

Abstract
TF-IDF is one of the most commonly used weighting metrics for measuring the relationship of words to documents. It is widely used for word feature extraction. In many research and applications, the thresholds of TF-IDF for selecting relevant words are only based on trial or experiences. Some cut-off strategies have been proposed in which the thresholds are selected based on Zipf’s law or feedbacks from model performances. However, the existing approaches are restricted in specific domains or tasks, and they ignore the imbalance of the number of representative words in different categories of documents. To address these issues, we apply game-theoretic shadowed set model to select the word features given TF-IDF information. Game-theoretic shadowed sets determine the thresholds of TF-IDF using game theory and repetition learning mechanism. Experimental results on real world news category dataset show that our model not only outperforms all baseline cut-off approaches, but also speeds up the classification algorithms.
Keywords: Feature extraction, TF-IDF, Text classification, Game-theoretic shadowed sets
Introduction
Term Frequency-Inverse Document Frequency, or TF-IDF, is one of the most commonly used weighting metrics for measuring the relationship of words and documents. It has been applied to word feature extraction for text categorization or other NLP tasks. The words with higher TF-IDF weights are regarded as more representative and are kept while the ones with lower weights are less representative and are discarded. An appropriate selection of word features is able to speed up the information retrieval process while preserving the model performance. However, for many works, the cutoff values or the thresholds of TF-IDF for selecting relevant words is only based on guess or experience [6, 11, 12]. Zipf’s law is used to select words whose IDF exceeds a certain value [10]; Lopes et al. [9] proposed a cut-off policy by balancing the precision and recall from the model performance.
Despite their success, those cut-off policies have certain issues. The cut-off policy that the number of words to keep is determined by looking at the precision and recall score of the model can be restricted in specific domains or tasks. In addition, the number of relevant words may vary in different categories of documents in certain domains. For instance, there exists an imbalance between the number of representative positive words and negative words in many sentiment classification tasks. Thus, a cut-off policy that is able to capture such imbalance is needed.
To address these issues, we employ game-theoretic shadowed sets (GTSS) to determine the thresholds for feature extraction. GTSS, proposed by Yao and Zhang, is a recent promising model for decision making in the shadowed set context [22]. We calculate the difference of TF-IDF for each word between documents as the measurement of relevance, and then use GTSS to derive the asymmetric thresholds for word extraction. GTSS model aims to determine and explain the thresholds from a tradeoff perspective. The words with the difference of TF-IDF less than 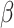 or greater than
or greater than 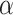 are selected. We regard the words whose difference of TF-IDF are between
are selected. We regard the words whose difference of TF-IDF are between 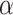 and
and  as neutral. These words can be safely removed since they can not contribute much in text classification.
as neutral. These words can be safely removed since they can not contribute much in text classification.
The results of our experiments on a real world news category dataset show that our model achieves significant improvement as compared with different TF-IDF based cut-off policies. In addition, we show our model can achieve comparable performance as compared to the model using all words’ TF-IDF as features, while greatly speed up the classification algorithms.
Related Work
TF-IDF is the most commonly used weighting metrics for measuring the relationship of words and documents. By considering the word or term frequency (TF) in the document as well as how unique or infrequent (IDF) a word in the whole corpus, TF-IDF assigns higher values to topic representative words while devalues the common words. There are many variations of TF-IDF [19, 20]. In our experiments, we use the basic form of TF-IDF and follow the notation given in [7]. The TF-IDF weighted value 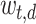 for the word t in the document d is thus defined as:
for the word t in the document d is thus defined as:
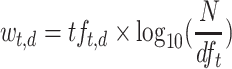 |
1 |
where  is the frequency of word t in the document d, N is the total number of documents in the collection, and
is the frequency of word t in the document d, N is the total number of documents in the collection, and  is the number of documents where word t occurs in.
is the number of documents where word t occurs in.
TF-IDF measures how relevant a word to a certain category of documents, and it is widely used to extract the most representative words as features for text classification or other NLP tasks. The extraction is often done by selecting top n words with the largest TF-IDF scores or setting a threshold below which the words are regarded as irrelevant and discarded. But an issue arises about how to choose such cut-off point or threshold so as to preserve the most relevant words. Many works choose such threshold only based on trial or experience [6, 11, 12, 23]. On the other hand, some approaches address the issue. Zipf’s law is used to select the words whose IDF exceeds a certain value in order to speed up information retrieval algorithms [4, 10]. Lopes et al. [9] proposed a cut-off policy which determines the number of words to keep by balancing precision and recall in downstream tasks. However, such cut-off points should not be backward induced by the performance of downstream task; rather, the thresholds should be derived before feeding the extracted words to the classifier to speed up the model without reducing the performance. In addition, for certain domains, the number of relevant words may vary in different categories of documents. For instance, the number of words relevant to positive articles and the number of words relevant to negative articles are often imbalanced in many sentiment analysis tasks. Therefore, the cut-off points or thresholds may also vary in different categories. By observing these drawbacks, we attempt to find asymmetric thresholds of TF-IDF for feature extraction by using game-theoretic shadowed sets.
