

Abstract
Analogical proportions, often denoted  , are statements of the form “A is to B as C is to D” that involve comparisons between items. They are at the basis of an inference mechanism that has been recognized as a suitable tool for classification and has led to a variety of analogical classifiers in the last decade. Given an object D to be classified, the basic idea of such classifiers is to look for triples of examples (A, B, C), in the learning set, that form an analogical proportion with D, on a maximum set of attributes. In the context of classification, objects A, B, C and D are assumed to be represented by vectors of feature values. Analogical inference relies on the fact that if a proportion
, are statements of the form “A is to B as C is to D” that involve comparisons between items. They are at the basis of an inference mechanism that has been recognized as a suitable tool for classification and has led to a variety of analogical classifiers in the last decade. Given an object D to be classified, the basic idea of such classifiers is to look for triples of examples (A, B, C), in the learning set, that form an analogical proportion with D, on a maximum set of attributes. In the context of classification, objects A, B, C and D are assumed to be represented by vectors of feature values. Analogical inference relies on the fact that if a proportion  is valid, one of the four components of the proportion can be computed from the three others. Based on this principle, analogical classifiers have a cubic complexity due to the search for all possible triples in a learning set to make a single prediction. A special case of analogical proportions involving only three items A, B and C are called continuous analogical proportions and are of the form “A is to B as B is to C” (hence denoted
is valid, one of the four components of the proportion can be computed from the three others. Based on this principle, analogical classifiers have a cubic complexity due to the search for all possible triples in a learning set to make a single prediction. A special case of analogical proportions involving only three items A, B and C are called continuous analogical proportions and are of the form “A is to B as B is to C” (hence denoted 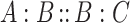 ). In this paper, we develop a new classification algorithm based on continuous analogical proportions and applied to numerical features. Focusing on pairs rather than triples, the proposed classifier enables us to compute an unknown midpoint item B given a pair of items (A, C). Experimental results of such classifier show an efficiency close to the previous analogy-based classifier while maintaining a reduced quadratic complexity.
). In this paper, we develop a new classification algorithm based on continuous analogical proportions and applied to numerical features. Focusing on pairs rather than triples, the proposed classifier enables us to compute an unknown midpoint item B given a pair of items (A, C). Experimental results of such classifier show an efficiency close to the previous analogy-based classifier while maintaining a reduced quadratic complexity.
Keywords: Classification, Analogical proportions, Continuous analogical proportions
Introduction
Reasoning by analogy establishes a parallel between two situations. More precisely, it enables us to relate two pairs of items (a, b) and (c, d) in such way that “a is to b as c is to d” on a comparison basis. This relationship, often noted  , expresses a kind of equality between the two pairs, i.e., the two items of the first pair are similar and differ in the same way as the two items of the second pair. The case of numerical (geometric) proportions where we have an equality between two ratios (i.e.,
, expresses a kind of equality between the two pairs, i.e., the two items of the first pair are similar and differ in the same way as the two items of the second pair. The case of numerical (geometric) proportions where we have an equality between two ratios (i.e.,  ) is at the origin of the name “analogical proportions”. Analogical proportions, when d is unknown, provides an extrapolation mechanism, which with numbers yields
) is at the origin of the name “analogical proportions”. Analogical proportions, when d is unknown, provides an extrapolation mechanism, which with numbers yields  , and
, and 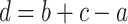 in case of arithmetic proportions (such that
in case of arithmetic proportions (such that  ). The analogical proportions-based extrapolation has been successfully applied to classification problems [4, 8]. The main drawback of algorithms using analogical proportions is their cubic complexity.
). The analogical proportions-based extrapolation has been successfully applied to classification problems [4, 8]. The main drawback of algorithms using analogical proportions is their cubic complexity.
A particular case of analogical proportions, named continuous analogical proportions, is obtained when the two central components are equal, namely they are statements of the form “a is to b as b is to c”. In case of numerical proportions, if we assume that b is unknown, it can be expressed in terms of a and c as 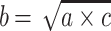 in the geometric case and
in the geometric case and 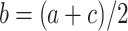 in the arithmetic case. Note that similar inequalities hold in both cases:
in the arithmetic case. Note that similar inequalities hold in both cases:  and
and 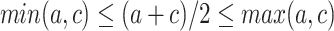 . This means that the continuous analogical proportion induces a form of interpolation between a and c in the numerical case by involving an intermediary value that can be obtained from a and c. A continuous analogical proportions-based interpolation was recently proposed as a way of enlarging a training set (before applying some standard classification methods), and led to good results [2]. In contrast to extrapolation, interpolation with analogy-based classifiers has a quadratic complexity.
. This means that the continuous analogical proportion induces a form of interpolation between a and c in the numerical case by involving an intermediary value that can be obtained from a and c. A continuous analogical proportions-based interpolation was recently proposed as a way of enlarging a training set (before applying some standard classification methods), and led to good results [2]. In contrast to extrapolation, interpolation with analogy-based classifiers has a quadratic complexity.
In this paper, we investigate the efficiency for classification of using such approach. The paper is organized as follows. Section 2 provides a short background on analogical proportions and more particularly on continuous ones. Then Sect. 3 surveys related work on analogical extrapolation. Section 4 presents the proposed interpolation approach for classification. Finally, Sect. 5 reports the results of our algorithm.
