at any time t in Tier-3, Tier-2 and Tier-1 by global cloud, regional cloud and cloudlet servers, respectively:
| (6) |
| (7) |
| (8) |
where mg,mCP and mCL are the number of servers in global cloud, regional cloud and cloudlet, respectively. are the average server utilization in each of global cloud, regional cloud and cloudlet, respectively at time t. For simplicity and due to the scope of the paper, we will ignore the process power at the sensor level and we will consider only the consumed power by the data transmission using the WiFi Technology to cloudlet, as we discussed in Section 1. The average server utilization in each cloud provider and at time t can be defined as:
| (9) |
| (10) |
| (11) |
where μg, μCP and μCL are the total number of service requests that a server can handle in one second in global cloud, regional cloud and cloudlet, respectively. To avoid Service Level Agreement (SLA) violations, we limit the average server utilization at each cloud provider by a constant upper bound of ⋎max ∈ (0, 1]. Thus, we have the following conditions: .
The delay at any tier is mainly a combination of data processing delay (or DP), Queuing delay (or DQ) and Transmission delay or (DT). So, the total delay at each tier can be expressed by Delay = DP + DQ + DT and it should be less than the maximum delay Dmax, as needed by SLA. The process delay in this expression includes the MapReduce infrastructure process engine. In this paper we will not go further in covering this topic because of space limitations. The total delay in Tier-1 is expressed by:
| (12) |
where
μ is the capacity of used server, λ is the traffic arrivals and γ is the utilization of the service in WBAN.
The total delay in Tier-2 can is expressed by:
| (13) |
here
and DT u, c is the distance between the user and cloudlet, which depends on WiFi Technology.
While the total delay in Tier-3 can is expressed by:
| (14) |
where
and DT c, r is the distance between cloudlet and the regional cloud provider. The propagation delay increases by10 ms every thousand kilometers (at each direction from and to the data center) when fiber optic links are used [37]. Without loss of generality, we assume that Dmax = 70 ms.
Finally, the total delay in Tier-4 can is expressed by:
| (15) |
where
and DT r, g is the distance between the regional and global cloud providers. As we discussed before, the propagation delay increases by10 ms every thousand kilometers and Dmax = 70 ms.
The goal is to minimize the combination of D S, U + D U, CL + D CL, CP + D CP, G. For simplicity, we assume that system is M/M/1 queuing system consists of a single queuing station with a single server (one buffer with one output link in a network context).
5. Performance results
5.1. System settings
Several sensor nodes (e.g. wearable nodes) are used to construct the WBAN by mounting them on a human subject. The sensor node can be mounted on the head, wrist, upper-arms, thighs, ankles and the waist area to collect different vital signs, as shown in Fig. 1. The mounted sensors send the measured data to the sink node. The sink sensor aggregates the collected data and sends it as one packet to a Personal Digital Assistant (PDA) or a smart phone via Bluetooth. Then, the aggregated data is sent using cellular data communication or WiFi to the cloud provider. The sensor node comprises of a Mica2Dot MOTE with Chipcon's SmartRF CC1000 radio chip [38] of 900 MHz which is manufactured by a TinyOS operating system, and a Crossbow Inc. sensor card of MTS510 [39]. The sensor node runs from a button cell of 570 mAH with overall weight of around 10 g. As Medium Access Control protocol, the default Carrier Sense Multiple Access protocol is used with small transmission range with communication data rate of 19.2 kbps [36], [37], [38].