Methodology
In this section, we will introduce our model in details. Our model aims to find an approach of extracting relevant words and discarding less relevant words based on TF-IDF information so as to speed up learning algorithms while preserving the model performance. We first calculate the difference of TF-IDF for each word between documents as one single score to measure the degree of relevance, and then use game-theoretic shadowed sets to derive the asymmetric thresholds for words extraction.
TF-IDF Difference as Relevance Measurement
Consider a binary text classification task with a set of two document classes 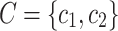 . For each word t, we calculate the difference of TF-IDF weighted value between document
. For each word t, we calculate the difference of TF-IDF weighted value between document 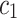 and
and 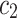 as:
as:
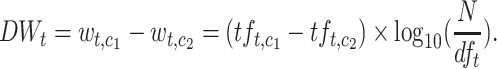 |
2 |
We use  to measure how relevant or representative the word t is to the document classes. The greater the magnitude of
to measure how relevant or representative the word t is to the document classes. The greater the magnitude of  , the more representative the word t is to distinguish the document categories. A large positive value of
, the more representative the word t is to distinguish the document categories. A large positive value of  indicates that a word t is not common word and more relevant to the document
indicates that a word t is not common word and more relevant to the document  , while a significant negative value shows the word t is representative to document
, while a significant negative value shows the word t is representative to document 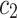 . If
. If 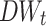 is closed to zero, then we regard the word t as neutral. In the next section, we will choose the cut-off thresholds for selecting the most representative word features by using the Game-theoretic Shadowed Sets method. For convenience, we here normalize the
is closed to zero, then we regard the word t as neutral. In the next section, we will choose the cut-off thresholds for selecting the most representative word features by using the Game-theoretic Shadowed Sets method. For convenience, we here normalize the  with min-max linear transformation.
with min-max linear transformation.
Shadowed Sets
A shadowed set S in the universe U maps the membership grades of the objects in U to a set  , i.e.,
, i.e., 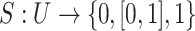 a pair of thresholds
a pair of thresholds 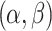 while
while 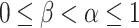 [13]. Shadowed sets are viewed as three-valued constructs induced by fuzzy sets, in which three values are interpreted as full membership, full exclusion, and uncertain membership [15]. Shadowed sets can capture the essence of fuzzy sets at the same time reducing the uncertainty from the unit interval to a shadowed region [15]. The shadowed set based three-value approximations are defined as a mapping from the universe U to a three-value set
[13]. Shadowed sets are viewed as three-valued constructs induced by fuzzy sets, in which three values are interpreted as full membership, full exclusion, and uncertain membership [15]. Shadowed sets can capture the essence of fuzzy sets at the same time reducing the uncertainty from the unit interval to a shadowed region [15]. The shadowed set based three-value approximations are defined as a mapping from the universe U to a three-value set 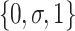 , if a single value
, if a single value 
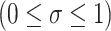 is chosen to replace the unit interval [0, 1] in the shadowed sets, that is [3],
is chosen to replace the unit interval [0, 1] in the shadowed sets, that is [3],
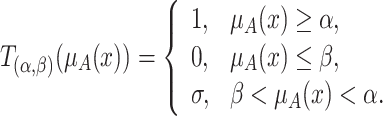 |
3 |
The membership grade 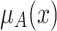 of an object x indicates the degree of the object x belonging to the concept A or the degree of the concept A applicable to x [21].
of an object x indicates the degree of the object x belonging to the concept A or the degree of the concept A applicable to x [21].
Given a concept A and an element x in the universe U, if the membership grade of this element 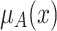 is greater than or equal to
is greater than or equal to 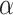 , the element x would be considered to belong to the concept A. An elevation operation elevates the membership grade
, the element x would be considered to belong to the concept A. An elevation operation elevates the membership grade 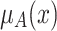 to 1 which represents a full membership grade [14]. If the membership grade
to 1 which represents a full membership grade [14]. If the membership grade  is less than or equal to
is less than or equal to 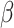 , the element x would not be considered to belong to the concept A. An reduction operation reduces the membership grade
, the element x would not be considered to belong to the concept A. An reduction operation reduces the membership grade  to 0 which represents a null membership grade [14]. If the membership grade
to 0 which represents a null membership grade [14]. If the membership grade  is between
is between  and
and 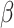 , the element x would be put in a shadowed area, which means it is hard to determine if x belongs to concept A.