Background on Analogical Proportions
An analogical proportion is a relationship on  between 4 items
between 4 items  . This 4-tuple, when it forms an analogical proportion is denoted
. This 4-tuple, when it forms an analogical proportion is denoted  and reads “A is to B as C is to D”. Both relationships “is to” and “as” depend on the nature of X [9]. As it is the case for numerical proportions, the relation of analogy still holds when the pairs (A, B) and (C, D) are exchanged, or when central items B and C are permuted (see [11] for other properties). In the following subsections, we recall analogical proportions in the Boolean setting (i.e.,
and reads “A is to B as C is to D”. Both relationships “is to” and “as” depend on the nature of X [9]. As it is the case for numerical proportions, the relation of analogy still holds when the pairs (A, B) and (C, D) are exchanged, or when central items B and C are permuted (see [11] for other properties). In the following subsections, we recall analogical proportions in the Boolean setting (i.e.,  ) and their extension for nominal and for real-valued settings (i.e.,
) and their extension for nominal and for real-valued settings (i.e.,  ), before considering the special case of continuous analogical proportions.
), before considering the special case of continuous analogical proportions.
Analogical Proportions in the Boolean Setting
Let us consider four items A, B, C and D, respectively described by their binary values  . Items A, B, C and D are in analogical proportion, which is denoted
. Items A, B, C and D are in analogical proportion, which is denoted  if and only if
if and only if  holds true (it can also be written
holds true (it can also be written  or simply
or simply  ). The truth table (Table 1) shows the six possible assignments for a 4-tuple to be in analogical proportion, out of sixteen possible configurations.
). The truth table (Table 1) shows the six possible assignments for a 4-tuple to be in analogical proportion, out of sixteen possible configurations.
Table 1.
Truth table for analogical proportion
| a | b | c | d |  |
|---|---|---|---|---|
| 0 | 0 | 0 | 0 | 1 |
| 0 | 0 | 1 | 1 | 1 |
| 0 | 1 | 0 | 1 | 1 |
| 1 | 0 | 1 | 0 | 1 |
| 1 | 1 | 0 | 0 | 1 |
| 1 | 1 | 1 | 1 | 1 |
Boolean analogical proportions can be expressed by the logical formula:
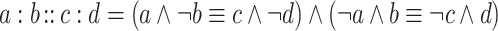 |
1 |
See [10, 12] for justification. This formula holds true for the 6 assignments shown in the truth table. It reads “a differs from b as c differs from d and b differs from a as d differs from c”, which fits with the expected meaning of analogy. An equivalent formula is obtained by negating the two sides of the first and the second equivalence in formula (1):
 |
2 |
Items are generally described by vectors of Boolean values rather than by a single value. A natural extension for vectors in 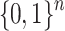 of the form
of the form 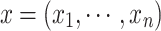 is obtained component-wise as follows:
is obtained component-wise as follows:
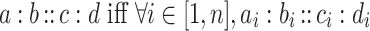 |
3 |
Nominal Extension
When a, b, c, d take their values in a finite set  (with more than 2 elements), we can derive three patterns of analogical proportions in the nominal case, from the six possible assignments for analogical proportions in the Boolean case. This generalization is thus defined by:
(with more than 2 elements), we can derive three patterns of analogical proportions in the nominal case, from the six possible assignments for analogical proportions in the Boolean case. This generalization is thus defined by:
 |
4 |
Multiple-Valued Extension
In case items are described by numerical attributes, it will be necessary to extend the logic modeling underlying analogical proportions in order to support a numerical setting. a, b, c, d are now real values normalized in the interval [0, 1] and their analogical proportion  is extended from
is extended from 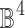 to
to 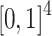 . Analogical proportions are no longer valid or invalid but the extent to which they hold is now a matter of degree. For example, if a, b, c, d have 1, 0, 1 and 0.1 as values respectively, we expect that
. Analogical proportions are no longer valid or invalid but the extent to which they hold is now a matter of degree. For example, if a, b, c, d have 1, 0, 1 and 0.1 as values respectively, we expect that  has a high value (close to 1) since 0.1 is close to 0.
has a high value (close to 1) since 0.1 is close to 0.
The extension of the logical expression of analogical proportions to the multiple-valued case requires the choice of appropriate connectives for preserving desirable properties [5]. To extend expression (2), conjunction, implication and equivalence operators are then replaced by the multiple valued connectives given in Table 2. This leads to the following expression P:
| 5 |
When a, b, c, d are restricted to  , the last expression coincide with the definition for the Boolean case (given by (1)), which highlights the agreement between the extension and the original idea of analogical proportion. For the interval [0, 1], we have
, the last expression coincide with the definition for the Boolean case (given by (1)), which highlights the agreement between the extension and the original idea of analogical proportion. For the interval [0, 1], we have  as soon as
as soon as  and as we expected, we get a high value for the 4-tuple (1, 0, 1, 0.1), indeed
and as we expected, we get a high value for the 4-tuple (1, 0, 1, 0.1), indeed 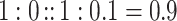 .
.
Table 2.
Multi-valued extension
| Operator | Extension |
|---|---|
Negation: 
|
 |
Implication: 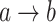
|
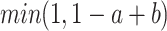 |
Conjunction: 
|
min(a, b) |
Equivalence: 
|
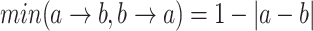 |
Moreover, since we have  ,
, 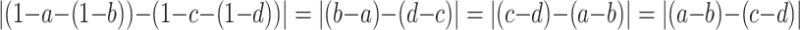 , and
, and  , it is easy to check a remarkable code independence property:
, it is easy to check a remarkable code independence property:  . Code independence means that 0 and 1 play symmetric roles, and it is the same to encode an attribute positively or negatively.
. Code independence means that 0 and 1 play symmetric roles, and it is the same to encode an attribute positively or negatively.
As items are commonly described by vectors, we can extend the notion of analogical proportion to vectors in  .