As data communication between the users’ mobile or electronic device and cloud service provider, either a WiFi or cellular data communications are used. A WiFi is a very popular communication technology for wirelessly data exchange between mobile device and internet using radio waves. Wifi is based on IEEE 802.11 standards [40] which can be capable as Wireless Local Area Network or (WLAN). On the other hand, cellular network is a radio distributed network over areas, where each mobile device is served by access points with transceiver spread in different locations. A cellular network communication allows large number of mobile devices to communicate with fixed transceivers of Internet and with each other. The differences between using these two communication technologies are the followings. A WBAN user with WiFi, is able to transmit the data to the cloud with low delay and low power compared with cellular network technology [41], but with limited transmission range of 100 m [42]. The successful transmitting data to the cloud service is supported by WiFi capability due to supporting the power constrained in WBAN sensors. In our prototype system, the WiFi technology is available by cloudlet in the covered area. Via WiFi, it was shown that, the transmission delay of 46 Bytes data packet will take roughly 0.045 ms [41], [43] and with a power cost of 30 mw. On the other hand, a cellular network connection (e.g. 3G, 4G and LTE) of longer transmission range, it is capable of sending the data packet to the cloud service from any location that is covered by cellular technology, which is geographically wider in area compared with the covered area of WiFi technology [41], [43]. Via cellular technology, it was shown that the transmission delay of 46 Bytes data packet will take roughly 0.45 ms and with a power cost of 300 mw [41], [43]. Though the WiFi is mostly free of charge in terms of power and delay, the cellular connection is very costly. Cellular connection is very important to support WBANs mobility in case of the absence of WiFi and cloudlet in the area and to support the scalability of the proposed system under large number of WBANs.
5.2. Data generation
In this section we develop a data generator engine in order to generate data to validate the performance of the proposed health awareness system. Since we are dealing with a very large scale system, we will focus only on collecting of few vital signs parameters, such as, blood pressure, temperature, blood pressure, heart rate and blood glucose. The collected data from each user is sent by on-body smart phone or tablet pcs to cloudlet in Tier-2 using WiFi communication technology in real-time manner [8], [9]. In our simulation results, the number of users is ranged from 1000 to 1,000,000. In the proposed system, we assume that each vital sign measured data from each user follows Normal or Gaussian distribution for a single data generation. While for data arrivals and transmissions it follows M/M/1 queueing system. We used Gaussian distribution for single data generation because it is frequently happening in vital sign and it has a continuous distribution. At the same time, it tells how frequently that the real observation fits between two real threshold values, which is considered as normal range. Then, it will help to detect the abnormal data. Gaussian distribution is very imperative and well known in many studies as statistics analysis for social and ordinary observations using real random variable with unknown distribution [8]. A random distribution N(τ, σ 2) with mean τ and standard deviation σ can be implemented using density function of.
As we discussed in Section C, we assume that system is M/M/1 queuing system consists of a single queuing station with a single server (one buffer with one output link in a network context). We assume that the transmitted data from each user follows M/M/1 queueing system with a Poisson arrival process of , with a mean of exponential interval of 1/λ and a mean of exponential service of 1/μ. In real-life system, this assumption is very match with the arrival data in proposed system. It is not only supporting a large scale data collection, in this system the impact of single users’ data is very small on the system resources [44]. On the other hand, the transmission of users data are independent, which means, each users’ data are independent of other users.
We used the above random distribution function to generate users vital signs data, like blood pressure, temperature, heart rate and blood glucose. To generate normal vital signs data, we followed NIH as data measurements. Therefore, the normal range of the measured temperature should be from 95 to 104 °F and average of 98 °F. However, the blood pressure is ranged from 90 to 140 mm/Hg, as a high, and from 60 to 90 mm/Hg, as a low, with averages of 115 mm/Hg and 75 mm/Hg, respectively. The level of Normal blood glucose is ranged from 82 to 110 mg/dL, or 4.4 to 6.1 mmol/L with average of 100 mg/dL. Then, the human heart rate is ranged from 60 to 100 bpm with average of 80 bpm. It should be noticed that, all of these values are matter of changed according to the gender, age or location. The data is called abnormal if it is not within the range that is decided by NIH. In order to detect the abnormality of the measured vital sign, we used threshold-based algorithm, where the data is called abnormal, if it is out of the proposed threshold range. In data generation, we tried to have some universal measurements to be used as sample study to evaluate our proposed system.
5.3. Performance metrics
The main parameter that we are going to look at it during our study is the performance delay of the proposed global health awareness system. The delay here is measuring the overall time that the system needs until the health service provider gets the output results from the collected and processed data in global cloud service provider. As we discussed in Section 4, the total delay depends on the computation delay, from the source of the collected data in WBAN sensors to the global cloud or health service provider. The amount of delay includes data processing delay, queuing delay and transmission delay. The main parameter that may impact on the delay is the number of monitored uses, which represents the covered area. Other parameters that have significant impact on the delay are the number of servers and the capacity of server in each cloud provider in each tier that we have. In next sections we will study the impact of number of users, number of servers and the server capacity on the system delay.