, the element x would be put in a shadowed area, which means it is hard to determine if x belongs to concept A. 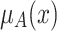 is mapped to
is mapped to 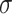 which represents the highest uncertainty, that is we are far more confident about including an element or excluding an element in the concept A. The membership grades between
which represents the highest uncertainty, that is we are far more confident about including an element or excluding an element in the concept A. The membership grades between 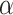 and
and 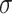 are reduced to
are reduced to  ; The membership grades between
; The membership grades between 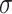 and
and  are elevated to
are elevated to  . We get two elevated areas,
. We get two elevated areas, 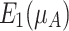 and
and 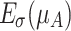 , and two reduced areas,
, and two reduced areas, 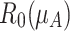 and
and  shown as the dotted areas and lined areas in Fig. 1 (a). Figure 1 (b) shows the shadowed set based three-value approximation after applying the elevation and reduction operations on all membership grades.
shown as the dotted areas and lined areas in Fig. 1 (a). Figure 1 (b) shows the shadowed set based three-value approximation after applying the elevation and reduction operations on all membership grades.
Fig. 1.
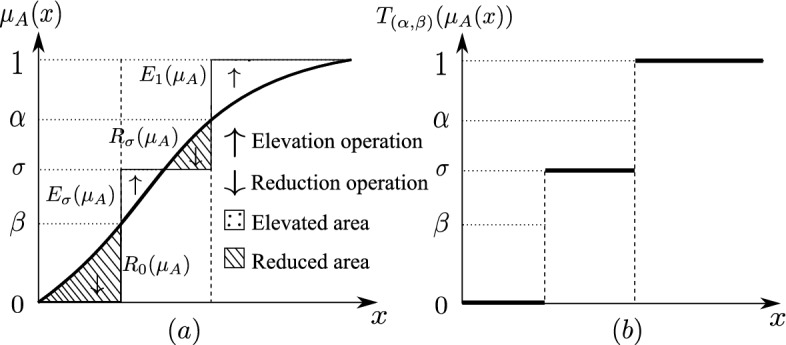
A shadowed set based three-value approximation
The vagueness is localized in the shadowed area as opposed to fuzzy sets where the vagueness is spread across the entire universe [5, 16].
Error Analysis
Shadowed set based three-value approximations use two operations, the elevation and reduction operations, to approximate the membership grades 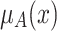 to a three-value set
to a three-value set 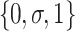 . Given an element x with the membership grade
. Given an element x with the membership grade  , the elevation operation changes the membership grade
, the elevation operation changes the membership grade  to 1 or
to 1 or 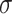 . The reduction operation changes the membership grade
. The reduction operation changes the membership grade 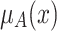 to 0 or
to 0 or 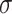 . These two operations change the original membership grades and produce the elevated and reduced areas which show the difference between the original membership grades and the mapped values 1,
. These two operations change the original membership grades and produce the elevated and reduced areas which show the difference between the original membership grades and the mapped values 1, 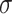 , and 0, as shown in Fig. 1(a). These areas can be viewed as the elevation and the reduction errors, respectively. The elevation operation produces two elevation errors
, and 0, as shown in Fig. 1(a). These areas can be viewed as the elevation and the reduction errors, respectively. The elevation operation produces two elevation errors 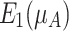 and
and 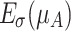 ; the reduction operation produces two reduction errors
; the reduction operation produces two reduction errors 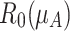 and
and 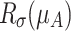 , that is
, that is
The elevation error
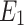 is produced when the membership grade
is produced when the membership grade 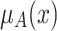 is greater than or equal to
is greater than or equal to 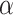 (i.e.,
(i.e., 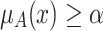 ), and the elevation operation elevates
), and the elevation operation elevates 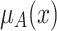 to 1. We have
to 1. We have 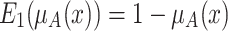 .
.The elevation error
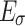 is produced when
is produced when 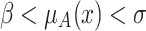 , and the elevation operation elevates
, and the elevation operation elevates 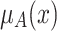 to
to 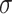 . We have
. We have 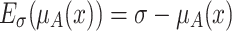 .
.The reduction error
 is produced when
is produced when 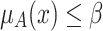 , and the reduction operation reduces
, and the reduction operation reduces 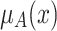 to 0. We have
to 0. We have 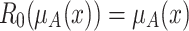 .