.
 |
6 |
where  refers to expression (5)).
refers to expression (5)).
Let us observe that  (i.e.
(i.e.  holds) if and only if the analogical proportion holds perfectly on every component:
holds) if and only if the analogical proportion holds perfectly on every component:
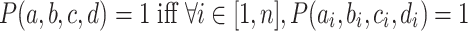 |
7 |
Inference with Analogical Proportions
Analogical proportion-based inference relies on a simple principle:if four Boolean vectors  ,
,  ,
, 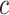 and
and  make a valid analogical proportion component-wise between their attribute values, then it is expected that their class labels also make a valid proportion [4].
make a valid analogical proportion component-wise between their attribute values, then it is expected that their class labels also make a valid proportion [4].
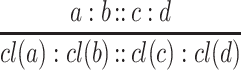 |
8 |
where  denotes to the class value of
denotes to the class value of 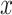 .
.
It means that the classification of a Boolean vector  is only possible when the equation
is only possible when the equation  is solvable1 (the classes of
is solvable1 (the classes of  ,
, 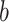 ,
, 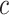 are known as they belong to the sample set), and the analogical proportion
are known as they belong to the sample set), and the analogical proportion  holds true. If these two criteria are met, we assign x to
holds true. If these two criteria are met, we assign x to 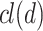 .
.
In the numerical case, where  are 4 real-valued vectors over
are 4 real-valued vectors over  (the numerical values are previously normalized), the inference principle strictly clones the Boolean setting:
(the numerical values are previously normalized), the inference principle strictly clones the Boolean setting:
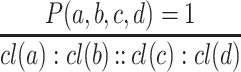 |
9 |
In practice, the resulting degree  is rarely equal to 1 but should be close to 1. Therefore Eq. (9) has to be adapted for a proper implementation.
is rarely equal to 1 but should be close to 1. Therefore Eq. (9) has to be adapted for a proper implementation.
Continuous Analogical Proportions
Continuous analogical proportions, denoted  , are ternary relations which are a special case of analogical proportions. This enables us to calculate b using a pair (a, c) only, rather than a triple as in the general case. In
, are ternary relations which are a special case of analogical proportions. This enables us to calculate b using a pair (a, c) only, rather than a triple as in the general case. In  the unique solutions of equations
the unique solutions of equations 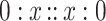 and
and  are respectively
are respectively  and
and 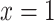 , while
, while  or 1 : x : : x : 0 have no solution.
or 1 : x : : x : 0 have no solution.
Drawing the parallel with the Boolean case, we deduce that the only solvable equation for the nominal case is 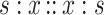 , having
, having 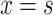 as solution, while
as solution, while  (
( ) has no solution.
) has no solution.
Contrary to these trivial cases, the multi-valued framework (Eq. (5)) is richer. We have
| 10 |
We notice that for  , we have
, we have 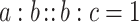 which fits the statement “A is to B as B is to C”. As we expect, we get a higher value of analogy (closer to 1) as b tends to
which fits the statement “A is to B as B is to C”. As we expect, we get a higher value of analogy (closer to 1) as b tends to 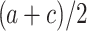 . Computing continuous analogy for items described by vectors is exactly the same as for the general case (i.e., for real-valued setting
. Computing continuous analogy for items described by vectors is exactly the same as for the general case (i.e., for real-valued setting  ).
).
Applying analogy-based inference for numerical values with continuous analogical proportions, we obtain:
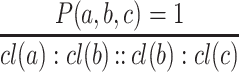 |
11 |
One may wonder if continuous analogical proportions could be efficient enough compared to general analogical proportions. As already said,  holds at degree 1 if and only if
holds at degree 1 if and only if  (from which one can extrapolate
(from which one can extrapolate  ). Now consider two continuous proportions:
). Now consider two continuous proportions:  (which corresponds to the interpolation
(which corresponds to the interpolation  ) and
) and  (which gives the interpolation
(which gives the interpolation  ). Adding each side of the two proportions yields
). Adding each side of the two proportions yields  , which is equivalent to
, which is equivalent to  . In this view, two intertwined interpolations may play the role of an extrapolation. However the above remark applies only to numerical values, but not to Boolean ones.
. In this view, two intertwined interpolations may play the role of an extrapolation. However the above remark applies only to numerical values, but not to Boolean ones.
Related Works on Analogical Proportions and Classification
Continuous analogical proportions have been recently applied to enlarge a training set for classification by creating artificial examples [2]. A somewhat related idea can be found in Lieber et al. [6] which extended the paradigm of classical Case-Based Reasoning by either performing a restricted form of interpolation to link the current case to pairs of known cases, or by extrapolation exploiting triples of known cases.
In the classification context, the authors in [3] introduce a measure of oddness with respect to a class that is computed on the basis of pairs made of two nearest neighbors in the same class; this amounts to replace the two neighbors by a fictitious representative of the class. Moreover, some other works have exploited analogical proportions to deal with classification problems. Most noteworthy are those based on using analogical dissimilarity [1] and applied to binary and nominal data and later the analogy-based classifier [4] applied to binary, nominal and numerical data. In the following subsections, we especially review these two latter works as they seem the closest to the approach that we are developing in this paper.
Classification by Analogical Dissimilarity
Analogical dissimilarity between binary objects is a measure that quantifies how far a 4-tuple (a, b, c, d) is from being in an analogical proportion. This is equivalent to the minimum number of bits to change in a 4-tuple to achieve a perfect analogy, thus when a 4-tuple is in analogical proportion, its analogical dissimilarity is zero. So for the next three examples of 4-tuples, we have  ,
, 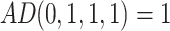 and finally
and finally  . In
. In 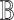 the value of an analogical dissimilarity is in [0, 2]. When dealing with vectors
the value of an analogical dissimilarity is in [0, 2]. When dealing with vectors  and
and 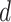 in
in  , analogical dissimilarity is defined as
, analogical dissimilarity is defined as  , in this case an analogical dissimilarity value belongs to the interval [0, 2m].