5.4. Multi-tier and number of users
To study the impact of number of user on delay, sets of experiments were carried out using extended MCC [14] simulator, which is an extended version of CloudExp [45]. The following settings were used in these experiments. The number of servers in each cloud service providers mg,mr and mc are set to be 1000, 100 and 10, respectively. Each user sends a data packet with its vital signs every 10 s. The server capacity is set to 10. For simplicity, the collection fraction of data F in each tier is set to 1. The number of cloudlets in each region is set to 10 and the total number of regions is set to 10. The total number of users are set to be 1000, 2000, 5000, 10,000, 20,000, 50,000, 100,000 and 1,000,000. Fig. 5 shows the delay performance results. Each data point in the figure represents runs of 10 experiments. The following observations can be made from Fig. 5. First, increasing the number of data set by monitoring more number of users will increase the delay exponentially at any tier we assigned to process the data. That is because of increasing the transmission delay, queuing delay and processing delay dramatically when the data goes to the upper tiers, as we discussed in Section 4 and Eqs. (12)–(15). The second observation that we can made from Fig. 5 is, as the process data goes to the upper tiers, the overall delay is increased. That is because of increasing the number of transmissions to the upper tiers and processing data in lower tiers will reduce the amount of data in queue, which significantly reduce the amount of delay.
Fig. 5.
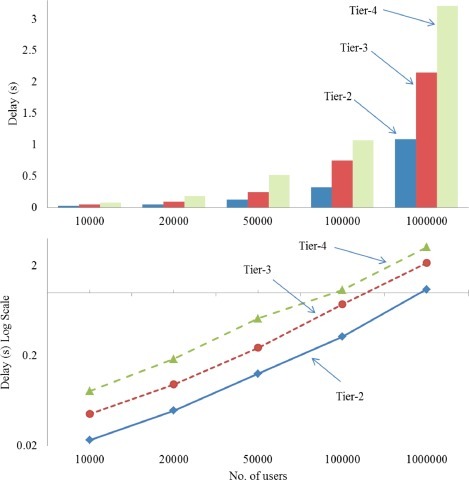
The impact of number of users on delay.
5.5. The impact of number of servers on delay
To study the impact of number of servers on delay, the following experiments we conducted. In these experiments the number of users are set to 100,000, the number of cloudlets and regional cloud, the capacity of server and all other parameter are set same as we discussed in Section D. The number of servers is changed from 10 to 200 in each tier. Fig. 6 shows the delay results. Same observations can be made as in Fig. 5. The amount of delay is increased by going to upper tier and total is decreased exponentially by increasing the number of servers. This is also clearly shown in Eqs. (12)–(15) when we discussed the mode in Section 4.
Fig. 6.
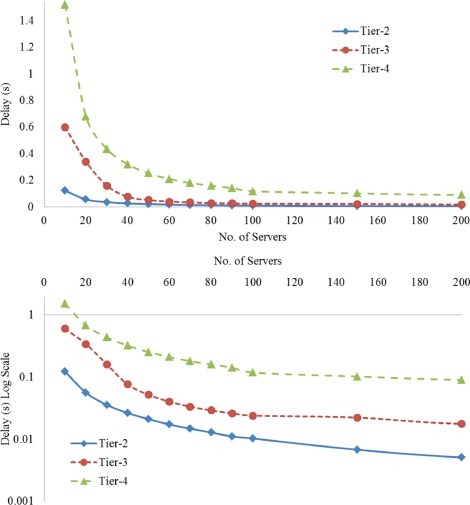
Impact of number of servers on system delay.
5.6. The impact of capacity of server on delay
In order to study the impact of the capacity of server on the delay, the following experiments we carried out. Same experiment settings are used as in previous experiments in last section. Here the capacity of server in each cloud provider is changed from 3 to 20. Fig. 7 shows the results of these experiments. Increasing the server's capacity will significantly decrease the overall delay. The server capacity does not have that impact on Tier-2 because of the low load in lower tier of cloudlet.
Fig. 7.