.The reduction error
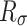 is produced when
is produced when 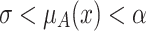 , and the reduction operation reduces
, and the reduction operation reduces 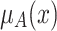 to
to 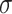 . We have
. We have 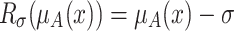 .
.
The elevation errors 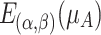 is the sum of two elevation errors produced by elevation operation. The total reduction errors
is the sum of two elevation errors produced by elevation operation. The total reduction errors  is the sum of two reduction errors produced by reduction operation. For discrete universe of discourse, we have a collection of membership values. The total elevation and reduction errors are calculated as [22],
is the sum of two reduction errors produced by reduction operation. For discrete universe of discourse, we have a collection of membership values. The total elevation and reduction errors are calculated as [22],
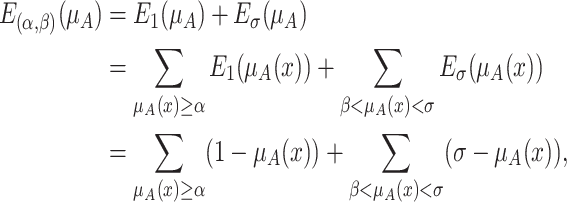 |
4 |
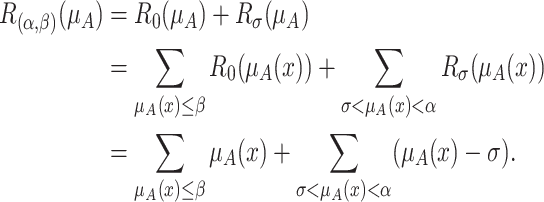 |
5 |
Given a fixed 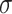 , the elevation and reduction errors change when the thresholds
, the elevation and reduction errors change when the thresholds 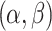 change. No matter which threshold changes and how they change, the elevation and reduction errors always change in opposite directions [22]. The decrease of one type of errors inevitably brings the increase of the other type of errors. The balanced shadowed set based three-value approximations are expected to represent a tradeoff between the elevation and reduction errors.
change. No matter which threshold changes and how they change, the elevation and reduction errors always change in opposite directions [22]. The decrease of one type of errors inevitably brings the increase of the other type of errors. The balanced shadowed set based three-value approximations are expected to represent a tradeoff between the elevation and reduction errors.
Game-Theoretic Shadowed Sets
Game-theoretic shadowed sets (GTSS) use game theory to determine the thresholds in the shadowed set context. The obtained thresholds represent a tradeoff between two different types of errors [22]. GTSS use a game mechanism to formulate games between the elevation and reduction errors. The strategies performed by two players are the changes of thresholds. Two game players compete with each other to maximize their own payoffs. A repetition learning mechanism is adopted to approach a compromise between two players by modifying game formulations repeatedly. The resulting thresholds are determined based on the game equilibria analysis and selected stopping criteria.
Game Formulation. Three elements should be considered when formulating a game G, i.e., game player set O, strategy profile set S, and utility functions u, 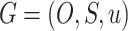 [8, 17]. The game players are the total elevation and reduction errors which are denoted by E and R, i.e.,
[8, 17]. The game players are the total elevation and reduction errors which are denoted by E and R, i.e., 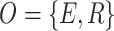 .
.
The strategy profile set is 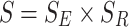 , where
, where  is a set of possible strategies for player E, and
is a set of possible strategies for player E, and 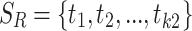 is a set of possible strategies for player R. We select
is a set of possible strategies for player R. We select  as the initial threshold values, which represent that we do not have any uncertainty on all membership grades and we have the smallest shadowed area. Starting from
as the initial threshold values, which represent that we do not have any uncertainty on all membership grades and we have the smallest shadowed area. Starting from 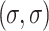 , we gradually make
, we gradually make 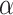 and
and 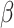 further to each other and increase the shadowed area.
further to each other and increase the shadowed area.  and
and  are two constant change steps, denoting the quantities that two players E and R use to change the thresholds, respectively. For example, we set the initial threshold values
are two constant change steps, denoting the quantities that two players E and R use to change the thresholds, respectively. For example, we set the initial threshold values 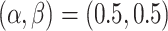 . The player E performs increasing
. The player E performs increasing  and the player R performs decreasing
and the player R performs decreasing 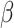 . When we set
. When we set 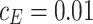 and
and 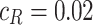 , we have
, we have 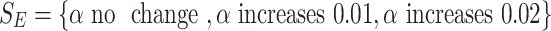 , and
, and 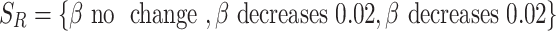 .