, in this case an analogical dissimilarity value belongs to the interval [0, 2m].
A classifier based on analogical dissimilarity is proposed in [1]. Given a training set S, and a constant k specifying the number of the least dissimilar triples, the basic algorithm for classifying an instance 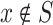 in a naive way, using analogical dissimilarities is as follows:
in a naive way, using analogical dissimilarities is as follows:
For each triple
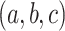 having a solution for the class equation
having a solution for the class equation  , compute the analogical dissimilarity
, compute the analogical dissimilarity 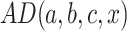 .
.Sort these triples by ascending order of their analogical dissimilarity
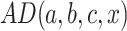 .
.If the k-th triple of the list has the value p, then let the
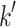 -th triple be the last triple of this list with the value p.
-th triple be the last triple of this list with the value p.For the first
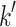 -th triples, solve the class equation and apply a voting strategy on the obtained class labels.
-th triples, solve the class equation and apply a voting strategy on the obtained class labels.Assign to
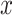 , the winner class.
, the winner class.
This procedure may be said naive since it looks for every possible triple from the training set S in order to compute the analogical dissimilarity 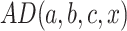 , therefore it has a complexity of
, therefore it has a complexity of 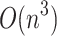 , n being the number of instances in the training set. To optimize this procedure, the authors propose the algorithm FADANA which performs an off line pre-processing on the training set in order to speed up on line computation.
, n being the number of instances in the training set. To optimize this procedure, the authors propose the algorithm FADANA which performs an off line pre-processing on the training set in order to speed up on line computation.
Analogical Proportions-Based Classifier
In a classification problem, objects A, B, C, D are assumed to be represented by vectors of attribute values, denoted  . Based on the previously defined AP inference, analogical classification rely on the idea that, if vectors
. Based on the previously defined AP inference, analogical classification rely on the idea that, if vectors  ,
,  ,
,  and
and  form a valid analogical proportion componentwise for all or for a large number of attributes (i.e.,
form a valid analogical proportion componentwise for all or for a large number of attributes (i.e.,  ), this still continue hold for their corresponding class labels. Thus the analogical proportion between classes
), this still continue hold for their corresponding class labels. Thus the analogical proportion between classes 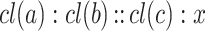 may serve for predicting the unknown class
may serve for predicting the unknown class 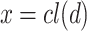 of the new instance
of the new instance 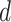 to be classified. This is done on the basis of triples
to be classified. This is done on the basis of triples  of examples in the sample set that form a valid analogical proportion with
of examples in the sample set that form a valid analogical proportion with  .
.
In a brute force way, AP-classifier proposed in [4], looks for all triples 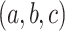 in the training set whose class equation
in the training set whose class equation 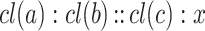 have a possible solution l. Then, for each of these triples, compute a truth value
have a possible solution l. Then, for each of these triples, compute a truth value  as the average of the truth values obtained in a componentwise manner using Eq. (5) (P can also be computed using the conservative extension, introduced in [5]). Finally, assign to
as the average of the truth values obtained in a componentwise manner using Eq. (5) (P can also be computed using the conservative extension, introduced in [5]). Finally, assign to  the class label having the highest value of P.
the class label having the highest value of P.
An optimized algorithm of this brute force procedure has been developed in [4] in which the authors rather search for suitable triples  by constraining
by constraining 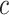 to be one of the k nearest neighbours of
to be one of the k nearest neighbours of  .
.
This algorithm processes as follows:
Look for each triple
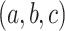 in the training set s.t:
in the training set s.t:  .
.Solve
 .
.If the previous analogical equation on classes has a solution l, increment the credit credit(l) with
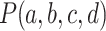 as
as 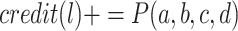 .
.Assign to
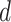 the class label having the highest credit as
the class label having the highest credit as 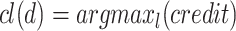 ).
).
Continuous Analogical Proportions-Based Classifier
Extrapolation and interpolation have been recognized as suitable tools for prediction and classification [6]. Continuous analogical proportions rely on the idea that if three items  ,
, 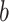 and
and 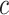 form a valid analogical proportion
form a valid analogical proportion  , this may establish the basic for interpolating
, this may establish the basic for interpolating  in case
in case  and
and  are known. As introduced in Sect. 2, in the numerical case
are known. As introduced in Sect. 2, in the numerical case 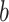 can be considered as the midpoint of (
can be considered as the midpoint of (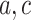 ) and may simply be computed from
) and may simply be computed from  and
and  .
.
In this section, we will show how continuous analogical proportions may help to develop an new classification algorithm dealing with numerical data and leading to a reduced complexity if compared to the previous Analogical Proportions-based classifiers.