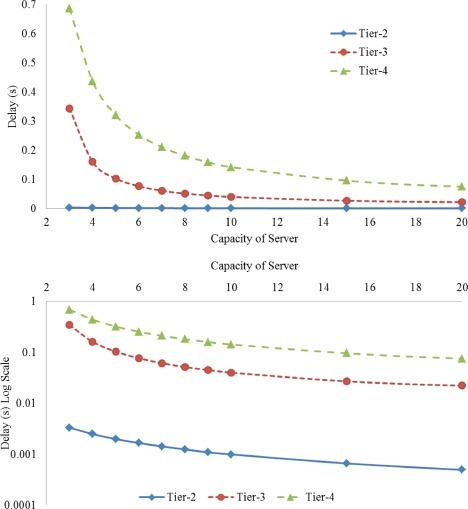
The Impact of capacity of server on system delay.
6. Conclusion and future work
In this paper, we presented a novel and holistic solution for the problem of constructing an effective global health awareness system that overcome the grand challenges associated with such systems. The system is built on the top of the resources rich and easy to deploy cloud computing system. Moreover, we extended the InterCloud system functionality to support a centralized control framework for a multi-tier cloud system. In this paper, integrated data processing, storing, sharing and transmitting with Intercloud as part of global health awareness system has been proposed, and coupled with MapReduce model in multi-tiers cloud provider. Each tier of the system is characterized with different processing capacity and data transfer delay overhead. These characteristics facilitate flexibility in using the system in different scenarios with different requirements. Also, we modeled the system end to end delay as a mixed integer liner programing optimization problem. Our results showed that processing the data in lower tier, like in cloudlet will significantly reduce the overall delay because of reducing the number of transmissions to the upper tiers and processing data in lower tiers will reduce the amount of data in queue, which significantly reduce the amount of delay.
Acknowledgments
This Project is supported by Research Deanship at Jordan University of Science and Technology, Grant nos. 20130179 and 20150050.
References
- 1.Peiris J.S.M., Guan Y., Yuen K.Y. Severe acute respiratory syndrome. Nat. Med. 2004;10:S88–S97. doi: 10.1038/nm1143. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 2.Flu.gov, H5N1 Avian Flu (H5N1 Bird Flu). [Online]. Available: http://www.flu.gov/about_the_flu/h5n1/. [Accessed: 29-Jun-2015].
- 3.Cecchine G., Moore M. Infectious disease and national security: strategic information needs. Rand Corp. 2006 [Google Scholar]
- 4.Calain P. Exploring the international arena of global public health surveillance. Health Policy Plan. 2007;22(1):2–12. doi: 10.1093/heapol/czl034. [DOI] [PubMed] [Google Scholar]
- 5.Cenciarelli O., Pietropaoli S., Malizia A., Carestia M., D’Amico F., Sassolini A., Di Giovanni D., Rea S., Gabbarini V., Tamburrini A. Ebola virus disease 2013-2014 outbreak in west Africa: an analysis of the epidemic spread and response. Int. J. Microbiol. 2015;2015 doi: 10.1155/2015/769121. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 6.Louis M.S. Global health surveillance. MMWR Surveill Summ. 2012;61:15–19. no. Suppl. [Google Scholar]
- 7.Jovanov E., Milenkovic A., Otto C., De Groen P., Johnson B., Warren S., Taibi G. Proceedings of the Twenty-seventh Annual International Conference of the Engineering in Medicine and Biology Society (IEEE-EMBS 2005) 2005. A WBAN system for ambulatory monitoring of physical activity and health status: Applications and challenges; pp. 3810–3813. [DOI] [PubMed] [Google Scholar]
- 8.Quwaider M., Jararweh Y. Proceedings of the Eighth International Conference for Internet Technology and Secured Transactions (ICITST 2013) 2013. Cloudlet-based for big data collection in body area networks; pp. 137–141. [Google Scholar]
- 9.Quwaider M., Jararweh Y. Cloudlet-based efficient data collection in wireless body area networks. Simul. Model. Pract. Theory. 2015;50(0):57–71. Jan. [Google Scholar]
- 10.WHO | Ebola virus disease, WHO. [Online]. Available: http://www.who.int/csr/disease/ebola/en/. [Accessed: 30-Oct-2014].