.
The payoffs of players are 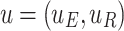 , and
, and 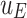 and
and  denote the payoff functions of players E and R, respectively. The payoff functions
denote the payoff functions of players E and R, respectively. The payoff functions 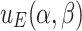 and
and 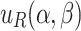 are defined by the elevation and reduction errors, respectively, that is,
are defined by the elevation and reduction errors, respectively, that is,
 |
6 |
where  and
and 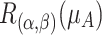 are defined in Eqs. (4) and (5). We try to minimize the elevation and reduction errors, so both players try to minimize their payoff values.
are defined in Eqs. (4) and (5). We try to minimize the elevation and reduction errors, so both players try to minimize their payoff values.
We use payoff tables to represent two-player games. Table 1 shows a payoff table example in which both players have 3 strategies.
Table 1.
An example of a payoff table
| R | ||||
|---|---|---|---|---|
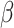 |
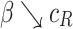 |
 |
||
| E | 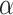 |
 |
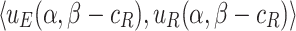 |
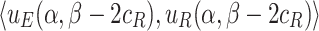 |
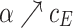 |
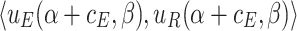 |
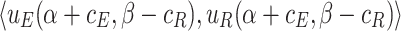 |
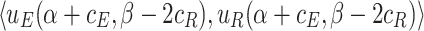 |
|
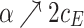 |
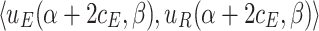 |
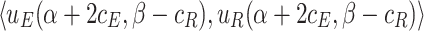 |
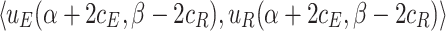 |
|
Repetition Learning Mechanism. The involved players are trying to maximize their own payoffs in the formulated games. But one player’s payoff is effected by the strategies performed by the other player. The balanced solution or game equilibrium is a strategy profile from which both players benefit. This game equilibrium represents both players reach a compromise or tradeoff on the conflict. The strategy profile 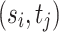 is a pure strategy Nash equilibrium, if for players E and R,
is a pure strategy Nash equilibrium, if for players E and R, 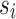 and
and  are the best responses to each other [17], this is,
are the best responses to each other [17], this is,
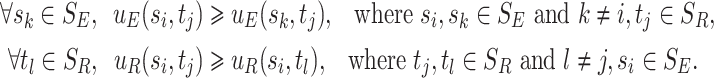 |
7 |
The above equations can be interpreted as a strategy profile such that no player would like to change his/her strategy or they would loss benefit if deriving from this strategy profile, provided this player has the knowledge of other player’s strategies.
The equilibrium of the current formulated game means the threshold pair corresponding this equilibrium are the best choices within the current strategy sets. We have to check if there are some threshold pairs near the current equilibrium that are better than the current ones. Thus we repeat the games with the updated initial thresholds. We may be able to find more suitable thresholds with repetition of thresholds modification.
We define the stopping criteria so that the iterations of games can stop at a proper time. There are many possible stopping criteria. For example, the payoff of each player is beyond a specific value; the thresholds 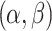 violate the constraint
violate the constraint  ; the current game equilibrium does not improve the payoffs gained by both players under the initial thresholds; no equilibrium exists. In this research, we compare the payoffs of both players under the initial thresholds and the thresholds corresponding to the current equilibrium. We set the stopping criteria as one of the players increases its payoff values, or there does not exist a pure strategy Nash equilibrium in the current game.
; the current game equilibrium does not improve the payoffs gained by both players under the initial thresholds; no equilibrium exists. In this research, we compare the payoffs of both players under the initial thresholds and the thresholds corresponding to the current equilibrium. We set the stopping criteria as one of the players increases its payoff values, or there does not exist a pure strategy Nash equilibrium in the current game.
Feature Extraction
We now select the most representative words by applying the thresholds ( ,
, 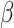 ) derived in previous sections. The words with normalized
) derived in previous sections. The words with normalized 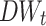 being greater than the upper threshold
being greater than the upper threshold 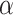 and less than the lower threshold
and less than the lower threshold 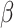 will be kept as our word features for text classification while the rest words are discarded.
will be kept as our word features for text classification while the rest words are discarded.