Basic Procedure
Given a training set  , s.t. the class label
, s.t. the class label 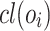 is known for each
is known for each  , the proposed algorithm aims to classify a new object
, the proposed algorithm aims to classify a new object  whose label
whose label  is unknown. Objects are assumed to be described by numerical attribute values. The main idea is to predict the label
is unknown. Objects are assumed to be described by numerical attribute values. The main idea is to predict the label 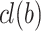 by interpolating labels of other objects in the training set S. Unlike algorithms previously mentioned in Sect. 3, continuous analogical proportions-based interpolation enables us to perform prediction using pairs of examples instead of triples. The basic idea is to find all pairs
by interpolating labels of other objects in the training set S. Unlike algorithms previously mentioned in Sect. 3, continuous analogical proportions-based interpolation enables us to perform prediction using pairs of examples instead of triples. The basic idea is to find all pairs 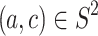 with known labels s.t. the equation
with known labels s.t. the equation  has a solution l, l being a potential prediction for
has a solution l, l being a potential prediction for 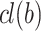 . If this equation is solvable, we should also check that the continuous analogical proportion holds on each feature j. Indeed we have
. If this equation is solvable, we should also check that the continuous analogical proportion holds on each feature j. Indeed we have 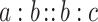 if and only if
if and only if  (i.e., for each feature j,
(i.e., for each feature j,  is being the exact midpoint of the pair
is being the exact midpoint of the pair 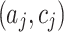 ,
, 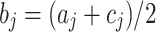 ).
).
As it is frequent to find multiple pairs  which may build a valid continuous analogical proportion with
which may build a valid continuous analogical proportion with  with different solutions for the equation
with different solutions for the equation 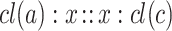 , it is necessary to set up a voting procedure to aggregate the potential labels for
, it is necessary to set up a voting procedure to aggregate the potential labels for  . This previous process can be described by the following procedure:
. This previous process can be described by the following procedure:
Find pairs
 such that the equation
such that the equation  has a valid solution l.
has a valid solution l.If the continuous analogical proportion
 is also valid, increment the score ScoreP(l) for label l.
is also valid, increment the score ScoreP(l) for label l.Assign to
 the label l having the highest ScoreP.
the label l having the highest ScoreP.
Algorithm
As already said, the simplest way is to consider pairs  for which the analogical equation
for which the analogical equation 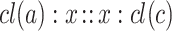 is solvable and the analogical proportion
is solvable and the analogical proportion  is valid.
is valid.
However, unlike for Boolean features, where 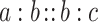 may hold for many pairs (a, c), it is not really the case for numerical features. In fact,
may hold for many pairs (a, c), it is not really the case for numerical features. In fact,  does not occur frequently. To deal with such situation in the numerical case, AP-classifiers [4] cumulate individual analogical credits
does not occur frequently. To deal with such situation in the numerical case, AP-classifiers [4] cumulate individual analogical credits  to the amount CreditP(l) each time the label l is a solution for the equation
to the amount CreditP(l) each time the label l is a solution for the equation 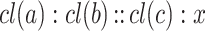 . Even though learning from the entire sample space is often beneficial (in contrast to k-NN principle which is based on a local search during learning), considering all pairs for prediction may seem unreasonable as this could blur the results. Instead of blindly considering all pairs
. Even though learning from the entire sample space is often beneficial (in contrast to k-NN principle which is based on a local search during learning), considering all pairs for prediction may seem unreasonable as this could blur the results. Instead of blindly considering all pairs  for prediction, we suggest to adapt the analogical inference, defined by Eq. (9), in such way to consider only pairs
for prediction, we suggest to adapt the analogical inference, defined by Eq. (9), in such way to consider only pairs  whose analogical score
whose analogical score  exceeds a certain threshold
exceeds a certain threshold  .
.
 |
12 |
This threshold is fixed on an empirical basis. Determining which threshold fits better with each type of dataset is still has to be investigated. The case of unclassified instances may be more likely to happen because of a conflict between multiple classes (i.e., max(ScoreP) is not unique) rather than because of no pairs were found to made a proper classification. That’s why we propose to record the best analogical score bestP(l), and even the number of pairs having this best value vote(l) in order to avoid this conflicting situation.
Experimentations and Discussion
In this section, we aim to evaluate the efficiency of the proposed algorithm to classify numerical data. For this aim, we test the CAP-classifier on a variety of datasets from the U.C.I. machine learning repository [7], we provide its experimental results and compare them to the AP-classifier [4] as well as to the state of the art ML classifiers, especially, k-NN, C4.5, JRIP and SVM classifiers.
Datasets for Experiments
The experimentations are done on datasets from the U.C.I. machine learning repository [7]. Table 3 presents a brief description of the numerical datasets selected for this study. Datasets with numerical attributes must be normalized before testing to fit the multi-valued setting of analogical proportion. A numeric attribute value r is rescaled into the interval [0, 1] as follows:
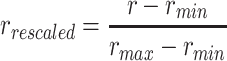 |
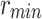 and
and  being the maximum and the minimum value of the attribute in the training set. We experiment over the following 9 datasets:
being the maximum and the minimum value of the attribute in the training set. We experiment over the following 9 datasets:
“Diabetes”, “W.B. Cancer”, “Heart”, “Ionosphere” are binary class datasets.
“Iris”, “Wine”, “Sat.Image”, “Ecoli” and “Segment” datasets are multiple class problems.
Table 3.
Description of numeric datasets
| Datasets | Instances | Numerical attrs. | Classes |
|---|---|---|---|
| Diabetes | 768 | 8 | 2 |
| W. B. Cancer | 699 | 9 | 2 |
| Heart | 270 | 13 | 2 |
| Ionosphere | 351 | 34 | 2 |
| Iris | 150 | 4 | 3 |
| Wine | 178 | 13 | 3 |
| Satellite Image | 1090 | 36 | 6 |
| Ecoli | 336 | 7 | 8 |
| Segment | 1500 | 19 | 7 |
Testing Protocol
In terms of protocol, we apply a standard 10 fold cross-validation technique. As usual, the final accuracy is obtained by averaging the 10 different accuracies for each fold.