- 11.Gubbi J., Buyya R., Marusic S., Palaniswami M. Internet of Things (IoT): A vision, architectural elements, and future directions. Future Gen. Comput. Syst. 2013;29(7):1645–1660. [Google Scholar]
- 12.Lee K.-H., Lee Y.-J., Choi H., Chung Y.D., Moon B. Parallel data processing with MapReduce: a survey. ACM SIGMOD Rec. 2012;40(4):11–20. [Google Scholar]
- 13.Jin C., Buyya R. European Conference on Parallel Processing. 2009. Mapreduce programming model for. net-based cloud computing; pp. 417–428. [Google Scholar]
- 14.Quwaider M., Jararweh Y., Al-Alyyoub M., Duwairi R. Experimental framework for mobile cloud computing system. Proc. Comput. Sci. 2015;52:1147–1152. [Google Scholar]
- 15.Wagener J., Spjuth O., Willighagen E.L., Wikberg J.E. XMPP for cloud computing in bioinformatics supporting discovery and invocation of asynchronous web services. BMC bioinform. 2009;10(1):279. doi: 10.1186/1471-2105-10-279. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 16.Fernández-Cardeñosa G., de la Torre-Díez I., López-Coronado M., Rodrigues J.J. Analysis of cloud-based solutions on EHRs systems in different scenarios. J. Med. Syst. 2012;36(6):3777–3782. doi: 10.1007/s10916-012-9850-2. [DOI] [PubMed] [Google Scholar]
- 17.Rolim C.O., Koch F.L., Westphall C.B., Werner J., Fracalossi A., Salvador G.S. Proceedings of the Second International Conference on eTELEMED’10. 2010. A cloud computing solution for patient's data collection in health care institutions, in eHealth, Telemedicine, and Social Medicine, 2010; pp. 95–99. [Google Scholar]
- 18.Kossmann D., Kraska T., Loesing S. Proceedings of the 2010 ACM SIGMOD International Conference on Management of Data. 2010. An evaluation of alternative architectures for transaction processing in the cloud; pp. 579–590. [Google Scholar]
- 19.Soror A.A., Minhas U.F., Aboulnaga A., Salem K., Kokosielis P., Kamath S. Automatic virtual machine configuration for database workloads. ACM Trans. Database Syst. (TODS. 2010;35(1):7. [Google Scholar]
- 20.Grozev N., Buyya R. Inter-Cloud architectures and application brokering: taxonomy and survey. Softw. Pract. Exp. 2014;44(3):369–390. [Google Scholar]
- 21.Buyya R., Ranjan R., Calheiros R.N. Algorithms and Architectures for Parallel Processing. Springer; 2010. Intercloud: Utility-oriented federation of cloud computing environments for scaling of application services; pp. 13–31. [Google Scholar]
- 22.Bernstein D., Ludvigson E., Sankar K., Diamond S., Morrow M. Proceedings of the Fourth International Conference on Internet and Web Applications and Services (ICIW ’09) 2009. Blueprint for the Intercloud – Protocols and formats for cloud computing interoperability; pp. 328–336. [Google Scholar]
- 23.Rochwerger B., Breitgand D., Levy E., Galis A., Nagin K., Llorente I.M., Montero R., Wolfsthal Y., Elmroth E., Caceres J., Ben-Yehuda M., Emmerich W., Galan F. The Reservoir model and architecture for open federated cloud computing. IBM J. Res. Dev. 2009;53(4):4:1–4:11. Jul. [Google Scholar]
- 24.Celesti A., Tusa F., Villari M., Puliafito A. Proceedings of the Third IEEE International Conference on Cloud Computing (CLOUD) 2010. How to enhance cloud architectures to enable cross-federation; pp. 337–345. [Google Scholar]
- 25.Ferrer A.J., HernáNdez F., Tordsson J., Elmroth E., Ali-Eldin A., Zsigri C., Sirvent R., Guitart J., Badia R.M., Djemame K., others OPTIMIS: A holistic approach to cloud service provisioning. Future Gen. Comput. Syst. 2012;28(1):66–77. [Google Scholar]
- 26.Buyya R., Yeo C.S., Venugopal S. Proceedings of the Tenth IEEE International Conference on High Performance Computing and Communications (HPCC’08) 2008. Market-oriented cloud computing: Vision, hype, and reality for delivering it services as computing utilities; pp. 5–13. [Google Scholar]