Experiments
Dataset and Evaluation Metrics
We evaluate our approach on the HuffPost news category dataset [18]. This dataset consists of 200,853 news headlines with short descriptions from HuffPost website during the year 2012 to 2018. It contains 31 categories of news such as politics, entertainment, business, healthy living, art, and so forth. We use the largest two categories, the 32,739 politics news and 14,257 entertainment news, as the binary text classification data in our experiments. The news text is obtained by concatenating the news headline and the corresponding short description. We extract 381449 words from these selected news. We use 80% data for training and 20% for testing, and adopt accuracy and F1 scores as metrics for model evaluation.
Deriving Thresholds with GTSS
We first normalize 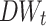 using min-max normalization linear transformation. The distribution of normalized
using min-max normalization linear transformation. The distribution of normalized  is shown in Fig. 2 Almost
is shown in Fig. 2 Almost 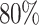 of words have the normalized
of words have the normalized 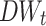 0.548054 so we set
0.548054 so we set 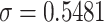 aiming to minimize the errors produced by mapping all
aiming to minimize the errors produced by mapping all 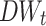 values to three values
values to three values 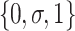 via game-theoretic shadowed set model. If we set
via game-theoretic shadowed set model. If we set 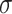 as other value instead of 0.548054, mapping the large amount of
as other value instead of 0.548054, mapping the large amount of 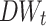 0.548054 to
0.548054 to  definitely will produce more errors.
definitely will produce more errors.
Fig. 2.

Normalized 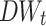 information
information
We formulate a competitive game between the elevation and reduction errors to obtain the thresholds. The game players are elevation and reduction errors, i.e.,  . The strategy profile set is
. The strategy profile set is 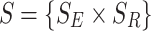 . The game is being played with the initial thresholds
. The game is being played with the initial thresholds 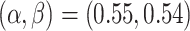 . Here,
. Here, 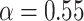 is the smallest value that greater than
is the smallest value that greater than  , and
, and 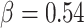 is the largest value that less than
is the largest value that less than 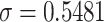 . The player E and R try to increase
. The player E and R try to increase  and decrease
and decrease 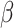 with the change steps as 0.01 and 0.02, respectively. The strategy set of E is
with the change steps as 0.01 and 0.02, respectively. The strategy set of E is 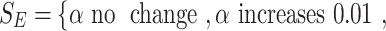
 . The corresponding
. The corresponding 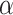 values are 0.55, 0.56, and 0.57. The strategy set of R is
values are 0.55, 0.56, and 0.57. The strategy set of R is 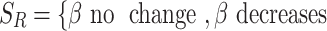
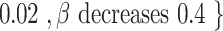 . The corresponding
. The corresponding 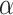 values are 0.54, 0.52, and 0.5. The payoff functions are defined in Eqs. (4) and (5). Table 2 is the payoff table. The cell at the right bottom corner is the game equilibrium whose strategy profile is (
values are 0.54, 0.52, and 0.5. The payoff functions are defined in Eqs. (4) and (5). Table 2 is the payoff table. The cell at the right bottom corner is the game equilibrium whose strategy profile is (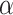 increases 0.02,
increases 0.02, 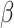 decreases 0.04). The payoffs of the players are (17689, 8742). We set the stopping criterion as one of players’ payoff increases. When the thresholds change from (0.55, 0.54) to (0.57, 0.5), the elevation error is decreased from 17933 to 17689, and the reduction error is decreased from 10472 to 8742. We repeat the game by setting (0.57, 0.5) as the initial thresholds.
decreases 0.04). The payoffs of the players are (17689, 8742). We set the stopping criterion as one of players’ payoff increases. When the thresholds change from (0.55, 0.54) to (0.57, 0.5), the elevation error is decreased from 17933 to 17689, and the reduction error is decreased from 10472 to 8742. We repeat the game by setting (0.57, 0.5) as the initial thresholds.
Table 2.
The payoff table
| R | ||||
|---|---|---|---|---|
 |
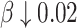 |
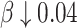 |
||
| E |  |
<17933, 10472> | <17965, 9624> | <18034, 8733> |
 |
<17690, 10476> | <17722, 9628> | <17792, 8738> | |
 |
<17588, 10480> | <17620, 9632> | <17689, 8742> | |
The competitive games are repeated four times. The result is shown in Table 3. In the fourth iteration, we find out that the payoff value of player E increases. The repetition of game is stopped and the final result is the initial thresholds of the fourth game 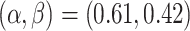 .
.
Table 3.