However, we have to tune the parameter 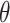 of the CAP-classifier as well as parameter k for AP-classifier and the ones of the classical classifiers (with which we compare our approach) before performing this cross-validation.
of the CAP-classifier as well as parameter k for AP-classifier and the ones of the classical classifiers (with which we compare our approach) before performing this cross-validation.
For this end, in each fold we keep only the corresponding training set (i.e. which represents 90% of the full dataset). On this training set, we again perform an inner 10-fold cross-validation with diverse values of the parameter. We then select the parameter value providing the best accuracy. The tuned parameter is then used to perform the initial cross-validation. As expected, these tuned parameters change with the target dataset. To be sure that our results are stable enough, we run each algorithm (with the previous procedure) 5 times so we have 5 different parameter optimizations. The displayed parameter  is the average value over the 5 different values (one for each run). The results shown in Table 4 are the average values obtained from 5 rounds of this complete process.
is the average value over the 5 different values (one for each run). The results shown in Table 4 are the average values obtained from 5 rounds of this complete process.
Table 4.
Results of CAP-classifier, AP-classifier and other ML classifiers obtained with the best parameter 
| Datasets | CAP-classifier | AP-classifier | k-NN | C4.5 | JRIP | SVM (RBF) | SVM (Poly) | |||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| acc. |  |
acc. |  |
acc. |  |
acc. | 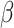 |
acc. |  |
acc. | 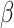 |
acc. |  |
|
| Diabetes | 72.81 | 0.906 | 73.28 | 11 | 73.42 | 11 | 74.73 | 0.2 | 74.63 | 5 | 77.37 | (8192, 3.051E−5) | 77.34 | (0.5, 1) |
| Cancer | 96.11 | 0.825 | 97.01 | 4 | 96.70 | 3 | 94.79 | 0.2 | 95.87 | 4 | 96.74 | (2, 2) | 96.92 | (2, 1) |
| Heart | 81.63 | 0.693 | 81.90 | 10 | 82.23 | 11 | 78.34 | 0.2 | 78.52 | 4 | 79.98 | (32, 0.125) | 83.77 | (0.5, 1) |
| Ionosphere | 86.44 | 0.887 | 90.55 | 1 | 88.80 | 1 | 89.56 | 0.1 | 89.01 | 5 | 94.70 | (2, 2) | 89.28 | (0.03125, 2) |
| iris | 95.73 | 0.913 | 94.89 | 5 | 94.88 | 3 | 94.25 | 0.2 | 93.65 | 6 | 94.13 | (32768, 0.5) | 96.13 | (512, 1) |
| Wine | 96.85 | 0.832 | 98.12 | 9 | 97.75 | 7 | 94.23 | 0,1 | 94.99 | 8 | 98.20 | (32768, 2) | 98.53 | (2, 1) |
| Sat image | 95.60 | 0.991 | 94.96 | 1 | 94.88 | 1 | 92.71 | 0.1 | 92.77 | 3 | 96.01 | (8, 2) | 95.11 | (0.5, 4) |
| Ecoli | 86.01 | 0.93 | 83.32 | 7 | 85.37 | 5 | 82.60 | 0.2 | 81.56 | 5 | 87.50 | (2, 8) | 87.50 | (8, 1) |
| Segment | 96.91 | 1 | 96.84 | 1 | 96.76 | 1 | 95.77 | 0.2 | 94.55 | 6 | 96.98 | (2048, 0.125) | 97.14 | (8, 4) |
| Average | 89.79 | 90.10 | 90.09 | 88.55 | 88.39 | 91.29 | 91.30 | |||||||
Results for CAP-Classifiers
In order to evaluate the efficiency of our algorithm, we compare the average accuracy over five 10-fold CV to the following existing classification approaches:
IBk: implements k-NN, using manhattan distance and the tuned parameter is the number of nearest neighbours during the inner cross-validation with the values
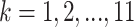 .
.C4.5: implements a generator of pruned or unpruned C4.5 decision tree. the tuned parameter is the confidence factor used for pruning with the values
 .
.JRip: implements the rule learner RIPPER (Repeated Incremental Pruning to Produce Error Reduction) an optimized version of IREP. The number of optimization runs with the values
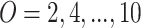 is tuned during the inner cross-validation.
is tuned during the inner cross-validation.SVM: an implementation of the Support Vector Machine classifier. We use SVM with both RBF and polynomial kernels and the tuned parameters are, successively gamma for the RBF Kernel, with
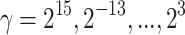 and the degree for the polynomial kernel,
and the degree for the polynomial kernel, 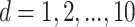 . The complexity parameter
. The complexity parameter  is also tuned.
is also tuned.AP-classifier: implements the analogical proportions-based classifier with the tuned parameter k with k being the number of nearest neighbours
 .
.CAP-classifier: We test the classifier and we tune the threshold
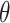 with values
with values 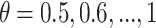 .
.
Results for AP-classifier as well as for classic ML classifiers are taken from [4], ML classifiers results are initially obtained by applying the free implementation of Weka software. Table 4 shows these experimental results.
Evaluation of CAP-Classifier and Comparison with Other ML Classifiers: If we analyse the results of CAP-classifier, we can conclude that:
As expected, the threshold
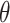 of the CAP-classifier change with the target dataset.
of the CAP-classifier change with the target dataset.The average
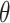 is approximately equal to 0.89. This proves that CAP-classifier obtains its highest accuracy only if the selected pairs, useful for predicting the class label, are relatively in analogy with the item to be classified.
is approximately equal to 0.89. This proves that CAP-classifier obtains its highest accuracy only if the selected pairs, useful for predicting the class label, are relatively in analogy with the item to be classified.For “Iris”, “Ecoli”, “Sat.Image” and “Segment” datasets, CAP-classifier performs better than AP-classifier, and even slightly better than SVM (polynomial kernel) on the “Sat.Image” dataset, which proves the ability of this classifier to deal with multi-class datasets (up to 8 class labels for these datasets).