- 27.Li A., Yang X., Kandula S., Zhang M. Proceedings of the Tenth ACM SIGCOMM Conference on Internet Measurement. 2010. CloudCmp: comparing public cloud providers; pp. 1–14. [Google Scholar]
- 28.Jackson K.R., Ramakrishnan L., Muriki K., Canon S., Cholia S., Shalf J., Wasserman H.J., Wright N.J. Proceedings of the Second IEEE International Conference on Cloud Computing Technology and Science (CloudCom 2010) 2010. Performance analysis of high performance computing applications on the amazon web services cloud; pp. 159–168. [Google Scholar]
- 29.Nagakura H., Sakurai A. Middleware for creating private clouds. Fujitsu Sci. Tech. J. (FSTJ) 2011;47(3):263–269. [Google Scholar]
- 30.Shiratori T., Hara H. Operations Visualization for private clouds. Fujitsu Sci. Tech. J. 2011;47(3):311–315. [Google Scholar]
- 31.Rallapalli S., Gondkar R.R. Proceedings of Third International Conference on Advanced Computing, Networking and Informatics. 2016. A study on cloud based soa suite for electronic healthcare records integration; pp. 143–150. [Google Scholar]
- 32.Bonomi F., Milito R., Zhu J., Addepalli S. Fog computing and its role in the internet of things. Proceedings of the First Edition of the MCC Workshop on Mobile Cloud Computing; New York, NY, USA; 2012. pp. 13–16. [Google Scholar]
- 33.Bonomi F., Milito R., Natarajan P., Zhu J. Fog computing: A platform for internet of things and analytics. In: Bessis N., Dobre C., editors. Big Data and Internet of Things: A Roadmap for Smart Environments. Springer International Publishing; 2014. pp. 169–186. [Google Scholar]
- 34.Quwaider M., Jararweh Y. Proceedings of the Fifth International Conference on Information and Communication Systems (ICICS) 2014. An efficient big data collection in Body Area Networks; pp. 1–6. [Google Scholar]
- 35.Quwaider M., Biswas S. Proceedings of the Eighth International Conference on Body Area Networks. 2013. Modeling energy harvesting sensors using accelerometer in body sensor networks; pp. 148–152. [Google Scholar]
- 36.Quwaider M., Jararweh Y. A cloud supported model for efficient community health awareness. Pervasive Mob. Comput. 2016;28:35–50. [Google Scholar]
- 37.Fan X., Weber W.-D., Barroso L.A. Power provisioning for a warehouse-sized computer. ACM SIGARCH Comput. Archit. News. 2007;35:13–23. [Google Scholar]
- 38.Link to Cipcon SmartRF CC1000 Datasheet, http://www.chipcon.com/files/CC1000_Data_Sheet_2_1.pdf.
- 39.Crossbow Technology, Inc., http://www.xbow.com. [Online]. Available: http://www.xbow.com.
- 40.Biswas S., Quwaider M. Proceedings of the SPIE Defense and Security Symposium, Multisensor, Multisource Information Fusion: Architectures, Algorithms, and Applications. 2008. Remote monitoring of soldier safety through body posture identification using wearable sensor networks; pp. 1–14. [Google Scholar]
- 41.R. Balani, Energy consumption analysis for bluetooth, wifi and cellular networks, [Online]. http://nesl.ee.ucla.edu/fw/documents/reports/2007/PowerAnalysis.pdf, 2007.
- 42.Joseph D.A., Manoj B.S., Murthy C. Proceedings of the Second ACM International Workshop on Wireless Mobile Applications and Services on WLAN Hotspots. 2004. Interoperability of Wi-Fi hotspots and cellular networks; pp. 127–136. [Google Scholar]
- 43.Dementyev A., Hodges S., Taylor S., Smith J. Proceedings of the Wireless Symposium (IWS), 2013. IEEE International; 2013. Power consumption analysis of Bluetooth Low Energy, ZigBee and ANT sensor nodes in a cyclic sleep scenario; pp. 1–4. [Google Scholar]
- 44.Sturgul J.R. first ed. Society for Mining, Metallurgy & Exploration, Incorporated; 2000. Mine Design: Examples Using Simulation with Cdrom. [Google Scholar]
- 45.Jararweh Y., Jarrah M., kharbutli M., Alshara Z., Alsaleh M.N., Al-Ayyoub M. CloudExp: A comprehensive cloud computing experimental framework. Simul. Model. Pract. Theory. 2014;49(0):180–192. Dec. [Google Scholar]