The repetition of game
Initial
|
Result
|
Payoffs | both decrease? | |
|---|---|---|---|---|
| 1 | (0.55, 0.54) | (0.57, 0.5) | <17689, 8742> |  |
| 2 | (0.57, 0.5) | (0.59, 0.46) | <17686, 6516> |  |
| 3 | (0.59, 0.46) | (0.61, 0.42) | <7832, 3934> |  |
| 4 | (0.61, 0.42) | (0.63, 0.38) | <8221, 2693> |  |
We got  , which means we keep the words with
, which means we keep the words with 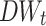 greater than 0.61 and less then 0.42, and discard the words with
greater than 0.61 and less then 0.42, and discard the words with  between 0.61 and 0.42.
between 0.61 and 0.42.
Baselines
We calculate the 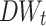 value for each single word and bi-gram, and then use Support Vector Machine (SVM) [1, 2] as our unique classifier to compare our approach with: (1) ALL, in which we keep all words with no feature extraction; (2) Sym-Cutoff, in which the symmetrical cut-off values are drawn purely based on a simple observation of the statistical distribution of
value for each single word and bi-gram, and then use Support Vector Machine (SVM) [1, 2] as our unique classifier to compare our approach with: (1) ALL, in which we keep all words with no feature extraction; (2) Sym-Cutoff, in which the symmetrical cut-off values are drawn purely based on a simple observation of the statistical distribution of 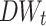 ; (3) Sym-N-Words, where we select 2n words given n smallest
; (3) Sym-N-Words, where we select 2n words given n smallest 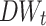 and n largest
and n largest 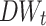 such that 2n is approximately equal to the total number of words extracted with our approach.
such that 2n is approximately equal to the total number of words extracted with our approach.
Results
We show the model performance of different extraction approaches on the new category dataset in Table 4. Our model is named as “Asym-GTSS-TH”. From the results, we can observe that: (1) Our approach achieves superior performance compared with Sym-Cutoff which is purely based on a guess given TF-IDF distribution. It verifies our claim that the GTSS can better capture the pattern of TF-IDF and provide a more robust range for selecting relevant words given TF-IDF for text classification; (2) The Sym-N-Words approach achieves close performance as ours, because it takes the advantage of the information of the number of words to keep derived with our thresholds. However, our approach still outperforms the Sym-N-words approach since it evenly selects relevant words for document 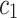 and
and 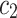 . It indicates that there exists imbalance of representative words between different categories of documents which is better captured by our model; (3) Compared with using all words’ TF-IDF score as input, our model discards more than 52% words and speed up the process of classification while preserving the performance.
. It indicates that there exists imbalance of representative words between different categories of documents which is better captured by our model; (3) Compared with using all words’ TF-IDF score as input, our model discards more than 52% words and speed up the process of classification while preserving the performance.
Table 4.
Summary of the performance of different feature extraction approaches
| Accuracy | F1-score | |
|---|---|---|
| ALL | 94.7 | 92.3 |
| Sym-Cutoff | 91.9 | 88.2 |
| Sym-N-Words | 94.5 | 91.7 |
| Asym-GTSS-TH | 94.6 | 91.9 |
Conclusion
In this paper, we propose a feature extraction approach based on TF-IDF and game-theoretic shadowed sets in which the asymmetric thresholds for selecting relevant words are derived by repetitive learning on the difference of TF-IDF for each word between documents. Our model can explore the pattern of TF-IDF distribution as well as capture the imbalance of the number of representative words in different categories. The experimental results on the news category dataset show that our model can achieve improvement as compared to other cut-off policies and speed up the information retrieval process. In the future, we will explore the consistency of our model performance on more real world datasets and test the generalization ability of our GTSS model on different metrics that measures the relevance of words, such as BNS and Chi-square.
Contributor Information
Marie-Jeanne Lesot, Email: marie-jeanne.lesot@lip6.fr.
Susana Vieira, Email: susana.vieira@tecnico.ulisboa.pt.
Marek Z. Reformat, Email: marek.reformat@ualberta.ca
João Paulo Carvalho, Email: joao.carvalho@inesc-id.pt.
Anna Wilbik, Email: a.m.wilbik@tue.nl.
Bernadette Bouchon-Meunier, Email: bernadette.bouchon-meunier@lip6.fr.
Ronald R. Yager, Email: yager@panix.com
Yan Zhang, Email: Yan.Zhang@csusb.edu.
Yue Zhou, Email: Yue.Zhou@csusb.edu.
JingTao Yao, Email: jtyao@cs.uregina.ca.