Moreover, we note that for most tested datasets, the optimized
 is close to 1. This fits our first intuition that CAP-classifier performs better when the selected pairs
is close to 1. This fits our first intuition that CAP-classifier performs better when the selected pairs 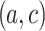 form a valid continuous analogical proportion with
form a valid continuous analogical proportion with  on all (case when
on all (case when 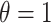 ) or maximum set of attributes (case when
) or maximum set of attributes (case when  ).
).CAP-classifier performs slightly less than AP-classifier for datasets “Diabetes”, “Cancer” and “Ionosphere” which are binary classification problems. We may expect that extrapolation, involving triples of examples and thus larger set of the search space is more appropriate for prediction than interpolation using only pairs for such datasets. Identifying the type of data that fits better with each kind of approaches is subject to further instigation.
For the rest of the datasets, CAP-classifier performs in the same way as the AP-classifier or k-NN. CAP-classifier achieves good results with a variety of datasets regardless the number of attributes (e.g., “Iris” with only 4 attributes, “Sat. image” with 36 attributes).
As it may be expected, using triples of items for classification is more informative than pairs since more examples are compared against each other in this case. Even though, CAP-classifier performs approximately the same average accuracy as AP-classifier exploiting triples (
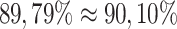 ) while keeping a lower complexity if compared to classic AP-classifiers. These results highlight the interest of continuous analogical proportions for classification.
) while keeping a lower complexity if compared to classic AP-classifiers. These results highlight the interest of continuous analogical proportions for classification.
Nearest Neighbors Pairs. In this sub-section, we would like to investigate better the characteristics of the pairs used for classification. For this reason, we check if voting pairs 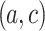 are close or not to the item
are close or not to the item 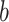 to be classified. To do that, we compute the proportion of pairs that are close to
to be classified. To do that, we compute the proportion of pairs that are close to 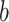 among all voting pairs. If this proportion is rather low, we can conclude that the proposed algorithm is able to correctly classify examples
among all voting pairs. If this proportion is rather low, we can conclude that the proposed algorithm is able to correctly classify examples  using pairs
using pairs  for which
for which  is just the midpoint of
is just the midpoint of  and
and 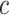 without being necessarily in their proximity.
without being necessarily in their proximity.
From a practical point, we adopt this strategy:
Given an item
 to be classified.
to be classified.Search for the k nearest neighbors
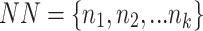 of
of 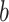 . In practice, we consider to test with
. In practice, we consider to test with 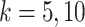 .
.Compute the percentage of voting pairs
 that are among the k nearest neighbors of
that are among the k nearest neighbors of  , i.e.
, i.e.  , D(x, y) being the distance between items x and y. If this percentage is low, it means that even if voting pairs
, D(x, y) being the distance between items x and y. If this percentage is low, it means that even if voting pairs  remain far to the item
remain far to the item 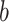 , the proposed interpolation-based approach succeeds to guess the correct label for
, the proposed interpolation-based approach succeeds to guess the correct label for 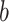 .
.
The results are shown in Table 5. In this supplementary experiment, we only consider testing examples whose voting pairs 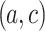 have a continuous analogical proportion
have a continuous analogical proportion  exceeding the threshold
exceeding the threshold 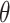 (see last column in Table 5).
(see last column in Table 5).
Table 5.
Proportion of pairs 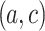 that are nearest neighbors to
that are nearest neighbors to 
| Datasets | % of pairs  that are among the 5 neighbors of that are among the 5 neighbors of 
|
% of pairs  that are among the 10 neighbors of that are among the 10 neighbors of 
|
% of examples  for which for which 
|
|---|---|---|---|
| Diabetes | 4.03% | 5.98% | 80.42% |
| Cancer | 5.35% | 8.29% | 94.32% |
| Heart | 6.85% | 9.01% | 95.04% |
| Ionosphere | 5.53% | 11.60% | 63.17% |
| Iris | 8.19% | 14.67% | 94.13% |
| Wine | 14.65% | 18.78% | 87.85% |
| Ecoli | 4.55% | 6.88% | 90.03% |
From these results we can note:
For
 (first column), the proportion of pairs
(first column), the proportion of pairs 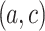 (among those exceeding the threshold) that are in the neighborhood of
(among those exceeding the threshold) that are in the neighborhood of  (those
(those 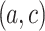 that are closest to
that are closest to 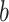 than its neighbor
than its neighbor 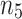 ) is less than 10% for all tested datasets except for “Wine” which is little higher. This demonstrates that for these datasets, the CAP-classifier exploits the entire space of pairs for prediction, indeed most of examples are predicted thanks to pairs
) is less than 10% for all tested datasets except for “Wine” which is little higher. This demonstrates that for these datasets, the CAP-classifier exploits the entire space of pairs for prediction, indeed most of examples are predicted thanks to pairs  that are located outside of the neighborhood of
that are located outside of the neighborhood of 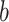 .
.Even when the number of nearest neighbors k is extended to 10, this proportion remains low for most of the datasets. Especially for “Diabetes” and “Ecoli”, the percentage of pairs in the neighborhood of
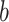 is close to
is close to 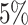 . For other datasets, this percentage is less than 20%.