References
- 1.Ben-Hur A, Horn D, Siegelmann HT, Vapnik V. Support vector clustering. J. Mach. Learn. Res. 2001;2(12):125–137. [Google Scholar]
- 2.Cortes C, Vapnik V. Support-vector networks. Mach. Learn. 1995;20(3):273–297. [Google Scholar]
- 3.Deng XF, Yao YY. Decision-theoretic three-way approximations of fuzzy sets. Inf. Sci. 2014;279:702–715. doi: 10.1016/j.ins.2014.04.022. [DOI] [Google Scholar]
- 4.Grossman DA, Frieder O. Information Retrieval: Algorithms and Heuristics. Netherlands: Springer; 2012. [Google Scholar]
- 5.Grzegorzewski P. Fuzzy number approximation via shadowed sets. Inf. Sci. 2013;225:35–46. doi: 10.1016/j.ins.2012.10.028. [DOI] [Google Scholar]
- 6.Jing, L.P., Huang, H.K., Shi, H.B.: Improved feature selection approach TFIDF in text mining. In: Proceedings of the International Conference on Machine Learning and Cybernetics, vol. 2, pp. 944–946. IEEE (2002)
- 7.Jurafsky, D., Martin, J.H.: Speech and Language Processing: An Introduction to Natural Language Processing, Computational Linguistics, and Speech Recognition. Pearson Education, Inc., New Jersey (2008)
- 8.Leyton-Brown K, Shoham Y. Essentials of game theory: a concise multidisciplinary introduction. Synth. Lect. Artif. Intell. Mach. Learn. 2008;2(1):1–88. doi: 10.2200/S00108ED1V01Y200802AIM003. [DOI] [Google Scholar]
- 9.Lopes L, Vieira R. Evaluation of cutoff policies for term extraction. J. Braz. Comput. Soc. 2015;21(1):1–13. doi: 10.1186/s13173-015-0025-0. [DOI] [Google Scholar]
- 10.Manning CD, Raghavan P, Schütze H. Introduction to Information Retrieval. Cambridge: Cambridge University Press; 2008. [Google Scholar]
- 11.Milios, E., Zhang, Y., He, B., Dong, L.: Automatic term extraction and document similarity in special text corpora. In: Proceedings of the 6th Conference of the Pacific Association for Computational Linguistics, pp. 275–284. Citeseer (2003)
- 12.Özgür A, Özgür L, Güngör T. Text categorization with class-based and corpus-based keyword selection. In: Yolum I, Güngör T, Gürgen F, Özturan C, editors. Computer and Information Sciences - ISCIS 2005; Heidelberg: Springer; 2005. pp. 606–615. [Google Scholar]
- 13.Pedrycz W. Shadowed sets: representing and processing fuzzy sets. IEEE Trans. Syst. Man Cybern. 1998;28(1):103–109. doi: 10.1109/3477.658584. [DOI] [PubMed] [Google Scholar]
- 14.Pedrycz, W.: Shadowed sets: bridging fuzzy and rough sets. In: Rough Fuzzy Hybridization: A New Trend in Decision-Making, pp. 179–199 (1999)
- 15.Pedrycz W. From fuzzy sets to shadowed sets: interpretation and computing. Int. J. Intell. Syst. 2009;24(1):48–61. doi: 10.1002/int.20323. [DOI] [Google Scholar]
- 16.Pedrycz W, Vukovich G. Granular computing with shadowed sets. Int. J. Intell. Syst. 2002;17(2):173–197. doi: 10.1002/int.10015. [DOI] [Google Scholar]
- 17.Rasmusen E. Games and Information: An Introduction to Game Theory. Oxford: Blackwell; 1989. [Google Scholar]
- 18.Misra, R.: News category dataset from HuffPost website (2018). 10.13140/RG.2.2.20331.18729
- 19.Salton G, Buckley C. Term-weighting approaches in automatic text retrieval. Inf. Process. Manag. 1988;24(5):513–523. doi: 10.1016/0306-4573(88)90021-0. [DOI] [Google Scholar]
- 20.Salton, G., McGill, M.J.: Introduction to Modern Information Retrieval. McGraw-Hill Inc. (1986)
- 21.Zadeh LA. Toward extended fuzzy logic - a first step. Fuzzy Sets Syst. 2009;160(21):3175–3181. doi: 10.1016/j.fss.2009.04.009. [DOI] [Google Scholar]
- 22.Zhang Y, Yao JT. Game theoretic approach to shadowed sets: a three-way tradeoff perspective. Inf. Sci. 2020;507:540–552. doi: 10.1016/j.ins.2018.07.058. [DOI] [Google Scholar]
- 23.Zuo, Z., Li, J., Anderson, P., Yang, L., Naik, N.: Grooming detection using fuzzy-rough feature selection and text classification. In: 2018 IEEE International Conference on Fuzzy Systems (FUZZ-IEEE), pp. 1–8. IEEE (2018)