. For other datasets, this percentage is less than 20%.Note that the behavior of our algorithm is quite different from the k-NN classifier. While this latter computes the similarity between the example
 to be classified and those in the training set, then classifies this example in the same way as its closest neighbors, our algorithm evaluates to what extent
to be classified and those in the training set, then classifies this example in the same way as its closest neighbors, our algorithm evaluates to what extent  is in continuous analogy with the pairs in the training set (these pairs are not necessarily in the proximity), then classifies it as the winning class having the highest number of voting pairs.
is in continuous analogy with the pairs in the training set (these pairs are not necessarily in the proximity), then classifies it as the winning class having the highest number of voting pairs.These last results show that voters
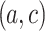 remain far from to the item
remain far from to the item 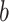 to be classified.
to be classified.
Conclusion
This paper studies the ability of continuous analogical proportions, namely statements of the form a is to b as b is to c, to classify numerical data and presents a classification algorithm for this end. The basic idea of the proposed approach is to search for all pairs of items, in the training set, that build a continuous analogical proportion on all or most of the features with the item to be classified. An analogical value is computed for each of these pairs and only those pairs whose score exceeds a given threshold are kept and used for prediction. In case no such pairs could be found for each class label, the best pair having the highest analogical value is rather used. Finally, the class label with the best score is assigned to the example to be classified. Experimental results show the interest of the CAP-classifier for classifying numerical data. In particular the proposed algorithm may slightly outperform some state-of-the-art ML algorithms (such as: k-NN, C4.5 and JRIP), as well as the AP-classifier on some datasets. This leads to conclude that for classification, building analogical proportions with three objects (using continuous analogical proportions) instead of four enables to get an overall average accuracy close to that of previous AP-classifier while reducing the complexity to be quadratic instead of being cubic.
Footnotes
Indeed the nominal equation 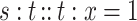 has no solution if
has no solution if  .
.
Contributor Information
Marie-Jeanne Lesot, Email: marie-jeanne.lesot@lip6.fr.
Susana Vieira, Email: susana.vieira@tecnico.ulisboa.pt.
Marek Z. Reformat, Email: marek.reformat@ualberta.ca
João Paulo Carvalho, Email: joao.carvalho@inesc-id.pt.
Anna Wilbik, Email: a.m.wilbik@tue.nl.
Bernadette Bouchon-Meunier, Email: bernadette.bouchon-meunier@lip6.fr.
Ronald R. Yager, Email: yager@panix.com
Marouane Essid, Email: marouane.essid@gmail.com.
Myriam Bounhas, Email: myriam_bounhas@yahoo.fr.
Henri Prade, Email: prade@irit.fr.
References
- 1.Bayoudh, S., Miclet, L., Delhay, A.: Learning by analogy: a classification rule for binary and nominal data. In: Proceedings of the International Joint Conference on Artificial Intelligence, IJCAI 2007, Hyderabad, India, 6–12 January, pp. 678–683 (2007)
- 2.Bounhas M, Prade H. An analogical interpolation method for enlarging a training dataset. In: Ben Amor N, Quost B, Theobald M, editors. Scalable Uncertainty Management; Cham: Springer; 2019. pp. 136–152. [Google Scholar]
- 3.Bounhas M, Prade H, Richard G. Oddness-based classification: a new way of exploiting neighbors. Int. J. Intell. Syst. 2018;33(12):2379–2401. doi: 10.1002/int.22035. [DOI] [Google Scholar]
- 4.Bounhas M, Prade H, Richard G. Analogy-based classifiers for nominal or numerical data. Int. J. Approx. Reason. 2017;91:36–55. doi: 10.1016/j.ijar.2017.08.010. [DOI] [Google Scholar]
- 5.Dubois D, Prade H, Richard G. Multiple-valued extensions of analogical proportions. Fuzzy Sets Syst. 2016;292:193–202. doi: 10.1016/j.fss.2015.03.019. [DOI] [Google Scholar]
- 6.Lieber J, Nauer E, Prade H, Richard G. Making the best of cases by approximation, interpolation and extrapolation. In: Cox MT, Funk P, Begum S, editors. Case-Based Reasoning Research and Development; Cham: Springer; 2018. pp. 580–596. [Google Scholar]
- 7.Metz, J., Murphy, P.M.: UCI Repository (2000). ftp://ftp.ics.uci.edu/pub/machine-learning-databases
- 8.Miclet L, Bayoudh S, Delhay A. Analogical dissimilarity: definition, algorithms and two experiments in machine learning. J. Artif. Intell. Res. 2008;32:793–824. doi: 10.1613/jair.2519. [DOI] [Google Scholar]
- 9.Miclet, L., Bayoudh, S., Delhay, A., Mouchére, H.: De l’utilisation de la proportion analogique en apprentissage artificiel. In: Actes des Journées Intelligence Artificielle Fondamentale, IAF 2007, Grenoble, 2–3 July 2007 (2007). http://www.cril.univ-artois.fr/konieczny/IAF07/
- 10.Miclet L, Prade H. Handling analogical proportions in classical logic and fuzzy logics settings. In: Sossai C, Chemello G, editors. Symbolic and Quantitative Approaches to Reasoning with Uncertainty; Heidelberg: Springer; 2009. pp. 638–650. [Google Scholar]
- 11.Prade H, Richard G. Analogical proportions: another logical view. In: Bramer M, Ellis R, Petridis M, editors. Research and Development in Intelligent Systems. London: Springer; 2010. pp. 121–134. [Google Scholar]
- 12.Prade H, Richard G. Analogical proportions: from equality to inequality. Int. J. Approx. Reason. 2018;101:234–254. doi: 10.1016/j.ijar.2018.07.005. [DOI] [Google Scholar]